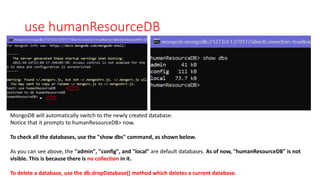
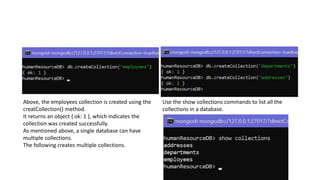
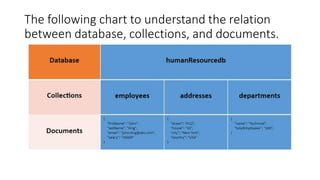
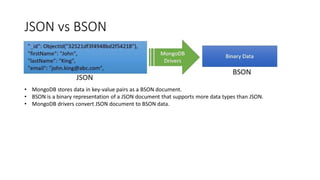
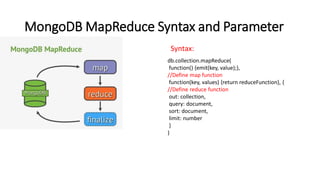
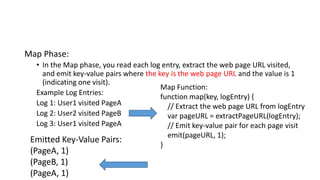
The document discusses MongoDB and MapReduce. It provides an introduction to MongoDB and NoSQL databases. It then explains the MapReduce programming paradigm in MongoDB, which allows processing large datasets and producing aggregated results. It describes the map and reduce functions used in MapReduce and provides an example of a simple MapReduce operation to count the number of visits to different web pages from log data.



![What is Document based storage?
• A Document is nothing but a data structure with name-value pairs like in
JSON.
• It is very easy to map any custom Object of any programming language with a
MongoDB Document.
• For example : Student object has attributes name, rollno and subjects, where
subjects is a List.
{
name : “Maria",
rollno : 1,
subjects : ["C Language", "C++", "Core Java"]
}](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/85/3-Mongodb-and-Mapreduce-Programming-pdf-5-320.jpg)








