Download as PDF, PPTX
















![Xpath selectors
Expression Meaning
name matches all nodes on the current level with
the specified name
name[n] matches the nth element on the current level
with the specified name
/ Do selection from the root
// Do selection from current node
* matches all nodes on the current level
. Or .. Select current / parent node
@name the attribute with the specified name
[@key='value'] all elements with an attribute that matches
the specified key/value pair
name[@key='value'] all elements with the specified name and an
attribute that matches the specified key/value
pair
[text()='value'] all elements with the specified text
name[text()='value'] all elements with the specified name and text](https://image.slidesharecdn.com/pydata-160409224139/85/Pydata-Python-tools-for-webscraping-20-320.jpg)





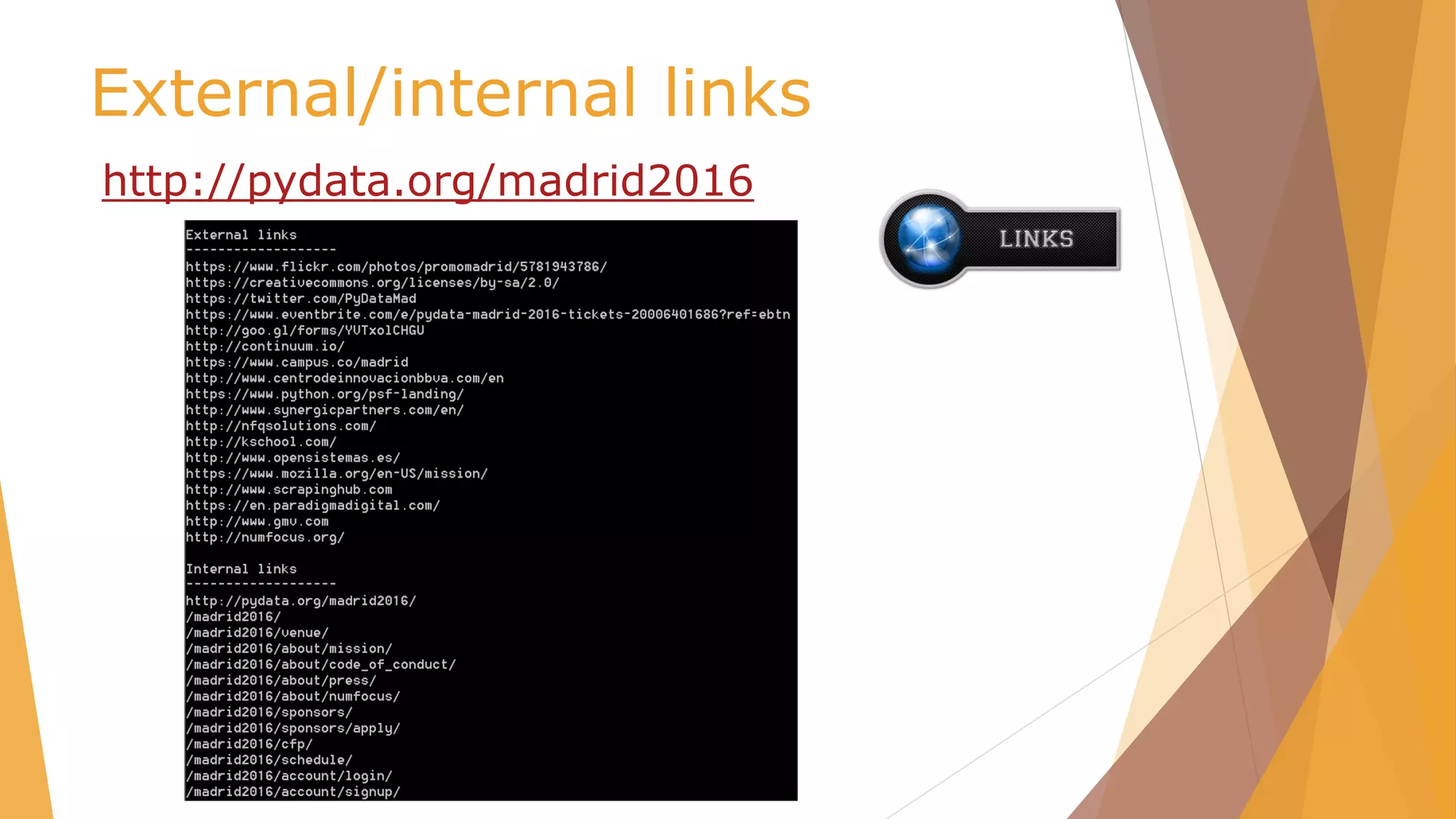
![Webscraping
pip install webscraping
#Download instance
D = download.Download()
#get page
html =
D.get('http://pydata.org/madrid2016/schedule/')
#get element where is located information
xpath.search(html, '//td[@class="slot slot-talk"]')](https://image.slidesharecdn.com/pydata-160409224139/85/Pydata-Python-tools-for-webscraping-26-320.jpg)
