Download as PDF, PPTX












![www.percona.com
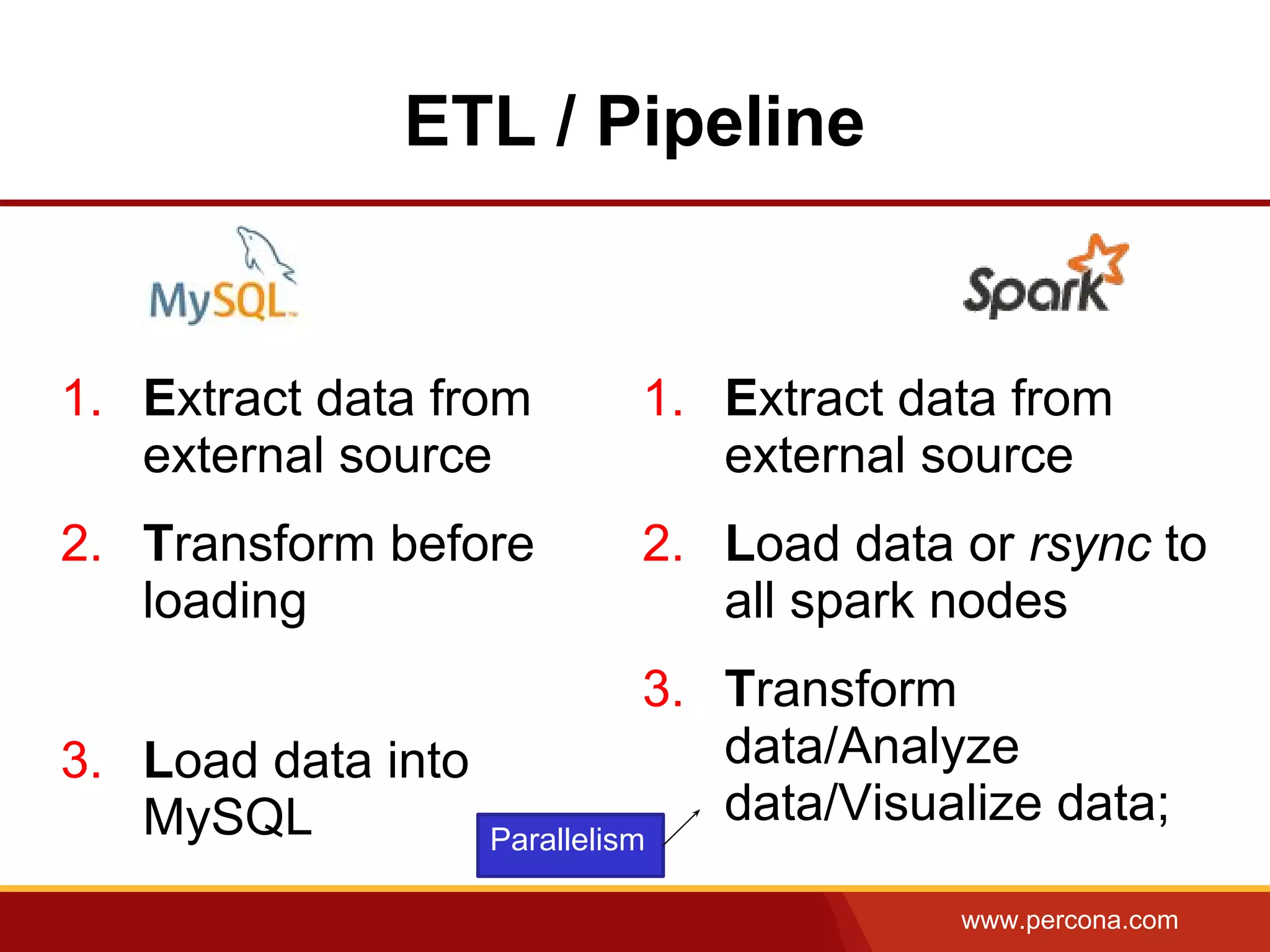
Spark and WikiStats: load pipeline
Row(project=p[0],
url=urllib.unquote(p[1]).lower(),
num_requests=int(p[2]),
content_size=int(p[3])))](https://image.slidesharecdn.com/usingapachesparkandmysqlfordataanalysis-170205010832/85/Using