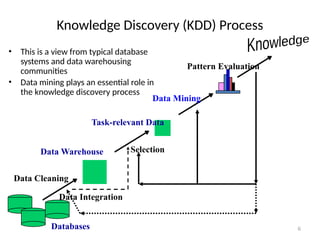
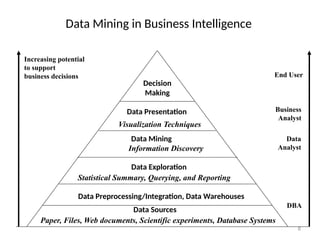
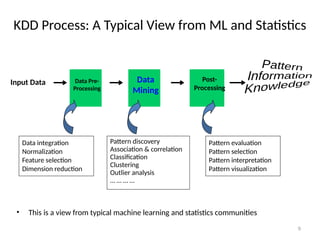
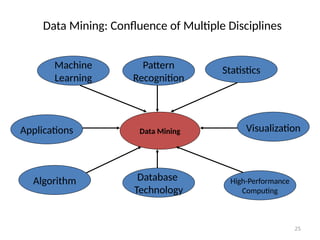
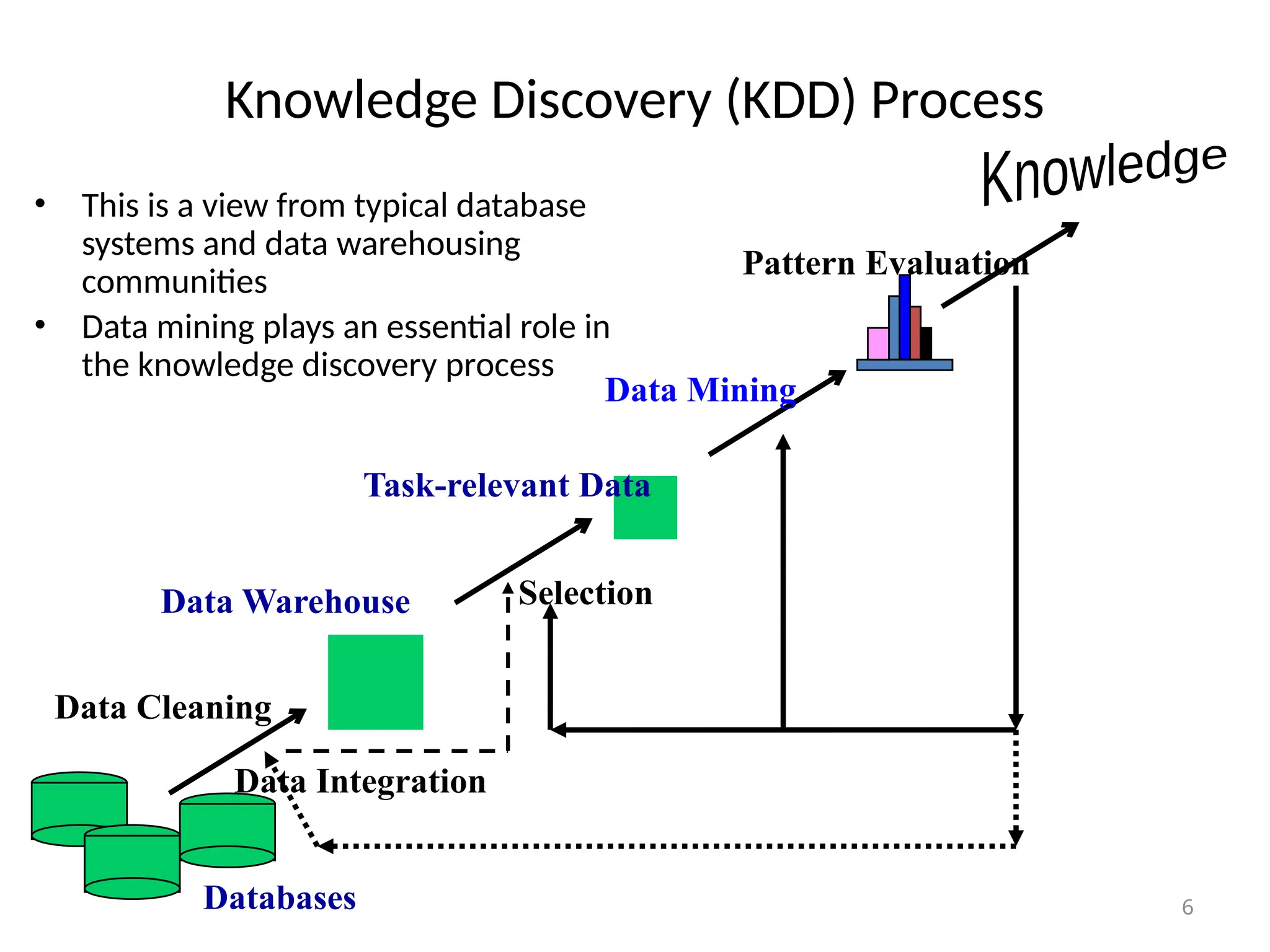
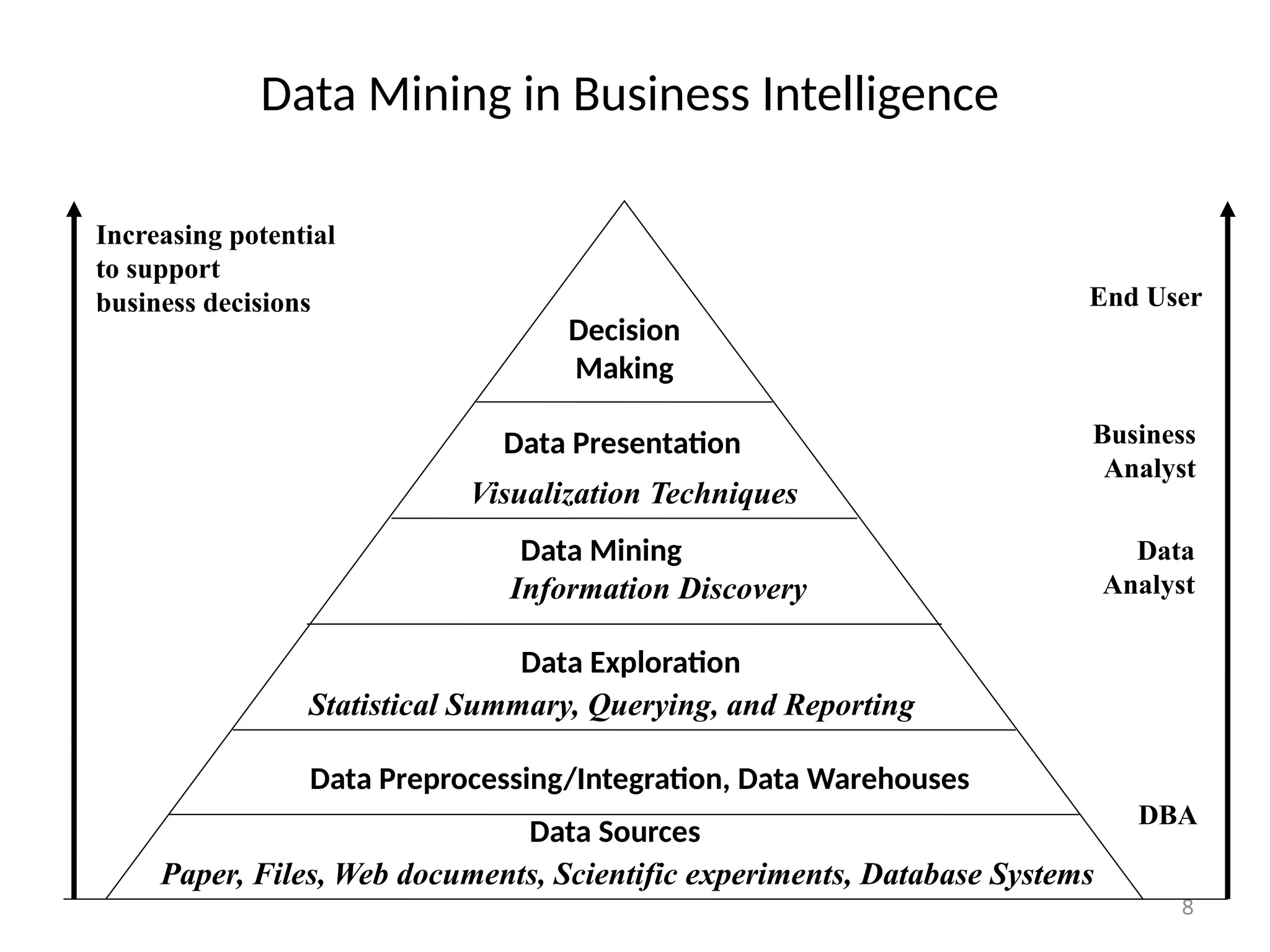
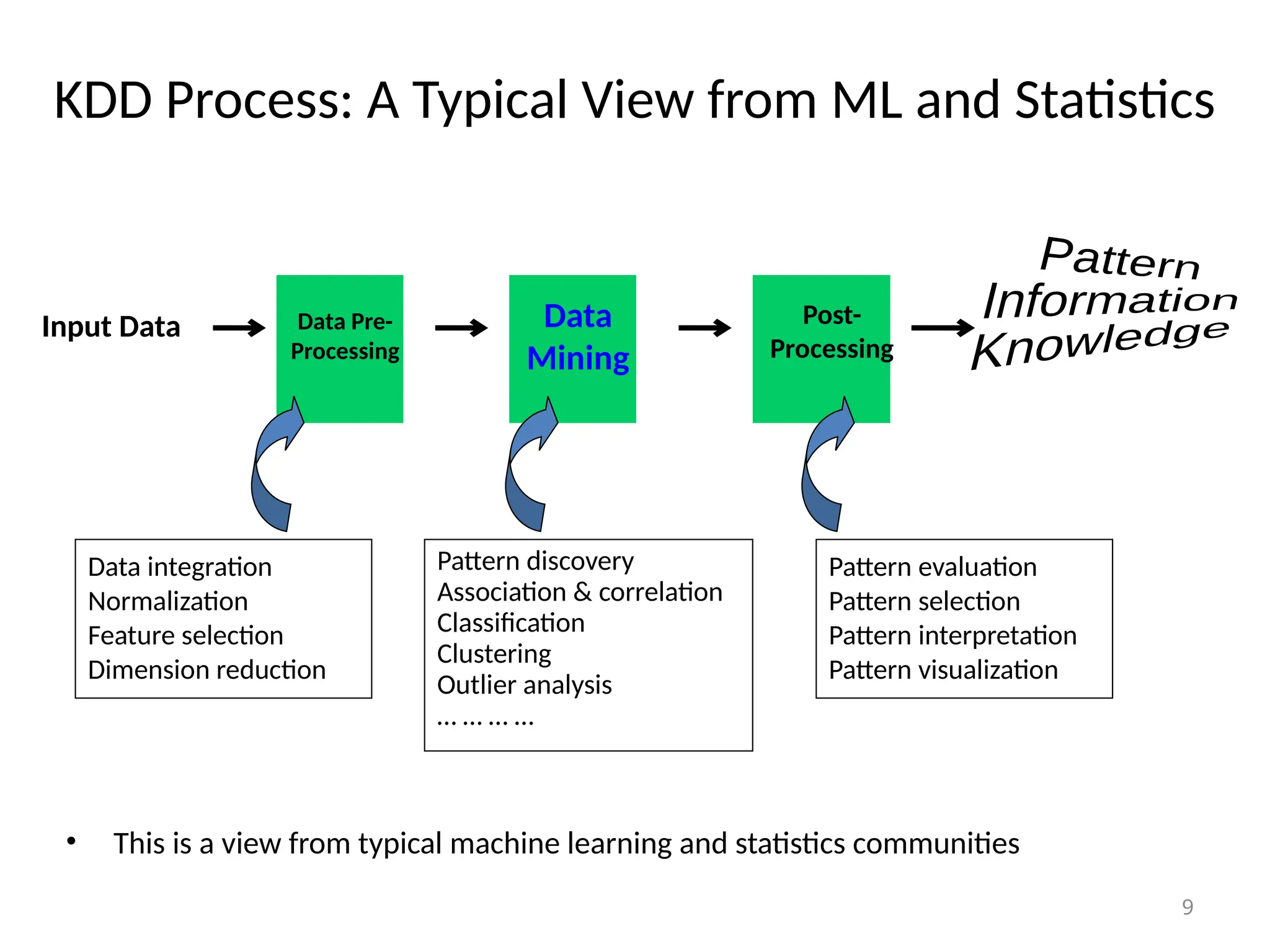
The document provides an extensive overview of data mining, including its definition, significance in handling large datasets, and various applications across fields such as business and science. It discusses the knowledge discovery (KDD) process, key methodologies, and challenges in data mining, emphasizing the importance of extracting valuable information from massive data collections. Additionally, it outlines data mining functionalities like classification, clustering, and association analysis, along with the technologies and issues involved.













