Downloaded 17 times

















































![v Use LOB locators instead of LOB host variables.
If you need to store only a portion of a LOB value at the client, or if your
client program manipulates the LOB data but does not need a copy of it,
LOB locators are a good choice. When a client program retrieves a LOB
column from a server into a locator, DB2 transfers only the 4-byte locator
value to the client, not the entire LOB value.
v Use stored procedure result sets.
When you return LOB data to a client program from a stored procedure, use
result sets rather than passing the LOB data to the client in parameters.
Using result sets to return data causes less LOB materialization and less
movement of data among address spaces.
v Set the CURRENT RULES special register to DB2.
When a DB2 server receives an OPEN request for a cursor, the server uses
the value in the CURRENT RULES special register to determine the type of
host variables that the associated statement uses to retrieve LOB values. If
you specify a value of DB2 for the CURRENT RULES special register before
you perform a CONNECT, and the first FETCH statement for the cursor uses
a LOB locator to retrieve LOB column values, DB2 lets you use only LOB
locators for all subsequent FETCH statements for that column until you close
the cursor. If the first FETCH statement uses a host variable, DB2 lets you
use only host variables for all subsequent FETCH statements for that column
until you close the cursor. However, if you set the value of CURRENT
RULES to STD, DB2 lets you use the same open cursor to fetch a LOB
column into either a LOB locator or a host variable.
Although a value of STD for the CURRENT RULES special register gives you
more programming flexibility when you retrieve LOB data, you get better
performance if you use a value of DB2. With the STD option, the server must
send and receive network messages for each FETCH statement to indicate
whether the data that is being transferred is a LOB locator or a LOB value.
With the DB2 option, the server knows the size of the LOB data after the first
FETCH, so an extra message about LOB data size is unnecessary. The server
can send multiple blocks of data to the requester at one time, which reduces
the total time for data transfer.
For example, suppose that an end user wants to browse through a large set of
employee records and look at pictures of only a few of those employees. At the
server, you set the CURRENT RULES special register to DB2. In the application,
you declare and open a cursor to select employee records. The application then
fetches all picture data into 4-byte LOB locators. Because DB2 knows that 4
bytes of LOB data is returned for each FETCH statement, DB2 can fill the
network buffers with locators for many pictures. When a user wants to see a
picture for a particular person, the application can retrieve the picture from the
server by assigning the value that is referenced by the LOB locator to a LOB
host variable. This situation is implemented in the following code:
SQL TYPE IS BLOB my_blob[1M];
SQL TYPE IS BLOB AS LOCATOR my_loc;
.
.
.
FETCH C1 INTO :my_loc;
/* Fetch BLOB into LOB locator */
.
.
.
SET :my_blob = :my_loc; /* Assign BLOB to host variable */
Restriction: You must use DRDA access to access LOB columns in a remote
table.
5. Minimize the use of parameter markers.
34
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-50-320.jpg)






















![example, you can determine the name of the data sharing group, the member
to which you are connecting, and whether the subsystem is in new-function
mode. If the DB2 subsystem that you connect to is not part of a data sharing
group, the fields in the EIB that are related to data sharing are blank. If the EIB
is not available (for example, if you name a subsystem that does not exist),
DB2 sets the 4-byte area to zeros.
The area to which eibptr points is below the 16-MB line.
You can omit this parameter when you make a CONNECT call.
If you specify this parameter in any language except assembler, you must also
specify retcode, reascode, and srdura. In assembler language, you can omit
retcode, reascode, and srdura by specifying commas as placeholders.
Macro DSNDEIB maps the EIB. It can be found in
prefix.SDSNMACS(DSNDEIB).
|
|
|
|
|
|
|
groupoverride
An 8-byte area that the application provides. This parameter is optional. If you
do not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If
groupoverride is not provided, ssnm is used as the group attachment name if it
matches a group attachment name.
|
|
|
If you specify this parameter in any language except assembler, you must also
specify retcode, reascode, srdura, and eibptr. In assembler language, you can omit
retcode, reascode, srdura, and eibptr by specifying commas as placeholders.
|
|
|
|
|
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Example of CAF CONNECT function calls
The following table shows a CONNECT call in each language.
Table 12. Examples of CAF CONNECT function calls
Language
Call example
Assembler
CALL
DSNALI,(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR, GRPOVER)
C1
fnret=dsnali(&functn[0],&ssid[0], &tecb, &secb,&ribptr,&retcode, &reascode, &srdura[0],
&eibptr, &grpover[0]);
COBOL
CALL ’DSNALI’ USING FUNCTN SSID TERMECB STARTECB RIBPTR RETCODE REASCODE SRDURA
EIBPTR GRPOVER.
Fortran
CALL
DSNALI(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR,GRPOVER)
PL/I1
CALL
DSNALI(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR,GRPOVER)
Note:
60
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-76-320.jpg)

![reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
groupoverride
An 8-byte area that the application provides. This field is optional. If you do
not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If you
do not specify groupoverride, ssnm is used as the group attachment name if it
matches a group attachment name. If you specify this parameter in any
language except assembler, you must also specify retcode and reascode. In
assembler language, you can omit these parameters by specifying commas as
placeholders.
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Examples of CAF OPEN calls
The following table shows an OPEN call in each language.
Table 13. Examples of CAF OPEN calls
Language
Call example
Assembler
CALL
C
1
DSNALI,(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER)
fnret=dsnali(&functn[0],&ssid[0], &planname[0],&retcode, &reascode,&grpover[0]);
COBOL
CALL
’DSNALI’ USING FUNCTN SSID PLANNAME RETCODE REASCODE GRPOVER.
Fortran
CALL
DSNALI(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER)
PL/I1
CALL
DSNALI(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER);
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related concepts
“Implicit connections to CAF” on page 52
Related tasks
“Invoking the call attachment facility” on page 44
CLOSE function for CAF
The CAF CLOSE function deallocates the plan that was created either explicitly by
a call to the OPEN function or implicitly at the first SQL call. Optionally, the
CLOSE function also disconnects the task, and possibly the address space, from
DB2.
If you did not issue an explicit CONNECT call for the task, the CLOSE function
deletes the task’s connection to DB2. If no other task in the address space has an
62
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-78-320.jpg)

![reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF CLOSE calls
The following table shows a CLOSE call in each language.
Table 14. Examples of CAF CLOSE calls
Language
Call example
Assembler
CALL
C
1
DSNALI,(FUNCTN,TERMOP,RETCODE, REASCODE)
fnret=dsnali(&functn[0], &termop[0], &retcode,&reascode);
COBOL
CALL
’DSNALI’ USING FUNCTN TERMOP RETCODE REASCODE.
Fortran
CALL
DSNALI(FUNCTN,TERMOP, RETCODE,REASCODE)
CALL
DSNALI(FUNCTN,TERMOP, RETCODE,REASCODE);
PL/I
1
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
DISCONNECT function for CAF
The CAF DISCONNECT function terminates a connection to DB2.
DISCONNECT removes the calling task’s connection to DB2. If no other task in the
address space has an active connection to DB2, DB2 also deletes the control block
structures that were created for the address space and removes the cross memory
authorization.
If an OPEN call is in effect, which means that a plan is allocated, when the
DISCONNECT call is issued, CAF issues an implicit CLOSE with the SYNC
parameter.
Using the DISCONNECT function is optional. Consider the following rules and
recommendations about when to use and not use the DISCONNECT function:
v Only those tasks that explicitly issued a CONNECT call can issue a
DISCONNECT call. If a CONNECT call was not used, a DISCONNECT call
causes an error.
v When shutting down your application you can improve the performance of this
shut down by explicitly calling the DISCONNECT function before the task
terminates. If you omit the DISCONNECT call, DB2 performs an implicit
DISCONNECT. In this case, DB2 performs the same actions when your task
terminates.
v If DB2 terminates, any task that issued a CONNECT call must issue a
DISCONNECT call to reset the CAF control blocks. The DISCONNECT function
returns the reset accomplished return codes and reason codes (+004 and
X’00C10824’). This action ensures that future connection requests from the task
work when DB2 is back on line.
64
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-80-320.jpg)
![v A task that did not explicitly issue a CONNECT call must issue a CLOSE call
instead of a DISCONNECT call. This action resets the CAF control blocks when
DB2 terminates.
The following diagram shows the syntax for the DISCONNECT function.
DSNALI DISCONNECT function
CALL DSNALI ( function
)
, retcode
, reascode
The single parameter points to the following area:
function
A 12-byte area that contains the word DISCONNECT followed by two blanks.
retcode
A 4-byte area in which CAF places the return code.
This field is optional. If you do not specify retcode, CAF places the return code
in register 15 and the reason code in register 0.
reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF DISCONNECT calls
The following table shows a DISCONNECT call in each language.
Table 15. Examples of CAF DISCONNECT calls
Language
Call example
Assembler
CALL
C
1
DSNALI(,FUNCTN,RETCODE,REASCODE)
fnret=dsnali(&functn[0], &retcode, &reascode);
COBOL
CALL
’DSNALI’ USING FUNCTN RETCODE REASCODE.
Fortran
CALL
DSNALI(FUNCTN,RETCODE,REASCODE)
CALL
DSNALI(FUNCTN,RETCODE,REASCODE);
PL/I
1
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
Chapter 2. Connecting to DB2 from your application program
65](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-81-320.jpg)

![This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF TRANSLATE calls
The following table shows a TRANSLATE call in each language.
Table 16. Examples of CAF TRANSLATE calls
Language
Call example
Assembler
CALL
C
1
fnret=dsnali(&functn[0], &sqlca, &retcode, &reascode);
COBOL
PL/I
DSNALI,(FUNCTN,SQLCA,RETCODE, REASCODE)
1
CALL
’DSNALI’ USING FUNCTN SQLCA RETCODE REASCODE.
CALL
DSNALI(FUNCTN,SQLCA,RETCODE, REASCODE);
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
Turning on a CAF trace
CAF does not capture any diagnostic trace messages unless you tell it to by
turning on a trace.
To turn on a CAF trace:
Allocate a DSNTRACE data set either dynamically or by including a DSNTRACE
DD statement in your JCL. CAF writes diagnostic trace messages to that data set.
The trace message numbers contain the last three digits of the reason codes.
Related concepts
“Examples of invoking CAF” on page 69
CAF return codes and reason codes
CAF provides the return codes and reason codes either to the corresponding
parameters that are specified in a CAF function call or, if you choose not to use
those parameters, to registers 15 and 0.
When the reason code begins with X’00F3’ except for X’00F30006’, you can use the
CAF TRANSLATE function to obtain error message text that can be printed and
displayed. These reason codes are issued by the subsystem support for allied
memories, a part of the DB2 subsystem support subcomponent that services all
DB2 connection and work requests.
For SQL calls, CAF returns standard SQL codes in the SQLCA. CAF returns IFI
return codes and reason codes in the instrumentation facility communication area
(IFCA).
The following table lists the CAF return codes and reason codes.
Chapter 2. Connecting to DB2 from your application program
67](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-83-320.jpg)





















![|
|
|
block that was loaded by subsystem ssnm when that subsystem was started.
This 4-byte area is a 31-bit pointer. If ssnm is not found, the 4-byte area is set to
0.
|
The area to which decpptr points is above the 16-MB line.
|
|
|
|
If you specify this parameter in any language except assembler, you must also
specify the retcode, reascode, and groupoverride parameters. In assembler
language, you can omit the retcode, reascode, and groupoverride parameters by
specifying commas as placeholders.
Example of RRSAF IDENTIFY function calls
The following table shows an IDENTIFY call in each language.
Table 25. Examples of RRSAF IDENTIFY calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR)
fnret=dsnrli(&idfyfn[0],&ssnm[0], &ribptr, &eibptr, &termecb, &startecb, &retcode,
&reascode,&grpover[0],&decpptr);
COBOL
CALL ’DSNRLI’ USING IDFYFN SSNM RIBTPR EIBPTR TERMECB STARTECB RETCODE REASCODE GRPOVER
DECPPTR.
Fortran
CALL
DSNRLI(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR)
CALL
DSNRLI(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Internal processing for the IDENTIFY function
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
When you call the IDENTIFY function, DB2 performs the following steps:
1. DB2 determines whether the user address space is authorized to connect to
DB2. DB2 invokes the z/OS SAF and passes a primary authorization ID to SAF.
That authorization ID is the 7-byte user ID that is associated with the address
space, unless an authorized function has built an ACEE for the address space.
If an authorized function has built an ACEE, DB2 passes the 8-byte user ID
from the ACEE. SAF calls an external security product, such as RACF, to
determine if the task is authorized to use the following items:
v The DB2 resource class (CLASS=DSNR)
v The DB2 subsystem (SUBSYS=ssnm)
v Connection type RRSAF
2. If that check is successful, DB2 calls the DB2 connection exit routine to perform
additional verification and possibly change the authorization ID.
3. DB2 searches for a matching trusted context in the system cache and then the
catalog based on the following criteria:
v The primary authorization ID matches a trusted context SYSTEM AUTHID.
v The job or started task name matches the JOBNAME attribute that is defined
for the identified trusted context.
If a trusted context is defined, DB2 checks if SECURITY LABEL is defined in
the trusted context. If SECURITY LABEL is defined, DB2 verifies the SECURITY
LABEL with RACF by using the RACROUTE VERIFY request. This security
Chapter 2. Connecting to DB2 from your application program
89](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-105-320.jpg)

![If you specify this parameter, you must also specify retcode.
|
|
|
|
|
|
groupoverride
An 8-byte area that the application provides. This parameter is optional. If you
do not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If
groupoverride is not provided, ssnm is used as the group attachment name if it
matches a group attachment name.
|
|
|
|
If you specify this parameter in any language except assembler, you must also
specify the retcode and reascode parameters. In assembler language, you can
omit the retcode and reascode parameters by specifying commas as
place-holders.
|
|
|
|
|
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Examples
Examples of RRSAF SWITCH TO calls: The following table shows a SWITCH TO
call in each language.
Table 26. Examples of RRSAF SWITCH TO calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SWITCHFN,SSNM,RETCODE,REASCODE,GRPOVER)
fnret=dsnrli(&switchfn[0], &ssnm[0], &retcode, &reascode,&grpover[0]);
COBOL
CALL
’DSNRLI’ USING SWITCHFN RETCODE REASCODE GRPOVER.
Fortran
CALL
DSNRLI(SWITCHFN,RETCODE,REASCODE,GRPOVER)
PL/I1
CALL
DSNRLI(SWITCHFN,RETCODE,REASCODE,GRPOVER);
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Example of using the SWITCH TO function to interact with multiple DB2
subsystems: The following example shows how you can use the SWITCH TO
function to interact with three DB2 subsystems.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
RRSAF calls for subsystem db21:
IDENTIFY
SIGNON
CREATE THREAD
Execute SQL on subsystem db21
SWITCH TO db22
IF retcode = 4 AND reascode = ’00C12205’X THEN
DO;
RRSAF calls on subsystem db22:
IDENTIFY
SIGNON
CREATE THREAD
END;
Execute SQL on subsystem db22
SWITCH TO db23
IF retcode = 4 AND reascode = ’00C12205’X THEN
Chapter 2. Connecting to DB2 from your application program
91](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-107-320.jpg)




![Table 28. Examples of RRSAF SIGNON calls
Language
Call example
assembler
CALL
C
1
DSNRLI,(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR)
fnret=dsnrli(&sgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &retcode, &reascode,
&userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING SGNONFN CORRID ACCTTKN ACCTINT RETCODE REASCODE USERID APPLNAME WSNAME
XIDPTR.
Fortran
CALL
DSNRLI(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR)
CALL
DSNRLI(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related information
z/OS Internet Library at ibm.com
AUTH SIGNON function for RRSAF
The RRSAF AUTH SIGNON function enables an APF-authorized program to pass
to DB2 either a primary authorization ID and, optionally, one or more secondary
authorization IDs, or an ACEE that is used for authorization checking. These IDs
are then associated with the connection.
Generally, you issue an AUTH SIGNON call after an IDENTIFY call and before a
CREATE THREAD call. You can also issue an AUTH SIGNON call if the
application is at a point of consistency, and one of the following conditions is true:
v The value of reuse in the CREATE THREAD call was RESET.
v The value of reuse in the CREATE THREAD call was INITIAL, no held cursors
are open, the package or plan is bound with KEEPDYNAMIC(NO), and all
special registers are at their initial state. If open held cursors exist or the package
or plan is bound with KEEPDYNAMIC(YES), a SIGNON call is permitted only if
the primary authorization ID has not changed.
The following diagram shows the syntax for the AUTH SIGNON function.
DSNRLI AUTH SIGNON function
CALL DSNRLI ( function, correlation-id, accounting-token,
accounting-interval, primary-authid, ACEE-address, secondary-authid
)
,retcode
,reascode
,user
,appl
,ws
,xid
,accounting-string
96
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-112-320.jpg)



![Table 29. Examples of RRSAF AUTH SIGNON calls (continued)
Language
C
1
Call example
fnret=dsnrli(&asgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &pauthid[0], &aceeptr,
&sauthid[0], &retcode, &reascode, &userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING ASGNONFN CORRID ACCTTKN ACCTINT PAUTHID ACEEPTR SAUTHID RETCODE REASCODE
USERID APPLNAME WSNAME XIDPTR.
Fortran
CALL DSNRLI(ASGNONFN,CORRID,ACCTTKN,ACCTINT,PAUTHID,ACEEPTR, SAUTHID,RETCODE,REASCODE,USERID,
APPLNAME,WSNAME,XIDPTR)
PL/I1
CALL DSNRLI(ASGNONFN,CORRID,ACCTTKN,ACCTINT,PAUTHID,ACEEPTR, SAUTHID,RETCODE,REASCODE,USERID,
APPLNAME,WSNAME,XIDPTR);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related reference
“SIGNON function for RRSAF” on page 92
CONTEXT SIGNON function for RRSAF
The RRSAF CONTEXT SIGNON function establishes a primary authorization ID
and one or more secondary authorization IDs for a connection.
Requirement: Before you invoke CONTEXT SIGNON, you must have called the
RRS context services function Set Context Data (CTXSDTA) to store a primary
authorization ID and optionally, the address of an ACEE in the context data whose
context key you supply as input to CONTEXT SIGNON.
The CONTEXT SIGNON function uses the context key to retrieve the primary
authorization ID from data that is associated with the current RRS context. DB2
uses the RRS context services function Retrieve Context Data (CTXRDTA) to
retrieve context data that contains the authorization ID and ACEE address. The
context data must have the following format:
Version number
A 4-byte area that contains the version number of the context data. Set this
area to 1.
Server product name
An 8-byte area that contains the name of the server product that set the
context data.
ALET
A 4-byte area that can contain an ALET value. DB2 does not reference this
area.
ACEE address
A 4-byte area that contains an ACEE address or 0 if an ACEE is not
provided. DB2 requires that the ACEE is in the home address space of the
task.
If you pass an ACEE address, the CONTEXT SIGNON function uses the
value in ACEEGRPN as the secondary authorization ID if the length of the
group name (ACEEGRPL) is not 0.
100
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-116-320.jpg)



![accounting-string
A one-byte length field and a 255-byte area in which you can put a value for a
DB2 accounting string. This value is placed in the DDF accounting trace
records in the QMDASQLI field, which is mapped by DSNDQMDA DSECT. If
accounting-string is less than 255 characters, you must pad it on the right with
zeros to a length of 255 bytes. The entire 256 bytes is mapped by DSNDQMDA
DSECT.
This parameter is optional. If you specify this accounting-string, you must also
specify retcode, reascode, user, appl and xid. If you do not specify this parameter,
no accounting string is associated with the connection.
You can also change the value of the accounting string with RRSAF functions
AUTH SIGNON, CONTEXT SIGNON, or SET_CLIENT_ID.
You can retrieve the DDF suffix portion of the accounting string with the
CURRENT CLIENT_ACCTNG special register. The suffix portion of
accounting-string can contain a maximum of 200 characters. The QMDASFLN
field contains the accounting suffix length, and the QMDASUFX field contains
the accounting suffix value. If the DDF accounting string is set, you cannot
query the accounting token with the CURRENT CLIENT_ACCTNG special
register.
Example of RRSAF CONTEXT SIGNON calls
The following table shows a CONTEXT SIGNON call in each language.
Table 30. Examples of RRSAF CONTEXT SIGNON calls
Language
Call example
Assembler
CALL DSNRLI,(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE,USERID,APPLNAME,
WSNAME,XIDPTR)
C1
fnret=dsnrli(&csgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &ctxtkey[0], &retcode,
&reascode, &userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING CSGNONFN CORRID ACCTTKN ACCTINT CTXTKEY RETCODE REASCODE USERID APPLNAME
WSNAME XIDPTR.
Fortran
CALL DSNRLI(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE, USERID,APPLNAME,
WSNAME,XIDPTR)
PL/I1
CALL DSNRLI(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE,USERID,APPLNAME,
WSNAME,XIDPTR);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related reference
“SIGNON function for RRSAF” on page 92
SET_ID function for RRSAF
The RRSAF SET_ID function sets a new value for the client program ID that can be
used to identify the end user. The function then passes this information to DB2
when the next SQL request is processed.
The following diagram shows the syntax of the SET_ID function.
104
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-120-320.jpg)
![DSNRLI SET_ID function
CALL DSNRLI ( function, program-id
)
, retcode
, reascode
Parameters point to the following areas:
function
An 18-byte area that contains SET_ID followed by 12 blanks.
program-id
An 80-byte area that contains the caller-provided string to be passed to DB2. If
program-id is less than 80 characters, you must pad it with blanks on the right
to a length of 80 characters.
DB2 places the contents of program-id into IFCID 316 records, along with other
statistics, so that you can identify which program is associated with a
particular SQL statement.
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF SET_ID calls
The following table shows a SET_ID call in each language.
Table 31. Examples of RRSAF SET_ID calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SETIDFN,PROGID,RETCODE,REASCODE)
fnret=dsnrli(&setidfn[0], &progid[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING SETIDFN PROGID RETCODE REASCODE.
Fortran
CALL
DSNRLI(SETIDFN,PROGID,RETCODE,REASCODE)
CALL
DSNRLI(SETIDFN,PROGID,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Chapter 2. Connecting to DB2 from your application program
105](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-121-320.jpg)


![Example of RRSAF SET_CLIENT_ID calls
The following table shows a SET_CLIENT_ID call in each language.
Table 32. Examples of RRSAF SET_CLIENT_ID calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE)
fnret=dsnrli(&seclidfn[0], &acct[0], &user[0], &appl[0], &ws[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING SECLIDFN ACCT USER APPL WS RETCODE REASCODE.
Fortran
CALL
DSNRLI(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE)
CALL
DSNRLI(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
CREATE THREAD function for RRSAF
The RRSAF CREATE THREAD function allocates the DB2 resources that are
required for an application to issue SQL or IFI requests. This function must
complete before the application can execute SQL statements or IFI requests.
The following diagram shows the syntax of the CREATE THREAD function.
DSNRLI CREATE THREAD function
CALL DSNRLI ( function, plan, collection, reuse
)
, retcode
, reascode
, pklistptr
Parameters point to the following areas:
function
An 18-byte area that contains CREATE THREAD followed by five blanks.
plan
An 8-byte DB2 plan name. RRSAF allocates the named plan.
If you provide a collection name instead of a plan name, specify the question
mark character (?) in the first byte of this field. DB2 then allocates a special
plan named ?RRSAF and uses the value that you specify for collection . When
DB2 allocates a plan named ?RRSAF, DB2 checks authorization to execute the
package in the same way as it checks authorization to execute a package from
a requester other than DB2 for z/OS.
108
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-124-320.jpg)

![v The collection names that you specify in the data area to which pklistptr
points
v An entry that contains * for the location, collection ID, and package name
If you also specify collection, DB2 ignores that value.
Each collection entry must be of the form collection-ID.*, *.collection-ID.*, or *.*.*.
collection-ID and must follow the naming conventions for a collection ID, as
described in the description of the BIND and REBIND options.
DB2 uses the collection names to locate a package that is associated with the
first SQL statement in the program. The entry that contains *.*.* lets the
application access remote locations and access packages in collections other
than the default collection that is specified at create thread time.
The application can use the SET CURRENT PACKAGESET statement to change
the collection ID that DB2 uses to locate a package.
This parameter is optional. If you specify this parameter, you must also specify
retcode and reascode.
If you provide a plan name in the plan field, DB2 ignores the pklistptr value.
Recommendation: Using a package list can have a negative impact on
performance. For better performance, specify a short package list.
Example of RRSAF CREATE THREAD calls
The following table shows a CREATE THREAD call in each language.
Table 33. Examples of RRSAF CREATE THREAD calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLISTPTR)
fnret=dsnrli(&crthrdfn[0], &plan[0], &collid[0], &reuse[0], &retcode, &reascode, &pklistptr);
COBOL
CALL
’DSNRLI’ USING CRTHRDFN PLAN COLLID REUSE RETCODE REASCODE PKLSTPTR.
Fortran
CALL
DSNRLI(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLSTPTR)
CALL
DSNRLI(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLSTPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
″Authorizing plan or package access through applications″ (DB2 Administration
Guide)
Related reference
″BIND and REBIND options″ (DB2 Command Reference)
TERMINATE THREAD function for RRSAF
The RRSAF TERMINATE THREAD function deallocates DB2 resources that are
associated with a plan and were previously allocated for an application by the
110
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-126-320.jpg)
![CREATE THREAD function. You can then use the CREATE THREAD function to
allocate another plan with the same connection.
If you call the TERMINATE THREAD function and the application is not at a point
of consistency, RRSAF returns reason code X’00C12211’.
The following diagram shows the syntax of the TERMINATE THREAD function.
DSNRLI TERMINATE THREAD function
CALL DSNRLI ( function,
)
, retcode
,
reascode
Parameters point to the following areas:
function
An 18-byte area the contains TERMINATE THREAD followed by two blanks.
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode, RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF TERMINATE THREAD calls
The following table shows a TERMINATE THREAD call in each language.
Table 34. Examples of RRSAF TERMINATE THREAD calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(TRMTHDFN,RETCODE,REASCODE)
fnret=dsnrli(&trmthdfn[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING TRMTHDFN RETCODE REASCODE.
Fortran
CALL
DSNRLI(TRMTHDFN,RETCODE,REASCODE)
CALL
DSNRLI(TRMTHDFN,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Chapter 2. Connecting to DB2 from your application program
111](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-127-320.jpg)

![Table 35. Examples of RRSAF TERMINATE IDENTIFY calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(TMIDFYFN,RETCODE,REASCODE)
fnret=dsnrli(&tmidfyfn[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING TMIDFYFN RETCODE REASCODE.
Fortran
CALL
DSNRLI(TMIDFYFN,RETCODE,REASCODE)
CALL
DSNRLI(TMIDFYFN,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
TRANSLATE function for RRSAF
The RRSAF TRANSLATE function converts a hexadecimal reason code for a DB2
error into a signed integer SQL code and a printable error message. The SQL code
and message text are placed in the SQLCODE and SQLSTATE host variables or
related fields of the SQLCA.
Consider the following rules and recommendations about when to use and not use
the TRANSLATE function:
v You cannot call the TRANSLATE function from the Fortran language.
v Call the TRANSLATE function only after a successful IDENTIFY operation. For
errors that occur during SQL or IFI requests, the TRANSLATE function performs
automatically.
v The TRANSLATE function translates codes that begin with X’00F3’, but it does
not translate RRSAF reason codes that begin with X’00C1’.
If you receive error reason code X’00F30040’ (resource unavailable) after an OPEN
request, the TRANSLATE function returns the name of the unavailable database
object in the last 44 characters of the SQLERRM field.
If the TRANSLATE function does not recognize the error reason code, it returns
SQLCODE -924 (SQLSTATE ’58006’) and places a printable copy of the original
DB2 function code and the return and error reason codes in the SQLERRM field.
The contents of registers 0 and 15 do not change, unless TRANSLATE fails. In this
case, register 0 is set to X’00C12204’, and register 15 is set to 200.
The following diagram shows the syntax of the TRANSLATE function.
DSNRLI TRANSLATE function
CALL DSNRLI ( function, sqlca
)
,
retcode
, reascode
Chapter 2. Connecting to DB2 from your application program
113](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-129-320.jpg)
![Parameters point to the following areas:
function
An 18-byte area that contains the word TRANSLATE followed by nine blanks.
sqlca
The program’s SQL communication area (SQLCA).
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode, RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF TRANSLATE calls
The following table shows a TRANSLATE call in each language.
Table 36. Examples of RRSAF TRANSLATE calls
Language
Call example
Assembler
CALL
C
1
fnret=dsnrli(&connfn[0], &sqlca, &retcode, &reascode);
COBOL
PL/I
DSNRLI,(XLATFN,SQLCA,RETCODE,REASCODE)
1
CALL
’DSNRLI’ USING XLATFN SQLCA RETCODE REASCODE.
CALL
DSNRLI(XLATFN,SQLCA,RETCODE,REASCODE);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
|
|
|
FIND_DB2_SYSTEMS function for RRSAF
|
The following diagram shows the syntax of the FIND_DB2_SYSTEMS function.
The RRSAF FIND_DB2_SYSTEMS function identifies all active DB2 subsystems on
a z/OS LPAR.
|
114
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-130-320.jpg)











![Table 39. Declarations generated by DCLGEN
SQL data type1
C
COBOL
PL/I
SMALLINT
short int
PIC S9(4) USAGE COMP
BIN FIXED(15)
INTEGER
long int
PIC S9(9) USAGE COMP
BIN FIXED(31)
PIC S9(p-s)V9(s) USAGE COMP-3
DEC FIXED(p,s)
DECIMAL(p,s) or
NUMERIC(p,s)
decimal(p,s)
2
If p>15, the PL/I
compiler must
support this
precision, or a
warning is
generated.
REAL or FLOAT(n) float
1 <= n <= 21
USAGE COMP-1
BIN FLOAT(n)
DOUBLE
PRECISION,
DOUBLE, or
FLOAT(n)
double
USAGE COMP-2
BIN FLOAT(n)
CHAR(1)
char
PIC X(1)
CHAR(1)
CHAR(n)
char var [n+1]
PIC X(n)
CHAR(n)
VARCHAR(n)
struct
{short int var_len;
char var_data[n];
} var;
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC X(n).
CHAR(n) VAR
CLOB(n)3
SQL TYPE IS CLOB_LOCATOR
USAGE SQL TYPE IS CLOB-LOCATOR
SQL TYPE IS
CLOB_LOCATOR
GRAPHIC(1)
sqldbchar
PIC G(1)
GRAPHIC(1)
GRAPHIC(n)
sqldbchar var[n+1];
PIC G(n) USAGE
DISPLAY-1.4
or
PIC N(n).4
GRAPHIC(n)
VARGRAPHIC(n)
struct VARGRAPH
{short len;
sqldbchar data[n];
} var;
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC G(n)
USAGE DISPLAY-1.4
or
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC N(n).4
GRAPHIC(n) VAR
DBCLOB(n)3
SQL TYPE IS DBCLOB_LOCATOR
USAGE SQL TYPE IS DBCLOB-LOCATOR
SQL TYPE IS
DBCLOB_LOCATOR
| BINARY(n)
|
SQL TYPE IS BINARY(n)
USAGE SQL TYPE IS BINARY(n)
SQL TYPE IS
BINARY(n)
| VARBINARY(n)
|
SQL TYPE IS VARBINARY(n)
USAGE SQL TYPE IS VARBINARY(n)
SQL TYPE IS
VARBINARY(n)
BLOB(n)3
SQL TYPE IS BLOB_LOCATOR
USAGE SQL TYPE IS BLOB-LOCATOR
SQL TYPE IS
BLOB_LOCATOR
DATE
char var[11]5
PIC X(10)5
CHAR(10)5
TIME
char var[9]6
PIC X(8)6
CHAR(8)6
TIMESTAMP
char var[27]
PIC X(26)
CHAR(26)
n>1
126
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-142-320.jpg)






![If you leave this field blank, DCLGEN generates a name that contains the
table or view name with a prefix of DCL. If the language is COBOL or
PL/I, and the table or view name consists of a DBCS string, the prefix
consists of DBCS characters.
For C, lowercase characters you enter in this field do not fold to uppercase.
9 FIELD NAME PREFIX
Specifies a prefix that DCLGEN uses to form field names in the output. For
example, if you choose ABCDE, the field names generated are ABCDE1,
ABCDE2, and so on.
DCLGEN accepts a field name prefix of up to 28 bytes that can include
special and double-byte characters. If you specify a single-byte or
mixed-string prefix and the first character is not alphabetic, apostrophes
must enclose the prefix. If you use special characters, avoid name conflicts.
For COBOL and PL/I, if the name is a DBCS string, DCLGEN generates
DBCS equivalents of the suffix numbers. For C, lowercase characters you
enter in this field do not fold to uppercase.
If you leave this field blank, the field names are the same as the column
names in the table or view.
10 DELIMIT DBCS
Tells DCLGEN whether to delimit DBCS table names and column names in
the table declaration. Use:
YES to enclose the DBCS table and column names with SQL delimiters.
NO to not delimit the DBCS table and column names.
11 COLUMN SUFFIX
Tells DCLGEN whether to form field names by attaching the column name
as a suffix to the value you specify in FIELD NAME PREFIX. For example,
if you specify YES, the field name prefix is NEW, and the column name is
EMPNO, the field name is NEWEMPNO.
If you specify YES, you must also enter a value in FIELD NAME PREFIX.
If you do not enter a field name prefix, DCLGEN issues a warning
message and uses the column names as the field names.
The default is NO, which does not use the column name as a suffix and
allows the value in FIELD NAME PREFIX to control the field names, if
specified.
12 INDICATOR VARS
Tells DCLGEN whether to generate an array of indicator variables for the
host variable structure.
If you specify YES, the array name is the table name with a prefix of I (or
DBCS letter <I> if the table name consists solely of double-byte characters).
The form of the data declaration depends on the language:
For a C program: short int Itable-name[n];
For a COBOL program: 01 Itable-name PIC S9(4) USAGE COMP OCCURS
n TIMES.
For a PL/I program: DCL Itable-name(n) BIN FIXED(15);
n is the number of columns in the table. For example, suppose you define
the following table:
CREATE TABLE HASNULLS (CHARCOL1 CHAR(1), CHARCOL2 CHAR(1));
You request an array of indicator variables for a COBOL program.
DCLGEN might generate the following host variable declaration:
Chapter 3. Including DB2 queries in an application program
133](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-149-320.jpg)


![v An SQLSTATE variable, which is declared as shown in the following table.
Table 41. SQLSTATE variable declarations
Language
How the SQLSTATE variable is declared
assembler
as a character string of length 5 (CL5)
C
as a character array of length 6
Example:
char SQLSTATE[6];
COBOL
Fortran
as PICTURE X(5)
1
PL/I
as CHARACTER*5
as CHARACTER(5)
Note:
1. In Fortran, this variable can also be called SQLSTA.
DB2 sets the SQLCODE (or SQLCOD) and SQLSTATE (or SQLSTA) values after
each SQL statement executes. An application should check these values to
determine whether the last SQL statement was successful. All SQL statements in
the program must be within the scope of the declaration of the SQLCODE and
SQLSTATE variables.
Whether you define the SQLCODE or SQLSTATE variable or an SQLCA in your
program depends on whether you specify the precompiler option STDSQL(YES) to
conform to the SQL standard, or STDSQL(NO) to conform to DB2 rules:
v If you specify the precompiler option STDSQL(YES): Do not define an SQLCA.
If you do, DB2 ignores your SQLCA, and your SQLCA definition causes
compile-time errors.
If you declare an SQLSTATE variable, it must not be an element of a structure.
You must declare the host variables SQLCODE (or SQLCOD) and SQLSTATE (or
SQLSTA) within a BEGIN DECLARE SECTION and END DECLARE SECTION
statement in your program declarations.
COBOL: When you use the precompiler option STDSQL(YES), you must declare
an SQLCODE variable. DB2 declares an SQLCA area for you in the
WORKING-STORAGE SECTION. DB2 controls the structure and location of the
SQLCA.
v If you specify the precompiler option STDSQL(NO): Include an SQLCA
explicitly.
REXX applications behave differently. When DB2 prepares a REXX procedure that
contains SQL statements, DB2 automatically includes an SQL communication area
(SQLCA) in the procedure. The REXX SQLCA differs from the SQLCA for other
languages in the following ways:
v The REXX SQLCA consists of a set of separate variables, rather than a structure.
If you use the ADDRESS DSNREXX ’CONNECT’ ssid syntax to connect to DB2, the
SQLCA variables are a set of simple variables.
If you connect to DB2 using the CALL SQLDBS ’ATTACH TO’ syntax, the SQLCA
variables are compound variables that begin with the stem SQLCA.
To define the SQL communications area:
1. Code the SQLCA directly in the program or use the following SQL INCLUDE
statement to request a standard SQLCA declaration.
136
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-152-320.jpg)









![To insert multiple rows, you can use the form of the INSERT statement that selects
values from another table or view. You can also use a form of the INSERT
statement that inserts multiple rows from values that are provided in host variable
arrays. For more information, see “Inserting multiple rows of data from host
variable arrays” on page 182.
Example: The following example inserts a single row into the activity table:
EXEC SQL
INSERT INTO DSN8910.ACT
VALUES (:HV-ACTNO, :HV-ACTKWD, :HV-ACTDESC)
END-EXEC.
Changing the coded character set ID of host variables
All DB2 string data, other than binary data, has an encoding scheme and a coded
character set ID (CCSID) associated with it. You can associate an encoding scheme
and a CCSID with individual host variables. Any data in those host variable is
then associated with that encoding scheme and CCSID.
You can use the DECLARE VARIABLE statement to associate an encoding scheme
and a CCSID with individual host variables. The DECLARE VARIABLE statement
has the following effects on a host variable:
v When you use the host variable to update a table, the local subsystem or the
remote server assumes that the data in the host variable is encoded with the
CCSID and encoding scheme that the DECLARE VARIABLE statement assigns.
v When you retrieve data from a local or remote table into the host variable, the
retrieved data is converted to the CCSID and encoding scheme that are assigned
by the DECLARE VARIABLE statement.
You can use the DECLARE VARIABLE statement in static or dynamic SQL
applications. However, you cannot use the DECLARE VARIABLE statement to
control the CCSID and encoding scheme of data that you retrieve or update using
an SQLDA.
When you use a DECLARE VARIABLE statement in a program, put the DECLARE
VARIABLE statement after the corresponding host variable declaration and before
your first reference to that host variable.
Example: Using a DECLARE VARIABLE statement to change the encoding scheme
of retrieved data: Suppose that you are writing a C program that runs on a DB2
for z/OS subsystem. The subsystem has an EBCDIC application encoding scheme.
The C program retrieves data from the following columns of a local table that is
defined with CCSID UNICODE.
PARTNUM CHAR(10)
JPNNAME GRAPHIC(10)
ENGNAME VARCHAR(30)
Because the application encoding scheme for the subsystem is EBCDIC, the
retrieved data is EBCDIC. To make the retrieved data Unicode, use DECLARE
VARIABLE statements to specify that the data that is retrieved from these columns
is encoded in the default Unicode CCSIDs for the subsystem. Suppose that you
want to retrieve the character data in Unicode CCSID 1208 and the graphic data in
Unicode CCSID 1200. Use DECLARE VARIABLE statements like these:
EXEC SQL BEGIN DECLARE SECTION;
char hvpartnum[11];
EXEC SQL DECLARE :hvpartnum VARIABLE CCSID 1208;
sqldbchar hvjpnname[11];
EXEC SQL DECLARE :hvjpnname VARIABLE CCSID 1200;
146
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-162-320.jpg)
![struct {
short len;
char d[30];
} hvengname;
EXEC SQL DECLARE :hvengname VARIABLE CCSID 1208;
EXEC SQL END DECLARE SECTION;
The BEGIN DECLARE SECTION and END DECLARE SECTION statements mark
the beginning and end of a host variable declare section.
Ensuring that DB2 correctly interprets character input data in
REXX programs
DB2 REXX Language Support can incorrectly interpret character literals as graphic
or numeric literals unless you mark them correctly.
To ensure that DB2 REXX Language Support does not interpret character literals as
graphic or numeric literals, precede and follow character literals with a double
quotation mark, followed by a single quotation mark, followed by another double
quotation mark ("’").
Enclosing the string in apostrophes is not adequate because REXX removes the
apostrophes when it assigns a literal to a variable. For example, suppose that you
want to pass the value in host variable stringvar to DB2. The value that you want
to pass is the string ’100’. The first thing that you need to do is to assign the string
to the host variable. You might write a REXX command like this:
stringvar = ’100’
After the command executes, stringvar contains the characters 100 (without the
apostrophes). DB2 REXX Language Support then passes the numeric value 100 to
DB2, which is not what you intended.
However, suppose that you write the command like this:
stringvar = "’"100"’"
In this case, REXX assigns the string ’100’ to stringvar, including the single
quotation marks. DB2 REXX Language Support then passes the string ’100’ to DB2,
which is the desired result.
Passing the data type of an input data type to DB2 for REXX
programs
In certain situations, you want to tell DB2 the data type to use for input data in a
REXX program. For example, if you are assigning or comparing input data to
columns of type SMALLINT, CHAR, or GRAPHIC, you should tell DB2 to use
those data types.
DB2 does not assign data types of SMALLINT, CHAR, or GRAPHIC to input data.
If you assign or compare this data to columns of type SMALLINT, CHAR, or
GRAPHIC, DB2 must do more work than if the data types of the input data and
columns match.
To indicate the data type of input data to DB2, use an SQLDA.
Example: Specifying CHAR: Suppose you want to tell DB2 that the data with
which you update the MIDINIT column of the EMP table is of type CHAR, rather
than VARCHAR. You need to set up an SQLDA that contains a description of a
CHAR column, and then prepare and execute the UPDATE statement using that
SQLDA:
Chapter 3. Including DB2 queries in an application program
147](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-163-320.jpg)






