Introduction to DataMining
Why use Data Mining?
Lecturer: Abdullahi Ahamad Shehu
(M.Sc. Data Science, M.Sc. Computer Science)
Office: Faculty of Computing Extension
2.
Contents
• Data vs.Information
• Data mining
• Methodology
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
3.
Data Banks
• Nowadayswe collect vast amounts of data, e.g.
• Shopping lists
• Bank transactions
• Medical records
• Web logs
• Drilling information (bottom hole pressure, mud flow, porosity, permeability …)
• Pandemic data (positive cases, hospitalisations, deaths, countries, population …)
• Weather data
• Raw data is not very useful
• Huge volume of data makes it difficult to handle.
4.
Getting Information fromData
• Information is required in order to solve problems.
• Data can be a superb source of information.
• This may be difficult to extract due to the volume of data.
• BUT once extracted, we can get an understanding of the
problem domain
• E.g.
• Customer profiles vs. what they buy
• Credit card transactions vs. fraud
• Drilling data vs. potential problem with drill (or scale or hydrate formation)
5.
Information
• Information isrequired in order to solve problems.
• E.g. discover fraudulent credit card use
• Input: various data regarding the current transaction.
• Output: whether the current transaction is fraudulent or not.
• Information: extracted from records of past transactions including
whether they were fraudulent or not. How to determine fraudulent
transactions.
6.
Contents
• Data vs.Information
• Data mining
• Methodology
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
7.
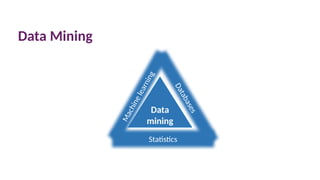
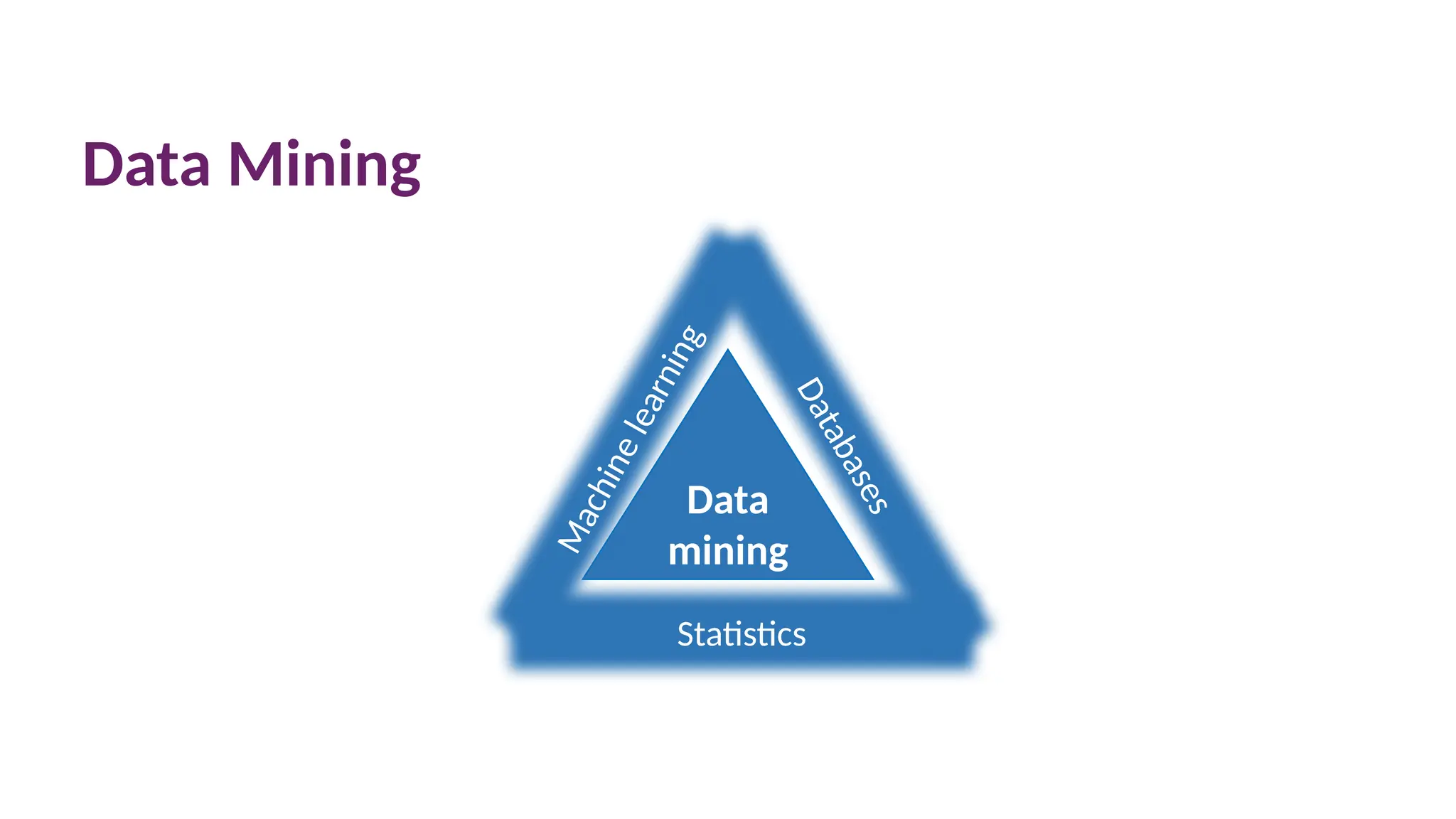
Data mining
• Datamining is the process of extracting information which is
implicitly stored in collections of data.
• Used to:
• Solve new problems (e.g. detect credit card fraud)
• Understand problems and their solutions (e.g. understand what
situations may lead to fraud).
• Main challenges:
• Work with large volumes of data
• Distinguish between interesting and uninteresting information
• Work with inaccurate and incomplete sets of data.
8.
…
• Aim: findstrong patterns in data
• Pattern strength is related to prediction strength
BUT
• Most patterns contained in data are not interesting
• Patterns may be
• Not always true (inexact)
• The result of chance (spurious)
• Missing data
• Inaccurate or erroneous data
9.
Example
• Shopping
• Strongpattern – people who buy bread also buy milk
• But this is not interesting!
• Weaker pattern – men who buy nappies on a Friday also buy beer
• More interesting
• Weaker – some men buy only nappies …
• Missing data – the gender of the shopper is unknown for some
transactions
• Inaccurate data – the gender of the shopper might have been
entered incorrectly
10.
Data Mining Requirements
Data
A(large) set of
past data
[including
outcome].
Machine learning
One or more
programs which
extract
relationships
(patterns)
between data,
i.e. information.
Evaluation
is the output
always/mostly
/rarely
correct?
What kind of
errors?
11.
Machine Learning
• Usedin data mining to obtain relationships (patterns) between data
• Learning
• Capable of changing behaviour in order to perform better
• Learning from examples
• Training data: examples used for learning
• [Validation data: examples used for tuning parameters]
• Test data: examples used to test learnt knowledge.
Types of DataMining
• SUPERVISED (prediction)
• Classification: predicts class for new problem. E.g
• Fraudulent transaction or not
• Fault diagnosis
• Regression: predicts numeric solution for new problem. E.g.
• House price
• Others
• Time Series: regression where measurements are taken over time.
14.
Types of DataMining
• UNSUPERVISED (knowledge discovery)
• Association Rules: find patterns in data
• Purchasing habits in supermarkets
• Clustering: groups data into clusters of similar cases
• Text Mining: extracts useful concepts from text data
• Others
• Summarisation: find compact definitions of data
• Deviation Detection: detects changes from norm.
• Database Segmentation: divides large DB into smaller databases which can
solve sub-problems.
15.
