Downloaded 2,114 times














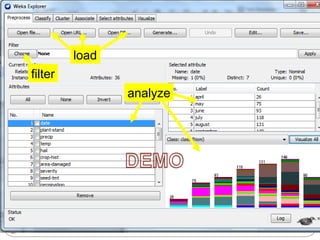
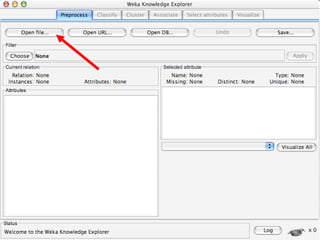

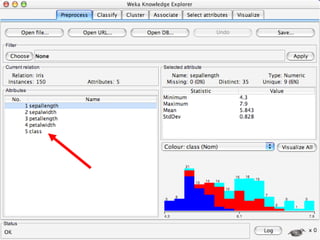
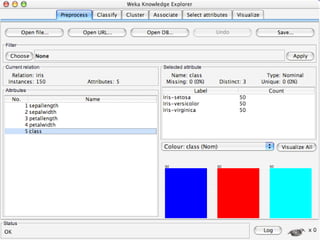
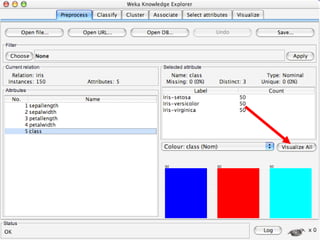
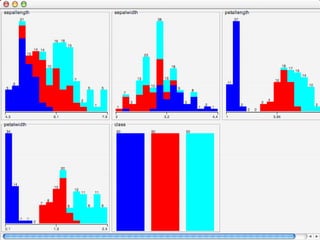
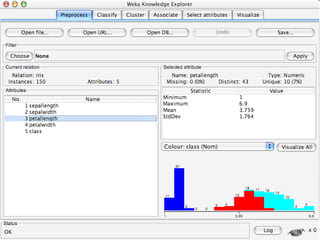
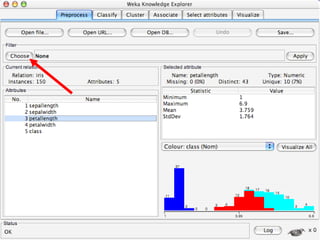

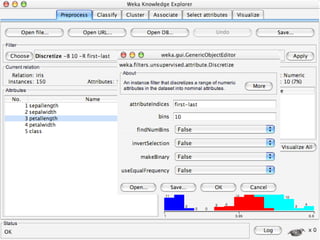
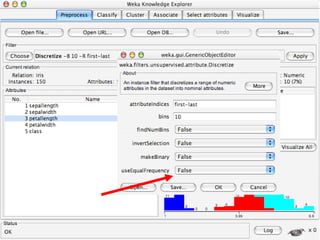
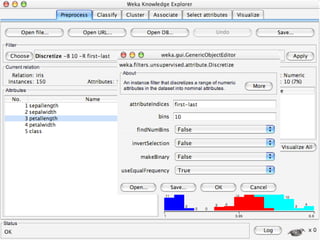
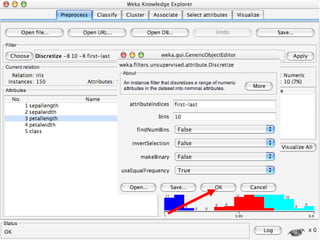
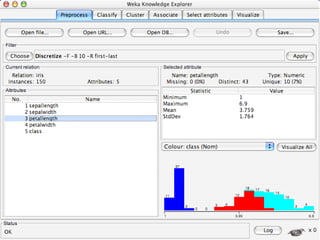
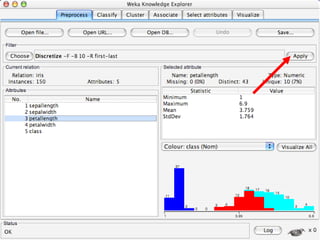
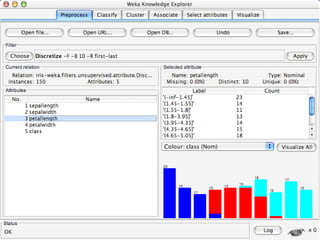




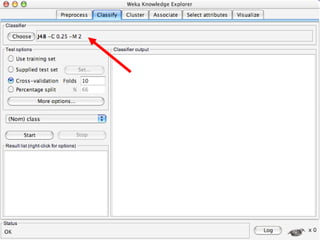
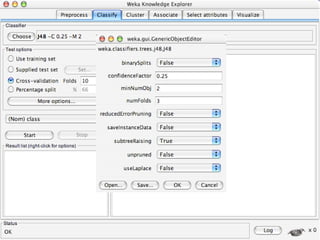
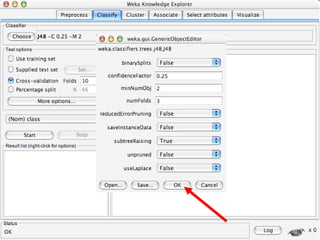
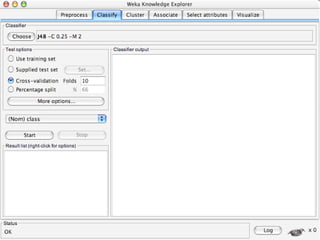
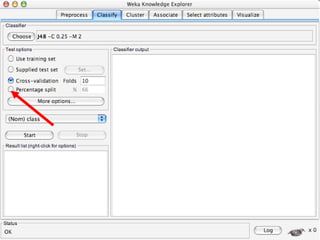
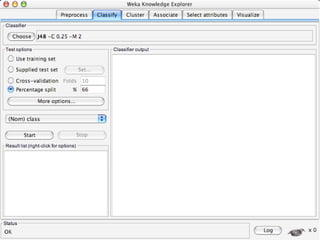

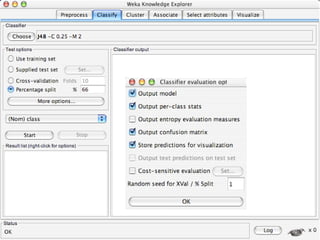
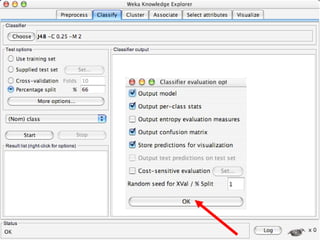
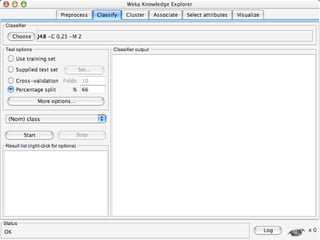
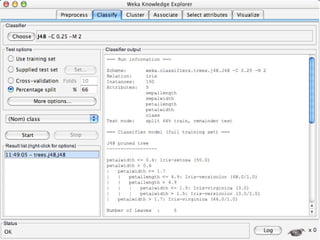

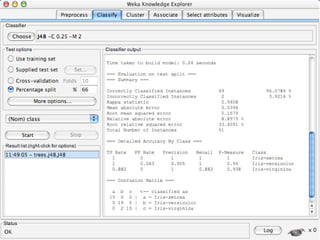
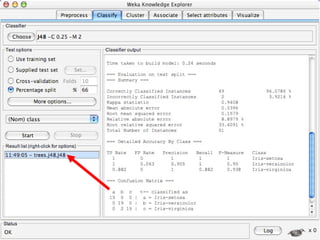
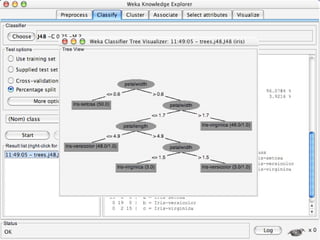
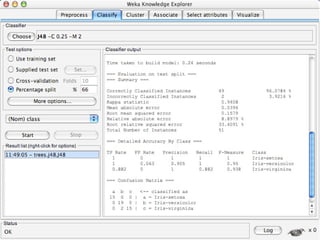





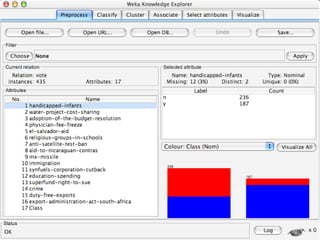
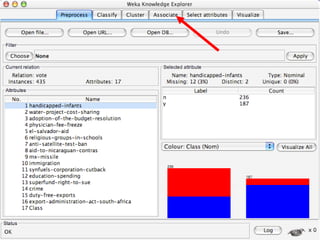

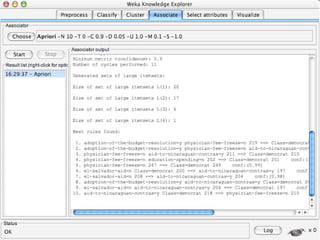


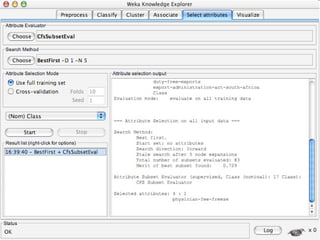
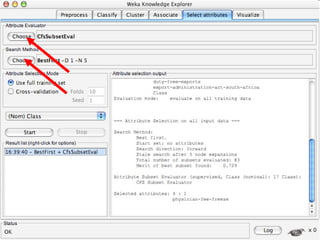

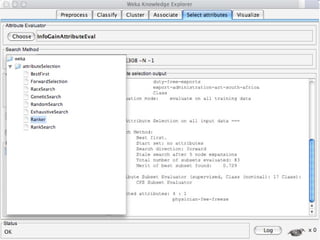

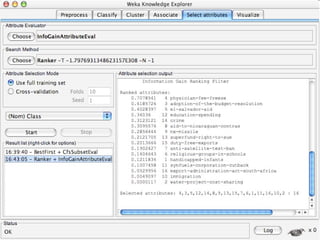


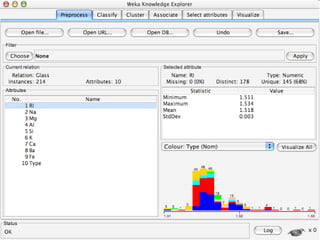
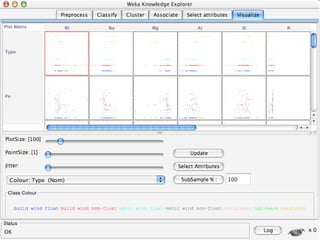
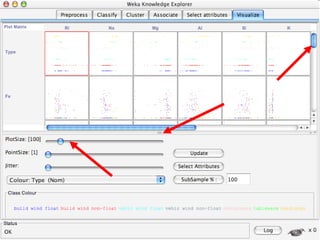
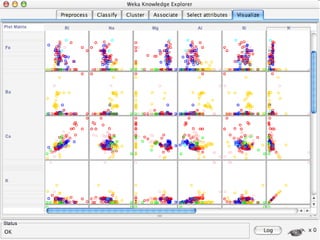
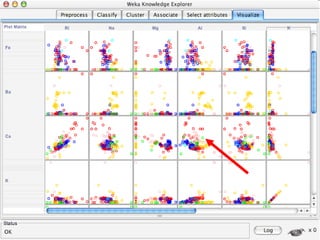
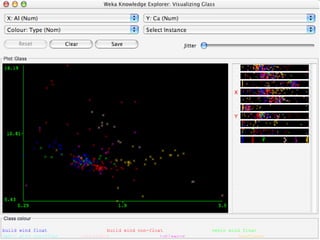
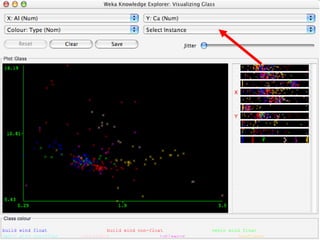
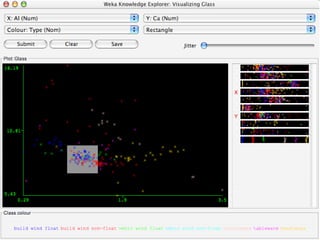
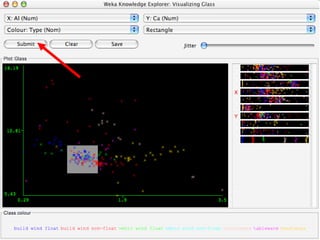
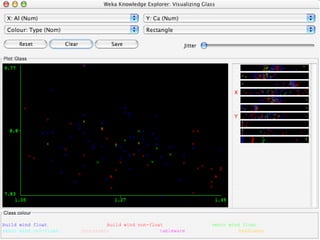