![char
auto
extern
static
const
volatile
unsigned
,
variable-name
*pointer-name
[
length ]
;
=expression
Notes:
1. On input, the string contained by the variable must be NUL-terminated.
2. On output, the string is NUL-terminated.
3. A NUL-terminated character host variable maps to a varying-length character
string (except for the NUL).
4. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
The following diagram shows the syntax for declarations of varying-length
character host variables that use the VARCHAR structured form.
int
struct
auto
extern
static
const
volatile
{
short
var-1
;
tag
char var-2 [ length ]
;
}
unsigned
,
variable-name
*pointer-name
;
={expression, expression}
Notes:
1. You cannot use var-1 and var-2 as host variables in an SQL statement.
2. You can use the struct tag to define other variables, but you cannot use them as
host variables in SQL.
3. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Example: The following examples show valid and invalid declarations of the
VARCHAR structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable VARCHAR vstring */
struct VARCHAR {
short len;
char s[10];
154
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-170-320.jpg)
![} vstring;
/* invalid declaration of host variable VARCHAR wstring */
struct VARCHAR wstring;
Graphic host variables in C or C++
The four valid forms for graphic host variables are:
v Single-graphic form
v NUL-terminated graphic form
v VARGRAPHIC structured form.
v DBCLOBs
Recommendation: Instead of using the C data type wchar_t to define graphic and
vargraphic host variables, use one of the following techniques:
v Define the sqldbchar data type by using the following typedef statement:
typedef unsigned short sqldbchar;
v Use the sqldbchar data type that is defined in the typedef statement in the
header files that are supplied by DB2.
v Use the C data type unsigned short.
The following diagrams show the syntax for forms other than DBCLOBs.
The following diagram shows the syntax for declarations of single-graphic host
variables.
,
sqldbchar
auto
extern
static
const
volatile
variable-name
*pointer-name
;
=expression
The single-graphic form declares a fixed-length graphic string of length 1. You
cannot use array notation in variable-name.
The following diagram shows the syntax for declarations of NUL-terminated
graphic host variables.
,
sqldbchar
auto
extern
static
const
volatile
variable-name
*pointer-name
[ length ]
;
=expression
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. On input, the string in variable-name must be NUL-terminated.
3. On output, the string is NUL-terminated.
4. The NUL-terminated graphic form does not accept single-byte characters into
variable-name.
5. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Chapter 3. Including DB2 queries in an application program
155](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-171-320.jpg)
![The following diagram shows the syntax for declarations of graphic host variables
that use the VARGRAPHIC structured form.
int
struct
auto
extern
static
const
volatile
sqldbchar var-2 [ length ]
{
short
var-1
;
tag
;
}
,
variable-name
*pointer-name
;
={ expression, expression}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. var-1 must be less than or equal to length.
3. You cannot use var-1 and var-2 as host variables in an SQL statement.
4. You can use the struct tag to define other variables, but you cannot use them as
host variables in SQL.
5. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Example: The following examples show valid and invalid declarations of graphic
host variables that use the VARGRAPHIC structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable structured vgraph */
struct VARGRAPH {
short len;
sqldbchar d[10];
} vgraph;
/* invalid declaration of host variable structured wgraph */
struct VARGRAPH wgraph;
Binary host variables in C or C++
|
|
|
|
The three valid forms of BINARY host variables are:
v Fixed-length strings
v Varying-length strings
v BLOBs
|
|
The following diagram shows the syntax for declarations of BINARY host
variables. The following diagrams show the syntax for forms other than BLOBs.
156
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-172-320.jpg)
![|
,
SQL TYPE IS BINARY ( length )
auto
extern
static
variable-name
;
const
volatile
|
|
|
Notes:
1. For BINARY host variables, the length must be in the range from 1 to 255.
|
|
The following diagram shows the syntax for declarations of VARBINARY host
variables.
|
|
SQL TYPE IS
auto
extern
static
|
|
const
volatile
(1)
VARBINARY
BINARY VARYING
( length )
,
variable-name
;
= { init-len , ″
init-data ″
}
|
|
Notes:
|
|
1
|
The C language does not have variables that correspond to the SQL binary data
types BINARY and VARBINARY. To create host variables that can be used with
these data types, use the SQL TYPE IS clause. The SQL precompiler replaces this
declaration with the C language structure in the output source member.
|
|
|
|
When you refer to a BINARY or VARBINARY host variable in an SQL statement,
you must use the variable that you specify in the SQL TYPE declaration. When
you refer to the host variable in a host language statement, you must use the
variable that DB2 generates.
|
|
Example: The following table shows examples of variables that DB2 generates
when you declare binary host variables.
|
Table 44. Examples of BINARY and VARBINARY variable declarations for C
|
You declare this variable
DB2 generates this variable
|
SQL TYPE IS BINARY(10) bin_var;
char bin_var[10]
|
|
|
|
|
SQL TYPE IS VARBINARY(10) vbin_var;
struct {
short length;
char data[10];
} vbin_var;
|
|
|
|
|
Important: Be careful when you use binary host variables with C and C++. The
SQL TYPE declaration for BINARY and VARBINARY does not account for the
NUL-terminator that C expects because binary strings are not NUL-terminated
strings. Furthermore, the binary host variable might contain zeroes at any point in
the string.
For VARBINARY host variables, the length must be in the range from 1 to
32 704.
Chapter 3. Including DB2 queries in an application program
157](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-173-320.jpg)


![ROWIDs in C or C++
The following diagram shows the syntax for declarations of ROWID host variables.
See “Large objects (LOBs)” on page 390 for a discussion of how to use these host
variables.
auto
extern
static
register
const
volatile
variable-name
*pointer-name
SQL TYPE IS ROWID ;
Notes on C variable declaration and usage
You should be aware of the following considerations when you declare C variables.
C data types with no SQL equivalent: C supports some data types and storage
classes with no SQL equivalents, for example, register storage class, typedef, and
long long,.
SQL data types with no C equivalent: If your C compiler does not have a decimal
data type, no exact equivalent exists for the SQL DECIMAL data type. In this case,
to hold the value of such a variable, you can use:
v An integer or floating-point variable, which converts the value. If you choose
integer, you will lose the fractional part of the number. If the decimal number
can exceed the maximum value for an integer, or if you want to preserve a
fractional value, you can use floating-point numbers. Floating-point numbers are
approximations of real numbers. Therefore, when you assign a decimal number
to a floating-point variable, the result might be different from the original
number.
v A character-string host variable. Use the CHAR function to get a string
representation of a decimal number.
v The DECIMAL function to explicitly convert a value to a decimal data type, as
in this example:
long duration=10100;
char result_dt[11];
/* 1 year and 1 month */
EXEC SQL SELECT START_DATE + DECIMAL(:duration,8,0)
INTO :result_dt FROM TABLE1;
The SQL data type DECFLOAT also has no equivalent in C.
|
Floating-point host variables: All floating-point data is stored in DB2 in
z/Architecture hexadecimal floating-point format. However, your host variable
data can be in z/Architecture hexadecimal floating-point format or IEEE binary
floating-point format. DB2 uses the FLOAT precompiler option to determine
whether your floating-point host variables are in IEEE binary floating-point or
z/Architecture hexadecimal floating-point format. DB2 does no checking to
determine whether the contents of a host variable match the precompiler option.
Therefore, you need to ensure that your floating-point data format matches the
precompiler option.
Graphic host variables: You can define graphic host variables by using one of the
following techniques:
v Define the sqldbchar data type by using the following typedef statement:
|
|
|
160
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-176-320.jpg)
![|
|
|
|
|
|
|
|
|
|
typedef unsigned short sqldbchar;
Use sqldbchar instead of wchar_t. Using sqldbchar or unsigned short lets you
manipulate DBCS and Unicode UTF-16 data in the same format in which it is
stored in DB2. Using sqldbchar also makes applications easier to port to other
DB2 platforms.
v Use the C data type unsigned short.
v Use the typedef statements in one of the following files or libraries:
1. SQL library, sql.h
2. DB2 CLI library, sqlcli.h
3. SQLUDF file in data set DSN910.SDSNC.H
|
Special locator C data types: The following locator data types are special SQL data
types that do not have C equivalents:
v Result set locator
v Table locator
v LOB locators
|
You cannot use them to define column types.
|
|
|
|
String host variables: For NUL-terminated string host variables, use the SQL
processing options PADNTSTR and NOPADNTSTR to specify whether the variable
should be padded with blanks. For a description of these options, see Table 148 on
page 854. The option that you specify determines where the NUL-terminator is
placed.
If you assign a string of length n to a NUL-terminated string host variable, the
variable has one of the values that is shown in the following table.
Table 45. Value of a NUL-terminated string host variable that is assigned a string of length n
If the length of the NUL-terminated string
host variable is...
Less than or equal to n
The variable is set to...
The source string up to a length of n-1 and a
NUL at the end of the string. 1
DB2 sets SQLWARN[1] to W and any
indicator variable that you provide to the
original length of the source string.
Equal to n+1
The source string and a NUL at the end of
the string. 1
Greater than n+1 and the source is a
fixed-length string
If PADNTSTR is in effect
The source string, blanks to pad the
value, and a NUL at the end of the
string.
If NOPADNTSTR is in effect
The source string and a NUL at the end
of the string.
Greater than n+1 and the source is a
varying-length string
The source string and a NUL at the end of
the string. 1
Note:
1. In these cases, whether NOPADNTSTR or PADNTSTR is in effect is irrelevant.
Chapter 3. Including DB2 queries in an application program
161](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-177-320.jpg)


















![Pointers as host variables in C and C++
If you use the DB2 coprocessor, you can use pointer host variables with statically
or dynamically allocated storage. These pointer host variables can point to numeric
data, non-numeric data, or a structure.
To declare pointer host variables, use an asterisk (*) to indicate that the variable is
a pointer. To reference a pointer host variable in an SQL statement, specify the
pointer host variable exactly as it was declared.
You can use the following types of pointer host variables:
scalar pointer host variable
A host variable that points to numeric or non-numeric scalar data.
The following table shows example declarations of scalar pointer host
variables and example references to such variables.
Table 48. Example declarations of and references to scalar pointer host variables
Declaration
Description
Reference
short *hvshortp;
hvshortp is a pointer host variable that
points to two bytes of storage.
EXEC SQL set:*hvshortp=123;
double *hvdoubp;
hvdoubp is a pointer host variable that
points to eight bytes of storage.
EXEC SQL set:*hvdoubp=456;
char (*hvcharpn) [20];
hvcharpn is a pointer host variable that
points to a nul-terminated character array
of up to 20 bytes.
EXEC SQL set:
*hvcharpn=’nul_terminated’;
1
Note:
1. When you reference pointers to nul-terminated character arrays, you do
not have to include the parentheses that were part of the declaration.
Restriction: You cannot use pointer host variables that point to character
data of an unknown length. For example, the following specification is not
supported: char * hvcharpu.
Instead, for character pointer host variables, you must specify the length of
the data by using a bounded character pointer host variable. A bounded
character pointer host variable is a host variable that is declared as a structure
with the following two elements:
v A 4-byte field that contains the length of the storage area.
v A pointer to the non-numeric dynamic storage area.
Example of a bounded character pointer host variable: The following
example declares a bounded character pointer host variable called
hvbcharp with two elements: len and data:
struct {
unsigned long len;
char * data;
} hvbcharp;
The following example references this bounded character pointer host
variable:
180
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-196-320.jpg)
![hvcharp.len = dynlen; 1
hvcharp.data = (char 8) malloc (hvcharp.len); 2
EXEC SQL set :hvcharp = ’data buffer with length’;
3
Note:
1. dynlen can be either a compile time constant or a variable with a value
that is assigned at run time.
2. Storage is dynamically allocated for hvcharp.data.
3. The SQL statement references the name of the structure, not an element
within the structure.
array pointer host variables
A host variable that is an array of pointers.
The following table shows example declarations of array pointer host
variables and examples references to such variables.
Table 49. Example declarations of and references to array pointer host variables
Declaration
Description
Reference
short * hvarrpl[6]
hvarrp1 is an array of 6 pointers that point EXEC SQL set:*hvarrpl[n]=123;
to two bytes of storage each.
double * hvarrp2[3]
hvarrp2 is an array of 3 pointers that point EXEC SQL set:*hvarrp2[n]=456;
to 8 bytes of storage each.
struct {
unsigned long len;
char * data; }
hvbarrp3[5];
hvbarrp3 is an array of 5 bounded
character pointers.
EXEC SQL set :hvarrp3[n] =
’data buffer with length’
1
structure array host variable
A host variable that points to a structure.
Example: The following example declares a table structure called tbl_struct.
struct tbl_struct
{
char colname[20];
small int colno;
small int coltype;
small int collen;
};
The following example declares a pointer to the structure tbl_struct.
Storage is allocated dynamically for up to n rows.
struct tbl_struct *ptr_tbl_struct =
(struct tbl_struct *) malloc (sizeof (struct tbl_struct) * n);
To reference this data is SQL statements, use the pointer as shown in the
following example. Assume that tbl_sel_cur is a declared cursor.
for (L_col_cnt = 0; L_col_cnt < n; L_con_cnt++)
{ ...
EXEC SQL FETCH tbl_sel_cur INTO :ptr_tbl_struct [L_col_cnt]
...
}
Restriction: You cannot use untyped pointers. For example, the following
declaration is not supported: void * untypedprt .
Chapter 3. Including DB2 queries in an application program
181](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-197-320.jpg)


![float
double
int
long
short
int
long long
decimal (
precision
)
, scale
,
variable-name [ dimension ]
;
,
= {
expression
}
Note:
1. dimension must be an integer constant between 1 and 32767.
Example: The following example shows a declaration of a numeric host variable
array:
EXEC SQL BEGIN DECLARE SECTION;
/* declaration of numeric host variable array */
long serial_num[10];
...
EXEC SQL END DECLARE SECTION;
Character host variable arrays in C or C++
The three valid forms for character host variable arrays are:
v NUL-terminated character form
v VARCHAR structured form
v CLOBs
The following diagrams show the syntax for forms other than CLOBs.
The following diagram shows the syntax for declarations of NUL-terminated
character host variable arrays.
char
auto
extern
static
const
volatile
unsigned
,
variable-name
[
dimension
]
[
length
]
;
,
=
{
expression
}
Notes:
1. On input, the strings contained in the variable arrays must be NUL-terminated.
184
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-200-320.jpg)
![2. On output, the strings are NUL-terminated.
3. The strings in a NUL-terminated character host variable array map to
varying-length character strings (except for the NUL).
4. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of varying-length
character host variable arrays that use the VARCHAR structured form.
int
struct
auto
extern
static
{
short
var-1
;
const
volatile
char var-2 [ length ]
;
}
unsigned
,
variable-name [ dimension ]
;
,
= {
|
|
expression
}
Notes:
1. var-1 must be a scalar numeric variable, and var-2 must be a scalar CHAR array
variable.
2. You can use the struct tag to define other variables, but you cannot use them as
host variable arrays in SQL.
3. dimension must be an integer constant between 1 and 32767.
Example: The following examples show valid and invalid declarations of
VARCHAR host variable arrays:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of VARCHAR host variable array */
struct VARCHAR {
short len;
char s[18];
} name[10];
/* invalid declaration of VARCHAR host variable array */
struct VARCHAR name[10];
Binary host variable arrays in C or C++
|
|
|
The following diagram shows the syntax for declarations of binary host variable
arrays. See “Large objects (LOBs)” on page 390 for a discussion of how to use
these host variable arrays.
|
Chapter 3. Including DB2 queries in an application program
185](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-201-320.jpg)
![|
|
SQL TYPE IS
auto
extern
static
register
|
|
BINARY
VARBINARY
const
volatile
(length)
,
variable-name [ dimension ]
;
|
Note:
1. dimension must be an integer constant between 1 and 32767.
|
Graphic host variable arrays in C or C++
The two valid forms for graphic host variable arrays are:
v NUL-terminated graphic form
v VARGRAPHIC structured form.
Recommendation: Instead of using the C data type wchar_t to define graphic and
vargraphic host variable arrays, use one of the following techniques:
v Define the sqldbchar data type by using the following typedef statement:
typedef unsigned short sqldbchar;
v Use the sqldbchar data type that is defined in the typedef statement in the
header files that are supplied by DB2.
v Use the C data type unsigned short.
The following diagram shows the syntax for declarations of NUL-terminated
graphic host variable arrays.
sqldbchar
auto
extern
static
const
volatile
unsigned
,
variable-name
[
dimension
]
[
length
]
;
,
=
{
expression
}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. On input, the strings contained in the variable arrays must be NUL-terminated.
3. On output, the string is NUL-terminated.
4. The NUL-terminated graphic form does not accept single-byte characters into
the variable array.
5. dimension must be an integer constant between 1 and 32767.
186
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-202-320.jpg)
![The following diagram shows the syntax for declarations of graphic host variable
arrays that use the VARGRAPHIC structured form.
int
struct
auto
extern
static
{
short
var-1
;
const
volatile
sqldbchar var-2 [ length ]
;
}
unsigned
,
variable-name [ dimension ]
;
,
= {
expression
}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. var-1 must be a scalar numeric variable, and var-2 must be a scalar char array
variable.
3. You can use the struct tag to define other variables, but you cannot use them as
host variable arrays in SQL.
4. dimension must be an integer constant between 1 and 32767.
Example: The following examples show valid and invalid declarations of graphic
host variable arrays that use the VARGRAPHIC structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable array vgraph */
struct VARGRAPH {
short len;
sqldbchar d[10];
} vgraph[20];
/* invalid declaration of host variable array vgraph */
struct VARGRAPH vgraph[20];
LOB, locator, file reference, and XML variable arrays in C or C++
The following diagram shows the syntax for declarations of BLOB, CLOB, and
DBCLOB host variable arrays and locators. See “Large objects (LOBs)” on page 390
for a discussion of how to use LOB variables.
SQL TYPE IS
auto
extern
static
register
const
volatile
Chapter 3. Including DB2 queries in an application program
187](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-203-320.jpg)
![|
BINARY LARGE OBJECT
BLOB
CHARACTER LARGE OBJECT
CHAR LARGE OBJECT
CLOB
DBCLOB
BLOB_LOCATOR
CLOB_LOCATOR
DBCLOB_LOCATOR
BLOB_FILE
CLOB_FILE
DBCLOB_FILE
(
length
)
K
M
G
,
variable-name [ dimension ]
;
,
= {
expression
}
Note:
1. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of BLOB, CLOB, and
DBCLOB host variable arrays, and file reference variable arrays for XML data
types
SQL TYPE IS XML AS
auto
extern
static
register
|
const
volatile
BINARY LARGE OBJECT
BLOB
CHARACTER LARGE OBJECT
CHAR LARGE OBJECT
CLOB
DBCLOB
BLOB_FILE
CLOB_FILE
DBCLOB_FILE
(
length
)
K
M
G
,
variable-name [ dimension ]
;
,
= {
Note:
188
Application Programming and SQL Guide
expression
}](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-204-320.jpg)
![1. dimension must be an integer constant between 1 and 32767.
ROWID variable arrays in C or C++
The following diagram shows the syntax for declarations of ROWID variable
arrays. See “Large objects (LOBs)” on page 390 for a discussion of how to use
these host variable arrays.
,
SQL TYPE IS ROWID
auto
extern
static
register
variable-name
[
dimension
]
;
const
volatile
Note:
1. dimension must be an integer constant between 1 and 32767.
COBOL syntax for host variable array declarations
In COBOL programs, you can specify numeric, character, graphic, LOB, XML, and
ROWID host variable arrays. You can also specify LOB locators and LOB and XML
file reference variables.
Only some of the valid COBOL declarations are valid host variable array
declarations. If the declaration for a variable array is not valid, any SQL statement
that references the variable array might result in the message UNDECLARED
HOST VARIABLE ARRAY.
Numeric host variable arrays: The three valid forms of numeric host variable
arrays are:
v Floating-point numbers
v Integers and small integers
v Decimal numbers
The following diagram shows the syntax for declarations of floating-point host
variable arrays.
level-1 variable-name
COMPUTATIONAL-1
COMP-1
COMPUTATIONAL-2
COMP-2
IS
USAGE
OCCURS dimension
.
TIMES
IS
VALUE
numeric-constant
Notes:
1. level-1 indicates a COBOL level between 2 and 48.
2. COMPUTATIONAL-1 and COMP-1 are equivalent.
3. COMPUTATIONAL-2 and COMP-2 are equivalent.
4. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of integer and small
integer host variable arrays.
Chapter 3. Including DB2 queries in an application program
189](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-205-320.jpg)









![Note:
1. dimension must be an integer constant between 1 and 32767.
Host structures in an SQL statement
A host structure is a group of host variables that can be referenced with a single
name. You define host structures with statements in the host language.
You can substitute a host structure for one or more host variables. You can also use
indicator variables (or indicator structures) with host structures.
You can use host structures in all host languages except REXX.
Host structures in C or C++
A C host structure contains an ordered group of data fields. For example:
struct {char c1[3];
struct {short len;
char data[5];
}c2;
char c3[2];
}target;
In this example, target is the name of a host structure consisting of the c1, c2, and
c3 fields. c1 and c3 are character arrays, and c2 is the host variable equivalent to
the SQL VARCHAR data type. The target host structure can be part of another host
structure but must be the deepest level of the nested structure.
The following diagram shows the syntax for declarations of host structures.
struct
auto
extern
static
const
volatile
packed
{
tag
Chapter 3. Including DB2 queries in an application program
199](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-215-320.jpg)
![|
float
double
var-1 ;
}
int
short
sqlint32
int
long
int
long long
decimal ( precision
, scale )
varchar structure
binary structure
vargraphic structure
SQL TYPE IS ROWID
LOB data type
char var-2
unsigned
[ length ]
sqldbchar var-5
;
[ length ]
variable-name
;
;
=expression
The following diagram shows the syntax for VARCHAR structures that are used
within declarations of host structures.
int
struct
{
tag
short
var-3 ;
signed
char var-4 [ length ] ; }
unsigned
The following diagram shows the syntax for VARGRAPHIC structures that are
used within declarations of host structures.
int
struct
{
tag
short
var-6 ; sqldbchar var-7 [ length ] ; }
signed
The following diagram shows the syntax for binary structures that are used within
declarations of host structures.
|
|
|
SQL TYPE IS
BINARY
VARBINARY
BINARY VARYING
(length)
|
The following diagram shows the syntax for LOB data types that are used within
declarations of host structures.
|
200
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-216-320.jpg)










![variable-name
DC
DS
H
1
L2
Figure 13. Indicator variable
Indicator variables and indicator variable arrays in C or C++
An indicator variable is a 2-byte integer (short int). An indicator variable array is
an array of 2-byte integers (short int). You use indicator variables and indicator
variable arrays in similar ways.
Using indicator variables: If you provide an indicator variable for the variable X,
when DB2 retrieves a null value for X, it puts a negative value in the indicator
variable and does not update X. Your program should check the indicator variable
before using X. If the indicator variable is negative, you know that X is null and
any value you find in X is irrelevant.
When your program uses X to assign a null value to a column, the program
should set the indicator variable to a negative number. DB2 then assigns a null
value to the column and ignores any value in X.
Using indicator variable arrays: When you retrieve data into a host variable array,
if a value in its indicator array is negative, you can disregard the contents of the
corresponding element in the host variable array.
Declaring indicator variables: You declare indicator variables in the same way as
host variables. You can mix the declarations of the two types of variables in any
way that seems appropriate.
Example: The following example shows a FETCH statement with the declarations
of the host variables that are needed for the FETCH statement:
EXEC SQL FETCH CLS_CURSOR INTO :ClsCd,
:Day :DayInd,
:Bgn :BgnInd,
:End :EndInd;
You can declare variables as follows:
EXEC SQL BEGIN DECLARE SECTION;
char ClsCd[8];
char Bgn[9];
char End[9];
short Day, DayInd, BgnInd, EndInd;
EXEC SQL END DECLARE SECTION;
The following figure shows the syntax for declarations of an indicator variable.
Chapter 3. Including DB2 queries in an application program
211](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-227-320.jpg)
![,
int
short
auto
extern
static
const
volatile
variable-name
signed
;
=
expression
Figure 14. Indicator variable
Declaring indicator variable arrays: The following figure shows the syntax for
declarations of an indicator array or a host structure indicator array.
int
short
auto
extern
static
const
volatile
signed
,
variable-name [ dimension ]
;
= expression
Figure 15. Host structure indicator array
Note: The dimension must be an integer constant between 1 and 32767.
Indicator variables and indicator variable arrays in COBOL
An indicator variable is a 2-byte integer (PIC S9(4) USAGE BINARY). An indicator
variable array is an array of 2-byte integers (PIC S9(4) USAGE BINARY). You use
indicator variables and indicator variable arrays in similar ways.
Using indicator variables: If you provide an indicator variable for the variable X,
when DB2 retrieves a null value for X, it puts a negative value in the indicator
variable and does not update X. Your program should check the indicator variable
before using X. If the indicator variable is negative, you know that X is null and
any value you find in X is irrelevant.
When your program uses X to assign a null value to a column, the program
should set the indicator variable to a negative number. DB2 then assigns a null
value to the column and ignores any value in X.
Using indicator variable arrays: When you retrieve data into a host variable array,
if a value in its indicator array is negative, you can disregard the contents of the
corresponding element in the host variable array.
Declaring indicator variables: You declare indicator variables in the same way as
host variables. You can mix the declarations of the two types of variables in any
way that seems appropriate. You can define indicator variables as scalar variables
or as array elements in a structure form or as an array variable using a single level
OCCURS clause.
212
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-228-320.jpg)




![For information about the multiple-row FETCH operation, see “Executing SQL
statements by using a rowset cursor” on page 637. For information about holes in
the result table of a cursor, see “Holes in the result table of a scrollable cursor” on
page 644.
Specifying an indicator array
You must associate an indicator array with a particular host variable array. The
indicator array contains small integers that indicate some information about each
value in the specified host variable array.
You can specify an indicator variable array, preceded by a colon, immediately after
the host variable array. Optionally, you can use the word INDICATOR between the
host variable array and its indicator variable array.
Example: Suppose that you declare a scrollable rowset cursor by using the
following statement:
EXEC SQL
DECLARE CURS1 SCROLL CURSOR WITH ROWSET POSITIONING FOR
SELECT PHONENO
FROM DSN8810.EMP
END-EXEC.
For information about using rowset cursors, see “Accessing data by using a
rowset-positioned cursor” on page 636.
The following two specifications of indicator arrays in the multiple-row FETCH
statement are equivalent:
EXEC SQL
FETCH NEXT ROWSET CURS1
FOR 10 ROWS
INTO :CBLPHONE :INDNULL
END-EXEC.
EXEC SQL
FETCH NEXT ROWSET CURS1
FOR 10 ROWS
INTO :CBLPHONE INDICATOR :INDNULL
END-EXEC.
After the multiple-row FETCH statement, you can test each element of the
INDNULL array for a negative value. If an element is negative, you can disregard
the contents of the corresponding element in the CBLPHONE host variable array.
Inserting null values by using indicator arrays
An indicator array is associated with a particular host variable array. If you need
to insert null values into a column, using an indicator array is an easy way to do
so.
You can use a negative value in an indicator array to insert a null value into a
column.
Example: Assume that host variable arrays hva1 and hva2 have been populated
with values that are to be inserted into the ACTNO and ACTKWD columns.
Assume the ACTDESC column allows nulls. To set the ACTDESC column to null,
assign -1 to the elements in its indicator array:
/* Initialize each indicator array */
for (i=0; i<10; i++) {
ind1[i] = 0;
ind2[i] = 0;
ind3[i] = -1;
}
Chapter 3. Including DB2 queries in an application program
217](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-233-320.jpg)






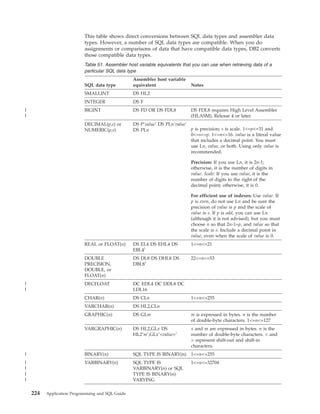


















































![– If you execute DESCRIBE on a statement before you open a cursor for that
statement, DB2 always prepares the statement on DESCRIBE. However, DB2
will not prepare the statement again on OPEN if the statement has already
been saved in the cache. If you execute DESCRIBE on a statement after you
open a cursor for that statement, DB2 prepared the statement only once if it is
not already saved in the cache. If the statement is already saved in the cache
and you execute DESCRIBE after you open a cursor for that statement, DB2
does not prepare the statement, it used the statement that is saved in the
cache.
To improve the performance of a program that is bound with REOPT(ONCE),
execute the DESCRIBE statement after you open a cursor. To prevent an
automatic DESCRIBE before a cursor is opened, do not use a PREPARE
statement with the INTO clause.
v If you use predictive governing for applications that are bound with
REOPT(ONCE), DB2 does not return a warning SQLCODE when dynamic SQL
statements exceed the predictive governing warning threshold. DB2 does return
an error SQLCODE when dynamic SQL statements exceed the predictive
governing error threshold. DB2 returns the error SQLCODE for an EXECUTE or
OPEN statement.
Dynamically executing an SQL statement by using EXECUTE
IMMEDIATE
In certain situations, you want your program to prepare and dynamically execute a
statement immediately after reading it.
Suppose that you design a program to read SQL DELETE statements, similar to
these, from a terminal:
DELETE FROM DSN8910.EMP WHERE EMPNO = ’000190’
DELETE FROM DSN8910.EMP WHERE EMPNO = ’000220’
After reading a statement, the program is to run it immediately.
Recall that you must prepare (precompile and bind) static SQL statements before
you can use them. You cannot prepare dynamic SQL statements in advance. The
SQL statement EXECUTE IMMEDIATE causes an SQL statement to prepare and
execute, dynamically, at run time.
Declaring the host variableBefore you prepare and execute an SQL statement, you
can read it into a host variable. If the maximum length of the SQL statement is 32
KB, declare the host variable as a character or graphic host variable according to
the following rules for the host languages:
|
|
|
v In assembler, PL/I, COBOL and C, you must declare a string host variable as a
varying-length string.
v In Fortran, it must be a fixed-length string variable.
If the length is greater than 32 KB, you must declare the host variable as a CLOB
or DBCLOB, and the maximum is 2 MB.
Example: Using a varying-length character host variable: This excerpt is from a C
program that reads a DELETE statement into the host variable dstring and executes
the statement:
EXEC SQL BEGIN DECLARE SECTION;
...
struct VARCHAR {
short len;
char s[40];
Chapter 3. Including DB2 queries in an application program
283](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-299-320.jpg)




![v SQLN
v SQLABC
v SQLD
v SQLVAR
v SQLNAME
Example: Assume that your program includes the standard SQLDA structure
declaration and declarations for the program variables that point to the SQLDA
structure. For C application programs, the following example code sets the
SQLDA fields:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
strcpy(sqldaptr->sqldaid,"SQLDA");
sqldaptr->sqldabc = 192;
/* number of bytes of storage allocated for the SQLDA */
sqldaptr->sqln = 4;
/* number of SQLVAR occurrences */
sqldaptr->sqld = 4;
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]));
/* Point to first SQLVAR */
varptr->sqltype = 500;
/* data type SMALLINT */
varptr->sqllen = 2;
varptr->sqldata = (char *) hva1;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]) + 1); /* Point to next SQLVAR */
varptr->sqltype = 452;
/* data type CHAR(6) */
varptr->sqllen = 6;
varptr->sqldata = (char *) hva2;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]) + 2); /* Point to next SQLVAR */
varptr->sqltype = 448;
/* data type VARCHAR(20) */
varptr->sqllen = 20;
varptr->sqldata = (char *) hva3;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
The SQLDA structure has the following fields:
v SQLDABC indicates the number of bytes of storage that are allocated for the
SQLDA. The storage includes a 16-byte header and 44 bytes for each
SQLVAR field. The value is SQLN x 44 + 16, or 192 for this example.
v SQLN is the number of SQLVAR occurrences, plus one for use by DB2 for
the host variable that contains the number n in the FOR n ROWS clause.
v SQLD is the number of variables in the SQLDA that are used by DB2 when
processing the INSERT statement.
v An SQLVAR occurrence specifies the attributes of an element of a host
variable array that corresponds to a value provided for a target column of
the INSERT. Within each SQLVAR:
– SQLTYPE indicates the data type of the elements of the host variable
array.
– SQLLEN indicates the length of a single element of the host variable array.
– SQLDATA points to the corresponding host variable array. Assume that
your program allocates the dynamic variable arrays hva1, hva2, and hva3.
– SQLNAME has two parts: the LENGTH and the DATA. The LENGTH is
8. The first two bytes of the DATA field is X’0000’. Bytes 5 and 6 of the
DATA field are a flag indicating whether the variable is an array or a FOR
n ROWS value. Bytes 7 and 8 are a two-byte binary integer representation
of the dimension of the array.
|
|
|
|
|
For more information about the SQLDA, see “Including dynamic SQL for
varying-list SELECT statements in your program” on page 266 and the topic
“SQL descriptor area (SQLDA)” in DB2 SQL Reference.
288
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-304-320.jpg)
















![|
|
|
|
|
|
Use the GET DIAGNOSTICS statement to handle multiple SQL errors that might
result from the execution of a single SQL statement. First, check SQLSTATE (or
SQLCODE) to determine whether diagnostic information should be retrieved by
using GET DIAGNOSTICS. This method is especially useful for diagnosing
problems that result from a multiple-row INSERT that is specified as NOT
ATOMIC CONTINUE ON SQLEXCEPTIONand multiple row MERGE statements.
Even if you use only the GET DIAGNOSTICS statement in your application
program to check for conditions, you must either include the instructions required
to use the SQLCA or you must declare SQLSTATE (or SQLCODE) separately in
your program.
Restriction: If you issue a GET DIAGNOSTICS statement immediately following
an SQL statement that uses private protocol access, DB2 returns an error.
When you use the GET DIAGNOSTICS statement, you assign the requested
diagnostic information to host variables. Declare each target host variable with a
data type that is compatible with the data type of the requested item. For a
description of available items and their data types, see “Data types for GET
DIAGNOSTICS items” on page 307.
To retrieve condition information, you must first retrieve the number of condition
items (that is, the number of errors and warnings that DB2 detected during the
execution of the last SQL statement). The number of condition items is at least one.
If the last SQL statement returned SQLSTATE ’00000’ (or SQLCODE 0), the number
of condition items is one.
Example: Using GET DIAGNOSTICS with multiple-row INSERT: You want to
display diagnostic information for each condition that might occur during the
execution of a multiple-row INSERT statement in your application program. You
specify the INSERT statement as NOT ATOMIC CONTINUE ON SQLEXCEPTION,
which means that execution continues regardless of the failure of any single-row
insertion. DB2 does not insert the row that was processed at the time of the error.
In the following example, the first GET DIAGNOSTICS statement returns the
number of rows inserted and the number of conditions returned. The second GET
DIAGNOSTICS statement returns the following items for each condition:
SQLCODE, SQLSTATE, and the number of the row (in the rowset that was being
inserted) for which the condition occurred.
EXEC SQL BEGIN DECLARE SECTION;
long row_count, num_condns, i;
long ret_sqlcode, row_num;
char ret_sqlstate[6];
...
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
INSERT INTO DSN8910.ACT
(ACTNO, ACTKWD, ACTDESC)
VALUES (:hva1, :hva2, :hva3)
FOR 10 ROWS
NOT ATOMIC CONTINUE ON SQLEXCEPTION;
EXEC SQL GET DIAGNOSTICS
:row_count = ROW_COUNT, :num_condns = NUMBER;
printf("Number of rows inserted = %dn", row_count);
for (i=1; i<=num_condns; i++) {
EXEC SQL GET DIAGNOSTICS CONDITION :i
Chapter 3. Including DB2 queries in an application program
305](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-321-320.jpg)
![:ret_sqlcode = DB2_RETURNED_SQLCODE,
:ret_sqlstate = RETURNED_SQLSTATE,
:row_num
= DB2_ROW_NUMBER;
printf("SQLCODE = %d, SQLSTATE = %s, ROW NUMBER = %dn",
ret_sqlcode, ret_sqlstate, row_num);
}
In the activity table, the ACTNO column is defined as SMALLINT. Suppose that
you declare the host variable array hva1 as an array with data type long, and you
populate the array so that the value for the fourth element is 32768.
If you check the SQLCA values after the INSERT statement, the value of
SQLCODE is equal to 0, the value of SQLSTATE is ’00000’, and the value of
SQLERRD(3) is 9 for the number of rows that were inserted. However, the INSERT
statement specified that 10 rows were to be inserted.
The GET DIAGNOSTICS statement provides you with the information that you
need to correct the data for the row that was not inserted. The printed output from
your program looks like this:
Number of rows inserted = 9
SQLCODE = -302, SQLSTATE = 22003, ROW NUMBER = 4
The value 32768 for the input variable is too large for the target column ACTNO.
You can print the MESSAGE_TEXT condition item. For information about
SQLCODE -302, see the topic “Error SQL codes” in DB2 Codes.
Retrieving statement and condition items:
When you use the GET DIAGNOSTICS statement, you assign the requested
diagnostic information to host variables. Declare each target host variable with a
data type that is compatible with the data type of the requested item.
To retrieve condition information, you must first retrieve the number of condition
items (that is, the number of errors and warnings that DB2 detected during the
execution of the last SQL statement). The number of condition items is at least one.
If the last SQL statement returned SQLSTATE ’00000’ (or SQLCODE 0), the number
of condition items is one.
Example: Using GET DIAGNOSTICS with multiple-row INSERT: You want to
display diagnostic information for each condition that might occur during the
execution of a multiple-row INSERT statement in your application program. You
specify the INSERT statement as NOT ATOMIC CONTINUE ON SQLEXCEPTION,
which means that execution continues regardless of the failure of any single-row
insertion. DB2 does not insert the row that was processed at the time of the error.
In the following example code, the first GET DIAGNOSTICS statement returns the
number of rows inserted and the number of conditions returned. The second GET
DIAGNOSTICS statement returns the following items for each condition:
SQLCODE, SQLSTATE, and the number of the row (in the rowset that was being
inserted) for which the condition occurred
EXEC SQL BEGIN DECLARE SECTION;
long row_count, num_condns, i;
long ret_sqlcode, row_num;
char ret_sqlstate[6];
...
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
306
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-322-320.jpg)



![eib
EXEC interface block
commarea
communication area
For more information on these parameters, see the appropriate application
programming guide for CICS. The remaining parameter descriptions are the same
as those for DSNTIAR. Both DSNTIAC and DSNTIAR format the SQLCA in the
same way.
You must define DSNTIA1 in the CSD. If you load DSNTIAR or DSNTIAC, you
must also define them in the CSD. For an example of CSD entry generation
statements for use with DSNTIAC, see member DSN8FRDO in the data set
prefix.SDSNSAMP.
The assembler source code for DSNTIAC and job DSNTEJ5A, which assembles and
link-edits DSNTIAC, are also in the data set prefix.SDSNSAMP.
Handling SQL error return codes in C or C++
You can use the subroutine DSNTIAR to convert an SQL return code into a text
message. DSNTIAR takes data from the SQLCA, formats it into a message, and
places the result in a message output area that you provide in your application
program. For concepts and more information about the behavior of DSNTIAR, see
“Displaying SQLCA fields by calling DSNTIAR” on page 299.
You can also use the MESSAGE_TEXT condition item field of the GET
DIAGNOSTICS statement to convert an SQL return code into a text message.
Programs that require long token message support should code the GET
DIAGNOSTICS statement instead of DSNTIAR. For more information about GET
DIAGNOSTICS, see “Checking the execution of SQL statements by using the GET
DIAGNOSTICS statement” on page 304.
DSNTIAR syntax:
rc = dsntiar(&sqlca, &message, &lrecl);
The DSNTIAR parameters have the following meanings:
&sqlca
An SQL communication area.
&message
An output area, in VARCHAR format, in which DSNTIAR places the message
text. The first halfword contains the length of the remaining area; its minimum
value is 240.
The output lines of text, each line being the length specified in &lrecl, are put
into this area. For example, you could specify the format of the output area as:
#define data_len 132
#define data_dim 10
struct error_struct {
short int error_len;
char error_text[data_dim][data_len];
. } error_message = {data_dim * data_len};
.
.
rc = dsntiar(&sqlca, &error_message, &data_len);
312
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-328-320.jpg)



