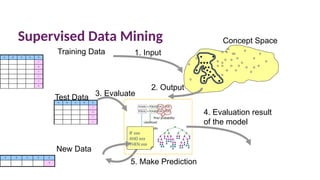
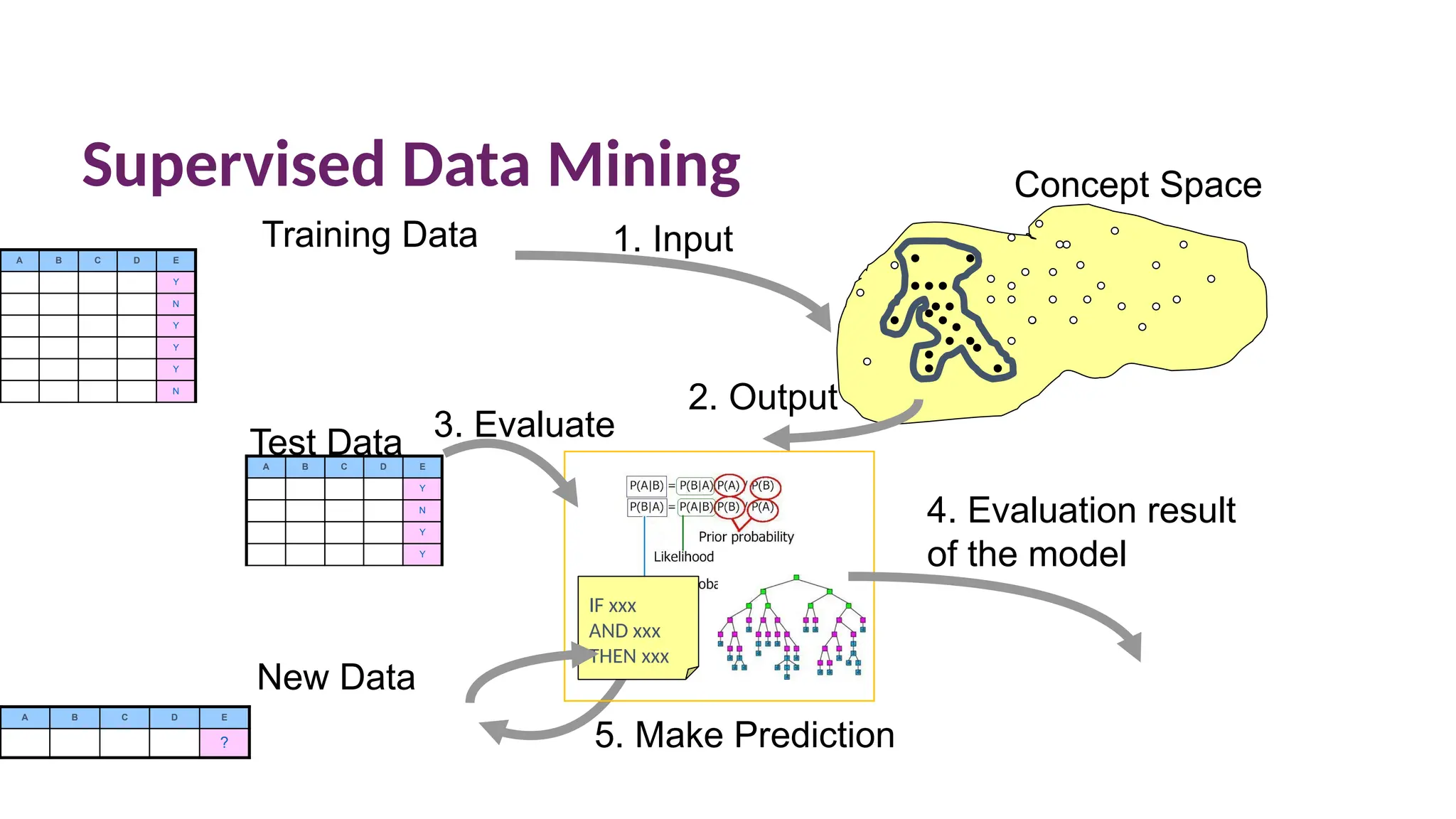
Supervised Data Mining
AB C D E
Y
N
Y
Y
Y
N
A B C D E
?
Training Data 1. Input
Concept Space
New Data
5. Make Prediction
IF xxx
AND xxx
THEN xxx
Test Data
A B C D E
Y
N
Y
Y
3. Evaluate
2. Output
4. Evaluation result
of the model
Contents
• Data vs.Information
• Data mining
• Methodology
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
18.
10 March 202518
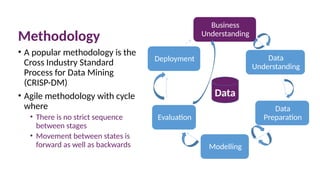
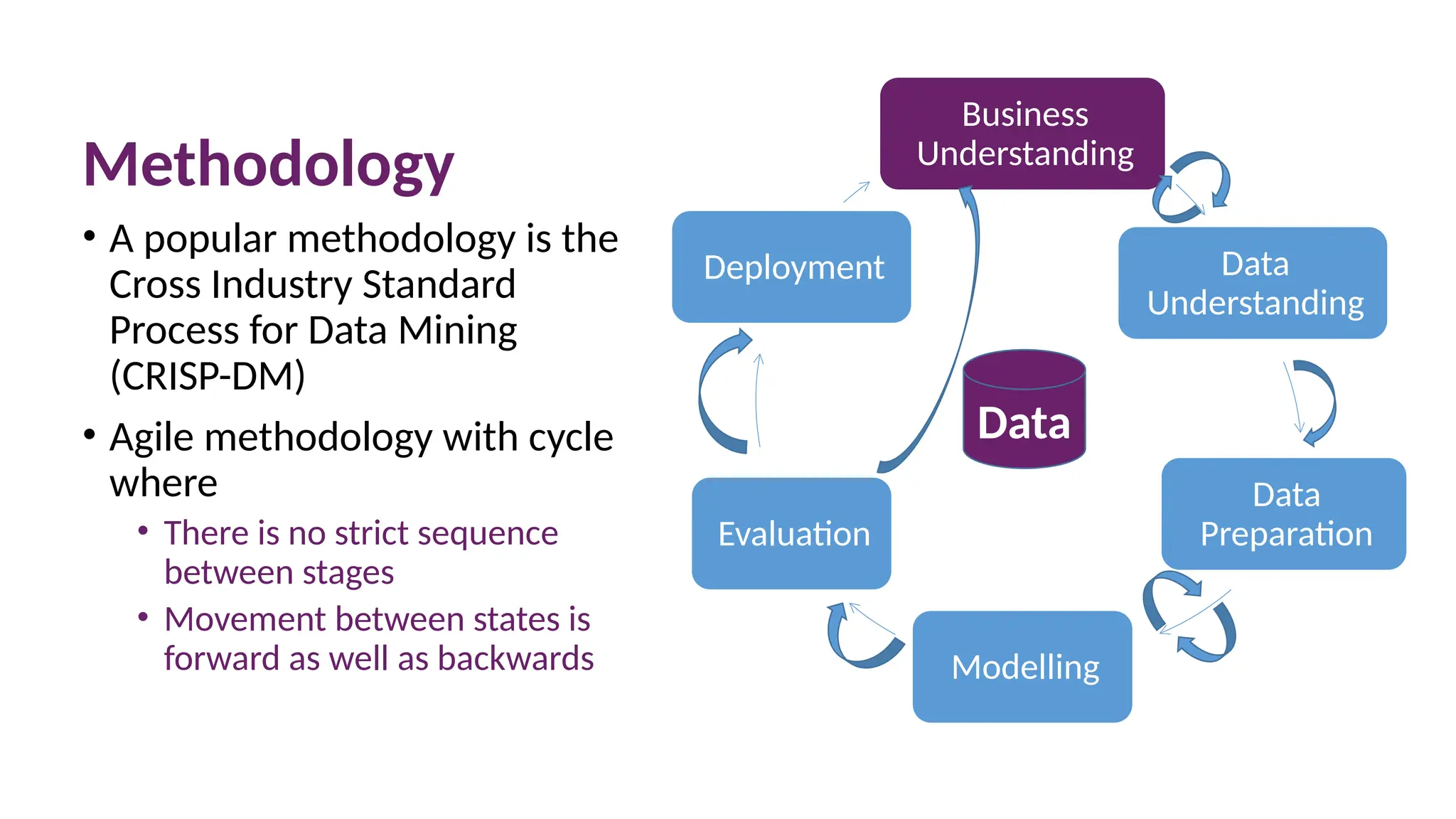
Methodology
• A popular methodology is the
Cross Industry Standard
Process for Data Mining
(CRISP-DM)
• Agile methodology with cycle
where
• There is no strict sequence
between stages
• Movement between states is
forward as well as backwards
Business
Understanding
Data
Understanding
Data
Preparation
Modelling
Evaluation
Deployment
Data
19.
Contents
• Data vs.Information
• Data mining
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
20.
