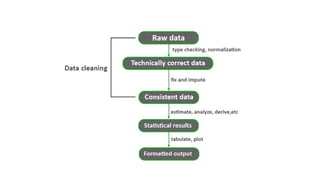
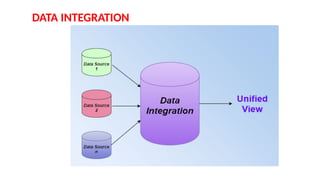
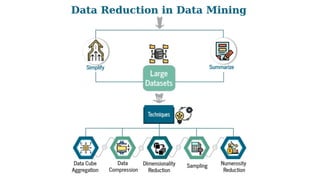
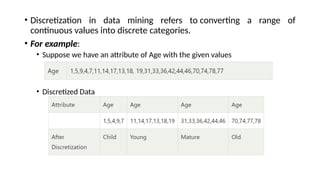
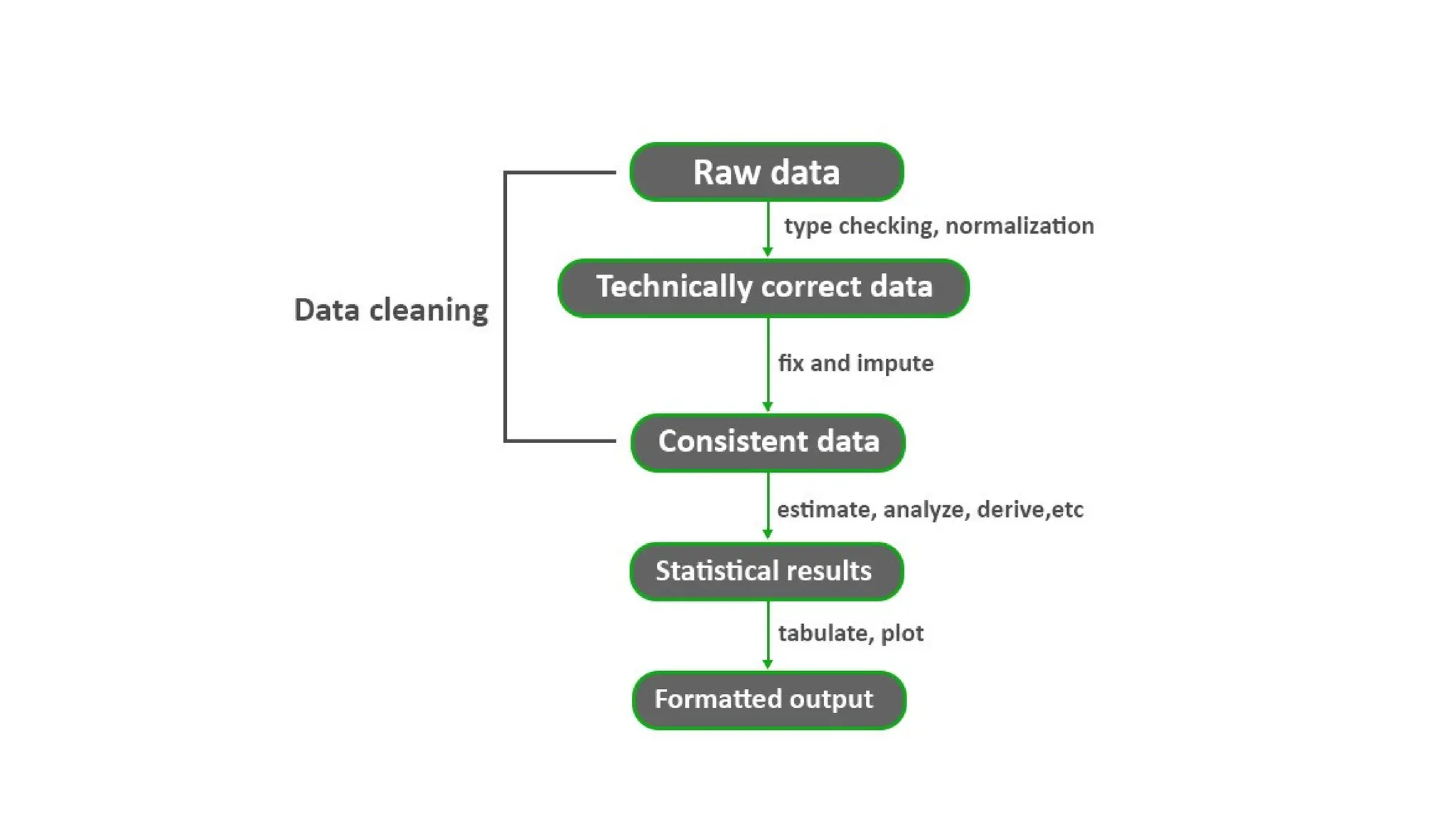
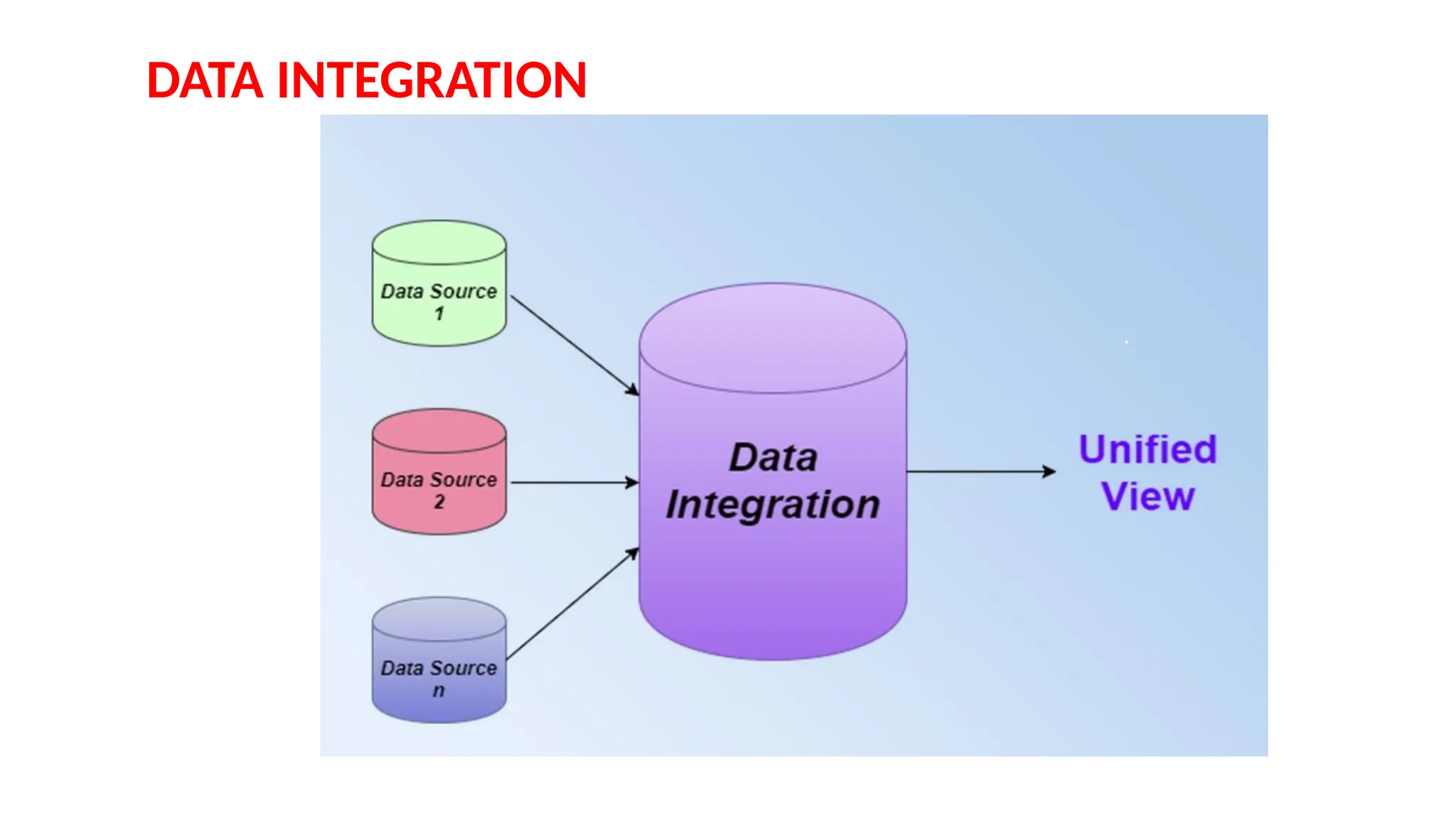