![/*
/*
/*
/*
*/
*/
*/
*/
Control-blocks
=
SQLCA
- sql communication area
/* Logic specification:
*/
/*
*/
/* There are four SQL sections.
*/
/*
*/
/* 1) STATIC SQL 1: using static cursor with a SELECT statement.
*/
/*
Two output host variables.
*/
/* 2) Dynamic SQL 2: Fixed-list SELECT, using same SELECT statement
*/
/*
used in SQL 1 to show the difference. The prepared string
*/
/*
:iptstr can be assigned with other dynamic-able SQL statements. */
/* 3) Dynamic SQL 3: Insert with parameter markers.
*/
/*
Using four parameter markers which represent four input host
*/
/*
variables within a host structure.
*/
/* 4) Dynamic SQL 4: EXECUTE IMMEDIATE
*/
/*
A GRANT statement is executed immediately by passing it to DB2 */
/*
via a varying string host variable. The example shows how to
*/
/*
set up the host variable before passing it.
*/
/*
*/
/**********************************************************************/
#include "stdio.h"
#include "stdefs.h"
EXEC SQL INCLUDE SQLCA;
EXEC SQL INCLUDE SQLDA;
EXEC SQL BEGIN DECLARE SECTION;
short edlevel;
struct { short len;
char x1[56];
} stmtbf1, stmtbf2, inpstr;
struct { short len;
char x1[15];
} lname;
short hv1;
struct { char deptno[4];
struct { short len;
char x[36];
} deptname;
char mgrno[7];
char admrdept[4];
} hv2;
short ind[4];
EXEC SQL END
DECLARE SECTION;
EXEC SQL DECLARE EMP TABLE
(EMPNO
CHAR(6)
FIRSTNAME
VARCHAR(12)
MIDINIT
CHAR(1)
LASTNAME
VARCHAR(15)
WORKDEPT
CHAR(3)
PHONENO
CHAR(4)
HIREDATE
DECIMAL(6)
JOBCODE
DECIMAL(3)
EDLEVEL
SMALLINT
SEX
CHAR(1)
BIRTHDATE
DECIMAL(6)
SALARY
DECIMAL(8,2)
FORFNAME
VARGRAPHIC(12)
FORMNAME
GRAPHIC(1)
FORLNAME
VARGRAPHIC(15)
FORADDR
VARGRAPHIC(256) )
EXEC SQL DECLARE DEPT TABLE
(
DEPTNO
DEPTNAME
332
Application Programming and SQL Guide
CHAR(3)
VARCHAR(36)
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
;
,
,](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-348-320.jpg)


































!["ISREDIT
"ISREDIT
"ISREDIT
"ISREDIT
Exit 20
|| SQLWARN.8",",
|| SQLWARN.9",",
|| SQLWARN.10"’"
LINE_AFTER "zdest" =
|| SQLERRD.2",",
|| SQLERRD.3",",
|| SQLERRD.4",",
|| SQLERRD.5",",
|| SQLERRD.6"’"
LINE_AFTER "zdest" =
LINE_AFTER "zdest" =
LINE_AFTER "zdest" =
MSGLINE ’SQLERRD ="SQLERRD.1",",
MSGLINE ’SQLERRP ="SQLERRP"’"
MSGLINE ’SQLERRMC ="SQLERRMC"’"
MSGLINE ’SQLCODE ="SQLCODE"’"
Example programs that call stored procedures
These examples can be used as models when you write applications that call
stored procedures. In addition to these example programs, DSN910.SDSNSAMP
contains sample jobs DSNTEJ6P and DSNTEJ6S and programs DSN8EP1 and
DSN8EP2, which you can run.
Example C program that calls a stored procedure
This example shows how to call the C language version of the GETPRML stored
procedure that uses the GENERAL WITH NULLS linkage convention. Because the
stored procedure returns result sets, this program checks for result sets and
retrieves the contents of the result sets.
The following figure contains the example C program that calls the GETPRML
stored procedure.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
main()
{
/************************************************************/
/* Include the SQLCA and SQLDA
*/
/************************************************************/
EXEC SQL INCLUDE SQLCA;
EXEC SQL INCLUDE SQLDA;
/************************************************************/
/* Declare variables that are not SQL-related.
*/
/************************************************************/
short int i;
/* Loop counter
*/
/************************************************************/
/* Declare the following:
*/
/* - Parameters used to call stored procedure GETPRML
*/
/* - An SQLDA for DESCRIBE PROCEDURE
*/
/* - An SQLDA for DESCRIBE CURSOR
*/
/* - Result set variable locators for up to three result
*/
/*
sets
*/
/************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char procnm[19];
/* INPUT parm -- PROCEDURE name */
char schema[9];
/* INPUT parm -- User’s schema */
long int out_code;
/* OUTPUT -- SQLCODE from the
*/
/*
SELECT operation.
*/
struct {
short int parmlen;
char parmtxt[254];
} parmlst;
/* OUTPUT -- RUNOPTS values
*/
/*
for the matching row in
*/
/*
catalog table SYSROUTINES */
struct indicators {
short int procnm_ind;
Chapter 3. Including DB2 queries in an application program
367](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-383-320.jpg)
![short int schema_ind;
short int out_code_ind;
short int parmlst_ind;
} parmind;
/* Indicator variable structure */
struct sqlda *proc_da;
/* SQLDA for DESCRIBE PROCEDURE */
struct sqlda *res_da;
/* SQLDA for DESCRIBE CURSOR
static volatile
SQL TYPE IS RESULT_SET_LOCATOR *loc1, *loc2, *loc3;
/* Locator variables
EXEC SQL END DECLARE SECTION;
*/
*/
/*************************************************************/
/* Allocate the SQLDAs to be used for DESCRIBE
*/
/* PROCEDURE and DESCRIBE CURSOR. Assume that at most
*/
/* three cursors are returned and that each result set
*/
/* has no more than five columns.
*/
/*************************************************************/
proc_da = (struct sqlda *)malloc(SQLDASIZE(3));
res_da = (struct sqlda *)malloc(SQLDASIZE(5));
/************************************************************/
/* Call the GETPRML stored procedure to retrieve the
*/
/* RUNOPTS values for the stored procedure.
In this
*/
/* example, we request the PARMLIST definition for the
*/
/* stored procedure named DSN8EP2.
*/
/*
*/
/* The call should complete with SQLCODE +466 because
*/
/* GETPRML returns result sets.
*/
/************************************************************/
strcpy(procnm,"dsn8ep2
");
/* Input parameter -- PROCEDURE to be found
*/
strcpy(schema,"
");
/* Input parameter -- Schema name for proc
*/
parmind.procnm_ind=0;
parmind.schema_ind=0;
parmind.out_code_ind=0;
/* Indicate that none of the input parameters */
/* have null values
*/
parmind.parmlst_ind=-1;
/* The parmlst parameter is an output parm.
*/
/* Mark PARMLST parameter as null, so the DB2 */
/* requester doesn’t have to send the entire */
/* PARMLST variable to the server. This
*/
/* helps reduce network I/O time, because
*/
/* PARMLST is fairly large.
*/
EXEC SQL
CALL GETPRML(:procnm INDICATOR :parmind.procnm_ind,
:schema INDICATOR :parmind.schema_ind,
:out_code INDICATOR :parmind.out_code_ind,
:parmlst INDICATOR :parmind.parmlst_ind);
if(SQLCODE!=+466)
/* If SQL CALL failed,
*/
{
/*
print the SQLCODE and any
*/
/*
message tokens
*/
printf("SQL CALL failed due to SQLCODE =
printf("sqlca.sqlerrmc = ");
for(i=0;i<sqlca.sqlerrml;i++)
printf("i]);
printf("n");
}
368
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-384-320.jpg)





![Example C stored procedure with a GENERAL linkage
convention
This example shows how to call a stored procedure that uses the GENERAL
linkage convention from a C program.
This example stored procedure does the following:
v Searches the DB2 catalog table SYSROUTINES for a row that matches the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
v Searches the DB2 catalog table SYSTABLES for all tables in which the value of
CREATOR matches the value of input parameter SCHEMA. The stored
procedure uses a cursor to return the table names.
The linkage convention used for this stored procedure is GENERAL.
The output parameters from this stored procedure contain the SQLCODE from the
SELECT statement and the value of the RUNOPTS column from SYSROUTINES.
The CREATE PROCEDURE statement for this stored procedure might look like
this:
CREATE PROCEDURE GETPRML(PROCNM CHAR(18) IN, SCHEMA CHAR(8) IN,
OUTCODE INTEGER OUT, PARMLST VARCHAR(254) OUT)
LANGUAGE C
DETERMINISTIC
READS SQL DATA
EXTERNAL NAME "GETPRML"
COLLID GETPRML
ASUTIME NO LIMIT
PARAMETER STYLE GENERAL
STAY RESIDENT NO
RUN OPTIONS "MSGFILE(OUTFILE),RPTSTG(ON),RPTOPTS(ON)"
WLM ENVIRONMENT SAMPPROG
PROGRAM TYPE MAIN
SECURITY DB2
RESULT SETS 2
COMMIT ON RETURN NO;
The following example is a C stored procedure with linkage convention GENERAL
#pragma runopts(plist(os))
#include <stdlib.h>
EXEC SQL INCLUDE SQLCA;
/***************************************************************/
/* Declare C variables for SQL operations on the parameters.
*/
/* These are local variables to the C program, which you must */
/* copy to and from the parameter list provided to the stored */
/* procedure.
*/
/***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char PROCNM[19];
char SCHEMA[9];
char PARMLST[255];
EXEC SQL END DECLARE SECTION;
/***************************************************************/
/* Declare cursors for returning result sets to the caller.
*/
/***************************************************************/
EXEC SQL DECLARE C1 CURSOR WITH RETURN FOR
SELECT NAME
FROM SYSIBM.SYSTABLES
374
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-390-320.jpg)
![WHERE CREATOR=:SCHEMA;
main(argc,argv)
int argc;
char *argv[];
{
/********************************************************/
/* Copy the input parameters into the area reserved in */
/* the program for SQL processing.
*/
/********************************************************/
strcpy(PROCNM, argv[1]);
strcpy(SCHEMA, argv[2]);
/********************************************************/
/* Issue the SQL SELECT against the SYSROUTINES
*/
/* DB2 catalog table.
*/
/********************************************************/
strcpy(PARMLST, "");
/* Clear PARMLST
*/
EXEC SQL
SELECT RUNOPTS INTO :PARMLST
FROM SYSIBM.ROUTINES
WHERE NAME=:PROCNM AND
SCHEMA=:SCHEMA;
/********************************************************/
/* Copy SQLCODE to the output parameter list.
*/
/********************************************************/
*(int *) argv[3] = SQLCODE;
/********************************************************/
/* Copy the PARMLST value returned by the SELECT back to*/
/* the parameter list provided to this stored procedure.*/
/********************************************************/
strcpy(argv[4], PARMLST);
/********************************************************/
/* Open cursor C1 to cause DB2 to return a result set
*/
/* to the caller.
*/
/********************************************************/
EXEC SQL OPEN C1;
}
Example C stored procedure with a GENERAL WITH NULLS
linkage convention
This example shows how to call a stored procedure that uses the GENERAL WITH
NULLS linkage convention from a C program.
This example stored procedure does the following:
v Searches the DB2 catalog table SYSROUTINES for a row that matches the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
v Searches the DB2 catalog table SYSTABLES for all tables in which the value of
CREATOR matches the value of input parameter SCHEMA. The stored
procedure uses a cursor to return the table names.
The linkage convention for this stored procedure is GENERAL WITH NULLS.
The output parameters from this stored procedure contain the SQLCODE from the
SELECT operation, and the value of the RUNOPTS column retrieved from the
SYSROUTINES table.
The CREATE PROCEDURE statement for this stored procedure might look like
this:
Chapter 3. Including DB2 queries in an application program
375](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-391-320.jpg)
![CREATE PROCEDURE GETPRML(PROCNM CHAR(18) IN, SCHEMA CHAR(8) IN,
OUTCODE INTEGER OUT, PARMLST VARCHAR(254) OUT)
LANGUAGE C
DETERMINISTIC
READS SQL DATA
EXTERNAL NAME "GETPRML"
COLLID GETPRML
ASUTIME NO LIMIT
PARAMETER STYLE GENERAL WITH NULLS
STAY RESIDENT NO
RUN OPTIONS "MSGFILE(OUTFILE),RPTSTG(ON),RPTOPTS(ON)"
WLM ENVIRONMENT SAMPPROG
PROGRAM TYPE MAIN
SECURITY DB2
RESULT SETS 2
COMMIT ON RETURN NO;
The following example is a C stored procedure with linkage convention GENERAL
WITH NULLS.
#pragma runopts(plist(os))
#include <stdlib.h>
EXEC SQL INCLUDE SQLCA;
/***************************************************************/
/* Declare C variables used for SQL operations on the
*/
/* parameters. These are local variables to the C program,
*/
/* which you must copy to and from the parameter list provided */
/* to the stored procedure.
*/
/***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char PROCNM[19];
char SCHEMA[9];
char PARMLST[255];
struct INDICATORS {
short int PROCNM_IND;
short int SCHEMA_IND;
short int OUT_CODE_IND;
short int PARMLST_IND;
} PARM_IND;
EXEC SQL END DECLARE SECTION;
/***************************************************************/
/* Declare cursors for returning result sets to the caller.
*/
/***************************************************************/
EXEC SQL DECLARE C1 CURSOR WITH RETURN FOR
SELECT NAME
FROM SYSIBM.SYSTABLES
WHERE CREATOR=:SCHEMA;
main(argc,argv)
int argc;
char *argv[];
{
/********************************************************/
/* Copy the input parameters into the area reserved in */
/* the local program for SQL processing.
*/
/********************************************************/
strcpy(PROCNM, argv[1]);
strcpy(SCHEMA, argv[2]);
/********************************************************/
376
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-392-320.jpg)
![/* Copy null indicator values for the parameter list.
*/
/********************************************************/
memcpy(&PARM_IND,(struct INDICATORS *) argv[5],
sizeof(PARM_IND));
/********************************************************/
/* If any input parameter is NULL, return an error
*/
/* return code and assign a NULL value to PARMLST.
*/
/********************************************************/
if (PARM_IND.PROCNM_IND<0 ||
PARM_IND.SCHEMA_IND<0 || {
*(int *) argv[3] = 9999;
/* set output return code */
PARM_IND.OUT_CODE_IND = 0;
/* value is not NULL
*/
PARM_IND.PARMLST_IND = -1;
/* PARMLST is NULL
*/
}
else {
/********************************************************/
/* If the input parameters are not NULL, issue the SQL */
/* SELECT against the SYSIBM.SYSROUTINES catalog
*/
/* table.
*/
/********************************************************/
strcpy(PARMLST, "");
/* Clear PARMLST
*/
EXEC SQL
SELECT RUNOPTS INTO :PARMLST
FROM SYSIBM.SYSROUTINES
WHERE NAME=:PROCNM AND
SCHEMA=:SCHEMA;
/********************************************************/
/* Copy SQLCODE to the output parameter list.
*/
/********************************************************/
*(int *) argv[3] = SQLCODE;
PARM_IND.OUT_CODE_IND = 0;
/* OUT_CODE is not NULL */
}
/********************************************************/
/* Copy the RUNOPTS value back to the output parameter */
/* area.
*/
/********************************************************/
strcpy(argv[4], PARMLST);
/********************************************************/
/* Copy the null indicators back to the output parameter*/
/* area.
*/
/********************************************************/
memcpy((struct INDICATORS *) argv[5],&PARM_IND,
sizeof(PARM_IND));
/********************************************************/
/* Open cursor C1 to cause DB2 to return a result set
*/
/* to the caller.
*/
/********************************************************/
EXEC SQL OPEN C1;
}
Example COBOL stored procedure with a GENERAL linkage
convention
This example shows how to call a stored procedure that uses the GENERAL
linkage convention from a COBOL program.
This example stored procedure does the following:
v Searches the catalog table SYSROUTINES for a row matching the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
Chapter 3. Including DB2 queries in an application program
377](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/85/DB2-Application-programming-and-sql-guide-393-320.jpg)









































































































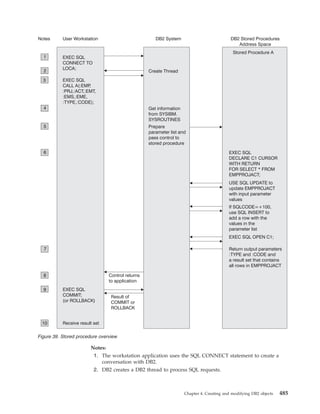























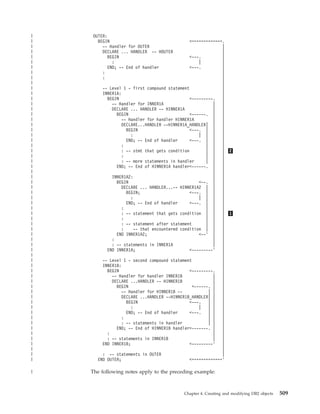




































































































































































































































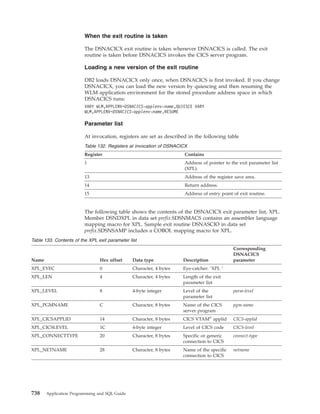























































































































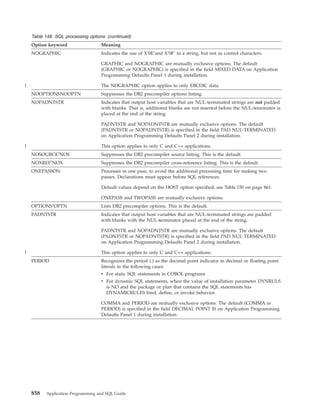














































































































































































































































































































![v Use LOB locators instead of LOB host variables.
If you need to store only a portion of a LOB value at the client, or if your
client program manipulates the LOB data but does not need a copy of it,
LOB locators are a good choice. When a client program retrieves a LOB
column from a server into a locator, DB2 transfers only the 4-byte locator
value to the client, not the entire LOB value.
v Use stored procedure result sets.
When you return LOB data to a client program from a stored procedure, use
result sets rather than passing the LOB data to the client in parameters.
Using result sets to return data causes less LOB materialization and less
movement of data among address spaces.
v Set the CURRENT RULES special register to DB2.
When a DB2 server receives an OPEN request for a cursor, the server uses
the value in the CURRENT RULES special register to determine the type of
host variables that the associated statement uses to retrieve LOB values. If
you specify a value of DB2 for the CURRENT RULES special register before
you perform a CONNECT, and the first FETCH statement for the cursor uses
a LOB locator to retrieve LOB column values, DB2 lets you use only LOB
locators for all subsequent FETCH statements for that column until you close
the cursor. If the first FETCH statement uses a host variable, DB2 lets you
use only host variables for all subsequent FETCH statements for that column
until you close the cursor. However, if you set the value of CURRENT
RULES to STD, DB2 lets you use the same open cursor to fetch a LOB
column into either a LOB locator or a host variable.
Although a value of STD for the CURRENT RULES special register gives you
more programming flexibility when you retrieve LOB data, you get better
performance if you use a value of DB2. With the STD option, the server must
send and receive network messages for each FETCH statement to indicate
whether the data that is being transferred is a LOB locator or a LOB value.
With the DB2 option, the server knows the size of the LOB data after the first
FETCH, so an extra message about LOB data size is unnecessary. The server
can send multiple blocks of data to the requester at one time, which reduces
the total time for data transfer.
For example, suppose that an end user wants to browse through a large set of
employee records and look at pictures of only a few of those employees. At the
server, you set the CURRENT RULES special register to DB2. In the application,
you declare and open a cursor to select employee records. The application then
fetches all picture data into 4-byte LOB locators. Because DB2 knows that 4
bytes of LOB data is returned for each FETCH statement, DB2 can fill the
network buffers with locators for many pictures. When a user wants to see a
picture for a particular person, the application can retrieve the picture from the
server by assigning the value that is referenced by the LOB locator to a LOB
host variable. This situation is implemented in the following code:
SQL TYPE IS BLOB my_blob[1M];
SQL TYPE IS BLOB AS LOCATOR my_loc;
.
.
.
FETCH C1 INTO :my_loc;
/* Fetch BLOB into LOB locator */
.
.
.
SET :my_blob = :my_loc; /* Assign BLOB to host variable */
Restriction: You must use DRDA access to access LOB columns in a remote
table.
5. Minimize the use of parameter markers.
34
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-50-2048.jpg)

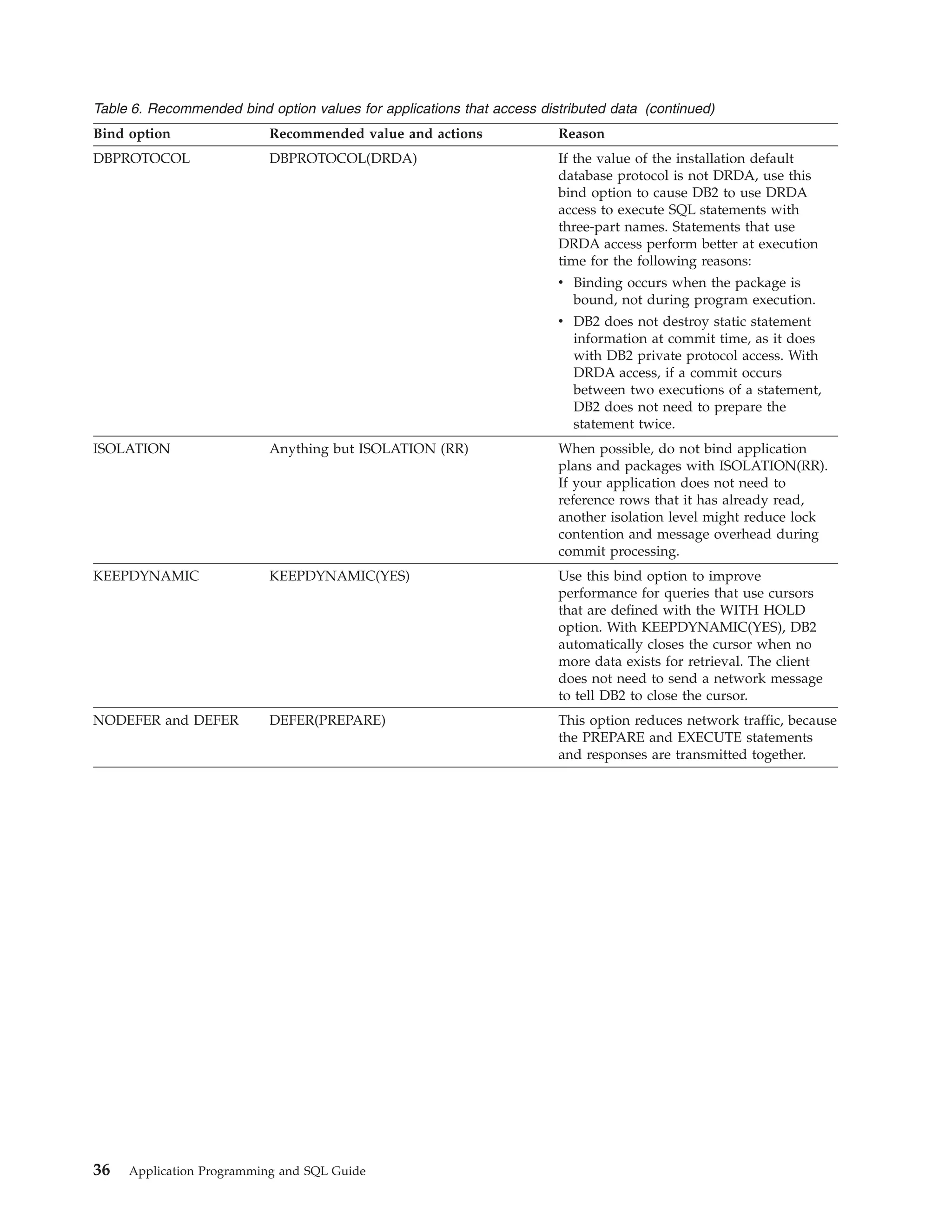











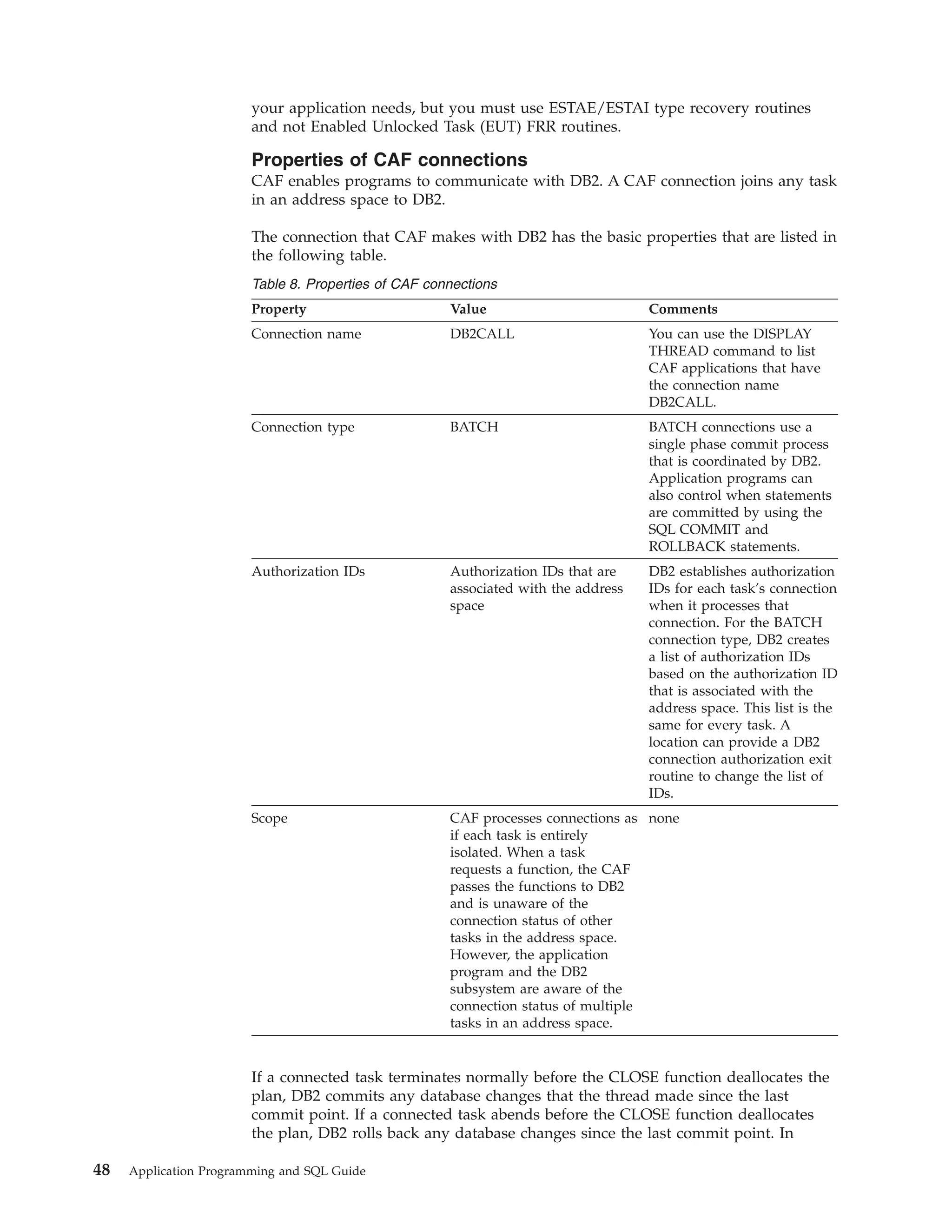







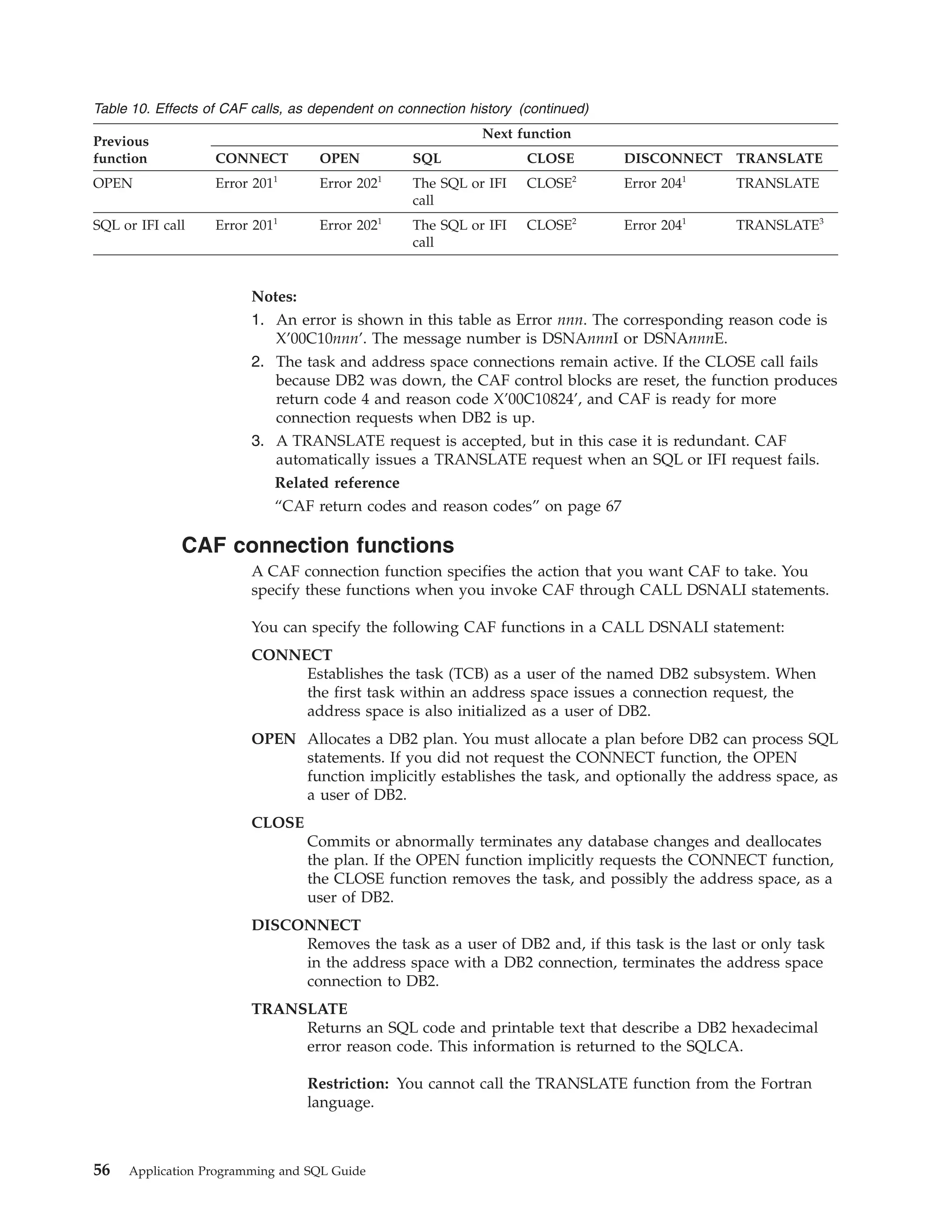



![example, you can determine the name of the data sharing group, the member
to which you are connecting, and whether the subsystem is in new-function
mode. If the DB2 subsystem that you connect to is not part of a data sharing
group, the fields in the EIB that are related to data sharing are blank. If the EIB
is not available (for example, if you name a subsystem that does not exist),
DB2 sets the 4-byte area to zeros.
The area to which eibptr points is below the 16-MB line.
You can omit this parameter when you make a CONNECT call.
If you specify this parameter in any language except assembler, you must also
specify retcode, reascode, and srdura. In assembler language, you can omit
retcode, reascode, and srdura by specifying commas as placeholders.
Macro DSNDEIB maps the EIB. It can be found in
prefix.SDSNMACS(DSNDEIB).
|
|
|
|
|
|
|
groupoverride
An 8-byte area that the application provides. This parameter is optional. If you
do not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If
groupoverride is not provided, ssnm is used as the group attachment name if it
matches a group attachment name.
|
|
|
If you specify this parameter in any language except assembler, you must also
specify retcode, reascode, srdura, and eibptr. In assembler language, you can omit
retcode, reascode, srdura, and eibptr by specifying commas as placeholders.
|
|
|
|
|
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Example of CAF CONNECT function calls
The following table shows a CONNECT call in each language.
Table 12. Examples of CAF CONNECT function calls
Language
Call example
Assembler
CALL
DSNALI,(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR, GRPOVER)
C1
fnret=dsnali(&functn[0],&ssid[0], &tecb, &secb,&ribptr,&retcode, &reascode, &srdura[0],
&eibptr, &grpover[0]);
COBOL
CALL ’DSNALI’ USING FUNCTN SSID TERMECB STARTECB RIBPTR RETCODE REASCODE SRDURA
EIBPTR GRPOVER.
Fortran
CALL
DSNALI(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR,GRPOVER)
PL/I1
CALL
DSNALI(FUNCTN,SSID,TERMECB,STARTECB,RIBPTR,RETCODE,REASCODE,SRDURA,
EIBPTR,GRPOVER)
Note:
60
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-76-2048.jpg)

![reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
groupoverride
An 8-byte area that the application provides. This field is optional. If you do
not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If you
do not specify groupoverride, ssnm is used as the group attachment name if it
matches a group attachment name. If you specify this parameter in any
language except assembler, you must also specify retcode and reascode. In
assembler language, you can omit these parameters by specifying commas as
placeholders.
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Examples of CAF OPEN calls
The following table shows an OPEN call in each language.
Table 13. Examples of CAF OPEN calls
Language
Call example
Assembler
CALL
C
1
DSNALI,(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER)
fnret=dsnali(&functn[0],&ssid[0], &planname[0],&retcode, &reascode,&grpover[0]);
COBOL
CALL
’DSNALI’ USING FUNCTN SSID PLANNAME RETCODE REASCODE GRPOVER.
Fortran
CALL
DSNALI(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER)
PL/I1
CALL
DSNALI(FUNCTN,SSID,PLANNAME, RETCODE,REASCODE,GRPOVER);
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related concepts
“Implicit connections to CAF” on page 52
Related tasks
“Invoking the call attachment facility” on page 44
CLOSE function for CAF
The CAF CLOSE function deallocates the plan that was created either explicitly by
a call to the OPEN function or implicitly at the first SQL call. Optionally, the
CLOSE function also disconnects the task, and possibly the address space, from
DB2.
If you did not issue an explicit CONNECT call for the task, the CLOSE function
deletes the task’s connection to DB2. If no other task in the address space has an
62
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-78-2048.jpg)

![reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF CLOSE calls
The following table shows a CLOSE call in each language.
Table 14. Examples of CAF CLOSE calls
Language
Call example
Assembler
CALL
C
1
DSNALI,(FUNCTN,TERMOP,RETCODE, REASCODE)
fnret=dsnali(&functn[0], &termop[0], &retcode,&reascode);
COBOL
CALL
’DSNALI’ USING FUNCTN TERMOP RETCODE REASCODE.
Fortran
CALL
DSNALI(FUNCTN,TERMOP, RETCODE,REASCODE)
CALL
DSNALI(FUNCTN,TERMOP, RETCODE,REASCODE);
PL/I
1
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
DISCONNECT function for CAF
The CAF DISCONNECT function terminates a connection to DB2.
DISCONNECT removes the calling task’s connection to DB2. If no other task in the
address space has an active connection to DB2, DB2 also deletes the control block
structures that were created for the address space and removes the cross memory
authorization.
If an OPEN call is in effect, which means that a plan is allocated, when the
DISCONNECT call is issued, CAF issues an implicit CLOSE with the SYNC
parameter.
Using the DISCONNECT function is optional. Consider the following rules and
recommendations about when to use and not use the DISCONNECT function:
v Only those tasks that explicitly issued a CONNECT call can issue a
DISCONNECT call. If a CONNECT call was not used, a DISCONNECT call
causes an error.
v When shutting down your application you can improve the performance of this
shut down by explicitly calling the DISCONNECT function before the task
terminates. If you omit the DISCONNECT call, DB2 performs an implicit
DISCONNECT. In this case, DB2 performs the same actions when your task
terminates.
v If DB2 terminates, any task that issued a CONNECT call must issue a
DISCONNECT call to reset the CAF control blocks. The DISCONNECT function
returns the reset accomplished return codes and reason codes (+004 and
X’00C10824’). This action ensures that future connection requests from the task
work when DB2 is back on line.
64
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-80-2048.jpg)
![v A task that did not explicitly issue a CONNECT call must issue a CLOSE call
instead of a DISCONNECT call. This action resets the CAF control blocks when
DB2 terminates.
The following diagram shows the syntax for the DISCONNECT function.
DSNALI DISCONNECT function
CALL DSNALI ( function
)
, retcode
, reascode
The single parameter points to the following area:
function
A 12-byte area that contains the word DISCONNECT followed by two blanks.
retcode
A 4-byte area in which CAF places the return code.
This field is optional. If you do not specify retcode, CAF places the return code
in register 15 and the reason code in register 0.
reascode
A 4-byte area in which CAF places a reason code.
This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF DISCONNECT calls
The following table shows a DISCONNECT call in each language.
Table 15. Examples of CAF DISCONNECT calls
Language
Call example
Assembler
CALL
C
1
DSNALI(,FUNCTN,RETCODE,REASCODE)
fnret=dsnali(&functn[0], &retcode, &reascode);
COBOL
CALL
’DSNALI’ USING FUNCTN RETCODE REASCODE.
Fortran
CALL
DSNALI(FUNCTN,RETCODE,REASCODE)
CALL
DSNALI(FUNCTN,RETCODE,REASCODE);
PL/I
1
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
Chapter 2. Connecting to DB2 from your application program
65](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-81-2048.jpg)

![This field is optional. If you do not specify reascode, CAF places the reason
code in register 0. If you specify reascode, you must also specify retcode.
Examples of CAF TRANSLATE calls
The following table shows a TRANSLATE call in each language.
Table 16. Examples of CAF TRANSLATE calls
Language
Call example
Assembler
CALL
C
1
fnret=dsnali(&functn[0], &sqlca, &retcode, &reascode);
COBOL
PL/I
DSNALI,(FUNCTN,SQLCA,RETCODE, REASCODE)
1
CALL
’DSNALI’ USING FUNCTN SQLCA RETCODE REASCODE.
CALL
DSNALI(FUNCTN,SQLCA,RETCODE, REASCODE);
Note:
v For C and PL/I applications, you must include the appropriate compiler
directives, because DSNALI is an assembler language program. These compiler
directives are described in the instructions for invoking CAF.
Related tasks
“Invoking the call attachment facility” on page 44
Turning on a CAF trace
CAF does not capture any diagnostic trace messages unless you tell it to by
turning on a trace.
To turn on a CAF trace:
Allocate a DSNTRACE data set either dynamically or by including a DSNTRACE
DD statement in your JCL. CAF writes diagnostic trace messages to that data set.
The trace message numbers contain the last three digits of the reason codes.
Related concepts
“Examples of invoking CAF” on page 69
CAF return codes and reason codes
CAF provides the return codes and reason codes either to the corresponding
parameters that are specified in a CAF function call or, if you choose not to use
those parameters, to registers 15 and 0.
When the reason code begins with X’00F3’ except for X’00F30006’, you can use the
CAF TRANSLATE function to obtain error message text that can be printed and
displayed. These reason codes are issued by the subsystem support for allied
memories, a part of the DB2 subsystem support subcomponent that services all
DB2 connection and work requests.
For SQL calls, CAF returns standard SQL codes in the SQLCA. CAF returns IFI
return codes and reason codes in the instrumentation facility communication area
(IFCA).
The following table lists the CAF return codes and reason codes.
Chapter 2. Connecting to DB2 from your application program
67](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-83-2048.jpg)





















