KEMBAR78
Daftar
Login
Running Apache Spark on AWS | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Noritaka Sekiyama
PDF, PPTX
982 views
Running Apache Spark on AWS
2019/09/26にdb tech showcase tokyo 2019で発表した「Running Apache Spark on AWS」のスライド資料です。
Software
◦
Read more
0
Save
Share
Embed
Download
Download as PDF, PPTX
1
/ 81
2
/ 81
3
/ 81
4
/ 81
5
/ 81
6
/ 81
7
/ 81
8
/ 81
9
/ 81
10
/ 81
11
/ 81
12
/ 81
13
/ 81
14
/ 81
15
/ 81
16
/ 81
17
/ 81
18
/ 81
19
/ 81
20
/ 81
21
/ 81
22
/ 81
23
/ 81
24
/ 81
25
/ 81
26
/ 81
27
/ 81
28
/ 81
29
/ 81
30
/ 81
31
/ 81
32
/ 81
33
/ 81
34
/ 81
35
/ 81
36
/ 81
37
/ 81
38
/ 81
39
/ 81
40
/ 81
41
/ 81
42
/ 81
43
/ 81
44
/ 81
45
/ 81
46
/ 81
47
/ 81
48
/ 81
49
/ 81
50
/ 81
51
/ 81
52
/ 81
53
/ 81
54
/ 81
55
/ 81
56
/ 81
57
/ 81
58
/ 81
59
/ 81
60
/ 81
61
/ 81
62
/ 81
63
/ 81
64
/ 81
65
/ 81
66
/ 81
67
/ 81
68
/ 81
69
/ 81
70
/ 81
71
/ 81
72
/ 81
73
/ 81
74
/ 81
75
/ 81
76
/ 81
77
/ 81
78
/ 81
79
/ 81
80
/ 81
81
/ 81
More Related Content
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPTX
Sparkにプルリク投げてみた
by
Noritaka Sekiyama
PDF
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
PDF
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
PPTX
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PDF
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
PDF
[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる
by
Takahiro Moteki
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
Sparkにプルリク投げてみた
by
Noritaka Sekiyama
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる
by
Takahiro Moteki
What's hot
PDF
Apache Sparkについて
by
BrainPad Inc.
PDF
Run Spark on EMRってどんな仕組みになってるの?
by
Satoshi Noto
PPTX
オンプレからAuroraへの移行とその効果
by
Masato Kataoka
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
PDF
Sparkパフォーマンス検証
by
BrainPad Inc.
PDF
20191120 AWS Black Belt Online Seminar Amazon Managed Streaming for Apache Ka...
by
Amazon Web Services Japan
PPTX
スケーラブルな Deep Leaning フレームワーク "Apache MXNet” を AWS で学ぶ
by
Amazon Web Services Japan
PDF
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
PDF
Growing up serverless
by
Amazon Web Services Japan
PPTX
Oracle racからaurora my sqlへの移行
by
recotech
PDF
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PPTX
研究用途でのAWSの利用事例と機械学習について
by
Yasuhiro Matsuo
PDF
20201214 AWS Black Belt Online Seminar 2020 年 AWS re:Invent 速報 Part2
by
Amazon Web Services Japan
PDF
ついに解禁!Amazon Aurora徹底検証!
by
Terui Masashi
PDF
MapReduceを置き換えるSpark 〜HadoopとSparkの統合〜 #cwt2015
by
Cloudera Japan
PDF
Apache Arrow 2019
by
Kouhei Sutou
PDF
AWS サービスアップデートまとめ re:Invent 2017 直前編
by
Amazon Web Services Japan
PDF
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
PDF
クラウド入門(AWS編)
by
株式会社オプト 仙台ラボラトリ
Apache Sparkについて
by
BrainPad Inc.
Run Spark on EMRってどんな仕組みになってるの?
by
Satoshi Noto
オンプレからAuroraへの移行とその効果
by
Masato Kataoka
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
Sparkパフォーマンス検証
by
BrainPad Inc.
20191120 AWS Black Belt Online Seminar Amazon Managed Streaming for Apache Ka...
by
Amazon Web Services Japan
スケーラブルな Deep Leaning フレームワーク "Apache MXNet” を AWS で学ぶ
by
Amazon Web Services Japan
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
Growing up serverless
by
Amazon Web Services Japan
Oracle racからaurora my sqlへの移行
by
recotech
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
研究用途でのAWSの利用事例と機械学習について
by
Yasuhiro Matsuo
20201214 AWS Black Belt Online Seminar 2020 年 AWS re:Invent 速報 Part2
by
Amazon Web Services Japan
ついに解禁!Amazon Aurora徹底検証!
by
Terui Masashi
MapReduceを置き換えるSpark 〜HadoopとSparkの統合〜 #cwt2015
by
Cloudera Japan
Apache Arrow 2019
by
Kouhei Sutou
AWS サービスアップデートまとめ re:Invent 2017 直前編
by
Amazon Web Services Japan
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
クラウド入門(AWS編)
by
株式会社オプト 仙台ラボラトリ
Similar to Running Apache Spark on AWS
PDF
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
PDF
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar 2016 Amazon EMR
by
Amazon Web Services Japan
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
PDF
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
PDF
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
PPTX
20170803 bigdataevent
by
Makoto Uehara
PPTX
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPTX
【AWS Summit Tokyo 2017】Amazon ECS と SpotFleet を活用した低コストでスケーラブルなジョブワーカーシステム
by
Kazuki Matsuda
PPTX
HPC on AWS 2020 Summer
by
Daisuke Miyamoto
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
AWS Black Belt Online Seminar 2016 Amazon EC2 Container Service
by
Amazon Web Services Japan
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
PPTX
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
PDF
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
PDF
Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)
by
Amazon Web Services Japan
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)
by
Amazon Web Services Japan
AWS Black Belt Online Seminar 2016 Amazon EMR
by
Amazon Web Services Japan
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
20111130 10 aws-meister-emr_long-public
by
Amazon Web Services Japan
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
Apache Big Data Miami 2017 - Hadoop Source Code Reading #23 #hadoopreading
by
Yahoo!デベロッパーネットワーク
20170803 bigdataevent
by
Makoto Uehara
ATN No.1 Hadoop vs Amazon EMR
by
AdvancedTechNight
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
【AWS Summit Tokyo 2017】Amazon ECS と SpotFleet を活用した低コストでスケーラブルなジョブワーカーシステム
by
Kazuki Matsuda
HPC on AWS 2020 Summer
by
Daisuke Miyamoto
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
AWS Black Belt Online Seminar 2016 Amazon EC2 Container Service
by
Amazon Web Services Japan
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
基幹業務もHadoop(EMR)で!!のその後
by
Keigo Suda
リクルートテクノロジーズ における EMR の活用とコスト圧縮方法
by
Tetsutaro Watanabe
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)
by
Amazon Web Services Japan
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
More from Noritaka Sekiyama
PPTX
5分ではじめるApache Spark on AWS
by
Noritaka Sekiyama
PDF
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
PDF
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
by
Noritaka Sekiyama
PDF
Introduction to New CloudWatch Agent
by
Noritaka Sekiyama
PPTX
Security Operations and Automation on AWS
by
Noritaka Sekiyama
PDF
運用視点でのAWSサポート利用Tips
by
Noritaka Sekiyama
PPTX
基礎から学ぶ? EC2マルチキャスト
by
Noritaka Sekiyama
PDF
Floodlightってぶっちゃけどうなの?
by
Noritaka Sekiyama
5分ではじめるApache Spark on AWS
by
Noritaka Sekiyama
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
by
Noritaka Sekiyama
Introduction to New CloudWatch Agent
by
Noritaka Sekiyama
Security Operations and Automation on AWS
by
Noritaka Sekiyama
運用視点でのAWSサポート利用Tips
by
Noritaka Sekiyama
基礎から学ぶ? EC2マルチキャスト
by
Noritaka Sekiyama
Floodlightってぶっちゃけどうなの?
by
Noritaka Sekiyama
Running Apache Spark on AWS
1.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Noritaka Sekiyama 2019.9.26 Running Apache Spark on AWS db tech showcase Tokyo 2019
2.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. ⾃⼰紹介 関⼭ 宜孝 Big Data Architect AWS Glue and Lake Formation • 約 5年間 AWS サポートにて技術⽀援を担当 • 2019.8 からプロダクトチームにジョイン • AWS でデータレイクを構築するための アーティファクトの実装や アーキテクティングの⽀援を担当 @moomindani
3.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 本セッションの狙い AWS クラウド上で Apache Spark を使いこなすための 便利機能、チューニング、実装と仕組み、 使い分けのベストプラクティスを学ぶ
4.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 本セッションで話さないこと Apache Spark で Amazon S3 を使いこなす⽅法 https://www.slideshare.net/ssuserca76a5/hcj2019-hadoop-sparks3
5.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. アジェンダ Spark on Amazon EMR • マルチマスター構成での Spark 活⽤ • メモリ管理のベストプラクティス • EMR における Spark の改善 Spark on AWS Glue • Glue における Spark の拡張 • Spark ジョブのオーケストレーション
6.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS 上で Apache Spark を利⽤する選択肢 Spark on Amazon EC2 Spark on Amazon EMR Spark on AWS Glue Amazon EC2 Amazon EMR AWS Glue
7.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on Amazon EMR
8.
© 2019, Amazon
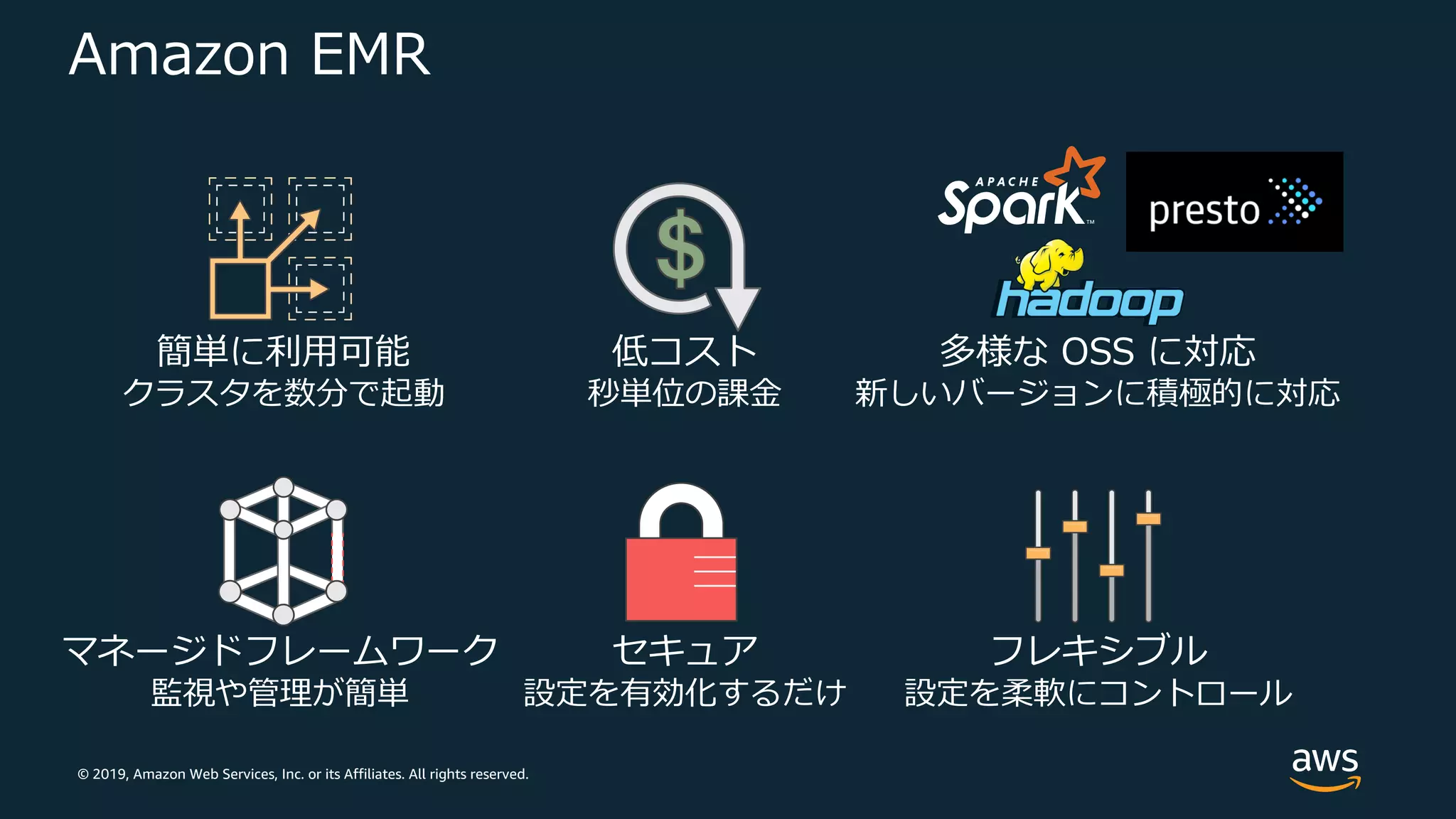
Web Services, Inc. or its Affiliates. All rights reserved. Amazon EMR 簡単に利⽤可能 クラスタを数分で起動 低コスト 秒単位の課⾦ 多様な OSS に対応 新しいバージョンに積極的に対応 マネージドフレームワーク 監視や管理が簡単 セキュア 設定を有効化するだけ フレキシブル 設定を柔軟にコントロール
9.
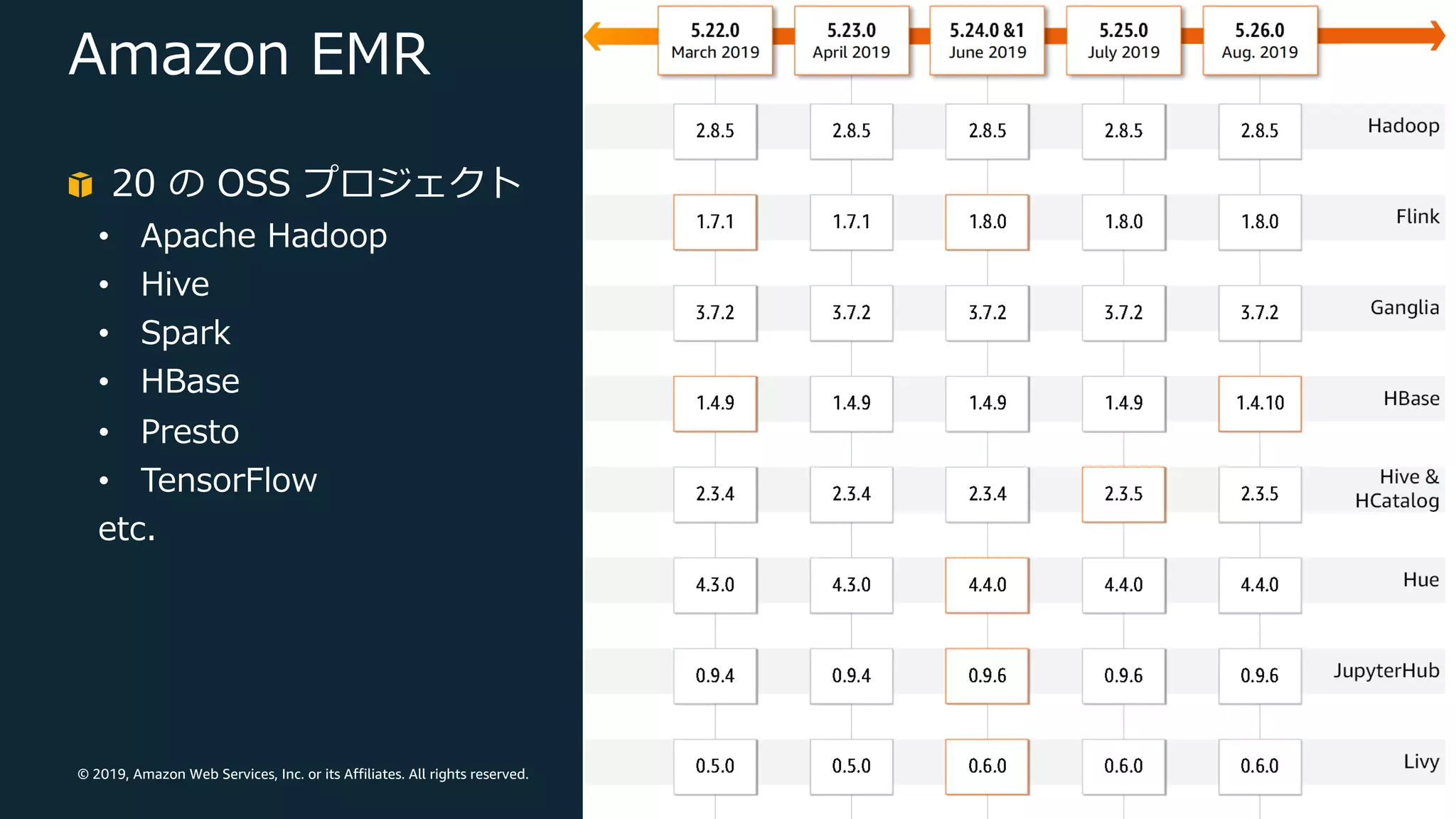
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Amazon EMR 20 の OSS プロジェクト • Apache Hadoop • Hive • Spark • HBase • Presto • TensorFlow etc.
10.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on Amazon EMR - マルチマスター構成での Spark 活⽤
11.
