Downloaded 122 times














































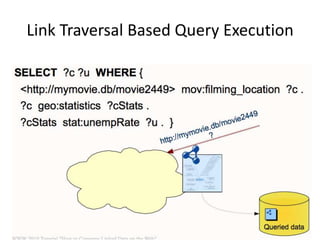
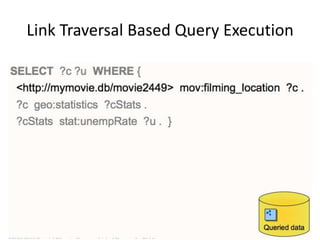


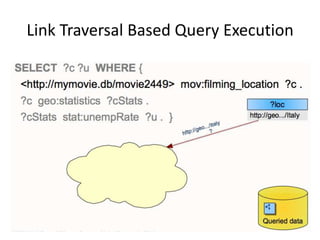
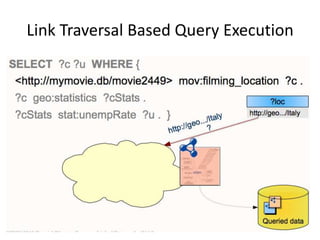

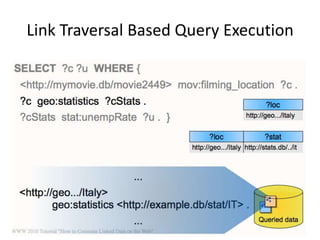
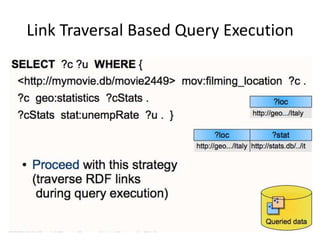



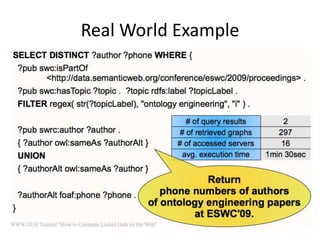









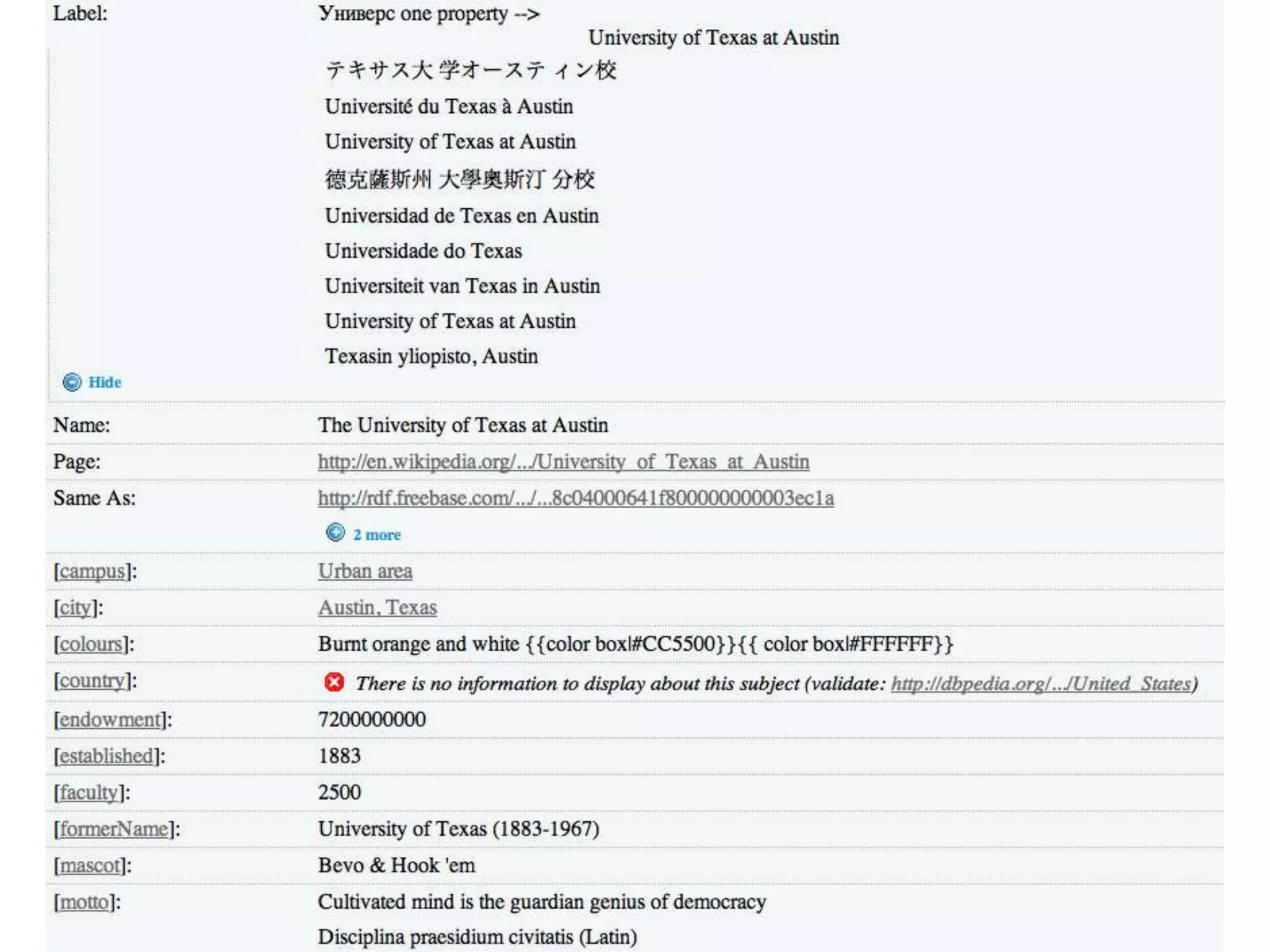