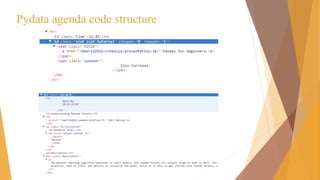





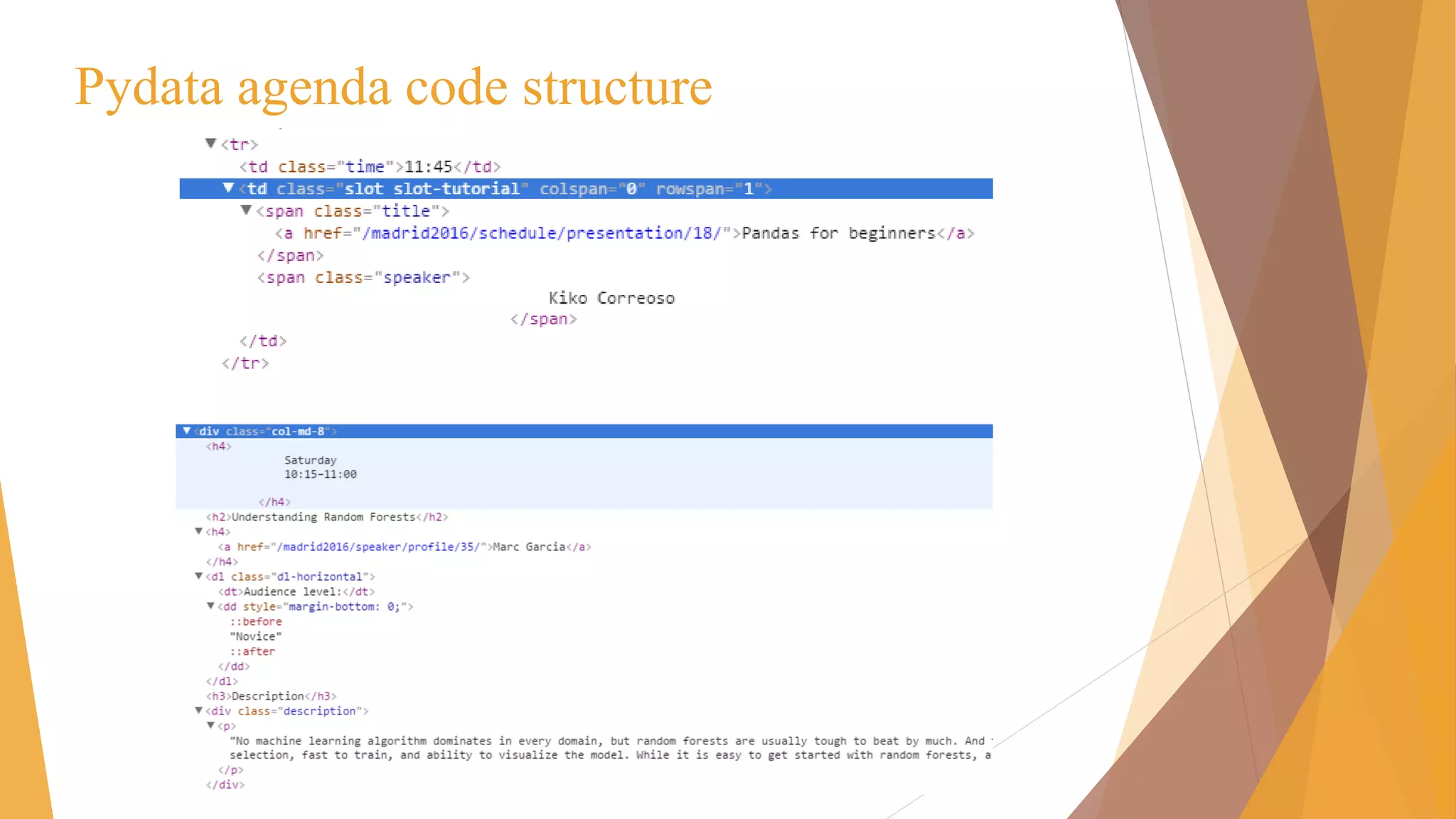
![Scrapy Shell
scrapy shell <url>
from scrapy.select import Selector
hxs = Selector(response)
Info = hxs.select(‘//div[@class=“slot-inner”]’)](https://image.slidesharecdn.com/pydata-160409224139/85/Pydata-Python-tools-for-webscraping-36-320.jpg)














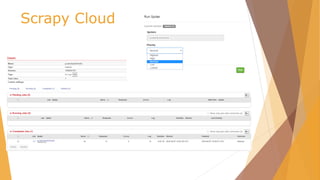
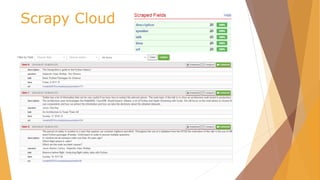
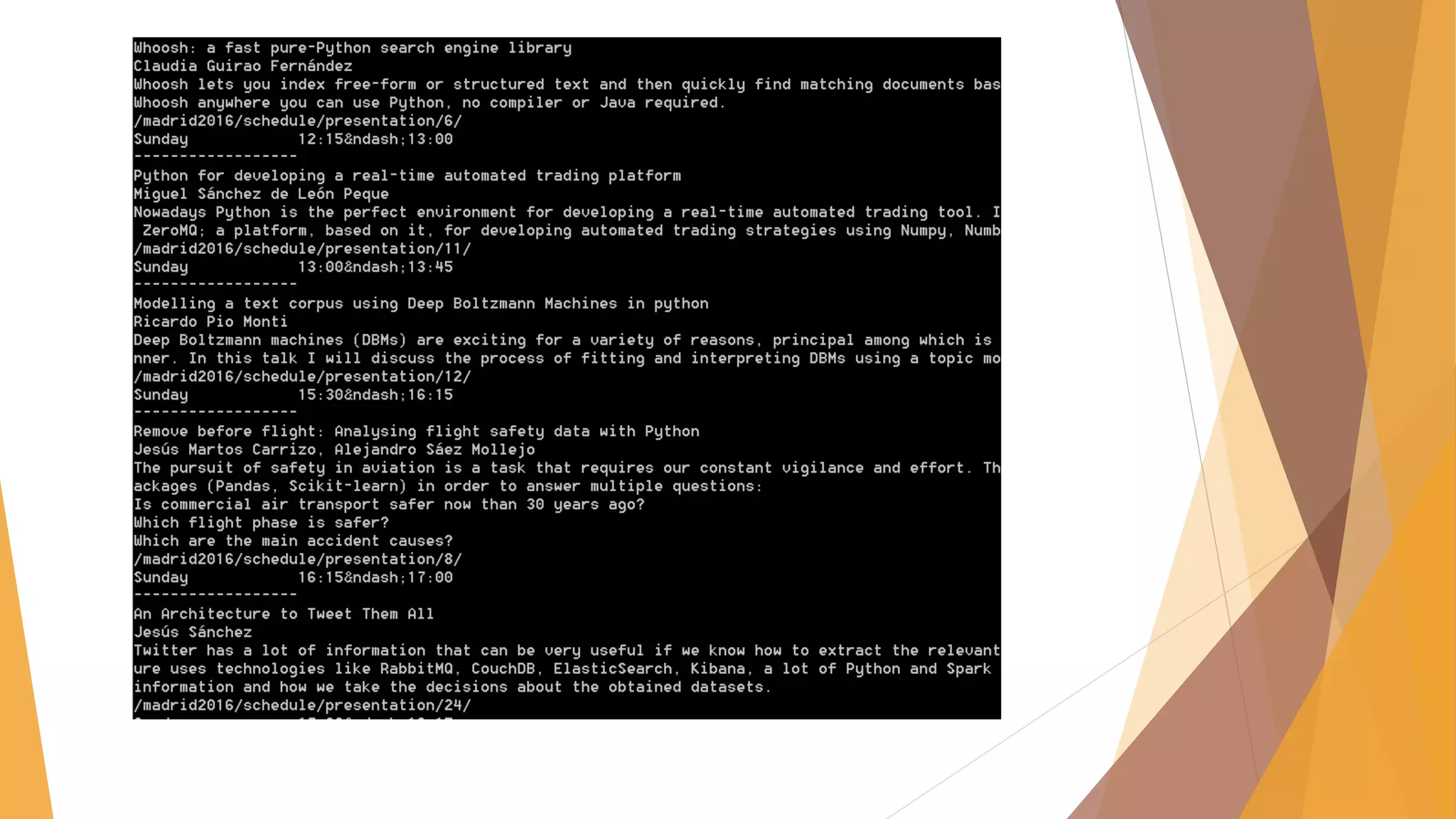
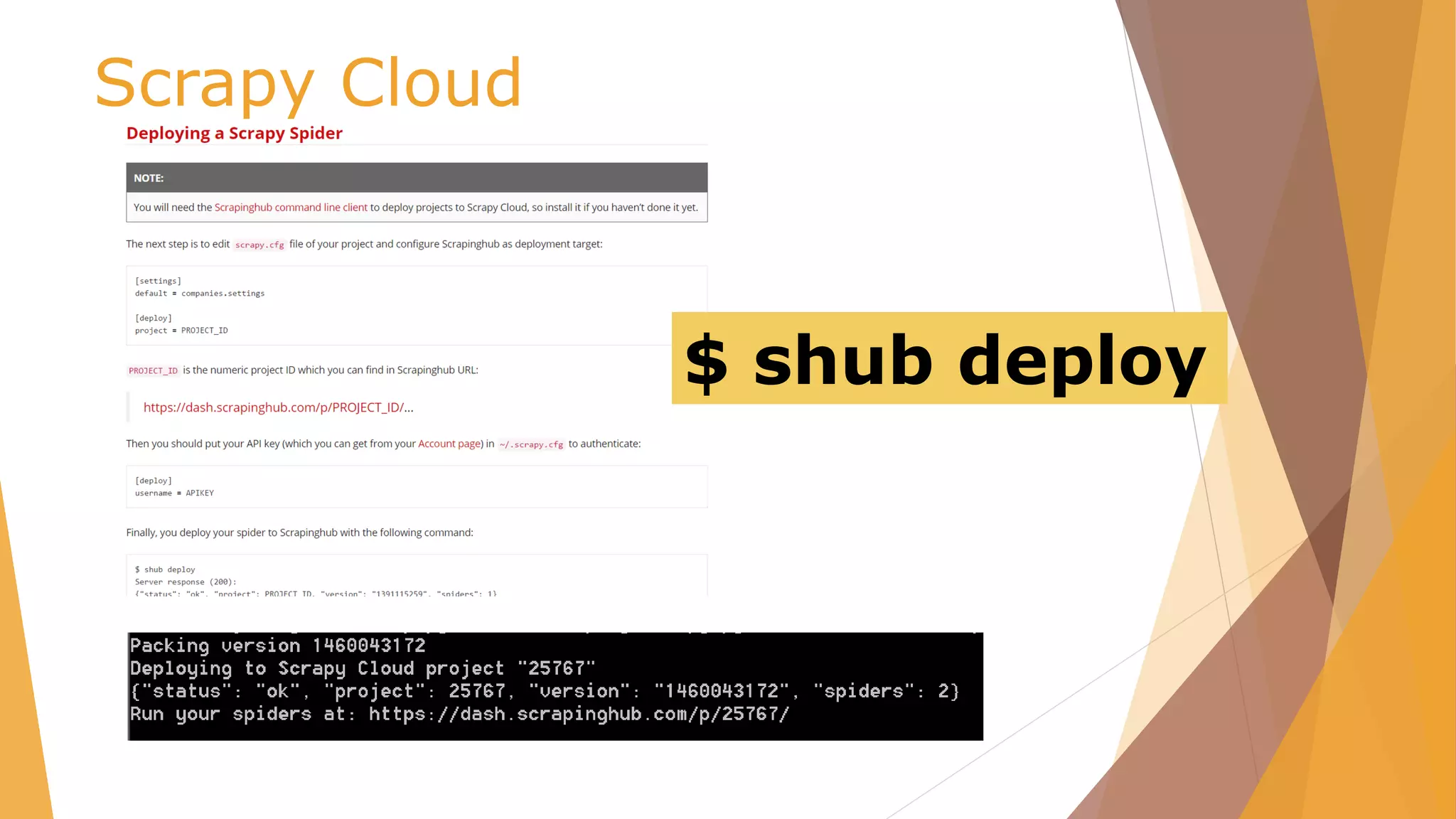
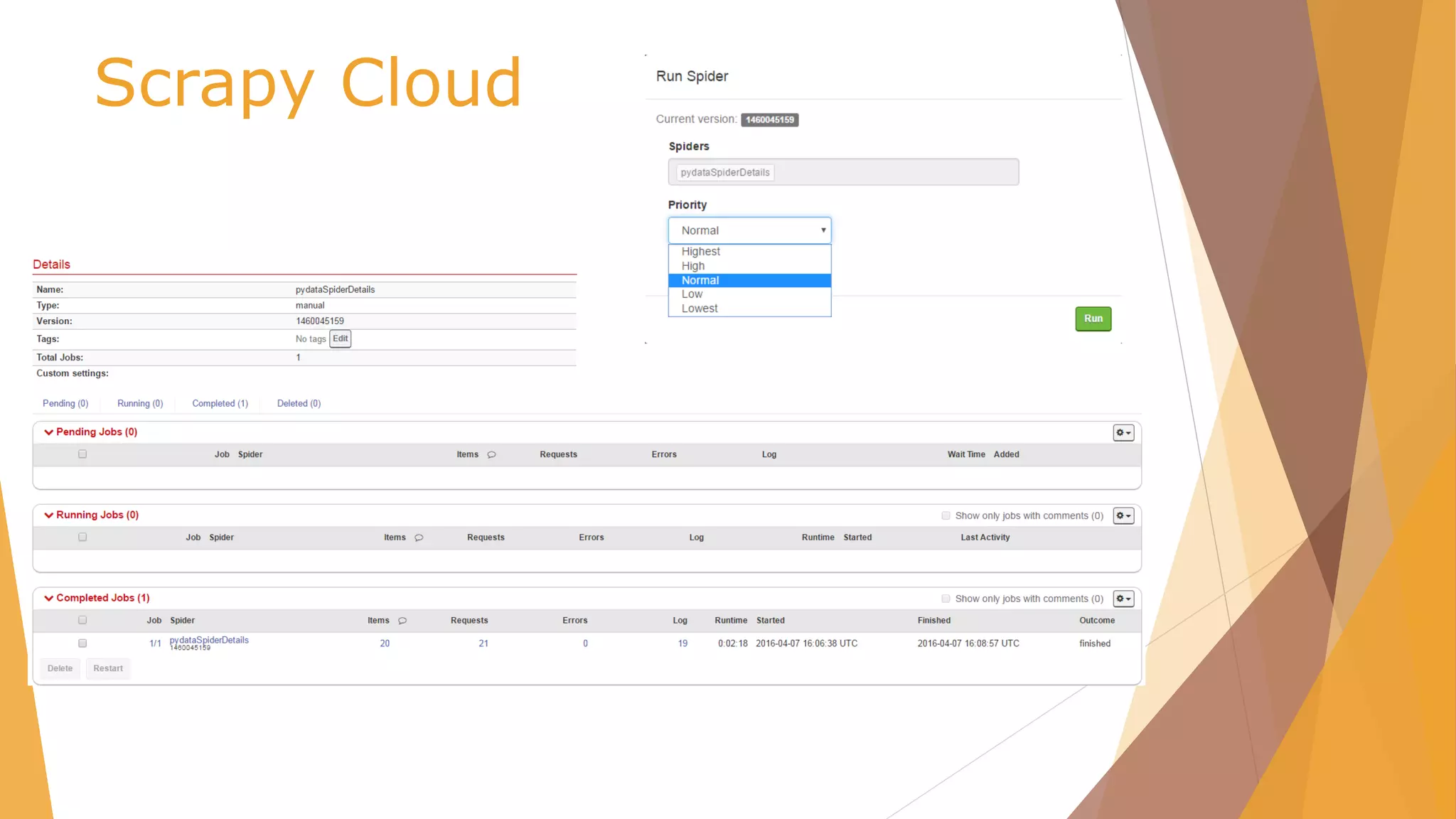
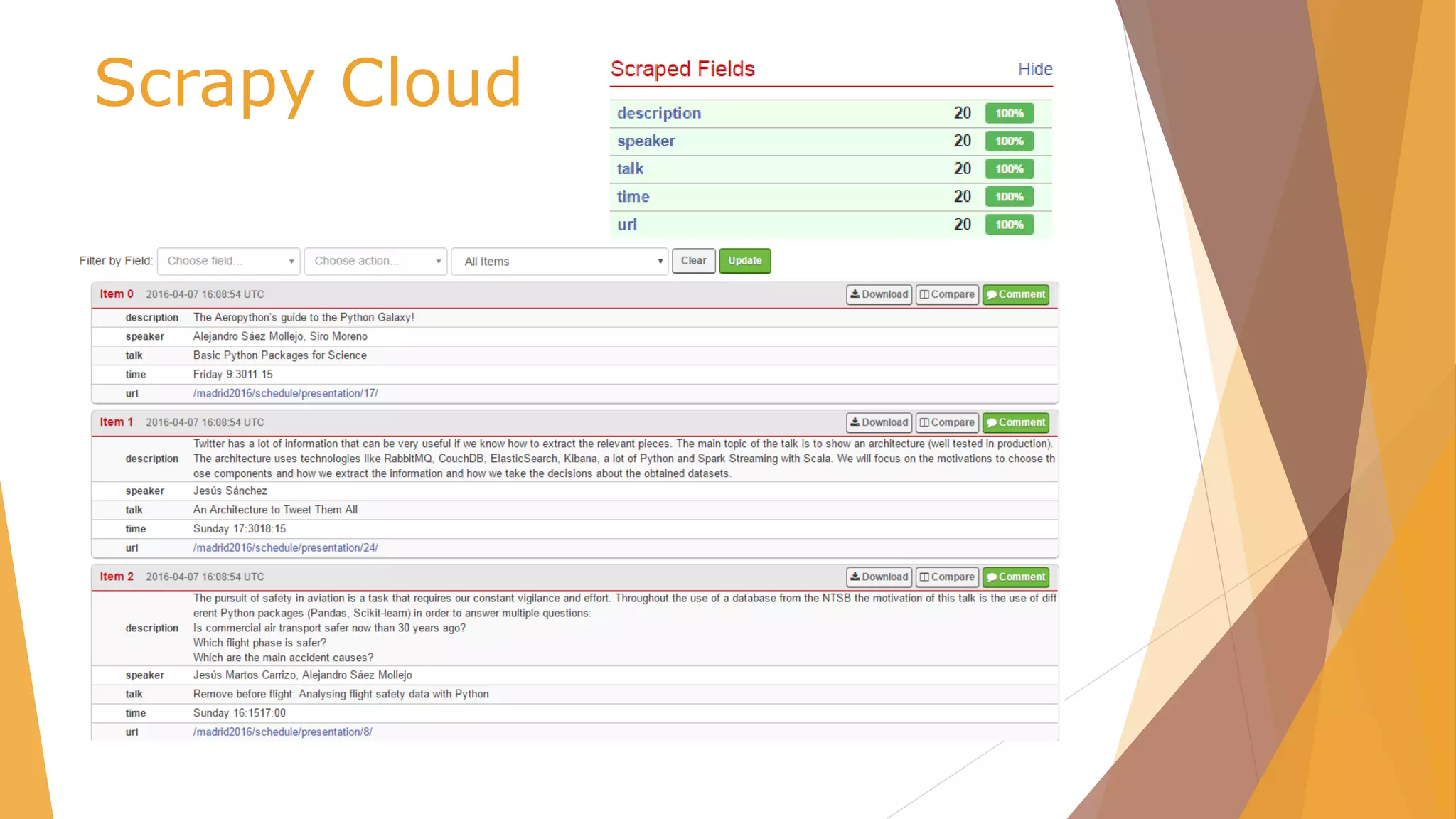