© 2019, Amazon
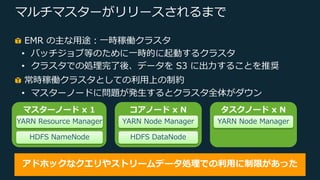
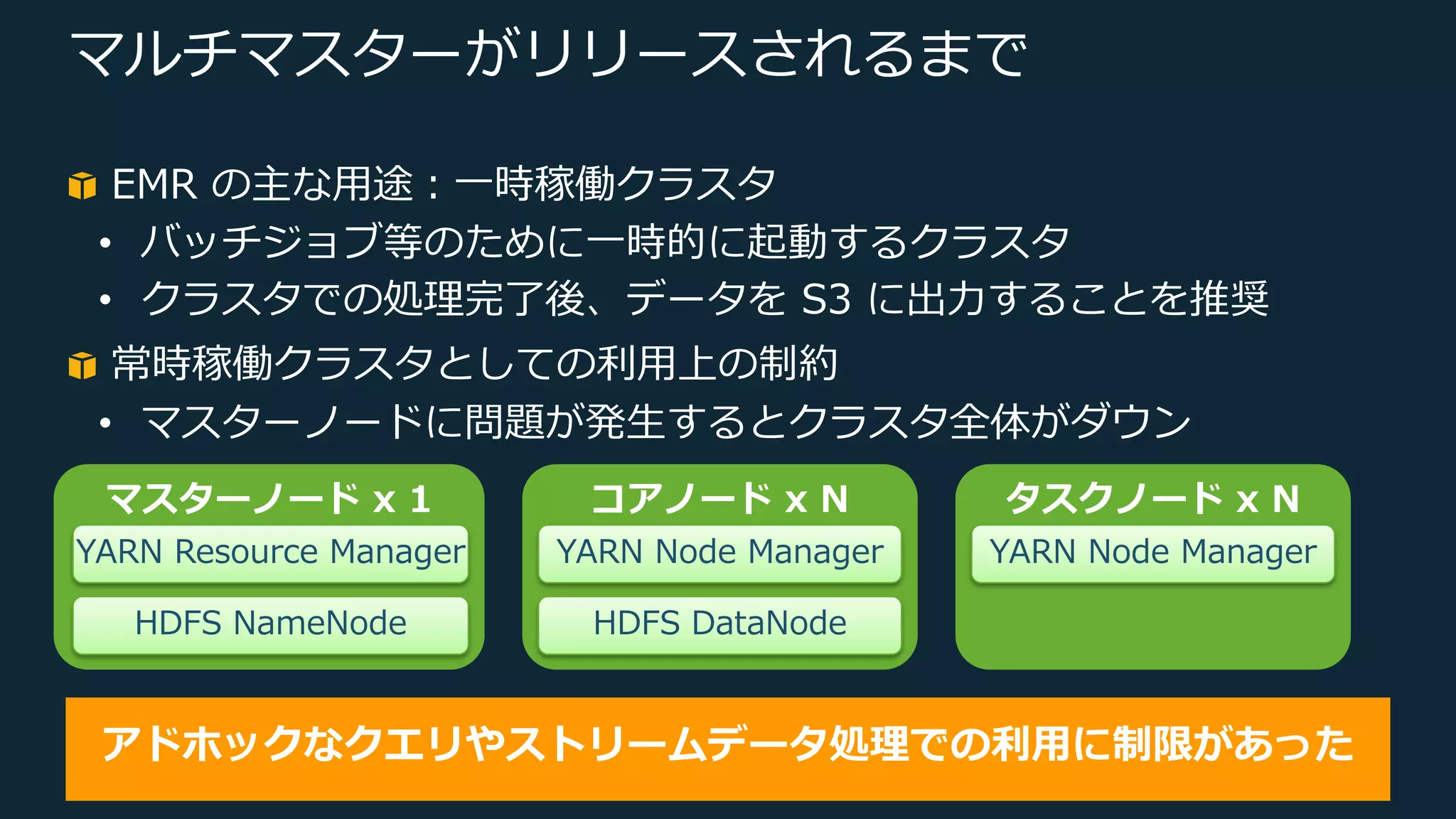
Web Services, Inc. or its Affiliates. All rights reserved. マルチマスターがリリースされるまで EMR の主な⽤途︓⼀時稼働クラスタ • バッチジョブ等のために⼀時的に起動するクラスタ • クラスタでの処理完了後、データを S3 に出⼒することを推奨 常時稼働クラスタとしての利⽤上の制約 • マスターノードに問題が発⽣するとクラスタ全体がダウン アドホックなクエリやストリームデータ処理での利⽤に制限があった マスターノード x 1 YARN Resource Manager HDFS NameNode コアノード x N YARN Node Manager HDFS DataNode タスクノード x N YARN Node Manager
12.
© 2019, Amazon
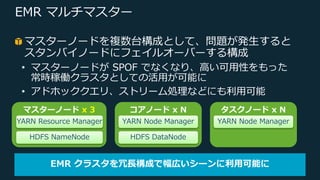
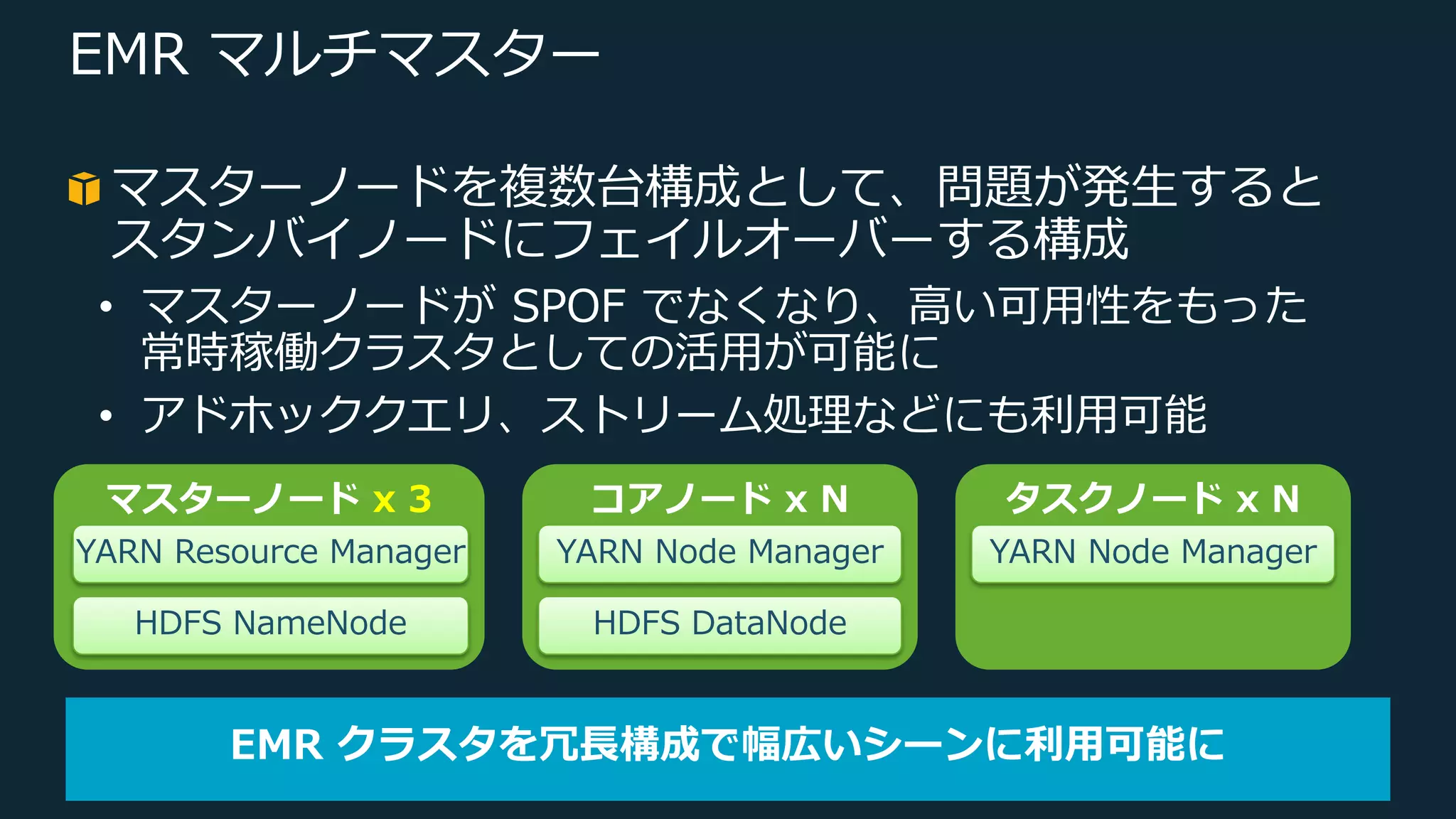
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスター マスターノードを複数台構成として、問題が発⽣すると スタンバイノードにフェイルオーバーする構成 • マスターノードが SPOF でなくなり、⾼い可⽤性をもった 常時稼働クラスタとしての活⽤が可能に • アドホッククエリ、ストリーム処理などにも利⽤可能 EMR クラスタを冗⻑構成で幅広いシーンに利⽤可能に マスターノード x 3 YARN Resource Manager HDFS NameNode コアノード x N YARN Node Manager HDFS DataNode タスクノード x N YARN Node Manager
13.
© 2019, Amazon
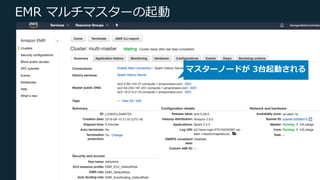
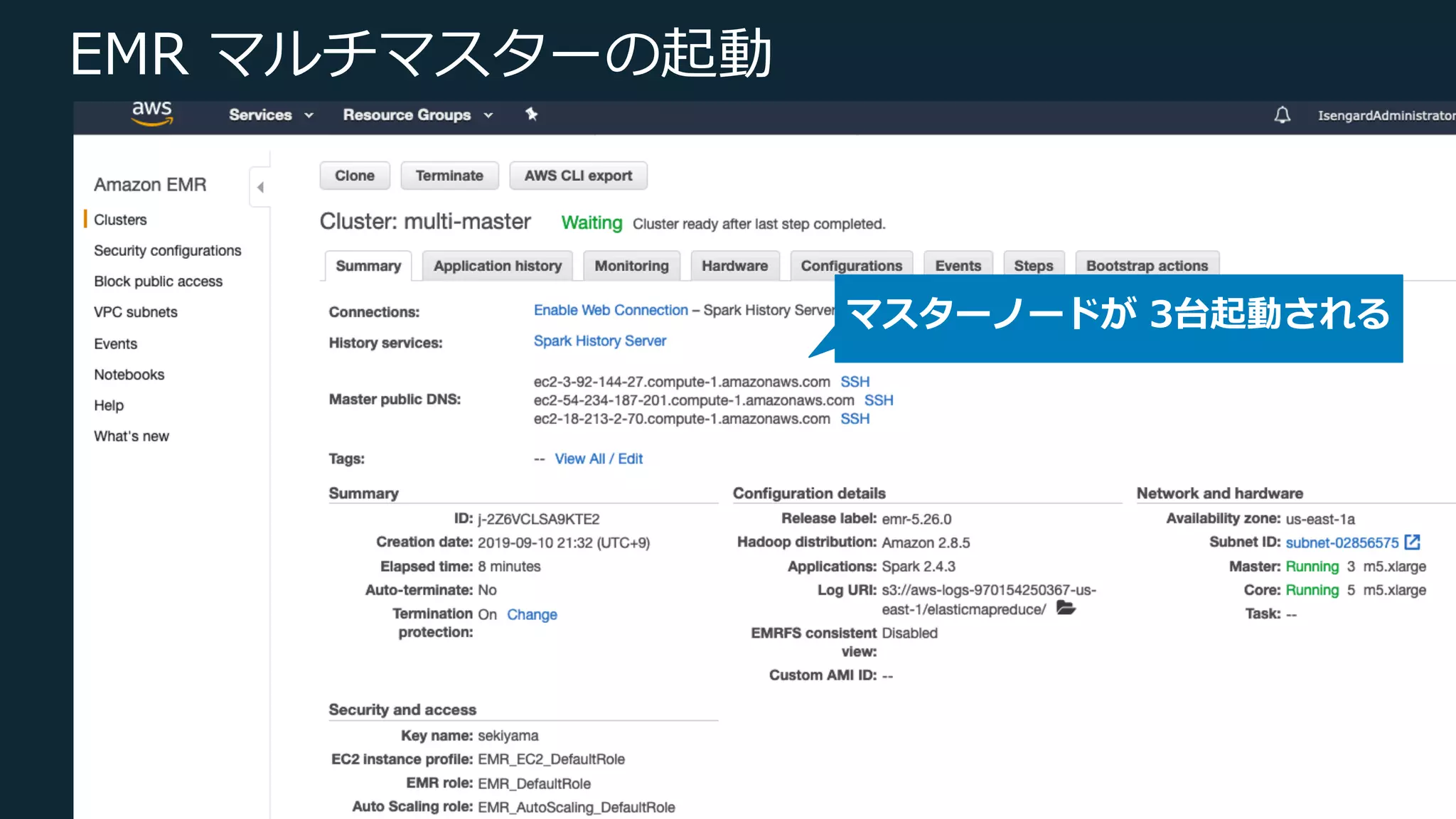
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動 マスターノードが 3台起動される
14.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動
15.
© 2019, Amazon
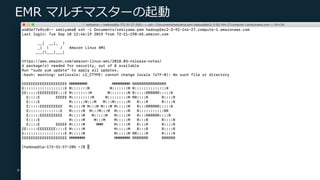
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動 yarn コマンドでステータス確認 $ yarn rmadmin -getAllServiceState ip-172-31-27-205.ec2.internal:8033 active ip-172-31-25-209.ec2.internal:8033 standby ip-172-31-25-142.ec2.internal:8033 standby マスターノード #1 YARN Resource Manager マスターノード #2 YARN Resource Manager マスターノード #3 YARN Resource Manager HDFS NameNode HDFS NameNode HDFS NameNode Active Standby Standby
16.
© 2019, Amazon
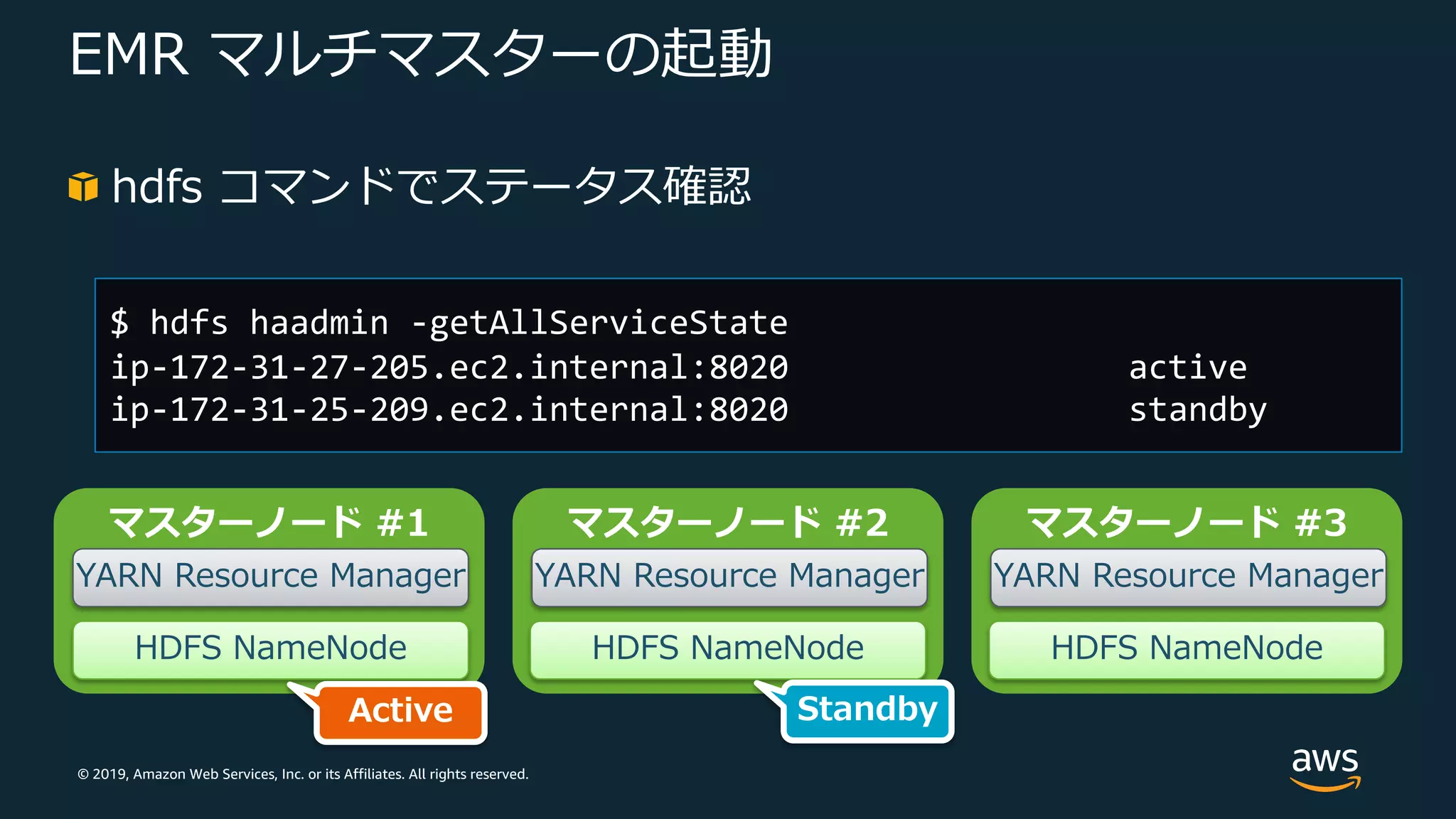
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動 hdfs コマンドでステータス確認 $ hdfs haadmin -getAllServiceState ip-172-31-27-205.ec2.internal:8020 active ip-172-31-25-209.ec2.internal:8020 standby マスターノード #1 YARN Resource Manager マスターノード #2 YARN Resource Manager マスターノード #3 YARN Resource Manager HDFS NameNode HDFS NameNode HDFS NameNode Active Standby
17.
