Download as PDF, PPTX
























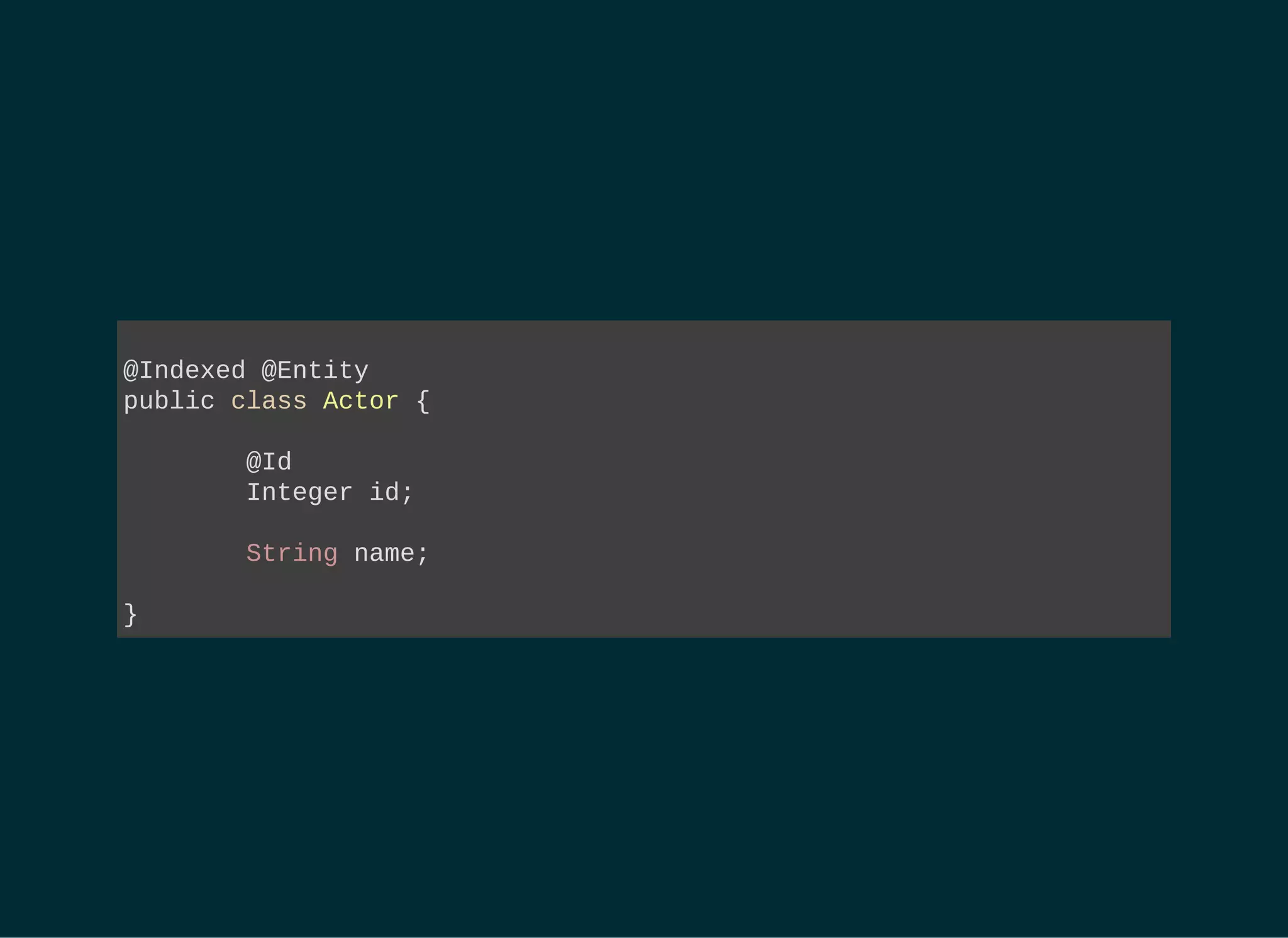
![RUN A LUCENE QUERY BUT GET JPA
MANAGED RESULTS
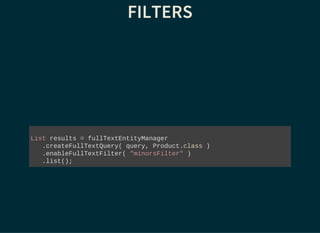
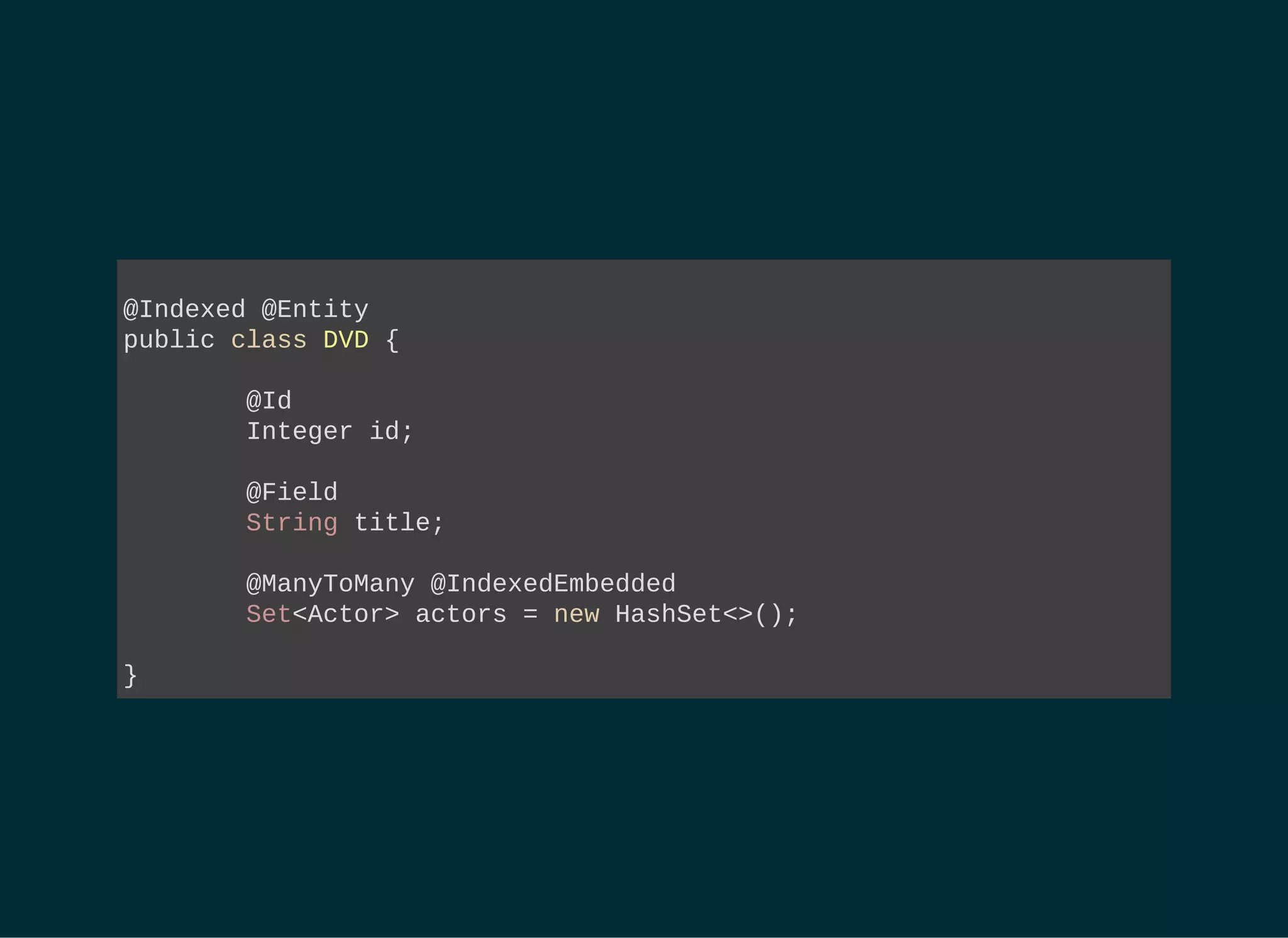
String[] productFields = { "title", "actors.name" };
org.apache.lucene.search.Query luceneQuery = // ...
FullTextEntityManager ftEm =
Search.getFullTextEntityManager( entityManager );
FullTextQuery query = // extends javax.persistence.Query
ftEm.createFullTextQuery( luceneQuery, DVD.class );
List dvds = // Managed entities!
