Download as PDF, PPTX





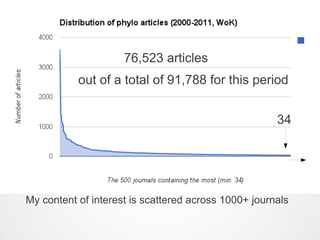







![It's largely only OA publishers
allowing content mining to occur
“When permission is requested [by researchers], 35% of publisher
respondents allow mining in the majority or all of cases”
[tellingly, 85% of those “35% of publishers” that allow it are Open
Access publishers, not subscription-access publishers]
from the Publishing Research Consortium's own report
(Smit & van der Graaf, 2011)
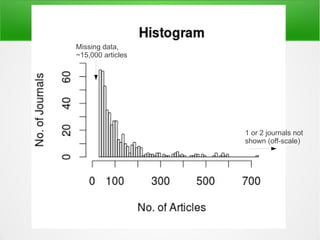
This is also the reason why only 13% of PMC is 'safe' to mine,
despite 100% of PMC being 'free to read' (ocular access only)](https://image.slidesharecdn.com/tdmv2-130308075114-phpapp01/85/Content-Mining-15-320.jpg)








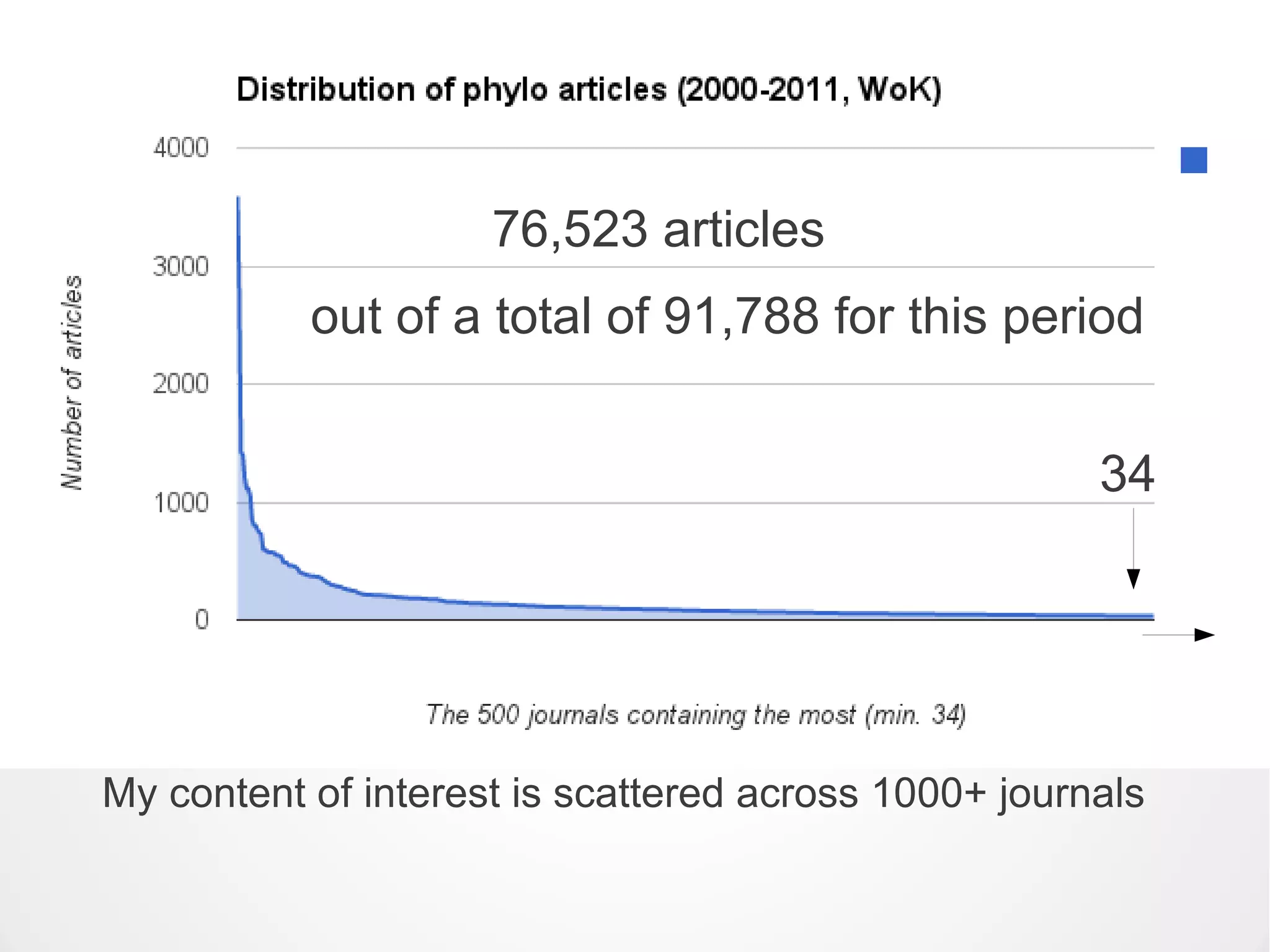







![It's largely only OA publishers
allowing content mining to occur
“When permission is requested [by researchers], 35% of publisher
respondents allow mining in the majority or all of cases”
[tellingly, 85% of those “35% of publishers” that allow it are Open
Access publishers, not subscription-access publishers]
