Downloaded 16 times

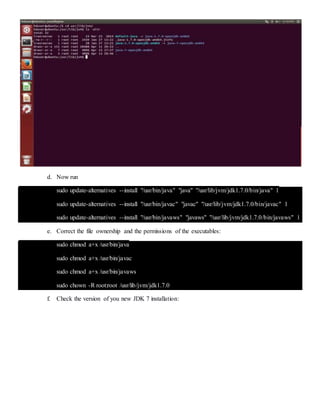

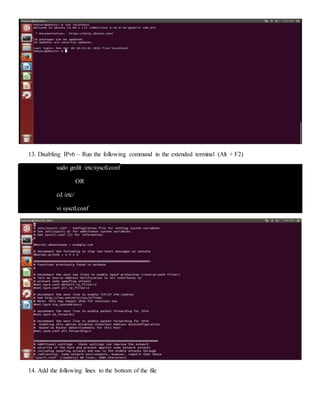
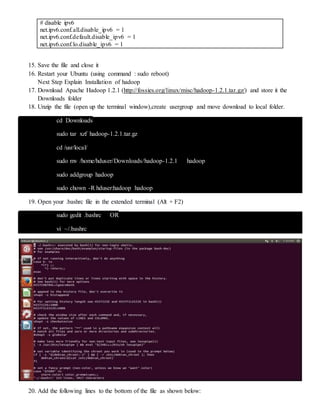

