About me
2
• Education
•NCU (MIS)、NCCU (CS)
• Experiences
• Telecom big data Innovation
• Retail Media Network (RMN)
• Customer Data Platform (CDP)
• Know-your-customer (KYC)
• Digital Transformation
• LLM Architecture & Development
• Research
• Data Ops (ML Ops)
• Generative AI research
• Business Data Analysis, AI
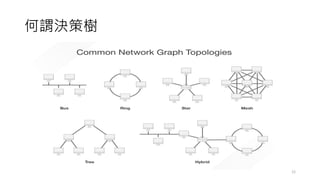
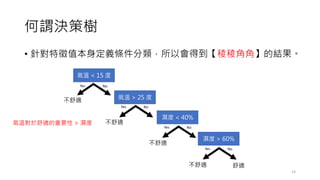
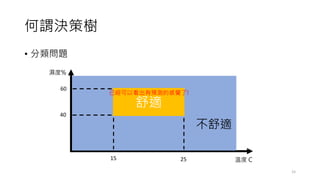
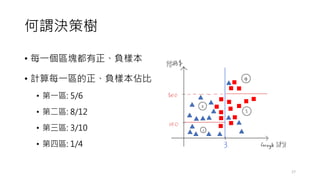
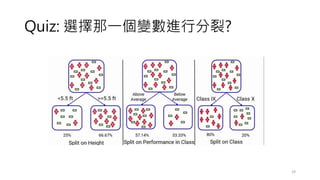
