참고할 만한 아키텍처가있나요?
너무 많아요, 뭘 써야 하죠?
어떻게 써야 하죠?
왜 많은 것 중 그걸 써야 하는거죠?
16.
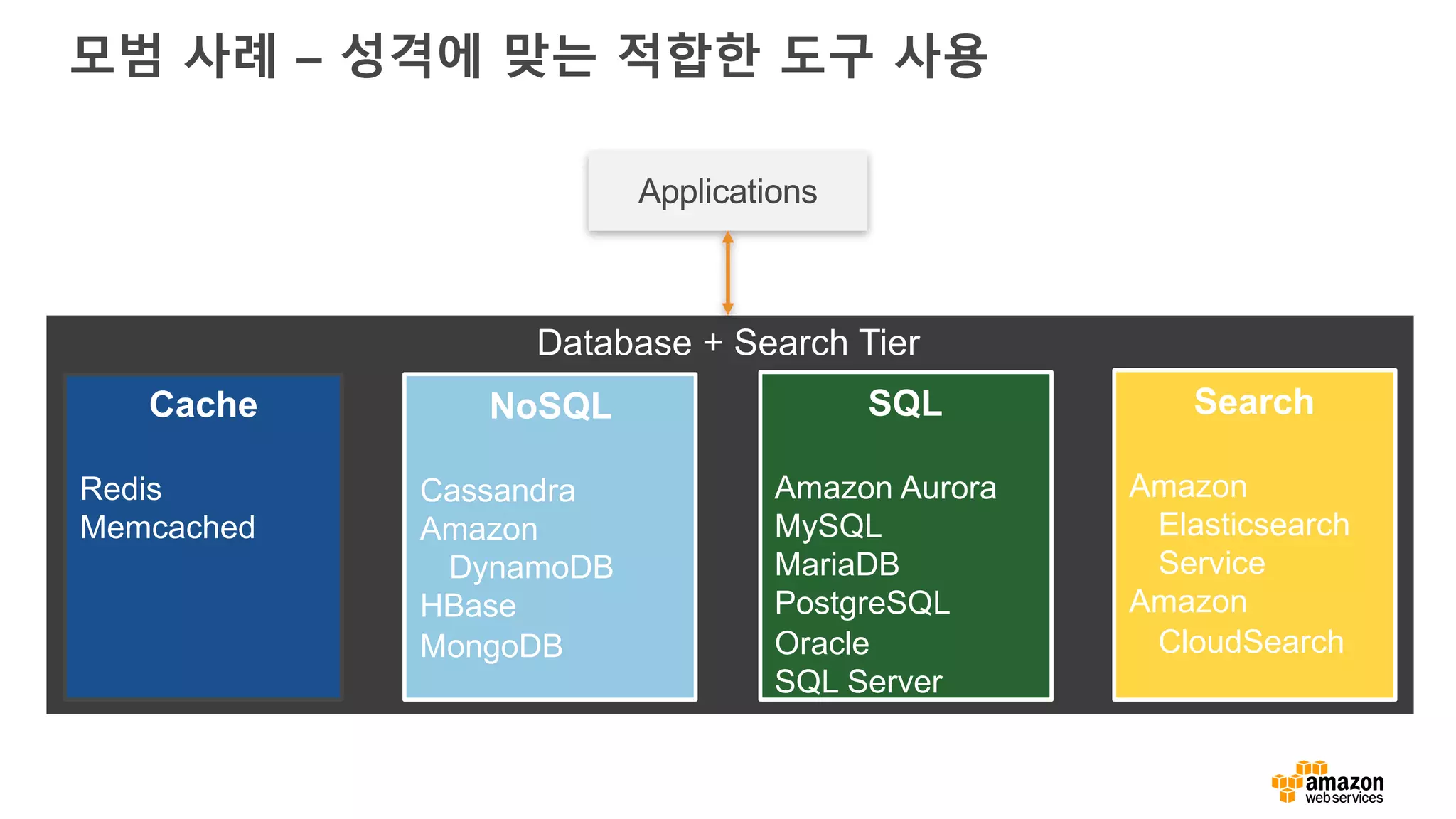
아키텍처 원리
• “데이터버스”의 비결합성
• Data → Store → Process → Answers
• 작업에 적합한 도구를 사용
• Data structure, latency, throughput, access patterns
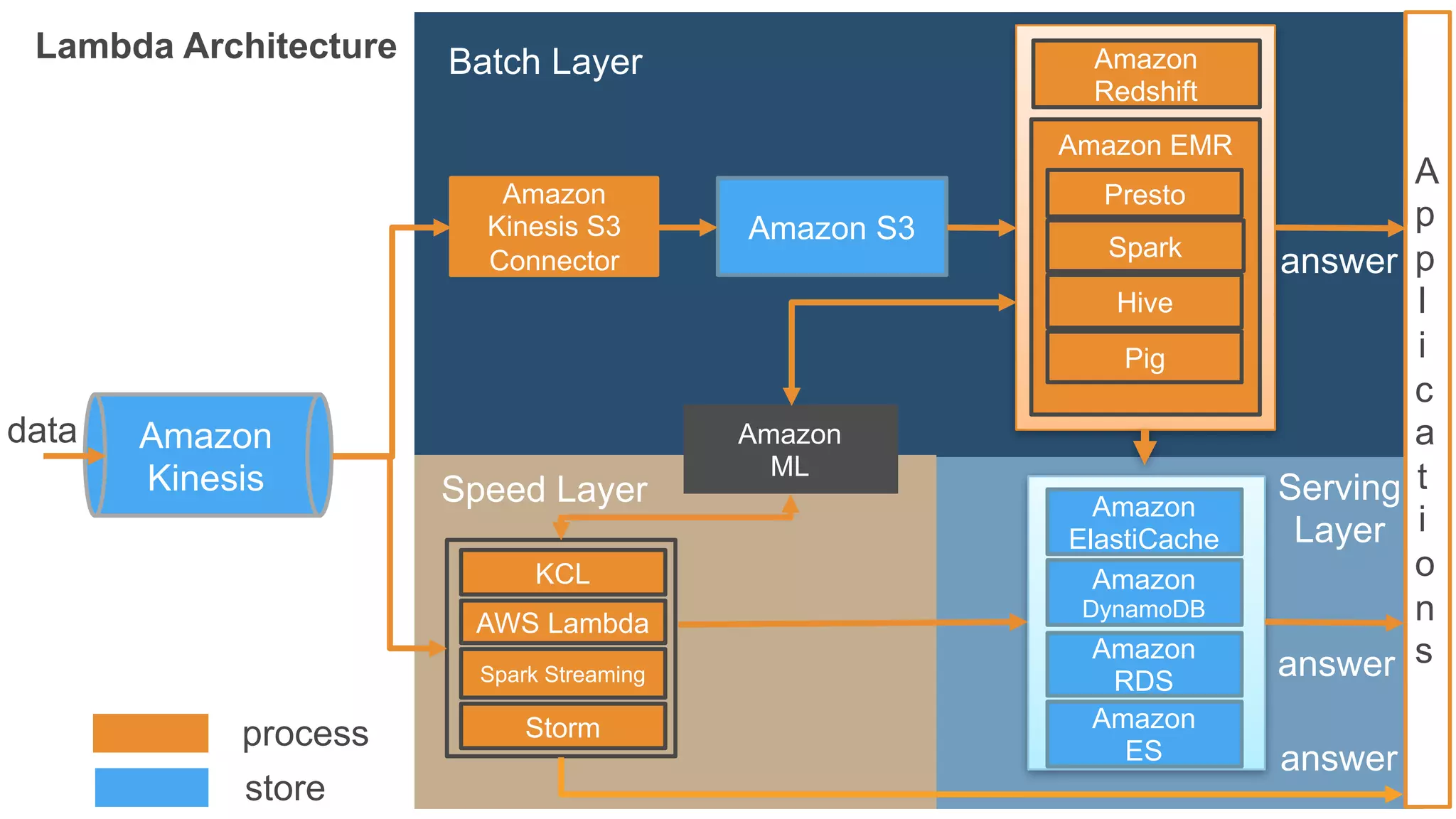
• 람다 아키텍처 활용
• Immutable (append-only) log, batch/speed/serving layer
• AWS 관리형 서비스의 활용
• No/low admin
• Big data != Big cost
17.
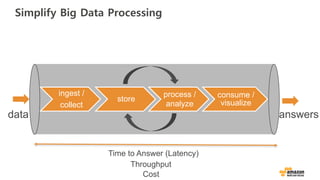
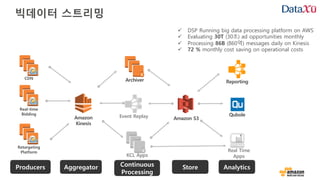
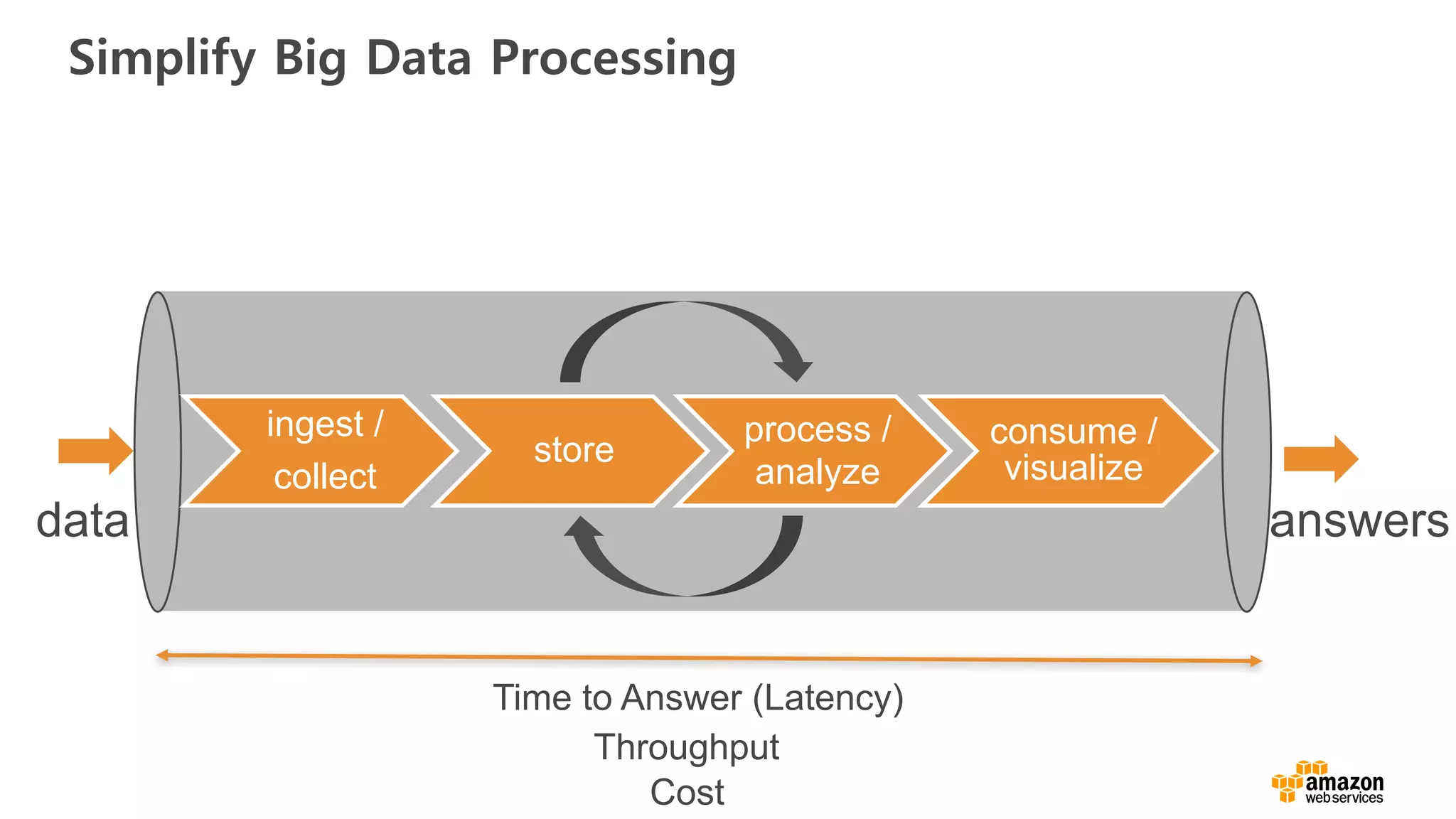
Simplify Big DataProcessing
ingest /
collect
store
process /
analyze
consume /
visualize
data answers
Time to Answer (Latency)
Throughput
Cost
18.
