
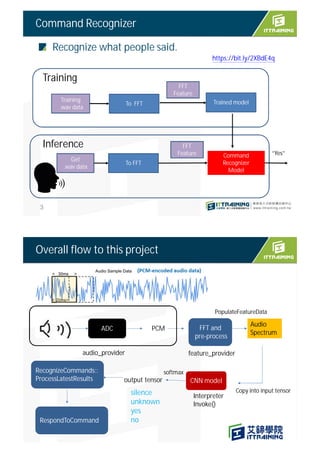






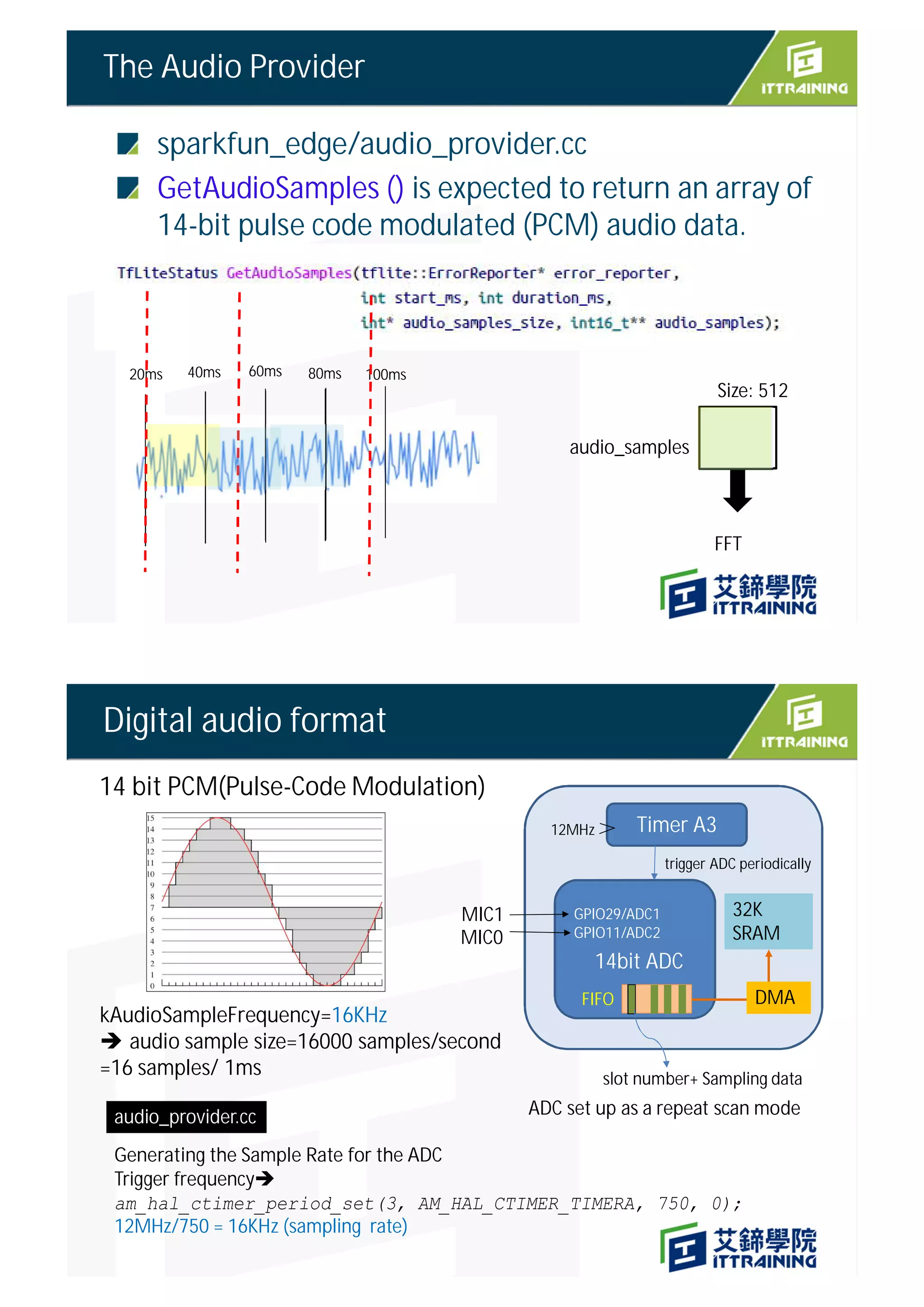
![sparkfun_edge/audio_provider.cc
Copy (size:kAdcSampleBufferSize)
GetAudioSamples()
sparkfun_edge/audio_provider.cc
g_ui32ADCSampleBuffer1 [kAdcSampleBufferSize]
g_audio_capture_buffer
g_audio_capture_buffer[g_audio_capture_buffer_start]
= temp.ui32Sample;
Copy(size: duration_ms)
30ms PCM audio data
GetAudioSamples
(int start_ms, int duration_ms)
g_audio_output_buffer
Copy when ADC Interrupt occurs
ui32Slot
ui32Sample
ADC data (Slot 1 +Slot2 )
g_ui32ADCSampleBuffer0 [kAdcSampleBufferSize]