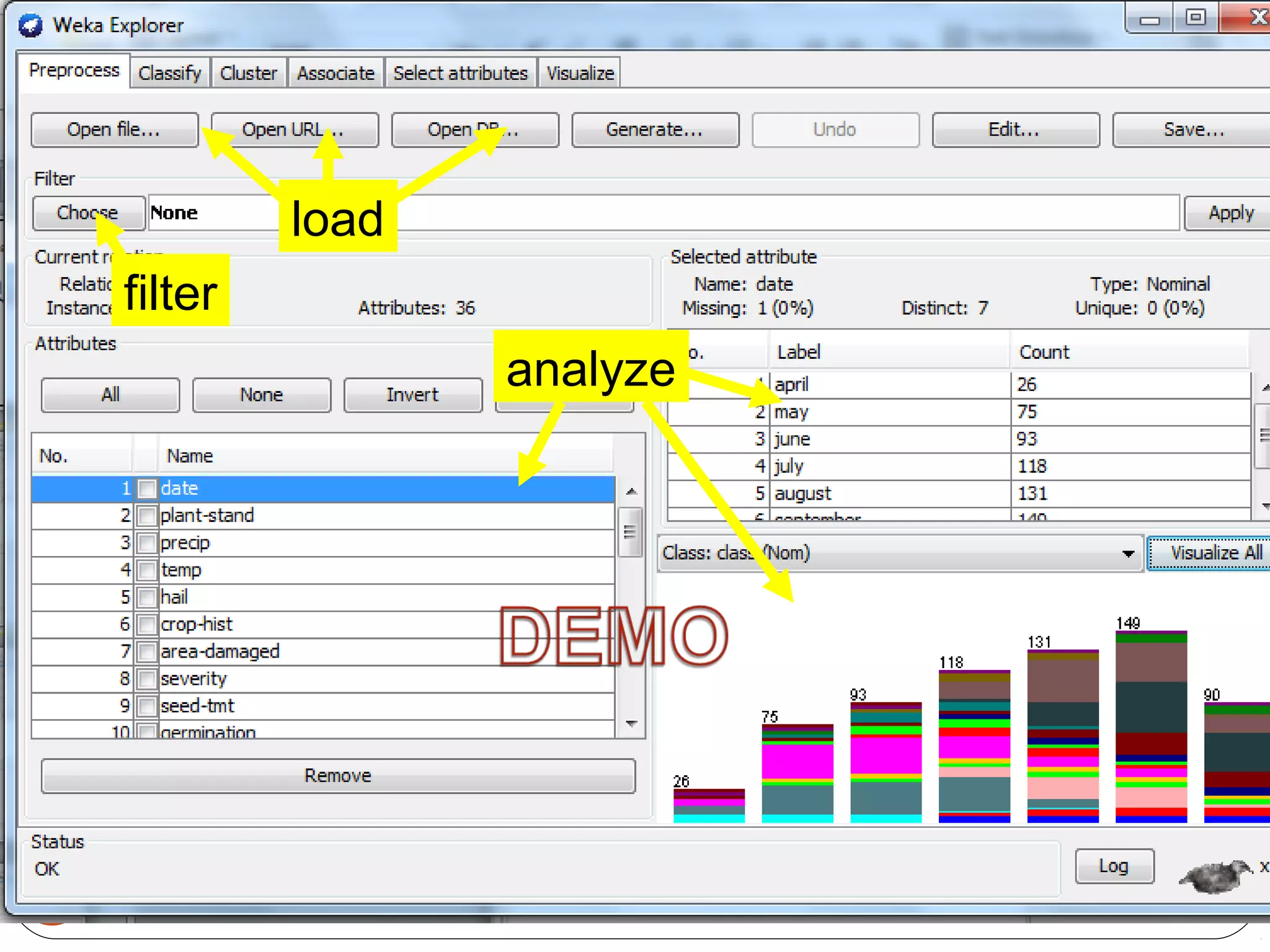
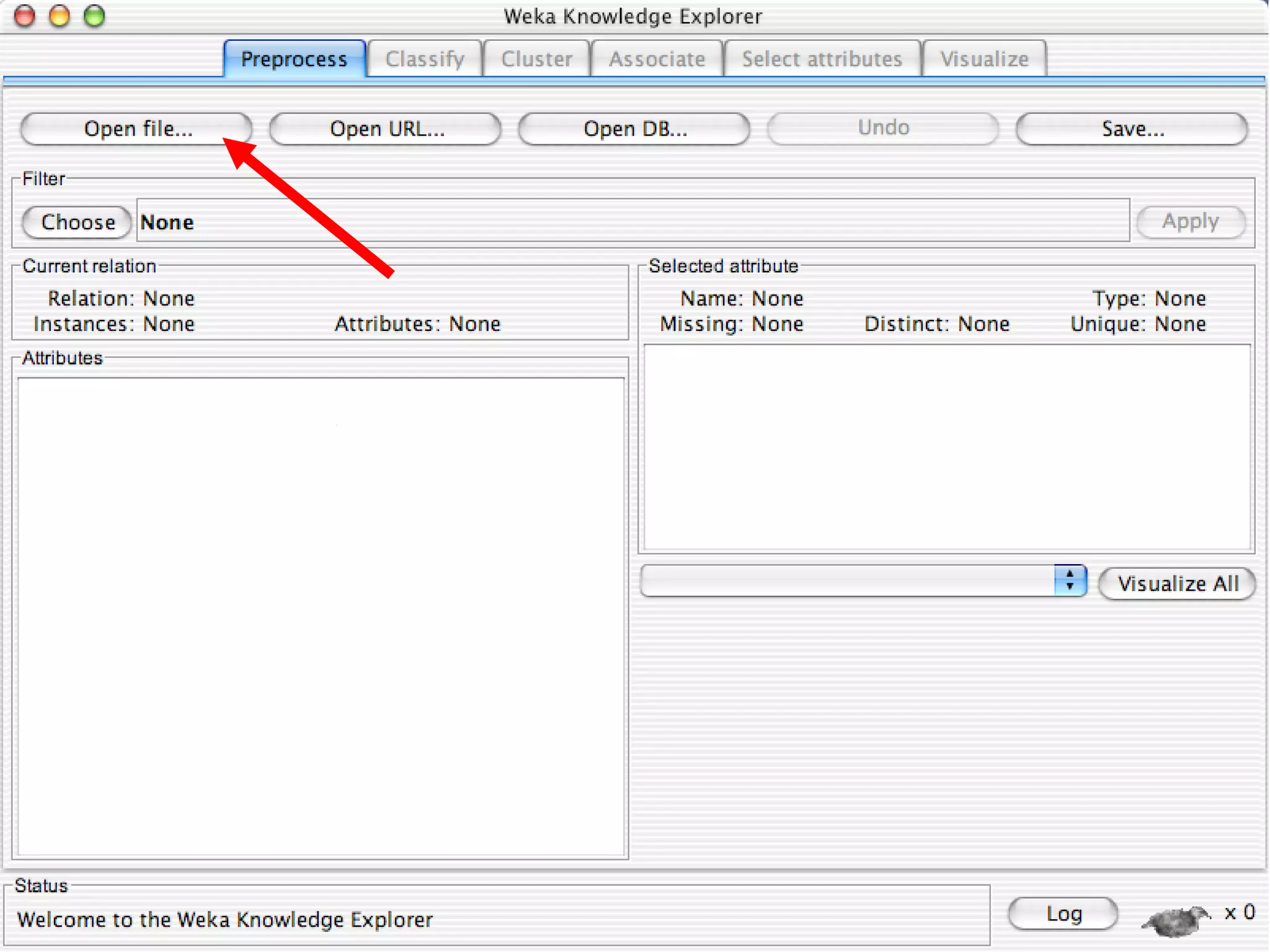
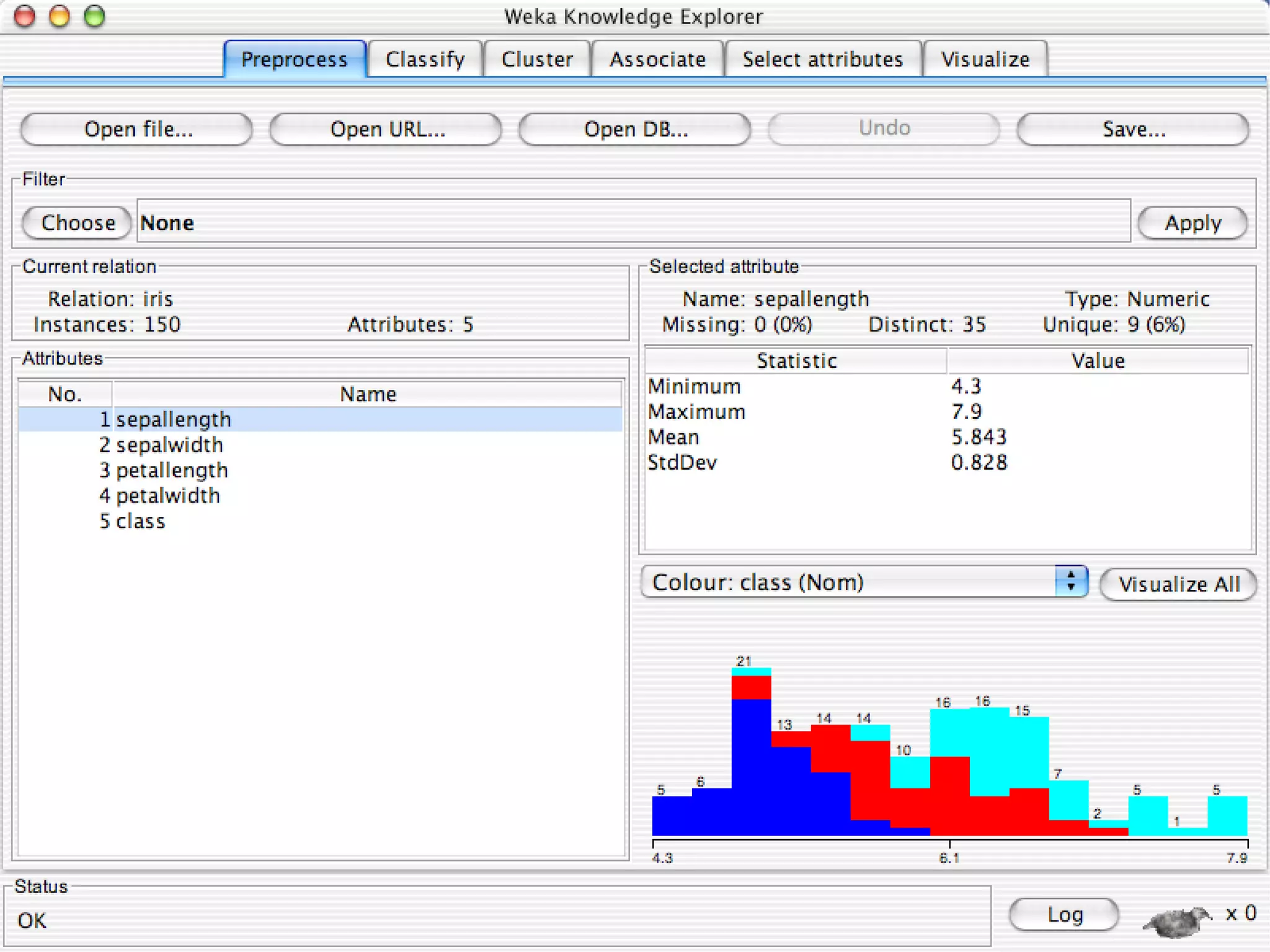
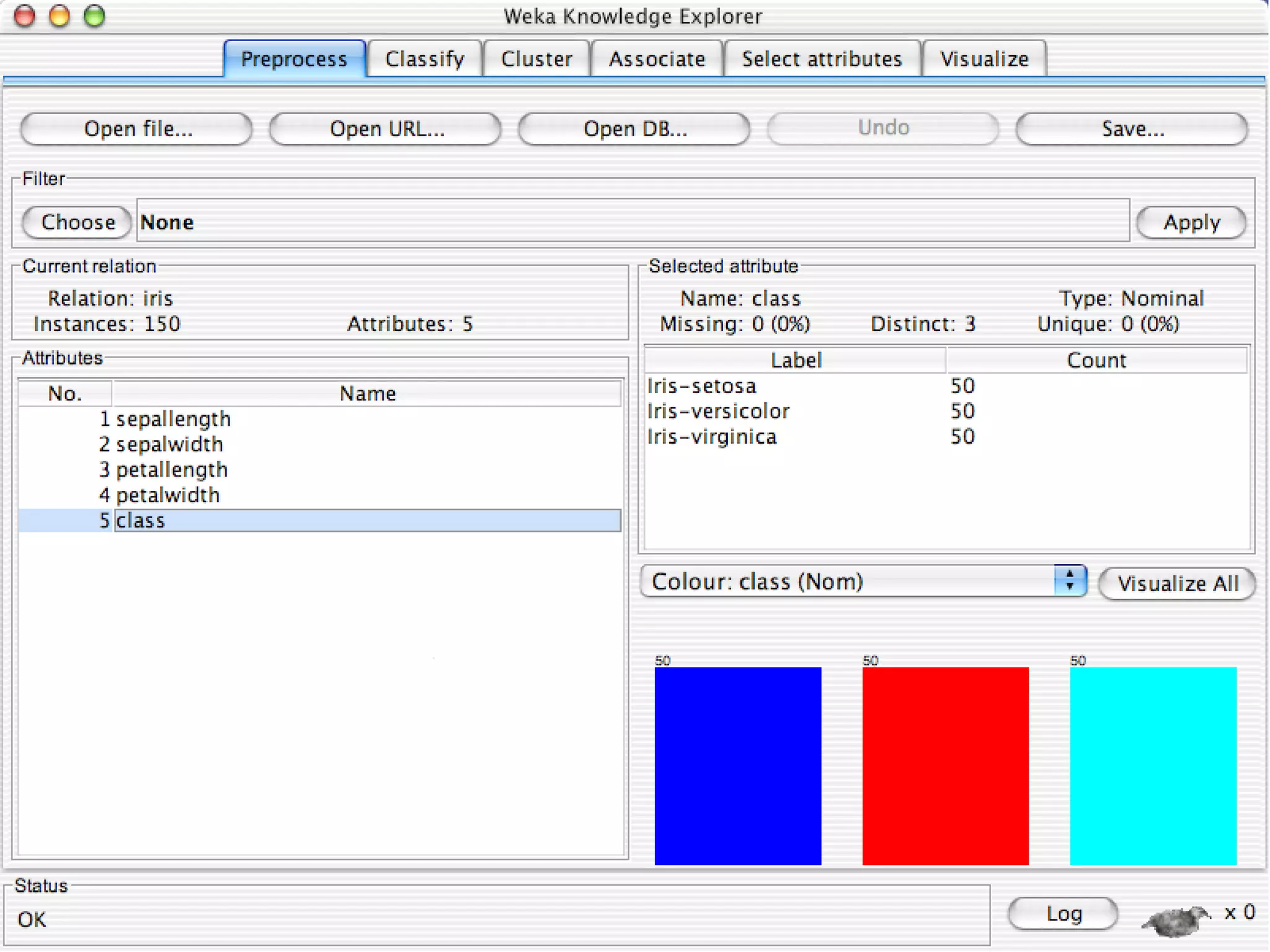
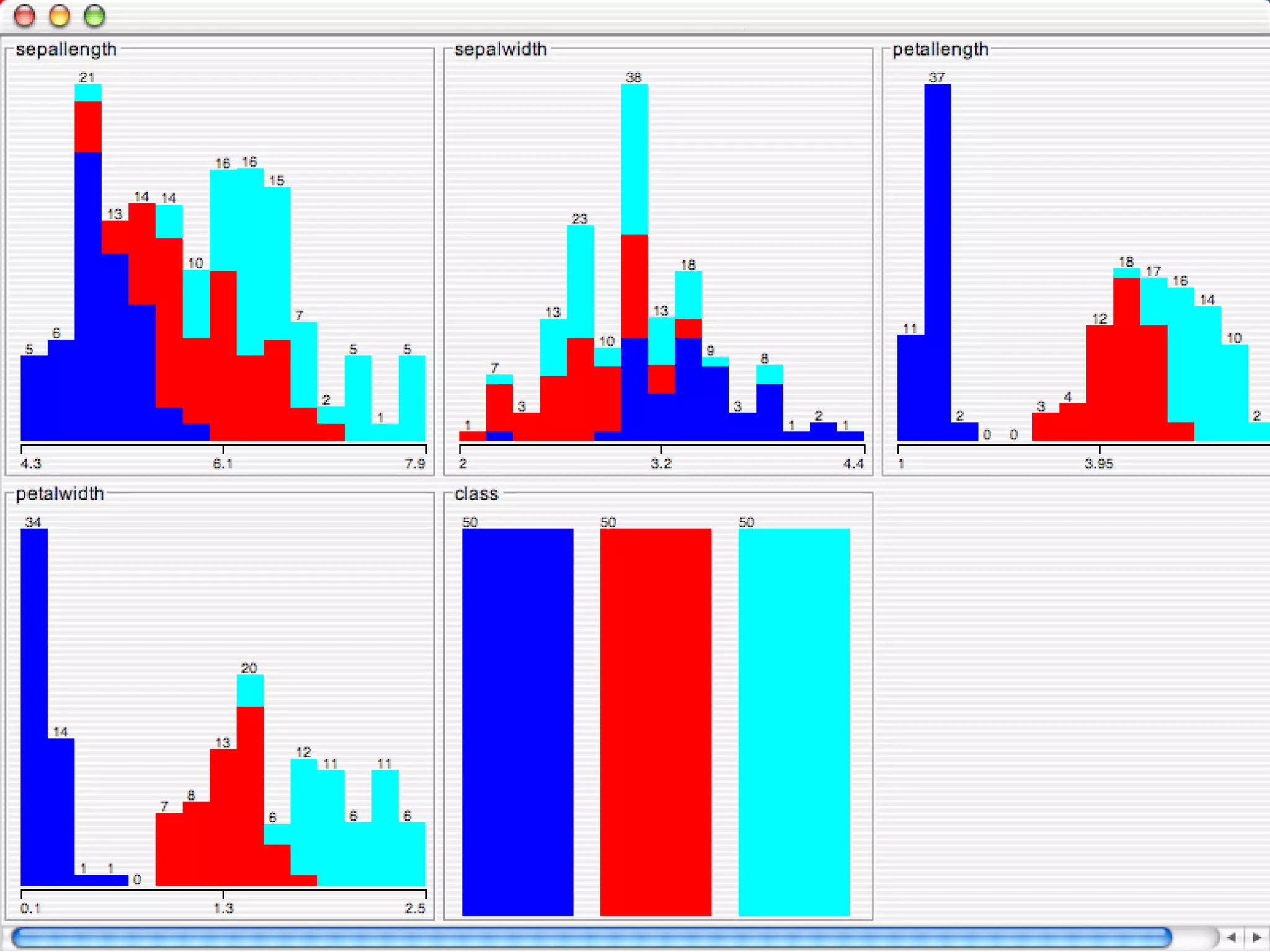
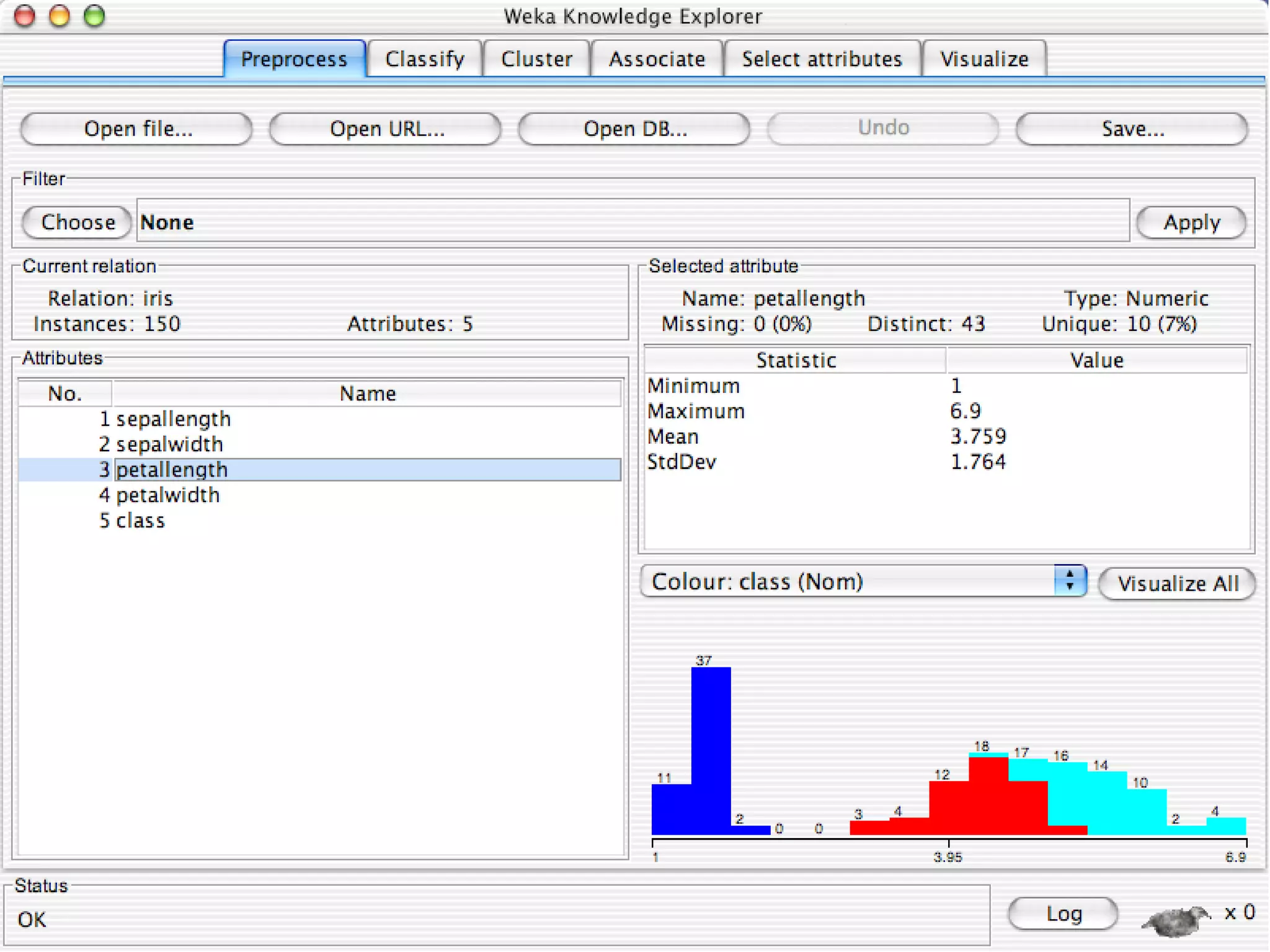
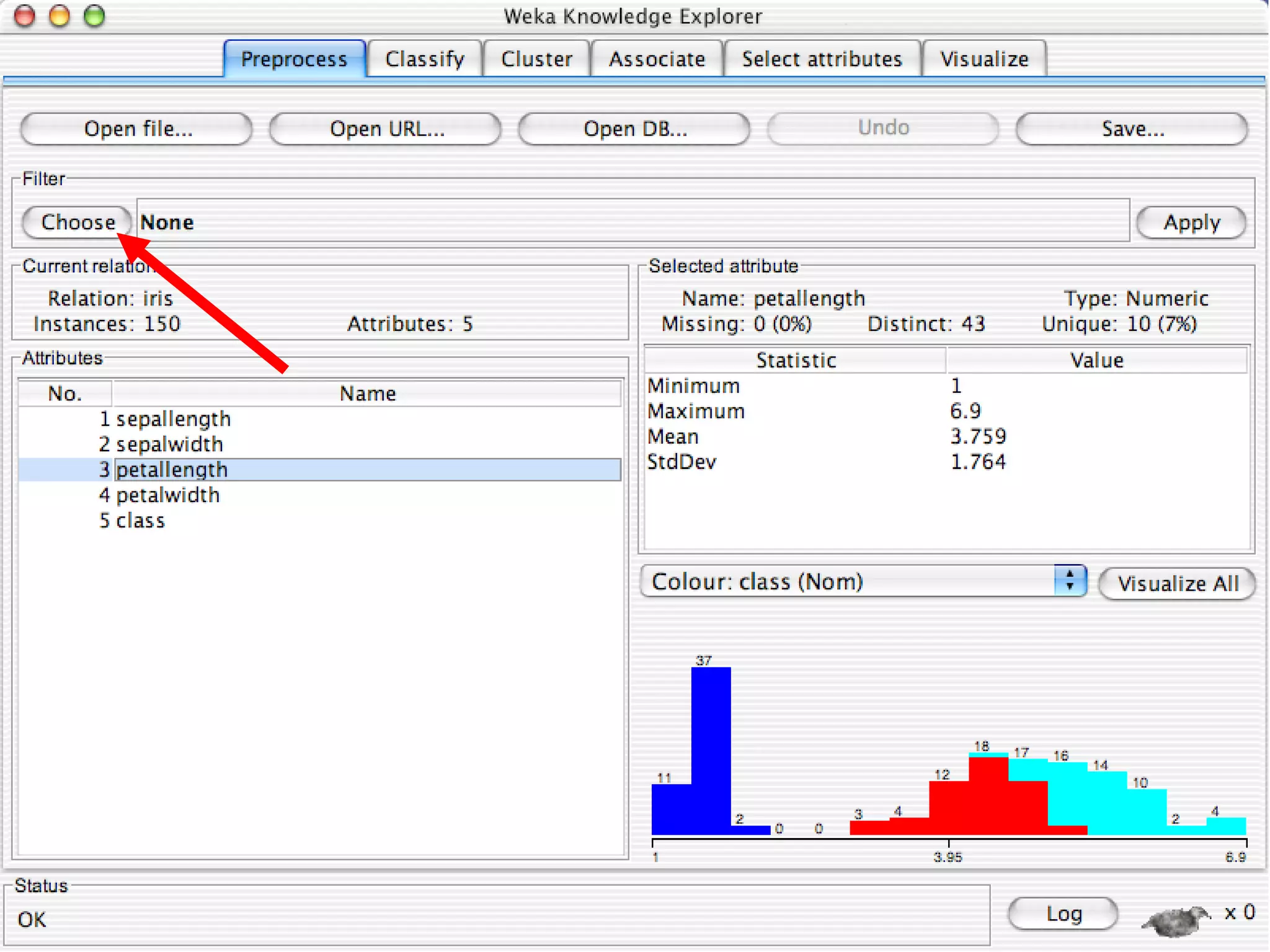
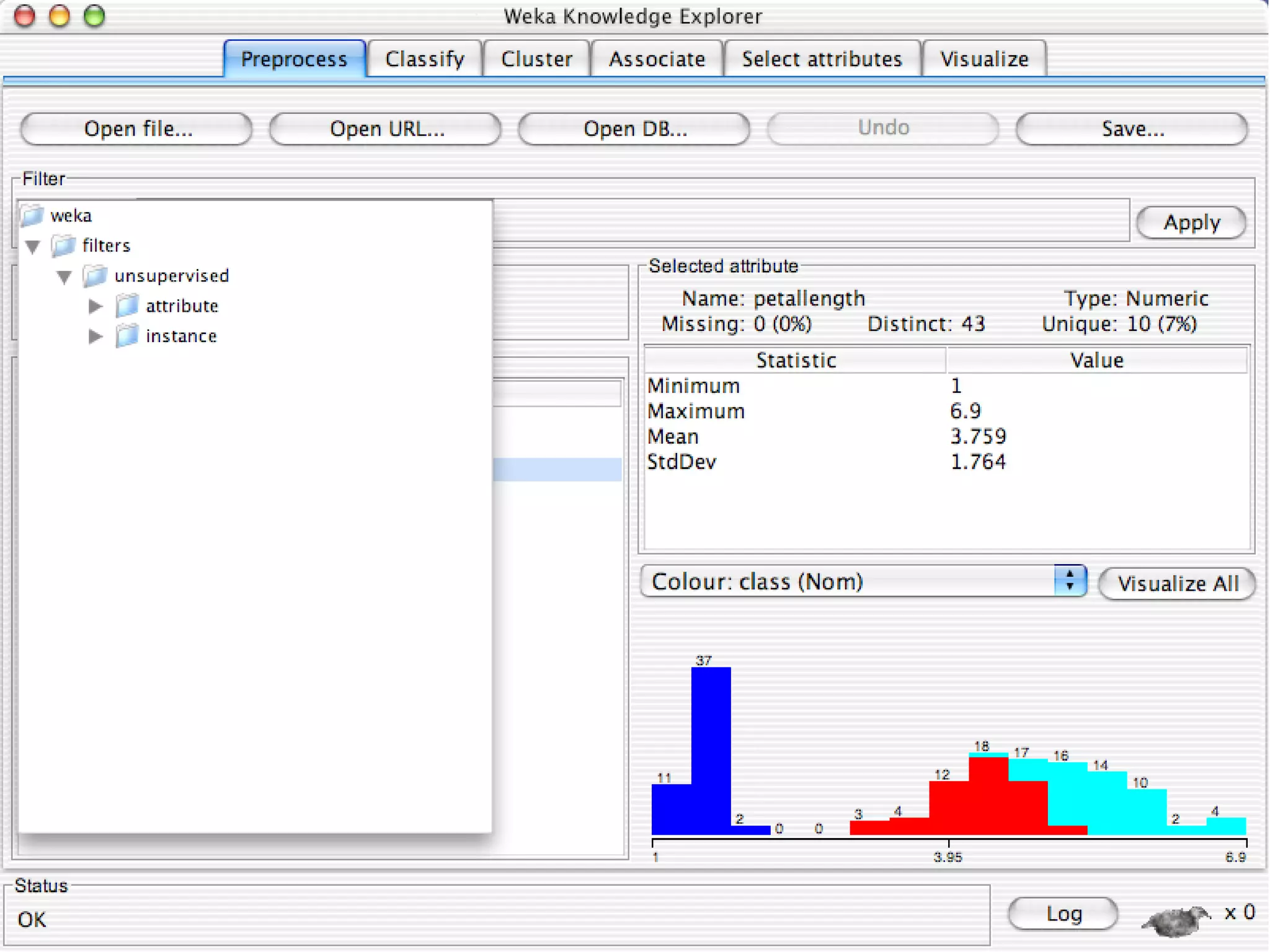
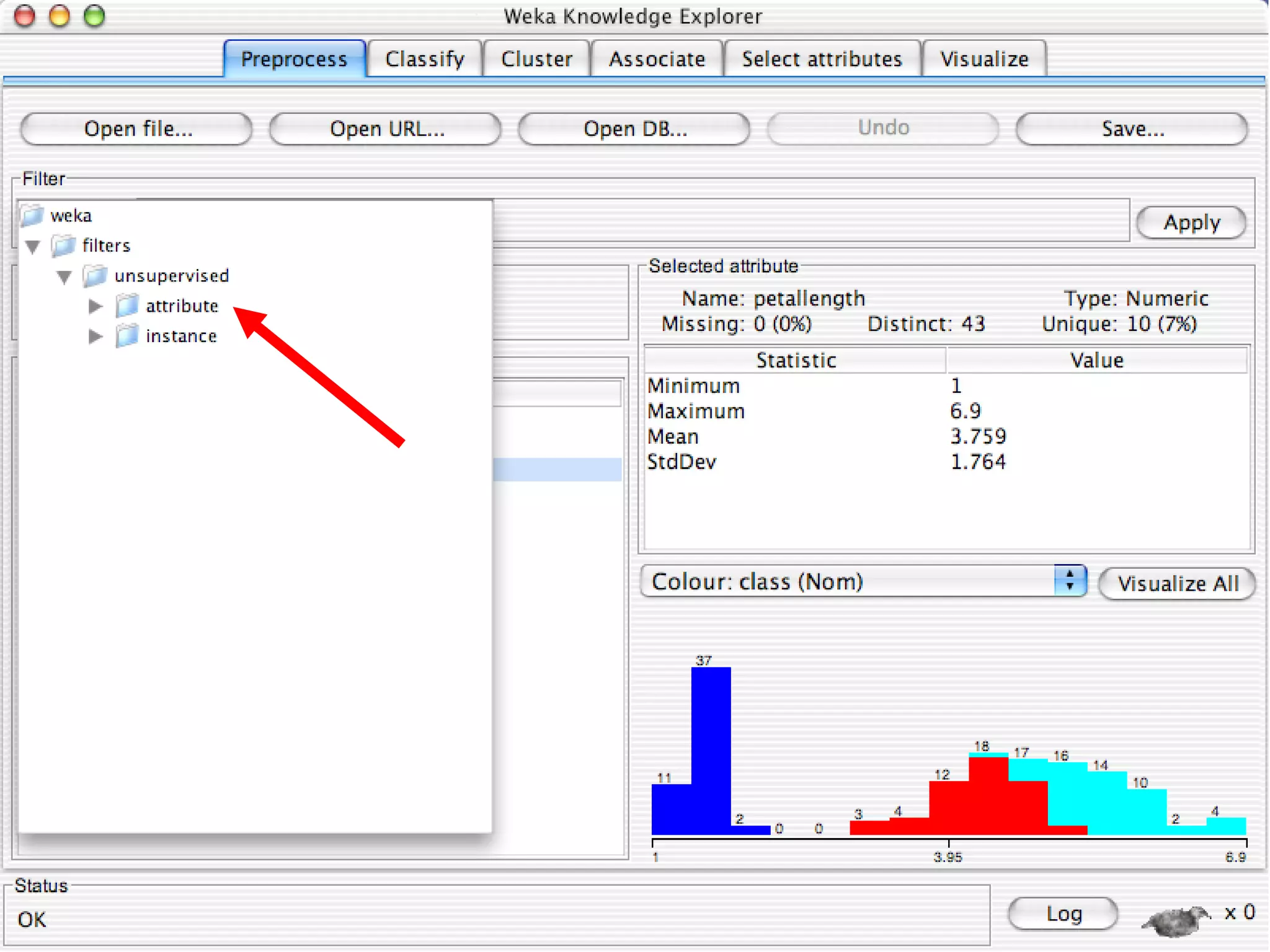
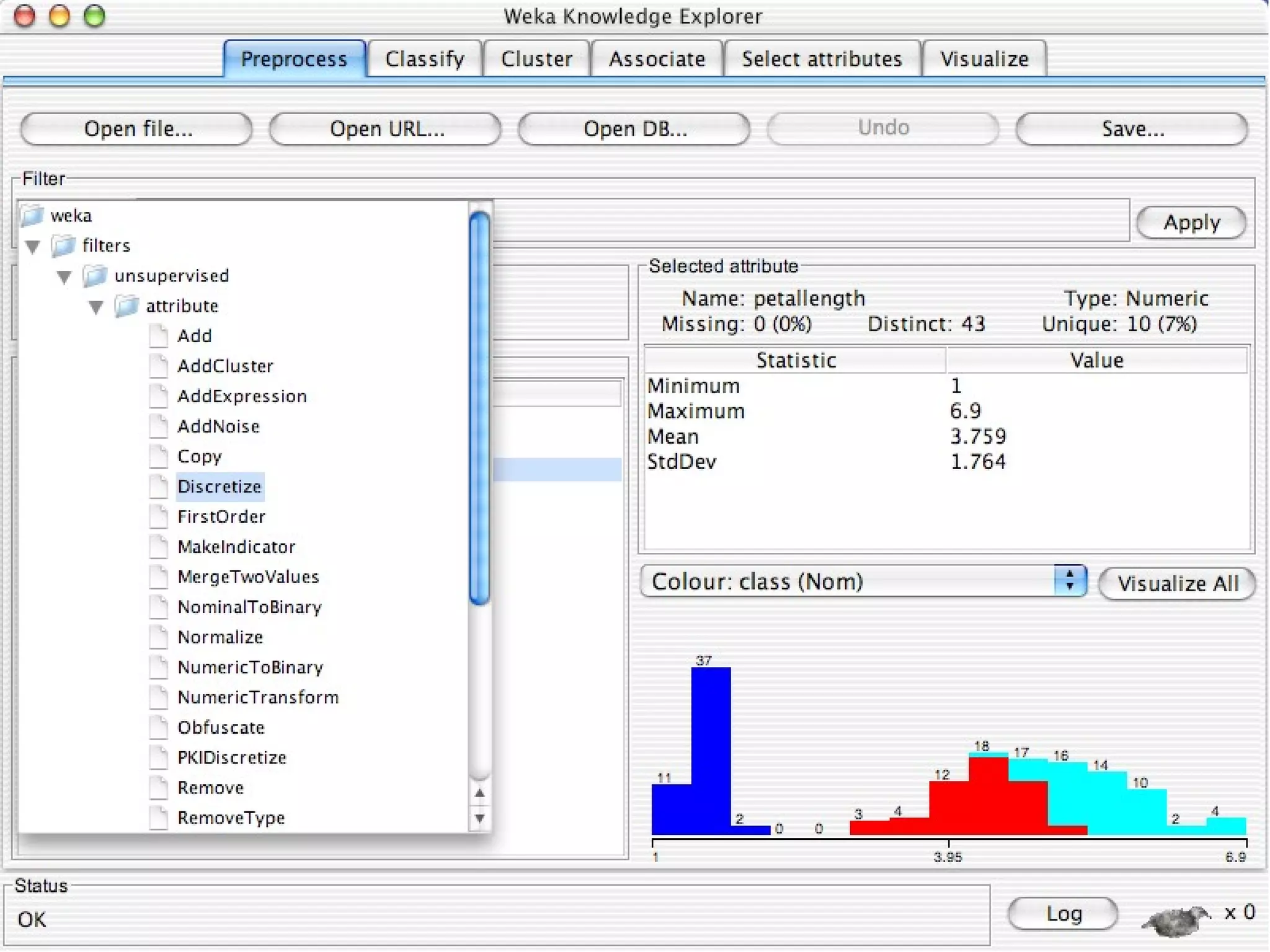
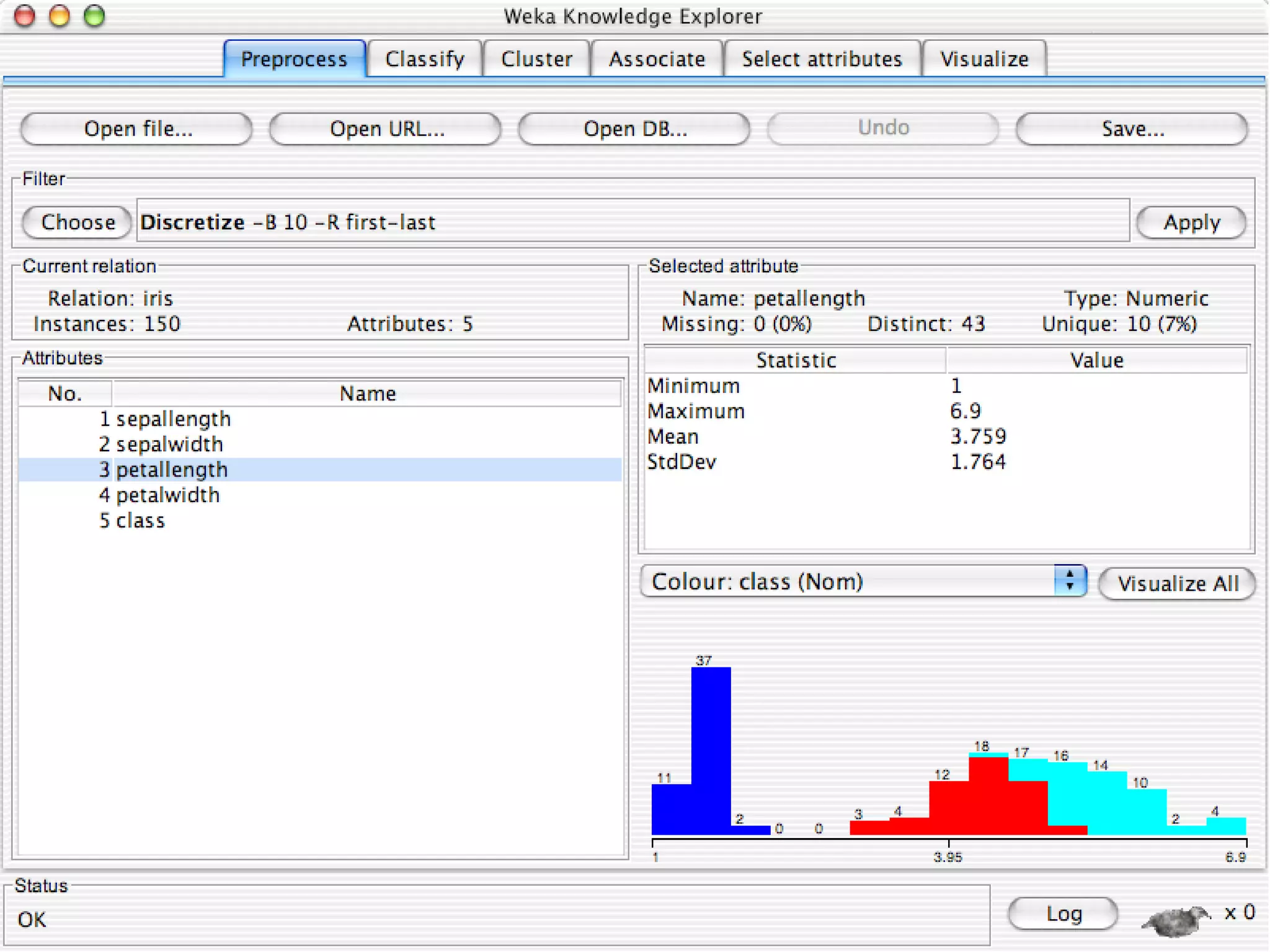
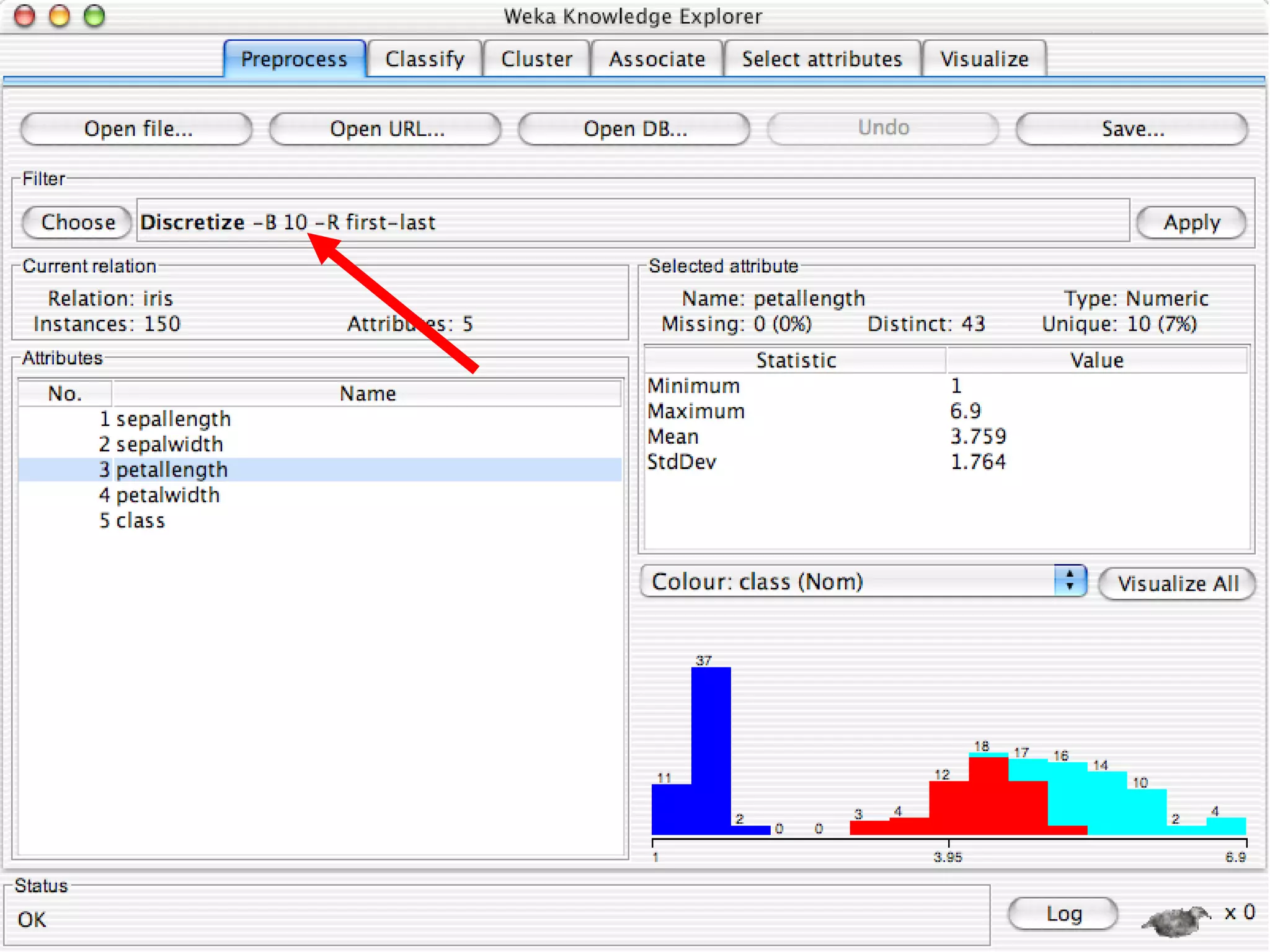
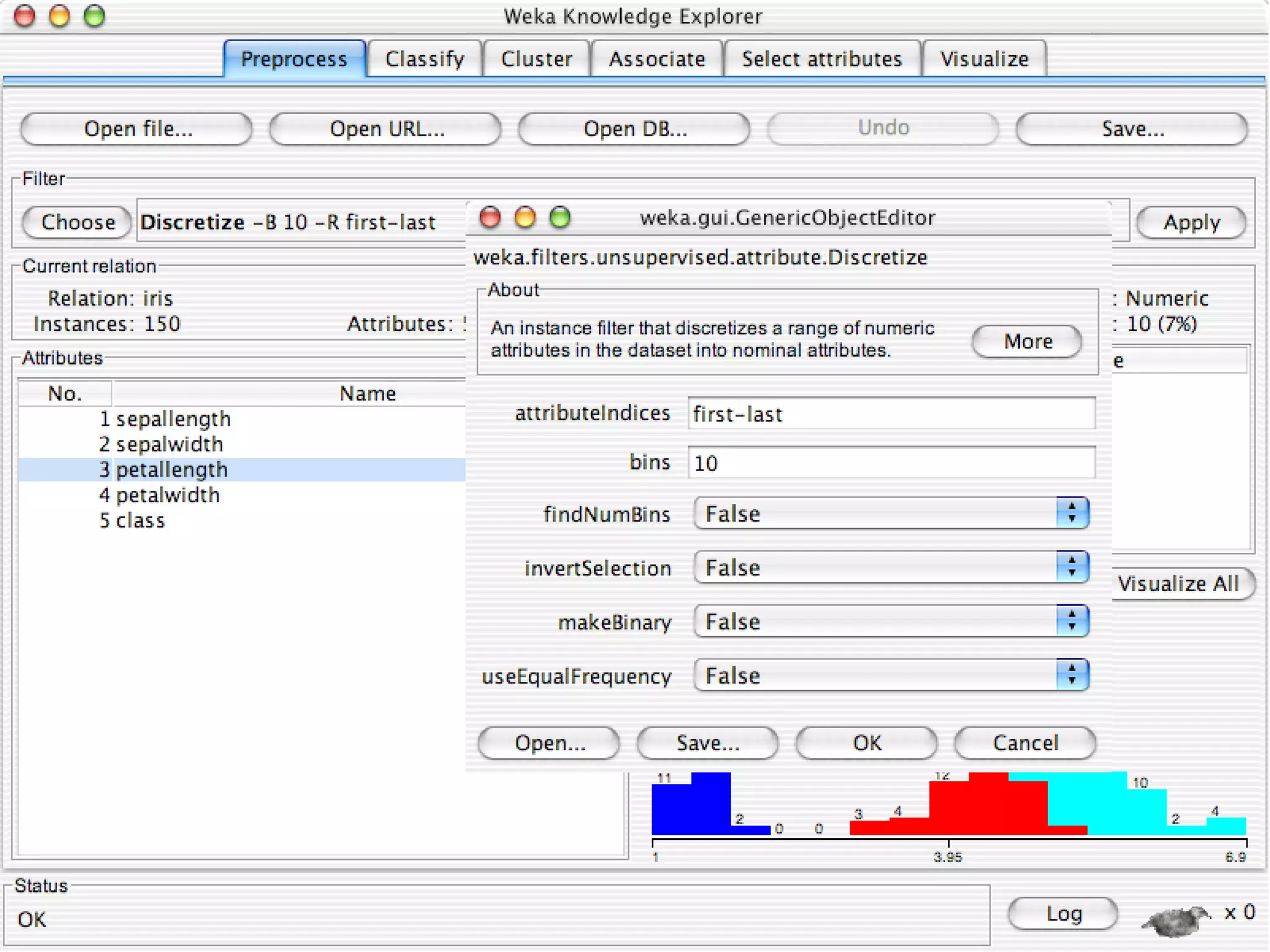
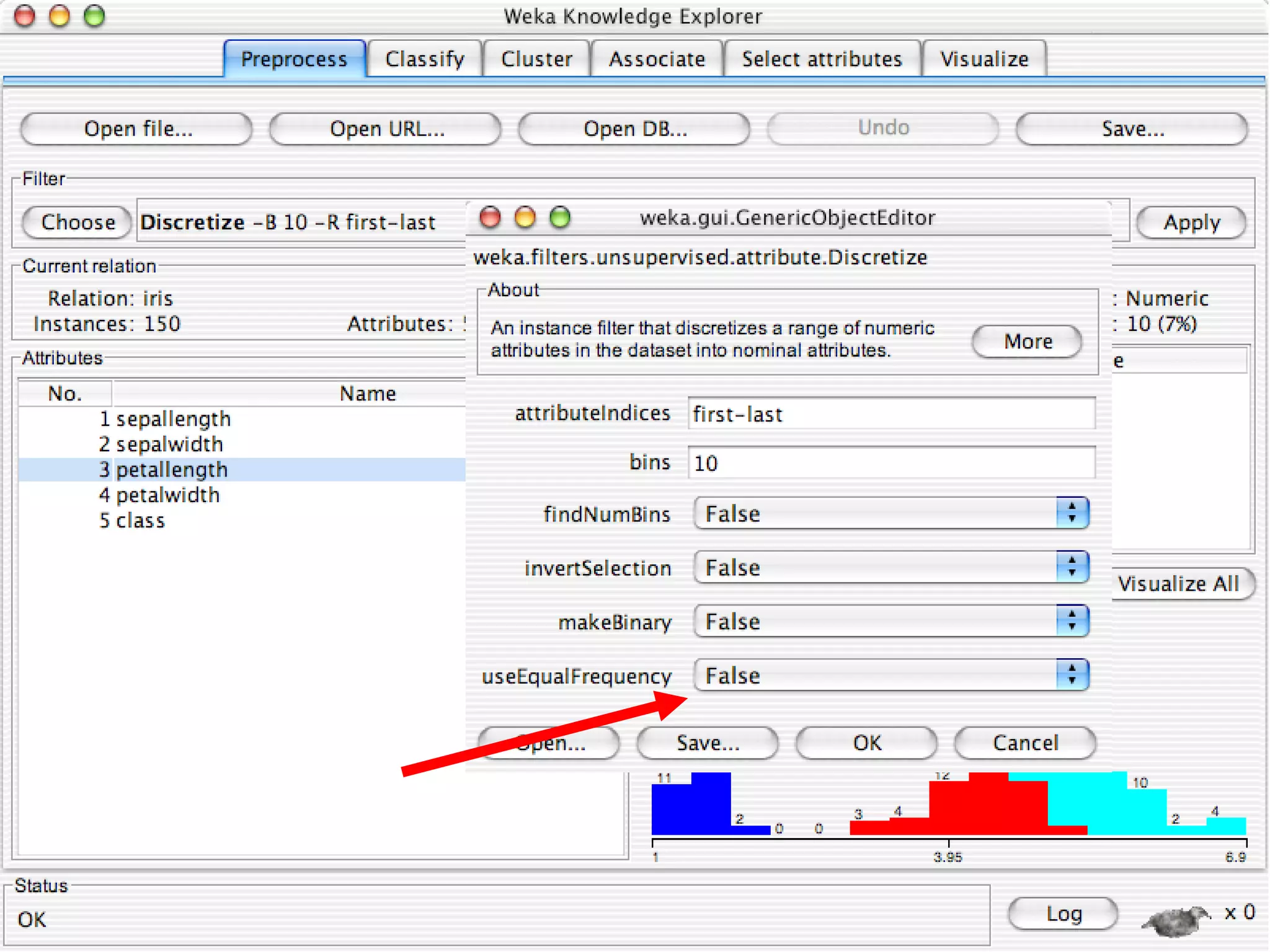
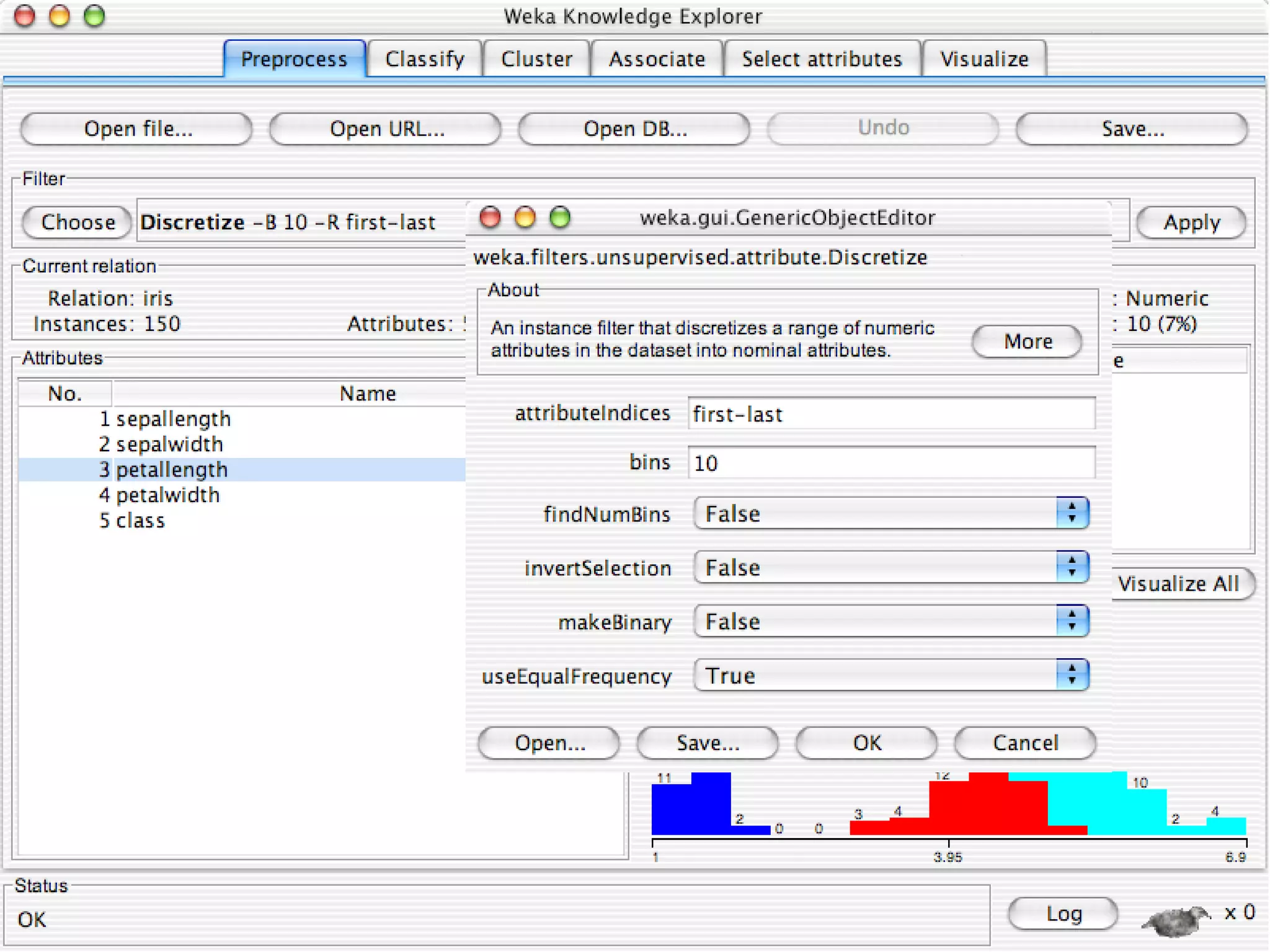
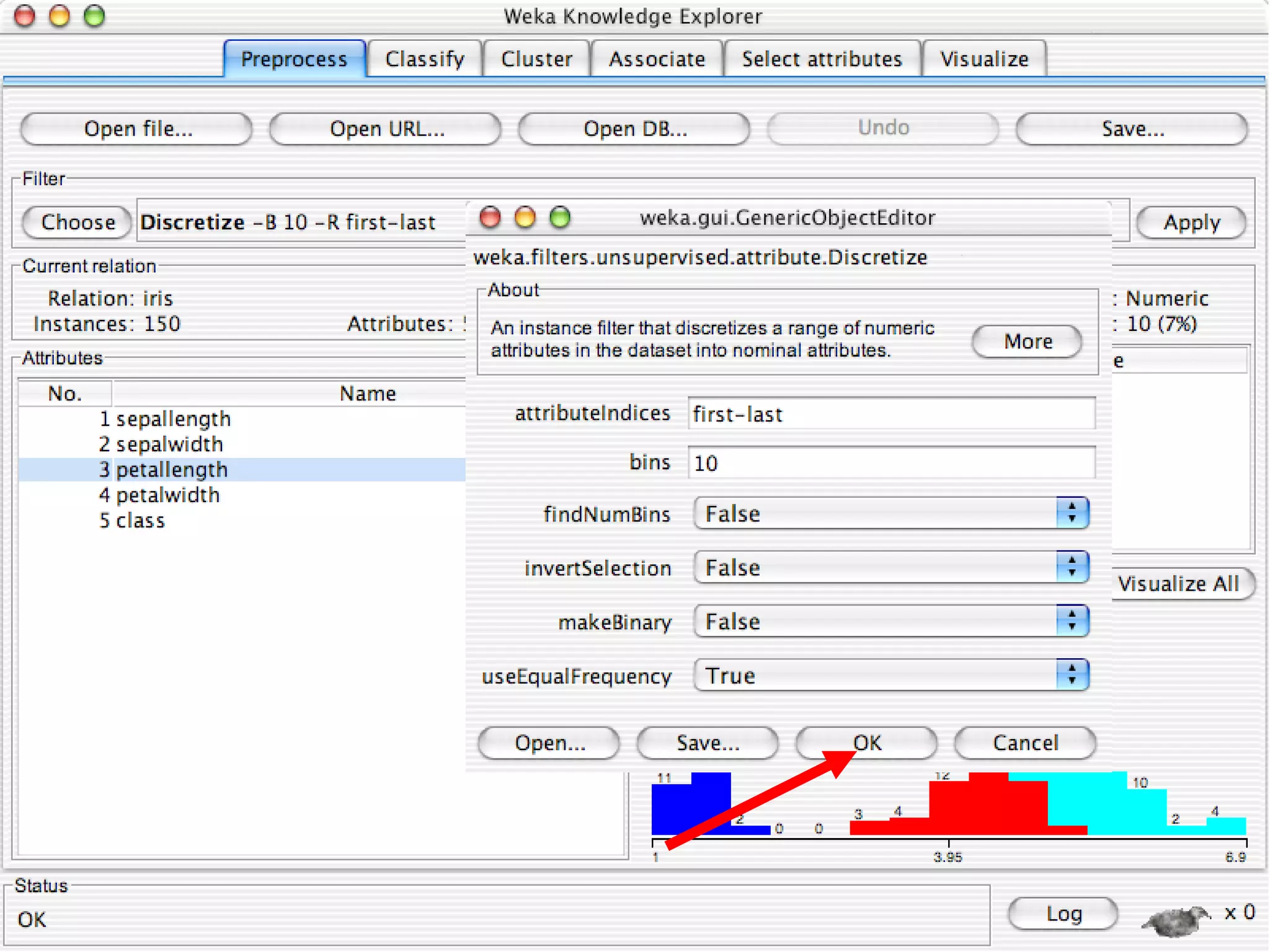
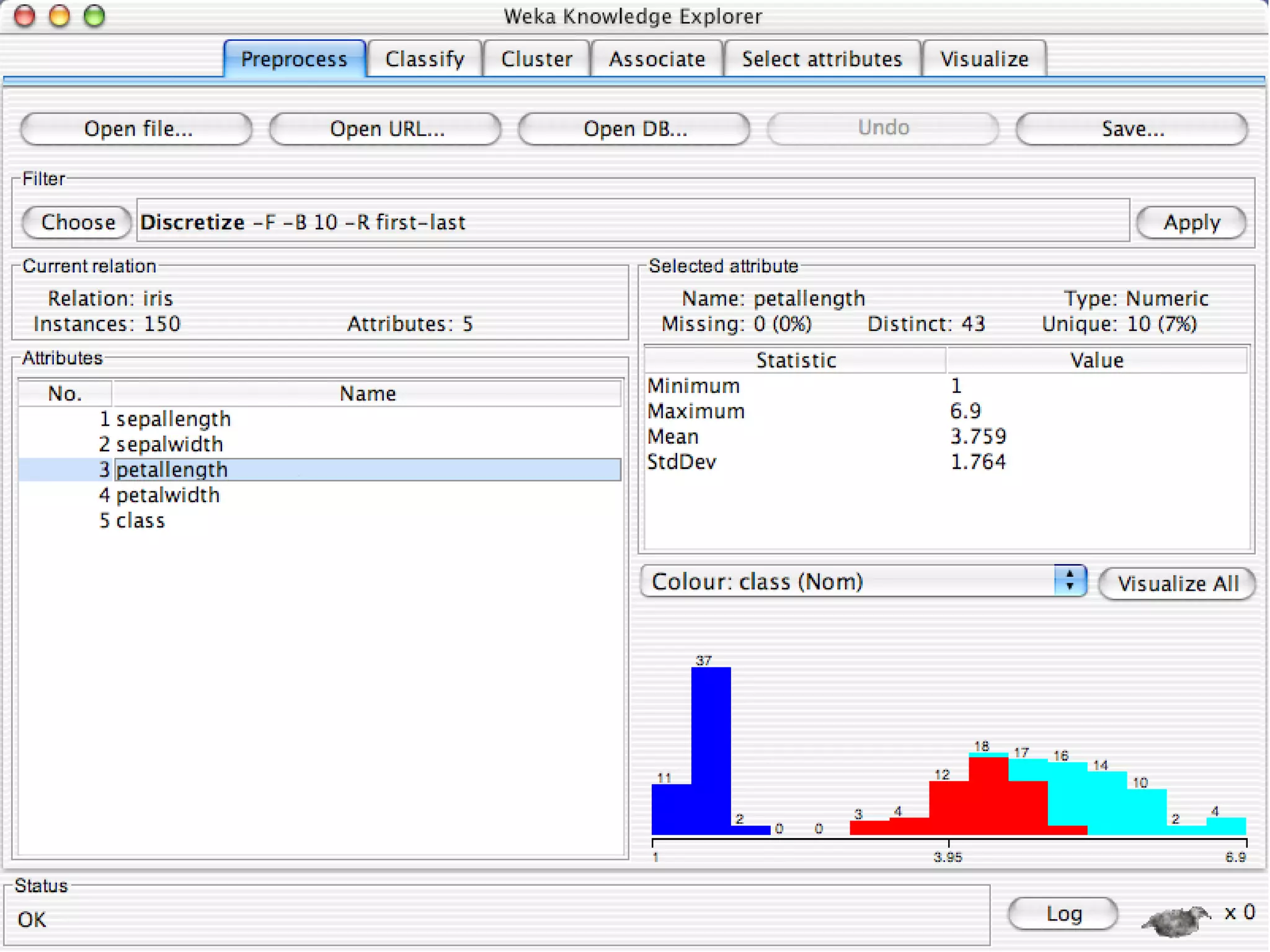
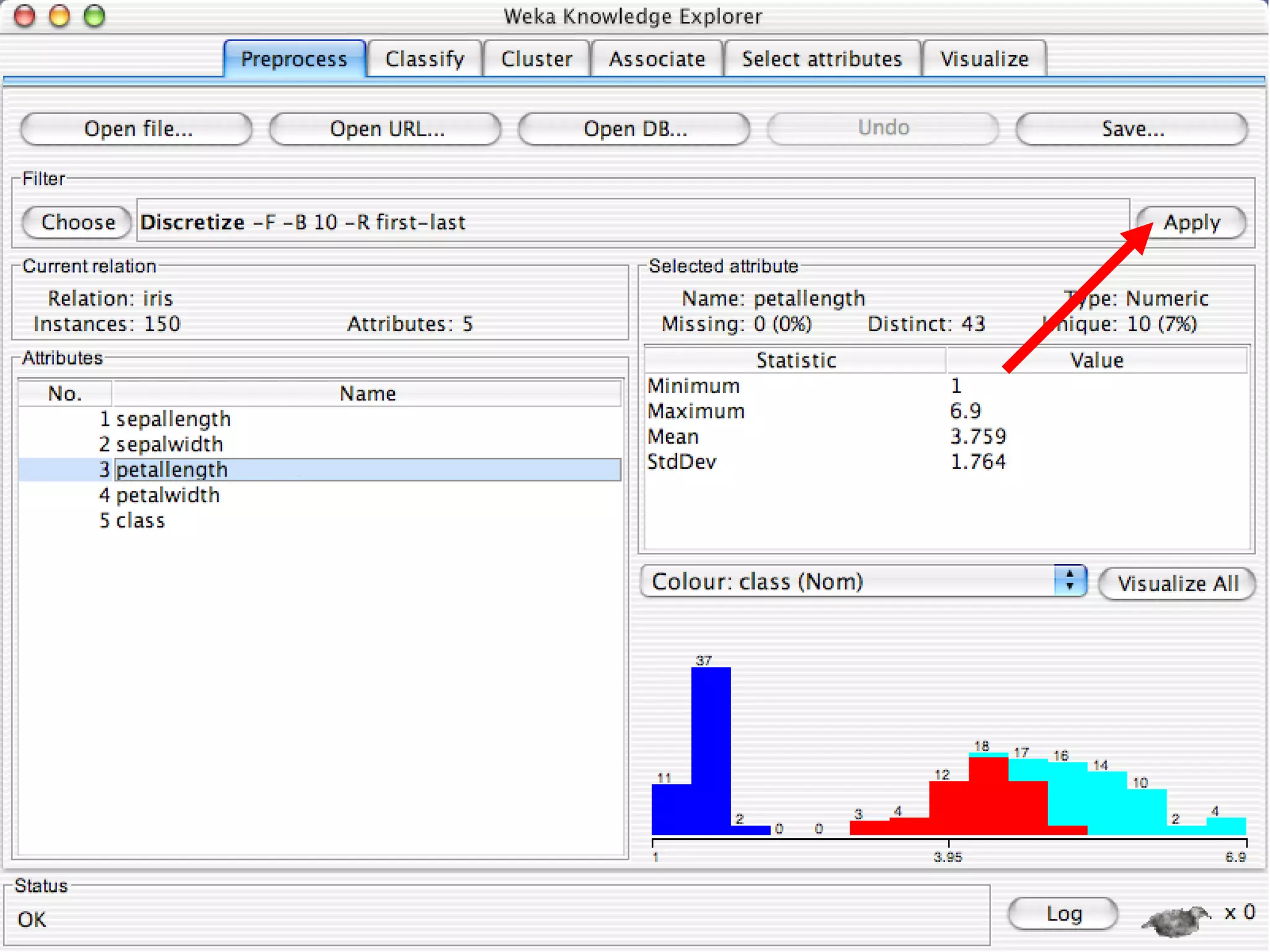


