





















![36 www.ExigenServices.com
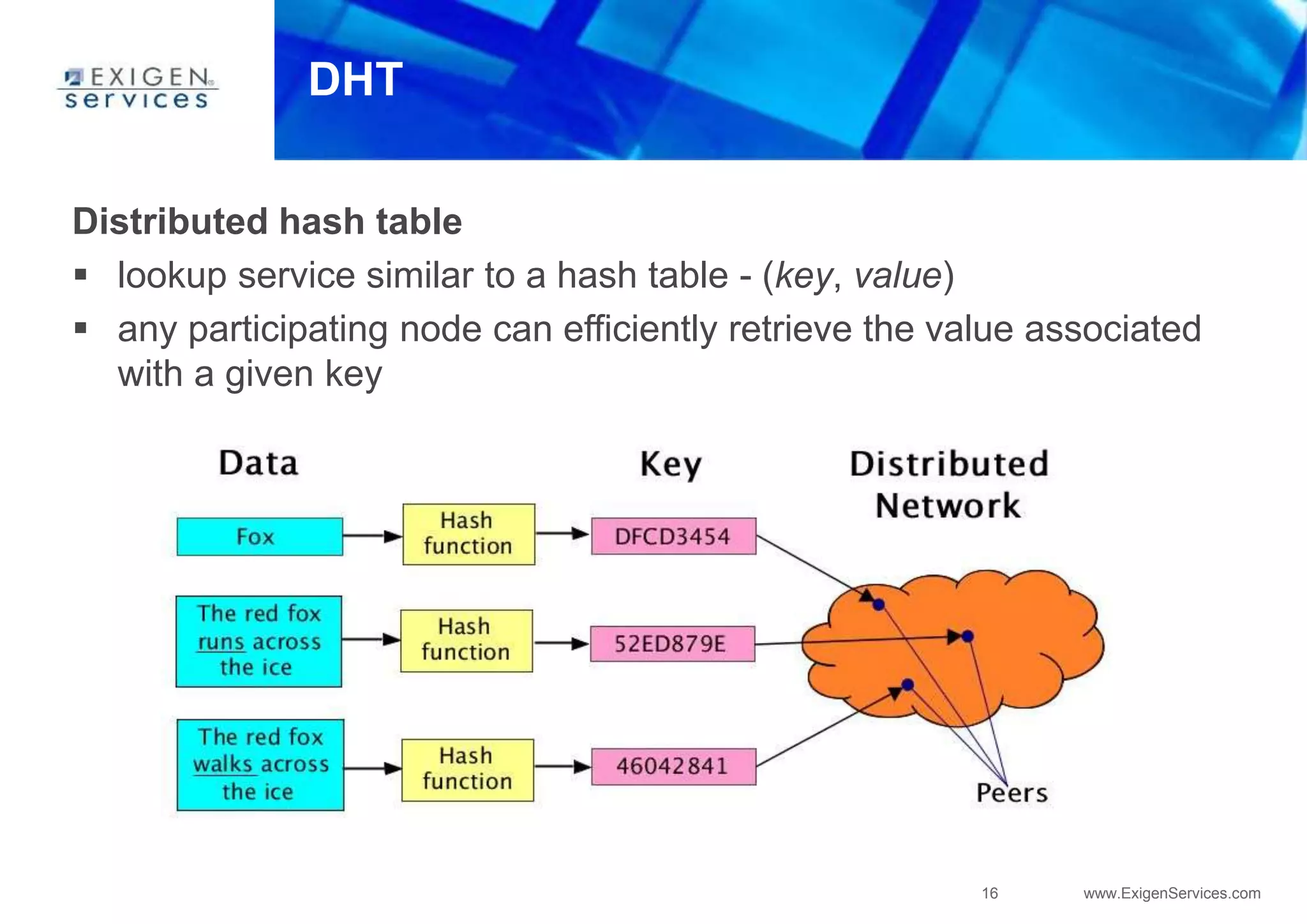
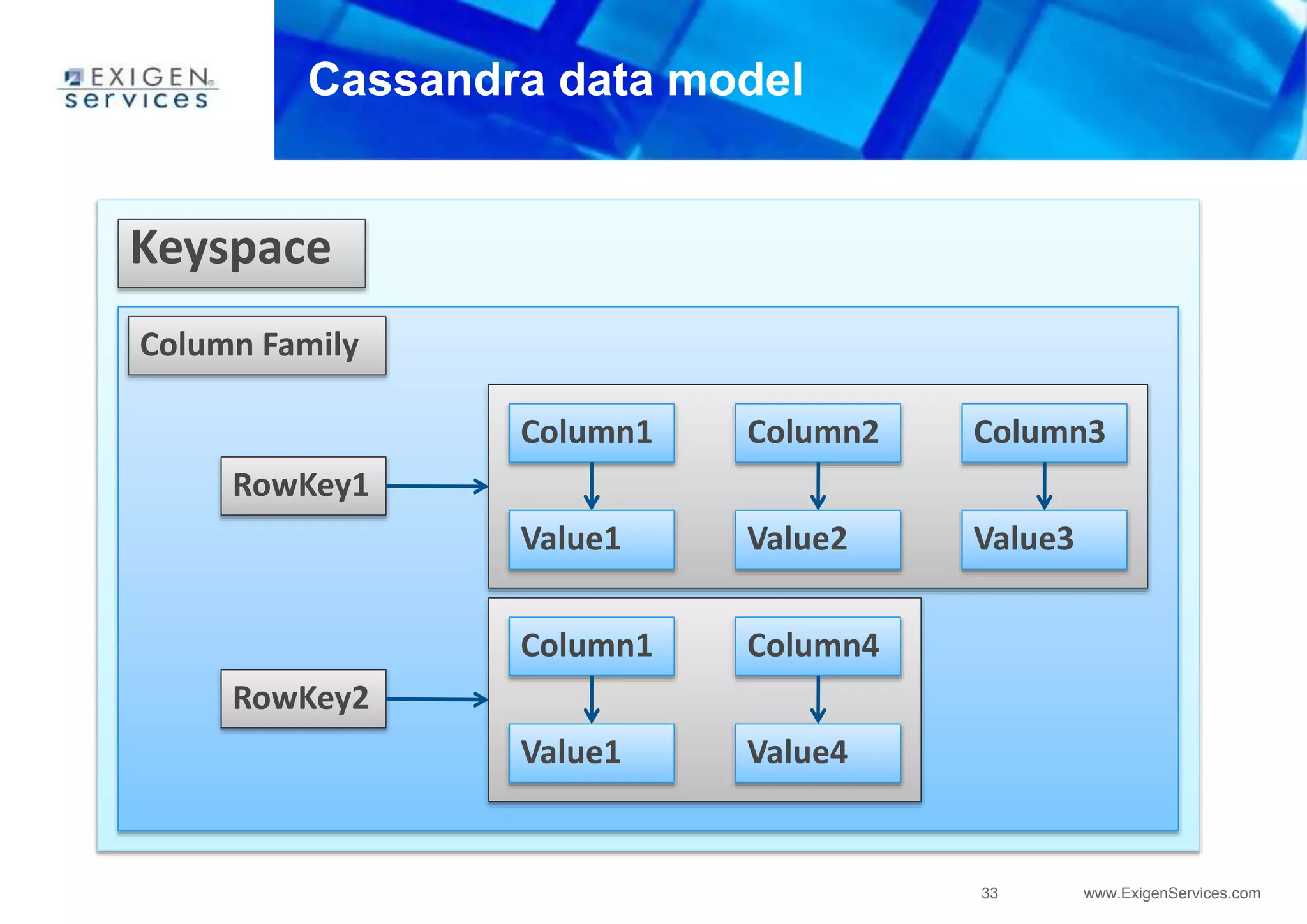
Key-value store
Four-dimensional hash map
[Keyspace][ColumnFamily][RowKey][Column]](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/85/Apache-cassandra-future-without-boundaries-part1-35-320.jpg)


![39 www.ExigenServices.com