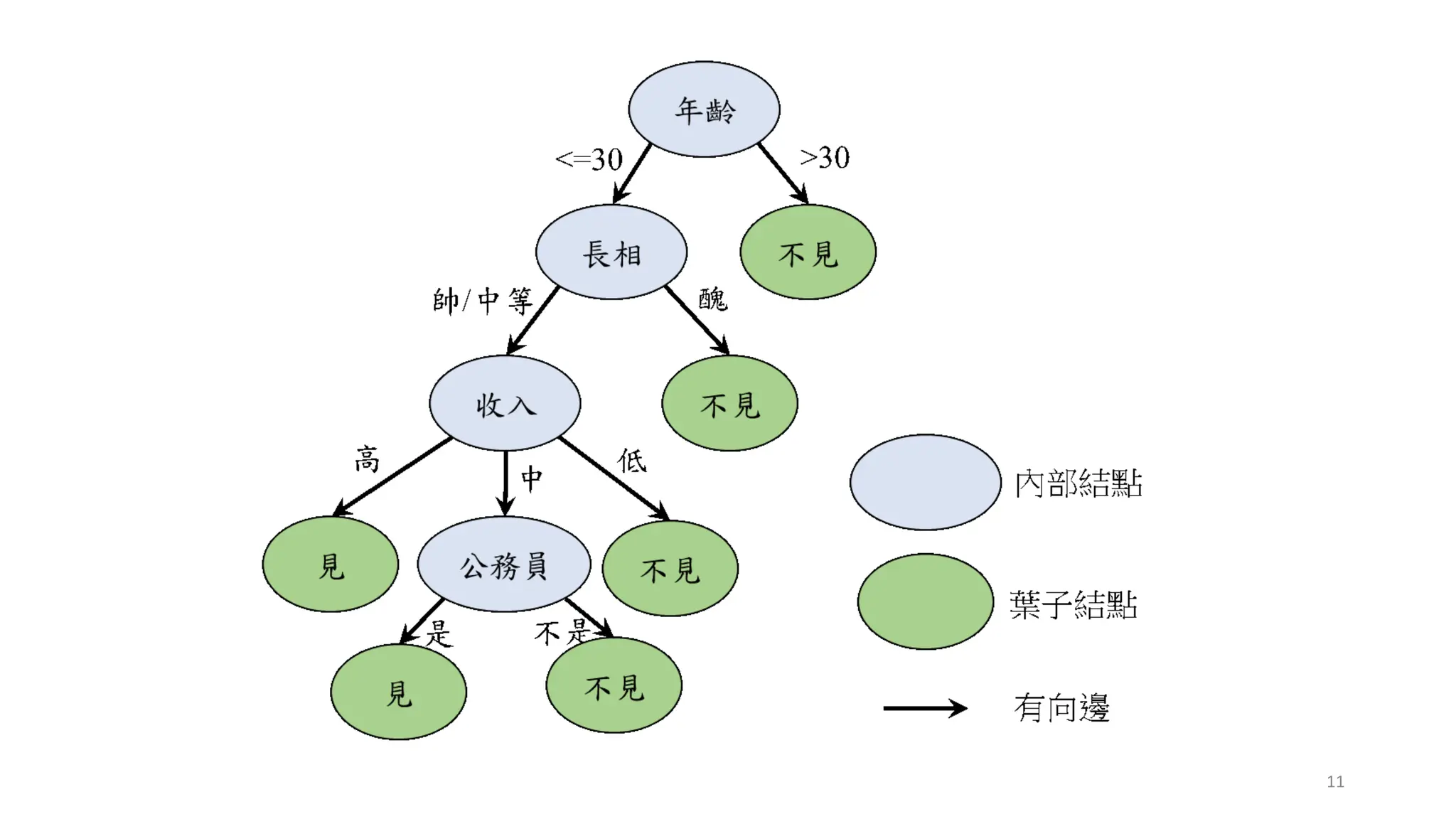
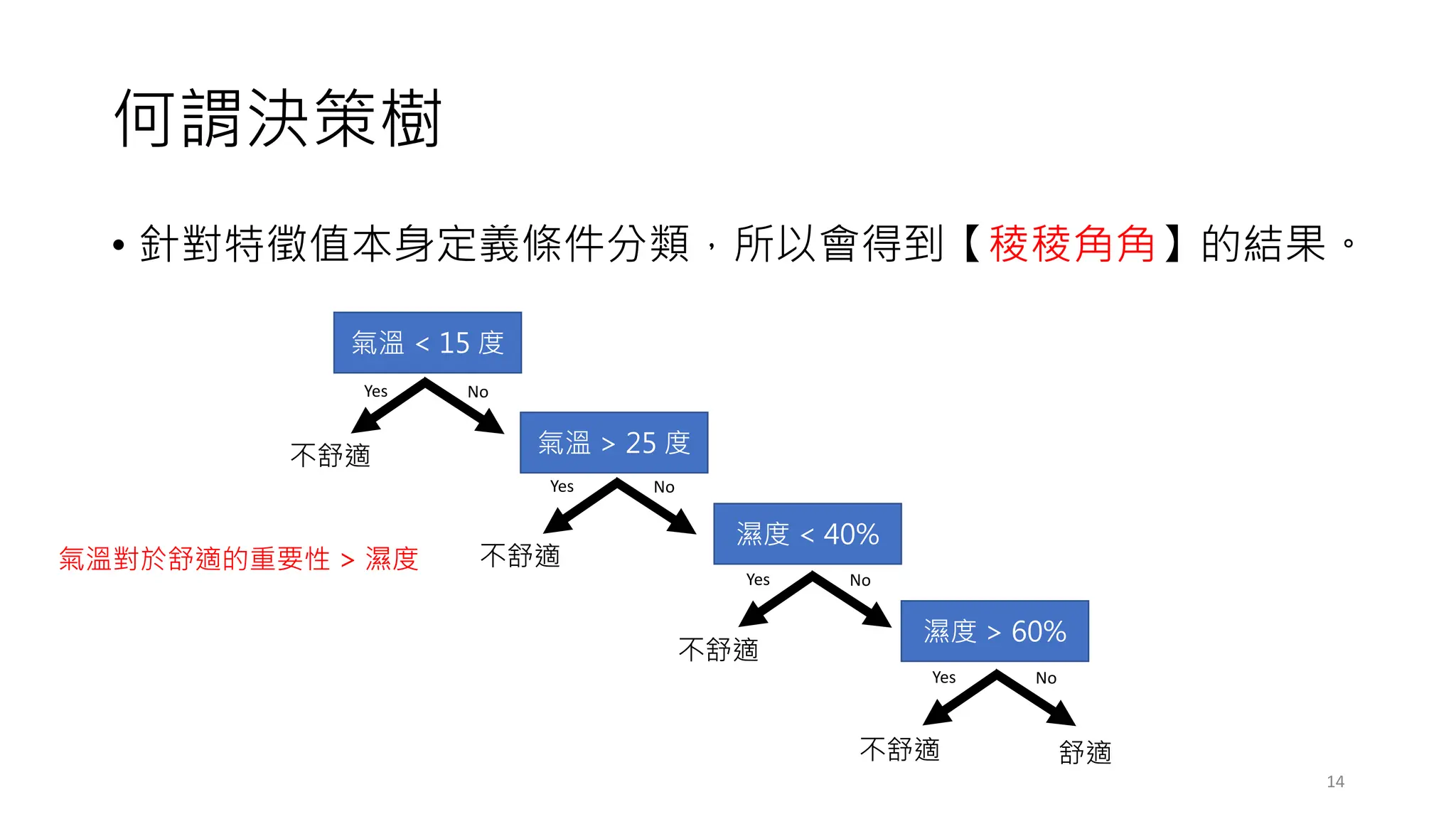
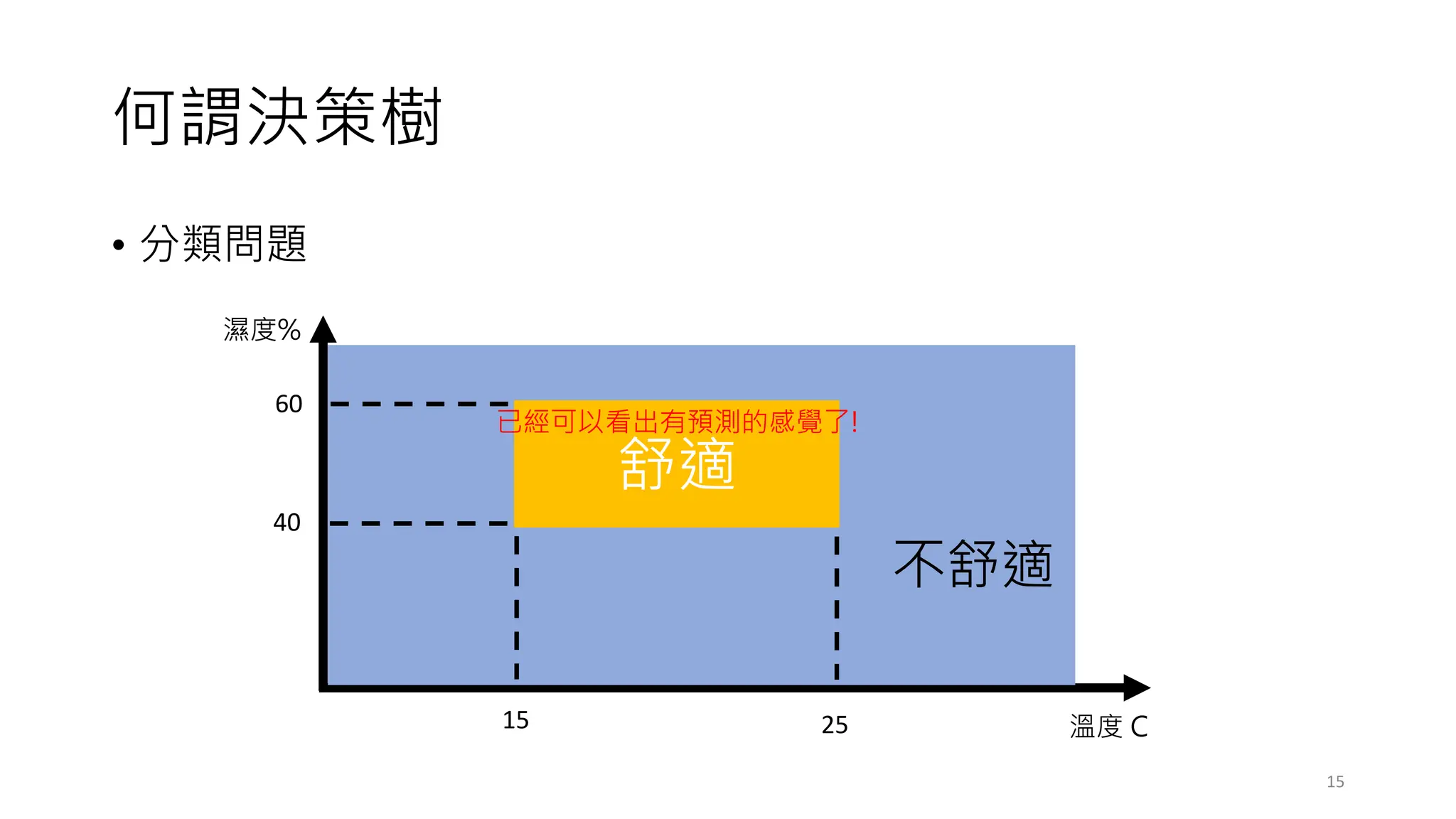
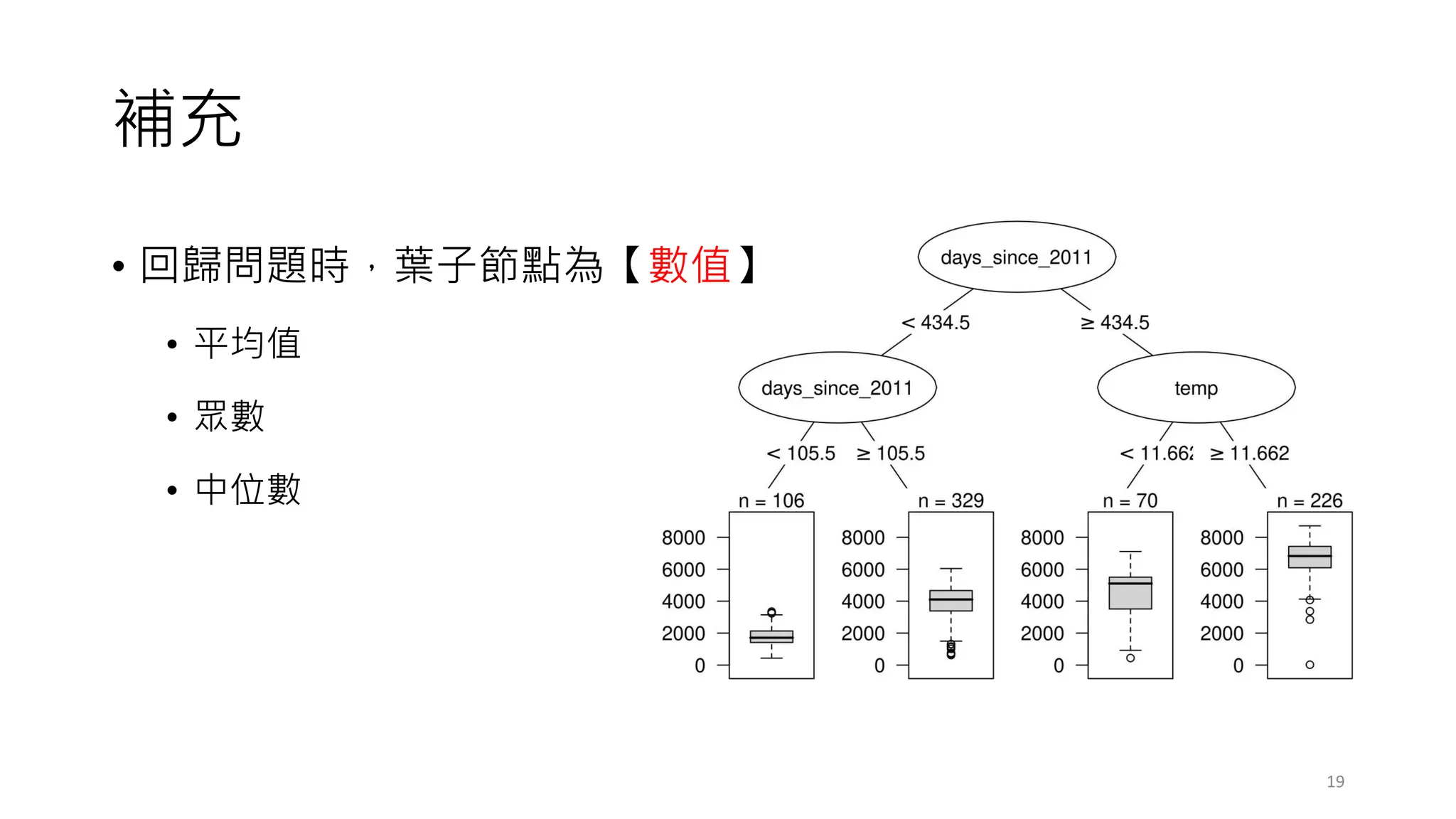