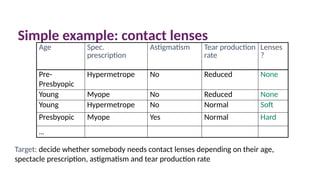
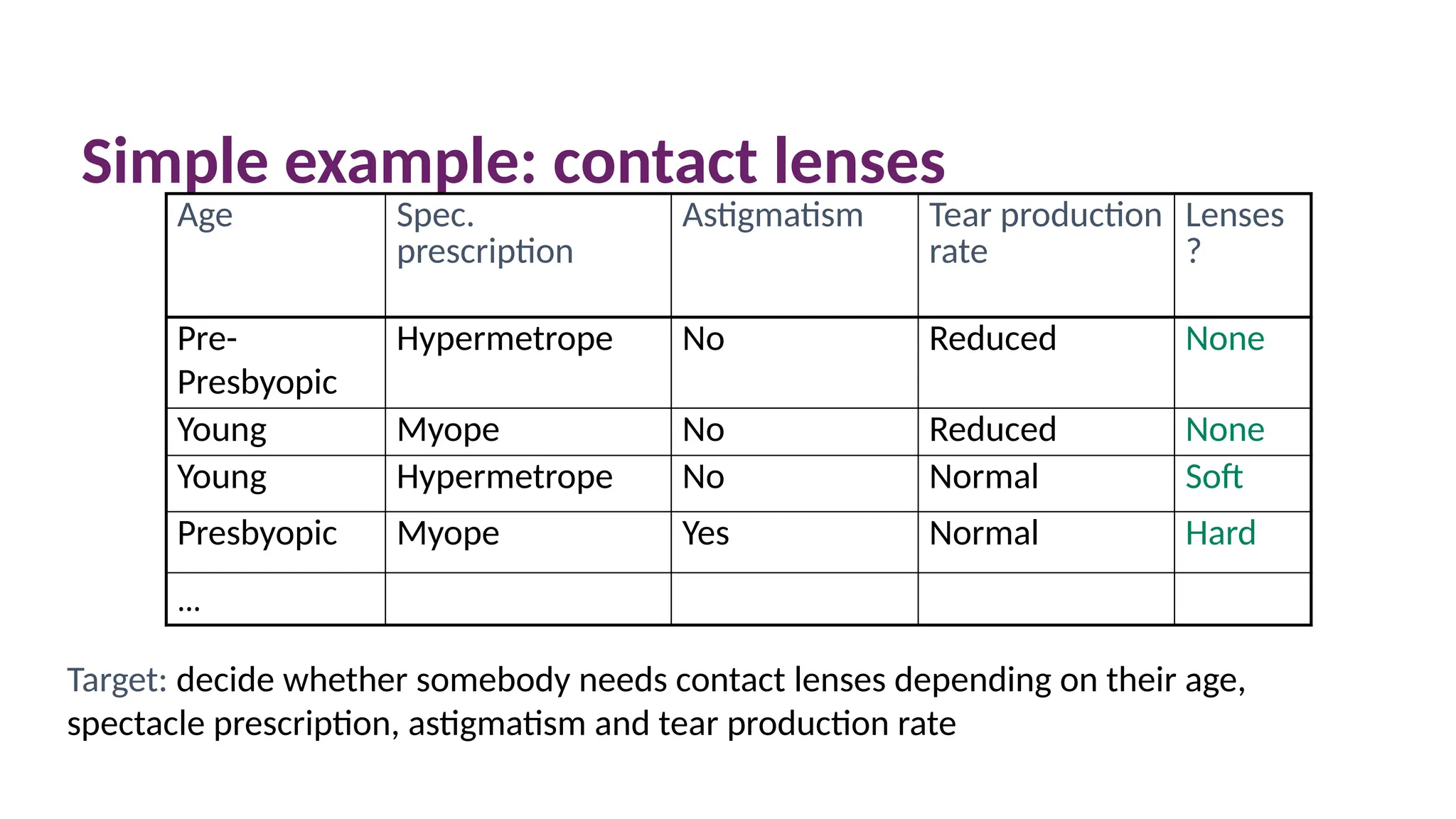
Simple example: contactlenses
Age Spec.
prescription
Astigmatism Tear production
rate
Lenses
?
Pre-
Presbyopic
Hypermetrope No Reduced None
Young Myope No Reduced None
Young Hypermetrope No Normal Soft
Presbyopic Myope Yes Normal Hard
…
Target: decide whether somebody needs contact lenses depending on their age,
spectacle prescription, astigmatism and tear production rate
21.
Information re. Lenses
•Sample rule
If tear production rate = reduced
then lenses = none
else
if age = young
and astigmatism = no
then lenses = soft
22.
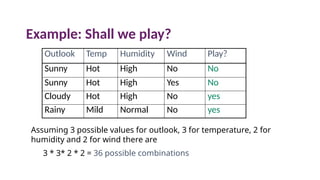
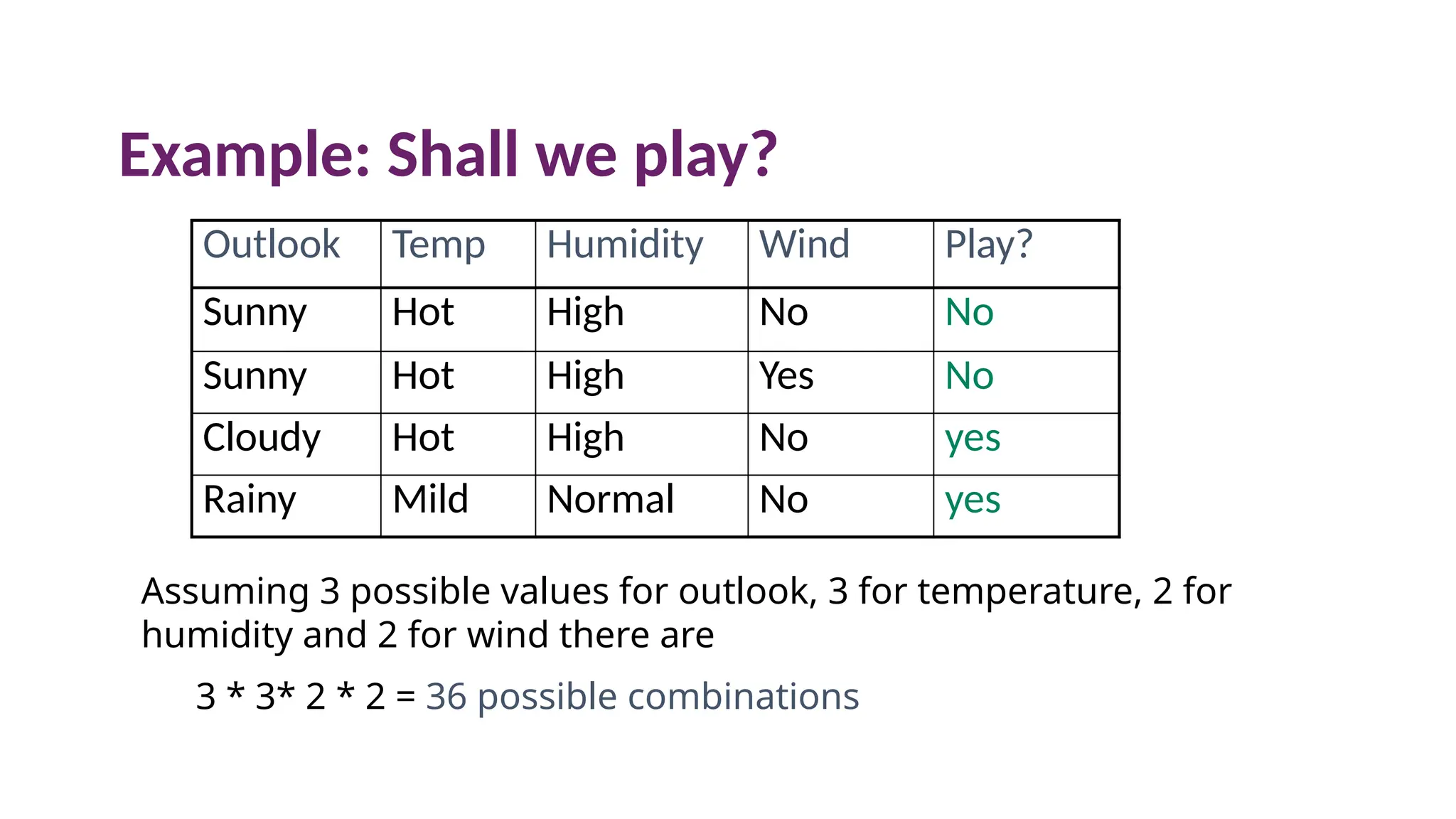
Example: Shall weplay?
Outlook Temp Humidity Wind Play?
Sunny Hot High No No
Sunny Hot High Yes No
Cloudy Hot High No yes
Rainy Mild Normal No yes
Assuming 3 possible values for outlook, 3 for temperature, 2 for
humidity and 2 for wind there are
3 * 3* 2 * 2 = 36 possible combinations
23.
Shall we play?Decision list
• If outlook = sunny
and humidity = high
then play = no
• If outlook = rainy
and wind = yes
then play = no
• If outlook = cloudy
then play = yes
• If humidity = normal
then play = yes
• If none of the above rules applies
then play = yes
24.
