Downloaded 31 times

















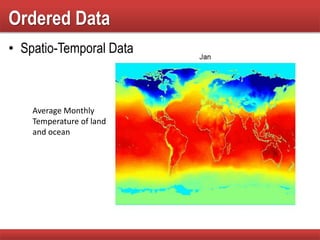

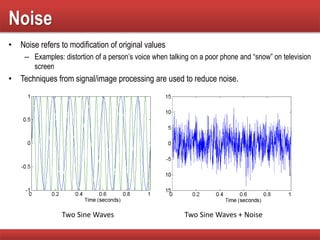





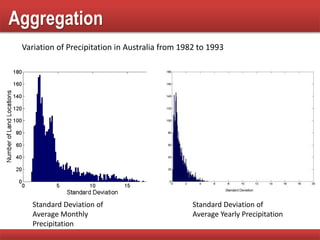




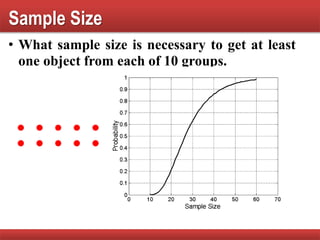
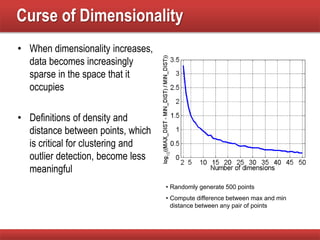




