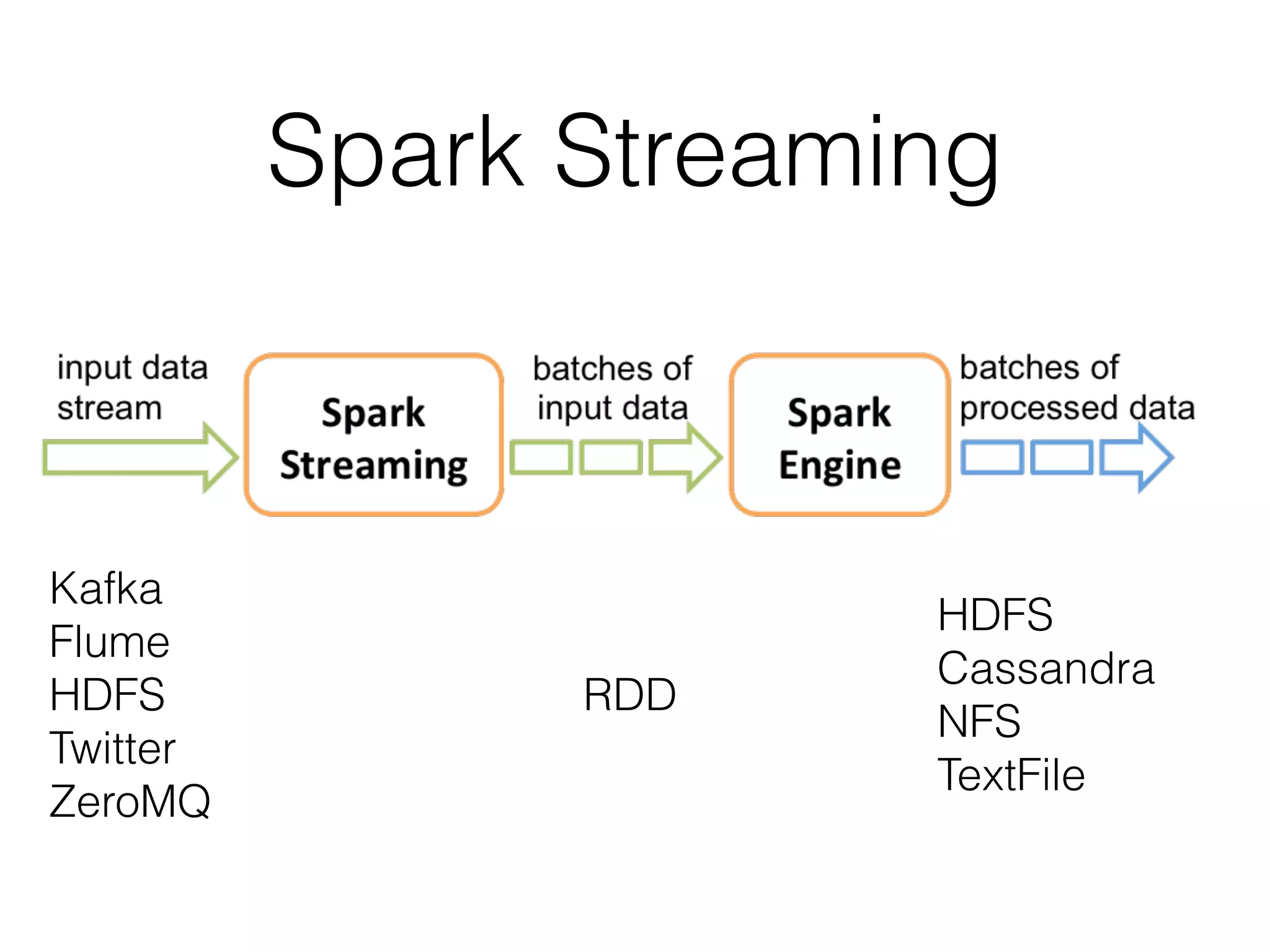
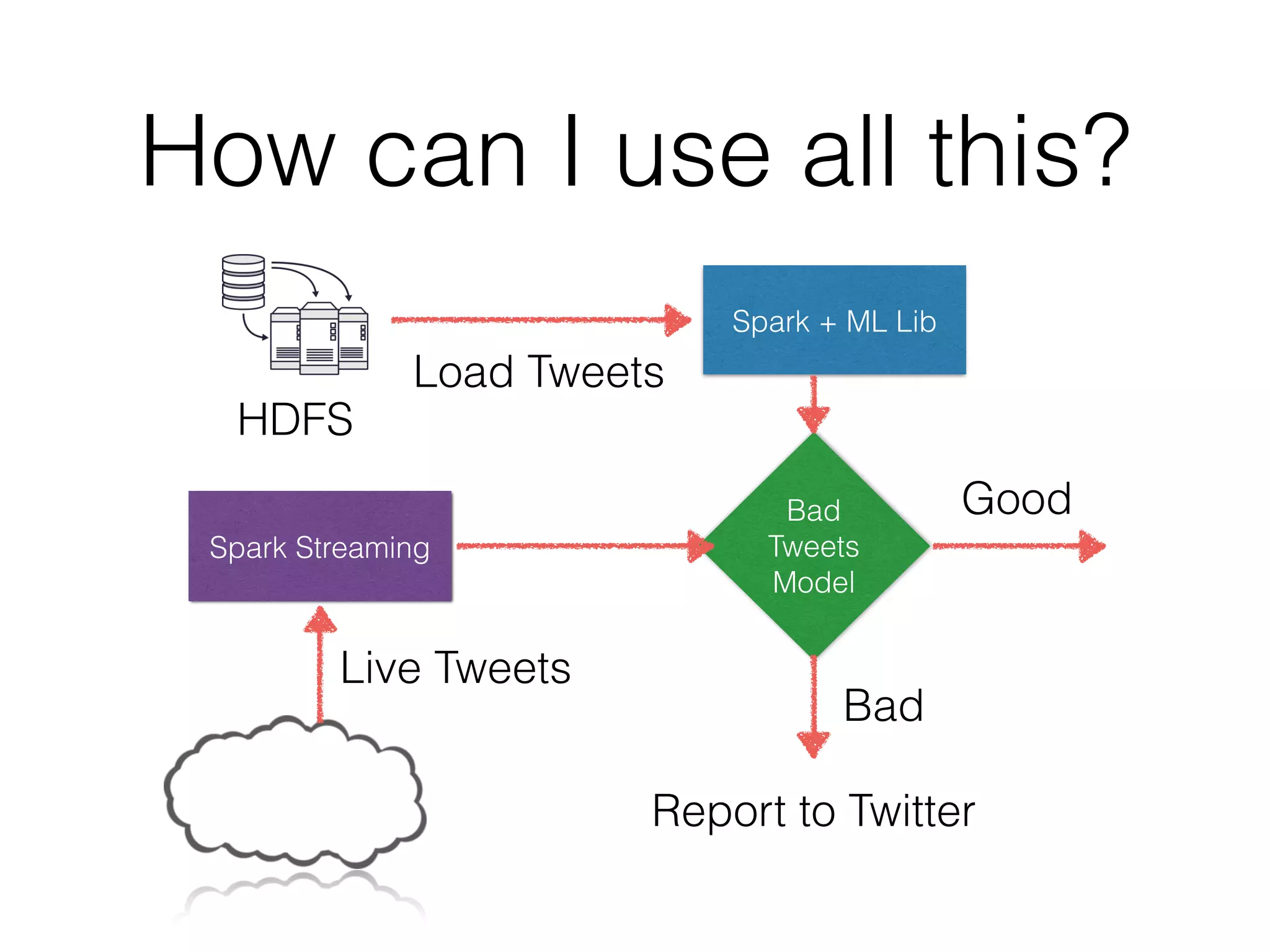
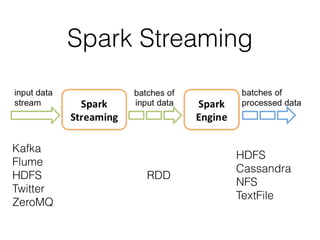
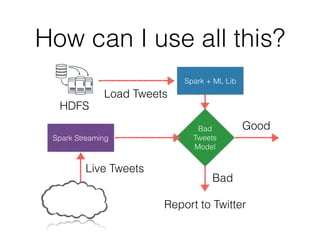
This document provides an introduction to Spark and PySpark for processing big data. It discusses what Spark is, how it differs from MapReduce by using in-memory caching for iterative queries. Spark operations on Resilient Distributed Datasets (RDDs) include transformations like map, filter, and actions that trigger computation. Spark can be used for streaming, machine learning using MLlib, and processing large datasets faster than MapReduce. The document provides examples of using PySpark on network logs and detecting good vs bad tweets in real-time.