© 2019, Amazon
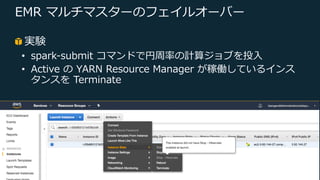
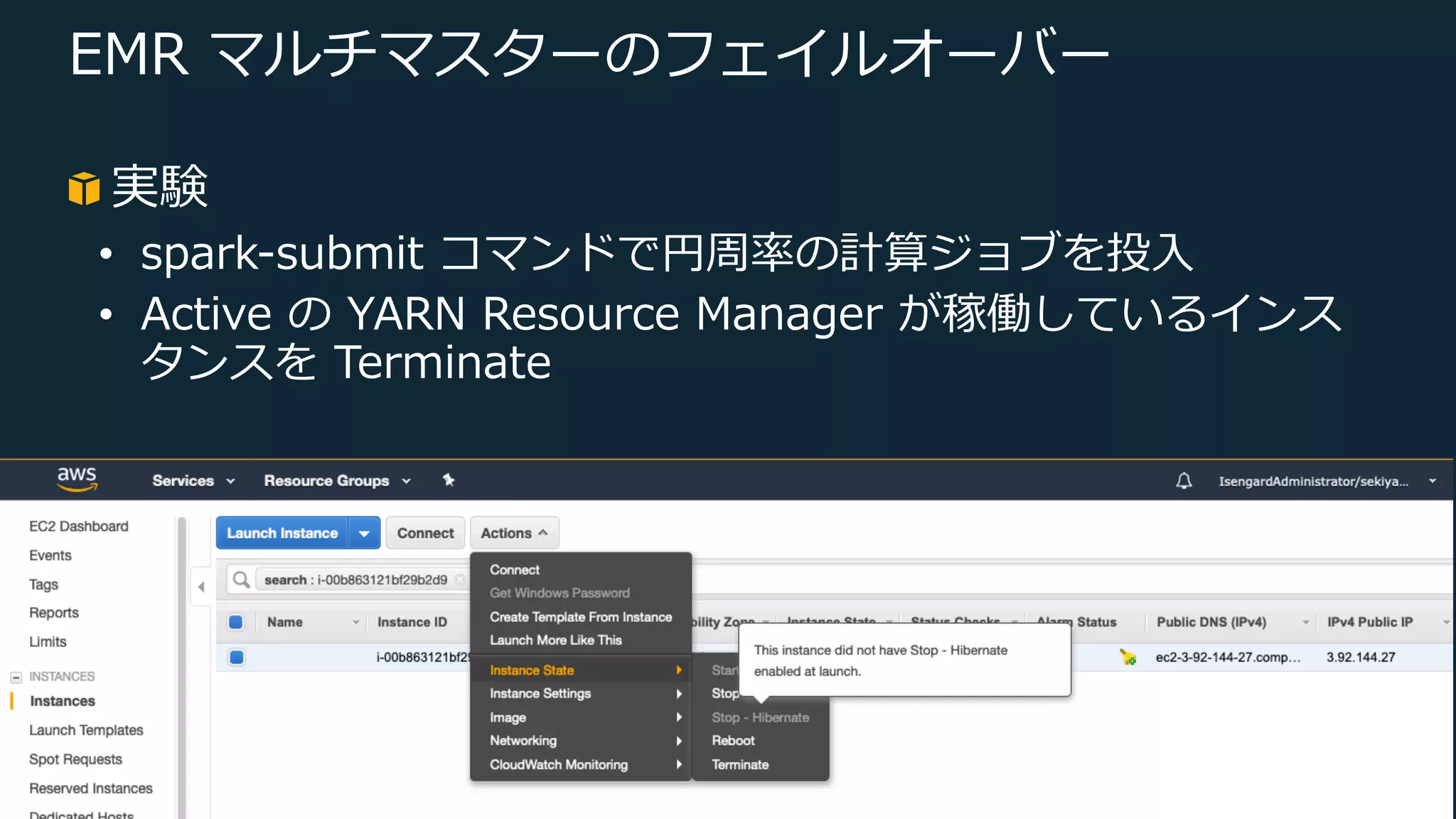
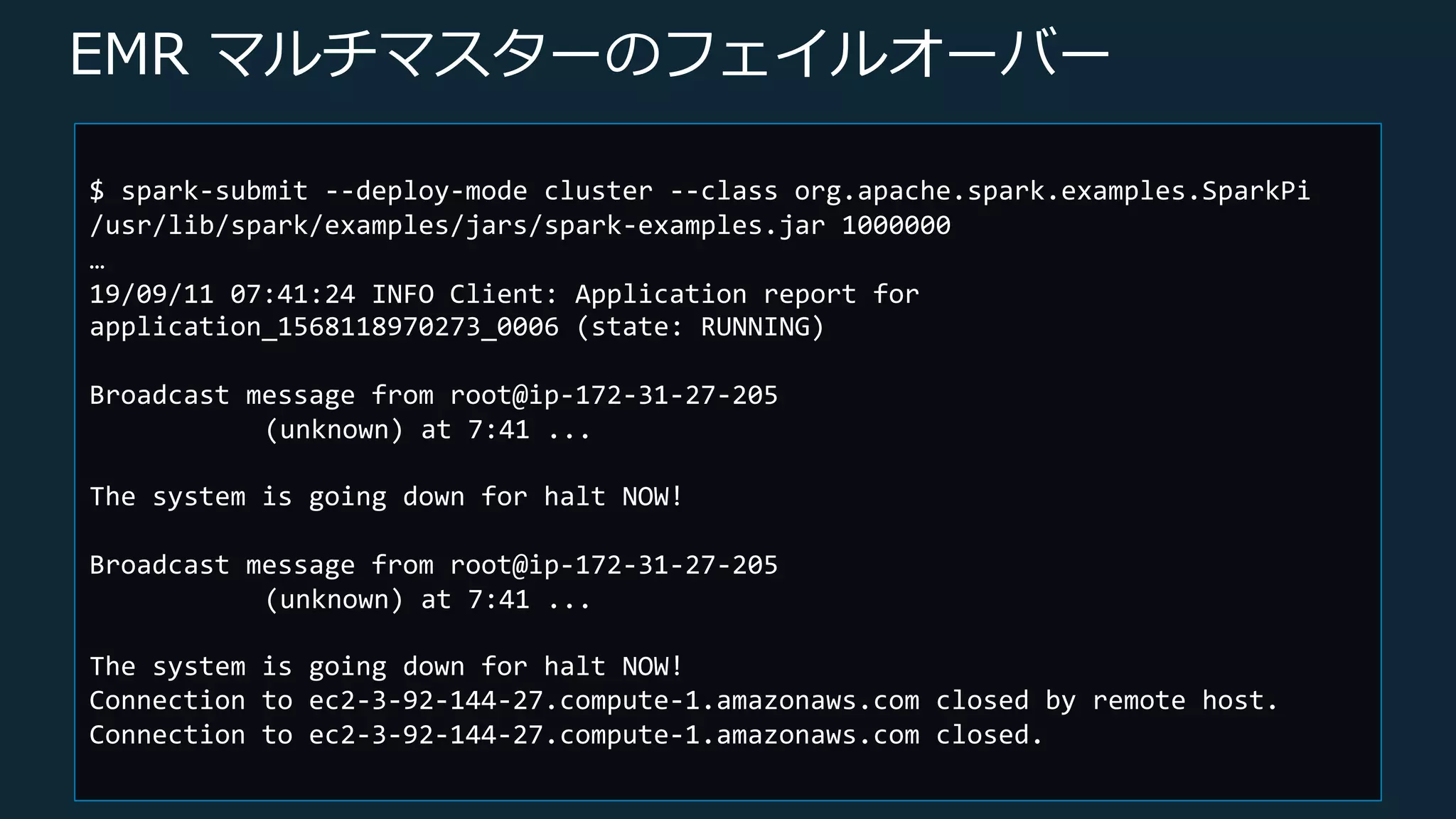
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターのフェイルオーバー 実験 • spark-submit コマンドで円周率の計算ジョブを投⼊ • Active の YARN Resource Manager が稼働しているインス タンスを Terminate
18.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターのフェイルオーバー $ spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi /usr/lib/spark/examples/jars/spark-examples.jar 1000000 … 19/09/11 07:41:24 INFO Client: Application report for application_1568118970273_0006 (state: RUNNING) Broadcast message from root@ip-172-31-27-205 (unknown) at 7:41 ... The system is going down for halt NOW! Broadcast message from root@ip-172-31-27-205 (unknown) at 7:41 ... The system is going down for halt NOW! Connection to ec2-3-92-144-27.compute-1.amazonaws.com closed by remote host. Connection to ec2-3-92-144-27.compute-1.amazonaws.com closed.
19.
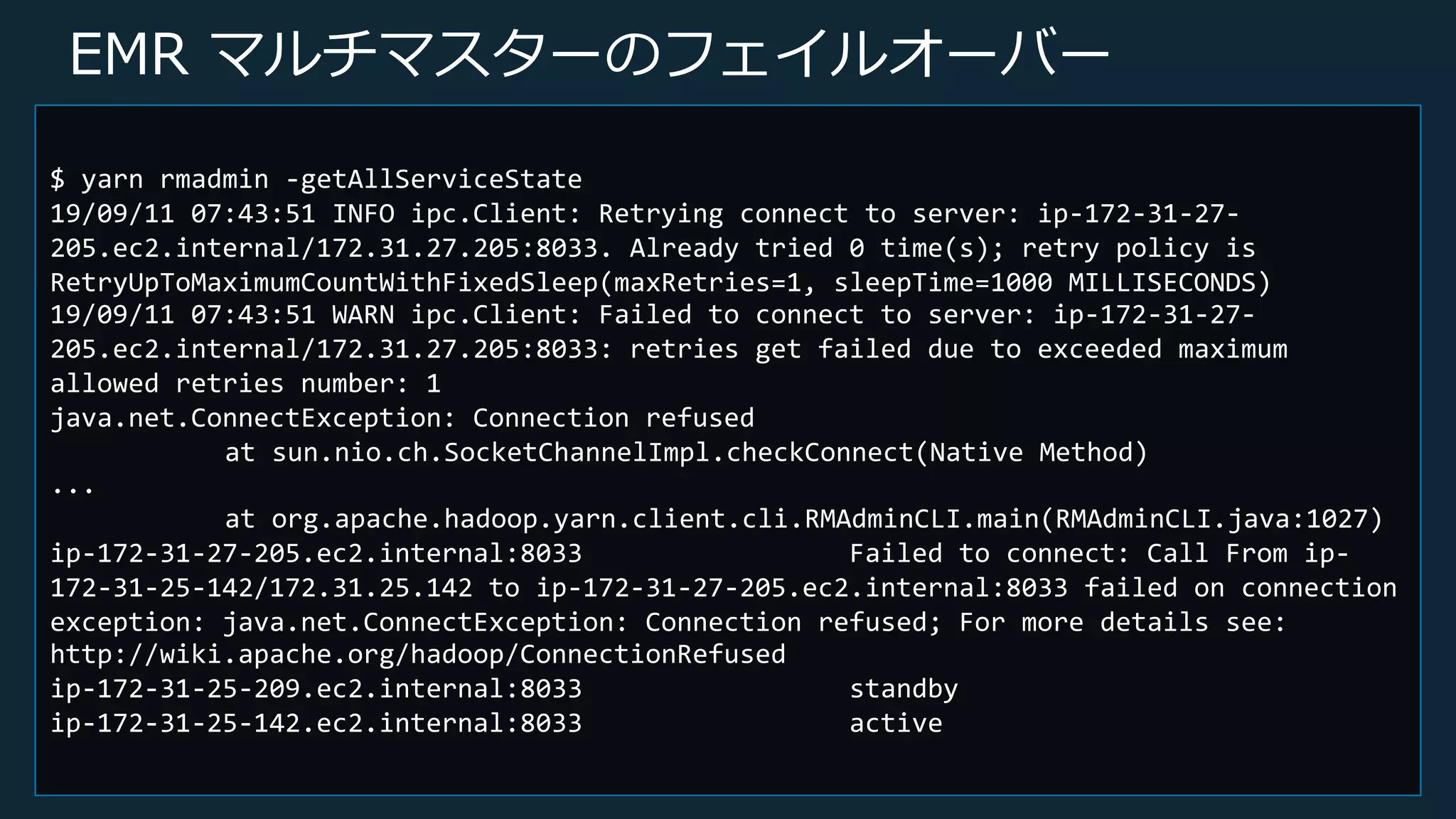
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターのフェイルオーバー $ yarn rmadmin -getAllServiceState 19/09/11 07:43:51 INFO ipc.Client: Retrying connect to server: ip-172-31-27- 205.ec2.internal/172.31.27.205:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS) 19/09/11 07:43:51 WARN ipc.Client: Failed to connect to server: ip-172-31-27- 205.ec2.internal/172.31.27.205:8033: retries get failed due to exceeded maximum allowed retries number: 1 java.net.ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) ... at org.apache.hadoop.yarn.client.cli.RMAdminCLI.main(RMAdminCLI.java:1027) ip-172-31-27-205.ec2.internal:8033 Failed to connect: Call From ip- 172-31-25-142/172.31.25.142 to ip-172-31-27-205.ec2.internal:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused ip-172-31-25-209.ec2.internal:8033 standby ip-172-31-25-142.ec2.internal:8033 active
20.
© 2019, Amazon
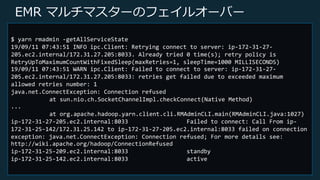
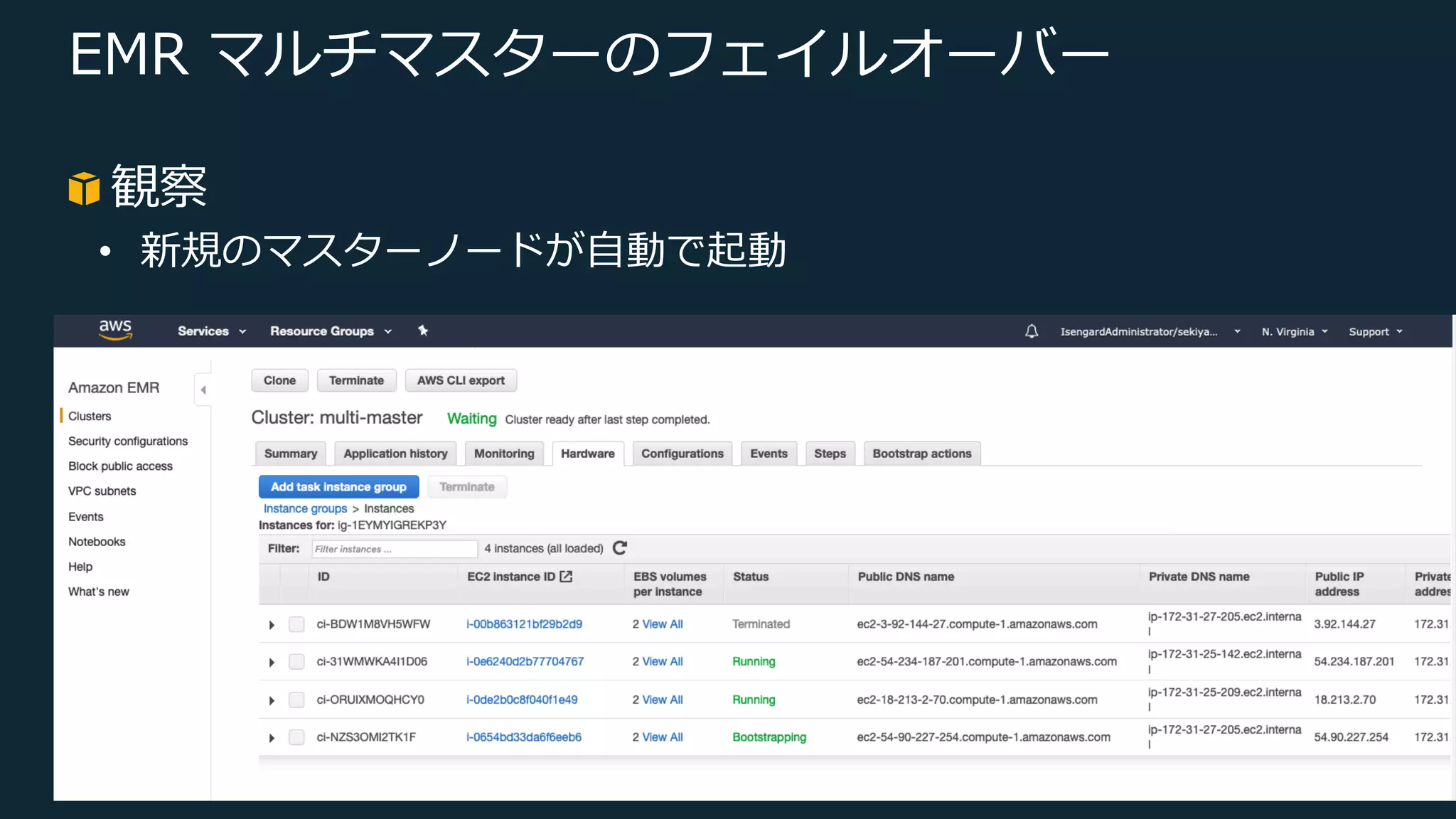
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターのフェイルオーバー 観察 • 新規のマスターノードが⾃動で起動
21.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動 観察 • yarn コマンドでステータス確認 $ yarn rmadmin -getAllServiceState ip-172-31-27-205.ec2.internal:8033 standby ip-172-31-25-209.ec2.internal:8033 standby ip-172-31-25-142.ec2.internal:8033 active マスターノード #4 YARN Resource Manager マスターノード #2 YARN Resource Manager マスターノード #3 YARN Resource Manager HDFS NameNode HDFS NameNode HDFS NameNode Standby Standby Active
22.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR マルチマスターの起動 観察 • yarn コマンドでアプリケーションのステータス確認 $ yarn application –list Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1 Application-Id Application-Name Application-Type User Queue State Final-State Progress application_1568118970273_0006 SparkPi SPARK hadoop default RUNNING UNDEFINED 10% 66.ec2.internal:35817
23.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on Amazon EMR - メモリ管理のベストプラクティス
24.
© 2019, Amazon
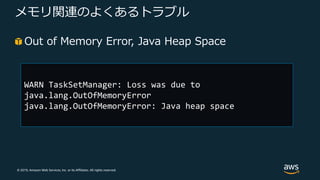
Web Services, Inc. or its Affiliates. All rights reserved. メモリ関連のよくあるトラブル Out of Memory Error, Java Heap Space WARN TaskSetManager: Loss was due to java.lang.OutOfMemoryError java.lang.OutOfMemoryError: Java heap space
25.
© 2019, Amazon
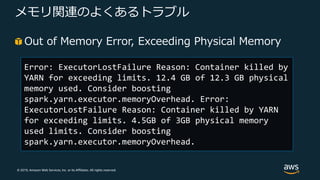
Web Services, Inc. or its Affiliates. All rights reserved. メモリ関連のよくあるトラブル Out of Memory Error, Exceeding Physical Memory Error: ExecutorLostFailure Reason: Container killed by YARN for exceeding limits. 12.4 GB of 12.3 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. Error: ExecutorLostFailure Reason: Container killed by YARN for exceeding limits. 4.5GB of 3GB physical memory used limits. Consider boosting spark.yarn.executor.memoryOverhead.
26.
© 2019, Amazon
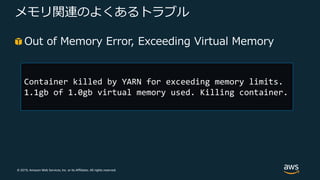
Web Services, Inc. or its Affiliates. All rights reserved. メモリ関連のよくあるトラブル Out of Memory Error, Exceeding Virtual Memory Container killed by YARN for exceeding memory limits. 1.1gb of 1.0gb virtual memory used. Killing container.
27.
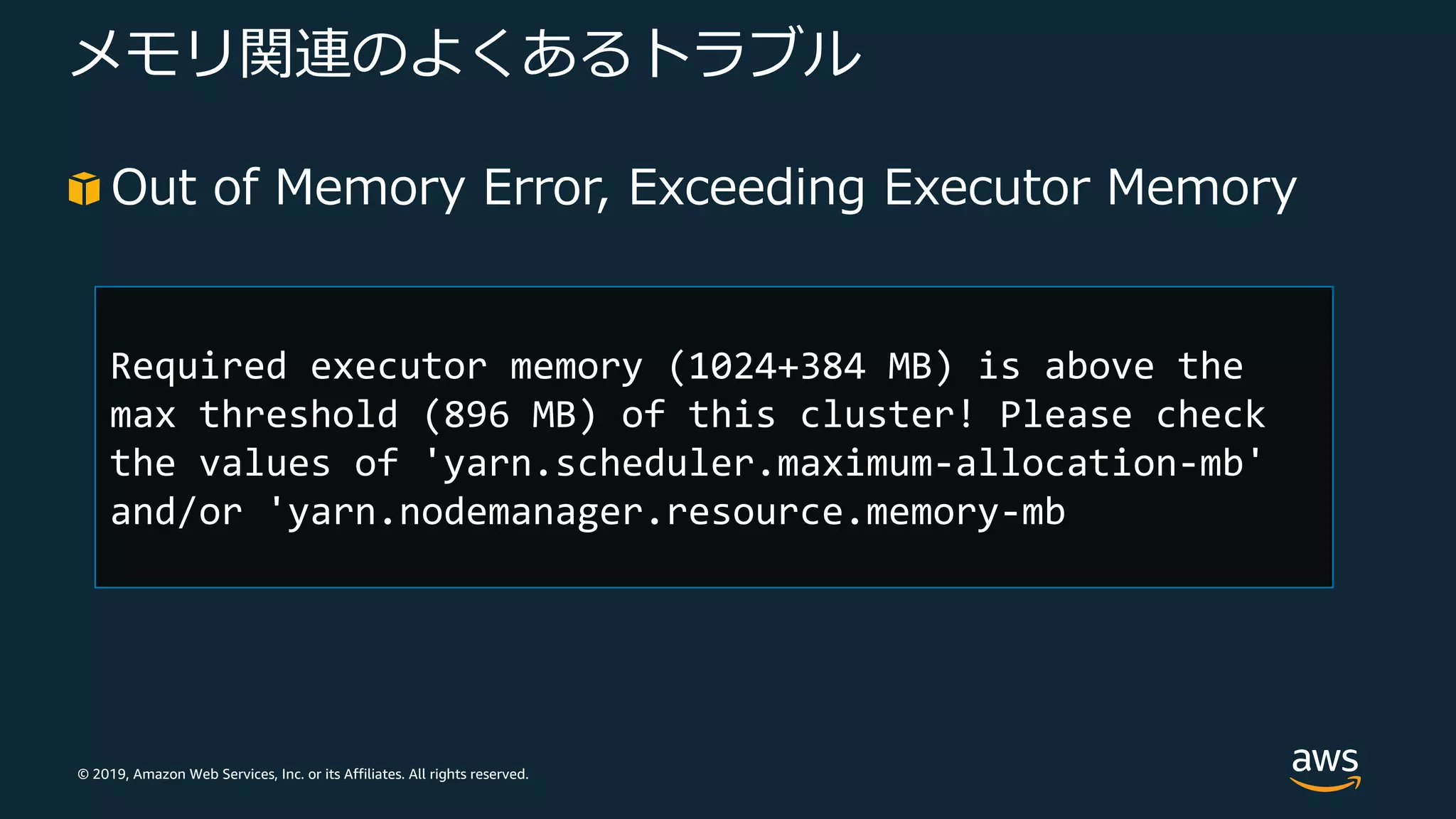
© 2019, Amazon
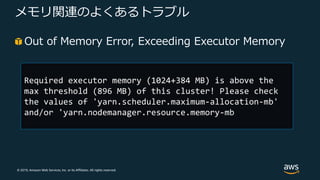
Web Services, Inc. or its Affiliates. All rights reserved. メモリ関連のよくあるトラブル Out of Memory Error, Exceeding Executor Memory Required executor memory (1024+384 MB) is above the max threshold (896 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb
28.
