About me
2
• Education
•NCU (MIS)、NCCU (CS)
• Experiences
• Telecom big data Innovation
• Retail Media Network (RMN)
• Customer Data Platform (CDP)
• Know-your-customer (KYC)
• Digital Transformation
• LLM Architecture & Development
• Research
• Data Ops (ML Ops)
• Generative AI research
• Business Data Analysis, AI
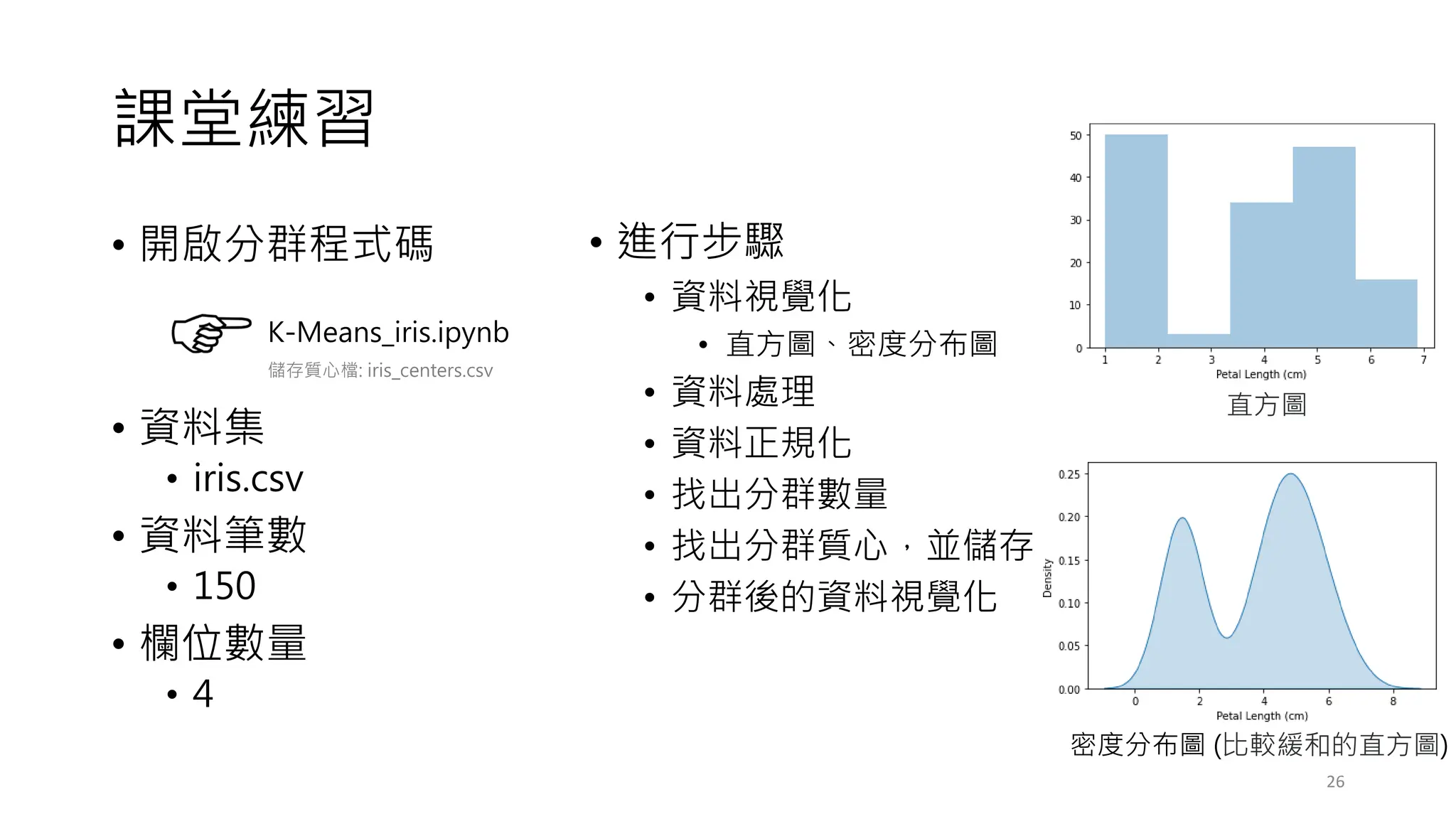
補充練習需要的套件
• 套件說明
• pipinstall pyod
• pip install yellowbrick
• pip install lightgbm
• pip install prince
5
(Python library for detecting anomalous/outlying objects.)
(Yellowbrick is a suite of visual analysis and diagnostic tools designed to
facilitate machine learning with scikit-learn.)
(Compiled library that is included in the wheel file supports both GPU and CPU versions out of the box.)
https://pypi.org/project/lightgbm/
(Prince is a library for doing factor analysis. This includes a variety of methods including principal
component analysis (PCA) and correspondence analysis (CA) .)