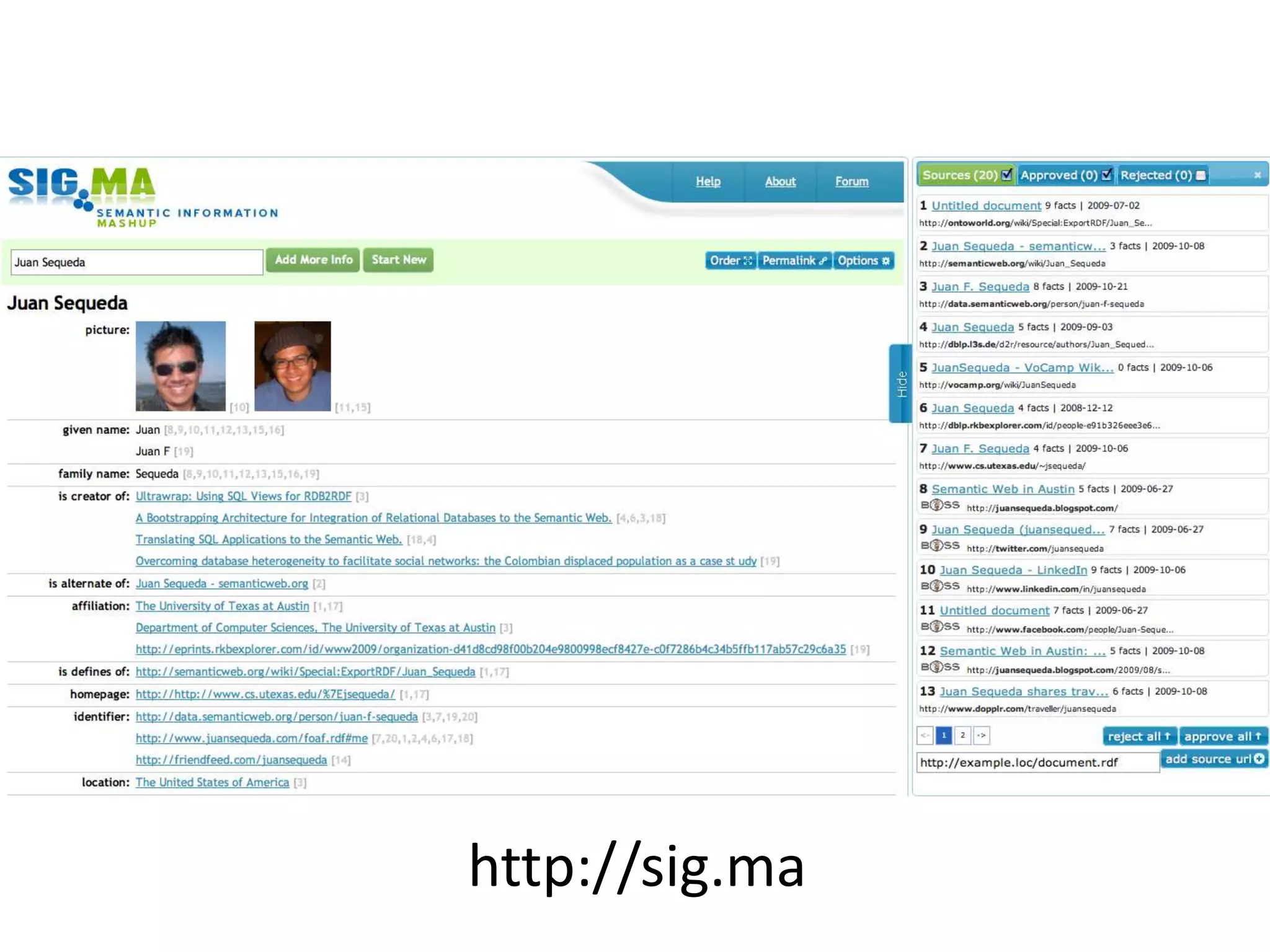



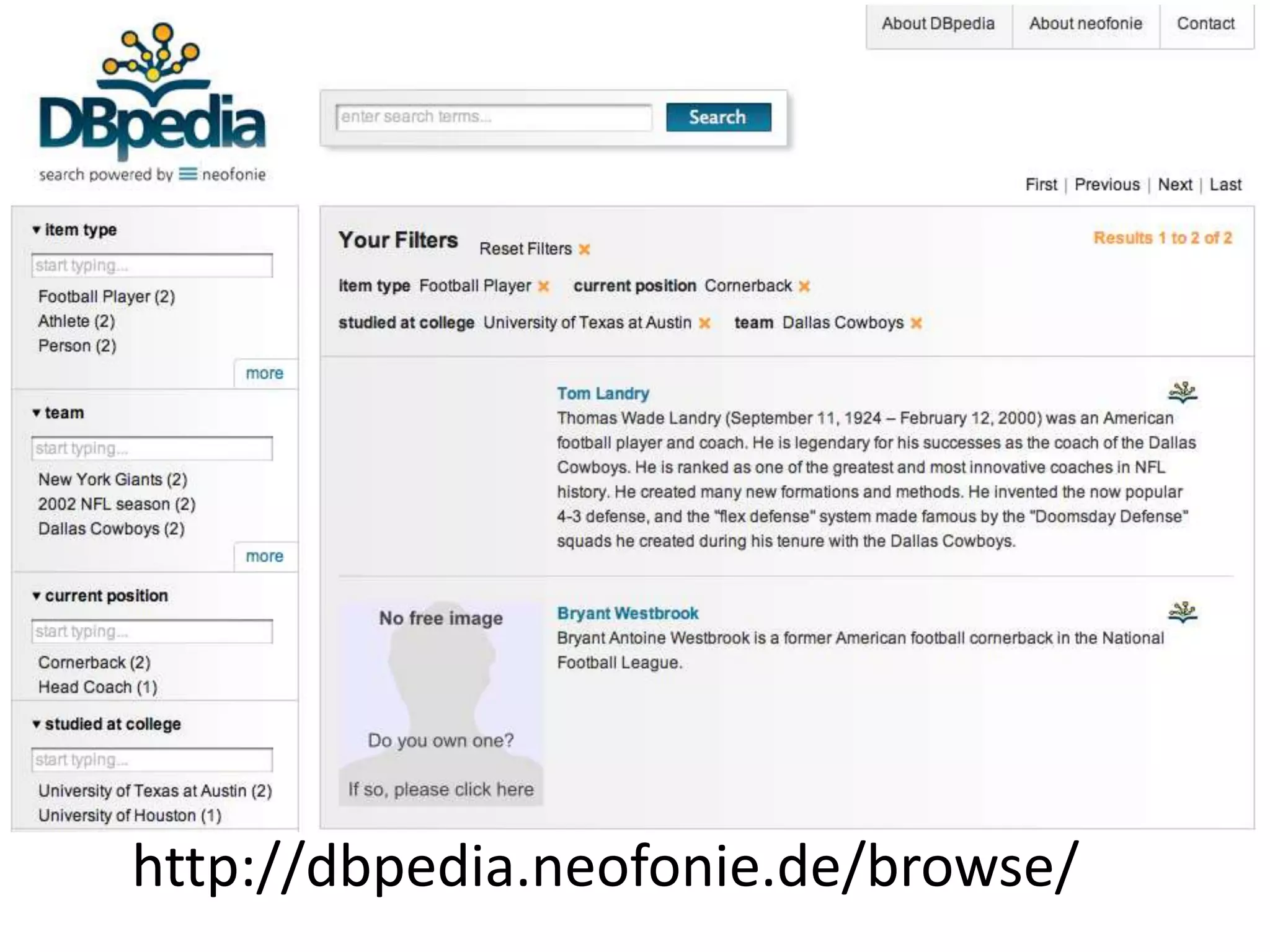
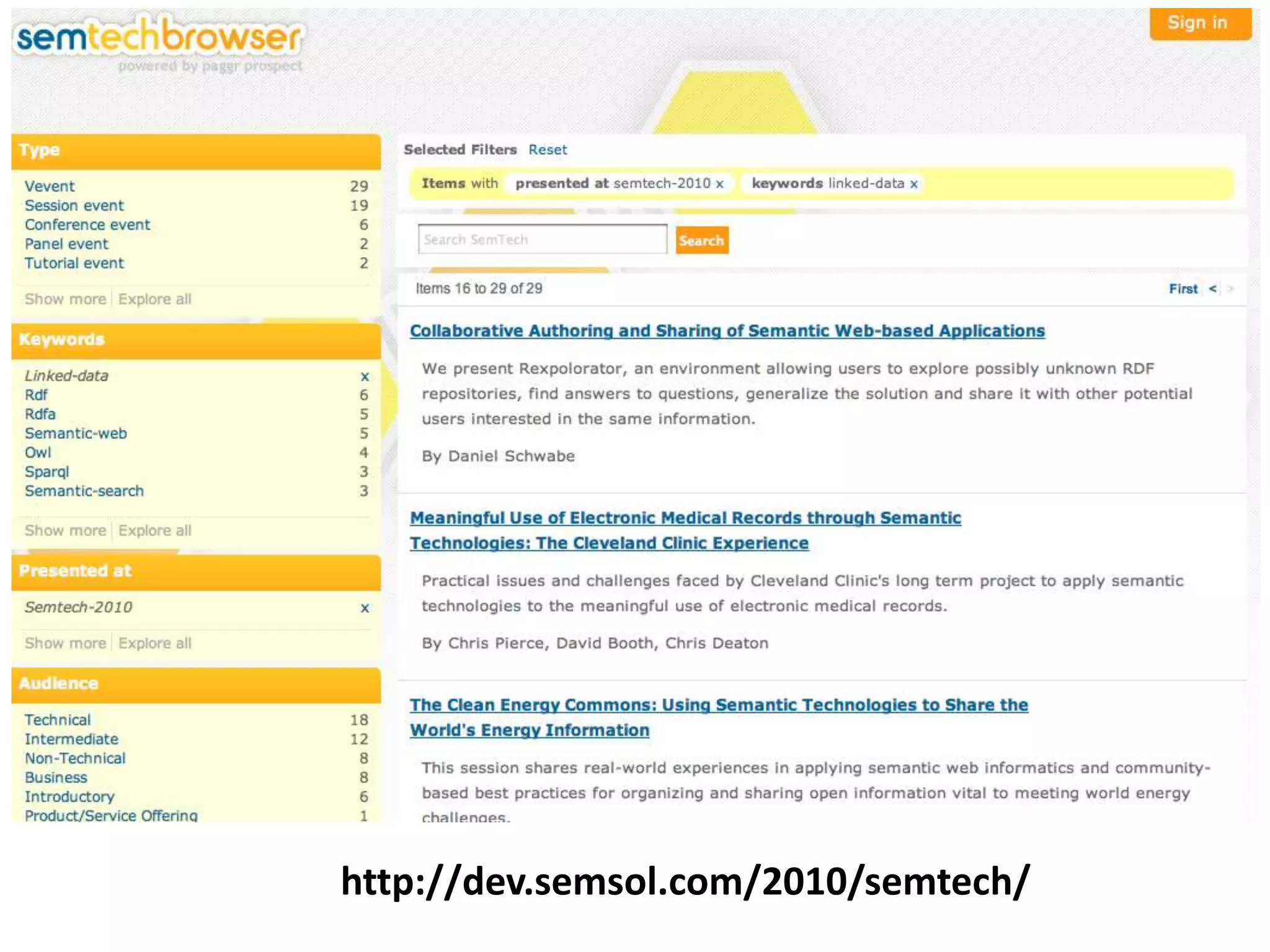






















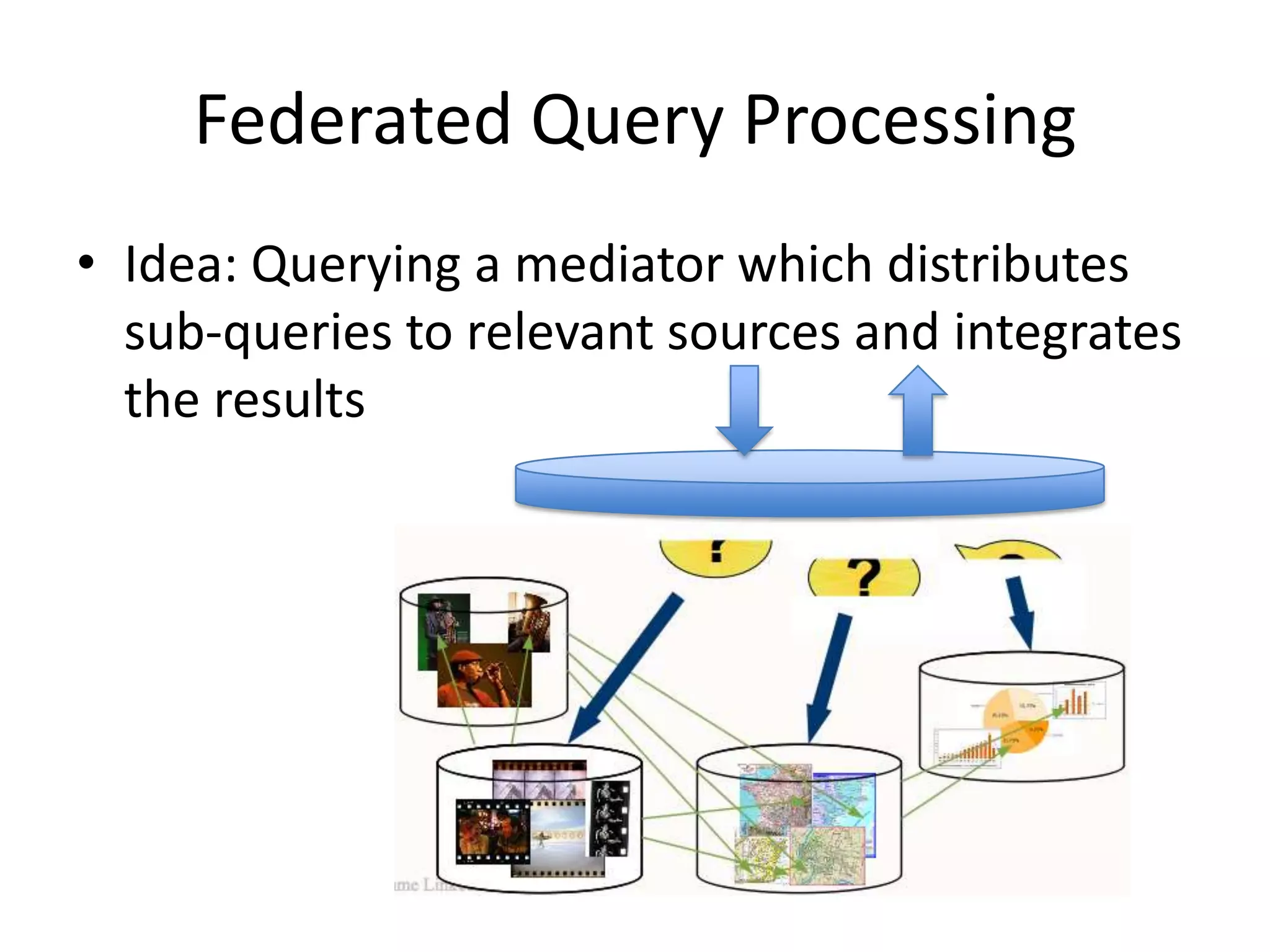








