Download as PDF, PPTX




![Science led to Python
5
Raja Muthupillai
Armando Manduca
Richard Ehman
Jim Greenleaf
1997
⇢0 (2⇡f)
2
Ui (a, f) = [Cijkl (a, f) Uk,l (a, f)],j
⌅ = r ⇥ U](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-5-320.jpg)


























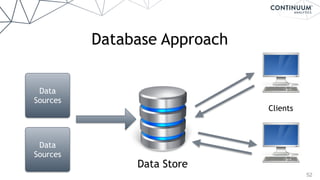





![58
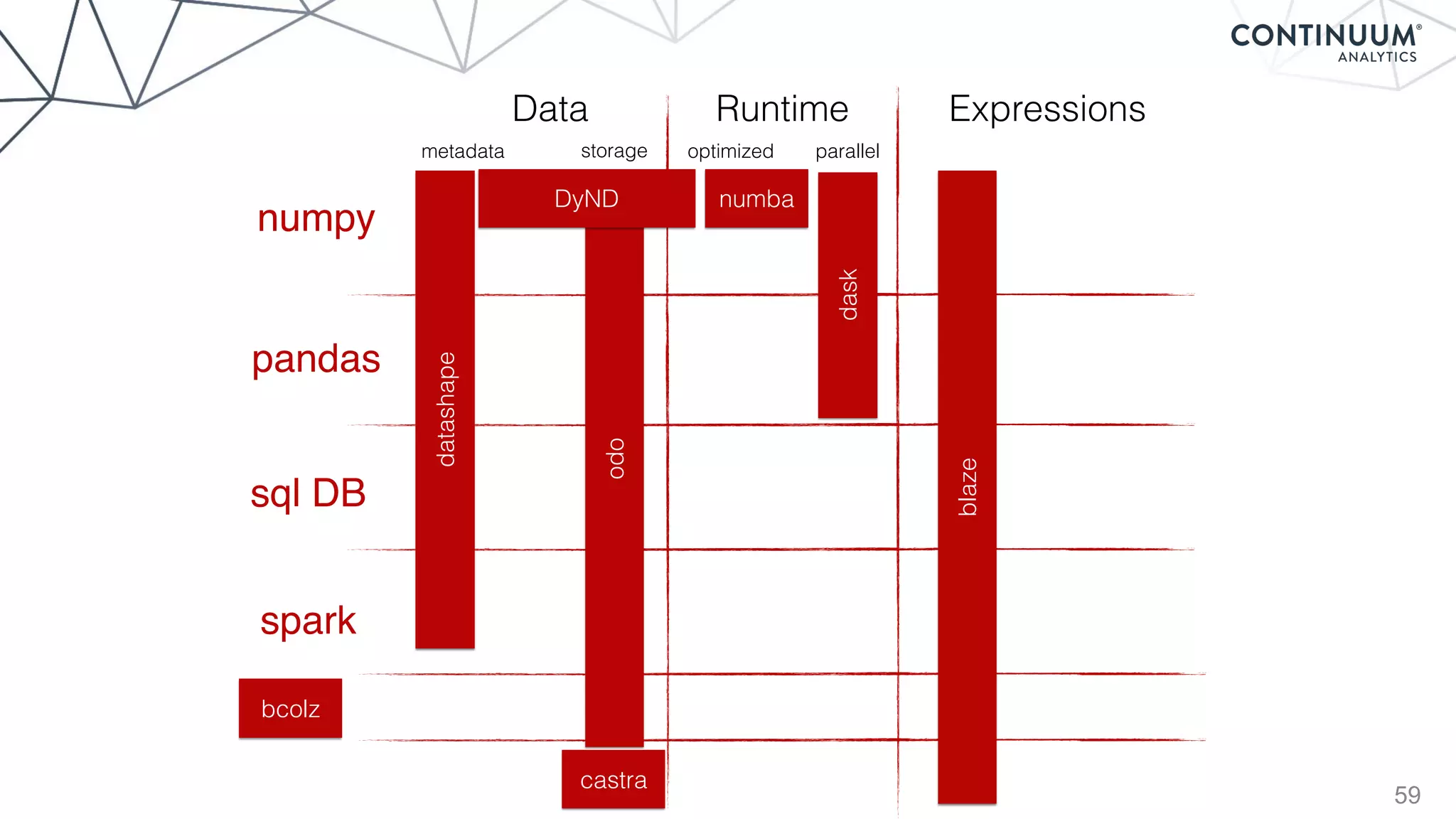
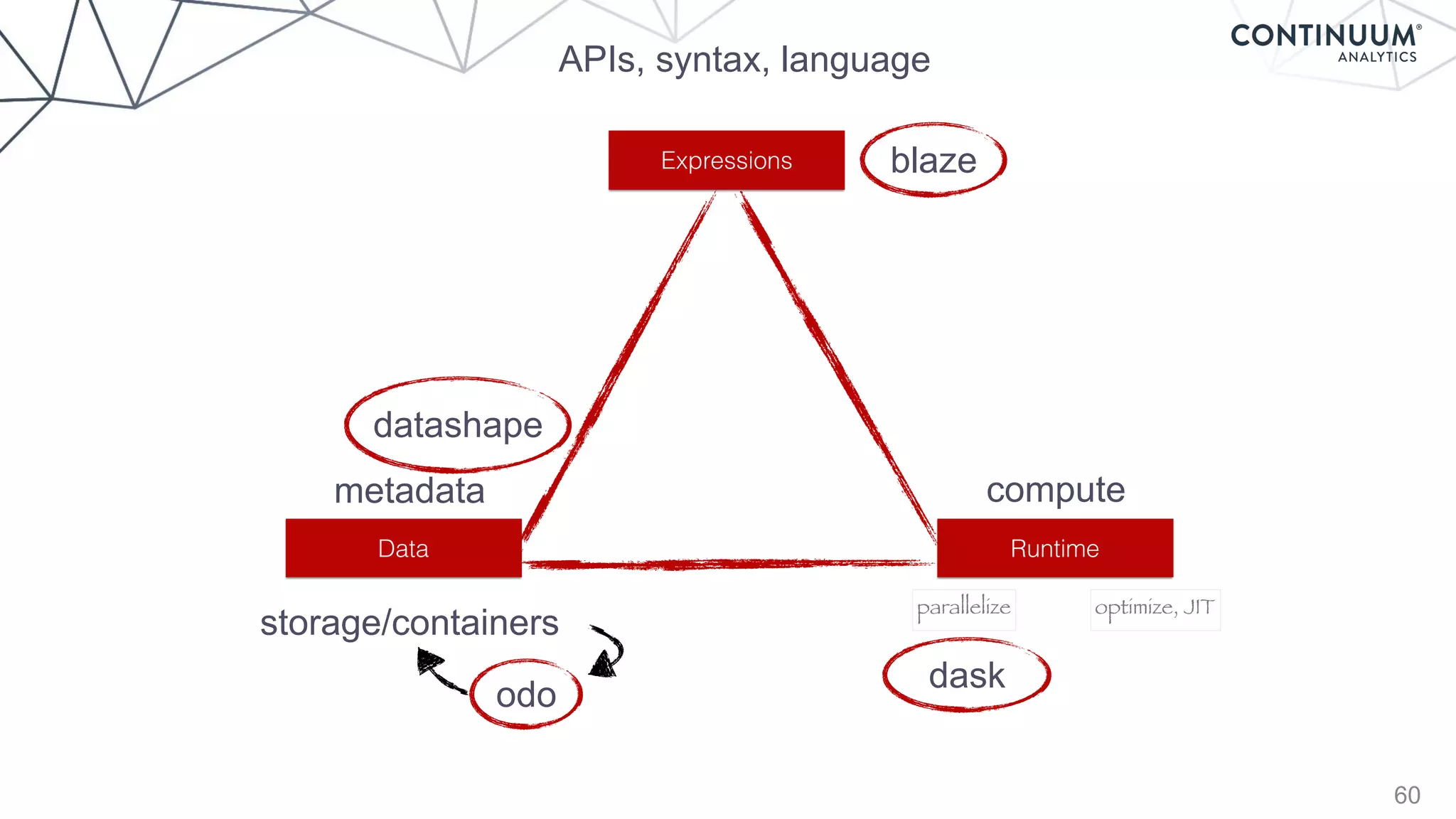
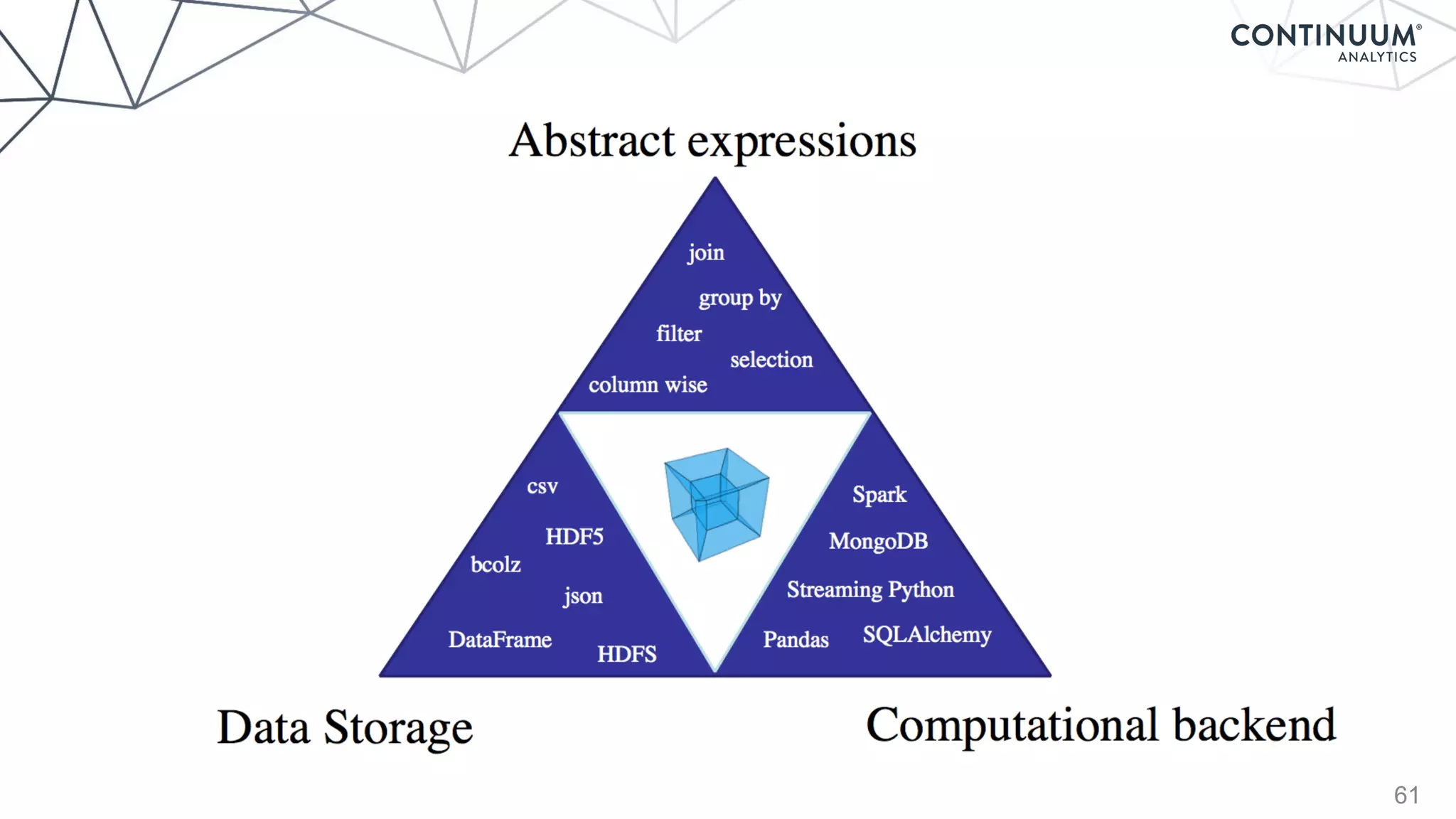
Blaze
+ - / * ^ []
join, groupby, filter
map, sort, take
where, topk
datashape,dtype,
shape,stride
hdf5,json,csv,xls
protobuf,avro,...
NumPy,Pandas,R,
Julia,K,SQL,Spark,
Mongo,Cassandra,...](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-58-320.jpg)
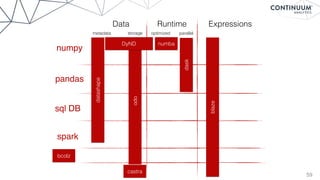