6.
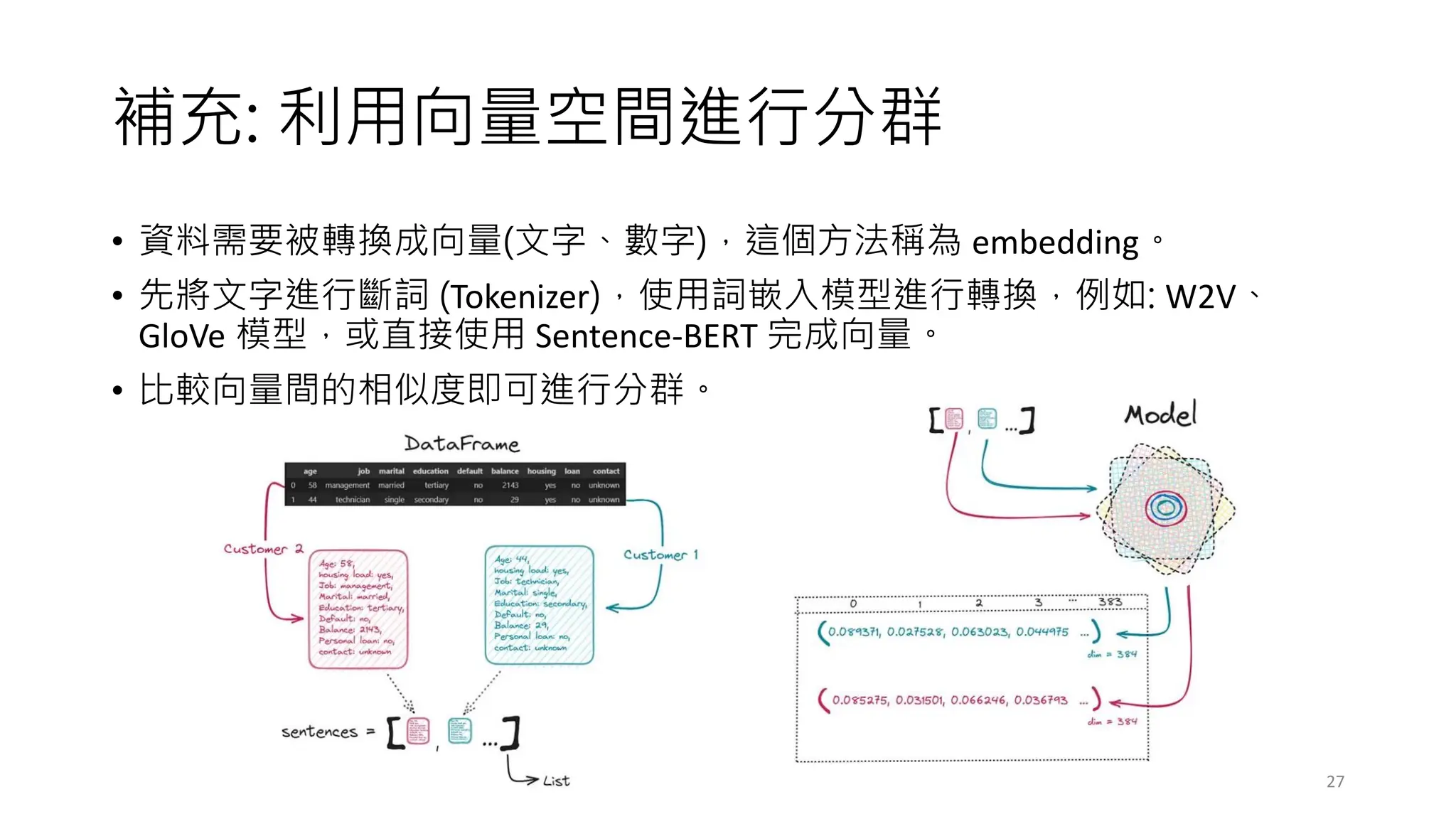
補充練習需要的套件
• 套件說明
• pipinstall sentence-transformers
• pip install plotly
• pip install shap
6
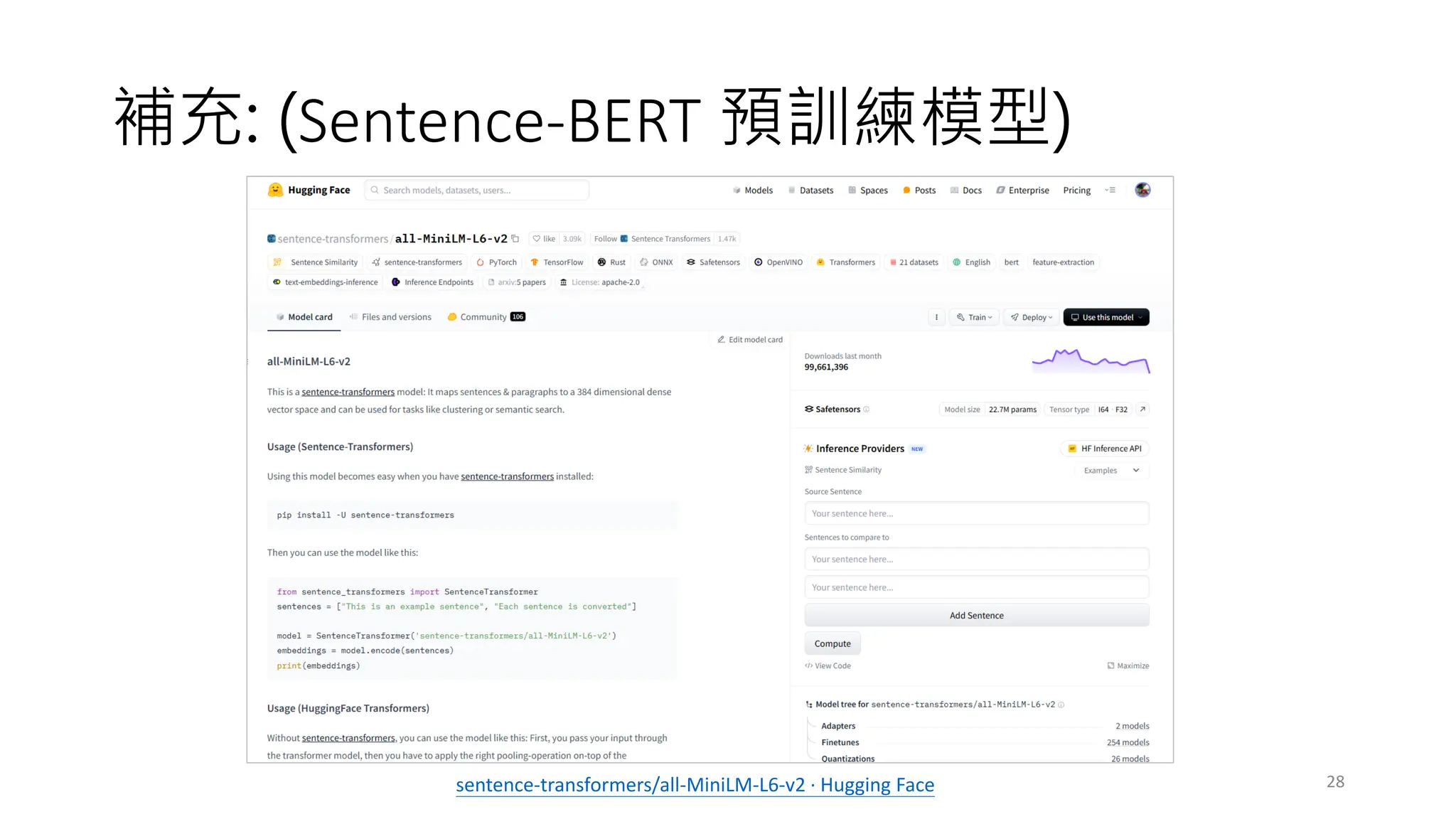
(This framework provides an easy method to compute dense vector representations
for sentences, paragraphs, and images.)
https://pypi.org/project/sentence-transformers
(To explain the output of any machine learning model.)
(An open-source, interactive data visualization library for Python.)
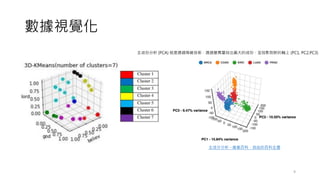
請注意,使用 plotly 的 3D 顯示,需要在 jupyterlab 3.x 的版本
用來觀察模型特徵之間的交互關係
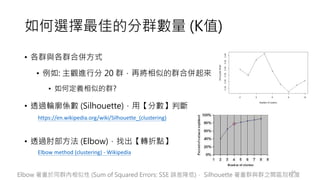
大數據運算,需要考量時間複雜度
• 每一筆資料都要跟【全部資料】計算距離,時間複雜度高
• 幾種方法可以增加速度
•透過程式面著手,如: 多執行緒 + In memory (採用 pyspark 套件)
• 雖然 Scikit-learn 預設採用【全核心】計算來增加速度,也可以考慮用
numpy 套件提升速度
• 採用GPU版本的 K-Means,如: cmML
19
Using NumPy to Speed Up K-Means Clustering by 70x | Paperspace Blog
K-Means Clustering Algorithm – What Is It and Why Does It Matter?