










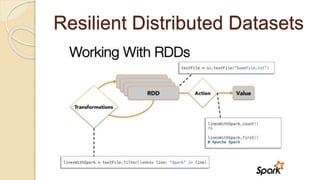



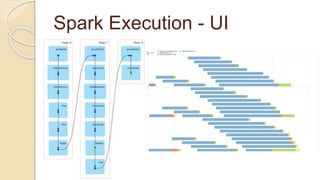


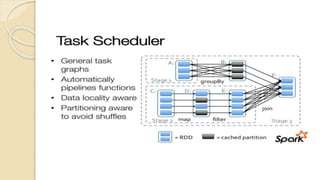

![Job Submission Tool
./bin/spark-submit <app-jar>
--class my.main.Class
--name myAppName
--master local[4]
--master spark://some-cluster](https://image.slidesharecdn.com/spark-101-first-steps-to-distributed-computing-uploaded-151012124645-lva1-app6891/85/Spark-101-First-steps-to-distributed-computing-25-320.jpg)







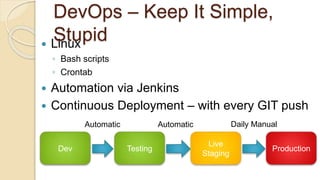



















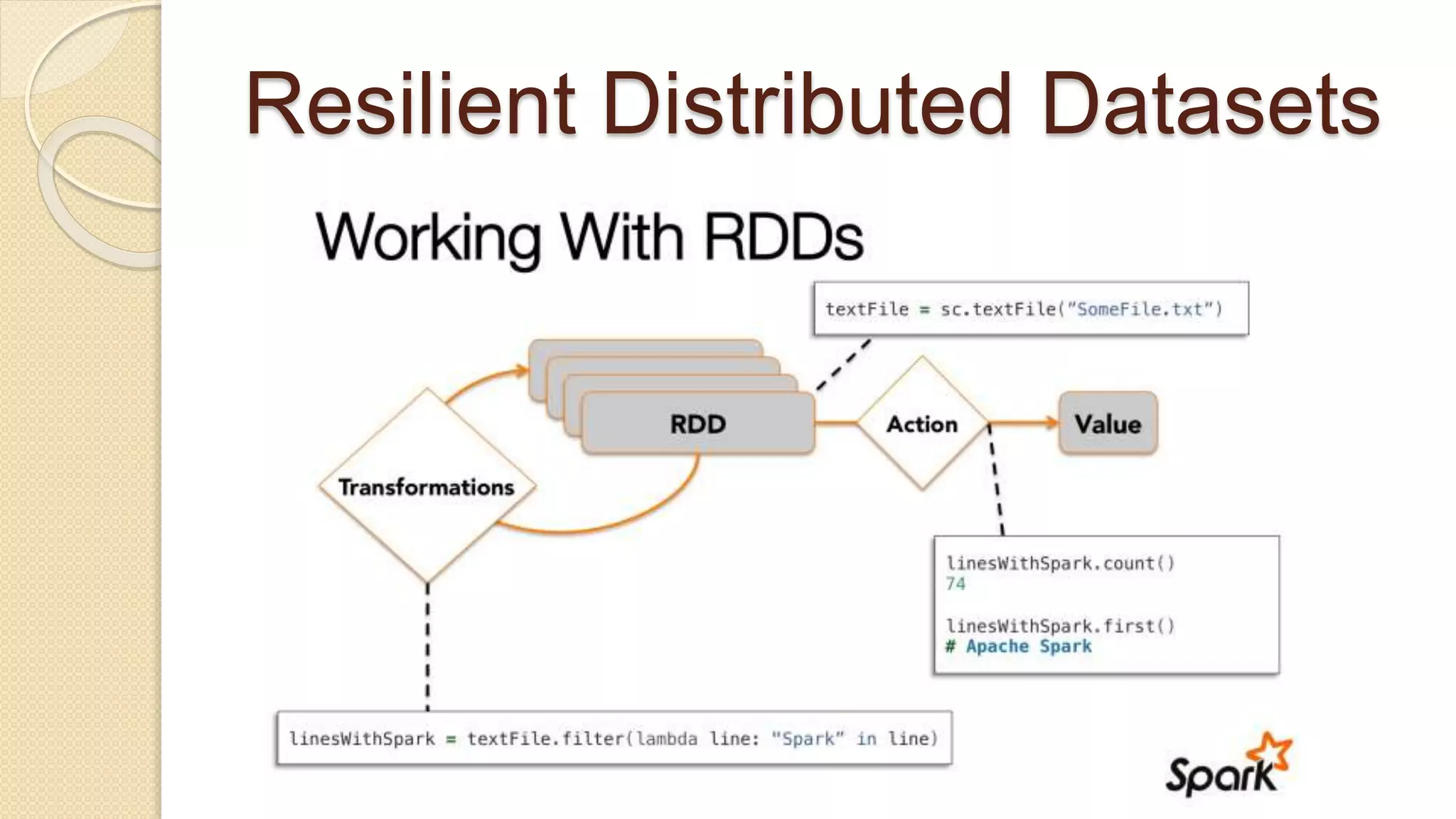



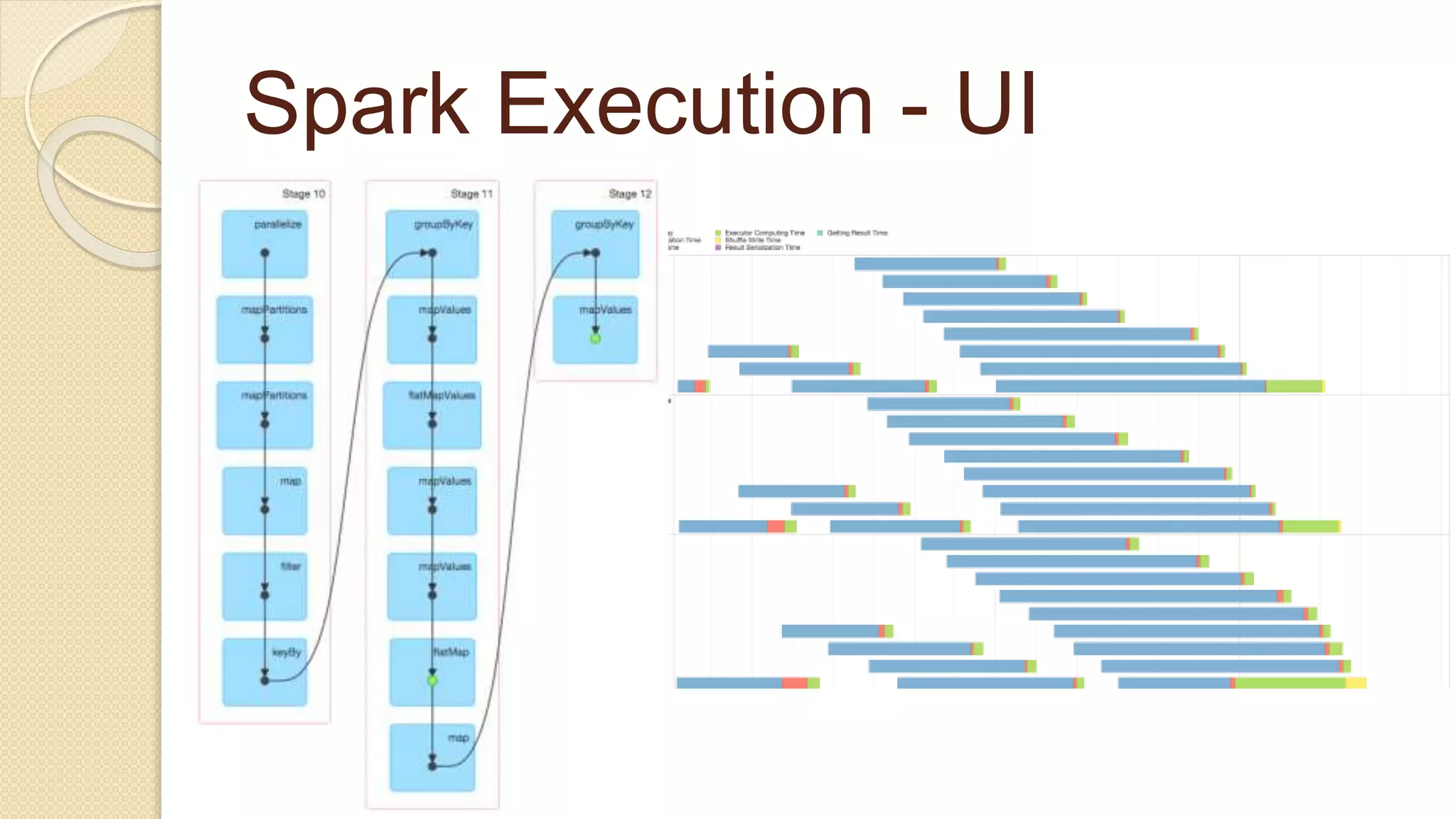


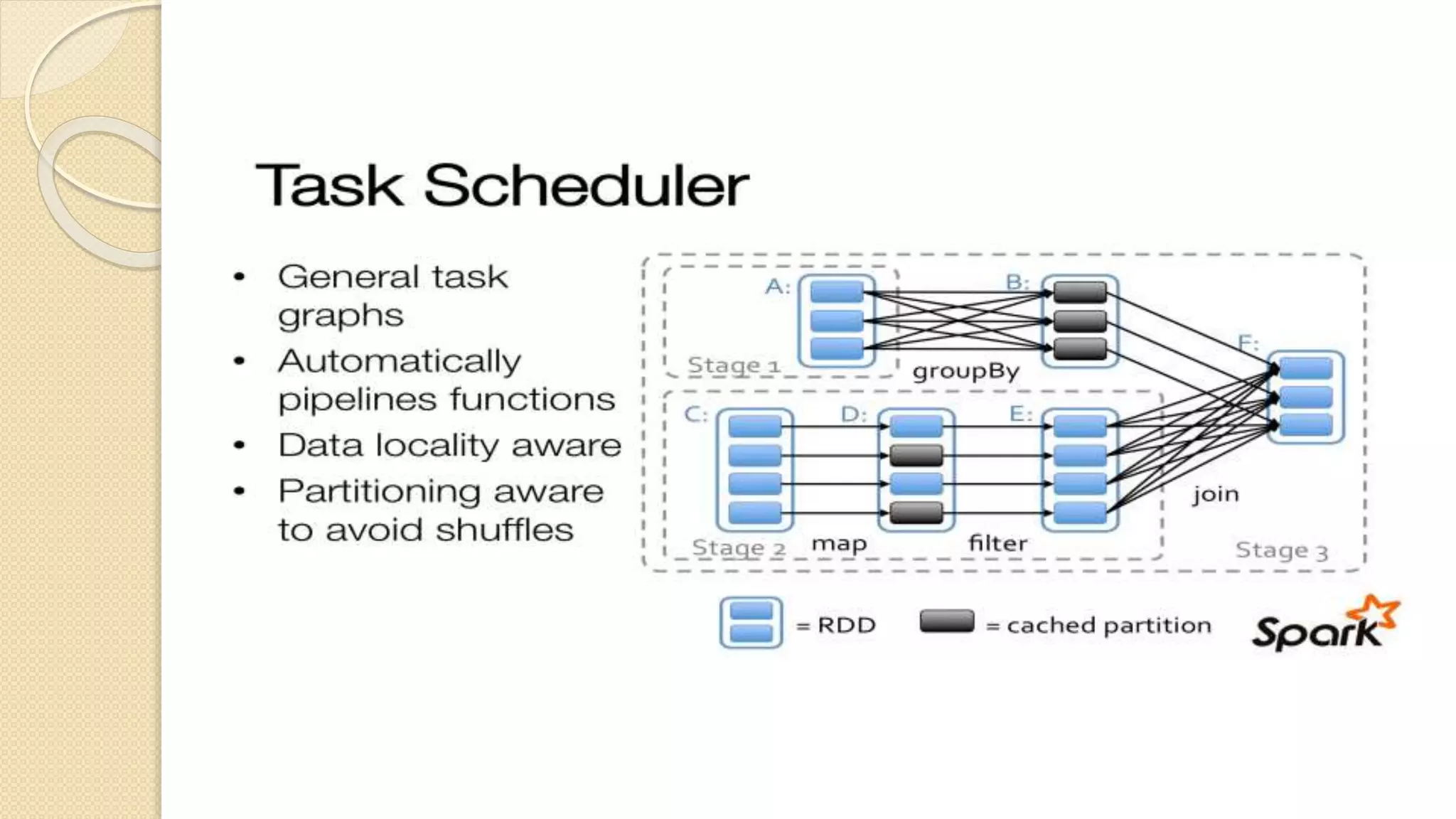

![Job Submission Tool
./bin/spark-submit <app-jar>
--class my.main.Class