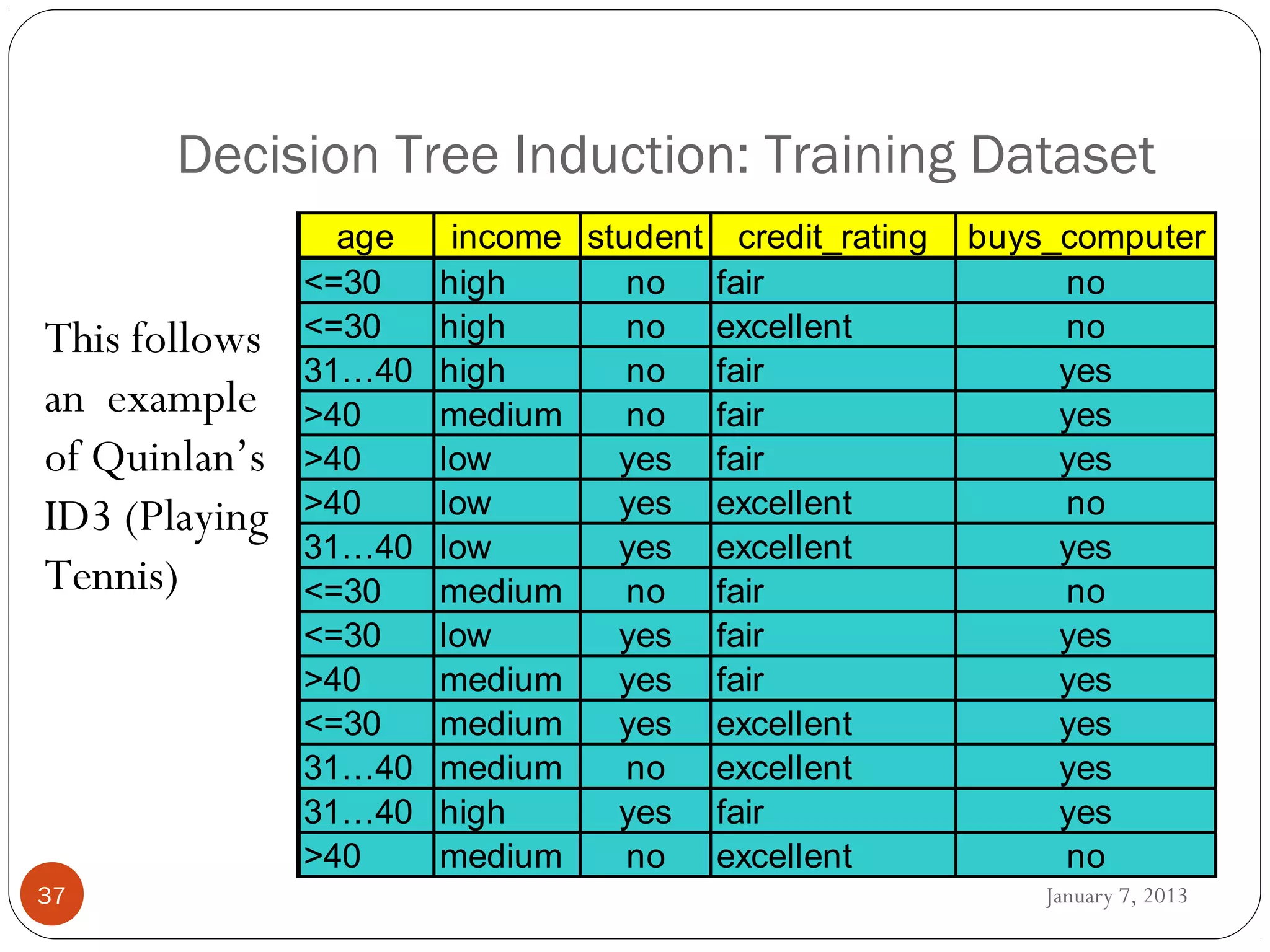
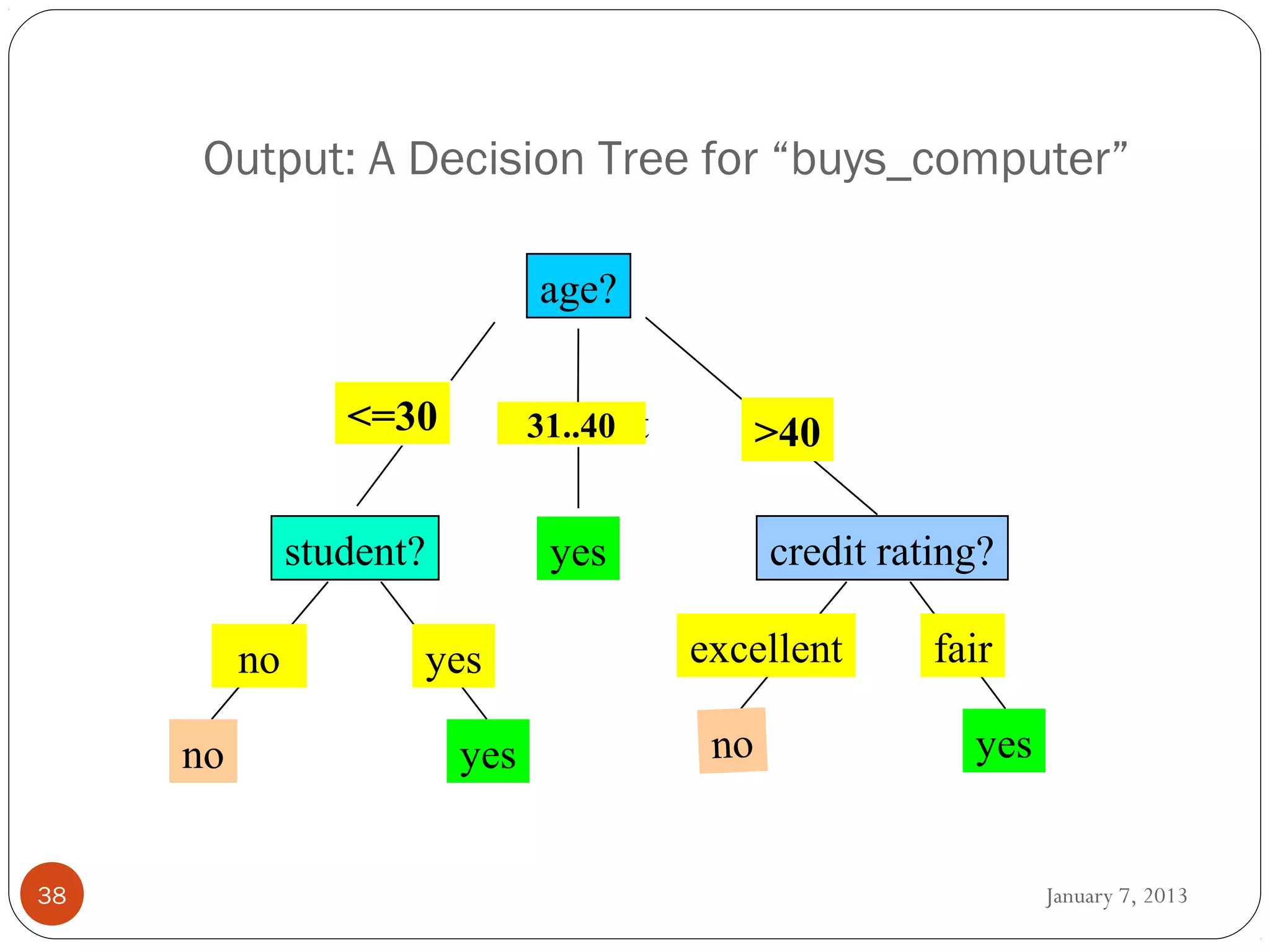


