Download as PDF, PPTX






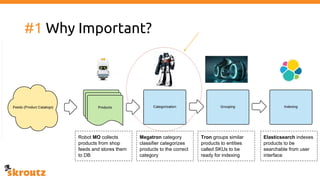








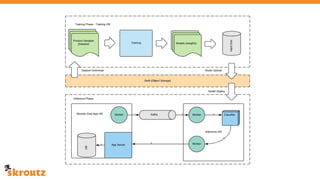
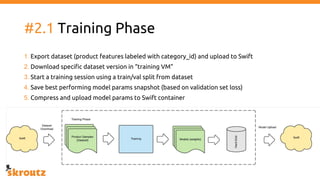
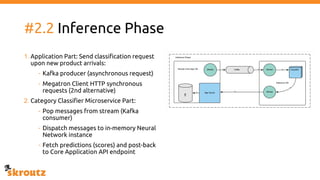








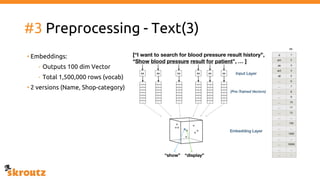

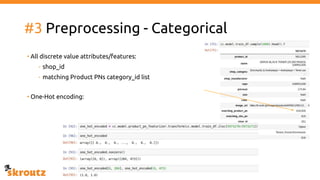




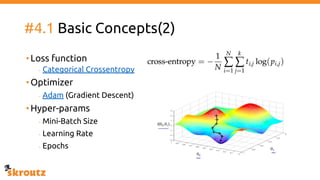

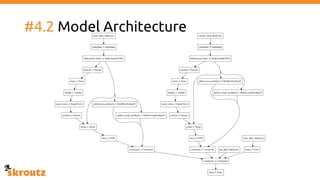

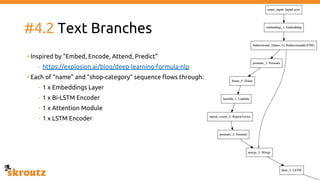
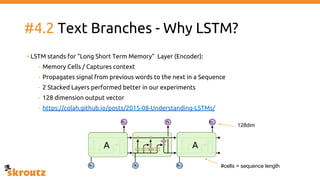

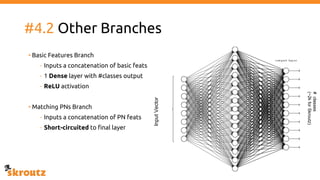
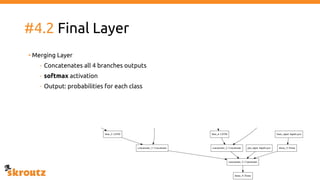





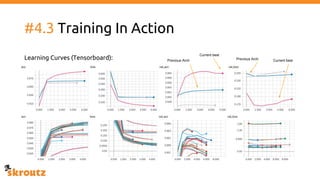


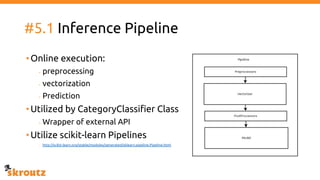




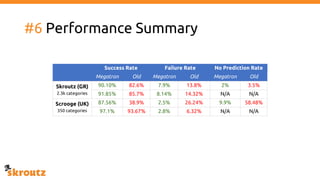
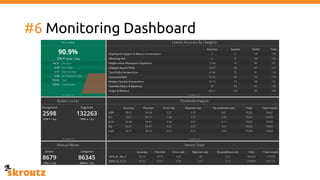








