Downloaded 659 times




















![+
31
More Info.
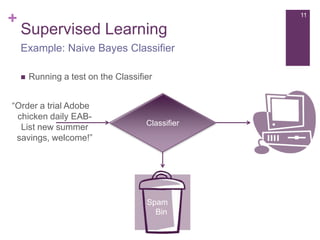
1.
“Scalable Similarity-Based Neighborhood Methods with
MapReduce” by Sebastian Schelter, Christoph Boden and
Volker Markl. – RecSys 2012.
2.
“Case Study Evaluation of Mahout as a Recommender Platform”
by Carlos E. Seminario and David C. Wilson - Workshop on
Recommendation Utility Evaluation: Beyond RMSE (RUE 2012)
3.
http://mahout.apache.org/ - Apache Mahout Project Page
4.
http://www.ibm.com/developerworks/java/library/j-mahout/ Introducing Apache Mahout
5.
[VIDEO] “Collaborative filtering at scale” by Sean Owen
6.
[BOOK] “Mahout in Action” by Owen et. al., Manning Pub.
© Varad Meru, 2013](https://image.slidesharecdn.com/introtomachinelearningandmahoutbigdata-140128111807-phpapp01/85/Machine-Learning-and-Apache-Mahout-An-Introduction-31-320.jpg)






















![+
31
More Info.
1.
“Scalable Similarity-Based Neighborhood Methods with
MapReduce” by Sebastian Schelter, Christoph Boden and
Volker Markl. – RecSys 2012.
2.
“Case Study Evaluation of Mahout as a Recommender Platform”
by Carlos E. Seminario and David C. Wilson - Workshop on
Recommendation Utility Evaluation: Beyond RMSE (RUE 2012)
3.
http://mahout.apache.org/ - Apache Mahout Project Page
4.
http://www.ibm.com/developerworks/java/library/j-mahout/ Introducing Apache Mahout
5.
[VIDEO] “Collaborative filtering at scale” by Sean Owen
6.
[BOOK] “Mahout in Action” by Owen et. al., Manning Pub.
© Varad Meru, 2013](https://image.slidesharecdn.com/introtomachinelearningandmahoutbigdata-140128111807-phpapp01/75/Machine-Learning-and-Apache-Mahout-An-Introduction-31-2048.jpg)