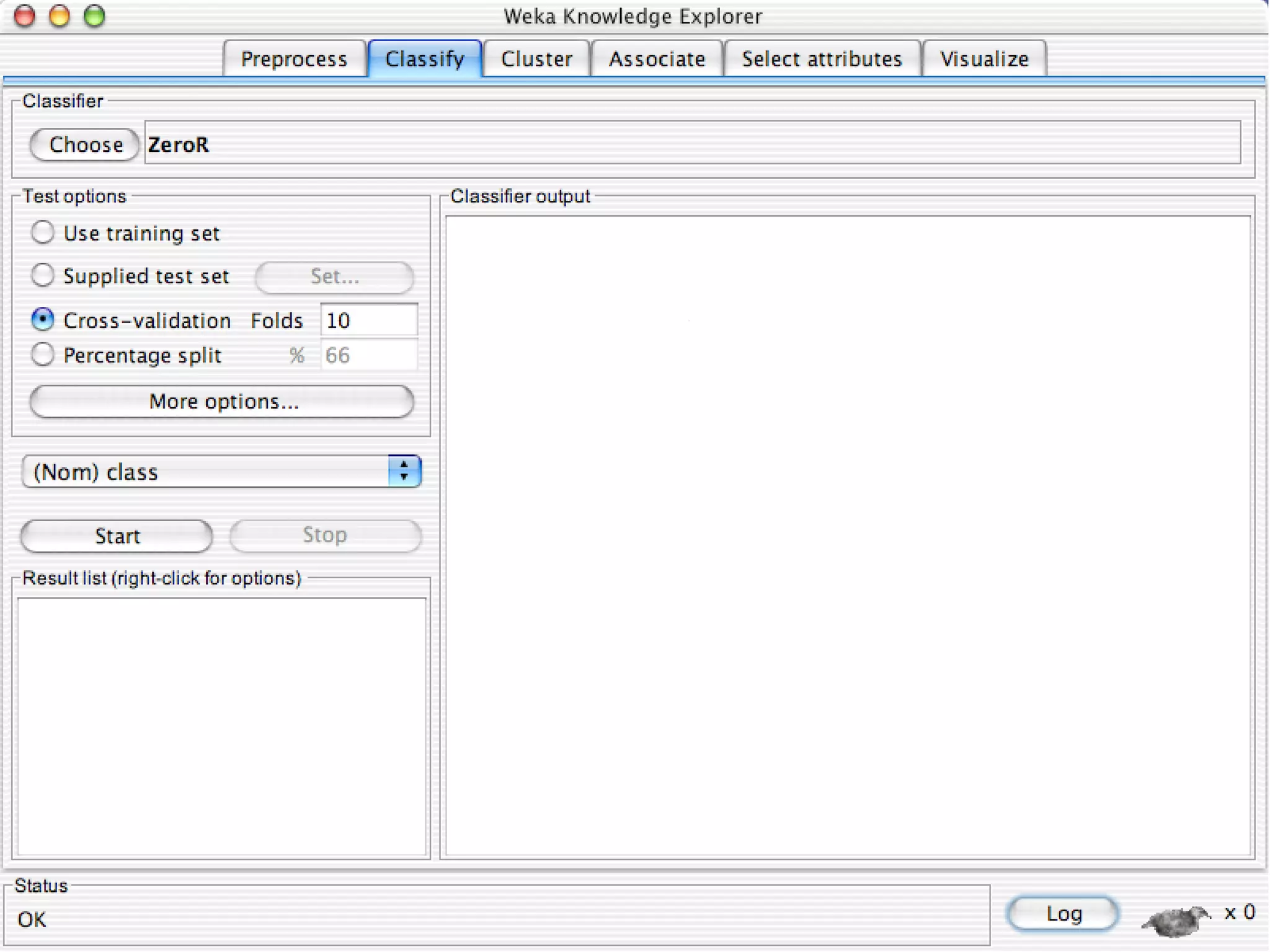
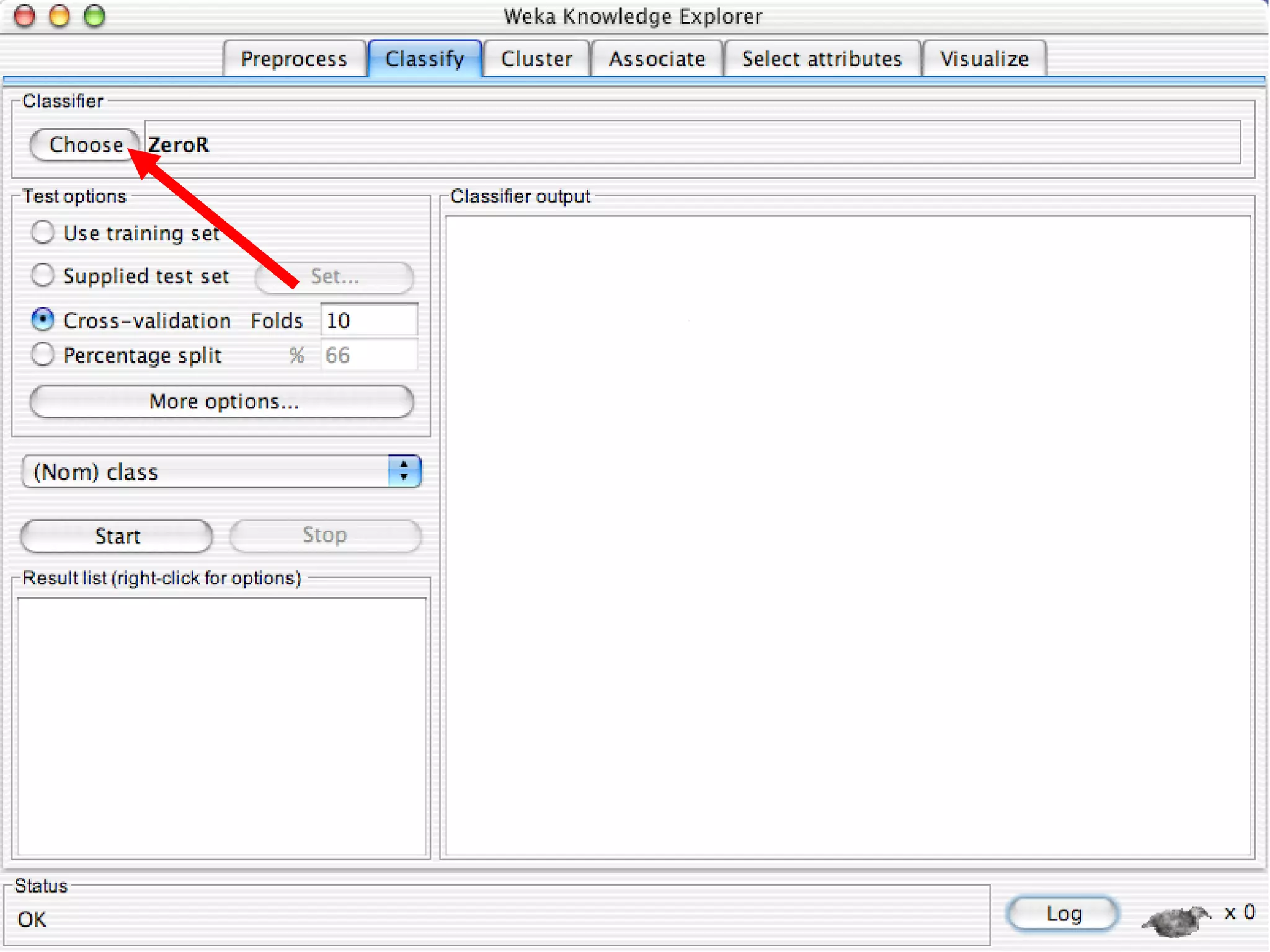
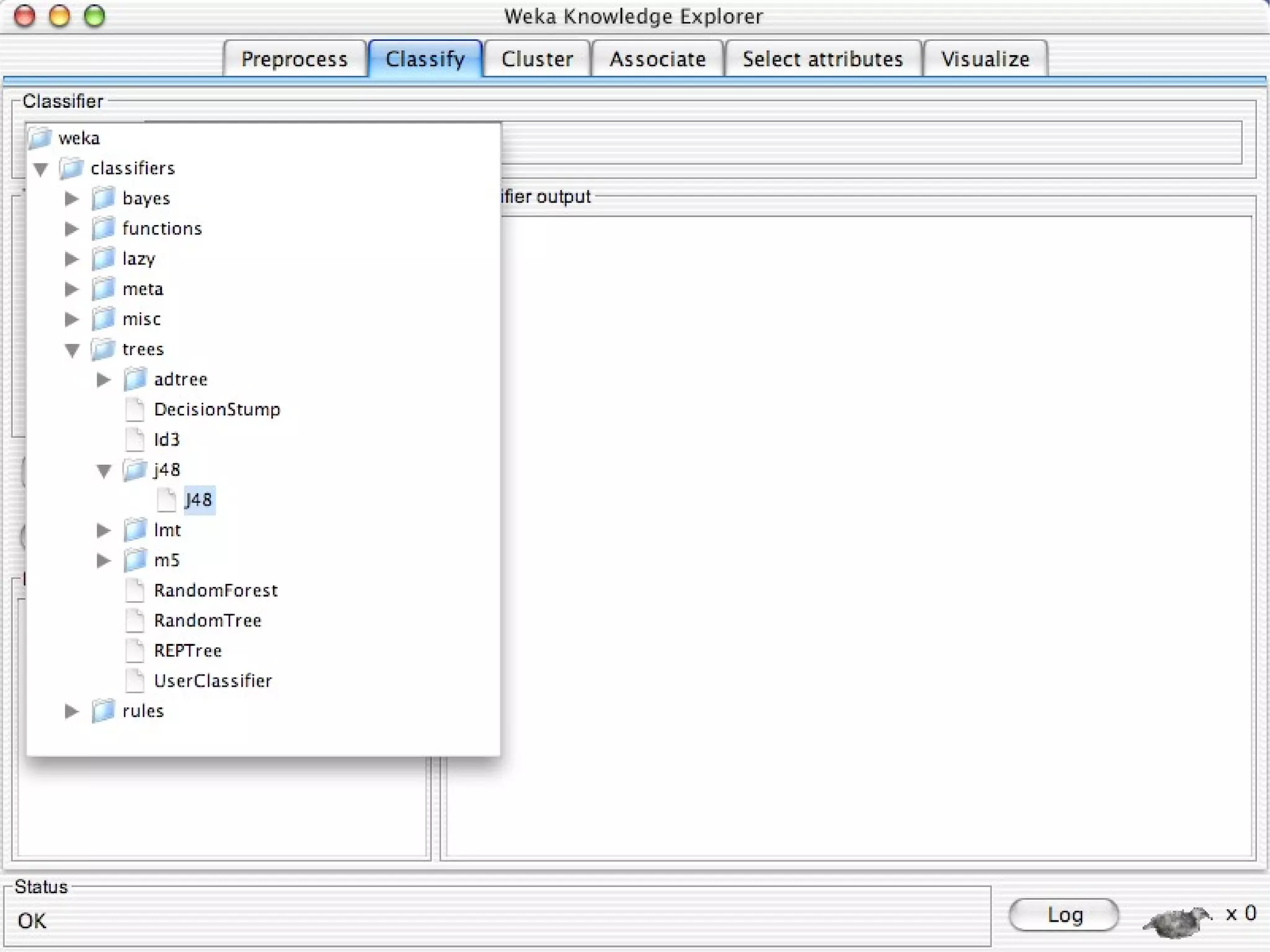
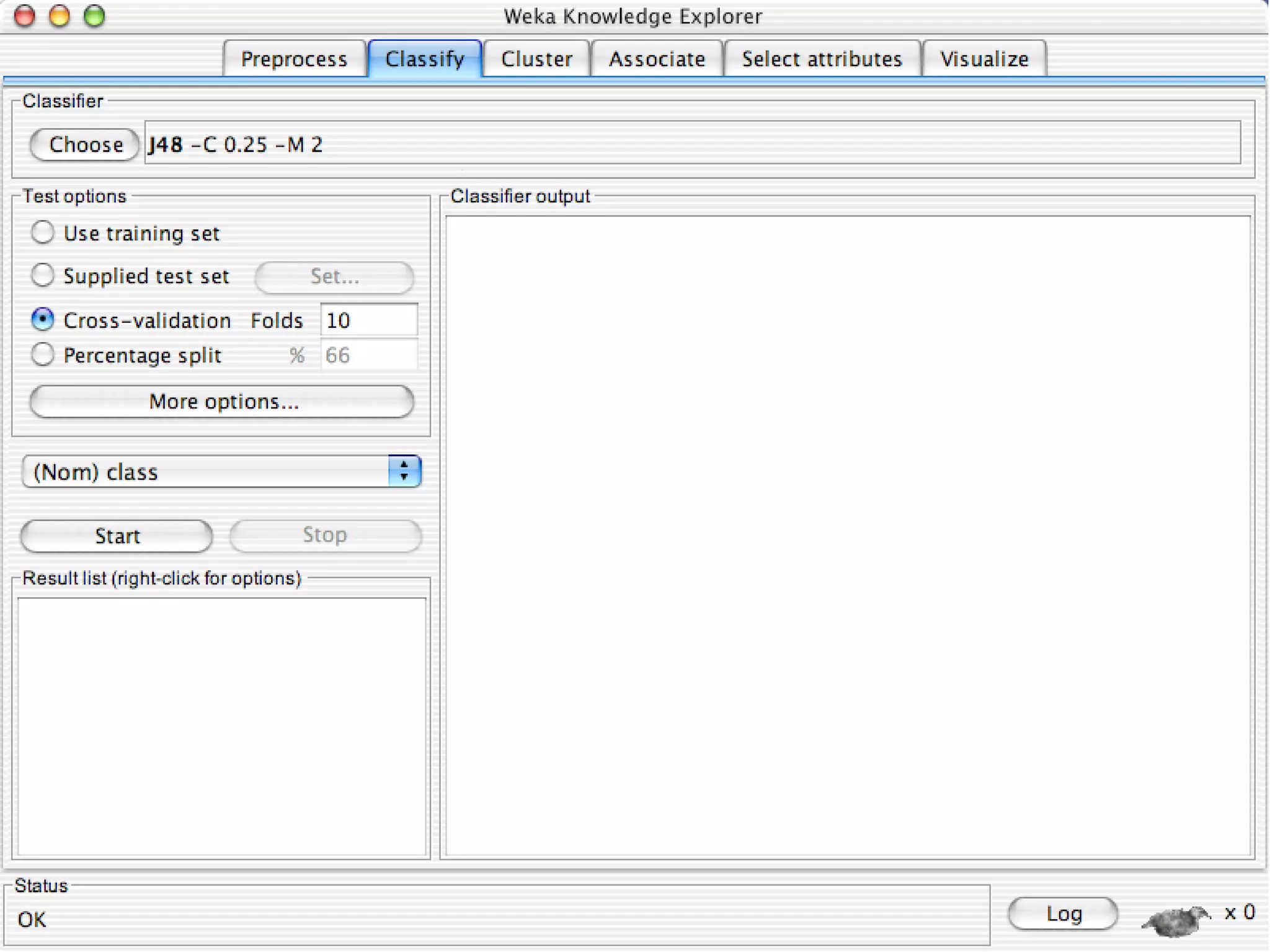
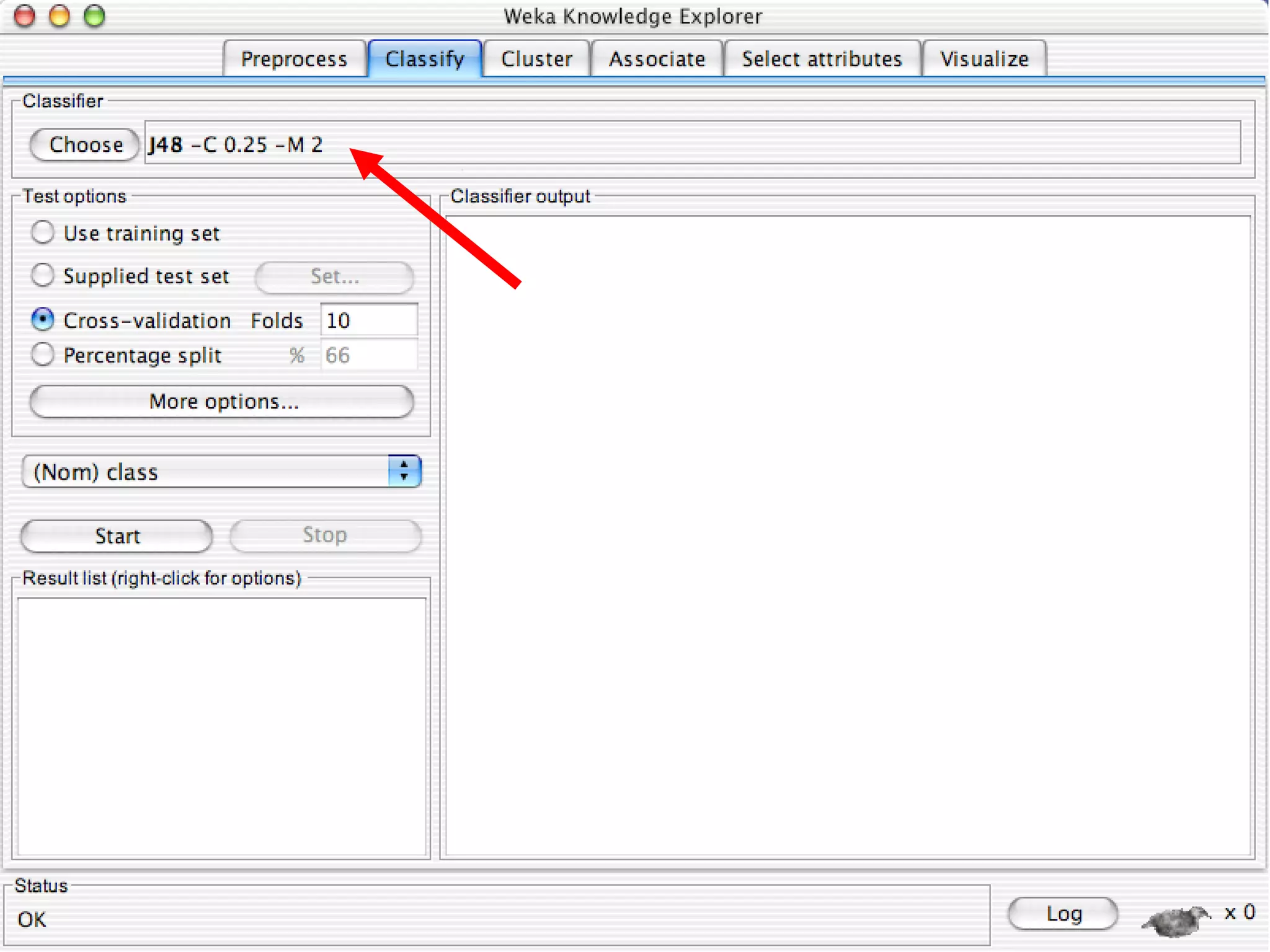
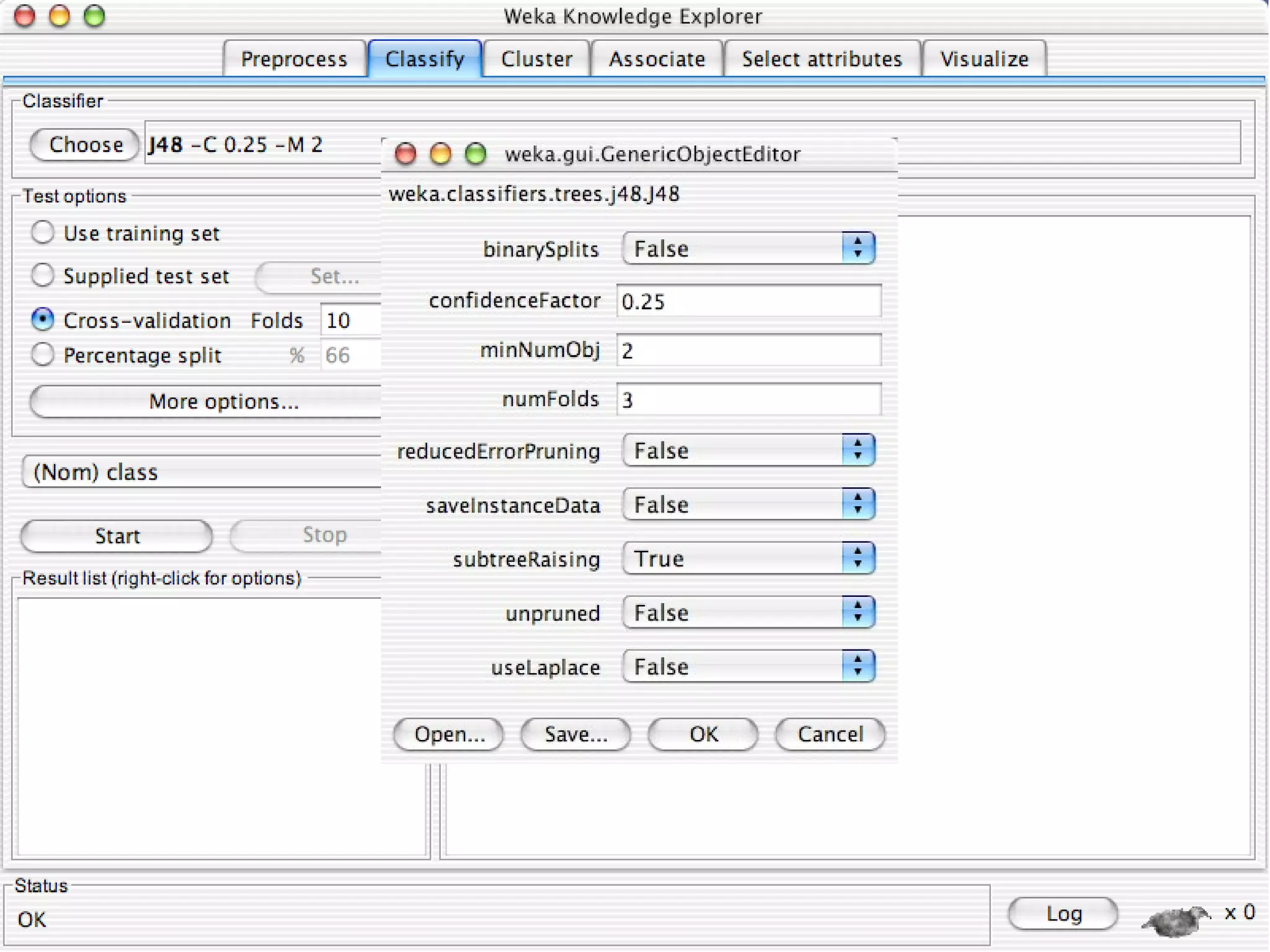
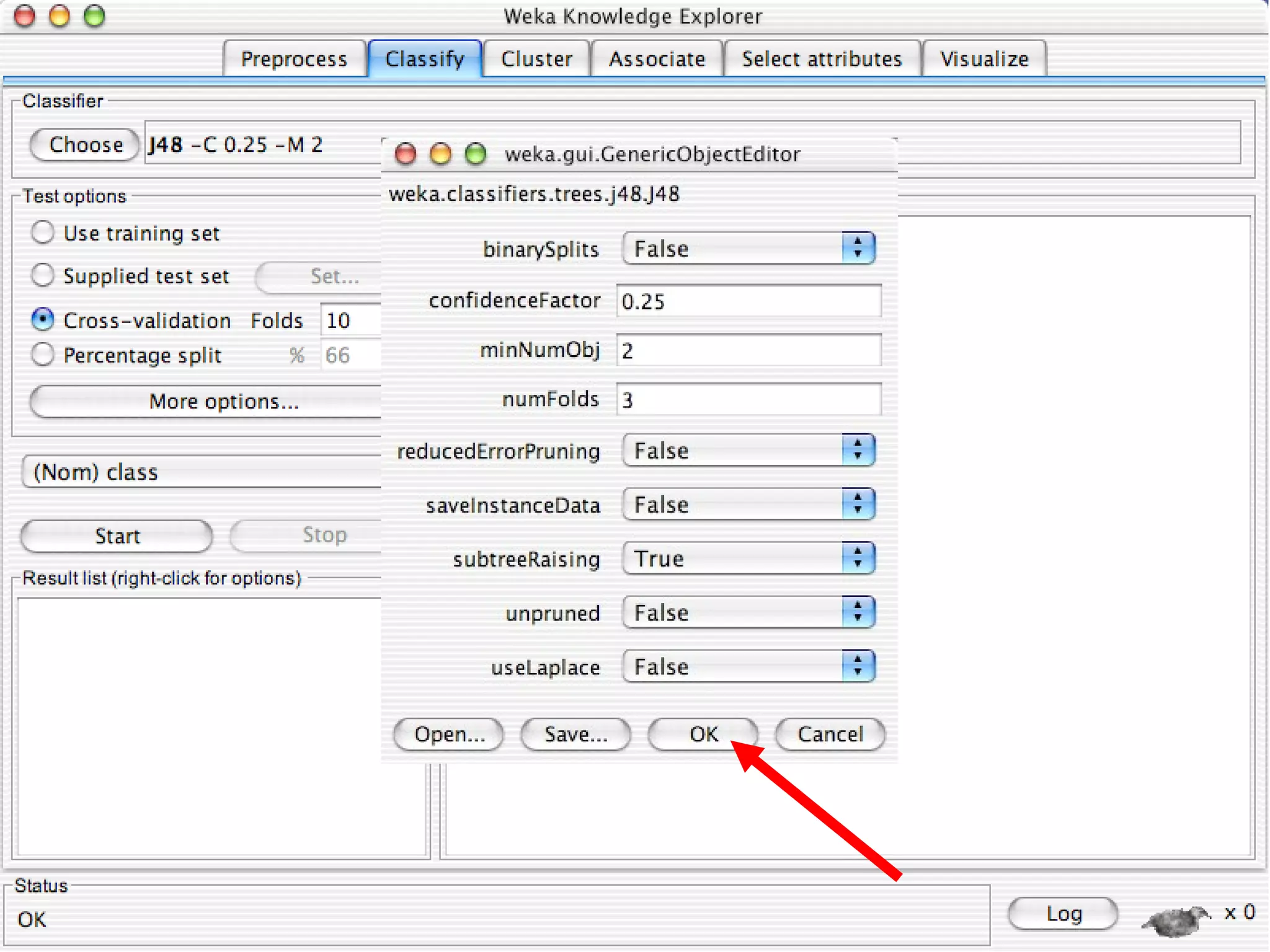
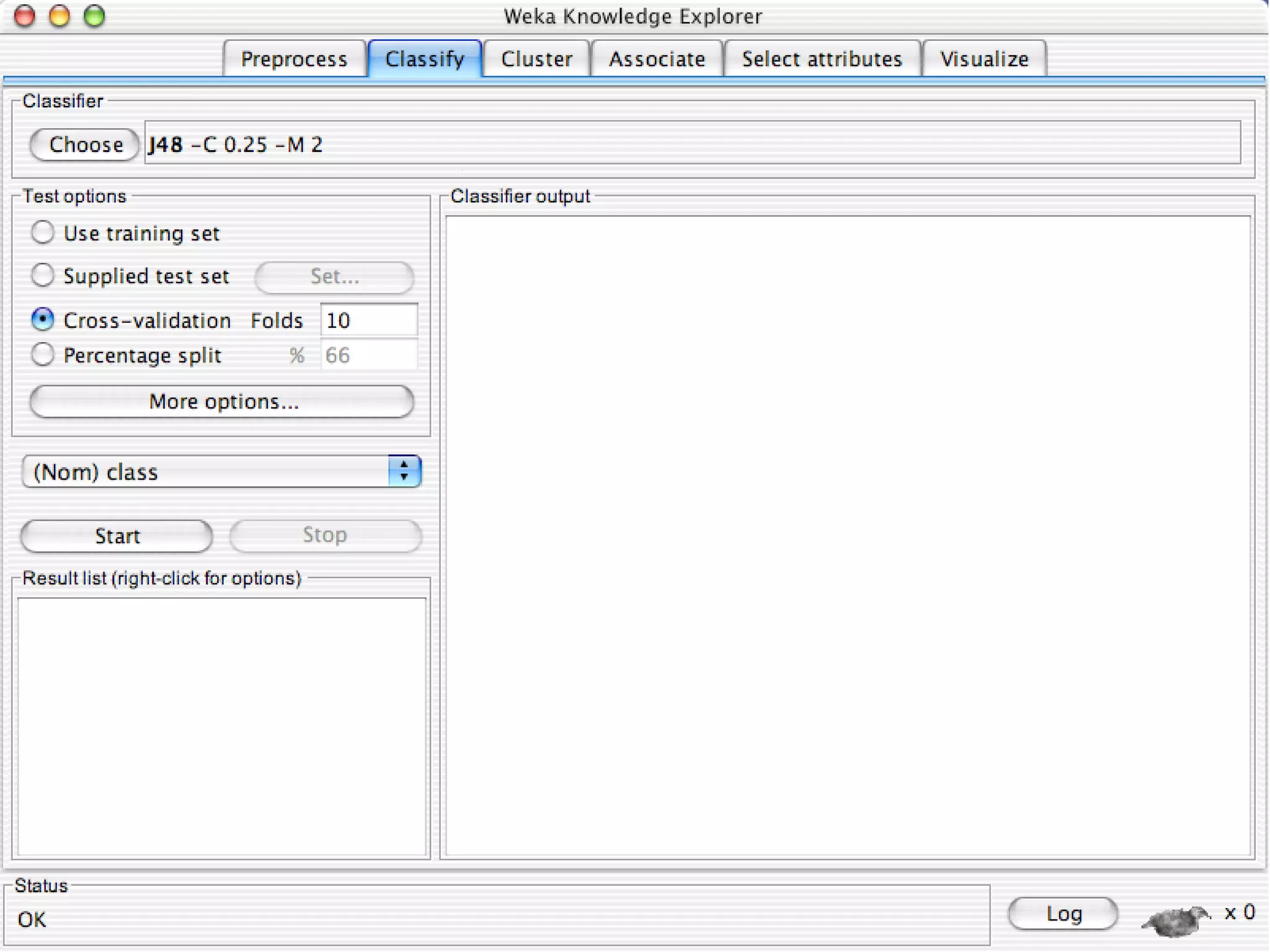
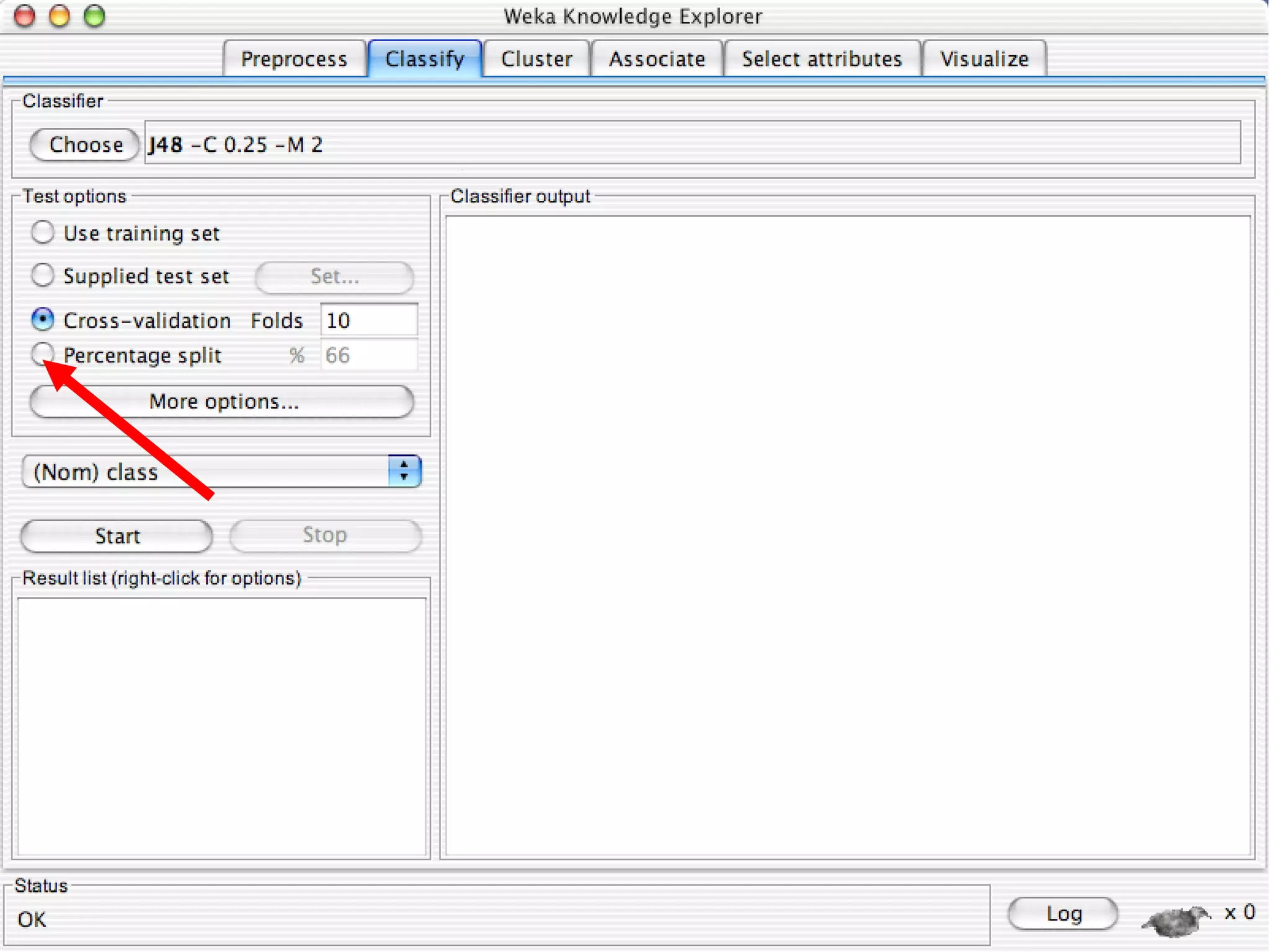
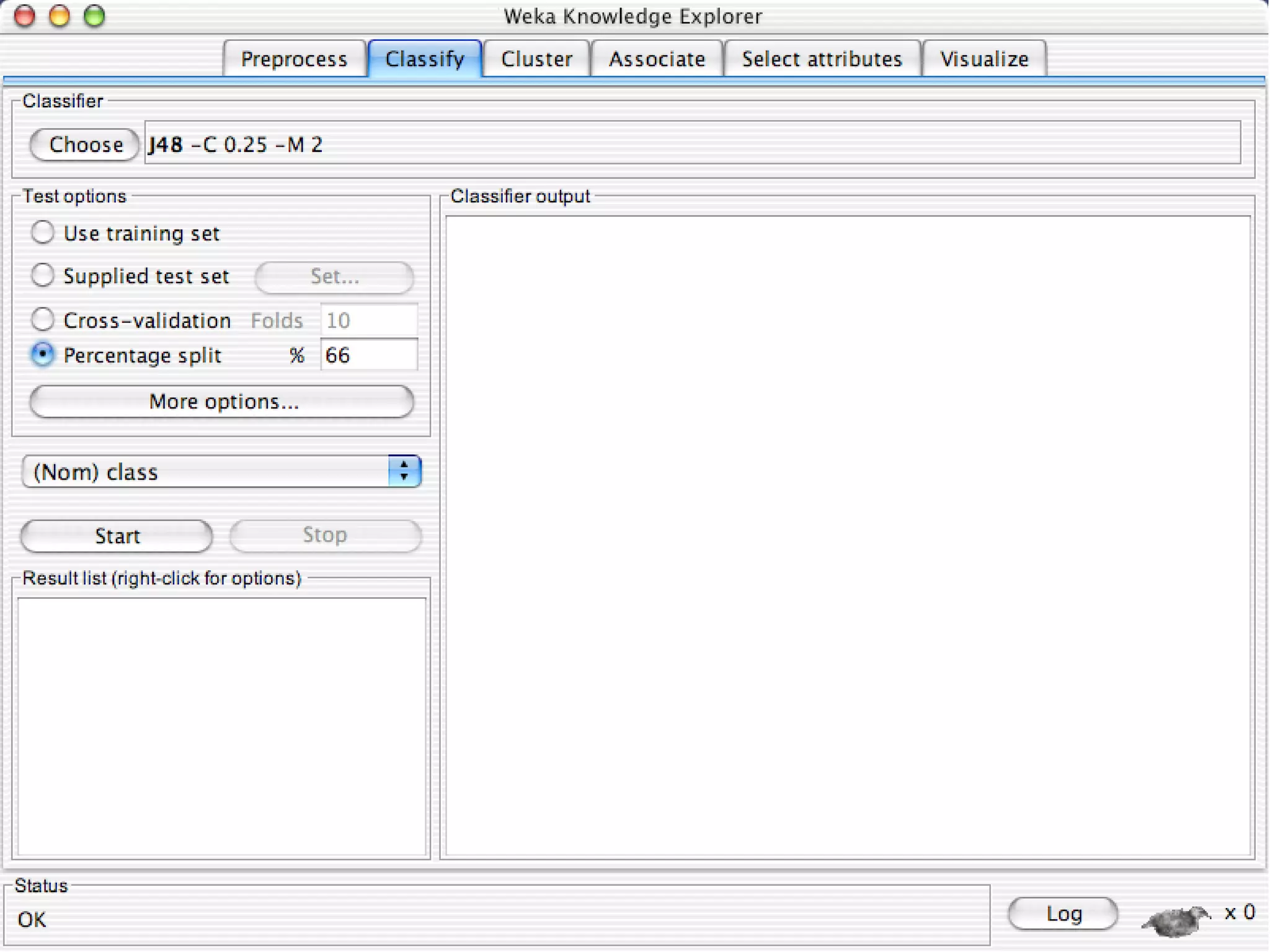
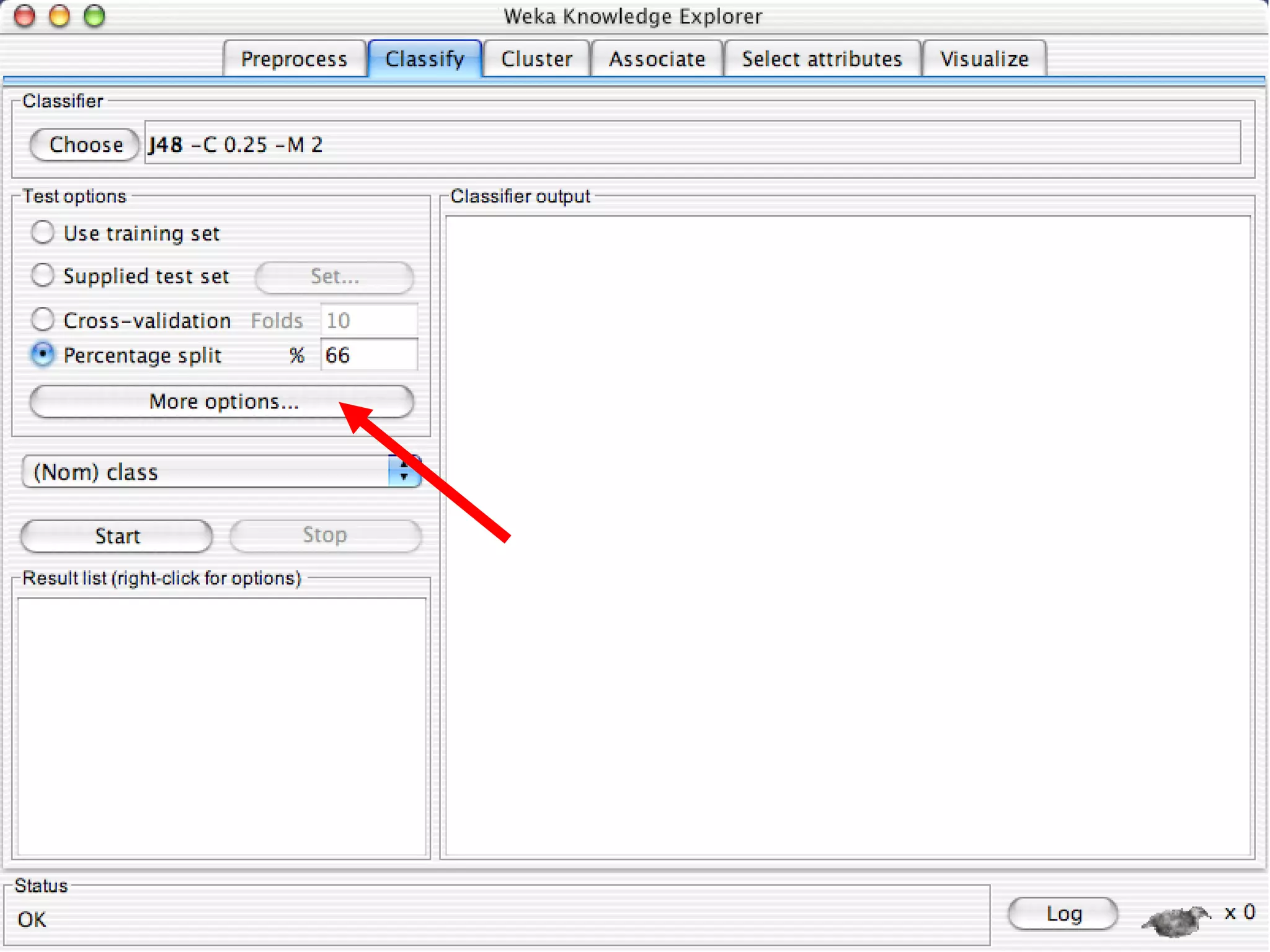
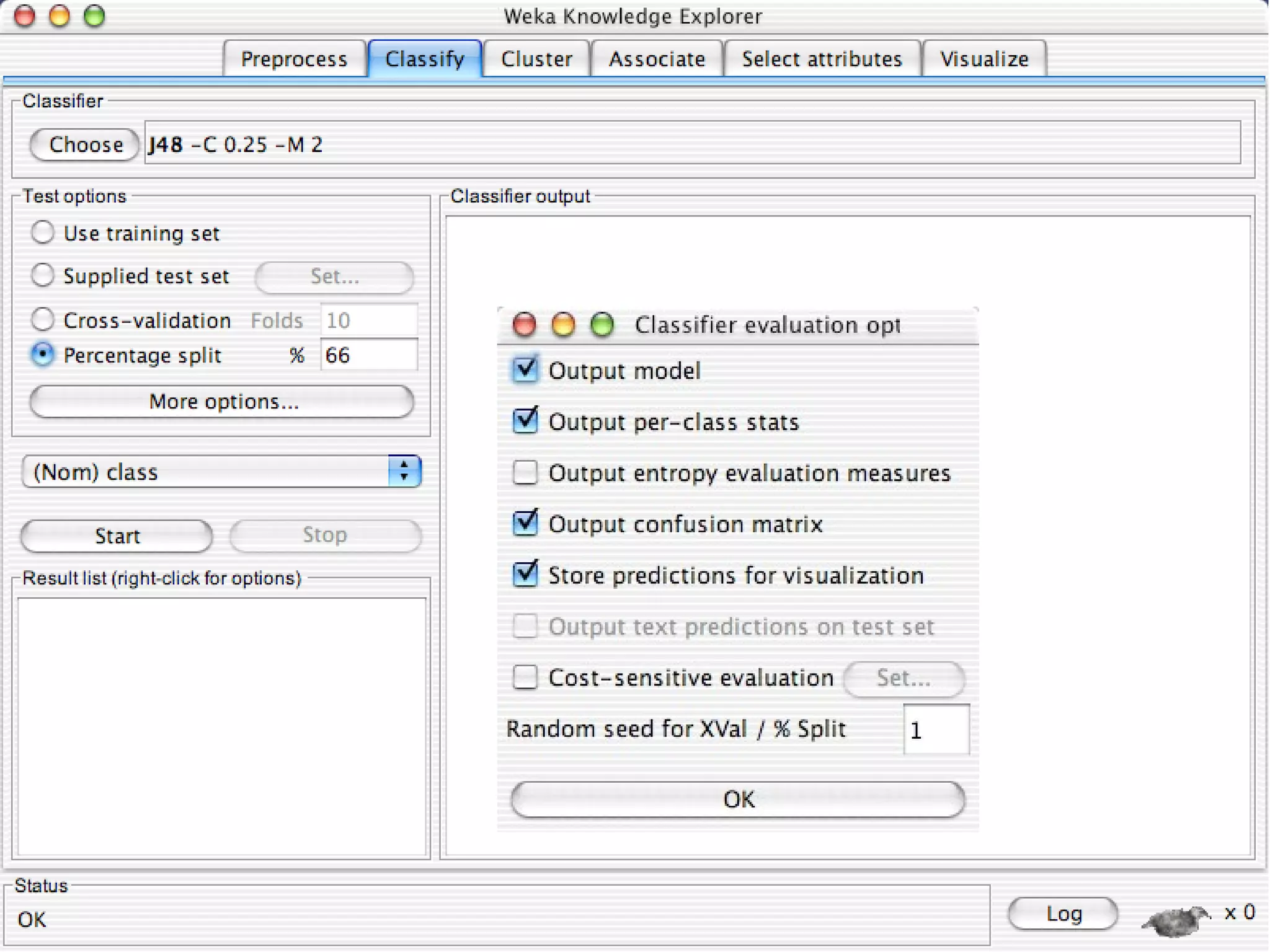
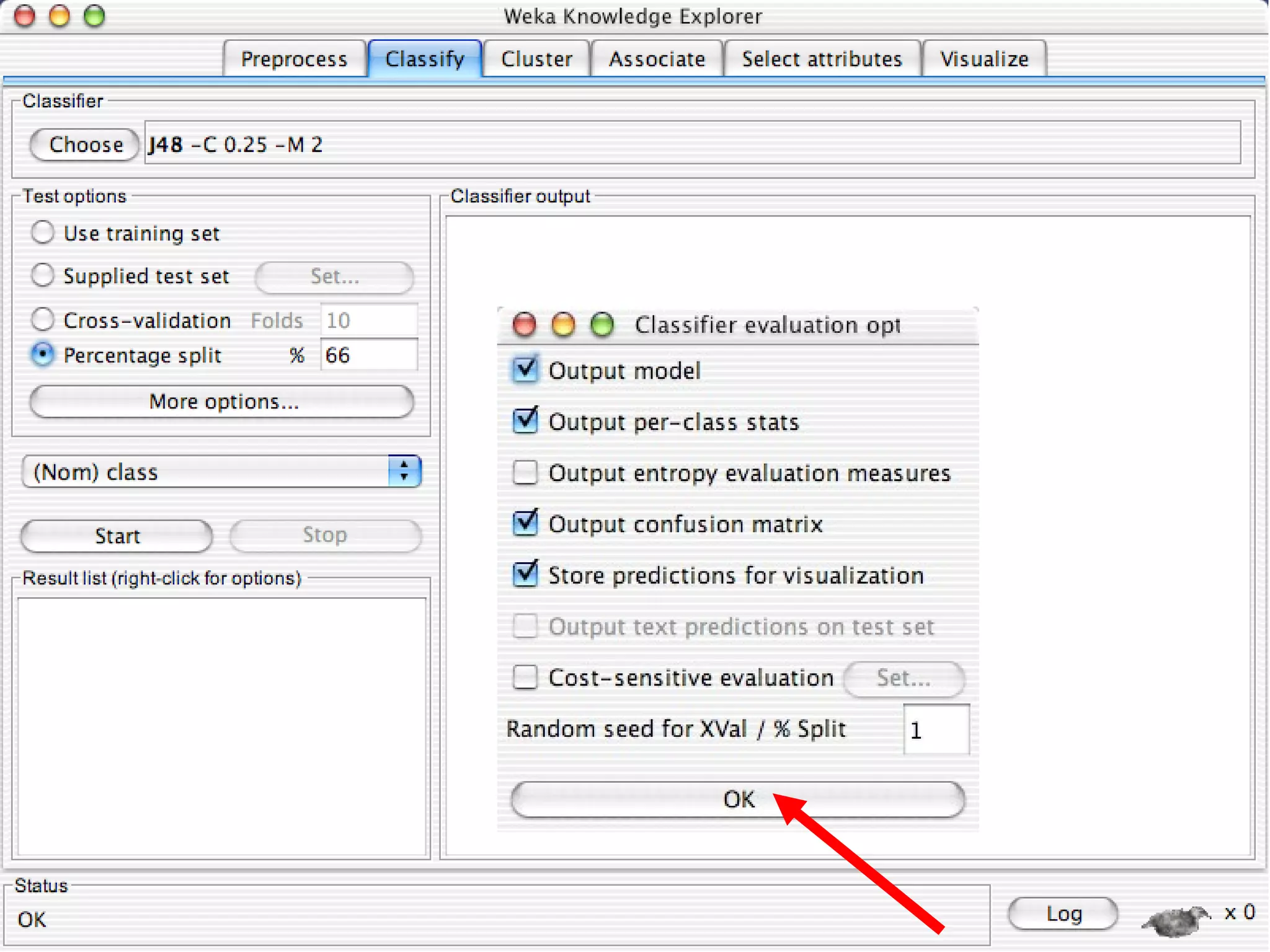
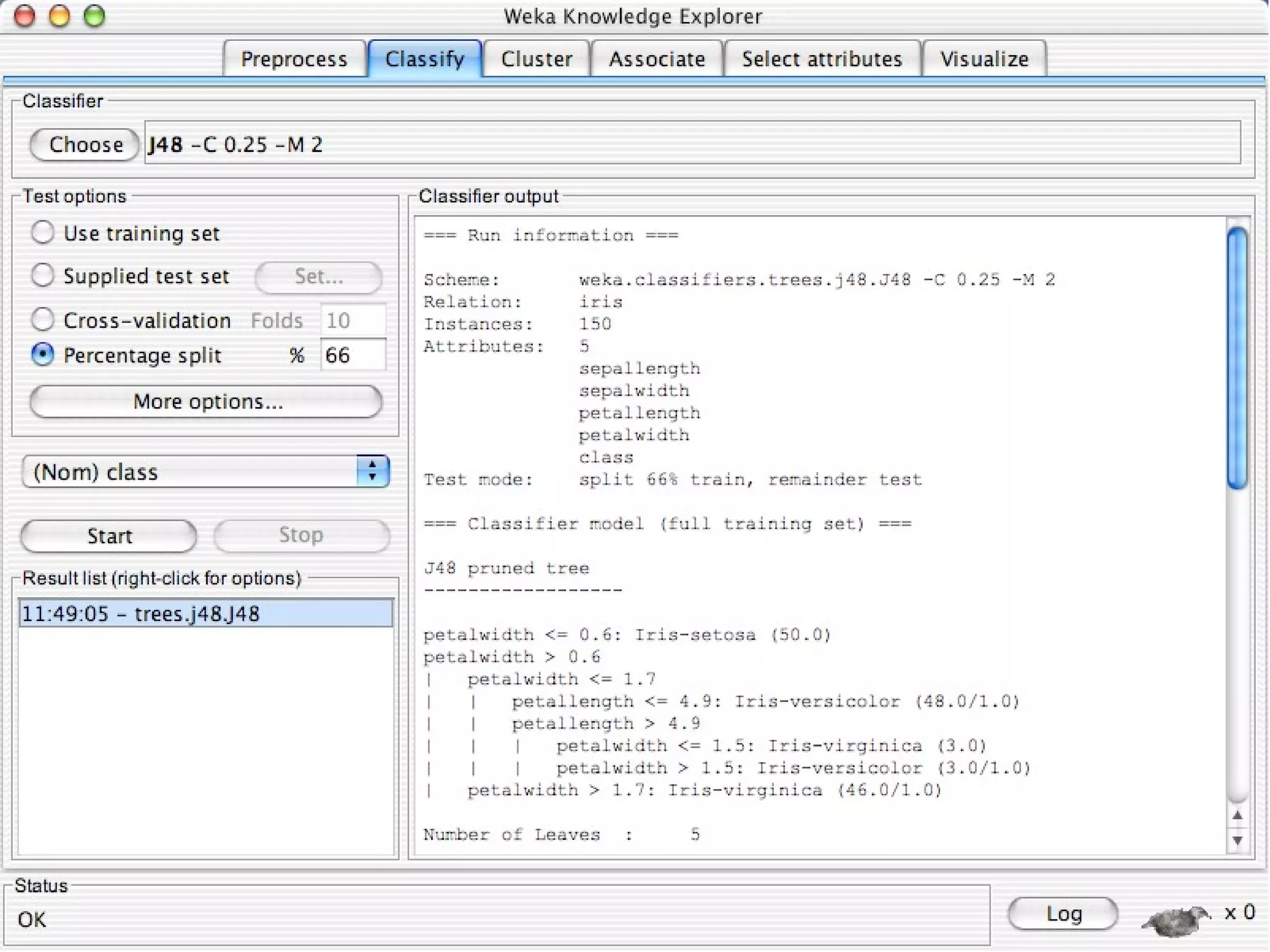