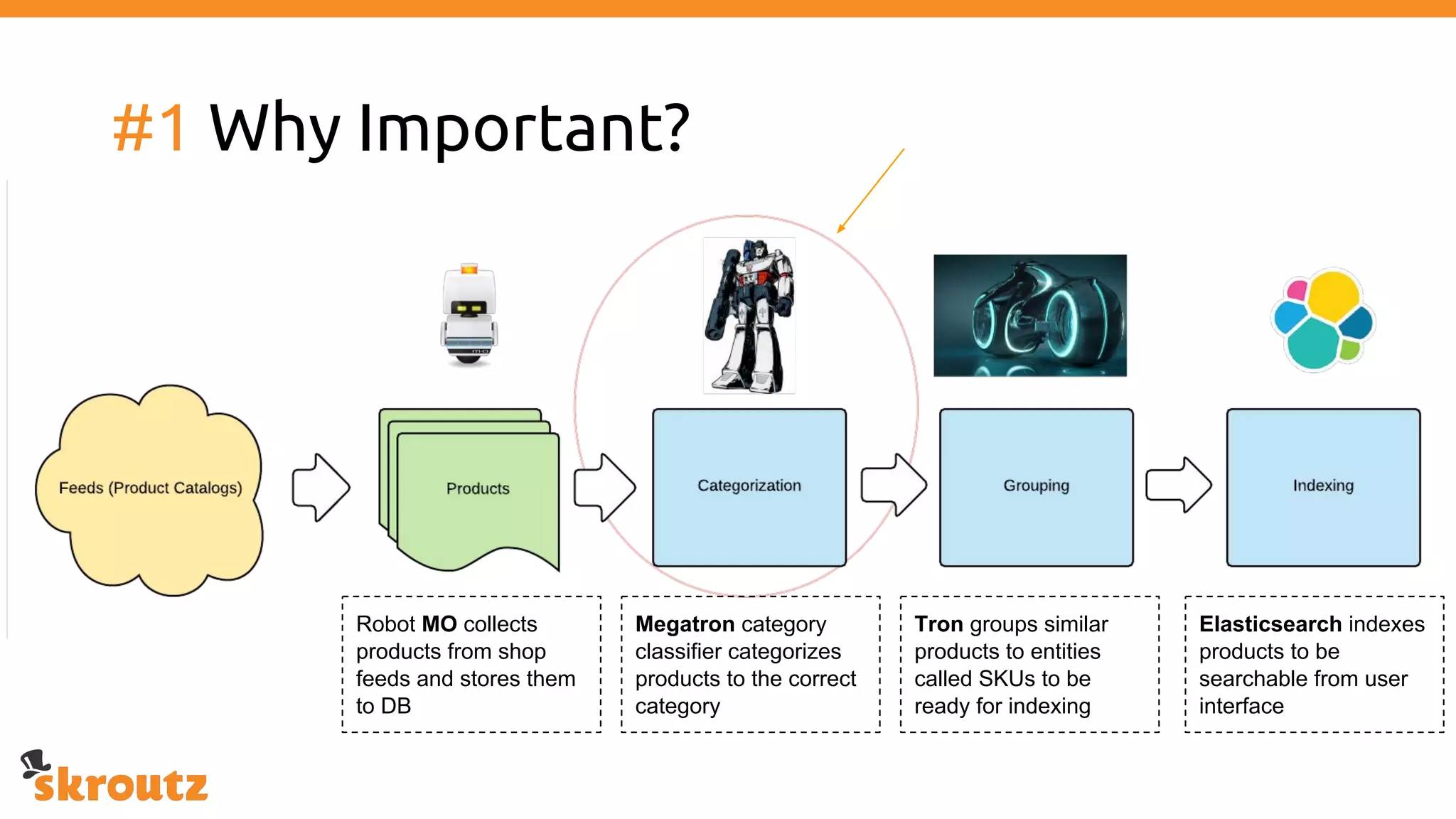








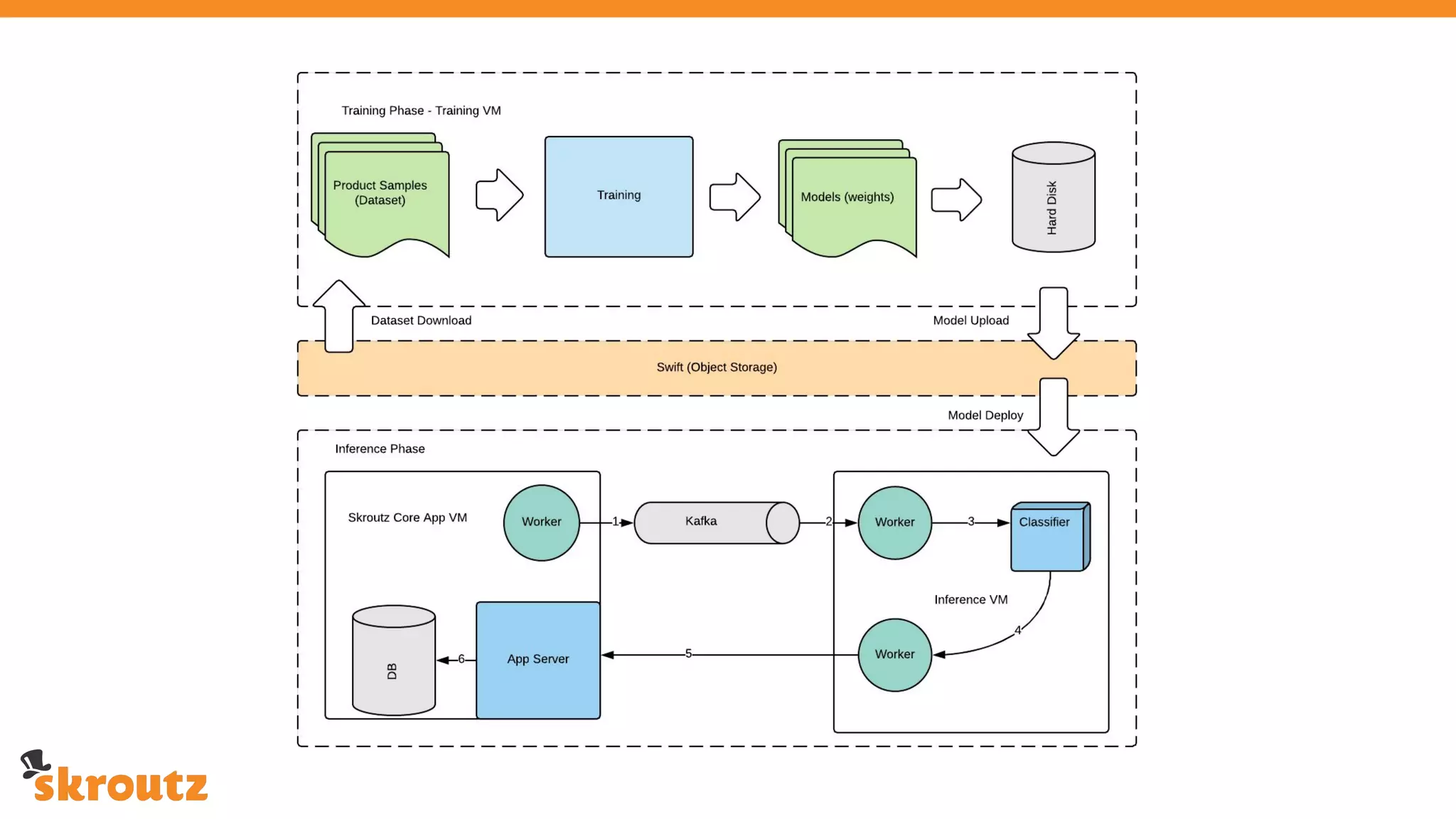
