KEMBAR78
Daftar
Login
S3 整合性モデルと Hadoop/Spark の話 | PPTX
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Noritaka Sekiyama
PPTX, PDF
3,268 views
S3 整合性モデルと Hadoop/Spark の話
Middleware Deep Talks (2019.5.23) @AWSLoft で発表したスライドです。
Data & Analytics
◦
Read more
1
Save
Share
Embed
Download
Download to read offline
1
/ 15
2
/ 15
3
/ 15
4
/ 15
5
/ 15
6
/ 15
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
15
/ 15
More Related Content
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PPTX
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
PDF
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
事例で学ぶApache Cassandra
by
Yuki Morishita
MongoDBが遅いときの切り分け方法
by
Tetsutaro Watanabe
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
What's hot
PDF
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
CyberAgent における OSS の CI/CD 基盤開発 myshoes #CICD2021
by
whywaita
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
Snowflake Architecture and Performance
by
Mineaki Motohashi
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
PDF
20190320 AWS Black Belt Online Seminar Amazon EBS
by
Amazon Web Services Japan
PDF
20200218 AWS Black Belt Online Seminar Next Generation Redshift
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
by
Amazon Web Services Japan
PDF
Embulk, an open-source plugin-based parallel bulk data loader
by
Sadayuki Furuhashi
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
PDF
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
PDF
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
20191016 AWS Black Belt Online Seminar Amazon Route 53 Resolver
by
Amazon Web Services Japan
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
by
NTT DATA Technology & Innovation
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
CyberAgent における OSS の CI/CD 基盤開発 myshoes #CICD2021
by
whywaita
AWSで作る分析基盤
by
Yu Otsubo
Snowflake Architecture and Performance
by
Mineaki Motohashi
分散システムについて語らせてくれ
by
Kumazaki Hiroki
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
20190320 AWS Black Belt Online Seminar Amazon EBS
by
Amazon Web Services Japan
20200218 AWS Black Belt Online Seminar Next Generation Redshift
by
Amazon Web Services Japan
AWS Black Belt Online Seminar 2017 Amazon DynamoDB
by
Amazon Web Services Japan
Embulk, an open-source plugin-based parallel bulk data loader
by
Sadayuki Furuhashi
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
20191016 AWS Black Belt Online Seminar Amazon Route 53 Resolver
by
Amazon Web Services Japan
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ...
by
NTT DATA Technology & Innovation
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
Similar to S3 整合性モデルと Hadoop/Spark の話
PDF
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
PDF
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
PPTX
【AWS Summit Tokyo 2017】Amazon ECS と SpotFleet を活用した低コストでスケーラブルなジョブワーカーシステム
by
Kazuki Matsuda
PPTX
Lv1から始めるWebサービスのインフラ構築
by
伊藤 祐策
PPTX
20170803 bigdataevent
by
Makoto Uehara
PPTX
AI/MLシステムにおけるビッグデータとの付き合い方
by
Shota Suzuki
PDF
Amazon Elasticsearch Serviceを利用したAWSのログ活用
by
真司 藤本
PDF
20161214 re growth-sapporo
by
Satoru Ishikawa
PDF
AWS Black Belt Online Seminar 2017 Amazon S3
by
Amazon Web Services Japan
PDF
AWS Black Belt Techシリーズ AWS Data Pipeline
by
Amazon Web Services Japan
PDF
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
PDF