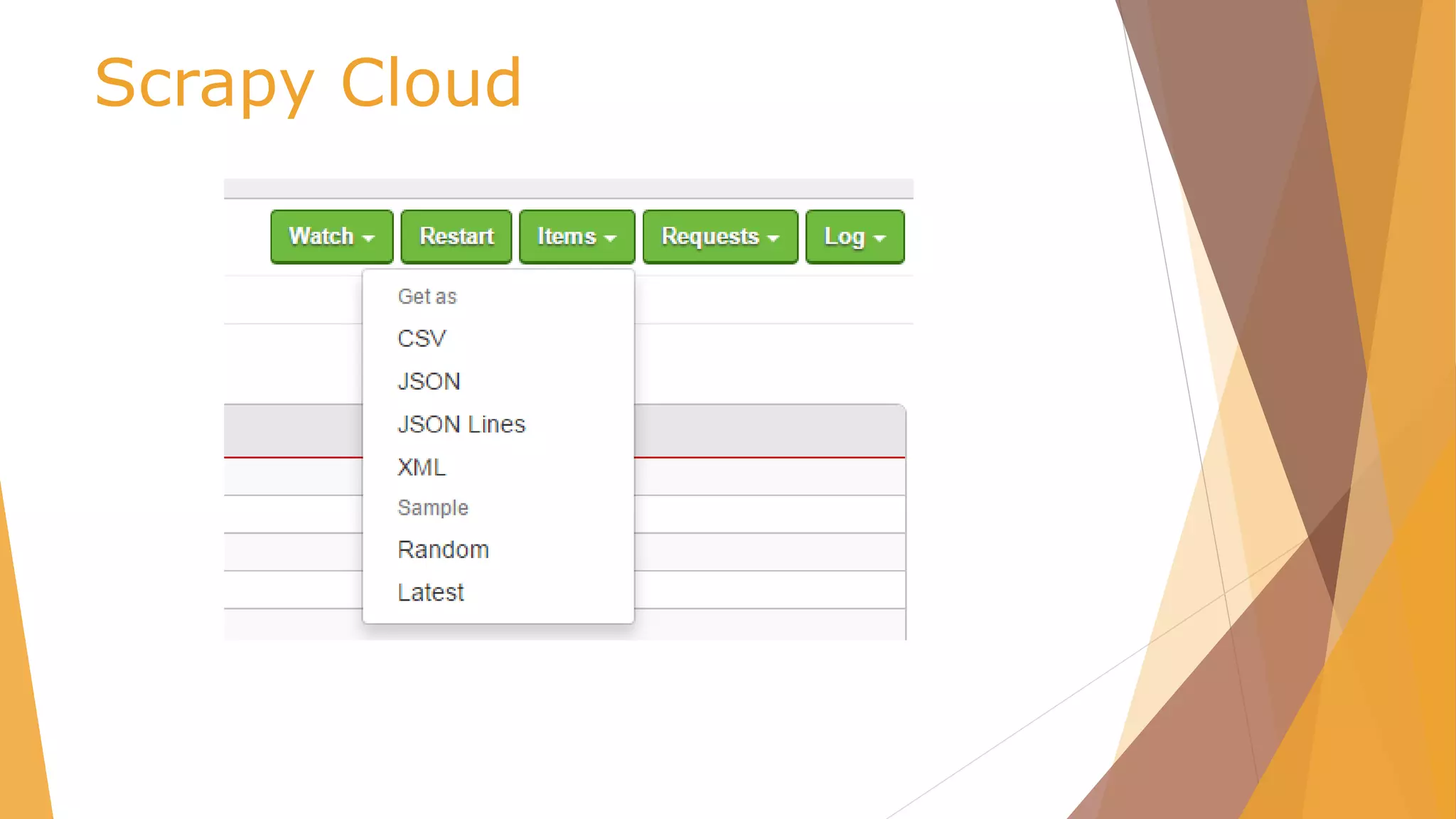
![Scrapy Cloud /scrapy.cfg
# Project: demo
[deploy]
url =https://dash.scrapinghub.com/api/scrapyd/
#API_KEY
username = ec6334d7375845fdb876c1d10b2b1622
password =
#project identifier
project = 25767](https://image.slidesharecdn.com/pydata-160409224139/85/Pydata-Python-tools-for-webscraping-51-320.jpg)



















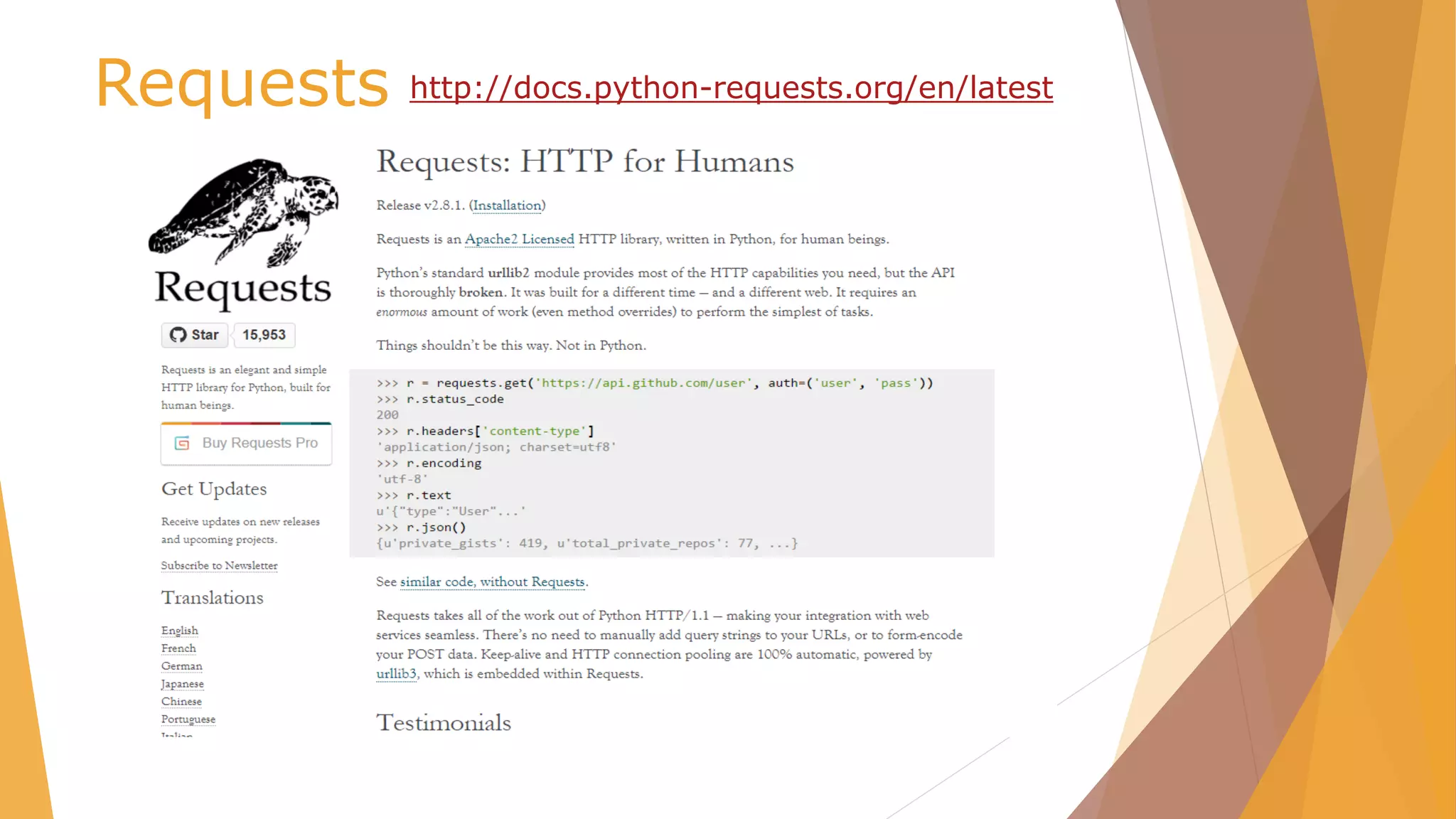


![Xpath selectors
Expression Meaning
name matches all nodes on the current level with
the specified name
name[n] matches the nth element on the current level
with the specified name
/ Do selection from the root