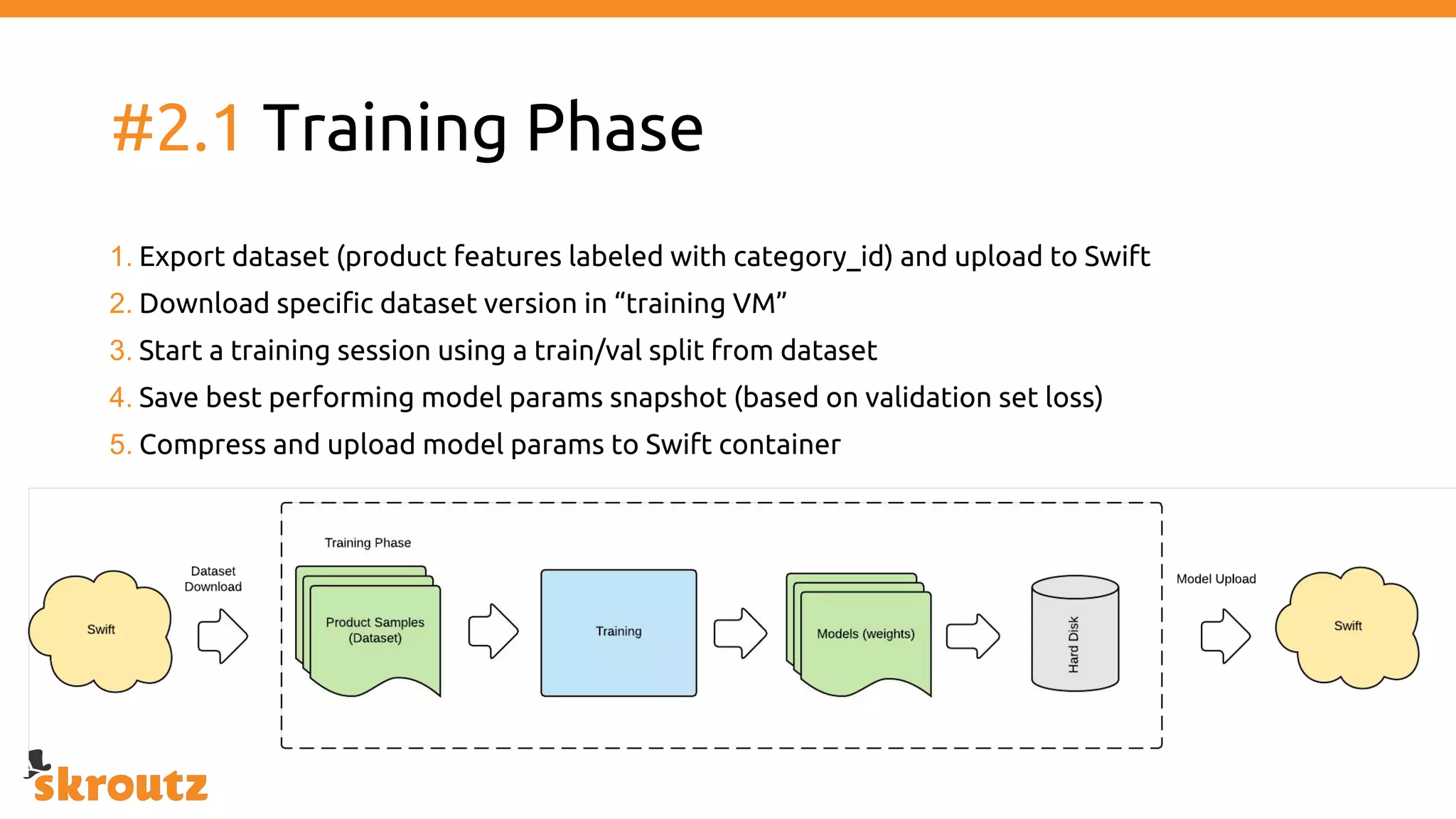
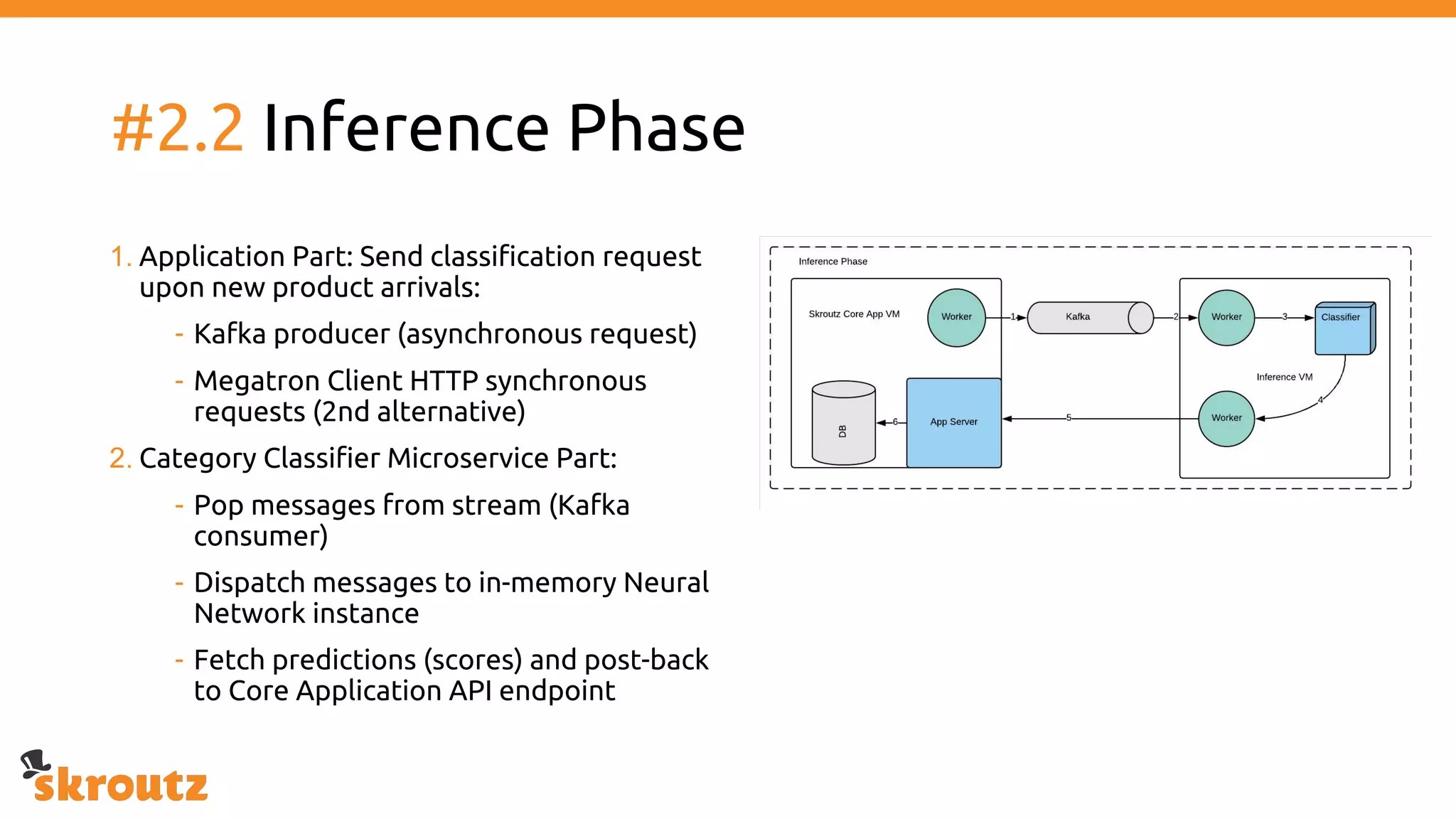







