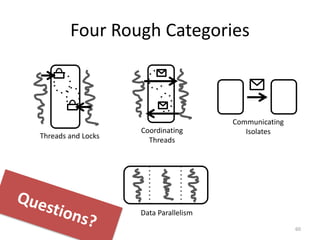
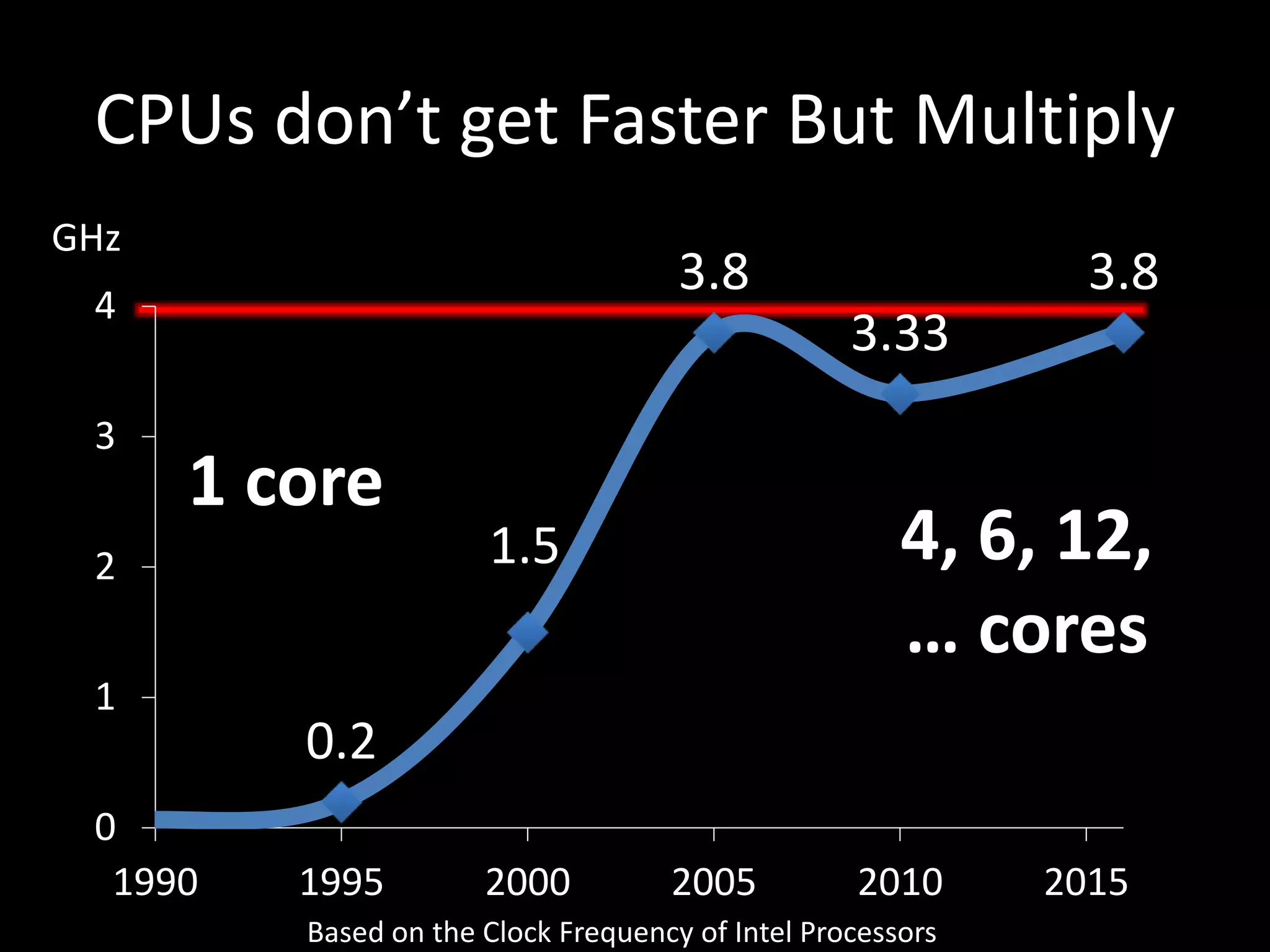
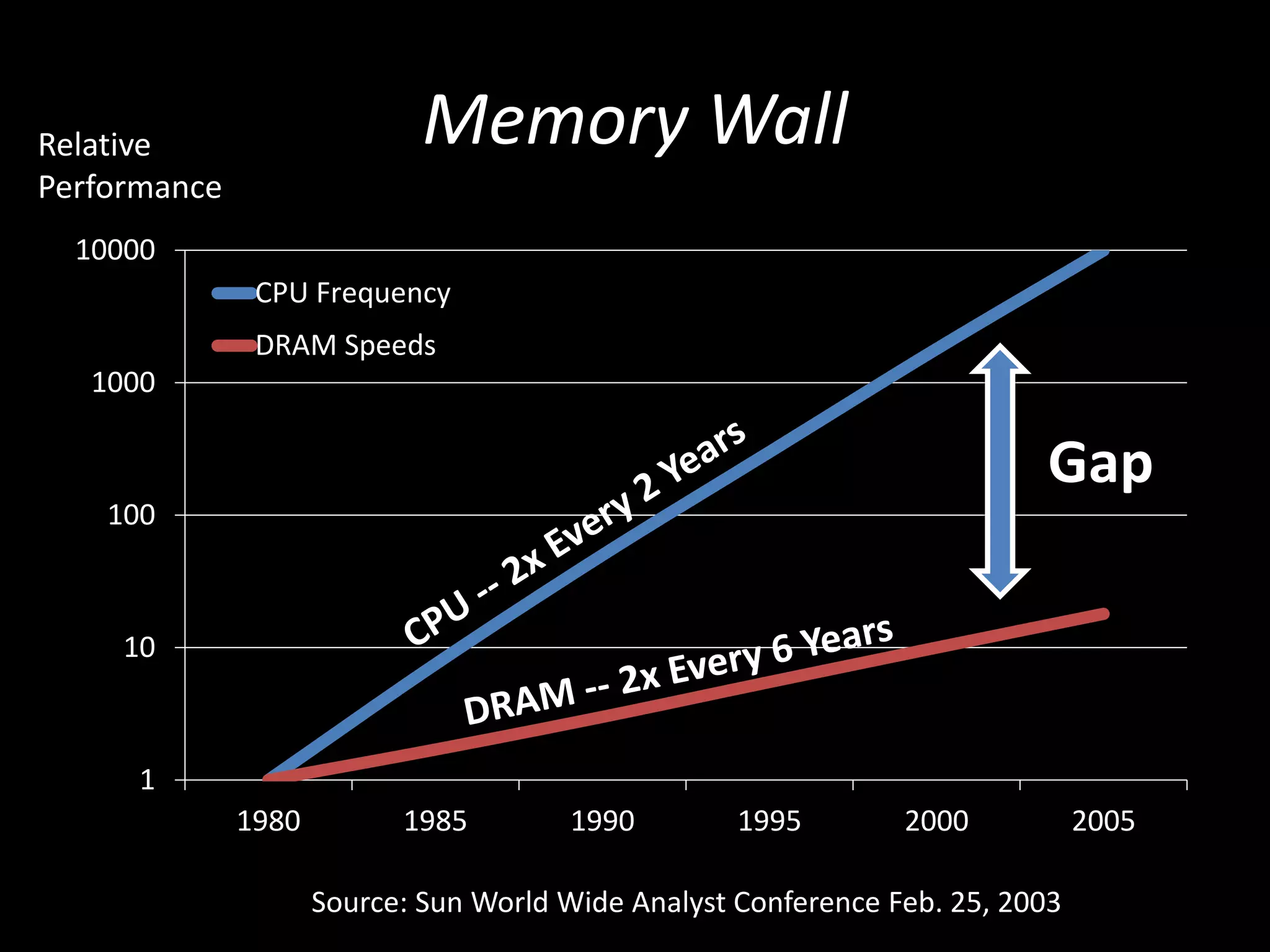
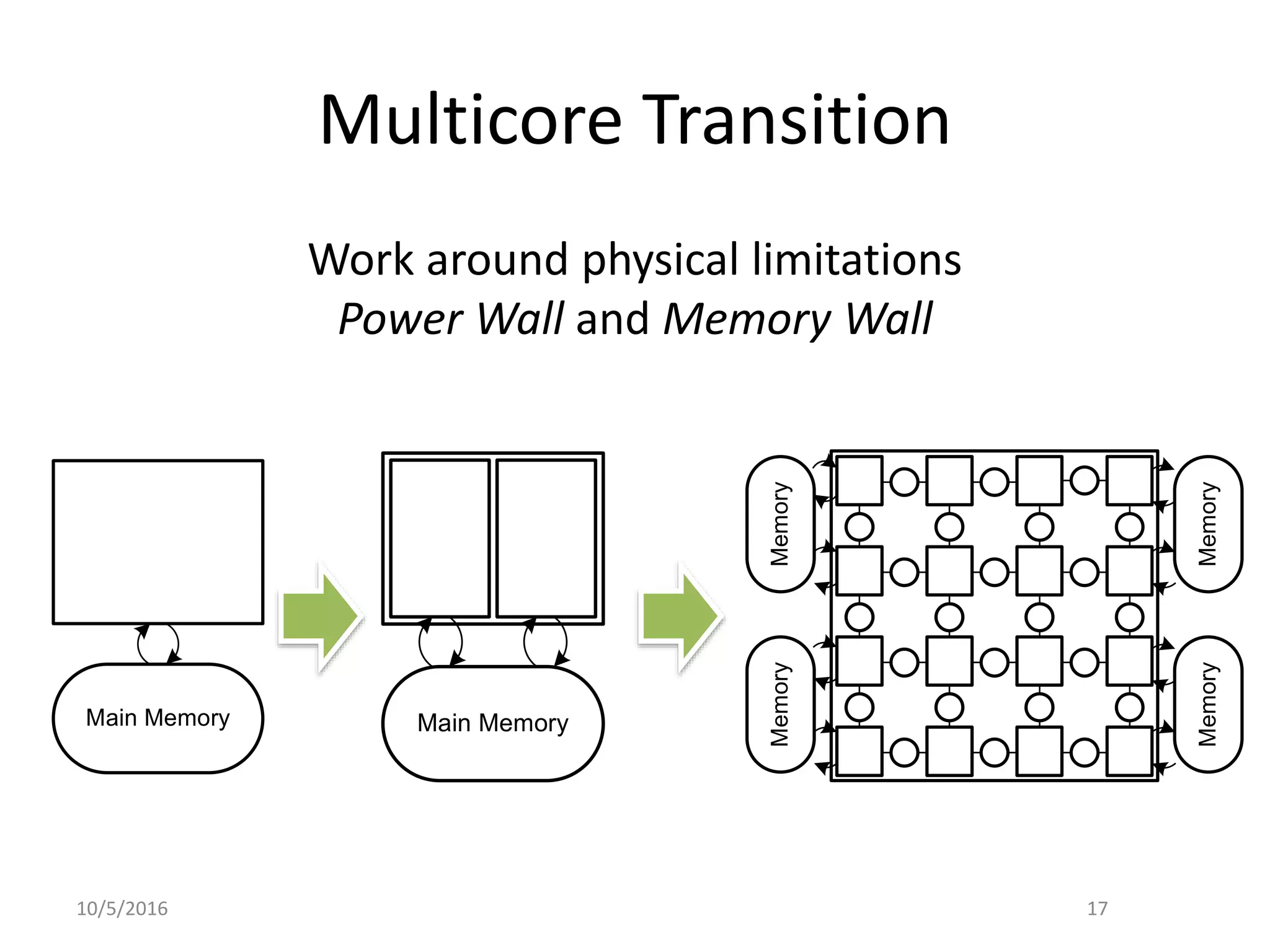
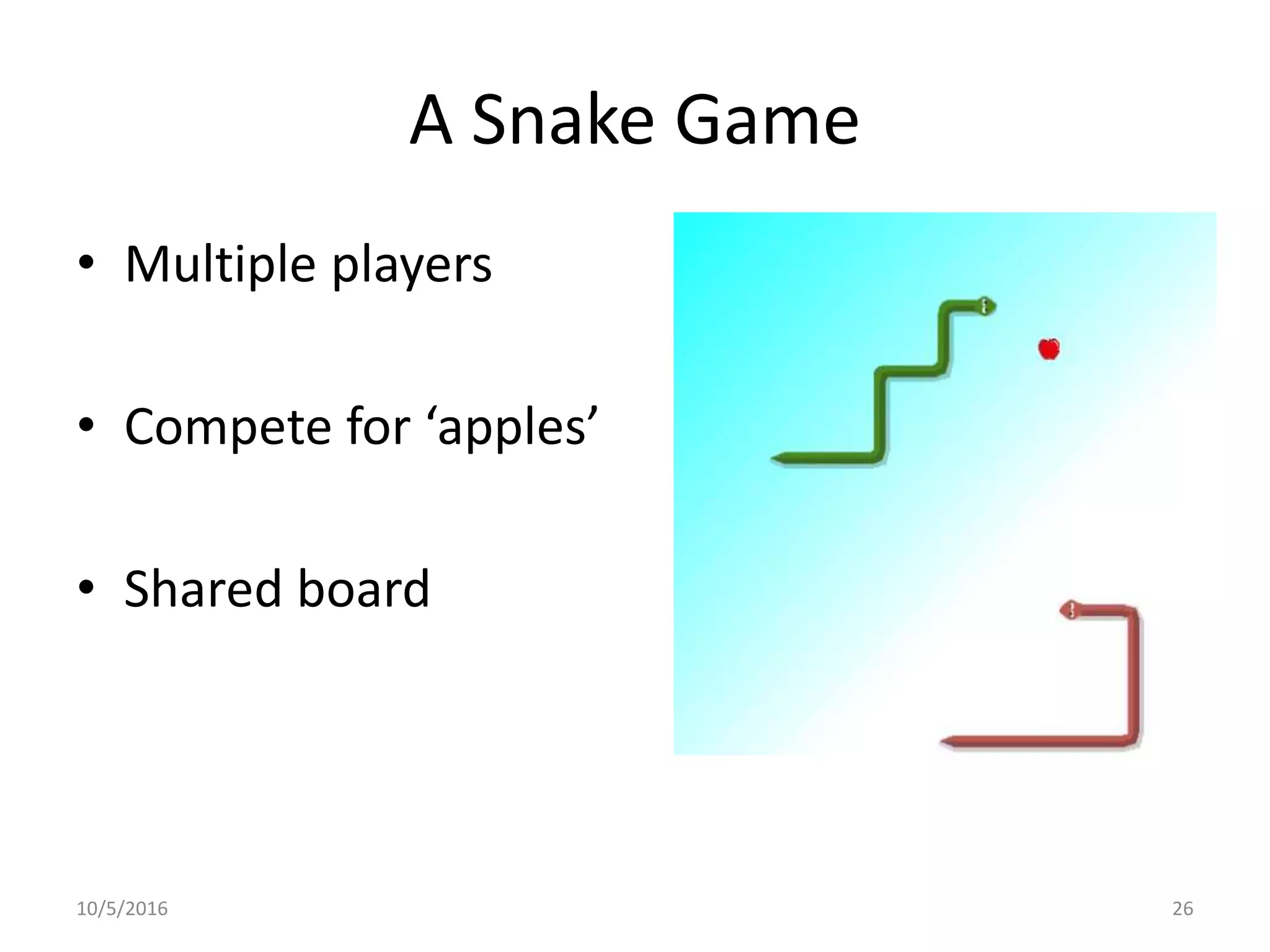
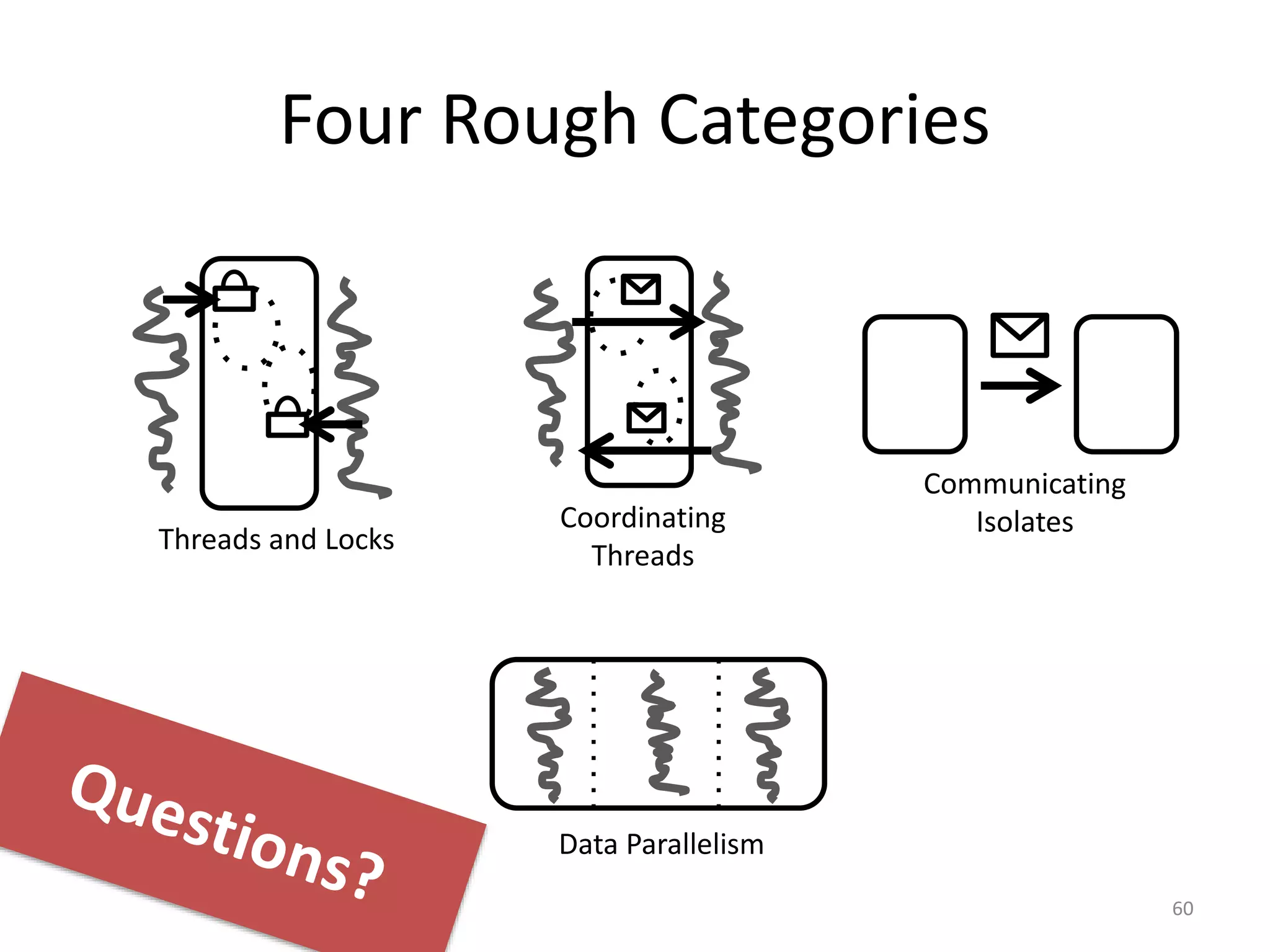
This document outlines the agenda, tasks, deadlines, grading, and timeline for a seminar on parallel and concurrent programming. The agenda includes an introduction to concurrent programming models, an overview of selected seminar papers, and student presentations. Students must present on a selected paper, provide