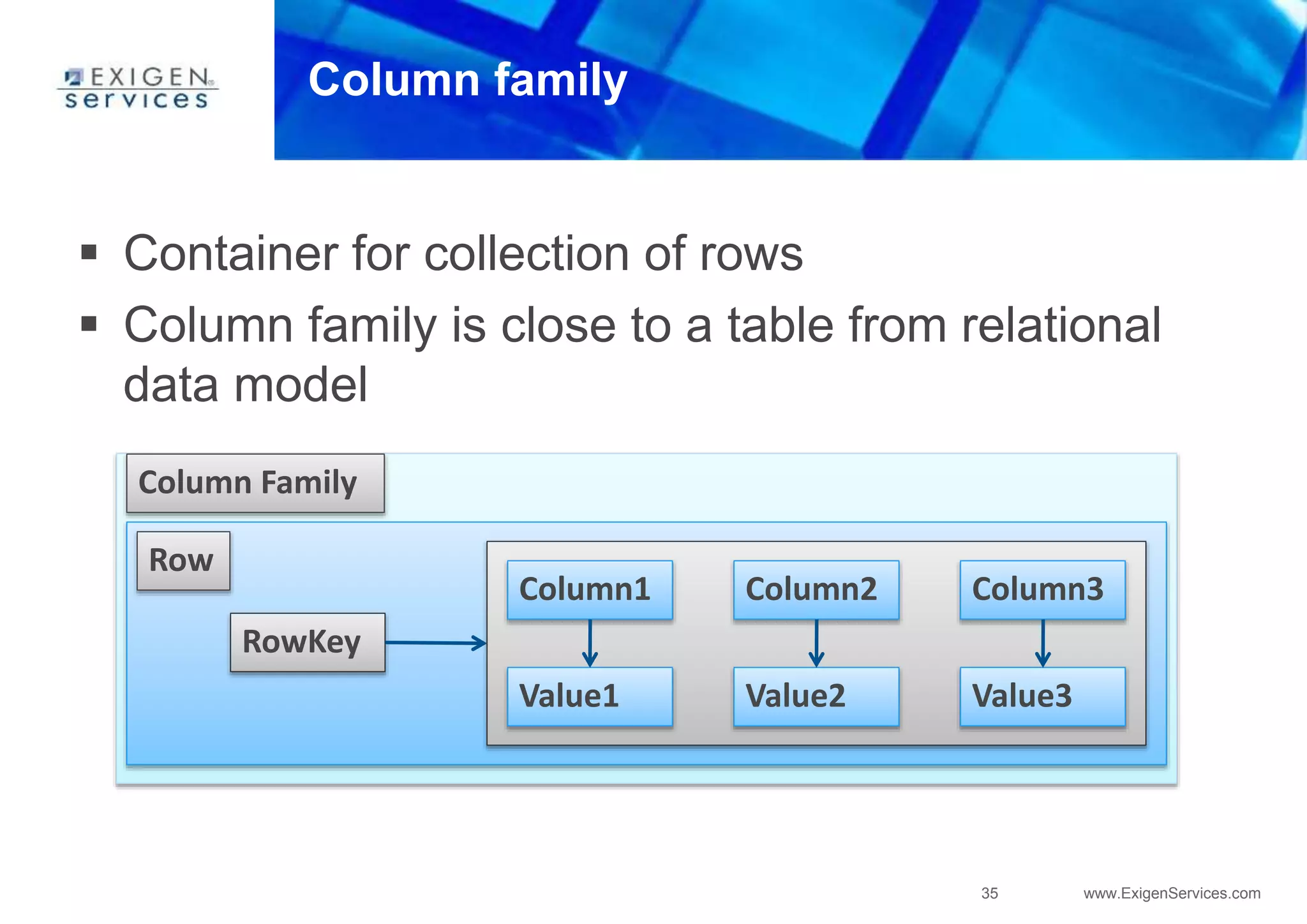
Column
Basic unit of data structure
Column
name: byte[] value: byte[] clock: long](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/85/Apache-cassandra-future-without-boundaries-part1-38-320.jpg)



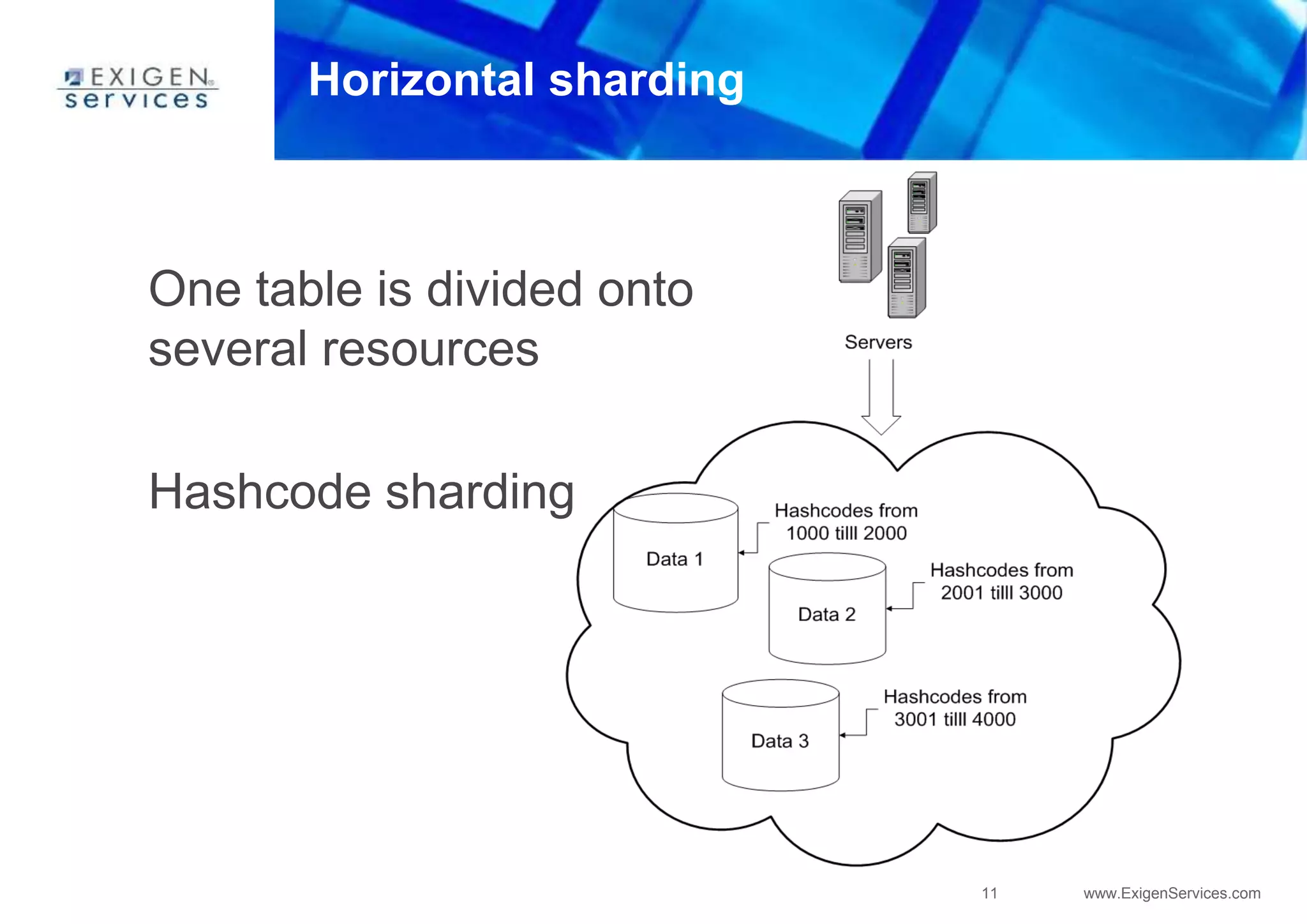
![44 www.ExigenServices.com
Super column
Super column
name: byte[] cols: Map<byte[], Column>