![62
Blaze Server
Provide
RESTful
web
API
over
any
data
supported
by
Blaze.
Server
side:
>>> my_spark_rdd = …
>>> from blaze import Server
>>> Server(my_spark_rdd).run()
Hosting computation on localhost:6363
Client
Side:
$ curl -H "Content-Type: application/json"
-d ’{"expr": {"op": "sum", "args": [ ... ] }’
my.domain.com:6363/compute.json
• Quickly share local data to collaborators
on the web.
• Expose any system (Mongo, SQL, Spark,
in-memory) simply
• Share local computation as well, sending
computations to server to run remotely.
• Conveniently drive remote server with
interactive Blaze client](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-62-320.jpg)



![dask.array: OOC, parallel, ND array
69
Arithmetic: +, *, ...
Reductions: mean, max, ...
Slicing: x[10:, 100:50:-2]
Fancy indexing: x[:, [3, 1, 2]]
Some linear algebra: tensordot, qr, svd
Parallel algorithms (approximate quantiles, topk, ...)
Slightly overlapping arrays
Integration with HDF5](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-69-320.jpg)
![dask.dataframe: OOC, parallel, ND array
70
Elementwise operations: df.x + df.y
Row-wise selections: df[df.x > 0]
Aggregations: df.x.max()
groupby-aggregate: df.groupby(df.x).y.max()
Value counts: df.x.value_counts()
Drop duplicates: df.x.drop_duplicates()
Join on index: dd.merge(df1, df2, left_index=True,
right_index=True)](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-70-320.jpg)
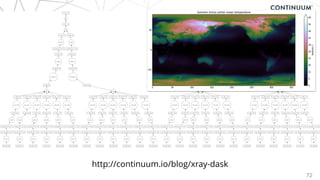
![73
from dask import dataframe as dd
columns = ["name", "amenity", "Longitude", "Latitude"]
data = dd.read_csv('POIWorld.csv', usecols=columns)
with_name = data[data.name.notnull()]
with_amenity = data[data.amenity.notnull()]
is_starbucks = with_name.name.str.contains('[Ss]tarbucks')
is_dunkin = with_name.name.str.contains('[Dd]unkin')
starbucks = with_name[is_starbucks]
dunkin = with_name[is_dunkin]
locs = dd.compute(starbucks.Longitude,
starbucks.Latitude,
dunkin.Longitude,
dunkin.Latitude)
# extract arrays of values fro the series:
lon_s, lat_s, lon_d, lat_d = [loc.values for loc in locs]
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
def draw_USA():
"""initialize a basemap centered on the continental USA"""
plt.figure(figsize=(14, 10))
return Basemap(projection='lcc', resolution='l',
llcrnrlon=-119, urcrnrlon=-64,
llcrnrlat=22, urcrnrlat=49,
lat_1=33, lat_2=45, lon_0=-95,
area_thresh=10000)
m = draw_USA()
# Draw map background
m.fillcontinents(color='white', lake_color='#eeeeee')
m.drawstates(color='lightgray')
m.drawcoastlines(color='lightgray')
m.drawcountries(color='lightgray')
m.drawmapboundary(fill_color='#eeeeee')
# Plot the values in Starbucks Green and Dunkin Donuts Orange
style = dict(s=5, marker='o', alpha=0.5, zorder=2)
m.scatter(lon_s, lat_s, latlon=True,
label="Starbucks", color='#00592D', **style)
m.scatter(lon_d, lat_d, latlon=True,
label="Dunkin' Donuts", color='#FC772A', **style)
plt.legend(loc='lower left', frameon=False);](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-73-320.jpg)