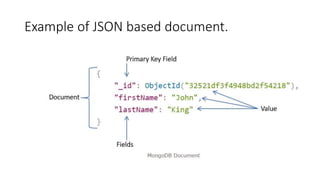
![Example of a document that contains an array
and an embedded document.
{
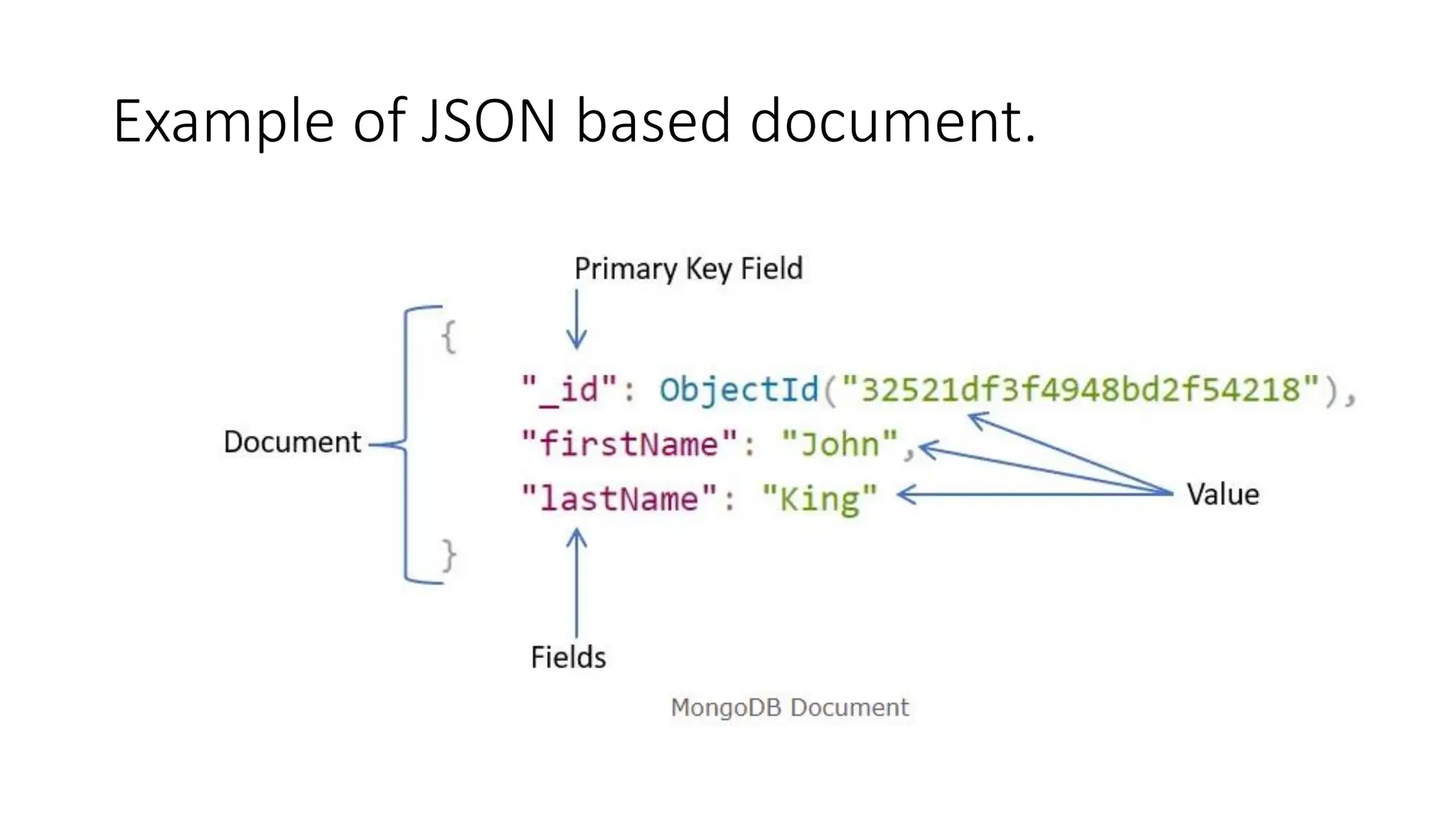
"_id": ObjectId("32521df3f4948bd2f54218"),
"firstName": "John",
"lastName": "King",
"email": "john.king@abc.com",
"salary": "33000",
"DoB": new Date('Mar 24, 2011'),
"skills": [ "Angular", "React", "MongoDB" ],
"address": {
"street":"Upper Street",
"house":"No 1",
"city":"New York",
"country":"USA"
}
}
MongoDB document stores data in JSON format.
In the document, "firstName", "lastName", "email", and "salary"
are the fields (like columns of a table in RDBMS) with their
corresponding values (e.g value of a column in a row).
Consider "_id" field as a primary key field that stores a unique
ObjectId.
"skills" is an array and "address" holds another JSON document.](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/85/3-Mongodb-and-Mapreduce-Programming-pdf-17-320.jpg)



![Array
• A field in a document can hold array.
• Arrays can hold any type of data or embedded documents.
• Array elements in a document can be accessed using dot notation with the
zero-based index position and enclose in quotes.
{
_id: ObjectId("32521df3f4948bd2f54218"),
firstName: "John",
lastName: "King",
email: "john.king@abc.com",
skills: [ "Angular", "React", "MongoDB" ],
}
The above document contains the skills field that holds an array of strings. To specify or access the second
element in the skills array, use skills.1.](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/85/3-Mongodb-and-Mapreduce-Programming-pdf-22-320.jpg)

![Datatypes Examples
String:
Examples:
"name": "John"
"city": "New York"
Number (Integer and Double):
Integer Example:
"age": 30
Double Example:
"price": 19.99
Boolean:
Examples:
"isStudent": true
"isWorking": false
Date:
Example:
"birthDate": ISODate("1990-05-15T00:00:00Z")
ObjectId: A unique identifier for documents within a collection.
MongoDB automatically assigns an ObjectId to each document.
Example:
{
"_id": ObjectId("5f5c6d8d165bc2a3a9825ef1"),
"name": "Alice"
}
Array: Represents an ordered list of values.
Example:
{
"hobbies": ["Reading", "Swimming", "Cooking"]
}](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/85/3-Mongodb-and-Mapreduce-Programming-pdf-24-320.jpg)









