













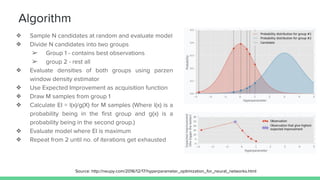
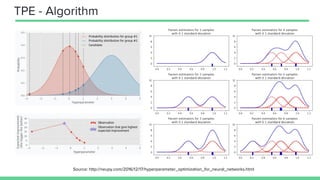


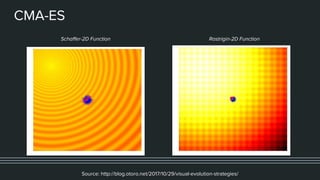


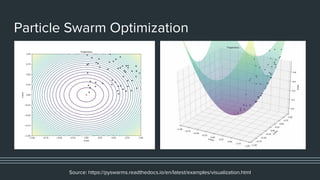


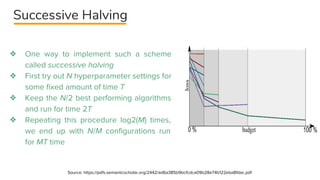











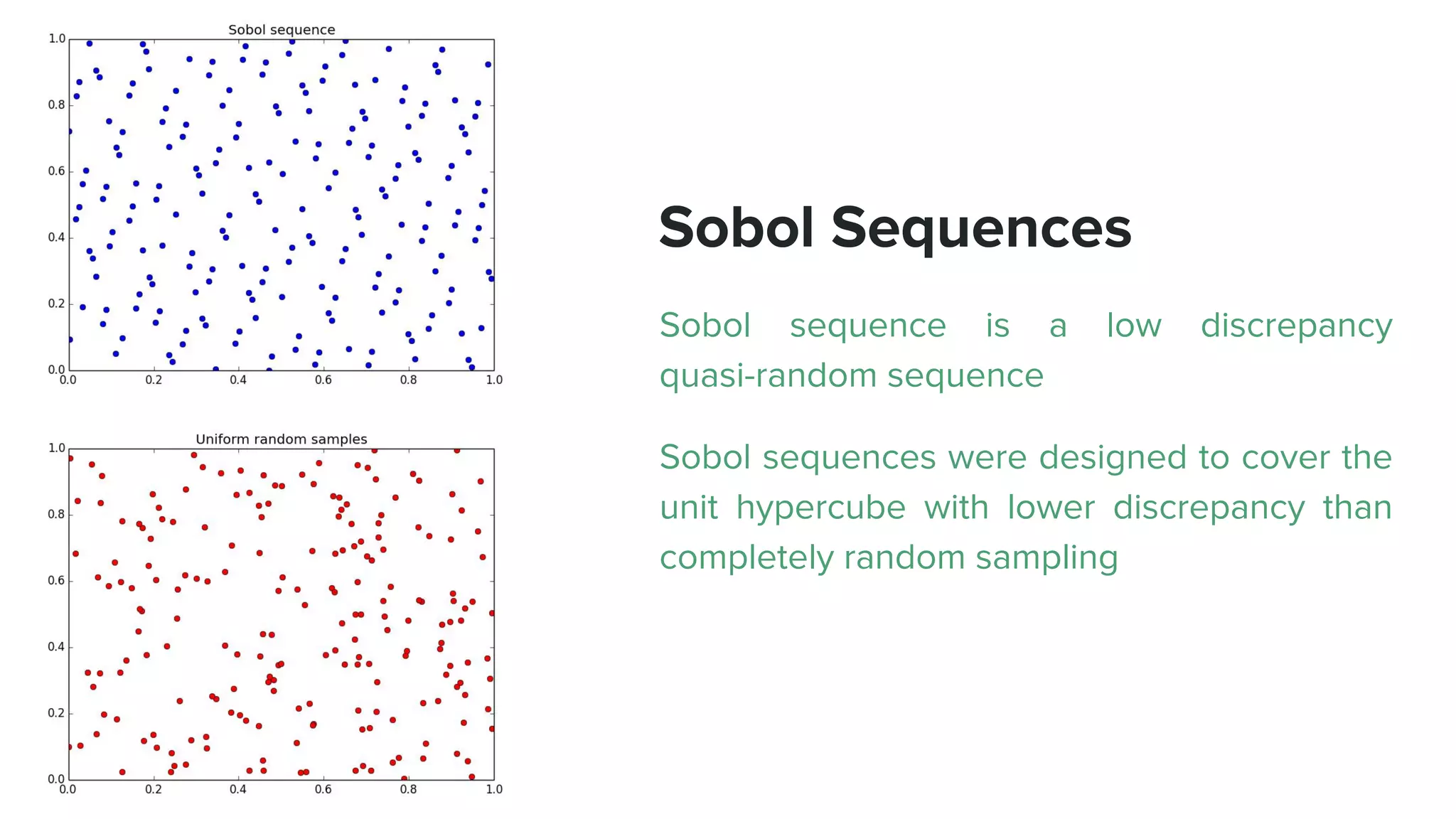



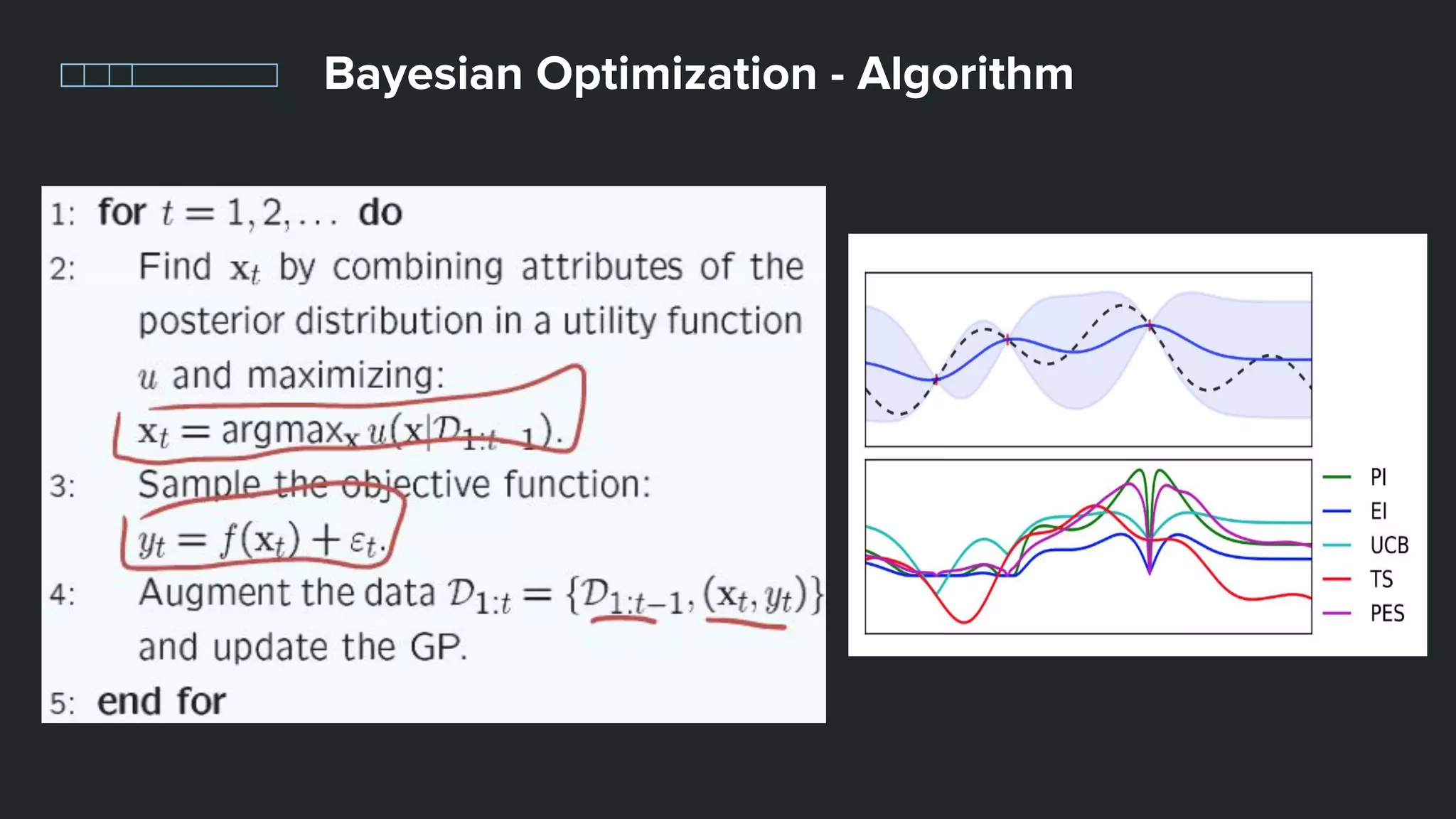
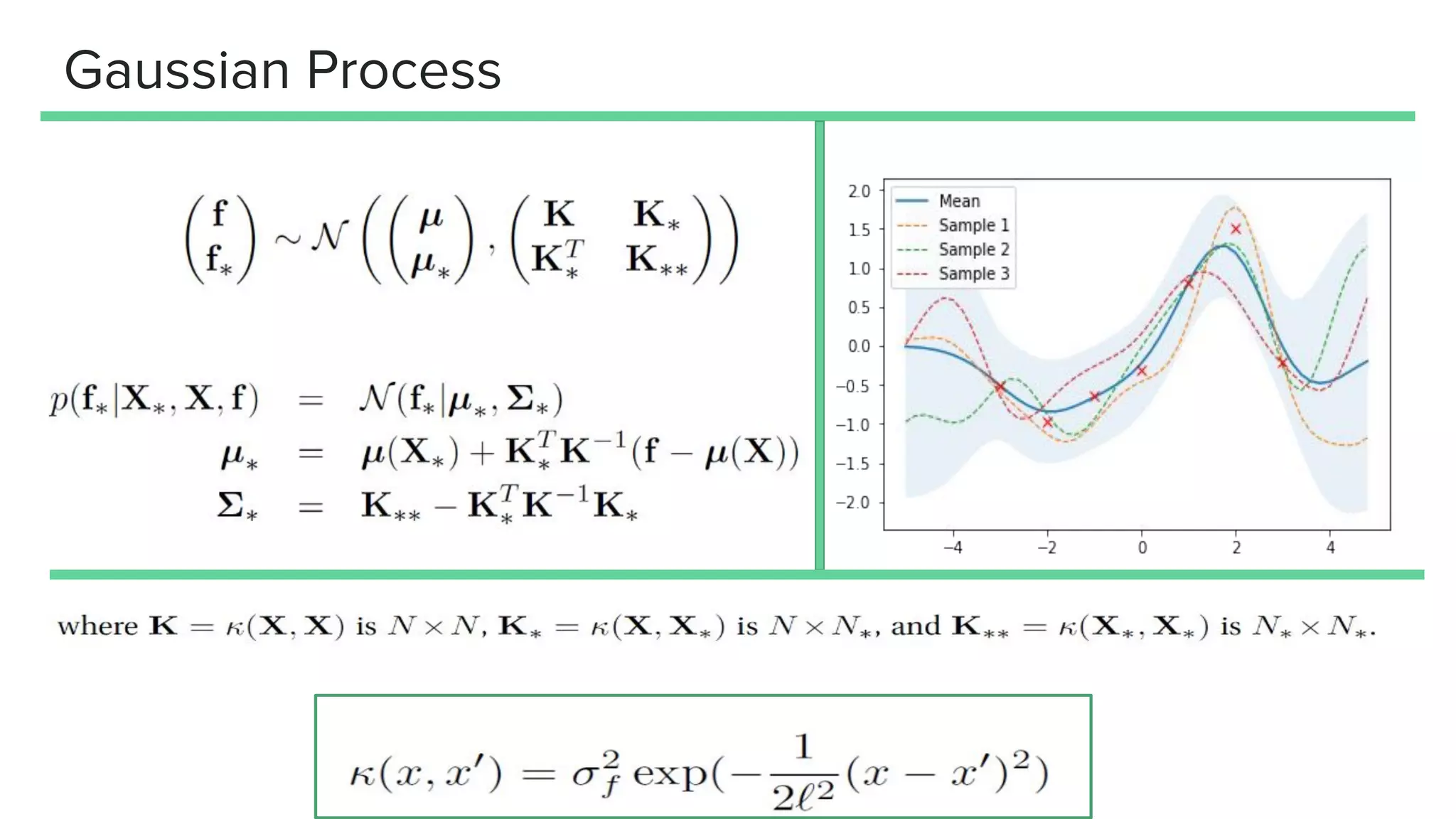