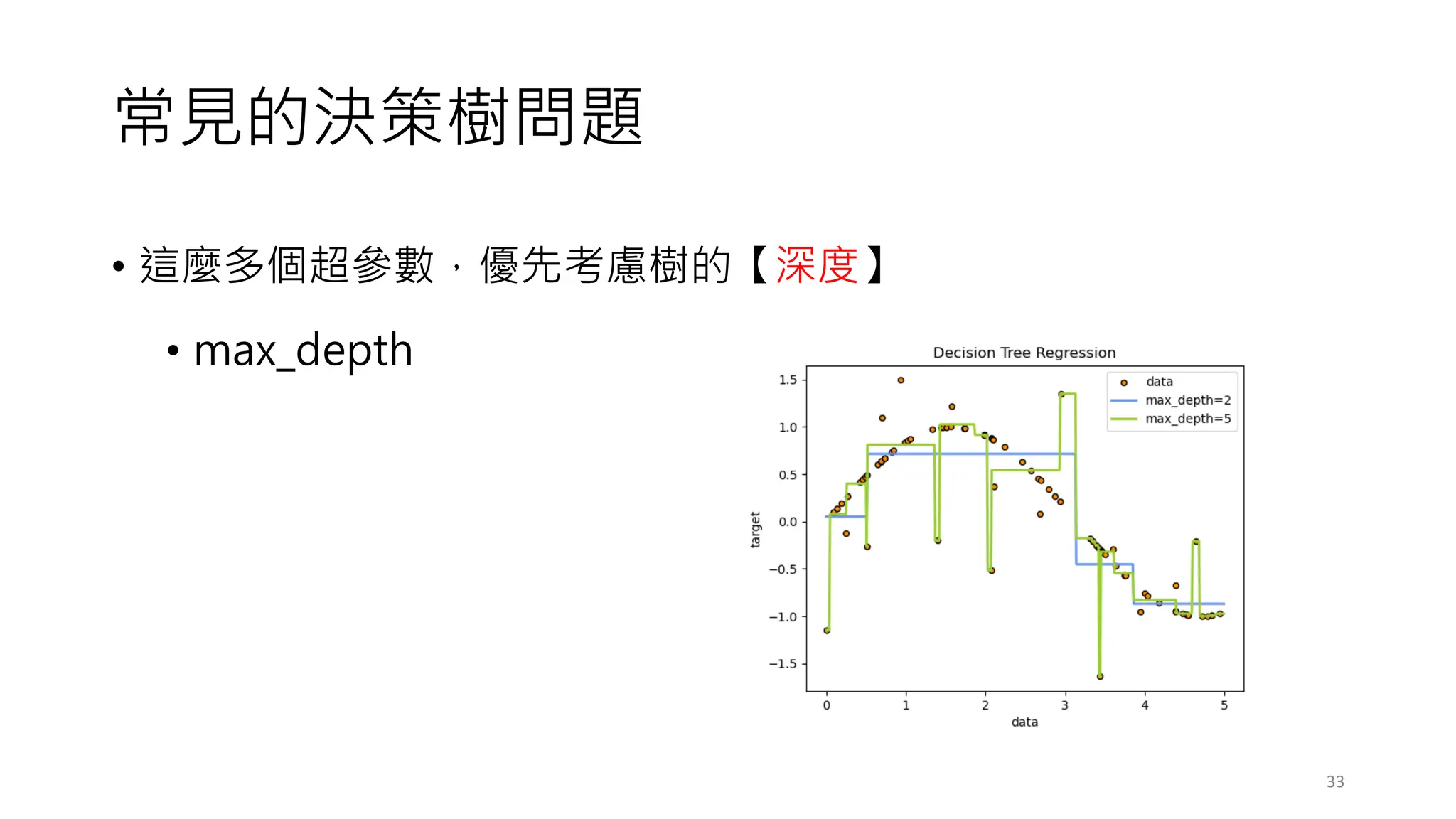
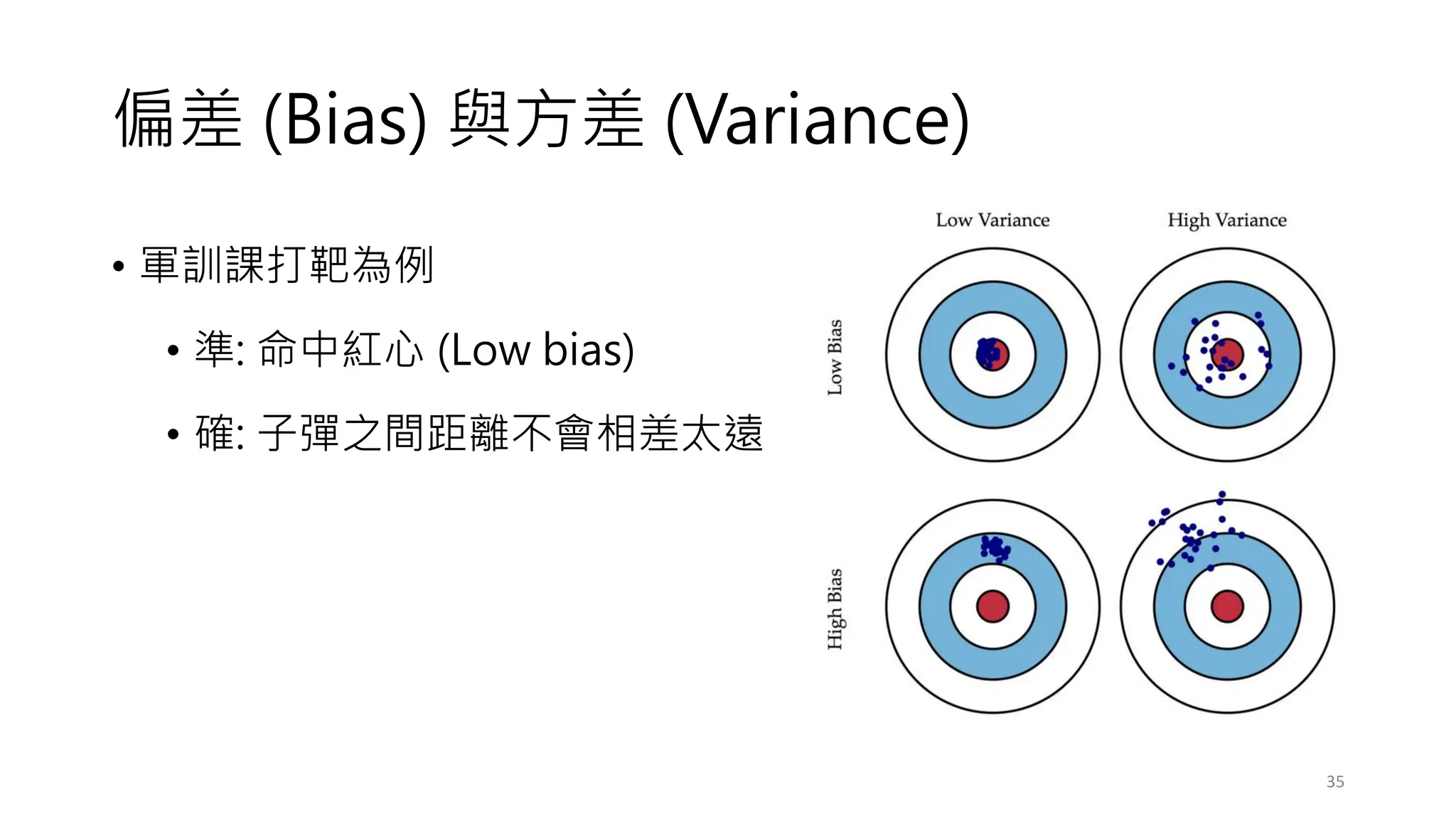
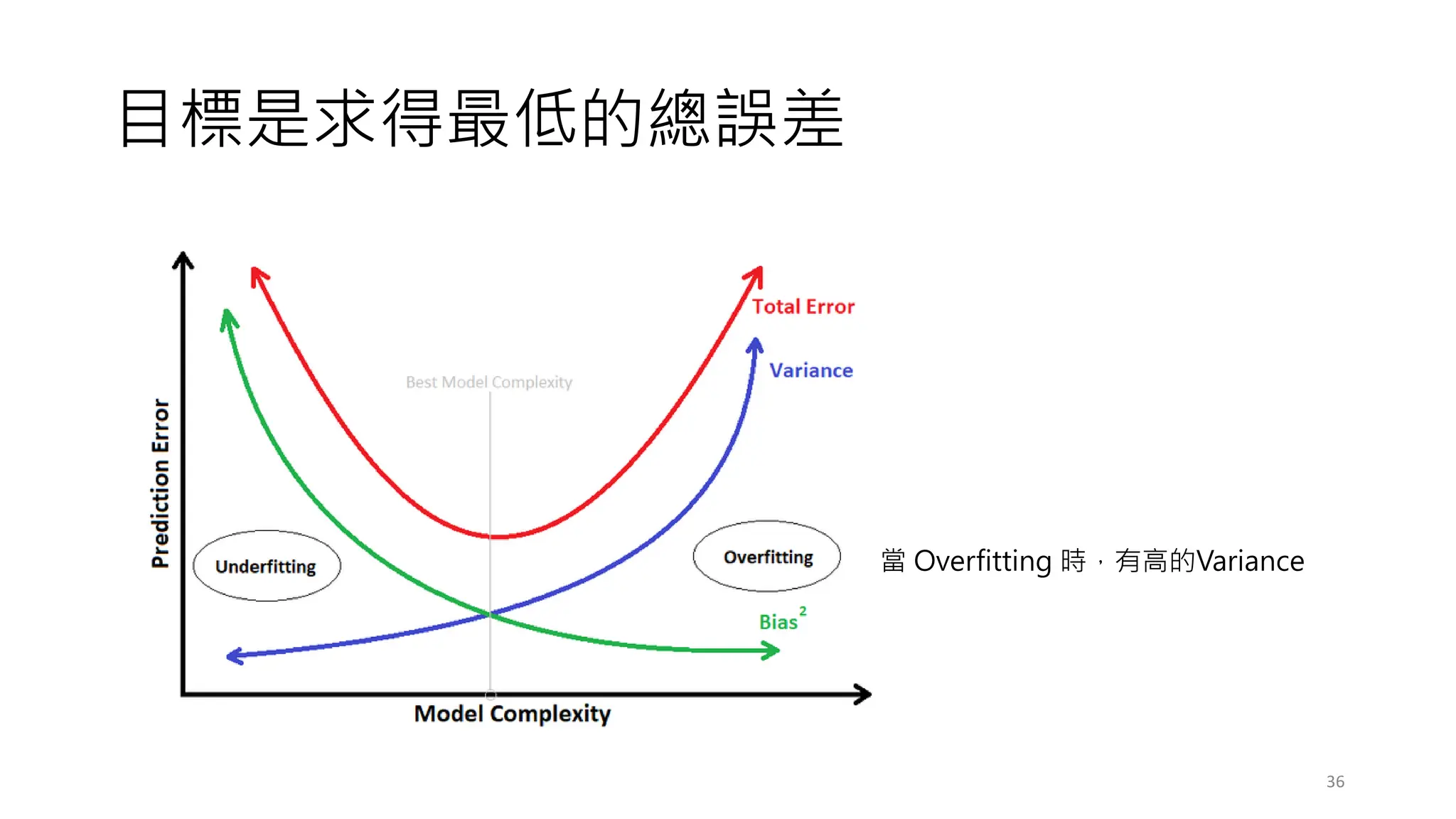
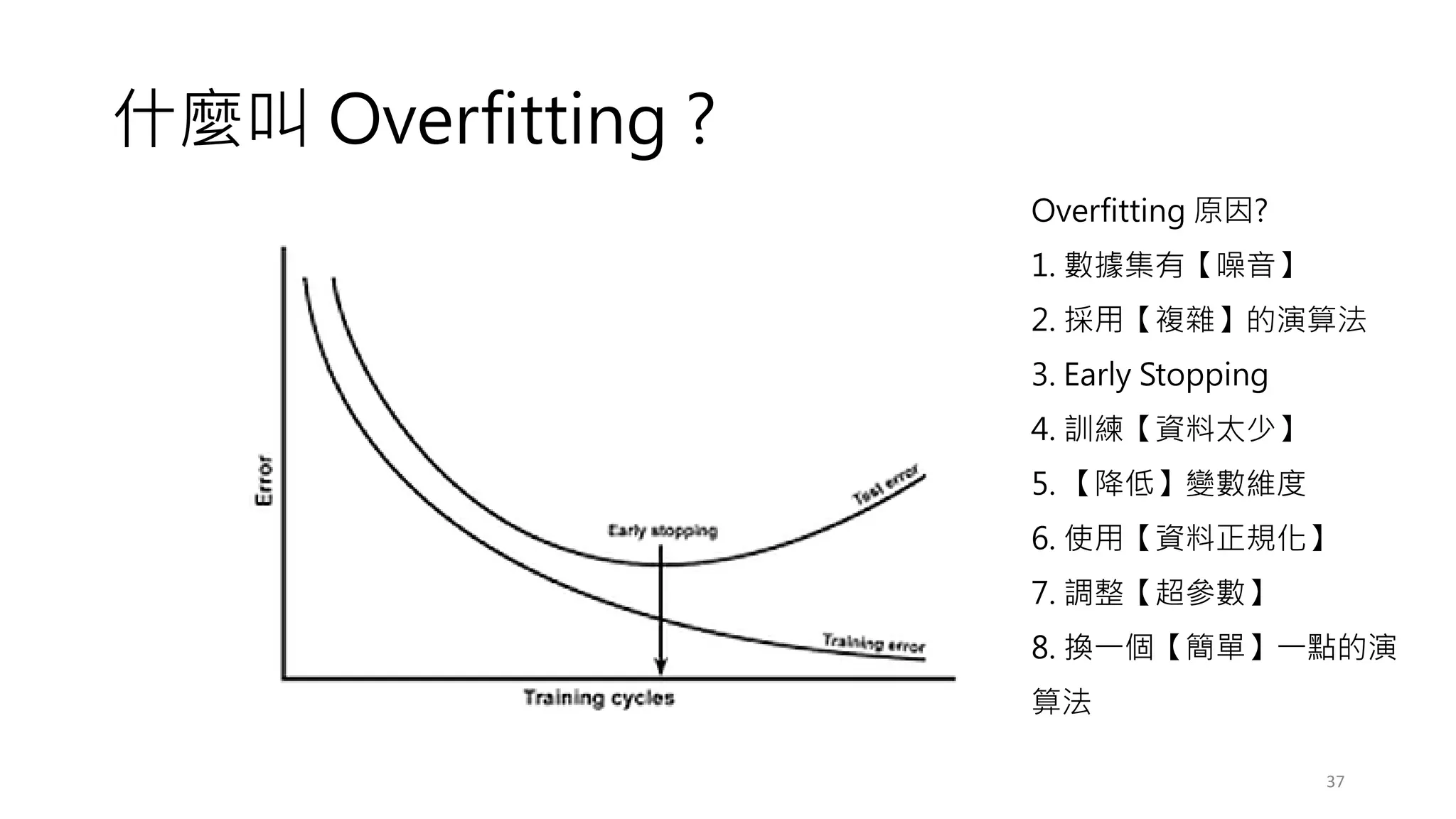
常見的決策樹問題
• 預剪枝 (Pre-Pruning),設定超參數(Hyper-parameters)
• Minimum samples for a node split (資料數目不得小於多少? 才能再產
生新的節點)
• Minimum samples for a terminal node (leaf) (要成為葉節點,最少需
要多少的資料數目?)