query.setMaxResults(100).getResultList();
int totalNbrOfResults = query.getResultSize();](https://image.slidesharecdn.com/apacheluceneforjavaeedevelopers-150723151345-lva1-app6891/85/Apache-Lucene-for-Java-EE-Developers-33-320.jpg)





















































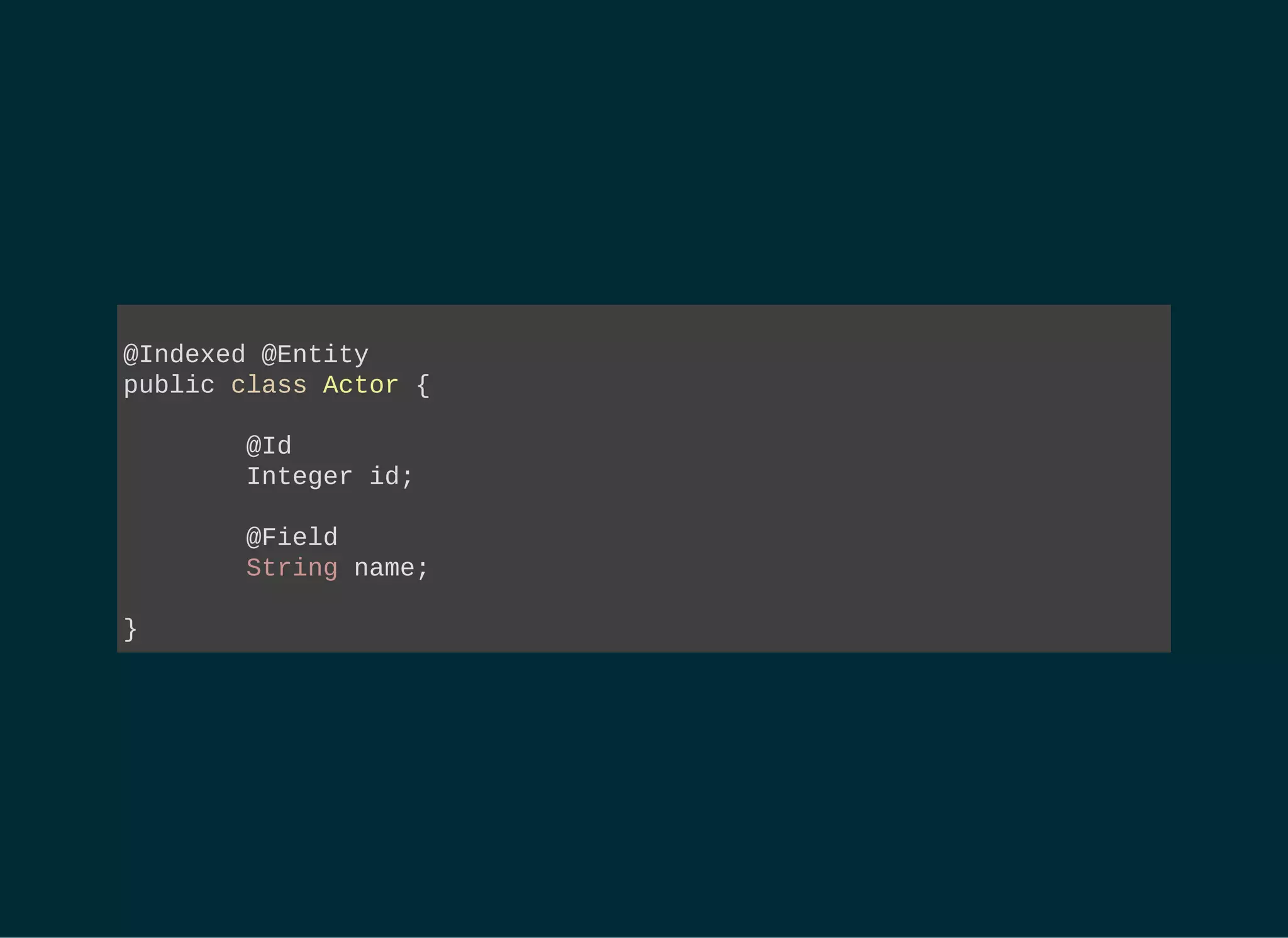


![RUN A LUCENE QUERY BUT GET JPA
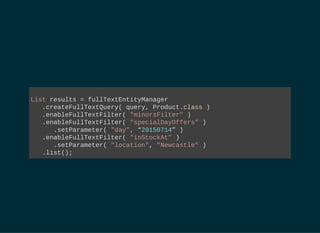
MANAGED RESULTS
String[] productFields = { "title", "actors.name" };
org.apache.lucene.search.Query luceneQuery = // ...