© 2019, Amazon
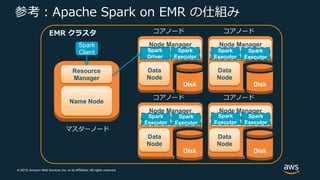
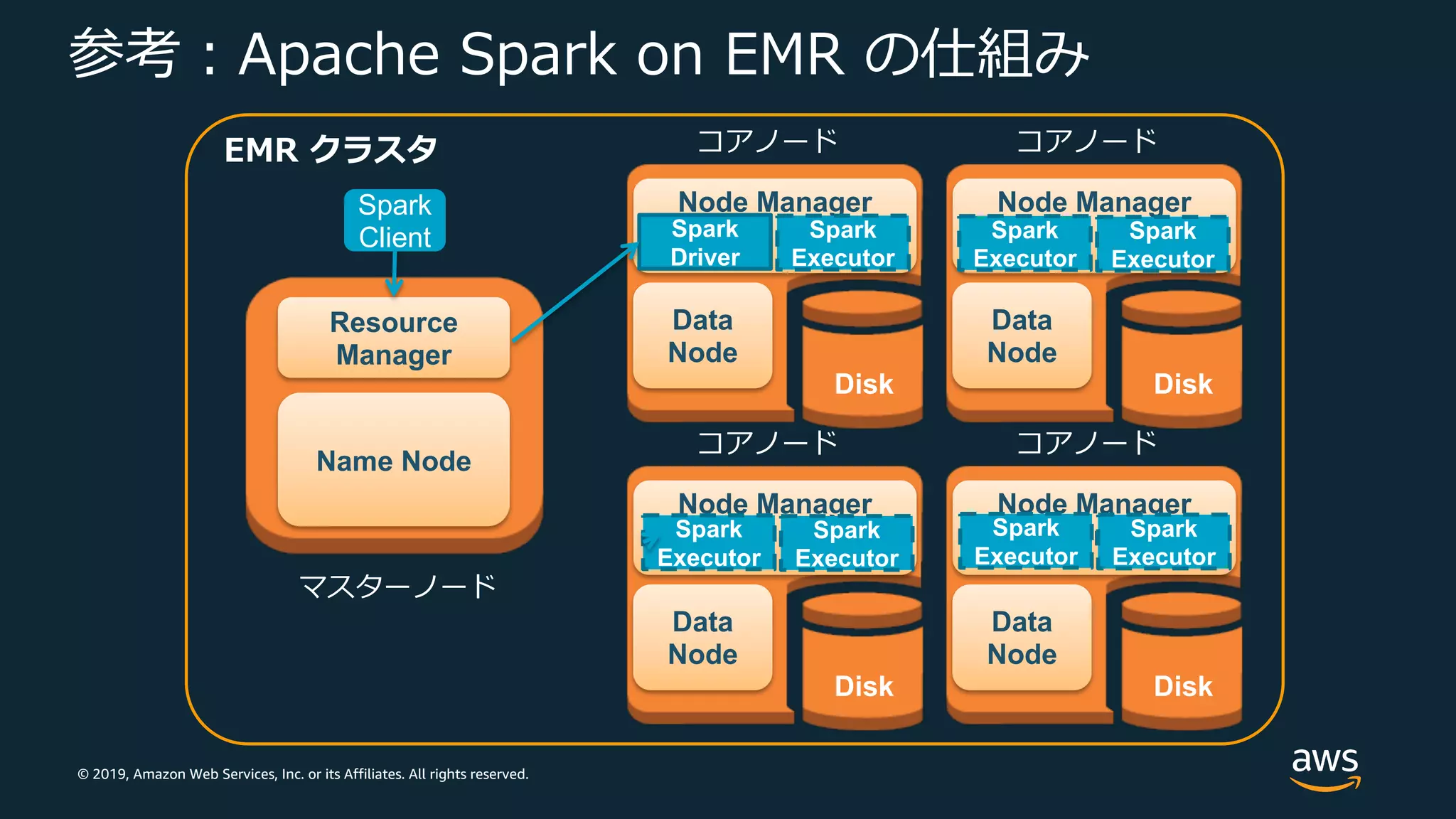
Web Services, Inc. or its Affiliates. All rights reserved. 参考︓Apache Spark on EMR の仕組み マスターノード Name Node Resource Manager Disk コアノード Data Node Node Manager Disk コアノード Data Node Node Manager Worker Disk コアノード Data Node Node Manager Spark Driver Disk コアノード Data Node Node Manager Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor EMR クラスタ Spark Client
29.
© 2019, Amazon
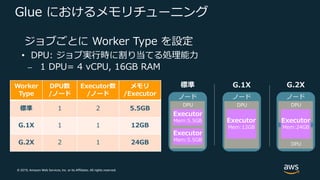
Web Services, Inc. or its Affiliates. All rights reserved. メモリ関連のよくあるトラブルの原因 Spark Executor インスタンス・Executor のメモリ量、コア数や並列 度が、データの規模に対して適切でない Spark Executor の物理メモリ量が YARN コンテナに割り当てられた メモリ量を超えた • 実⾏したクエリがメモリインテンシブな処理を含んでいて Spark Executor メモリとメモリオーバーヘッドを⾜した値が不⼗分 ⎼ 例︓キャッシング、シャッフリング、集約 (reduceByKey, groupBy) • Spark Executor メモリとメモリオーバーヘッドを⾜した値が yarn.scheduler.maximum-allocation-mb を超えた Spark Executor インスタンス上で GC 等の処理を実⾏するためのメ モリが利⽤可能でない
30.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 最適なインスタンスタイプとノード数の選択 インスタンスタイプ・ファミリ • メモリインテンシブ︓R • CPU インテンシブ︓C • CPU/メモリバランス型︓M インスタンス・ノード数 • ⼊⼒データセットのサイズ • アプリケーションの実⾏時間や頻度の要件
31.
© 2019, Amazon
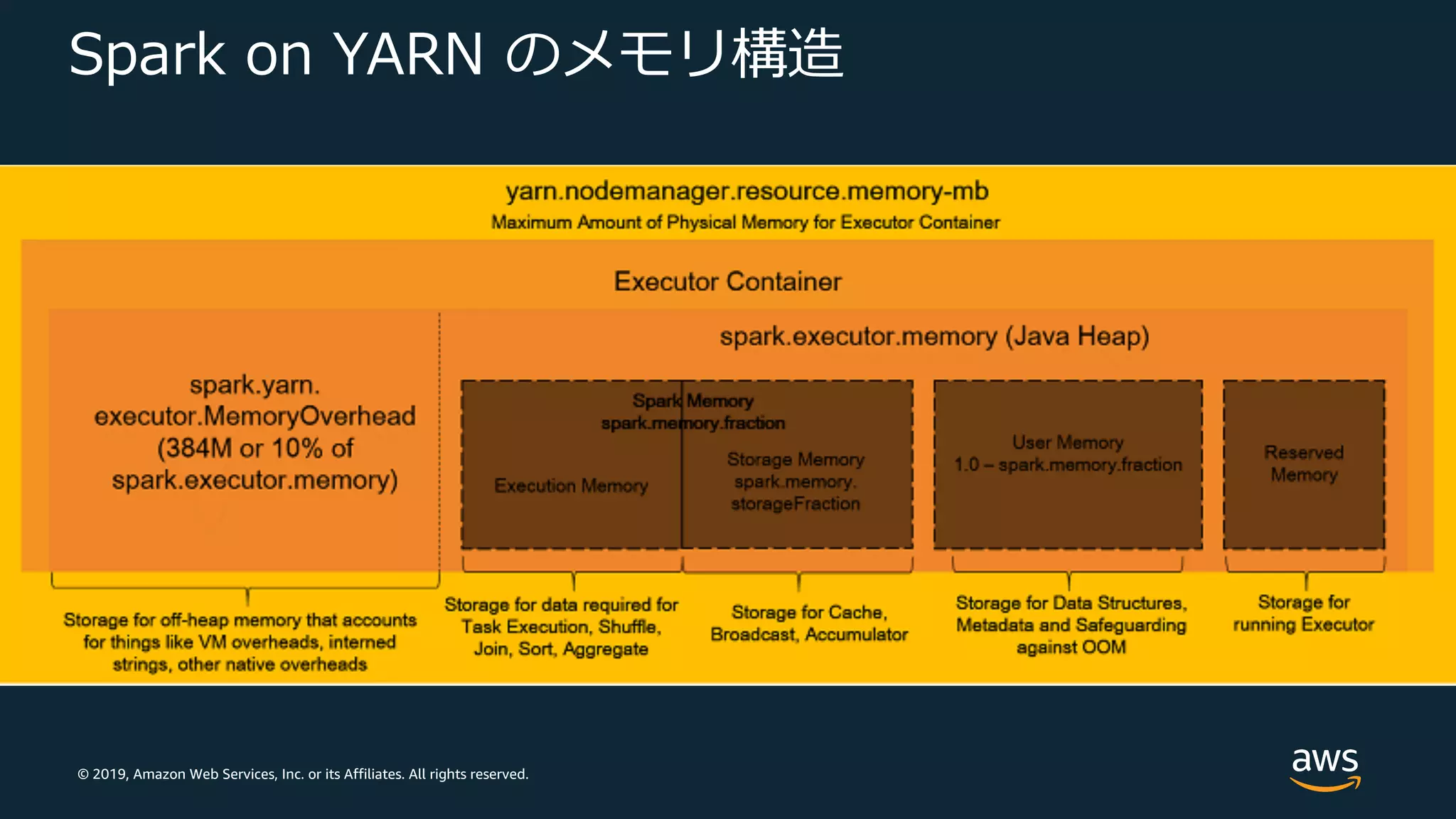
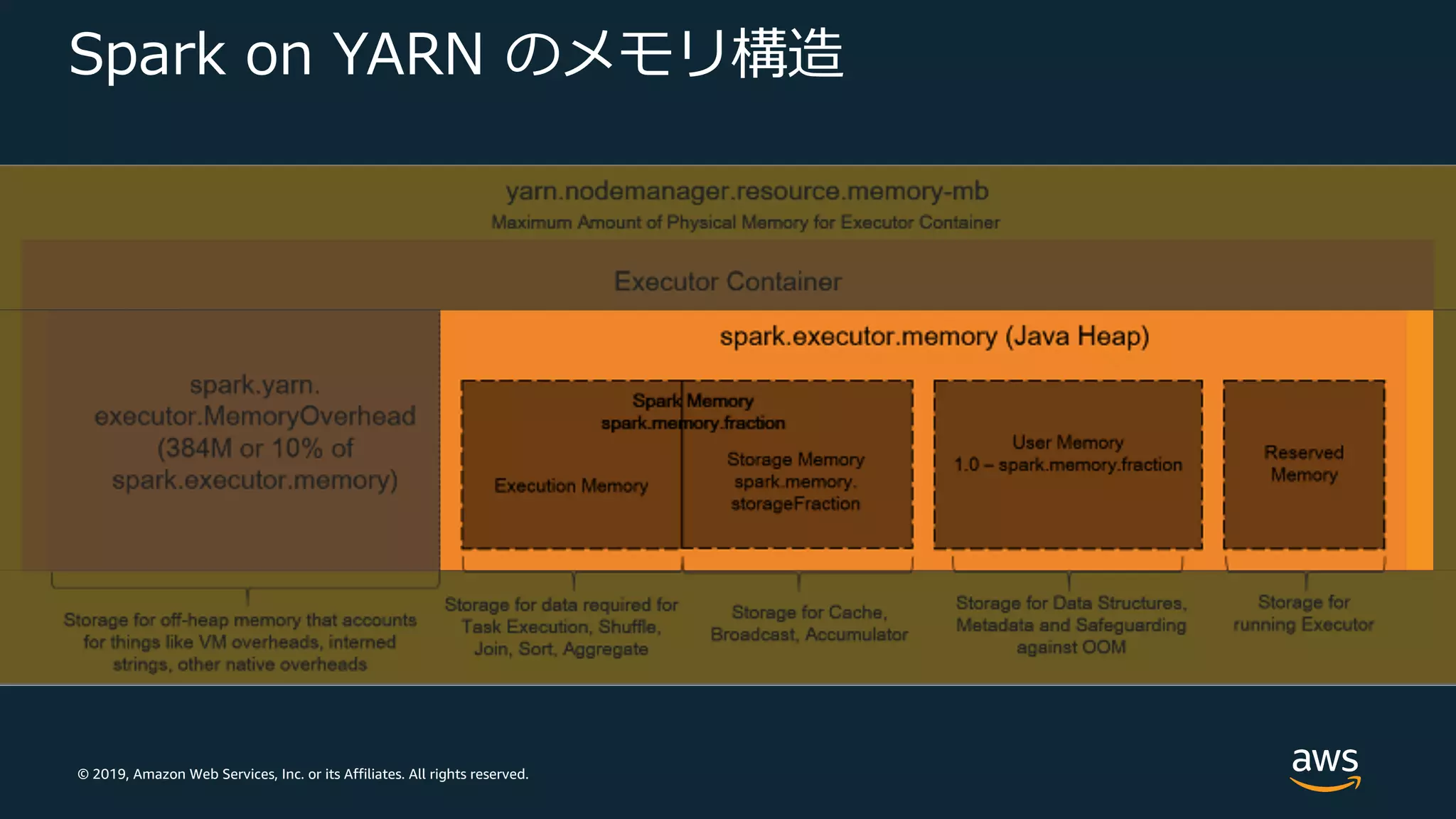
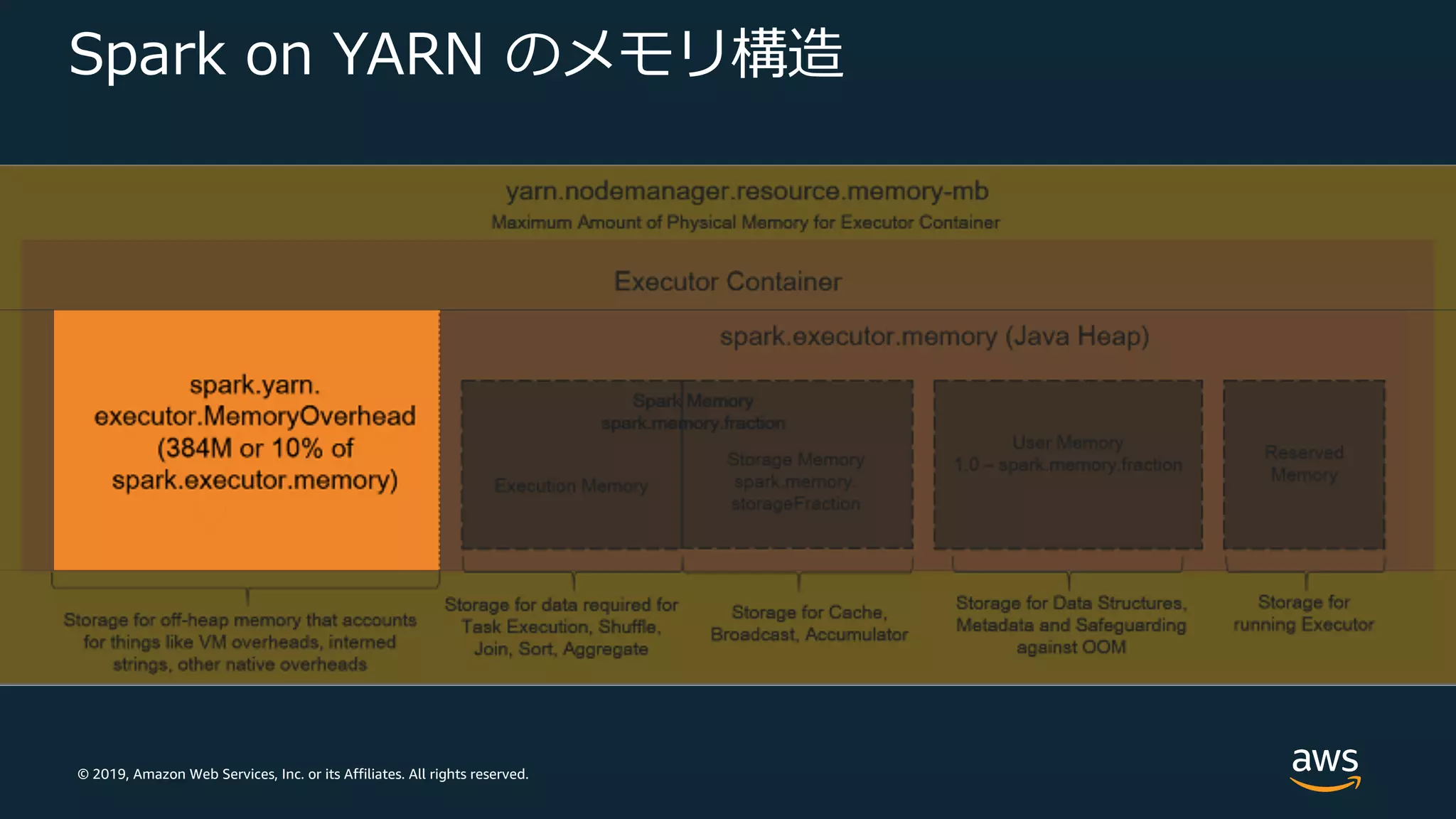
Web Services, Inc. or its Affiliates. All rights reserved. Spark on YARN のメモリ構造
32.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on YARN のメモリ構造
33.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on YARN のメモリ構造
34.