-Apache-Spark-and-MySQL-for-Data-Analysis-16-320.jpg)



















![www.percona.com
Spark and WikiStats: load pipeline
Row(project=p[0],
url=urllib.unquote(p[1]).lower(),
num_requests=int(p[2]),
content_size=int(p[3])))](https://image.slidesharecdn.com/usingapachesparkandmysqlfordataanalysis-170205010832/75/Using-Apache-Spark-and-MySQL-for-Data-Analysis-16-2048.jpg)



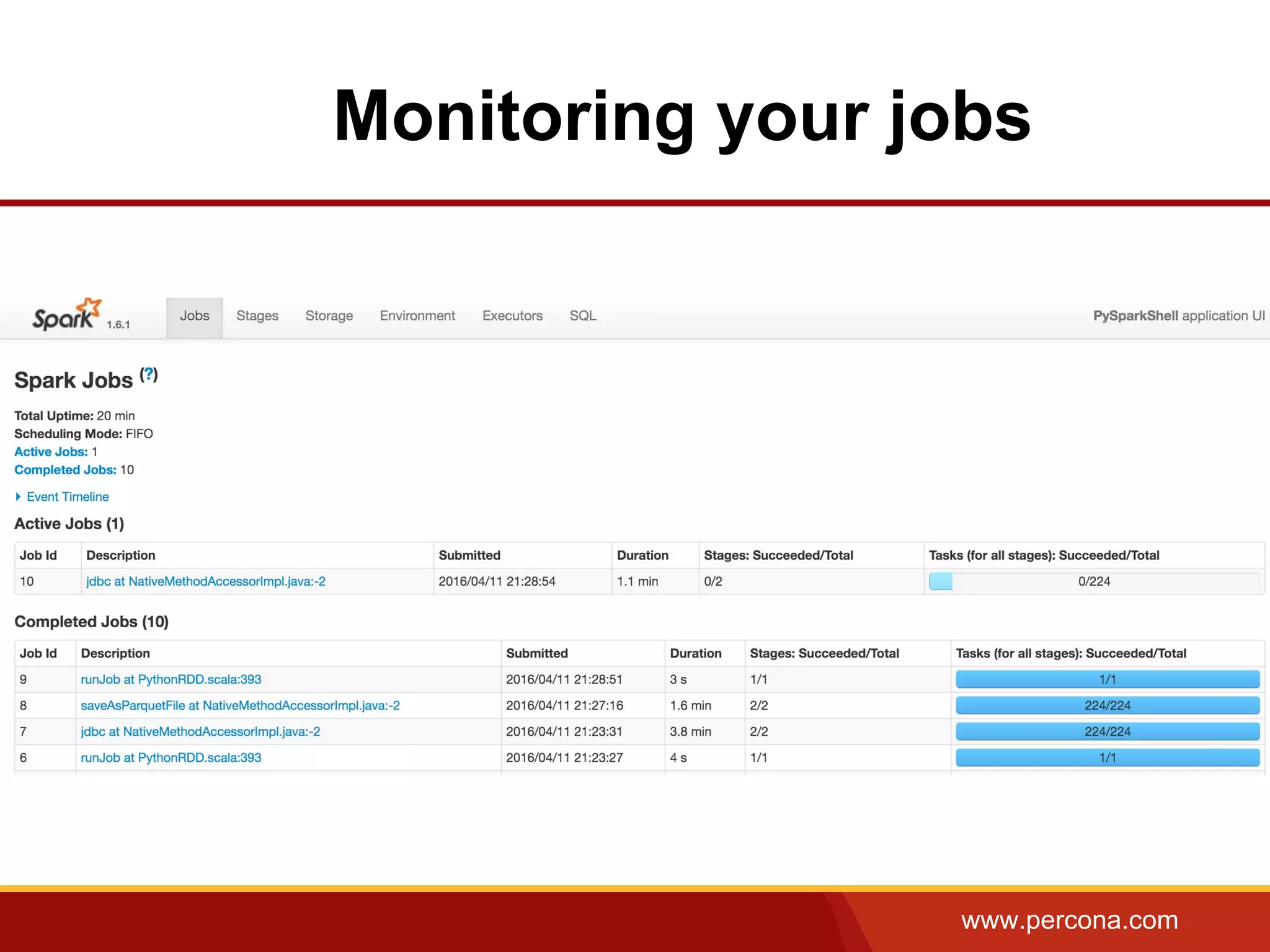
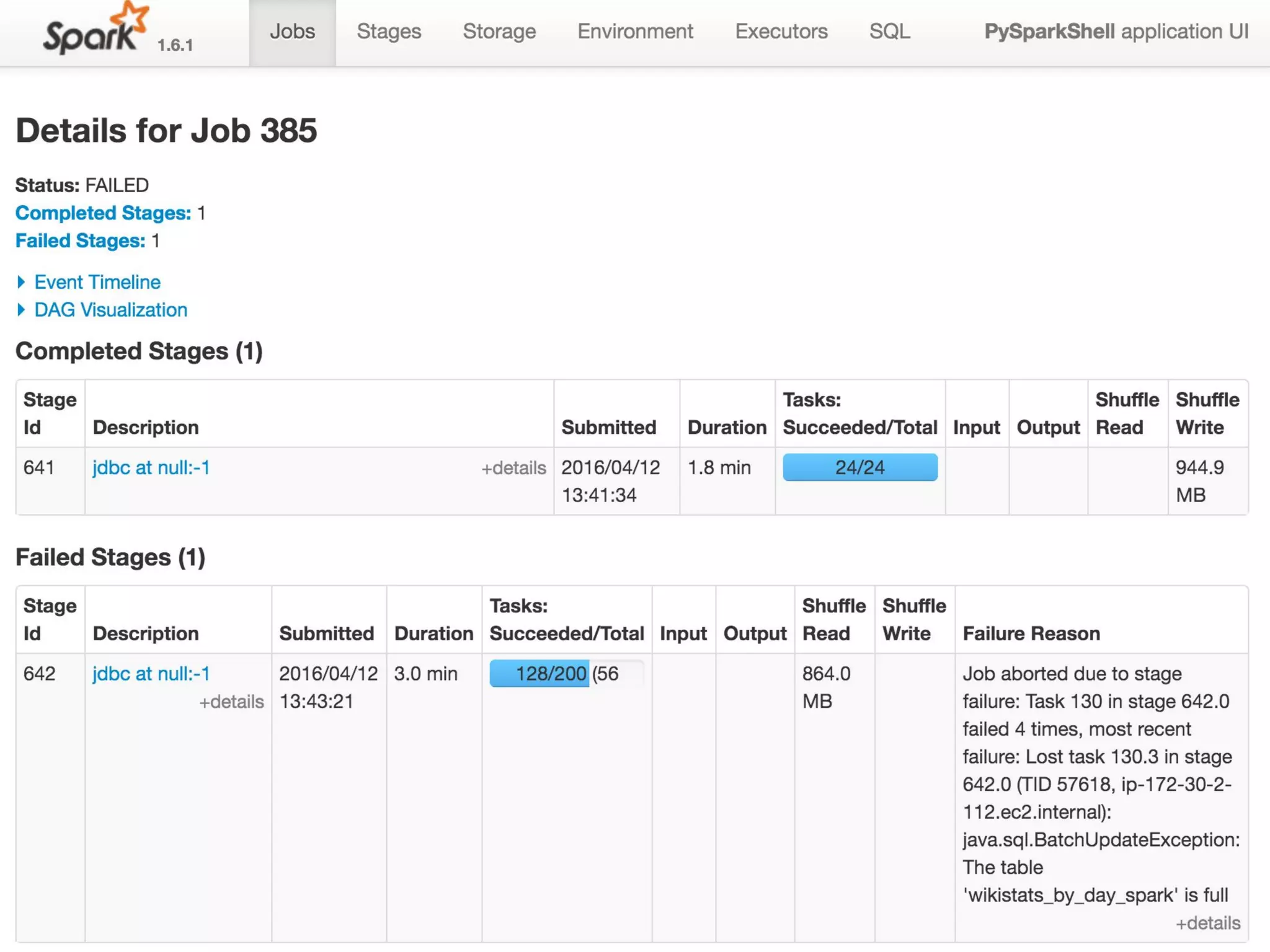
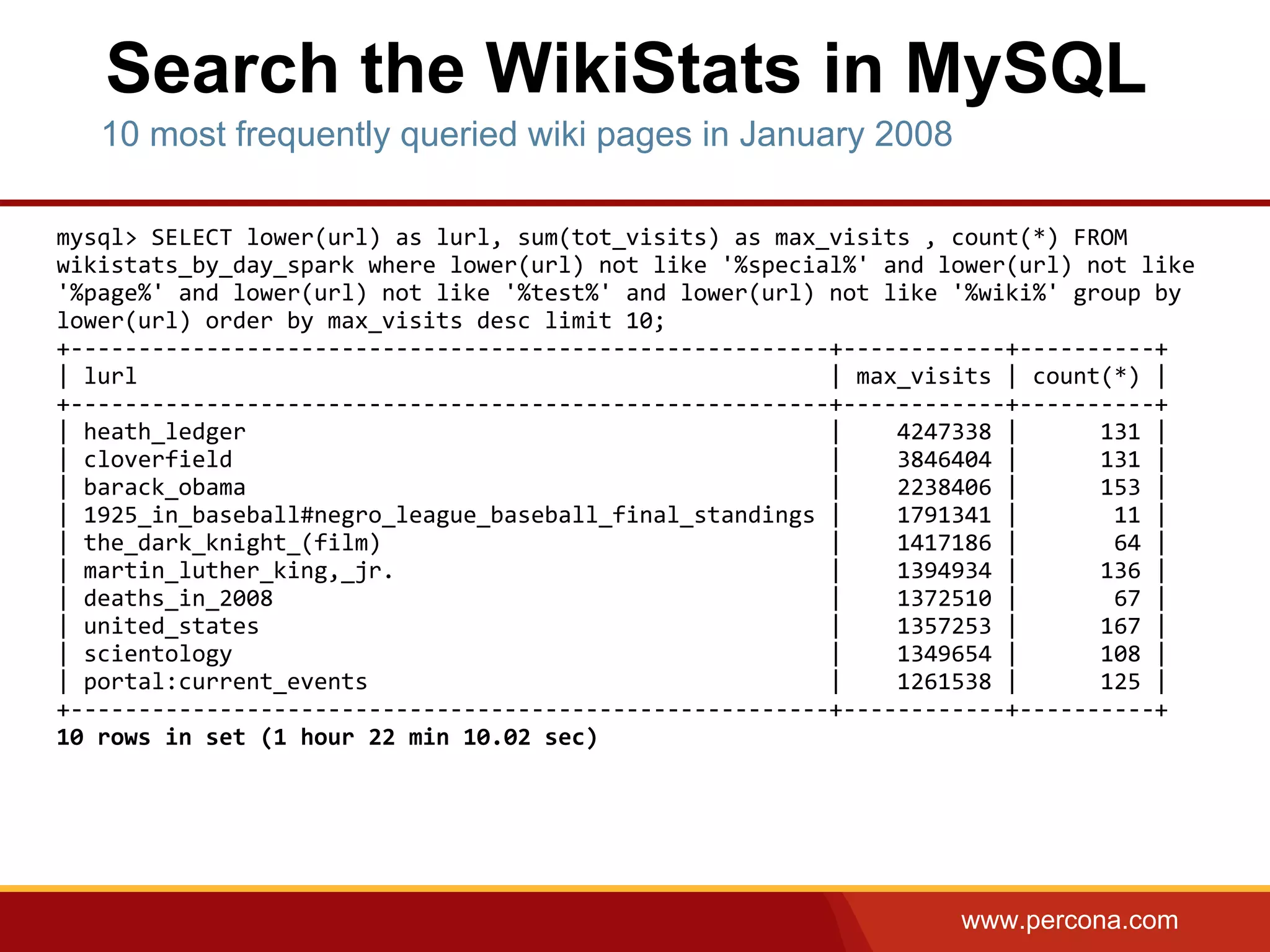
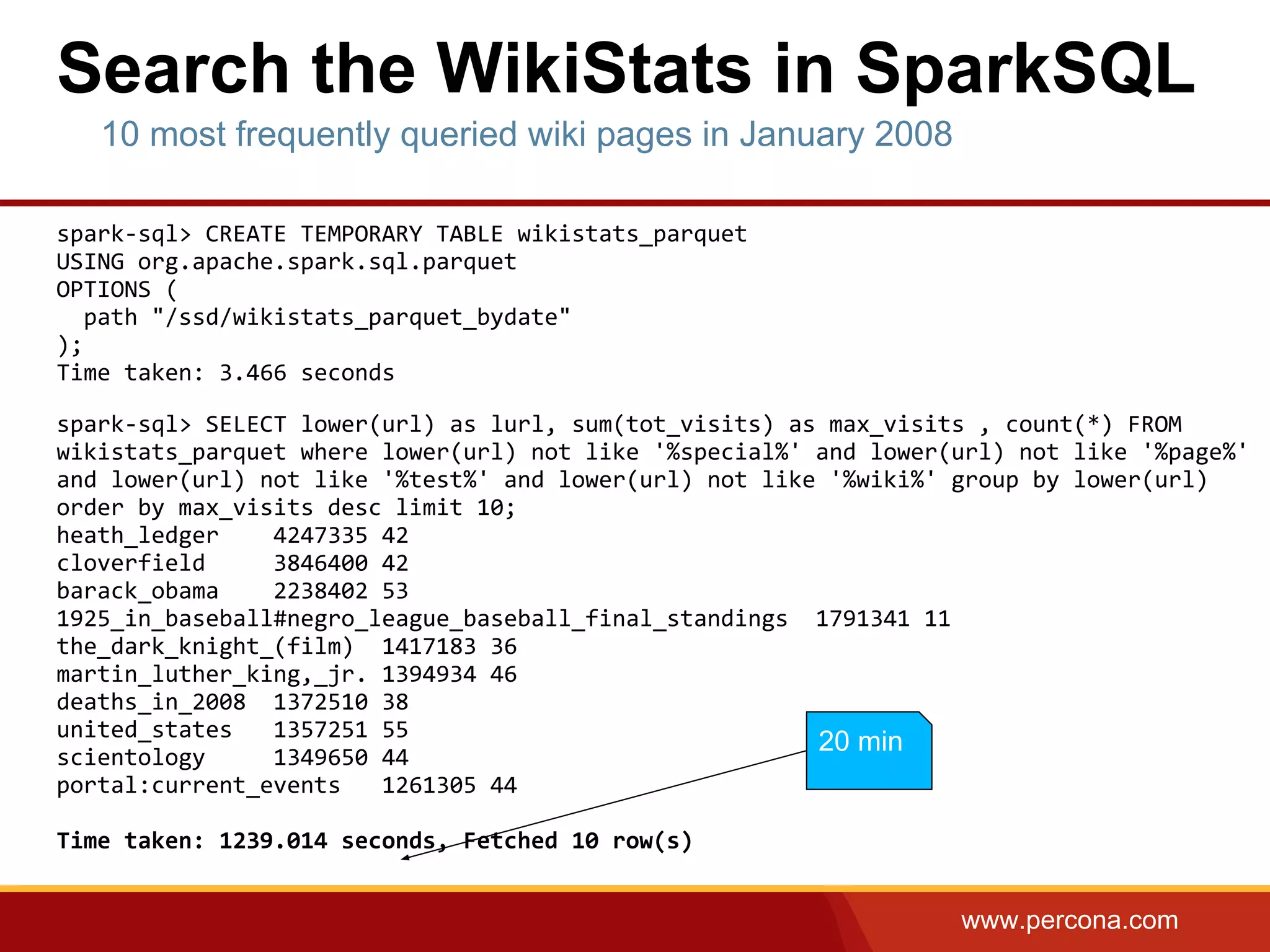





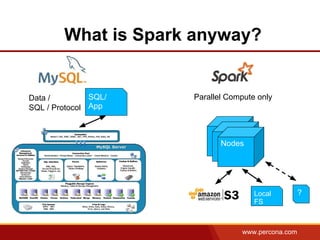
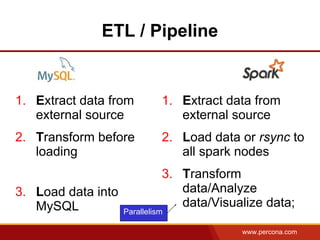
