Download as PDF, PPTX




![Небольшое отступление о железе
● В AWS инстанс x1.32xlarge (128 vCPU, 1952 Mb памяти, 2 x 1920 Mb SSD)
стоит 9603$ в месяц [1];
● SSD на 1 Тб стоит от ~20 000 рублей [2].
[1]: https://aws.amazon.com/ec2/pricing/on-demand/
[2]: Samsung MZ-75E1T0BW, https://market.yandex.ru/product/11929060](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-5-320.jpg)


![Fun facts!
Потоковая репликация:
● Не работает между разными архитектурами;
● Не работает между разными версиями PostgreSQL [1].
[1] Согласно https://simply.name/ru/upgrading-postgres-to-9.4.html типичное
время даунтайма при обновлении версии составляет несколько минут.](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-9-320.jpg)



![Ограничения логической репликации
● Реплицируемые таблицы должны иметь primary key;
● DDL, TRUNCATE и sequences не реплицируются;
● Поддержка триггеров реализована не до конца [1].
[1]: https://postgr.es/m/20171009141341.GA16999@e733.localdomain](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-13-320.jpg)
![Logical decoding
$ pg_recvlogical --slot=myslot --dbname=eax --user=eax
--create-slot --plugin=test_decoding
$ pg_recvlogical --slot=myslot --dbname=eax --user=eax --start -f -
BEGIN 560
COMMIT 560
BEGIN 561
table public.test: INSERT: k[text]:'aaa' v[text]:'bbb'
COMMIT 561](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-14-320.jpg)
![Logical decoding: JSON
● Есть больше одного стороннего расширения...
● … но на сегодня все сломаны на 10-ке [1][2] :(
[1]: https://github.com/eulerto/wal2json/issues/33
[2]: https://github.com/posix4e/jsoncdc/issues/77](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-15-320.jpg)



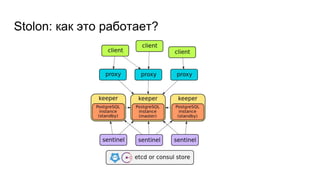
![Fun facts!
● Stolon направляет и чтение, и запись в мастер. Но есть воркэраунд [1];
● Использует Consul или etcd чисто как key-value, в частности, не знает
про поддержку Consul’ом DNS.
[1]: https://github.com/sorintlab/stolon/issues/132](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-20-320.jpg)
![Consul
Коротко о главном:
● Разрабатывается HashiCorp, подарившей миру Packer и Vagrant;
● Написан на языке Go, использует протокол Raft;
● Решение для service discovery, как ZooKeeper или etcd;
● Распределенное key-value хранилище с REST-интерфейсом;
● Имеет CAS, встроенный мониторинг, локи, подписки на обновления, …;
● Умеет отдавать информацию о сервисах по DNS;
● Тестируется Jepsen’ом [1].
[1]: https://www.consul.io/docs/internals/jepsen.html](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-21-320.jpg)
![Fun facts!
● У Consul есть красивый веб-интерфейс с информацией о
зарегистрированных сервисах;
● Поверх него (ровно как и поверх Cassandra или Couchbase) можно
довольно легко написать выбор лидера, используя подход под
названием leader lease [1].
[1]: http://eax.me/go-leader-election/](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-22-320.jpg)


![synchronous_standby_names
● synchronous_standby_names = ‘*’
○ Ждем подтверждения от одной любой реплики
● synchronous_standby_names = ANY 2(node1,node2,node3);
○ Коммит на кворум
○ Появилось в версии 10
● Другие варианты [1] не очень полезны.
[1]: https://www.postgresql.org/docs/current/static/runtime-config-replication.html](https://image.slidesharecdn.com/9-171116141802/85/PostgreSQL-Postgres-Professional-25-320.jpg)