ui32TargetAddress
kAdcSampleBufferSize =2 slot* 1024 samples per slot
16000
512
Audio data is transferred by
DMA transfer](https://image.slidesharecdn.com/4speechrecognitionsparkfun-211030072021/85/TinyML-4-speech-recognition-13-320.jpg)
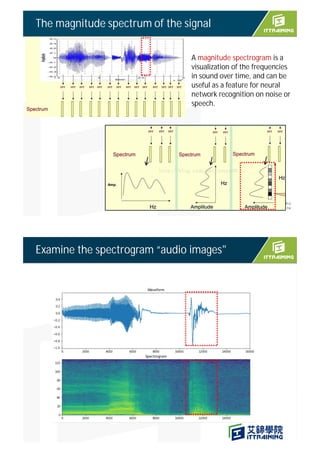
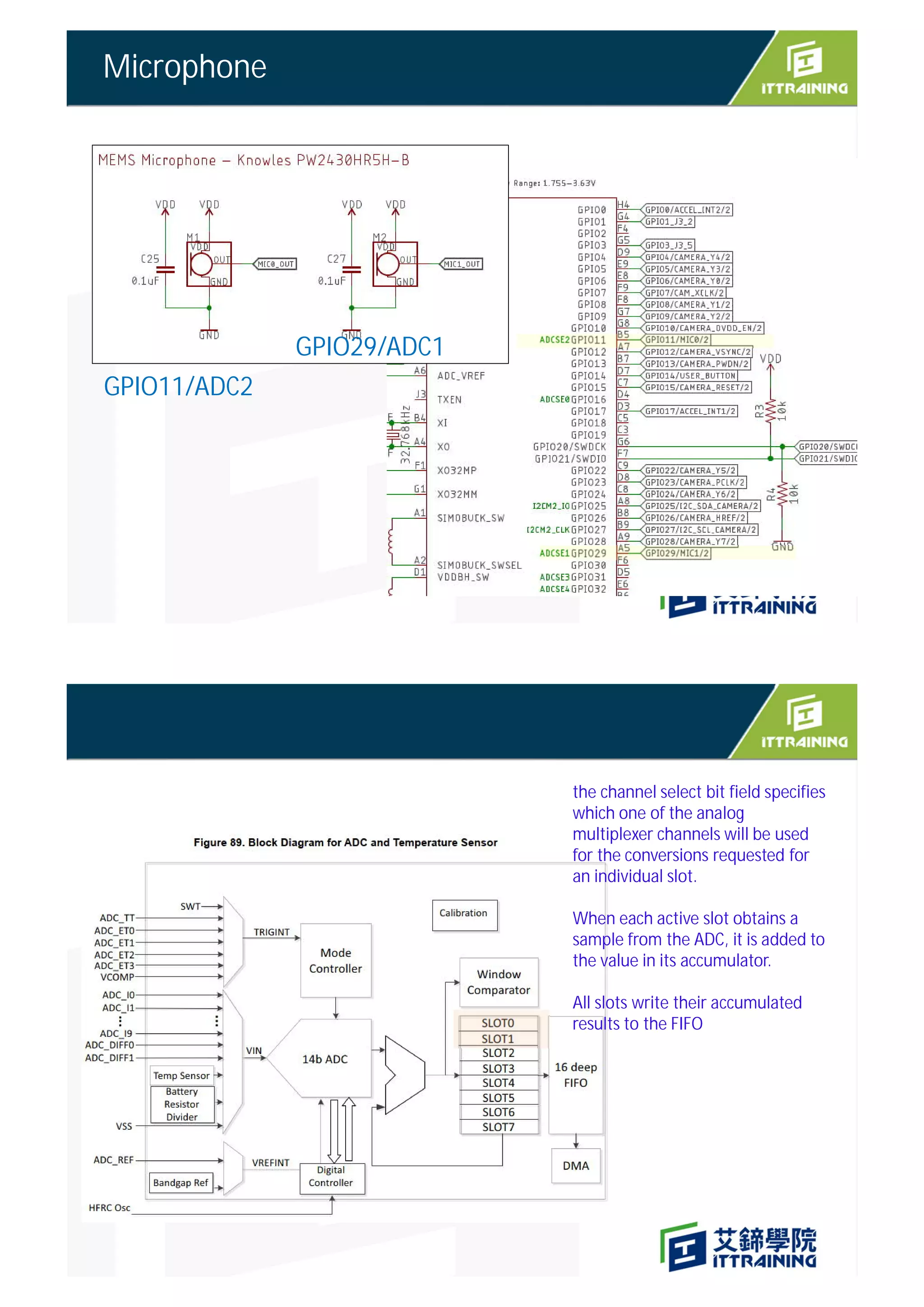
![GetAudioSamples()
start_ms
start_ms+duration_ms
g_audio_capture_buffer
g_audio_output_buffer
當ISR發生一次, time stamp 就加1, 16 次ISR 表示共讀了16 * 1000 samples, , 約略經過1ms
Time stamp 計算方式
16000
g_audio_output_buffer[kMaxAudioSampleSize]
kMaxAudioSampleSize =512 ( power of two)