a summary and questions in advance, and submit a written report by the deadline. The report can focus on the theoretical treatment of a paper or practical reproduction of experiments. Attendance, the quality of the presentation and discussion, and the write-up determine grading. Consultations are available to prepare the presentation and agree on the report focus.












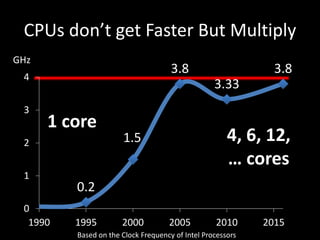


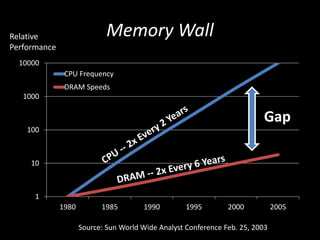
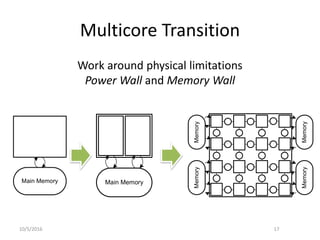



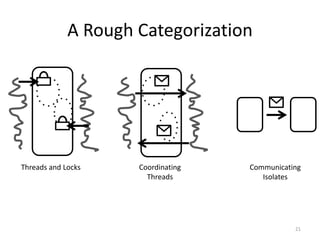
