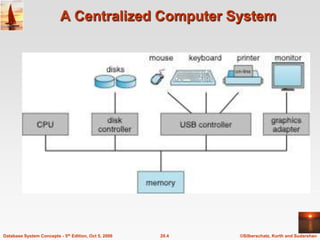
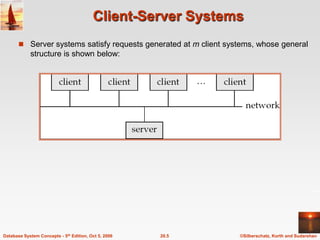
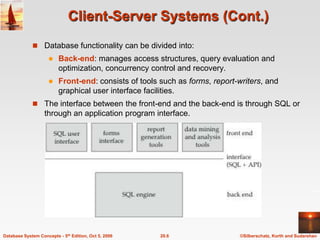
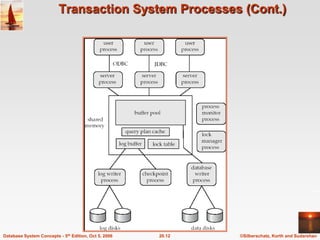
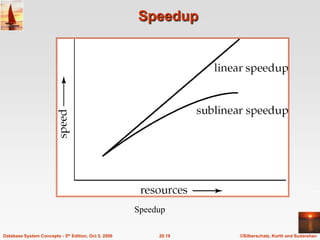
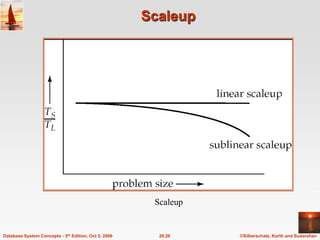
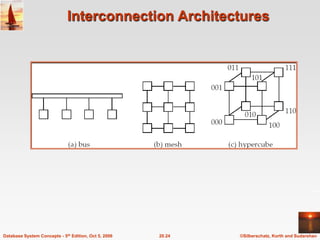
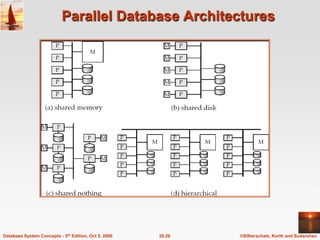
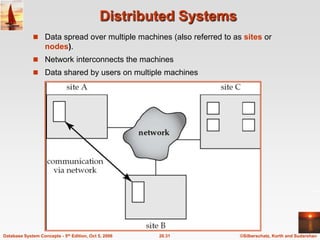