• Cannot store map of super columns (only one
level deep)
• Five-dimensional hash:
[Keyspace][ColumnFamily][Key][SuperColumn][SubColumn]
Stores map of subcolumns](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/85/Apache-cassandra-future-without-boundaries-part1-43-320.jpg)








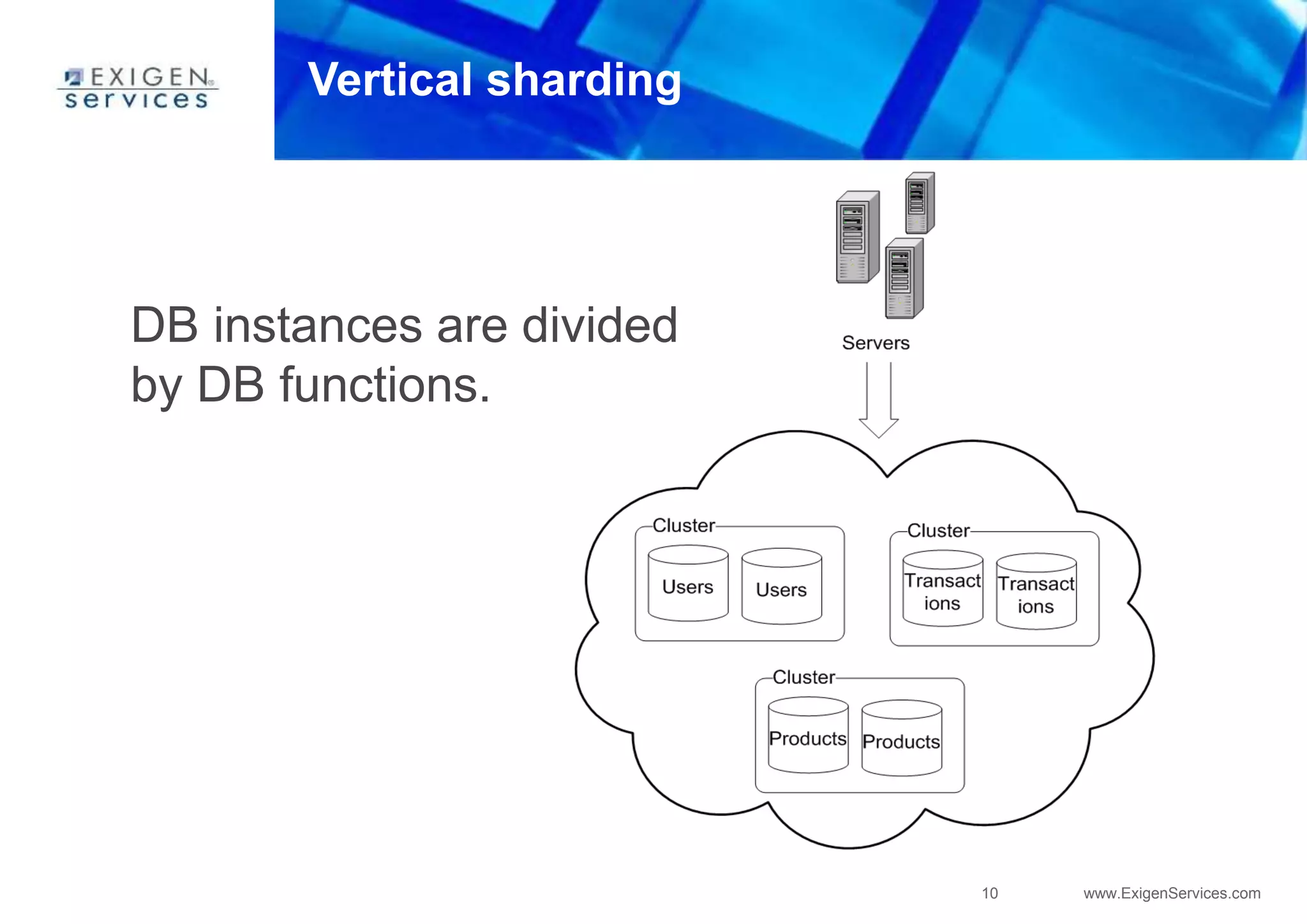















![36 www.ExigenServices.com