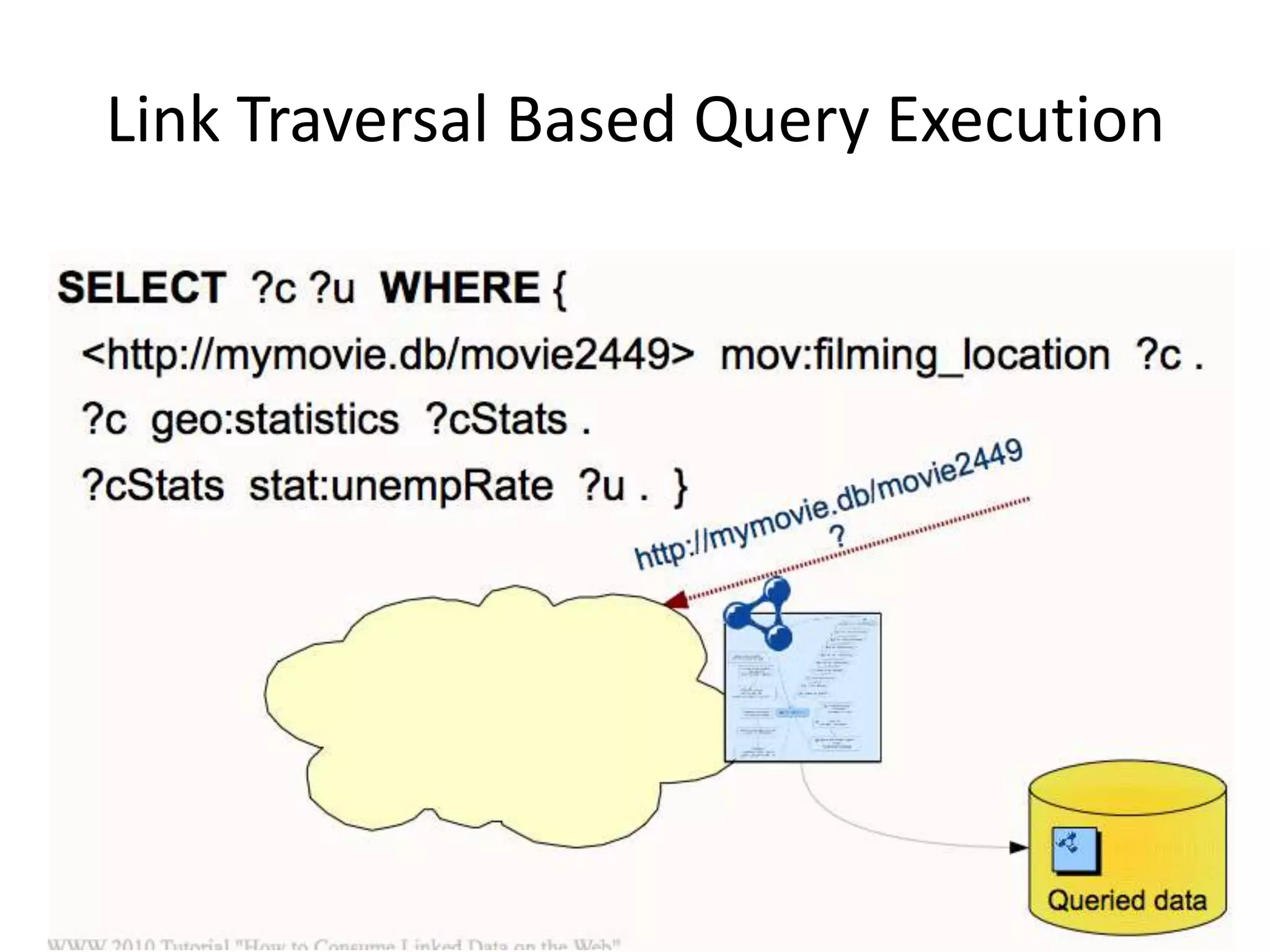
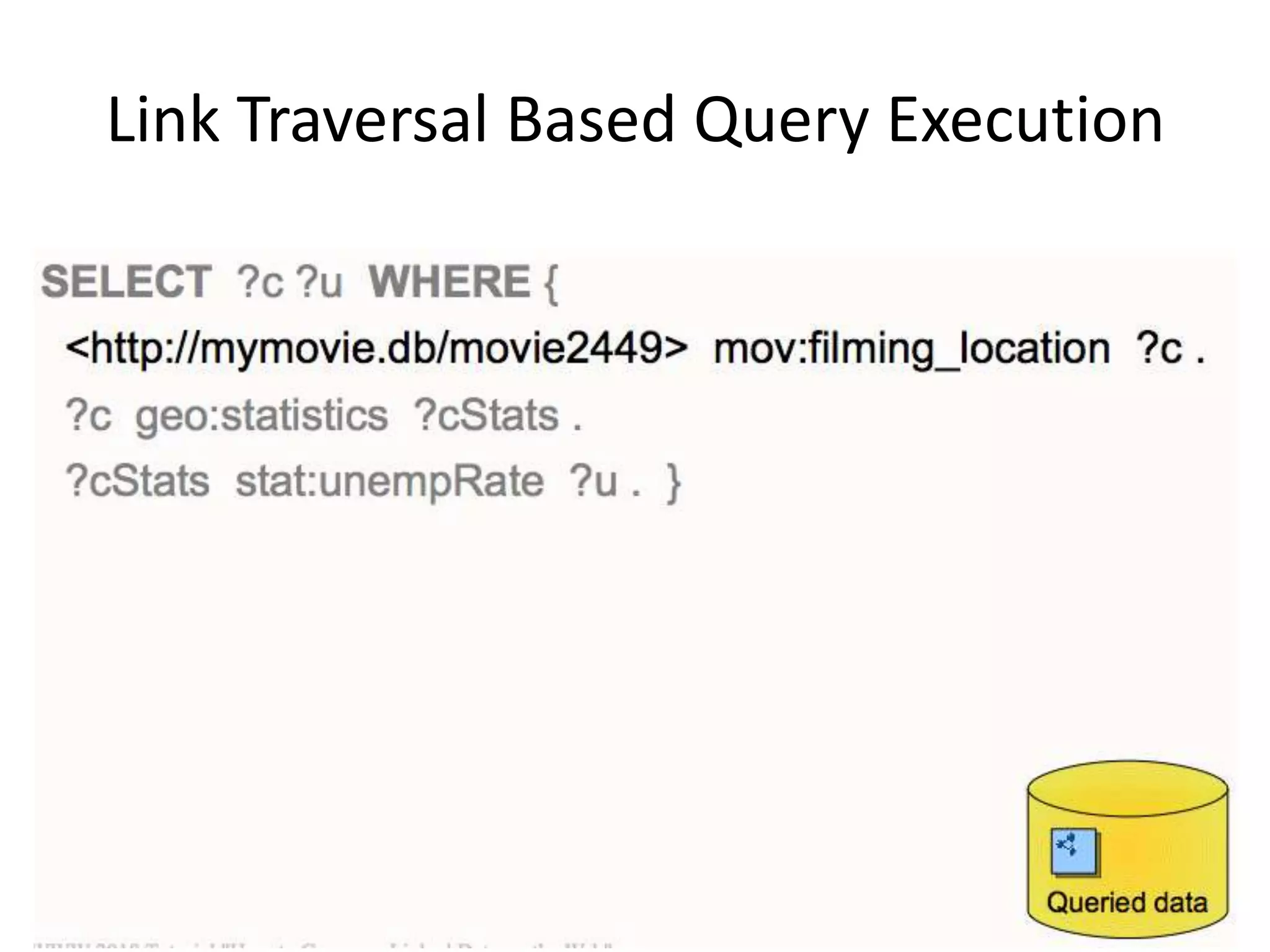


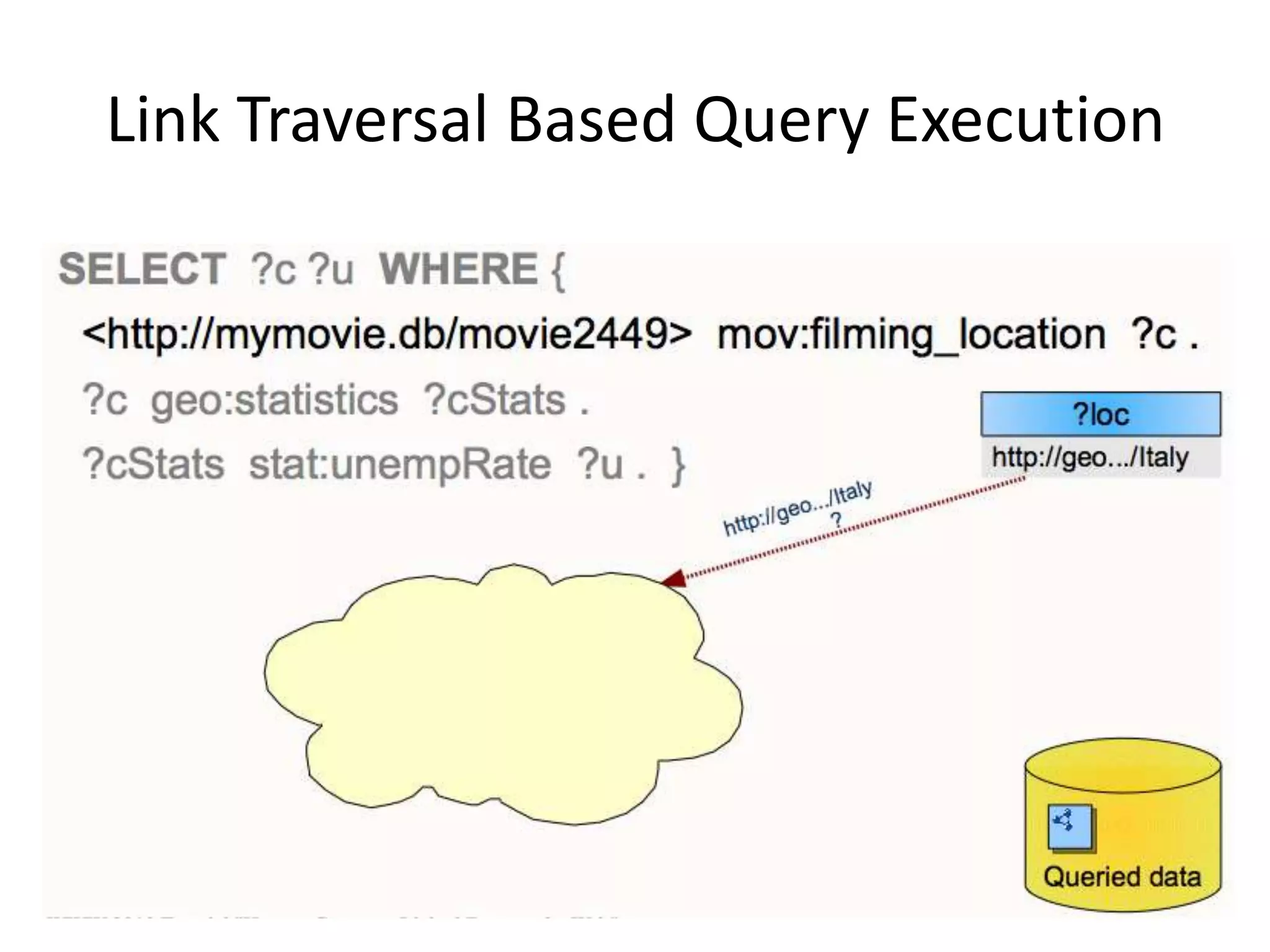
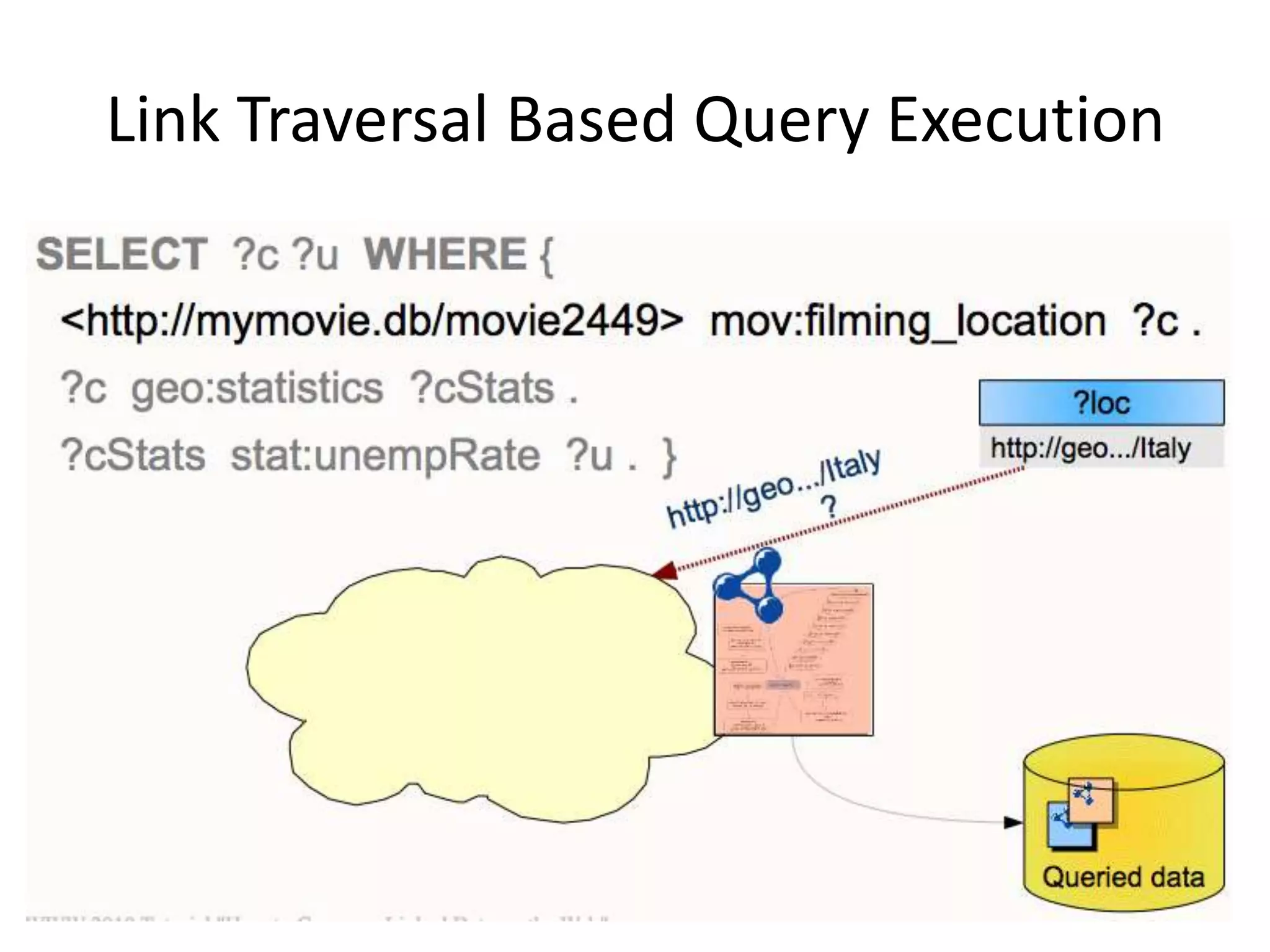

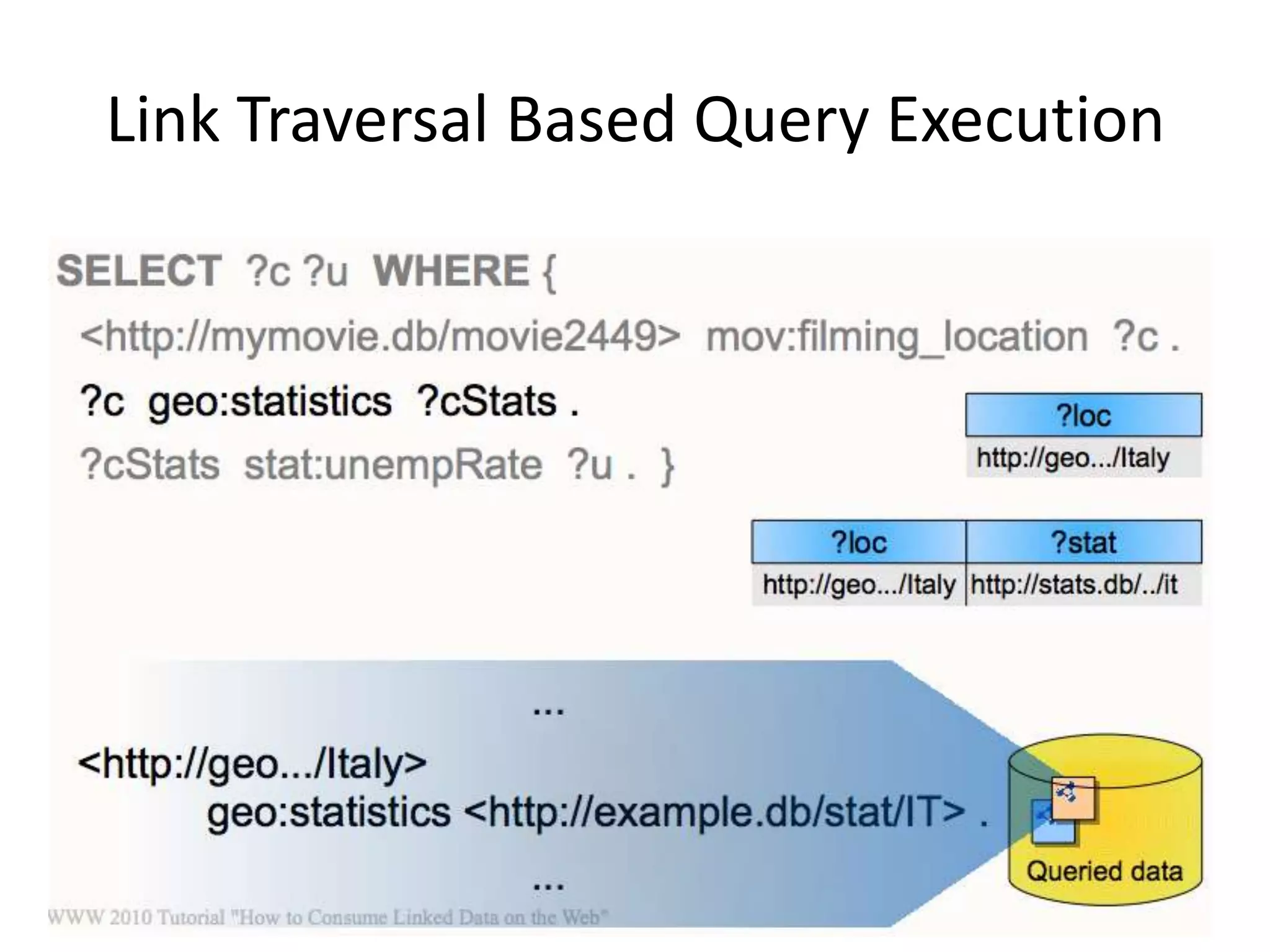