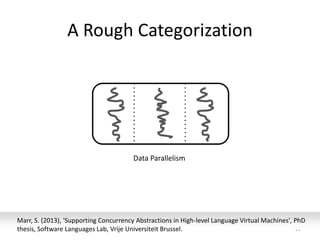


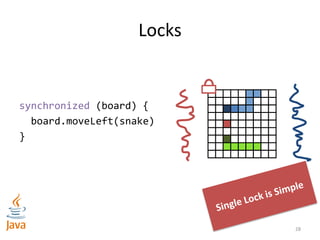
![Optimized Locking for more Parallelism
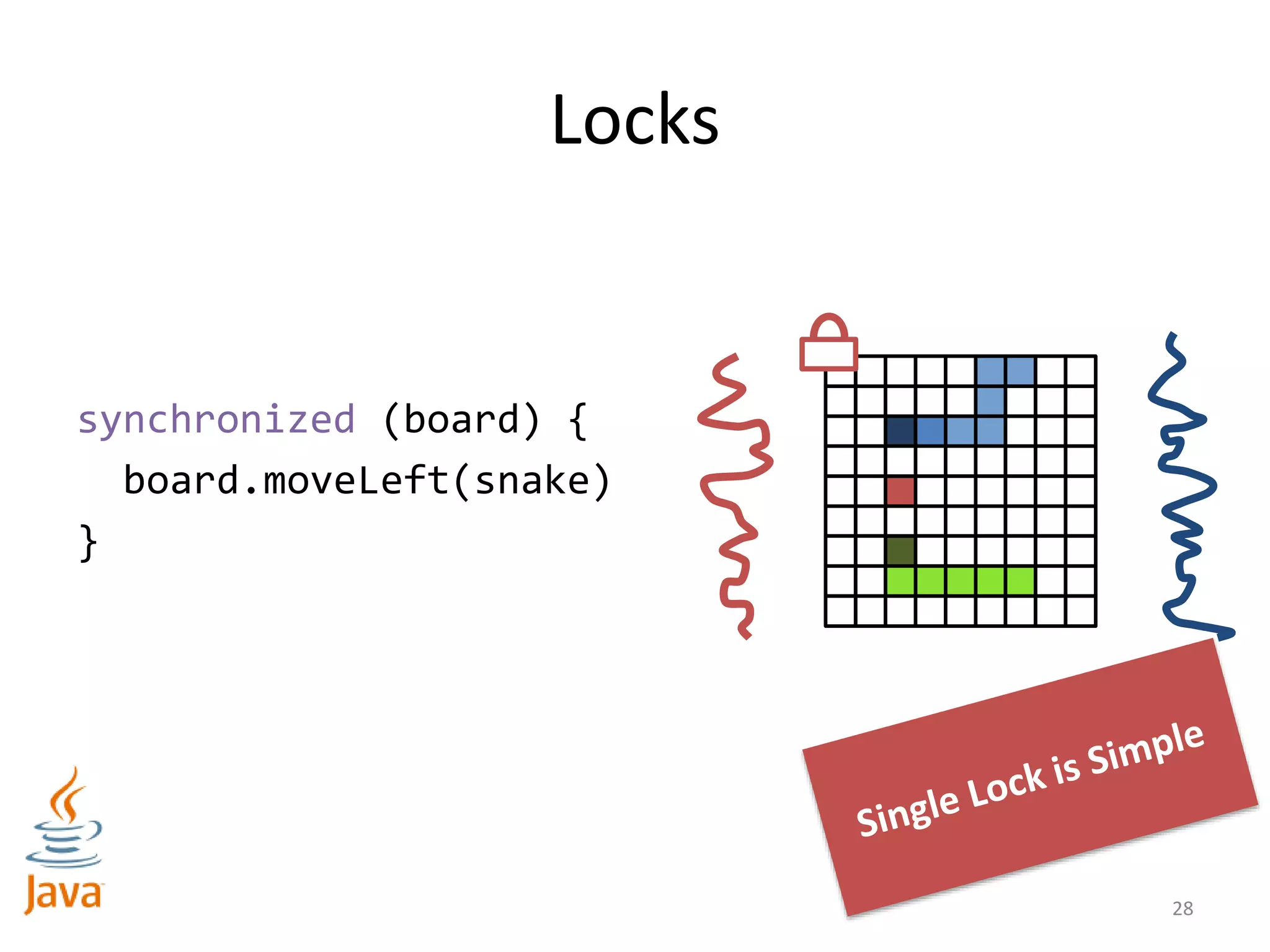
synchronized (board[3][3]) {
synchronized (board[3][2]) {
board.moveLeft(snake)
}
}
29
Strategy: Lock only cells you need to update
What could go
wrong?](https://image.slidesharecdn.com/intro-lecture-161005135117/85/Seminar-on-Parallel-and-Concurrent-Programming-29-320.jpg)


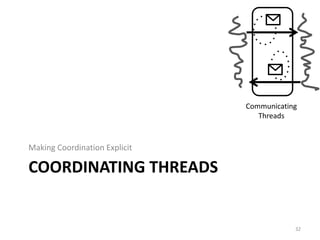


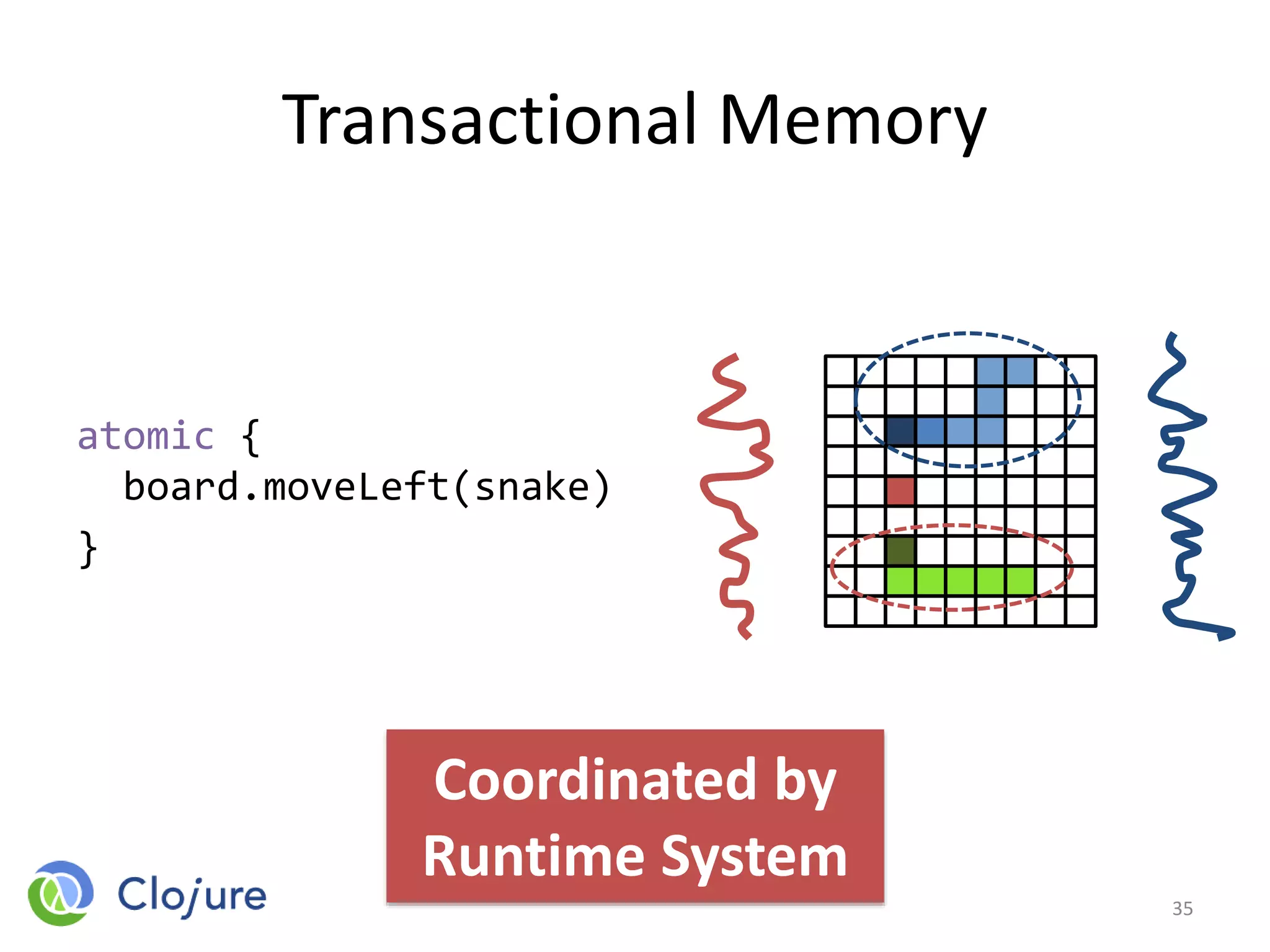
![Some Issues
atomic {
dataArray = getData();
