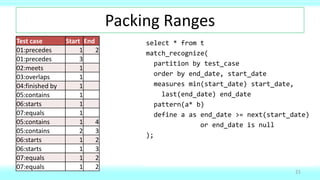
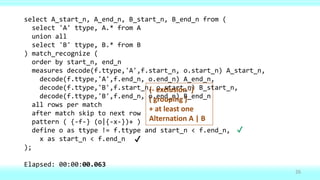
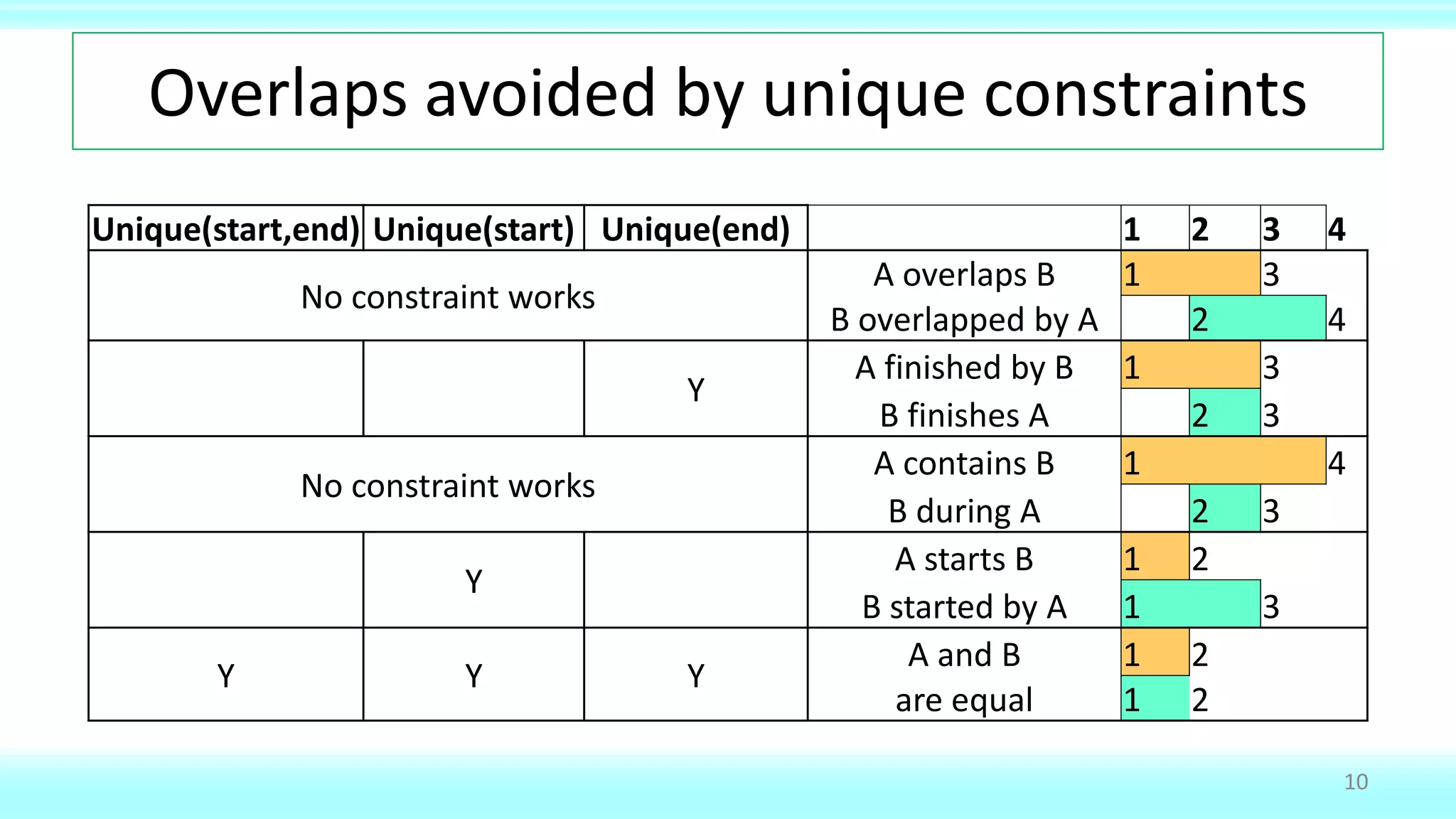
This document provides an overview of defining and working with ranges of values in databases. It defines ranges as two values that can be compared, discusses design choices around inclusive vs exclusive end values for ranges, and provides examples of SQL queries for common range-related tasks like finding gaps, intersections (overlaps), unioning ranges, and joining tables with range columns. The document also discusses techniques for ensuring ranges don't overlap like using virtual or semi-virtual ranges.