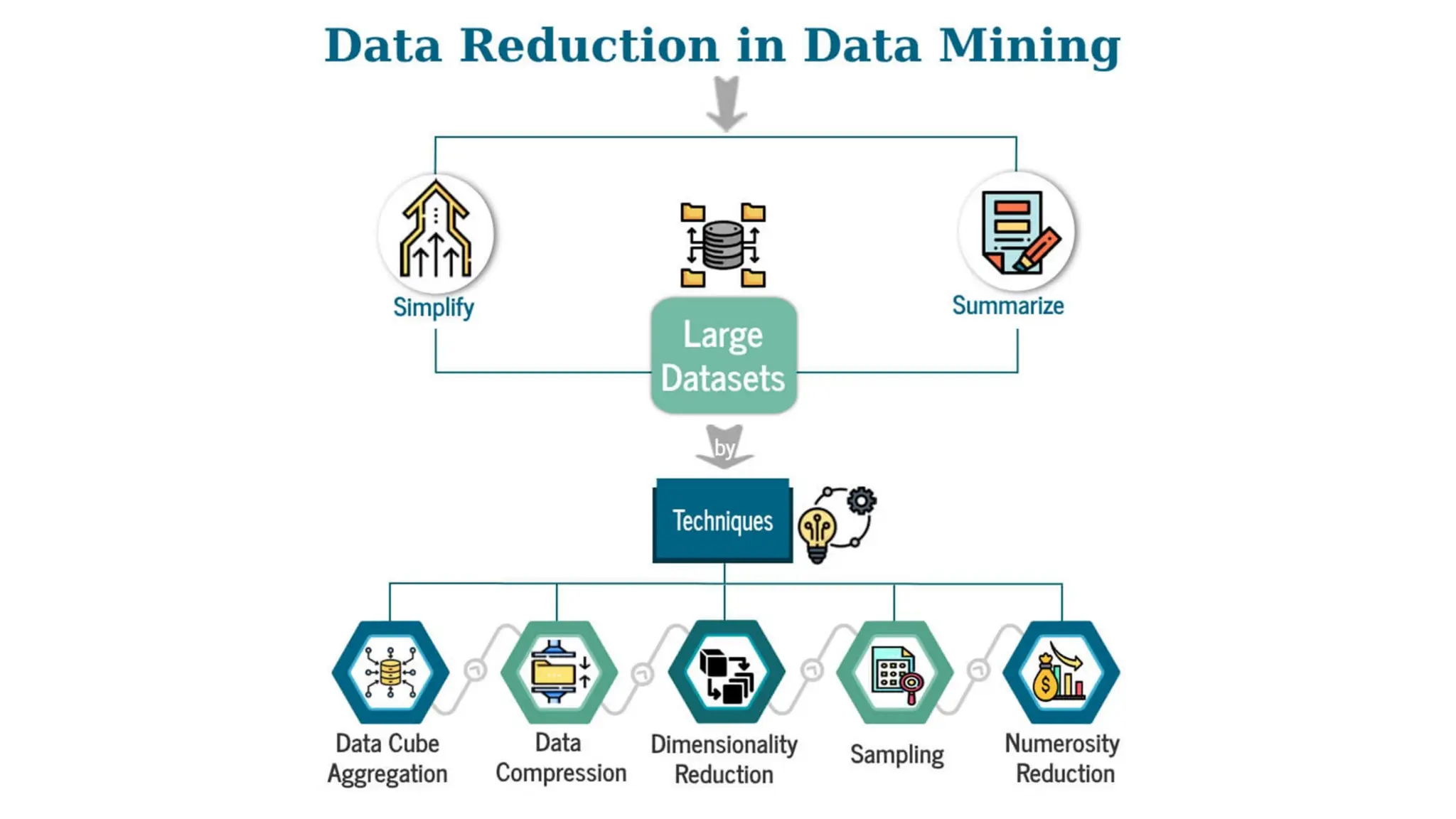
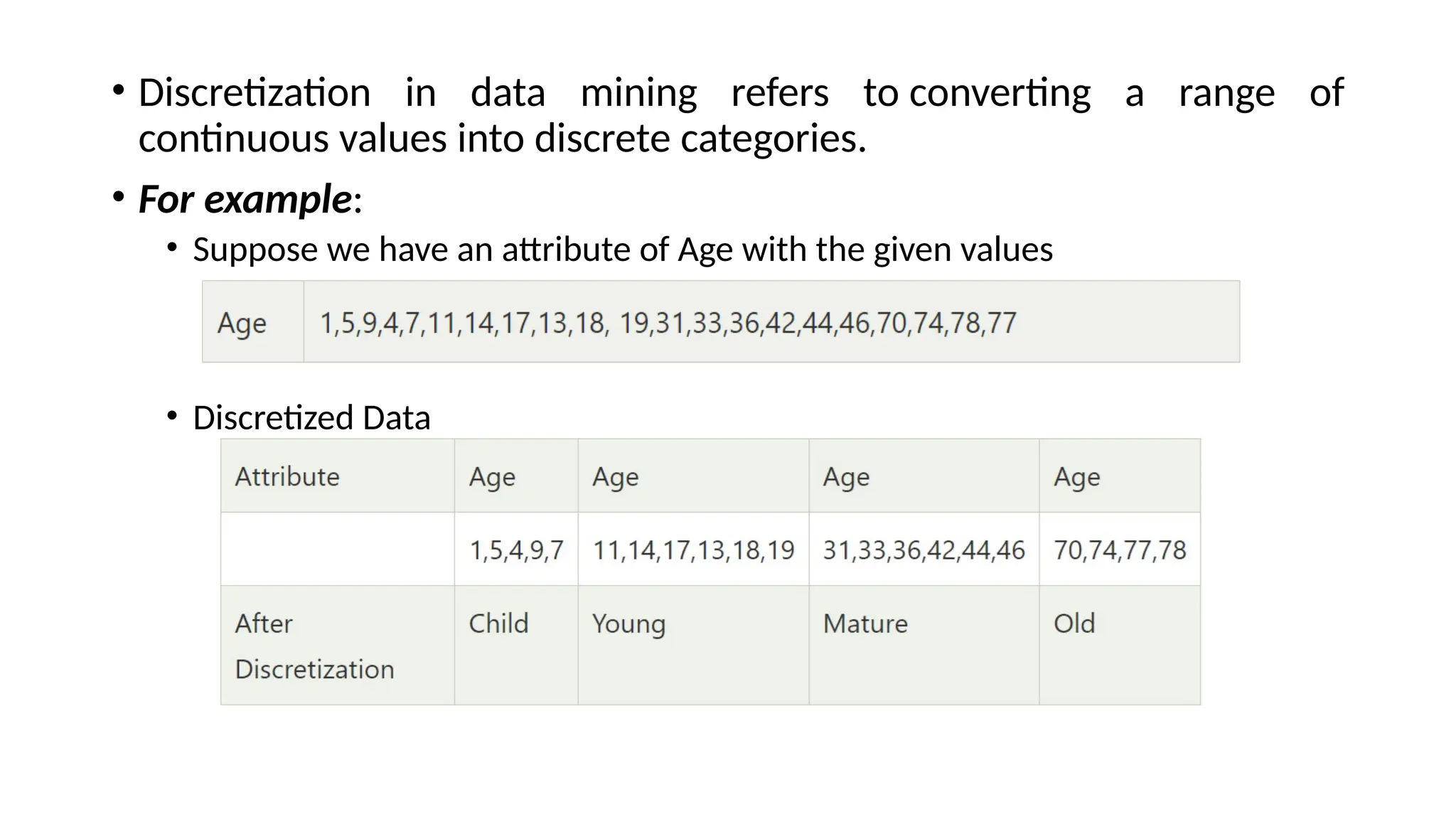
Data preprocessing is a crucial step in the data mining process that involves cleaning and transforming raw data into a structured format suitable for analysis. Common issues addressed include missing values, noisy data, outliers, and duplicates, employing techniques such as imputation and noise filtering. Data integration merges data from multiple sources into a unified view, utilizing approaches like tight and loose coupling, and aims to enhance data quality for improved analytics.











































































































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