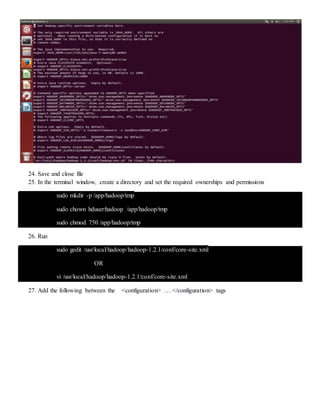
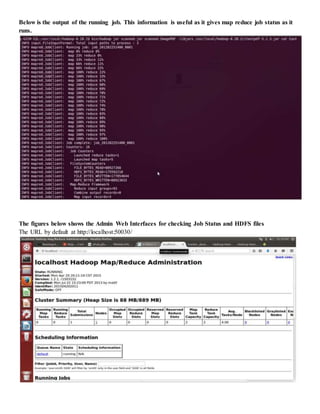
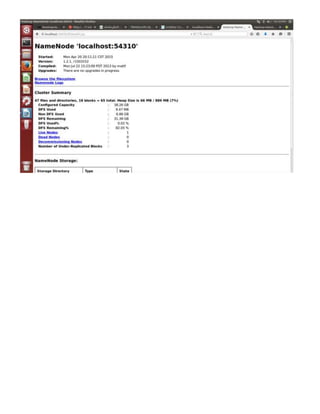


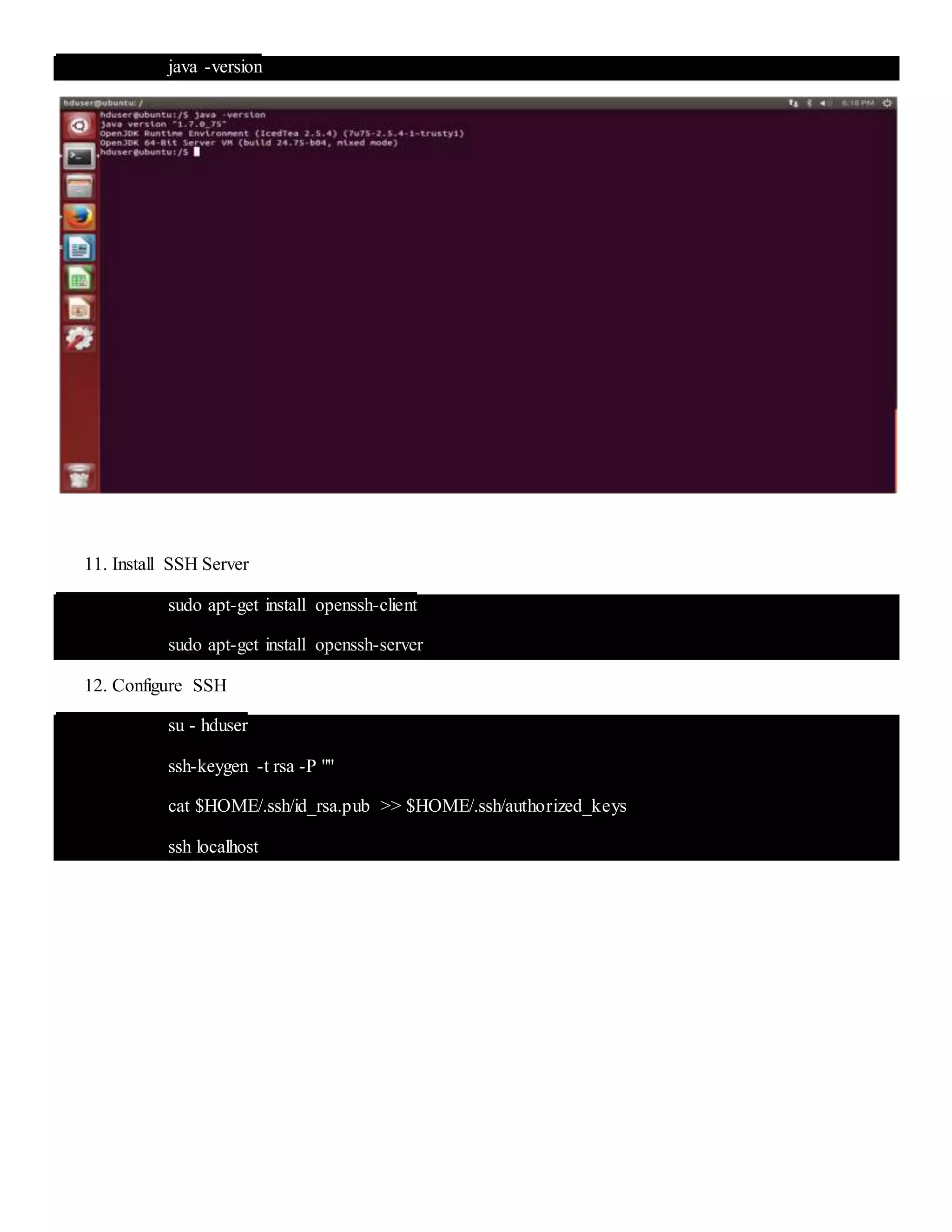