• Maximum depth of tree (vertical depth) (限制樹的高度最多幾層?)
• Maximum number of terminal nodes (限制最終葉節點的數量?)
32
42
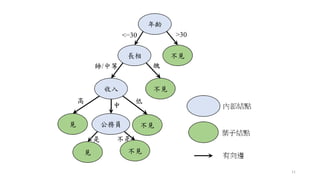
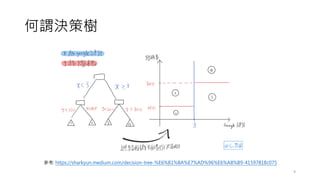
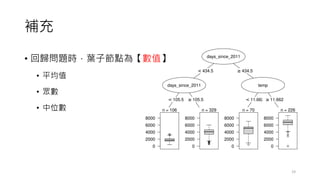
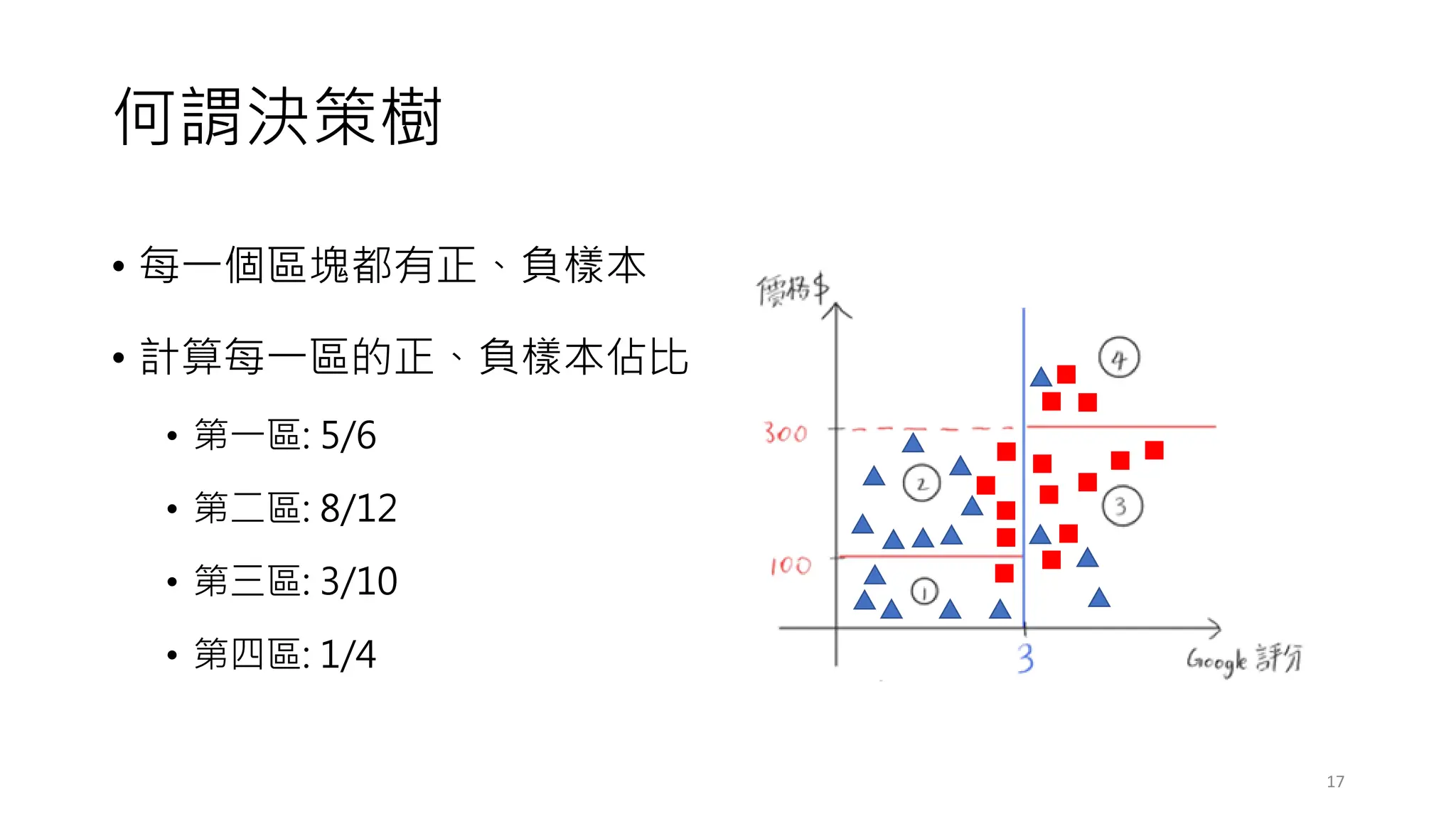
1. 一共有 3個 classes,分別是: Setosa、 Virginica、Versicolor (三個顏色)。
2. 節點由 node #0 開始至 node#8,生成方式以先深後廣 (DFS)。
3. 特徵重要性排序為 petal.length,接下來為 petal.width、sepal.width。
4. 請注意每一個node內容的 samples數量。