fork { compute(dataArray[0]); }
compute(dataArray[1]);
}
37
P2.2 Transactional Tasks: Parallelism in Software Transactions, J. Swalens et al.
P1.1 Transactional Data Structure Libraries, A. Spiegelman et al.
P1.2 Type-Aware Transactions for Faster Concurrent Code, N. Herman et al.
What happens with
forked thread when
transaction aborts?](https://image.slidesharecdn.com/intro-lecture-161005135117/85/Seminar-on-Parallel-and-Concurrent-Programming-37-320.jpg)
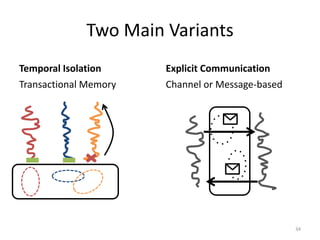
![Channel-based Communication
coordChannel ! (#moveLeft, snake)
38
for i in players():
msg ? coordChannels[i]
match msg:
(#moveLeft, snake):
board[…,…] = …
Player Thread
Coordinator Thread
Coordinator Thread
Player Thread Player Thread
send
receive
High-level communication
but no safety guarantees](https://image.slidesharecdn.com/intro-lecture-161005135117/85/Seminar-on-Parallel-and-Concurrent-Programming-38-320.jpg)



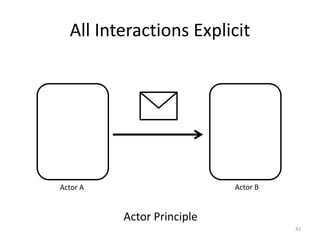

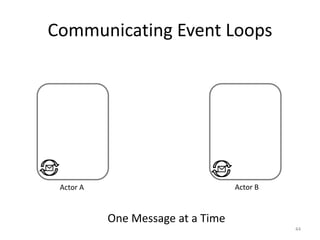
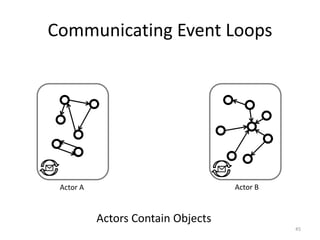
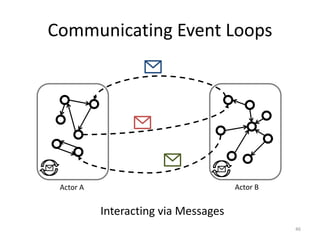
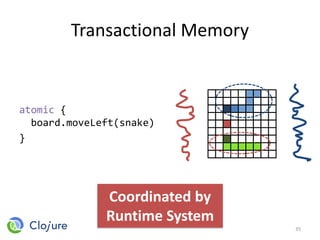