© 2019, Amazon
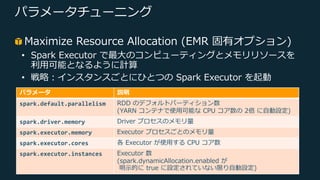
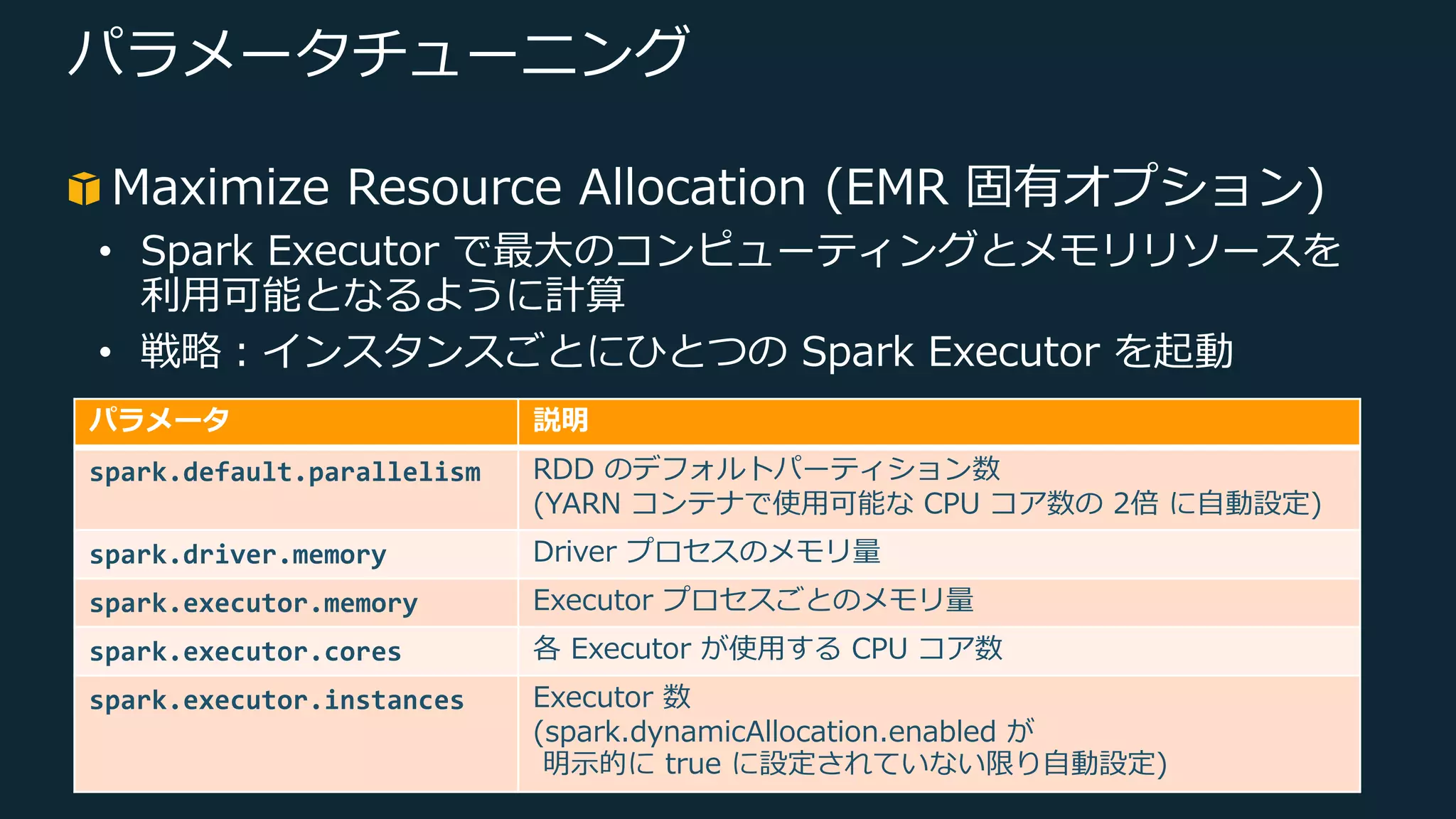
Web Services, Inc. or its Affiliates. All rights reserved. パラメータチューニング Maximize Resource Allocation (EMR 固有オプション) • Spark Executor で最⼤のコンピューティングとメモリリソースを 利⽤可能となるように計算 • 戦略︓インスタンスごとにひとつの Spark Executor を起動 パラメータ 説明 spark.default.parallelism RDD のデフォルトパーティション数 (YARN コンテナで使⽤可能な CPU コア数の 2倍 に⾃動設定) spark.driver.memory Driver プロセスのメモリ量 spark.executor.memory Executor プロセスごとのメモリ量 spark.executor.cores 各 Executor が使⽤する CPU コア数 spark.executor.instances Executor 数 (spark.dynamicAllocation.enabled が 明⽰的に true に設定されていない限り⾃動設定)
35.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. パラメータチューニング ユースケース例 • ⼊⼒データセット︓ S3 上に配置された数千ファイル、計 200 TB • EMR クラスタ︓ ⎼ マスター︓r5.12xlarge ⎼ コア︓r5.12xlarge x 19ノード ※r5.12xlarge: 48 vCPU, 384GB RAM
36.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. パラメータチューニング パラメータ 解説 値 spark.executor.cores 経験則から 5 vcore を設定 5 vcore spark.executor.memory [インスタンス毎の Executor 数] ([インスタンス毎の vcore 数] - 1)/ spark.executors.cores = (48 - 1)/ 5 = 47 / 5 ≒ 9 [Executor 毎の合計メモリ量] [インスタンス毎のメモリ量]/ [インスタンス毎の Executor 数] = 383 / 9 ≒ 42 spark.executor.memory = [Executor 毎の合計メモリ量] * 0.9 ≒ 37 37 GB spark.yarn.executor.memoryOverhead [Executor 毎の合計メモリ量] * 0.1 ≒ 5 5 GB spark.driver.memory spark.executor.memory を流⽤ 37 GB spark.driver.cores spark.executor.cores を流⽤ 5 vcore spark.executor.instances ([インスタンス毎の Executor 数] * [コアノード数]) -1(Driver) = 9 * 19 -1 = 170 170 spark.default.parallelism spark.executor.instances * spark.executors.cores * 2 = 170 * 5 * 2 = 1700 1700
37.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on Amazon EMR - EMR における Spark の改善
38.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR における Spark の改善 2019.6.11 EMR 5.24.0 (Hadoop 2.8.5, Spark 2.4.2) • Dynamic partition pruning • Flatten scalar subqueries • DISTINCT before INTERSECT 2019.7.17 EMR 5.25.0 (Hadoop 2.8.5, Spark 2.4.3) • Bloom filter join • Optimized join reorder 2019.8.8 EMR 5.26.0 (Hadoop 2.8.5, Spark 2.4.3) 2019.9.5 EMR 6.0.0 beta (Hadoop 3.1.0, Spark 2.4.3) 2019.9.23 EMR 5.27.0 (Hadoop 2.8.5, Spark 2.4.4)
39.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Dynamic partition pruning スキャン対象のパーティションを削減 • Spark SQL 実⾏時にパーティションを動的に選択して読み 込むことで、データの読み取り量を削減し、実⾏時間を短縮 • バニラ Spark 2.4.2 の元来の pushdown に加えて実装 • EMR 5.24 にて導⼊ (EMR 5.26 以降でデフォルト有効) ⎼ spark.sql.dynamicPartitionPruning.enabled
40.
© 2019, Amazon
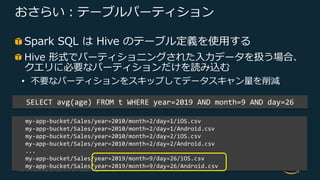
Web Services, Inc. or its Affiliates. All rights reserved. おさらい︓テーブルパーティション Spark SQL は Hive のテーブル定義を使⽤する Hive 形式でパーティショニングされた⼊⼒データを扱う場合、 クエリに必要なパーティションだけを読み込む • 不要なパーティションをスキップしてデータスキャン量を削減 my-app-bucket/Sales/year=2010/month=2/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=2/day=1/Android.csv my-app-bucket/Sales/year=2010/month=2/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=2/day=2/Android.csv ... my-app-bucket/Sales/year=2019/month=9/day=26/iOS.csv my-app-bucket/Sales/year=2019/month=9/day=26/Android.csv SELECT avg(age) FROM t WHERE year=2019 AND month=9 AND day=26
41.
© 2019, Amazon
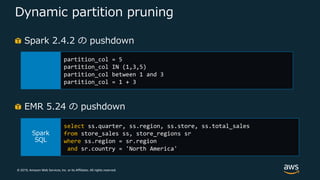
Web Services, Inc. or its Affiliates. All rights reserved. Dynamic partition pruning Spark 2.4.2 の pushdown partition_col = 5 partition_col IN (1,3,5) partition_col between 1 and 3 partition_col = 1 + 3 EMR 5.24 の pushdown select ss.quarter, ss.region, ss.store, ss.total_sales from store_sales ss, store_regions sr where ss.region = sr.region and sr.country = 'North America'
42.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Flatten scalar subqueries 特定条件のサブクエリを含むクエリを効率化 • 同⼀のテーブルに対する Scalar サブクエリを含む Spark SQL 実⾏時に Optimizer が Scalar サブクエリをフラット化 • EMR 5.24 にて導⼊ (EMR 5.26 以降でデフォルト有効) ⎼ spark.sql.optimizer.flattenScalarSubqueriesWithAggregates.enabled
43.
© 2019, Amazon
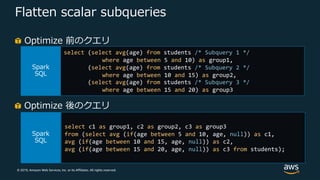
Web Services, Inc. or its Affiliates. All rights reserved. Flatten scalar subqueries Optimize 前のクエリ select (select avg(age) from students /* Subquery 1 */ where age between 5 and 10) as group1, (select avg(age) from students /* Subquery 2 */ where age between 10 and 15) as group2, (select avg(age) from students /* Subquery 3 */ where age between 15 and 20) as group3 select c1 as group1, c2 as group2, c3 as group3 from (select avg (if(age between 5 and 10, age, null)) as c1, avg (if(age between 10 and 15, age, null)) as c2, avg (if(age between 15 and 20, age, null)) as c3 from students); Optimize 後のクエリ
44.
© 2019, Amazon
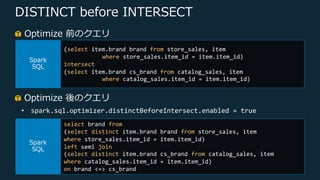
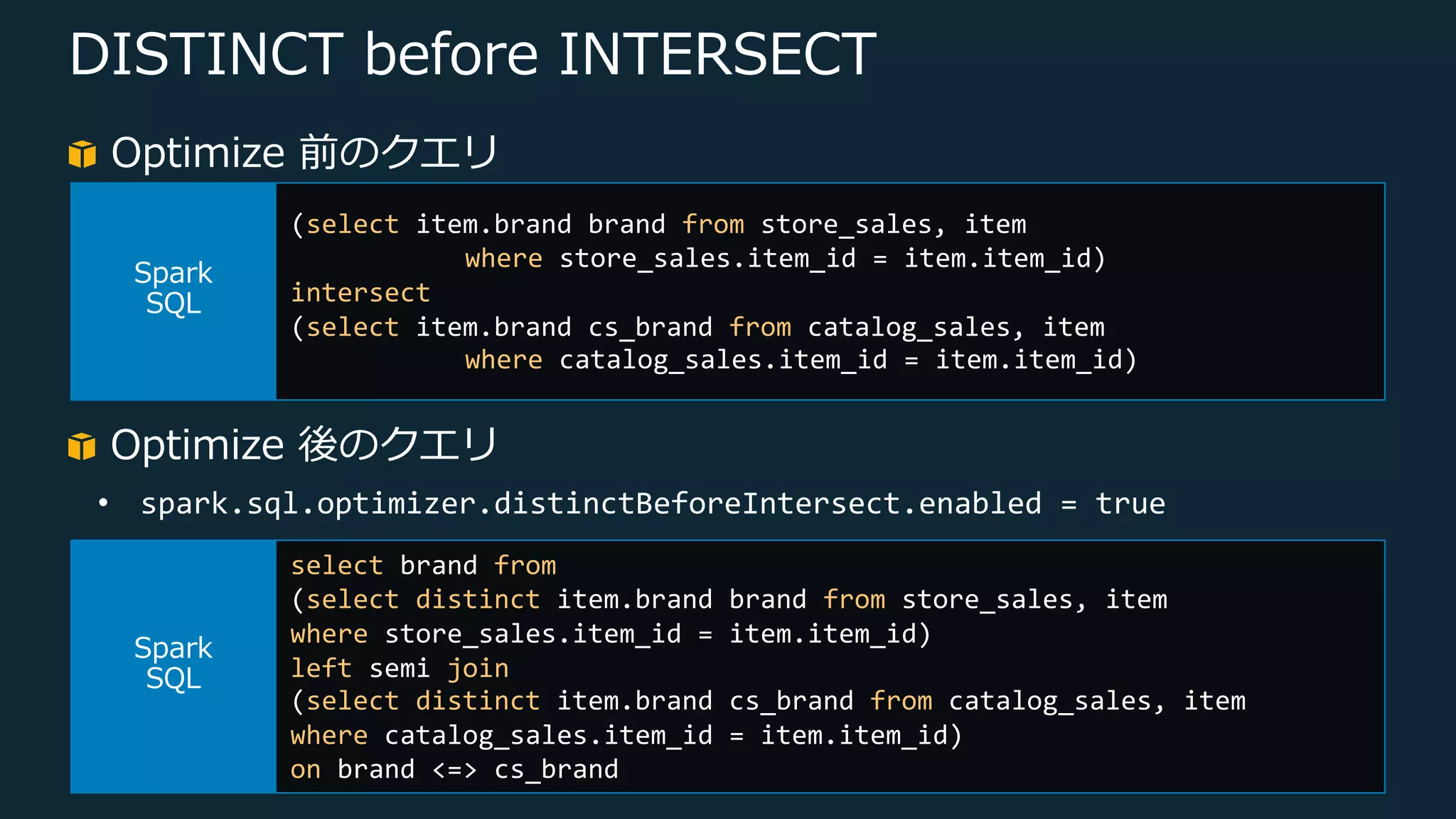
Web Services, Inc. or its Affiliates. All rights reserved. DISTINCT before INTERSECT できるだけ Shuffle を回避 • INTERSECT を含む Spark SQL 実⾏時に INTERSECT のの⼦ 要素に DISTINCT を追加 →Sort Merge Join を Broadcast Hash Join に変換 • EMR 5.24 にて導⼊ (EMR 5.26 以降でデフォルト有効) ⎼ spark.sql.optimizer.distinctBeforeIntersect.enabled
45.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 参考︓Spark SQL における JOIN Shuffle Hash Join • Shuffle してからパーティションごとに JOIN Sort Merge Join • Shuffle してソートしてからパーティションごとに JOIN • すべてのデータをあらかじめ読む必要をなくする Broadcsat Hash Join • JOIN 対象のテーブルに⼗分⼩さいテーブルがある場合、その テーブルをすべての Executor ノードにブロードキャストする • Broadcast したテーブルをパーティションごとに JOIN
46.
© 2019, Amazon
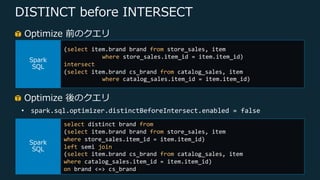
Web Services, Inc. or its Affiliates. All rights reserved. DISTINCT before INTERSECT Optimize 前のクエリ (select item.brand brand from store_sales, item where store_sales.item_id = item.item_id) intersect (select item.brand cs_brand from catalog_sales, item where catalog_sales.item_id = item.item_id) select distinct brand from (select item.brand brand from store_sales, item where store_sales.item_id = item.item_id) left semi join (select item.brand cs_brand from catalog_sales, item where catalog_sales.item_id = item.item_id) on brand <=> cs_brand Optimize 後のクエリ • spark.sql.optimizer.distinctBeforeIntersect.enabled = false
47.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. DISTINCT before INTERSECT Optimize 前のクエリ (select item.brand brand from store_sales, item where store_sales.item_id = item.item_id) intersect (select item.brand cs_brand from catalog_sales, item where catalog_sales.item_id = item.item_id) select brand from (select distinct item.brand brand from store_sales, item where store_sales.item_id = item.item_id) left semi join (select distinct item.brand cs_brand from catalog_sales, item where catalog_sales.item_id = item.item_id) on brand <=> cs_brand Optimize 後のクエリ • spark.sql.optimizer.distinctBeforeIntersect.enabled = true
48.