Part of the word “yes” being captured in our window
One Problem : Audio is live streaming
YES
??](https://image.slidesharecdn.com/4speechrecognitionsparkfun-211030072021/85/TinyML-4-speech-recognition-14-320.jpg)










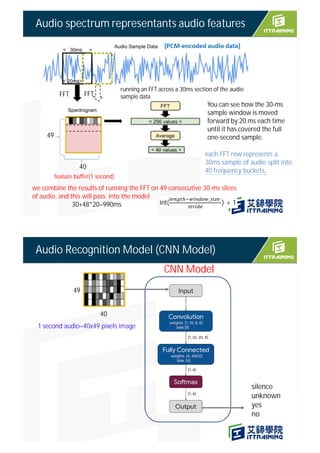
![sparkfun_edge/audio_provider.cc
Copy (size:kAdcSampleBufferSize)
GetAudioSamples()
sparkfun_edge/audio_provider.cc
g_ui32ADCSampleBuffer1 [kAdcSampleBufferSize]
g_audio_capture_buffer
g_audio_capture_buffer[g_audio_capture_buffer_start]
= temp.ui32Sample;
Copy(size: duration_ms)
30ms PCM audio data
GetAudioSamples
(int start_ms, int duration_ms)
g_audio_output_buffer
Copy when ADC Interrupt occurs
ui32Slot
ui32Sample
ADC data (Slot 1 +Slot2 )
g_ui32ADCSampleBuffer0 [kAdcSampleBufferSize]
ui32TargetAddress
kAdcSampleBufferSize =2 slot* 1024 samples per slot
16000
512
Audio data is transferred by
DMA transfer](https://image.slidesharecdn.com/4speechrecognitionsparkfun-211030072021/75/TinyML-4-speech-recognition-13-2048.jpg)
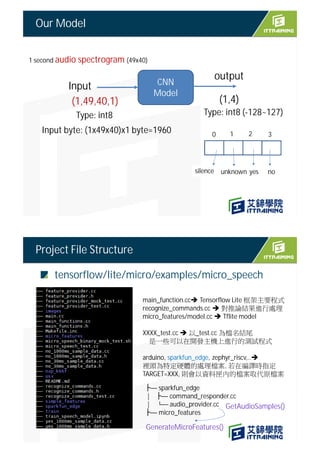
![GetAudioSamples()
start_ms
start_ms+duration_ms
g_audio_capture_buffer
g_audio_output_buffer