![|
|
|
block that was loaded by subsystem ssnm when that subsystem was started.
This 4-byte area is a 31-bit pointer. If ssnm is not found, the 4-byte area is set to
0.
|
The area to which decpptr points is above the 16-MB line.
|
|
|
|
If you specify this parameter in any language except assembler, you must also
specify the retcode, reascode, and groupoverride parameters. In assembler
language, you can omit the retcode, reascode, and groupoverride parameters by
specifying commas as placeholders.
Example of RRSAF IDENTIFY function calls
The following table shows an IDENTIFY call in each language.
Table 25. Examples of RRSAF IDENTIFY calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR)
fnret=dsnrli(&idfyfn[0],&ssnm[0], &ribptr, &eibptr, &termecb, &startecb, &retcode,
&reascode,&grpover[0],&decpptr);
COBOL
CALL ’DSNRLI’ USING IDFYFN SSNM RIBTPR EIBPTR TERMECB STARTECB RETCODE REASCODE GRPOVER
DECPPTR.
Fortran
CALL
DSNRLI(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR)
CALL
DSNRLI(IDFYFN,SSNM,RIBPTR,EIBPTR,TERMECB,STARTECB, RETCODE,REASCODE,GRPOVER,DECPPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Internal processing for the IDENTIFY function
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
When you call the IDENTIFY function, DB2 performs the following steps:
1. DB2 determines whether the user address space is authorized to connect to
DB2. DB2 invokes the z/OS SAF and passes a primary authorization ID to SAF.
That authorization ID is the 7-byte user ID that is associated with the address
space, unless an authorized function has built an ACEE for the address space.
If an authorized function has built an ACEE, DB2 passes the 8-byte user ID
from the ACEE. SAF calls an external security product, such as RACF, to
determine if the task is authorized to use the following items:
v The DB2 resource class (CLASS=DSNR)
v The DB2 subsystem (SUBSYS=ssnm)
v Connection type RRSAF
2. If that check is successful, DB2 calls the DB2 connection exit routine to perform
additional verification and possibly change the authorization ID.
3. DB2 searches for a matching trusted context in the system cache and then the
catalog based on the following criteria:
v The primary authorization ID matches a trusted context SYSTEM AUTHID.
v The job or started task name matches the JOBNAME attribute that is defined
for the identified trusted context.
If a trusted context is defined, DB2 checks if SECURITY LABEL is defined in
the trusted context. If SECURITY LABEL is defined, DB2 verifies the SECURITY
LABEL with RACF by using the RACROUTE VERIFY request. This security
Chapter 2. Connecting to DB2 from your application program
89](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-105-2048.jpg)

![If you specify this parameter, you must also specify retcode.
|
|
|
|
|
|
groupoverride
An 8-byte area that the application provides. This parameter is optional. If you
do not want group attach to be attempted, specify ’NOGROUP’. This string
indicates that the subsystem name that is specified by ssnm is to be used as a
DB2 subsystem name, even if ssnm matches a group attachment name. If
groupoverride is not provided, ssnm is used as the group attachment name if it
matches a group attachment name.
|
|
|
|
If you specify this parameter in any language except assembler, you must also
specify the retcode and reascode parameters. In assembler language, you can
omit the retcode and reascode parameters by specifying commas as
place-holders.
|
|
|
|
|
|
Recommendation: Avoid using the groupoverride parameter when possible,
because it limits the ability to do dynamic workload routing in a Parallel
Sysplex. However, you should use this parameter in a data sharing
environment when you want to connect to a specific member of a data sharing
group, and the subsystem name of that member is the same as the group
attachment name.
Examples
Examples of RRSAF SWITCH TO calls: The following table shows a SWITCH TO
call in each language.
Table 26. Examples of RRSAF SWITCH TO calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SWITCHFN,SSNM,RETCODE,REASCODE,GRPOVER)
fnret=dsnrli(&switchfn[0], &ssnm[0], &retcode, &reascode,&grpover[0]);
COBOL
CALL
’DSNRLI’ USING SWITCHFN RETCODE REASCODE GRPOVER.
Fortran
CALL
DSNRLI(SWITCHFN,RETCODE,REASCODE,GRPOVER)
PL/I1
CALL
DSNRLI(SWITCHFN,RETCODE,REASCODE,GRPOVER);
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Example of using the SWITCH TO function to interact with multiple DB2
subsystems: The following example shows how you can use the SWITCH TO
function to interact with three DB2 subsystems.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
RRSAF calls for subsystem db21:
IDENTIFY
SIGNON
CREATE THREAD
Execute SQL on subsystem db21
SWITCH TO db22
IF retcode = 4 AND reascode = ’00C12205’X THEN
DO;
RRSAF calls on subsystem db22:
IDENTIFY
SIGNON
CREATE THREAD
END;
Execute SQL on subsystem db22
SWITCH TO db23
IF retcode = 4 AND reascode = ’00C12205’X THEN
Chapter 2. Connecting to DB2 from your application program
91](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-107-2048.jpg)




![Table 28. Examples of RRSAF SIGNON calls
Language
Call example
assembler
CALL
C
1
DSNRLI,(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR)
fnret=dsnrli(&sgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &retcode, &reascode,
&userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING SGNONFN CORRID ACCTTKN ACCTINT RETCODE REASCODE USERID APPLNAME WSNAME
XIDPTR.
Fortran
CALL
DSNRLI(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR)
CALL
DSNRLI(SGNONFN,CORRID,ACCTTKN,ACCTINT, RETCODE,REASCODE,USERID,APPLNAME,WSNAME,XIDPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related information
z/OS Internet Library at ibm.com
AUTH SIGNON function for RRSAF
The RRSAF AUTH SIGNON function enables an APF-authorized program to pass
to DB2 either a primary authorization ID and, optionally, one or more secondary
authorization IDs, or an ACEE that is used for authorization checking. These IDs
are then associated with the connection.
Generally, you issue an AUTH SIGNON call after an IDENTIFY call and before a
CREATE THREAD call. You can also issue an AUTH SIGNON call if the
application is at a point of consistency, and one of the following conditions is true:
v The value of reuse in the CREATE THREAD call was RESET.
v The value of reuse in the CREATE THREAD call was INITIAL, no held cursors
are open, the package or plan is bound with KEEPDYNAMIC(NO), and all
special registers are at their initial state. If open held cursors exist or the package
or plan is bound with KEEPDYNAMIC(YES), a SIGNON call is permitted only if
the primary authorization ID has not changed.
The following diagram shows the syntax for the AUTH SIGNON function.
DSNRLI AUTH SIGNON function
CALL DSNRLI ( function, correlation-id, accounting-token,
accounting-interval, primary-authid, ACEE-address, secondary-authid
)
,retcode
,reascode
,user
,appl
,ws
,xid
,accounting-string
96
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-112-2048.jpg)



![Table 29. Examples of RRSAF AUTH SIGNON calls (continued)
Language
C
1
Call example
fnret=dsnrli(&asgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &pauthid[0], &aceeptr,
&sauthid[0], &retcode, &reascode, &userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING ASGNONFN CORRID ACCTTKN ACCTINT PAUTHID ACEEPTR SAUTHID RETCODE REASCODE
USERID APPLNAME WSNAME XIDPTR.
Fortran
CALL DSNRLI(ASGNONFN,CORRID,ACCTTKN,ACCTINT,PAUTHID,ACEEPTR, SAUTHID,RETCODE,REASCODE,USERID,
APPLNAME,WSNAME,XIDPTR)
PL/I1
CALL DSNRLI(ASGNONFN,CORRID,ACCTTKN,ACCTINT,PAUTHID,ACEEPTR, SAUTHID,RETCODE,REASCODE,USERID,
APPLNAME,WSNAME,XIDPTR);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related reference
“SIGNON function for RRSAF” on page 92
CONTEXT SIGNON function for RRSAF
The RRSAF CONTEXT SIGNON function establishes a primary authorization ID
and one or more secondary authorization IDs for a connection.
Requirement: Before you invoke CONTEXT SIGNON, you must have called the
RRS context services function Set Context Data (CTXSDTA) to store a primary
authorization ID and optionally, the address of an ACEE in the context data whose
context key you supply as input to CONTEXT SIGNON.
The CONTEXT SIGNON function uses the context key to retrieve the primary
authorization ID from data that is associated with the current RRS context. DB2
uses the RRS context services function Retrieve Context Data (CTXRDTA) to
retrieve context data that contains the authorization ID and ACEE address. The
context data must have the following format:
Version number
A 4-byte area that contains the version number of the context data. Set this
area to 1.
Server product name
An 8-byte area that contains the name of the server product that set the
context data.
ALET
A 4-byte area that can contain an ALET value. DB2 does not reference this
area.
ACEE address
A 4-byte area that contains an ACEE address or 0 if an ACEE is not
provided. DB2 requires that the ACEE is in the home address space of the
task.
If you pass an ACEE address, the CONTEXT SIGNON function uses the
value in ACEEGRPN as the secondary authorization ID if the length of the
group name (ACEEGRPL) is not 0.
100
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-116-2048.jpg)



![accounting-string
A one-byte length field and a 255-byte area in which you can put a value for a
DB2 accounting string. This value is placed in the DDF accounting trace
records in the QMDASQLI field, which is mapped by DSNDQMDA DSECT. If
accounting-string is less than 255 characters, you must pad it on the right with
zeros to a length of 255 bytes. The entire 256 bytes is mapped by DSNDQMDA
DSECT.
This parameter is optional. If you specify this accounting-string, you must also
specify retcode, reascode, user, appl and xid. If you do not specify this parameter,
no accounting string is associated with the connection.
You can also change the value of the accounting string with RRSAF functions
AUTH SIGNON, CONTEXT SIGNON, or SET_CLIENT_ID.
You can retrieve the DDF suffix portion of the accounting string with the
CURRENT CLIENT_ACCTNG special register. The suffix portion of
accounting-string can contain a maximum of 200 characters. The QMDASFLN
field contains the accounting suffix length, and the QMDASUFX field contains
the accounting suffix value. If the DDF accounting string is set, you cannot
query the accounting token with the CURRENT CLIENT_ACCTNG special
register.
Example of RRSAF CONTEXT SIGNON calls
The following table shows a CONTEXT SIGNON call in each language.
Table 30. Examples of RRSAF CONTEXT SIGNON calls
Language
Call example
Assembler
CALL DSNRLI,(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE,USERID,APPLNAME,
WSNAME,XIDPTR)
C1
fnret=dsnrli(&csgnonfn[0], &corrid[0], &accttkn[0], &acctint[0], &ctxtkey[0], &retcode,
&reascode, &userid[0], &applname[0], &wsname[0], &xidptr);
COBOL
CALL ’DSNRLI’ USING CSGNONFN CORRID ACCTTKN ACCTINT CTXTKEY RETCODE REASCODE USERID APPLNAME
WSNAME XIDPTR.
Fortran
CALL DSNRLI(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE, USERID,APPLNAME,
WSNAME,XIDPTR)
PL/I1
CALL DSNRLI(CSGNONFN,CORRID,ACCTTKN,ACCTINT,CTXTKEY, RETCODE,REASCODE,USERID,APPLNAME,
WSNAME,XIDPTR);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Related reference
“SIGNON function for RRSAF” on page 92
SET_ID function for RRSAF
The RRSAF SET_ID function sets a new value for the client program ID that can be
used to identify the end user. The function then passes this information to DB2
when the next SQL request is processed.
The following diagram shows the syntax of the SET_ID function.
104
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-120-2048.jpg)
![DSNRLI SET_ID function
CALL DSNRLI ( function, program-id
)
, retcode
, reascode
Parameters point to the following areas:
function
An 18-byte area that contains SET_ID followed by 12 blanks.
program-id
An 80-byte area that contains the caller-provided string to be passed to DB2. If
program-id is less than 80 characters, you must pad it with blanks on the right
to a length of 80 characters.
DB2 places the contents of program-id into IFCID 316 records, along with other
statistics, so that you can identify which program is associated with a
particular SQL statement.
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF SET_ID calls
The following table shows a SET_ID call in each language.
Table 31. Examples of RRSAF SET_ID calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SETIDFN,PROGID,RETCODE,REASCODE)
fnret=dsnrli(&setidfn[0], &progid[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING SETIDFN PROGID RETCODE REASCODE.
Fortran
CALL
DSNRLI(SETIDFN,PROGID,RETCODE,REASCODE)
CALL
DSNRLI(SETIDFN,PROGID,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Chapter 2. Connecting to DB2 from your application program
105](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-121-2048.jpg)


![Example of RRSAF SET_CLIENT_ID calls
The following table shows a SET_CLIENT_ID call in each language.
Table 32. Examples of RRSAF SET_CLIENT_ID calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE)
fnret=dsnrli(&seclidfn[0], &acct[0], &user[0], &appl[0], &ws[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING SECLIDFN ACCT USER APPL WS RETCODE REASCODE.
Fortran
CALL
DSNRLI(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE)
CALL
DSNRLI(SECLIDFN,ACCT,USER,APPL,WS,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
CREATE THREAD function for RRSAF
The RRSAF CREATE THREAD function allocates the DB2 resources that are
required for an application to issue SQL or IFI requests. This function must
complete before the application can execute SQL statements or IFI requests.
The following diagram shows the syntax of the CREATE THREAD function.
DSNRLI CREATE THREAD function
CALL DSNRLI ( function, plan, collection, reuse
)
, retcode
, reascode
, pklistptr
Parameters point to the following areas:
function
An 18-byte area that contains CREATE THREAD followed by five blanks.
plan
An 8-byte DB2 plan name. RRSAF allocates the named plan.
If you provide a collection name instead of a plan name, specify the question
mark character (?) in the first byte of this field. DB2 then allocates a special
plan named ?RRSAF and uses the value that you specify for collection . When
DB2 allocates a plan named ?RRSAF, DB2 checks authorization to execute the
package in the same way as it checks authorization to execute a package from
a requester other than DB2 for z/OS.
108
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-124-2048.jpg)

![v The collection names that you specify in the data area to which pklistptr
points
v An entry that contains * for the location, collection ID, and package name
If you also specify collection, DB2 ignores that value.
Each collection entry must be of the form collection-ID.*, *.collection-ID.*, or *.*.*.
collection-ID and must follow the naming conventions for a collection ID, as
described in the description of the BIND and REBIND options.
DB2 uses the collection names to locate a package that is associated with the
first SQL statement in the program. The entry that contains *.*.* lets the
application access remote locations and access packages in collections other
than the default collection that is specified at create thread time.
The application can use the SET CURRENT PACKAGESET statement to change
the collection ID that DB2 uses to locate a package.
This parameter is optional. If you specify this parameter, you must also specify
retcode and reascode.
If you provide a plan name in the plan field, DB2 ignores the pklistptr value.
Recommendation: Using a package list can have a negative impact on
performance. For better performance, specify a short package list.
Example of RRSAF CREATE THREAD calls
The following table shows a CREATE THREAD call in each language.
Table 33. Examples of RRSAF CREATE THREAD calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLISTPTR)
fnret=dsnrli(&crthrdfn[0], &plan[0], &collid[0], &reuse[0], &retcode, &reascode, &pklistptr);
COBOL
CALL
’DSNRLI’ USING CRTHRDFN PLAN COLLID REUSE RETCODE REASCODE PKLSTPTR.
Fortran
CALL
DSNRLI(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLSTPTR)
CALL
DSNRLI(CRTHRDFN,PLAN,COLLID,REUSE,RETCODE,REASCODE,PKLSTPTR);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
″Authorizing plan or package access through applications″ (DB2 Administration
Guide)
Related reference
″BIND and REBIND options″ (DB2 Command Reference)
TERMINATE THREAD function for RRSAF
The RRSAF TERMINATE THREAD function deallocates DB2 resources that are
associated with a plan and were previously allocated for an application by the
110
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-126-2048.jpg)
![CREATE THREAD function. You can then use the CREATE THREAD function to
allocate another plan with the same connection.
If you call the TERMINATE THREAD function and the application is not at a point
of consistency, RRSAF returns reason code X’00C12211’.
The following diagram shows the syntax of the TERMINATE THREAD function.
DSNRLI TERMINATE THREAD function
CALL DSNRLI ( function,
)
, retcode
,
reascode
Parameters point to the following areas:
function
An 18-byte area the contains TERMINATE THREAD followed by two blanks.
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode, RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF TERMINATE THREAD calls
The following table shows a TERMINATE THREAD call in each language.
Table 34. Examples of RRSAF TERMINATE THREAD calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(TRMTHDFN,RETCODE,REASCODE)
fnret=dsnrli(&trmthdfn[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING TRMTHDFN RETCODE REASCODE.
Fortran
CALL
DSNRLI(TRMTHDFN,RETCODE,REASCODE)
CALL
DSNRLI(TRMTHDFN,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
Chapter 2. Connecting to DB2 from your application program
111](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-127-2048.jpg)

![Table 35. Examples of RRSAF TERMINATE IDENTIFY calls
Language
Call example
Assembler
CALL
C
1
DSNRLI,(TMIDFYFN,RETCODE,REASCODE)
fnret=dsnrli(&tmidfyfn[0], &retcode, &reascode);
COBOL
CALL
’DSNRLI’ USING TMIDFYFN RETCODE REASCODE.
Fortran
CALL
DSNRLI(TMIDFYFN,RETCODE,REASCODE)
CALL
DSNRLI(TMIDFYFN,RETCODE,REASCODE);
PL/I
1
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
TRANSLATE function for RRSAF
The RRSAF TRANSLATE function converts a hexadecimal reason code for a DB2
error into a signed integer SQL code and a printable error message. The SQL code
and message text are placed in the SQLCODE and SQLSTATE host variables or
related fields of the SQLCA.
Consider the following rules and recommendations about when to use and not use
the TRANSLATE function:
v You cannot call the TRANSLATE function from the Fortran language.
v Call the TRANSLATE function only after a successful IDENTIFY operation. For
errors that occur during SQL or IFI requests, the TRANSLATE function performs
automatically.
v The TRANSLATE function translates codes that begin with X’00F3’, but it does
not translate RRSAF reason codes that begin with X’00C1’.
If you receive error reason code X’00F30040’ (resource unavailable) after an OPEN
request, the TRANSLATE function returns the name of the unavailable database
object in the last 44 characters of the SQLERRM field.
If the TRANSLATE function does not recognize the error reason code, it returns
SQLCODE -924 (SQLSTATE ’58006’) and places a printable copy of the original
DB2 function code and the return and error reason codes in the SQLERRM field.
The contents of registers 0 and 15 do not change, unless TRANSLATE fails. In this
case, register 0 is set to X’00C12204’, and register 15 is set to 200.
The following diagram shows the syntax of the TRANSLATE function.
DSNRLI TRANSLATE function
CALL DSNRLI ( function, sqlca
)
,
retcode
, reascode
Chapter 2. Connecting to DB2 from your application program
113](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-129-2048.jpg)
![Parameters point to the following areas:
function
An 18-byte area that contains the word TRANSLATE followed by nine blanks.
sqlca
The program’s SQL communication area (SQLCA).
retcode
A 4-byte area in which RRSAF places the return code.
This parameter is optional. If you do not specify retcode, RRSAF places the
return code in register 15 and the reason code in register 0.
reascode
A 4-byte area in which RRSAF places the reason code.
This parameter is optional. If you do not specify reascode, RRSAF places the
reason code in register 0.
If you specify reascode, you must also specify retcode.
Example of RRSAF TRANSLATE calls
The following table shows a TRANSLATE call in each language.
Table 36. Examples of RRSAF TRANSLATE calls
Language
Call example
Assembler
CALL
C
1
fnret=dsnrli(&connfn[0], &sqlca, &retcode, &reascode);
COBOL
PL/I
DSNRLI,(XLATFN,SQLCA,RETCODE,REASCODE)
1
CALL
’DSNRLI’ USING XLATFN SQLCA RETCODE REASCODE.
CALL
DSNRLI(XLATFN,SQLCA,RETCODE,REASCODE);
Note:
1. For C, C++, and PL/I applications, you must include the appropriate compiler
directives, because DSNRLI is an assembler language program. These compiler
directives are described in the instructions for invoking RRSAF.
Related tasks
“Invoking the Resource Recovery Services attachment facility” on page 75
|
|
|
FIND_DB2_SYSTEMS function for RRSAF
|
The following diagram shows the syntax of the FIND_DB2_SYSTEMS function.
The RRSAF FIND_DB2_SYSTEMS function identifies all active DB2 subsystems on
a z/OS LPAR.
|
114
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-130-2048.jpg)











![Table 39. Declarations generated by DCLGEN
SQL data type1
C
COBOL
PL/I
SMALLINT
short int
PIC S9(4) USAGE COMP
BIN FIXED(15)
INTEGER
long int
PIC S9(9) USAGE COMP
BIN FIXED(31)
PIC S9(p-s)V9(s) USAGE COMP-3
DEC FIXED(p,s)
DECIMAL(p,s) or
NUMERIC(p,s)
decimal(p,s)
2
If p>15, the PL/I
compiler must
support this
precision, or a
warning is
generated.
REAL or FLOAT(n) float
1 <= n <= 21
USAGE COMP-1
BIN FLOAT(n)
DOUBLE
PRECISION,
DOUBLE, or
FLOAT(n)
double
USAGE COMP-2
BIN FLOAT(n)
CHAR(1)
char
PIC X(1)
CHAR(1)
CHAR(n)
char var [n+1]
PIC X(n)
CHAR(n)
VARCHAR(n)
struct
{short int var_len;
char var_data[n];
} var;
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC X(n).
CHAR(n) VAR
CLOB(n)3
SQL TYPE IS CLOB_LOCATOR
USAGE SQL TYPE IS CLOB-LOCATOR
SQL TYPE IS
CLOB_LOCATOR
GRAPHIC(1)
sqldbchar
PIC G(1)
GRAPHIC(1)
GRAPHIC(n)
sqldbchar var[n+1];
PIC G(n) USAGE
DISPLAY-1.4
or
PIC N(n).4
GRAPHIC(n)
VARGRAPHIC(n)
struct VARGRAPH
{short len;
sqldbchar data[n];
} var;
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC G(n)
USAGE DISPLAY-1.4
or
10 var.
49 var_LEN PIC 9(4)
USAGE COMP.
49 var_TEXT PIC N(n).4
GRAPHIC(n) VAR
DBCLOB(n)3
SQL TYPE IS DBCLOB_LOCATOR
USAGE SQL TYPE IS DBCLOB-LOCATOR
SQL TYPE IS
DBCLOB_LOCATOR
| BINARY(n)
|
SQL TYPE IS BINARY(n)
USAGE SQL TYPE IS BINARY(n)
SQL TYPE IS
BINARY(n)
| VARBINARY(n)
|
SQL TYPE IS VARBINARY(n)
USAGE SQL TYPE IS VARBINARY(n)
SQL TYPE IS
VARBINARY(n)
BLOB(n)3
SQL TYPE IS BLOB_LOCATOR
USAGE SQL TYPE IS BLOB-LOCATOR
SQL TYPE IS
BLOB_LOCATOR
DATE
char var[11]5
PIC X(10)5
CHAR(10)5
TIME
char var[9]6
PIC X(8)6
CHAR(8)6
TIMESTAMP
char var[27]
PIC X(26)
CHAR(26)
n>1
126
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-142-2048.jpg)






![If you leave this field blank, DCLGEN generates a name that contains the
table or view name with a prefix of DCL. If the language is COBOL or
PL/I, and the table or view name consists of a DBCS string, the prefix
consists of DBCS characters.
For C, lowercase characters you enter in this field do not fold to uppercase.
9 FIELD NAME PREFIX
Specifies a prefix that DCLGEN uses to form field names in the output. For
example, if you choose ABCDE, the field names generated are ABCDE1,
ABCDE2, and so on.
DCLGEN accepts a field name prefix of up to 28 bytes that can include
special and double-byte characters. If you specify a single-byte or
mixed-string prefix and the first character is not alphabetic, apostrophes
must enclose the prefix. If you use special characters, avoid name conflicts.
For COBOL and PL/I, if the name is a DBCS string, DCLGEN generates
DBCS equivalents of the suffix numbers. For C, lowercase characters you
enter in this field do not fold to uppercase.
If you leave this field blank, the field names are the same as the column
names in the table or view.
10 DELIMIT DBCS
Tells DCLGEN whether to delimit DBCS table names and column names in
the table declaration. Use:
YES to enclose the DBCS table and column names with SQL delimiters.
NO to not delimit the DBCS table and column names.
11 COLUMN SUFFIX
Tells DCLGEN whether to form field names by attaching the column name
as a suffix to the value you specify in FIELD NAME PREFIX. For example,
if you specify YES, the field name prefix is NEW, and the column name is
EMPNO, the field name is NEWEMPNO.
If you specify YES, you must also enter a value in FIELD NAME PREFIX.
If you do not enter a field name prefix, DCLGEN issues a warning
message and uses the column names as the field names.
The default is NO, which does not use the column name as a suffix and
allows the value in FIELD NAME PREFIX to control the field names, if
specified.
12 INDICATOR VARS
Tells DCLGEN whether to generate an array of indicator variables for the
host variable structure.
If you specify YES, the array name is the table name with a prefix of I (or
DBCS letter <I> if the table name consists solely of double-byte characters).
The form of the data declaration depends on the language:
For a C program: short int Itable-name[n];
For a COBOL program: 01 Itable-name PIC S9(4) USAGE COMP OCCURS
n TIMES.
For a PL/I program: DCL Itable-name(n) BIN FIXED(15);
n is the number of columns in the table. For example, suppose you define
the following table:
CREATE TABLE HASNULLS (CHARCOL1 CHAR(1), CHARCOL2 CHAR(1));
You request an array of indicator variables for a COBOL program.
DCLGEN might generate the following host variable declaration:
Chapter 3. Including DB2 queries in an application program
133](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-149-2048.jpg)


![v An SQLSTATE variable, which is declared as shown in the following table.
Table 41. SQLSTATE variable declarations
Language
How the SQLSTATE variable is declared
assembler
as a character string of length 5 (CL5)
C
as a character array of length 6
Example:
char SQLSTATE[6];
COBOL
Fortran
as PICTURE X(5)
1
PL/I
as CHARACTER*5
as CHARACTER(5)
Note:
1. In Fortran, this variable can also be called SQLSTA.
DB2 sets the SQLCODE (or SQLCOD) and SQLSTATE (or SQLSTA) values after
each SQL statement executes. An application should check these values to
determine whether the last SQL statement was successful. All SQL statements in
the program must be within the scope of the declaration of the SQLCODE and
SQLSTATE variables.
Whether you define the SQLCODE or SQLSTATE variable or an SQLCA in your
program depends on whether you specify the precompiler option STDSQL(YES) to
conform to the SQL standard, or STDSQL(NO) to conform to DB2 rules:
v If you specify the precompiler option STDSQL(YES): Do not define an SQLCA.
If you do, DB2 ignores your SQLCA, and your SQLCA definition causes
compile-time errors.
If you declare an SQLSTATE variable, it must not be an element of a structure.
You must declare the host variables SQLCODE (or SQLCOD) and SQLSTATE (or
SQLSTA) within a BEGIN DECLARE SECTION and END DECLARE SECTION
statement in your program declarations.
COBOL: When you use the precompiler option STDSQL(YES), you must declare
an SQLCODE variable. DB2 declares an SQLCA area for you in the
WORKING-STORAGE SECTION. DB2 controls the structure and location of the
SQLCA.
v If you specify the precompiler option STDSQL(NO): Include an SQLCA
explicitly.
REXX applications behave differently. When DB2 prepares a REXX procedure that
contains SQL statements, DB2 automatically includes an SQL communication area
(SQLCA) in the procedure. The REXX SQLCA differs from the SQLCA for other
languages in the following ways:
v The REXX SQLCA consists of a set of separate variables, rather than a structure.
If you use the ADDRESS DSNREXX ’CONNECT’ ssid syntax to connect to DB2, the
SQLCA variables are a set of simple variables.
If you connect to DB2 using the CALL SQLDBS ’ATTACH TO’ syntax, the SQLCA
variables are compound variables that begin with the stem SQLCA.
To define the SQL communications area:
1. Code the SQLCA directly in the program or use the following SQL INCLUDE
statement to request a standard SQLCA declaration.
136
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-152-2048.jpg)









![To insert multiple rows, you can use the form of the INSERT statement that selects
values from another table or view. You can also use a form of the INSERT
statement that inserts multiple rows from values that are provided in host variable
arrays. For more information, see “Inserting multiple rows of data from host
variable arrays” on page 182.
Example: The following example inserts a single row into the activity table:
EXEC SQL
INSERT INTO DSN8910.ACT
VALUES (:HV-ACTNO, :HV-ACTKWD, :HV-ACTDESC)
END-EXEC.
Changing the coded character set ID of host variables
All DB2 string data, other than binary data, has an encoding scheme and a coded
character set ID (CCSID) associated with it. You can associate an encoding scheme
and a CCSID with individual host variables. Any data in those host variable is
then associated with that encoding scheme and CCSID.
You can use the DECLARE VARIABLE statement to associate an encoding scheme
and a CCSID with individual host variables. The DECLARE VARIABLE statement
has the following effects on a host variable:
v When you use the host variable to update a table, the local subsystem or the
remote server assumes that the data in the host variable is encoded with the
CCSID and encoding scheme that the DECLARE VARIABLE statement assigns.
v When you retrieve data from a local or remote table into the host variable, the
retrieved data is converted to the CCSID and encoding scheme that are assigned
by the DECLARE VARIABLE statement.
You can use the DECLARE VARIABLE statement in static or dynamic SQL
applications. However, you cannot use the DECLARE VARIABLE statement to
control the CCSID and encoding scheme of data that you retrieve or update using
an SQLDA.
When you use a DECLARE VARIABLE statement in a program, put the DECLARE
VARIABLE statement after the corresponding host variable declaration and before
your first reference to that host variable.
Example: Using a DECLARE VARIABLE statement to change the encoding scheme
of retrieved data: Suppose that you are writing a C program that runs on a DB2
for z/OS subsystem. The subsystem has an EBCDIC application encoding scheme.
The C program retrieves data from the following columns of a local table that is
defined with CCSID UNICODE.
PARTNUM CHAR(10)
JPNNAME GRAPHIC(10)
ENGNAME VARCHAR(30)
Because the application encoding scheme for the subsystem is EBCDIC, the
retrieved data is EBCDIC. To make the retrieved data Unicode, use DECLARE
VARIABLE statements to specify that the data that is retrieved from these columns
is encoded in the default Unicode CCSIDs for the subsystem. Suppose that you
want to retrieve the character data in Unicode CCSID 1208 and the graphic data in
Unicode CCSID 1200. Use DECLARE VARIABLE statements like these:
EXEC SQL BEGIN DECLARE SECTION;
char hvpartnum[11];
EXEC SQL DECLARE :hvpartnum VARIABLE CCSID 1208;
sqldbchar hvjpnname[11];
EXEC SQL DECLARE :hvjpnname VARIABLE CCSID 1200;
146
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-162-2048.jpg)
![struct {
short len;
char d[30];
} hvengname;
EXEC SQL DECLARE :hvengname VARIABLE CCSID 1208;
EXEC SQL END DECLARE SECTION;
The BEGIN DECLARE SECTION and END DECLARE SECTION statements mark
the beginning and end of a host variable declare section.
Ensuring that DB2 correctly interprets character input data in
REXX programs
DB2 REXX Language Support can incorrectly interpret character literals as graphic
or numeric literals unless you mark them correctly.
To ensure that DB2 REXX Language Support does not interpret character literals as
graphic or numeric literals, precede and follow character literals with a double
quotation mark, followed by a single quotation mark, followed by another double
quotation mark ("’").
Enclosing the string in apostrophes is not adequate because REXX removes the
apostrophes when it assigns a literal to a variable. For example, suppose that you
want to pass the value in host variable stringvar to DB2. The value that you want
to pass is the string ’100’. The first thing that you need to do is to assign the string
to the host variable. You might write a REXX command like this:
stringvar = ’100’
After the command executes, stringvar contains the characters 100 (without the
apostrophes). DB2 REXX Language Support then passes the numeric value 100 to
DB2, which is not what you intended.
However, suppose that you write the command like this:
stringvar = "’"100"’"
In this case, REXX assigns the string ’100’ to stringvar, including the single
quotation marks. DB2 REXX Language Support then passes the string ’100’ to DB2,
which is the desired result.
Passing the data type of an input data type to DB2 for REXX
programs
In certain situations, you want to tell DB2 the data type to use for input data in a
REXX program. For example, if you are assigning or comparing input data to
columns of type SMALLINT, CHAR, or GRAPHIC, you should tell DB2 to use
those data types.
DB2 does not assign data types of SMALLINT, CHAR, or GRAPHIC to input data.
If you assign or compare this data to columns of type SMALLINT, CHAR, or
GRAPHIC, DB2 must do more work than if the data types of the input data and
columns match.
To indicate the data type of input data to DB2, use an SQLDA.
Example: Specifying CHAR: Suppose you want to tell DB2 that the data with
which you update the MIDINIT column of the EMP table is of type CHAR, rather
than VARCHAR. You need to set up an SQLDA that contains a description of a
CHAR column, and then prepare and execute the UPDATE statement using that
SQLDA:
Chapter 3. Including DB2 queries in an application program
147](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-163-2048.jpg)






![char
auto
extern
static
const
volatile
unsigned
,
variable-name
*pointer-name
[
length ]
;
=expression
Notes:
1. On input, the string contained by the variable must be NUL-terminated.
2. On output, the string is NUL-terminated.
3. A NUL-terminated character host variable maps to a varying-length character
string (except for the NUL).
4. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
The following diagram shows the syntax for declarations of varying-length
character host variables that use the VARCHAR structured form.
int
struct
auto
extern
static
const
volatile
{
short
var-1
;
tag
char var-2 [ length ]
;
}
unsigned
,
variable-name
*pointer-name
;
={expression, expression}
Notes:
1. You cannot use var-1 and var-2 as host variables in an SQL statement.
2. You can use the struct tag to define other variables, but you cannot use them as
host variables in SQL.
3. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Example: The following examples show valid and invalid declarations of the
VARCHAR structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable VARCHAR vstring */
struct VARCHAR {
short len;
char s[10];
154
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-170-2048.jpg)
![} vstring;
/* invalid declaration of host variable VARCHAR wstring */
struct VARCHAR wstring;
Graphic host variables in C or C++
The four valid forms for graphic host variables are:
v Single-graphic form
v NUL-terminated graphic form
v VARGRAPHIC structured form.
v DBCLOBs
Recommendation: Instead of using the C data type wchar_t to define graphic and
vargraphic host variables, use one of the following techniques:
v Define the sqldbchar data type by using the following typedef statement:
typedef unsigned short sqldbchar;
v Use the sqldbchar data type that is defined in the typedef statement in the
header files that are supplied by DB2.
v Use the C data type unsigned short.
The following diagrams show the syntax for forms other than DBCLOBs.
The following diagram shows the syntax for declarations of single-graphic host
variables.
,
sqldbchar
auto
extern
static
const
volatile
variable-name
*pointer-name
;
=expression
The single-graphic form declares a fixed-length graphic string of length 1. You
cannot use array notation in variable-name.
The following diagram shows the syntax for declarations of NUL-terminated
graphic host variables.
,
sqldbchar
auto
extern
static
const
volatile
variable-name
*pointer-name
[ length ]
;
=expression
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. On input, the string in variable-name must be NUL-terminated.
3. On output, the string is NUL-terminated.
4. The NUL-terminated graphic form does not accept single-byte characters into
variable-name.
5. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Chapter 3. Including DB2 queries in an application program
155](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-171-2048.jpg)
![The following diagram shows the syntax for declarations of graphic host variables
that use the VARGRAPHIC structured form.
int
struct
auto
extern
static
const
volatile
sqldbchar var-2 [ length ]
{
short
var-1
;
tag
;
}
,
variable-name
*pointer-name
;
={ expression, expression}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. var-1 must be less than or equal to length.
3. You cannot use var-1 and var-2 as host variables in an SQL statement.
4. You can use the struct tag to define other variables, but you cannot use them as
host variables in SQL.
5. The DB2 coprocessor is required if you use the pointer notation of the host
variable.
Example: The following examples show valid and invalid declarations of graphic
host variables that use the VARGRAPHIC structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable structured vgraph */
struct VARGRAPH {
short len;
sqldbchar d[10];
} vgraph;
/* invalid declaration of host variable structured wgraph */
struct VARGRAPH wgraph;
Binary host variables in C or C++
|
|
|
|
The three valid forms of BINARY host variables are:
v Fixed-length strings
v Varying-length strings
v BLOBs
|
|
The following diagram shows the syntax for declarations of BINARY host
variables. The following diagrams show the syntax for forms other than BLOBs.
156
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-172-2048.jpg)
![|
,
SQL TYPE IS BINARY ( length )
auto
extern
static
variable-name
;
const
volatile
|
|
|
Notes:
1. For BINARY host variables, the length must be in the range from 1 to 255.
|
|
The following diagram shows the syntax for declarations of VARBINARY host
variables.
|
|
SQL TYPE IS
auto
extern
static
|
|
const
volatile
(1)
VARBINARY
BINARY VARYING
( length )
,
variable-name
;
= { init-len , ″
init-data ″
}
|
|
Notes:
|
|
1
|
The C language does not have variables that correspond to the SQL binary data
types BINARY and VARBINARY. To create host variables that can be used with
these data types, use the SQL TYPE IS clause. The SQL precompiler replaces this
declaration with the C language structure in the output source member.
|
|
|
|
When you refer to a BINARY or VARBINARY host variable in an SQL statement,
you must use the variable that you specify in the SQL TYPE declaration. When
you refer to the host variable in a host language statement, you must use the
variable that DB2 generates.
|
|
Example: The following table shows examples of variables that DB2 generates
when you declare binary host variables.
|
Table 44. Examples of BINARY and VARBINARY variable declarations for C
|
You declare this variable
DB2 generates this variable
|
SQL TYPE IS BINARY(10) bin_var;
char bin_var[10]
|
|
|
|
|
SQL TYPE IS VARBINARY(10) vbin_var;
struct {
short length;
char data[10];
} vbin_var;
|
|
|
|
|
Important: Be careful when you use binary host variables with C and C++. The
SQL TYPE declaration for BINARY and VARBINARY does not account for the
NUL-terminator that C expects because binary strings are not NUL-terminated
strings. Furthermore, the binary host variable might contain zeroes at any point in
the string.
For VARBINARY host variables, the length must be in the range from 1 to
32 704.
Chapter 3. Including DB2 queries in an application program
157](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-173-2048.jpg)