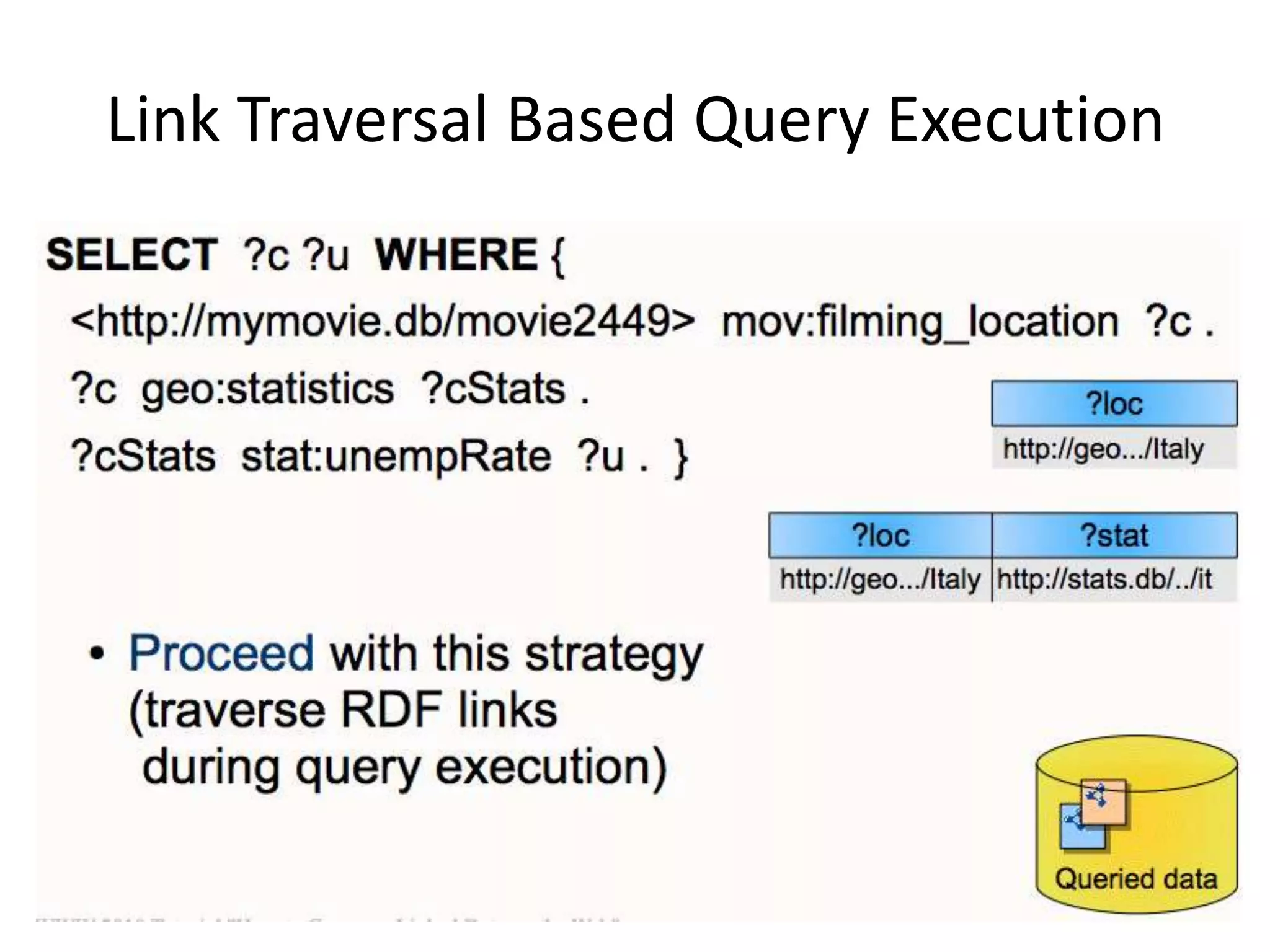



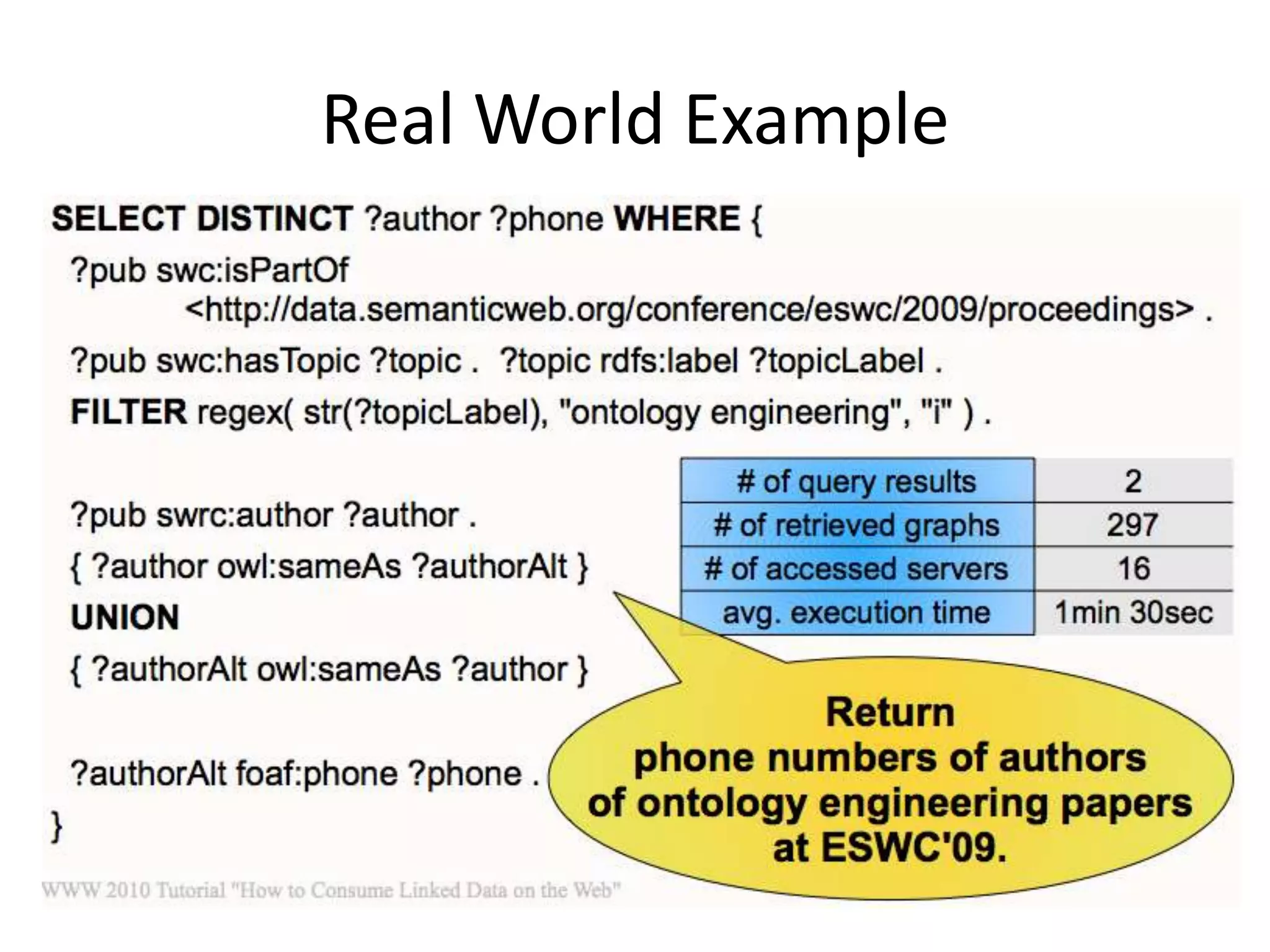



This document discusses various approaches for building applications that consume linked data from multiple datasets on the web. It describes characteristics of linked data applications and generic applications like linked data browsers and search engines. It also covers domain-specific applications, faceted browsers, SPARQL endpoints, and techniques for accessing and querying linked data including follow-up queries, querying local caches, crawling data, federated query processing, and on-the-fly dereferencing of URIs. The advantages and disadvantages of each technique are discussed.











































































