© 2019, Amazon
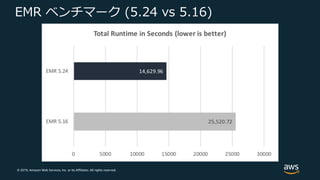
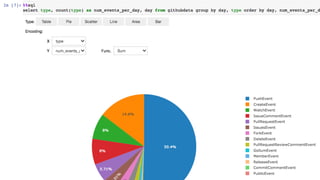
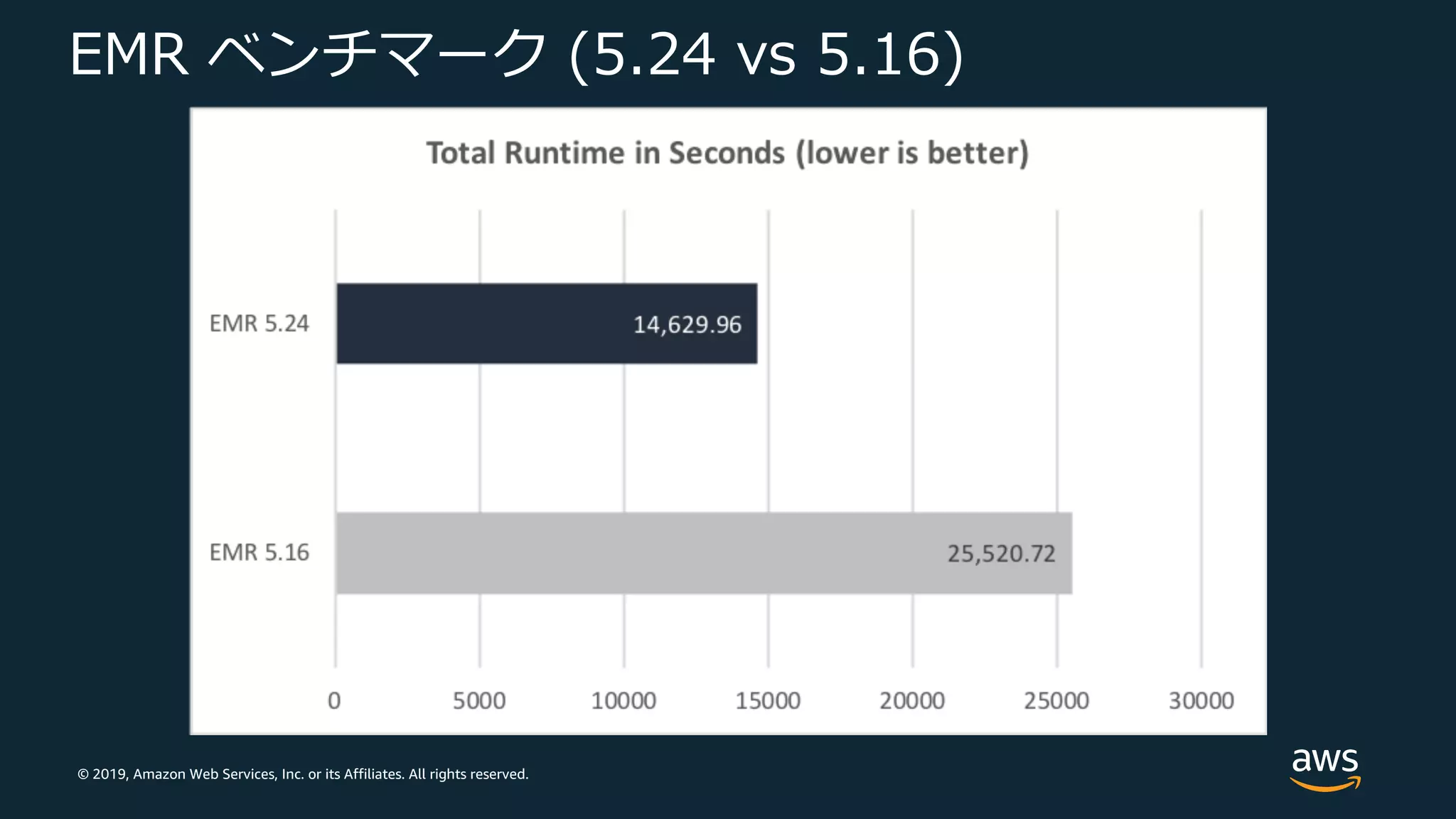
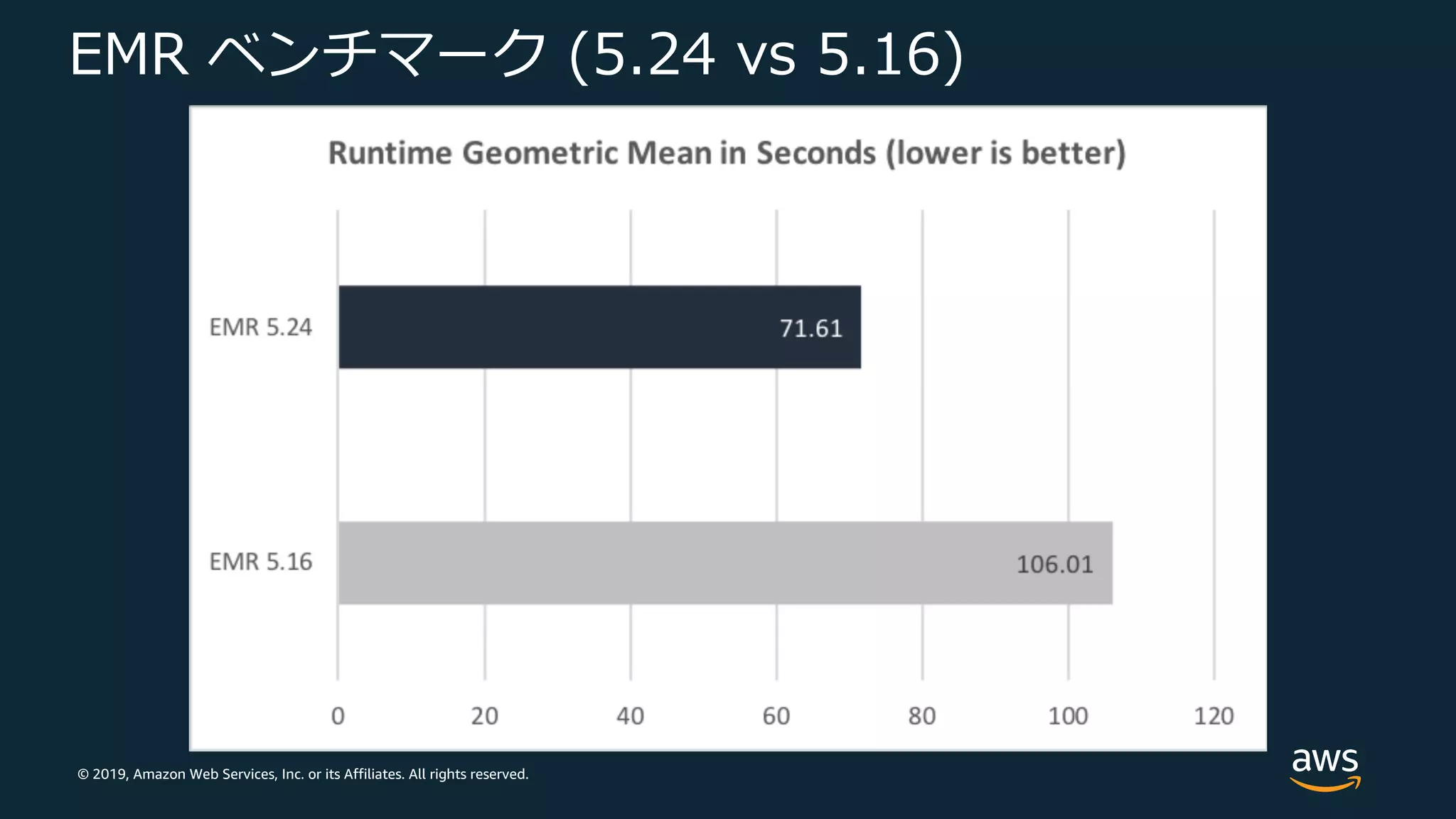
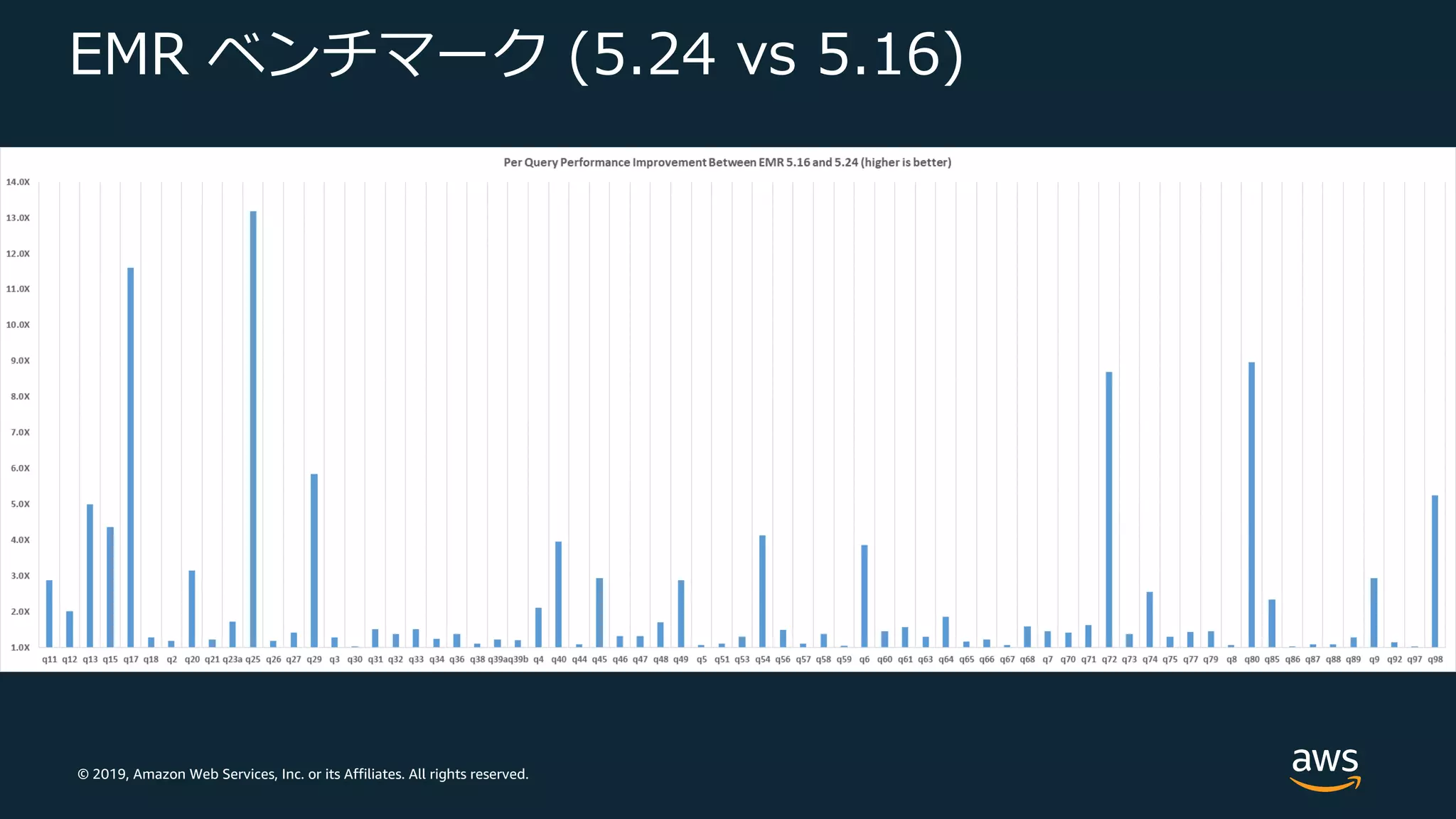
Web Services, Inc. or its Affiliates. All rights reserved. EMR ベンチマーク (5.24 vs 5.16) TPC-DS 3TB • マスター: 1 c4.8xlarge • コア: 5 c4.8xlarge
49.
© 2019, Amazon
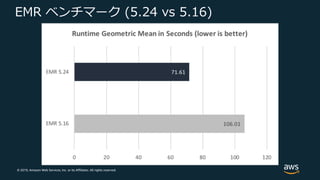
Web Services, Inc. or its Affiliates. All rights reserved. EMR ベンチマーク (5.24 vs 5.16)
50.
© 2019, Amazon
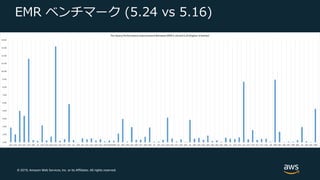
Web Services, Inc. or its Affiliates. All rights reserved. EMR ベンチマーク (5.24 vs 5.16)
51.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMR ベンチマーク (5.24 vs 5.16)
52.
© 2019, Amazon
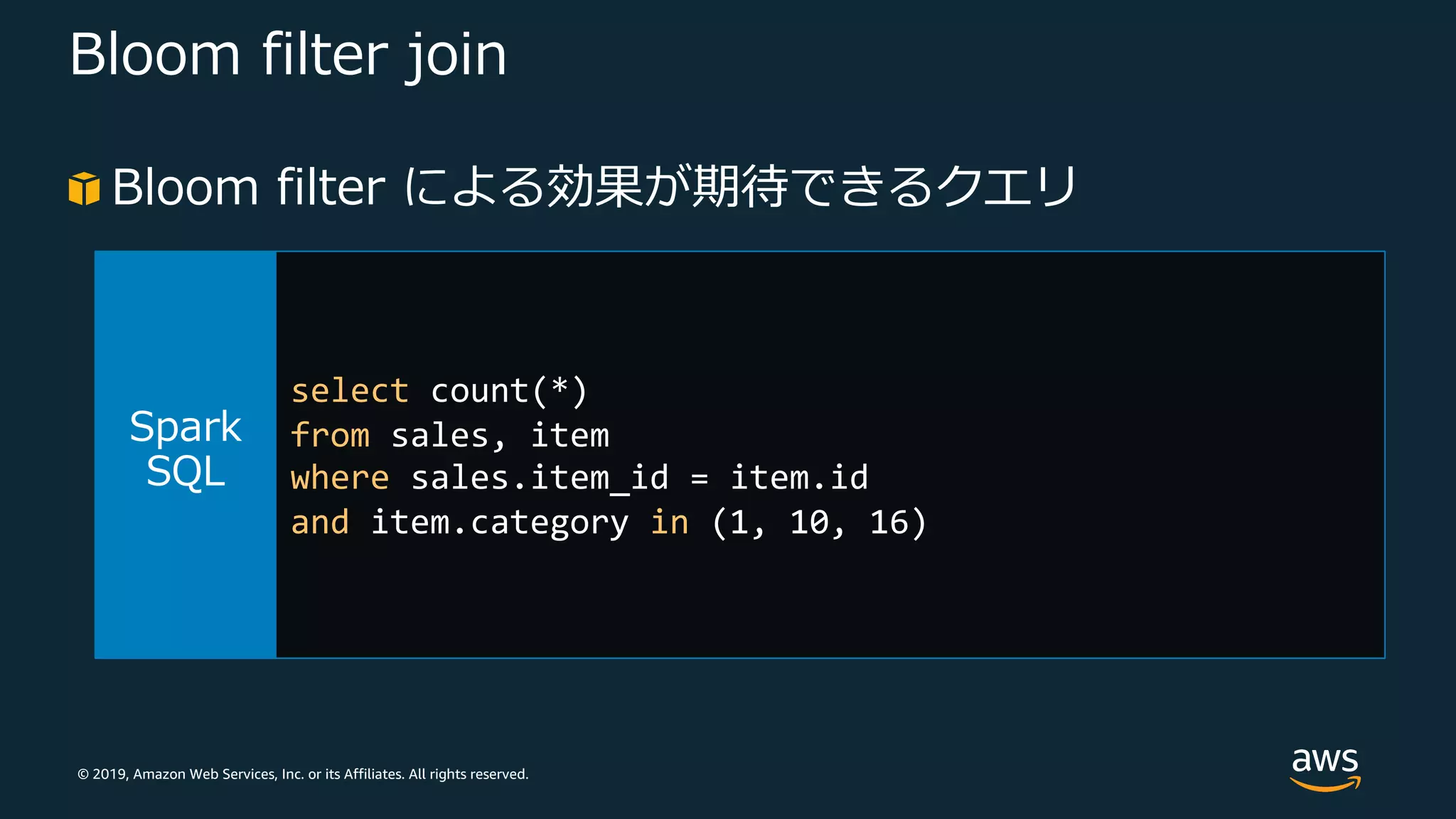
Web Services, Inc. or its Affiliates. All rights reserved. Bloom filter join JOIN の前にフィルタリング • Bloom filter を使って JOIN 対象の⼀⽅を事前フィルタリ ングすることでクエリを⾼速化 • EMR 5.25 にて導⼊ (EMR 5.26 以降でデフォルト有効) ⎼ spark.sql.bloomFilterJoin.enabled Bloom filter • 空間効率の⾼い確率的なデータ構造 • 要素が集合のメンバーであるかをチェックするのに使⽤
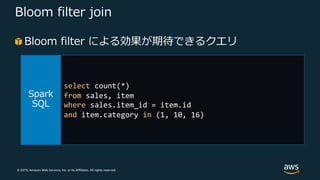
53.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Bloom filter join Bloom filter による効果が期待できるクエリ select count(*) from sales, item where sales.item_id = item.id and item.category in (1, 10, 16)
54.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Optimized join reorder テーブルの JOIN の順番を最適化 • Spark デフォルトでは左から右に並んでいるとおり JOIN • この設定を有効化すると、⼩さい JOIN を先に実⾏して計算量の ⼤きい JOIN を後回しにするかたちで JOIN の順番を⼊れ替え • EMR 5.25 にて導⼊ (EMR 5.26 以降でデフォルト有効) ⎼ spark.sql.optimizer.sizeBasedJoinReorder.enabled
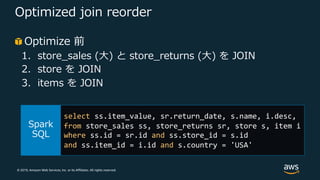
55.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Optimized join reorder Optimize 前 1. store_sales (⼤) と store_returns (⼤) を JOIN 2. store を JOIN 3. items を JOIN select ss.item_value, sr.return_date, s.name, i.desc, from store_sales ss, store_returns sr, store s, item i where ss.id = sr.id and ss.store_id = s.id and ss.item_id = i.id and s.country = 'USA'
56.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Optimized join reorder Optimize 後 1. store_sales (⼤) と store を JOIN (store はフィルタをもち store_returns より⼩さいため) 2. store_returns (⼤) を JOIN 3. items を JOIN select ss.item_value, sr.return_date, s.name, i.desc, from store_sales ss, store_returns sr, store s, item i where ss.id = sr.id and ss.store_id = s.id and ss.item_id = i.id and s.country = 'USA'
57.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on AWS Glue
58.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS Glue 様々なデータソースのメタデータを収集・活⽤した、 フルマネージドでサーバーレスなETLサービス
59.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS Glueの特徴 AWS Glue サーバーレス 柔軟な起動⽅法 コードに集中 データソースの メタデータ管理 VPC内からのアクセス 他のAWSサービスと 容易に連携 Notebookでの開発セキュア
60.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. サーバーレス Apache Spark 実⾏環境 AWS Glue は サーバーレス Apache Spark 実⾏環境 としても利⽤可能 x
61.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on AWS Glue - Glue における Spark の拡張
62.
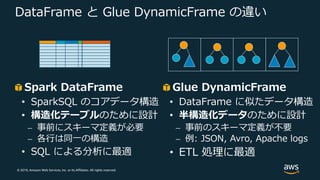
© 2019, Amazon
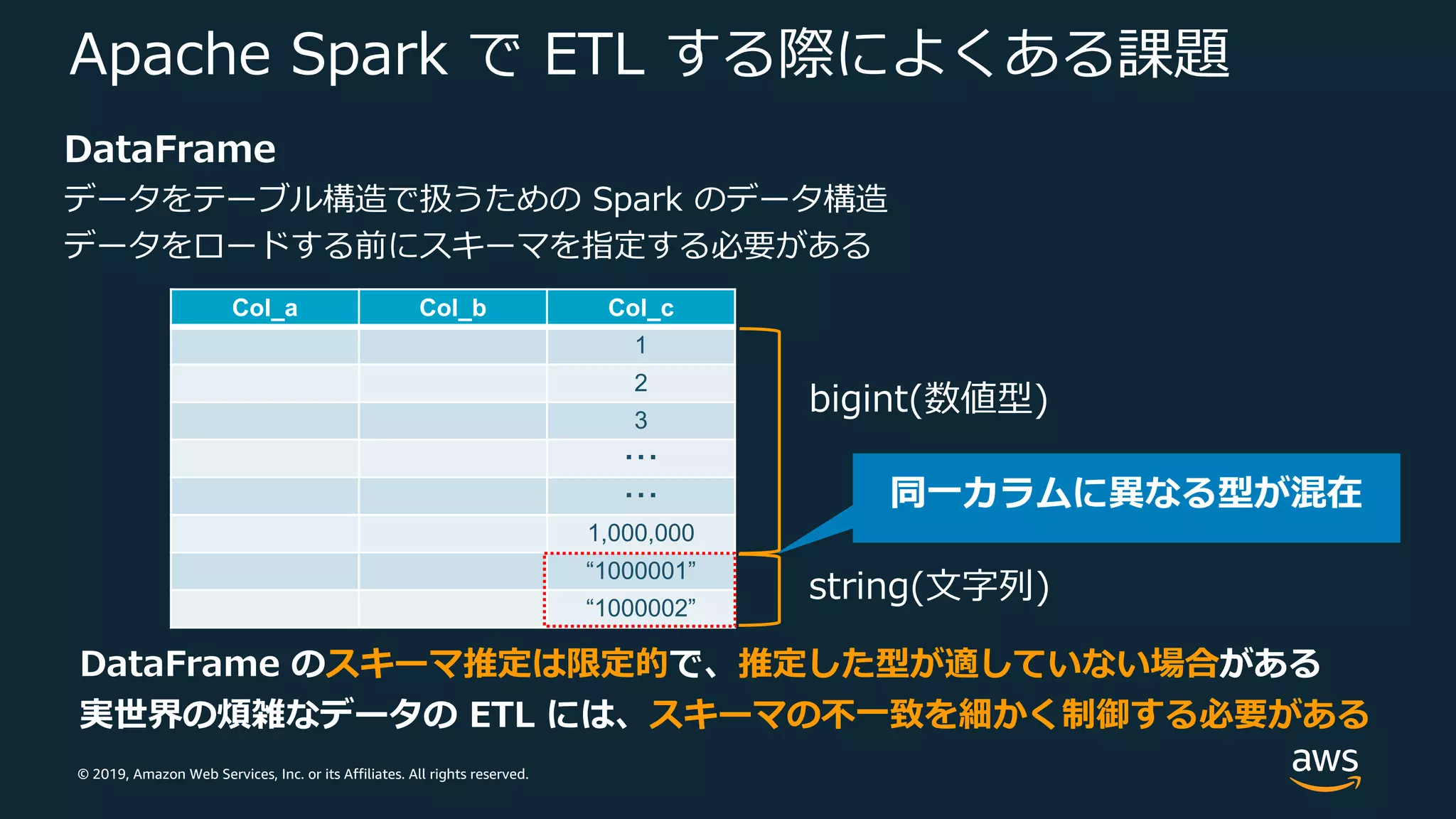
Web Services, Inc. or its Affiliates. All rights reserved. Apache Spark で ETL する際によくある課題 DataFrame データをテーブル構造で扱うための Spark のデータ構造 データをロードする前にスキーマを指定する必要がある Col_a Col_b Col_c 1 2 3 ・・・ ・・・ 1,000,000 “1000001” “1000002” bigint(数値型) string(⽂字列) DataFrame のスキーマ推定は限定的で、推定した型が適していない場合がある 実世界の煩雑なデータの ETL には、スキーマの不⼀致を細かく制御する必要がある
63.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. DynamicFrame とは Spark DataFrame と似た Glue 特有のデータ表現 • Spark で ETL する際によくある課題を解決するために設計 • DataFrame と DynamicFrame 間で相互に変換可能 • データをロード時する際にスキーマ定義が不要 • ”Schema on the Fly” を採⽤ • 複数の型の可能性を残して、後から選択可能(Choice型)
64.