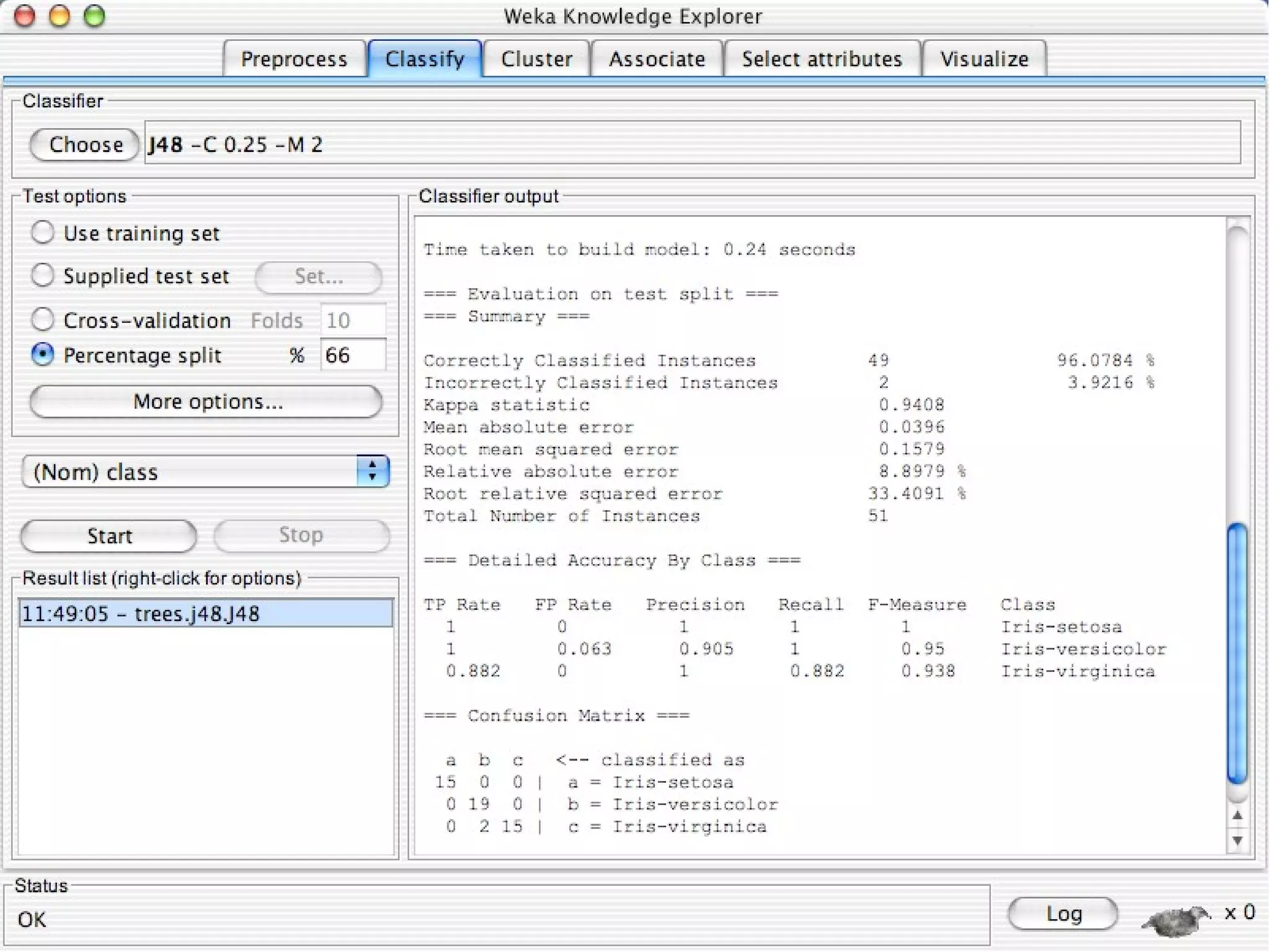
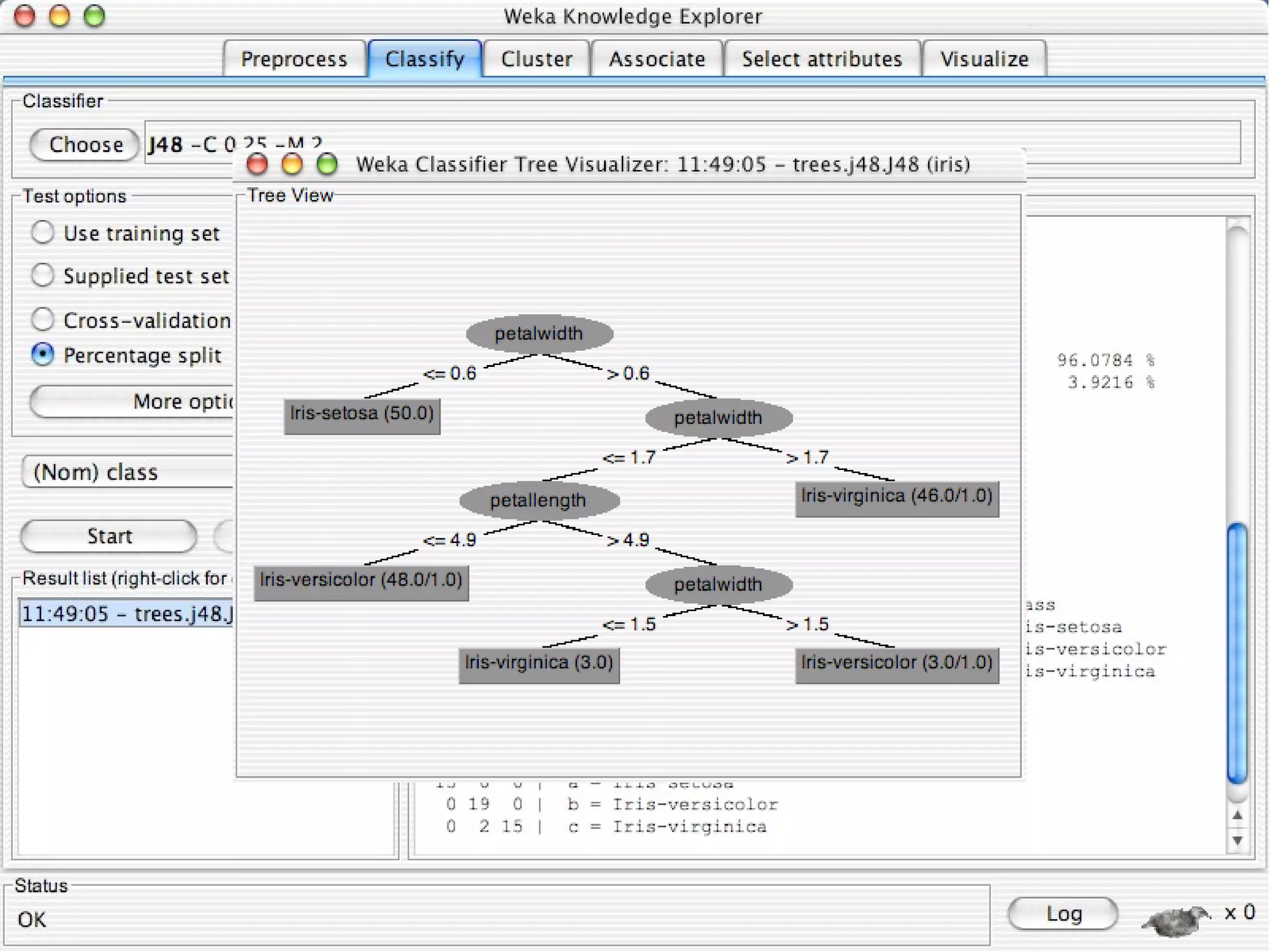
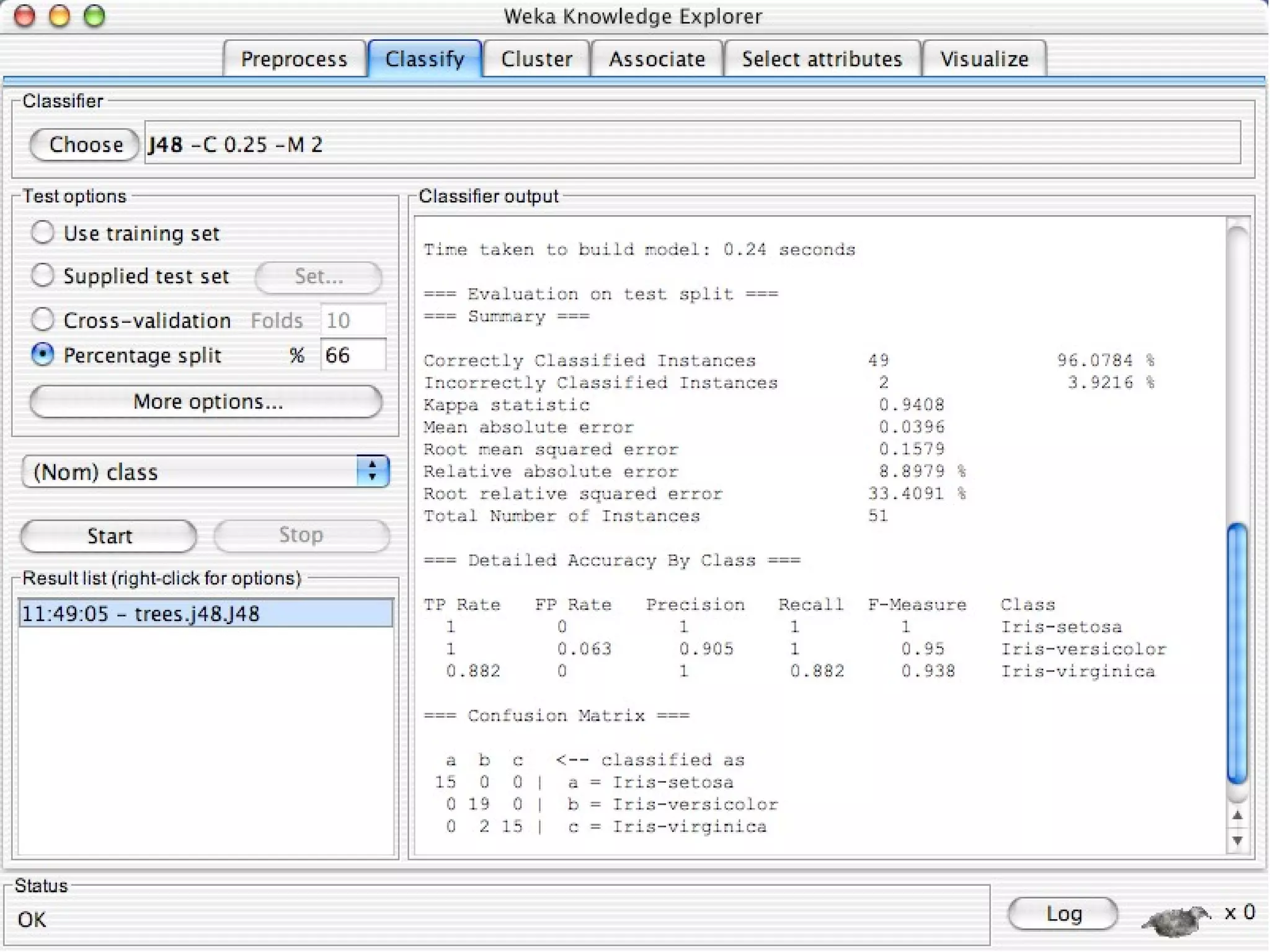