![Небольшое отступление о железе
● В AWS инстанс x1.32xlarge (128 vCPU, 1952 Mb памяти, 2 x 1920 Mb SSD)
стоит 9603$ в месяц [1];
● SSD на 1 Тб стоит от ~20 000 рублей [2].
[1]: https://aws.amazon.com/ec2/pricing/on-demand/
[2]: Samsung MZ-75E1T0BW, https://market.yandex.ru/product/11929060](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-5-2048.jpg)


![Fun facts!
Потоковая репликация:
● Не работает между разными архитектурами;
● Не работает между разными версиями PostgreSQL [1].
[1] Согласно https://simply.name/ru/upgrading-postgres-to-9.4.html типичное
время даунтайма при обновлении версии составляет несколько минут.](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-9-2048.jpg)



![Ограничения логической репликации
● Реплицируемые таблицы должны иметь primary key;
● DDL, TRUNCATE и sequences не реплицируются;
● Поддержка триггеров реализована не до конца [1].
[1]: https://postgr.es/m/20171009141341.GA16999@e733.localdomain](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-13-2048.jpg)
![Logical decoding
$ pg_recvlogical --slot=myslot --dbname=eax --user=eax
--create-slot --plugin=test_decoding
$ pg_recvlogical --slot=myslot --dbname=eax --user=eax --start -f -
BEGIN 560
COMMIT 560
BEGIN 561
table public.test: INSERT: k[text]:'aaa' v[text]:'bbb'
COMMIT 561](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-14-2048.jpg)
![Logical decoding: JSON
● Есть больше одного стороннего расширения...
● … но на сегодня все сломаны на 10-ке [1][2] :(
[1]: https://github.com/eulerto/wal2json/issues/33
[2]: https://github.com/posix4e/jsoncdc/issues/77](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-15-2048.jpg)