Key-value store
Four-dimensional hash map
[Keyspace][ColumnFamily][RowKey][Column]](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/75/Apache-cassandra-future-without-boundaries-part1-35-2048.jpg)


![39 www.ExigenServices.com
Column
Basic unit of data structure
Column
name: byte[] value: byte[] clock: long](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/75/Apache-cassandra-future-without-boundaries-part1-38-2048.jpg)



![44 www.ExigenServices.com
Super column
Super column
name: byte[] cols: Map<byte[], Column>
• Cannot store map of super columns (only one
level deep)
• Five-dimensional hash:
[Keyspace][ColumnFamily][Key][SuperColumn][SubColumn]
Stores map of subcolumns](https://image.slidesharecdn.com/apachecassandra-futurewithoutboundariespart1-150806100800-lva1-app6892/75/Apache-cassandra-future-without-boundaries-part1-43-2048.jpg)


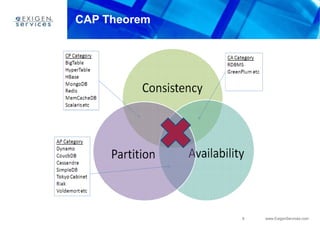
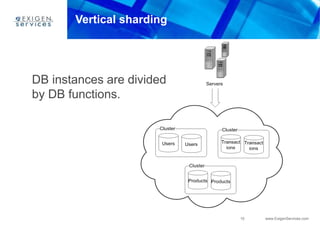
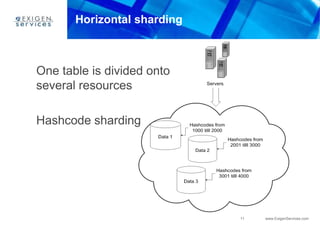
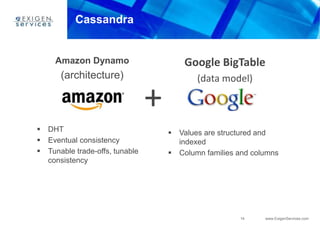
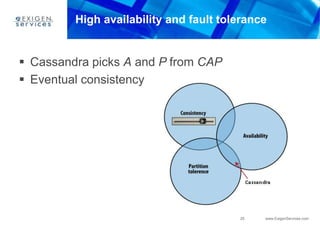
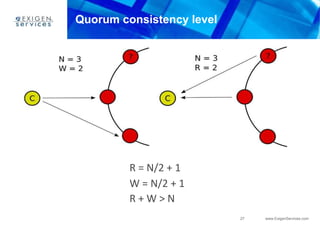