FullTextEntityManager ftEm =
Search.getFullTextEntityManager( entityManager );
FullTextQuery query = // extends javax.persistence.Query
ftEm.createFullTextQuery( luceneQuery, DVD.class );
List dvds = // Managed entities!
query.setMaxResults(100).getResultList();
int totalNbrOfResults = query.getResultSize();](https://image.slidesharecdn.com/apacheluceneforjavaeedevelopers-150723151345-lva1-app6891/75/Apache-Lucene-for-Java-EE-Developers-33-2048.jpg)





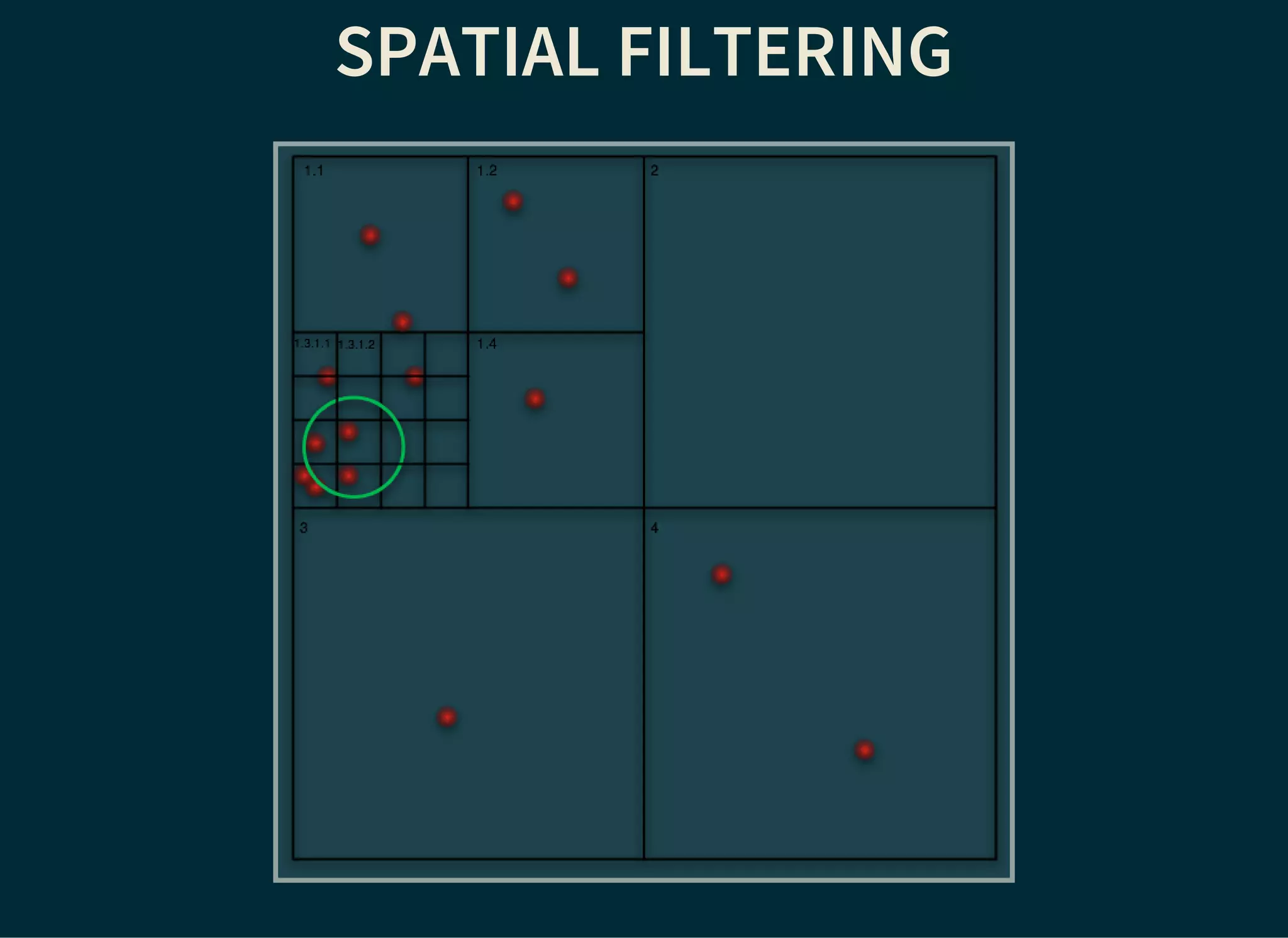



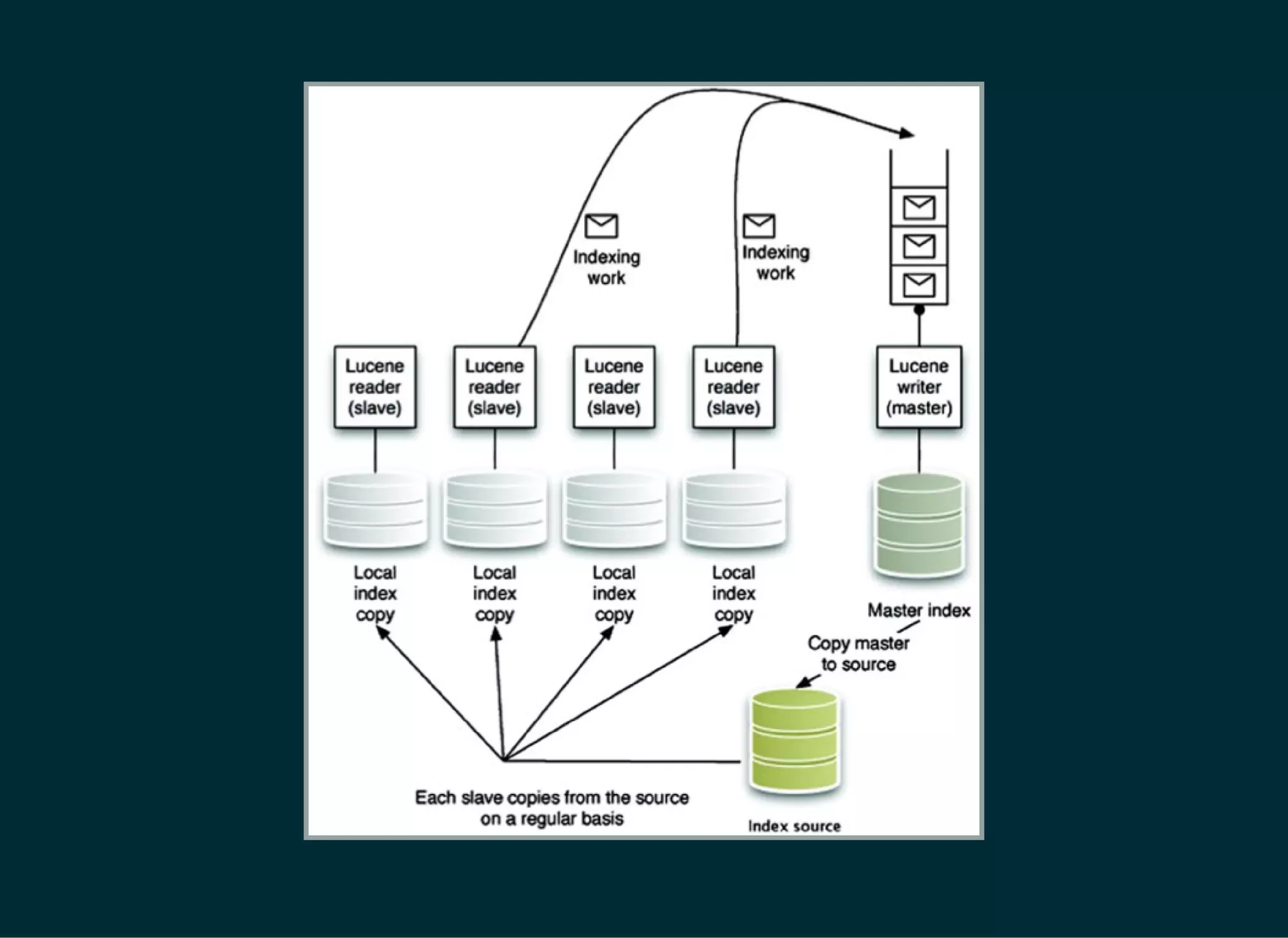
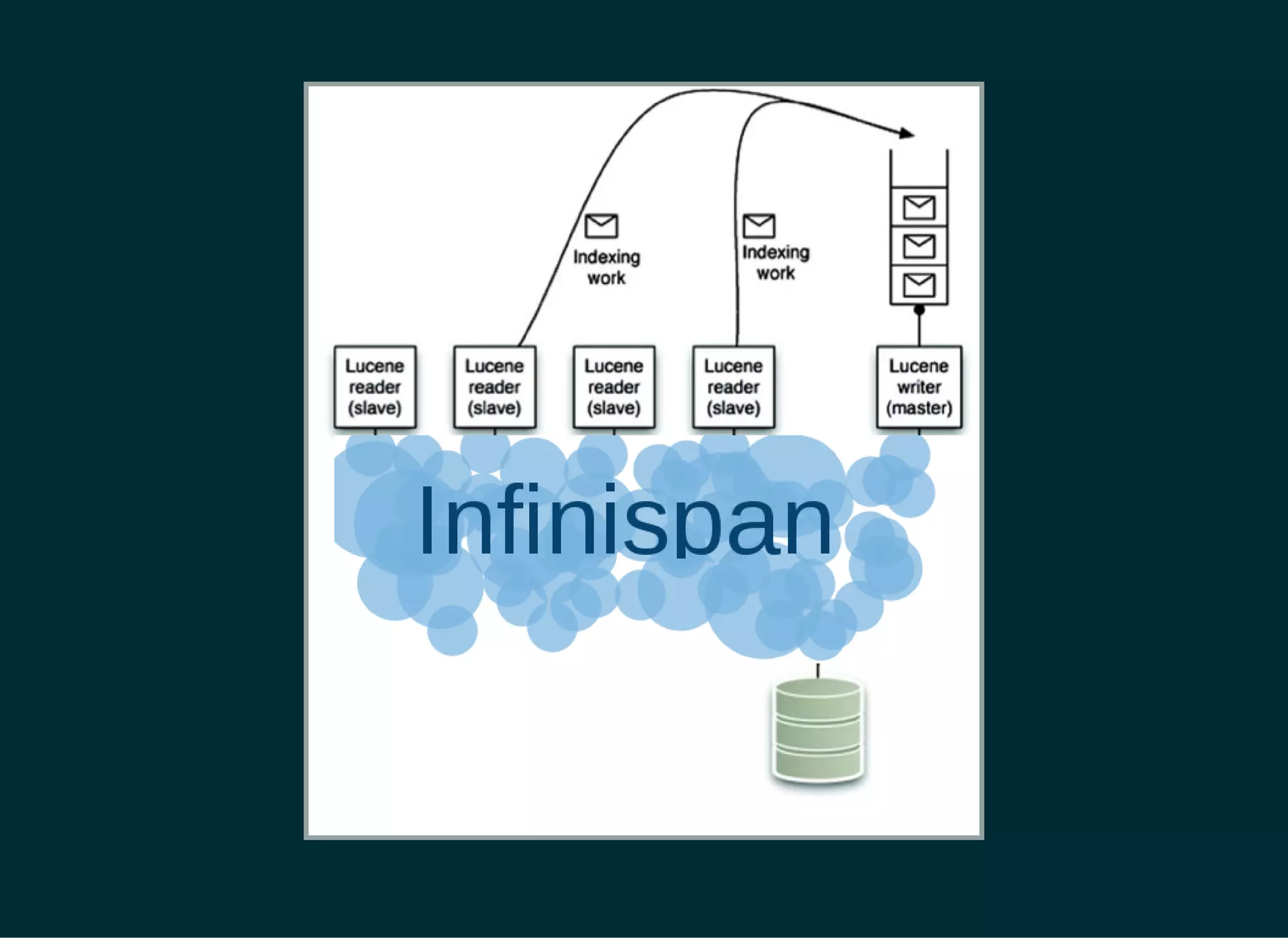





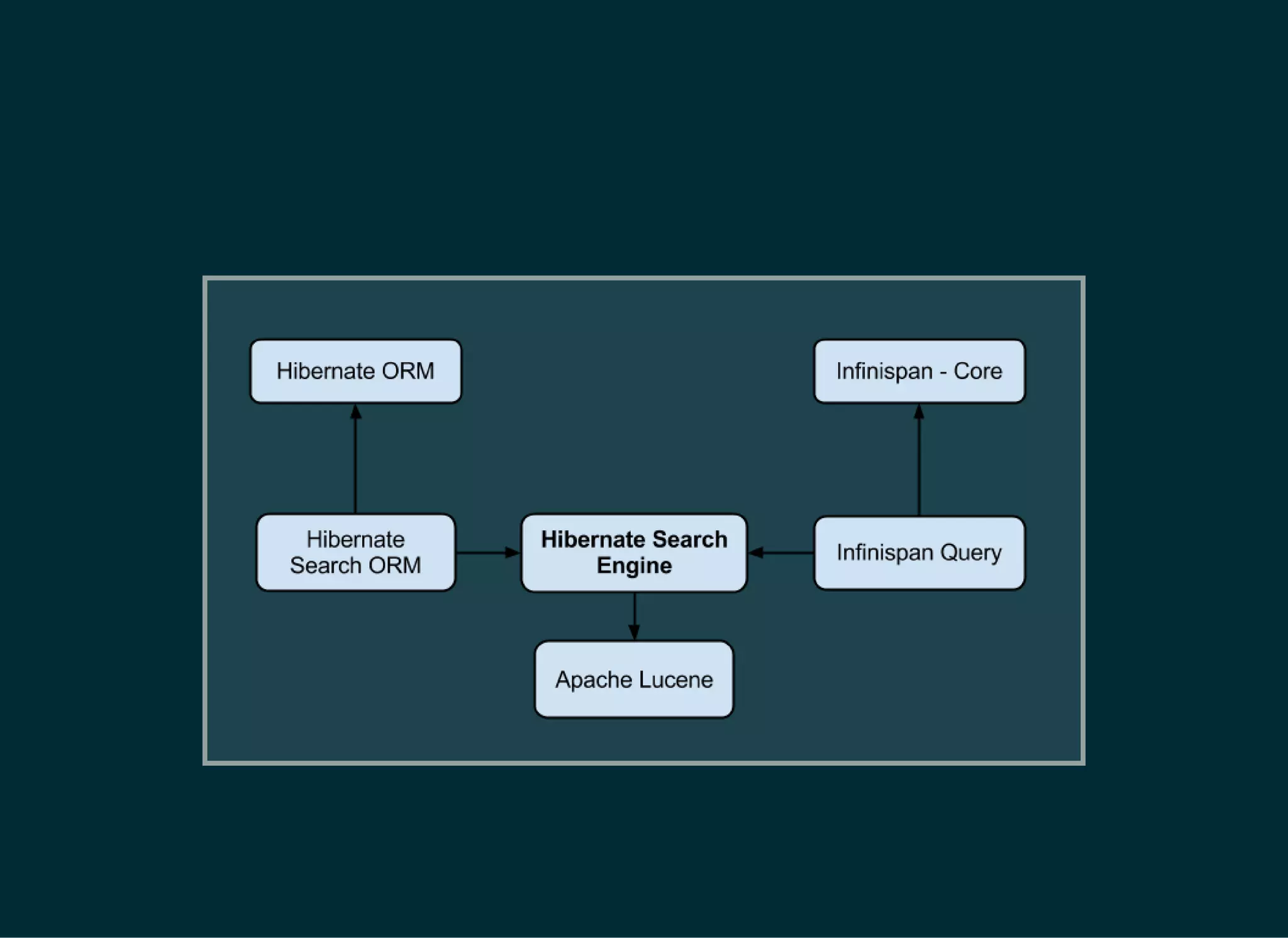