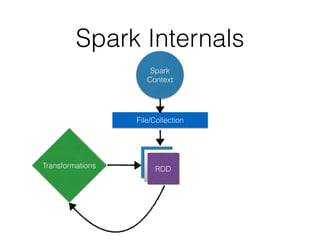
![Spark Internals
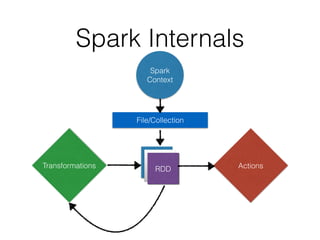
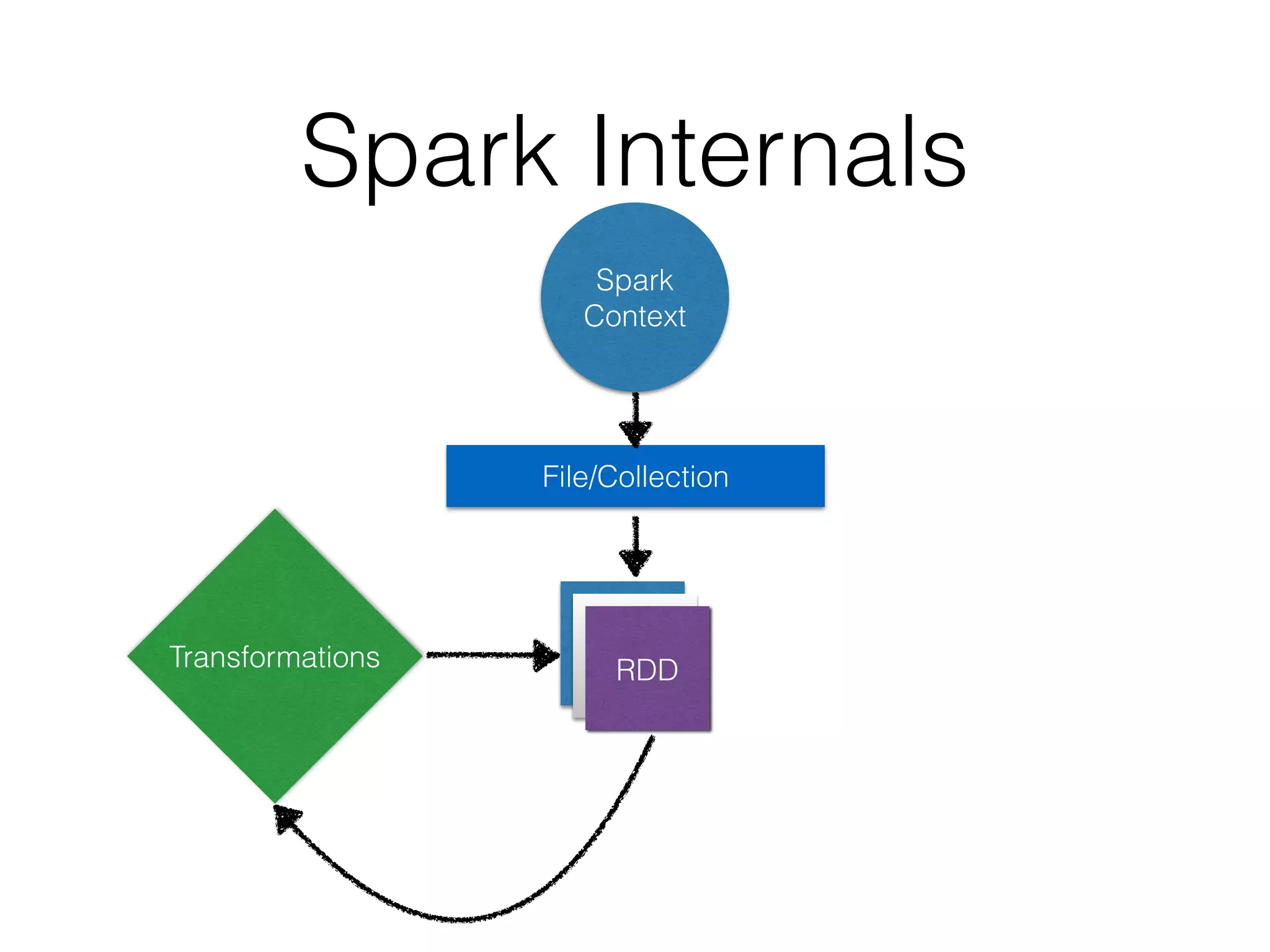
The Key Idea
Resilient Distributed Datasets
• Basic unit of abstraction of data
• Immutable
• Persistance
>>> data = [90, 14, 20, 86, 43, 55, 30, 94 ]
>>> distData = sc.parallelize(data)
ParallelCollectionRDD[13] at parallelize at
PythonRDD.scala:364](https://image.slidesharecdn.com/spark-150511063017-lva1-app6891/85/Python-and-Bigdata-An-Introduction-to-Spark-PySpark-13-320.jpg)




![Spark Internals
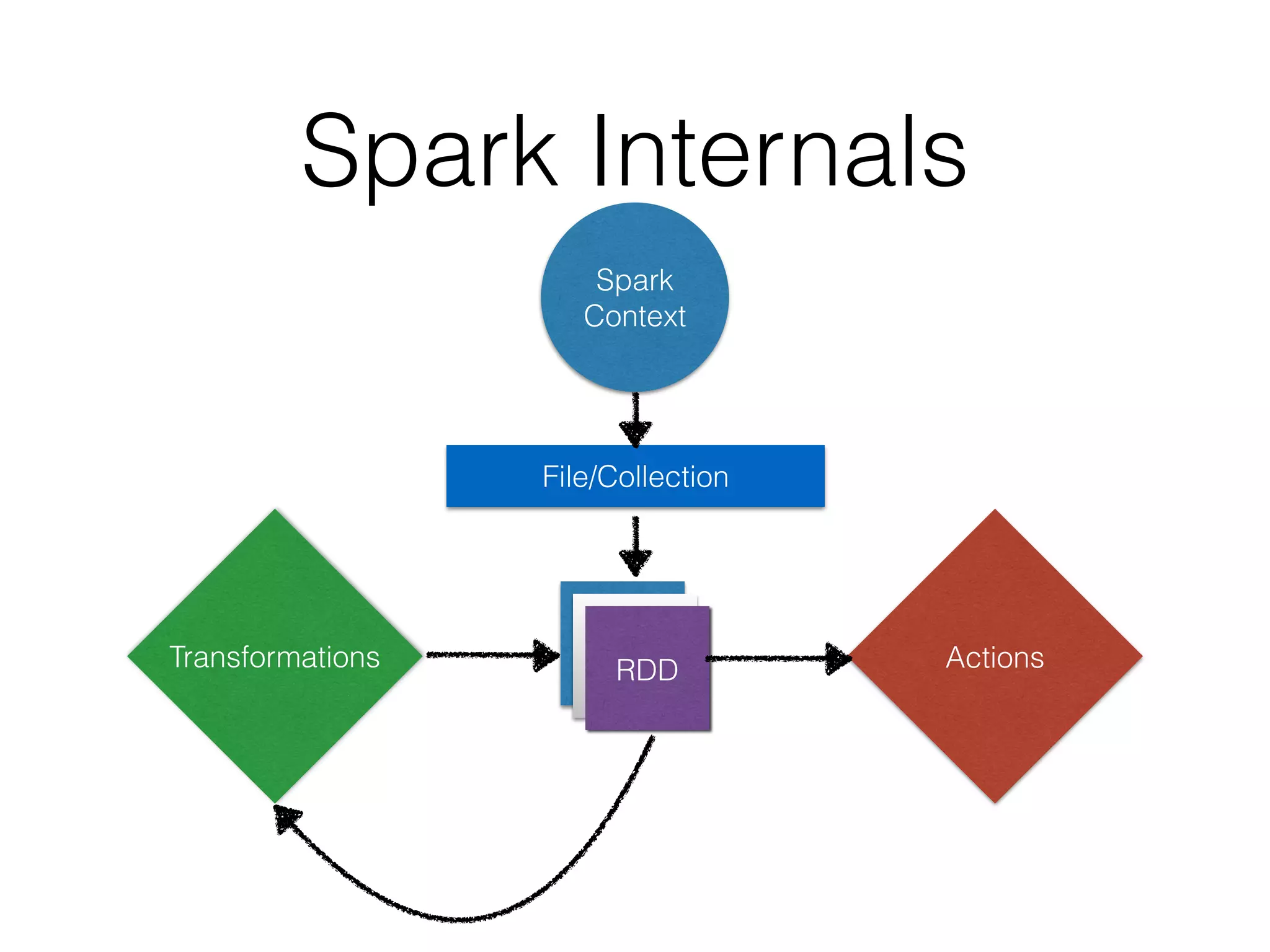