Accelerating AdTech on AWS #AWSAdTechJP
by
Eiji Shinohara
PDF
Cm re growth-devio-mtup11-sapporo-004
by
Satoru Ishikawa
PDF
AWSの様々なアーキテクチャ
by
Kameda Harunobu
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
PPTX
re:invent2018 総ざらえ
by
真乙 九龍
PDF
AWS Glueを使った Serverless ETL の実装パターン
by
seiichi arai
PDF
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
【AWS Summit Tokyo 2017】Amazon ECS と SpotFleet を活用した低コストでスケーラブルなジョブワーカーシステム
by
Kazuki Matsuda
Lv1から始めるWebサービスのインフラ構築
by
伊藤 祐策
20170803 bigdataevent
by
Makoto Uehara
AI/MLシステムにおけるビッグデータとの付き合い方
by
Shota Suzuki
Amazon Elasticsearch Serviceを利用したAWSのログ活用
by
真司 藤本
20161214 re growth-sapporo
by
Satoru Ishikawa
AWS Black Belt Online Seminar 2017 Amazon S3
by
Amazon Web Services Japan
AWS Black Belt Techシリーズ AWS Data Pipeline
by
Amazon Web Services Japan
Modernizing Big Data Workload Using Amazon EMR & AWS Glue
by
Noritaka Sekiyama
Accelerating AdTech on AWS #AWSAdTechJP
by
Eiji Shinohara
Cm re growth-devio-mtup11-sapporo-004
by
Satoru Ishikawa
AWSの様々なアーキテクチャ
by
Kameda Harunobu
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
re:invent2018 総ざらえ
by
真乙 九龍
AWS Glueを使った Serverless ETL の実装パターン
by
seiichi arai
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
More from Noritaka Sekiyama
PPTX
5分ではじめるApache Spark on AWS
by
Noritaka Sekiyama
PDF
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
PPTX
Sparkにプルリク投げてみた
by
Noritaka Sekiyama
PDF
Running Apache Spark on AWS
by
Noritaka Sekiyama
PDF
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
PDF
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
by
Noritaka Sekiyama
PDF
Introduction to New CloudWatch Agent
by
Noritaka Sekiyama
PPTX
Security Operations and Automation on AWS
by
Noritaka Sekiyama
PDF
運用視点でのAWSサポート利用Tips
by
Noritaka Sekiyama
PPTX
基礎から学ぶ? EC2マルチキャスト
by
Noritaka Sekiyama
PDF
Floodlightってぶっちゃけどうなの?
by
Noritaka Sekiyama
5分ではじめるApache Spark on AWS
by
Noritaka Sekiyama
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
Sparkにプルリク投げてみた
by
Noritaka Sekiyama
Running Apache Spark on AWS
by
Noritaka Sekiyama
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
Amazon S3 Best Practice and Tuning for Hadoop/Spark in the Cloud
by
Noritaka Sekiyama
Introduction to New CloudWatch Agent
by
Noritaka Sekiyama
Security Operations and Automation on AWS
by
Noritaka Sekiyama
運用視点でのAWSサポート利用Tips
by
Noritaka Sekiyama
基礎から学ぶ? EC2マルチキャスト
by
Noritaka Sekiyama
Floodlightってぶっちゃけどうなの?
by
Noritaka Sekiyama
S3 整合性モデルと Hadoop/Spark の話
1.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Noritaka Sekiyama Senior Cloud Support Engineer, Amazon Web Services Japan 2019.05.23 S3 整合性モデルと Hadoop/Spark の話
2.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 関山 宜孝 (Noritaka Sekiyama) Senior Cloud Support Engineer - AWS サポートの中の人 - 専門は Big Data (EMR, Glue, Athena, …) - AWS Glue の専門家 - Apache Spark 好き Who I am... @moomindani
3.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 今日話すこと • S3 整合性モデルの話 • Hadoop/Spark と S3 整合性モデルの関係と緩和方法 (Hadoop/Spark を使ったことのない方、あまり興味のない方にも、 ミドルウェアから S3 を活用する工夫の一例としてお聞きいただければ) 今日話さないこと • Hadoop/Spark の仕組み、最新動向 アジェンダ
4.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. オブジェクトストレージサービス • 高いスケーラビリティ、可用性、耐障害性 (99.999999999%)、セ キュリティ、およびパフォーマンスを提供 • 単一オブジェクトの最大サイズ: 5TB • オブジェクトはバケット配下のユニークなキー名で管理される • ディレクトリは S3 コンソール上では疑似的に表現されるが、実態としては存 在しない • ファイルシステムではない 従量課金 • 主に、保管されたデータサイズと、リクエストに対して課金 Amazon S3
5.
