Downloaded 140 times










![TableScan
● Table scan is a trait to be implemented for reading data
● It’s Base Relation that can produce all of it’s tuples as
an RDD of Row objects
● Methods to override
○ def buildScan(): RDD[Row]
● In csv example, we use sc.textFile to create RDD and
then Row.fromSeq to convert to an ROW
● CsvTableScanExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/85/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-12-320.jpg)



![CreateTableRelationProvider
● DefaultSource should implement
CreateTableRelationProvider in order to support save
call
● Override createRelation method to implement save
mechanism
● Convert RDD[Row] to String and use saveAsTextFile to
save
● Ex : CsvSaveExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/85/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-16-320.jpg)

![PrunedScan
● CsvRelation should implement PrunedScan trait to
optimize the columns access
● PrunedScan gives information to the data source which
columns it wants to access
● When we build RDD[Row] we only give columns need
● No performance benefit in Csv data, just for demo. But it
has great performance benefits in sources like jdbc
● Ex : SalesSumExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/85/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-18-320.jpg)

![PrunedFilterScan
● CsvRelation should implement PrunedFilterScan trait
to optimize filtering
● PrunedFilterScan pushes filters to data source
● When we build RDD[Row] we only give rows which
satisfy the filter
● It’s an optimization. The filters will be evaluated again.
● Ex :CsvFilerExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/85/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-20-320.jpg)










![TableScan
● Table scan is a trait to be implemented for reading data
● It’s Base Relation that can produce all of it’s tuples as
an RDD of Row objects
● Methods to override
○ def buildScan(): RDD[Row]
● In csv example, we use sc.textFile to create RDD and
then Row.fromSeq to convert to an ROW
● CsvTableScanExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/75/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-12-2048.jpg)



![CreateTableRelationProvider
● DefaultSource should implement
CreateTableRelationProvider in order to support save
call
● Override createRelation method to implement save
mechanism
● Convert RDD[Row] to String and use saveAsTextFile to
save
● Ex : CsvSaveExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/75/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-16-2048.jpg)

![PrunedScan
● CsvRelation should implement PrunedScan trait to
optimize the columns access
● PrunedScan gives information to the data source which
columns it wants to access
● When we build RDD[Row] we only give columns need
● No performance benefit in Csv data, just for demo. But it
has great performance benefits in sources like jdbc
● Ex : SalesSumExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/75/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-18-2048.jpg)

![PrunedFilterScan
● CsvRelation should implement PrunedFilterScan trait
to optimize filtering
● PrunedFilterScan pushes filters to data source
● When we build RDD[Row] we only give rows which
satisfy the filter
● It’s an optimization. The filters will be evaluated again.
● Ex :CsvFilerExample.scala](https://image.slidesharecdn.com/anatomyofdatasourceapi-150628132506-lva1-app6892/75/Anatomy-of-Data-Source-API-A-deep-dive-into-Spark-Data-source-API-20-2048.jpg)

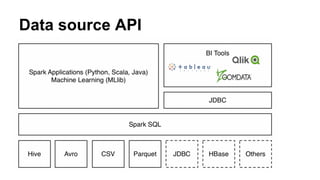
The document provides an in-depth look at the Spark Data Source API, covering features like schema discovery, data type inference, and order of operations for loading and saving structured data, particularly focusing on CSV sources. It details building a CSV data source, including automatic schema discovery and optimizations such as column pruning and filter push. The content illustrates the implementation of various traits necessary for supporting user schema definitions, reading, saving, and optimizing data access.




















































































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