>>> increment_rdd = distData.map(mapFunc)
>>> increment_rdd.collect()
[91, 15, 21, 87, 44, 56, 31, 95]
>>>
>>> increment_rdd.filter(filterFunc).collect()
[44, 56]
OR
>>> distData.map(mapFunc).filter(filterFunc).collect()
[44, 56]](https://image.slidesharecdn.com/spark-150511063017-lva1-app6891/85/Python-and-Bigdata-An-Introduction-to-Spark-PySpark-20-320.jpg)















![Spark Internals
The Key Idea
Resilient Distributed Datasets
• Basic unit of abstraction of data
• Immutable
• Persistance
>>> data = [90, 14, 20, 86, 43, 55, 30, 94 ]
>>> distData = sc.parallelize(data)
ParallelCollectionRDD[13] at parallelize at
PythonRDD.scala:364](https://image.slidesharecdn.com/spark-150511063017-lva1-app6891/75/Python-and-Bigdata-An-Introduction-to-Spark-PySpark-13-2048.jpg)




![Spark Internals
>>> increment_rdd = distData.map(mapFunc)
>>> increment_rdd.collect()
[91, 15, 21, 87, 44, 56, 31, 95]
>>>
>>> increment_rdd.filter(filterFunc).collect()
[44, 56]
OR
>>> distData.map(mapFunc).filter(filterFunc).collect()
[44, 56]](https://image.slidesharecdn.com/spark-150511063017-lva1-app6891/75/Python-and-Bigdata-An-Introduction-to-Spark-PySpark-20-2048.jpg)