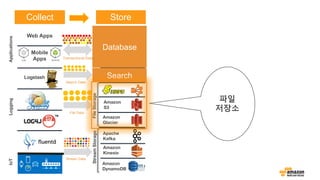
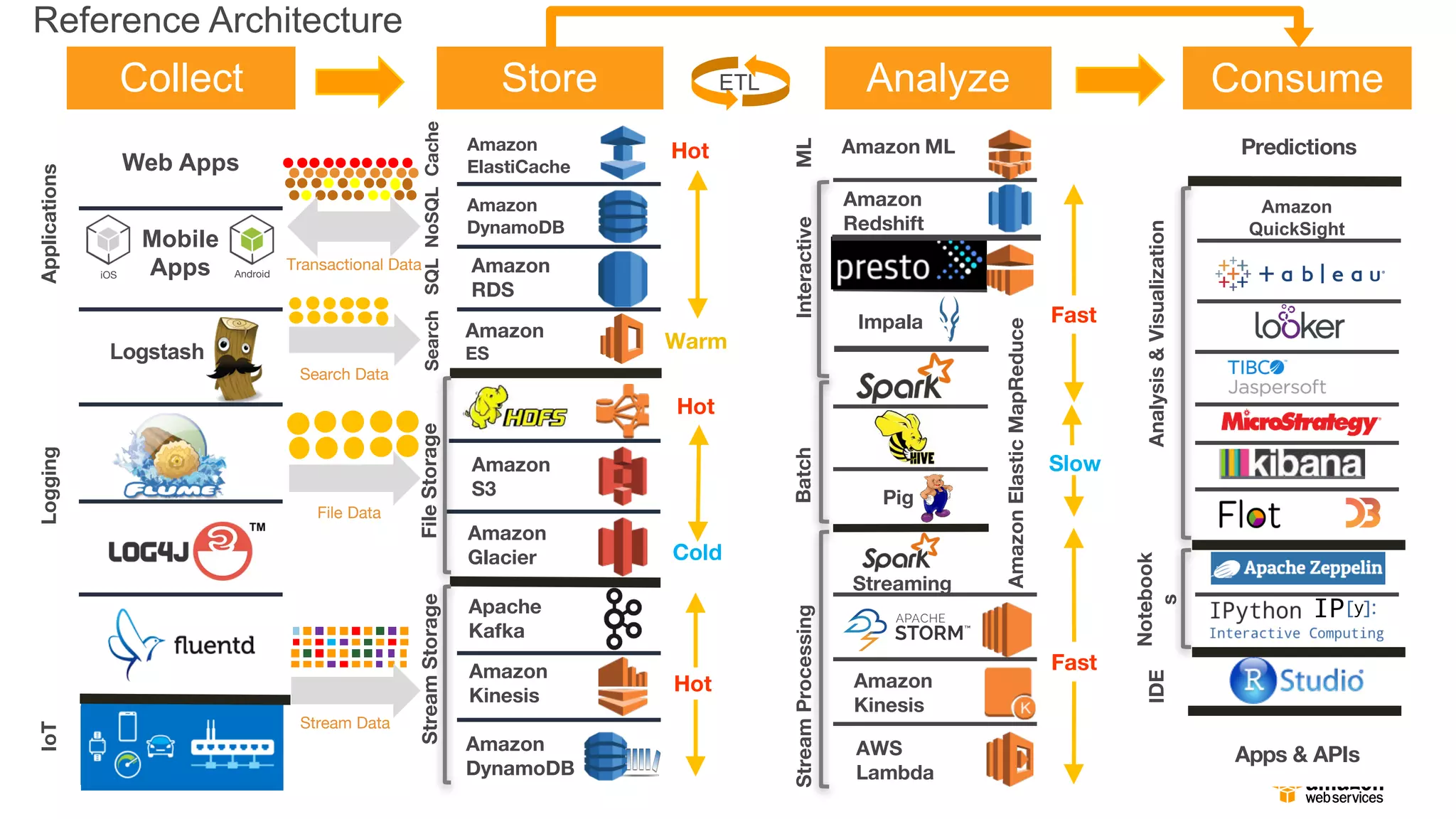
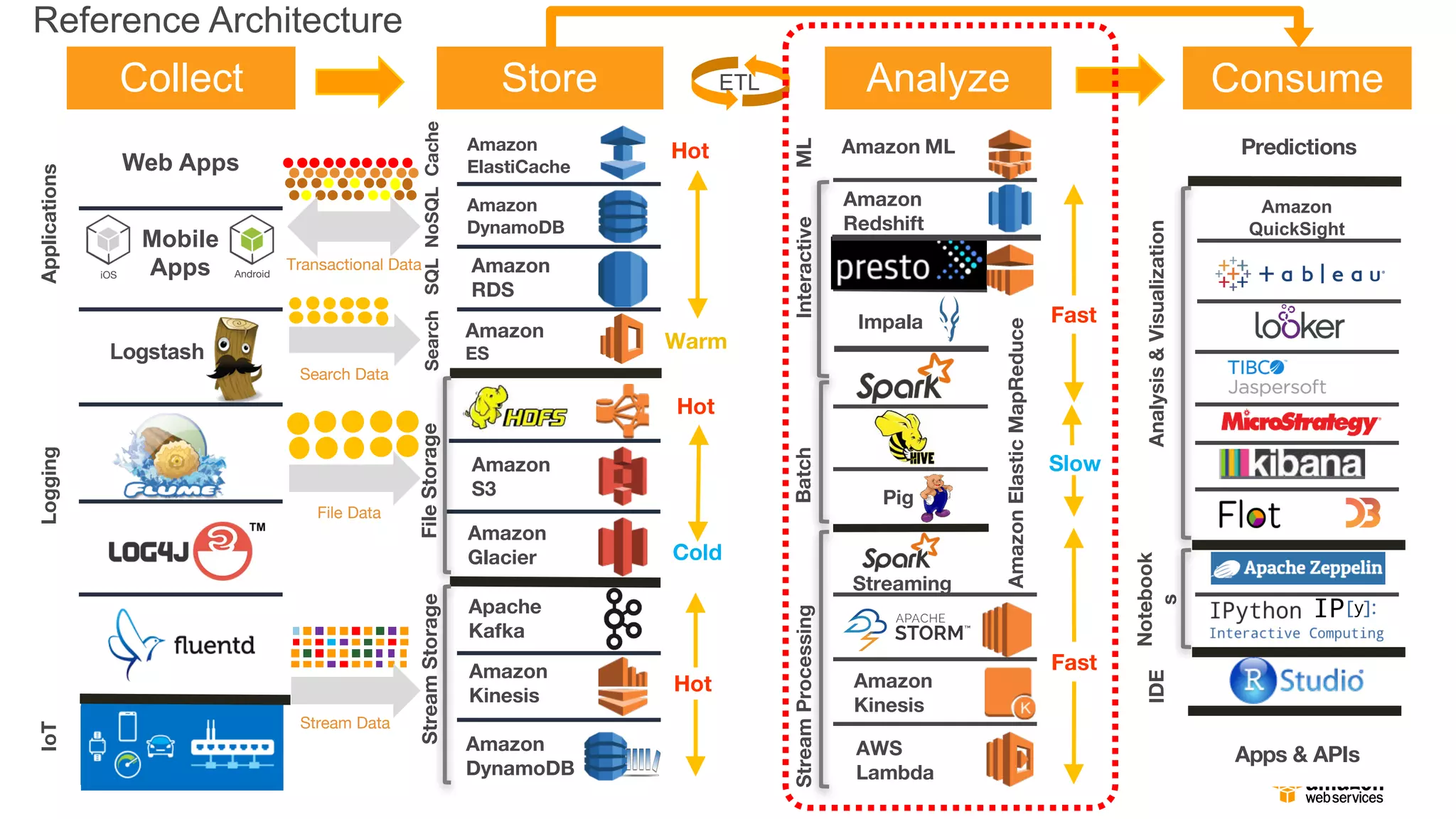
Collect Store AnalyzeConsume
A
iOS Android
Web Apps
Logstash
Amazon
RDS
Amazon
DynamoDB
Amazon
ES
Amazon
S3
Apache
Kafka
Amazon
Glacier
Amazon
Kinesis
Amazon
DynamoDB
Amazon
Redshift
Impala
Pig
Amazon ML
Streaming
Amazon
Kinesis
AWS
Lambda
AmazonElasticMapReduce
Amazon
ElastiCache
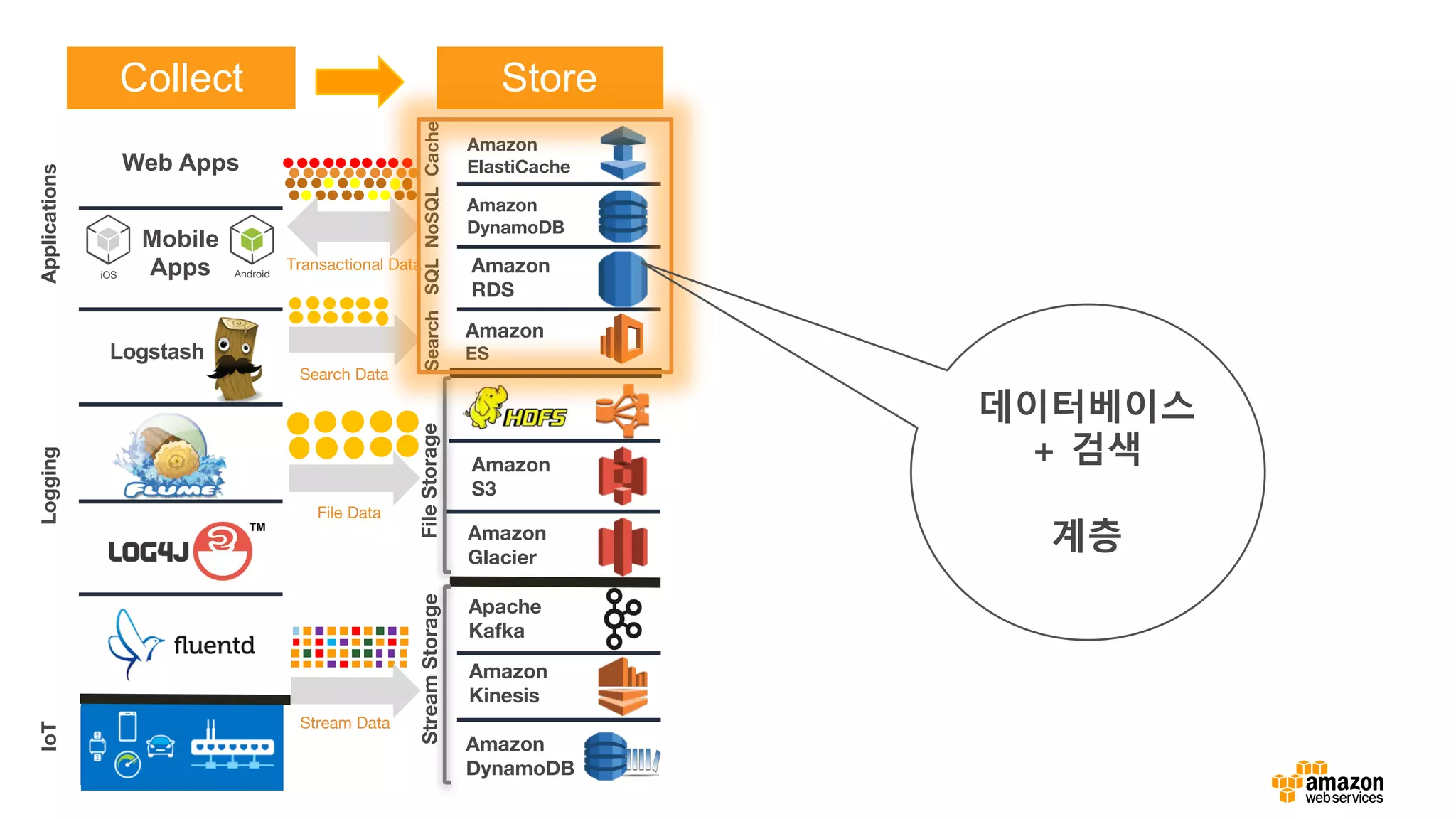
SearchSQLNoSQLCache
StreamProcessingBatchInteractive
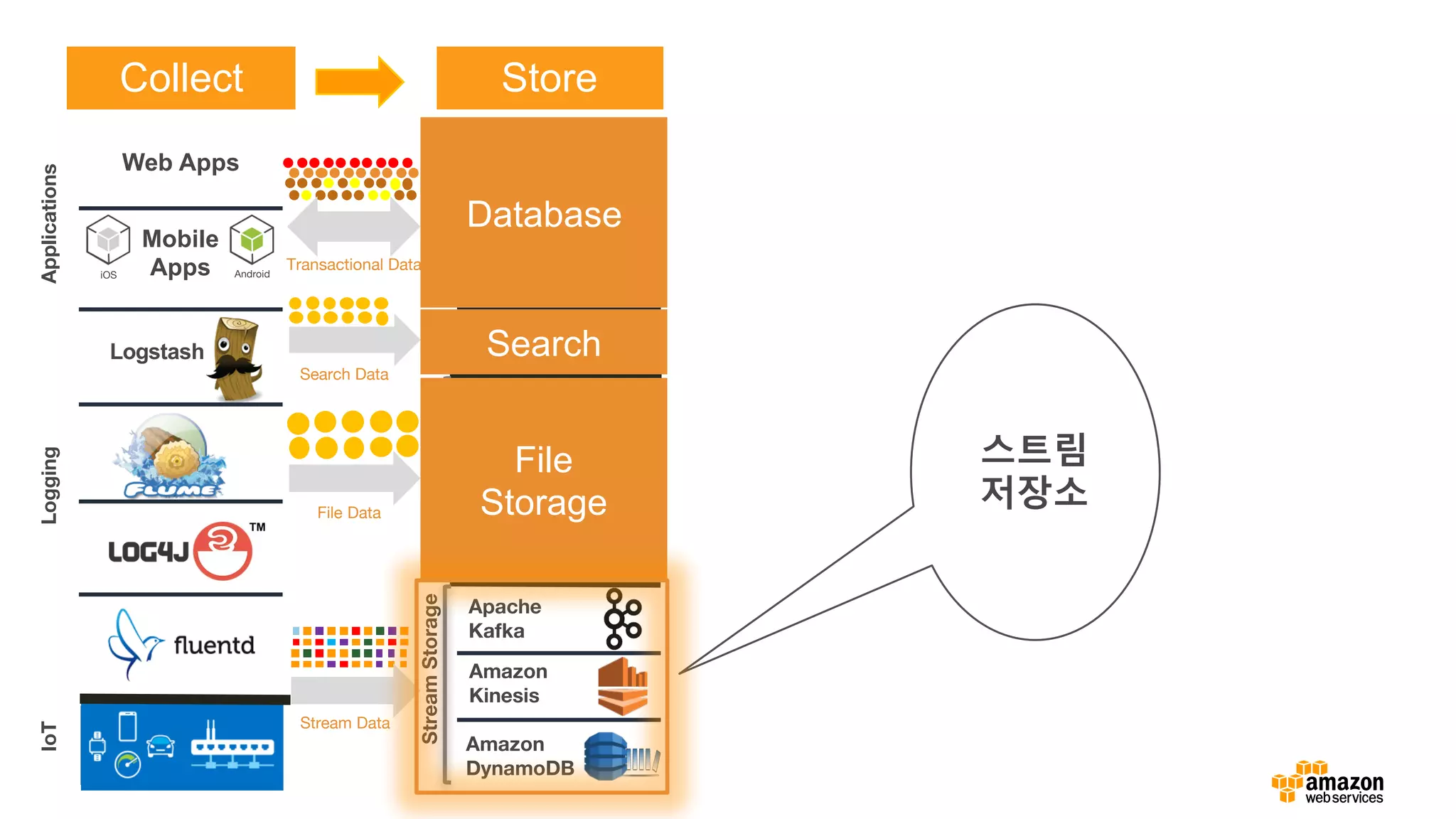
Logging
StreamStorage
IoTApplications
FileStorage
Analysis&Visualization
Hot
Cold
Warm
Hot
Slow
Hot
ML
Fast
Fast
Amazon
QuickSight
Transactional Data
File Data
Stream Data
Notebook
s
Predictions
Apps & APIs
Mobile
Apps
IDE
Search Data
ETL
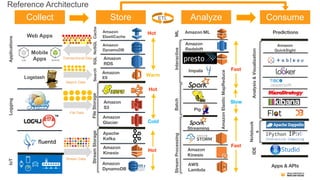
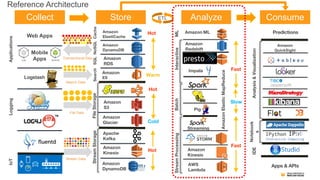
Reference Architecture
19.
