Download as PDF, PPTX








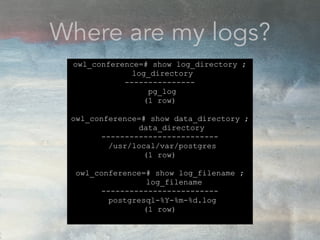
![Having good looking logs
(and logging everything like a crazy owl)
owl_conference=# SHOW config_file;
config_file
-----------------------------------------
/usr/local/var/postgres/postgresql.conf
(1 row)
In your postgresql.conf
log_filename = 'postgresql-%Y-%m-%d.log'
log_statement = 'all'
logging_collector = on
log_min_duration_statement = 0
log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,host=%h,app=%a'](https://image.slidesharecdn.com/conformsharefinal-170314181520/85/Conf-orm-explain-10-320.jpg)
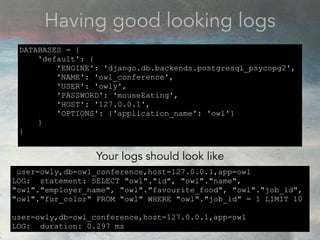








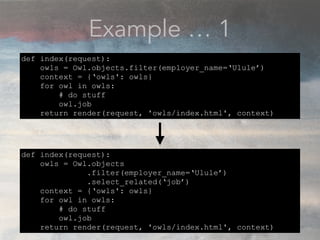




























![Having good looking logs