© 2019, Amazon
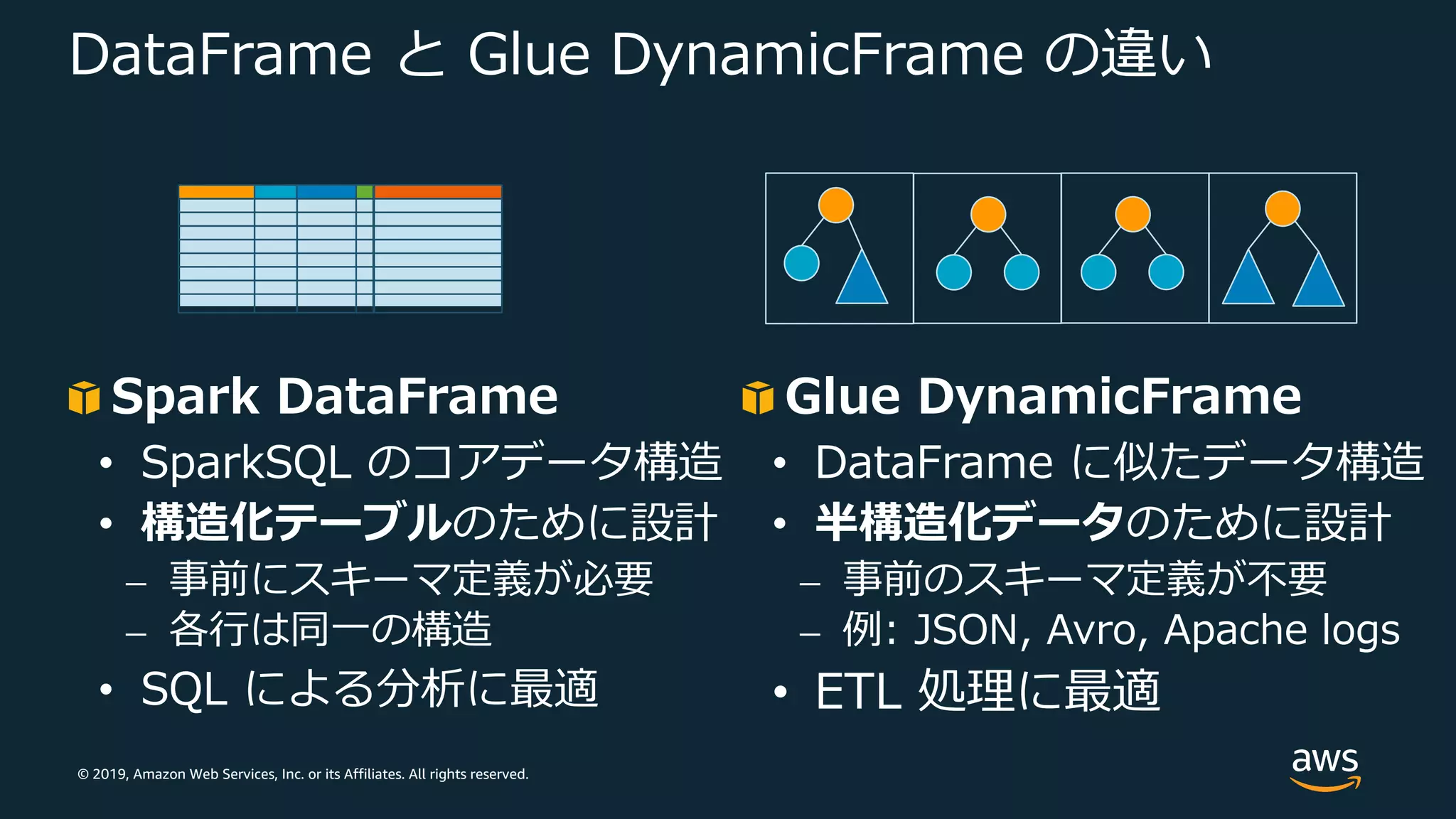
Web Services, Inc. or its Affiliates. All rights reserved. DataFrame と Glue DynamicFrame の違い Spark DataFrame • SparkSQL のコアデータ構造 • 構造化テーブルのために設計 ⎼ 事前にスキーマ定義が必要 ⎼ 各⾏は同⼀の構造 • SQL による分析に最適 Glue DynamicFrame • DataFrame に似たデータ構造 • 半構造化データのために設計 ⎼ 事前のスキーマ定義が不要 ⎼ 例: JSON, Avro, Apache logs • ETL 処理に最適
65.
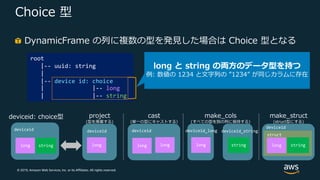
© 2019, Amazon
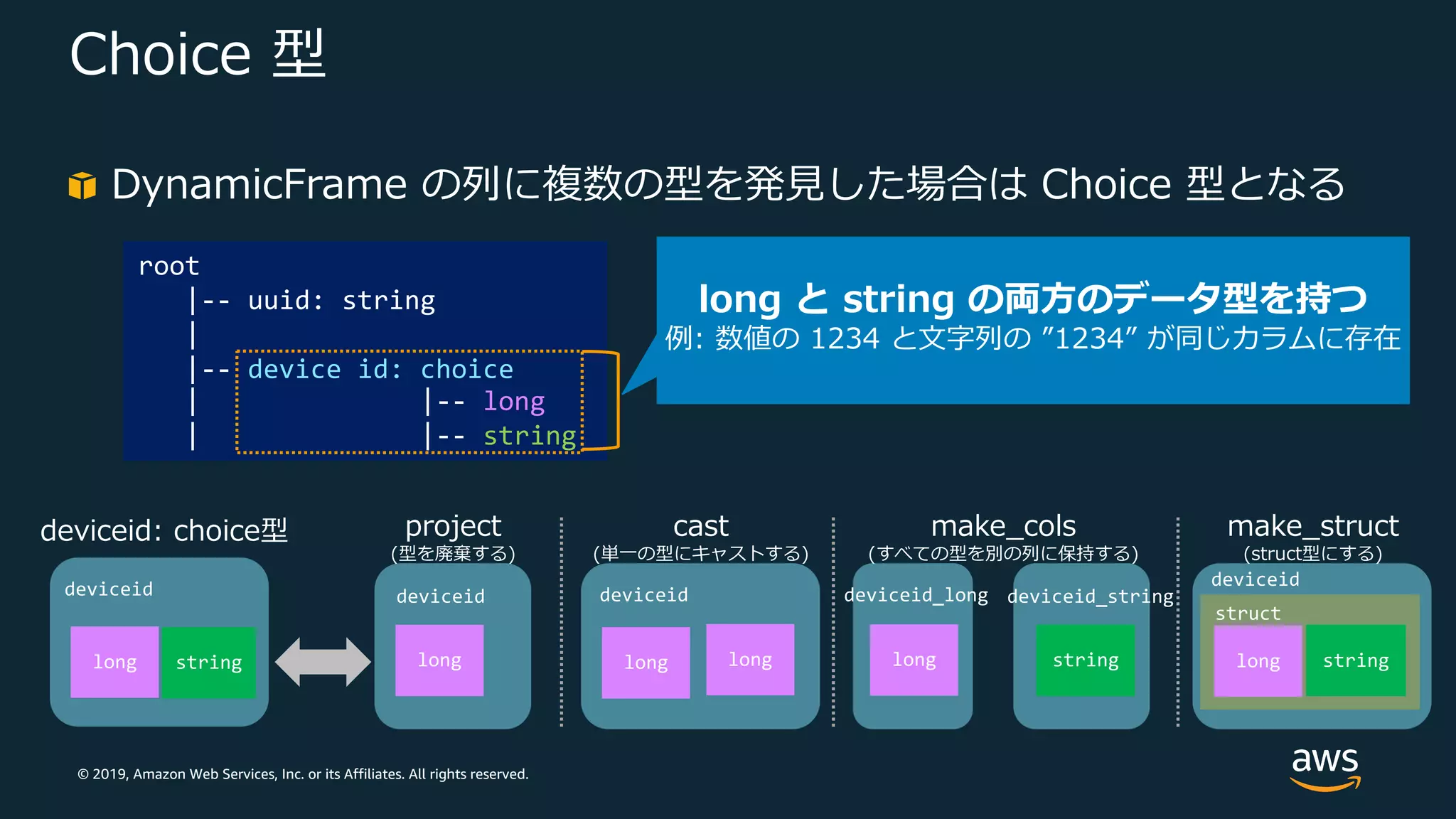
Web Services, Inc. or its Affiliates. All rights reserved. struct Choice 型 root |-- uuid: string | |-- device id: choice | |-- long | |-- string project (型を廃棄する) cast (単⼀の型にキャストする) make_cols (すべての型を別の列に保持する) deviceid: choice型 long string long long long stringlong deviceid deviceid deviceid deviceid_long deviceid_string long deviceid make_struct (struct型にする) string long と string の両⽅のデータ型を持つ 例: 数値の 1234 と⽂字列の ”1234” が同じカラムに存在 DynamicFrame の列に複数の型を発⾒した場合は Choice 型となる
66.
© 2019, Amazon
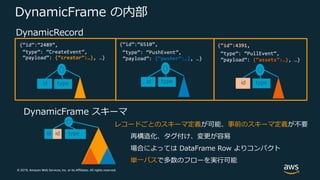
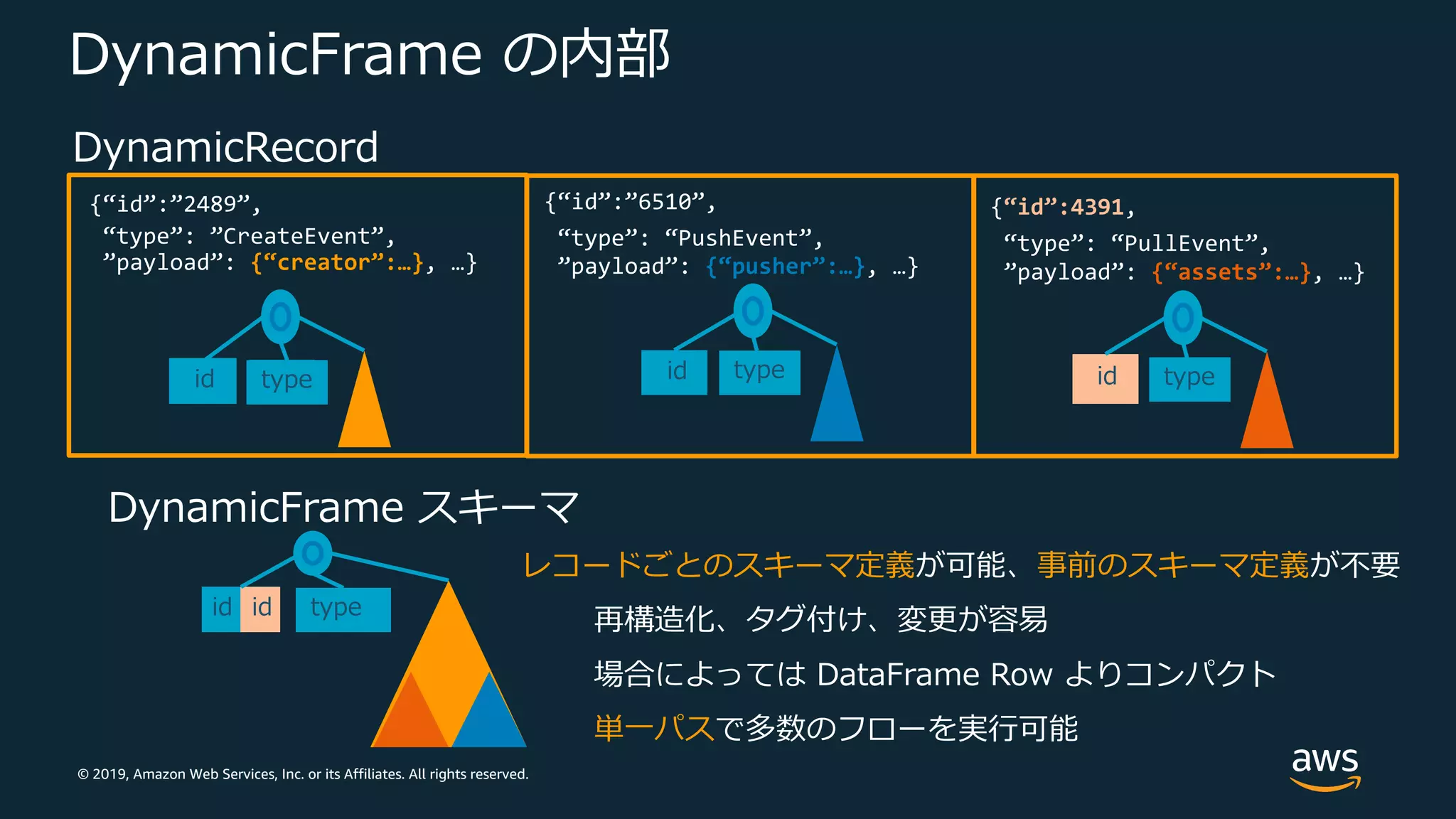
Web Services, Inc. or its Affiliates. All rights reserved. DynamicFrame の内部 レコードごとのスキーマ定義が可能、事前のスキーマ定義が不要 再構造化、タグ付け、変更が容易 場合によっては DataFrame Row よりコンパクト 単⼀パスで多数のフローを実⾏可能 {“id”:”2489”, “type”: ”CreateEvent”, ”payload”: {“creator”:…}, …} DynamicRecord typeid typeid DynamicFrame スキーマ typeid {“id”:4391, “type”: “PullEvent”, ”payload”: {“assets”:…}, …} typeid {“id”:”6510”, “type”: “PushEvent”, ”payload”: {“pusher”:…}, …} id
67.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Glue Parquet Writer Glue 独⾃のカスタム Parquet Writer による書き込み⾼速化 • 標準の Parquet Writer: ⎼ スキーマを設定 -> ⾏グループを 書き込む • Glue Parquet Writer: 1. 列の書き込みを開始 (必要な場合フィールドを追加) 2. 最初の⾏グループを閉じ、ス キーマを書き込む ⾏グループ 1 ⾏グループ 2 列 1 列 2 列 1 列 2 … … ⾏グループ メタデータ (スキーマを含む)
68.
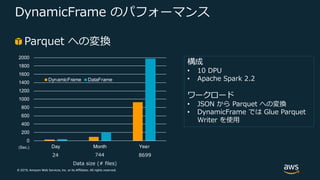
© 2019, Amazon
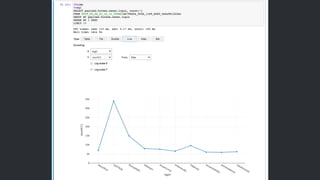
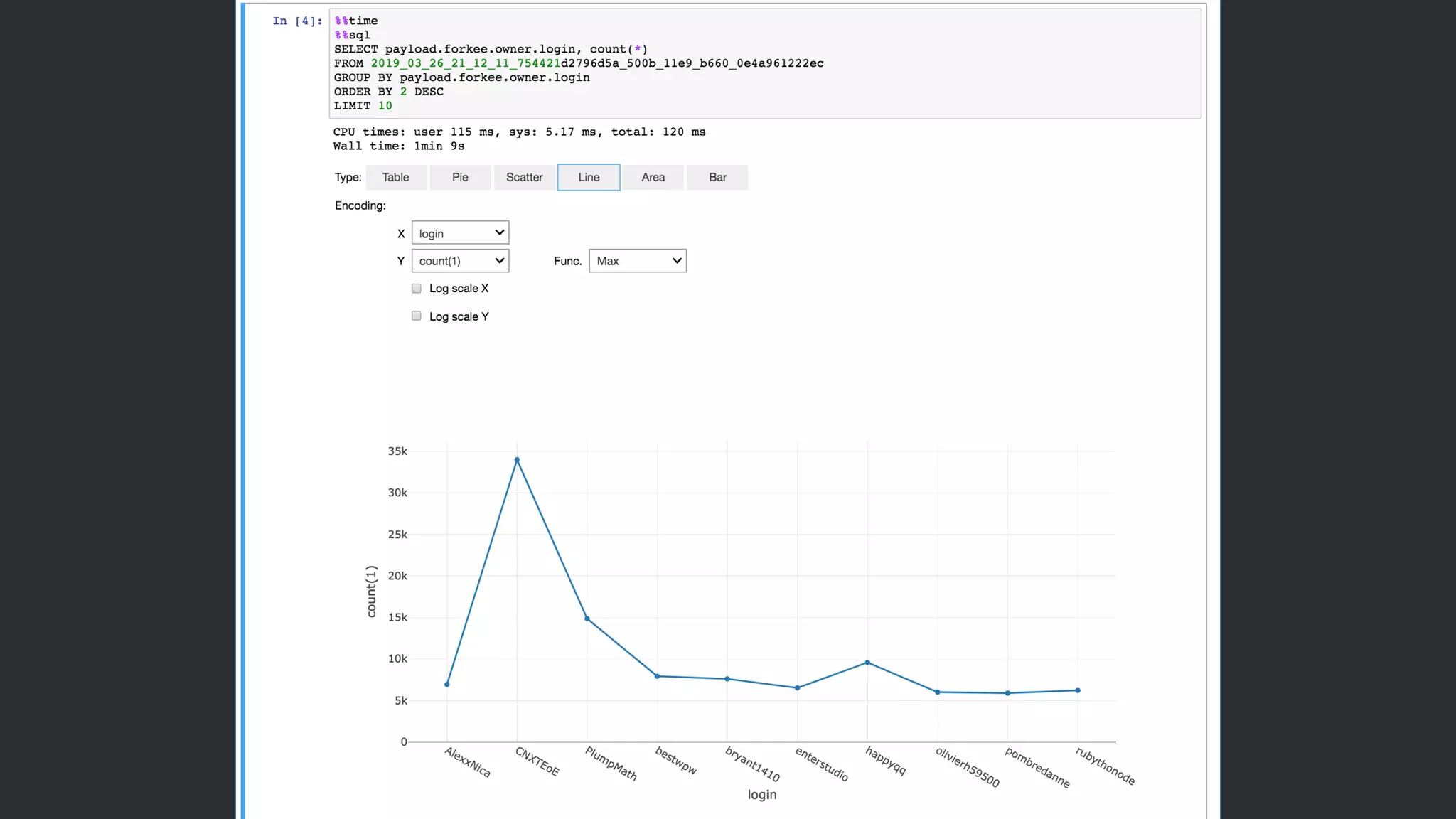
Web Services, Inc. or its Affiliates. All rights reserved. DynamicFrame のパフォーマンス Parquet への変換 0 200 400 600 800 1000 1200 1400 1600 1800 2000 Day Month Year DynamicFrame DataFrame Data size (# files) 24 744 8699 構成 • 10 DPU • Apache Spark 2.2 ワークロード • JSON から Parquet への変換 • DynamicFrame では Glue Parquet Writer を使⽤ (Sec.)