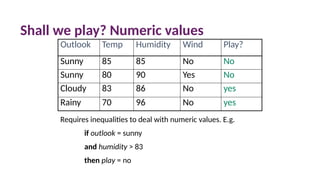
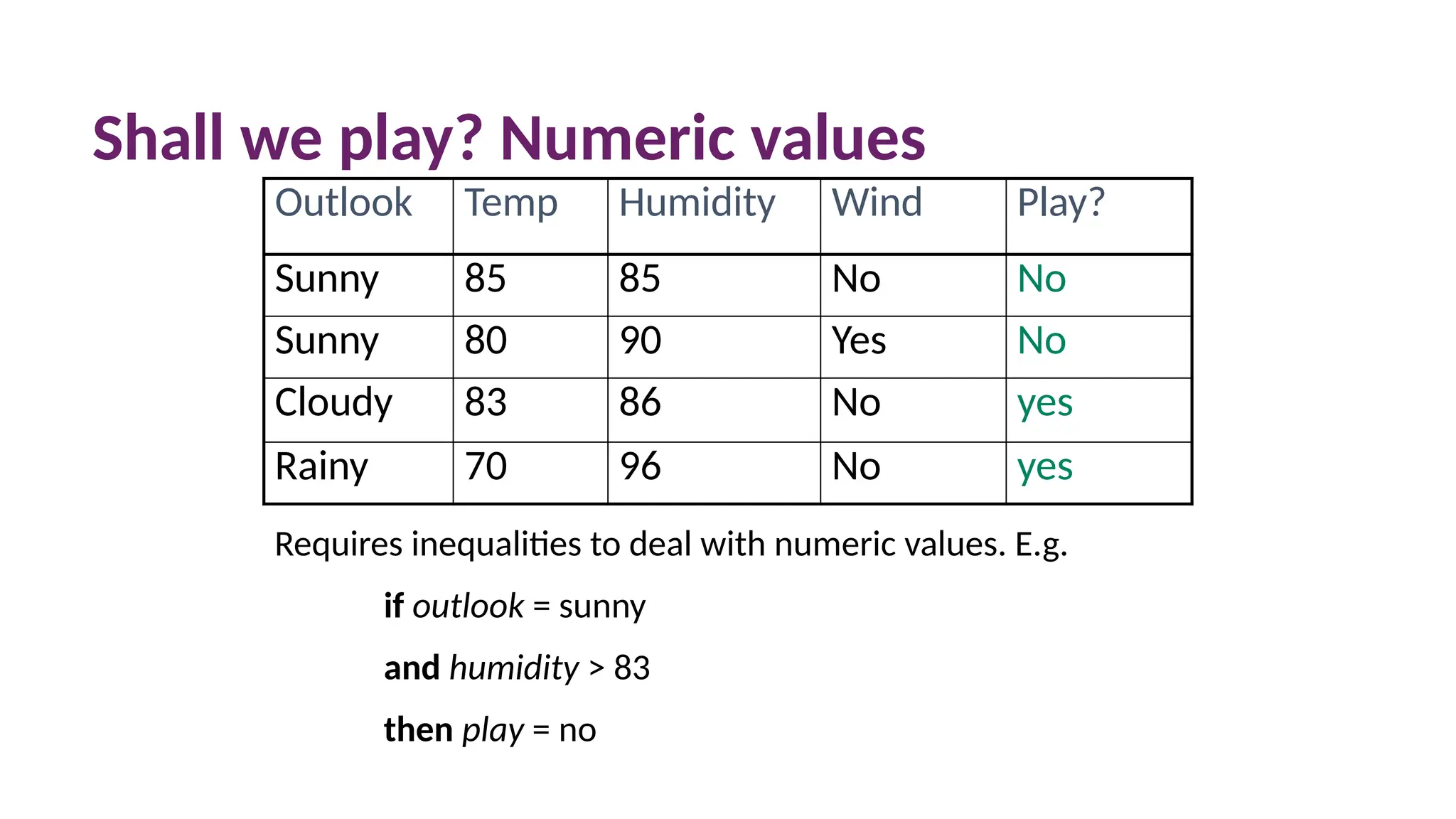
Shall we play?Numeric values
Outlook Temp Humidity Wind Play?
Sunny 85 85 No No
Sunny 80 90 Yes No
Cloudy 83 86 No yes
Rainy 70 96 No yes
Requires inequalities to deal with numeric values. E.g.
if outlook = sunny
and humidity > 83
then play = no
25.
Information presented
• Maybe
• Complete, i.e. covers all possibilities
• Incomplete
• Accuracy may be
• 100%, i.e. works all the time
• < 100%
26.
Type of information
•Classification rule: predicts the value of a particular attribute
• Association rule: predicts the value of a single or a combination of
attributes. Unlike with classification, there is no target attribute to learn
• E.g. if temperature = cool
then humidity = normal
if humidity = normal
and wind = no
then play = yes
27.
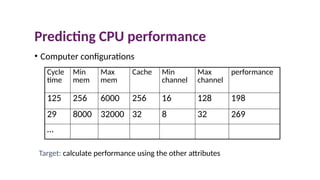
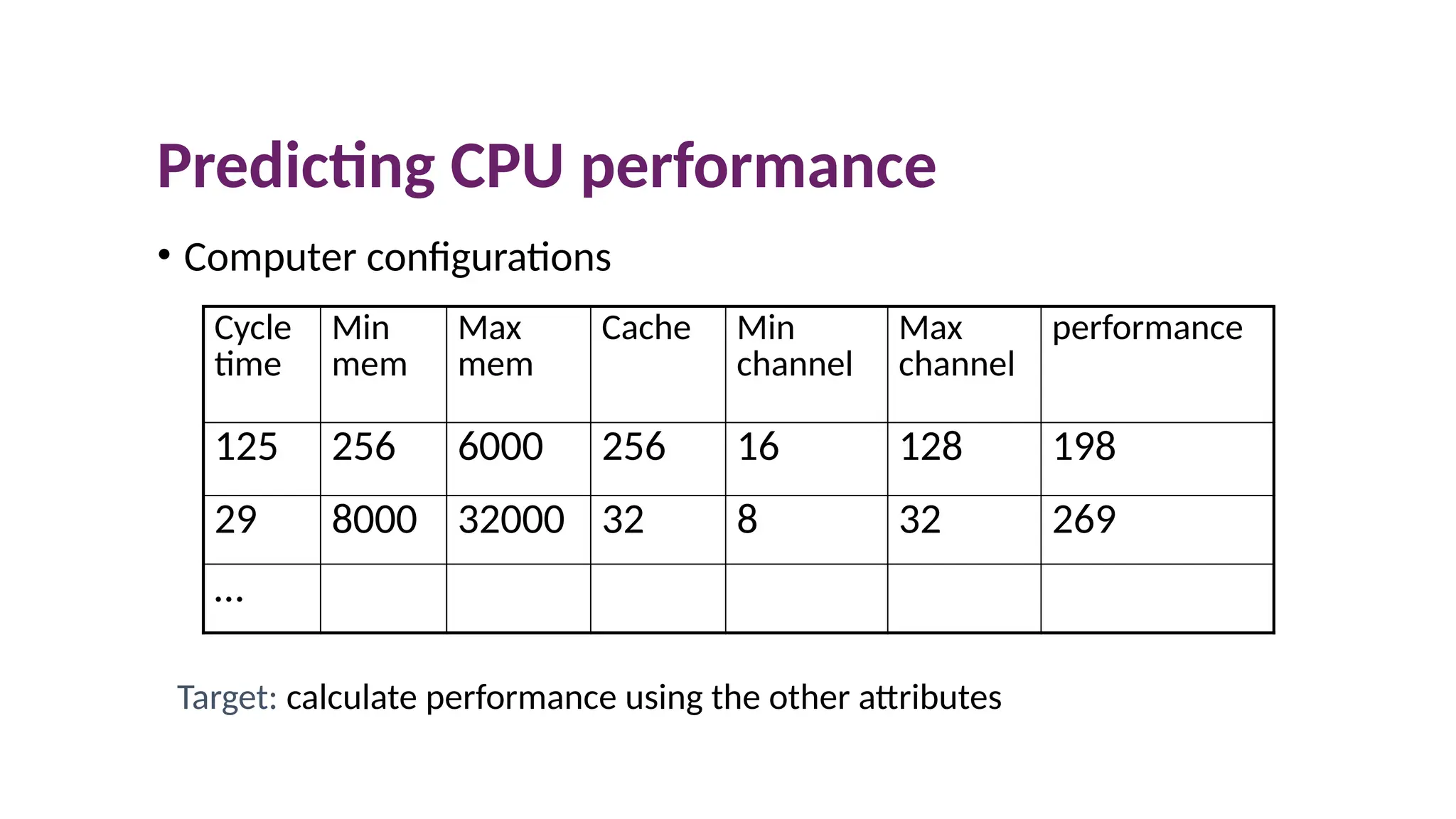
Predicting CPU performance
•Computer configurations
Cycle
time
Min
mem
Max
mem
Cache Min
channel
Max
channel
performance
125 256 6000 256 16 128 198
29 8000 32000 32 8 32 269
…
Target: calculate performance using the other attributes
28.
Linear Regression
•Rules includea weighted function
•E.g.
• Performance =
- 55.9
+ 0.0489 cycle time
+ 0.0153 min memory
+ 0.0056 max memory
+ 0.641 cache
- 0.27 min channels
+ 1.48 max channels
29.
