0% found this document useful (0 votes)
135 views23 pagesDF PD - Read - Excel ('Sample - Superstore - XLS') : Anjaliassignmnet - Ipy NB
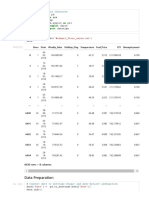
This document provides a summary of analyzing sales data from a furniture retailer. It includes:
1. Importing libraries and loading the sales data. Visualizing the data to analyze trends by product category, sub-category, region, and year.
2. Developing a predictive forecasting model for furniture sales. The time series data is preprocessed, decomposed to analyze trends and seasonality, and different ARIMA models are fit to the data.
3. The best performing ARIMA model is identified as SARIMAX(1,1,1)x(1,1,0,12) based on having the lowest AIC value, and will be used to forecast future furniture sales.
Uploaded by
sumaira khanCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
135 views23 pagesDF PD - Read - Excel ('Sample - Superstore - XLS') : Anjaliassignmnet - Ipy NB
This document provides a summary of analyzing sales data from a furniture retailer. It includes:
1. Importing libraries and loading the sales data. Visualizing the data to analyze trends by product category, sub-category, region, and year.
2. Developing a predictive forecasting model for furniture sales. The time series data is preprocessed, decomposed to analyze trends and seasonality, and different ARIMA models are fit to the data.
3. The best performing ARIMA model is identified as SARIMAX(1,1,1)x(1,1,0,12) based on having the lowest AIC value, and will be used to forecast future furniture sales.
Uploaded by
sumaira khanCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 23