(and logging everything like a crazy owl)
owl_conference=# SHOW config_file;
config_file
-----------------------------------------
/usr/local/var/postgres/postgresql.conf
(1 row)
In your postgresql.conf
log_filename = 'postgresql-%Y-%m-%d.log'
log_statement = 'all'
logging_collector = on
log_min_duration_statement = 0
log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,host=%h,app=%a'](https://image.slidesharecdn.com/conformsharefinal-170314181520/75/Conf-orm-explain-10-2048.jpg)


















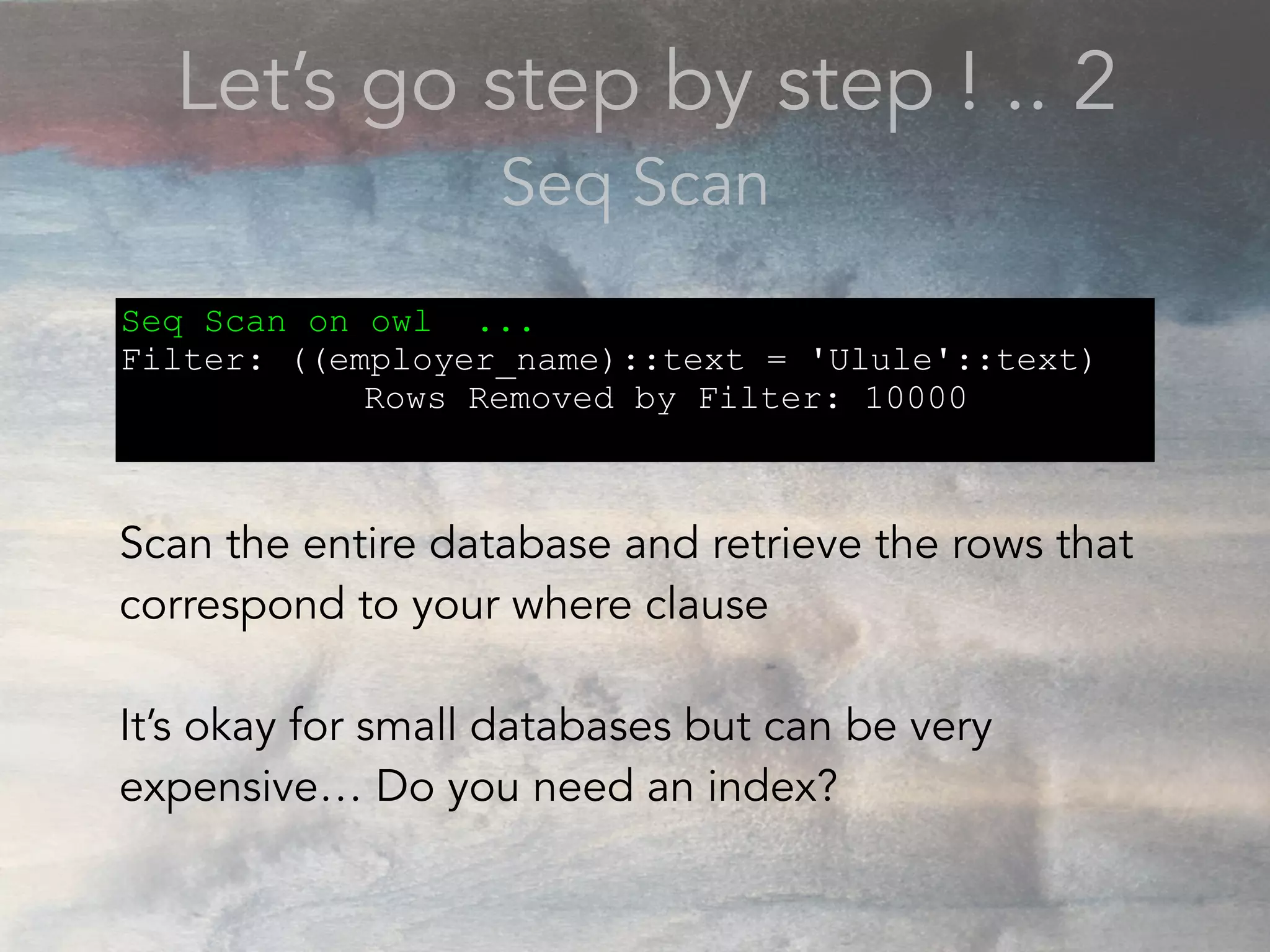
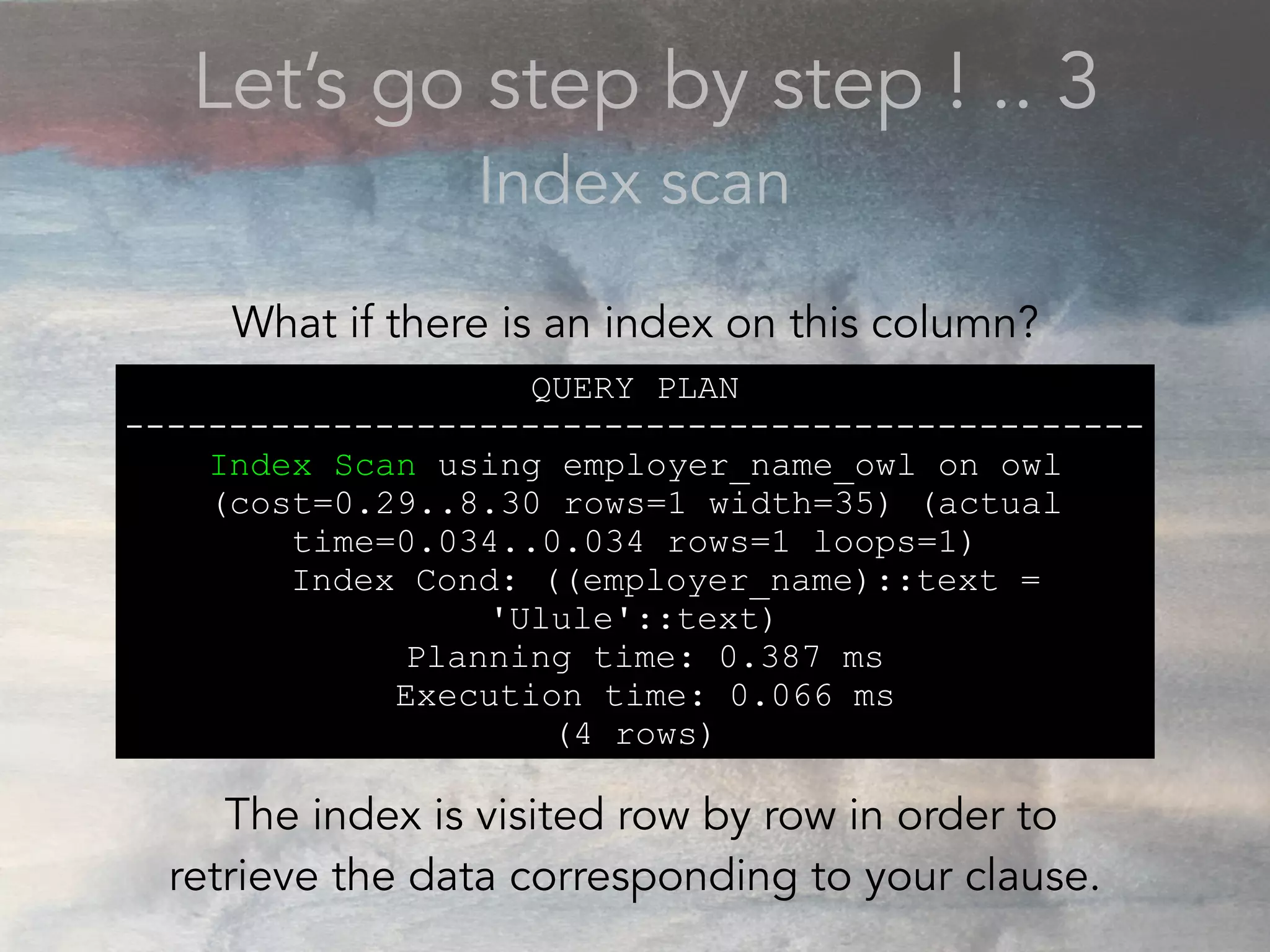
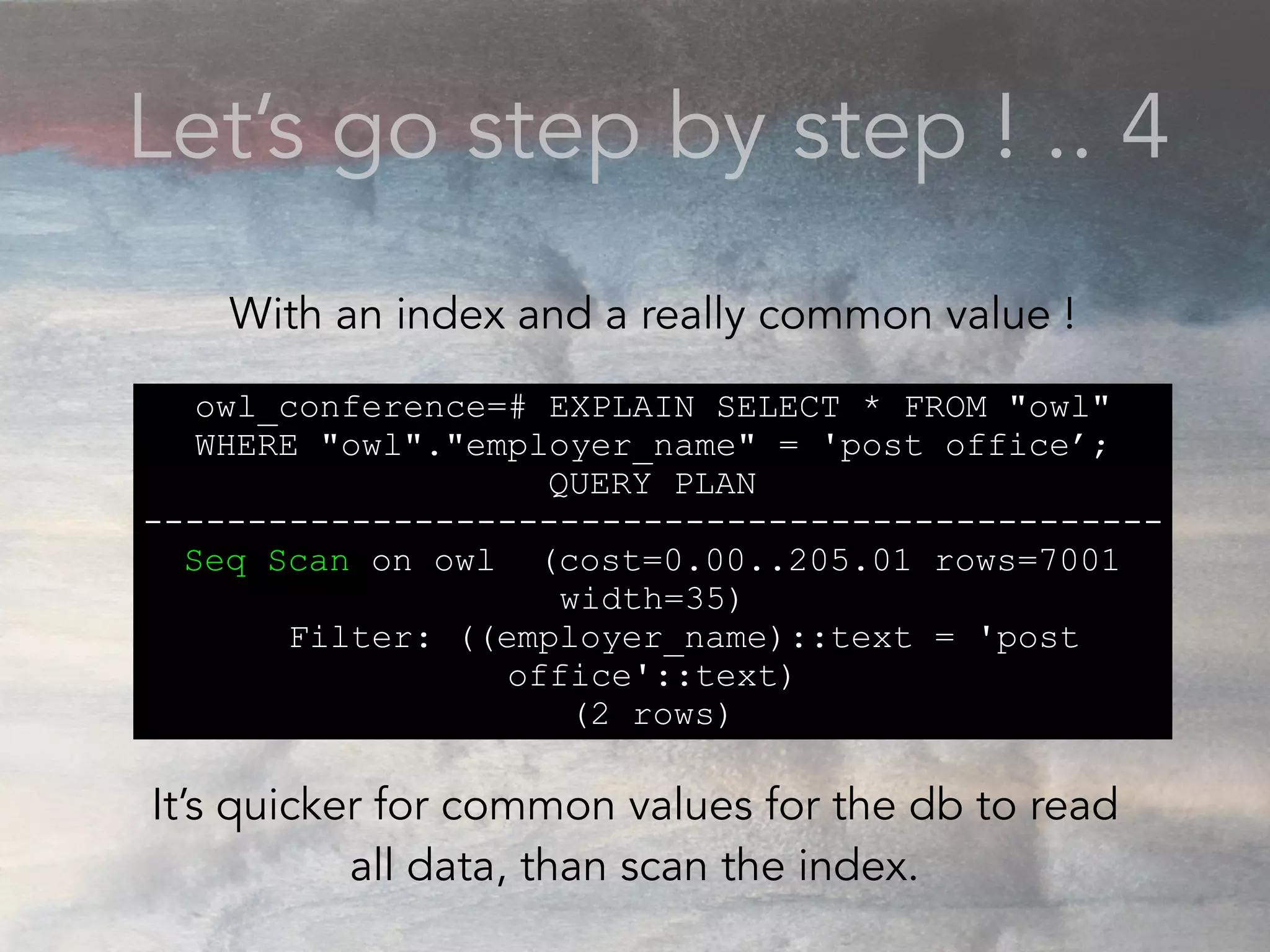



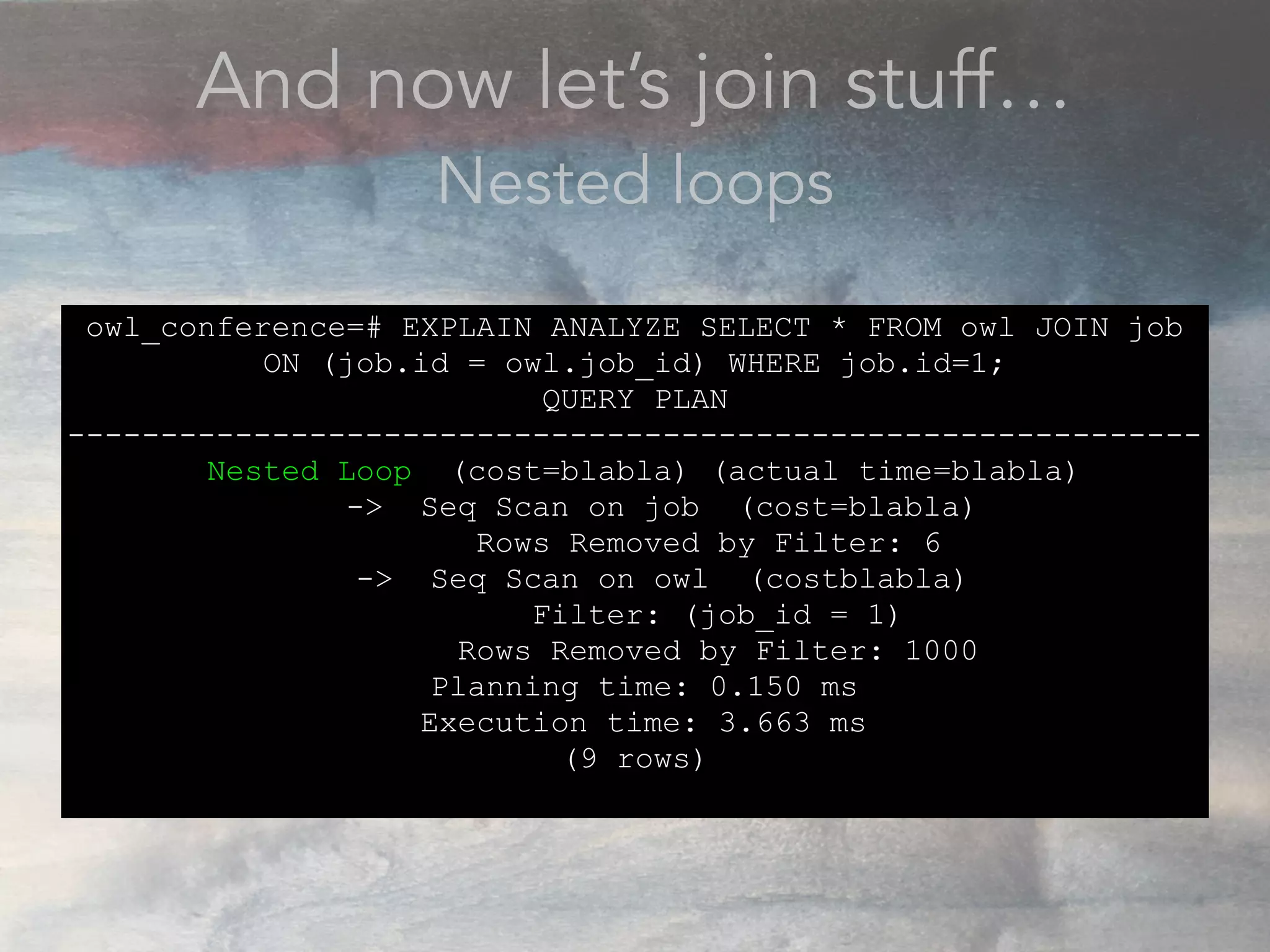
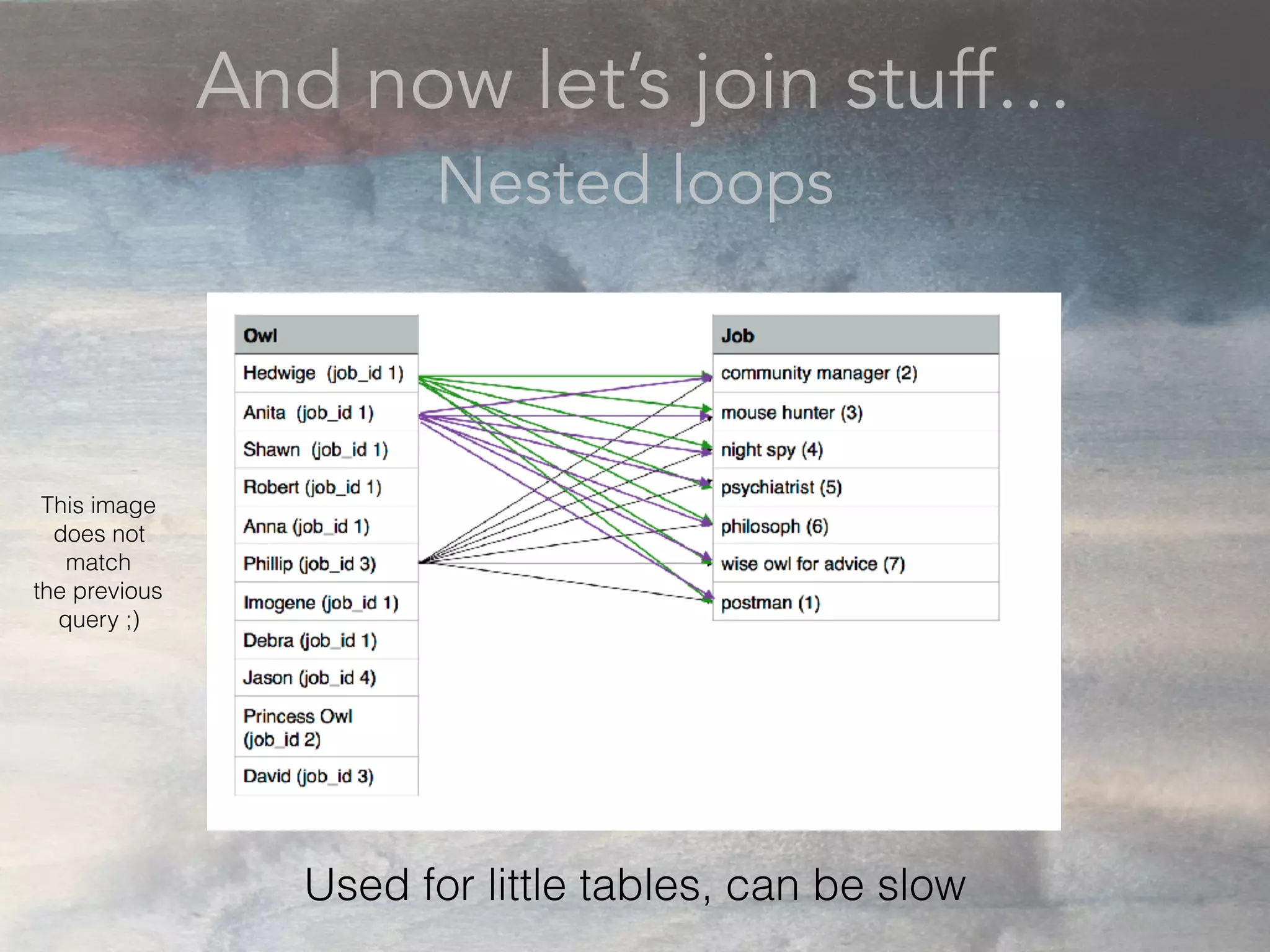
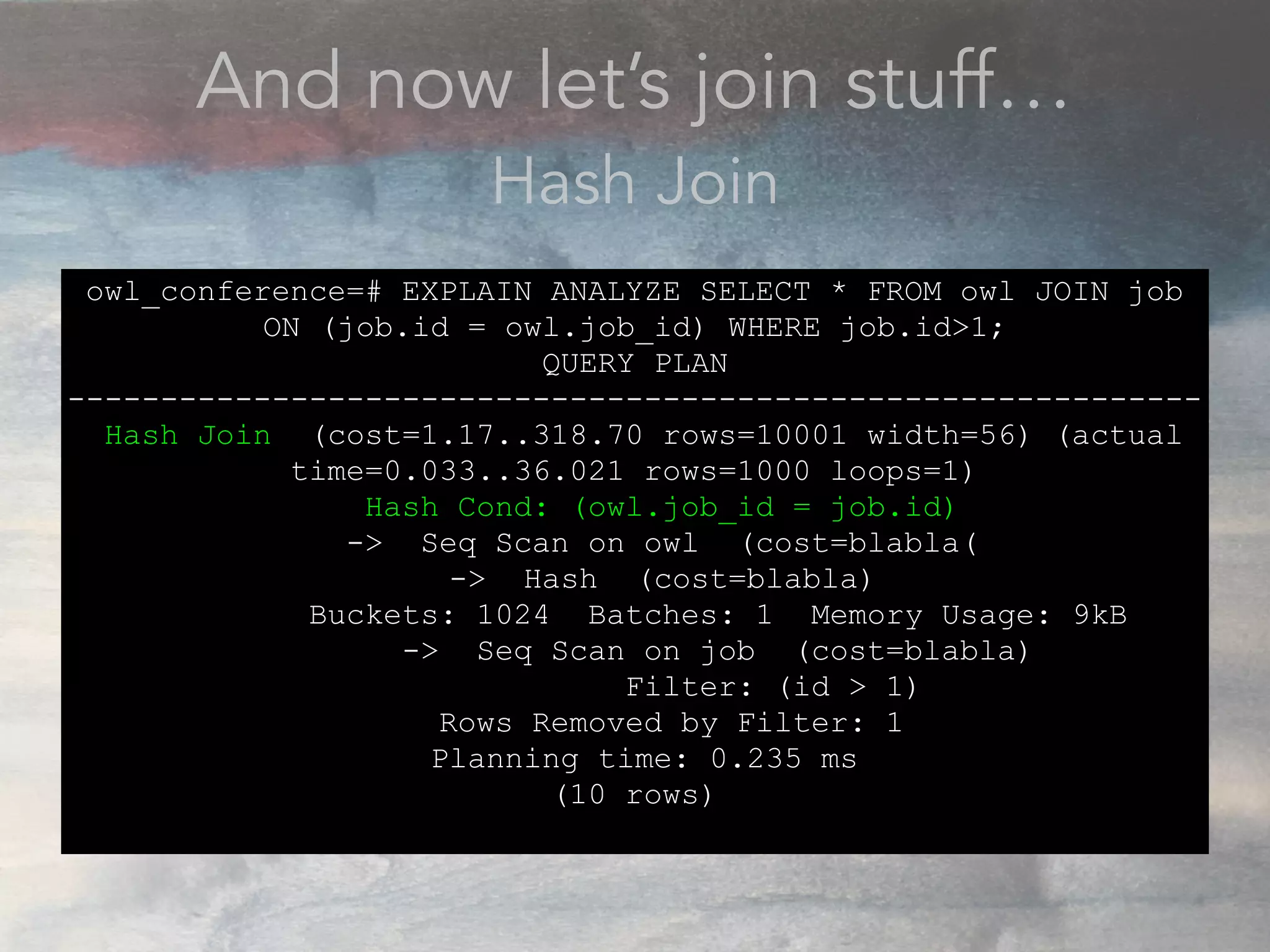