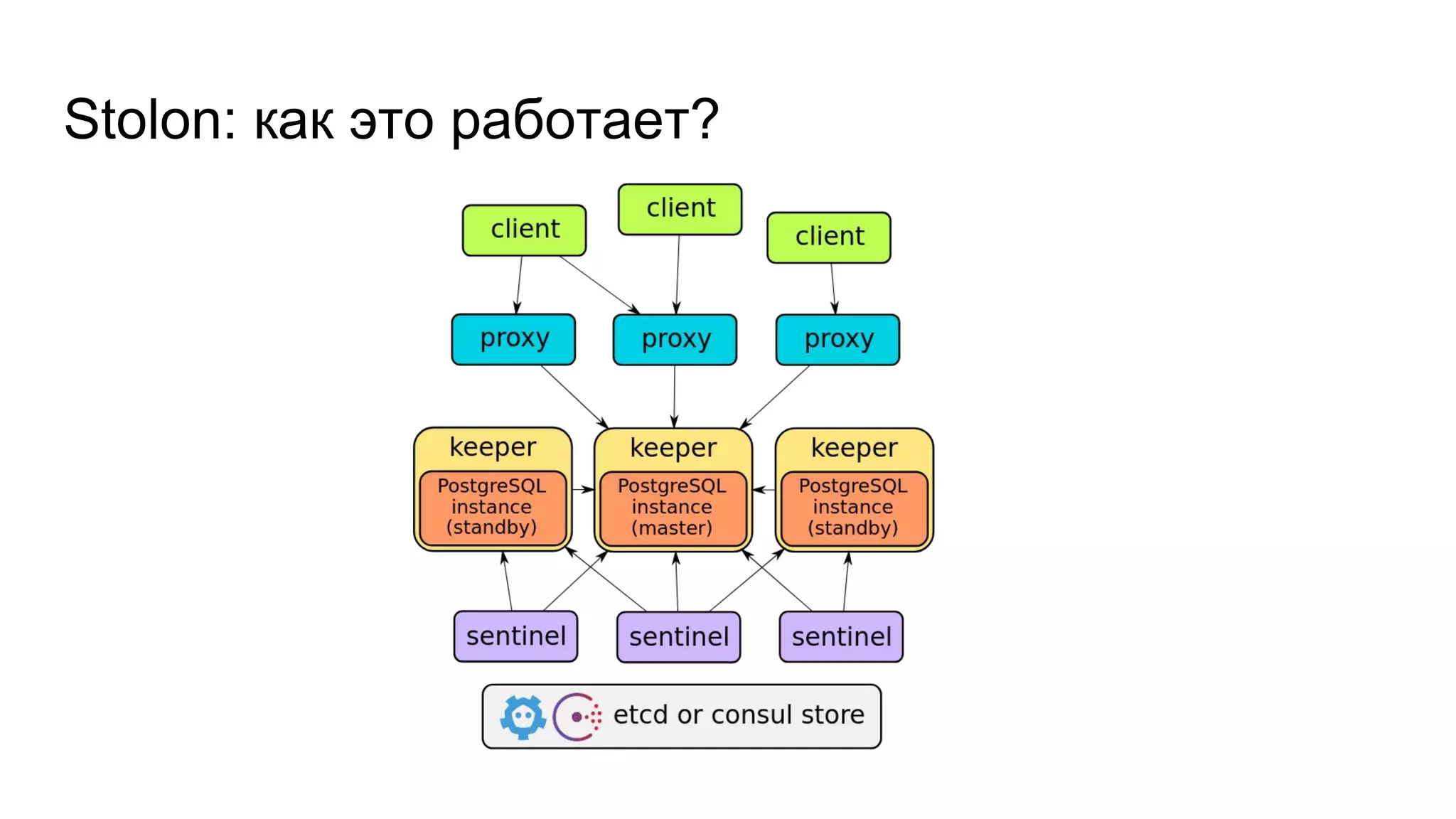
![Fun facts!
● Stolon направляет и чтение, и запись в мастер. Но есть воркэраунд [1];
● Использует Consul или etcd чисто как key-value, в частности, не знает
про поддержку Consul’ом DNS.
[1]: https://github.com/sorintlab/stolon/issues/132](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-20-2048.jpg)
![Consul
Коротко о главном:
● Разрабатывается HashiCorp, подарившей миру Packer и Vagrant;
● Написан на языке Go, использует протокол Raft;
● Решение для service discovery, как ZooKeeper или etcd;
● Распределенное key-value хранилище с REST-интерфейсом;
● Имеет CAS, встроенный мониторинг, локи, подписки на обновления, …;
● Умеет отдавать информацию о сервисах по DNS;
● Тестируется Jepsen’ом [1].
[1]: https://www.consul.io/docs/internals/jepsen.html](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-21-2048.jpg)
![Fun facts!
● У Consul есть красивый веб-интерфейс с информацией о
зарегистрированных сервисах;
● Поверх него (ровно как и поверх Cassandra или Couchbase) можно
довольно легко написать выбор лидера, используя подход под
названием leader lease [1].
[1]: http://eax.me/go-leader-election/](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-22-2048.jpg)


![synchronous_standby_names
● synchronous_standby_names = ‘*’
○ Ждем подтверждения от одной любой реплики
● synchronous_standby_names = ANY 2(node1,node2,node3);
○ Коммит на кворум
○ Появилось в версии 10
● Другие варианты [1] не очень полезны.
[1]: https://www.postgresql.org/docs/current/static/runtime-config-replication.html](https://image.slidesharecdn.com/9-171116141802/75/PostgreSQL-Postgres-Professional-25-2048.jpg)