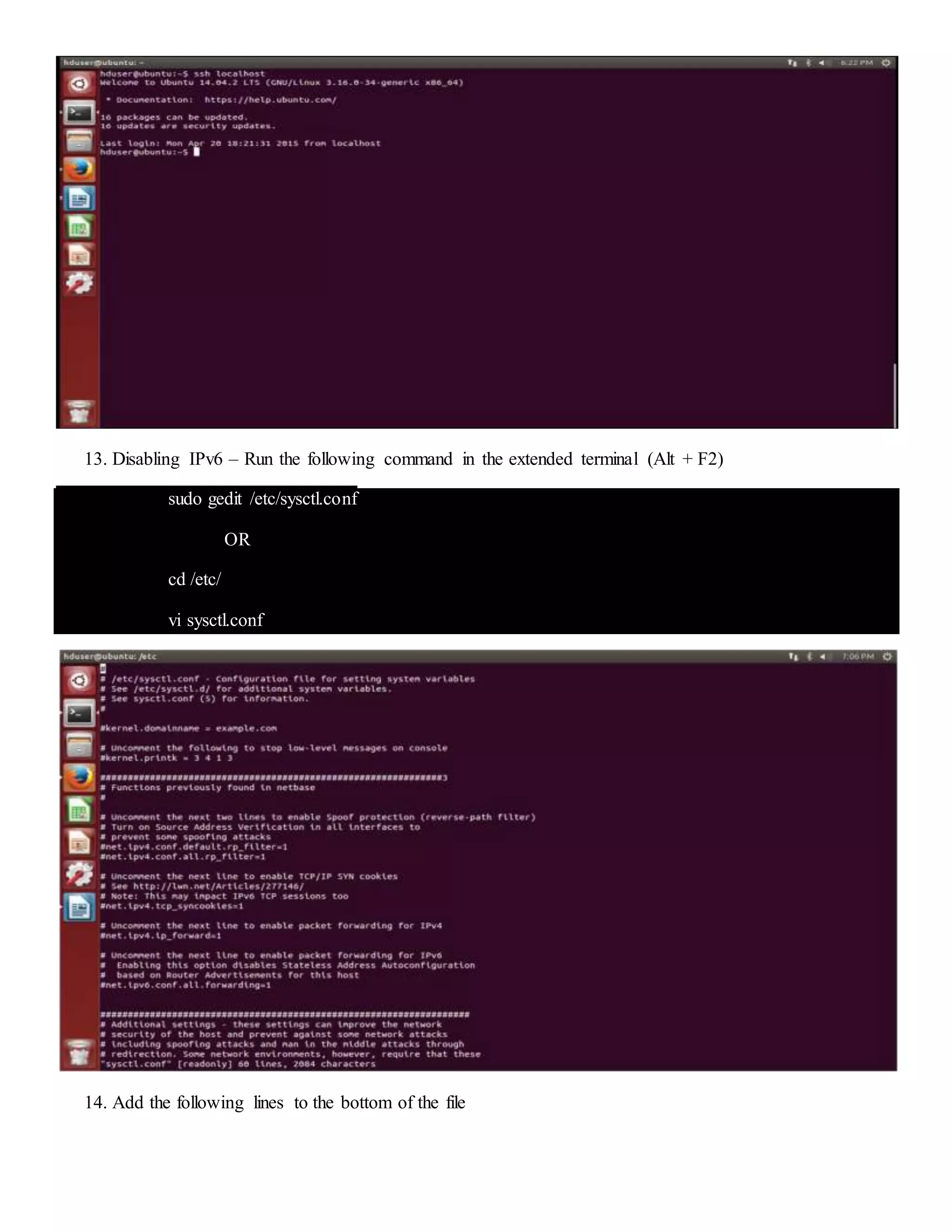

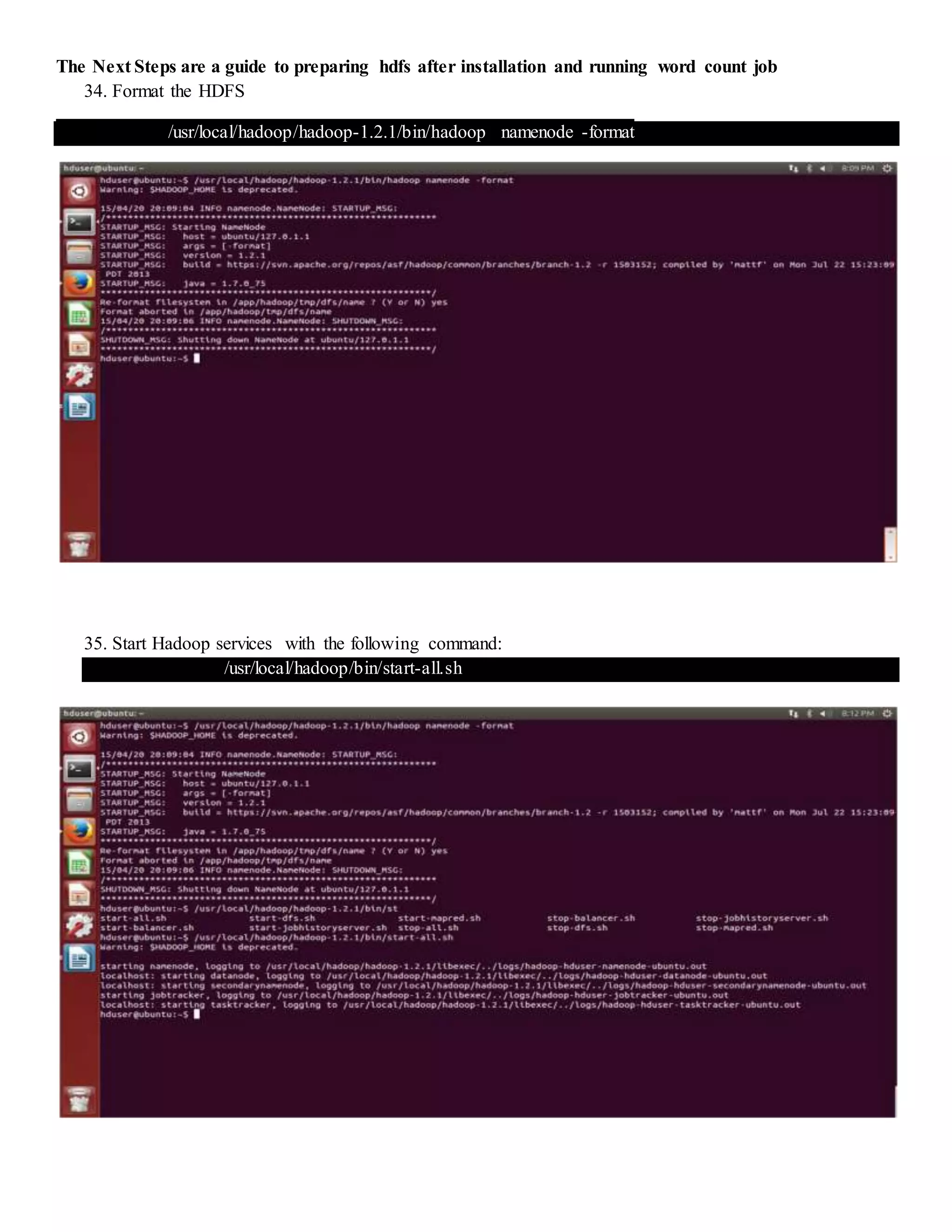
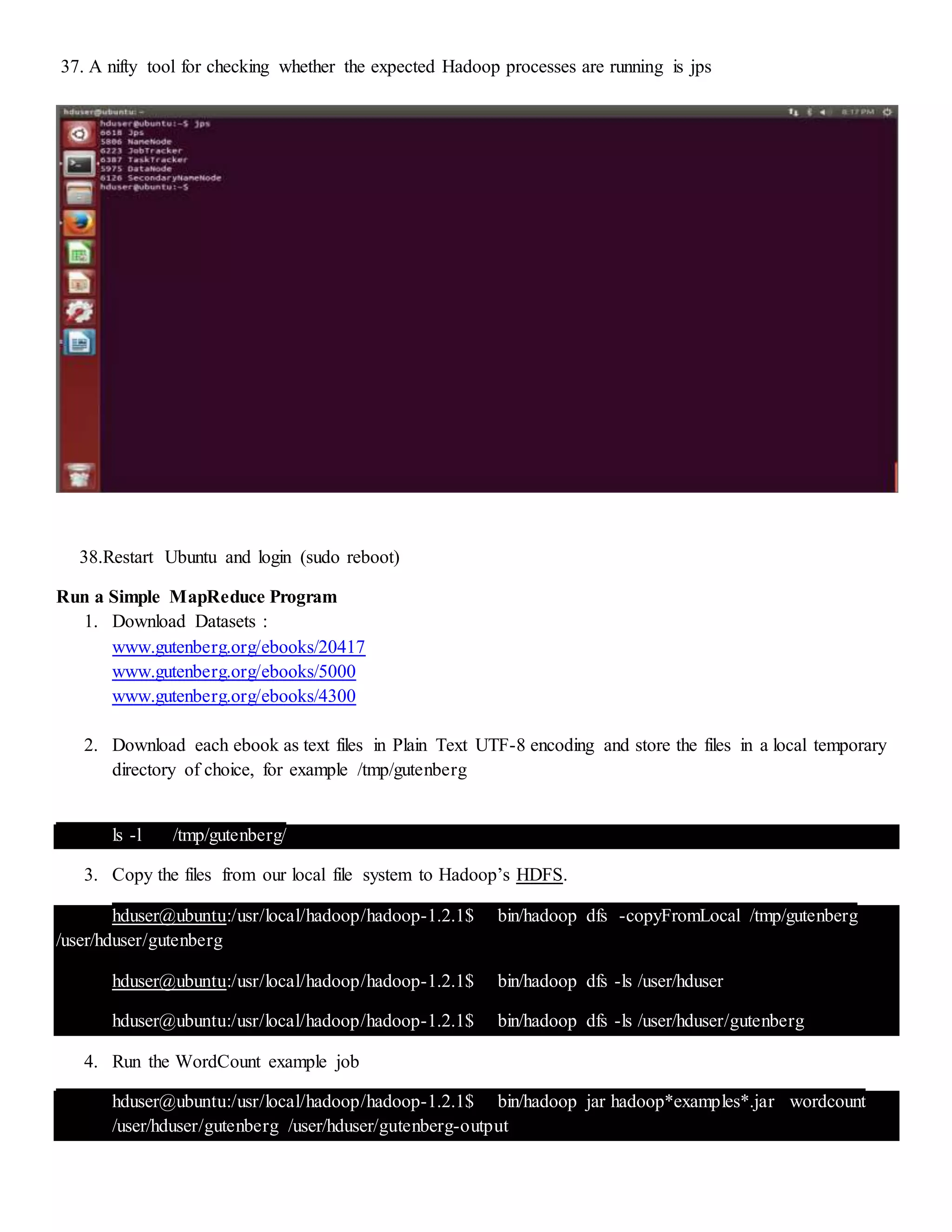
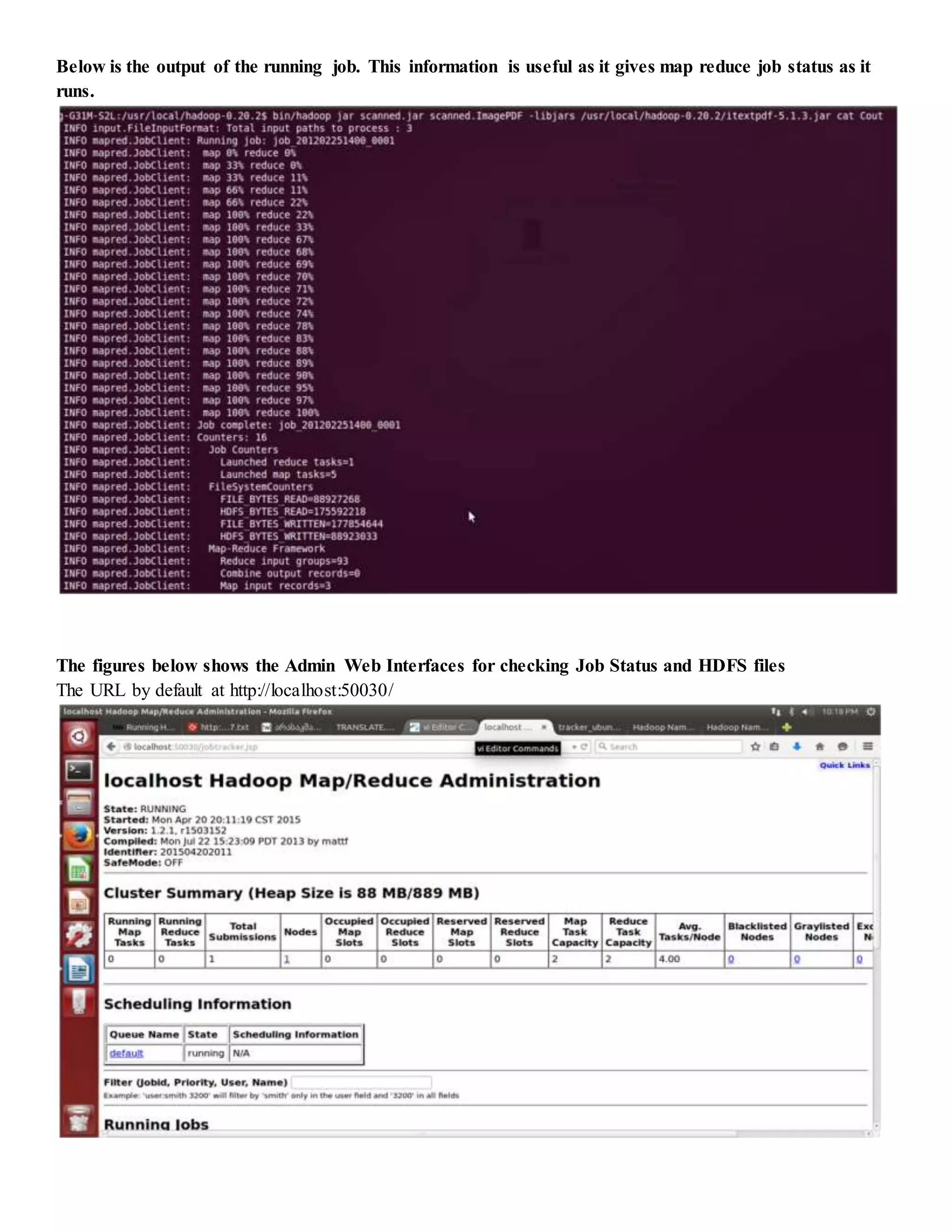