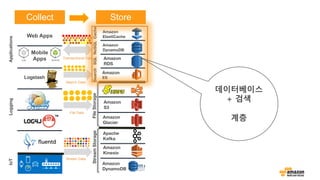
Collect Store AnalyzeConsume
A
iOS Android
Web Apps
Logstash
Amazon
RDS
Amazon
DynamoDB
Amazon
ES
Amazon
S3
Apache
Kafka
Amazon
Glacier
Amazon
Kinesis
Amazon
DynamoDB
Amazon
Redshift
Impala
Pig
Amazon ML
Streaming
Amazon
Kinesis
AWS
Lambda
AmazonElasticMapReduce
Amazon
ElastiCache
SearchSQLNoSQLCache
StreamProcessingBatchInteractive
Logging
StreamStorage
IoTApplications
FileStorage
Analysis&Visualization
Hot
Cold
Warm
Hot
Slow
Hot
ML
Fast
Fast
Amazon
QuickSight
Transactional Data
File Data
Stream Data
Notebook
s
Predictions
Apps & APIs
Mobile
Apps
IDE
Search Data
ETL
Reference Architecture
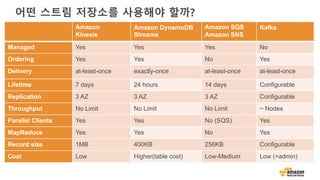
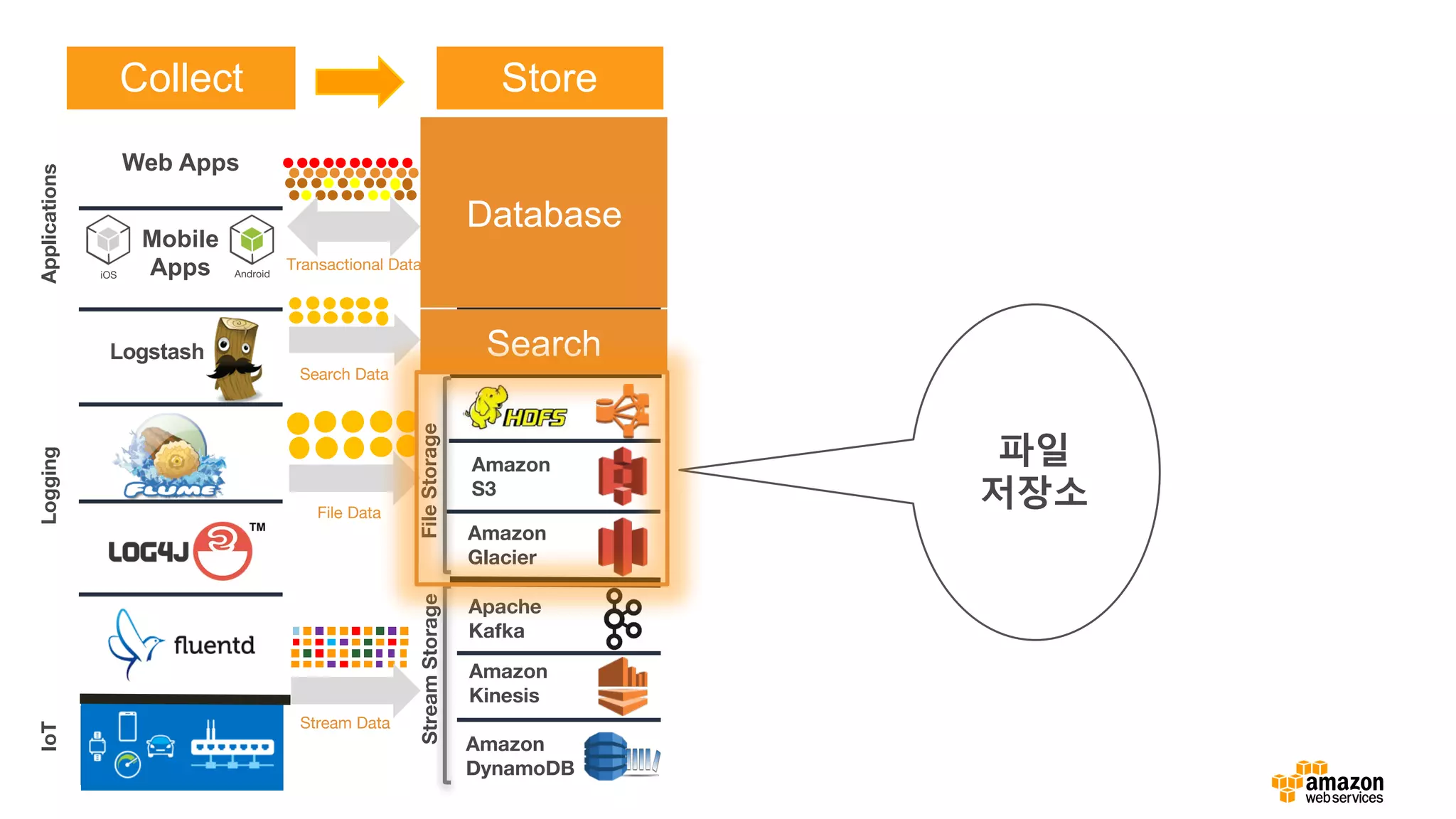
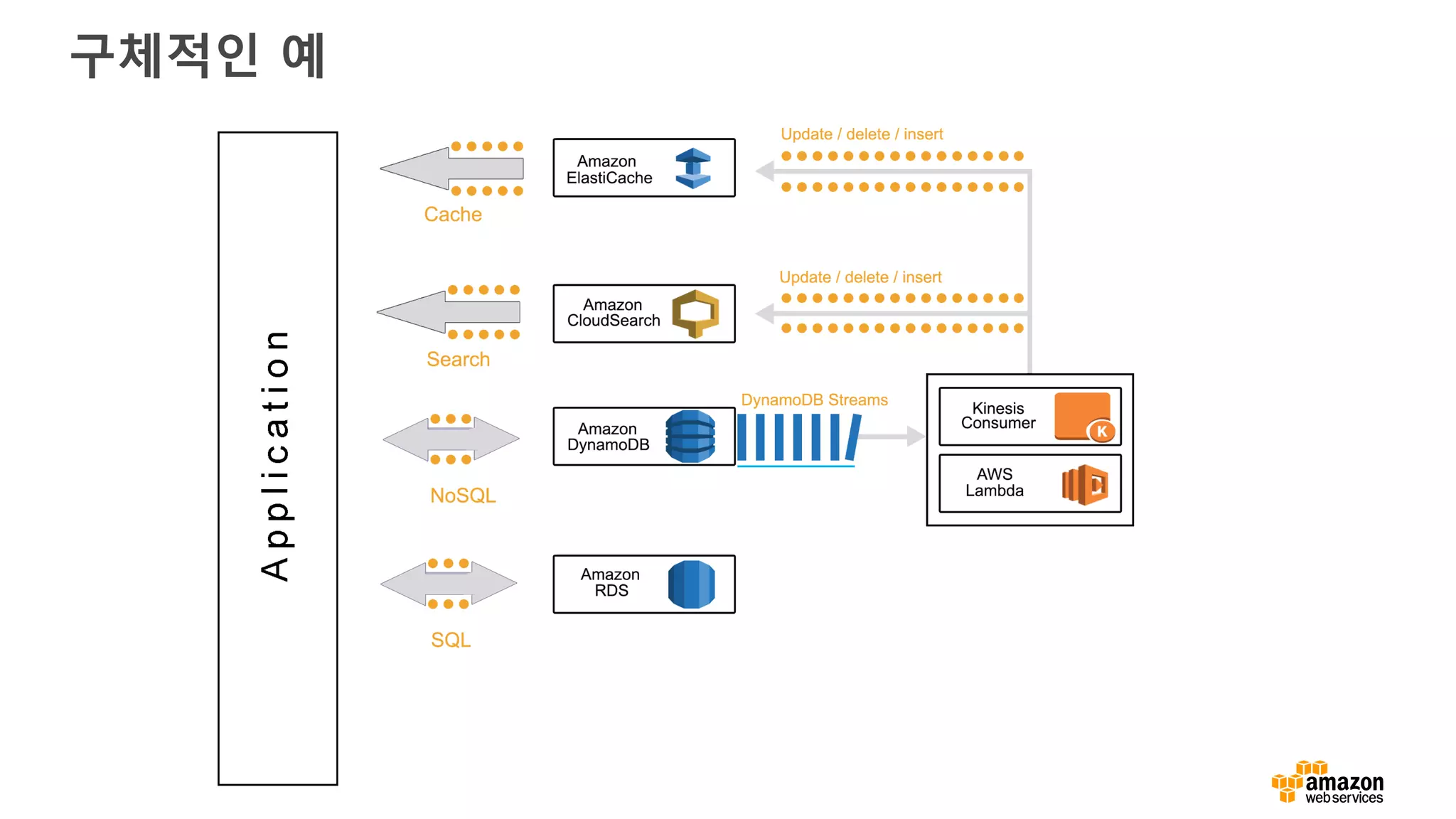
왜 Amazon S3가 빅데이터에 좋은가?
• 기본적으로 빅데이터 프레임워크 지원(Spark, Hive, Presto, etc.)
• 스토리지를 위한 컴퓨팅 클러스터가 불필요 (HDFS와 다름)
• Amazon EC2 스팟 인스턴스를 활용하여 하둡 클러스터 운영 가능
• 동일한 데이터로 여러 종류(Spark, Hive, Presto) 클러스터를 동시에 사용
• 오브젝트 갯수 무제한
• 99.999999999%의 내구성을 위한 설계
• 고 가용성 – AZ 장애 극복
• 수명주기를 활용한 계층-스토리지 (Standard, IA, Amazon Glacier)
• 보안 – SSL, client/server-side encryption at rest
• 저비용
• 매우 높은 대역폭 – 총 처리량 제한 없음
25.
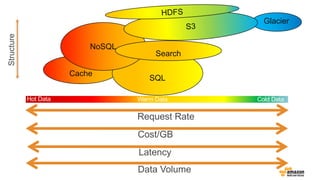
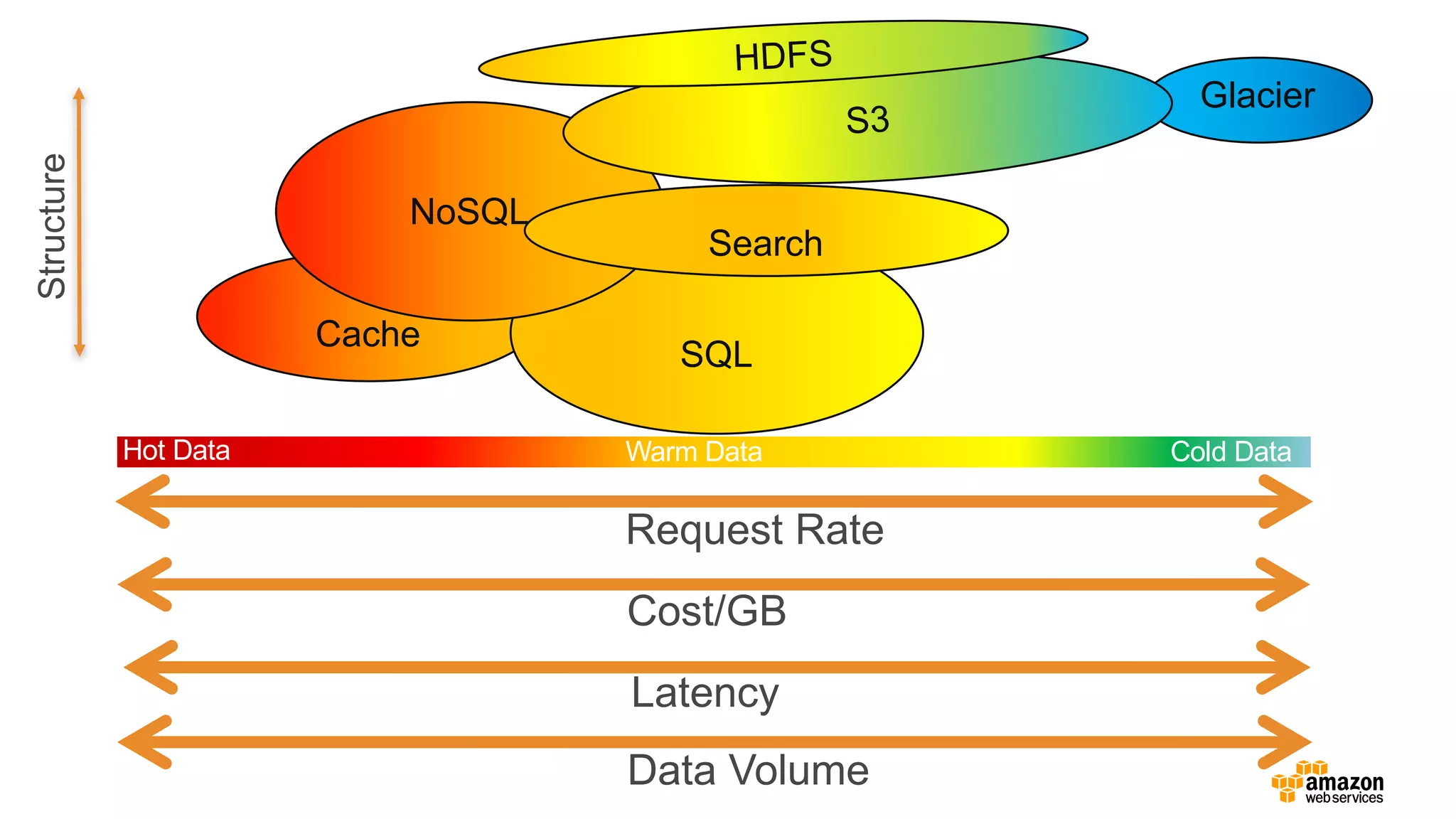
• 매우 자주접근하는(hot) 데이터는 HDFS
사용
• 자주 접근하는 데이터는 Amazon S3
Standard 사용
• 드물게 접근하는 데이터는 Amazon S3
Standard – IA 사용
• 거의 접근하지 않는(cold) 데이터는 Amazon
Glacier 사용하여 아카이브
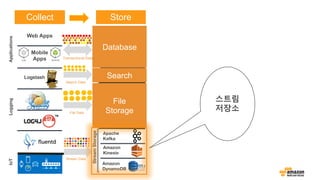
S3와 HDFS, Amazon Glacier를 함께…
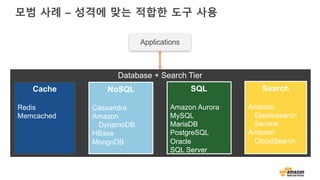
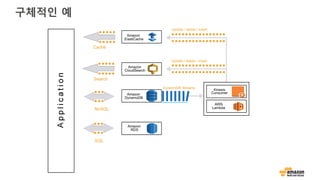
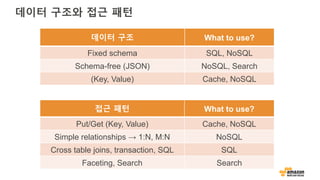