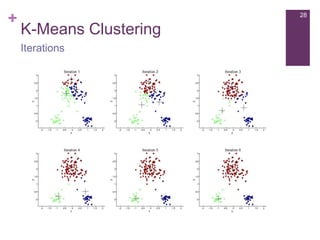
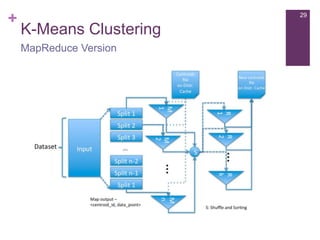
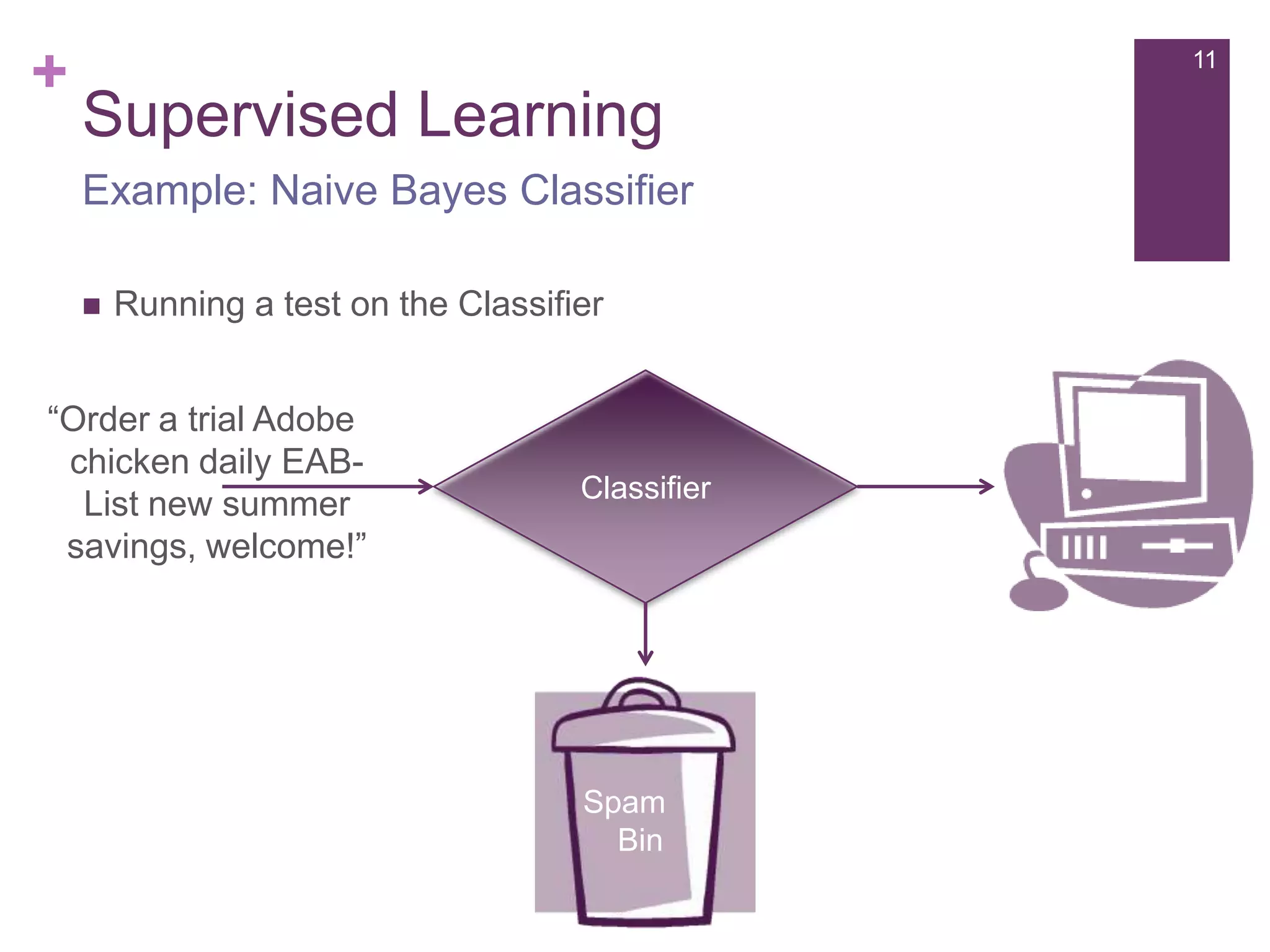
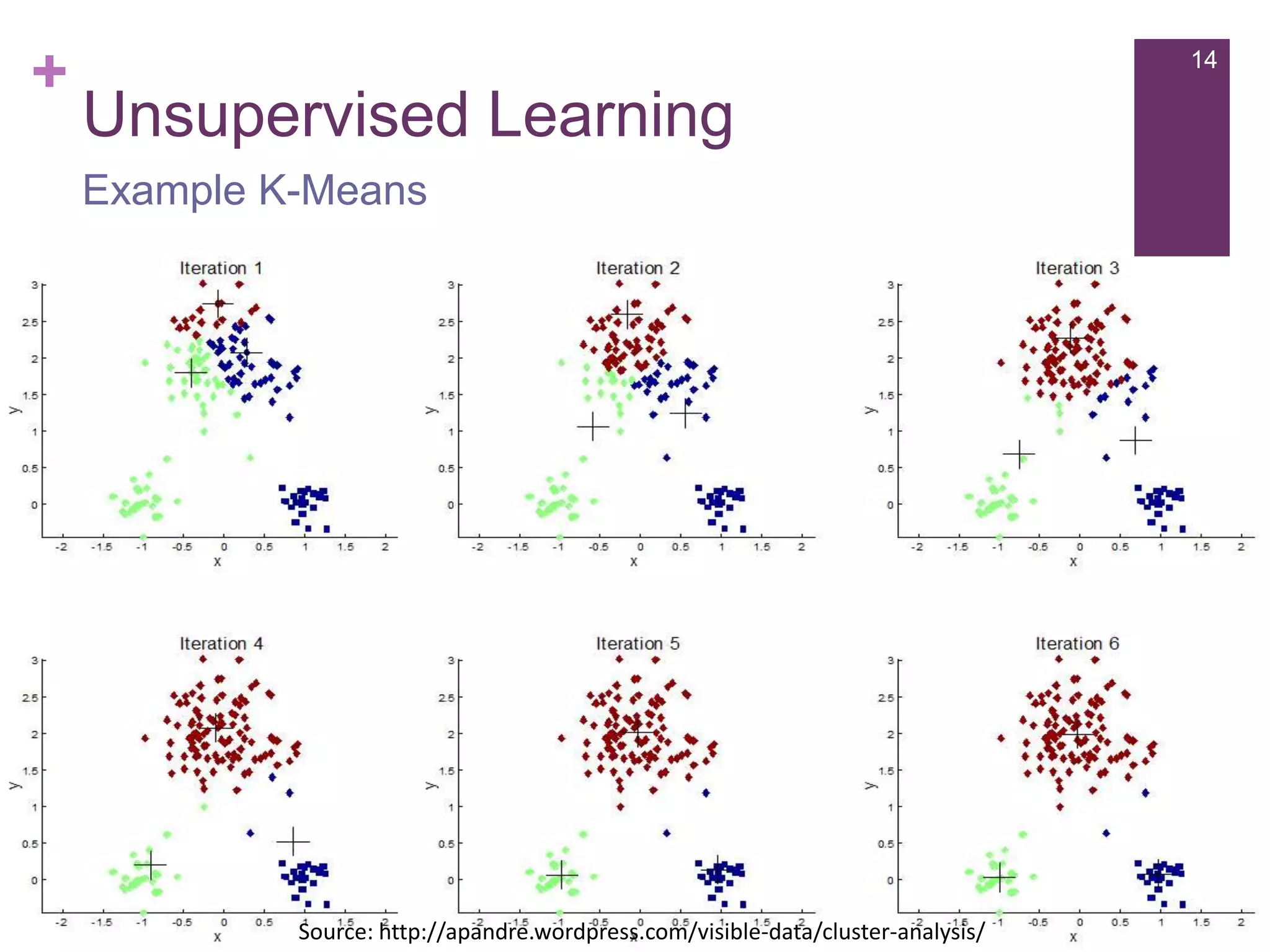
The document provides an overview of machine learning, its types, and applications, focusing on Apache Mahout, a scalable machine learning library. It discusses various learning algorithms such as supervised, unsupervised, and reinforcement learning, along with examples and applications including recommendation systems. Additionally, it outlines the architecture of Mahout and its relevance to big data processing.

































































