from the Publishing Research Consortium's own report
(Smit & van der Graaf, 2011)
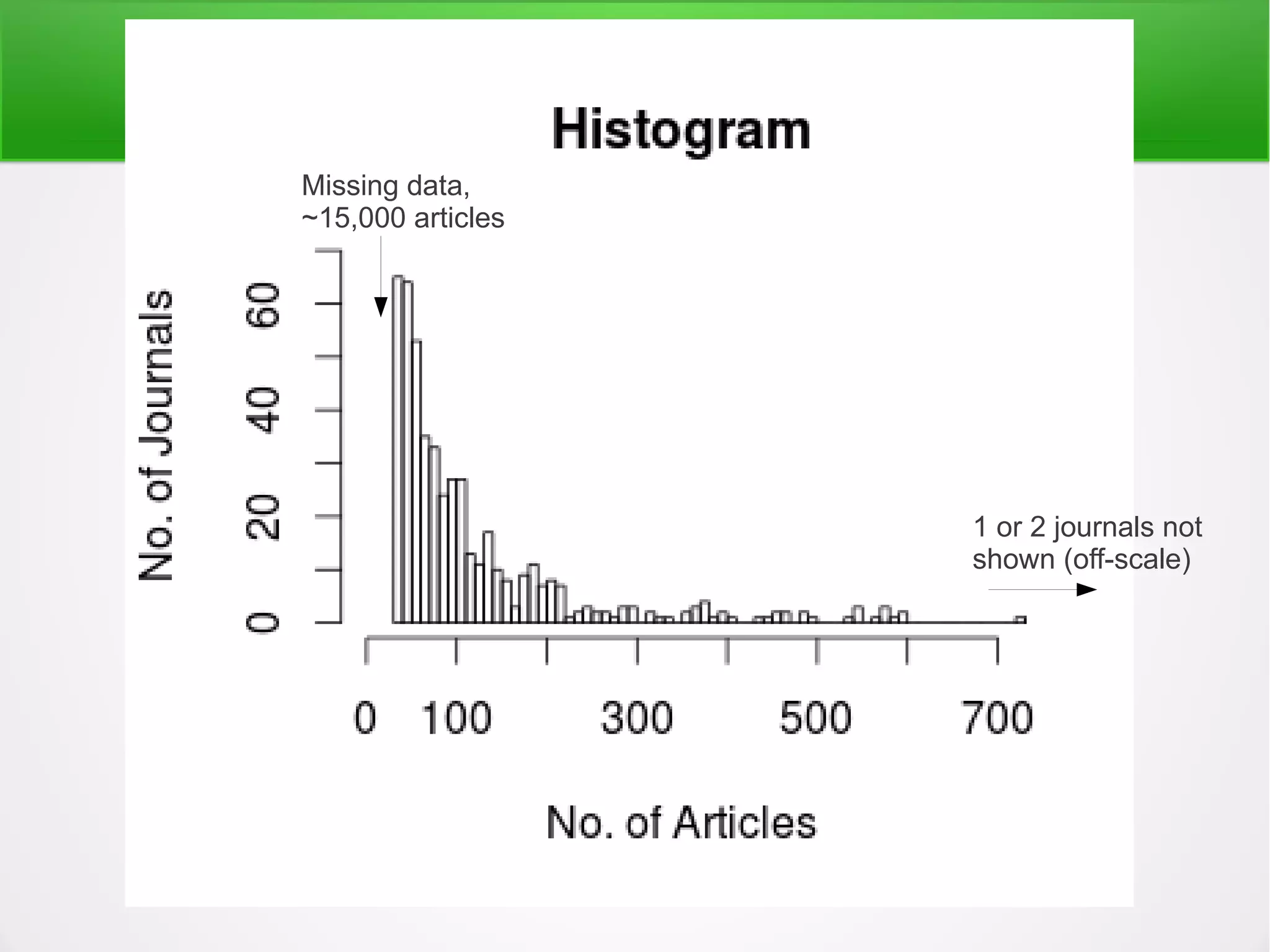
This is also the reason why only 13% of PMC is 'safe' to mine,
despite 100% of PMC being 'free to read' (ocular access only)](https://image.slidesharecdn.com/tdmv2-130308075114-phpapp01/75/Content-Mining-15-2048.jpg)




The document discusses the concept of content mining, emphasizing the need to liberate facts trapped in copyrighted scholarly articles for open access. It highlights the challenges faced by researchers due to restrictive licensing agreements and the blockages from major publishers, which hinder the content mining process. Changes in UK laws are anticipated to facilitate non-commercial content mining research, providing a more favorable environment for liberating factual information.

















































![Open scholarship [a FOSTER open science talk]](https://cdn.slidesharecdn.com/ss_thumbnails/openscholarshipfoster-140904081612-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










