Downloaded 10 times






![© 2023 Intuit Inc. All rights reserved. 9
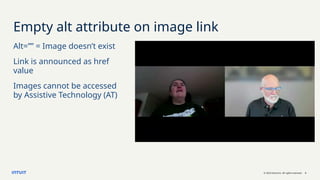
Improve your prompts
Simple alt text
Describe the image in under 100 characters, focusing
on visible elements and actions. Exclude emotions or
subjective details. Use an 8th grade reading level.
Describe purpose with context
Determine the purpose of this image based on this
surrounding text: "[insert text]". Describe the image in
under 100 characters, focusing on visible elements and actions.
Exclude emotions or subjective details. Use an 8th grade
reading level.](https://image.slidesharecdn.com/webaim-verboseaitheaccessibilitychallenge-250917182003-b0d9b623/85/WebAIM-Verbose-AI-The-Accessibility-Challenge-9-320.jpg)




















![© 2023 Intuit Inc. All rights reserved. 9
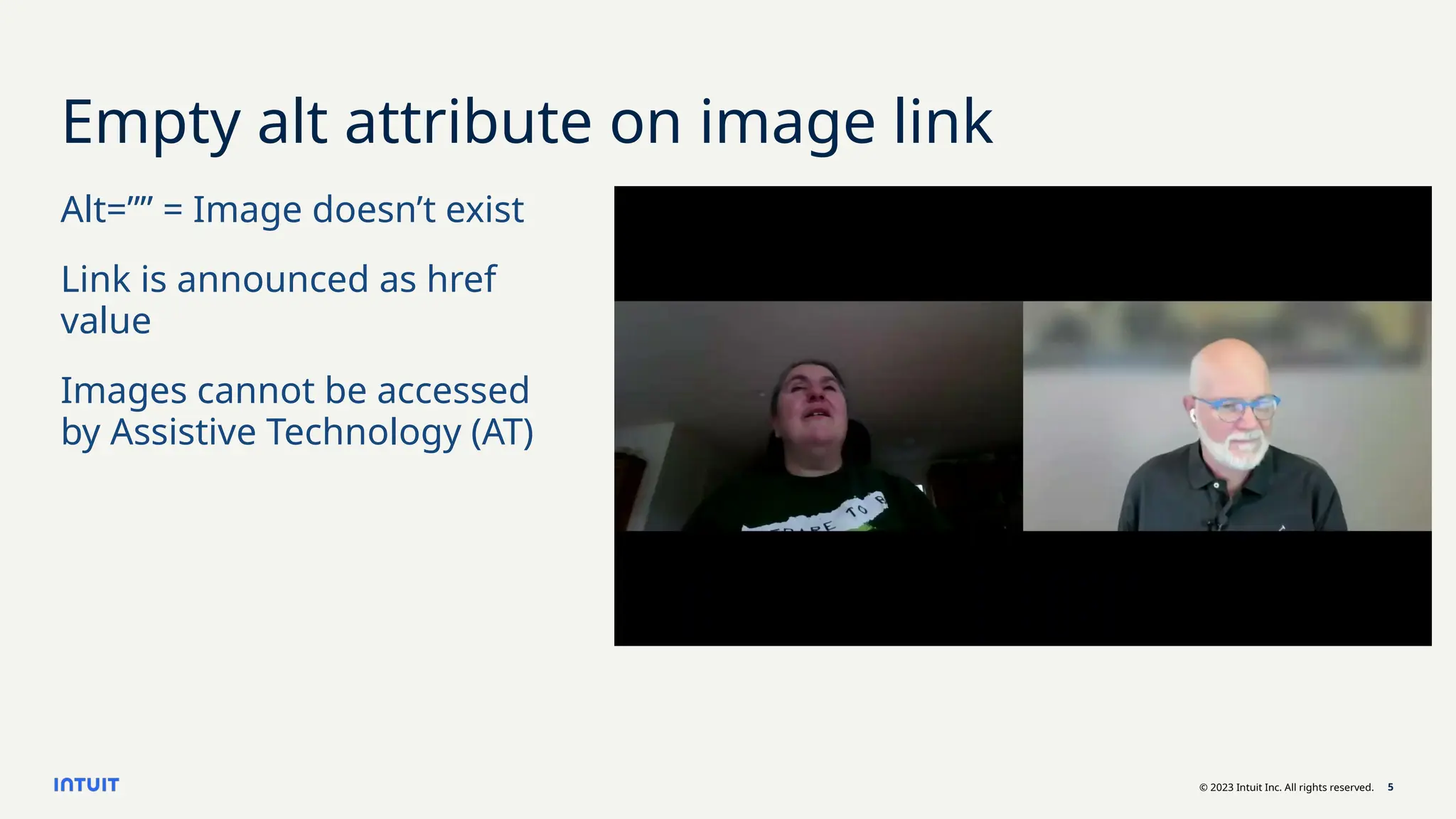
Improve your prompts
Simple alt text
Describe the image in under 100 characters, focusing
on visible elements and actions. Exclude emotions or
subjective details. Use an 8th grade reading level.
Describe purpose with context
Determine the purpose of this image based on this
surrounding text: "[insert text]". Describe the image in
under 100 characters, focusing on visible elements and actions.
Exclude emotions or subjective details. Use an 8th grade
reading level.](https://image.slidesharecdn.com/webaim-verboseaitheaccessibilitychallenge-250917182003-b0d9b623/75/WebAIM-Verbose-AI-The-Accessibility-Challenge-9-2048.jpg)















This presentation tackles AI-generated image descriptions that unintentionally create overly verbose screen reader experiences, thus hindering accessibility. We'll explore how, despite significant advancements in AI, the generated descriptions often include superfluous details that make it burdensome for visually impaired users to navigate digital content efficiently. By examining real-world examples and user feedback, we'll illustrate the impact of verbosity on accessibility and the overall user experience. Potential description bias can come from how people engineer their prompts. Almost all LLMs will create problematic descriptions when the word "blind" is in the prompt, but will generally do a better job if "nonvisual" is used instead depending on the context and intent of the image. A crucial aspect we'll emphasize is the importance of context. An image description should not just list visual elements but also convey the image's relevance to the surrounding content. Imagine a shopping site that describes happy people on the beach, but neglects clothing details. This contextual approach ensures that users understand the significance of the image within the broader context of the page. There is an art to this kind of information conveyance. We'll showcase potential solutions and best practices for creating concise yet informative image descriptions. This Includes guidelines for manual creation, as well as innovative AI techniques that balance detail and brevity.



































