![17
Data Mining Function: (2) Association and Correlation
Analysis
• Frequent patterns (or frequent itemsets)
– What items are frequently purchased together in your
Walmart?
• Association, correlation vs. causality
– A typical association rule
• Diaper Beer [0.5%, 75%] (support, confidence)
– Are strongly associated items also strongly correlated?
• How to mine such patterns and rules efficiently in large
datasets?
• How to use such patterns for classification, clustering, and
other applications?](https://image.slidesharecdn.com/topic1-intro-250113223636-000f3832/85/Topic-1-Intro-data-mining-master-ALEX-pptx-17-320.jpg)


























![17
Data Mining Function: (2) Association and Correlation
Analysis
• Frequent patterns (or frequent itemsets)
– What items are frequently purchased together in your
Walmart?
• Association, correlation vs. causality
– A typical association rule
• Diaper Beer [0.5%, 75%] (support, confidence)
– Are strongly associated items also strongly correlated?
• How to mine such patterns and rules efficiently in large
datasets?
• How to use such patterns for classification, clustering, and
other applications?](https://image.slidesharecdn.com/topic1-intro-250113223636-000f3832/75/Topic-1-Intro-data-mining-master-ALEX-pptx-17-2048.jpg)





















































![Title Lorem Ipsum [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/titleloremipsumautosaved-240127094542-a0aa1346-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

