![• After iterating over each document Emit function will give back the
data like this:
{“A”:[80, 90]}, {“B”:[99, 90]}, {“C”:[90] }
and upto this point it is what map() function does.
The data given by emit function is grouped by sales key, Now this data
will be input to our reduce function.
Reduce function is where actual aggregation of data takes place.
In our example we will pick the Max of each sales like for
sales A:[80, 90] = 90 (Max) B:[99, 90] = 99 (max) , C:[90] = 90(max).](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/85/3-Mongodb-and-Mapreduce-Programming-pdf-36-320.jpg)
























![What is Document based storage?
• A Document is nothing but a data structure with name-value pairs like in
JSON.
• It is very easy to map any custom Object of any programming language with a
MongoDB Document.
• For example : Student object has attributes name, rollno and subjects, where
subjects is a List.
{
name : “Maria",
rollno : 1,
subjects : ["C Language", "C++", "Core Java"]
}](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/75/3-Mongodb-and-Mapreduce-Programming-pdf-5-2048.jpg)




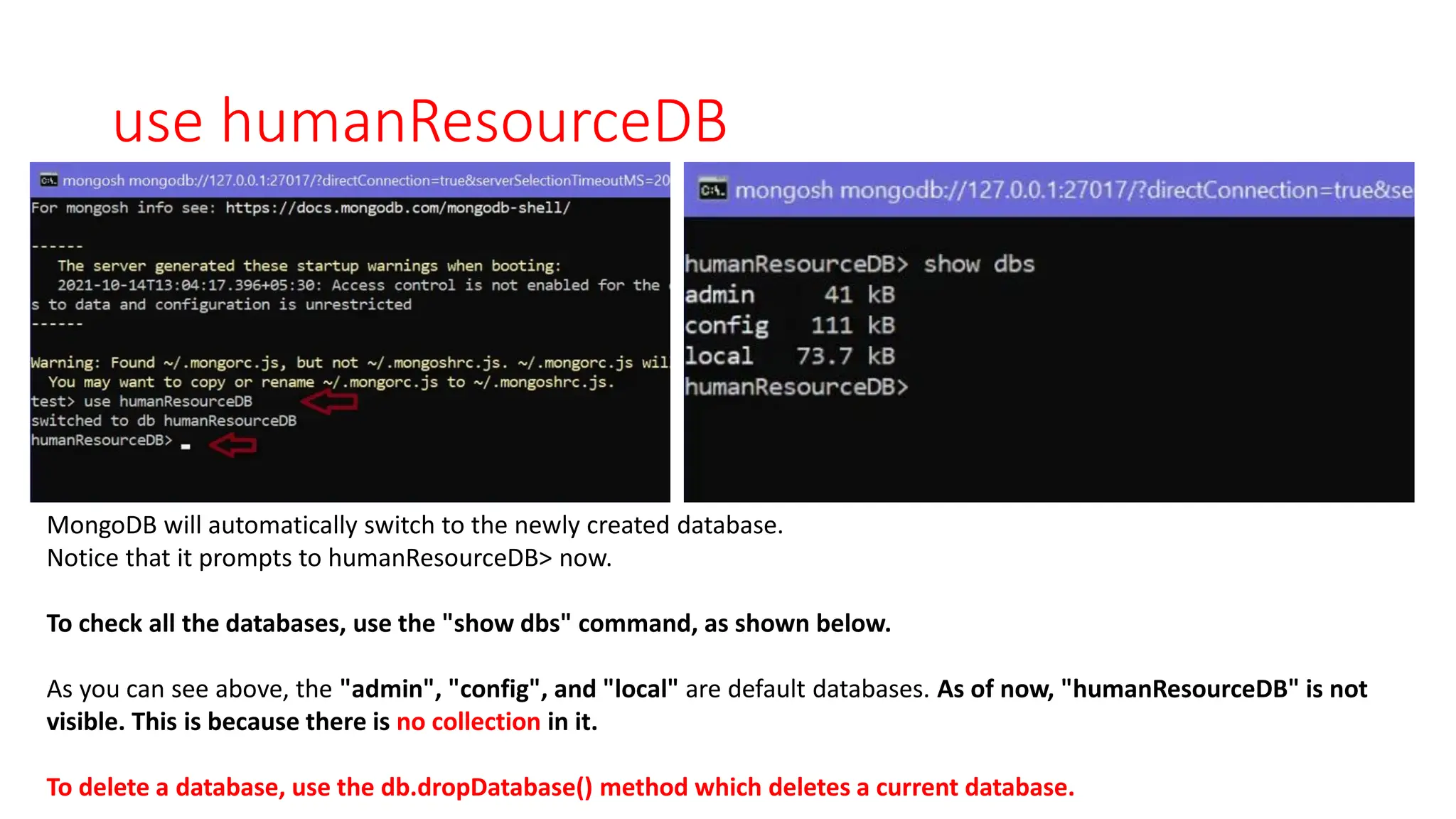




![Example of a document that contains an array
and an embedded document.
{
"_id": ObjectId("32521df3f4948bd2f54218"),
"firstName": "John",
"lastName": "King",
"email": "john.king@abc.com",
"salary": "33000",
"DoB": new Date('Mar 24, 2011'),
"skills": [ "Angular", "React", "MongoDB" ],
"address": {
"street":"Upper Street",
"house":"No 1",
"city":"New York",
"country":"USA"
}
}
MongoDB document stores data in JSON format.
In the document, "firstName", "lastName", "email", and "salary"
are the fields (like columns of a table in RDBMS) with their
corresponding values (e.g value of a column in a row).
Consider "_id" field as a primary key field that stores a unique
ObjectId.
"skills" is an array and "address" holds another JSON document.](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/75/3-Mongodb-and-Mapreduce-Programming-pdf-17-2048.jpg)