![ROWIDs in C or C++
The following diagram shows the syntax for declarations of ROWID host variables.
See “Large objects (LOBs)” on page 390 for a discussion of how to use these host
variables.
auto
extern
static
register
const
volatile
variable-name
*pointer-name
SQL TYPE IS ROWID ;
Notes on C variable declaration and usage
You should be aware of the following considerations when you declare C variables.
C data types with no SQL equivalent: C supports some data types and storage
classes with no SQL equivalents, for example, register storage class, typedef, and
long long,.
SQL data types with no C equivalent: If your C compiler does not have a decimal
data type, no exact equivalent exists for the SQL DECIMAL data type. In this case,
to hold the value of such a variable, you can use:
v An integer or floating-point variable, which converts the value. If you choose
integer, you will lose the fractional part of the number. If the decimal number
can exceed the maximum value for an integer, or if you want to preserve a
fractional value, you can use floating-point numbers. Floating-point numbers are
approximations of real numbers. Therefore, when you assign a decimal number
to a floating-point variable, the result might be different from the original
number.
v A character-string host variable. Use the CHAR function to get a string
representation of a decimal number.
v The DECIMAL function to explicitly convert a value to a decimal data type, as
in this example:
long duration=10100;
char result_dt[11];
/* 1 year and 1 month */
EXEC SQL SELECT START_DATE + DECIMAL(:duration,8,0)
INTO :result_dt FROM TABLE1;
The SQL data type DECFLOAT also has no equivalent in C.
|
Floating-point host variables: All floating-point data is stored in DB2 in
z/Architecture hexadecimal floating-point format. However, your host variable
data can be in z/Architecture hexadecimal floating-point format or IEEE binary
floating-point format. DB2 uses the FLOAT precompiler option to determine
whether your floating-point host variables are in IEEE binary floating-point or
z/Architecture hexadecimal floating-point format. DB2 does no checking to
determine whether the contents of a host variable match the precompiler option.
Therefore, you need to ensure that your floating-point data format matches the
precompiler option.
Graphic host variables: You can define graphic host variables by using one of the
following techniques:
v Define the sqldbchar data type by using the following typedef statement:
|
|
|
160
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-176-2048.jpg)
![|
|
|
|
|
|
|
|
|
|
typedef unsigned short sqldbchar;
Use sqldbchar instead of wchar_t. Using sqldbchar or unsigned short lets you
manipulate DBCS and Unicode UTF-16 data in the same format in which it is
stored in DB2. Using sqldbchar also makes applications easier to port to other
DB2 platforms.
v Use the C data type unsigned short.
v Use the typedef statements in one of the following files or libraries:
1. SQL library, sql.h
2. DB2 CLI library, sqlcli.h
3. SQLUDF file in data set DSN910.SDSNC.H
|
Special locator C data types: The following locator data types are special SQL data
types that do not have C equivalents:
v Result set locator
v Table locator
v LOB locators
|
You cannot use them to define column types.
|
|
|
|
String host variables: For NUL-terminated string host variables, use the SQL
processing options PADNTSTR and NOPADNTSTR to specify whether the variable
should be padded with blanks. For a description of these options, see Table 148 on
page 854. The option that you specify determines where the NUL-terminator is
placed.
If you assign a string of length n to a NUL-terminated string host variable, the
variable has one of the values that is shown in the following table.
Table 45. Value of a NUL-terminated string host variable that is assigned a string of length n
If the length of the NUL-terminated string
host variable is...
Less than or equal to n
The variable is set to...
The source string up to a length of n-1 and a
NUL at the end of the string. 1
DB2 sets SQLWARN[1] to W and any
indicator variable that you provide to the
original length of the source string.
Equal to n+1
The source string and a NUL at the end of
the string. 1
Greater than n+1 and the source is a
fixed-length string
If PADNTSTR is in effect
The source string, blanks to pad the
value, and a NUL at the end of the
string.
If NOPADNTSTR is in effect
The source string and a NUL at the end
of the string.
Greater than n+1 and the source is a
varying-length string
The source string and a NUL at the end of
the string. 1
Note:
1. In these cases, whether NOPADNTSTR or PADNTSTR is in effect is irrelevant.
Chapter 3. Including DB2 queries in an application program
161](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-177-2048.jpg)


















![Pointers as host variables in C and C++
If you use the DB2 coprocessor, you can use pointer host variables with statically
or dynamically allocated storage. These pointer host variables can point to numeric
data, non-numeric data, or a structure.
To declare pointer host variables, use an asterisk (*) to indicate that the variable is
a pointer. To reference a pointer host variable in an SQL statement, specify the
pointer host variable exactly as it was declared.
You can use the following types of pointer host variables:
scalar pointer host variable
A host variable that points to numeric or non-numeric scalar data.
The following table shows example declarations of scalar pointer host
variables and example references to such variables.
Table 48. Example declarations of and references to scalar pointer host variables
Declaration
Description
Reference
short *hvshortp;
hvshortp is a pointer host variable that
points to two bytes of storage.
EXEC SQL set:*hvshortp=123;
double *hvdoubp;
hvdoubp is a pointer host variable that
points to eight bytes of storage.
EXEC SQL set:*hvdoubp=456;
char (*hvcharpn) [20];
hvcharpn is a pointer host variable that
points to a nul-terminated character array
of up to 20 bytes.
EXEC SQL set:
*hvcharpn=’nul_terminated’;
1
Note:
1. When you reference pointers to nul-terminated character arrays, you do
not have to include the parentheses that were part of the declaration.
Restriction: You cannot use pointer host variables that point to character
data of an unknown length. For example, the following specification is not
supported: char * hvcharpu.
Instead, for character pointer host variables, you must specify the length of
the data by using a bounded character pointer host variable. A bounded
character pointer host variable is a host variable that is declared as a structure
with the following two elements:
v A 4-byte field that contains the length of the storage area.
v A pointer to the non-numeric dynamic storage area.
Example of a bounded character pointer host variable: The following
example declares a bounded character pointer host variable called
hvbcharp with two elements: len and data:
struct {
unsigned long len;
char * data;
} hvbcharp;
The following example references this bounded character pointer host
variable:
180
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-196-2048.jpg)
![hvcharp.len = dynlen; 1
hvcharp.data = (char 8) malloc (hvcharp.len); 2
EXEC SQL set :hvcharp = ’data buffer with length’;
3
Note:
1. dynlen can be either a compile time constant or a variable with a value
that is assigned at run time.
2. Storage is dynamically allocated for hvcharp.data.
3. The SQL statement references the name of the structure, not an element
within the structure.
array pointer host variables
A host variable that is an array of pointers.
The following table shows example declarations of array pointer host
variables and examples references to such variables.
Table 49. Example declarations of and references to array pointer host variables
Declaration
Description
Reference
short * hvarrpl[6]
hvarrp1 is an array of 6 pointers that point EXEC SQL set:*hvarrpl[n]=123;
to two bytes of storage each.
double * hvarrp2[3]
hvarrp2 is an array of 3 pointers that point EXEC SQL set:*hvarrp2[n]=456;
to 8 bytes of storage each.
struct {
unsigned long len;
char * data; }
hvbarrp3[5];
hvbarrp3 is an array of 5 bounded
character pointers.
EXEC SQL set :hvarrp3[n] =
’data buffer with length’
1
structure array host variable
A host variable that points to a structure.
Example: The following example declares a table structure called tbl_struct.
struct tbl_struct
{
char colname[20];
small int colno;
small int coltype;
small int collen;
};
The following example declares a pointer to the structure tbl_struct.
Storage is allocated dynamically for up to n rows.
struct tbl_struct *ptr_tbl_struct =
(struct tbl_struct *) malloc (sizeof (struct tbl_struct) * n);
To reference this data is SQL statements, use the pointer as shown in the
following example. Assume that tbl_sel_cur is a declared cursor.
for (L_col_cnt = 0; L_col_cnt < n; L_con_cnt++)
{ ...
EXEC SQL FETCH tbl_sel_cur INTO :ptr_tbl_struct [L_col_cnt]
...
}
Restriction: You cannot use untyped pointers. For example, the following
declaration is not supported: void * untypedprt .
Chapter 3. Including DB2 queries in an application program
181](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-197-2048.jpg)


![float
double
int
long
short
int
long long
decimal (
precision
)
, scale
,
variable-name [ dimension ]
;
,
= {
expression
}
Note:
1. dimension must be an integer constant between 1 and 32767.
Example: The following example shows a declaration of a numeric host variable
array:
EXEC SQL BEGIN DECLARE SECTION;
/* declaration of numeric host variable array */
long serial_num[10];
...
EXEC SQL END DECLARE SECTION;
Character host variable arrays in C or C++
The three valid forms for character host variable arrays are:
v NUL-terminated character form
v VARCHAR structured form
v CLOBs
The following diagrams show the syntax for forms other than CLOBs.
The following diagram shows the syntax for declarations of NUL-terminated
character host variable arrays.
char
auto
extern
static
const
volatile
unsigned
,
variable-name
[
dimension
]
[
length
]
;
,
=
{
expression
}
Notes:
1. On input, the strings contained in the variable arrays must be NUL-terminated.
184
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-200-2048.jpg)
![2. On output, the strings are NUL-terminated.
3. The strings in a NUL-terminated character host variable array map to
varying-length character strings (except for the NUL).
4. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of varying-length
character host variable arrays that use the VARCHAR structured form.
int
struct
auto
extern
static
{
short
var-1
;
const
volatile
char var-2 [ length ]
;
}
unsigned
,
variable-name [ dimension ]
;
,
= {
|
|
expression
}
Notes:
1. var-1 must be a scalar numeric variable, and var-2 must be a scalar CHAR array
variable.
2. You can use the struct tag to define other variables, but you cannot use them as
host variable arrays in SQL.
3. dimension must be an integer constant between 1 and 32767.
Example: The following examples show valid and invalid declarations of
VARCHAR host variable arrays:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of VARCHAR host variable array */
struct VARCHAR {
short len;
char s[18];
} name[10];
/* invalid declaration of VARCHAR host variable array */
struct VARCHAR name[10];
Binary host variable arrays in C or C++
|
|
|
The following diagram shows the syntax for declarations of binary host variable
arrays. See “Large objects (LOBs)” on page 390 for a discussion of how to use
these host variable arrays.
|
Chapter 3. Including DB2 queries in an application program
185](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-201-2048.jpg)
![|
|
SQL TYPE IS
auto
extern
static
register
|
|
BINARY
VARBINARY
const
volatile
(length)
,
variable-name [ dimension ]
;
|
Note:
1. dimension must be an integer constant between 1 and 32767.
|
Graphic host variable arrays in C or C++
The two valid forms for graphic host variable arrays are:
v NUL-terminated graphic form
v VARGRAPHIC structured form.
Recommendation: Instead of using the C data type wchar_t to define graphic and
vargraphic host variable arrays, use one of the following techniques:
v Define the sqldbchar data type by using the following typedef statement:
typedef unsigned short sqldbchar;
v Use the sqldbchar data type that is defined in the typedef statement in the
header files that are supplied by DB2.
v Use the C data type unsigned short.
The following diagram shows the syntax for declarations of NUL-terminated
graphic host variable arrays.
sqldbchar
auto
extern
static
const
volatile
unsigned
,
variable-name
[
dimension
]
[
length
]
;
,
=
{
expression
}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. On input, the strings contained in the variable arrays must be NUL-terminated.
3. On output, the string is NUL-terminated.
4. The NUL-terminated graphic form does not accept single-byte characters into
the variable array.
5. dimension must be an integer constant between 1 and 32767.
186
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-202-2048.jpg)
![The following diagram shows the syntax for declarations of graphic host variable
arrays that use the VARGRAPHIC structured form.
int
struct
auto
extern
static
{
short
var-1
;
const
volatile
sqldbchar var-2 [ length ]
;
}
unsigned
,
variable-name [ dimension ]
;
,
= {
expression
}
Notes:
1. length must be a decimal integer constant greater than 1 and not greater than
16352.
2. var-1 must be a scalar numeric variable, and var-2 must be a scalar char array
variable.
3. You can use the struct tag to define other variables, but you cannot use them as
host variable arrays in SQL.
4. dimension must be an integer constant between 1 and 32767.
Example: The following examples show valid and invalid declarations of graphic
host variable arrays that use the VARGRAPHIC structured form:
EXEC SQL BEGIN DECLARE SECTION;
/* valid declaration of host variable array vgraph */
struct VARGRAPH {
short len;
sqldbchar d[10];
} vgraph[20];
/* invalid declaration of host variable array vgraph */
struct VARGRAPH vgraph[20];
LOB, locator, file reference, and XML variable arrays in C or C++
The following diagram shows the syntax for declarations of BLOB, CLOB, and
DBCLOB host variable arrays and locators. See “Large objects (LOBs)” on page 390
for a discussion of how to use LOB variables.
SQL TYPE IS
auto
extern
static
register
const
volatile
Chapter 3. Including DB2 queries in an application program
187](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-203-2048.jpg)
![|
BINARY LARGE OBJECT
BLOB
CHARACTER LARGE OBJECT
CHAR LARGE OBJECT
CLOB
DBCLOB
BLOB_LOCATOR
CLOB_LOCATOR
DBCLOB_LOCATOR
BLOB_FILE
CLOB_FILE
DBCLOB_FILE
(
length
)
K
M
G
,
variable-name [ dimension ]
;
,
= {
expression
}
Note:
1. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of BLOB, CLOB, and
DBCLOB host variable arrays, and file reference variable arrays for XML data
types
SQL TYPE IS XML AS
auto
extern
static
register
|
const
volatile
BINARY LARGE OBJECT
BLOB
CHARACTER LARGE OBJECT
CHAR LARGE OBJECT
CLOB
DBCLOB
BLOB_FILE
CLOB_FILE
DBCLOB_FILE
(
length
)
K
M
G
,
variable-name [ dimension ]
;
,
= {
Note:
188
Application Programming and SQL Guide
expression
}](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-204-2048.jpg)
![1. dimension must be an integer constant between 1 and 32767.
ROWID variable arrays in C or C++
The following diagram shows the syntax for declarations of ROWID variable
arrays. See “Large objects (LOBs)” on page 390 for a discussion of how to use
these host variable arrays.
,
SQL TYPE IS ROWID
auto
extern
static
register
variable-name
[
dimension
]
;
const
volatile
Note:
1. dimension must be an integer constant between 1 and 32767.
COBOL syntax for host variable array declarations
In COBOL programs, you can specify numeric, character, graphic, LOB, XML, and
ROWID host variable arrays. You can also specify LOB locators and LOB and XML
file reference variables.
Only some of the valid COBOL declarations are valid host variable array
declarations. If the declaration for a variable array is not valid, any SQL statement
that references the variable array might result in the message UNDECLARED
HOST VARIABLE ARRAY.
Numeric host variable arrays: The three valid forms of numeric host variable
arrays are:
v Floating-point numbers
v Integers and small integers
v Decimal numbers
The following diagram shows the syntax for declarations of floating-point host
variable arrays.
level-1 variable-name
COMPUTATIONAL-1
COMP-1
COMPUTATIONAL-2
COMP-2
IS
USAGE
OCCURS dimension
.
TIMES
IS
VALUE
numeric-constant
Notes:
1. level-1 indicates a COBOL level between 2 and 48.
2. COMPUTATIONAL-1 and COMP-1 are equivalent.
3. COMPUTATIONAL-2 and COMP-2 are equivalent.
4. dimension must be an integer constant between 1 and 32767.
The following diagram shows the syntax for declarations of integer and small
integer host variable arrays.
Chapter 3. Including DB2 queries in an application program
189](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-205-2048.jpg)









![Note:
1. dimension must be an integer constant between 1 and 32767.
Host structures in an SQL statement
A host structure is a group of host variables that can be referenced with a single
name. You define host structures with statements in the host language.
You can substitute a host structure for one or more host variables. You can also use
indicator variables (or indicator structures) with host structures.
You can use host structures in all host languages except REXX.
Host structures in C or C++
A C host structure contains an ordered group of data fields. For example:
struct {char c1[3];
struct {short len;
char data[5];
}c2;
char c3[2];
}target;
In this example, target is the name of a host structure consisting of the c1, c2, and
c3 fields. c1 and c3 are character arrays, and c2 is the host variable equivalent to
the SQL VARCHAR data type. The target host structure can be part of another host
structure but must be the deepest level of the nested structure.
The following diagram shows the syntax for declarations of host structures.
struct
auto
extern
static
const
volatile
packed
{
tag
Chapter 3. Including DB2 queries in an application program
199](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-215-2048.jpg)
![|
float
double
var-1 ;
}
int
short
sqlint32
int
long
int
long long
decimal ( precision
, scale )
varchar structure
binary structure
vargraphic structure
SQL TYPE IS ROWID
LOB data type
char var-2
unsigned
[ length ]
sqldbchar var-5
;
[ length ]
variable-name
;
;
=expression
The following diagram shows the syntax for VARCHAR structures that are used
within declarations of host structures.
int
struct
{
tag
short
var-3 ;
signed
char var-4 [ length ] ; }
unsigned
The following diagram shows the syntax for VARGRAPHIC structures that are
used within declarations of host structures.
int
struct
{
tag
short
var-6 ; sqldbchar var-7 [ length ] ; }
signed
The following diagram shows the syntax for binary structures that are used within
declarations of host structures.
|
|
|
SQL TYPE IS
BINARY
VARBINARY
BINARY VARYING
(length)
|
The following diagram shows the syntax for LOB data types that are used within
declarations of host structures.
|
200
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-216-2048.jpg)










![variable-name
DC
DS
H
1
L2
Figure 13. Indicator variable
Indicator variables and indicator variable arrays in C or C++
An indicator variable is a 2-byte integer (short int). An indicator variable array is
an array of 2-byte integers (short int). You use indicator variables and indicator
variable arrays in similar ways.
Using indicator variables: If you provide an indicator variable for the variable X,
when DB2 retrieves a null value for X, it puts a negative value in the indicator
variable and does not update X. Your program should check the indicator variable
before using X. If the indicator variable is negative, you know that X is null and
any value you find in X is irrelevant.
When your program uses X to assign a null value to a column, the program
should set the indicator variable to a negative number. DB2 then assigns a null
value to the column and ignores any value in X.
Using indicator variable arrays: When you retrieve data into a host variable array,
if a value in its indicator array is negative, you can disregard the contents of the
corresponding element in the host variable array.
Declaring indicator variables: You declare indicator variables in the same way as
host variables. You can mix the declarations of the two types of variables in any
way that seems appropriate.
Example: The following example shows a FETCH statement with the declarations
of the host variables that are needed for the FETCH statement:
EXEC SQL FETCH CLS_CURSOR INTO :ClsCd,
:Day :DayInd,
:Bgn :BgnInd,
:End :EndInd;
You can declare variables as follows:
EXEC SQL BEGIN DECLARE SECTION;
char ClsCd[8];
char Bgn[9];
char End[9];
short Day, DayInd, BgnInd, EndInd;
EXEC SQL END DECLARE SECTION;
The following figure shows the syntax for declarations of an indicator variable.
Chapter 3. Including DB2 queries in an application program
211](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-227-2048.jpg)
![,
int
short
auto
extern
static
const
volatile
variable-name
signed
;
=
expression
Figure 14. Indicator variable
Declaring indicator variable arrays: The following figure shows the syntax for
declarations of an indicator array or a host structure indicator array.
int
short
auto
extern
static
const
volatile
signed
,
variable-name [ dimension ]
;
= expression
Figure 15. Host structure indicator array
Note: The dimension must be an integer constant between 1 and 32767.
Indicator variables and indicator variable arrays in COBOL
An indicator variable is a 2-byte integer (PIC S9(4) USAGE BINARY). An indicator
variable array is an array of 2-byte integers (PIC S9(4) USAGE BINARY). You use
indicator variables and indicator variable arrays in similar ways.
Using indicator variables: If you provide an indicator variable for the variable X,
when DB2 retrieves a null value for X, it puts a negative value in the indicator
variable and does not update X. Your program should check the indicator variable
before using X. If the indicator variable is negative, you know that X is null and
any value you find in X is irrelevant.
When your program uses X to assign a null value to a column, the program
should set the indicator variable to a negative number. DB2 then assigns a null
value to the column and ignores any value in X.
Using indicator variable arrays: When you retrieve data into a host variable array,
if a value in its indicator array is negative, you can disregard the contents of the
corresponding element in the host variable array.
Declaring indicator variables: You declare indicator variables in the same way as
host variables. You can mix the declarations of the two types of variables in any
way that seems appropriate. You can define indicator variables as scalar variables
or as array elements in a structure form or as an array variable using a single level
OCCURS clause.
212
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-228-2048.jpg)




![For information about the multiple-row FETCH operation, see “Executing SQL
statements by using a rowset cursor” on page 637. For information about holes in
the result table of a cursor, see “Holes in the result table of a scrollable cursor” on
page 644.
Specifying an indicator array
You must associate an indicator array with a particular host variable array. The
indicator array contains small integers that indicate some information about each
value in the specified host variable array.
You can specify an indicator variable array, preceded by a colon, immediately after
the host variable array. Optionally, you can use the word INDICATOR between the
host variable array and its indicator variable array.
Example: Suppose that you declare a scrollable rowset cursor by using the
following statement:
EXEC SQL
DECLARE CURS1 SCROLL CURSOR WITH ROWSET POSITIONING FOR
SELECT PHONENO
FROM DSN8810.EMP
END-EXEC.
For information about using rowset cursors, see “Accessing data by using a
rowset-positioned cursor” on page 636.
The following two specifications of indicator arrays in the multiple-row FETCH
statement are equivalent:
EXEC SQL
FETCH NEXT ROWSET CURS1
FOR 10 ROWS
INTO :CBLPHONE :INDNULL
END-EXEC.
EXEC SQL
FETCH NEXT ROWSET CURS1
FOR 10 ROWS
INTO :CBLPHONE INDICATOR :INDNULL
END-EXEC.
After the multiple-row FETCH statement, you can test each element of the
INDNULL array for a negative value. If an element is negative, you can disregard
the contents of the corresponding element in the CBLPHONE host variable array.
Inserting null values by using indicator arrays
An indicator array is associated with a particular host variable array. If you need
to insert null values into a column, using an indicator array is an easy way to do
so.
You can use a negative value in an indicator array to insert a null value into a
column.
Example: Assume that host variable arrays hva1 and hva2 have been populated
with values that are to be inserted into the ACTNO and ACTKWD columns.
Assume the ACTDESC column allows nulls. To set the ACTDESC column to null,
assign -1 to the elements in its indicator array:
/* Initialize each indicator array */
for (i=0; i<10; i++) {
ind1[i] = 0;
ind2[i] = 0;
ind3[i] = -1;
}
Chapter 3. Including DB2 queries in an application program
217](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-233-2048.jpg)




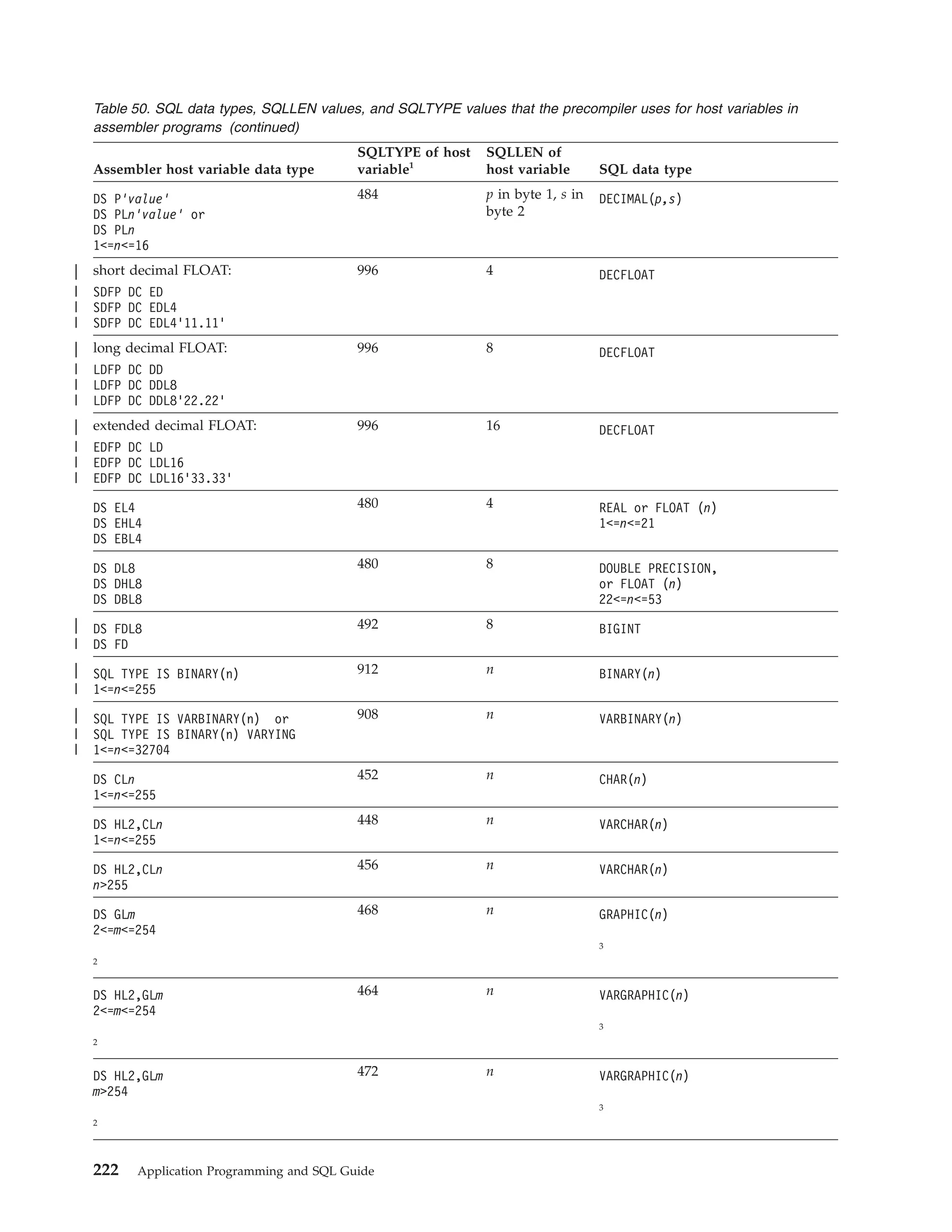
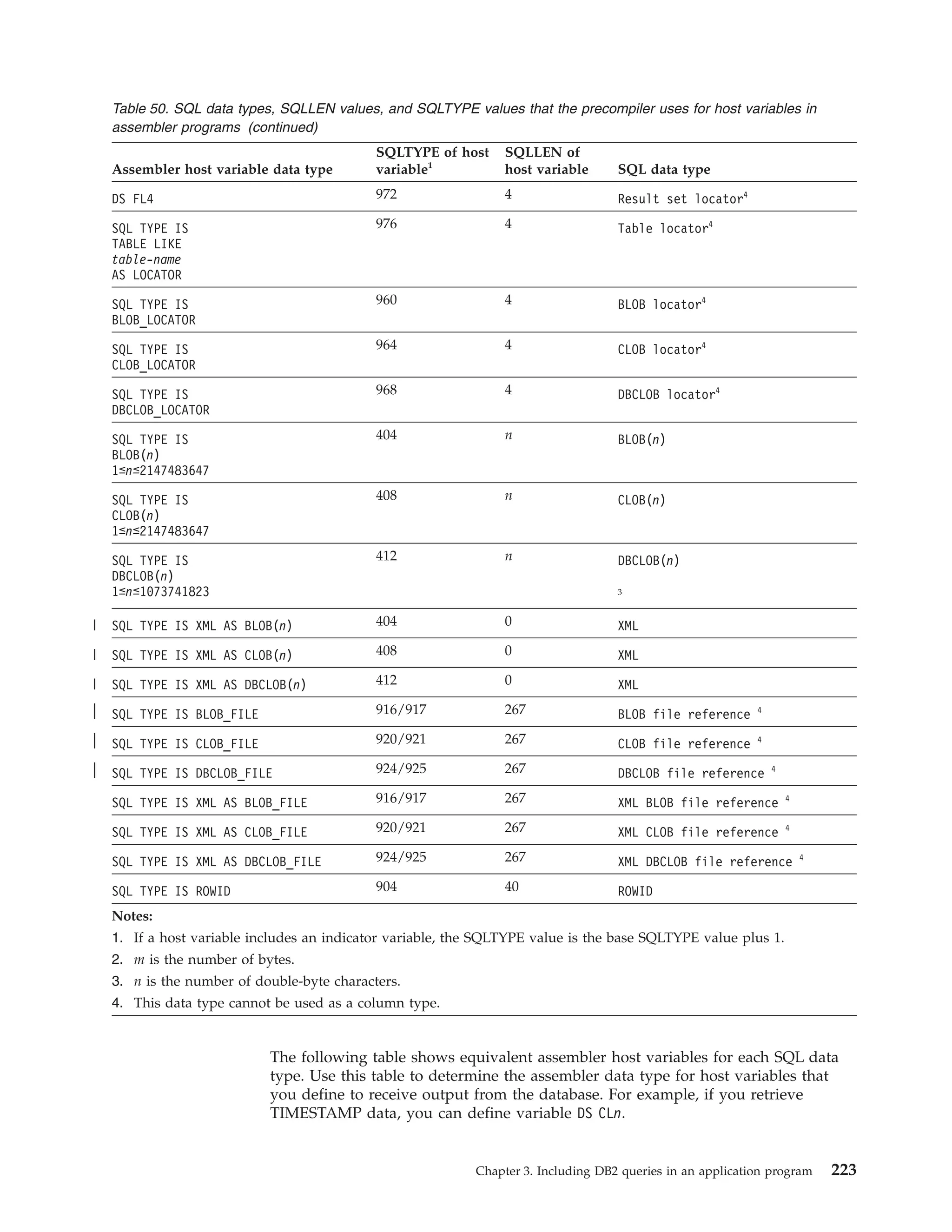
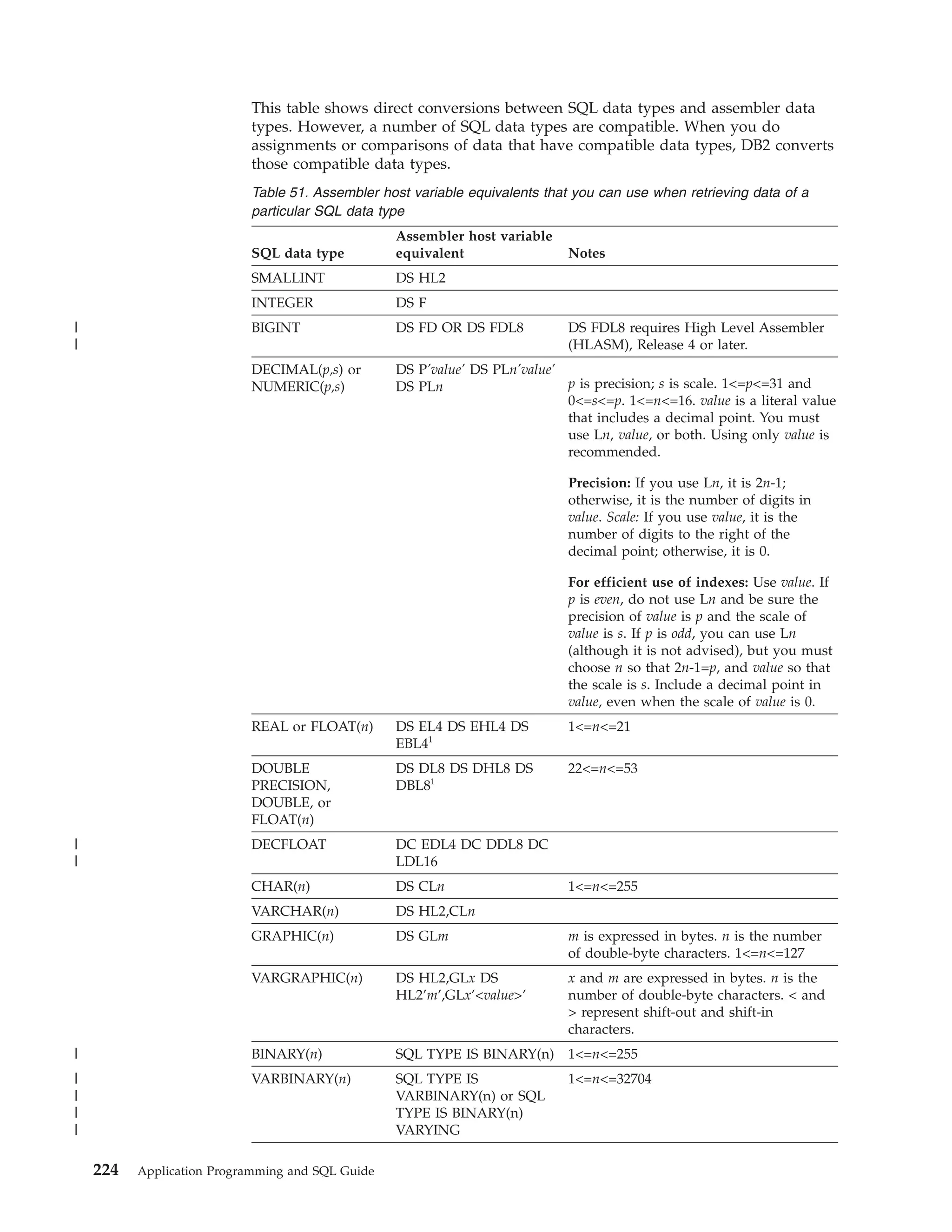
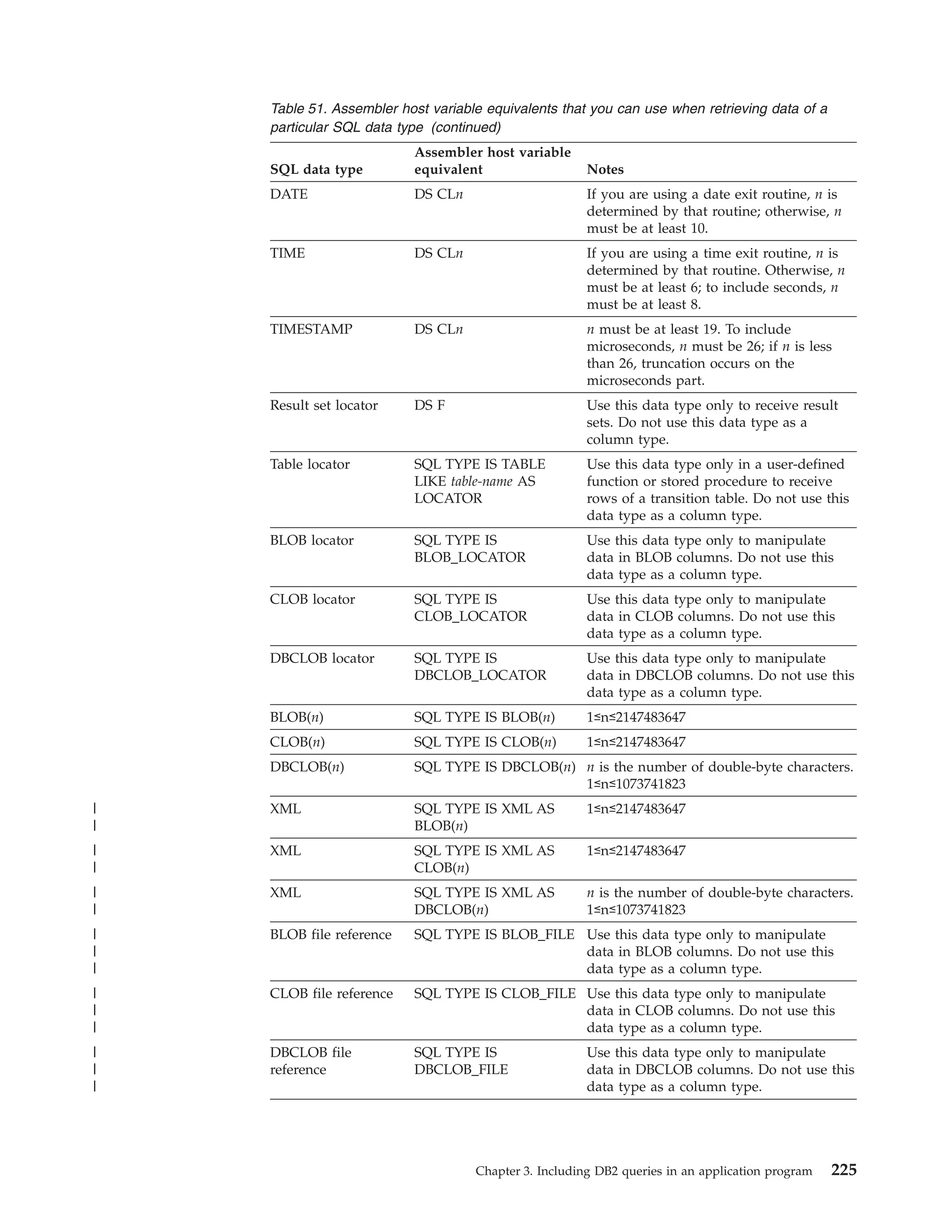



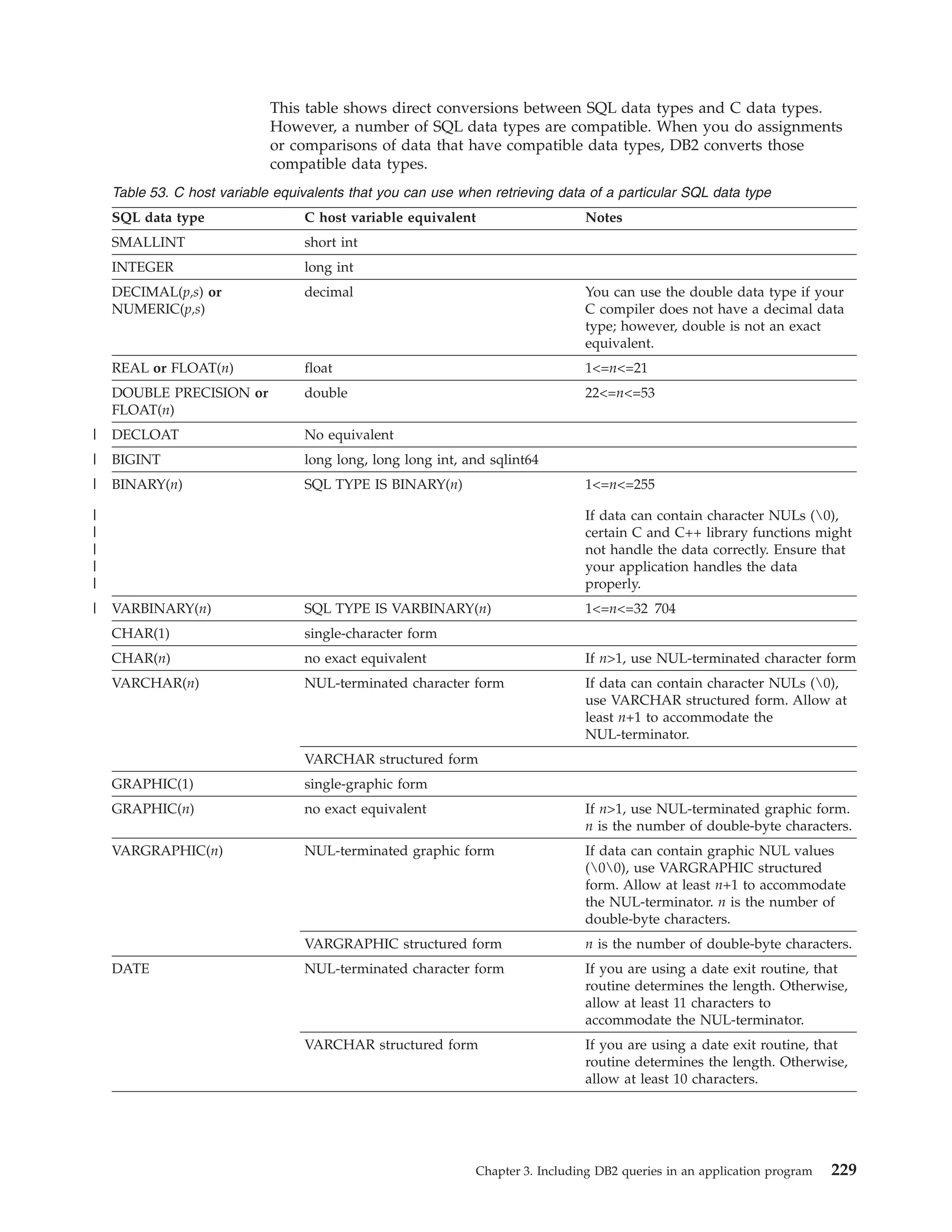
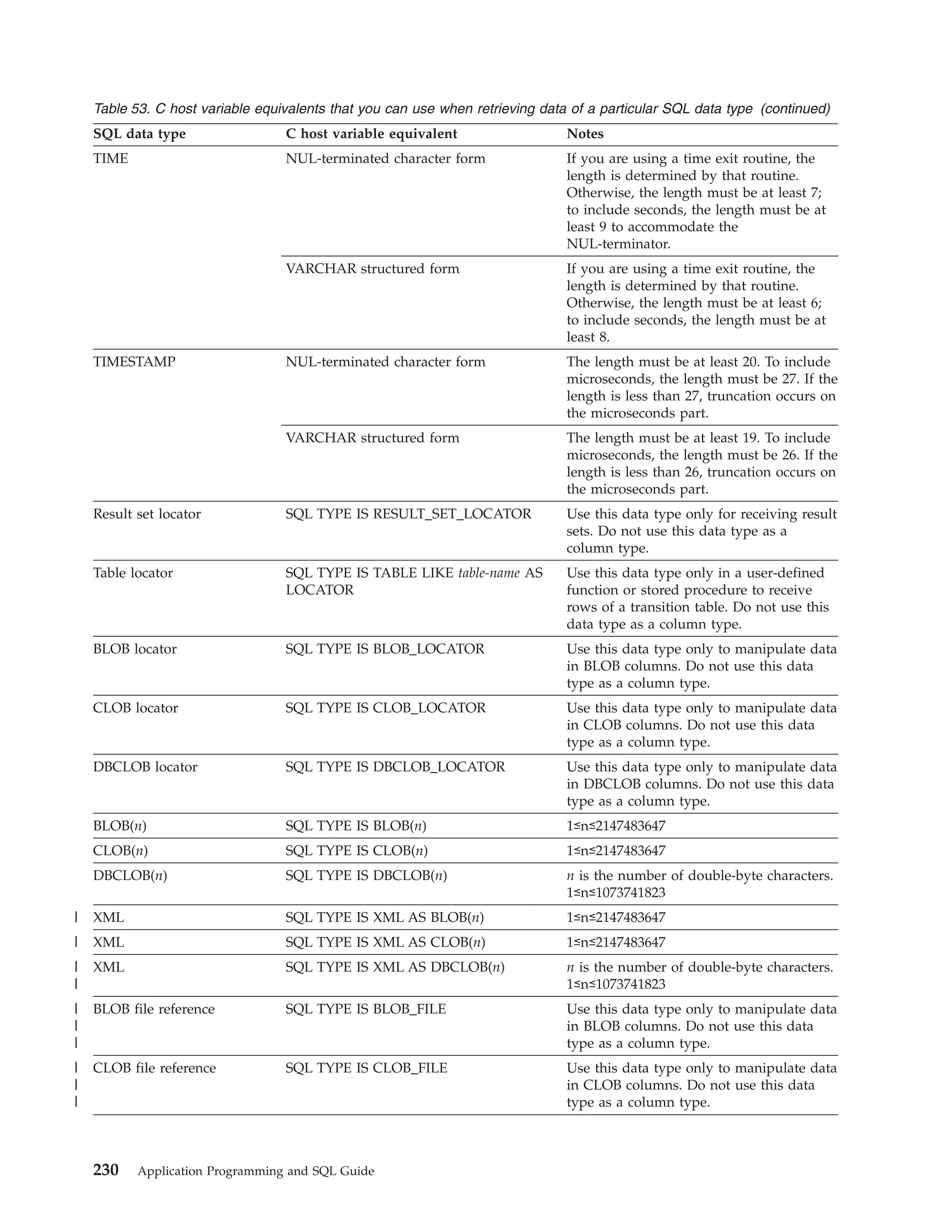