© 2019, Amazon
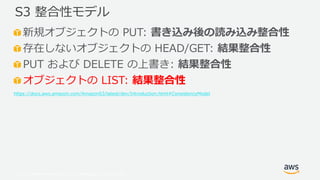
Web Services, Inc. or its Affiliates. All rights reserved. 新規オブジェクトの PUT: 書き込み後の読み込み整合性 存在しないオブジェクトの HEAD/GET: 結果整合性 PUT および DELETE の上書き: 結果整合性 オブジェクトの LIST: 結果整合性 https://docs.aws.amazon.com/AmazonS3/latest/dev/Introduction.html#ConsistencyModel S3 整合性モデル
6.
© 2019, Amazon
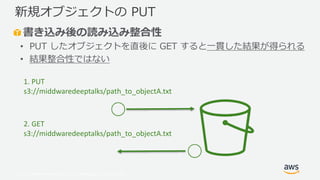
Web Services, Inc. or its Affiliates. All rights reserved. 書き込み後の読み込み整合性 • PUT したオブジェクトを直後に GET すると一貫した結果が得られる • 結果整合性ではない 新規オブジェクトの PUT 1. PUT s3://middwaredeeptalks/path_to_objectA.txt 2. GET s3://middwaredeeptalks/path_to_objectA.txt
7.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 結果整合性 • PUT 前のオブジェクトを存在確認のために HEAD/GET して、 その後にオブジェクトを PUT して GET すると結果整合性となる 存在しないオブジェクトの HEAD/GET 1. HEAD or GET s3://middwaredeeptalks/path_to_objectB.txt 2. PUT s3://middwaredeeptalks/path_to_objectB.txt 3. GET s3://middwaredeeptalks/path_to_objectB.txt
8.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 結果整合性 • 既存オブジェクトを PUT して GET すると古いデータが返却される場 合がある • 既存オブジェクトを DELETE して GET すると削除済データが返却さ れる場合がある PUT および DELETE の上書き 1. PUT/DELETE s3://middwaredeeptalks/path_to_objectC.txt 2. GET s3://middwaredeeptalks/path_to_objectC.txt
9.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 結果整合性 • 新規オブジェクトを PUT して直後に LIST すると、追加されたオブ ジェクトがリストに含まれない場合がある • 既存オブジェクトを DELETE して直後に LIST すると、削除済のオブ ジェクトがリストに含まれる場合がある 特に LIST 結果整合性は、Hadoop/Spark に影響が大きい オブジェクトの LIST 1. PUT s3://middwaredeeptalks/path_to_objectD.txt 2. LIST s3://middwaredeeptalks/
10.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 入力データの取得 • 引数にとった S3 の任意のパスのデータを分散処理のために取得 1. 対象のパスを LIST 2. LIST で返却されたキーに対して HEAD (存在確認) 3. LIST で返却されたキーに対して GET (オブジェクト取得) • 複数のジョブを多段で構成してパイプラインを組む場合、前段の ジョブの出力を後段のジョブの入力に使用することになる ⎼ 例:複数ステップの ETL データ処理パイプライン – ステップ1: 入力の生データを整形、フォーマット変換 – ステップ2: 変換後のデータを入力として統計処理 Hadoop/Spark から S3 へのよくある操作その1
11.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 中間データの最終出力先への移動 • 中間出力先にデータを一時的に書きこみ、その後で対象のパスの データを LIST して最終出力先に MV/RENAME ⎼ 中途半端な状態のデータを見えなくするため • S3 には MV/RENAME の概念がないため、以下の手続きが必要 1. 中間出力先のパスを LIST 2. LIST で返却されたキーから最終出力先のキーへ COPY (オブ ジェクトコピー) 3. LIST で返却されたキーに対して DELETE (元オブジェクト削 除) (HDFS の MV/RENAME は非常に高速だが、S3 では時間がかかる) Hadoop/Spark から S3 へのよくある操作その2
12.