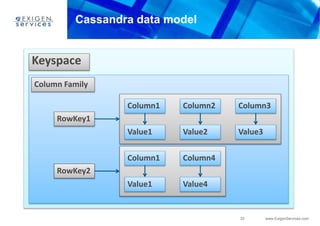
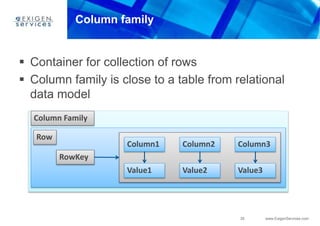
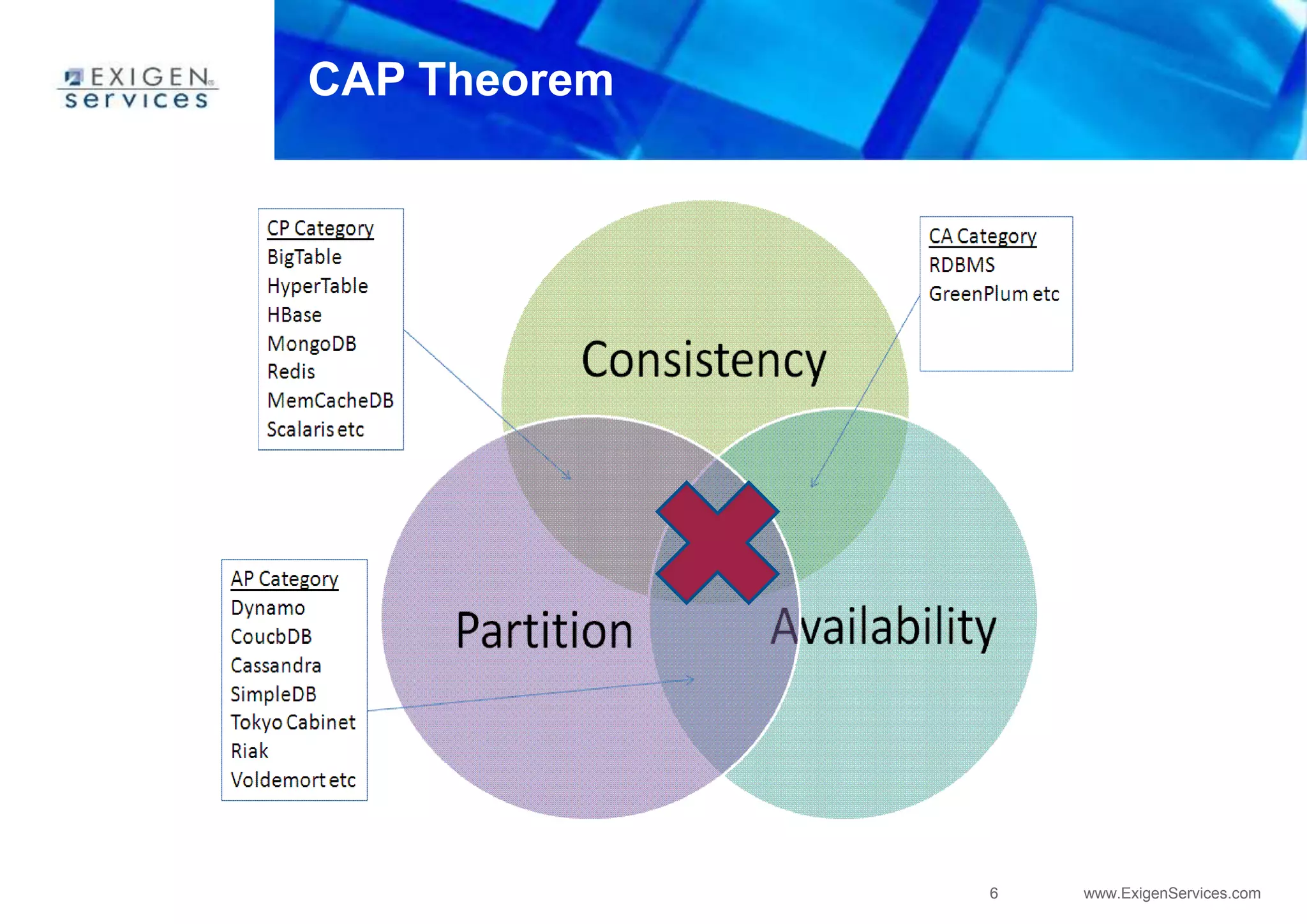
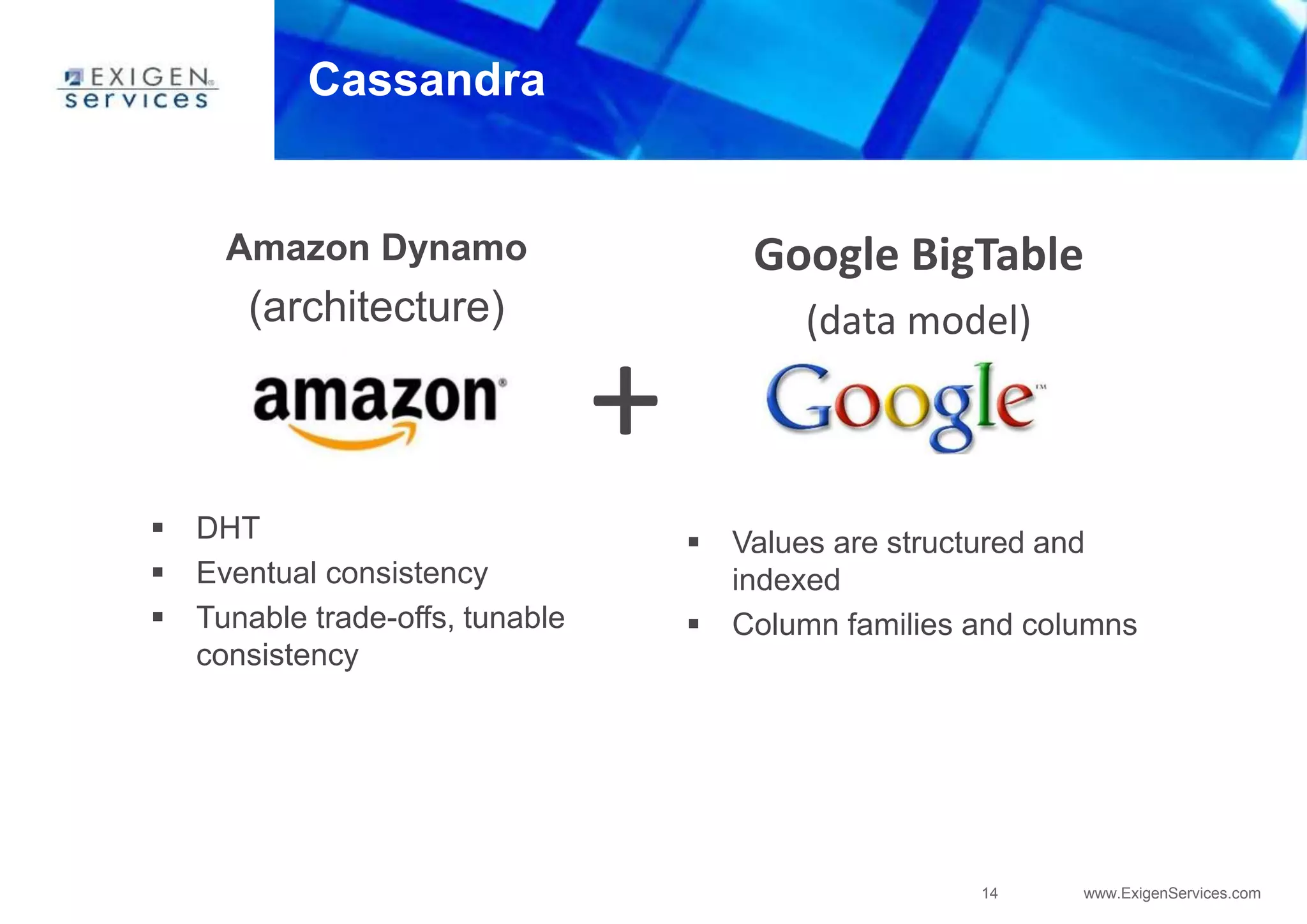
This document provides an overview of Apache Cassandra and compares it to relational database management systems (RDBMS). It describes Cassandra's data model using a key-value store with rows and columns organized into column families within keyspaces. Cassandra is a decentralized, distributed system that provides high availability and scalability through horizontal partitioning and replication across nodes. It offers tunable consistency levels and supports both row- and column-oriented data models.












































