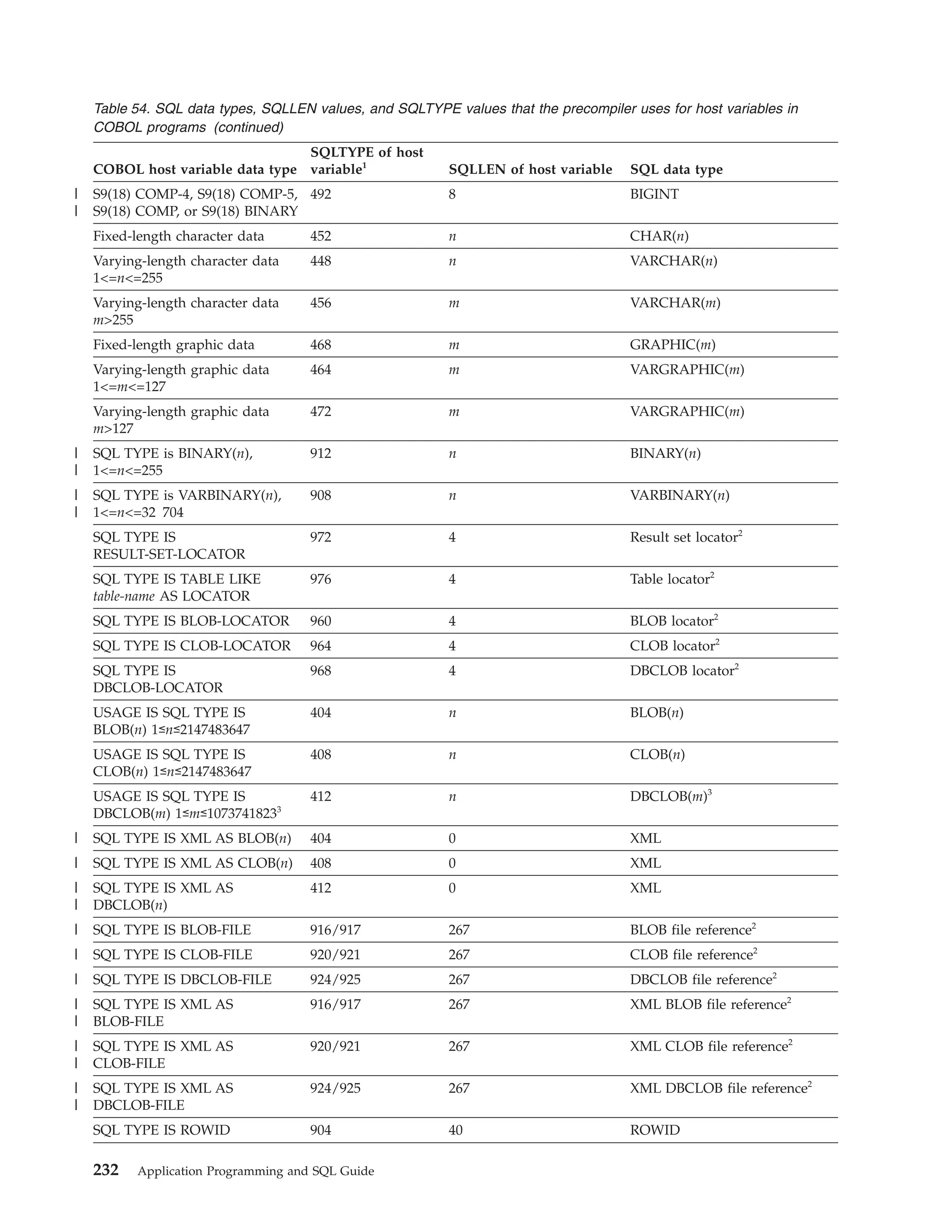

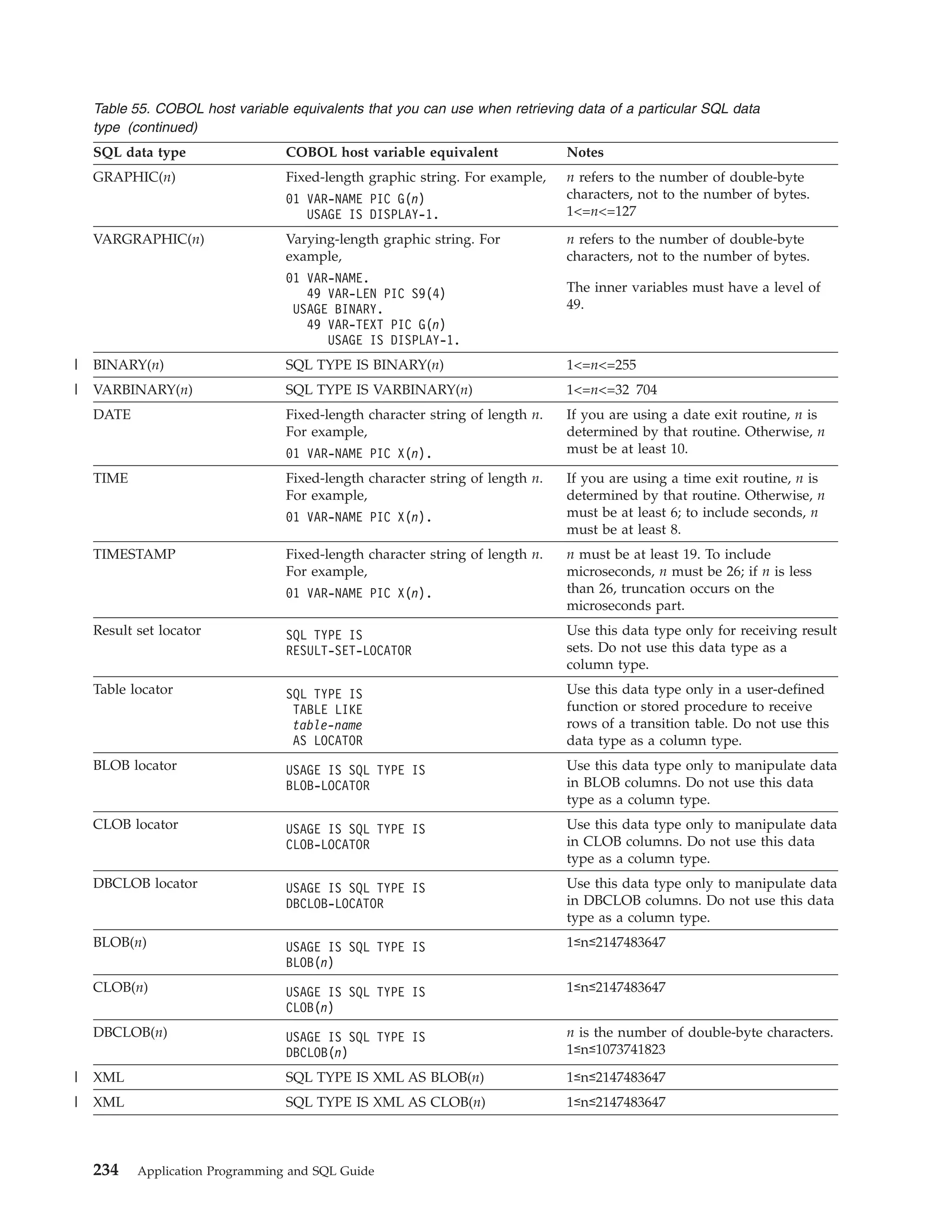

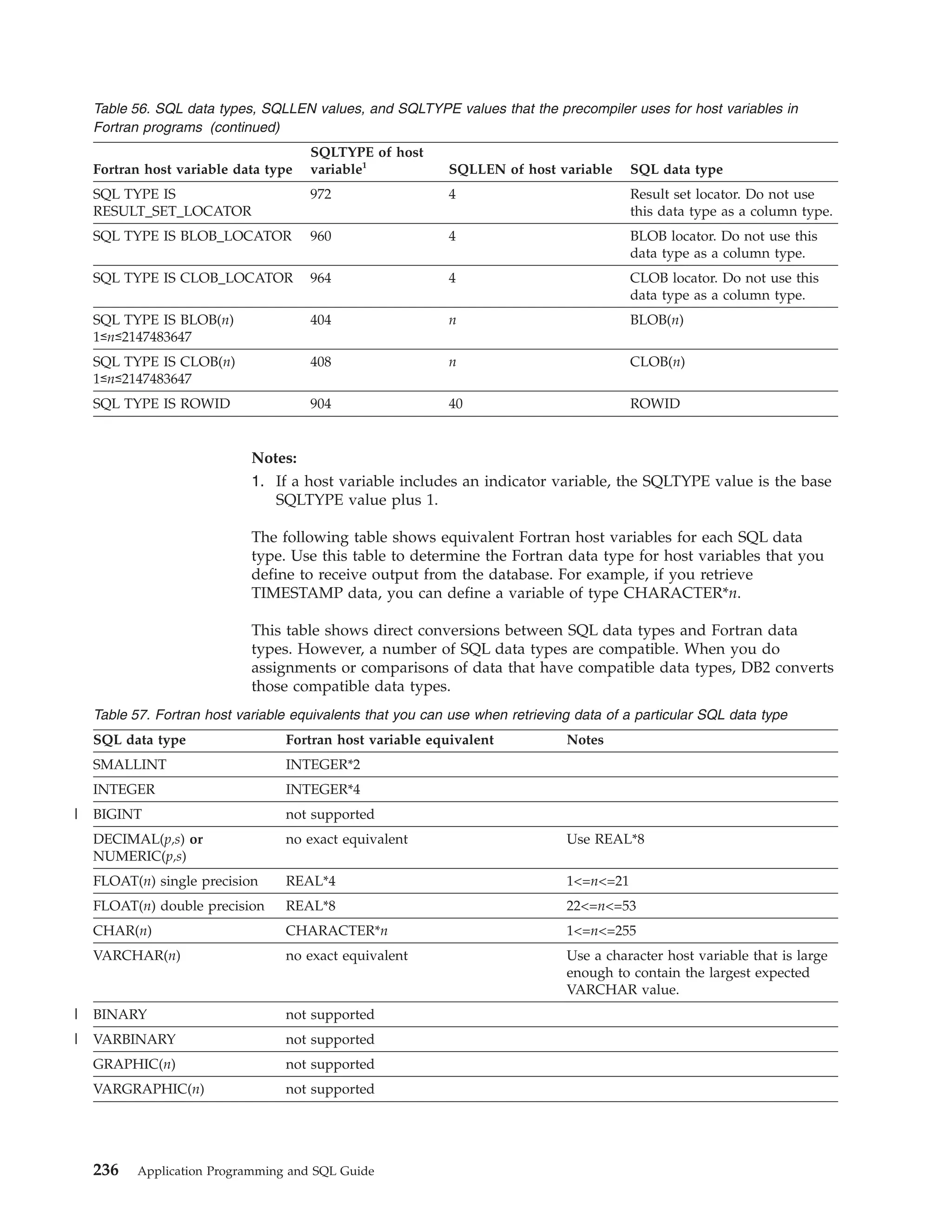
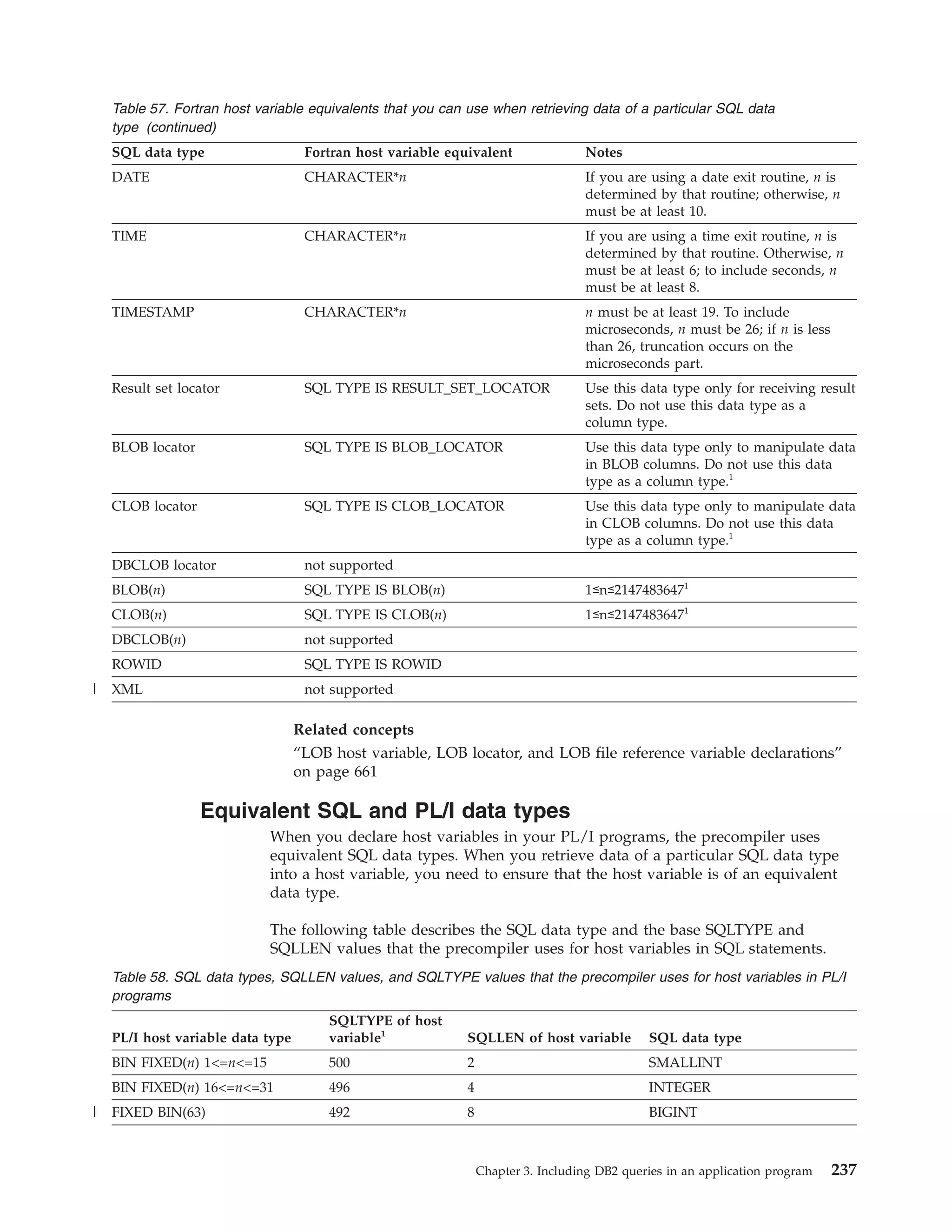
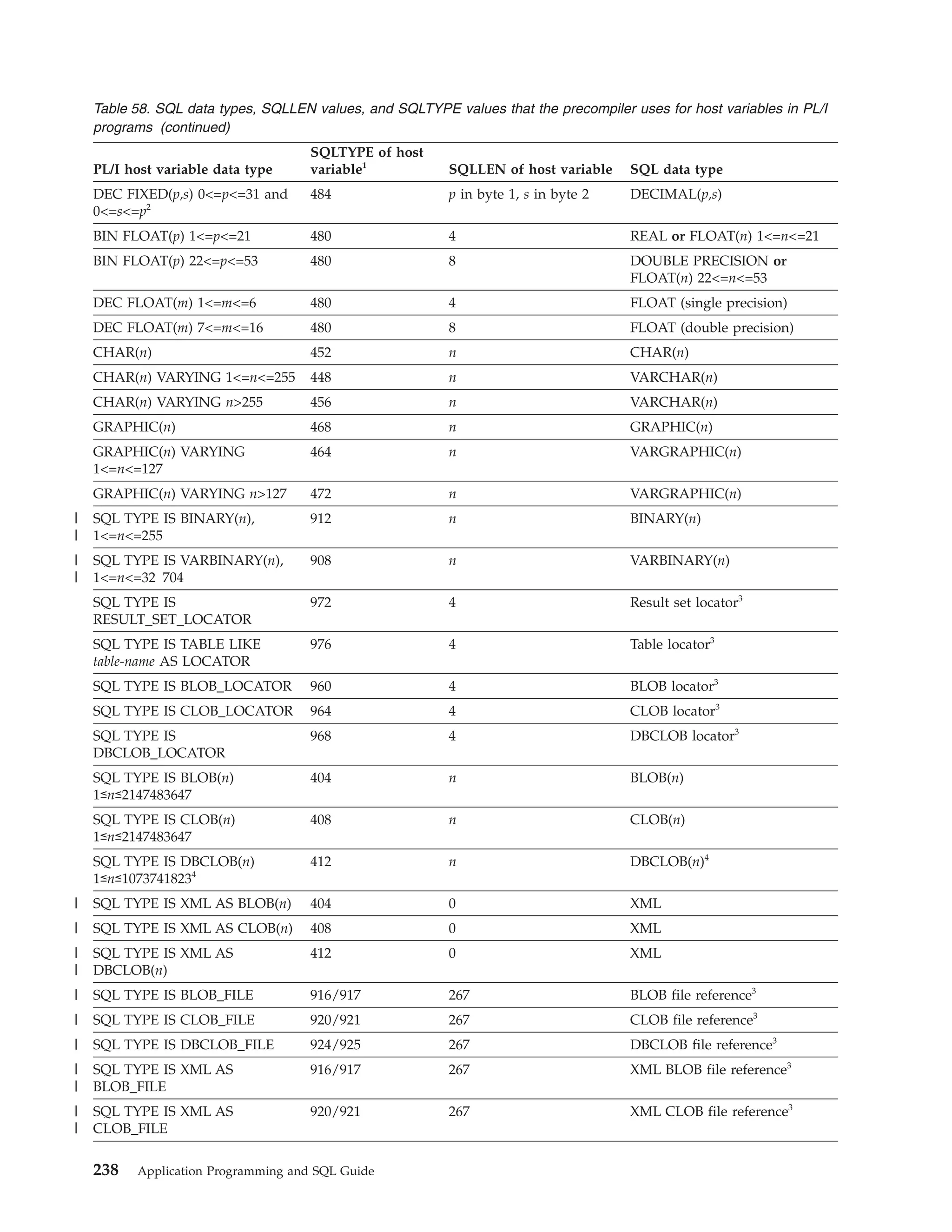





























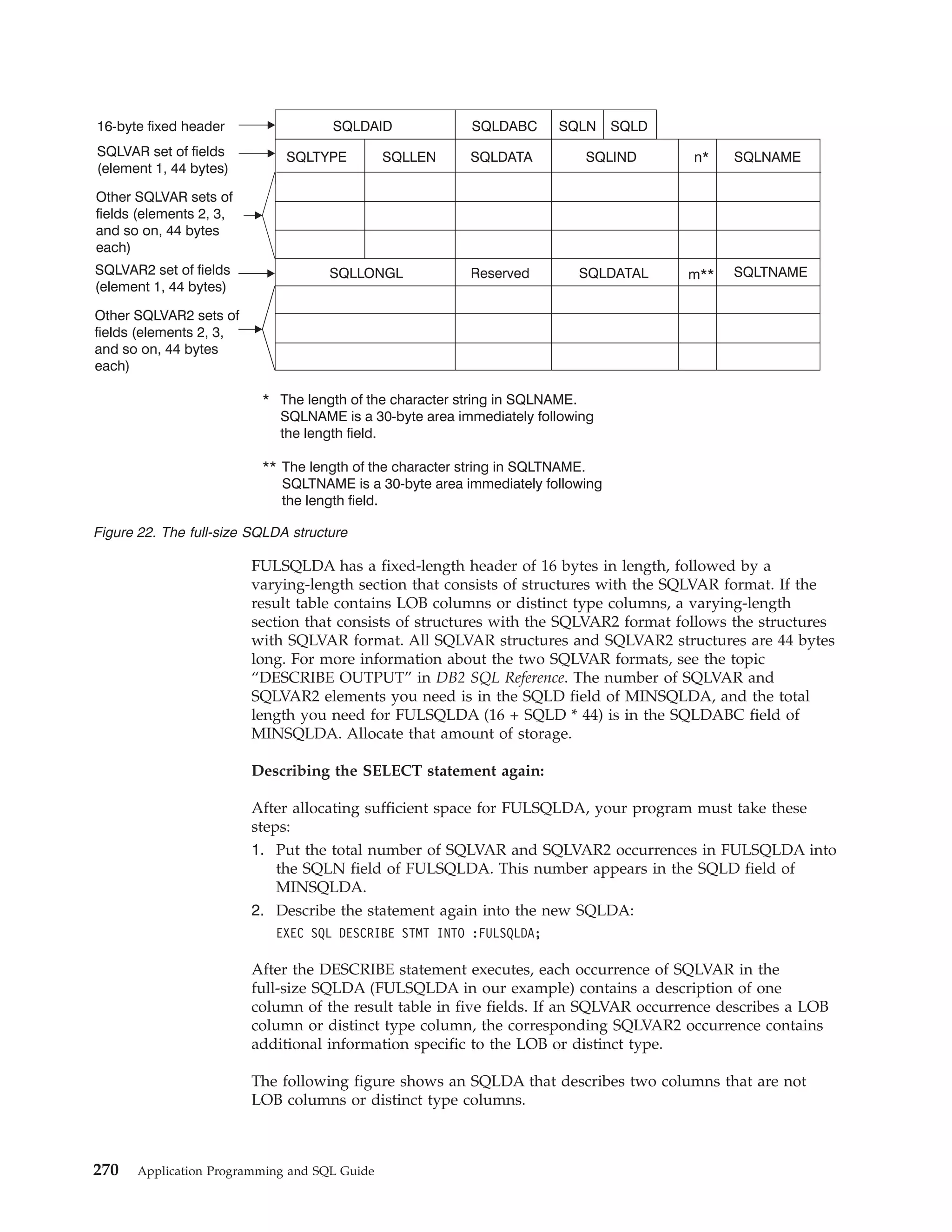












![– If you execute DESCRIBE on a statement before you open a cursor for that
statement, DB2 always prepares the statement on DESCRIBE. However, DB2
will not prepare the statement again on OPEN if the statement has already
been saved in the cache. If you execute DESCRIBE on a statement after you
open a cursor for that statement, DB2 prepared the statement only once if it is
not already saved in the cache. If the statement is already saved in the cache
and you execute DESCRIBE after you open a cursor for that statement, DB2
does not prepare the statement, it used the statement that is saved in the
cache.
To improve the performance of a program that is bound with REOPT(ONCE),
execute the DESCRIBE statement after you open a cursor. To prevent an
automatic DESCRIBE before a cursor is opened, do not use a PREPARE
statement with the INTO clause.
v If you use predictive governing for applications that are bound with
REOPT(ONCE), DB2 does not return a warning SQLCODE when dynamic SQL
statements exceed the predictive governing warning threshold. DB2 does return
an error SQLCODE when dynamic SQL statements exceed the predictive
governing error threshold. DB2 returns the error SQLCODE for an EXECUTE or
OPEN statement.
Dynamically executing an SQL statement by using EXECUTE
IMMEDIATE
In certain situations, you want your program to prepare and dynamically execute a
statement immediately after reading it.
Suppose that you design a program to read SQL DELETE statements, similar to
these, from a terminal:
DELETE FROM DSN8910.EMP WHERE EMPNO = ’000190’
DELETE FROM DSN8910.EMP WHERE EMPNO = ’000220’
After reading a statement, the program is to run it immediately.
Recall that you must prepare (precompile and bind) static SQL statements before
you can use them. You cannot prepare dynamic SQL statements in advance. The
SQL statement EXECUTE IMMEDIATE causes an SQL statement to prepare and
execute, dynamically, at run time.
Declaring the host variableBefore you prepare and execute an SQL statement, you
can read it into a host variable. If the maximum length of the SQL statement is 32
KB, declare the host variable as a character or graphic host variable according to
the following rules for the host languages:
|
|
|
v In assembler, PL/I, COBOL and C, you must declare a string host variable as a
varying-length string.
v In Fortran, it must be a fixed-length string variable.
If the length is greater than 32 KB, you must declare the host variable as a CLOB
or DBCLOB, and the maximum is 2 MB.
Example: Using a varying-length character host variable: This excerpt is from a C
program that reads a DELETE statement into the host variable dstring and executes
the statement:
EXEC SQL BEGIN DECLARE SECTION;
...
struct VARCHAR {
short len;
char s[40];
Chapter 3. Including DB2 queries in an application program
283](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-299-2048.jpg)




![v SQLN
v SQLABC
v SQLD
v SQLVAR
v SQLNAME
Example: Assume that your program includes the standard SQLDA structure
declaration and declarations for the program variables that point to the SQLDA
structure. For C application programs, the following example code sets the
SQLDA fields:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
strcpy(sqldaptr->sqldaid,"SQLDA");
sqldaptr->sqldabc = 192;
/* number of bytes of storage allocated for the SQLDA */
sqldaptr->sqln = 4;
/* number of SQLVAR occurrences */
sqldaptr->sqld = 4;
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]));
/* Point to first SQLVAR */
varptr->sqltype = 500;
/* data type SMALLINT */
varptr->sqllen = 2;
varptr->sqldata = (char *) hva1;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]) + 1); /* Point to next SQLVAR */
varptr->sqltype = 452;
/* data type CHAR(6) */
varptr->sqllen = 6;
varptr->sqldata = (char *) hva2;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
varptr = (struct sqlvar *) (&(sqldaptr->sqlvar[0]) + 2); /* Point to next SQLVAR */
varptr->sqltype = 448;
/* data type VARCHAR(20) */
varptr->sqllen = 20;
varptr->sqldata = (char *) hva3;
varptr->sqlname.length = 8;
memcpy(varptr->sqlname.data, "x00x00x00x00x00x01x00x14",varptr->sqlname.length);
The SQLDA structure has the following fields:
v SQLDABC indicates the number of bytes of storage that are allocated for the
SQLDA. The storage includes a 16-byte header and 44 bytes for each
SQLVAR field. The value is SQLN x 44 + 16, or 192 for this example.
v SQLN is the number of SQLVAR occurrences, plus one for use by DB2 for
the host variable that contains the number n in the FOR n ROWS clause.
v SQLD is the number of variables in the SQLDA that are used by DB2 when
processing the INSERT statement.
v An SQLVAR occurrence specifies the attributes of an element of a host
variable array that corresponds to a value provided for a target column of
the INSERT. Within each SQLVAR:
– SQLTYPE indicates the data type of the elements of the host variable
array.
– SQLLEN indicates the length of a single element of the host variable array.
– SQLDATA points to the corresponding host variable array. Assume that
your program allocates the dynamic variable arrays hva1, hva2, and hva3.
– SQLNAME has two parts: the LENGTH and the DATA. The LENGTH is
8. The first two bytes of the DATA field is X’0000’. Bytes 5 and 6 of the
DATA field are a flag indicating whether the variable is an array or a FOR
n ROWS value. Bytes 7 and 8 are a two-byte binary integer representation
of the dimension of the array.
|
|
|
|
|
For more information about the SQLDA, see “Including dynamic SQL for
varying-list SELECT statements in your program” on page 266 and the topic
“SQL descriptor area (SQLDA)” in DB2 SQL Reference.
288
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-304-2048.jpg)
















![|
|
|
|
|
|
Use the GET DIAGNOSTICS statement to handle multiple SQL errors that might
result from the execution of a single SQL statement. First, check SQLSTATE (or
SQLCODE) to determine whether diagnostic information should be retrieved by
using GET DIAGNOSTICS. This method is especially useful for diagnosing
problems that result from a multiple-row INSERT that is specified as NOT
ATOMIC CONTINUE ON SQLEXCEPTIONand multiple row MERGE statements.
Even if you use only the GET DIAGNOSTICS statement in your application
program to check for conditions, you must either include the instructions required
to use the SQLCA or you must declare SQLSTATE (or SQLCODE) separately in
your program.
Restriction: If you issue a GET DIAGNOSTICS statement immediately following
an SQL statement that uses private protocol access, DB2 returns an error.
When you use the GET DIAGNOSTICS statement, you assign the requested
diagnostic information to host variables. Declare each target host variable with a
data type that is compatible with the data type of the requested item. For a
description of available items and their data types, see “Data types for GET
DIAGNOSTICS items” on page 307.
To retrieve condition information, you must first retrieve the number of condition
items (that is, the number of errors and warnings that DB2 detected during the
execution of the last SQL statement). The number of condition items is at least one.
If the last SQL statement returned SQLSTATE ’00000’ (or SQLCODE 0), the number
of condition items is one.
Example: Using GET DIAGNOSTICS with multiple-row INSERT: You want to
display diagnostic information for each condition that might occur during the
execution of a multiple-row INSERT statement in your application program. You
specify the INSERT statement as NOT ATOMIC CONTINUE ON SQLEXCEPTION,
which means that execution continues regardless of the failure of any single-row
insertion. DB2 does not insert the row that was processed at the time of the error.
In the following example, the first GET DIAGNOSTICS statement returns the
number of rows inserted and the number of conditions returned. The second GET
DIAGNOSTICS statement returns the following items for each condition:
SQLCODE, SQLSTATE, and the number of the row (in the rowset that was being
inserted) for which the condition occurred.
EXEC SQL BEGIN DECLARE SECTION;
long row_count, num_condns, i;
long ret_sqlcode, row_num;
char ret_sqlstate[6];
...
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
INSERT INTO DSN8910.ACT
(ACTNO, ACTKWD, ACTDESC)
VALUES (:hva1, :hva2, :hva3)
FOR 10 ROWS
NOT ATOMIC CONTINUE ON SQLEXCEPTION;
EXEC SQL GET DIAGNOSTICS
:row_count = ROW_COUNT, :num_condns = NUMBER;
printf("Number of rows inserted = %dn", row_count);
for (i=1; i<=num_condns; i++) {
EXEC SQL GET DIAGNOSTICS CONDITION :i
Chapter 3. Including DB2 queries in an application program
305](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-321-2048.jpg)
![:ret_sqlcode = DB2_RETURNED_SQLCODE,
:ret_sqlstate = RETURNED_SQLSTATE,
:row_num
= DB2_ROW_NUMBER;
printf("SQLCODE = %d, SQLSTATE = %s, ROW NUMBER = %dn",
ret_sqlcode, ret_sqlstate, row_num);
}
In the activity table, the ACTNO column is defined as SMALLINT. Suppose that
you declare the host variable array hva1 as an array with data type long, and you
populate the array so that the value for the fourth element is 32768.
If you check the SQLCA values after the INSERT statement, the value of
SQLCODE is equal to 0, the value of SQLSTATE is ’00000’, and the value of
SQLERRD(3) is 9 for the number of rows that were inserted. However, the INSERT
statement specified that 10 rows were to be inserted.
The GET DIAGNOSTICS statement provides you with the information that you
need to correct the data for the row that was not inserted. The printed output from
your program looks like this:
Number of rows inserted = 9
SQLCODE = -302, SQLSTATE = 22003, ROW NUMBER = 4
The value 32768 for the input variable is too large for the target column ACTNO.
You can print the MESSAGE_TEXT condition item. For information about
SQLCODE -302, see the topic “Error SQL codes” in DB2 Codes.
Retrieving statement and condition items:
When you use the GET DIAGNOSTICS statement, you assign the requested
diagnostic information to host variables. Declare each target host variable with a
data type that is compatible with the data type of the requested item.
To retrieve condition information, you must first retrieve the number of condition
items (that is, the number of errors and warnings that DB2 detected during the
execution of the last SQL statement). The number of condition items is at least one.
If the last SQL statement returned SQLSTATE ’00000’ (or SQLCODE 0), the number
of condition items is one.
Example: Using GET DIAGNOSTICS with multiple-row INSERT: You want to
display diagnostic information for each condition that might occur during the
execution of a multiple-row INSERT statement in your application program. You
specify the INSERT statement as NOT ATOMIC CONTINUE ON SQLEXCEPTION,
which means that execution continues regardless of the failure of any single-row
insertion. DB2 does not insert the row that was processed at the time of the error.
In the following example code, the first GET DIAGNOSTICS statement returns the
number of rows inserted and the number of conditions returned. The second GET
DIAGNOSTICS statement returns the following items for each condition:
SQLCODE, SQLSTATE, and the number of the row (in the rowset that was being
inserted) for which the condition occurred
EXEC SQL BEGIN DECLARE SECTION;
long row_count, num_condns, i;
long ret_sqlcode, row_num;
char ret_sqlstate[6];
...
EXEC SQL END DECLARE SECTION;
...
EXEC SQL
306
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-322-2048.jpg)

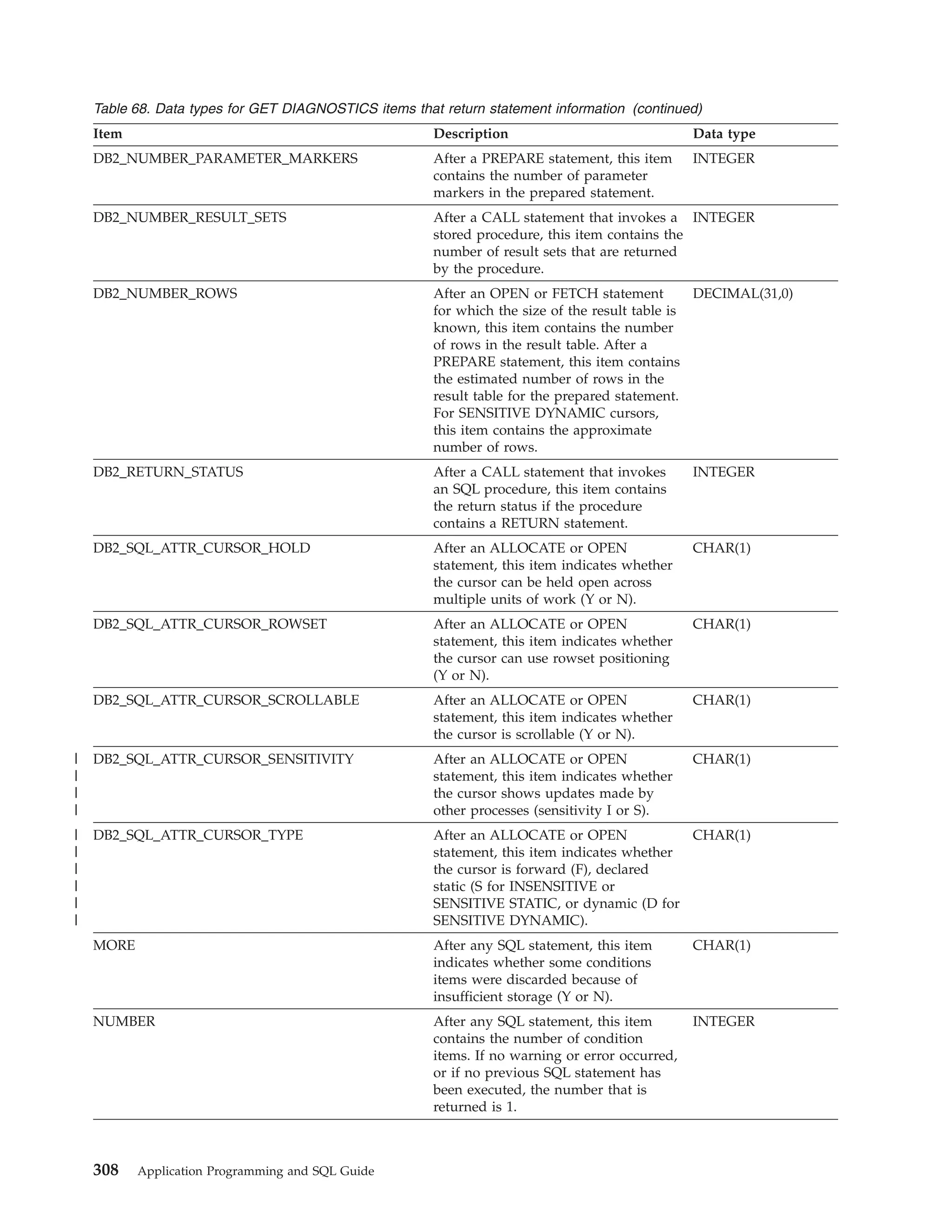
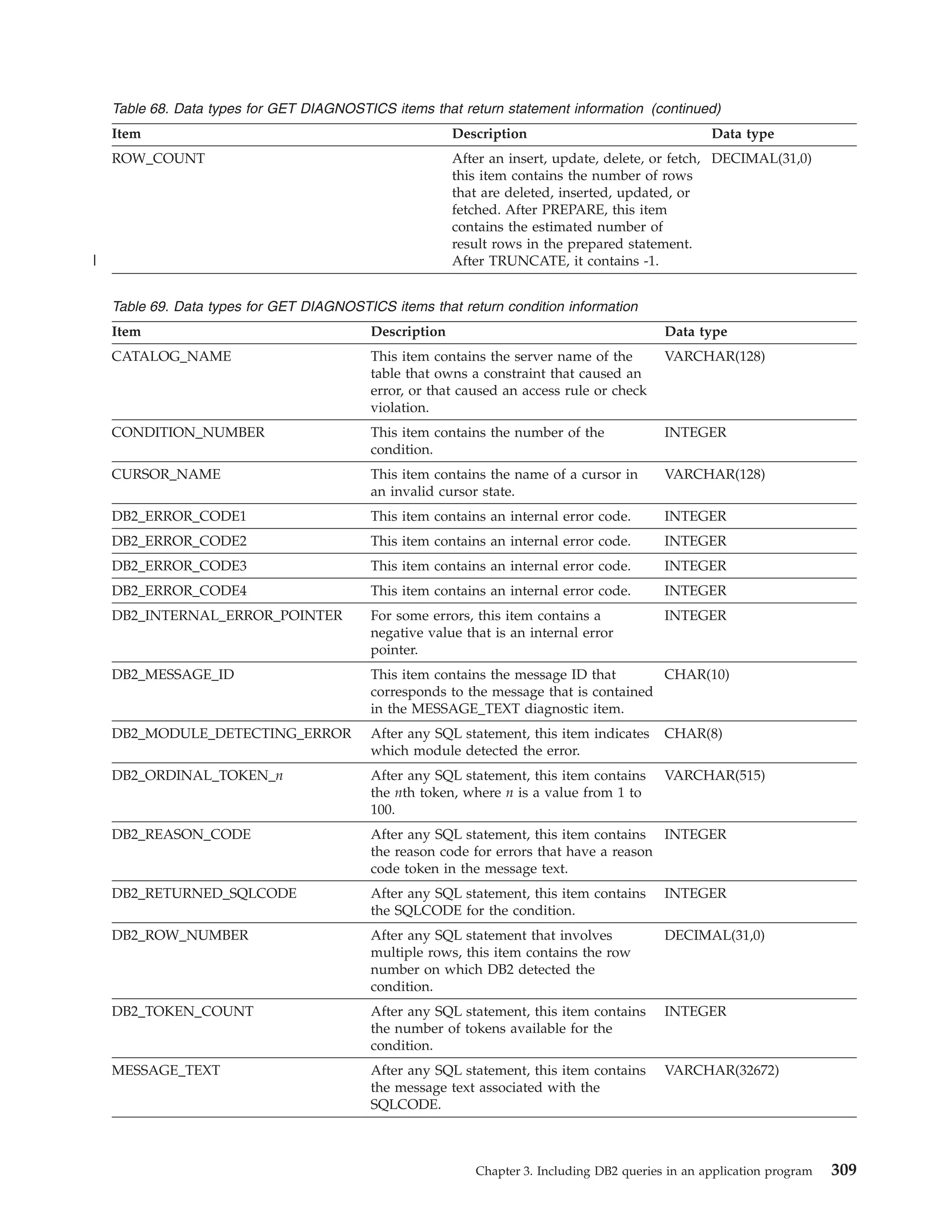


