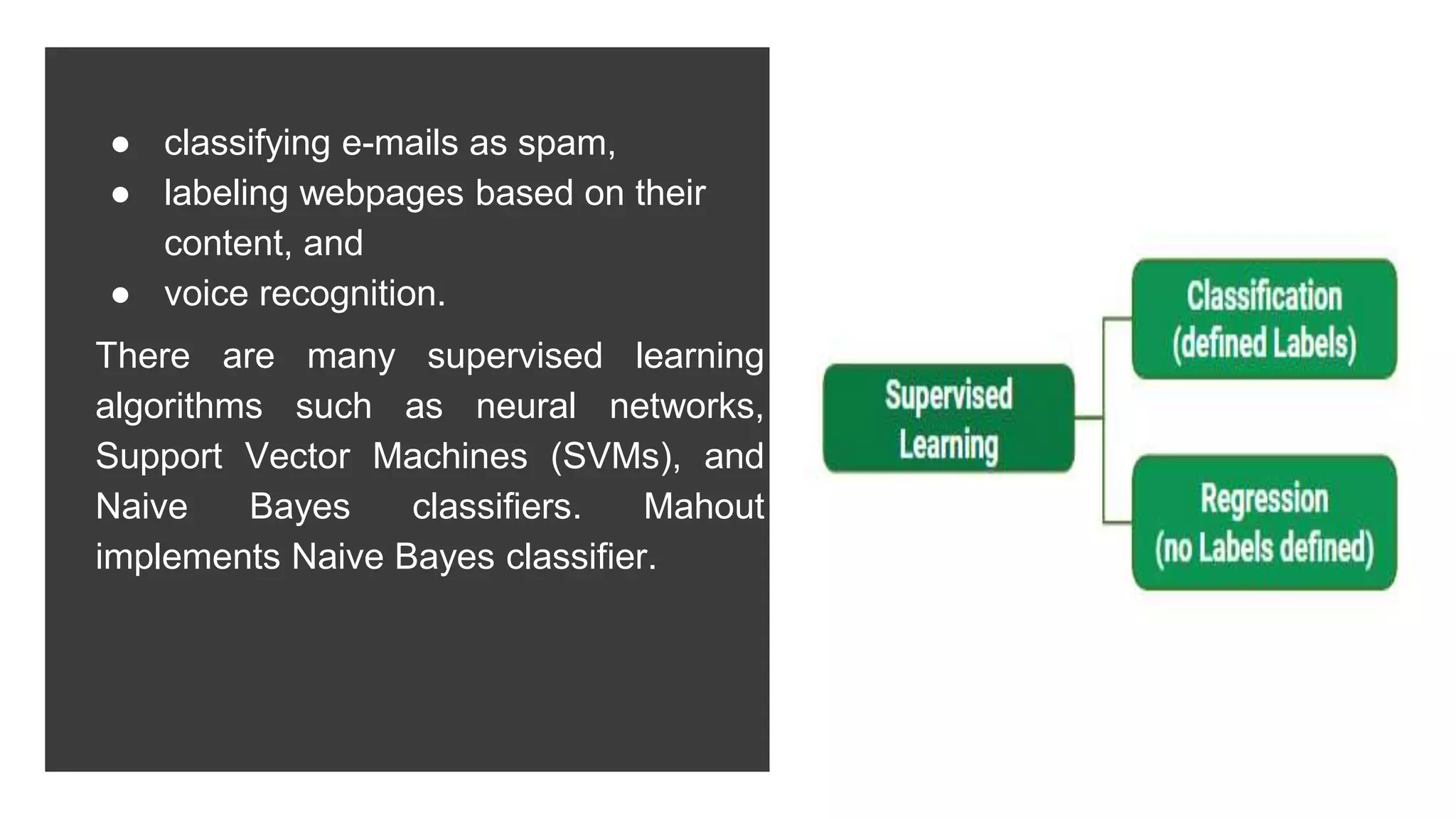
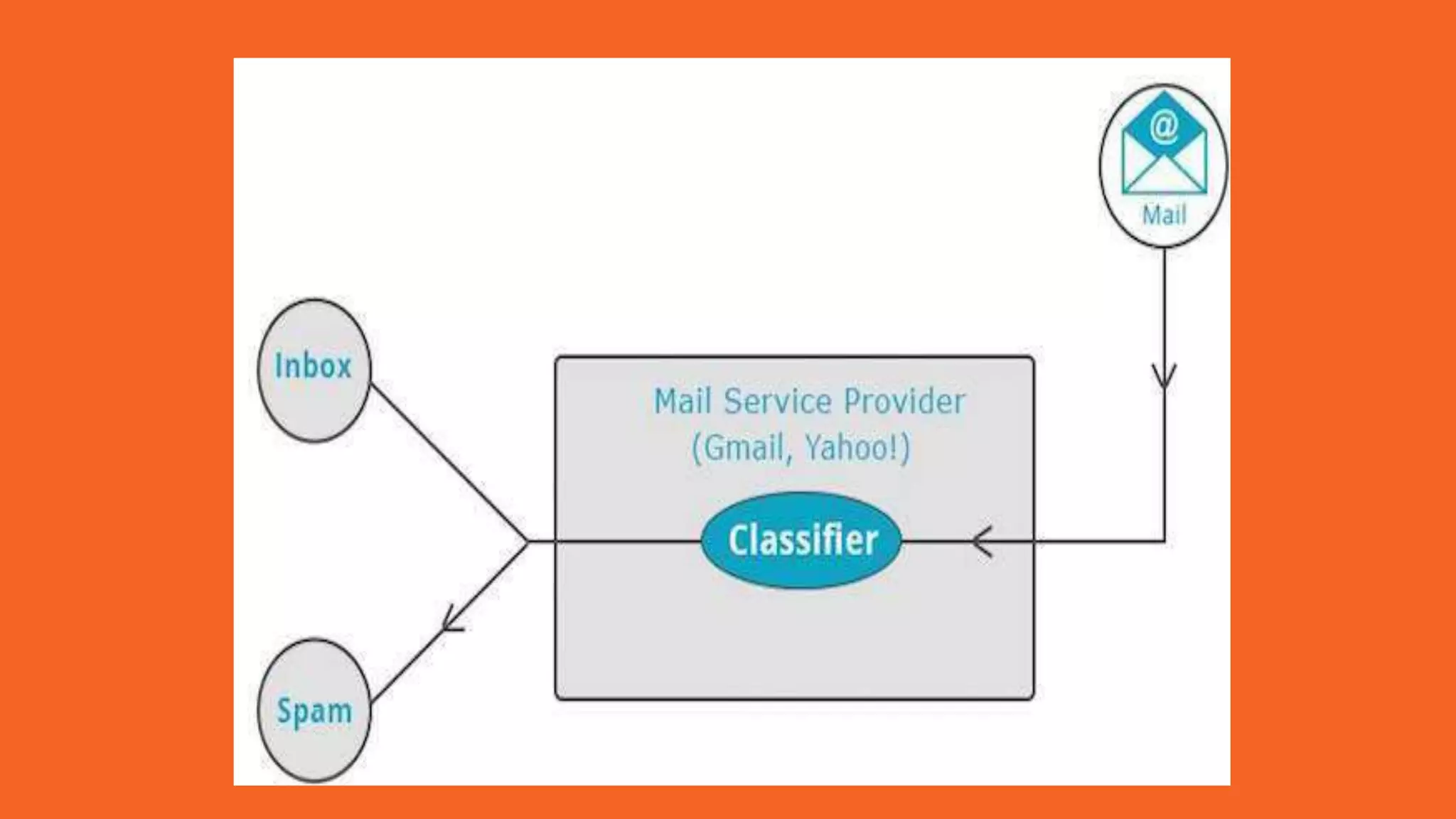
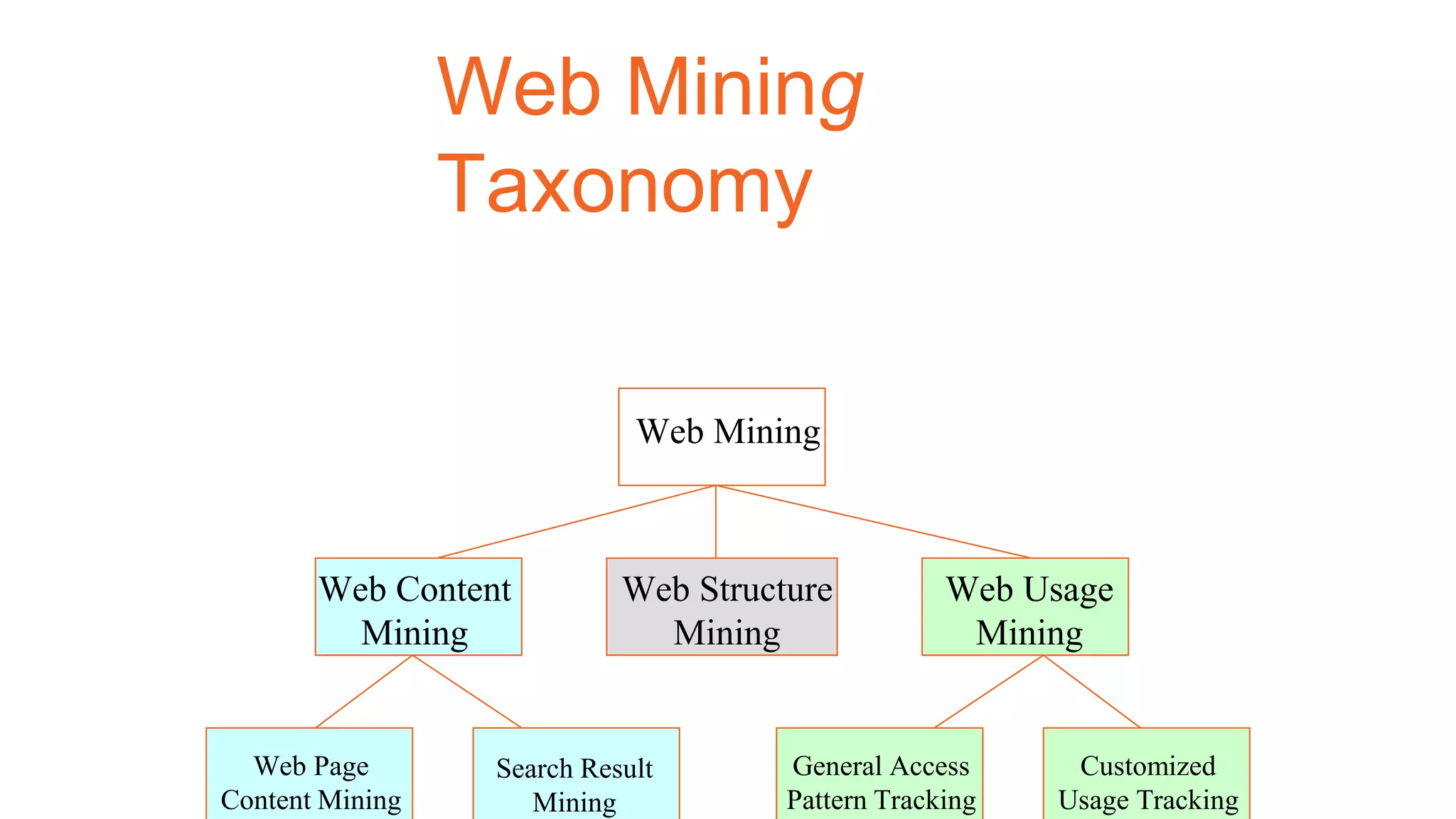
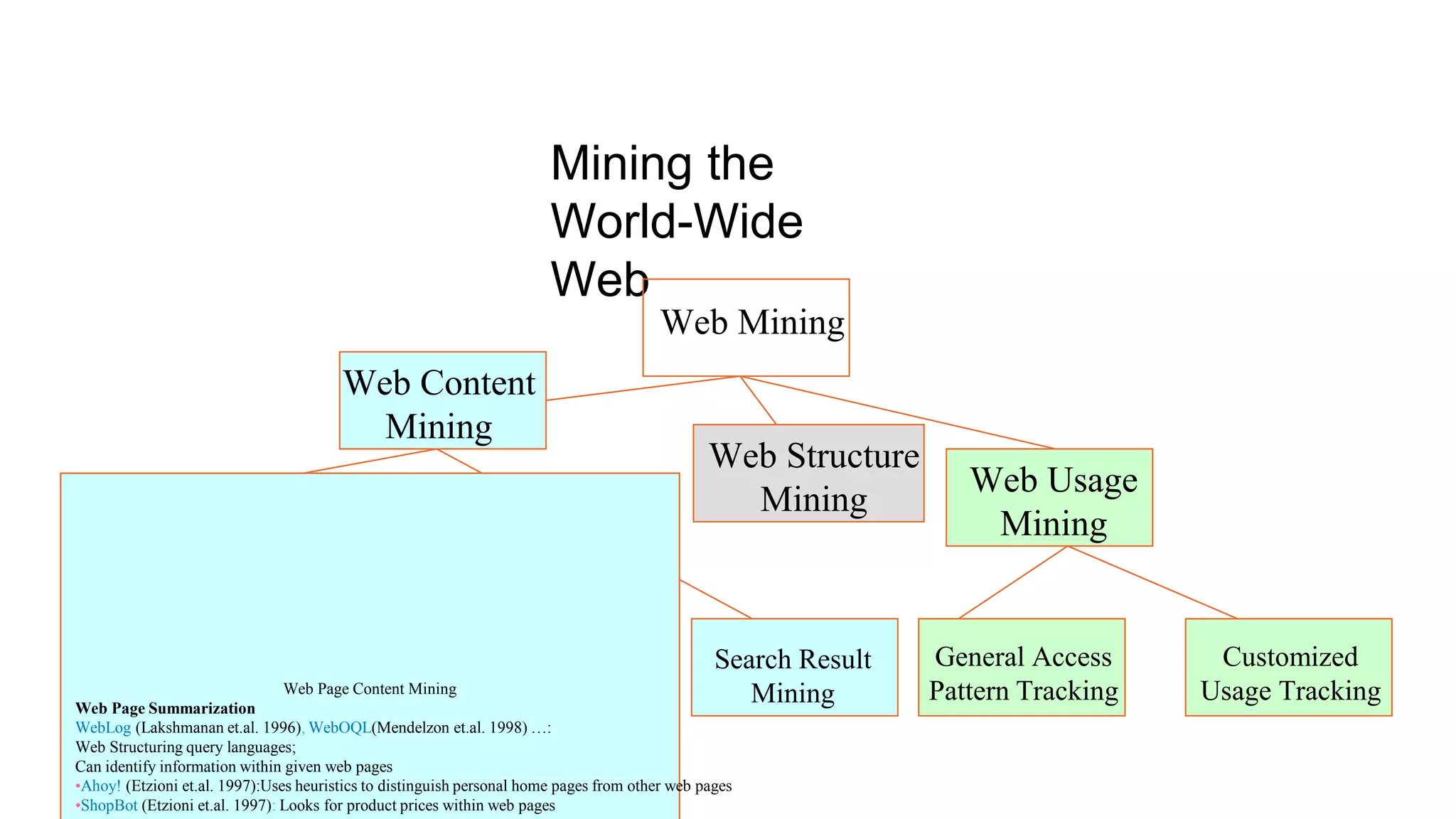
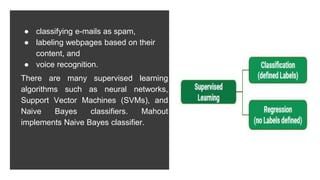
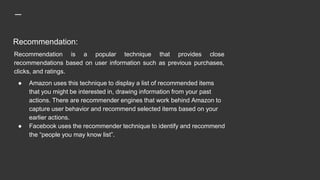
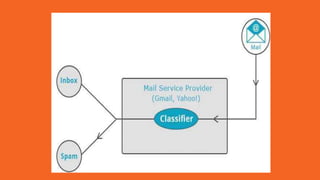
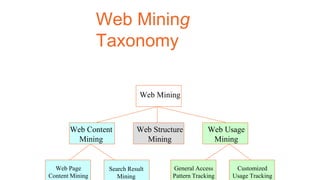
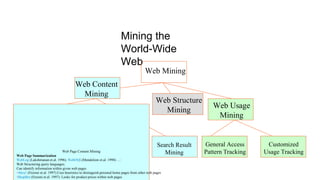
Apache Mahout is an open source machine learning library that provides algorithms for recommendation, classification, clustering and other machine learning techniques. It started as a sub-project of Apache Lucene in 2008 and