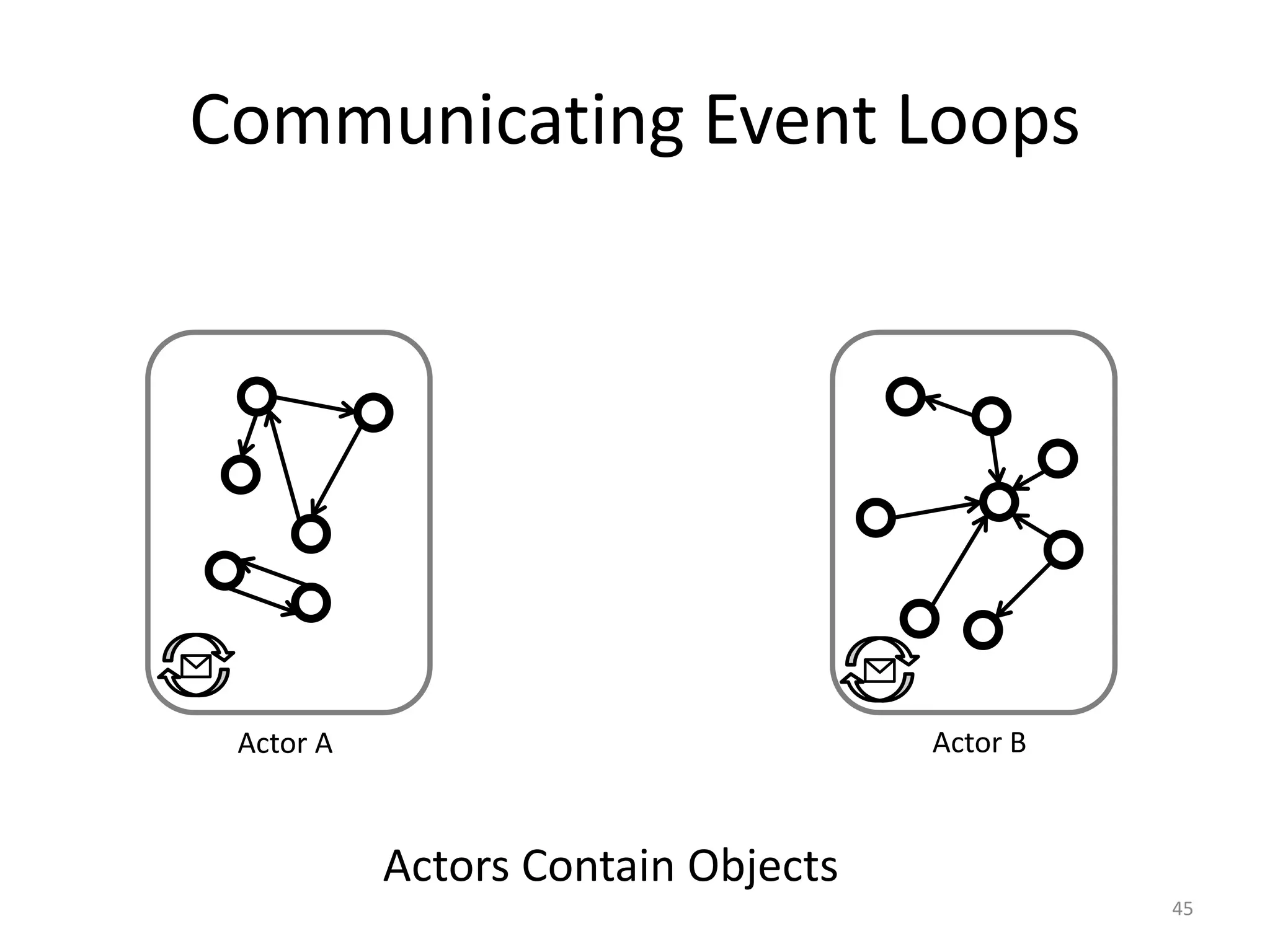
![Message-based Communication
47
Player 1
Player 1
Board Actor
board <- moveLeft(snake)
class Board {
private array;
public moveLeft(snake) {
array[snake.x][snake.y] = ...
}
}
Player Actor
Board Actor
async send
actors.create(Board)
actors.create(Snake)
actors.create(Snake)
Main Program](https://image.slidesharecdn.com/intro-lecture-161005135117/85/Seminar-on-Parallel-and-Concurrent-Programming-47-320.jpg)






























![Optimized Locking for more Parallelism
synchronized (board[3][3]) {
synchronized (board[3][2]) {
board.moveLeft(snake)
}
}
29
Strategy: Lock only cells you need to update
What could go
wrong?](https://image.slidesharecdn.com/intro-lecture-161005135117/75/Seminar-on-Parallel-and-Concurrent-Programming-29-2048.jpg)




![Some Issues
atomic {
dataArray = getData();
fork { compute(dataArray[0]); }
compute(dataArray[1]);
}
37
P2.2 Transactional Tasks: Parallelism in Software Transactions, J. Swalens et al.
P1.1 Transactional Data Structure Libraries, A. Spiegelman et al.
P1.2 Type-Aware Transactions for Faster Concurrent Code, N. Herman et al.