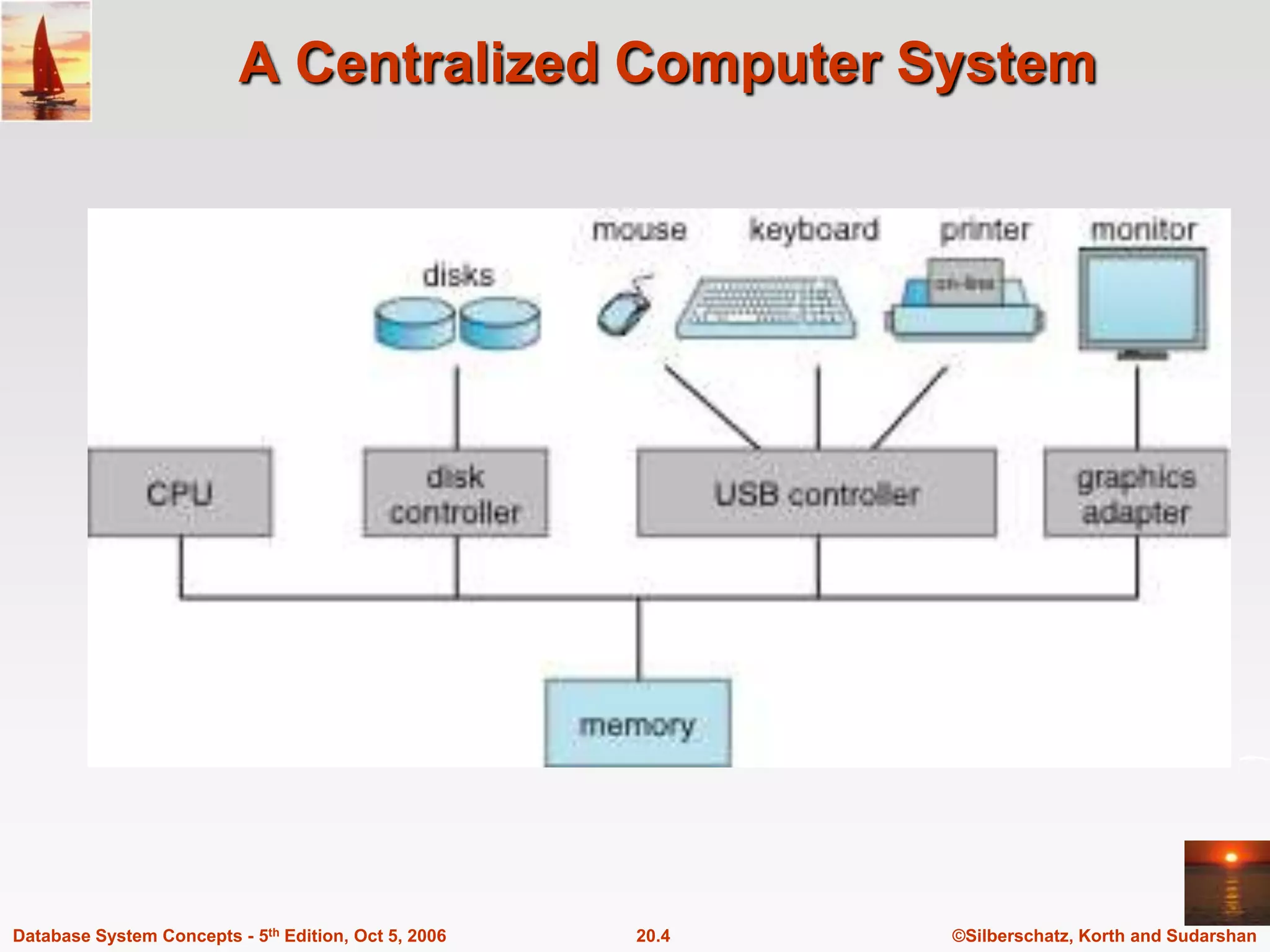
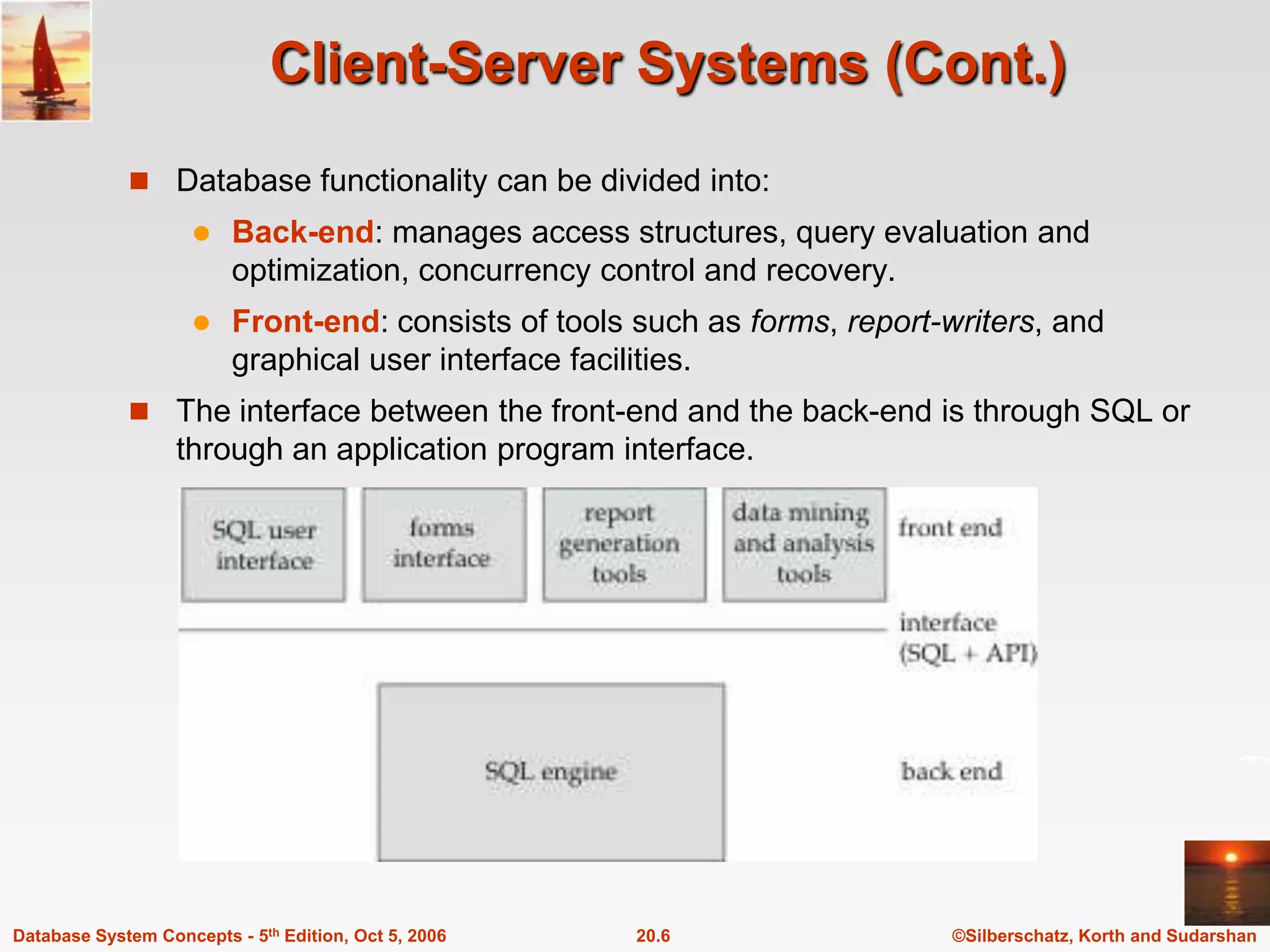
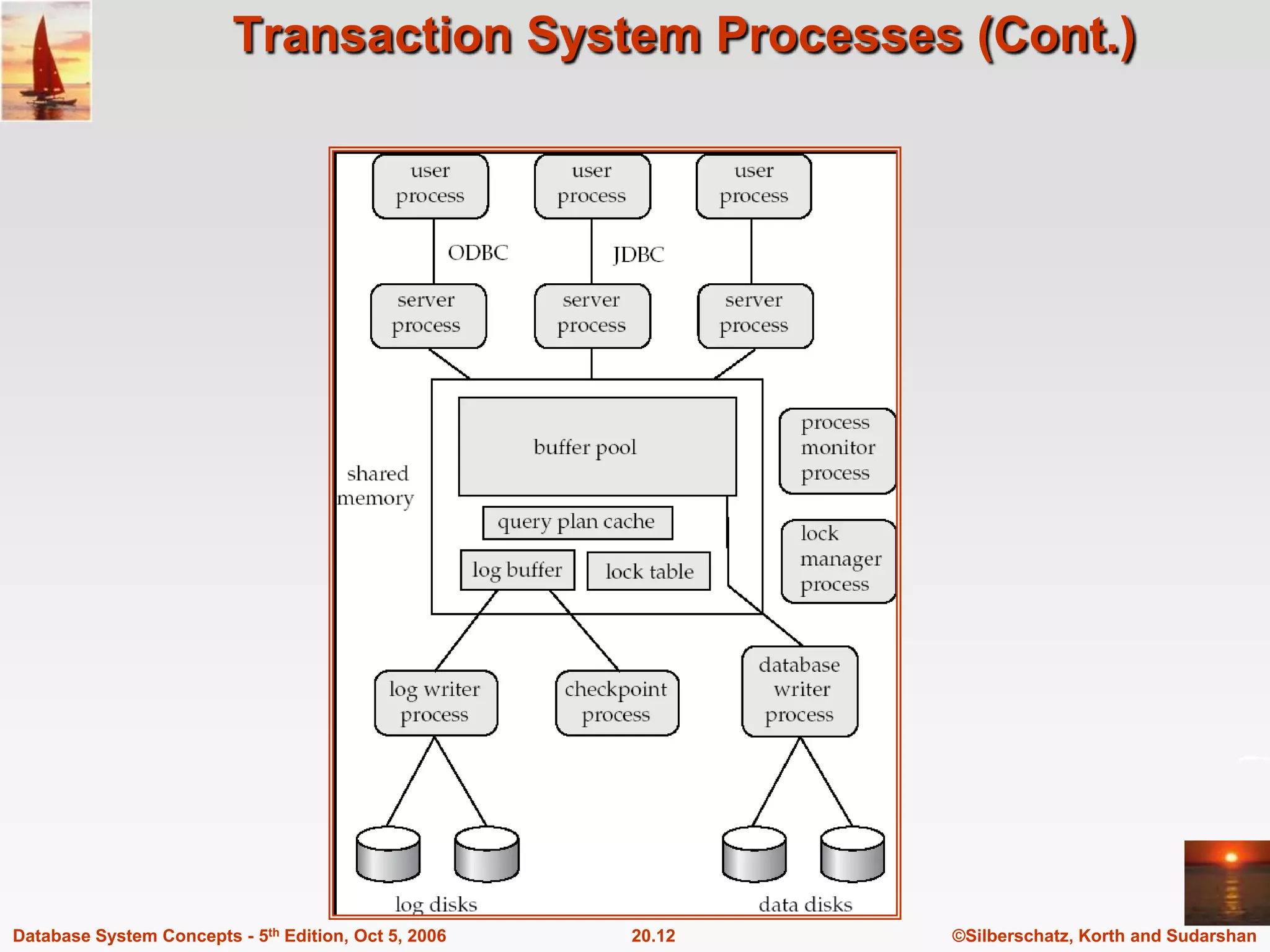
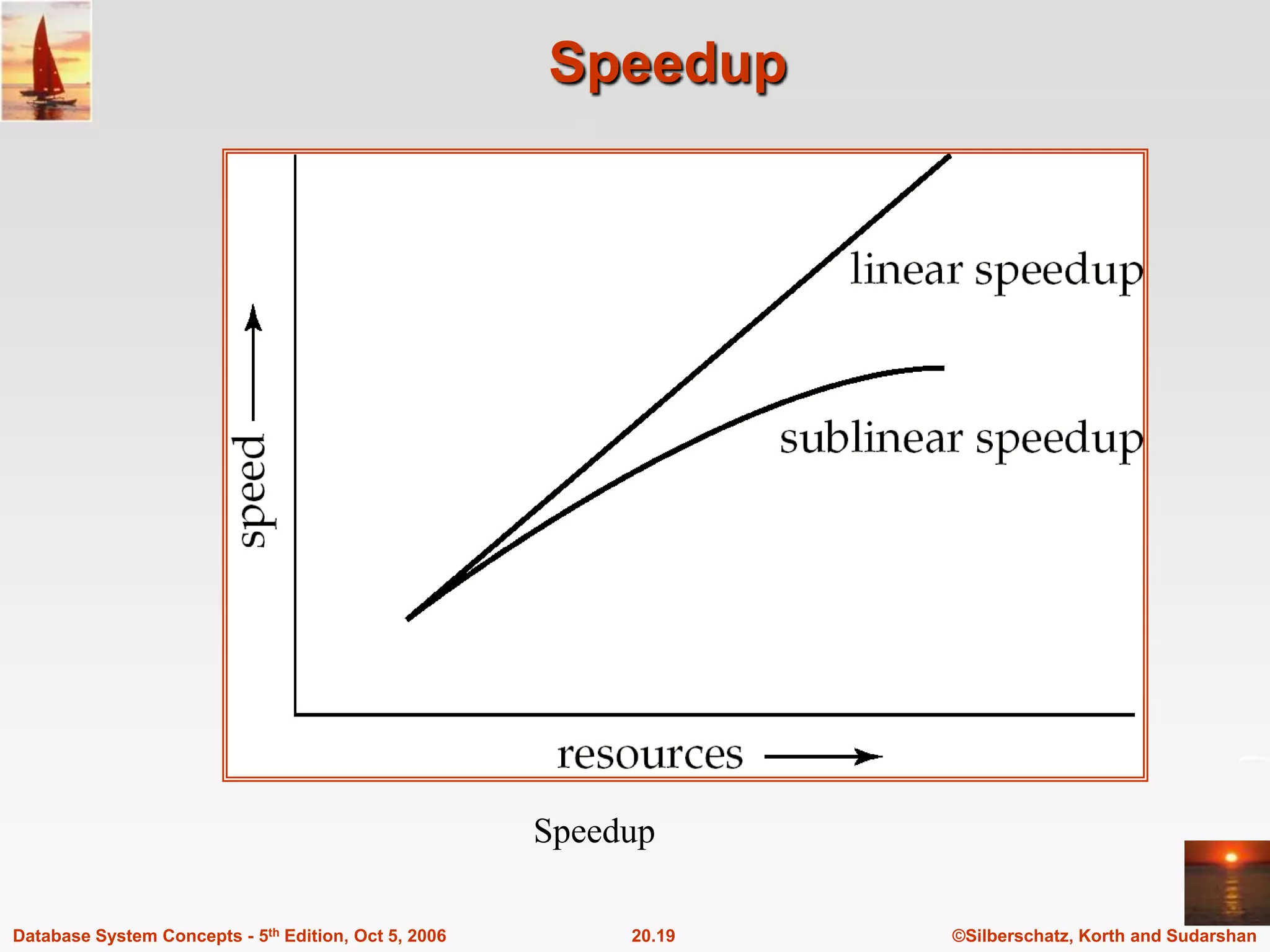