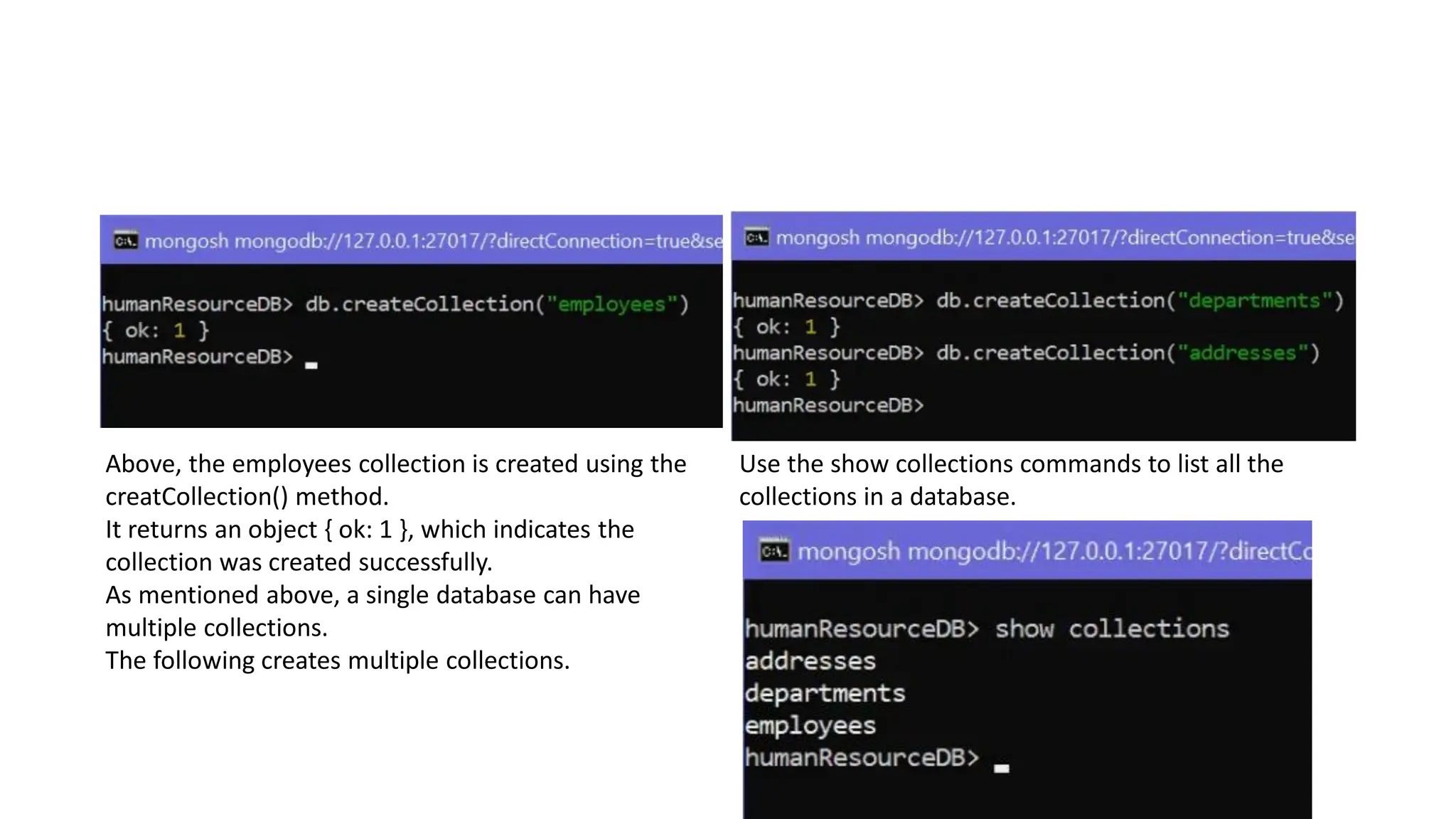
![Array
• A field in a document can hold array.
• Arrays can hold any type of data or embedded documents.
• Array elements in a document can be accessed using dot notation with the
zero-based index position and enclose in quotes.
{
_id: ObjectId("32521df3f4948bd2f54218"),
firstName: "John",
lastName: "King",
email: "john.king@abc.com",
skills: [ "Angular", "React", "MongoDB" ],
}
The above document contains the skills field that holds an array of strings. To specify or access the second
element in the skills array, use skills.1.](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/75/3-Mongodb-and-Mapreduce-Programming-pdf-22-2048.jpg)

![Datatypes Examples
String:
Examples:
"name": "John"
"city": "New York"
Number (Integer and Double):
Integer Example:
"age": 30
Double Example:
"price": 19.99
Boolean:
Examples:
"isStudent": true
"isWorking": false
Date:
Example:
"birthDate": ISODate("1990-05-15T00:00:00Z")
ObjectId: A unique identifier for documents within a collection.
MongoDB automatically assigns an ObjectId to each document.
Example:
{
"_id": ObjectId("5f5c6d8d165bc2a3a9825ef1"),
"name": "Alice"
}
Array: Represents an ordered list of values.
Example:
{
"hobbies": ["Reading", "Swimming", "Cooking"]
}](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/75/3-Mongodb-and-Mapreduce-Programming-pdf-24-2048.jpg)











![• After iterating over each document Emit function will give back the
data like this:
{“A”:[80, 90]}, {“B”:[99, 90]}, {“C”:[90] }
and upto this point it is what map() function does.
The data given by emit function is grouped by sales key, Now this data
will be input to our reduce function.
Reduce function is where actual aggregation of data takes place.
In our example we will pick the Max of each sales like for
sales A:[80, 90] = 90 (Max) B:[99, 90] = 99 (max) , C:[90] = 90(max).](https://image.slidesharecdn.com/3-mongodbandmapreduceprogramming-231206034422-0d353b1c/75/3-Mongodb-and-Mapreduce-Programming-pdf-36-2048.jpg)















































![Data Structures - Lecture 7 [Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-7linkedlists-150121011916-conversion-gate02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








