became a top-level Apache project in 2010. Mahout implements many popular machine learning algorithms like naive bayes classification, k-means clustering, and uses the Apache Hadoop framework to provide scalability in distributed environments. Major companies like Facebook, LinkedIn, and Yahoo use Mahout for applications such as recommendations, user modeling, and pattern mining.

![Apache mahout
Apache Mahout is a project of the Apache Software
Foundation to produce free implementations of distributed
or otherwise scalable machine learning algorithms focused
primarily on linear algebra.
the past, many of the implementations use the Apache
Hadoop platform, however today it is primarily focused on
Apache Spark.[3][4]
Mahout also provides Java/Scala libraries for common
maths operations (focused on linear algebra and statistics)
and primitive Java collections. Mahout is a work in proIn
gress; a number of algorithms have been implemented.[5]](https://image.slidesharecdn.com/yourbigidea-210610143448/85/Apache-mahout-and-R-mining-complex-dataobject-2-320.jpg)





















![Apache mahout
Apache Mahout is a project of the Apache Software
Foundation to produce free implementations of distributed
or otherwise scalable machine learning algorithms focused
primarily on linear algebra.
the past, many of the implementations use the Apache
Hadoop platform, however today it is primarily focused on
Apache Spark.[3][4]
Mahout also provides Java/Scala libraries for common
maths operations (focused on linear algebra and statistics)
and primitive Java collections. Mahout is a work in proIn
gress; a number of algorithms have been implemented.[5]](https://image.slidesharecdn.com/yourbigidea-210610143448/75/Apache-mahout-and-R-mining-complex-dataobject-2-2048.jpg)