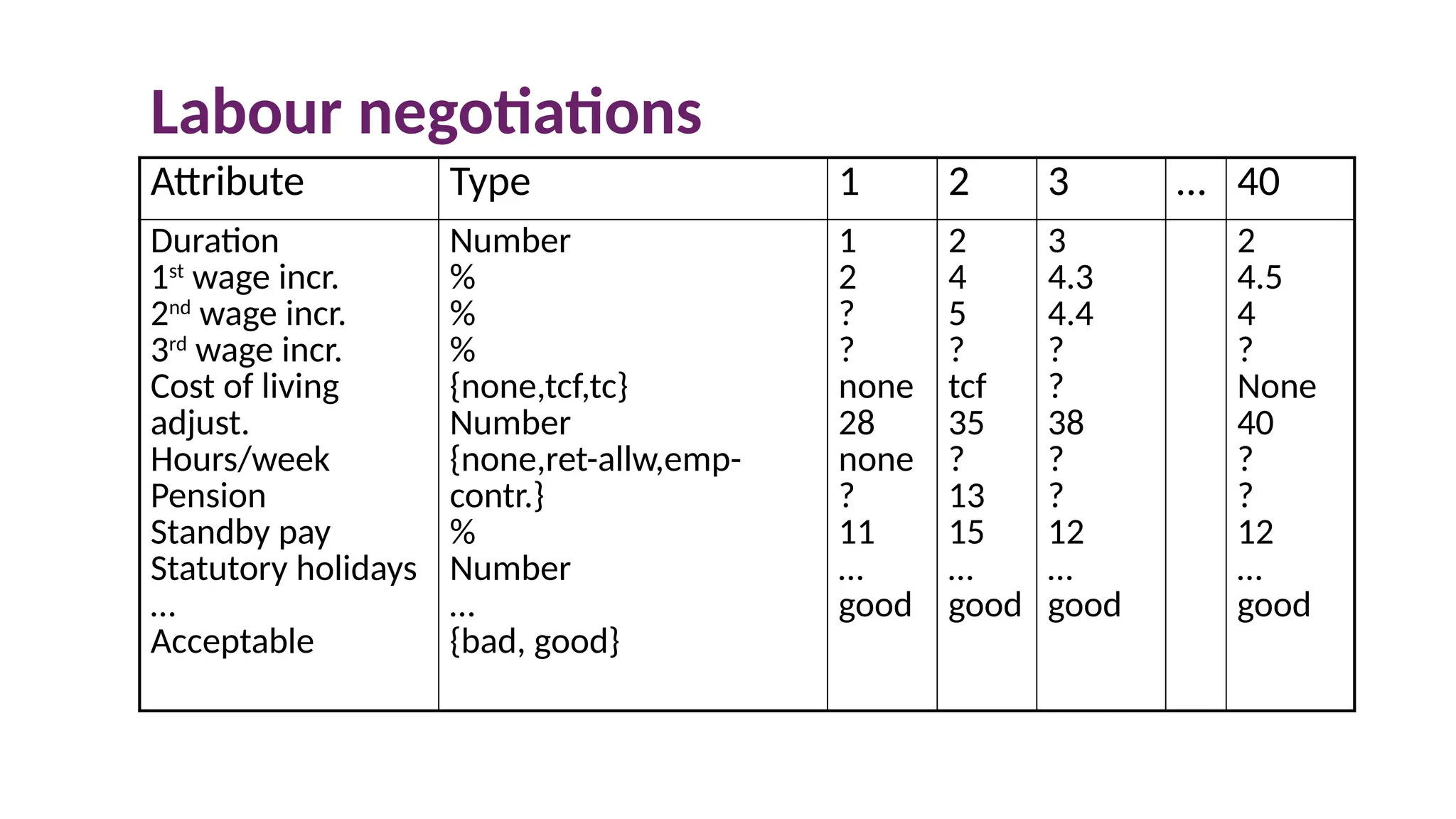
Labour negotiations
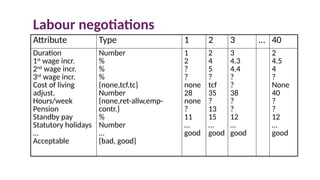
Attribute Type1 2 3 … 40
Duration
1st
wage incr.
2nd
wage incr.
3rd
wage incr.
Cost of living
adjust.
Hours/week
Pension
Standby pay
Statutory holidays
…
Acceptable
Number
%
%
%
{none,tcf,tc}
Number
{none,ret-allw,emp-
contr.}
%
Number
…
{bad, good}
1
2
?
?
none
28
none
?
11
…
good
2
4
5
?
tcf
35
?
13
15
…
good
3
4.3
4.4
?
?
38
?
?
12
…
good
2
4.5
4
?
None
40
?
?
12
…
good
30.
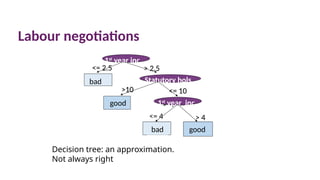
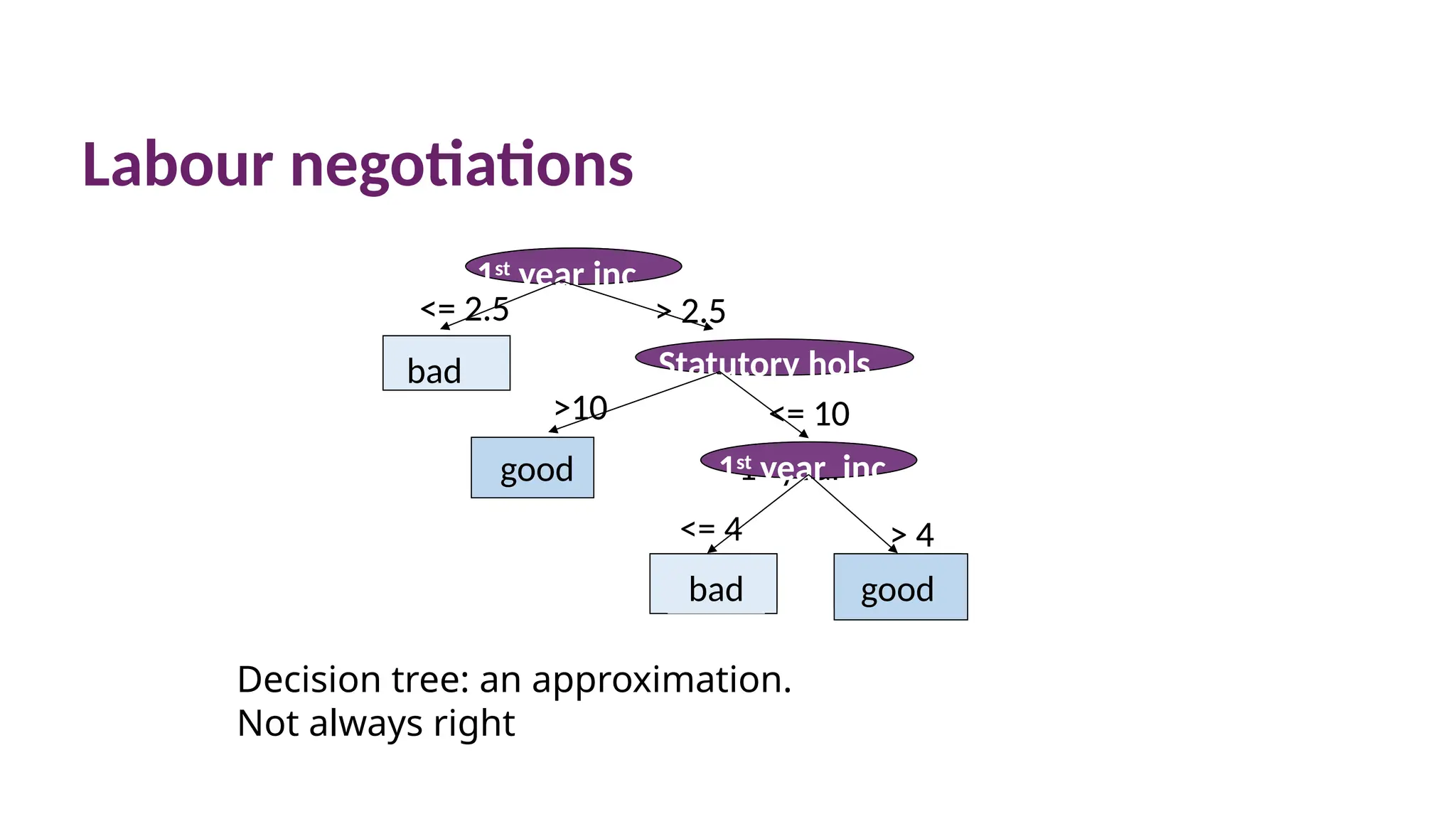
Labour negotiations
Decision tree:an approximation.
Not always right
1st
year
ba
good
<= 2.5 > 2.5
>10 <= 10
<= 4 > 4
1st
year inc
Statutory hols
1st
year inc
bad
good
bad
good
<= 2.5 > 2.5
>10 <= 10
> 4
31.