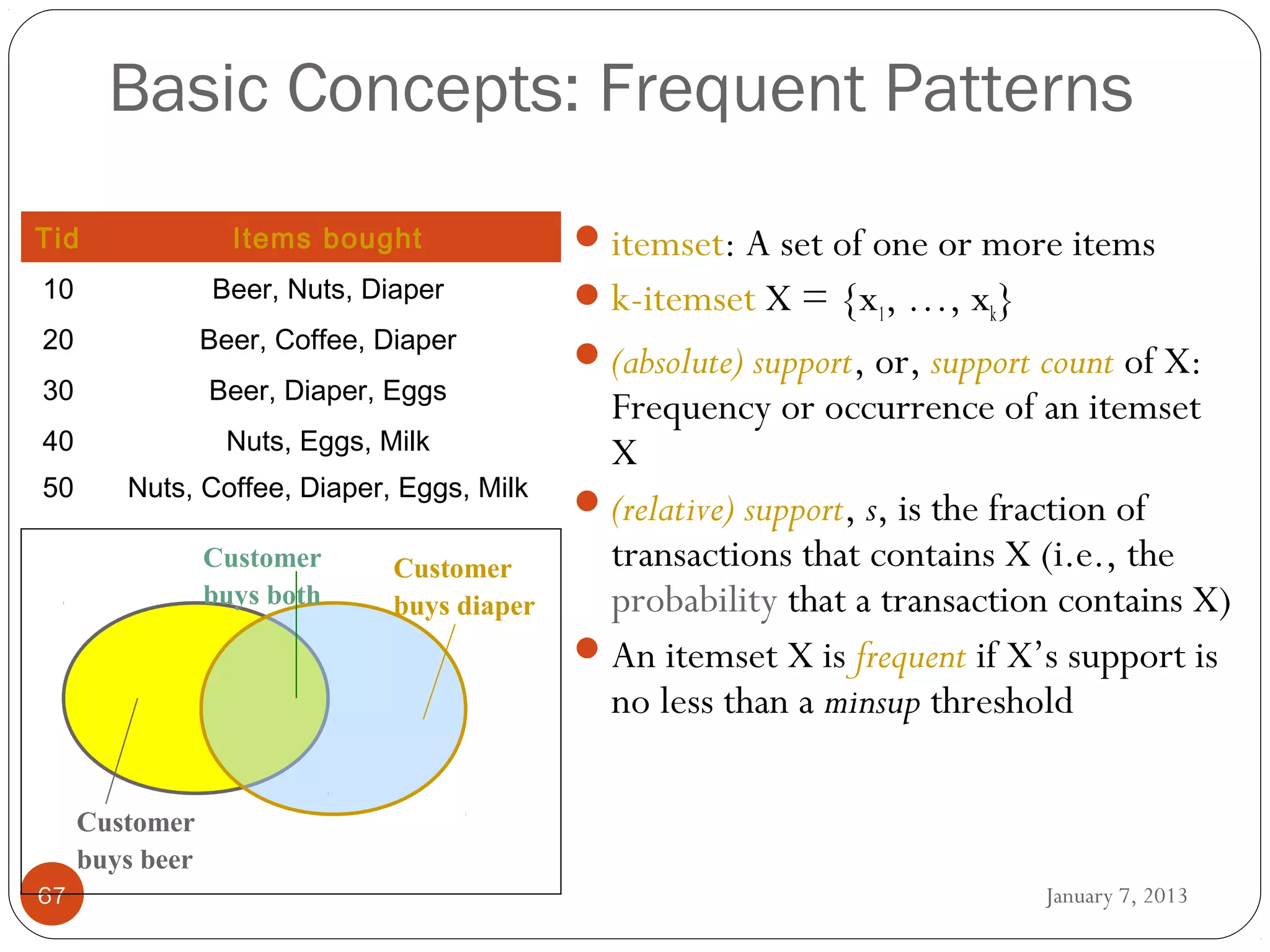
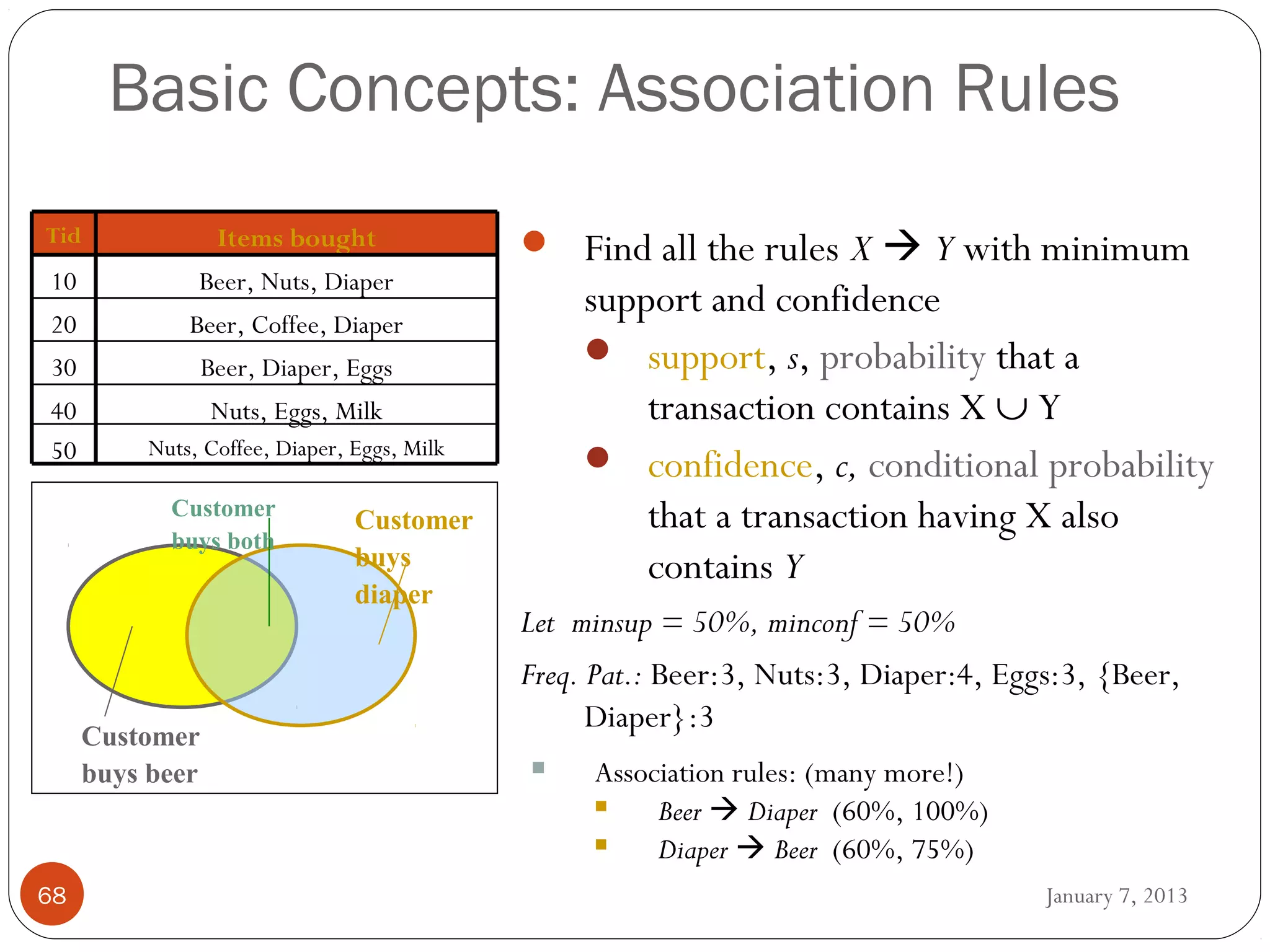