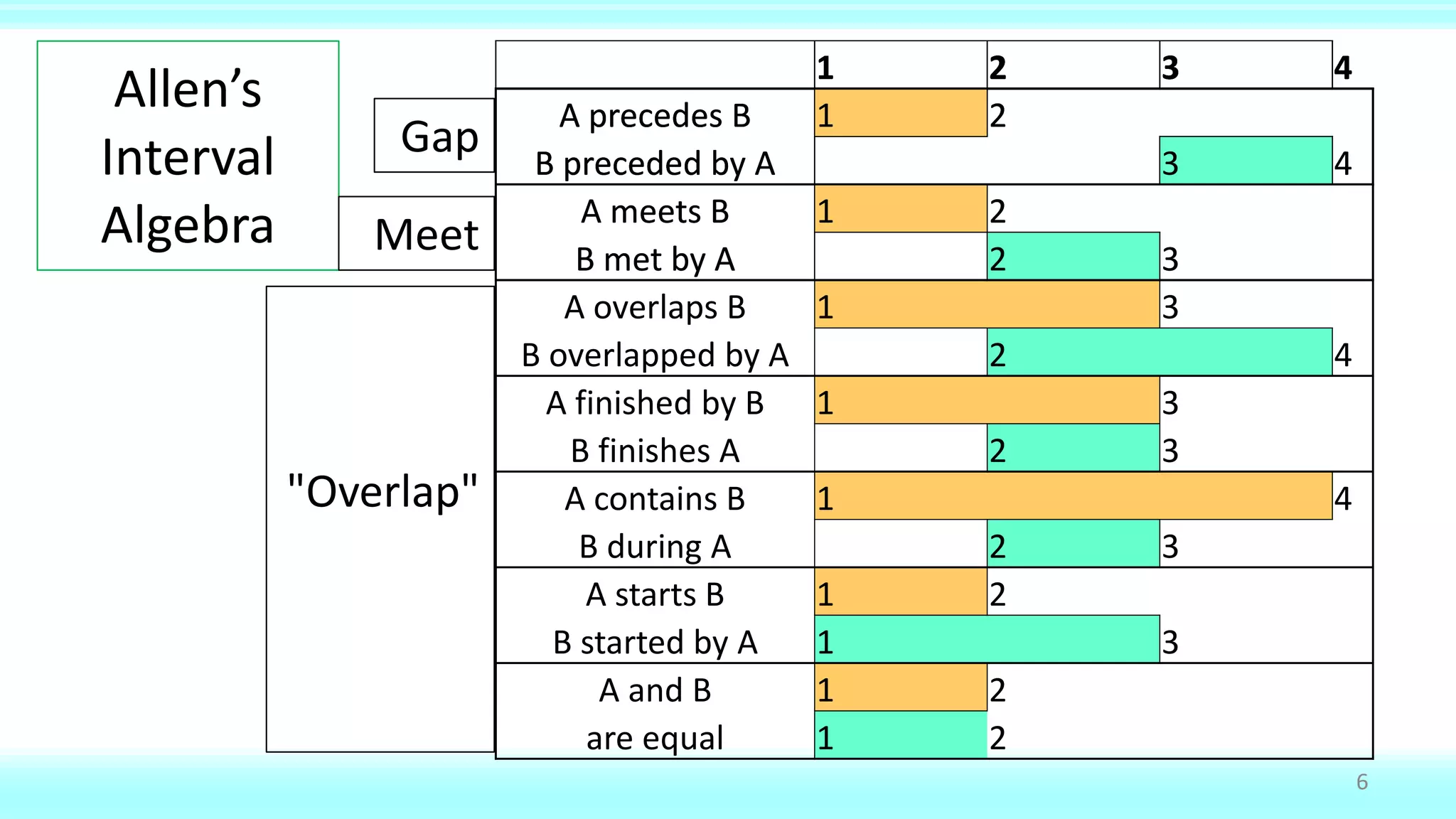
![End value: Inclusive or Exclusive
• Design must allow ranges to "meet"
• Discrete quantities can be inclusive
– [1-3] meets [4-6] : no intermediate integer
– [Jan. 1-31] meets [Feb. 1-28] : no intermediate date
• Continuous quantities require exclusive
– Most ranges are continuous (including dates, really)
7](https://image.slidesharecdn.com/rangesrangeseverywhere-161116100050/85/Ranges-ranges-everywhere-Oracle-SQL-7-320.jpg)






















![End value: Inclusive or Exclusive
• Design must allow ranges to "meet"
• Discrete quantities can be inclusive
– [1-3] meets [4-6] : no intermediate integer
– [Jan. 1-31] meets [Feb. 1-28] : no intermediate date
• Continuous quantities require exclusive
– Most ranges are continuous (including dates, really)
7](https://image.slidesharecdn.com/rangesrangeseverywhere-161116100050/75/Ranges-ranges-everywhere-Oracle-SQL-7-2048.jpg)


















































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)












