Download to read offline


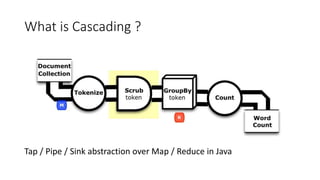















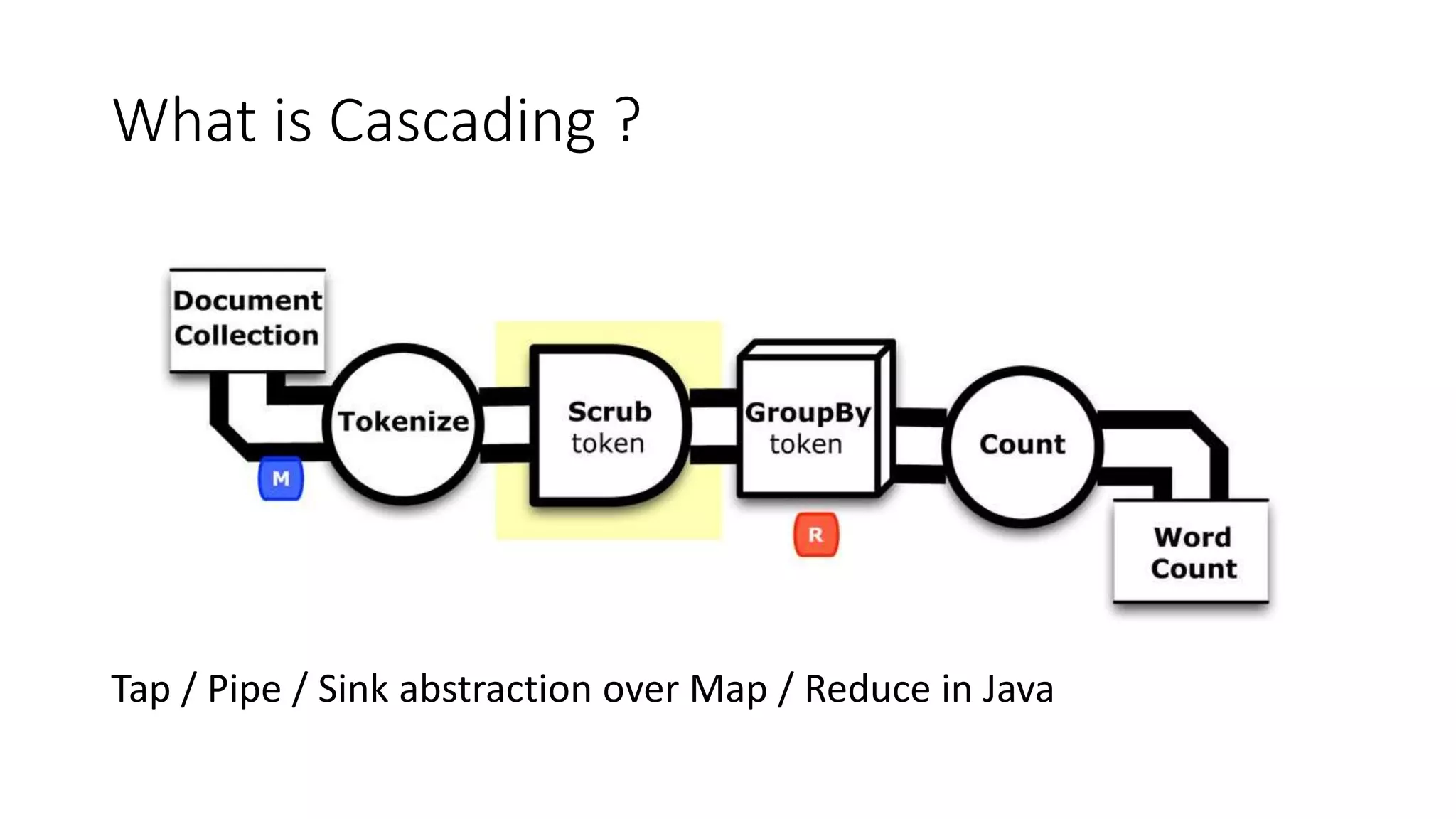


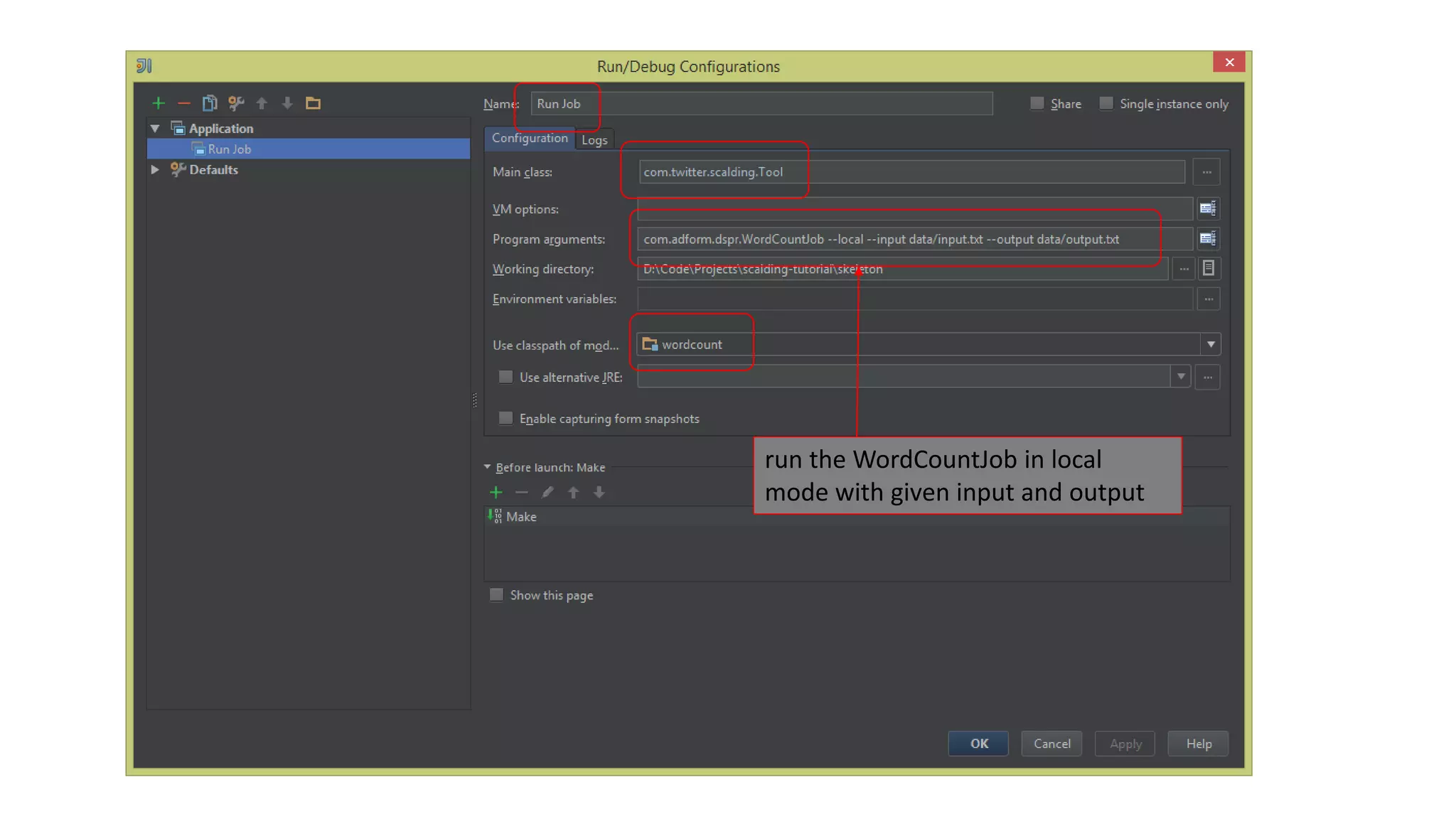



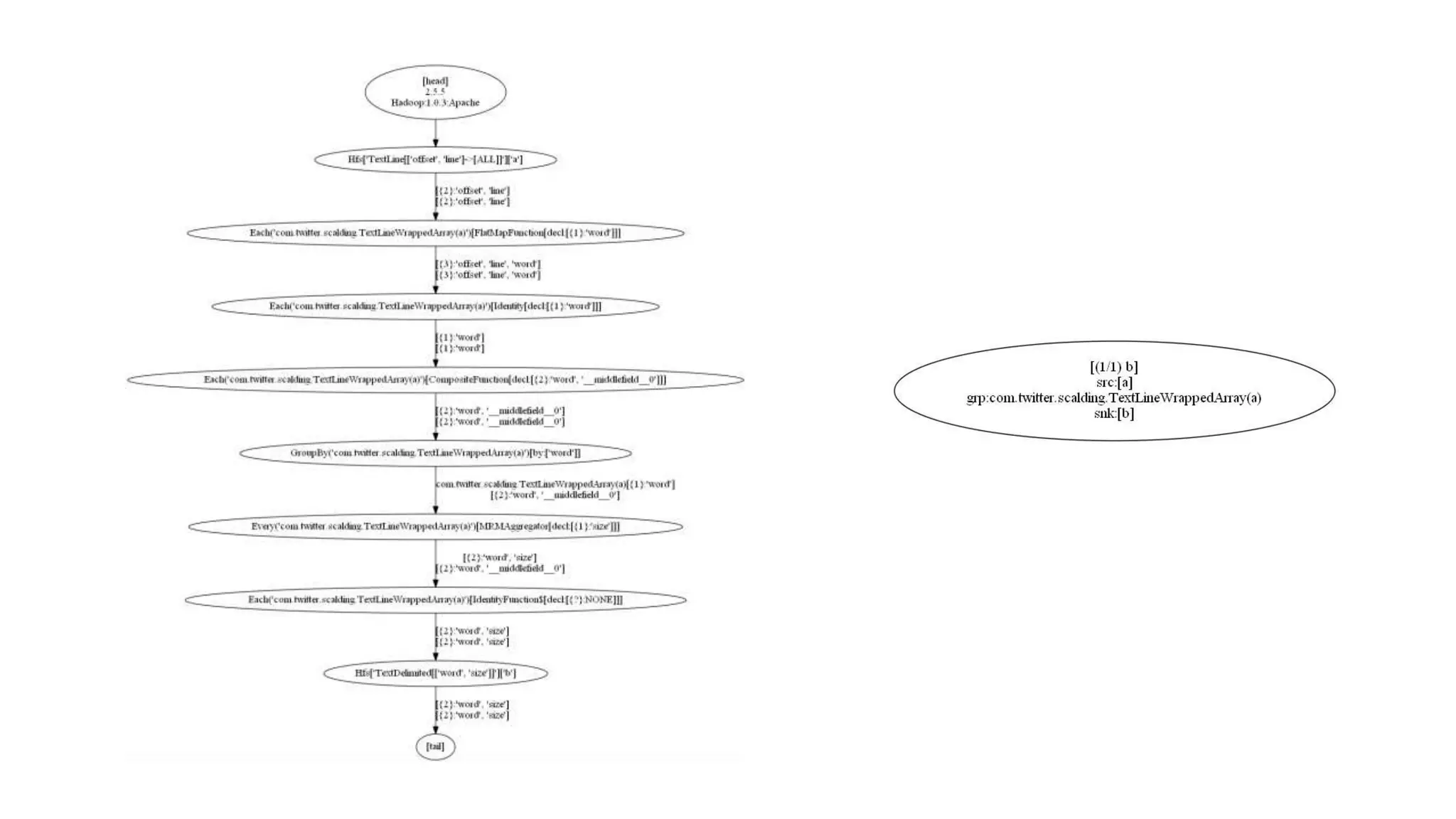









This document provides a quick guide to Scalding, a Scala wrapper for the Cascading framework that allows for MapReduce-style programming in Scala. Scalding represents data as in-memory collections and allows processing without scripting or user-defined functions. It provides an abstraction over Hadoop MapReduce through concepts like taps, pipes, and sinks. The document demonstrates a word count example in Scalding and provides instructions for building, testing, and deploying Scalding jobs on EMR as well as developing with both field-based and typed APIs. It also shares the author's experiences using Scalding.






































































![[Не]практичные типы](https://cdn.slidesharecdn.com/ss_thumbnails/random-120710152756-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