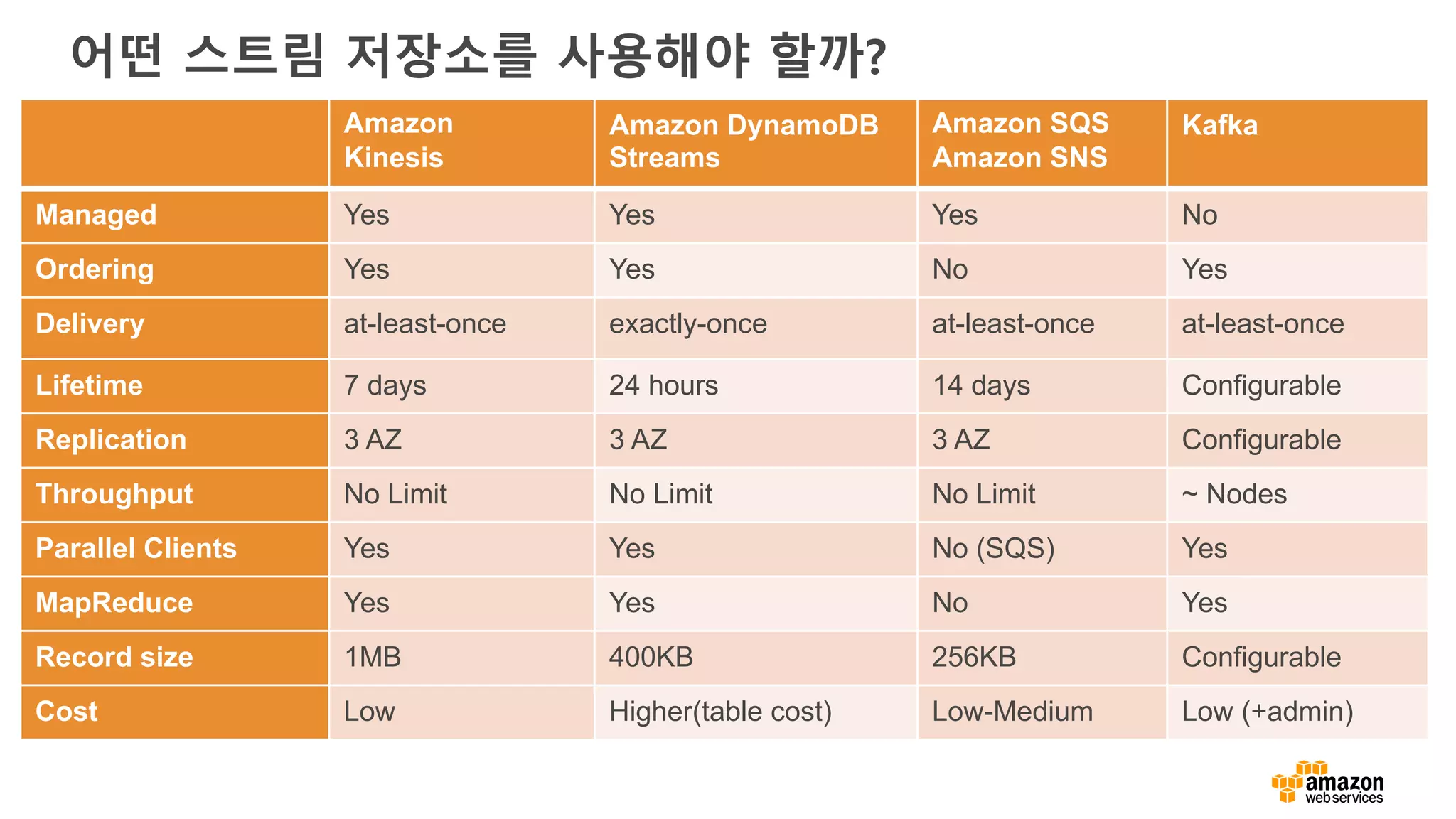
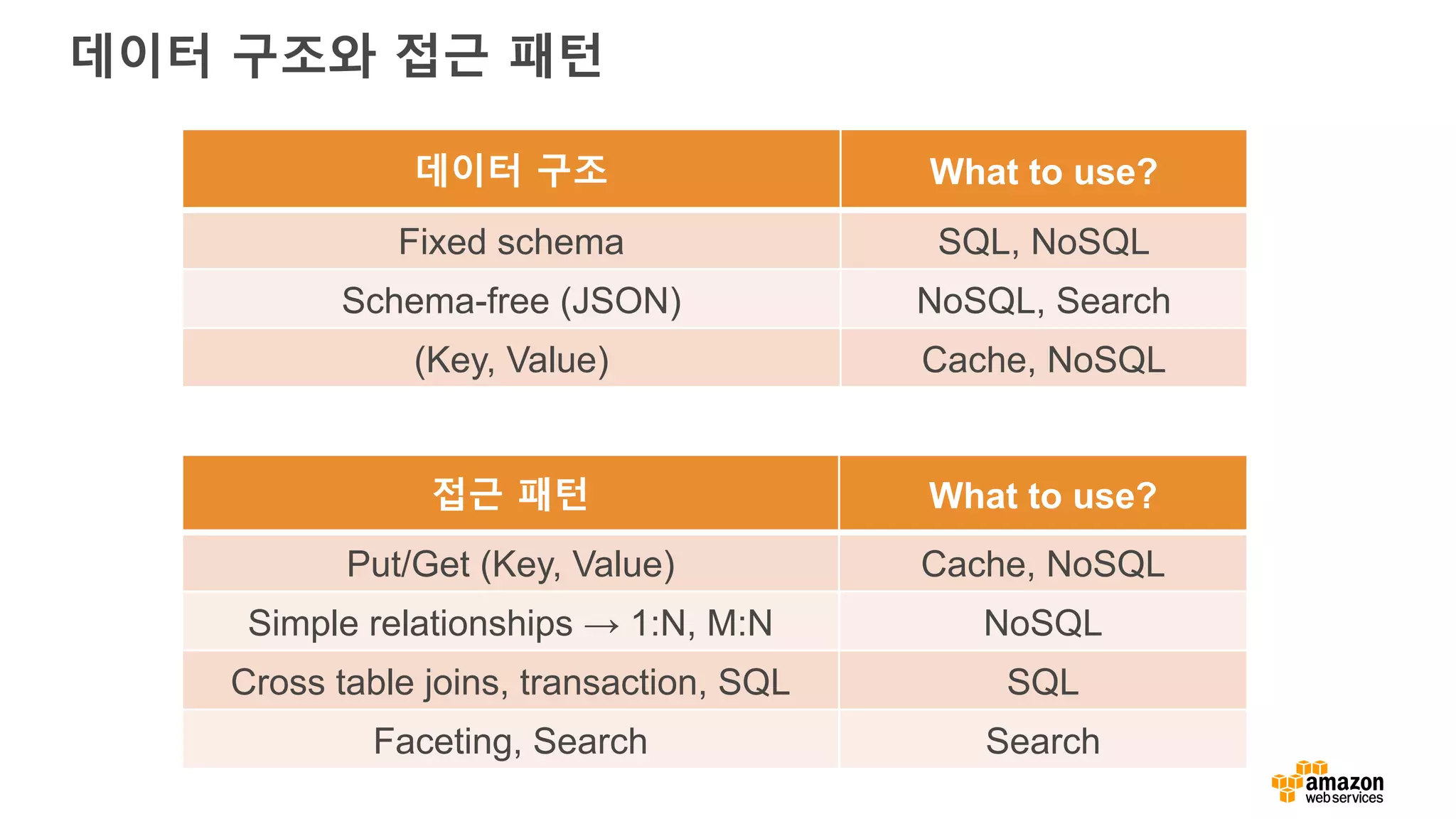
데이터 구조와 접근패턴
접근 패턴 What to use?
Put/Get (Key, Value) Cache, NoSQL
Simple relationships → 1:N, M:N NoSQL
Cross table joins, transaction, SQL SQL
Faceting, Search Search
데이터 구조 What to use?
Fixed schema SQL, NoSQL
Schema-free (JSON) NoSQL, Search
(Key, Value) Cache, NoSQL
Collect Store AnalyzeConsume
A
iOS Android
Web Apps
Logstash
Amazon
RDS
Amazon
DynamoDB
Amazon
ES
Amazon
S3
Apache
Kafka
Amazon
Glacier
Amazon
Kinesis
Amazon
DynamoDB
Amazon
Redshift
Impala
Pig
Amazon ML
Streaming
Amazon
Kinesis
AWS
Lambda
AmazonElasticMapReduce
Amazon
ElastiCache
SearchSQLNoSQLCache
StreamProcessingBatchInteractive
Logging
StreamStorage
IoTApplications
FileStorage
Analysis&Visualization
Hot
Cold
Warm
Hot
Slow
Hot
ML
Fast
Fast
Amazon
QuickSight
Transactional Data
File Data
Stream Data
Notebook
s
Predictions
Apps & APIs
Mobile
Apps
IDE
Search Data
ETL
Reference Architecture
32.
처리와 분석
데이터 분석은유용한 정보를 발견, 결론을 제시, 의사
결정의 목적으로 데이터를 검사, 정제, 변환, 모델링하는
과정을 의미
예시)
대화형 대시보드 à 대화형 분석(Interactive Analytics)
일일/주간/월간 보고서 à 배치 분석(Batch Analytics)
결제/부정행위 경고, 1분 측정 à 실시간 분석(Real-Time Analytics)
심리 분석, 예측 모델 à 기계 학습(Machine Learning)
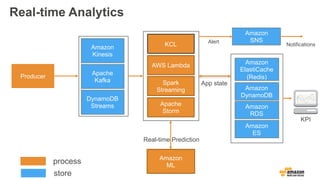
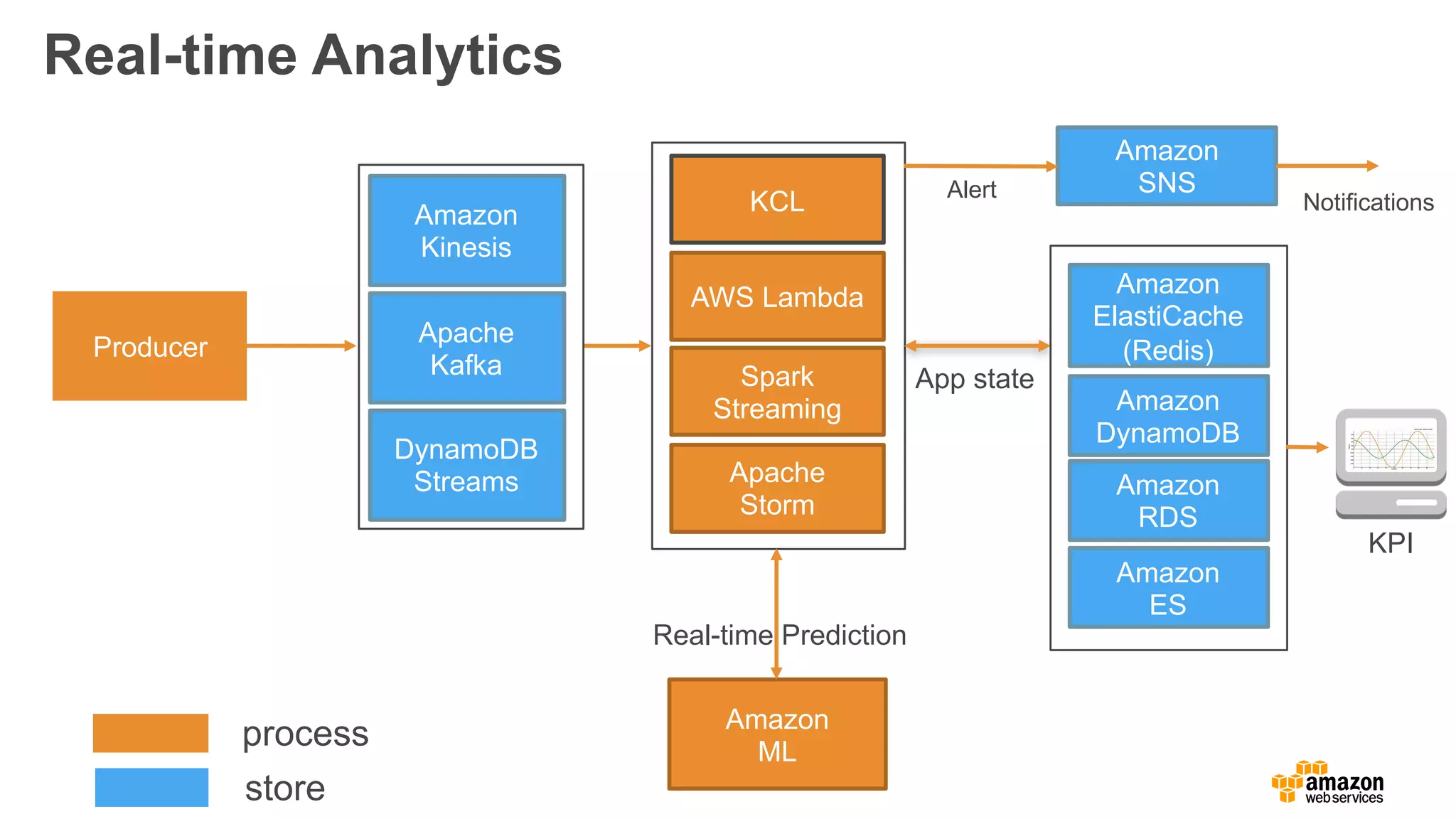
실시간 분석
소량의 hot데이터를 대상
답변을 얻기까지 적은 시간(수밀리초 ~ 수초)이 걸림
실시간 (이벤트)
- 데이터 스트림의 이벤트에 실시간으로 응답
- 예: 결제/부정행위 알림
근 실시간 (마이크로 배치)
- 데이터 스트림의 마이크로 배치를 통한 근 실시간
운영
- 예: 1분 측정
36.
기계 학습을 통한예측
기계 학습(ML)은 명시적으로 프로그래밍 하지 않고도 컴퓨터가 학습
할 수 있는 능력을 제공
기계 학습 알고리즘:
감독 학습 ß “teach” 프로그램
- Classification ß 이 거래가 부정행위 인가? (Yes/No)
- Regression ß 고객의 LTV 는?