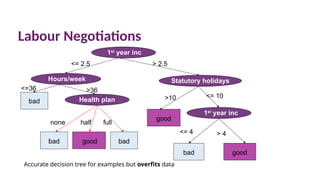
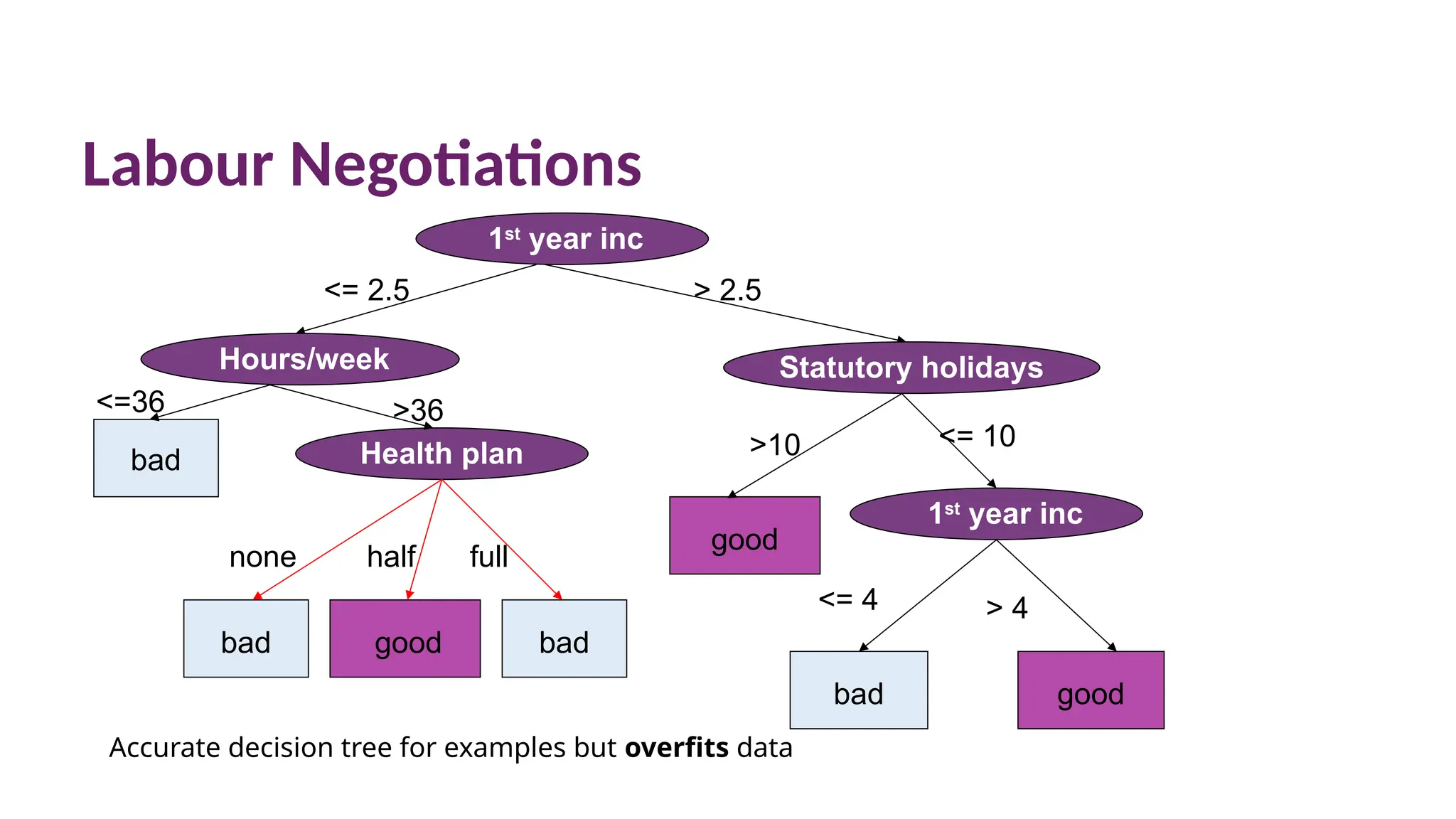
Labour Negotiations
Accurate decisiontree for examples but overfits data
1st
year inc
bad
<= 2.5 > 2.5
Statutory holidays
1st
year inc
bad
good
good
>10 <= 10
<= 4 > 4
Hours/week
Health plan
bad bad
good
none half full
<=36 >36
32.
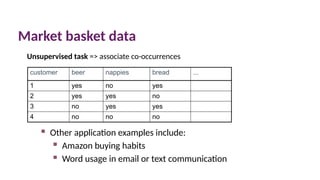
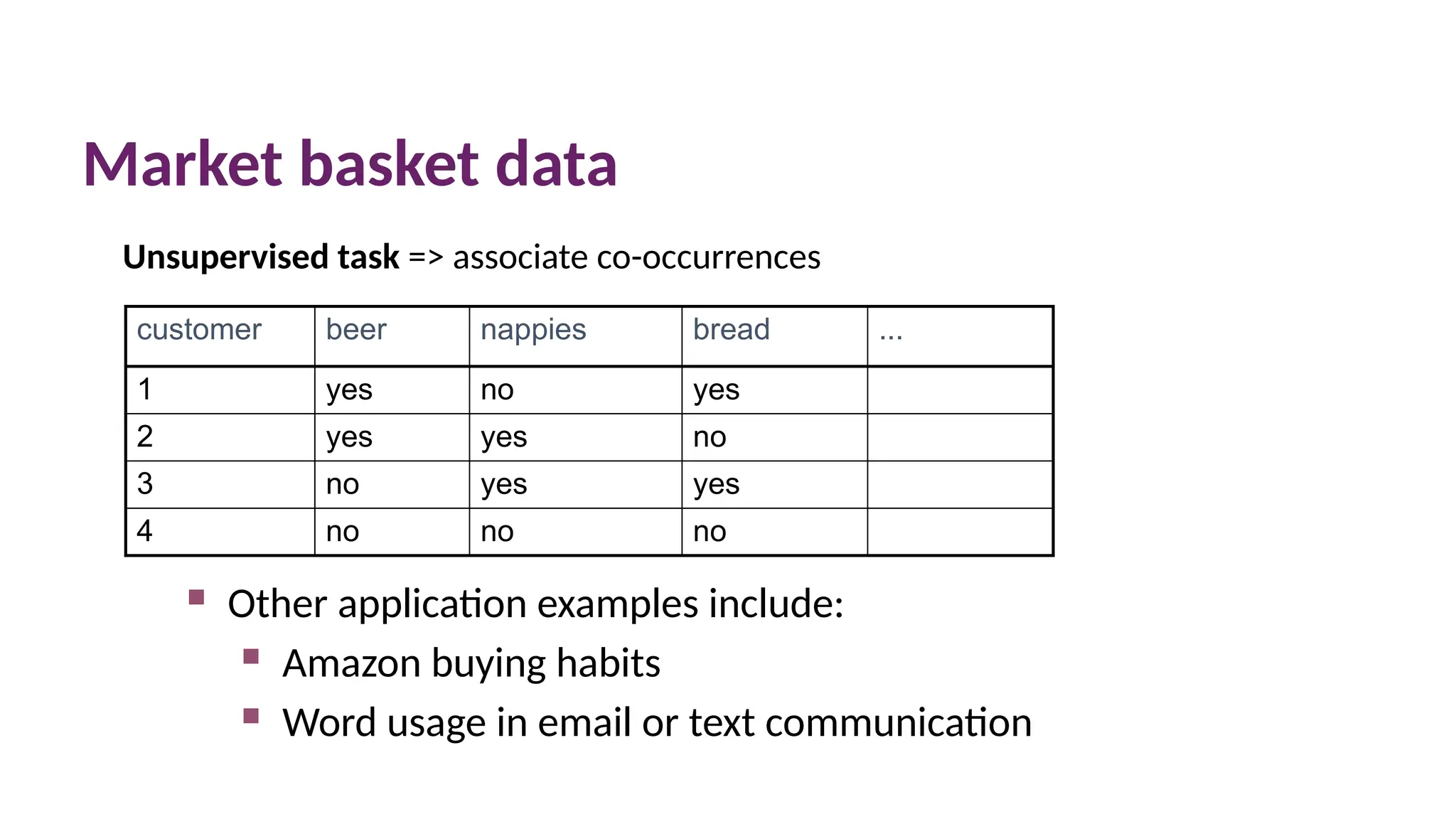
Market basket data
customerbeer nappies bread ...
1 yes no yes
2 yes yes no
3 no yes yes
4 no no no
Other application examples include:
Amazon buying habits
Word usage in email or text communication
Unsupervised task => associate co-occurrences
33.
Output: Association Rules
•Association rule
• If beer = yes and crisps = no then nappy = yes
• If beer = yes then nappy = yes and bread = no
Different from
• If outlook = sunny and windy = no then play = yes
• Predicted attribute changes [ not always play]
• Like classification rules BUT
• used to infer the value of any attribute (not just class)
• or a combination of attributes
34.
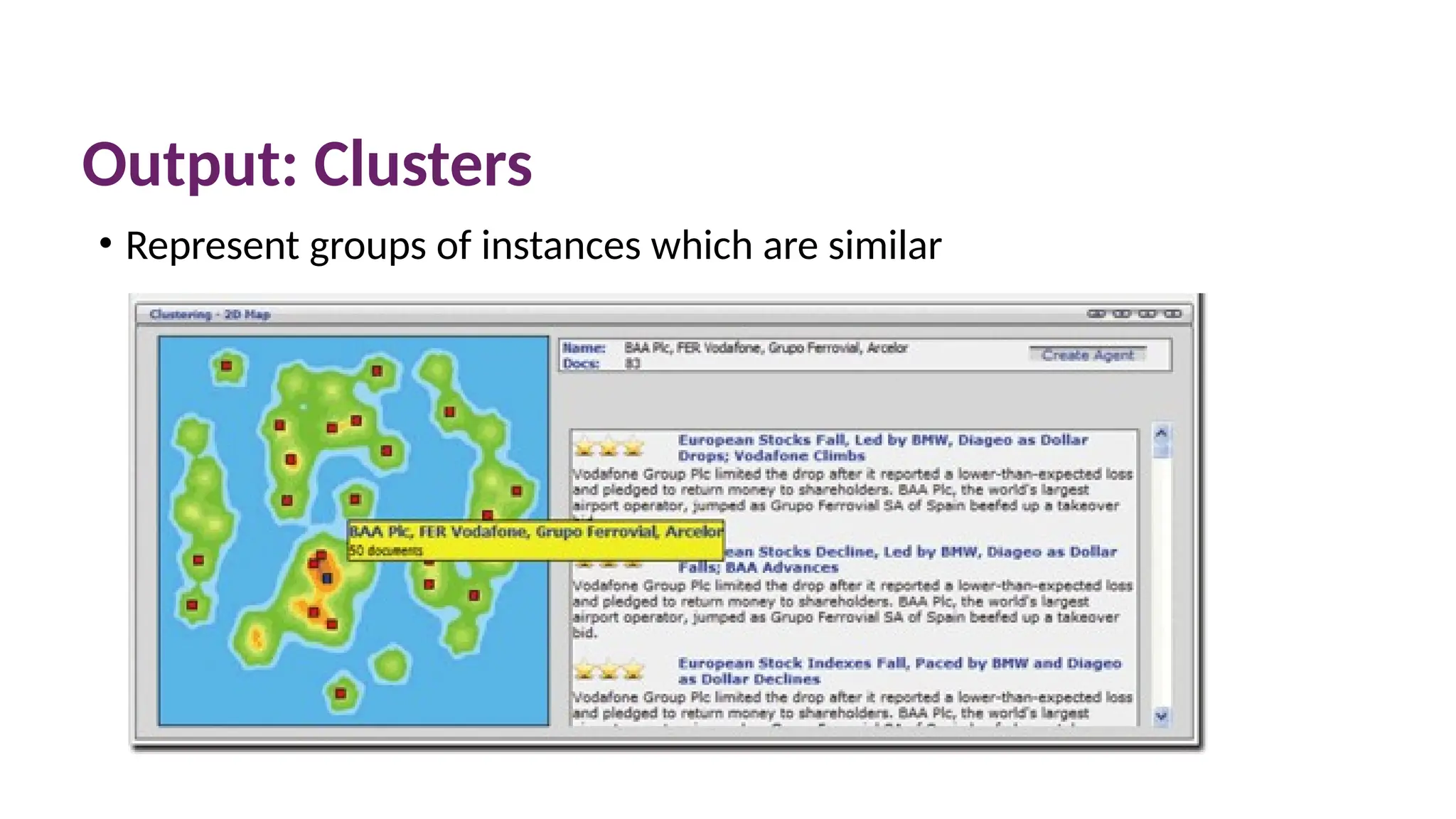
Clustering Collection ofDocuments
Doc.ID Keywords in Title Keywords in Body text
125 {Explosive Data Gro
wth}
{Software got better, and open-source movements and
also the science of analysis became better... }
29 {Data
Mining Community's
Top Resource}
{special techniques are used to find patterns in data}
…
Unsupervised task: form clusters
• Generally the bag of words will need to be pre-processed and converted into a vector
form to enable a data mining algorithm to work with it
• Other examples: clustering of images, clustering of customers by similar buying habits
etc.