![eib
EXEC interface block
commarea
communication area
For more information on these parameters, see the appropriate application
programming guide for CICS. The remaining parameter descriptions are the same
as those for DSNTIAR. Both DSNTIAC and DSNTIAR format the SQLCA in the
same way.
You must define DSNTIA1 in the CSD. If you load DSNTIAR or DSNTIAC, you
must also define them in the CSD. For an example of CSD entry generation
statements for use with DSNTIAC, see member DSN8FRDO in the data set
prefix.SDSNSAMP.
The assembler source code for DSNTIAC and job DSNTEJ5A, which assembles and
link-edits DSNTIAC, are also in the data set prefix.SDSNSAMP.
Handling SQL error return codes in C or C++
You can use the subroutine DSNTIAR to convert an SQL return code into a text
message. DSNTIAR takes data from the SQLCA, formats it into a message, and
places the result in a message output area that you provide in your application
program. For concepts and more information about the behavior of DSNTIAR, see
“Displaying SQLCA fields by calling DSNTIAR” on page 299.
You can also use the MESSAGE_TEXT condition item field of the GET
DIAGNOSTICS statement to convert an SQL return code into a text message.
Programs that require long token message support should code the GET
DIAGNOSTICS statement instead of DSNTIAR. For more information about GET
DIAGNOSTICS, see “Checking the execution of SQL statements by using the GET
DIAGNOSTICS statement” on page 304.
DSNTIAR syntax:
rc = dsntiar(&sqlca, &message, &lrecl);
The DSNTIAR parameters have the following meanings:
&sqlca
An SQL communication area.
&message
An output area, in VARCHAR format, in which DSNTIAR places the message
text. The first halfword contains the length of the remaining area; its minimum
value is 240.
The output lines of text, each line being the length specified in &lrecl, are put
into this area. For example, you could specify the format of the output area as:
#define data_len 132
#define data_dim 10
struct error_struct {
short int error_len;
char error_text[data_dim][data_len];
. } error_message = {data_dim * data_len};
.
.
rc = dsntiar(&sqlca, &error_message, &data_len);
312
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-328-2048.jpg)



















![/*
/*
/*
/*
*/
*/
*/
*/
Control-blocks
=
SQLCA
- sql communication area
/* Logic specification:
*/
/*
*/
/* There are four SQL sections.
*/
/*
*/
/* 1) STATIC SQL 1: using static cursor with a SELECT statement.
*/
/*
Two output host variables.
*/
/* 2) Dynamic SQL 2: Fixed-list SELECT, using same SELECT statement
*/
/*
used in SQL 1 to show the difference. The prepared string
*/
/*
:iptstr can be assigned with other dynamic-able SQL statements. */
/* 3) Dynamic SQL 3: Insert with parameter markers.
*/
/*
Using four parameter markers which represent four input host
*/
/*
variables within a host structure.
*/
/* 4) Dynamic SQL 4: EXECUTE IMMEDIATE
*/
/*
A GRANT statement is executed immediately by passing it to DB2 */
/*
via a varying string host variable. The example shows how to
*/
/*
set up the host variable before passing it.
*/
/*
*/
/**********************************************************************/
#include "stdio.h"
#include "stdefs.h"
EXEC SQL INCLUDE SQLCA;
EXEC SQL INCLUDE SQLDA;
EXEC SQL BEGIN DECLARE SECTION;
short edlevel;
struct { short len;
char x1[56];
} stmtbf1, stmtbf2, inpstr;
struct { short len;
char x1[15];
} lname;
short hv1;
struct { char deptno[4];
struct { short len;
char x[36];
} deptname;
char mgrno[7];
char admrdept[4];
} hv2;
short ind[4];
EXEC SQL END
DECLARE SECTION;
EXEC SQL DECLARE EMP TABLE
(EMPNO
CHAR(6)
FIRSTNAME
VARCHAR(12)
MIDINIT
CHAR(1)
LASTNAME
VARCHAR(15)
WORKDEPT
CHAR(3)
PHONENO
CHAR(4)
HIREDATE
DECIMAL(6)
JOBCODE
DECIMAL(3)
EDLEVEL
SMALLINT
SEX
CHAR(1)
BIRTHDATE
DECIMAL(6)
SALARY
DECIMAL(8,2)
FORFNAME
VARGRAPHIC(12)
FORMNAME
GRAPHIC(1)
FORLNAME
VARGRAPHIC(15)
FORADDR
VARGRAPHIC(256) )
EXEC SQL DECLARE DEPT TABLE
(
DEPTNO
DEPTNAME
332
Application Programming and SQL Guide
CHAR(3)
VARCHAR(36)
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
;
,
,](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-348-2048.jpg)


































!["ISREDIT
"ISREDIT
"ISREDIT
"ISREDIT
Exit 20
|| SQLWARN.8",",
|| SQLWARN.9",",
|| SQLWARN.10"’"
LINE_AFTER "zdest" =
|| SQLERRD.2",",
|| SQLERRD.3",",
|| SQLERRD.4",",
|| SQLERRD.5",",
|| SQLERRD.6"’"
LINE_AFTER "zdest" =
LINE_AFTER "zdest" =
LINE_AFTER "zdest" =
MSGLINE ’SQLERRD ="SQLERRD.1",",
MSGLINE ’SQLERRP ="SQLERRP"’"
MSGLINE ’SQLERRMC ="SQLERRMC"’"
MSGLINE ’SQLCODE ="SQLCODE"’"
Example programs that call stored procedures
These examples can be used as models when you write applications that call
stored procedures. In addition to these example programs, DSN910.SDSNSAMP
contains sample jobs DSNTEJ6P and DSNTEJ6S and programs DSN8EP1 and
DSN8EP2, which you can run.
Example C program that calls a stored procedure
This example shows how to call the C language version of the GETPRML stored
procedure that uses the GENERAL WITH NULLS linkage convention. Because the
stored procedure returns result sets, this program checks for result sets and
retrieves the contents of the result sets.
The following figure contains the example C program that calls the GETPRML
stored procedure.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
main()
{
/************************************************************/
/* Include the SQLCA and SQLDA
*/
/************************************************************/
EXEC SQL INCLUDE SQLCA;
EXEC SQL INCLUDE SQLDA;
/************************************************************/
/* Declare variables that are not SQL-related.
*/
/************************************************************/
short int i;
/* Loop counter
*/
/************************************************************/
/* Declare the following:
*/
/* - Parameters used to call stored procedure GETPRML
*/
/* - An SQLDA for DESCRIBE PROCEDURE
*/
/* - An SQLDA for DESCRIBE CURSOR
*/
/* - Result set variable locators for up to three result
*/
/*
sets
*/
/************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char procnm[19];
/* INPUT parm -- PROCEDURE name */
char schema[9];
/* INPUT parm -- User’s schema */
long int out_code;
/* OUTPUT -- SQLCODE from the
*/
/*
SELECT operation.
*/
struct {
short int parmlen;
char parmtxt[254];
} parmlst;
/* OUTPUT -- RUNOPTS values
*/
/*
for the matching row in
*/
/*
catalog table SYSROUTINES */
struct indicators {
short int procnm_ind;
Chapter 3. Including DB2 queries in an application program
367](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-383-2048.jpg)
![short int schema_ind;
short int out_code_ind;
short int parmlst_ind;
} parmind;
/* Indicator variable structure */
struct sqlda *proc_da;
/* SQLDA for DESCRIBE PROCEDURE */
struct sqlda *res_da;
/* SQLDA for DESCRIBE CURSOR
static volatile
SQL TYPE IS RESULT_SET_LOCATOR *loc1, *loc2, *loc3;
/* Locator variables
EXEC SQL END DECLARE SECTION;
*/
*/
/*************************************************************/
/* Allocate the SQLDAs to be used for DESCRIBE
*/
/* PROCEDURE and DESCRIBE CURSOR. Assume that at most
*/
/* three cursors are returned and that each result set
*/
/* has no more than five columns.
*/
/*************************************************************/
proc_da = (struct sqlda *)malloc(SQLDASIZE(3));
res_da = (struct sqlda *)malloc(SQLDASIZE(5));
/************************************************************/
/* Call the GETPRML stored procedure to retrieve the
*/
/* RUNOPTS values for the stored procedure.
In this
*/
/* example, we request the PARMLIST definition for the
*/
/* stored procedure named DSN8EP2.
*/
/*
*/
/* The call should complete with SQLCODE +466 because
*/
/* GETPRML returns result sets.
*/
/************************************************************/
strcpy(procnm,"dsn8ep2
");
/* Input parameter -- PROCEDURE to be found
*/
strcpy(schema,"
");
/* Input parameter -- Schema name for proc
*/
parmind.procnm_ind=0;
parmind.schema_ind=0;
parmind.out_code_ind=0;
/* Indicate that none of the input parameters */
/* have null values
*/
parmind.parmlst_ind=-1;
/* The parmlst parameter is an output parm.
*/
/* Mark PARMLST parameter as null, so the DB2 */
/* requester doesn’t have to send the entire */
/* PARMLST variable to the server. This
*/
/* helps reduce network I/O time, because
*/
/* PARMLST is fairly large.
*/
EXEC SQL
CALL GETPRML(:procnm INDICATOR :parmind.procnm_ind,
:schema INDICATOR :parmind.schema_ind,
:out_code INDICATOR :parmind.out_code_ind,
:parmlst INDICATOR :parmind.parmlst_ind);
if(SQLCODE!=+466)
/* If SQL CALL failed,
*/
{
/*
print the SQLCODE and any
*/
/*
message tokens
*/
printf("SQL CALL failed due to SQLCODE =
printf("sqlca.sqlerrmc = ");
for(i=0;i<sqlca.sqlerrml;i++)
printf("i]);
printf("n");
}
368
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-384-2048.jpg)





![Example C stored procedure with a GENERAL linkage
convention
This example shows how to call a stored procedure that uses the GENERAL
linkage convention from a C program.
This example stored procedure does the following:
v Searches the DB2 catalog table SYSROUTINES for a row that matches the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
v Searches the DB2 catalog table SYSTABLES for all tables in which the value of
CREATOR matches the value of input parameter SCHEMA. The stored
procedure uses a cursor to return the table names.
The linkage convention used for this stored procedure is GENERAL.
The output parameters from this stored procedure contain the SQLCODE from the
SELECT statement and the value of the RUNOPTS column from SYSROUTINES.
The CREATE PROCEDURE statement for this stored procedure might look like
this:
CREATE PROCEDURE GETPRML(PROCNM CHAR(18) IN, SCHEMA CHAR(8) IN,
OUTCODE INTEGER OUT, PARMLST VARCHAR(254) OUT)
LANGUAGE C
DETERMINISTIC
READS SQL DATA
EXTERNAL NAME "GETPRML"
COLLID GETPRML
ASUTIME NO LIMIT
PARAMETER STYLE GENERAL
STAY RESIDENT NO
RUN OPTIONS "MSGFILE(OUTFILE),RPTSTG(ON),RPTOPTS(ON)"
WLM ENVIRONMENT SAMPPROG
PROGRAM TYPE MAIN
SECURITY DB2
RESULT SETS 2
COMMIT ON RETURN NO;
The following example is a C stored procedure with linkage convention GENERAL
#pragma runopts(plist(os))
#include <stdlib.h>
EXEC SQL INCLUDE SQLCA;
/***************************************************************/
/* Declare C variables for SQL operations on the parameters.
*/
/* These are local variables to the C program, which you must */
/* copy to and from the parameter list provided to the stored */
/* procedure.
*/
/***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char PROCNM[19];
char SCHEMA[9];
char PARMLST[255];
EXEC SQL END DECLARE SECTION;
/***************************************************************/
/* Declare cursors for returning result sets to the caller.
*/
/***************************************************************/
EXEC SQL DECLARE C1 CURSOR WITH RETURN FOR
SELECT NAME
FROM SYSIBM.SYSTABLES
374
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-390-2048.jpg)
![WHERE CREATOR=:SCHEMA;
main(argc,argv)
int argc;
char *argv[];
{
/********************************************************/
/* Copy the input parameters into the area reserved in */
/* the program for SQL processing.
*/
/********************************************************/
strcpy(PROCNM, argv[1]);
strcpy(SCHEMA, argv[2]);
/********************************************************/
/* Issue the SQL SELECT against the SYSROUTINES
*/
/* DB2 catalog table.
*/
/********************************************************/
strcpy(PARMLST, "");
/* Clear PARMLST
*/
EXEC SQL
SELECT RUNOPTS INTO :PARMLST
FROM SYSIBM.ROUTINES
WHERE NAME=:PROCNM AND
SCHEMA=:SCHEMA;
/********************************************************/
/* Copy SQLCODE to the output parameter list.
*/
/********************************************************/
*(int *) argv[3] = SQLCODE;
/********************************************************/
/* Copy the PARMLST value returned by the SELECT back to*/
/* the parameter list provided to this stored procedure.*/
/********************************************************/
strcpy(argv[4], PARMLST);
/********************************************************/
/* Open cursor C1 to cause DB2 to return a result set
*/
/* to the caller.
*/
/********************************************************/
EXEC SQL OPEN C1;
}
Example C stored procedure with a GENERAL WITH NULLS
linkage convention
This example shows how to call a stored procedure that uses the GENERAL WITH
NULLS linkage convention from a C program.
This example stored procedure does the following:
v Searches the DB2 catalog table SYSROUTINES for a row that matches the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
v Searches the DB2 catalog table SYSTABLES for all tables in which the value of
CREATOR matches the value of input parameter SCHEMA. The stored
procedure uses a cursor to return the table names.
The linkage convention for this stored procedure is GENERAL WITH NULLS.
The output parameters from this stored procedure contain the SQLCODE from the
SELECT operation, and the value of the RUNOPTS column retrieved from the
SYSROUTINES table.
The CREATE PROCEDURE statement for this stored procedure might look like
this:
Chapter 3. Including DB2 queries in an application program
375](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-391-2048.jpg)
![CREATE PROCEDURE GETPRML(PROCNM CHAR(18) IN, SCHEMA CHAR(8) IN,
OUTCODE INTEGER OUT, PARMLST VARCHAR(254) OUT)
LANGUAGE C
DETERMINISTIC
READS SQL DATA
EXTERNAL NAME "GETPRML"
COLLID GETPRML
ASUTIME NO LIMIT
PARAMETER STYLE GENERAL WITH NULLS
STAY RESIDENT NO
RUN OPTIONS "MSGFILE(OUTFILE),RPTSTG(ON),RPTOPTS(ON)"
WLM ENVIRONMENT SAMPPROG
PROGRAM TYPE MAIN
SECURITY DB2
RESULT SETS 2
COMMIT ON RETURN NO;
The following example is a C stored procedure with linkage convention GENERAL
WITH NULLS.
#pragma runopts(plist(os))
#include <stdlib.h>
EXEC SQL INCLUDE SQLCA;
/***************************************************************/
/* Declare C variables used for SQL operations on the
*/
/* parameters. These are local variables to the C program,
*/
/* which you must copy to and from the parameter list provided */
/* to the stored procedure.
*/
/***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
char PROCNM[19];
char SCHEMA[9];
char PARMLST[255];
struct INDICATORS {
short int PROCNM_IND;
short int SCHEMA_IND;
short int OUT_CODE_IND;
short int PARMLST_IND;
} PARM_IND;
EXEC SQL END DECLARE SECTION;
/***************************************************************/
/* Declare cursors for returning result sets to the caller.
*/
/***************************************************************/
EXEC SQL DECLARE C1 CURSOR WITH RETURN FOR
SELECT NAME
FROM SYSIBM.SYSTABLES
WHERE CREATOR=:SCHEMA;
main(argc,argv)
int argc;
char *argv[];
{
/********************************************************/
/* Copy the input parameters into the area reserved in */
/* the local program for SQL processing.
*/
/********************************************************/
strcpy(PROCNM, argv[1]);
strcpy(SCHEMA, argv[2]);
/********************************************************/
376
Application Programming and SQL Guide](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-392-2048.jpg)
![/* Copy null indicator values for the parameter list.
*/
/********************************************************/
memcpy(&PARM_IND,(struct INDICATORS *) argv[5],
sizeof(PARM_IND));
/********************************************************/
/* If any input parameter is NULL, return an error
*/
/* return code and assign a NULL value to PARMLST.
*/
/********************************************************/
if (PARM_IND.PROCNM_IND<0 ||
PARM_IND.SCHEMA_IND<0 || {
*(int *) argv[3] = 9999;
/* set output return code */
PARM_IND.OUT_CODE_IND = 0;
/* value is not NULL
*/
PARM_IND.PARMLST_IND = -1;
/* PARMLST is NULL
*/
}
else {
/********************************************************/
/* If the input parameters are not NULL, issue the SQL */
/* SELECT against the SYSIBM.SYSROUTINES catalog
*/
/* table.
*/
/********************************************************/
strcpy(PARMLST, "");
/* Clear PARMLST
*/
EXEC SQL
SELECT RUNOPTS INTO :PARMLST
FROM SYSIBM.SYSROUTINES
WHERE NAME=:PROCNM AND
SCHEMA=:SCHEMA;
/********************************************************/
/* Copy SQLCODE to the output parameter list.
*/
/********************************************************/
*(int *) argv[3] = SQLCODE;
PARM_IND.OUT_CODE_IND = 0;
/* OUT_CODE is not NULL */
}
/********************************************************/
/* Copy the RUNOPTS value back to the output parameter */
/* area.
*/
/********************************************************/
strcpy(argv[4], PARMLST);
/********************************************************/
/* Copy the null indicators back to the output parameter*/
/* area.
*/
/********************************************************/
memcpy((struct INDICATORS *) argv[5],&PARM_IND,
sizeof(PARM_IND));
/********************************************************/
/* Open cursor C1 to cause DB2 to return a result set
*/
/* to the caller.
*/
/********************************************************/
EXEC SQL OPEN C1;
}
Example COBOL stored procedure with a GENERAL linkage
convention
This example shows how to call a stored procedure that uses the GENERAL
linkage convention from a COBOL program.
This example stored procedure does the following:
v Searches the catalog table SYSROUTINES for a row matching the input
parameters from the client program. The two input parameters contain values
for NAME and SCHEMA.
Chapter 3. Including DB2 queries in an application program
377](https://image.slidesharecdn.com/applicationprogrammingandsqlguide-140106200920-phpapp01/75/DB2-Application-programming-and-sql-guide-393-2048.jpg)




































