자율 학습 ß let it learn by itself
- Clustering ß 시장 세분화
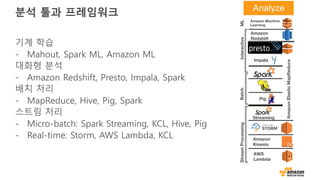
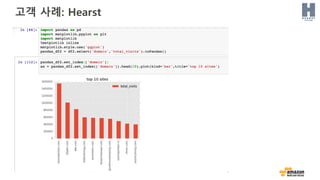
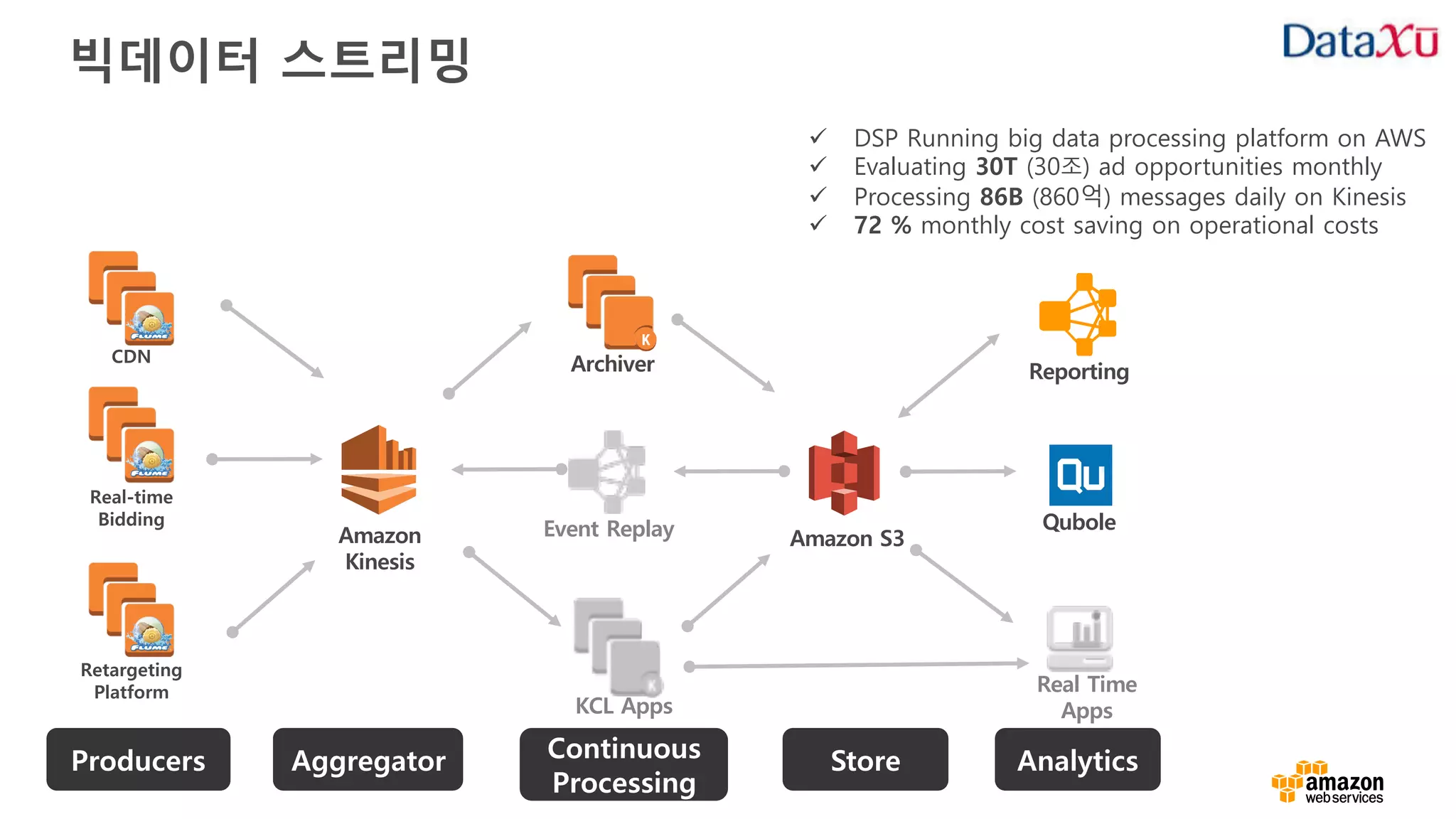
고객 사례: Hearst
Hearstis one of the world’s largest media and
information companies, with more than 360
businesses.
I don’t know how we could
have made our clickstream
data pipeline work without
Amazon Kinesis.
Peter Jaffe
Data Scientist,
Hearst Corporation
”
“ • 실시간 클릭스트림 이벤트와 트렌드 콘텐츠를
분석할 플랫폼 개발이 필요 했었음
• Amazon Kinesis Streams 와 Amazon
Kinesis Firehose 를 사용해서 매일 발생하는
30 TB 의 클릭스트림 데이터를 전송하고
있음
• 복잡한 데이터 사이언스 일과 분석 쿼리에
Amazon Redshift 를 사용함
• 300 여개 이상의 웹사이트에서 생성되는
데이터가 처리됨
• 수분 이내에 에디터로 클릭스트림 데이터를
전달 함
• 트렌드 콘텐츠의 재순환이 25 퍼센트 이상
증가함
https://aws.amazon.com/solutions/case-studies/hearst/
39.
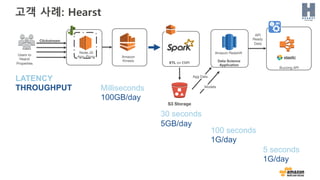
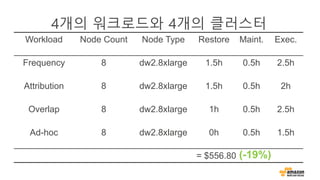
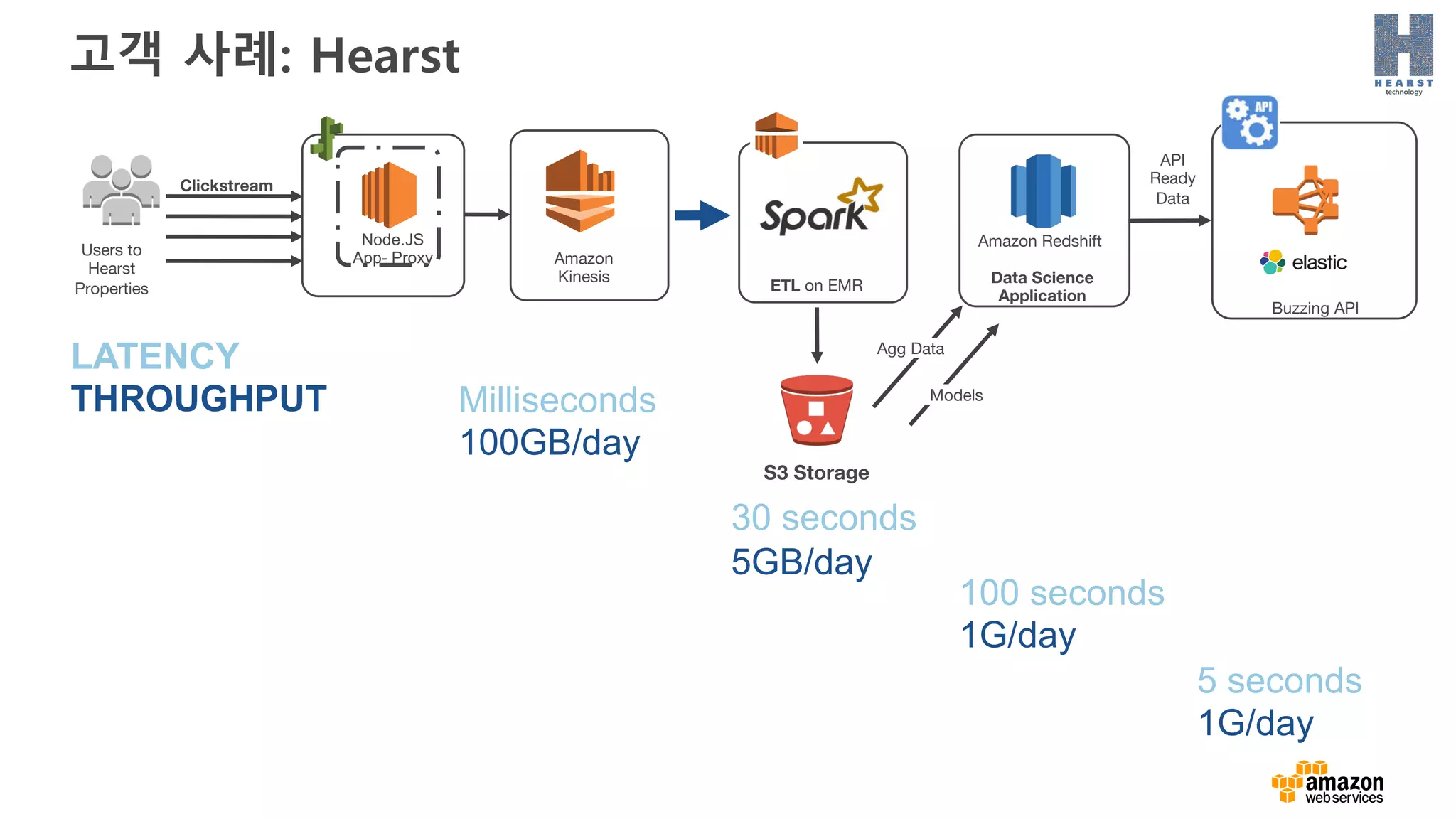
고객 사례: Hearst
BuzzingAPI
API
Ready
Data
Amazon
Kinesis
S3 Storage
Node.JS
App- ProxyUsers to
Hearst
Properties
Clickstream
Data Science
Application
Amazon Redshift
ETL on EMR
100 seconds
1G/day
30 seconds
5GB/day
5 seconds
1G/day
Milliseconds
100GB/day
LATENCY
THROUGHPUT Models
Agg Data
40.
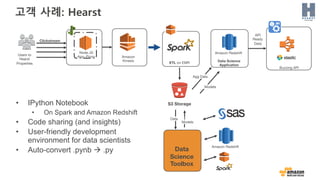
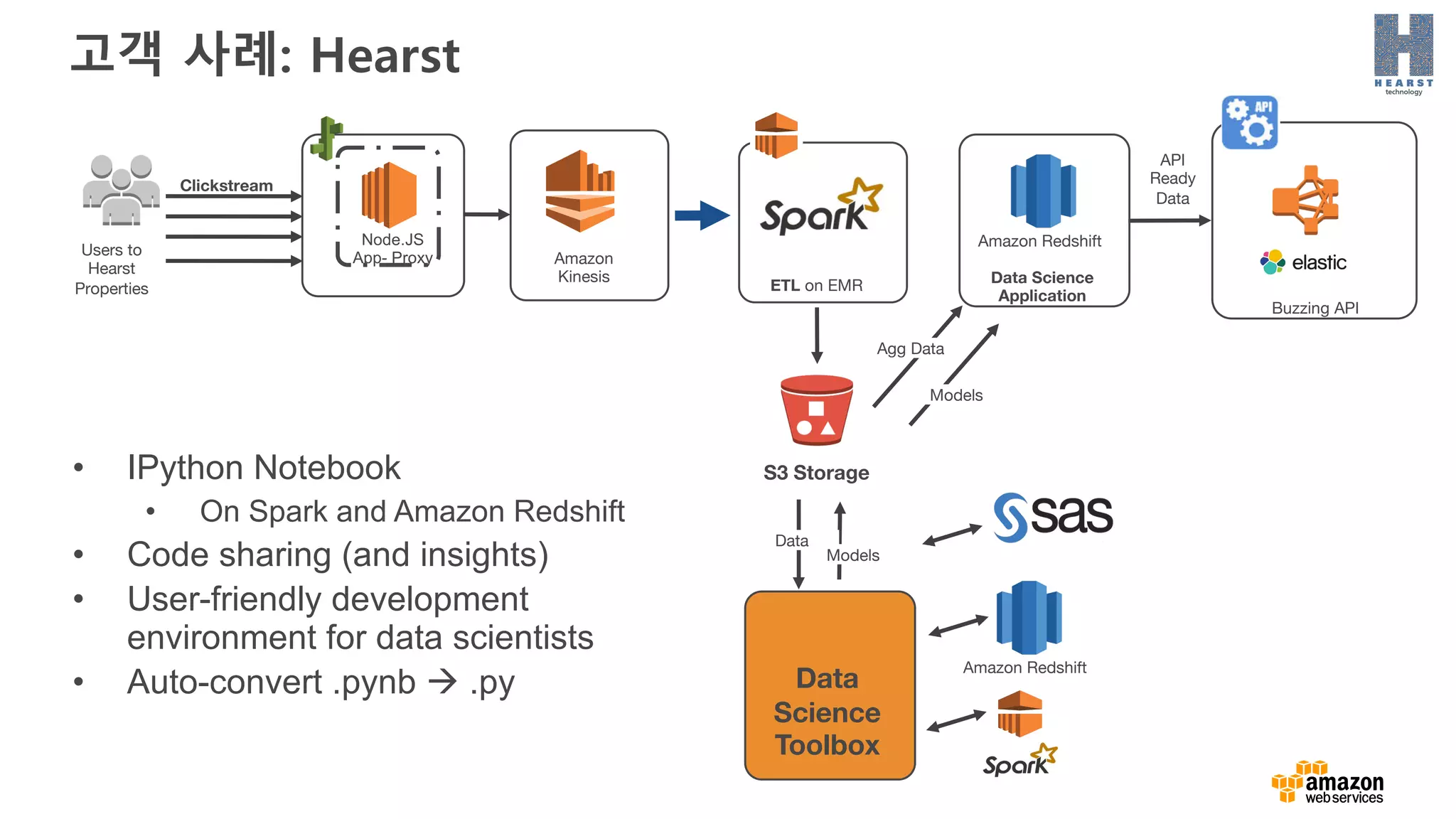
고객 사례: Hearst
BuzzingAPI
API
Ready
Data
Amazon
Kinesis
S3 Storage
Node.JS
App- ProxyUsers to
Hearst
Properties
Clickstream
Data Science
Application
Amazon Redshift
ETL on EMR
Models
Agg Data
Data
Science
Toolbox
Data
Models
Amazon Redshift
• IPython Notebook
• On Spark and Amazon Redshift
• Code sharing (and insights)
• User-friendly development
environment for data scientists
• Auto-convert .pynb à .py
Redshift 의 AdTech 활용 사례
• 어트리뷰선 분석 (Attribution Analysis)
• 캠페인 성능 (Campaign Performance)
• 데이터 관리 (Data Management)
• 실시간 경매 (Real-Time Bidding)
• 리타겟팅 (Retargeting)
48.
왜 Redshift 일까요?
•엄청난 데이터
– 160GB – 2TB
– S3 로의 접근
– 싱글 클러스터 vs 멀티 클러스터
• 가능하면 저렴하게!
– $1000/TB/매년
– 비용 때문에 데이터를 잃어 버릴 순 없죠
– 데이터는 온라인 일 수도, 오프라인 일 수도 있습니다!
• 시간은 돈!
– MPP 컬럼너: 수십억개의 이벤트에 쿼리를 수행 후 결과를 얻을 수 있습니다!