// Do selection from current node
* matches all nodes on the current level
. Or .. Select current / parent node
@name the attribute with the specified name
[@key='value'] all elements with an attribute that matches
the specified key/value pair
name[@key='value'] all elements with the specified name and an
attribute that matches the specified key/value
pair
[text()='value'] all elements with the specified text
name[text()='value'] all elements with the specified name and text](https://image.slidesharecdn.com/pydata-160409224139/75/Pydata-Python-tools-for-webscraping-20-2048.jpg)




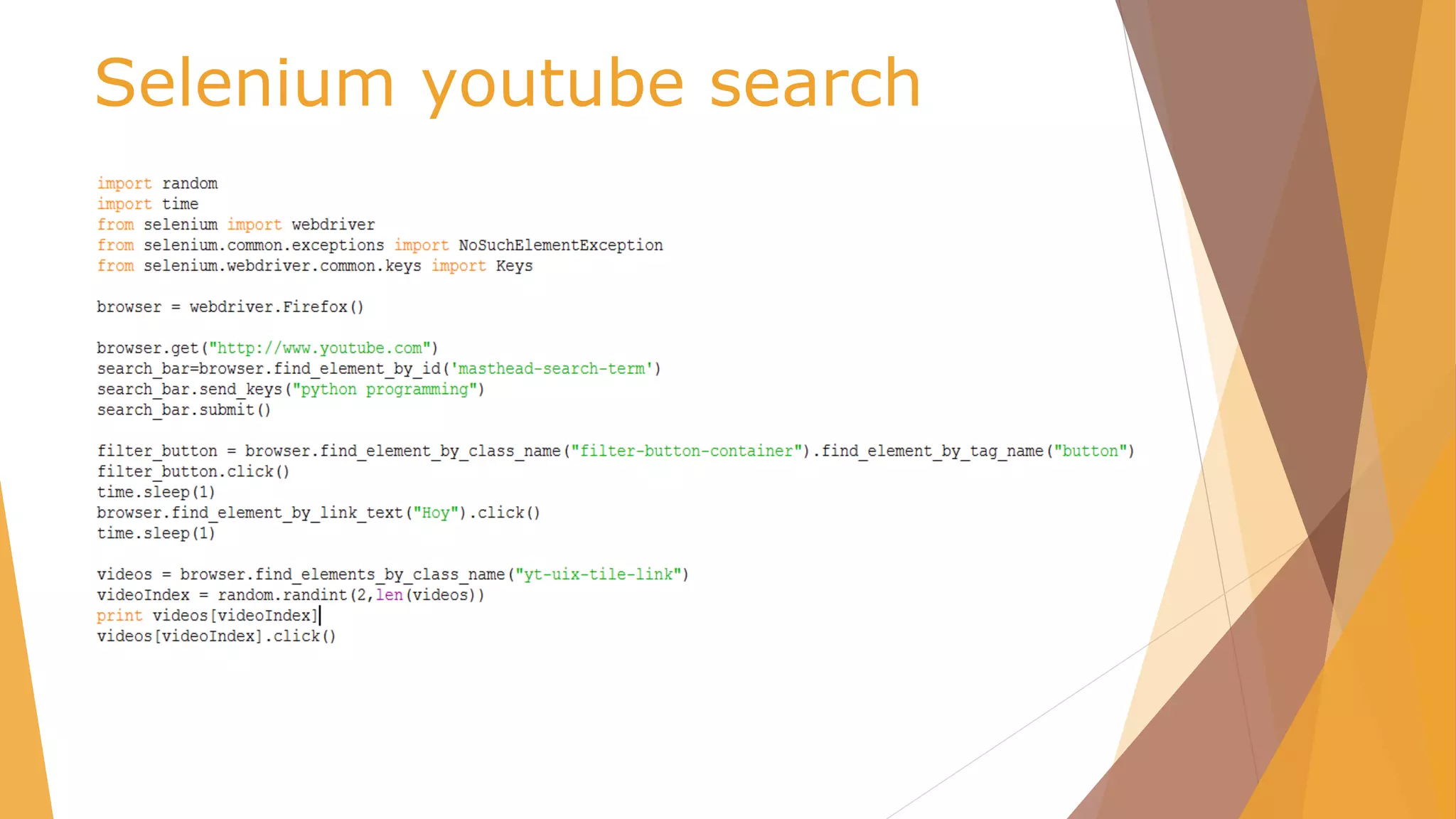
![Webscraping
pip install webscraping
#Download instance
D = download.Download()
#get page
html =
D.get('http://pydata.org/madrid2016/schedule/')
#get element where is located information
xpath.search(html, '//td[@class="slot slot-talk"]')](https://image.slidesharecdn.com/pydata-160409224139/75/Pydata-Python-tools-for-webscraping-26-2048.jpg)





![Scrapy Shell
scrapy shell <url>
from scrapy.select import Selector
hxs = Selector(response)
Info = hxs.select(‘//div[@class=“slot-inner”]’)](https://image.slidesharecdn.com/pydata-160409224139/75/Pydata-Python-tools-for-webscraping-36-2048.jpg)