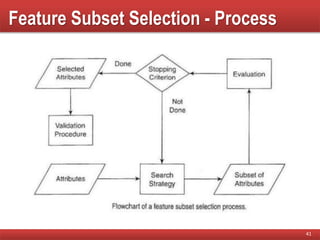


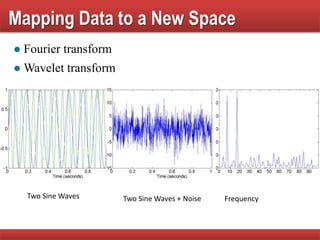






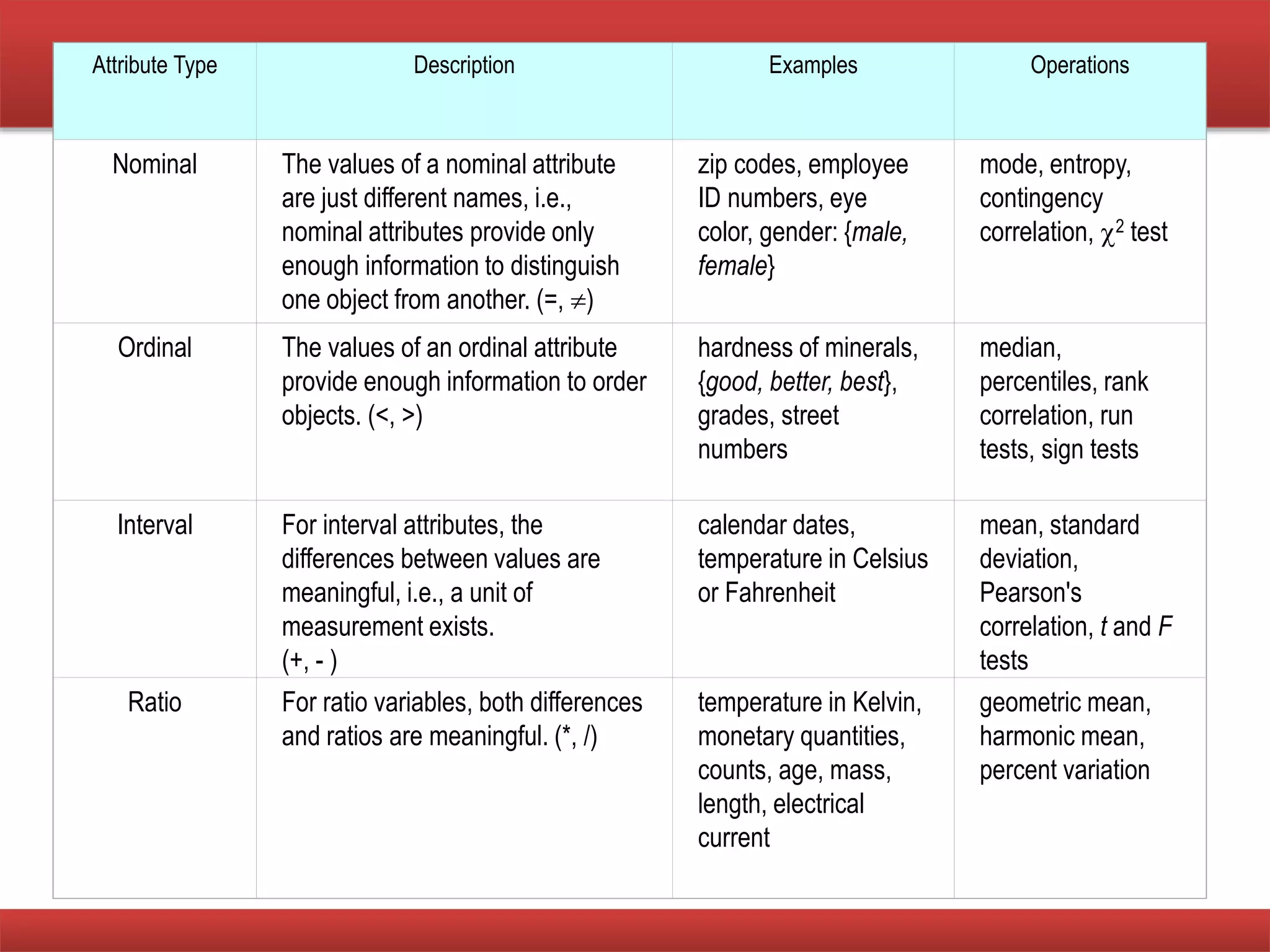












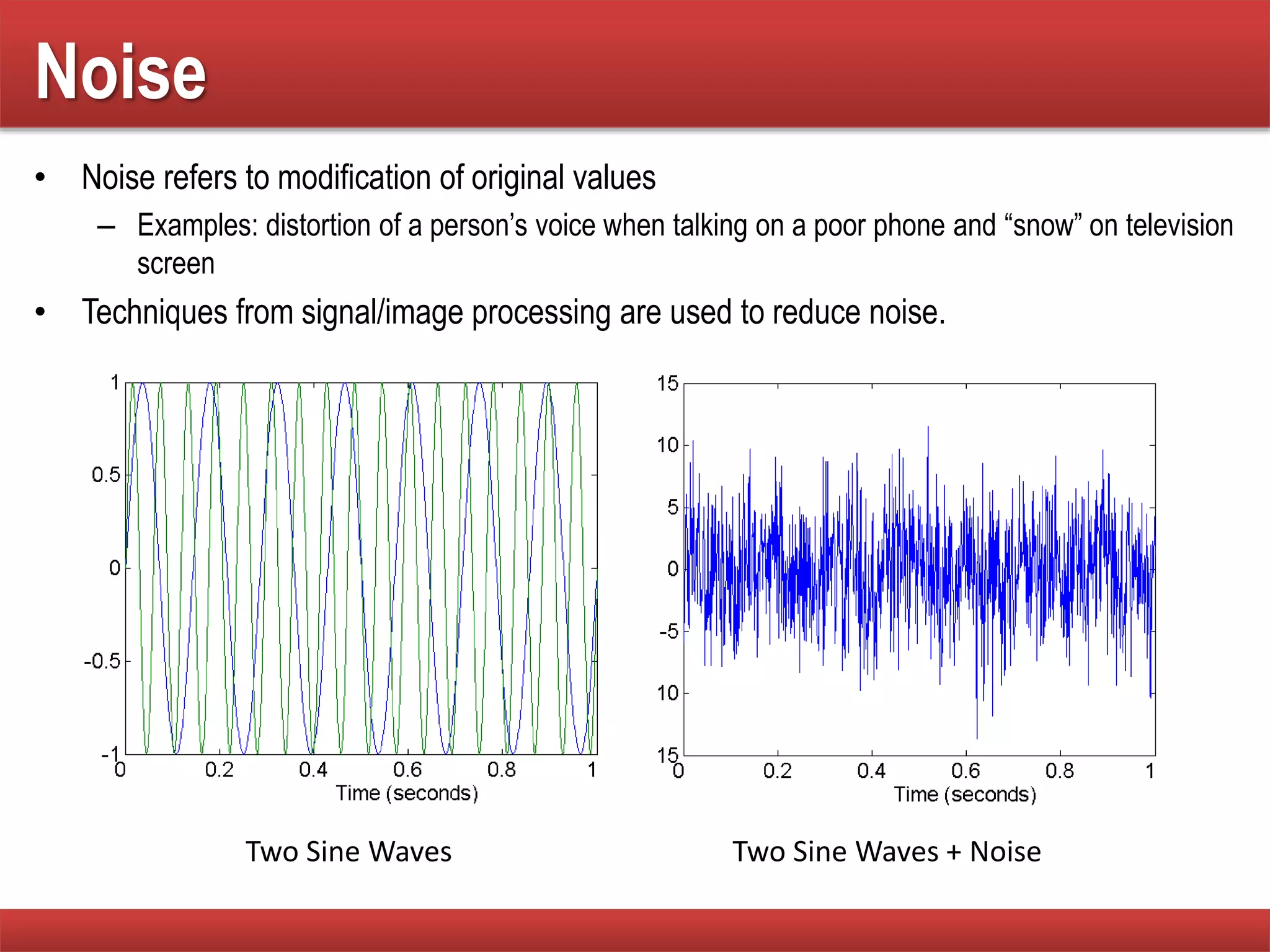