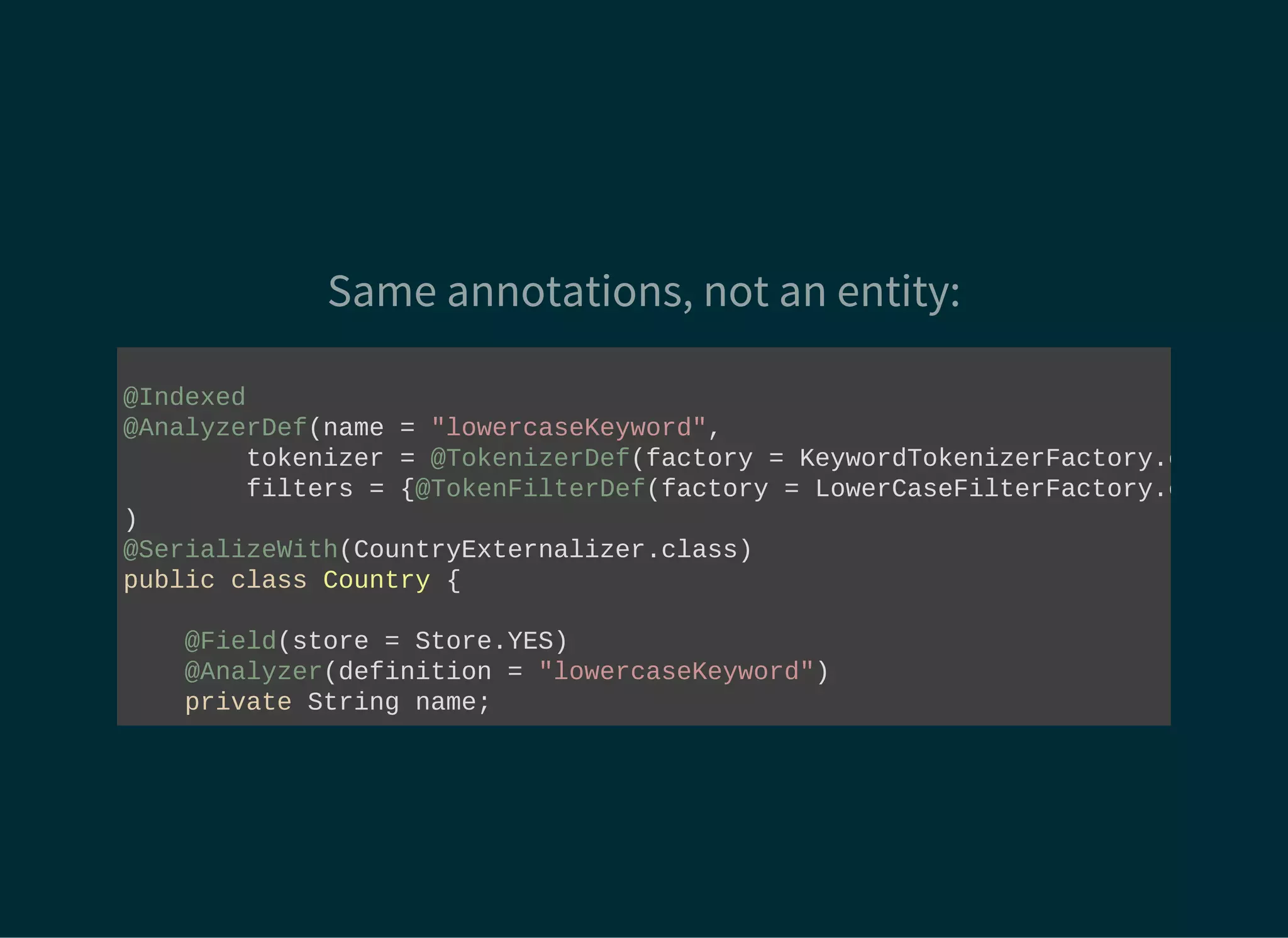















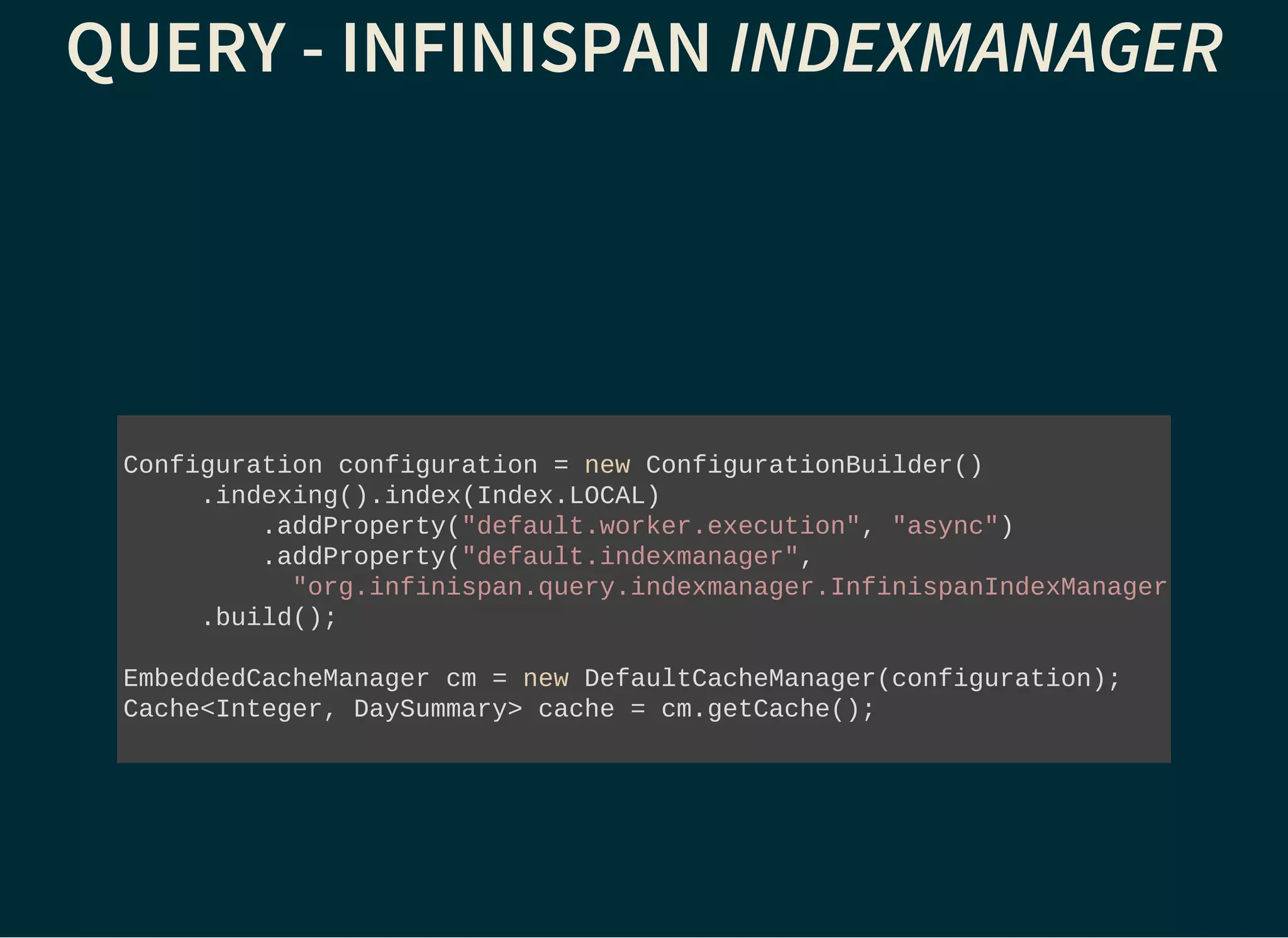
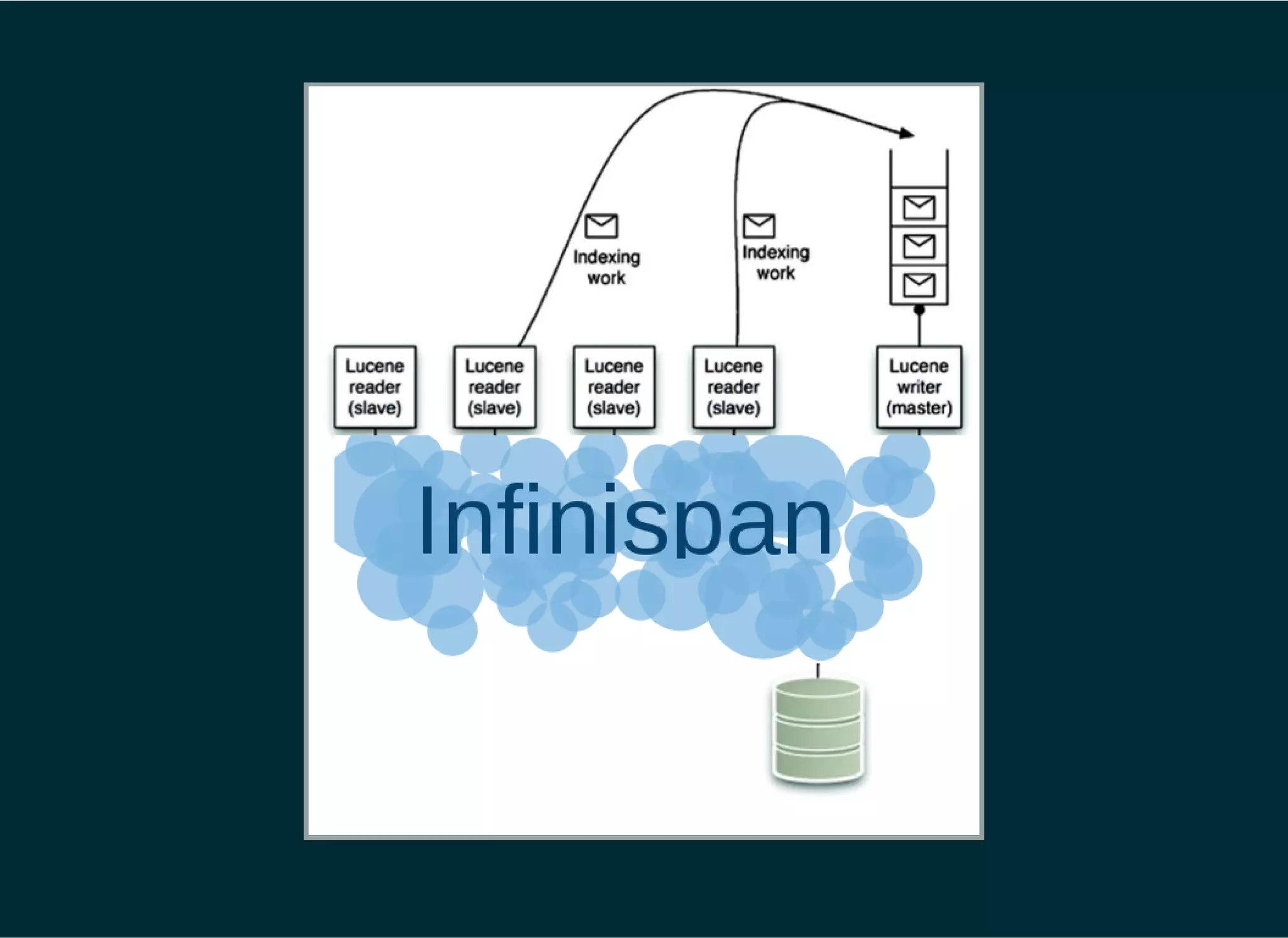

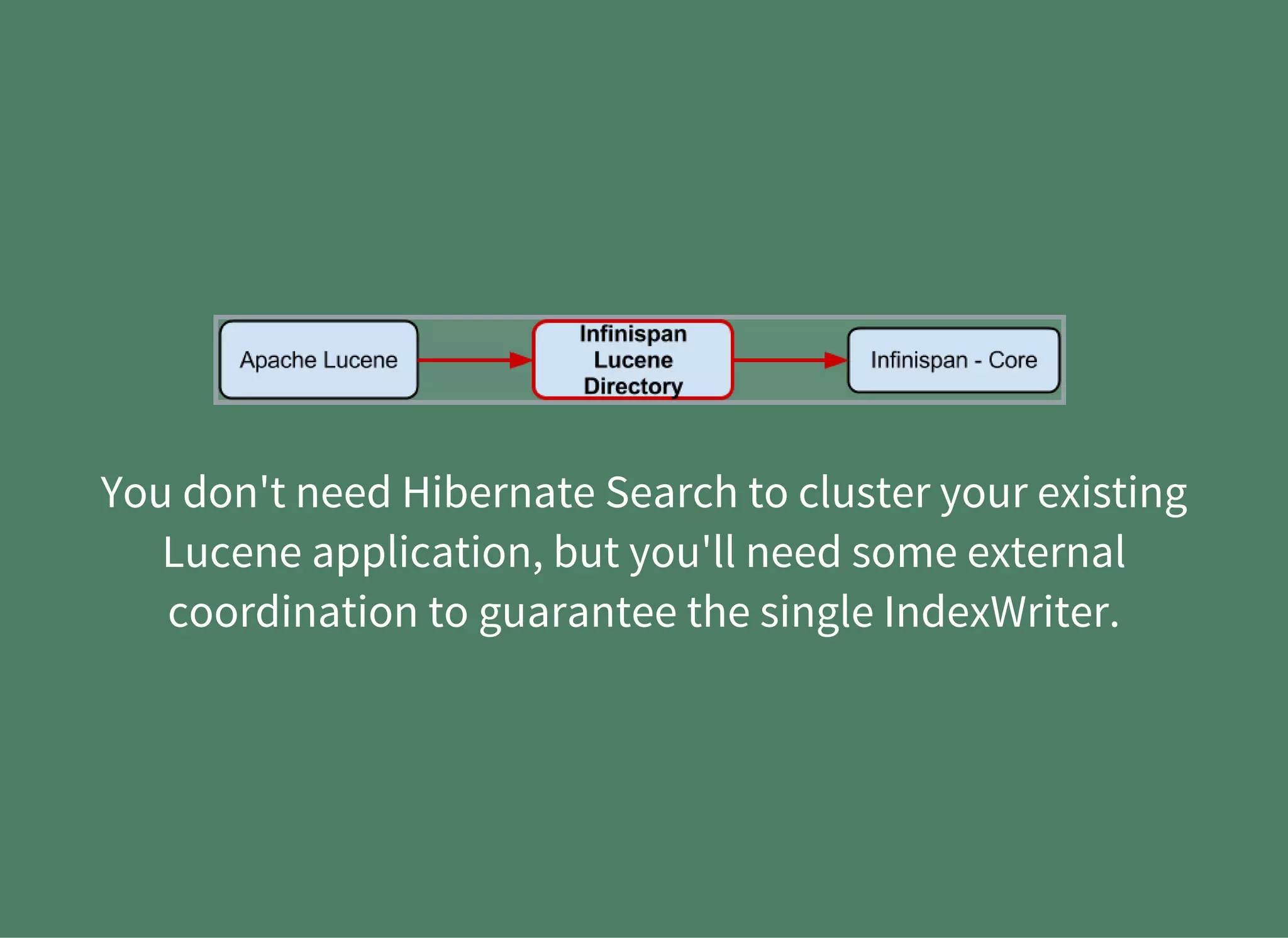





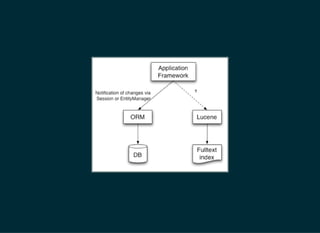
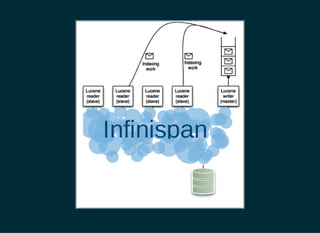
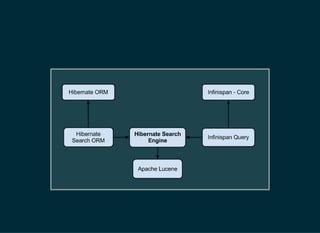