![Scrapy Cloud /scrapy.cfg
# Project: demo
[deploy]
url =https://dash.scrapinghub.com/api/scrapyd/
#API_KEY
username = ec6334d7375845fdb876c1d10b2b1622
password =
#project identifier
project = 25767](https://image.slidesharecdn.com/pydata-160409224139/75/Pydata-Python-tools-for-webscraping-51-2048.jpg)





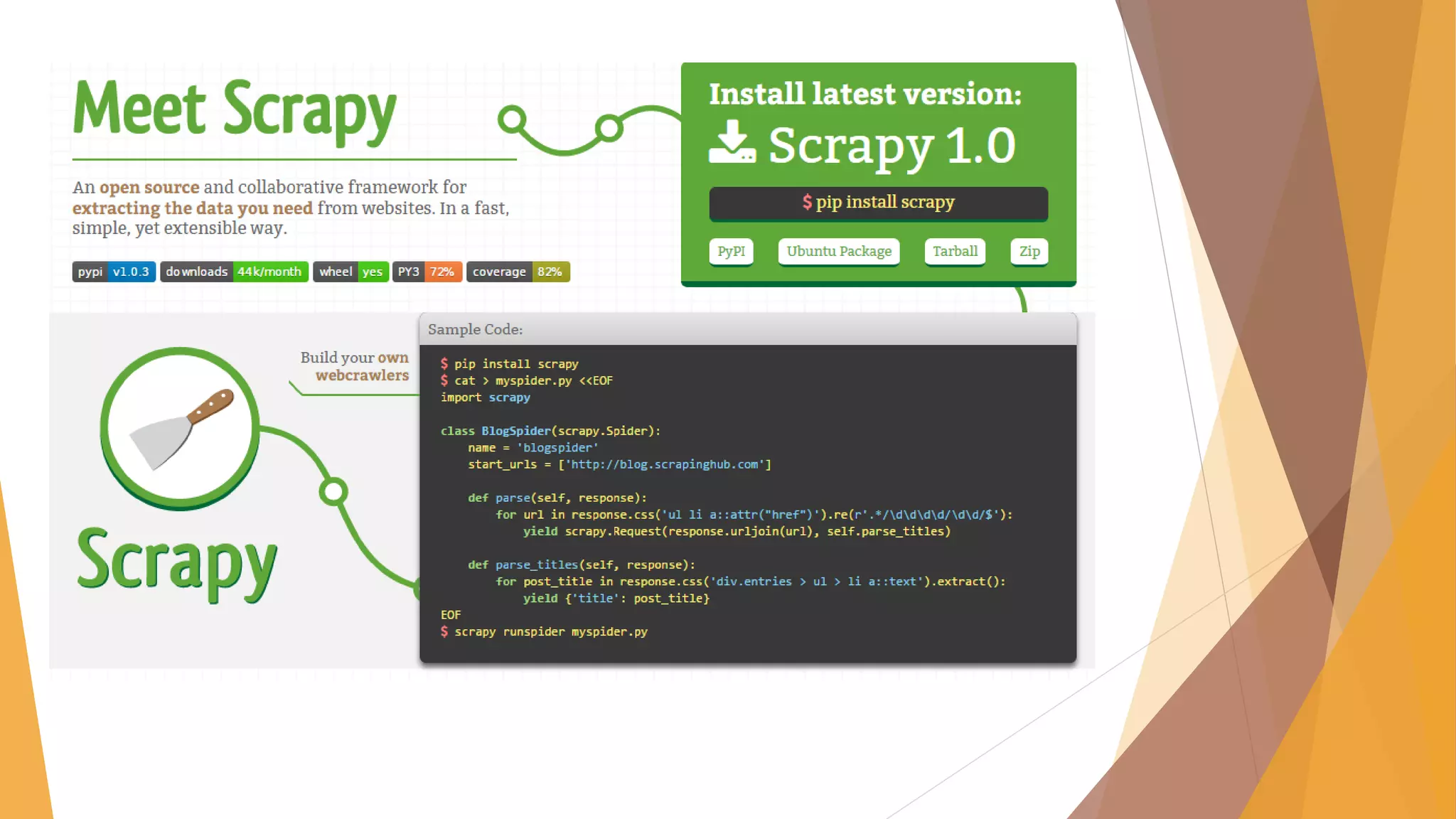
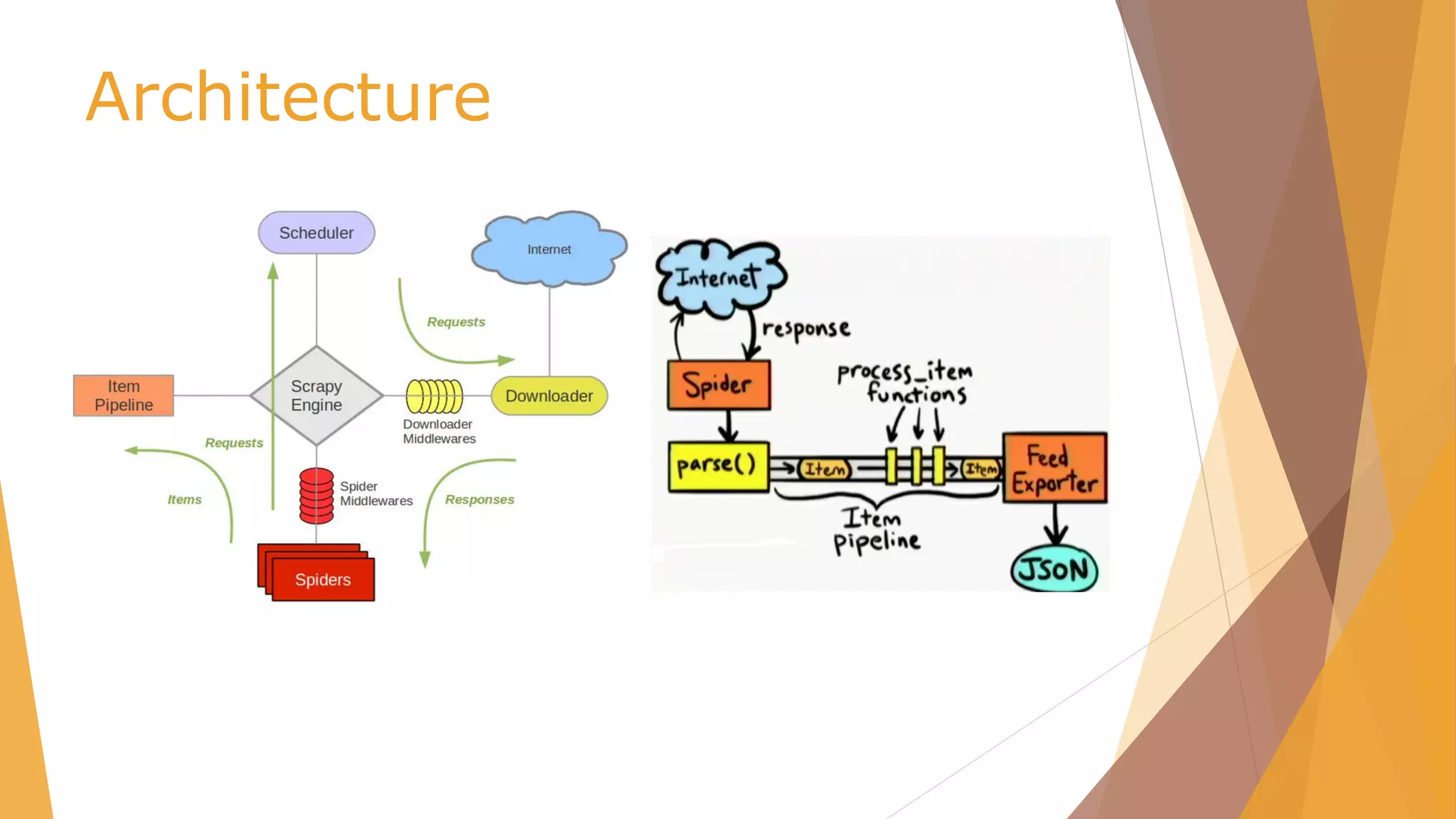
Python tools for webscraping provides an overview of scraping techniques like screen scraping, report mining, and web scraping using spiders and crawlers. It then demonstrates various Python libraries for web scraping including Selenium, Requests, Beautiful Soup, PyQuery, Scrapy, and Scrapy Cloud. The document shows how to scrape data from websites using these tools and techniques.


































































![[DSC Europe 24] Domagoj Maric - Modern Web Data Extraction: Techniques, Tools...](https://cdn.slidesharecdn.com/ss_thumbnails/domagojmaric-modernwebdataextractionfinal-250218225444-c7bcad20-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





















![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