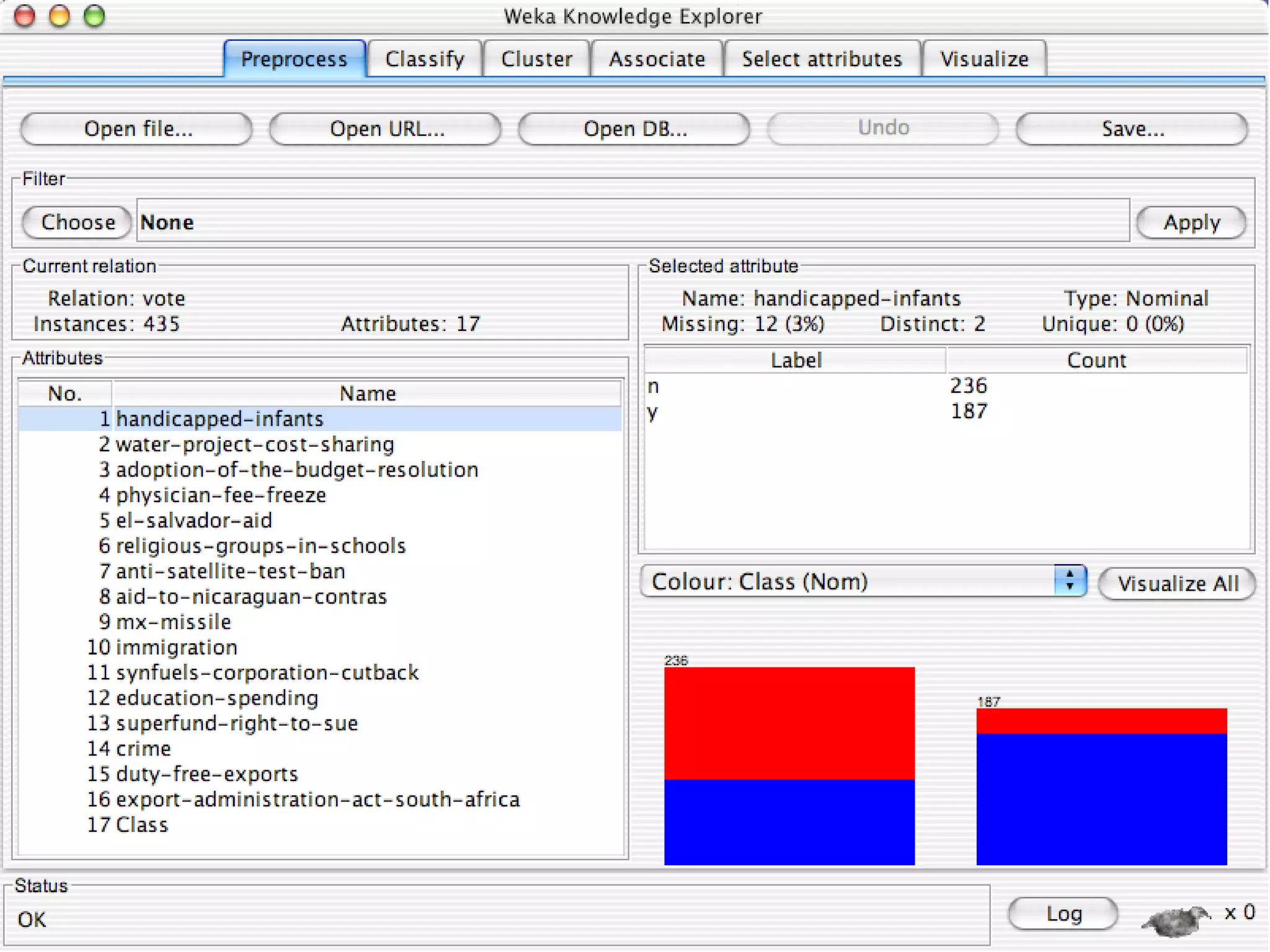
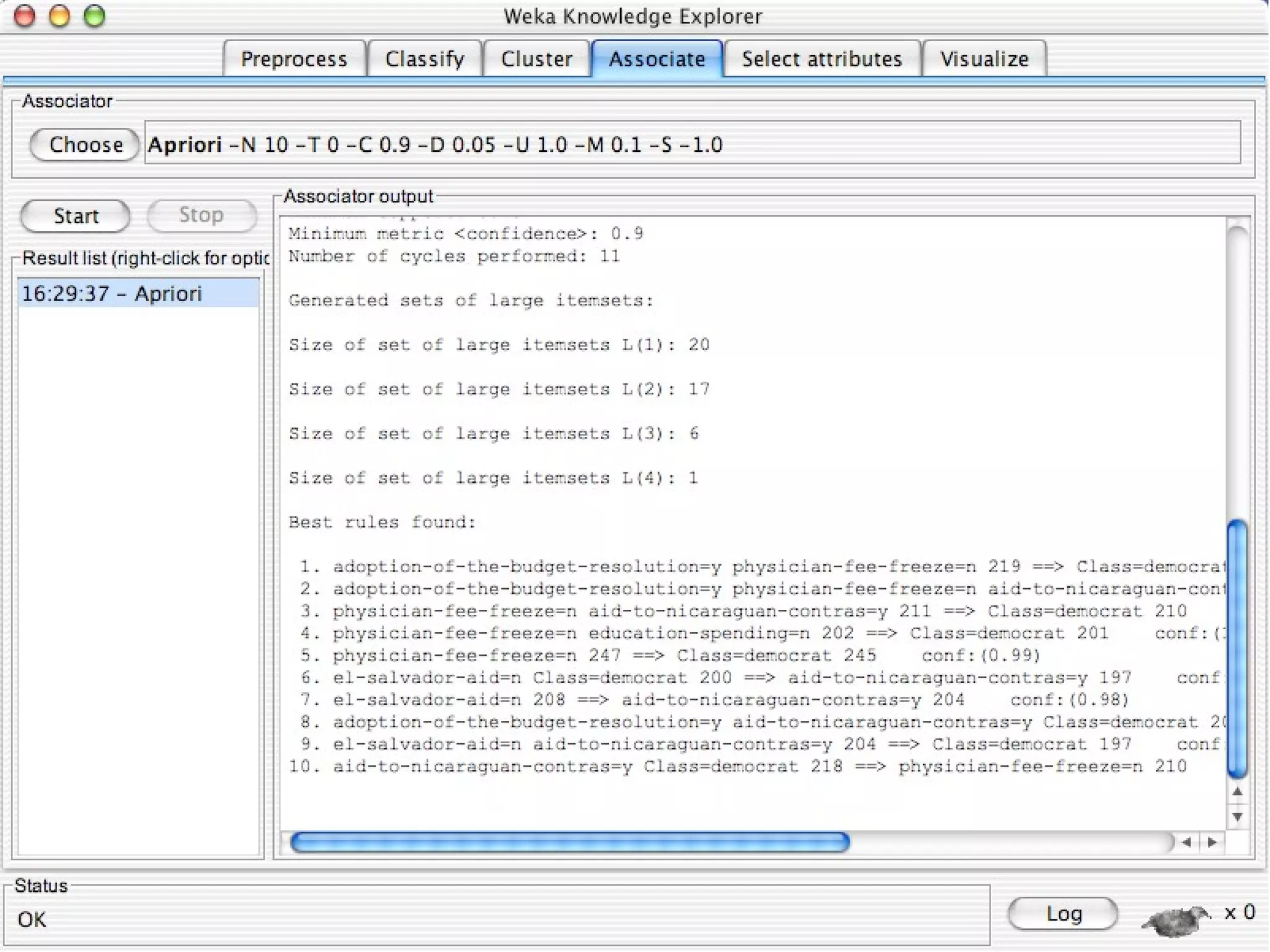


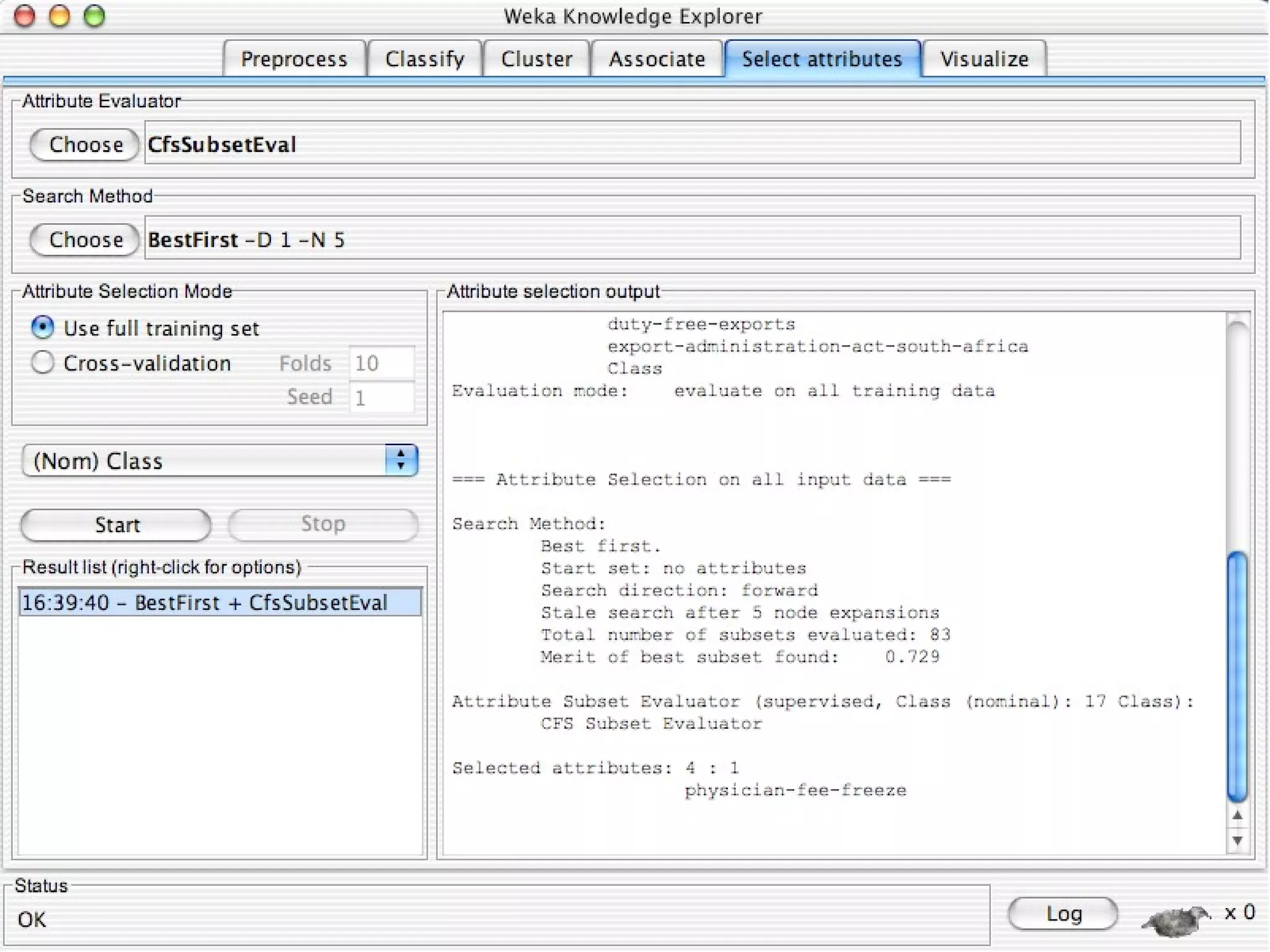
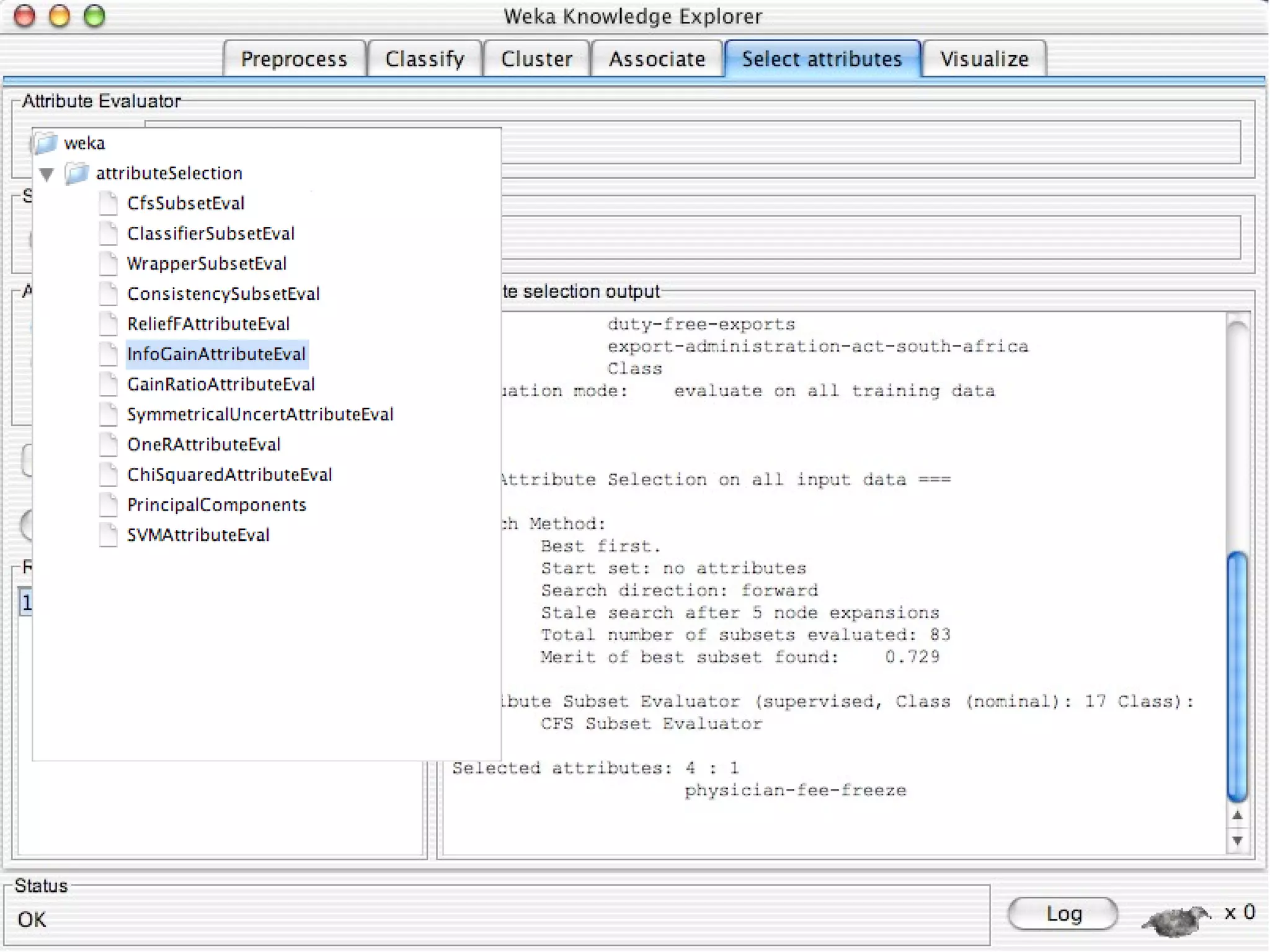
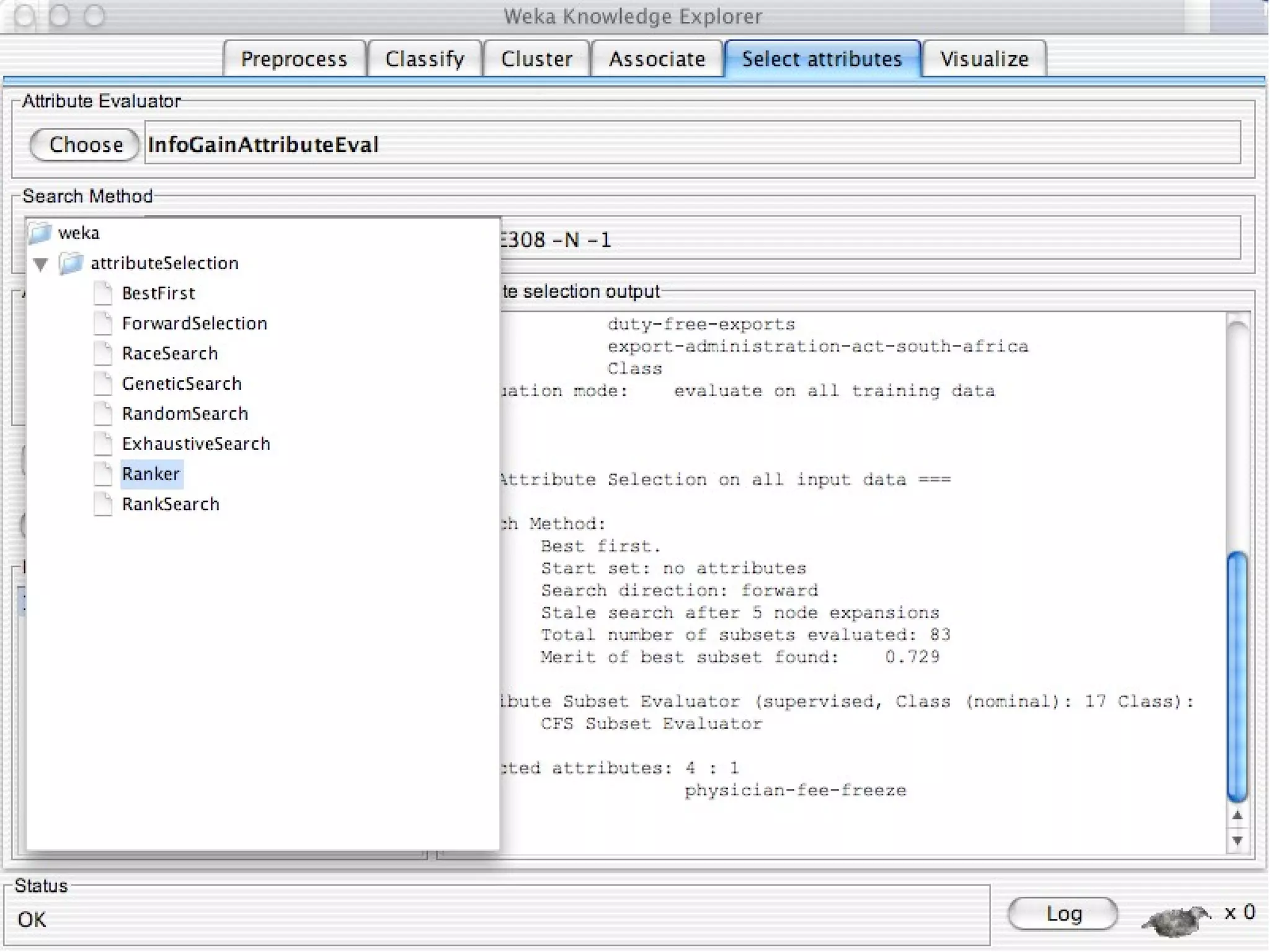
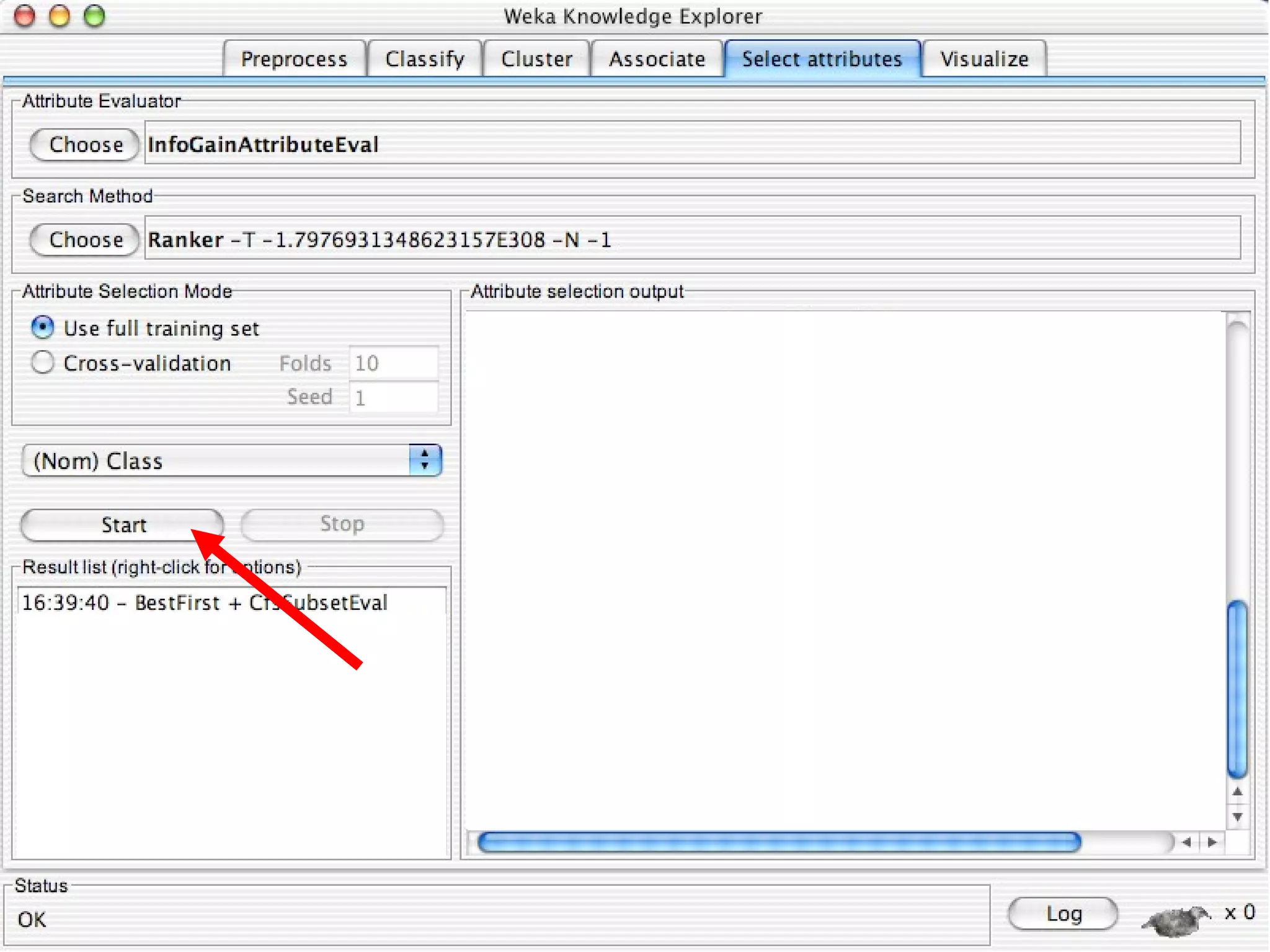