--name myAppName
--master local[4]
--master spark://some-cluster](https://image.slidesharecdn.com/spark-101-first-steps-to-distributed-computing-uploaded-151012124645-lva1-app6891/75/Spark-101-First-steps-to-distributed-computing-25-2048.jpg)







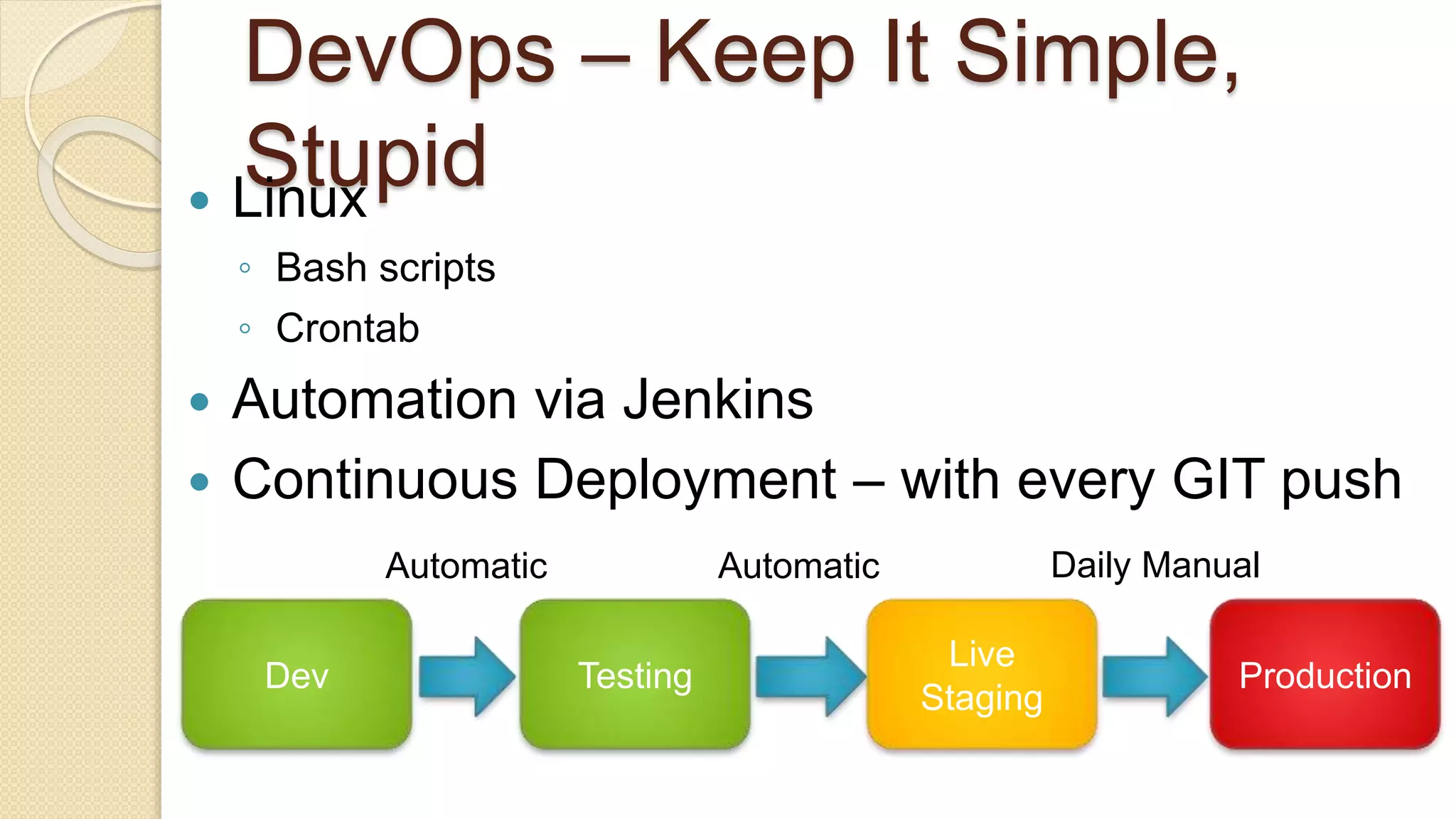


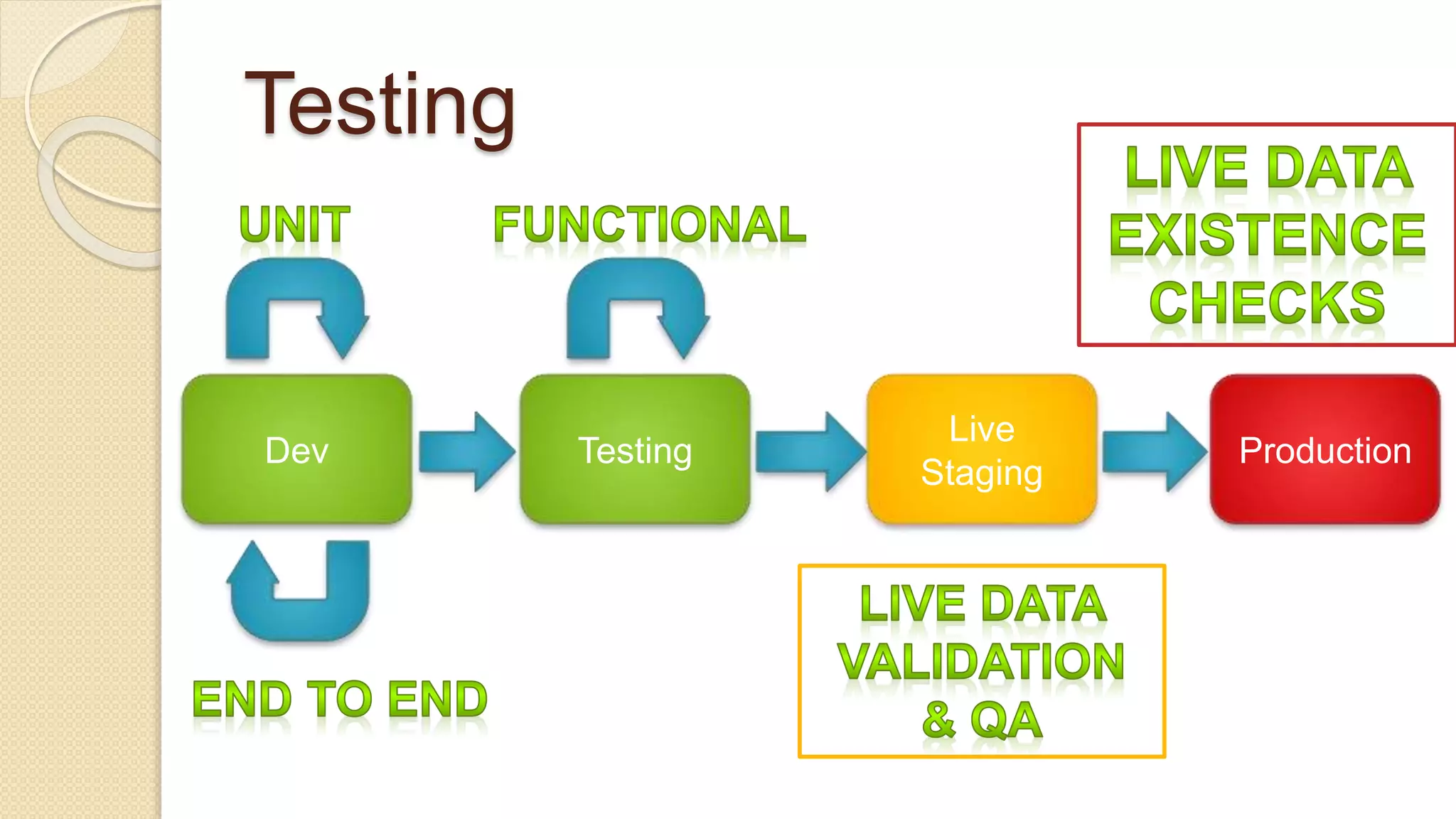



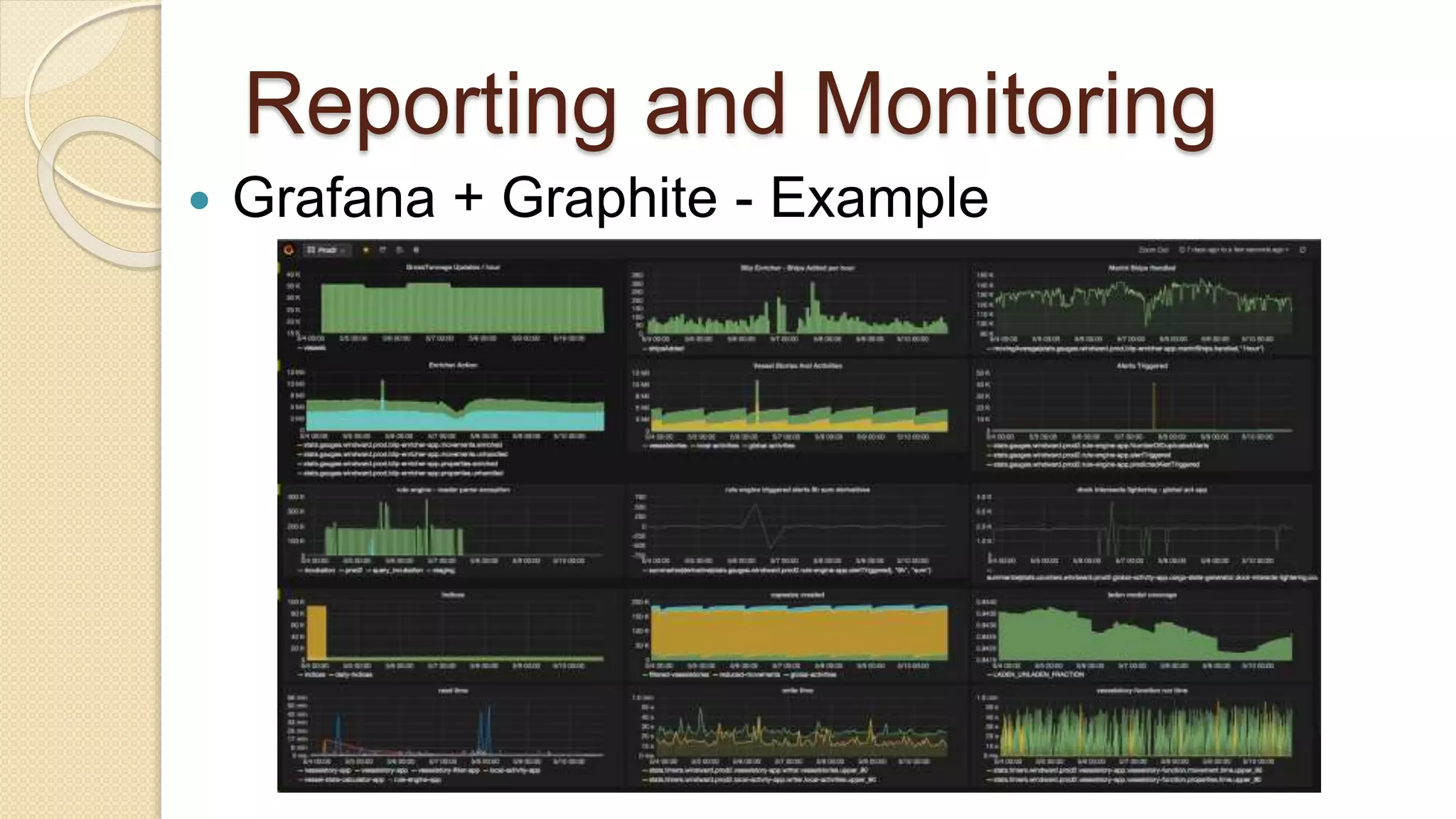
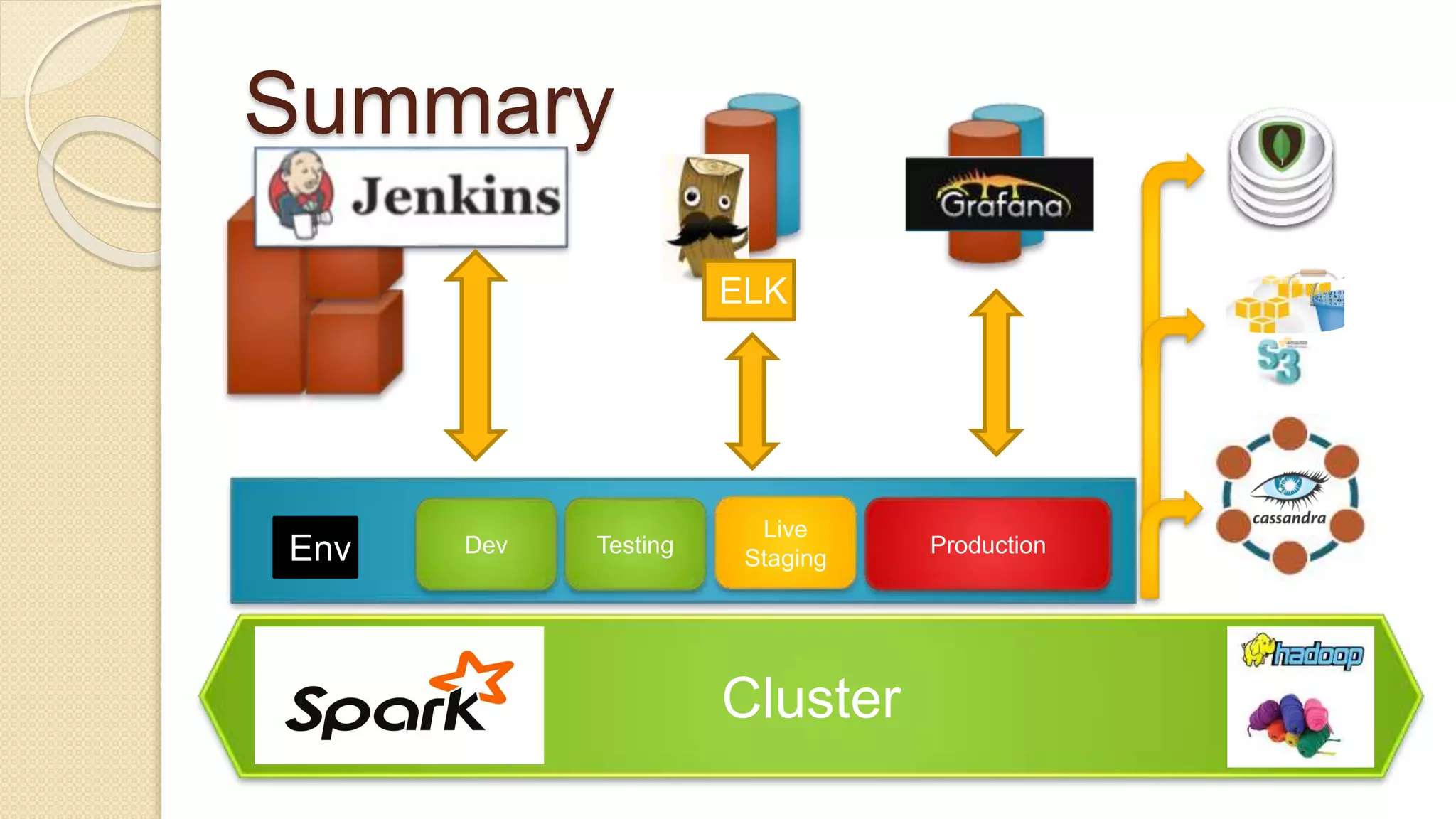
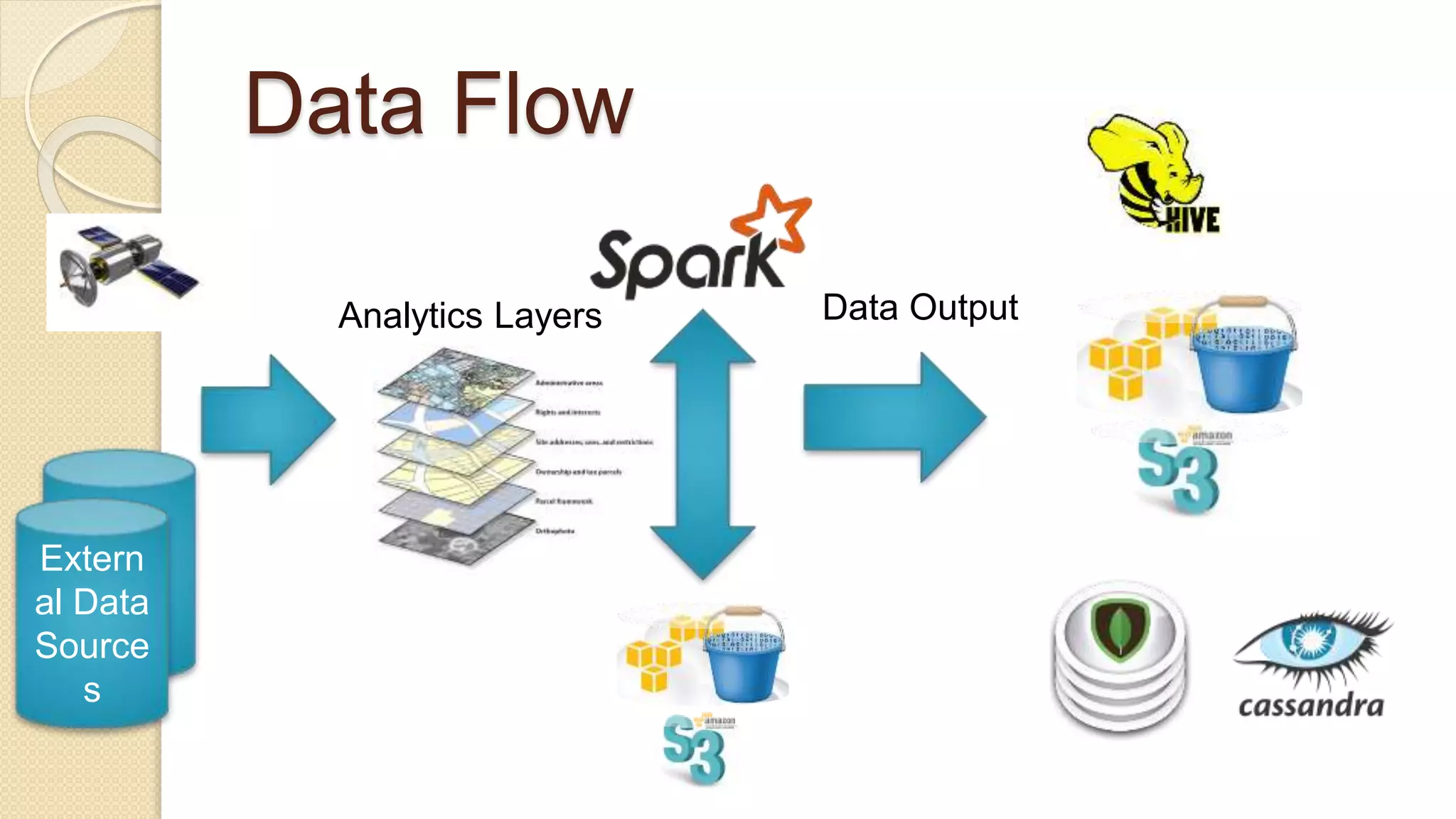




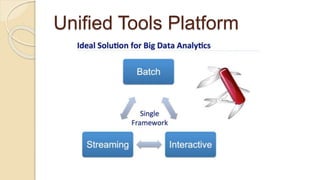
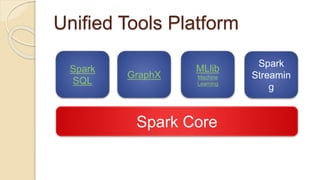
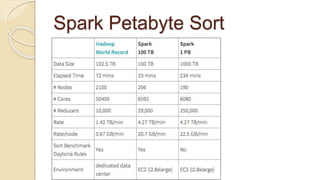
Demi Ben-Ari presents an overview of Apache Spark, a powerful distributed cluster computing framework designed for efficient data processing and analysis. The document covers Spark's features, architecture, API support, and development practices, highlighting its capabilities for both in-memory and disk computation. Additionally, it discusses resource management, testing techniques, and logging approaches, concluding that Spark is widely adopted and essential for managing large-scale data.






































































