69.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 継続的データ処理の効率化 ブックマーク機能 • ジョブの実⾏状態を保持 ⎼ Timestamp を⾒て処理済みデータを再度処理しないように回避 ⎼ 処理結果のデータをターゲットに重複出⼒しないように回避 • 定常的にETL処理が必要な場合において有効 S3 prefix |-- file 1 (updated: 2019/09/25 15:00) |-- file 2 (updated: 2019/09/26 10:00) |-- file 3 (updated: 2019/09/26 13:00) S3 prefix |-- file 1 (updated: 2019/09/25 15:00) |-- file 2 (updated: 2019/09/26 10:00) |-- file 3 (updated: 2019/09/26 13:00) |-- file 4 (updated: 2019/09/26 14:30) Run (2019/09/26 14:00) Run (2019/09/26 15:00) □ □ □ ☑ ☑ ☑ □ new
70.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 多数のスモールファイルの取り扱い DynamicFrame による ファイルのグルーピング Driver によるファイルの リスティングの最適化
71.
© 2019, Amazon
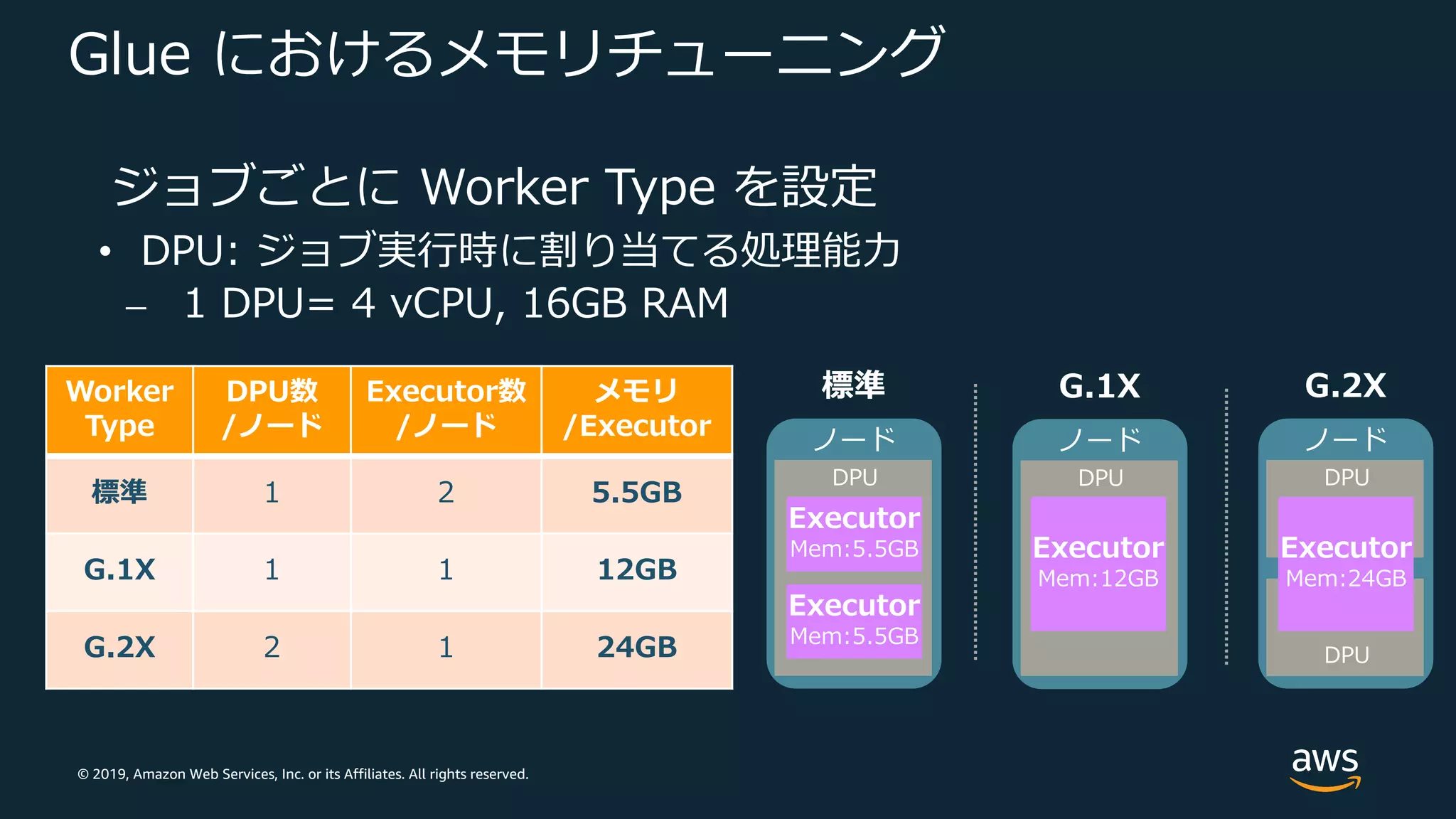
Web Services, Inc. or its Affiliates. All rights reserved. Glue におけるメモリチューニング ジョブごとに Worker Type を設定 • DPU: ジョブ実⾏時に割り当てる処理能⼒ ⎼ 1 DPU= 4 vCPU, 16GB RAM Worker Type DPU数 /ノード Executor数 /ノード メモリ /Executor 標準 1 2 5.5GB G.1X 1 1 12GB G.2X 2 1 24GB 標準 Executor Mem:5.5GB ノード Executor Mem:5.5GB DPU G.1X ノード DPU G.2X ノード DPU DPU Executor Mem:24GB Executor Mem:12GB
72.
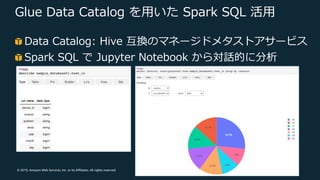
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Glue Data Catalog を⽤いた Spark SQL 活⽤ Data Catalog: Hive 互換のマネージドメタストアサービス Spark SQL で Jupyter Notebook から対話的に分析
73.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved.
74.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved.
75.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved.
76.
© 2019, Amazon
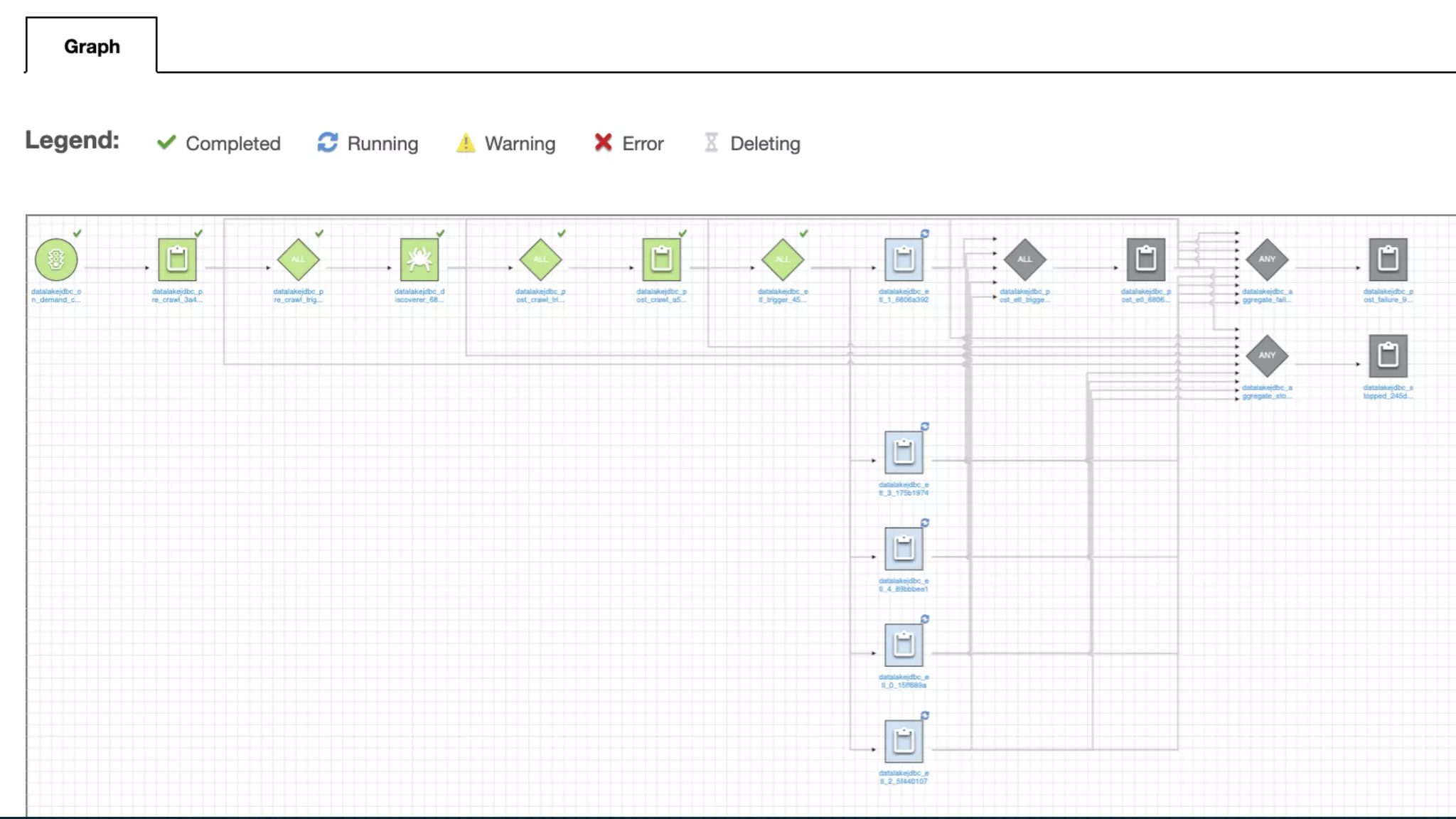
Web Services, Inc. or its Affiliates. All rights reserved. Spark on AWS Glue - Spark ジョブのオーケストレーション
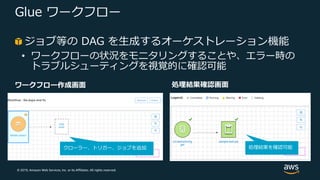
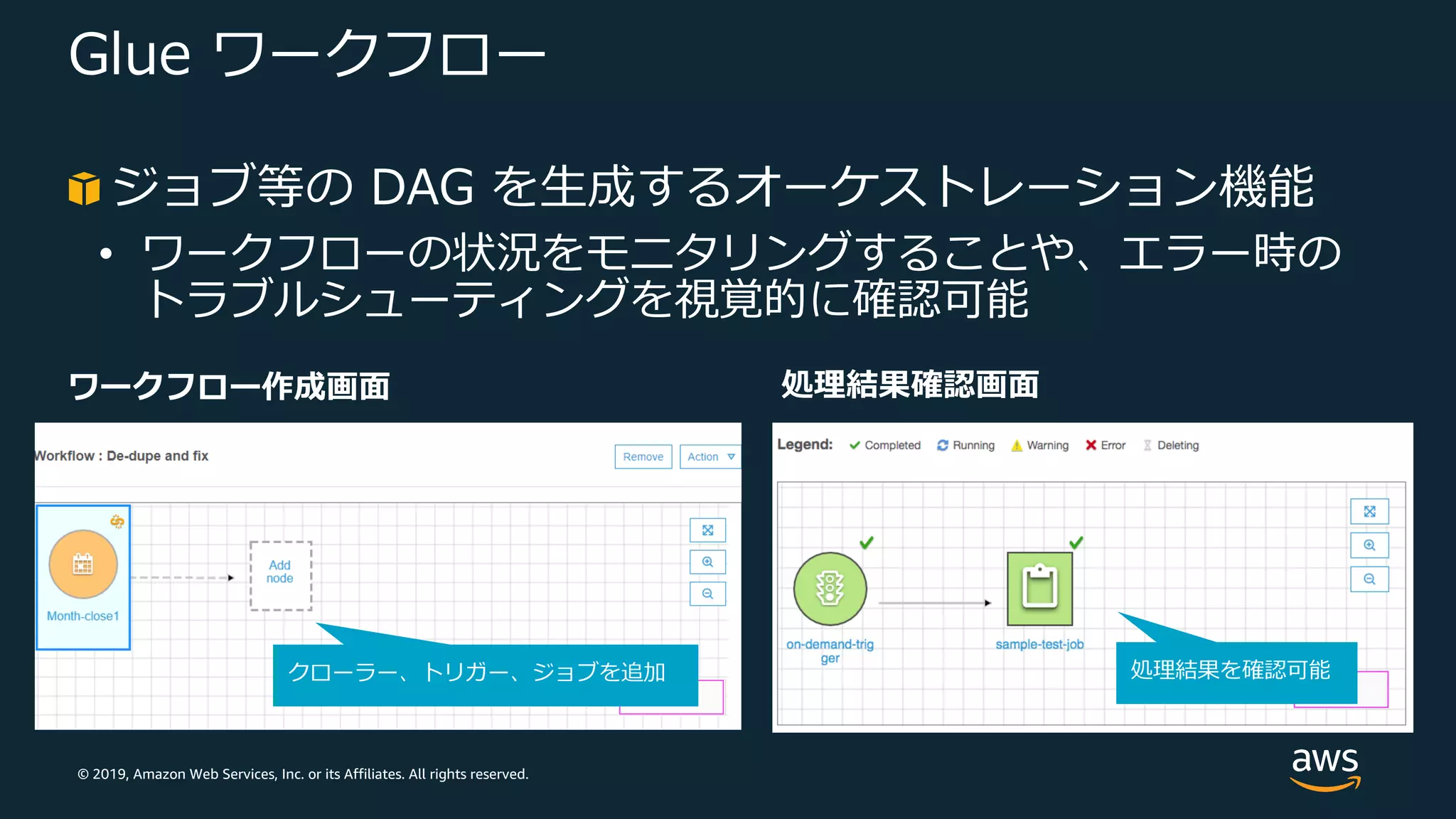
77.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Glue ワークフロー ジョブ等の DAG を⽣成するオーケストレーション機能 • ワークフローの状況をモニタリングすることや、エラー時の トラブルシューティングを視覚的に確認可能 クローラー、トリガー、ジョブを追加 処理結果を確認可能 ワークフロー作成画⾯ 処理結果確認画⾯
78.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved.
79.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Spark on EMR と Spark on Glue の使い分け Spark on Amazon EMR • 汎⽤ワークロード • カスタマイズ可能な環境が必要な場合 • Spark 以外の分散処理エンジンを併⽤したい場合 • Spark (Structured) Streaming を使いたい場合 Spark on AWS Glue • 汎⽤/ETL ワークロード • サーバーレス/マネージド環境を希望する場合 • マネージドなワークフローを構築したい場合
80.
© 2017, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. We are Hiring!!
81.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Thank you! 右の QR コードから 本セッションのアンケートに ご協⼒いただけますと⼤変幸いです
Download













![© 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
EMR マルチマスターの起動
観察
• yarn コマンドでアプリケーションのステータス確認
$ yarn application –list
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress
application_1568118970273_0006 SparkPi SPARK hadoop default RUNNING UNDEFINED 10%
66.ec2.internal:35817](https://image.slidesharecdn.com/20190926dbtstokyorunningapachesparkonawssekiyama-200226105923/85/Running-Apache-Spark-on-AWS-22-320.jpg)





![© 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
パラメータチューニング
パラメータ 解説 値
spark.executor.cores 経験則から 5 vcore を設定 5 vcore
spark.executor.memory [インスタンス毎の Executor 数]
([インスタンス毎の vcore 数] - 1)/ spark.executors.cores
= (48 - 1)/ 5 = 47 / 5 ≒ 9
[Executor 毎の合計メモリ量]
[インスタンス毎のメモリ量]/ [インスタンス毎の Executor 数]
= 383 / 9 ≒ 42
spark.executor.memory
= [Executor 毎の合計メモリ量] * 0.9 ≒ 37
37 GB
spark.yarn.executor.memoryOverhead [Executor 毎の合計メモリ量] * 0.1 ≒ 5 5 GB
spark.driver.memory spark.executor.memory を流⽤ 37 GB
spark.driver.cores spark.executor.cores を流⽤ 5 vcore
spark.executor.instances ([インスタンス毎の Executor 数] * [コアノード数]) -1(Driver)
= 9 * 19 -1 = 170
170
spark.default.parallelism spark.executor.instances * spark.executors.cores * 2
= 170 * 5 * 2 = 1700
1700](https://image.slidesharecdn.com/20190926dbtstokyorunningapachesparkonawssekiyama-200226105923/85/Running-Apache-Spark-on-AWS-36-320.jpg)



































![© 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
EMR マルチマスターの起動
観察
• yarn コマンドでアプリケーションのステータス確認
$ yarn application –list
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress
application_1568118970273_0006 SparkPi SPARK hadoop default RUNNING UNDEFINED 10%
66.ec2.internal:35817](https://image.slidesharecdn.com/20190926dbtstokyorunningapachesparkonawssekiyama-200226105923/75/Running-Apache-Spark-on-AWS-22-2048.jpg)







![© 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
パラメータチューニング
パラメータ 解説 値
spark.executor.cores 経験則から 5 vcore を設定 5 vcore
spark.executor.memory [インスタンス毎の Executor 数]
([インスタンス毎の vcore 数] - 1)/ spark.executors.cores
= (48 - 1)/ 5 = 47 / 5 ≒ 9
[Executor 毎の合計メモリ量]
[インスタンス毎のメモリ量]/ [インスタンス毎の Executor 数]
= 383 / 9 ≒ 42
spark.executor.memory
= [Executor 毎の合計メモリ量] * 0.9 ≒ 37
37 GB
spark.yarn.executor.memoryOverhead [Executor 毎の合計メモリ量] * 0.1 ≒ 5 5 GB
spark.driver.memory spark.executor.memory を流⽤ 37 GB
spark.driver.cores spark.executor.cores を流⽤ 5 vcore
spark.executor.instances ([インスタンス毎の Executor 数] * [コアノード数]) -1(Driver)
= 9 * 19 -1 = 170
170
spark.default.parallelism spark.executor.instances * spark.executors.cores * 2
= 170 * 5 * 2 = 1700
1700](https://image.slidesharecdn.com/20190926dbtstokyorunningapachesparkonawssekiyama-200226105923/75/Running-Apache-Spark-on-AWS-36-2048.jpg)






































![[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる](https://cdn.slidesharecdn.com/ss_thumbnails/dljawsbigdata11clouderaonawsamazonemr3-180207013607-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

























