Downloaded 237 times

















![Format a new system
notroot@ubuntu:/usr/local/hadoop/conf$ su - hduser
Password:
hduser@ubuntu:~$ /usr/local/hadoop/bin/hadoop namenode -format
13/04/03 13:41:24 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu.localdomain/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.4
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1393290;
compiled by 'hortonfo' on Wed Oct 3 05:13:58 UTC 2012
************************************************************/
Re-format filesystem in /hadoop_data/name ? (Y or N) Y
13/04/03 13:41:26 INFO util.GSet: VM type = 32-bit
13/04/03 13:41:26 INFO util.GSet: 2% max memory = 19.33375 MB
13/04/03 13:41:26 INFO util.GSet: capacity = 2^22 = 4194304 entries
….
13/04/03 13:41:28 INFO common.Storage: Storage directory /hadoop_data/name has been successfully formatted.
13/04/03 13:41:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu.localdomain/127.0.1.1
************************************************************/
Do not format a running Hadoop file system as you will lose all the
data currently in the cluster (in HDFS)!](https://image.slidesharecdn.com/hadoopsingleclusterinstallation-130527124305-phpapp01/85/Hadoop-single-cluster-installation-18-320.jpg)





























![Format a new system
notroot@ubuntu:/usr/local/hadoop/conf$ su - hduser
Password:
hduser@ubuntu:~$ /usr/local/hadoop/bin/hadoop namenode -format
13/04/03 13:41:24 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ubuntu.localdomain/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.4
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1393290;
compiled by 'hortonfo' on Wed Oct 3 05:13:58 UTC 2012
************************************************************/
Re-format filesystem in /hadoop_data/name ? (Y or N) Y
13/04/03 13:41:26 INFO util.GSet: VM type = 32-bit
13/04/03 13:41:26 INFO util.GSet: 2% max memory = 19.33375 MB
13/04/03 13:41:26 INFO util.GSet: capacity = 2^22 = 4194304 entries
….
13/04/03 13:41:28 INFO common.Storage: Storage directory /hadoop_data/name has been successfully formatted.
13/04/03 13:41:28 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu.localdomain/127.0.1.1
************************************************************/
Do not format a running Hadoop file system as you will lose all the
data currently in the cluster (in HDFS)!](https://image.slidesharecdn.com/hadoopsingleclusterinstallation-130527124305-phpapp01/75/Hadoop-single-cluster-installation-18-2048.jpg)








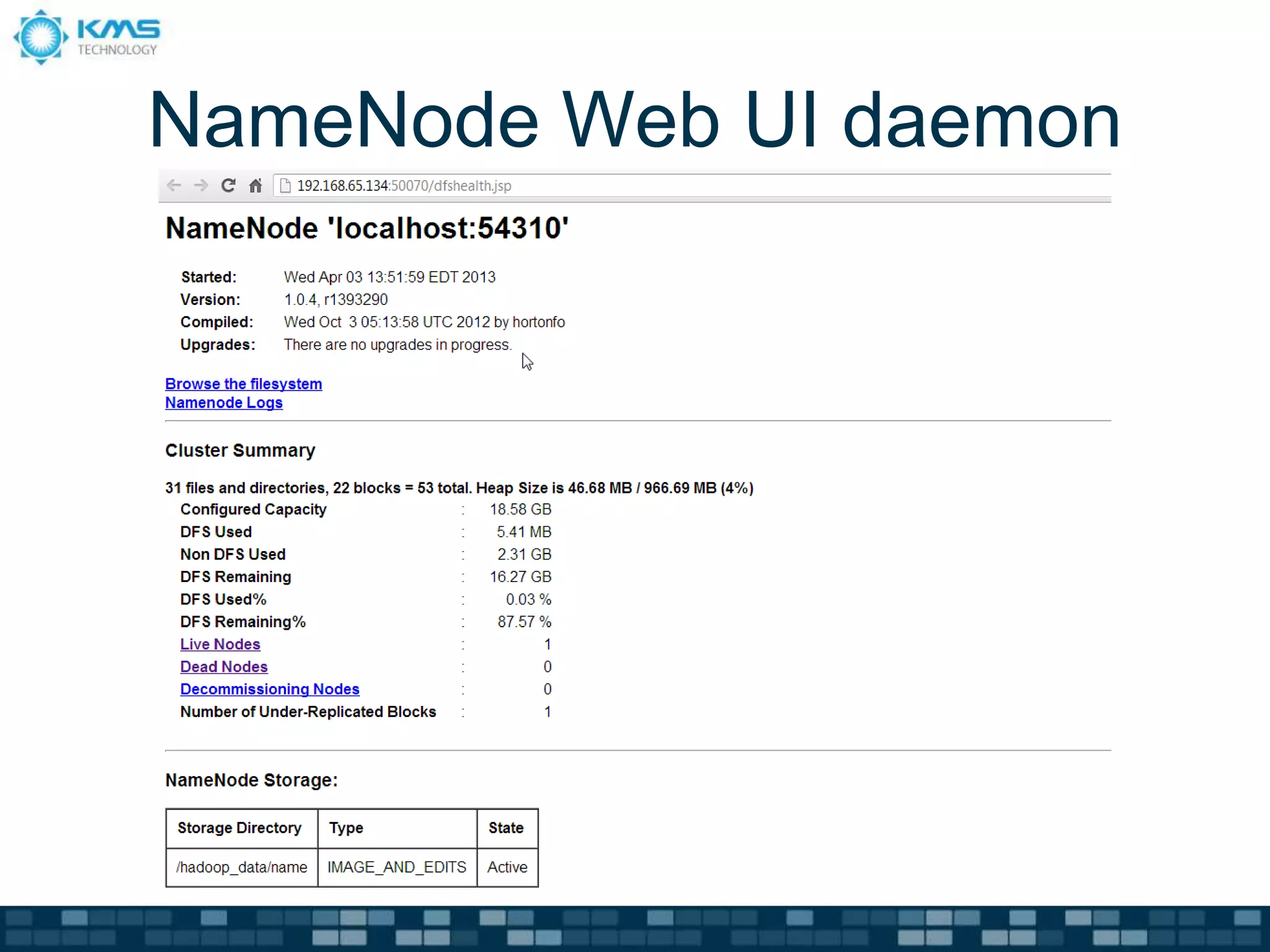





The document details the steps for installing Hadoop on an Ubuntu server, including prerequisites such as installing JDK, SSH, and Hadoop itself. It describes how to configure the environment, start a single-node cluster, run a MapReduce job using example eBooks, and check the Hadoop process status. Configuration files and command examples are provided for clarity throughout the installation process.



























































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