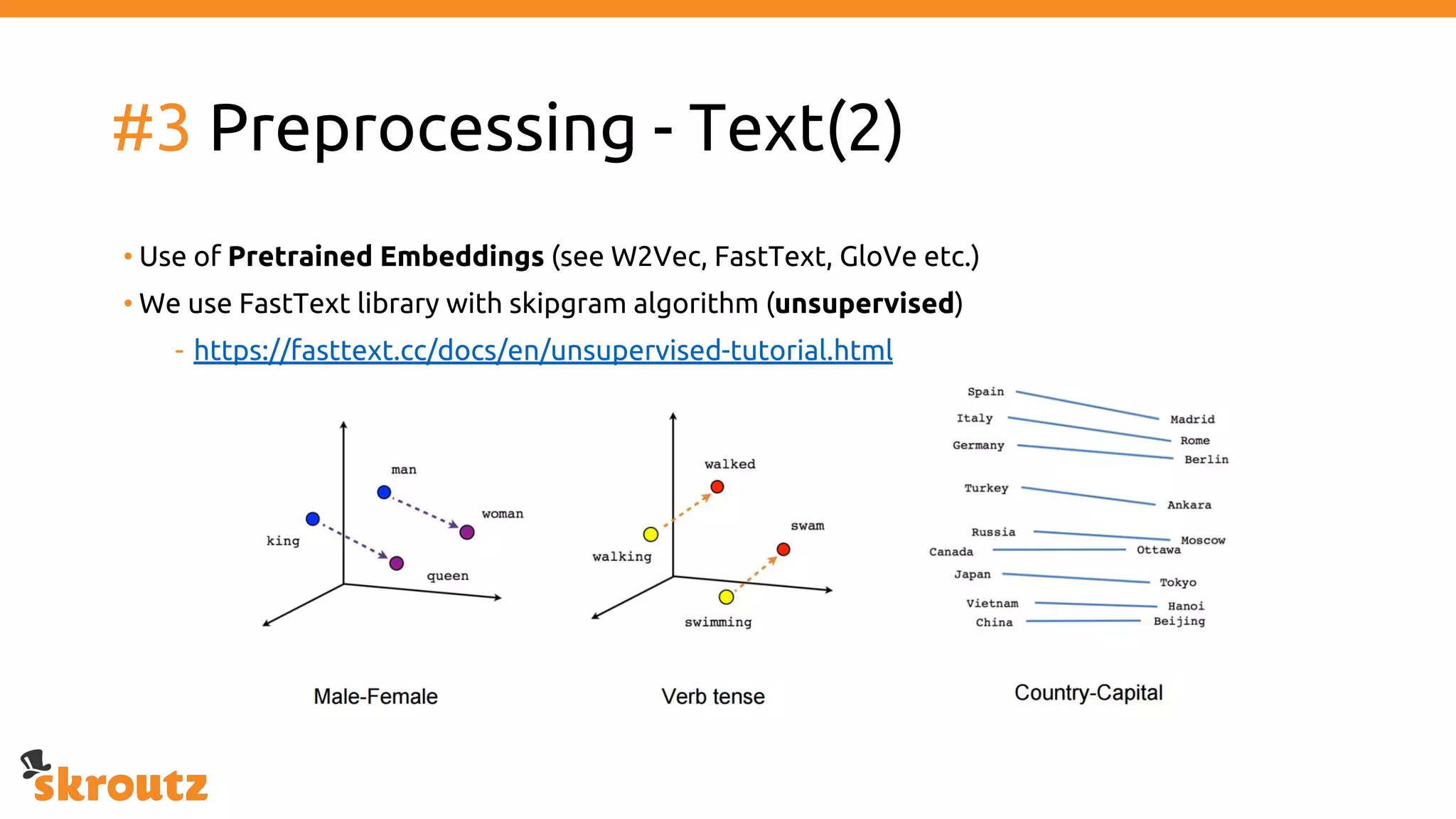
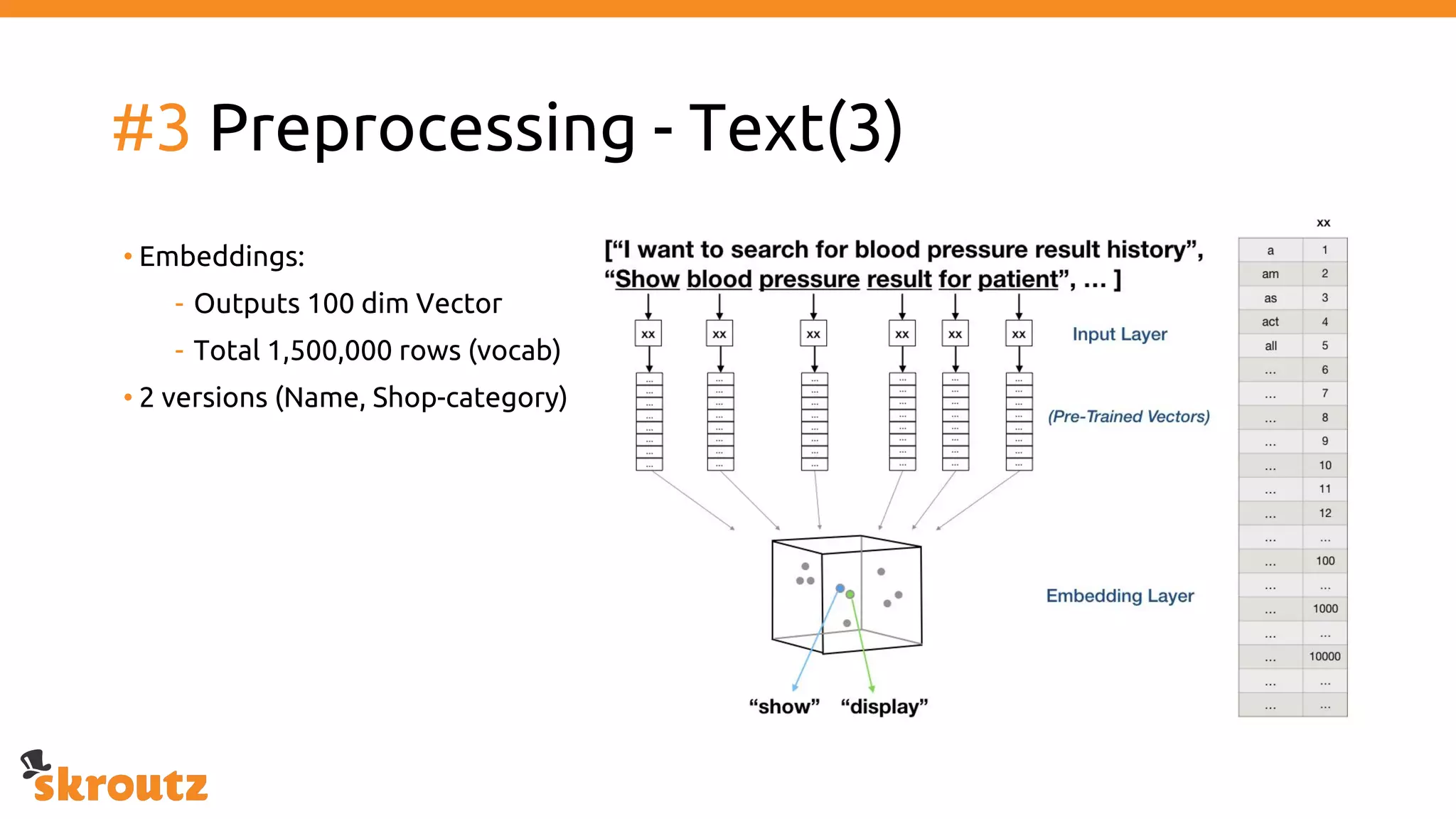