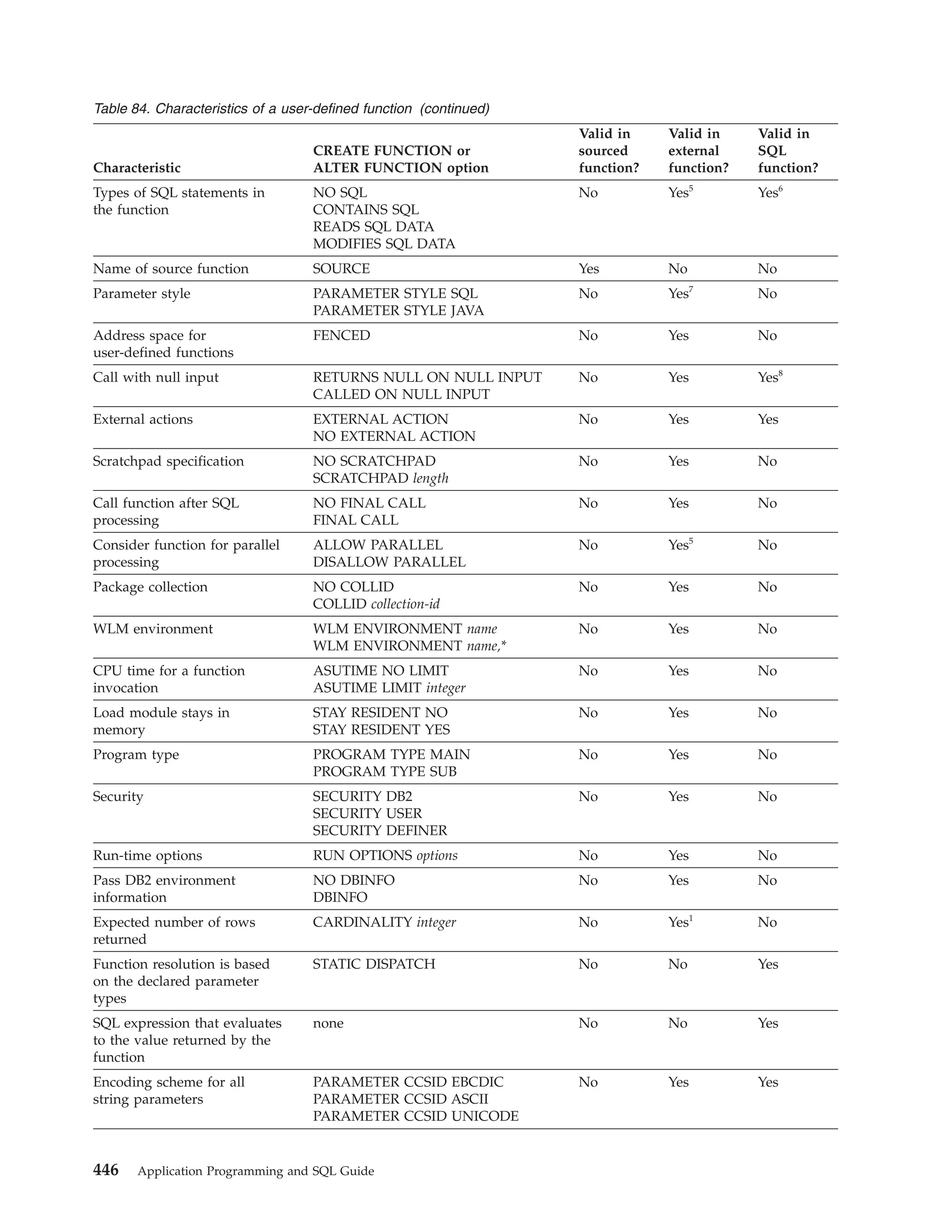

























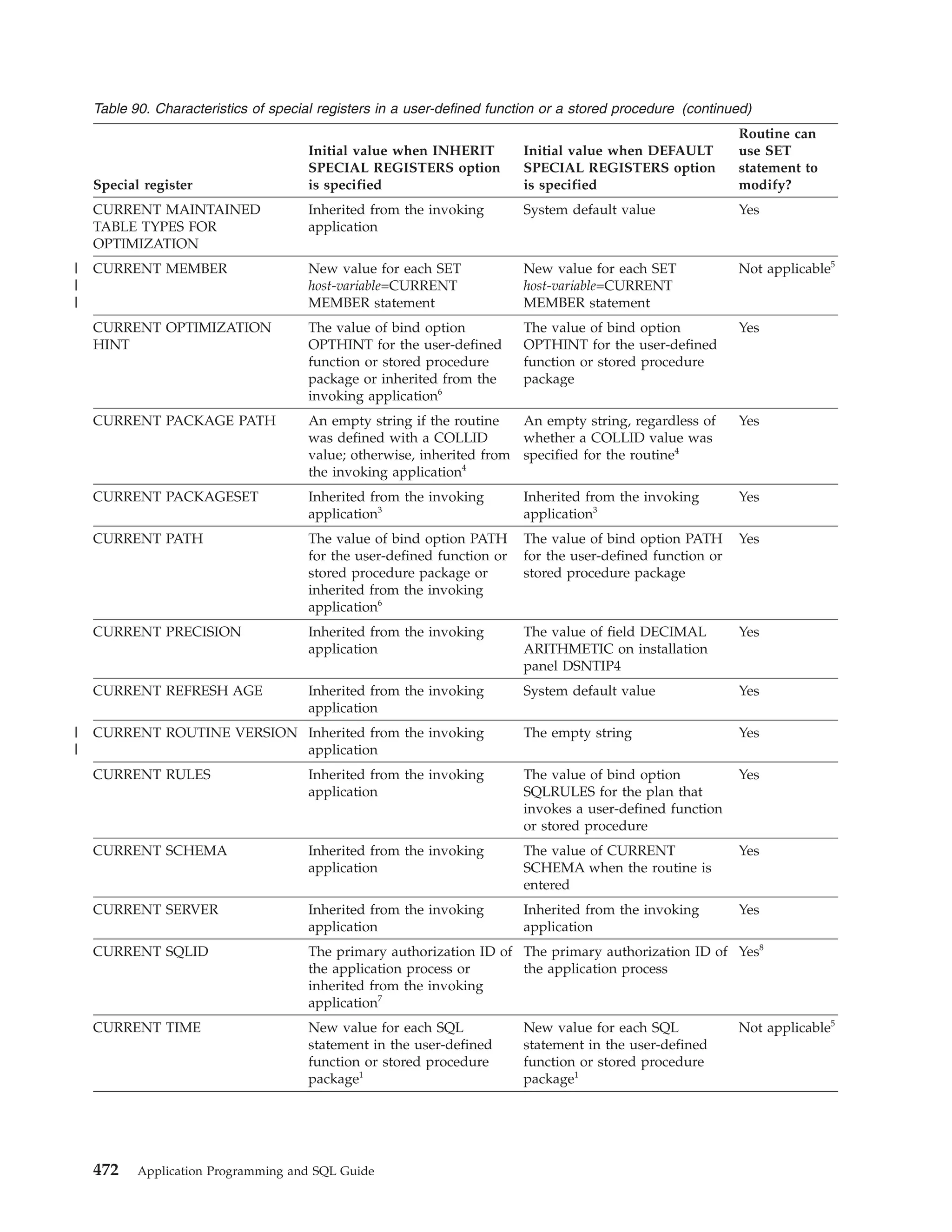












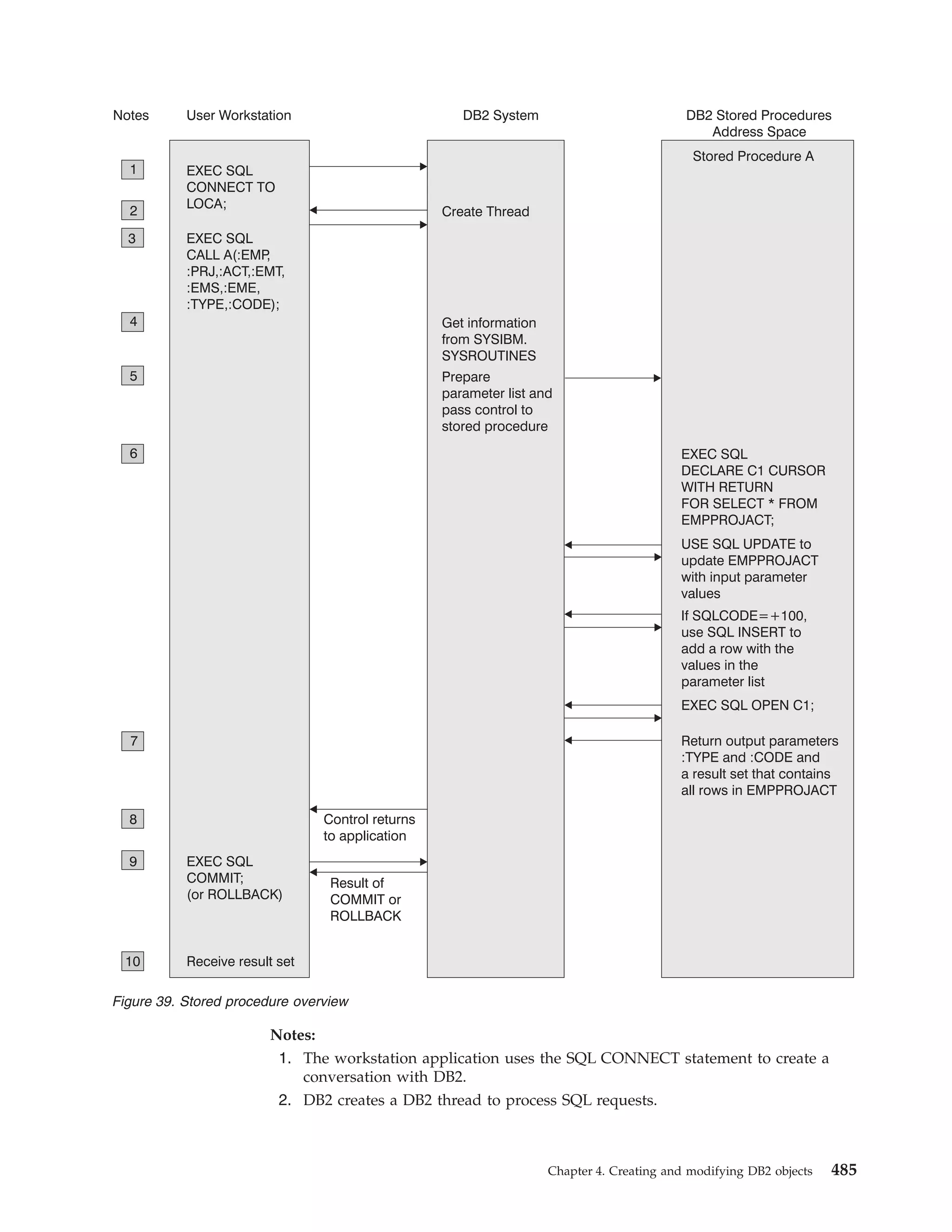























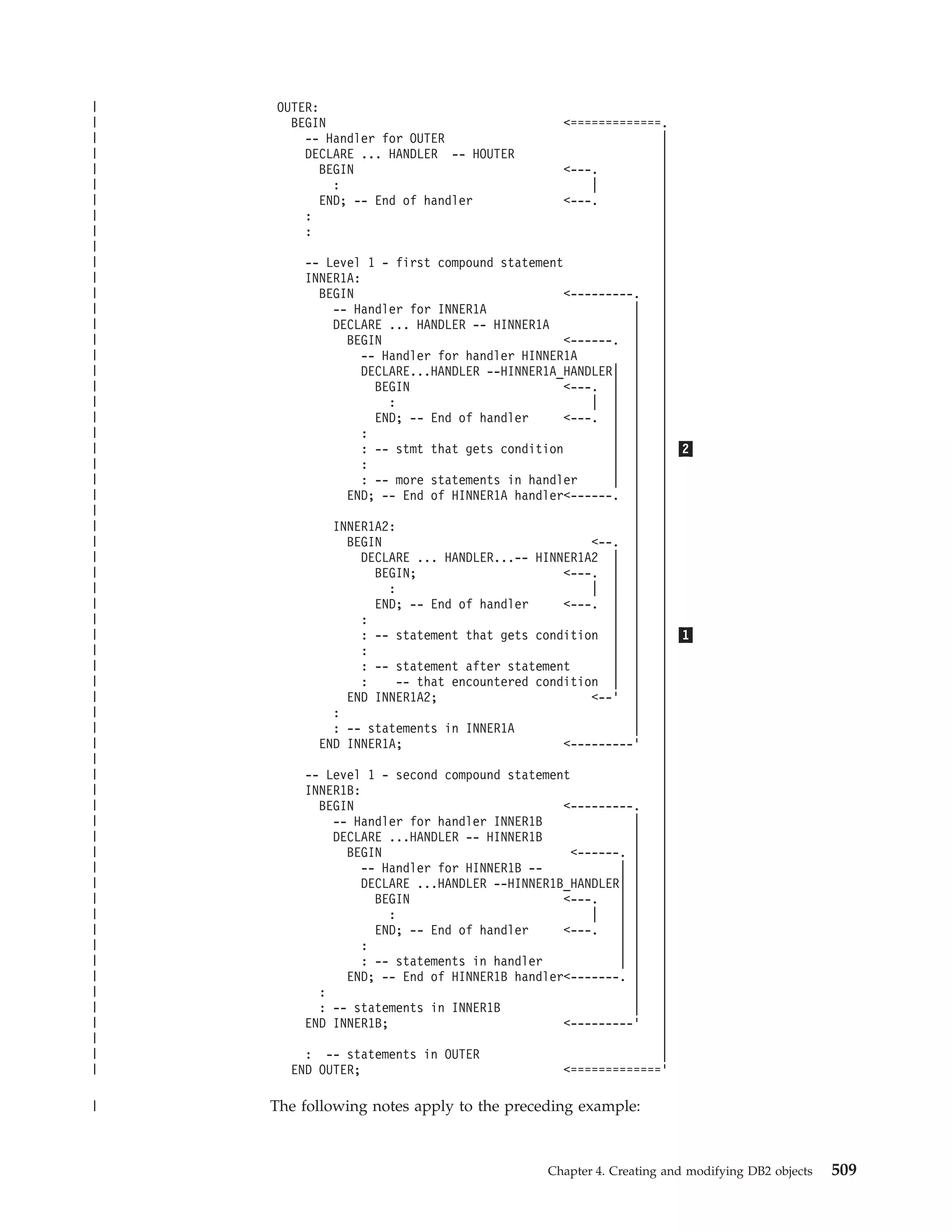





































































































































































































































































































































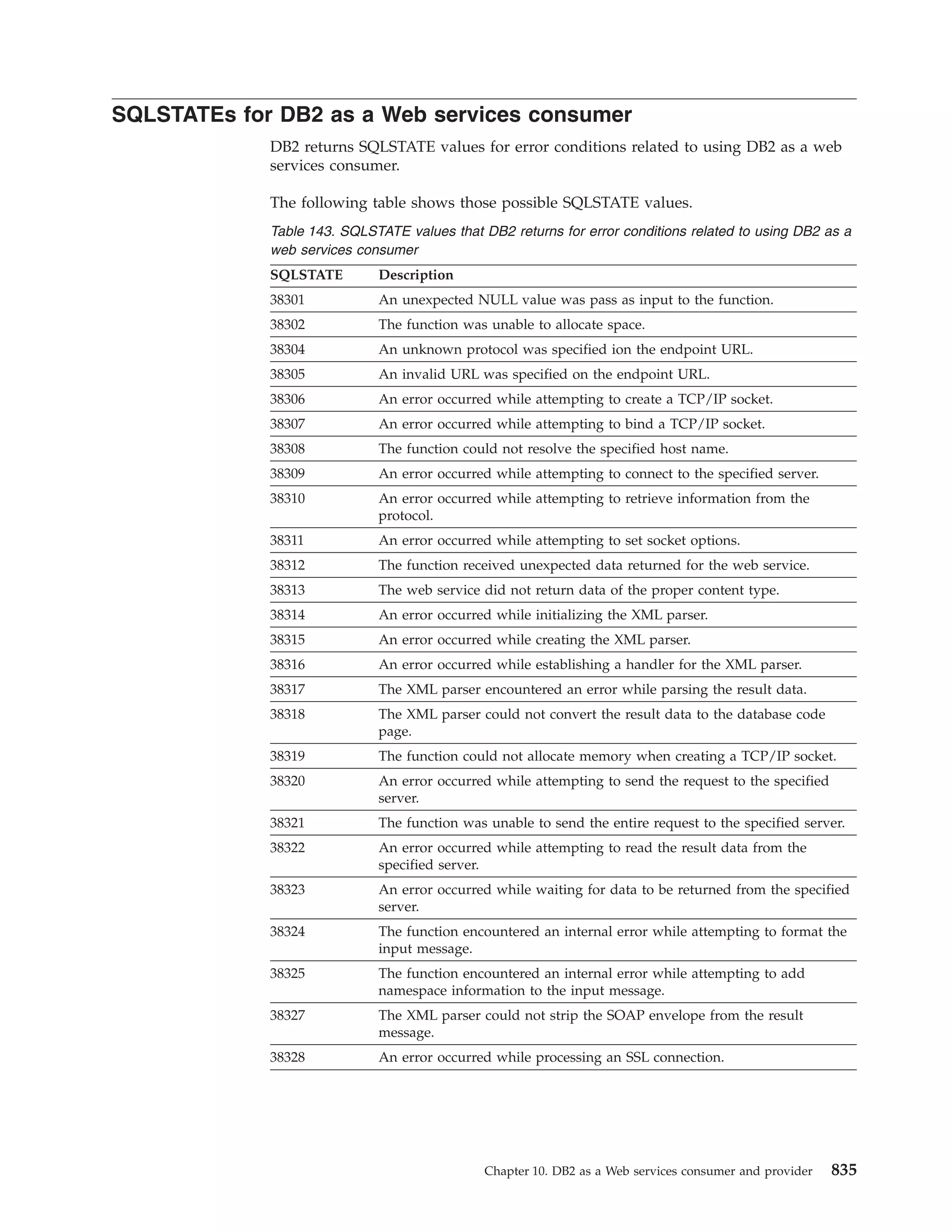






















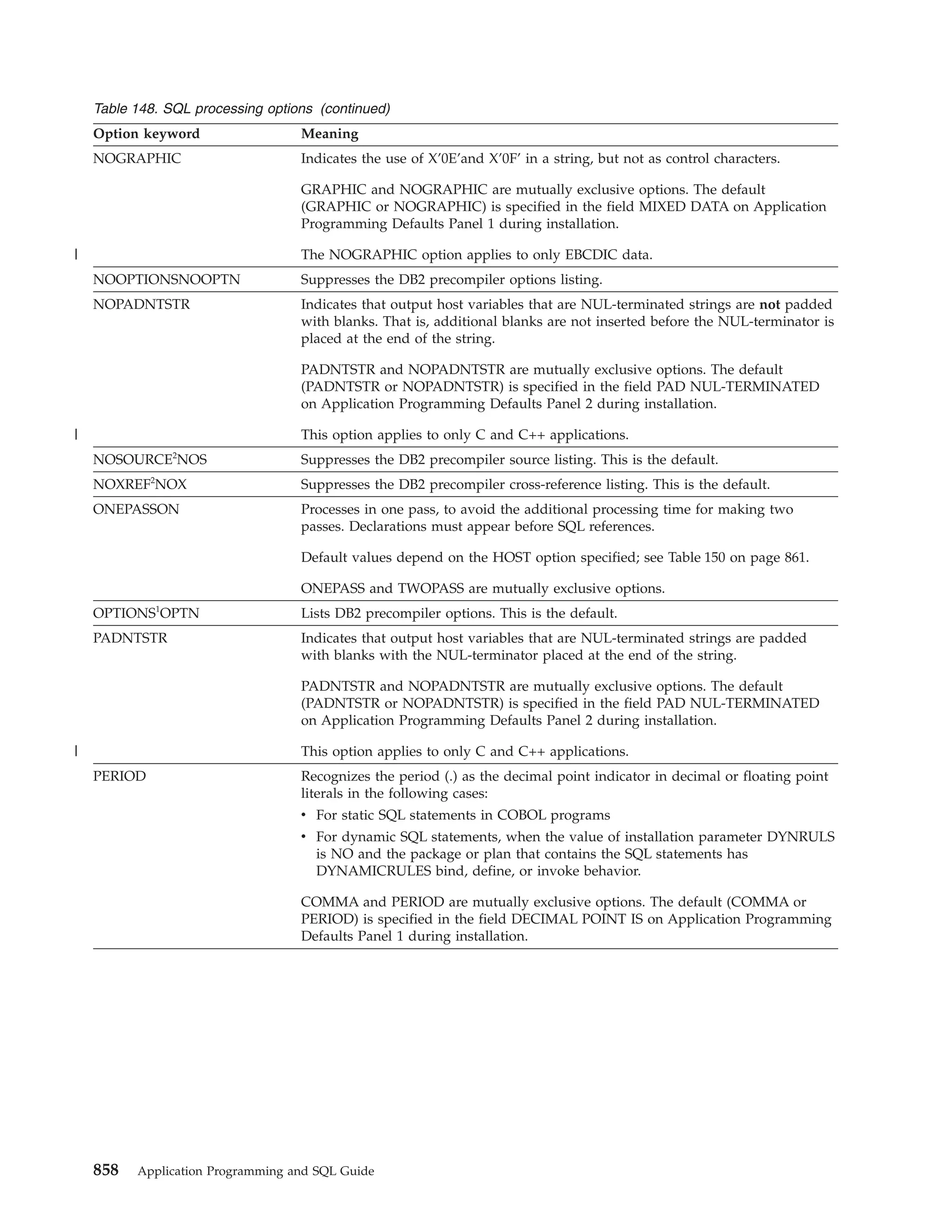


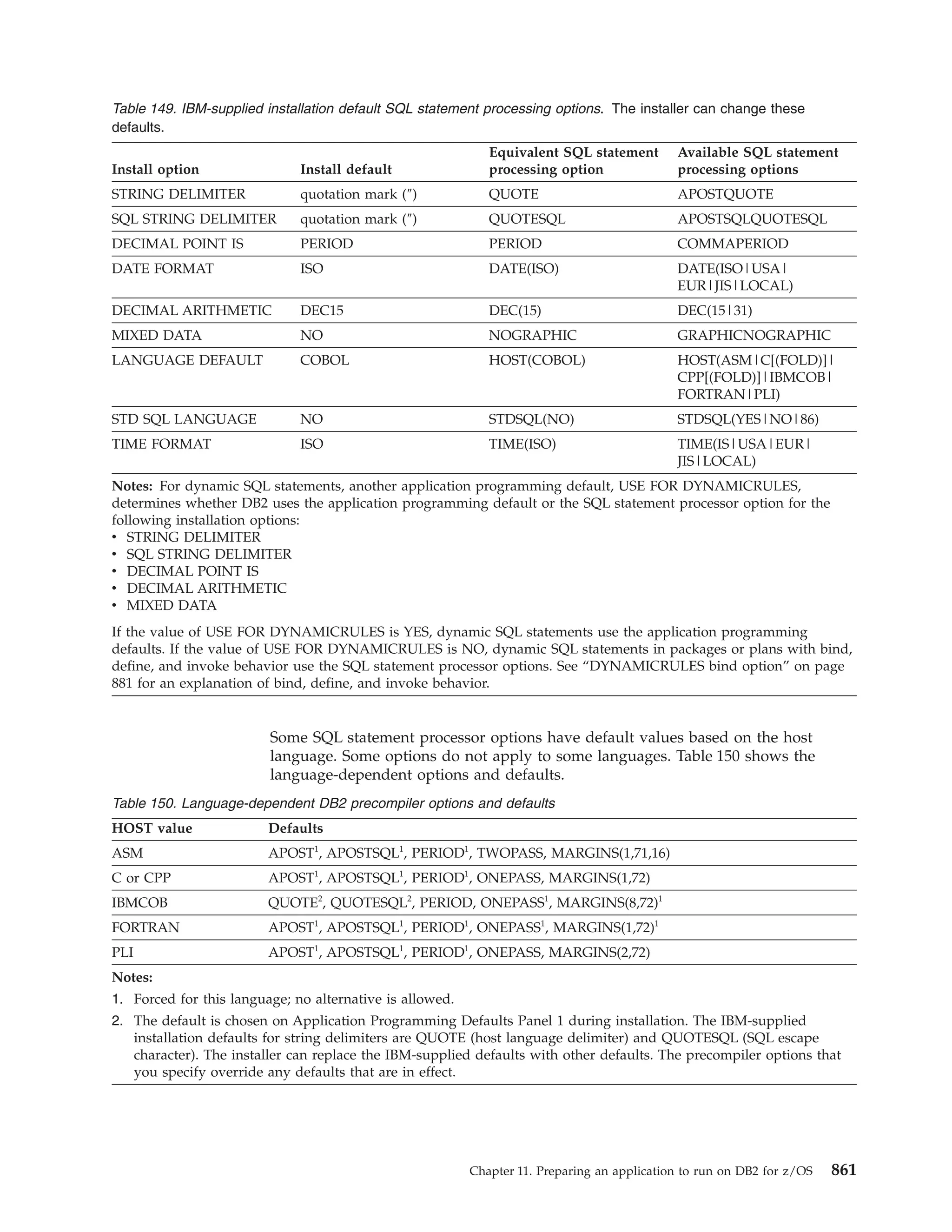

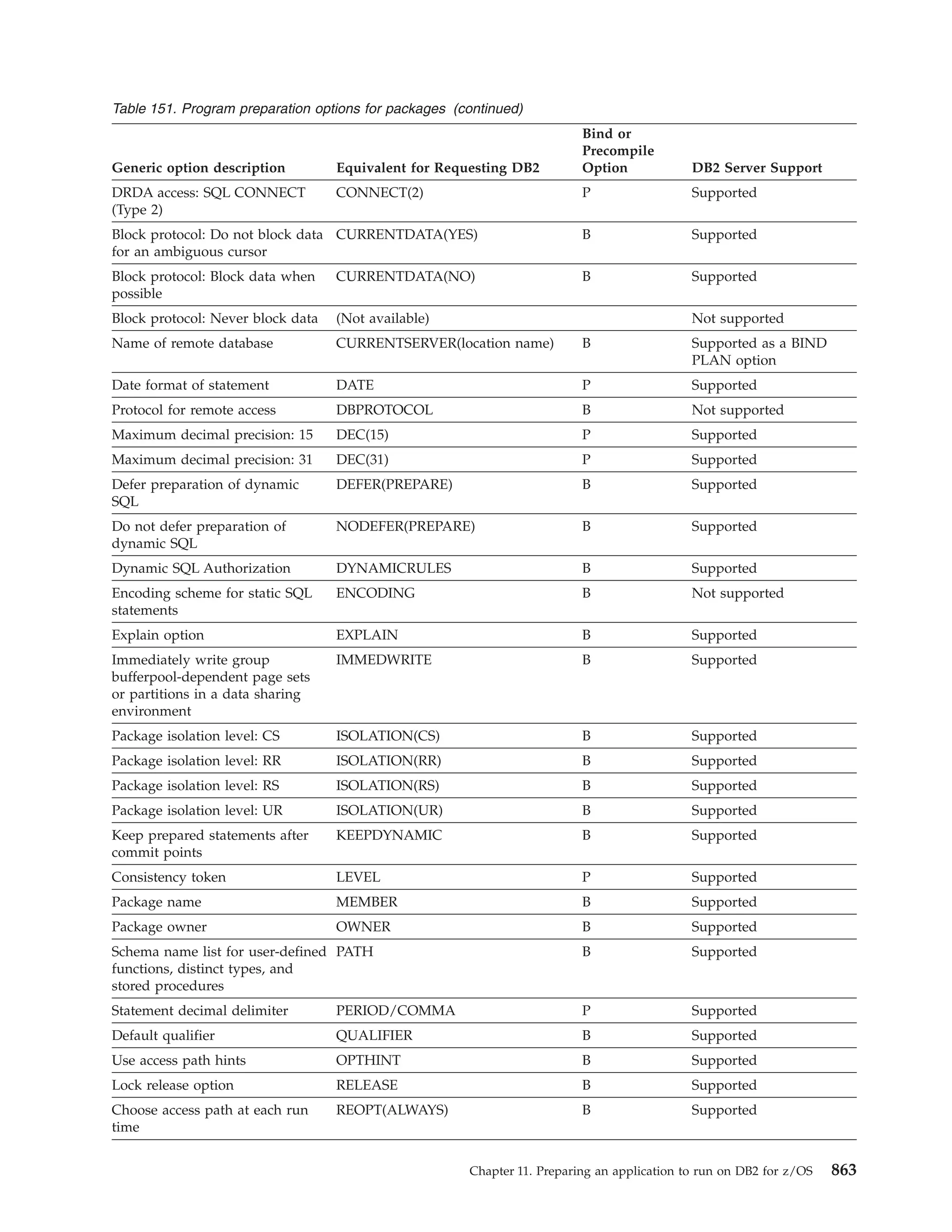
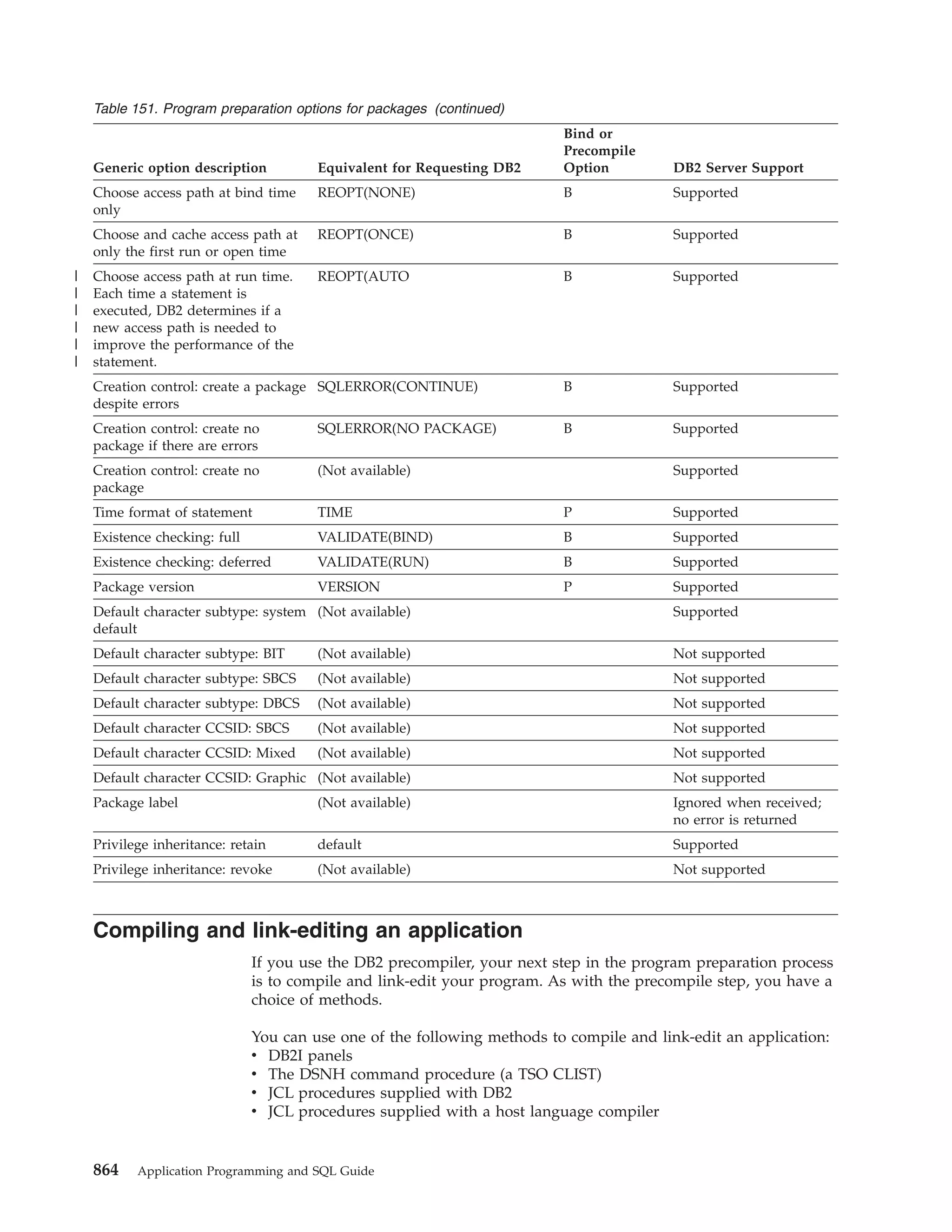





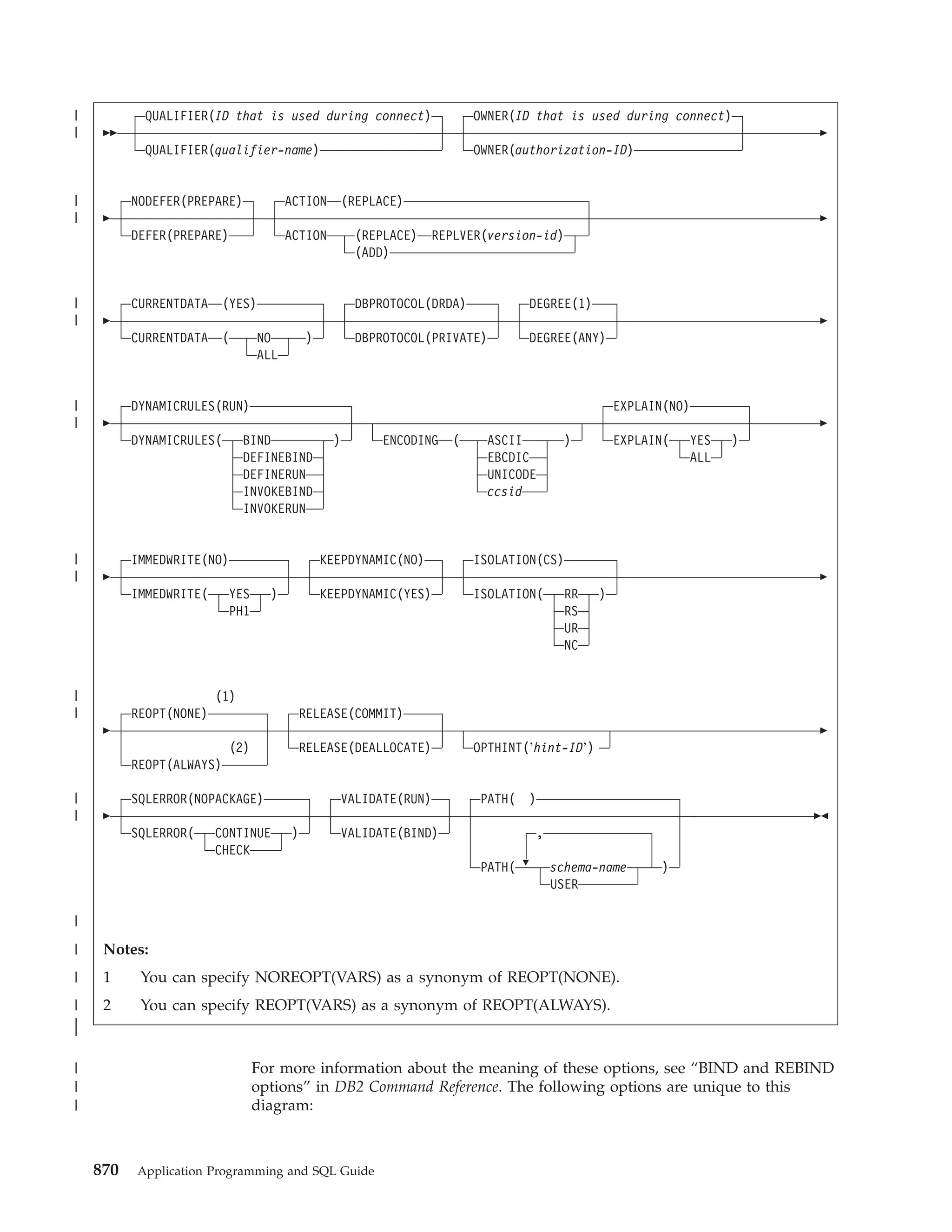











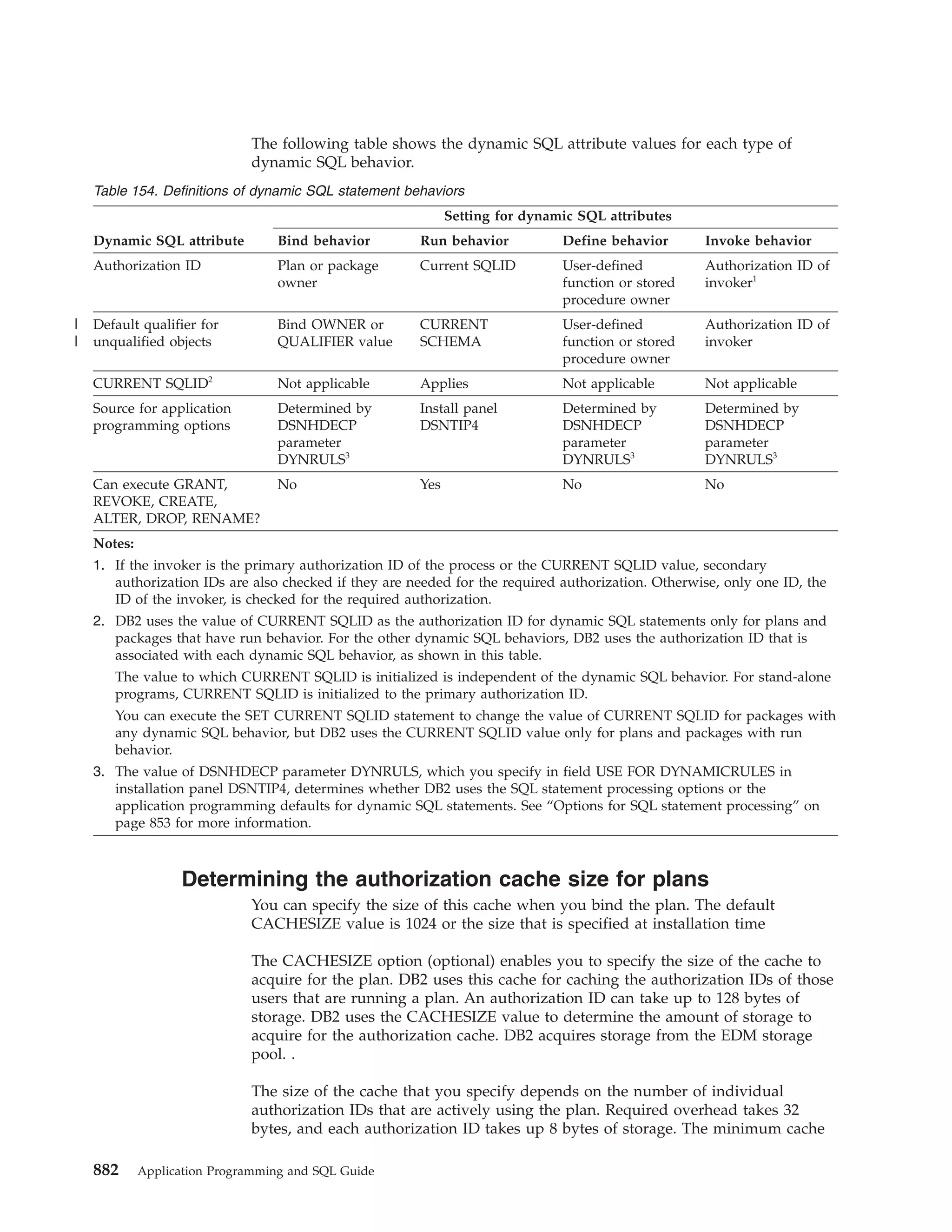













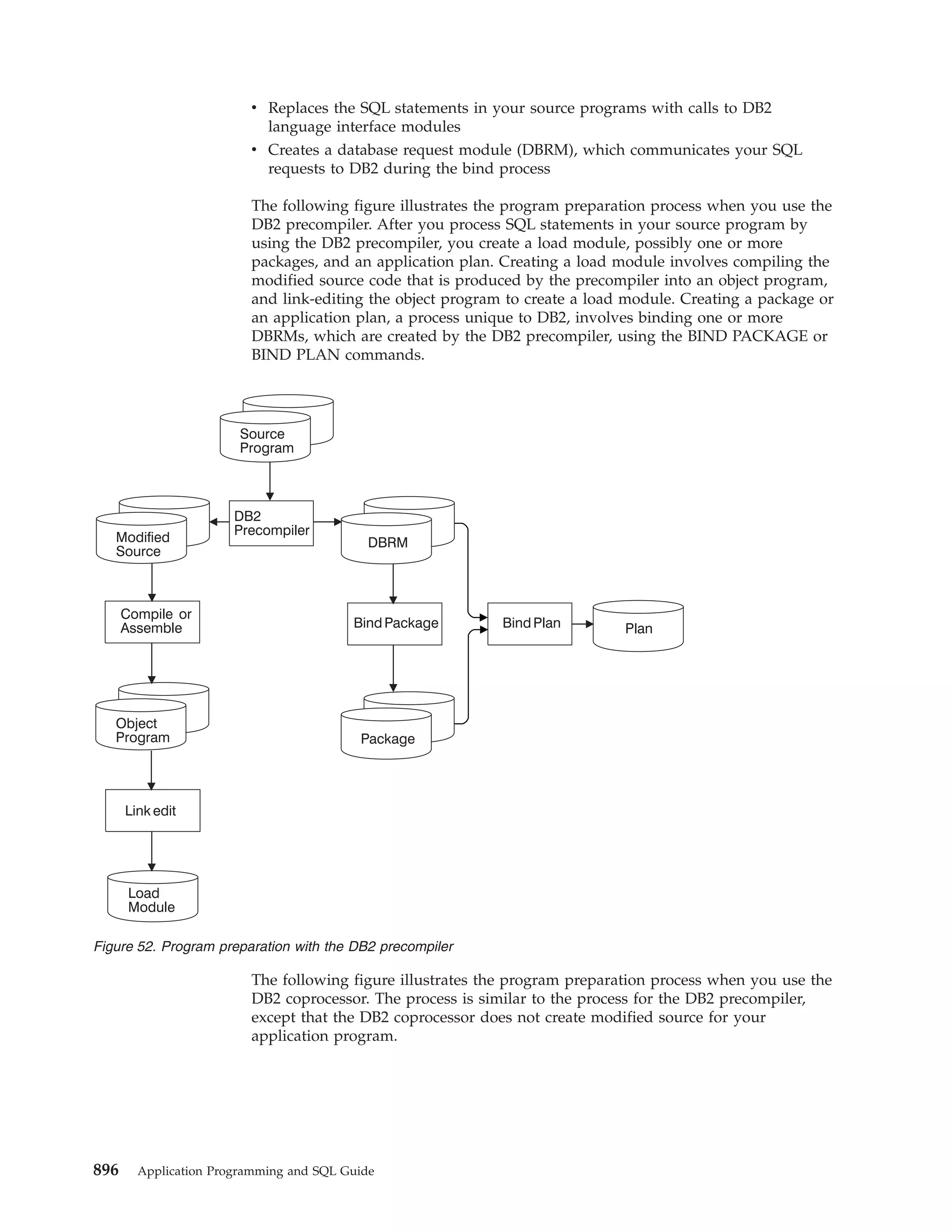







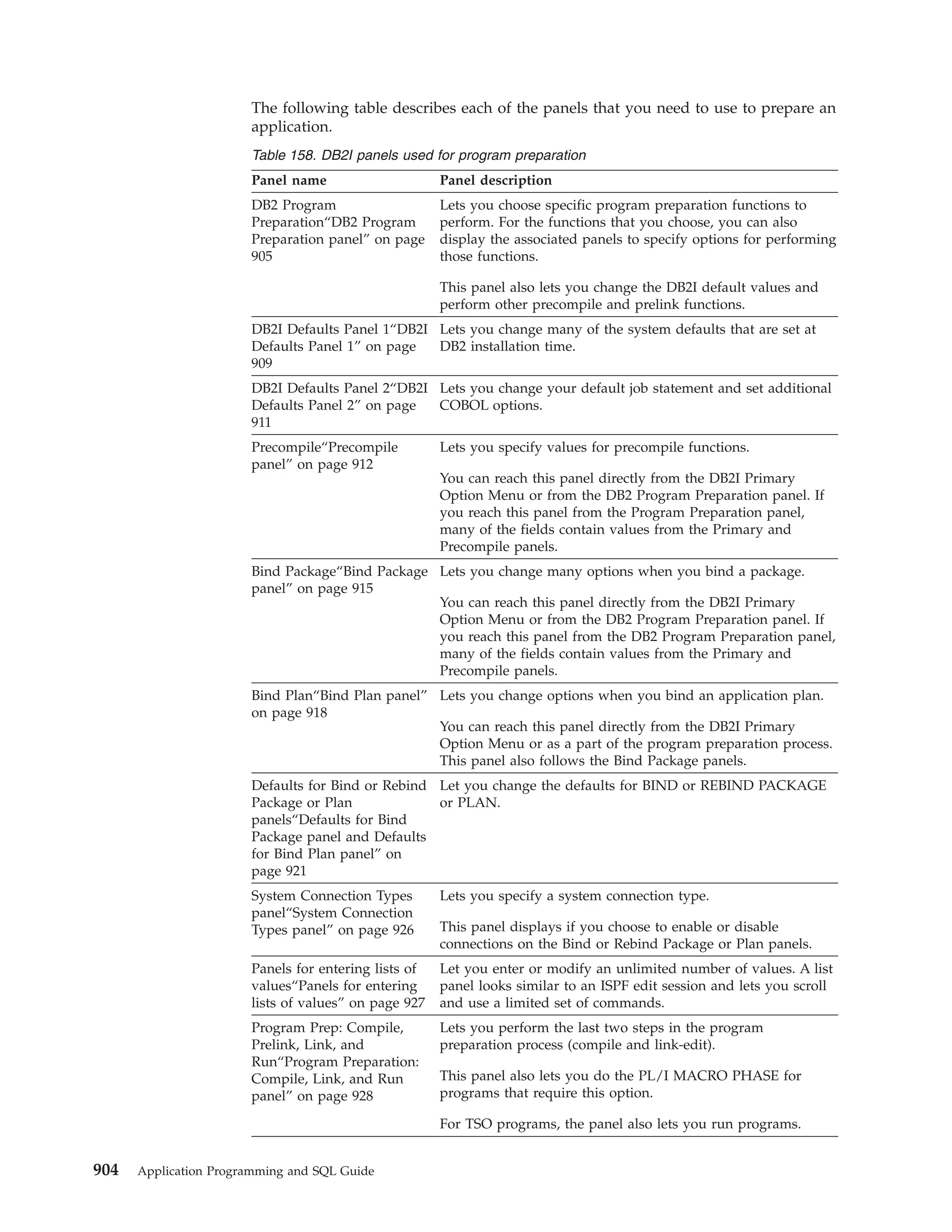




























































































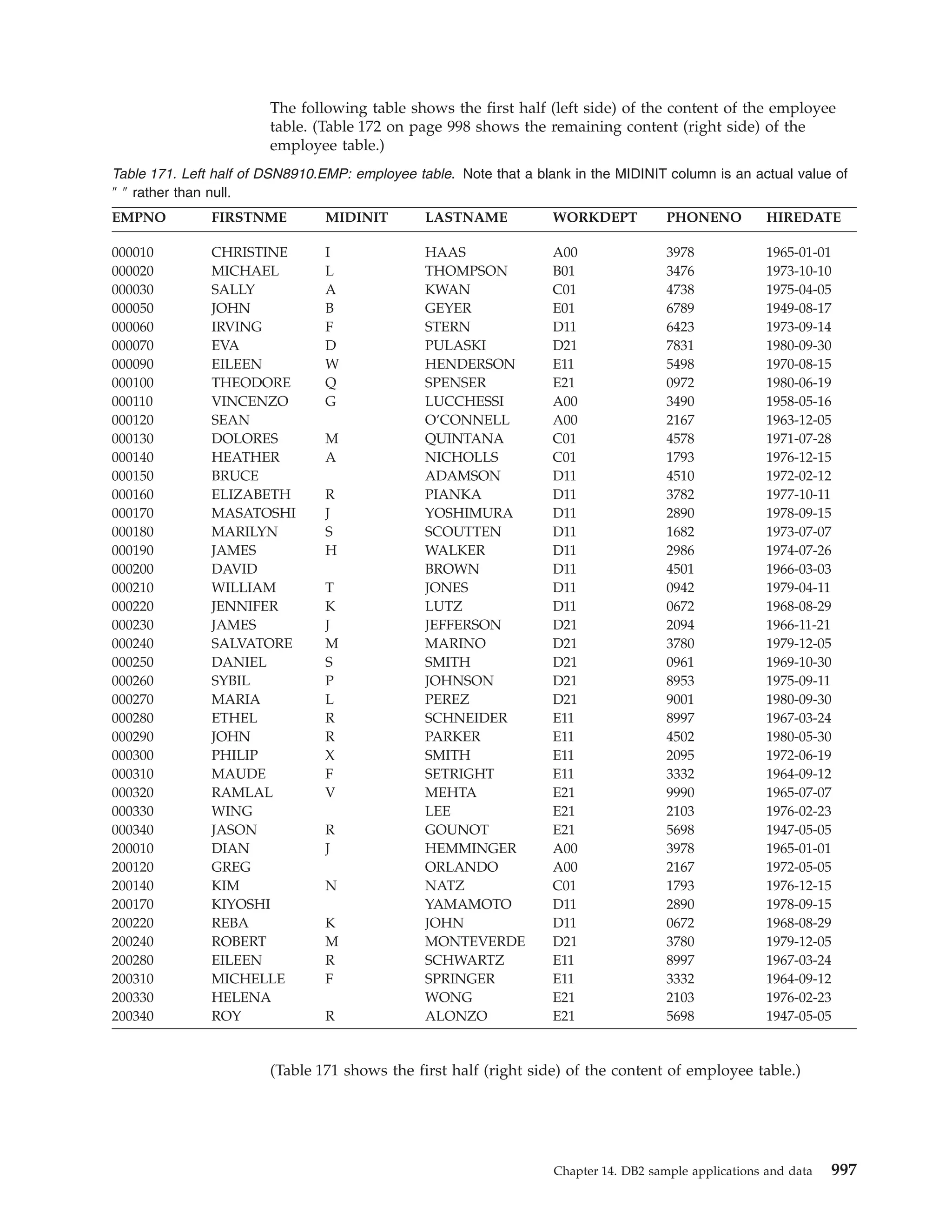
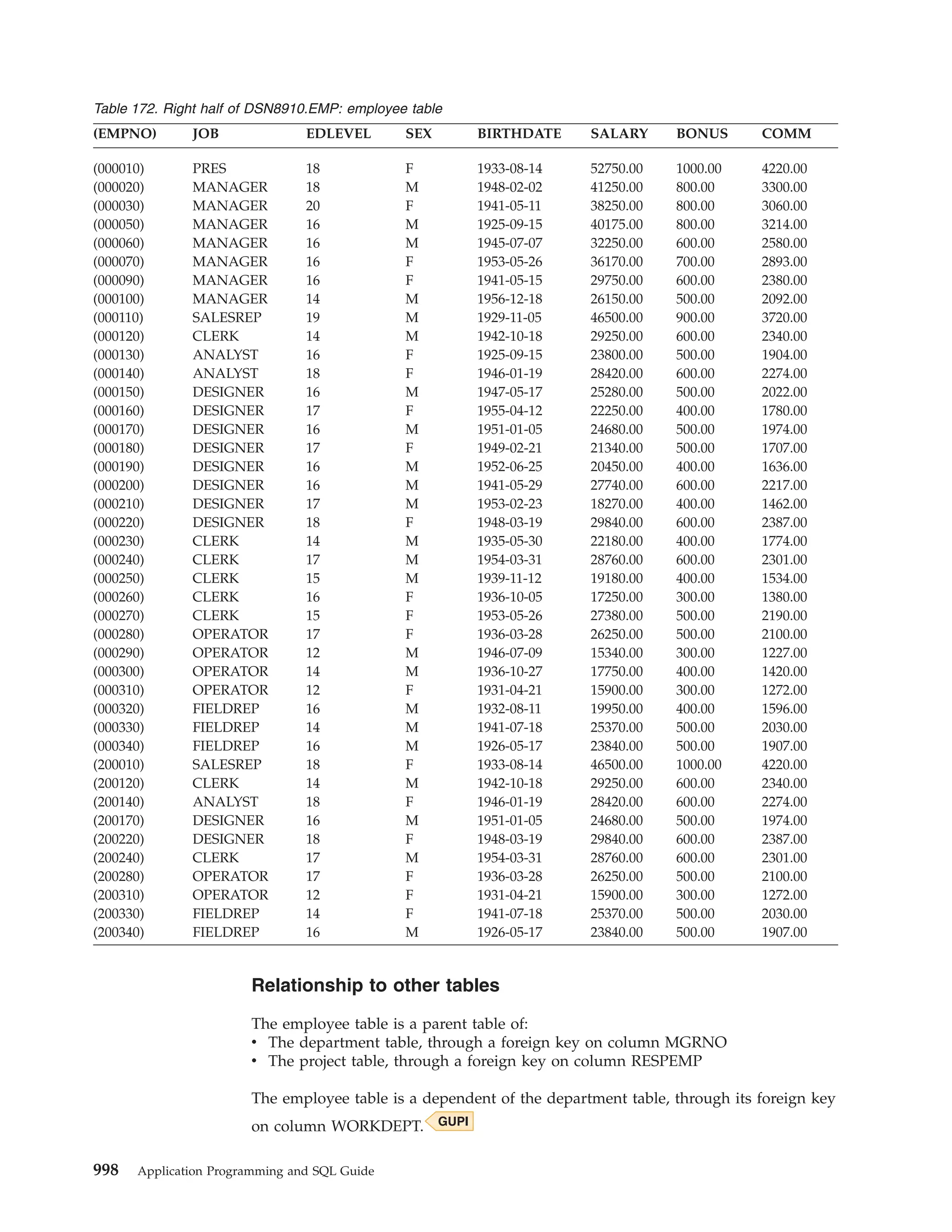











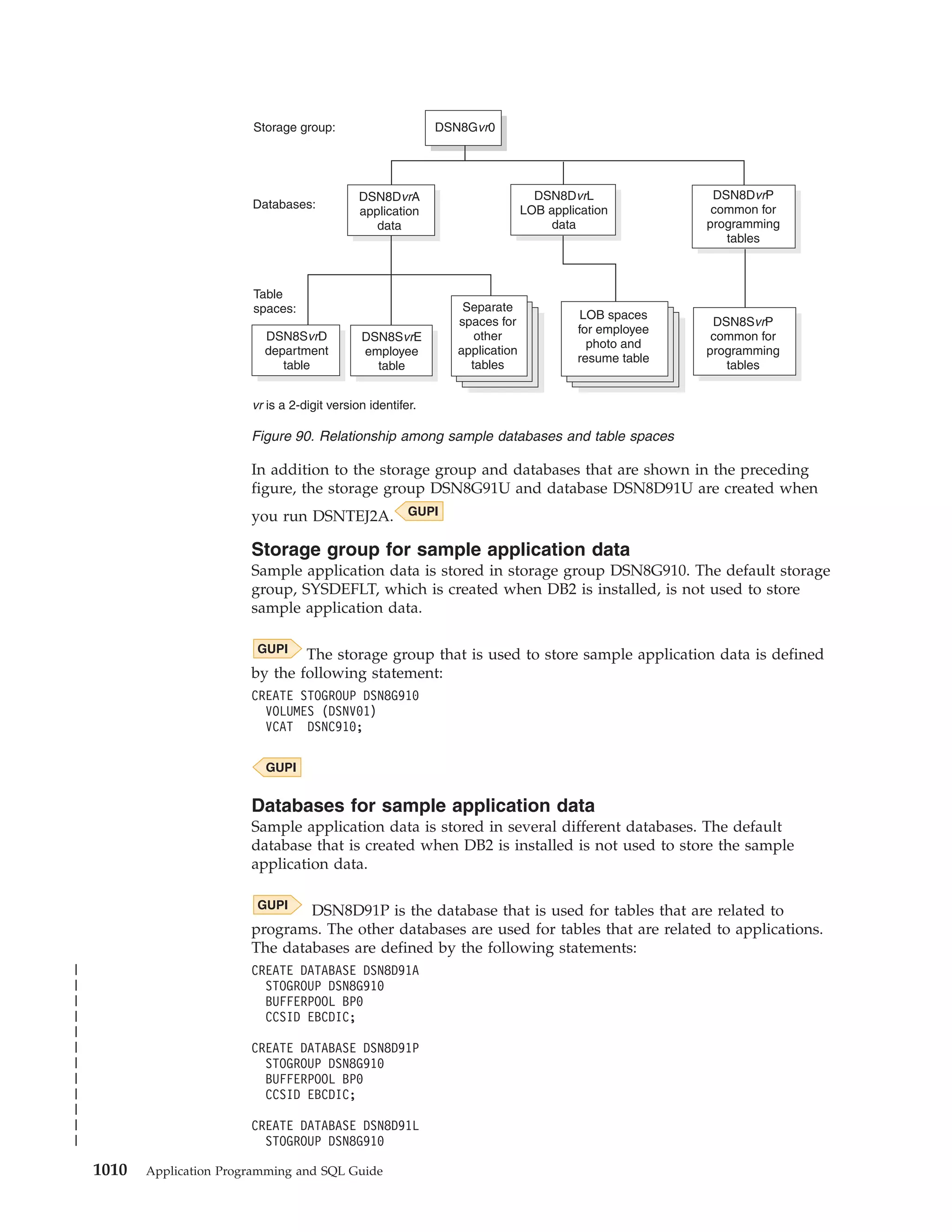








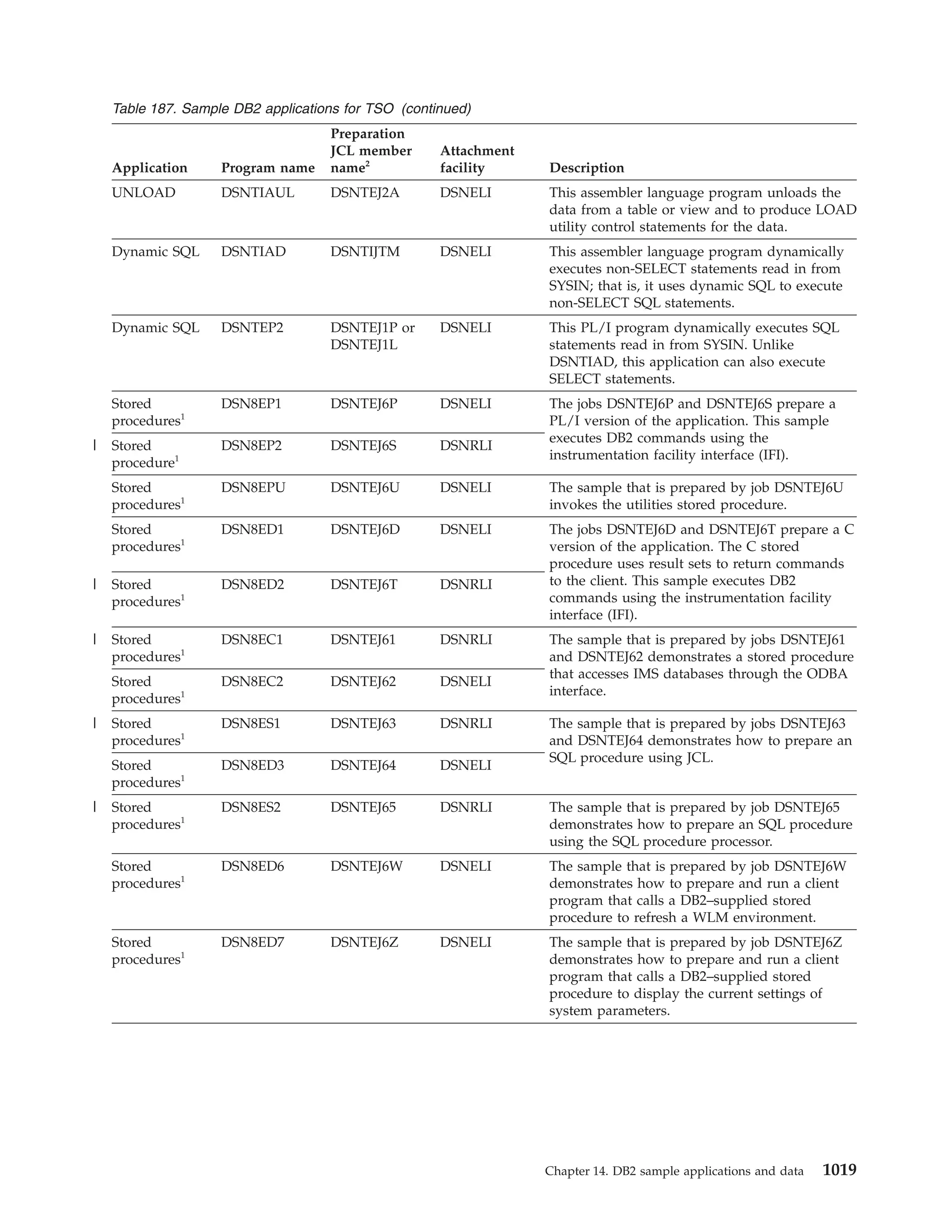





































































































This document provides an overview and reference information for DB2 Version 9.1 for z/OS, including: - Details on who should use the guide and how to read syntax diagrams - Guidelines for planning and designing DB2 applications - Methods for connecting application programs to DB2 - Techniques for embedding SQL statements in different programming languages - Approaches for handling SQL errors and checking statement execution

































































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