© 2019, Amazon
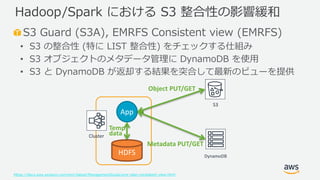
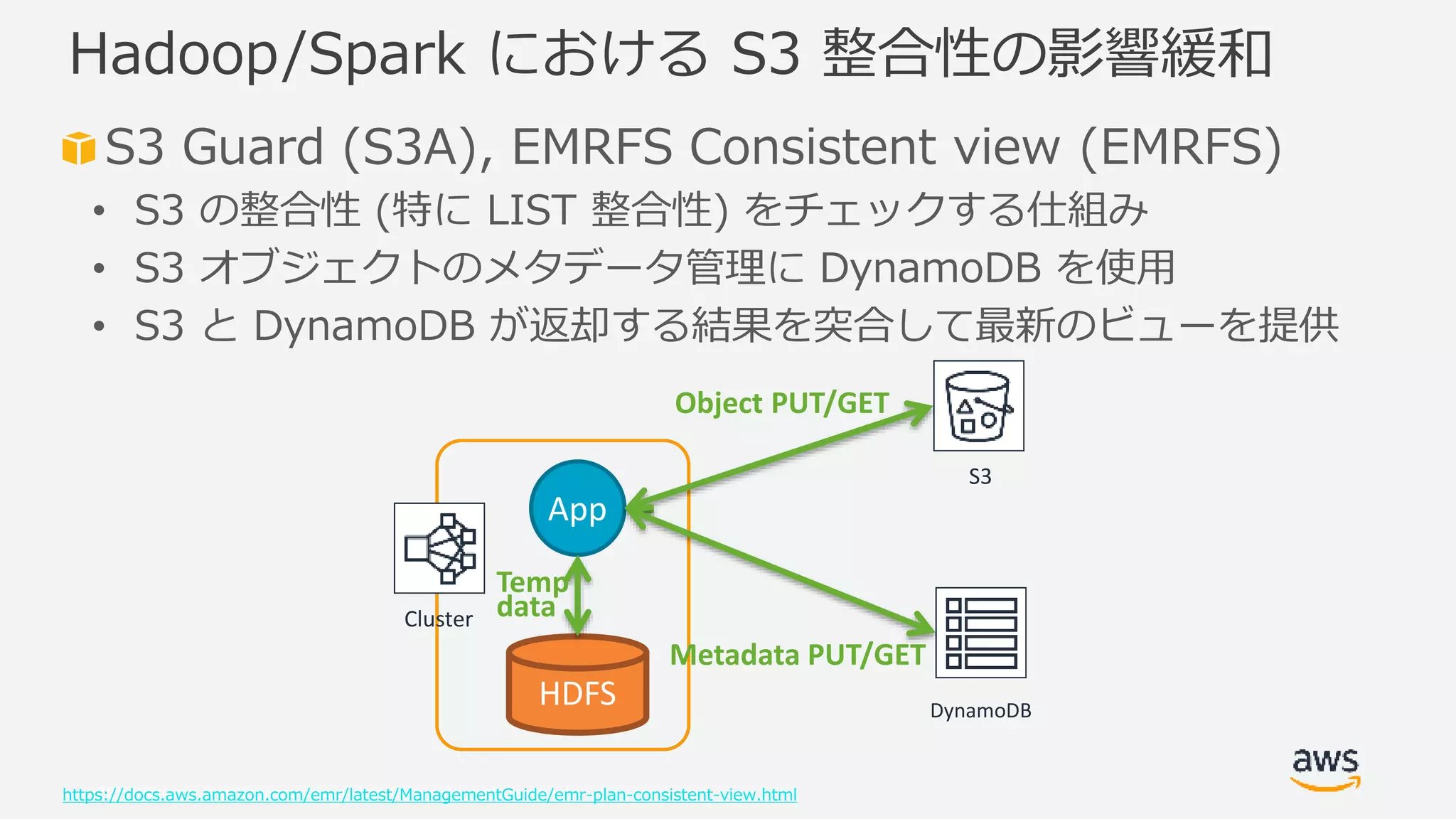
Web Services, Inc. or its Affiliates. All rights reserved. S3 Guard (S3A), EMRFS Consistent view (EMRFS) • S3 の整合性 (特に LIST 整合性) をチェックする仕組み • S3 オブジェクトのメタデータ管理に DynamoDB を使用 • S3 と DynamoDB が返却する結果を突合して最新のビューを提供 https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-consistent-view.html Hadoop/Spark における S3 整合性の影響緩和 Cluster S3 HDFS App Temp data DynamoDB Object PUT/GET Metadata PUT/GET
13.
