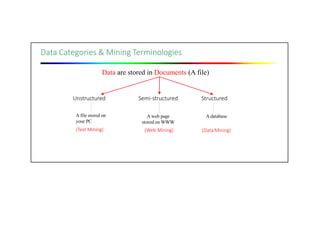
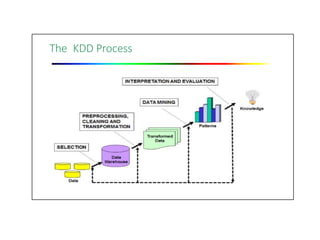
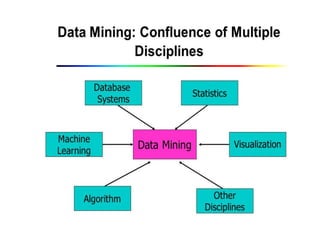
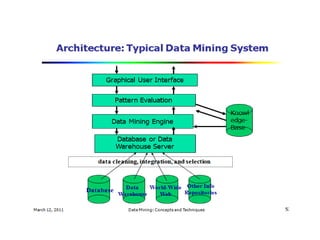
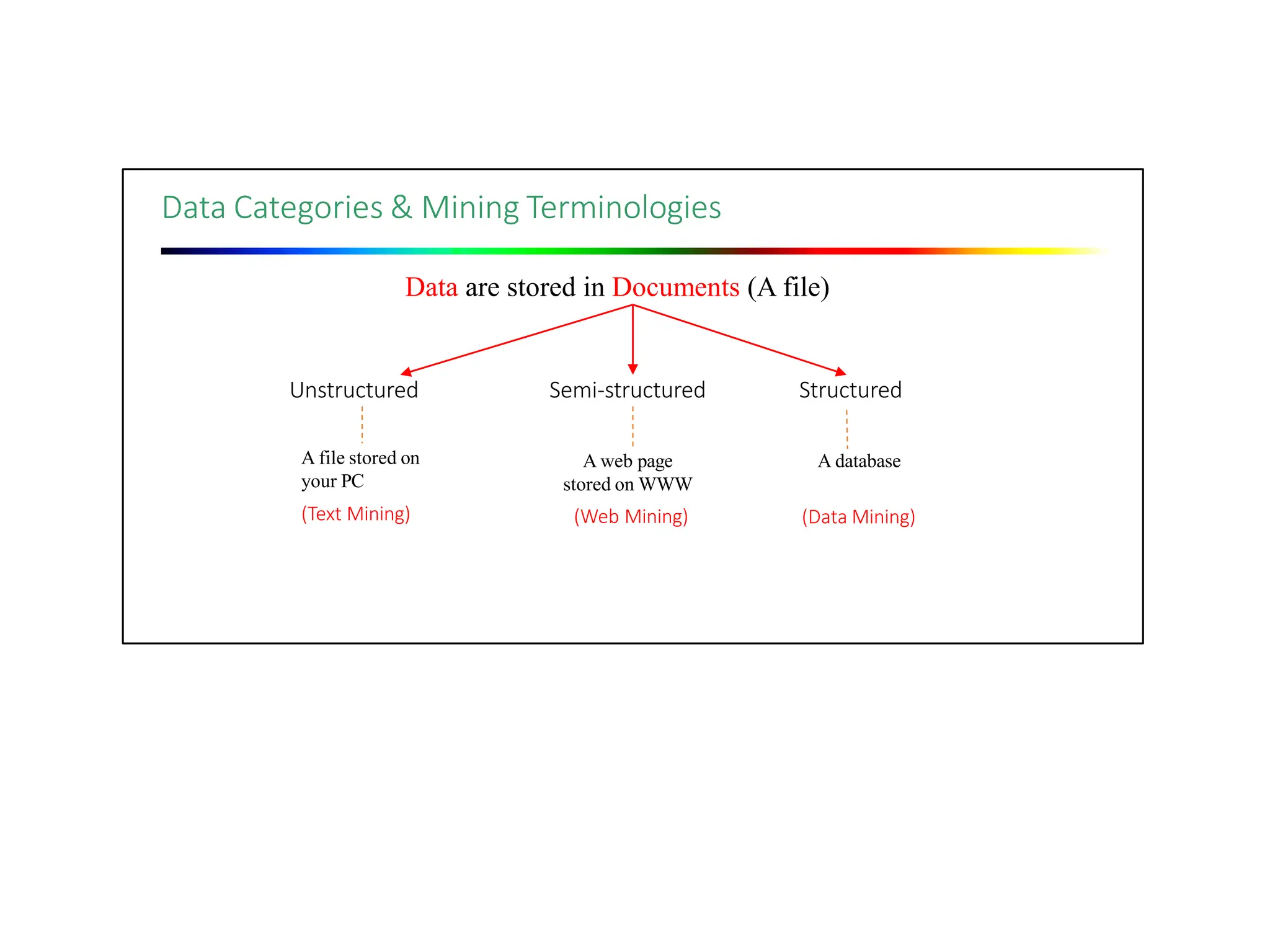
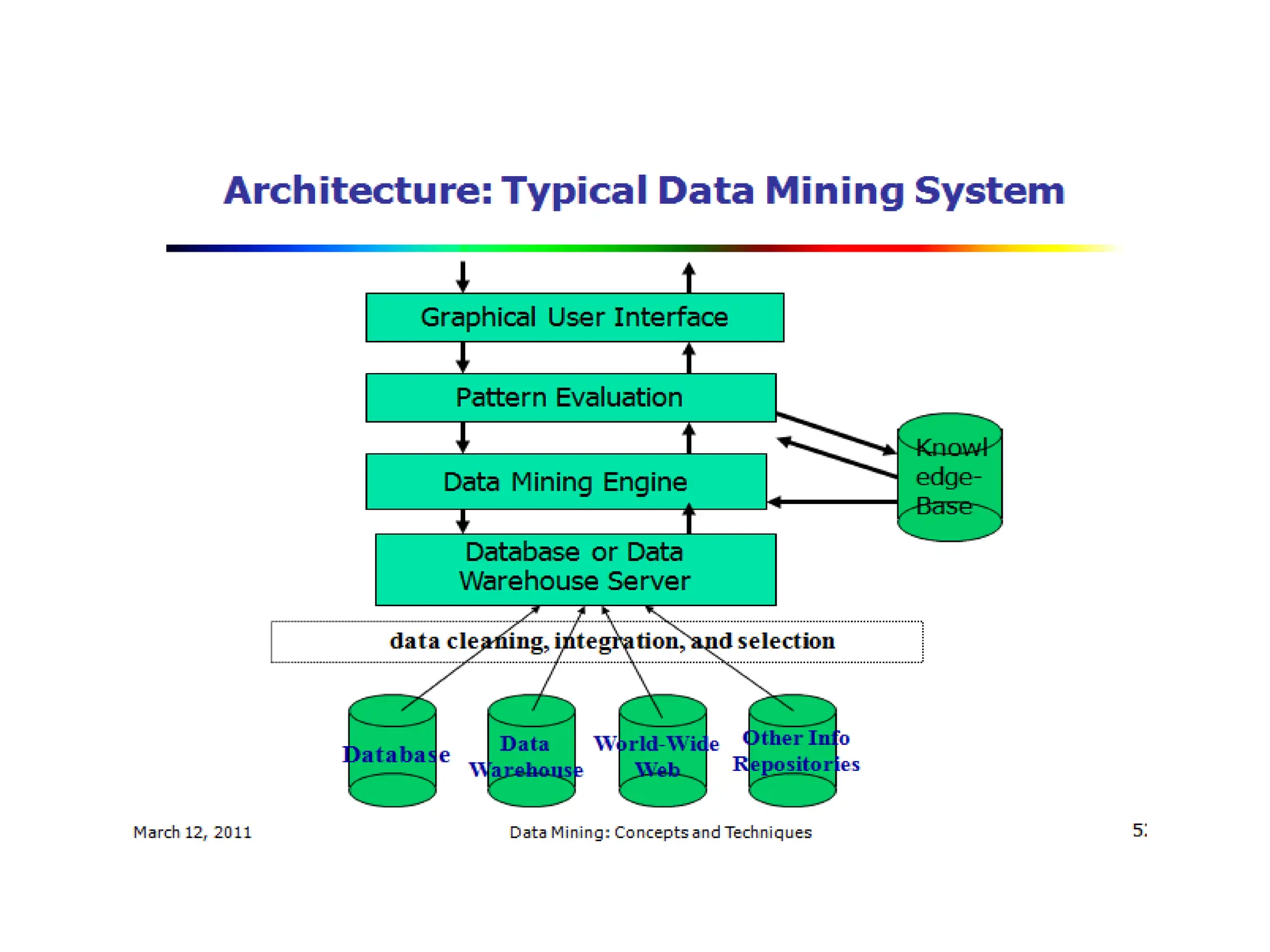
The document outlines the prerequisites for data mining, including knowledge of discrete mathematics, probability theory, and algorithms. It explains data as unprocessed facts that transform into information when analyzed, which can then contribute to knowledge. Covers data mining processes, functionalities, tools, issues, and diverse applications ranging from business to scientific research.