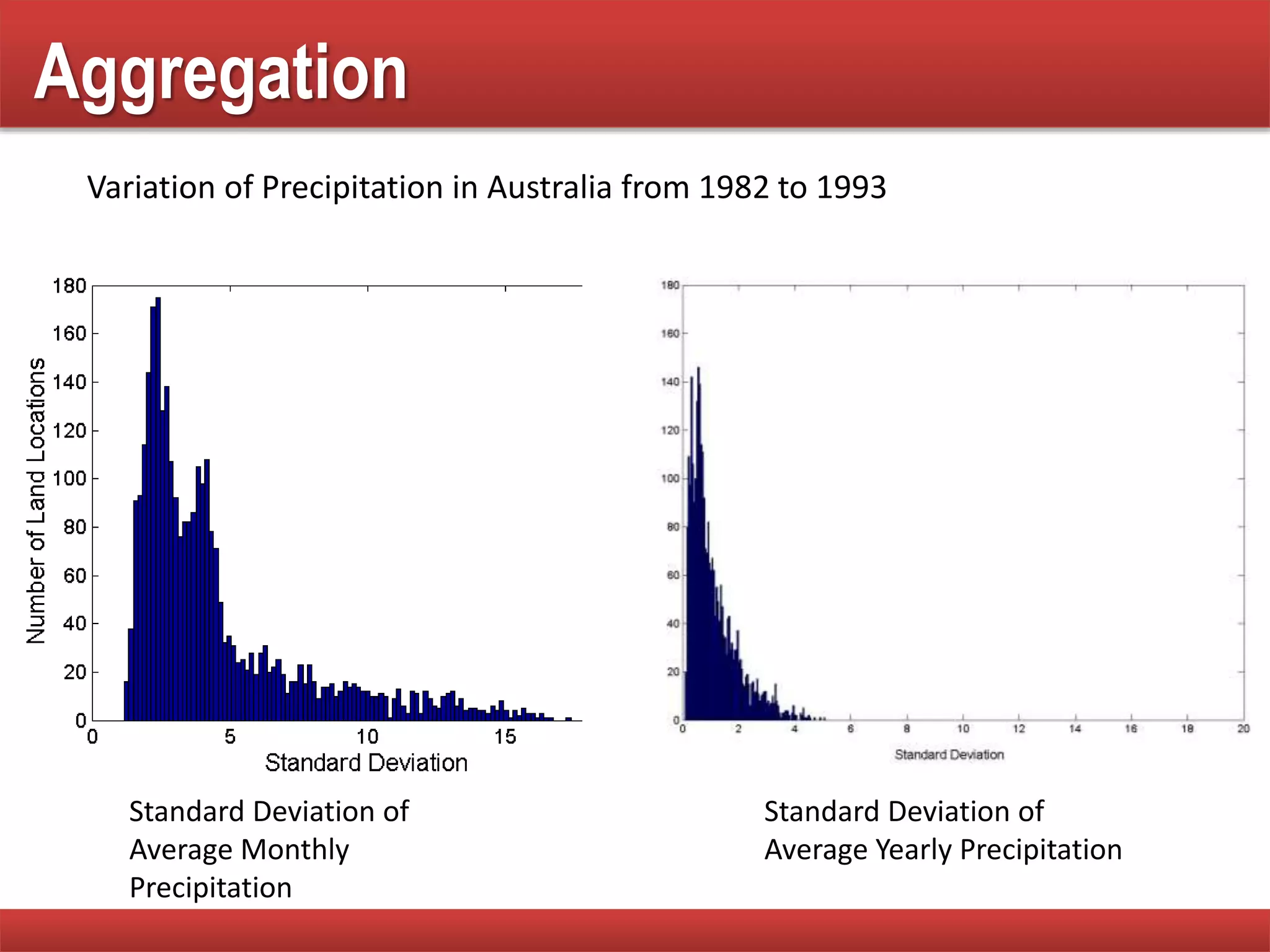





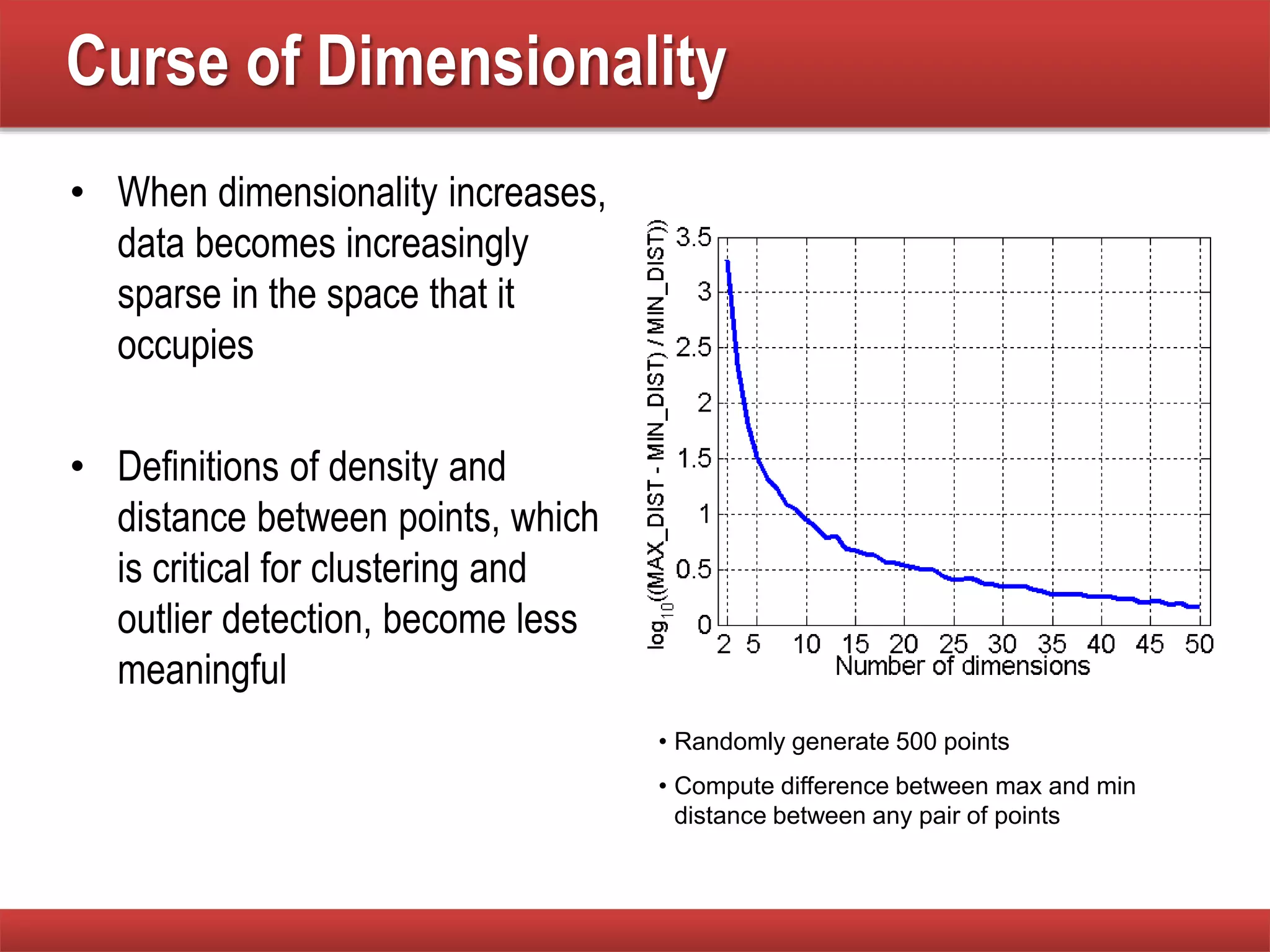




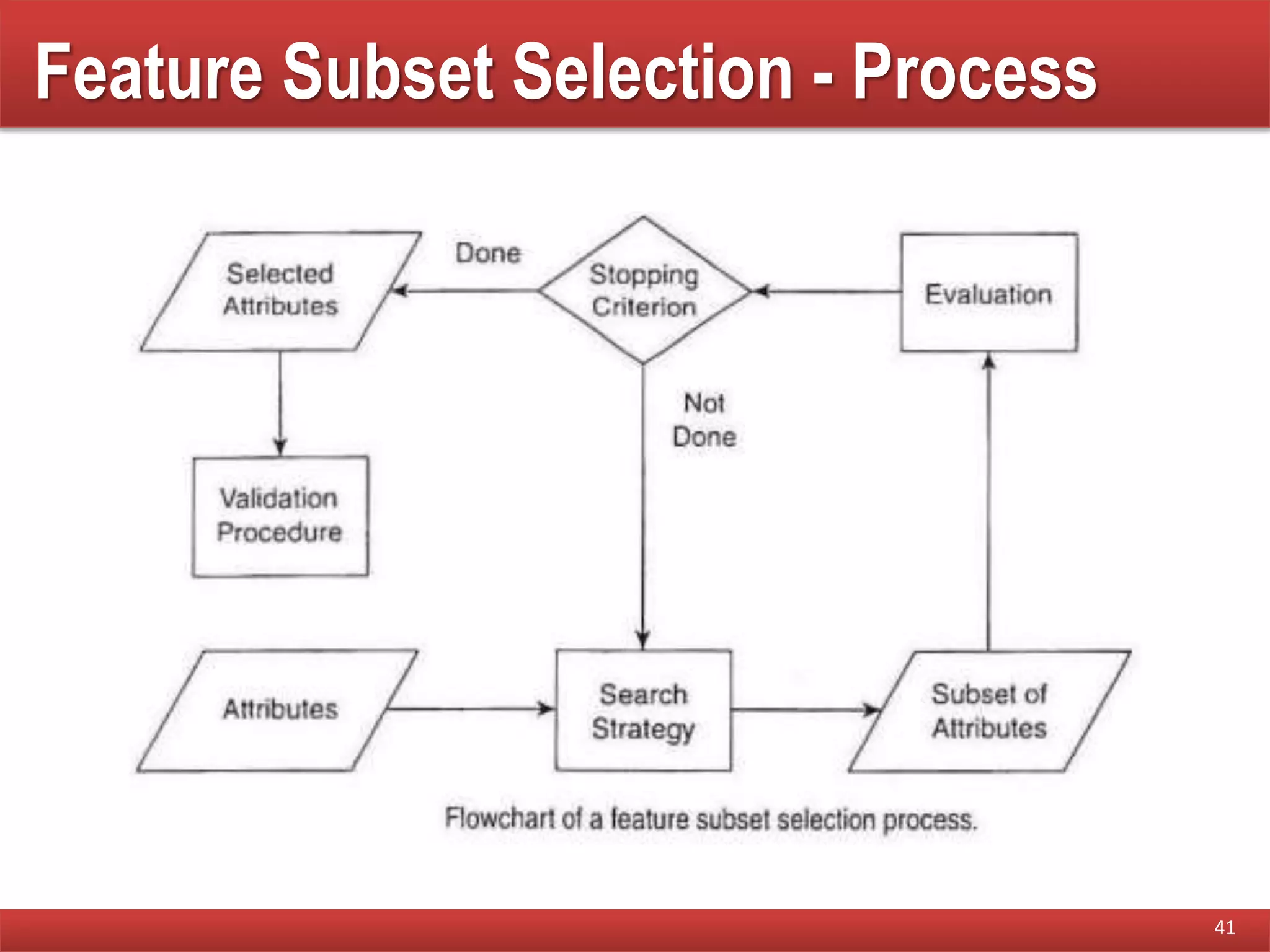


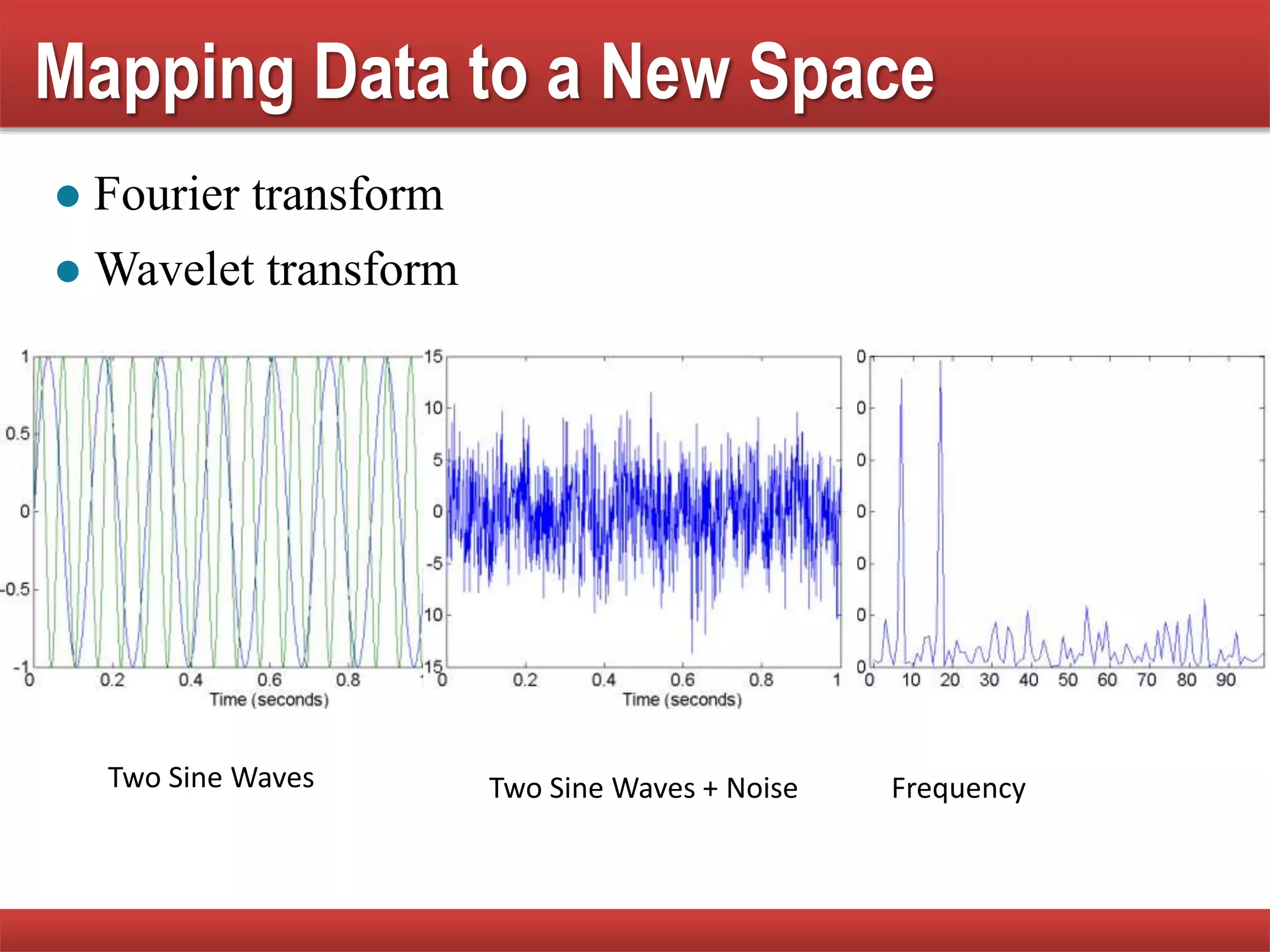

The document provides an overview of data mining concepts, focusing on the definition of data and its attributes, different types of attributes, their properties, and how they relate to data structures. It also discusses various aspects of structured data, data quality issues, and preprocessing techniques including sampling, dimensionality reduction, and feature selection. Key methodologies for managing data quality and enhancing data utility for analysis are highlighted throughout the lecture.





























![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

























