Contents
• Data vs.Information
• Data mining
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
37.
Applications
• Automatic estimationof organisms in zooplankton samples
• Maintenance schedules of heavy machinery.
• Autoclave layout for aircraft parts
• Automated completion of repetitive forms
• Loan decision-making
• Image screening
• …etc
38.
Should an applicantget a loan?
• Statistical model deals with 90% cases
• 10% cases referred to loan officers
• 50% referred cases are bad
• BUT referred customers generate money!!!
• Expert gets 50% of referred cases right
• Solution: use data mining to aid decision of borderline cases
39.
Should an applicantget a loan?
• 1000 training examples
• 20 attributes
• Extracted rules accurately predict 70% referred cases
• Much better than human expert!
• Rules could be used to explain to customers the reasons for the
company’s decision.
40.
Detecting Oil Spillsfrom Images
• Data: radar satellite images
• Oil spills: dark regions with changing size and shape
• BUT weather conditions can also cause this effect!!!
• So spill detection is a specialised job.
• Problems:
• very few training examples
• data is not balanced (most dark areas are NOT spills)
no
yes
41.
Detecting Oil Spillsfrom Images
• Normalised image used for extraction of dark regions
• 7 attributes used: size, shape, area, intensity, sharpness and
jaggedness of boundaries, proximity to other regions, info about
background in vicinity of region.
• Batch: regions from a specific image
• Adjustable false alarm rate required
42.
Contents
• Data vs.Information
• Data mining
• Methodology
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
43.
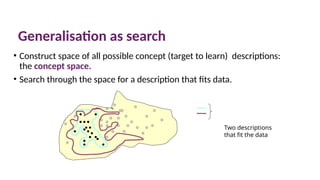
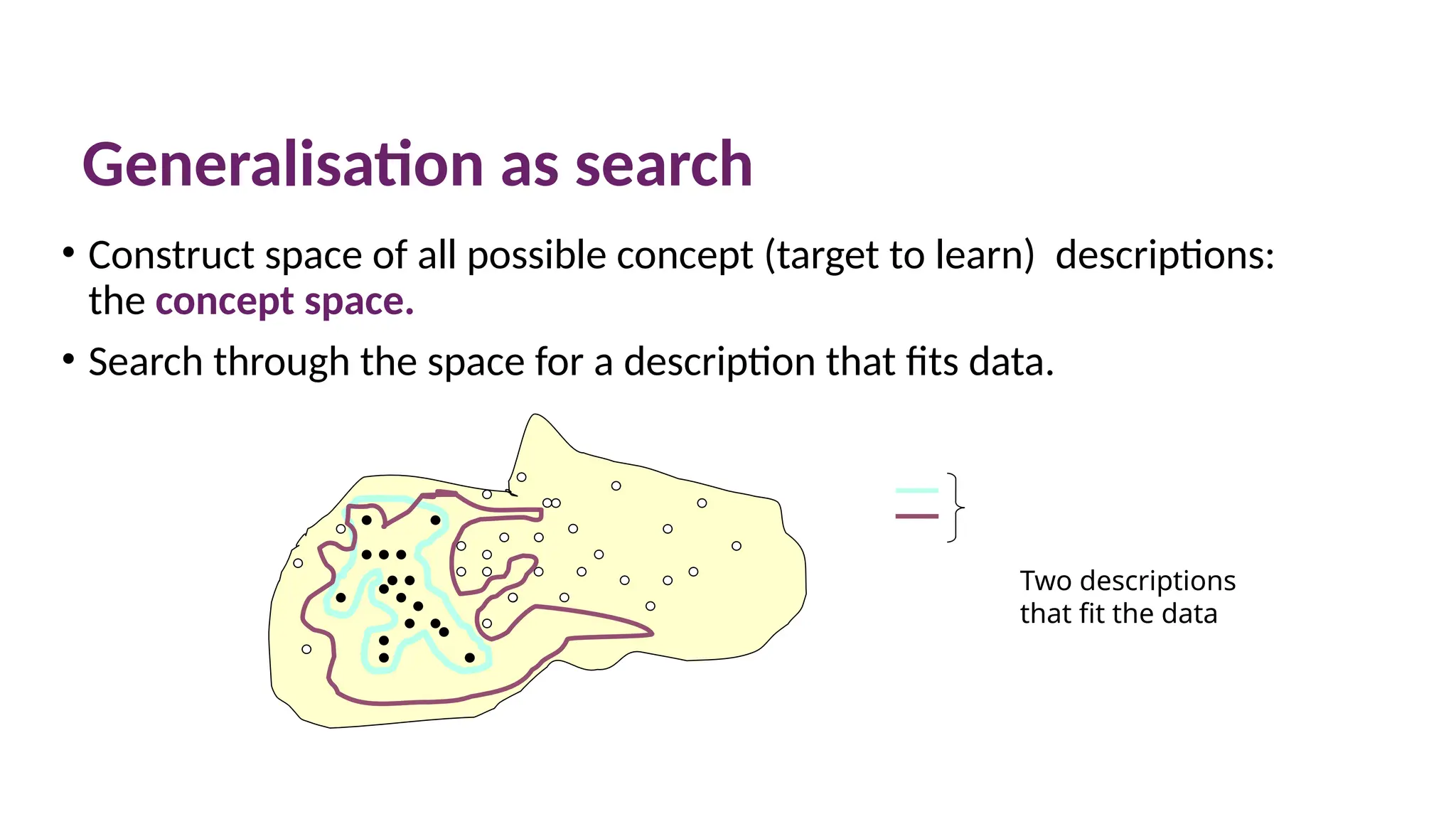
Generalisation as search
•Construct space of all possible concept (target to learn) descriptions:
the concept space.
• Search through the space for a description that fits data.
Two descriptions
that fit the data
44.
Concept space
• Setof possible concept descriptions may be enormous.
• E.g. deciding whether to play or not (the weather problem):
• 4 possibilities for outlook: sunny, overcast, rainy or not in rule.
• 4 for temperature, 3 for weather , 3 for humidity and 2 for play (outcome
so it has to be in the rule).
• 4 * 4 * 3 * 3 * 2 = 288 possibilities for each rule.
• Assumption: rule set no bigger than data set (14).
• Approx. 2.7 * 1034
different rule sets!!!!!
45.
Enumerating concept space
•There are techniques to make enumeration more feasible.
• But
• It is rare to find only ONE acceptable description
• Find several (lots): which is best?
• Not find any (description language is not expressive enough or noisy data)
• Machine learning techniques use heuristics to narrow down the
search
• Heuristic: rule of the thumb. “Trick” which usually works. Not
guaranteed to find a (optimal) solution.
46.
Bias
• Machine learningtechniques bias search by
• Choosing a concept description language: language bias
• Selecting the order in which space is searched: search bias
• Avoiding overfitting: overfitting-avoidance bias
47.
Language bias
• Doesthe language restrict the concepts which can be learnt?
• Concept: divides data into sets of examples - one for each class (solution, outcome) value.
• Universal language: can express all possible subsets of examples.
• Domain knowledge: redundant or impossible combinations of attribute values are not
considered.
• Reduction of the search space
• Disjunction (or): ensures language can represent any subset when using rules.
• Can be expressed using a separate rule for each option.
• If a or b then c → if a then c
if b then c
48.
Search bias
• Manyconcept descriptions fit data
• Find best
• Simplest?