© 2019, Amazon
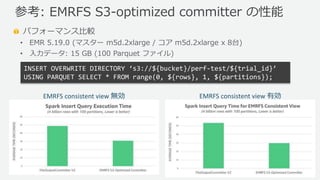
Web Services, Inc. or its Affiliates. All rights reserved. S3A Committer, EMRFS S3-optimized committer • S3 マルチパートアップロードの仕組みを活用 • ジョブ/タスクコミットフェーズ中に S3 への LIST/RENAME オペレー ションを回避し、アプリケーションのパフォーマンスを向上 • ジョブ/タスクコミットフェーズで S3 結果整合性による問題を回避し、 タスク失敗時のジョブの正確性を向上 ⎼ 中間出力先にデータを一時的に書きこむ代わりに、マルチパートアップロードを開始 (この時点ではファイルは見えない) ⎼ 書き込みが完了したら MV/RENAME する代わりに、マルチパートアップロードを終了 (LIST してコピーとかしなくていい) https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-s3-optimized-committer.html https://aws.amazon.com/blogs/big-data/improve-apache-spark-write-performance-on-apache-parquet-formats-with-the-emrfs-s3-optimized- committer/ Hadoop/Spark における S3 整合性の影響緩和
14.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. マルチパートアップロードの開始 • 開始リクエストを送信してアップロードIDを取得 各パートのアップロード • アップロードIDとパート番号を添えてアップロード • 明示的に完了/中止しないとパートは残存し、ストレージ課金が継続 マルチパートアップロードの完了/中止 • パート番号に基づいて昇順に連結したオブジェクトを S3 上に生成 • 個々のパートは解放され、ストレージも解放される 参考:マルチパートアップロードの流れ マルチパート アップロード の開始 各パートの アップロード マルチパート アップロード の完了/中止
15.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. パフォーマンス比較 • EMR 5.19.0 (マスター m5d.2xlarge / コア m5d.2xlarge x 8台) • 入力データ: 15 GB (100 Parquet ファイル) 参考: EMRFS S3-optimized committer の性能 EMRFS consistent view 無効 EMRFS consistent view 有効 INSERT OVERWRITE DIRECTORY ‘s3://${bucket}/perf-test/${trial_id}’ USING PARQUET SELECT * FROM range(0, ${rows}, 1, ${partitions});
Editor's Notes
#6
皆さんの中には「S3は結果整合性だ」といった話を聞いたことがある方もいらっしゃるのではないかと思います。 ご存知の通り S3 には特有の整合性モデルがあります。 ここでは 4種類の異なる操作について、S3 がどのような整合性を提供しているのか説明します。 まず、新規オブジェクトの PUT に対しては、書き込み後の読み取り整合性となっています。 これは、PUT したオブジェクトを直後に GET すると一貫した結果が得られる、ということです。この操作に限っては、結果整合性ではない点にご注意ください。 次に、存在しないオブジェクトの HEAD/GET、そして PUT および DELETE の上書き、これらはいずれも結果整合性です。 Hadoop/Spark のようなワークロードで重要なのはオブジェクトの LIST ですが、こちらも結果整合性です。 どういうことかというと、新規オブジェクトを PUT して直後に LIST すると、追加されたオブジェクトがリストに含まれない場合があります。 また、既存オブジェクトを DELETE して直後に LIST すると、削除済のオブジェクトがリストに含まれる場合がある、ということになります。 -- https://docs.aws.amazon.com/AmazonS3/latest/dev/Introduction.html#ConsistencyModel
#15
マルチパートアップロードというのはサイズの大きいファイルを S3 にアップロードするために S3 側で用意している仕組みで、3つのステップで構成されます。 第1のステップでは、マルチパートアップロードを開始します。 第2のステップでは、対象のマルチパートアップロードに、ファイルを構成する複数のパートをアップロードしていきます。 このとき、マルチパートアップロードを明示的に完了または中止しないと、このパートは残存し、S3 のストレージ課金が継続します。 第3のステップでは、マルチパートアップロードを完了または中止します。 この時点で、複数のパートが連結され、最終的なファイルが S3 上に出力されます。併せて、個々のパートは解放され、ストレージ課金も停止します。
Download