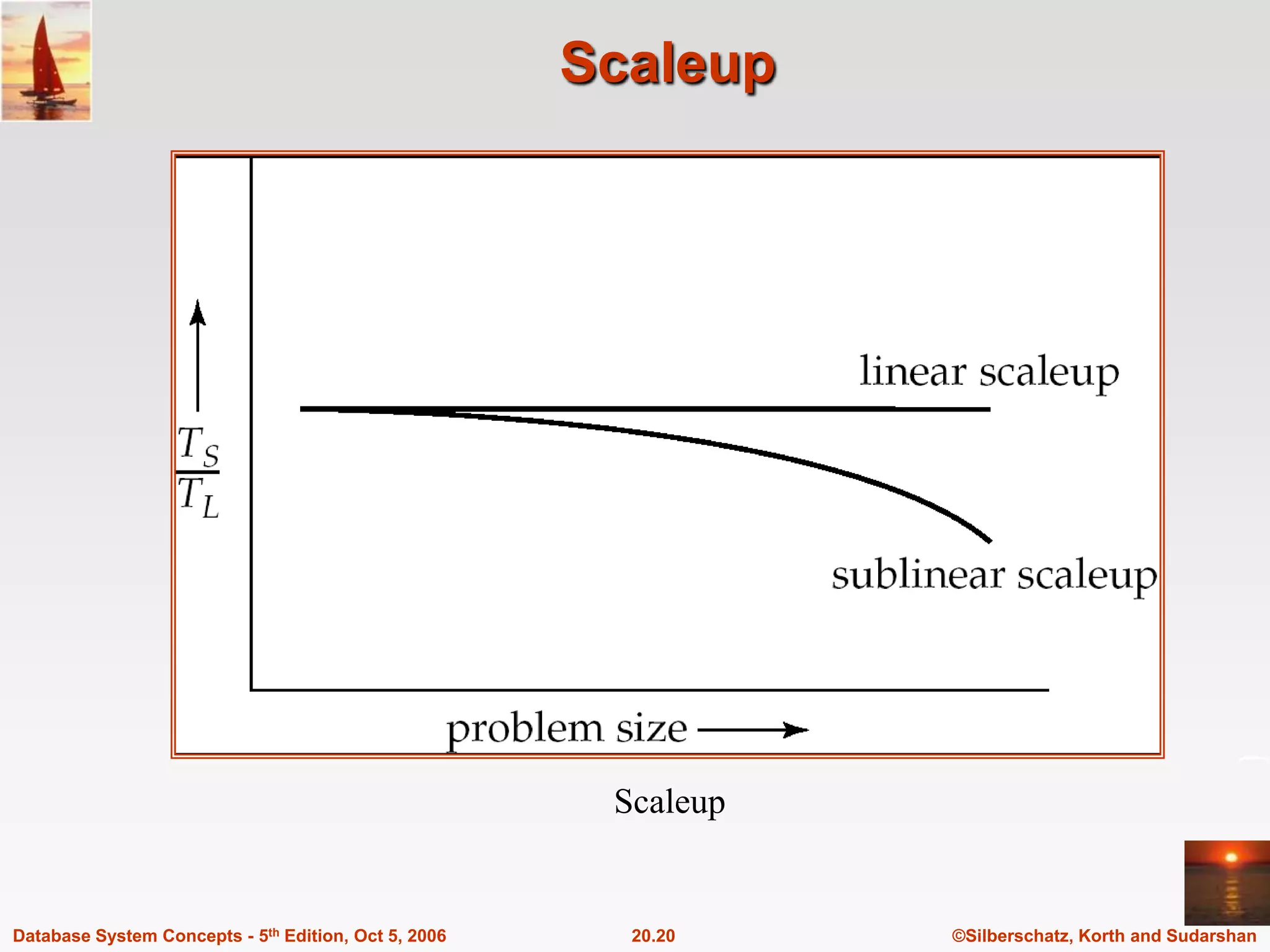
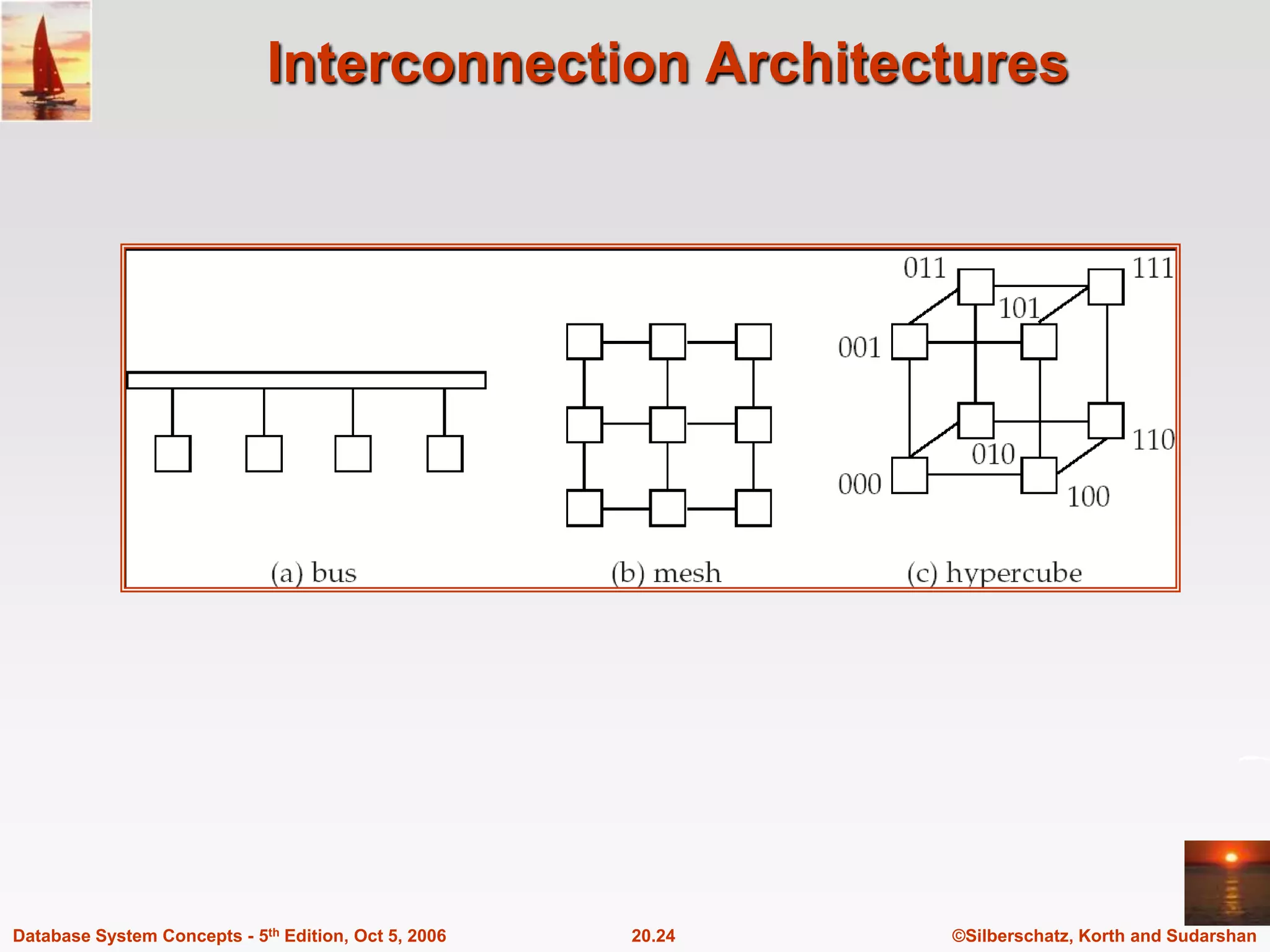
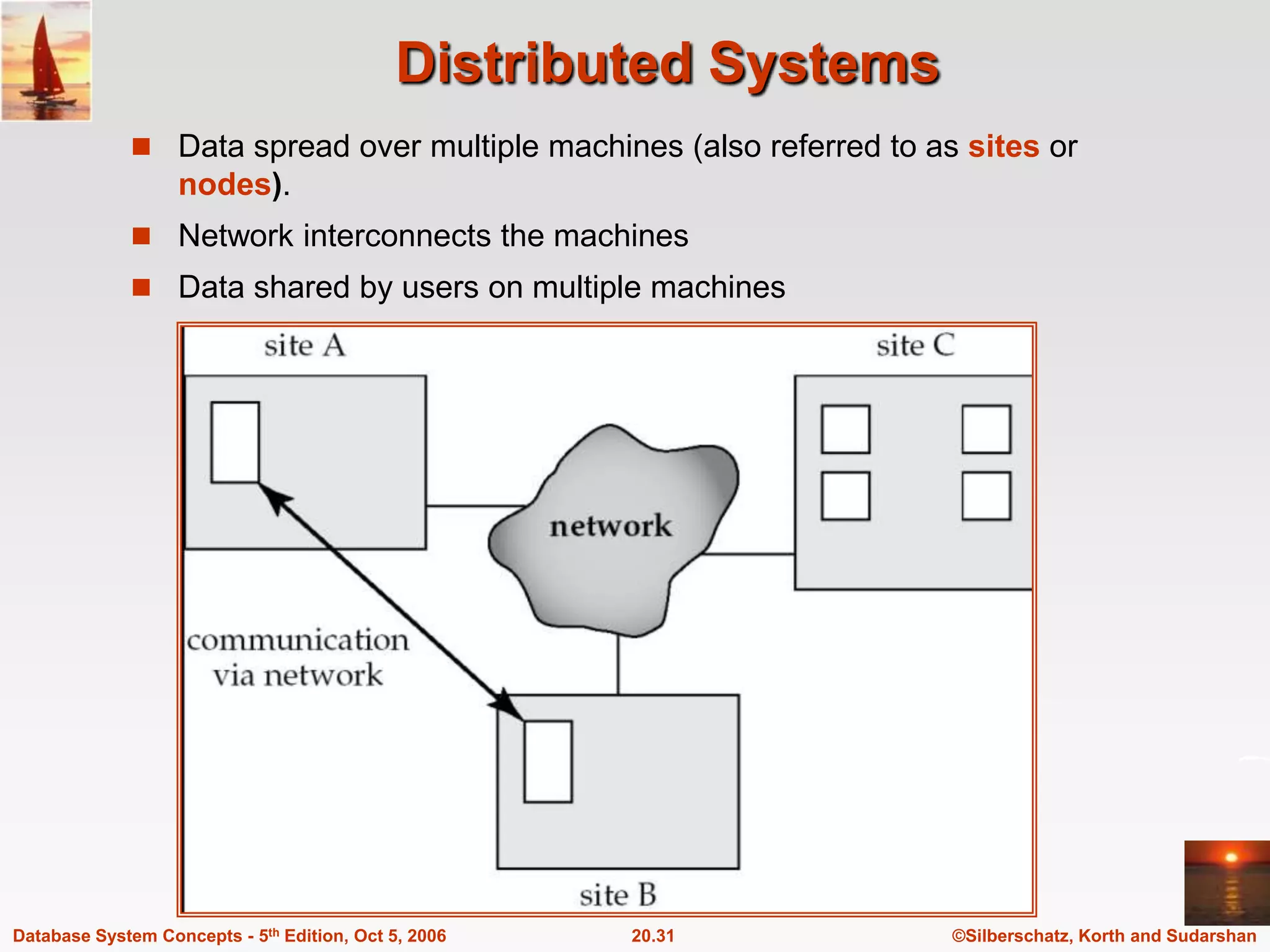
The document discusses different database system architectures including centralized, client-server, server-based transaction processing, data servers, parallel, and distributed systems. It covers key aspects of each architecture such as hardware components, process structure, advantages and limitations. The main types are centralized systems with one computer, client-server with backend database servers and frontend tools, parallel systems using multiple processors for improved performance, and distributed systems with data and users spread across a network.