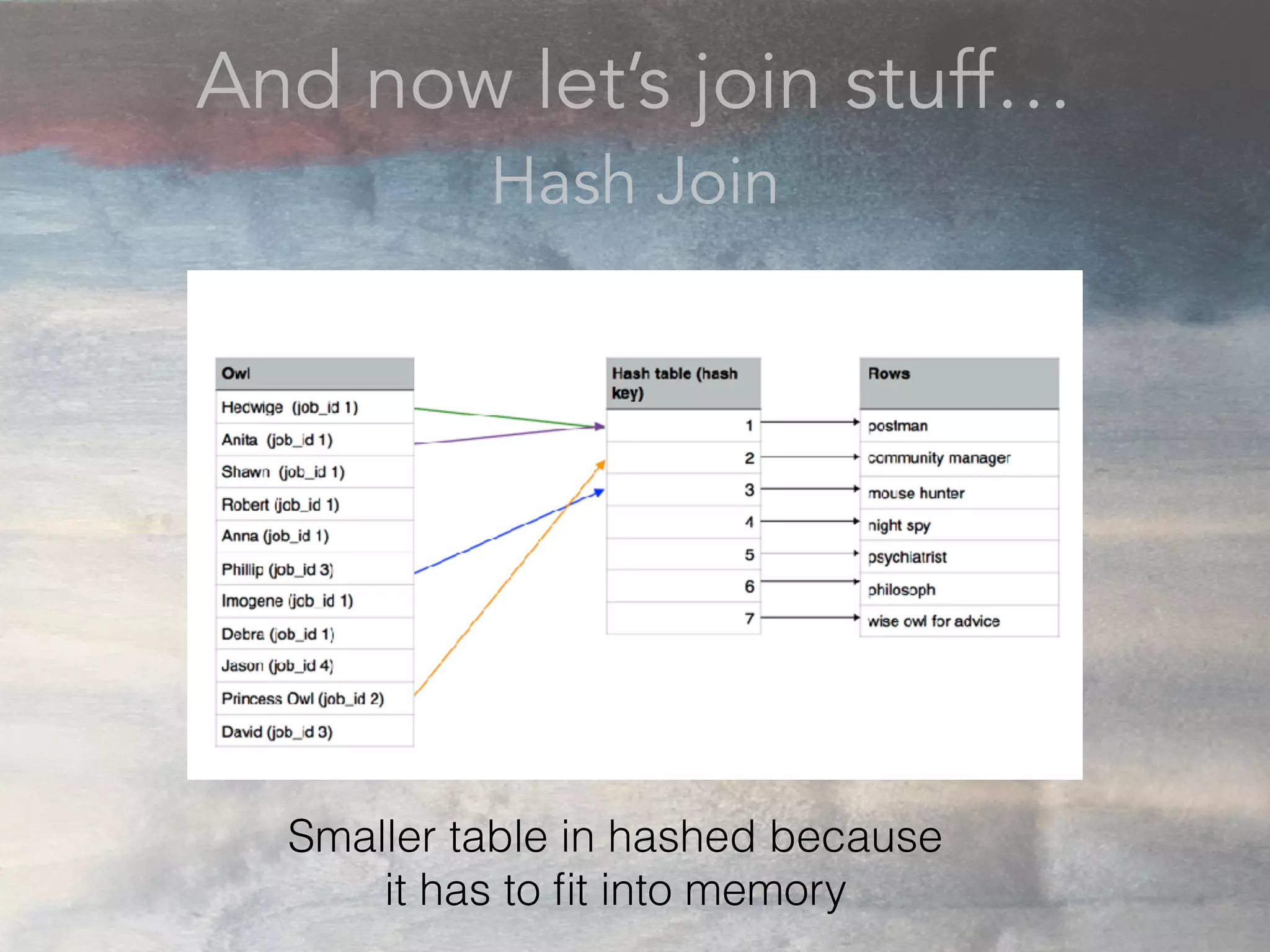
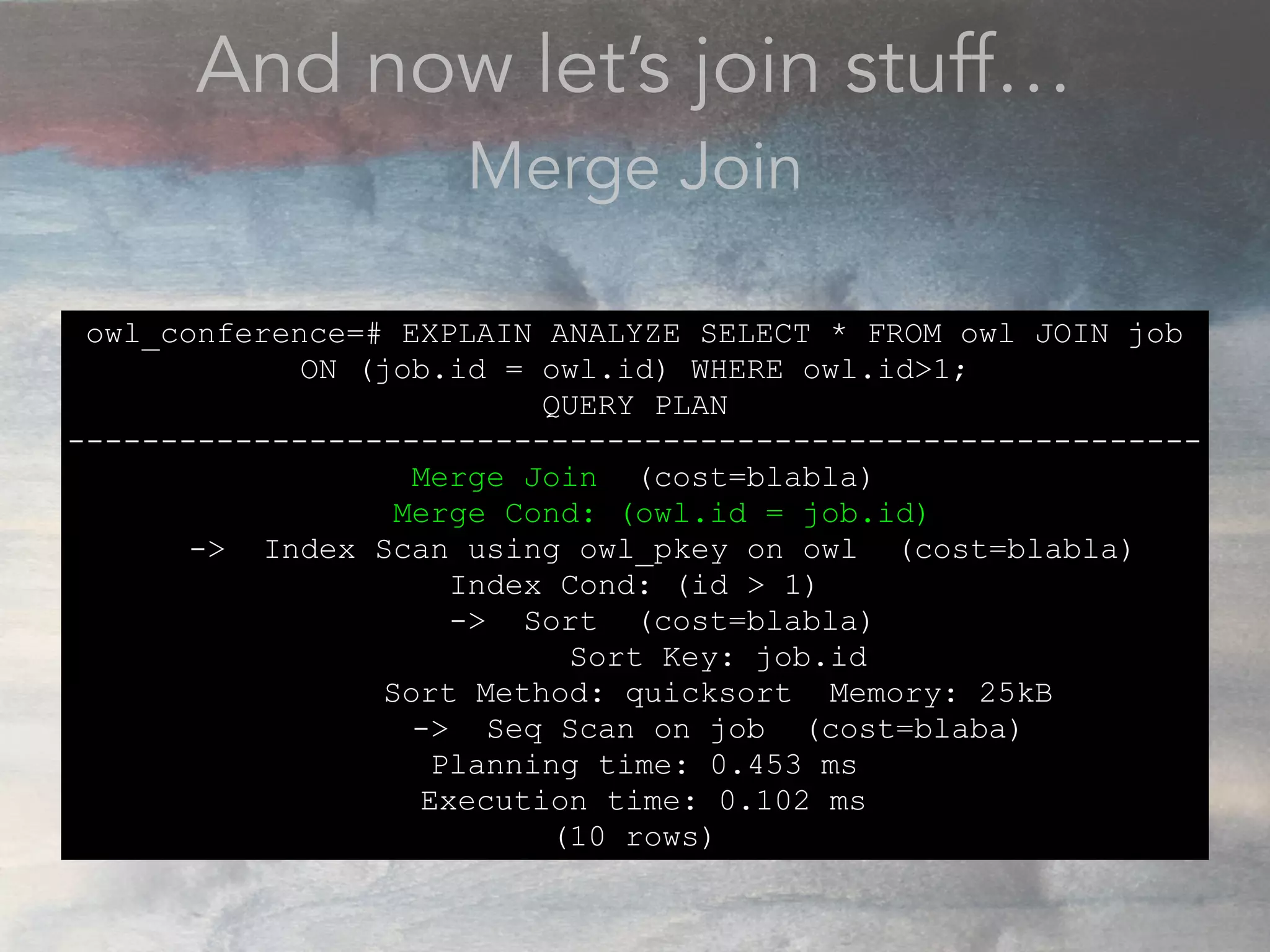
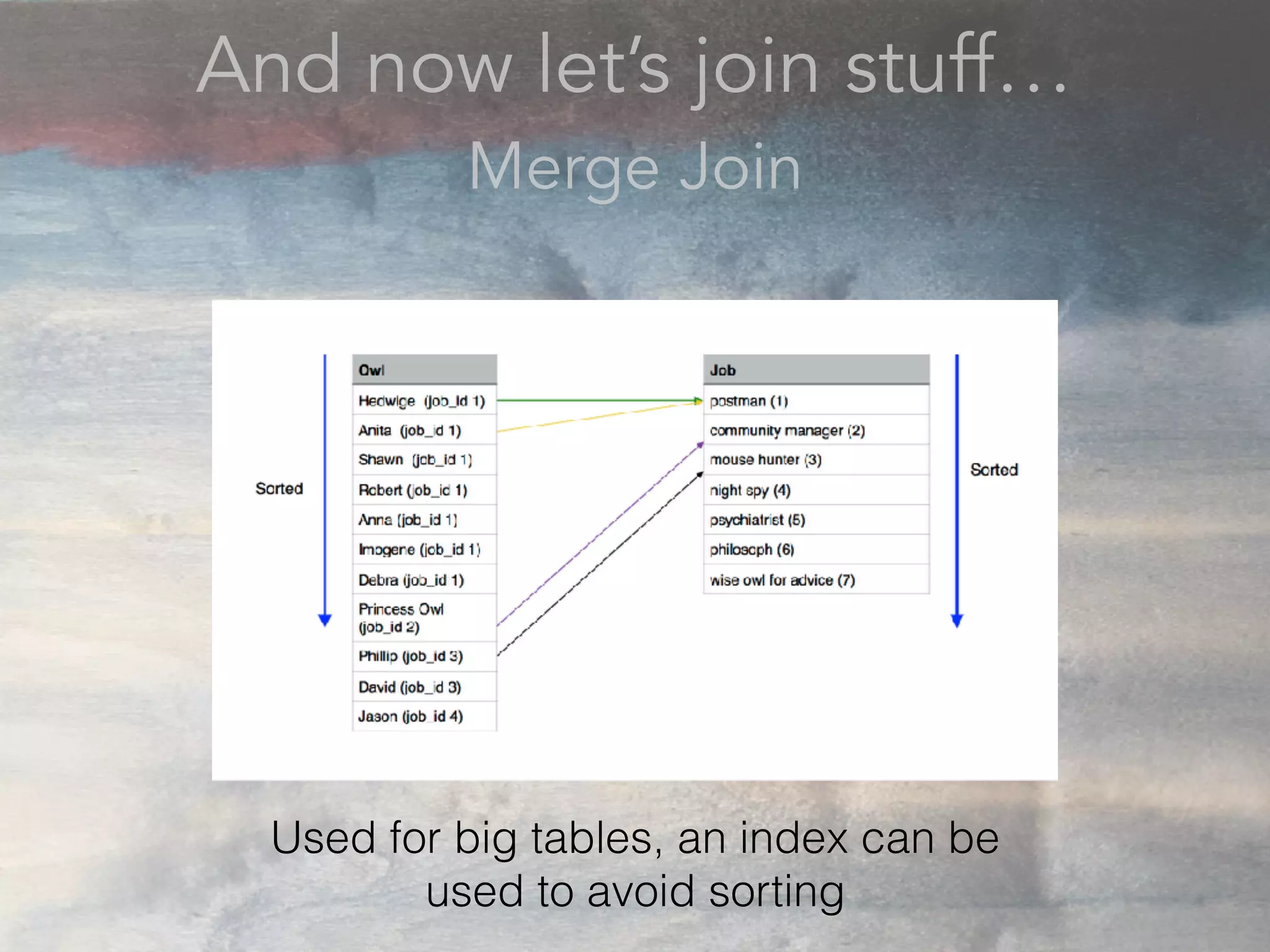

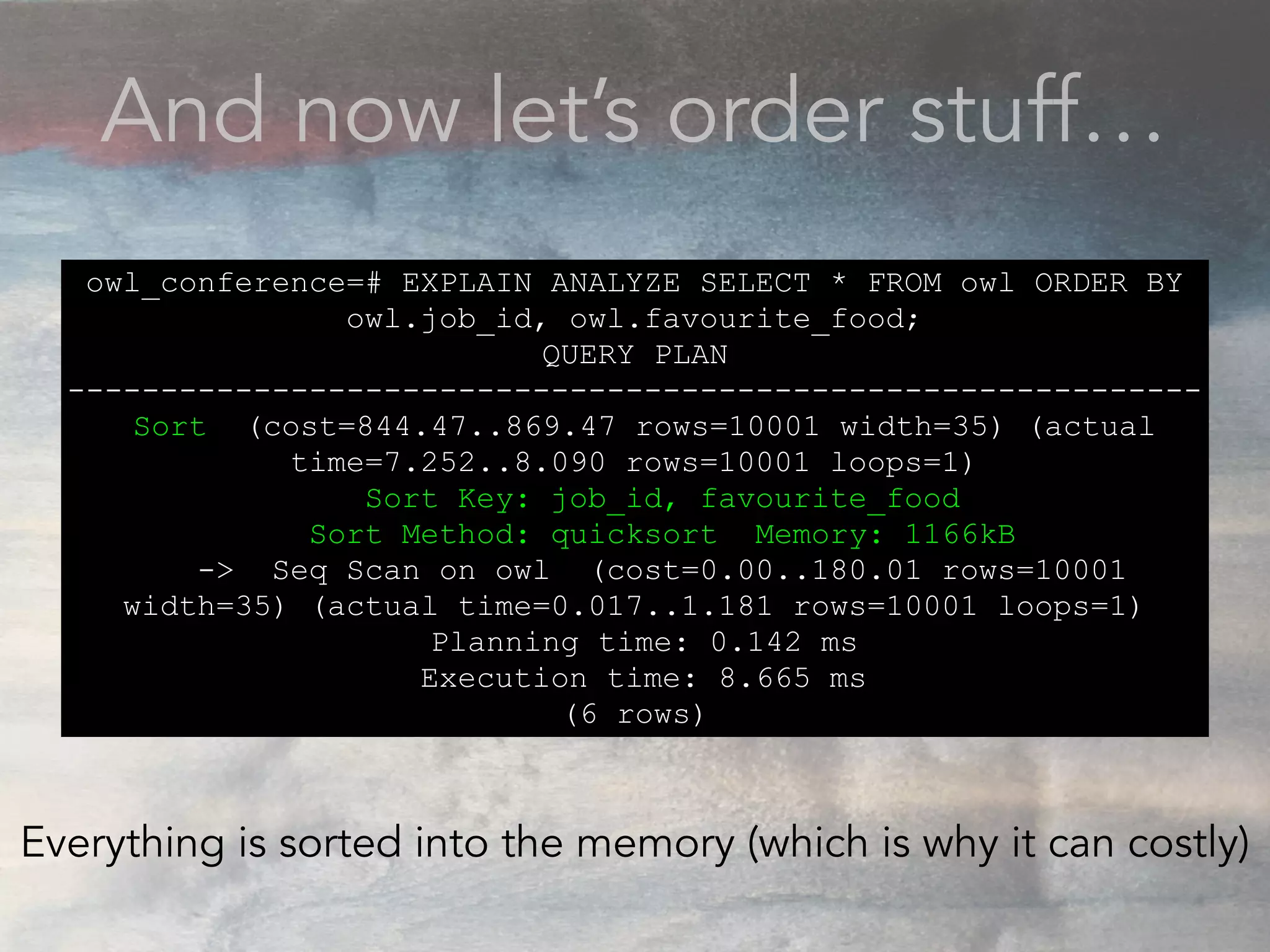
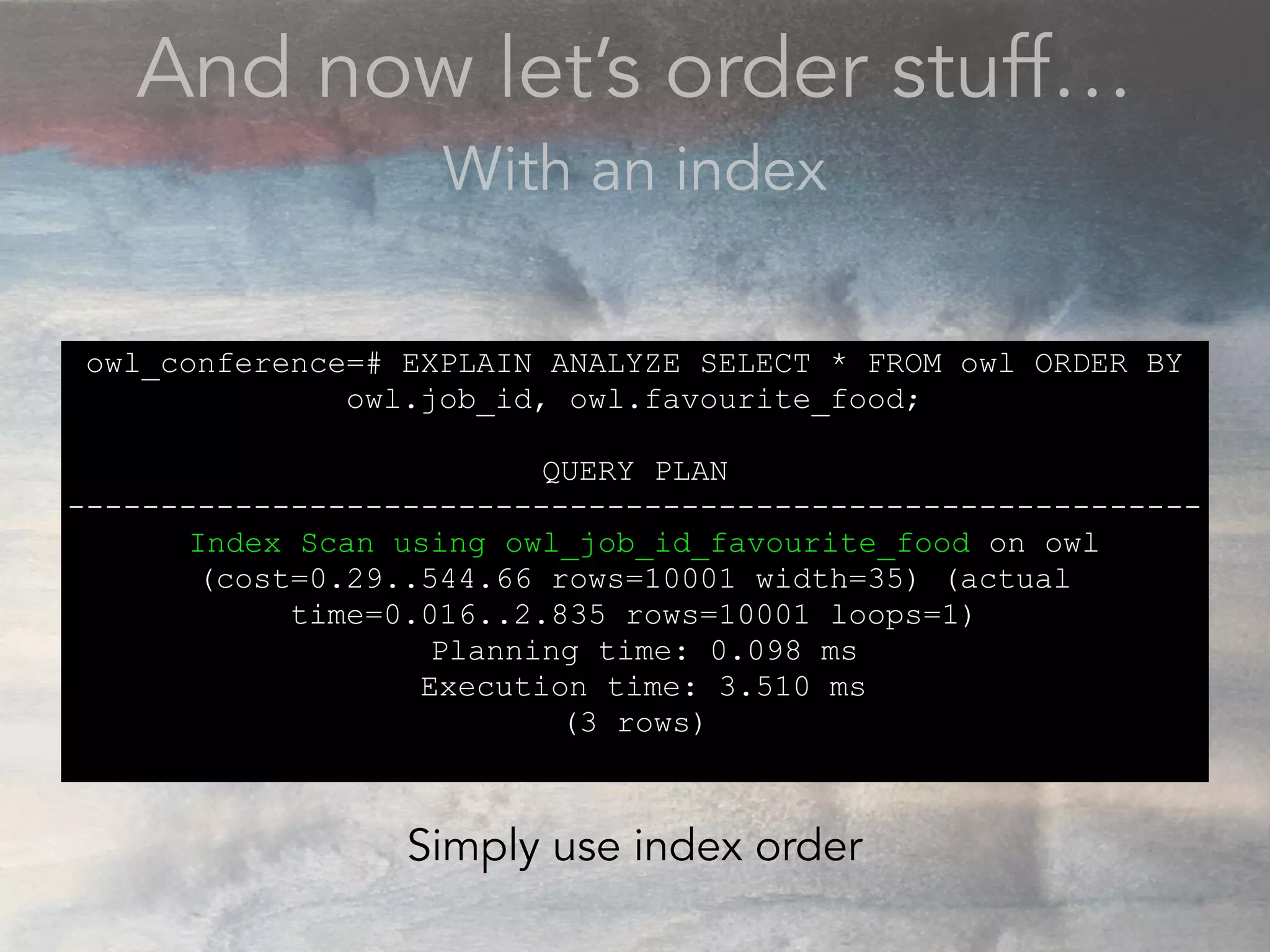
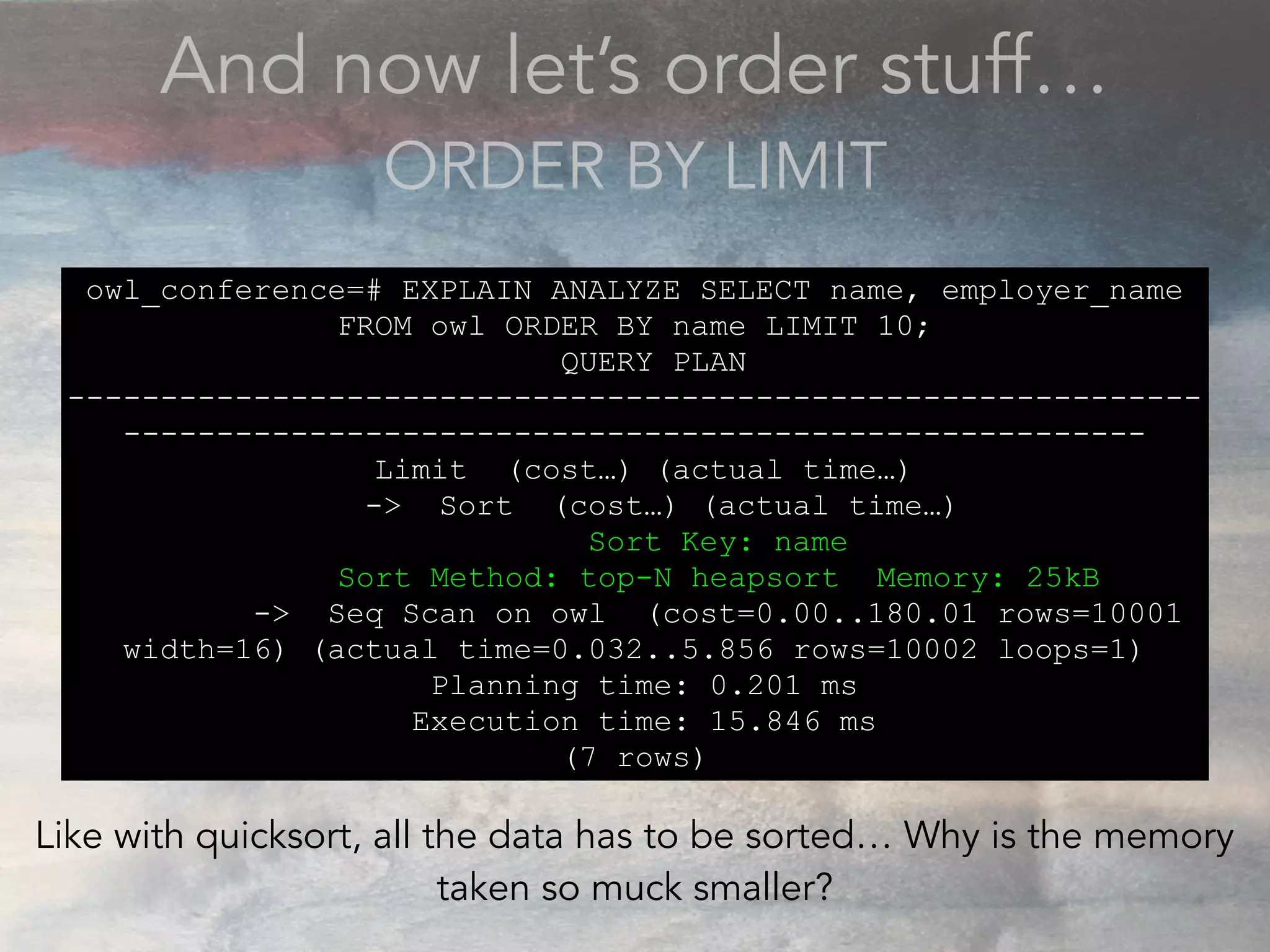









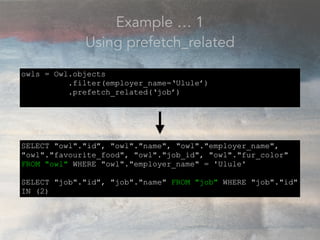
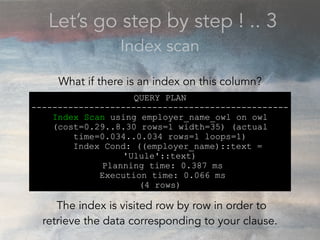