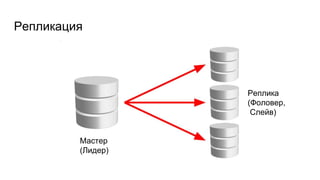
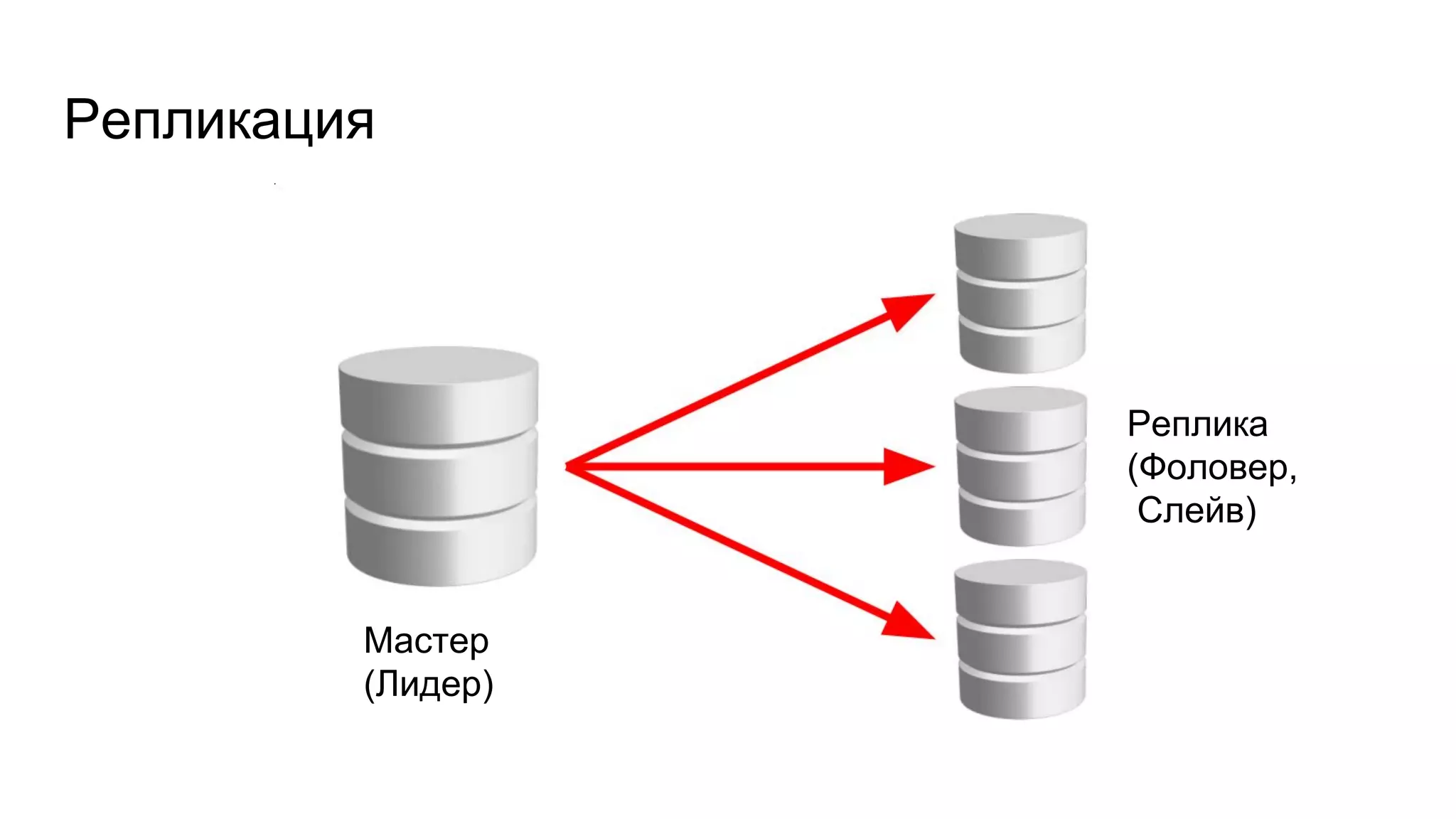
Доклад Александра Алексеева рассказывает о новых технологиях репликации в PostgreSQL и направлен на аудиторию, не имеющую большого опыта в этой области. Он описывает физическую и логическую репликацию, а также возможности автоматического фейловера, детализируя их преимущества и ограничения. В конце предоставлены ссылки на дополнительные материалы для дальнейшего изучения.



































