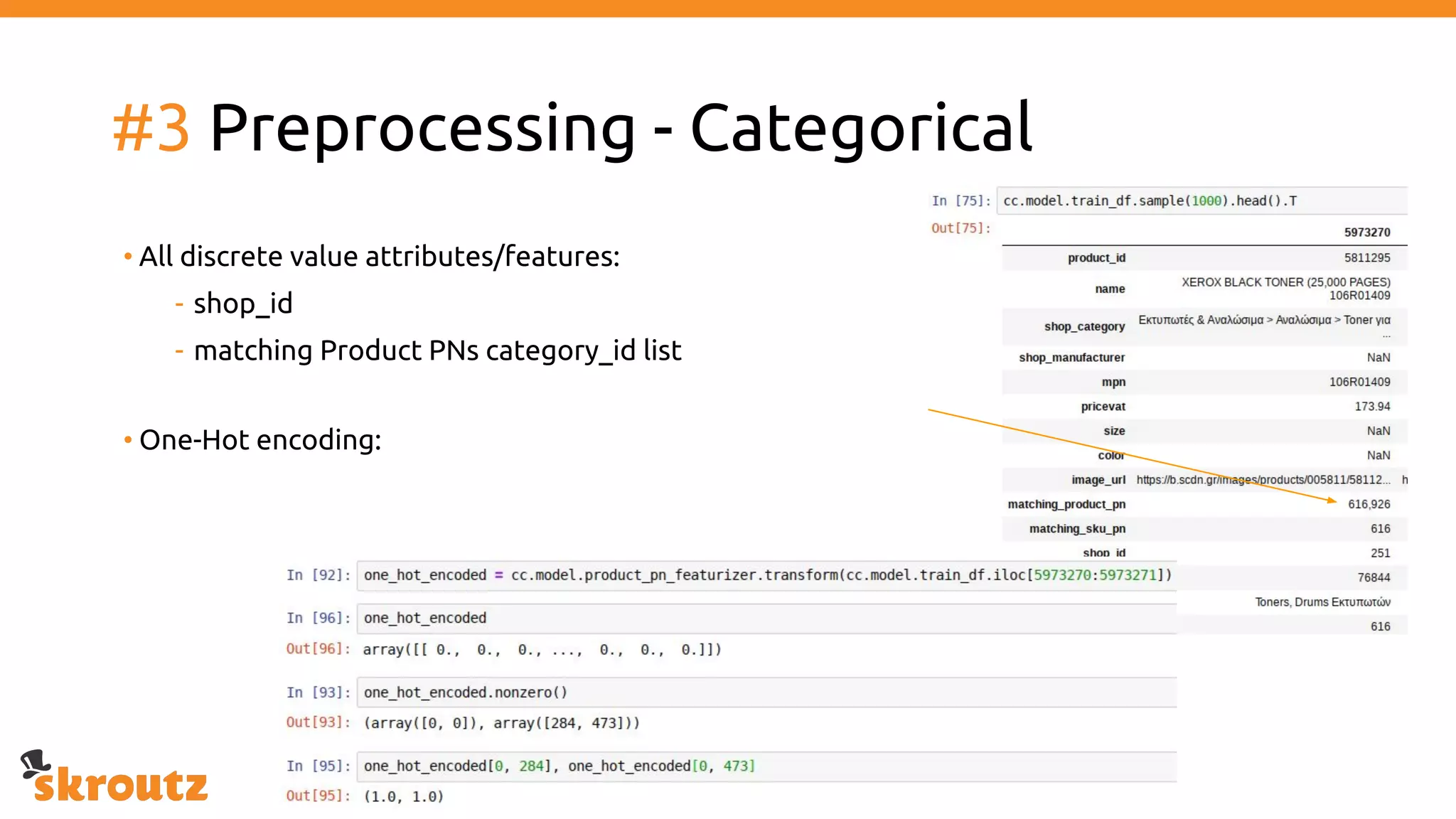




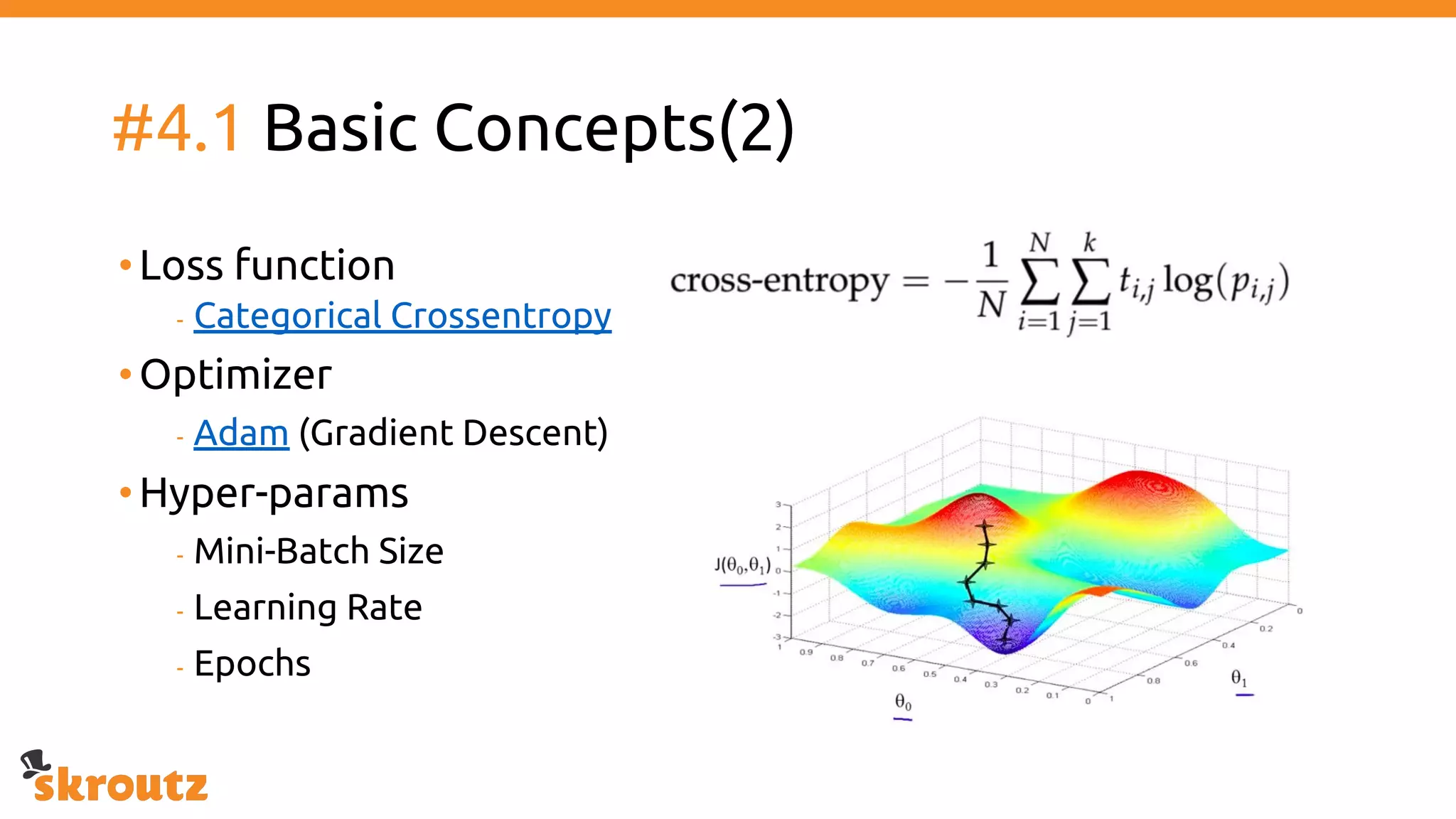