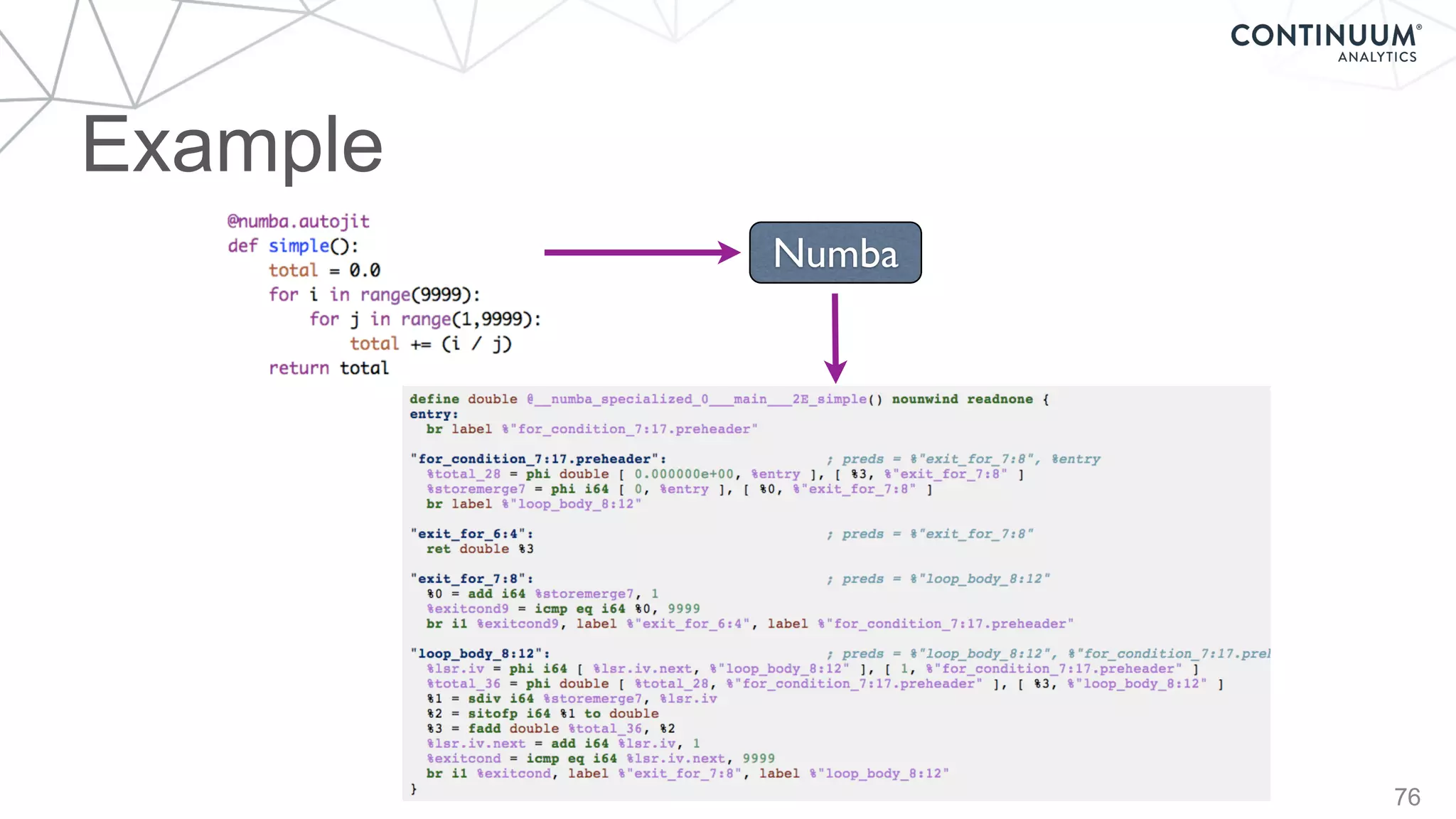
![77
@jit('void(f8[:,:],f8[:,:],f8[:,:])')
def filter(image, filt, output):
M, N = image.shape
m, n = filt.shape
for i in range(m//2, M-m//2):
for j in range(n//2, N-n//2):
result = 0.0
for k in range(m):
for l in range(n):
result += image[i+k-m//2,j+l-n//2]*filt[k, l]
output[i,j] = result
~1500x speed-up](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/85/Continuum-Analytics-and-Python-77-320.jpg)



















![Science led to Python
5
Raja Muthupillai
Armando Manduca
Richard Ehman
Jim Greenleaf
1997
⇢0 (2⇡f)
2
Ui (a, f) = [Cijkl (a, f) Uk,l (a, f)],j
⌅ = r ⇥ U](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-5-2048.jpg)
































![58
Blaze
+ - / * ^ []
join, groupby, filter
map, sort, take
where, topk
datashape,dtype,
shape,stride
hdf5,json,csv,xls
protobuf,avro,...
NumPy,Pandas,R,
Julia,K,SQL,Spark,
Mongo,Cassandra,...](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-58-2048.jpg)
![62
Blaze Server
Provide
RESTful
web
API
over
any
data
supported
by
Blaze.
Server
side:
>>> my_spark_rdd = …
>>> from blaze import Server
>>> Server(my_spark_rdd).run()
Hosting computation on localhost:6363
Client
Side:
$ curl -H "Content-Type: application/json"
-d ’{"expr": {"op": "sum", "args": [ ... ] }’
my.domain.com:6363/compute.json
• Quickly share local data to collaborators
on the web.
• Expose any system (Mongo, SQL, Spark,
in-memory) simply
• Share local computation as well, sending
computations to server to run remotely.
• Conveniently drive remote server with
interactive Blaze client](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-62-2048.jpg)