– SSD
– approximate 기능
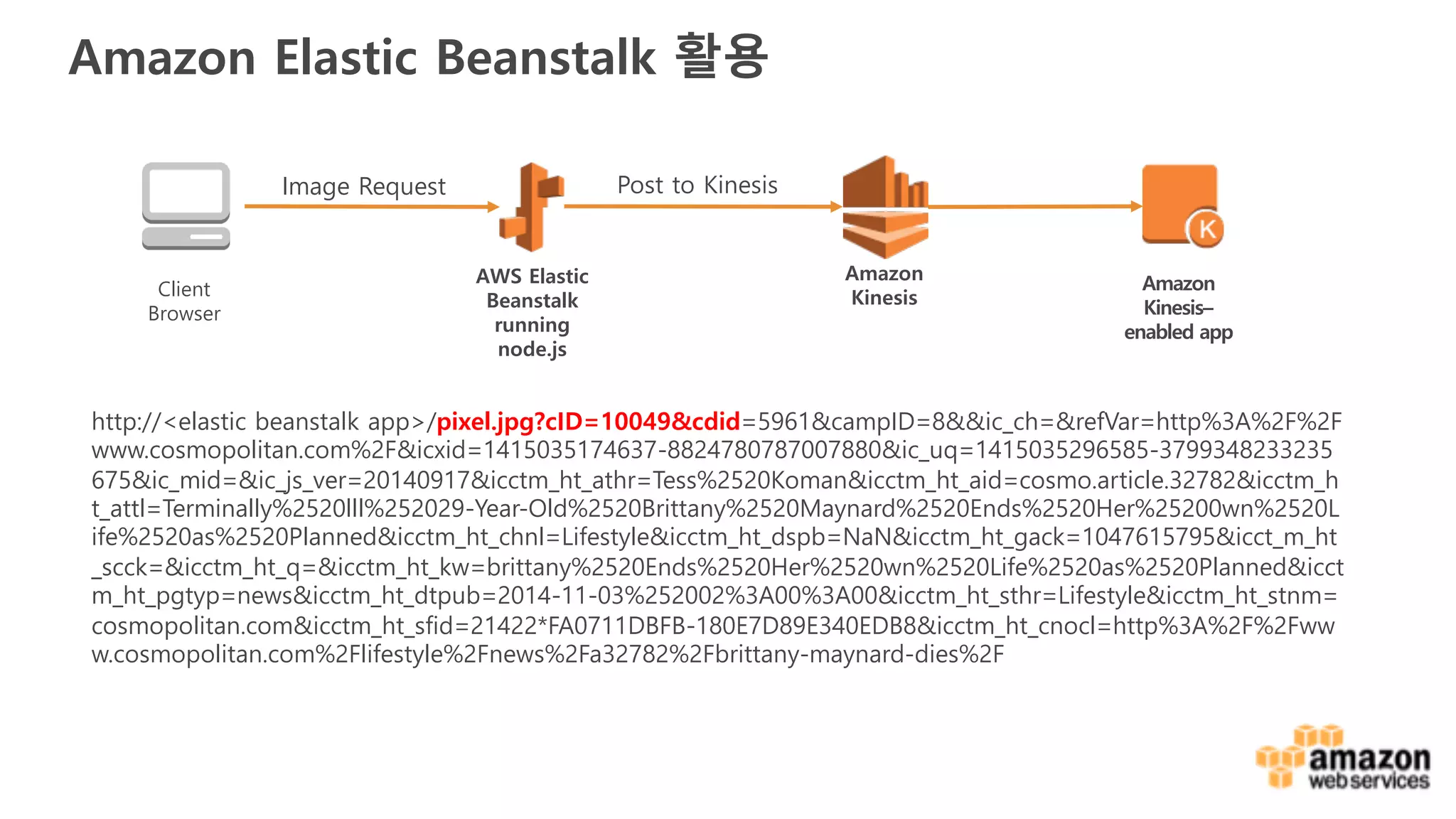
COPY from JSON
•Ingest JSON directly into Amazon Redshift
• If you have a 1:1 mapping between JSON elements
and column names, use ‘auto’
• Map elements to columns using a JSONPaths file
51.
데이터 관리
• 일반적으로최종 고객에게 분석 결과를 제공
• 중앙 클러스터가 모든 데이터에 대해 작업하고, 고객별
클러스터를 가동
• 주변 영향 없이 고객마다 독립적으로 클러스터를 확장
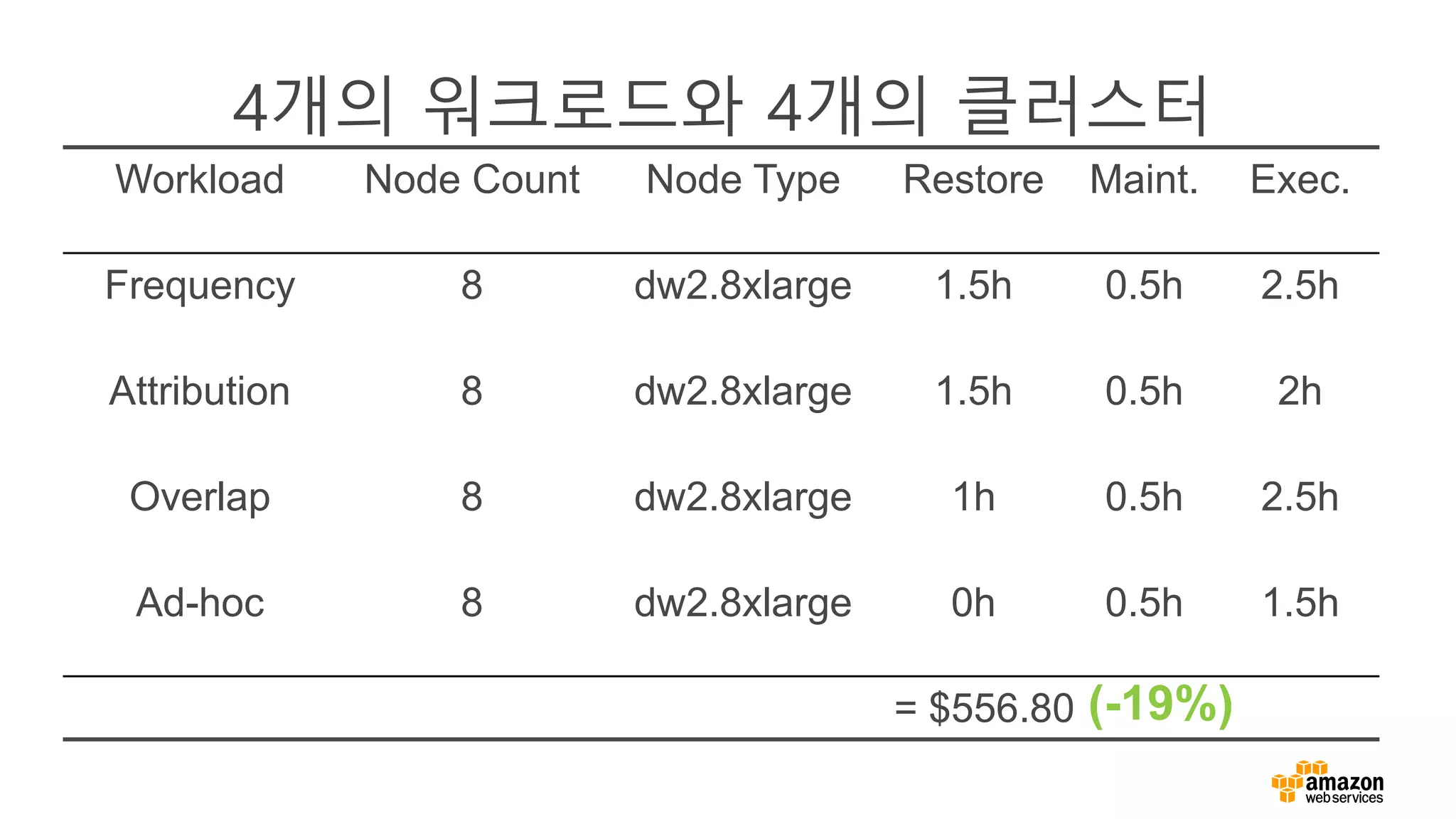
• 1개의 노드로 구성된 10개의 클러스터와, 10개의 노드로
구성된 1개의 클러스터의 가격 차이 없음
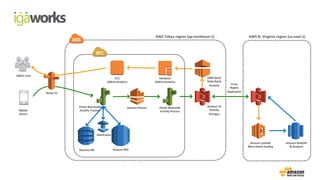
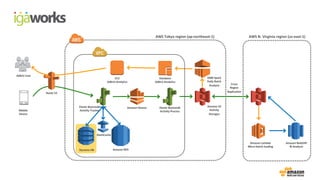
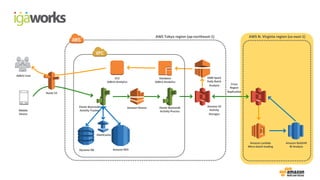
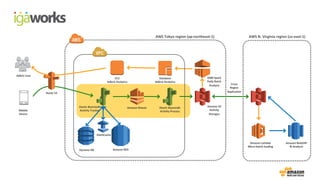
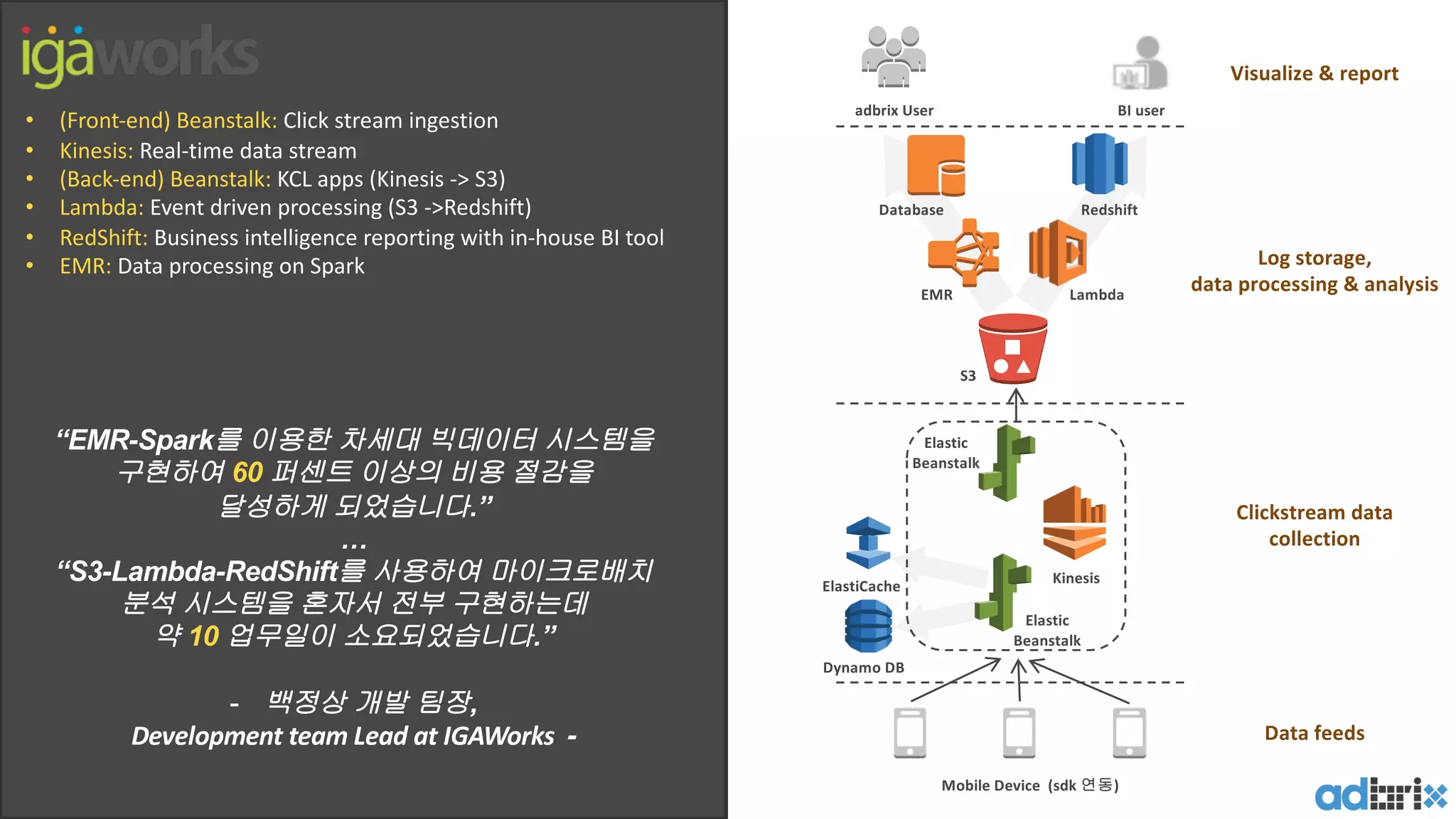
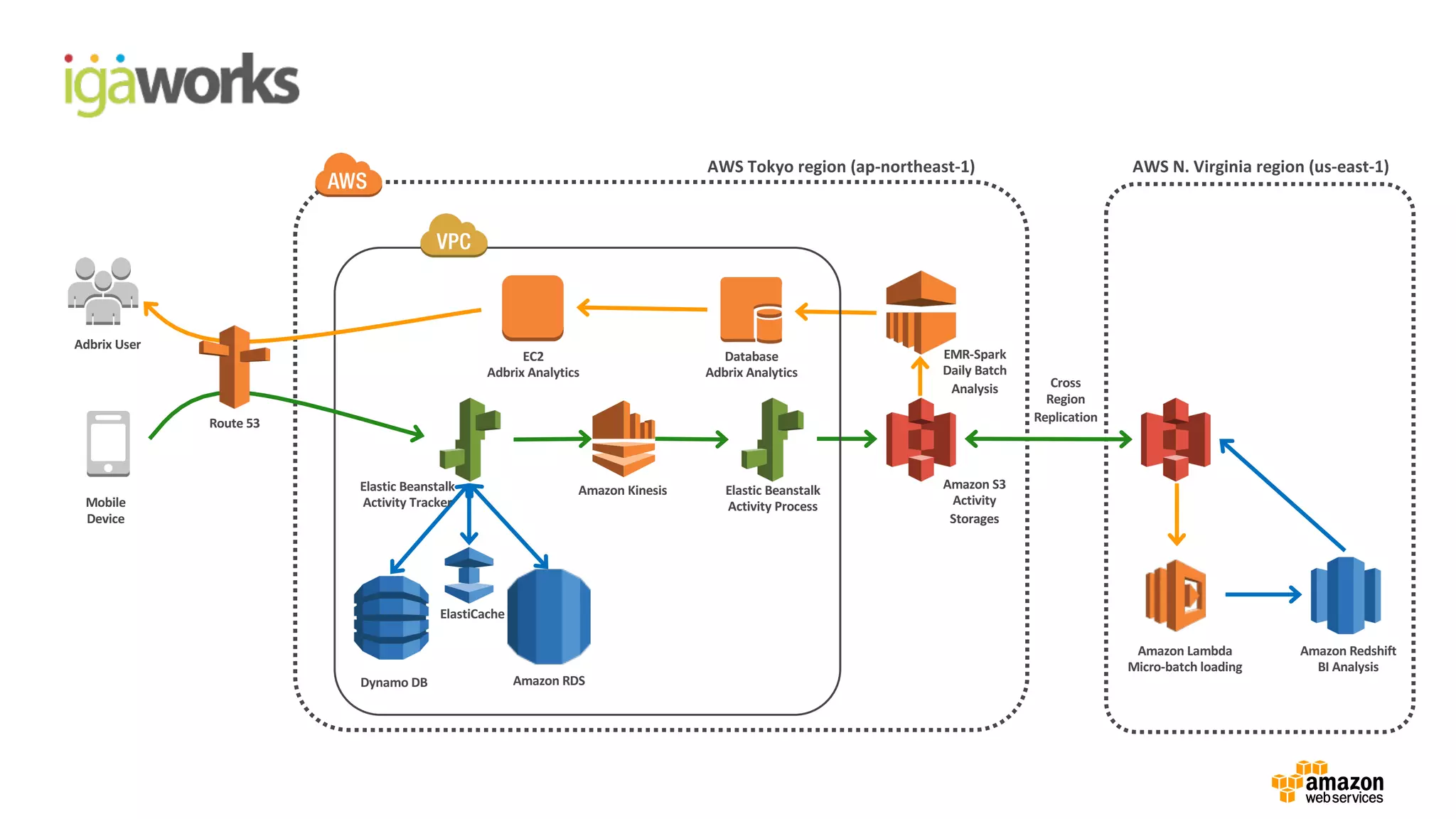
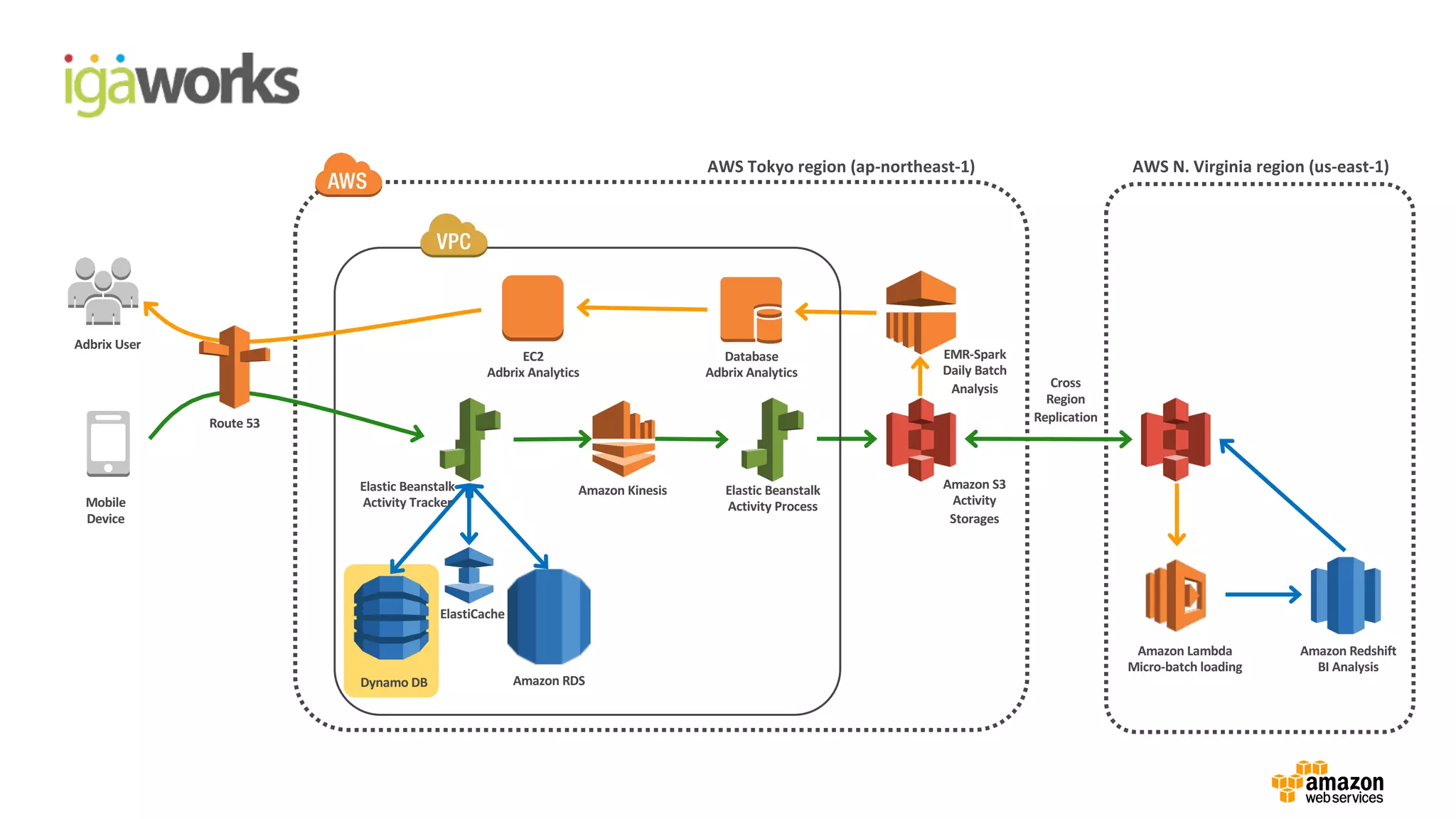