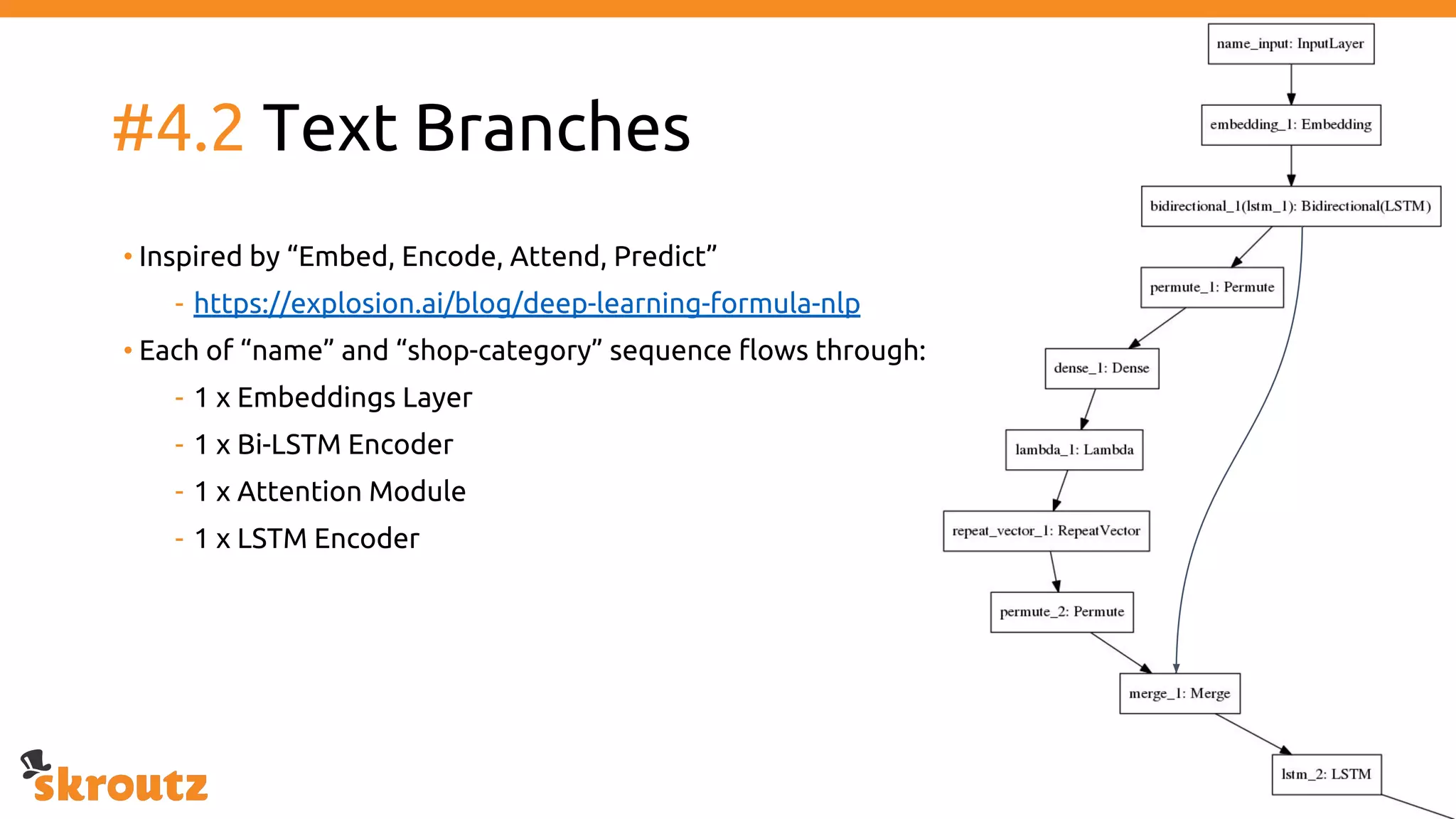
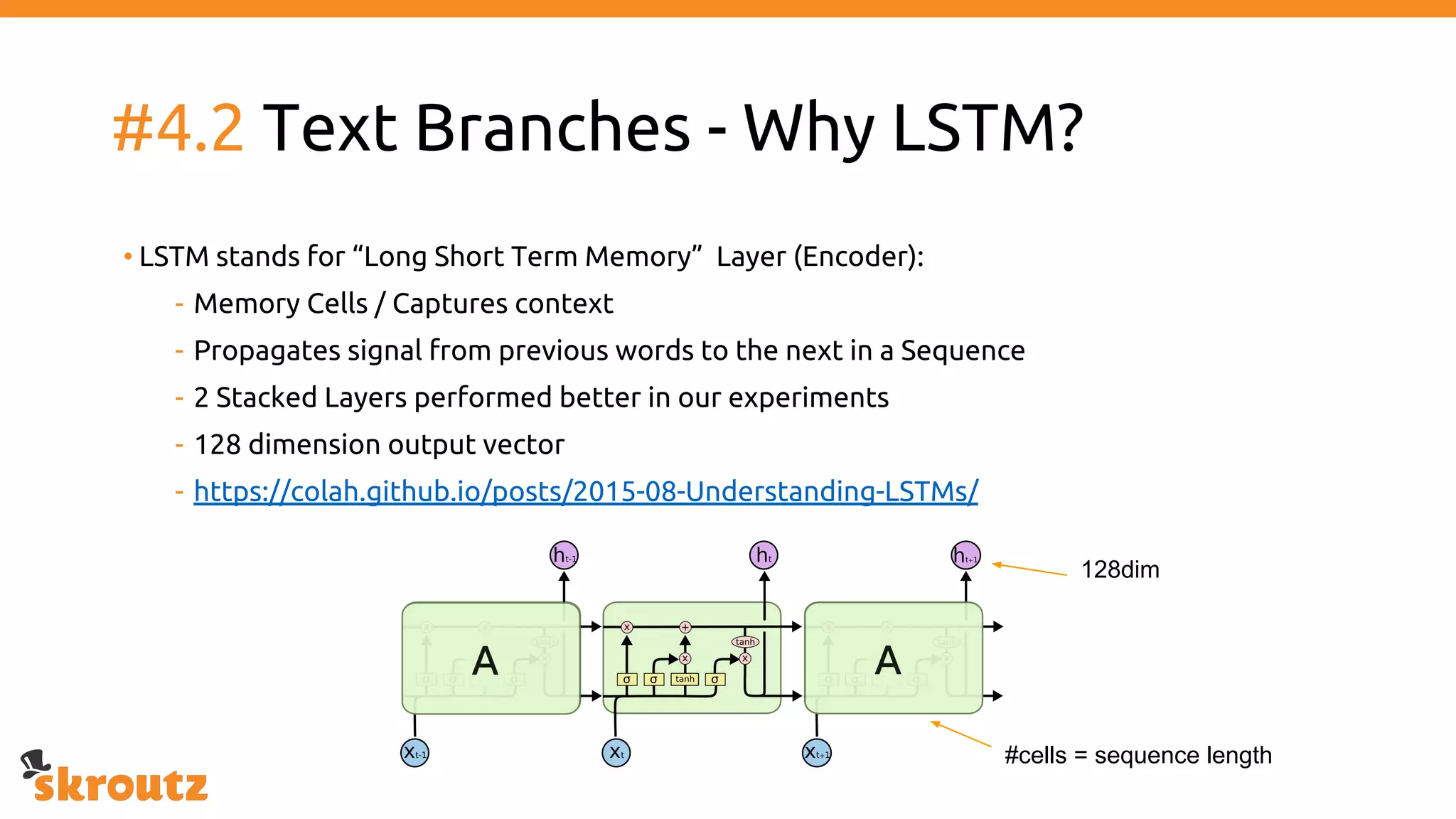