5. 某種程度來說,分裂到 node #5 即可。
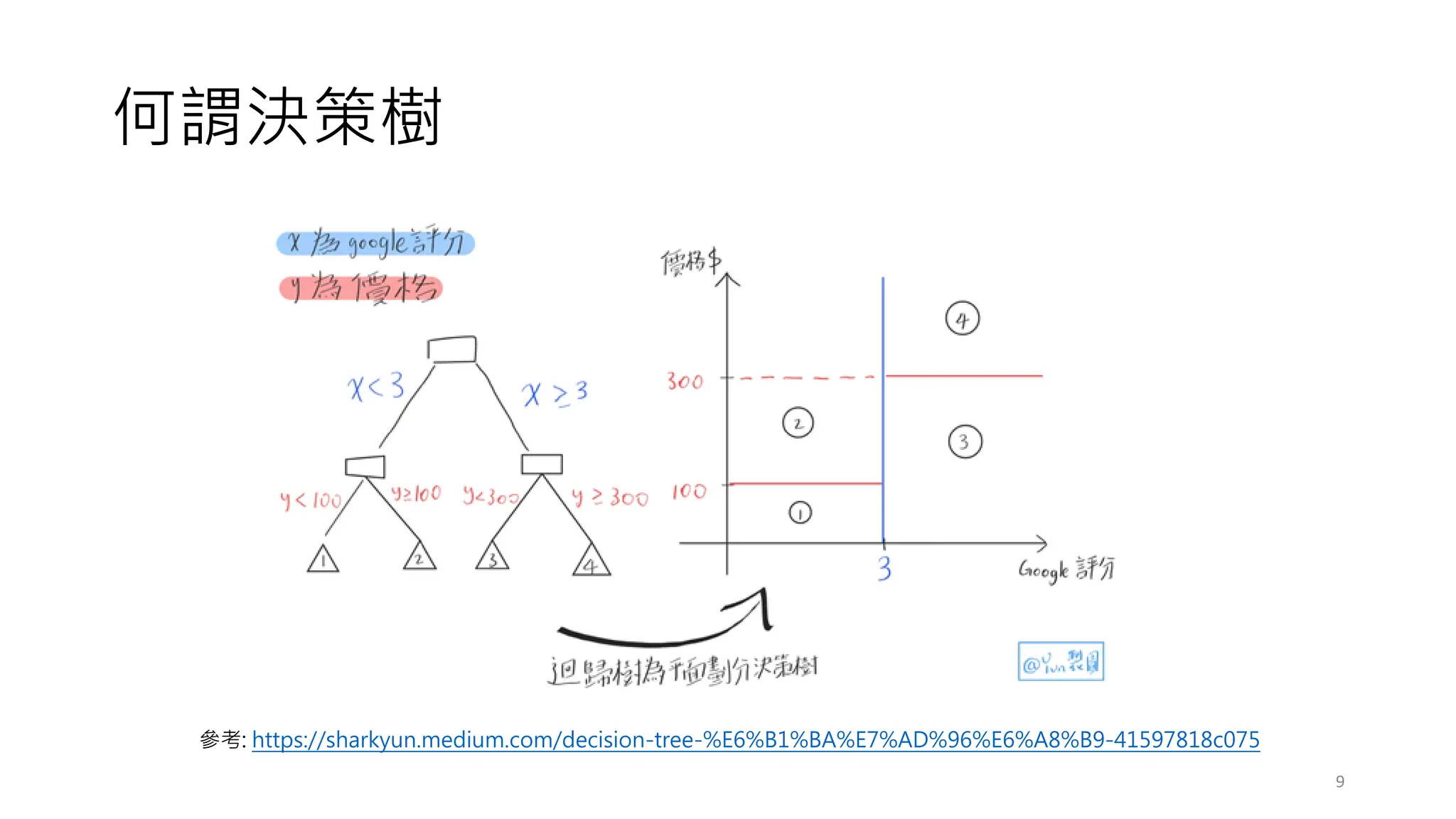
產生 SQL 語法
共五個葉子節點,表示有五段 SQL Case When
Select case
when petal.length <=2.35 then 0
when petal.length >2.35 and petal.length <=5.05 and petal.width <=1.75 then 1
when petal.length >2.35 and petal.length <=5.05 and petal.width >1.75 and sepal.width <=3.1 then 2
when petal.length >2.35 and petal.length <=5.05 and petal.width >1.75 and sepal.width >3.1 then 1
when petal.length >2.35 and petal.length > 5.05 then 2