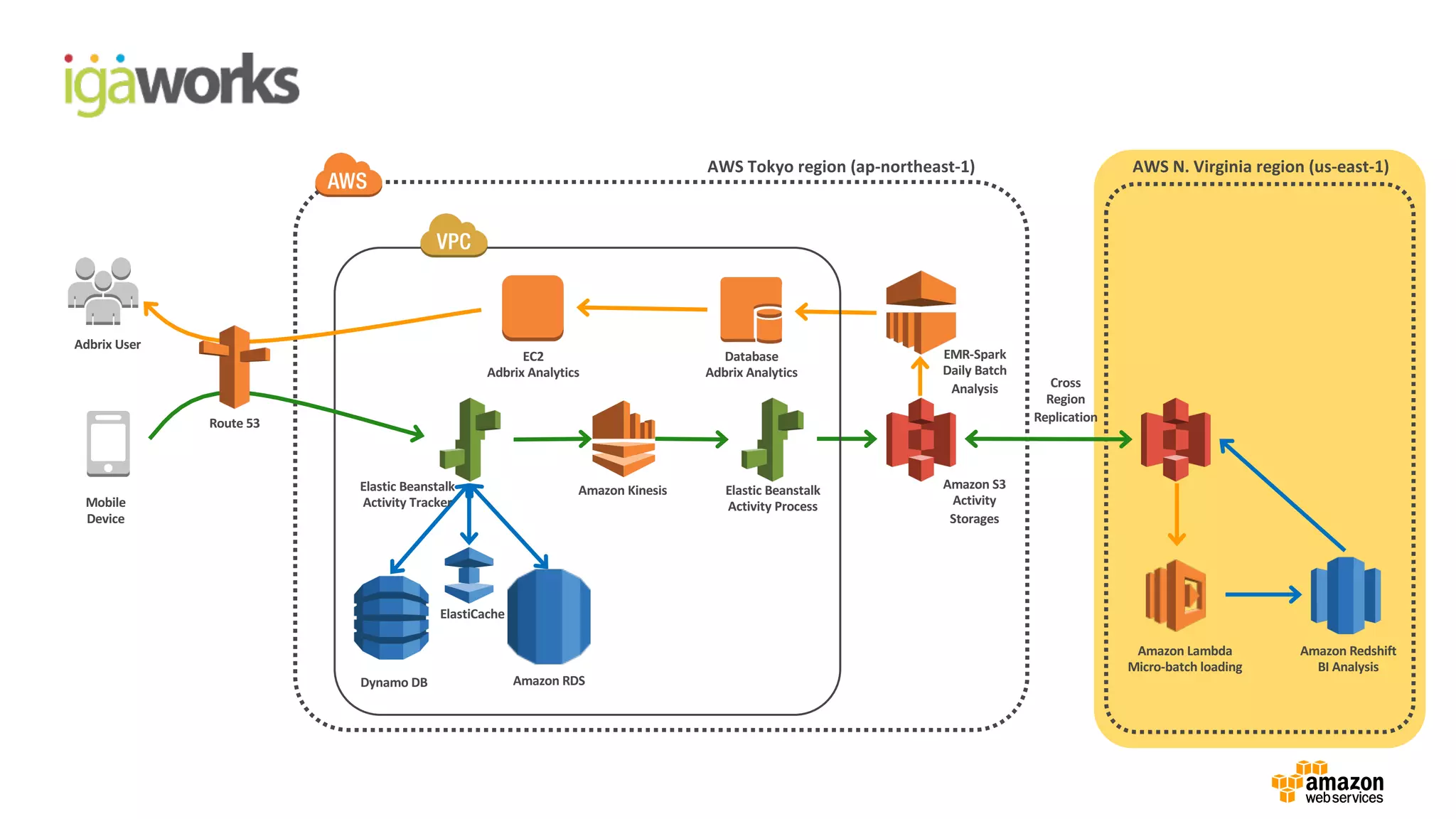
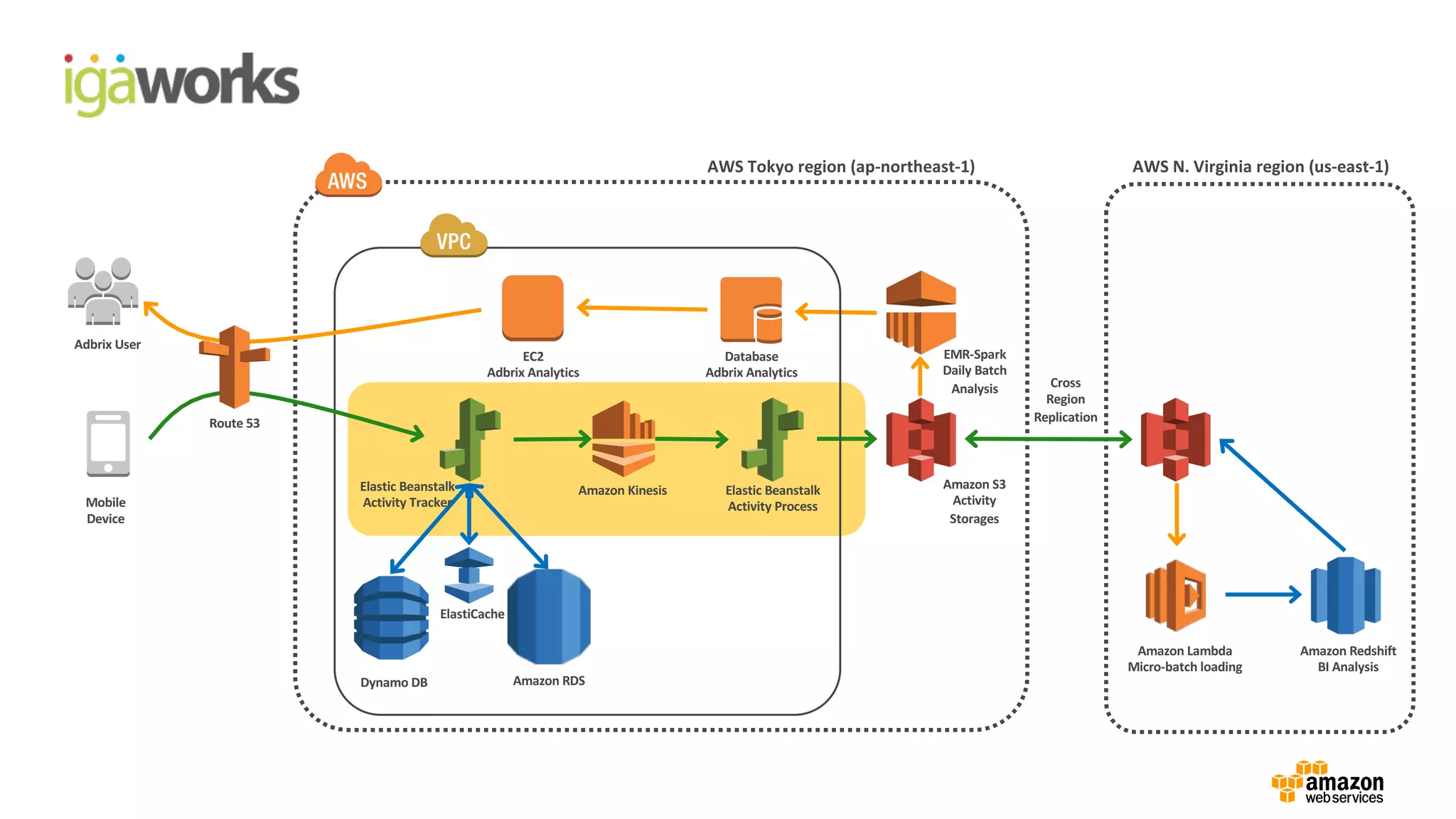
• (Front-end) Beanstalk: Click stream ingestion
• Kinesis: Real-time data stream
•(Back-end) Beanstalk: KCL apps (Kinesis -> S3)
• Lambda: Event driven processing (S3 ->Redshift)
• RedShift: Business intelligence reporting with in-house BI tool
• EMR: Data processing on Spark
Mobile Device (sdk 연동)
Elastic
Beanstalk
Kinesis
Elastic
Beanstalk
Clickstream data
collection
Data feeds
Log storage,
data processing & analysis
S3
EMR Lambda
Redshift
adbrix User BI user
Visualize & report
Database
ElastiCache
Dynamo DB
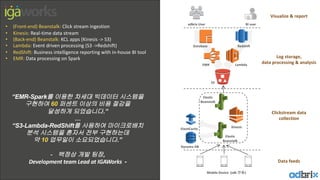
“EMR-Spark를 이용한 차세대 빅데이터 시스템을
구현하여 60 퍼센트 이상의 비용 절감을
달성하게 되었습니다.”
…
“S3-Lambda-RedShift를 사용하여 마이크로배치
분석 시스템을 혼자서 전부 구현하는데
약 10 업무일이 소요되었습니다.”