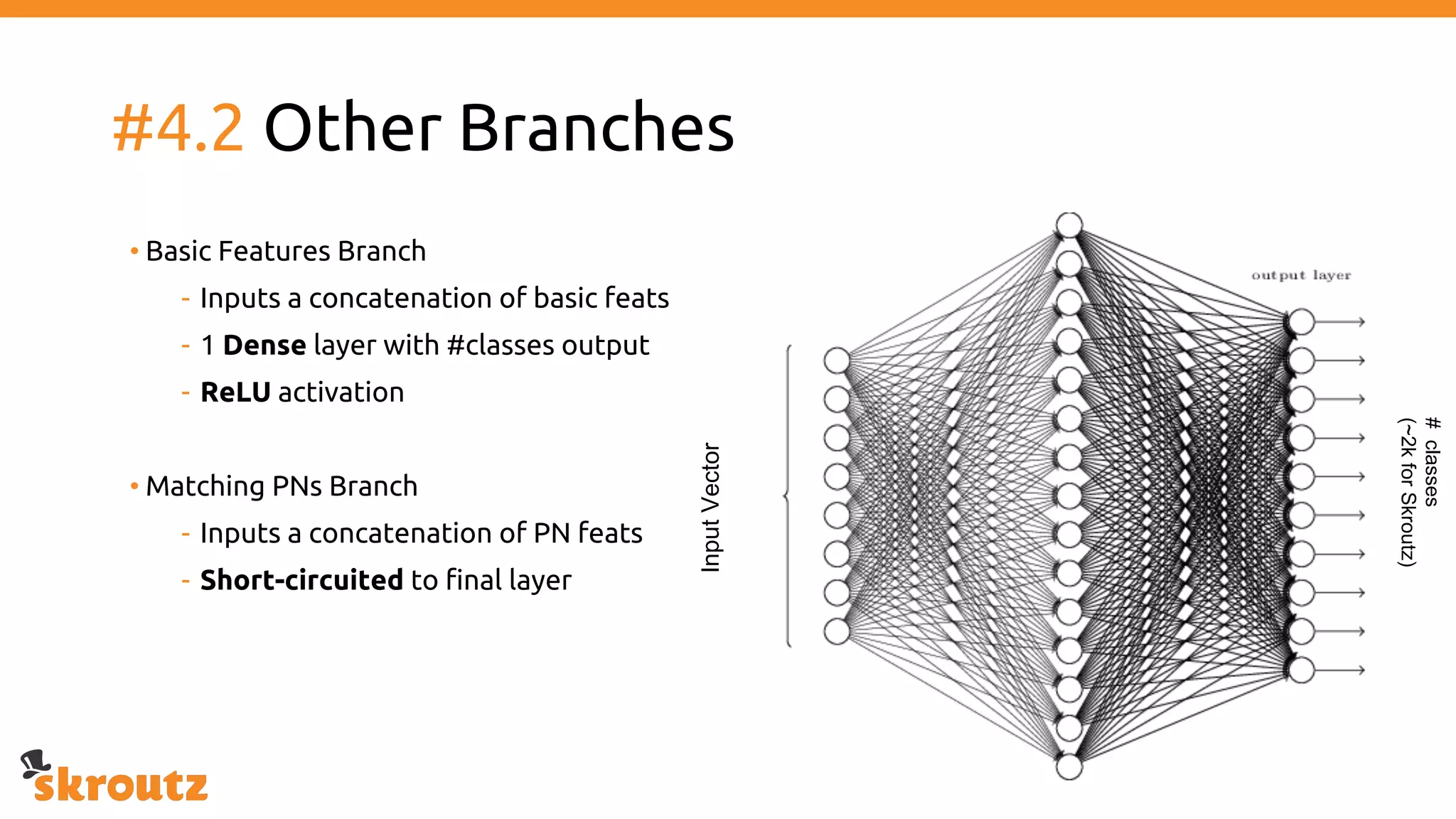
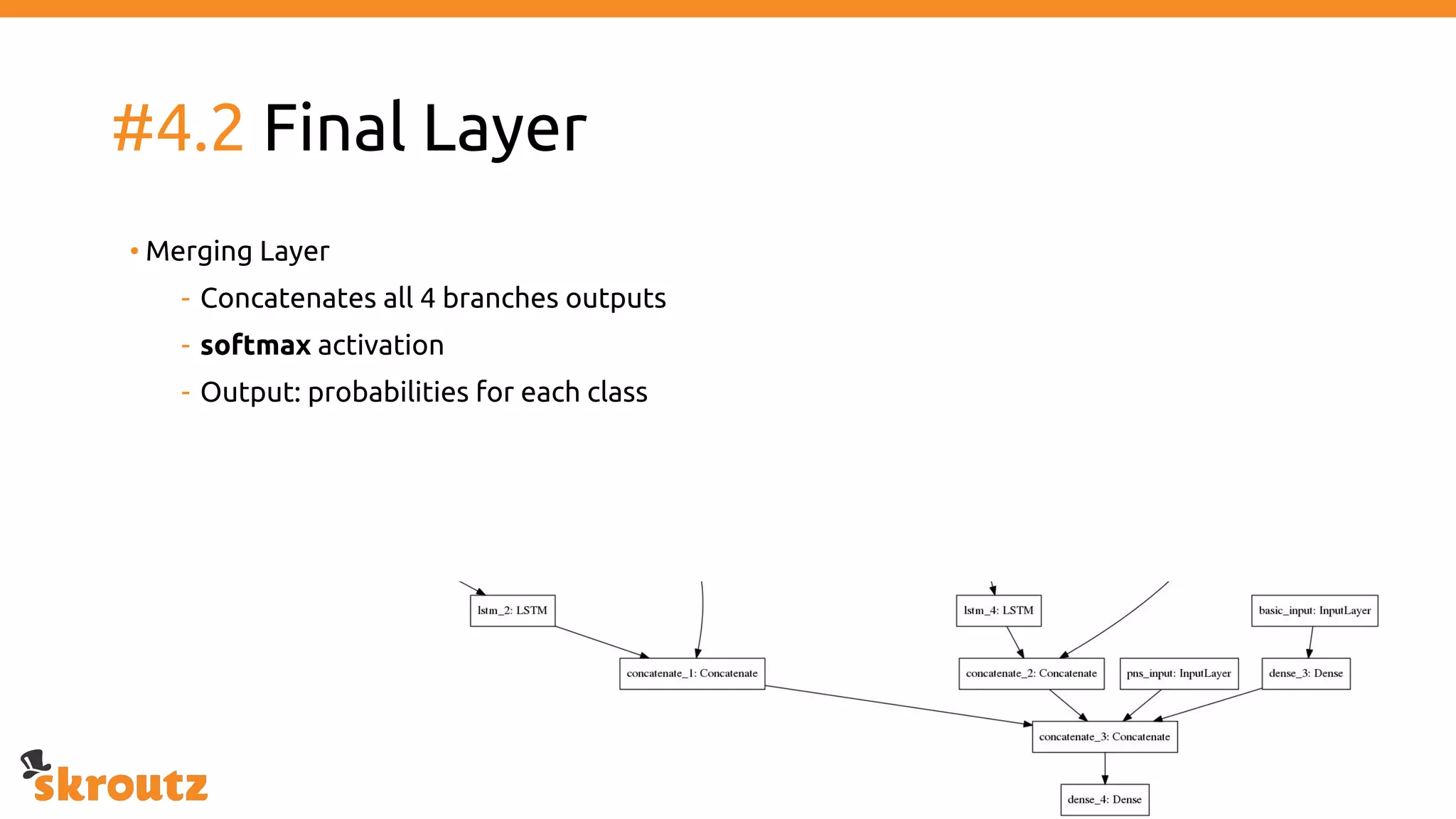
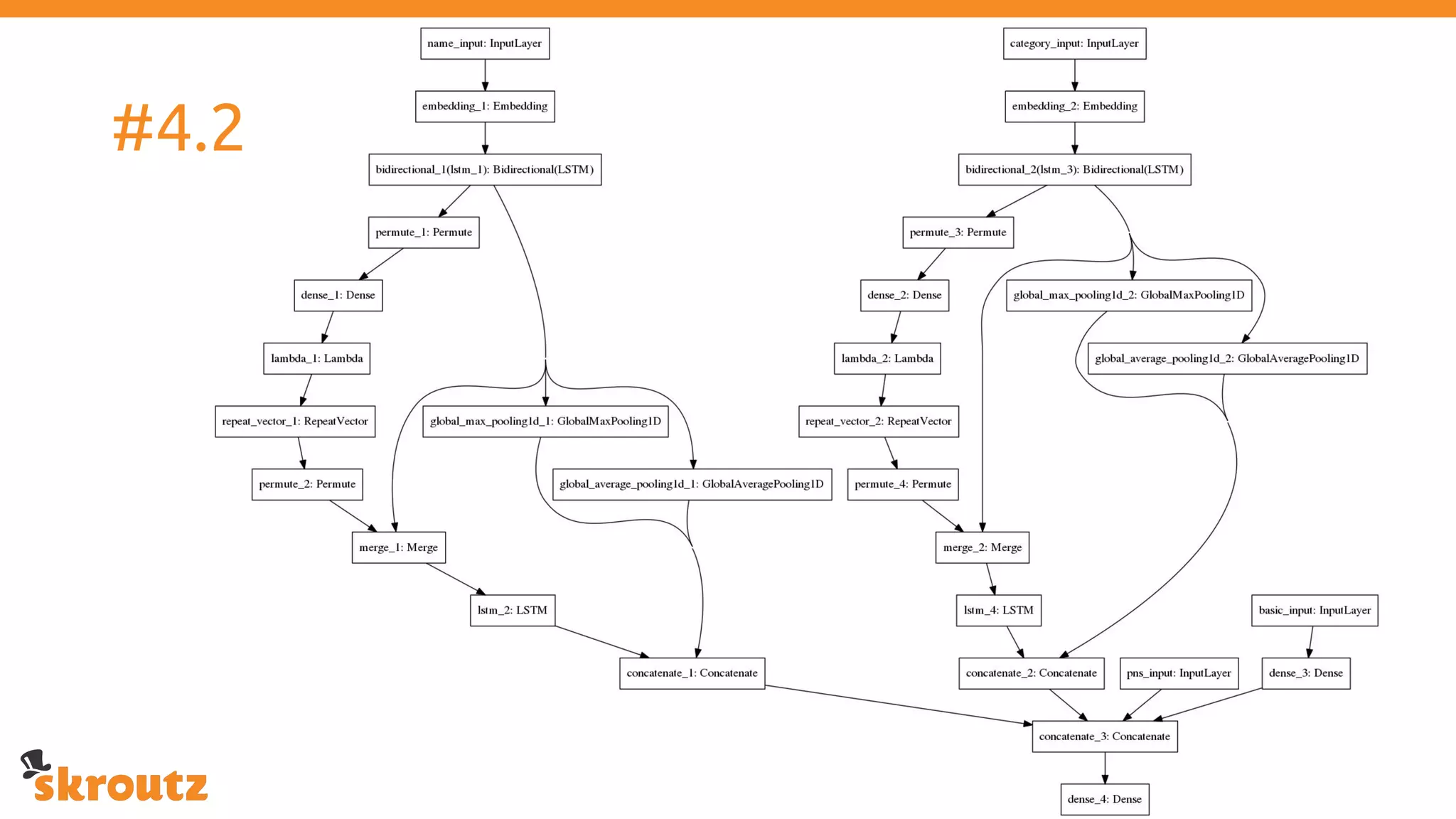