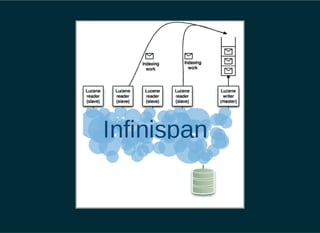
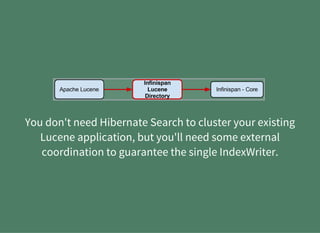
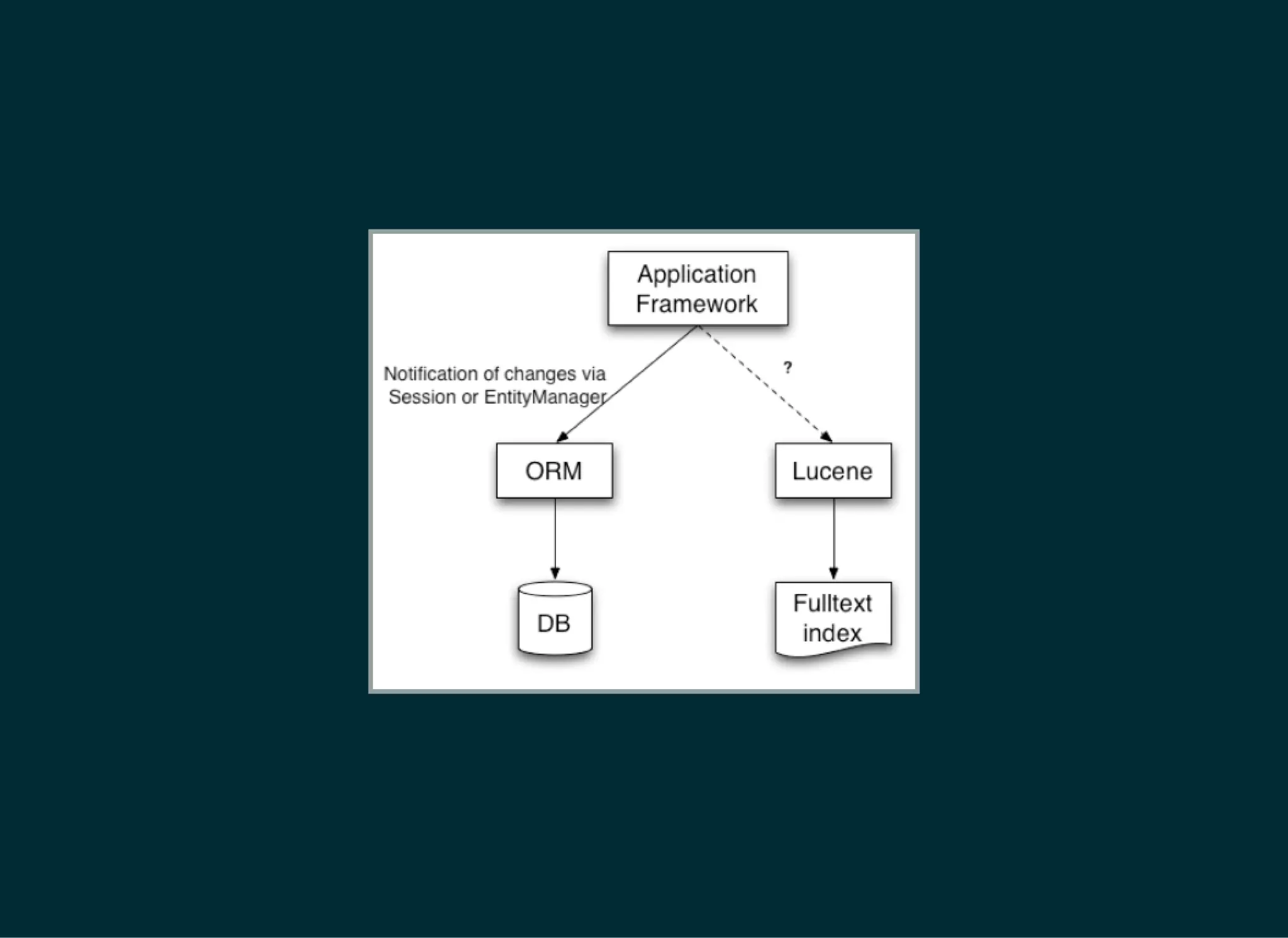
The document provides a detailed introduction to Apache Lucene for Java EE developers, highlighting its integration with Hibernate and Infinispan for search functionality in applications. It covers key concepts such as search engine requirements, index management, and how to effectively implement Lucene within a JPA context. Additionally, it outlines future plans and improvements for both Infinispan and Hibernate Search, emphasizing the importance of efficient search capabilities in modern applications.


![Faster java ee builds with gradle [con4921]](https://cdn.slidesharecdn.com/ss_thumbnails/fasterjavaeebuildswithgradlecon4921-160927042155-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









































