當ISR發生一次, time stamp 就加1, 16 次ISR 表示共讀了16 * 1000 samples, , 約略經過1ms
Time stamp 計算方式
16000
g_audio_output_buffer[kMaxAudioSampleSize]
kMaxAudioSampleSize =512 ( power of two)
Part of the word “yes” being captured in our window
One Problem : Audio is live streaming
YES
??](https://image.slidesharecdn.com/4speechrecognitionsparkfun-211030072021/75/TinyML-4-speech-recognition-14-2048.jpg)




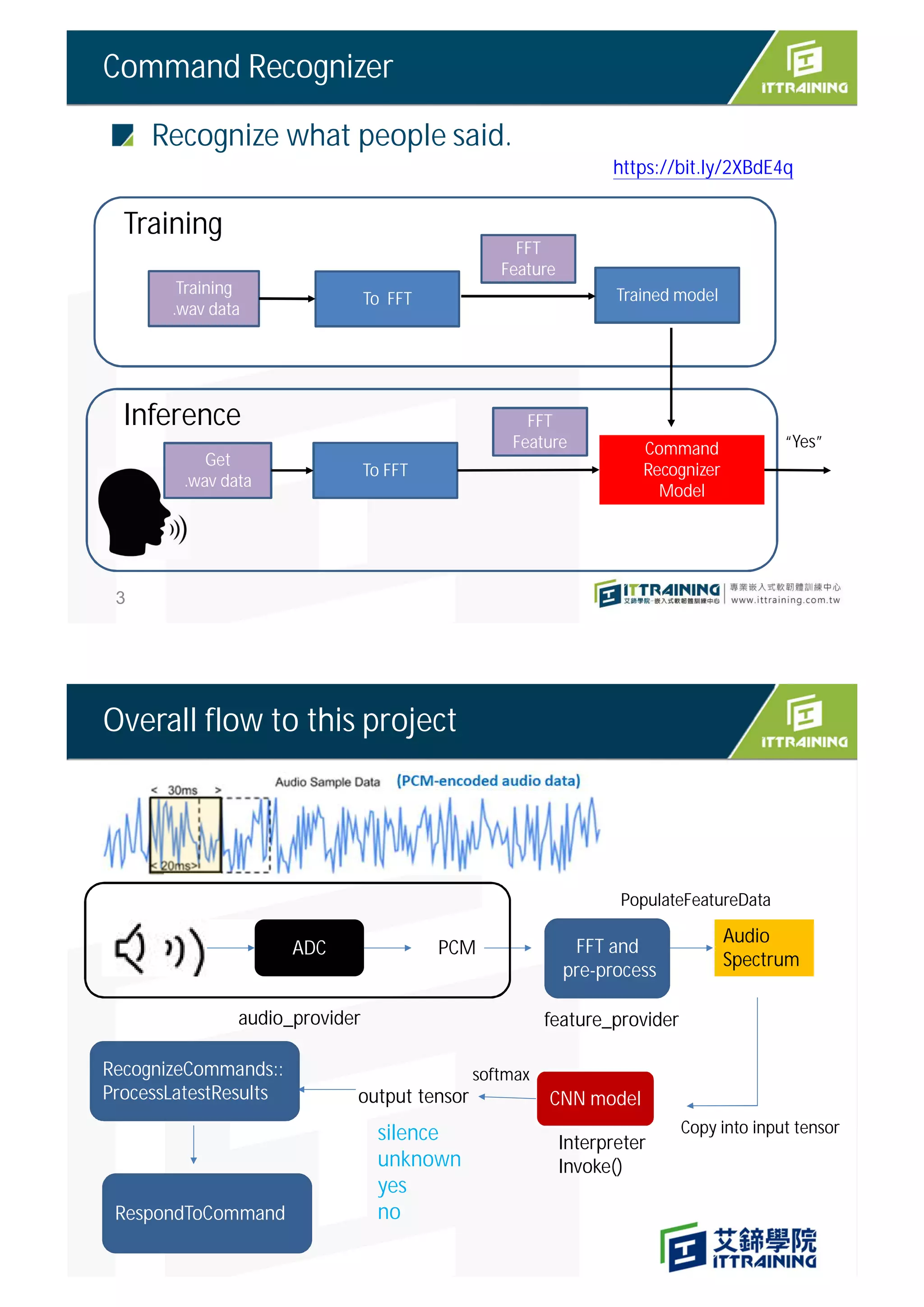
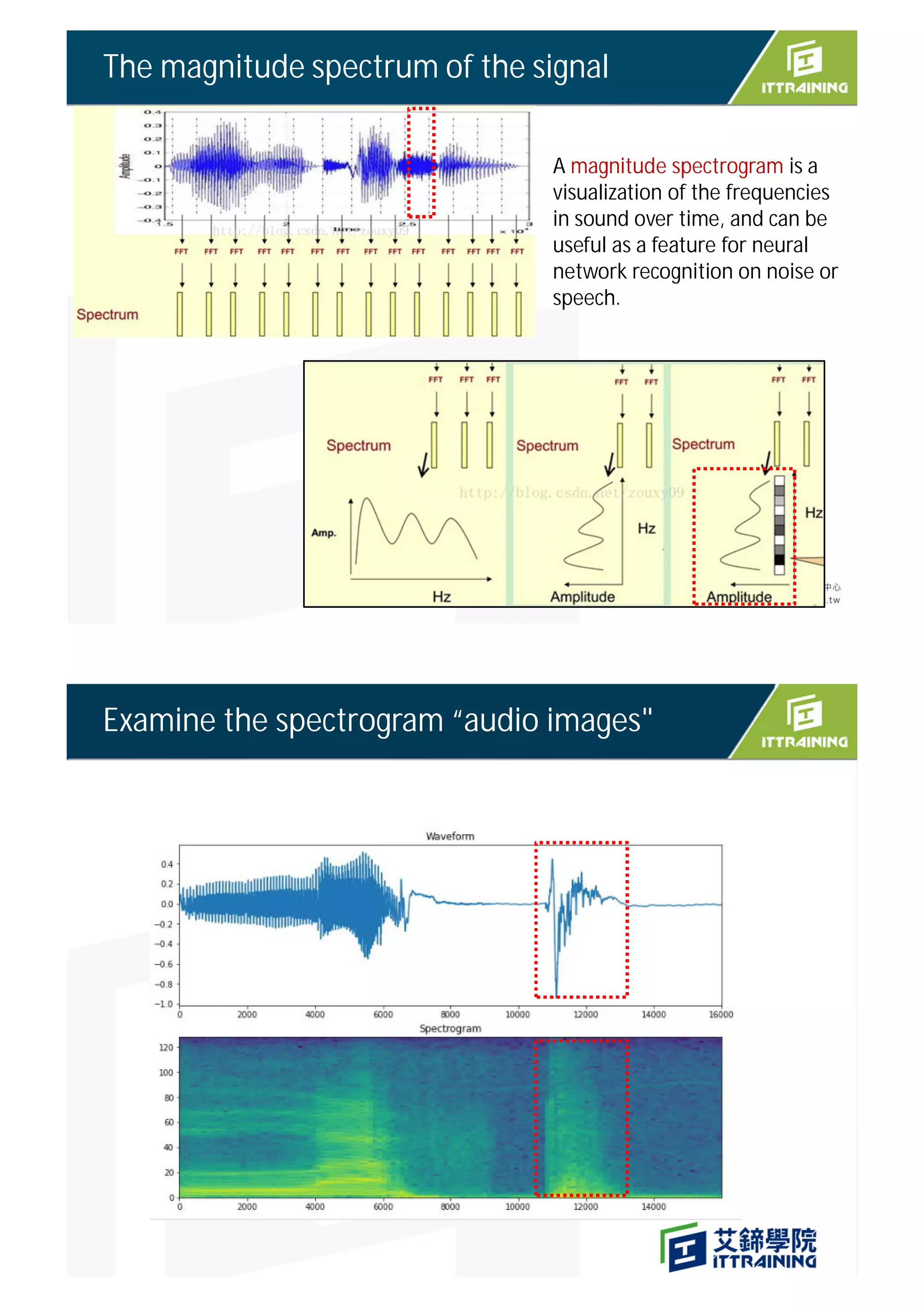
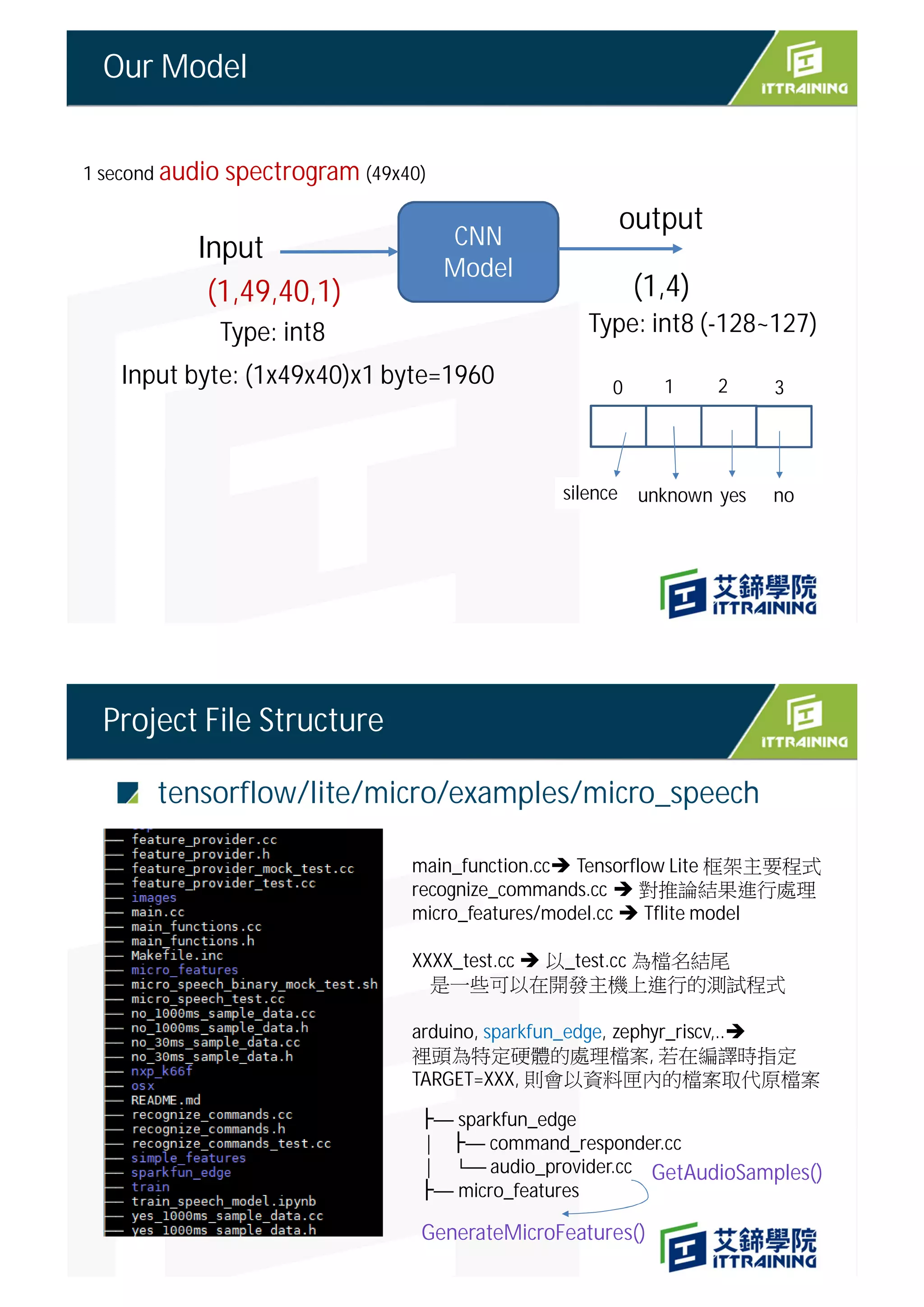
The document outlines the project on deploying a micro-speech recognition command recognizer for 'yes' and 'no' commands on a microcontroller, detailing the training process using FFT features derived from audio data. It describes the flow of processing audio signals through different components like the audio provider and feature provider, culminating in the implementation of a CNN model for audio recognition. The project involves specific hardware setup and programming instructions, including how to capture and process audio samples for command recognition.























































