• Fit: statistically agrees with the data
• So there may be some cases where it doesn’t agree with the data.
• Best description: use heuristic to search
• it may not be optimal
• E.g. finding best rule at each stage may not give best combination of rules.
• Type of search
• Start with general description and specialise
• Start with specific description and generalise
• Overfitting avoidance bias: bias towards simple concept descriptions
49.
Contents
• Data vs.Information
• Data mining
• Methodology
• Examples: input and output
• Applications
• Generalisation as search
• Ethical and professional issues
• Summary
50.
10 March 202550
Ethical and professional issues
• GDPR
• The UK Government Data Ethics framework
• The BCS code of conduct
51.
Data Protection
• GDPRdescribes how (personal) data should be used by organisations,
businesses, the government and the general public. See
ec.europa.eu/commission/priorities/justice-and-fundamental-rights/data-
protection/2018-reform-eu-data-protection-rules_en [accessed 17/09/2019] )
• It includes
• Data processing
• Data movement
52.
Ethical Issues
• Howare ethical issues dealt with?
• E.g. use applicant’s sex, religion or race in order to decide whether to give a
loan - unethical
• BUT these same attributes are OK when used in medical application
• The use of data for certain applications may pose problems
• E.g. postcode may be a strong indicator of an individual’s race.
• Data collected for a particular reason should not be used (using data mining) for a
completely different purpose without appropriate consent.
• Information mined may be surprising: red car owners are more likely to have
problems paying their car loans in France.
53.
Ethical issues
• Anonymisationof data
• Does NOT guarantee data is “anonymous”
• E.g. Staff satisfaction questionnaire which asks for race and position
• There may be only one person of that race with that position
• E.g. 85% Americans identified by postcode, birth date and gender
• In the UK, postcode and car model may be enough to identify a person even if car model is
“common”.
54.
Ethical issues
• Outputfrom data mining must be carefully considered
• Arguments purely based on statistics are not sufficient
• Caveats should be put on conclusions
55.
10 March 202555
The data ethics framework
• See
• https://www.gov.uk/government/publications/data-ethics-framework/data-ethics-fra
mework
[accessed 25/09/2020]
• Main principles
1. Start with clear user need and public benefit
2. Be aware of relevant legislation and codes of practice
3. Use data that is proportionate to the user need
4. Understand the limitations of the data
5. Ensure robust practices and work within your skillset
6. Make your work transparent and be accountable
7. Embed data use responsibly
56.
10 March 202556
The data ethics workbook
• “Should be completed collectively by practitioners, data governance or
information assurance specialists, and subject matter experts like
service staff or policy professionals”
• Also decide how often to reassess the project with respect to the
framework principles.
• See questions to be answered at
• https://www.gov.uk/government/publications/data-ethics-workbook/data-et
hics-workbook
[accessed 25/09/2020]
57.
10 March 202557
BCS professional conduct
• The British Computer Society has a professional code of conduct
available at
• https://www.bcs.org/membership/become-a-member/bcs-code-of-conduct/
[ accessed 25/09/2020]
• Principles
• Make IT for everyone
• Show what you know, learn what you don’t
• Respect the organisation or the individual you work for
• Keep IT real, keep IT professional, pass IT on.
58.
Contents
• Data vs.Information
• Data mining
• Examples: input and output
• Data mining and machine learning
• Applications
• Generalisation as search
• Ethical issues
• Summary
59.
Summary
• Very valuableinformation can be extracted from data
• Relies on a large set of examples and machine learning techniques.
• Methodology is often agile, e.g. CRISP-DM
• Format of input and output constrain what can be learnt.
• Wide range of applications.
• Ethical issues restrict use of data for certain purposes.









![Data Mining Requirements
Data
A (large) set of
past data
[including
outcome].
Machine learning
One or more
programs which
extract
relationships
(patterns)
between data,
i.e. information.
Evaluation
is the output
always/mostly
/rarely
correct?
What kind of
errors?](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-10-320.jpg)
![Machine Learning
• Used in data mining to obtain relationships (patterns) between data
• Learning
• Capable of changing behaviour in order to perform better
• Learning from examples
• Training data: examples used for learning
• [Validation data: examples used for tuning parameters]
• Test data: examples used to test learnt knowledge.](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-11-320.jpg)









![Output: Association Rules
• Association rule
• If beer = yes and crisps = no then nappy = yes
• If beer = yes then nappy = yes and bread = no
Different from
• If outlook = sunny and windy = no then play = yes
• Predicted attribute changes [ not always play]
• Like classification rules BUT
• used to infer the value of any attribute (not just class)
• or a combination of attributes](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-33-320.jpg)
















![Data Protection
• GDPR describes how (personal) data should be used by organisations,
businesses, the government and the general public. See
ec.europa.eu/commission/priorities/justice-and-fundamental-rights/data-
protection/2018-reform-eu-data-protection-rules_en [accessed 17/09/2019] )
• It includes
• Data processing
• Data movement](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-51-320.jpg)



![10 March 2025 55
The data ethics framework
• See
• https://www.gov.uk/government/publications/data-ethics-framework/data-ethics-fra
mework
[accessed 25/09/2020]
• Main principles
1. Start with clear user need and public benefit
2. Be aware of relevant legislation and codes of practice
3. Use data that is proportionate to the user need
4. Understand the limitations of the data
5. Ensure robust practices and work within your skillset
6. Make your work transparent and be accountable
7. Embed data use responsibly](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-55-320.jpg)
![10 March 2025 56
The data ethics workbook
• “Should be completed collectively by practitioners, data governance or
information assurance specialists, and subject matter experts like
service staff or policy professionals”
• Also decide how often to reassess the project with respect to the
framework principles.
• See questions to be answered at
• https://www.gov.uk/government/publications/data-ethics-workbook/data-et
hics-workbook
[accessed 25/09/2020]](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-56-320.jpg)
![10 March 2025 57
BCS professional conduct
• The British Computer Society has a professional code of conduct
available at
• https://www.bcs.org/membership/become-a-member/bcs-code-of-conduct/
[ accessed 25/09/2020]
• Principles
• Make IT for everyone
• Show what you know, learn what you don’t
• Respect the organisation or the individual you work for
• Keep IT real, keep IT professional, pass IT on.](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/85/01-data-mining-introduction-bayero-u-pptx-57-320.jpg)











![Data Mining Requirements
Data
A (large) set of
past data
[including
outcome].
Machine learning
One or more
programs which
extract
relationships
(patterns)
between data,
i.e. information.
Evaluation
is the output
always/mostly
/rarely
correct?
What kind of
errors?](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-10-2048.jpg)
![Machine Learning
• Used in data mining to obtain relationships (patterns) between data
• Learning
• Capable of changing behaviour in order to perform better
• Learning from examples
• Training data: examples used for learning
• [Validation data: examples used for tuning parameters]
• Test data: examples used to test learnt knowledge.](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-11-2048.jpg)









![Output: Association Rules
• Association rule
• If beer = yes and crisps = no then nappy = yes
• If beer = yes then nappy = yes and bread = no
Different from
• If outlook = sunny and windy = no then play = yes
• Predicted attribute changes [ not always play]
• Like classification rules BUT
• used to infer the value of any attribute (not just class)
• or a combination of attributes](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-33-2048.jpg)















![Data Protection
• GDPR describes how (personal) data should be used by organisations,
businesses, the government and the general public. See
ec.europa.eu/commission/priorities/justice-and-fundamental-rights/data-
protection/2018-reform-eu-data-protection-rules_en [accessed 17/09/2019] )
• It includes
• Data processing
• Data movement](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-51-2048.jpg)



![10 March 2025 55
The data ethics framework
• See
• https://www.gov.uk/government/publications/data-ethics-framework/data-ethics-fra
mework
[accessed 25/09/2020]
• Main principles
1. Start with clear user need and public benefit
2. Be aware of relevant legislation and codes of practice
3. Use data that is proportionate to the user need
4. Understand the limitations of the data
5. Ensure robust practices and work within your skillset
6. Make your work transparent and be accountable
7. Embed data use responsibly](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-55-2048.jpg)
![10 March 2025 56
The data ethics workbook
• “Should be completed collectively by practitioners, data governance or
information assurance specialists, and subject matter experts like
service staff or policy professionals”
• Also decide how often to reassess the project with respect to the
framework principles.
• See questions to be answered at
• https://www.gov.uk/government/publications/data-ethics-workbook/data-et
hics-workbook
[accessed 25/09/2020]](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-56-2048.jpg)
![10 March 2025 57
BCS professional conduct
• The British Computer Society has a professional code of conduct
available at
• https://www.bcs.org/membership/become-a-member/bcs-code-of-conduct/
[ accessed 25/09/2020]
• Principles
• Make IT for everyone
• Show what you know, learn what you don’t
• Respect the organisation or the individual you work for
• Keep IT real, keep IT professional, pass IT on.](https://image.slidesharecdn.com/01-dm-intro-250310172754-186482d4/75/01-data-mining-introduction-bayero-u-pptx-57-2048.jpg)
















































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