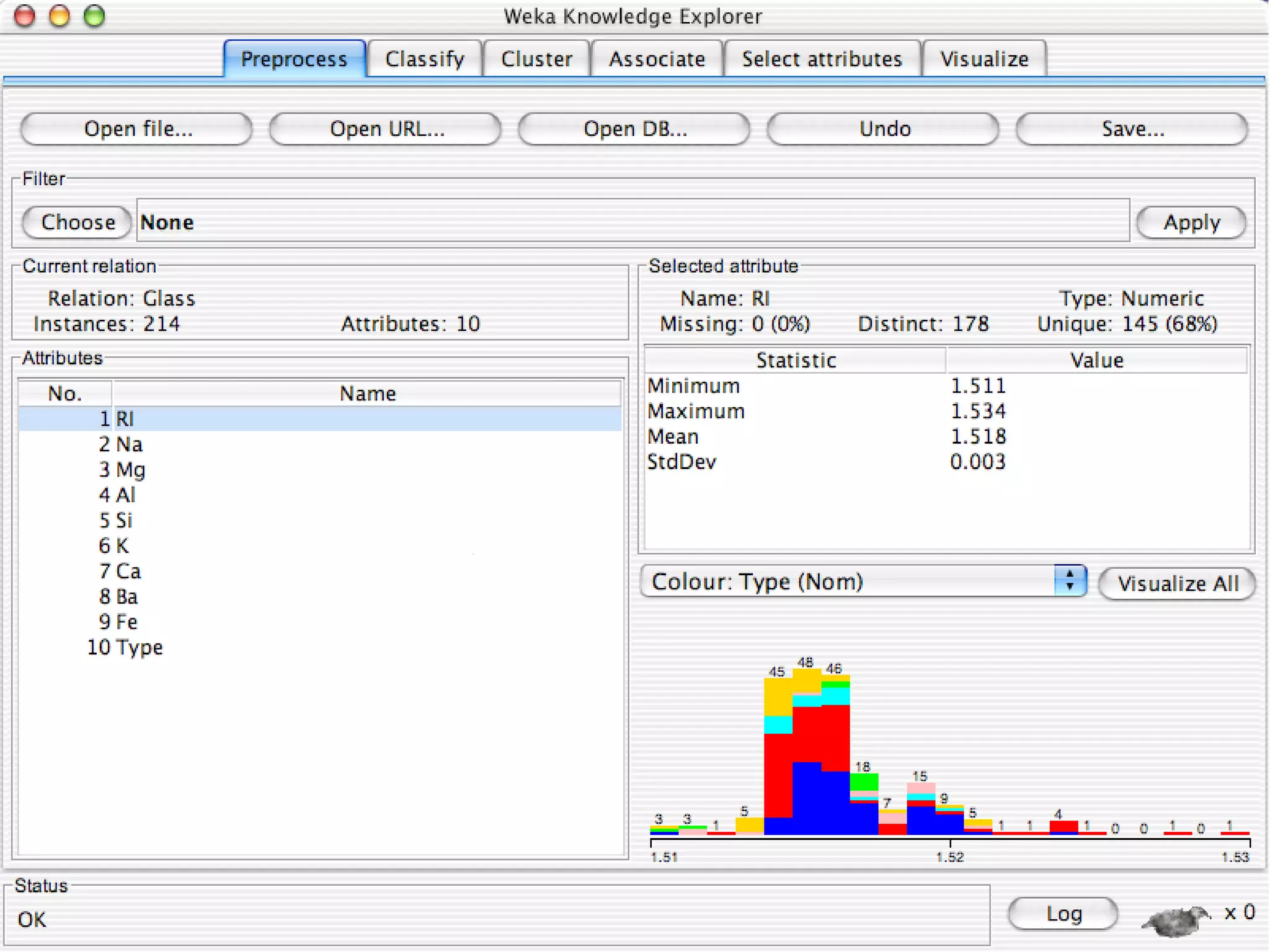
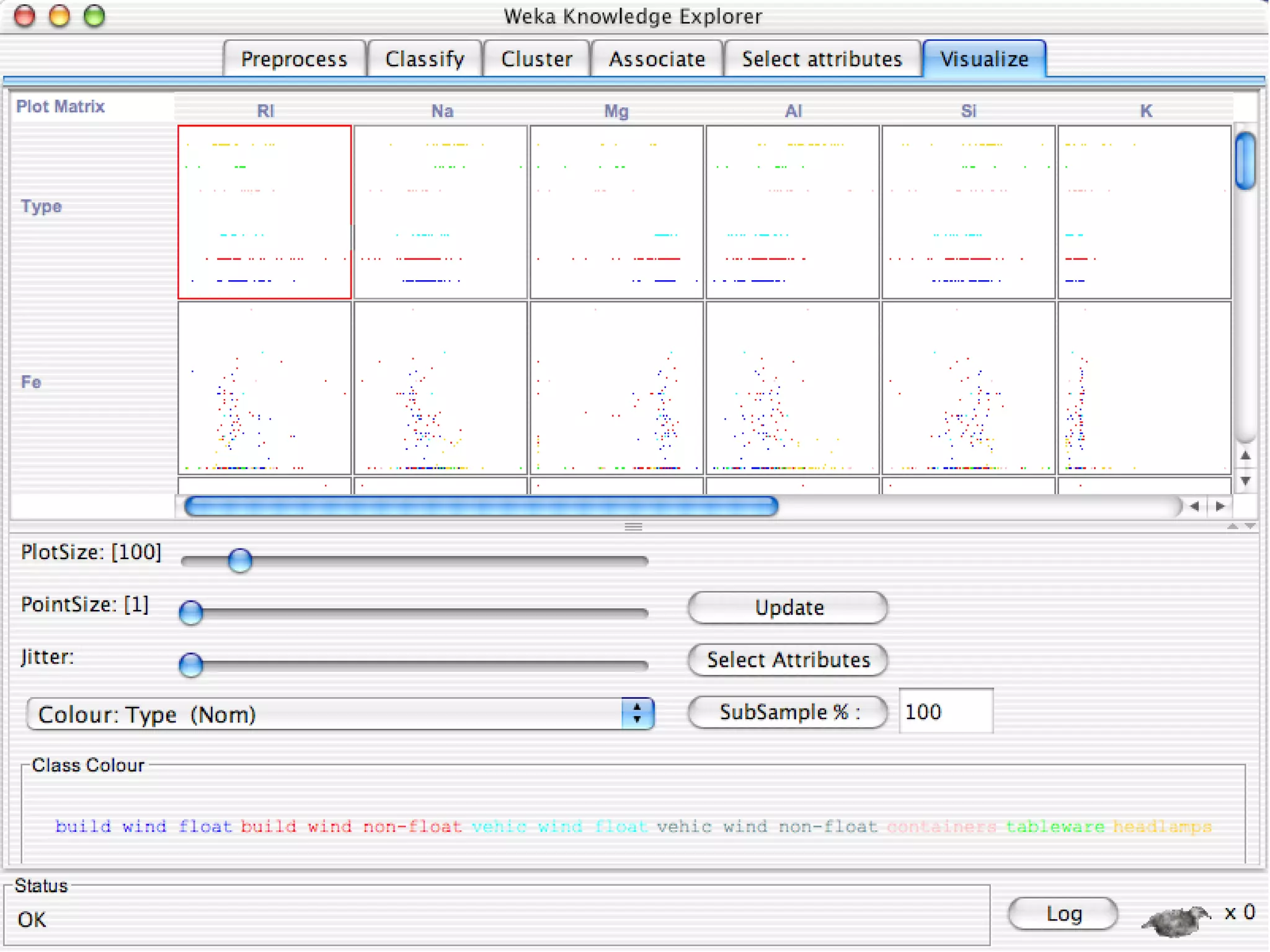
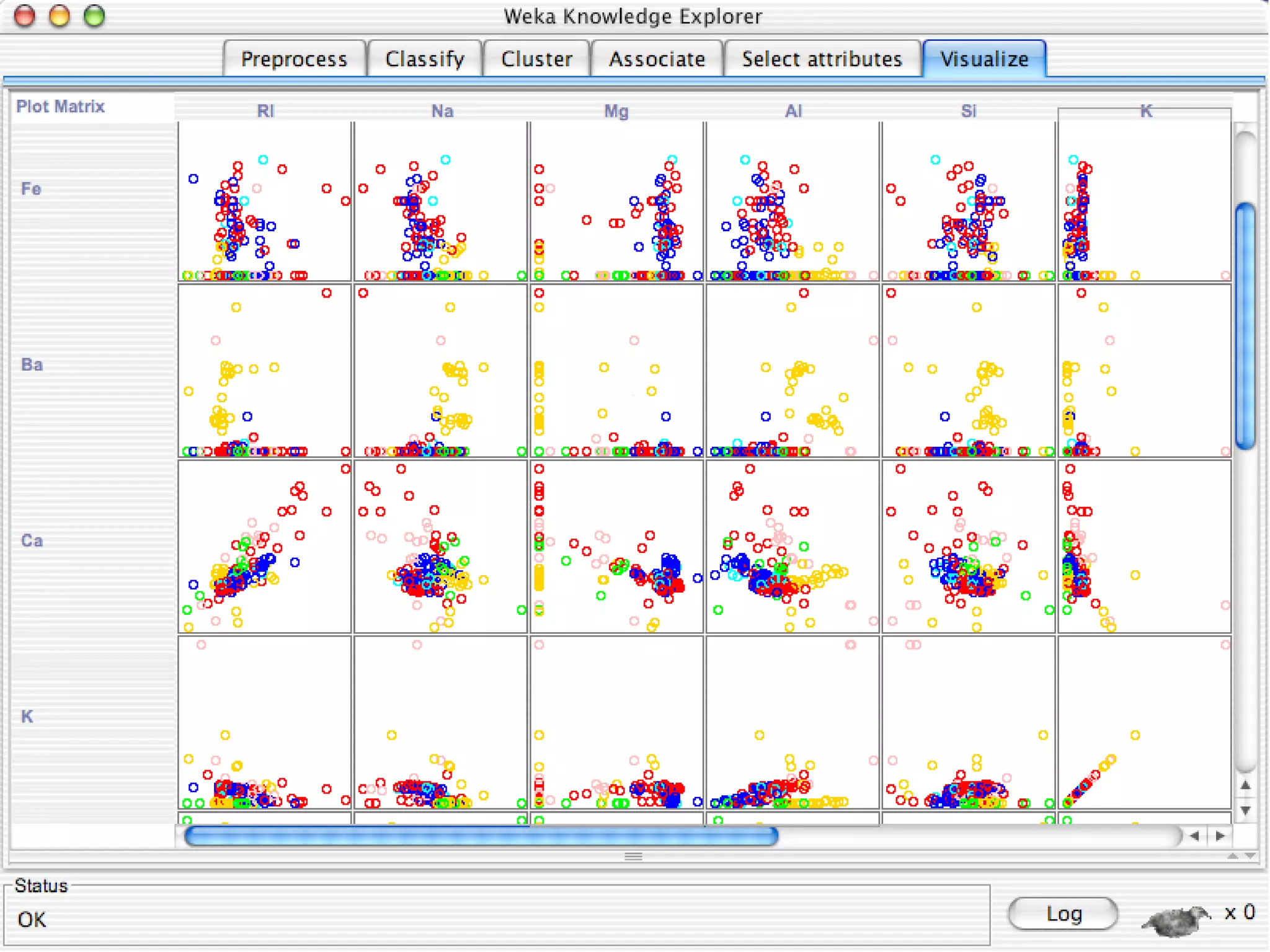
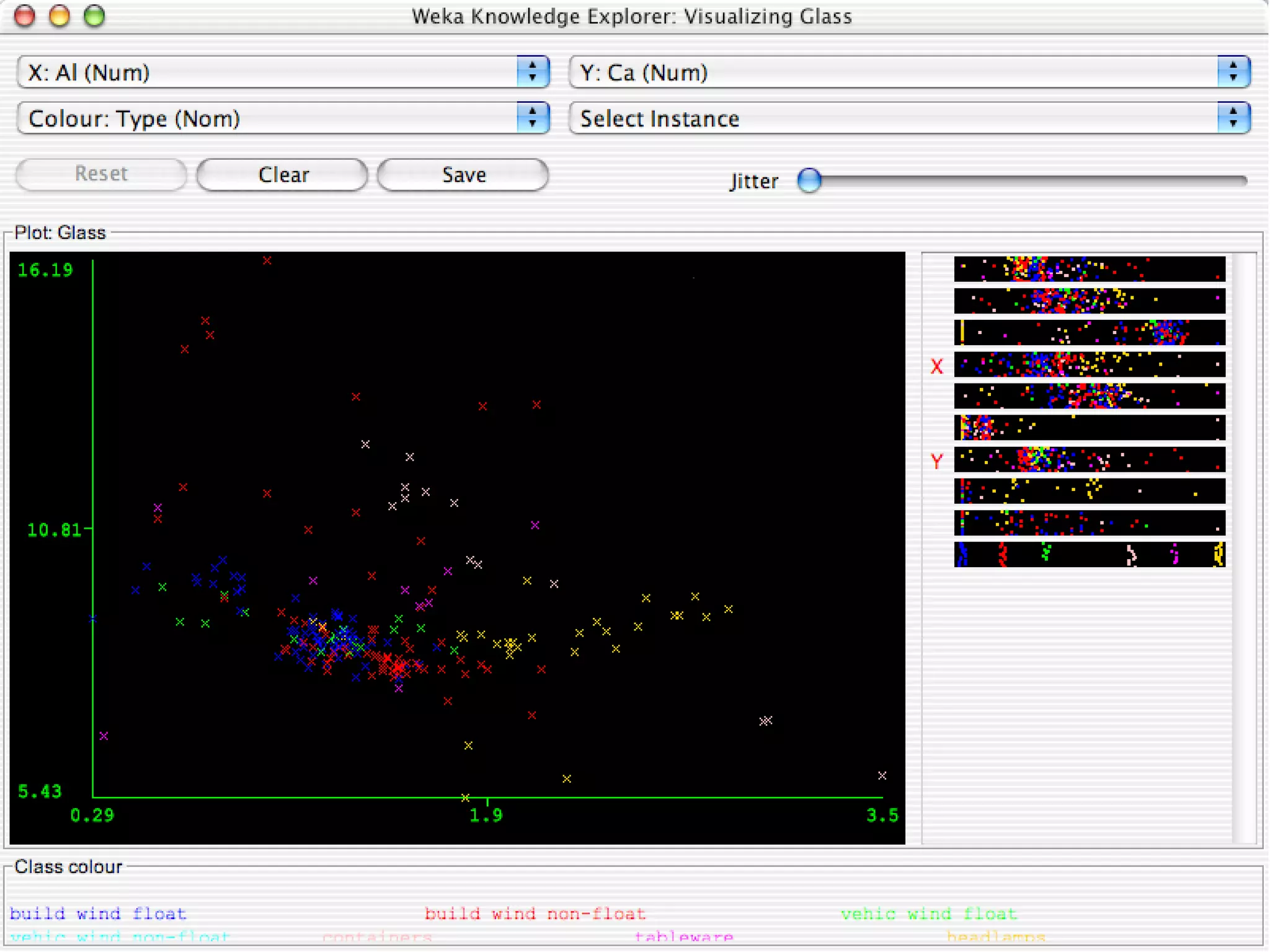
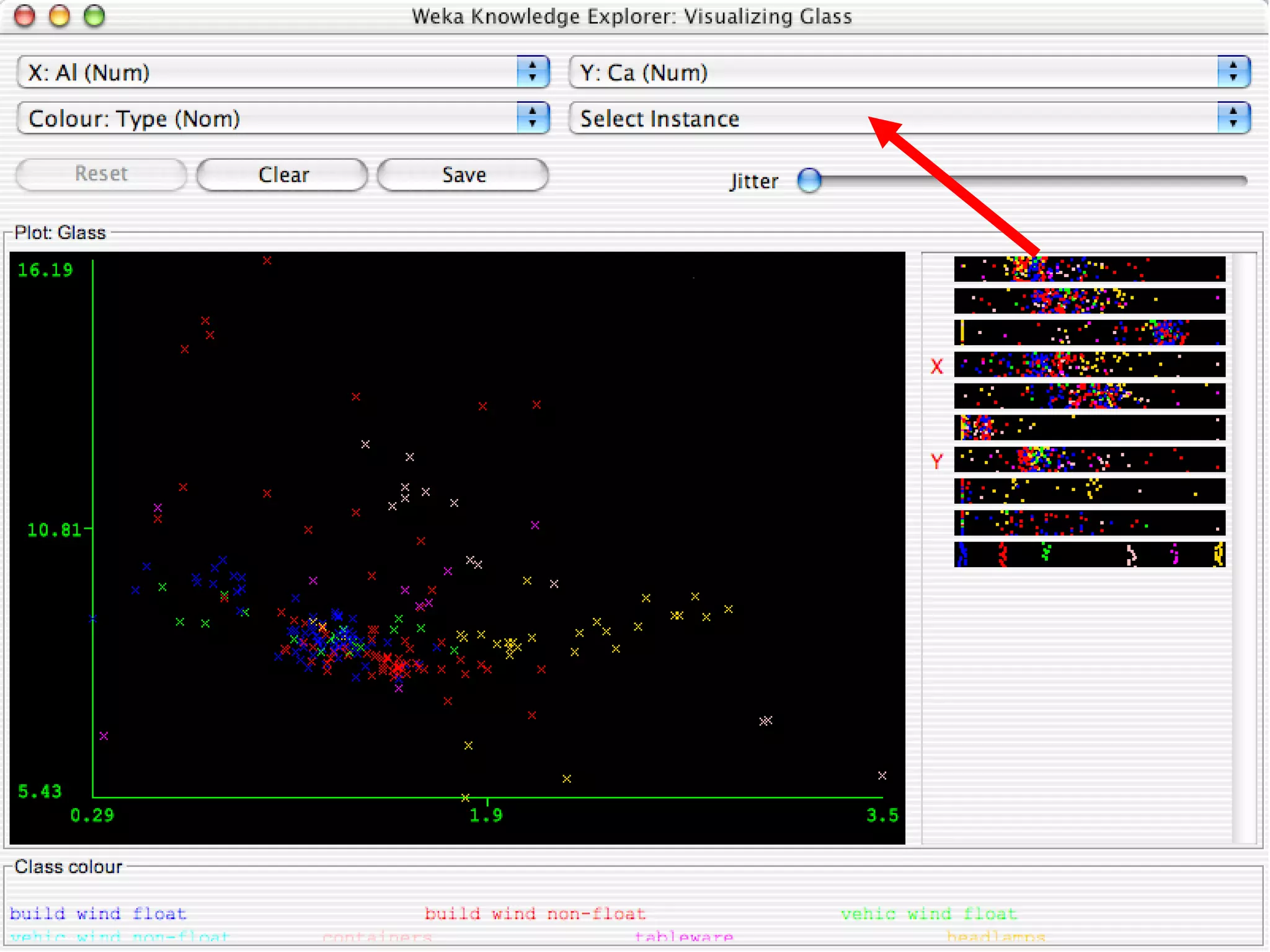
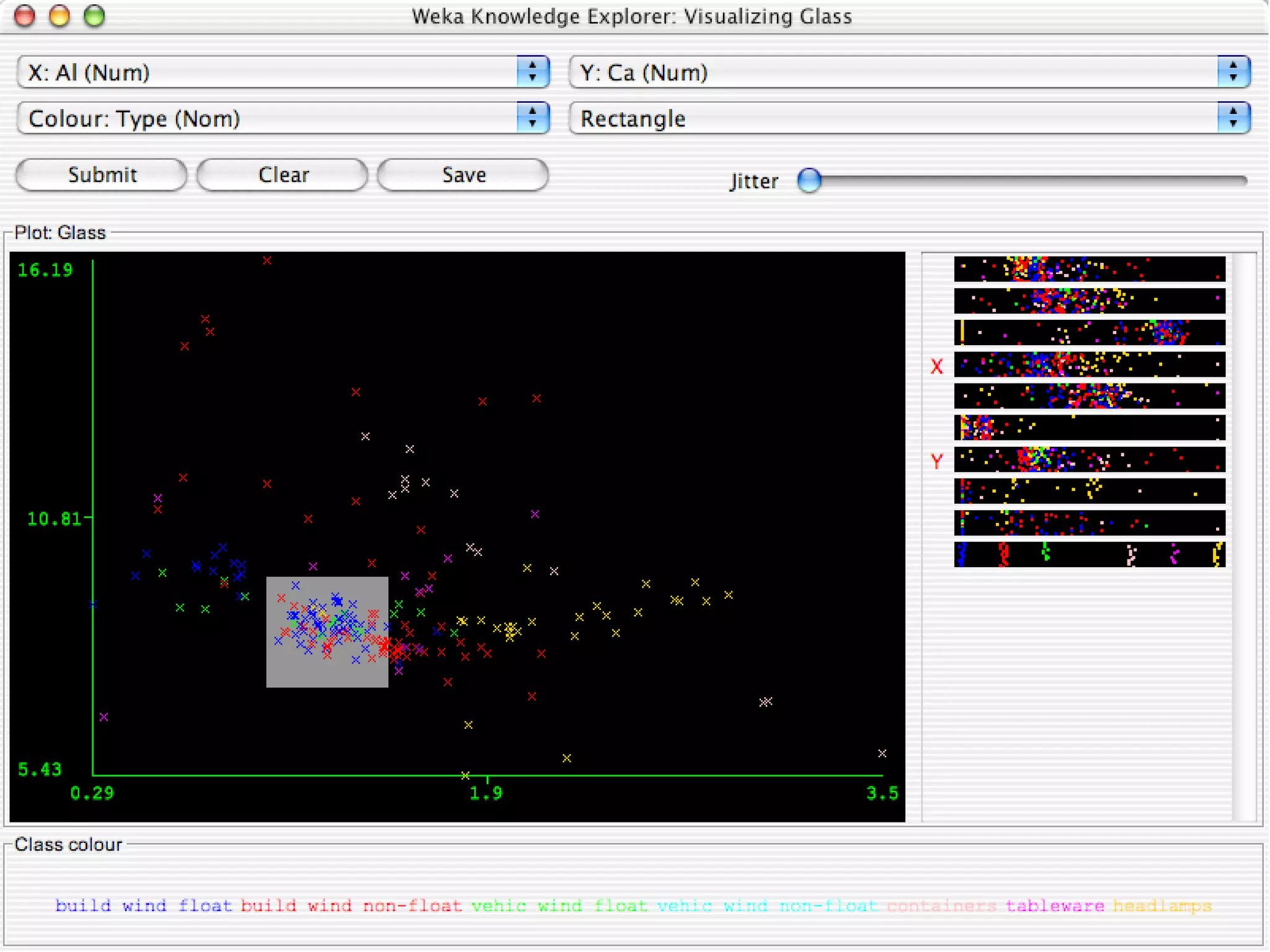
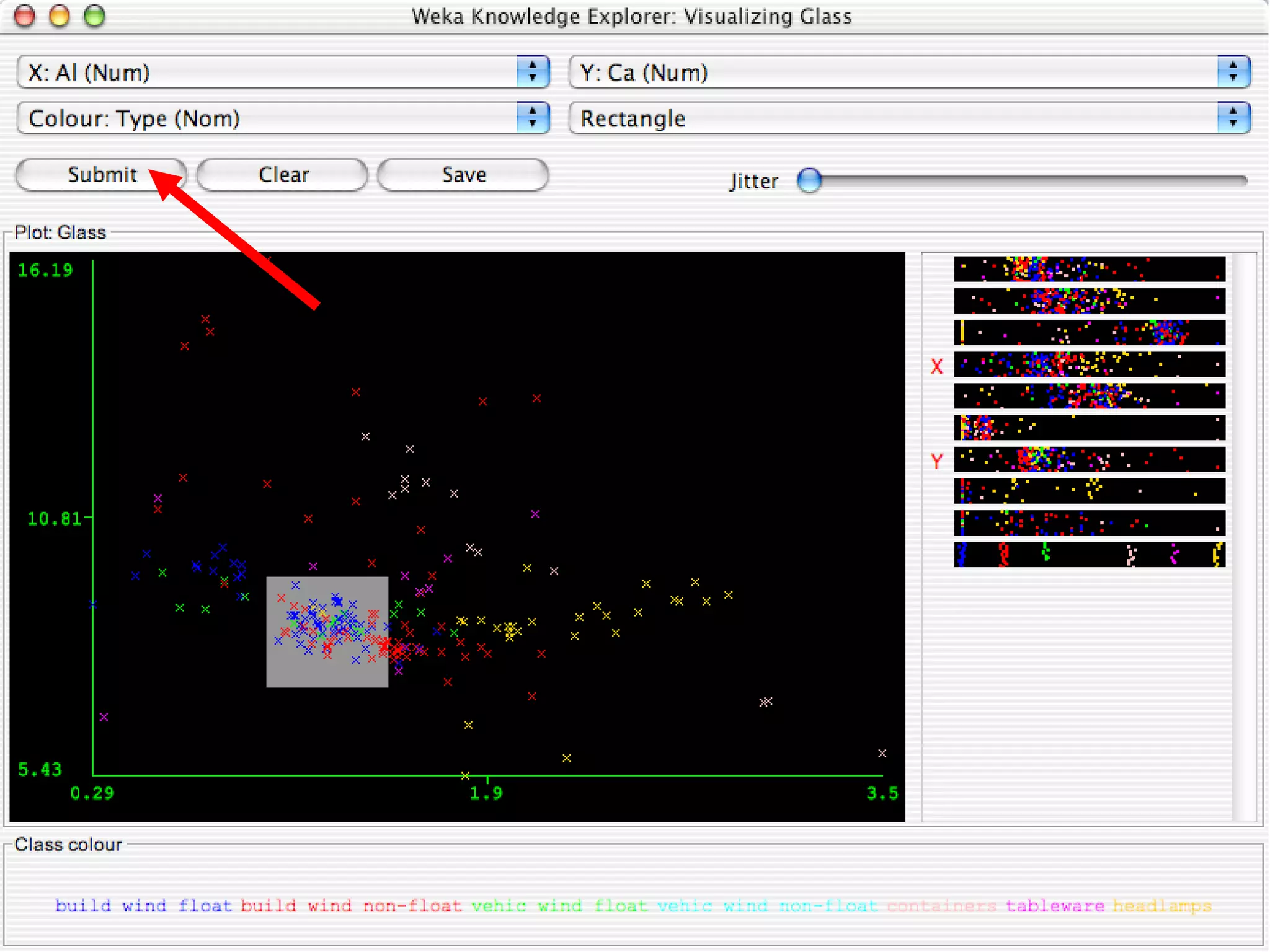


WEKA is a collection of machine learning algorithms for data mining tasks developed in Java by the University of Waikato. It contains tools for data pre-processing, classification, regression, clustering, association rules, and feature selection. The Explorer interface in WEKA provides tools to load data, preprocess data using filters, analyze data using these machine learning algorithms, and evaluate results.








































![Microsoft PowerPoint - weka [Read-Only]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoft-powerpoint-weka-readonly3765-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




