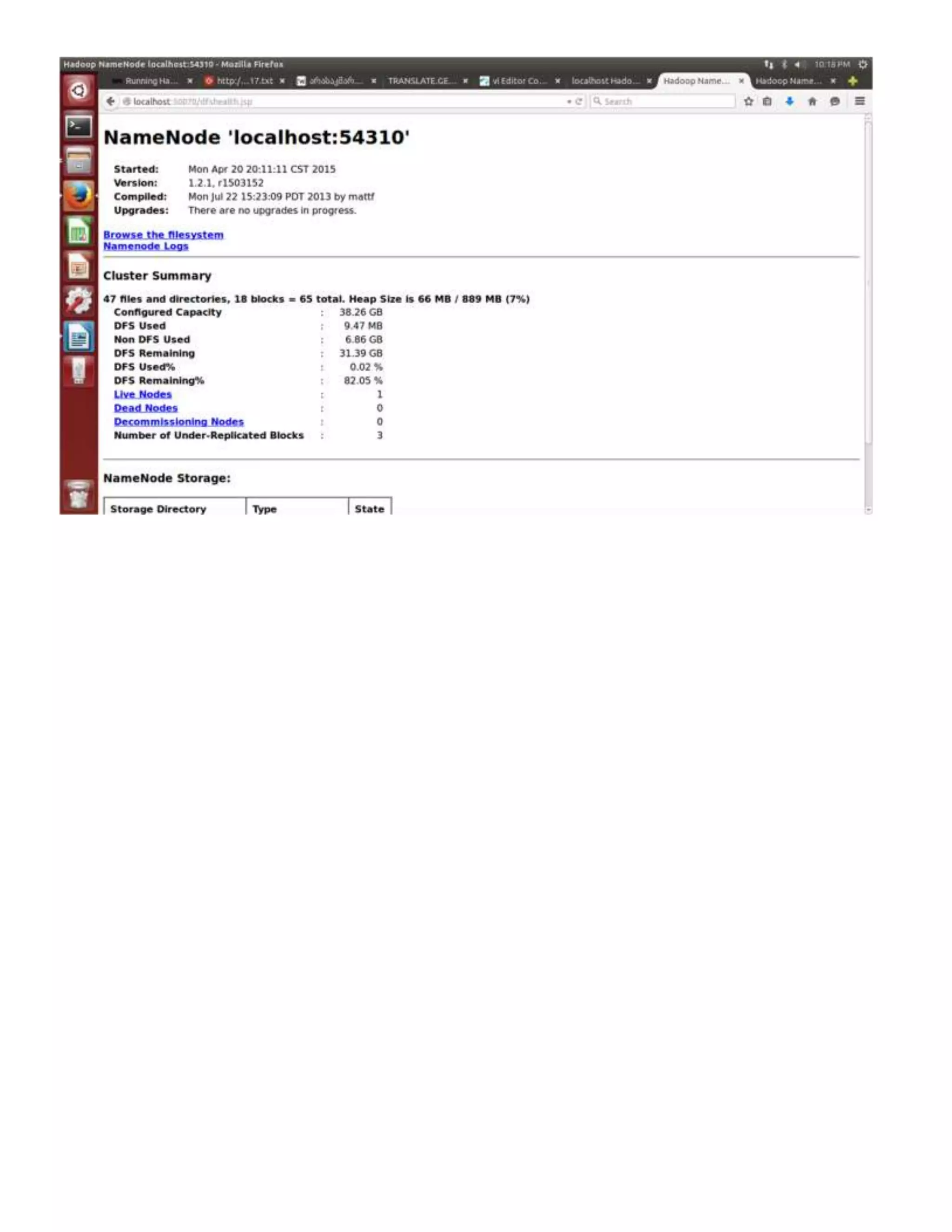

The document provides step-by-step instructions for installing a single-node Hadoop cluster on Ubuntu Linux using VMware. It details downloading and configuring required software like Java, SSH, and Hadoop. Configuration files are edited to set properties for core Hadoop functions and enable HDFS. Finally, sample data is copied to HDFS and a word count MapReduce job is run to test the installation.







































