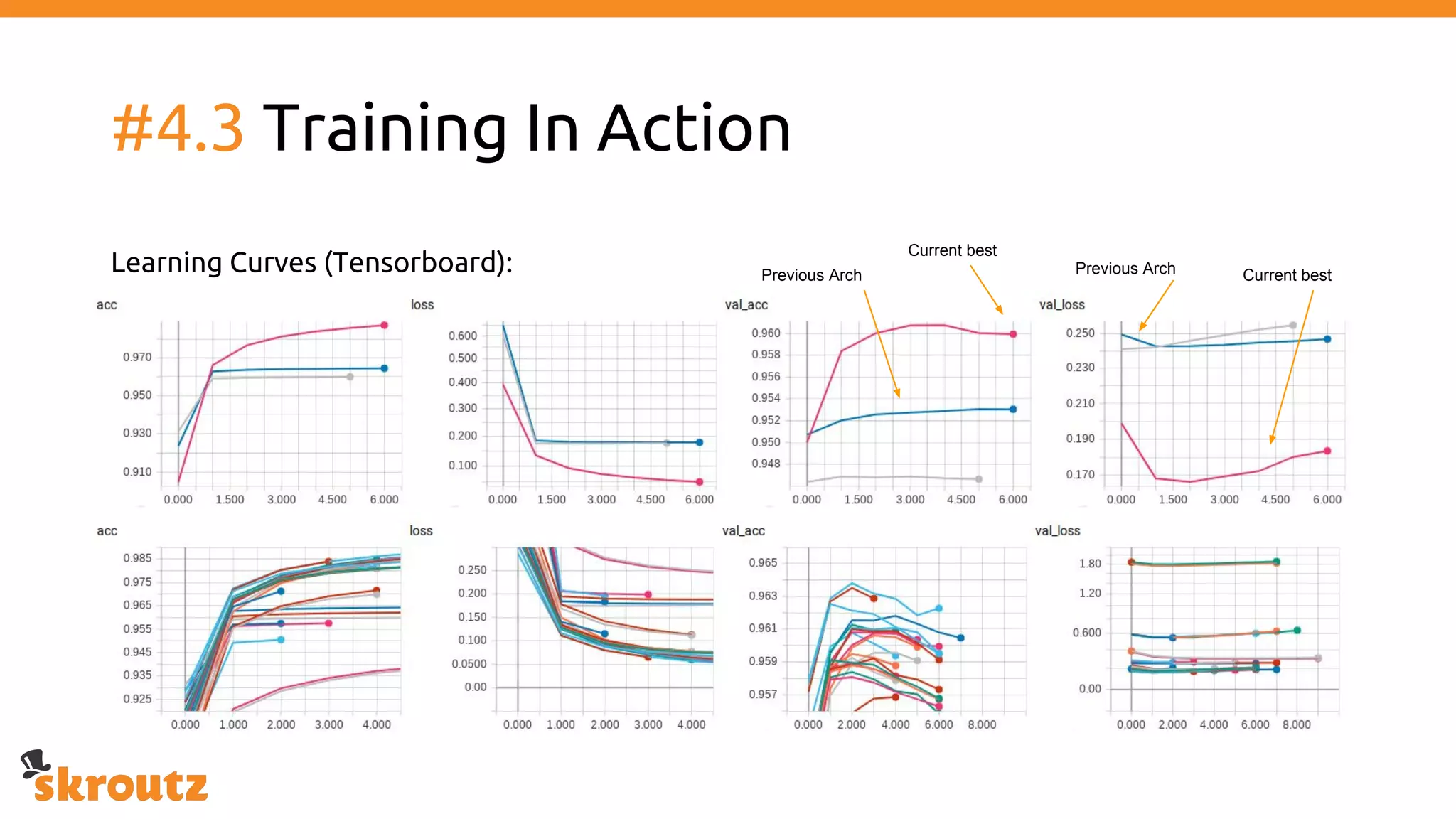







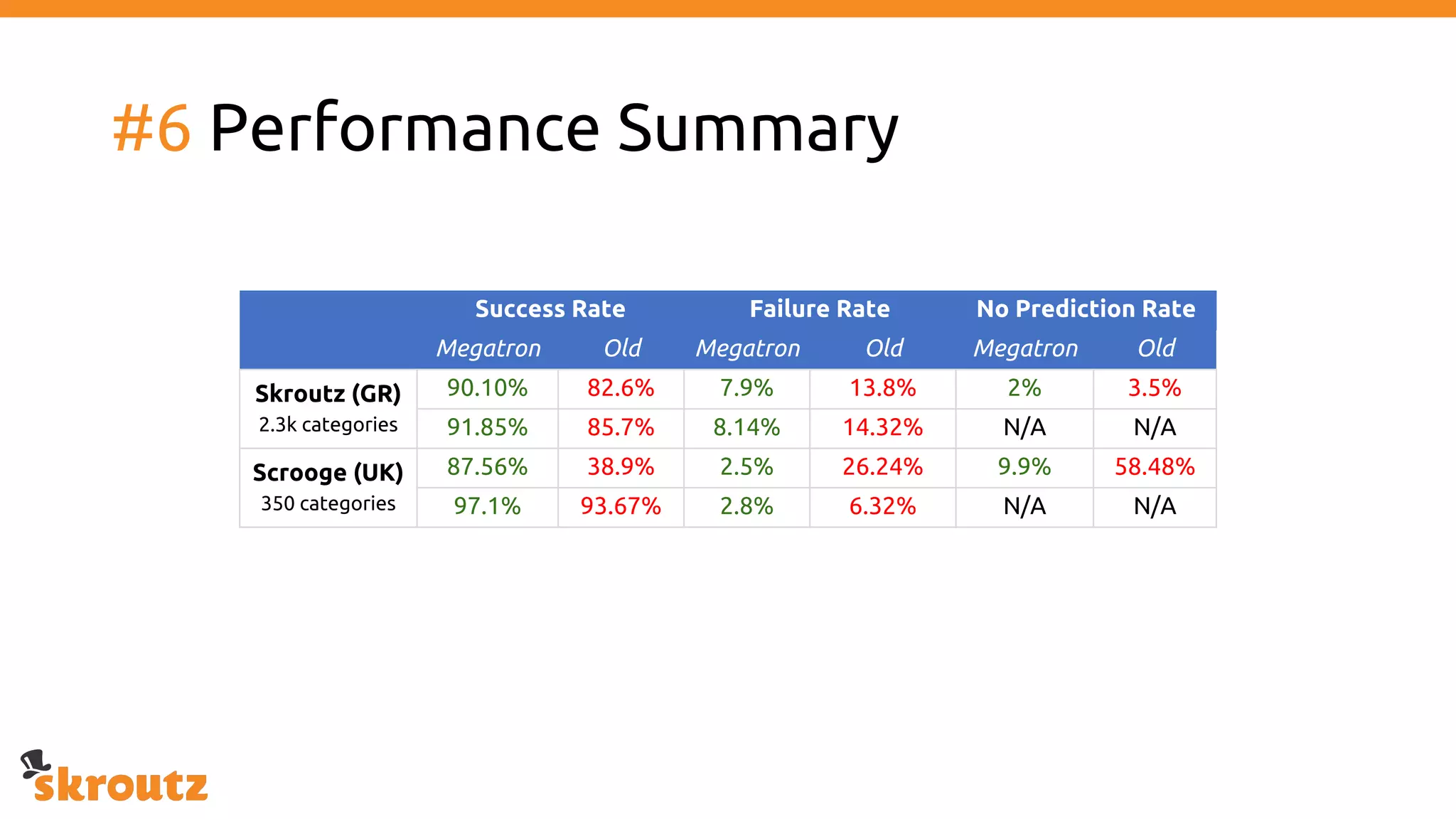
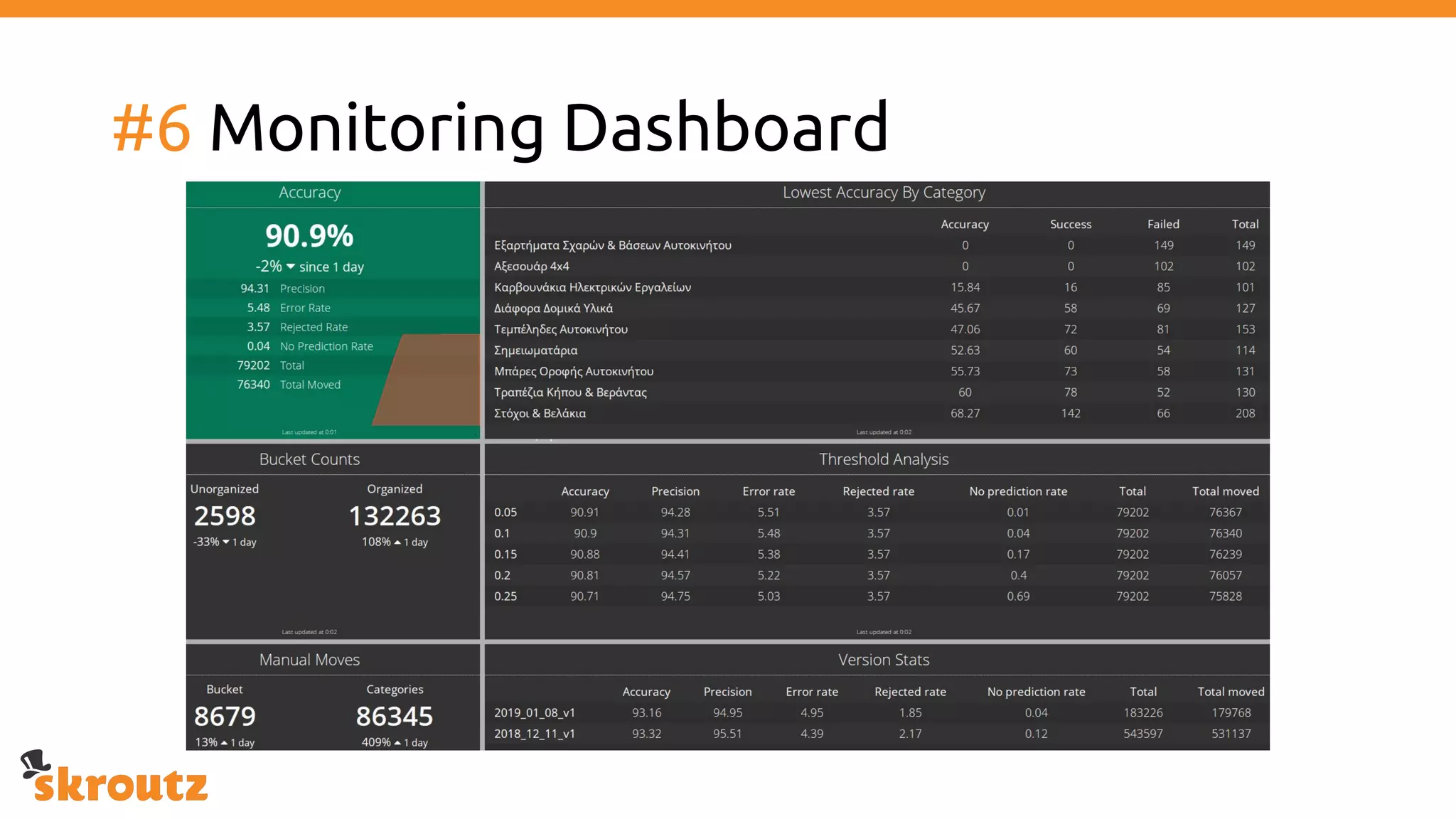




The document provides a comprehensive overview of the skroutz.gr marketplace, which simplifies online shopping by categorizing over 11 million products from 3,200 merchants. It details the limitations of the old categorization system and introduces a new solution using a supervised learning model called 'megatron', which enhances product classification with minimal human intervention. Performance improvements are highlighted, showing a significant reduction in error rates and increased efficiency in content management.


















































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