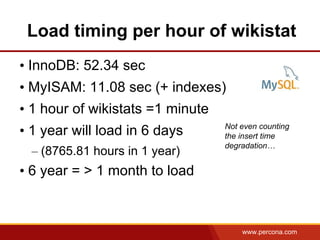
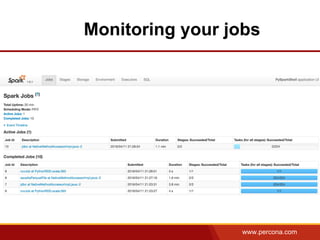
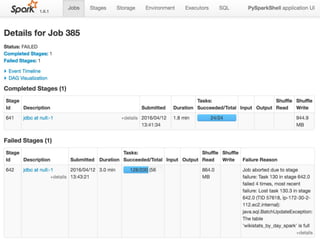
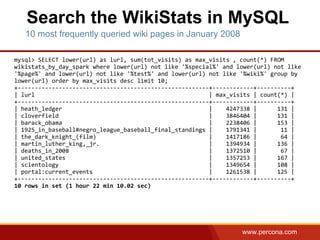
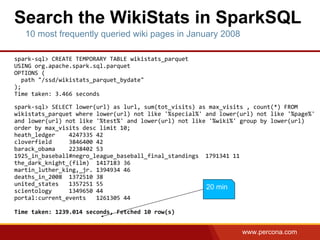
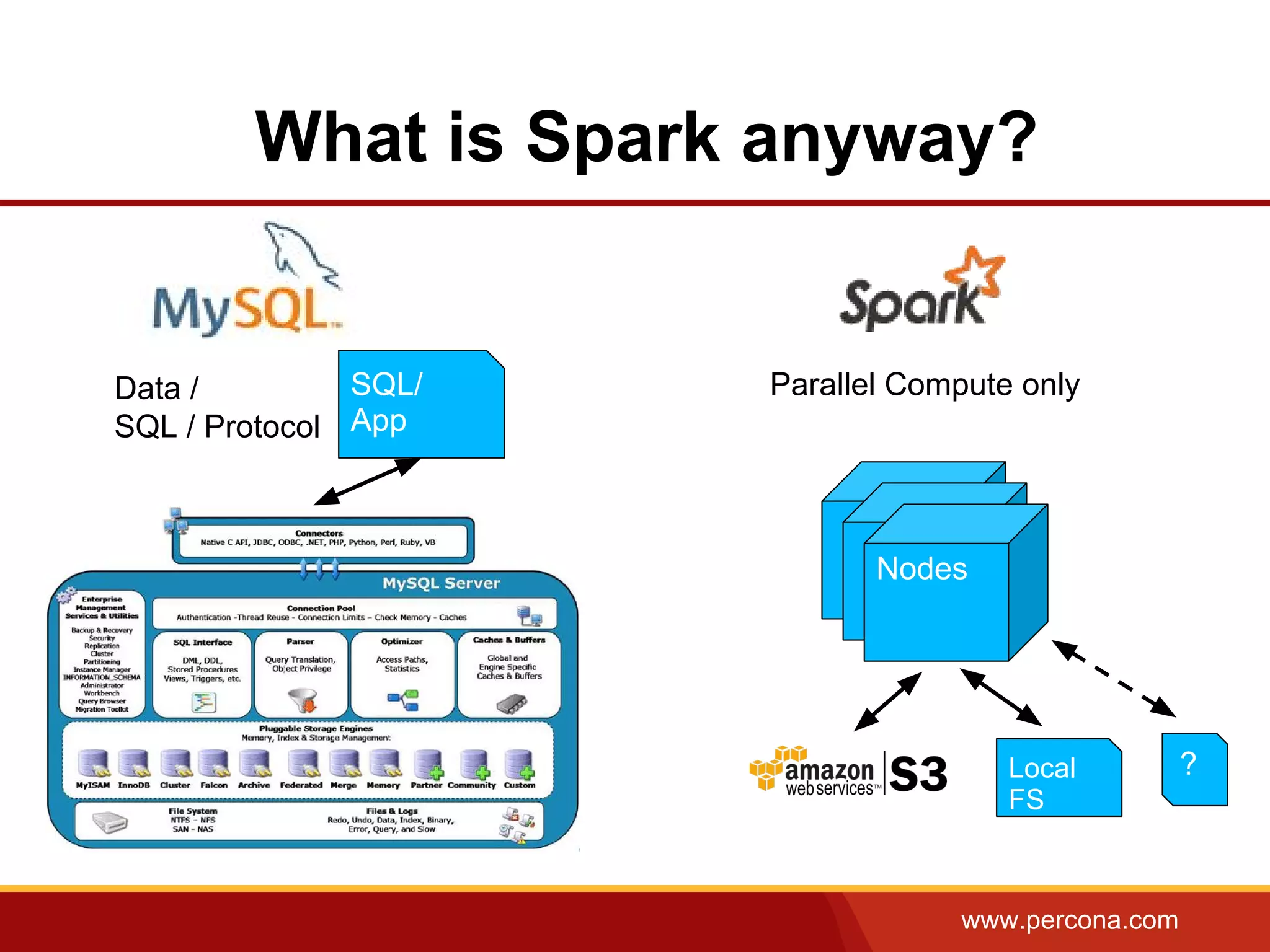
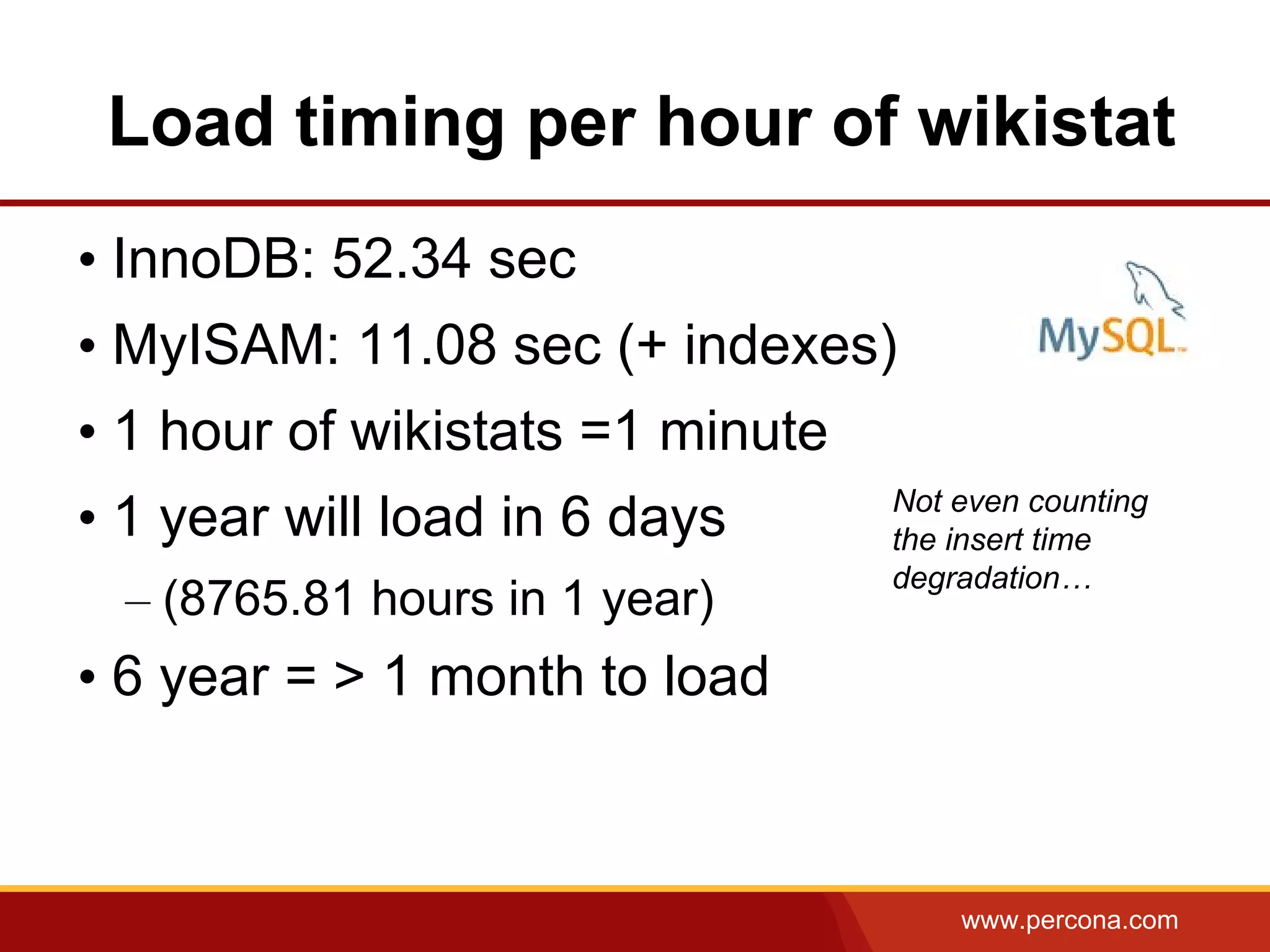
The document discusses using Apache Spark and MySQL for data analysis. It provides examples of loading Wikipedia usage statistics (Wikistats) data into both MySQL and Spark for analysis. Loading the full 10+ TB of Wikistats data into MySQL took over a month, while Spark was able to scan and analyze the entire dataset in under an hour by leveraging its ability to perform distributed, parallel processing across multiple nodes. The document compares key differences between Spark and MySQL for big data processing, such as Spark's lack of indexes but ability to perform full scans in parallel across nodes.

![[오픈소스컨설팅]Session 4. dev ops 구성 사례와 전망](https://cdn.slidesharecdn.com/ss_thumbnails/session4-161124020726-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















![[NDC 2018] 유체역학 엔진 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc18fluidenginedevelopmentverfinal-180427164620-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[125]웹 성능 최적화에 필요한 브라우저의 모든 것](https://cdn.slidesharecdn.com/ss_thumbnails/125webproc-181011045612-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















































![Introduction into MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-210717011329-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