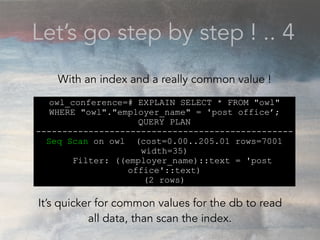
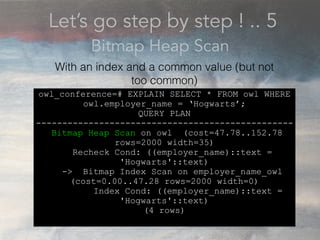
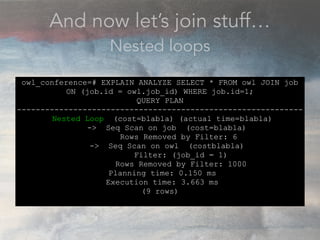
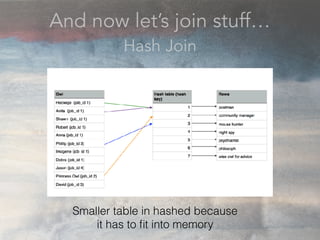
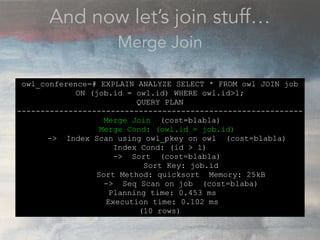
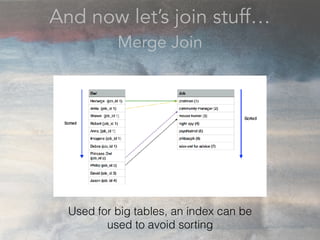
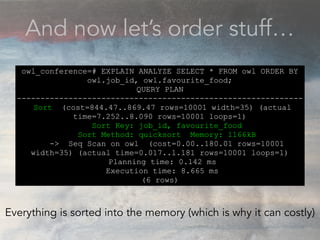
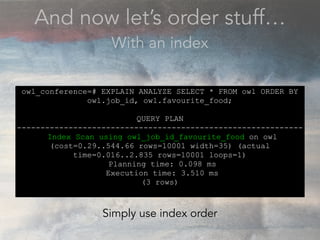
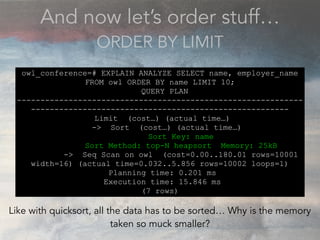
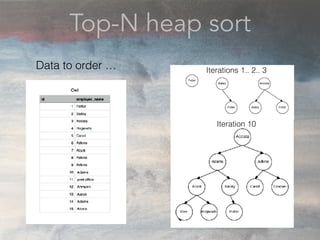
- The document discusses performance problems that can arise from ORM use and how to identify them. It recommends examining database logs to see queries being executed. Different types of scans like sequential, index, and bitmap scans are explained. Techniques like select_related, prefetch_related, and using indexes are suggested to reduce queries. The EXPLAIN command is demonstrated to analyze query plans and identify optimizations.



























![Java 8 Puzzlers [as presented at OSCON 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/java8puzzlersoscon2016-160522043417-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



























