![dask.array: OOC, parallel, ND array
69
Arithmetic: +, *, ...
Reductions: mean, max, ...
Slicing: x[10:, 100:50:-2]
Fancy indexing: x[:, [3, 1, 2]]
Some linear algebra: tensordot, qr, svd
Parallel algorithms (approximate quantiles, topk, ...)
Slightly overlapping arrays
Integration with HDF5](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-69-2048.jpg)
![dask.dataframe: OOC, parallel, ND array
70
Elementwise operations: df.x + df.y
Row-wise selections: df[df.x > 0]
Aggregations: df.x.max()
groupby-aggregate: df.groupby(df.x).y.max()
Value counts: df.x.value_counts()
Drop duplicates: df.x.drop_duplicates()
Join on index: dd.merge(df1, df2, left_index=True,
right_index=True)](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-70-2048.jpg)


![73
from dask import dataframe as dd
columns = ["name", "amenity", "Longitude", "Latitude"]
data = dd.read_csv('POIWorld.csv', usecols=columns)
with_name = data[data.name.notnull()]
with_amenity = data[data.amenity.notnull()]
is_starbucks = with_name.name.str.contains('[Ss]tarbucks')
is_dunkin = with_name.name.str.contains('[Dd]unkin')
starbucks = with_name[is_starbucks]
dunkin = with_name[is_dunkin]
locs = dd.compute(starbucks.Longitude,
starbucks.Latitude,
dunkin.Longitude,
dunkin.Latitude)
# extract arrays of values fro the series:
lon_s, lat_s, lon_d, lat_d = [loc.values for loc in locs]
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
def draw_USA():
"""initialize a basemap centered on the continental USA"""
plt.figure(figsize=(14, 10))
return Basemap(projection='lcc', resolution='l',
llcrnrlon=-119, urcrnrlon=-64,
llcrnrlat=22, urcrnrlat=49,
lat_1=33, lat_2=45, lon_0=-95,
area_thresh=10000)
m = draw_USA()
# Draw map background
m.fillcontinents(color='white', lake_color='#eeeeee')
m.drawstates(color='lightgray')
m.drawcoastlines(color='lightgray')
m.drawcountries(color='lightgray')
m.drawmapboundary(fill_color='#eeeeee')
# Plot the values in Starbucks Green and Dunkin Donuts Orange
style = dict(s=5, marker='o', alpha=0.5, zorder=2)
m.scatter(lon_s, lat_s, latlon=True,
label="Starbucks", color='#00592D', **style)
m.scatter(lon_d, lat_d, latlon=True,
label="Dunkin' Donuts", color='#FC772A', **style)
plt.legend(loc='lower left', frameon=False);](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-73-2048.jpg)

![77
@jit('void(f8[:,:],f8[:,:],f8[:,:])')
def filter(image, filt, output):
M, N = image.shape
m, n = filt.shape
for i in range(m//2, M-m//2):
for j in range(n//2, N-n//2):
result = 0.0
for k in range(m):
for l in range(n):
result += image[i+k-m//2,j+l-n//2]*filt[k, l]
output[i,j] = result
~1500x speed-up](https://image.slidesharecdn.com/continuumandpython-151002015905-lva1-app6891/75/Continuum-Analytics-and-Python-77-2048.jpg)
















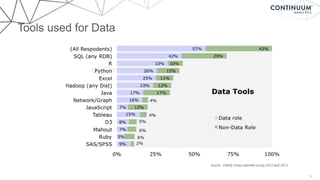
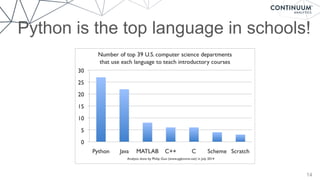
Continuum Analytics, co-founded by Travis Oliphant, focuses on utilizing Python for data science and analytics, addressing challenges posed by the exponential growth of data. The Anaconda platform serves as an enterprise solution for data exploration, advanced analytics, and rapid application deployment, gaining massive popularity with over 2 million downloads in two years. The document discusses the importance of powerful, accessible languages for data science and outlines various tools and technologies that facilitate effective data analysis and visualization.







































