- 백정상 개발 팀장,
Development team Lead at IGAWorks -
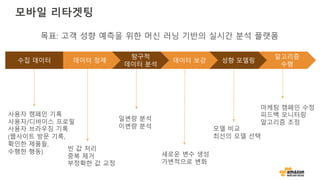
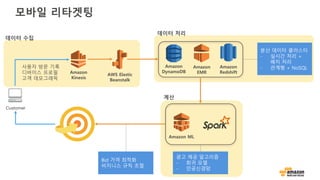
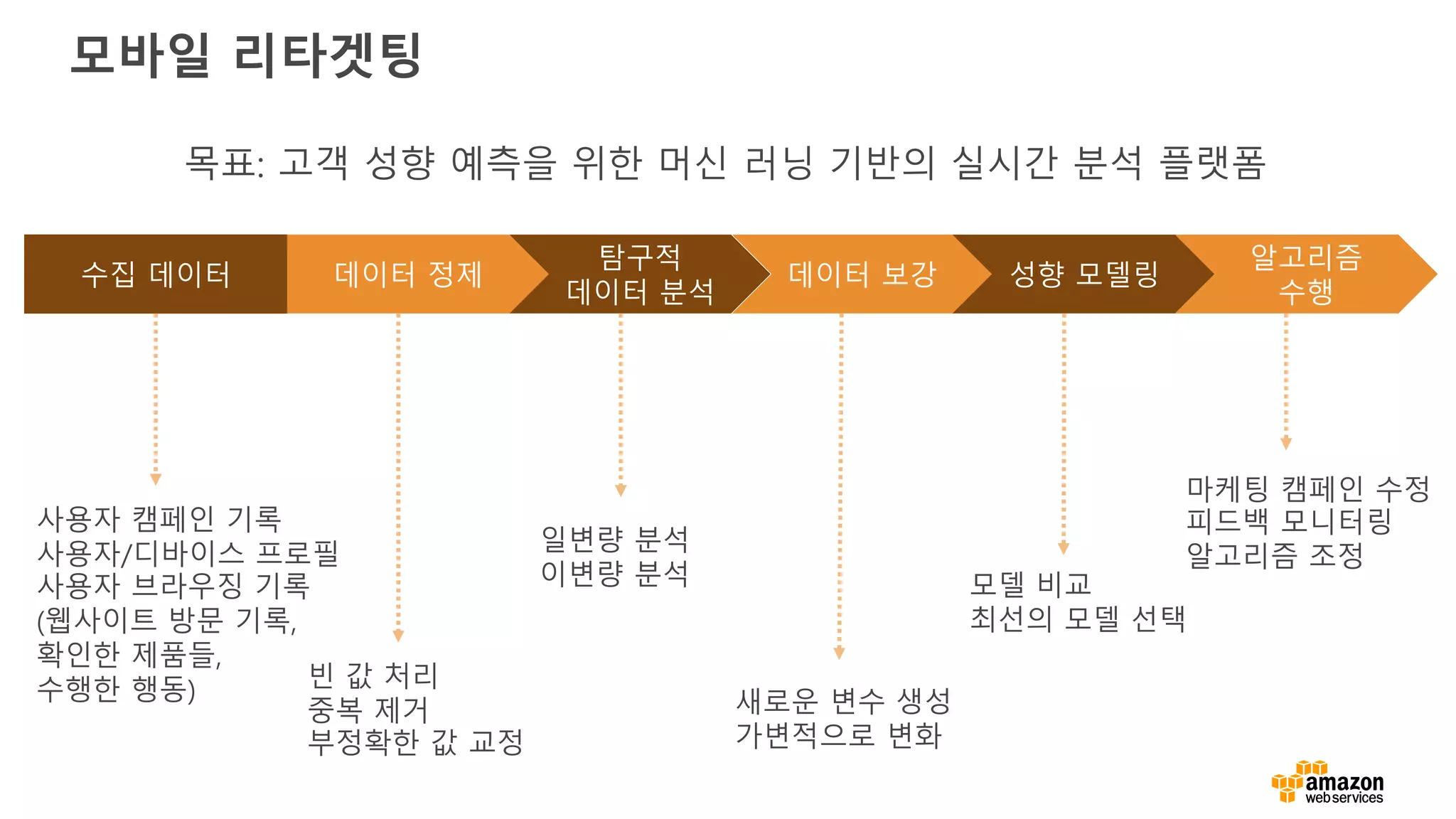
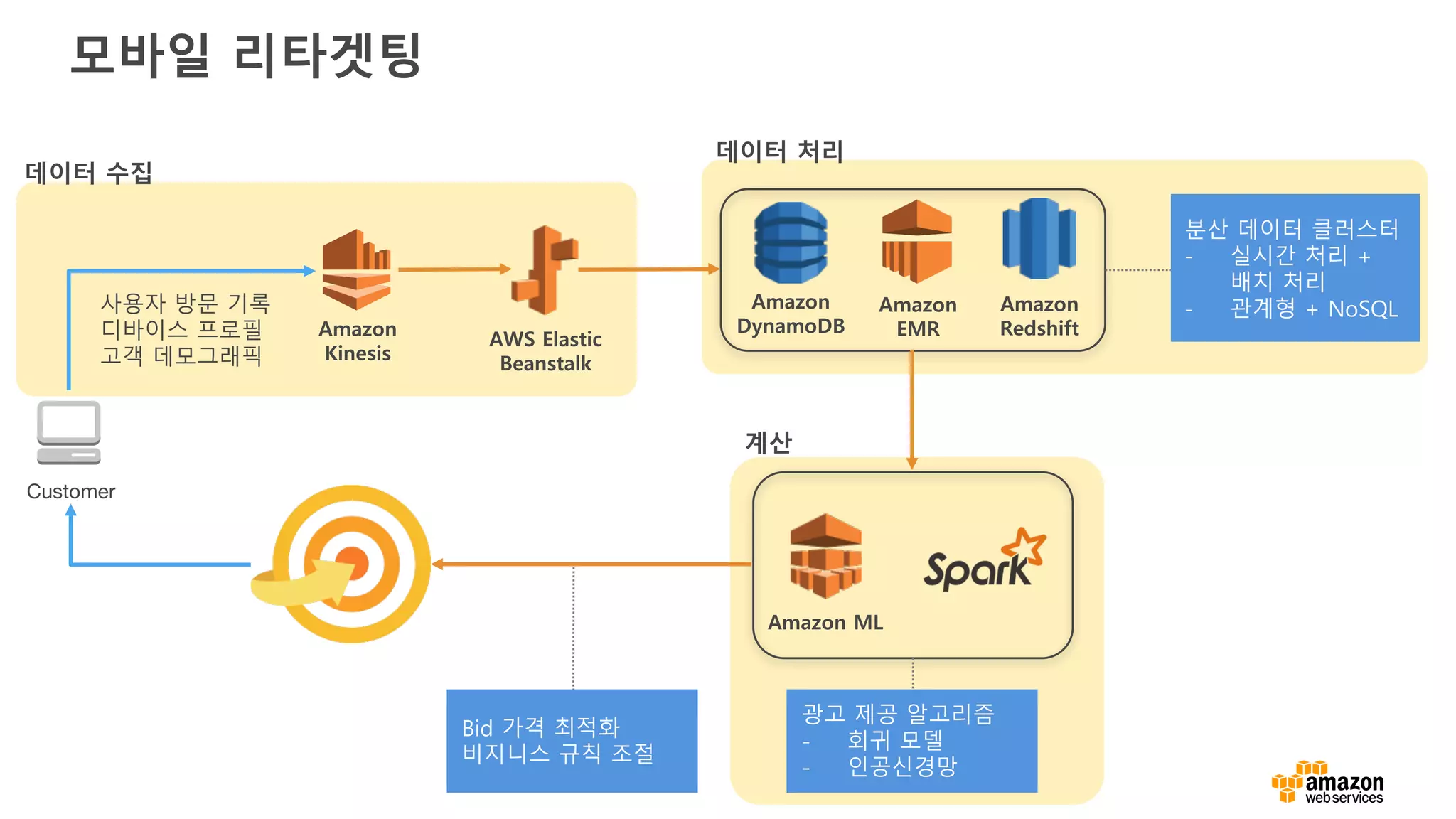
모바일 리타겟팅
수집 데이터데이터 정제
탐구적
데이터 분석
데이터 보강 성향 모델링
알고리즘
수행
빈 값 처리
중복 제거
부정확한 값 교정
일변량 분석
이변량 분석
사용자 캠페인 기록
사용자/디바이스 프로필
사용자 브라우징 기록
(웹사이트 방문 기록,
확인한 제품들,
수행한 행동) 새로운 변수 생성
가변적으로 변화
모델 비교
최선의 모델 선택
마케팅 캠페인 수정
피드백 모니터링
알고리즘 조정
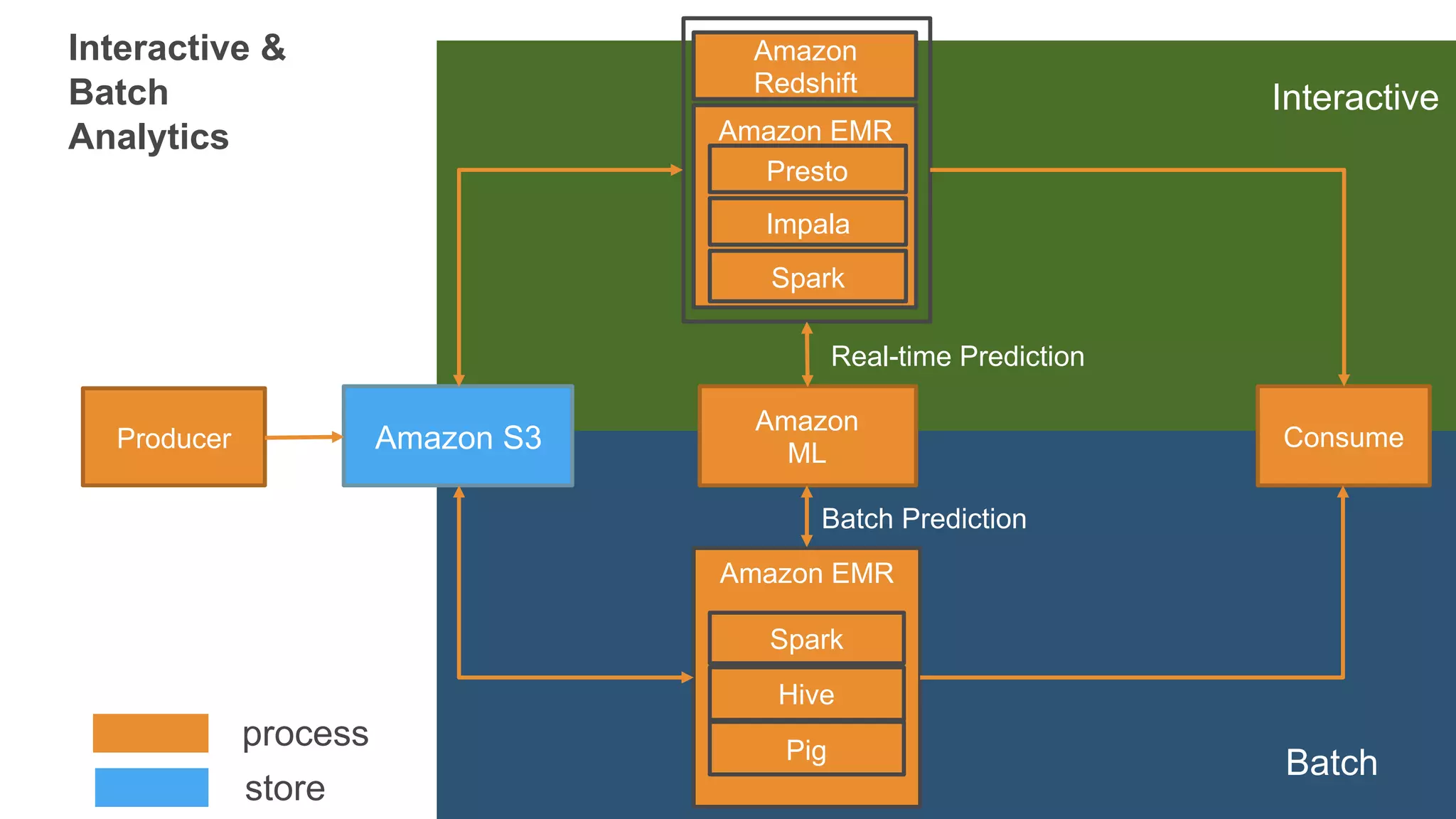
목표: 고객 성향 예측을 위한 머신 러닝 기반의 실시간 분석 플랫폼
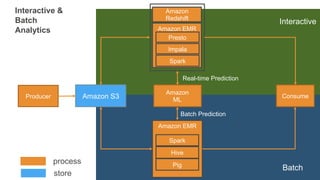
Interactive &
Batch
Analytics
Producer AmazonS3
Amazon EMR
Hive
Pig
Spark
Amazon
ML
process
store
Consume
Amazon
Redshift
Amazon EMR
Presto
Impala
Spark
Batch
Interactive
Batch Prediction
Real-time Prediction
79.
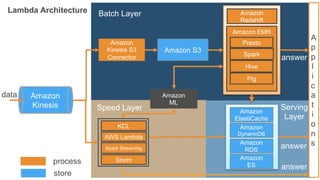
Batch Layer
Amazon
Kinesis
data
process
store
Lambda Architecture
Amazon
KinesisS3
Connector
Amazon S3
A
p
p
l
i
c
a
t
i
o
n
s
Amazon
Redshift
Amazon EMR
Presto
Hive
Pig
Spark
answer
Speed Layer
answer
Serving
Layer
Amazon
ElastiCache
Amazon
DynamoDB
Amazon
RDS
Amazon
ES
answer
Amazon
ML
KCL
AWS Lambda
Spark Streaming
Storm
80.
이번 세션에서 얻어갈점
• 비결합된 “데이터 버스”를 구축하세요!
– Data → Store → Process → Answers
• 때에 맞는 적절한 툴을 활용 하세요!
– Data Structure, latency, throughput, access patterns
• Lambda 아키텍처를 적극 고려해 보세요!
– Immutable (append-only) log, batch/speed/serving layer
• AWS 관리형 서비스를 활용 하세요!
– No/low admin
• 항상 비용을 고려하세요!
– Big Data != Big Cost
81.
이번 세션에서 얻어갈점
• 하나의 거대한 클러스터 보다 다수의 작은 클러스터가 좋을 때가 많아요!
– 클라우드의 장점을 적극 활용하세요, 언제든 켜고 끌 수 있어요
• S3 를 Data lake 로 사용해보세요!
– 다른 서비스들과의 통합이 매우 자유로워요
82.
Sacrificial Architecture
For manypeople throwing away a code
base is a sign of failure, perhaps
understandable given the inherent
exploratory nature of software
development, but still failure. But often
the best code you can write now is code
you'll discard in a couple of years time.
http://martinfowler.com/bliki/SacrificialArchitecture.html
83.
피드백은 언제든 환영합니다!
AWS공식 블로그: http://aws.amazon.com/ko/blogs/korea
AWS 공식 소셜 미디어
@AWSKorea AWSKorea
AmazonWebServices AWSKorea





















































































































![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









![[ Pycon Korea 2017 ] Infrastructure as Code를위한 Ansible 활용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2017iacansible-170811160817-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









![[1주차] 알파 유저를 위한 AWS 스터디](https://cdn.slidesharecdn.com/ss_thumbnails/awsforalphausers1-150813083228-lva1-app6892-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[백서 요약] Building a Real-Time Bidding Platform on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/2016rtbwhitepaperko-v01-160707024553-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
























![[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략](https://cdn.slidesharecdn.com/ss_thumbnails/datafreedomdatabase-171027021754-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