What happens with
forked thread when
transaction aborts?](https://image.slidesharecdn.com/intro-lecture-161005135117/75/Seminar-on-Parallel-and-Concurrent-Programming-37-2048.jpg)
![Channel-based Communication
coordChannel ! (#moveLeft, snake)
38
for i in players():
msg ? coordChannels[i]
match msg:
(#moveLeft, snake):
board[…,…] = …
Player Thread
Coordinator Thread
Coordinator Thread
Player Thread Player Thread
send
receive
High-level communication
but no safety guarantees](https://image.slidesharecdn.com/intro-lecture-161005135117/75/Seminar-on-Parallel-and-Concurrent-Programming-38-2048.jpg)




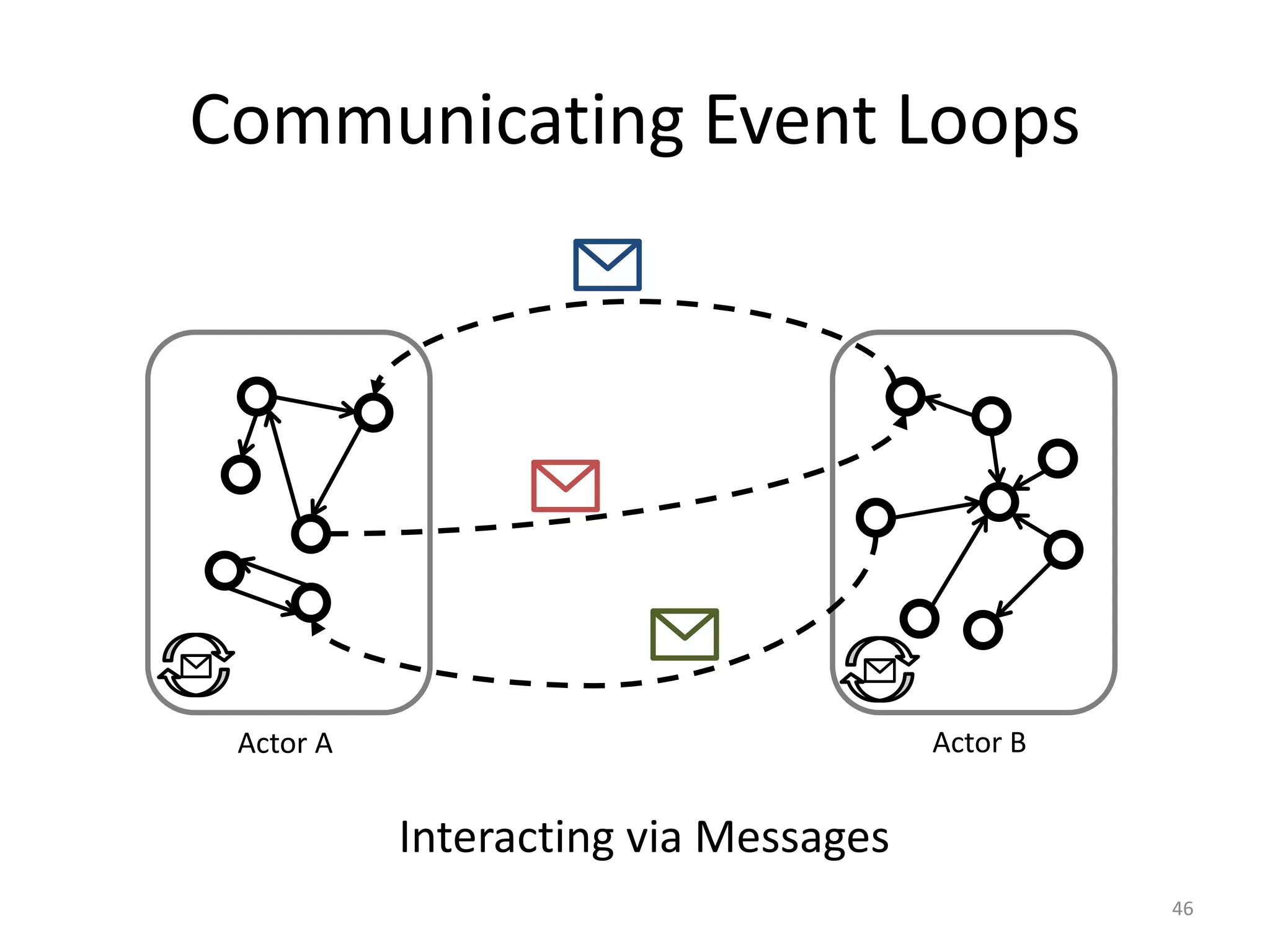
![Message-based Communication
47
Player 1
Player 1
Board Actor
board <- moveLeft(snake)
class Board {
private array;
public moveLeft(snake) {
array[snake.x][snake.y] = ...
}
}
Player Actor
Board Actor
async send
actors.create(Board)
actors.create(Snake)
actors.create(Snake)
Main Program](https://image.slidesharecdn.com/intro-lecture-161005135117/75/Seminar-on-Parallel-and-Concurrent-Programming-47-2048.jpg)























![[Question Paper] Linux Administration (75:25 Pattern) [April / 2015]](https://cdn.slidesharecdn.com/ss_thumbnails/linux-qp-75-25-april-2015-170831130550-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









































