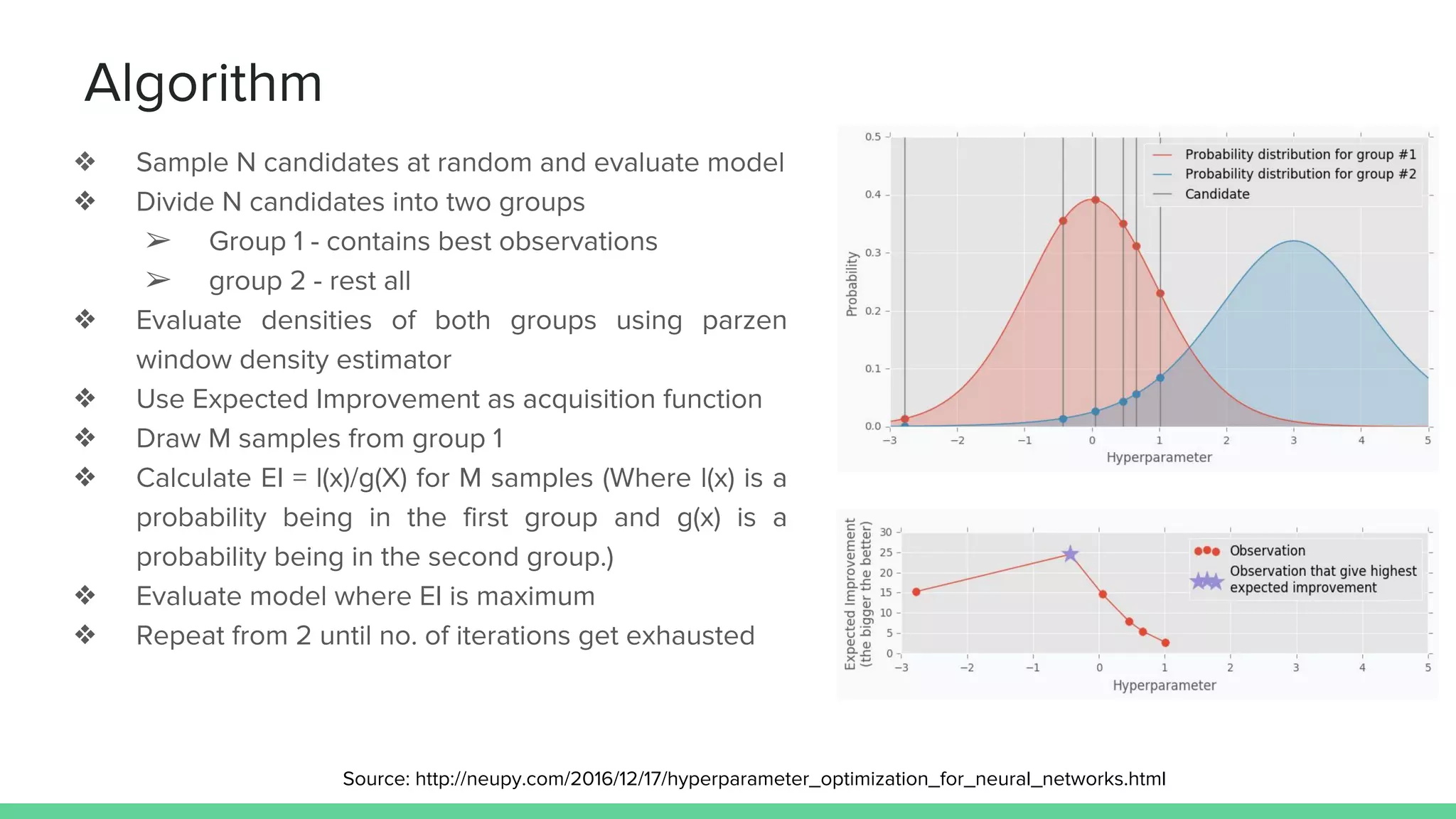
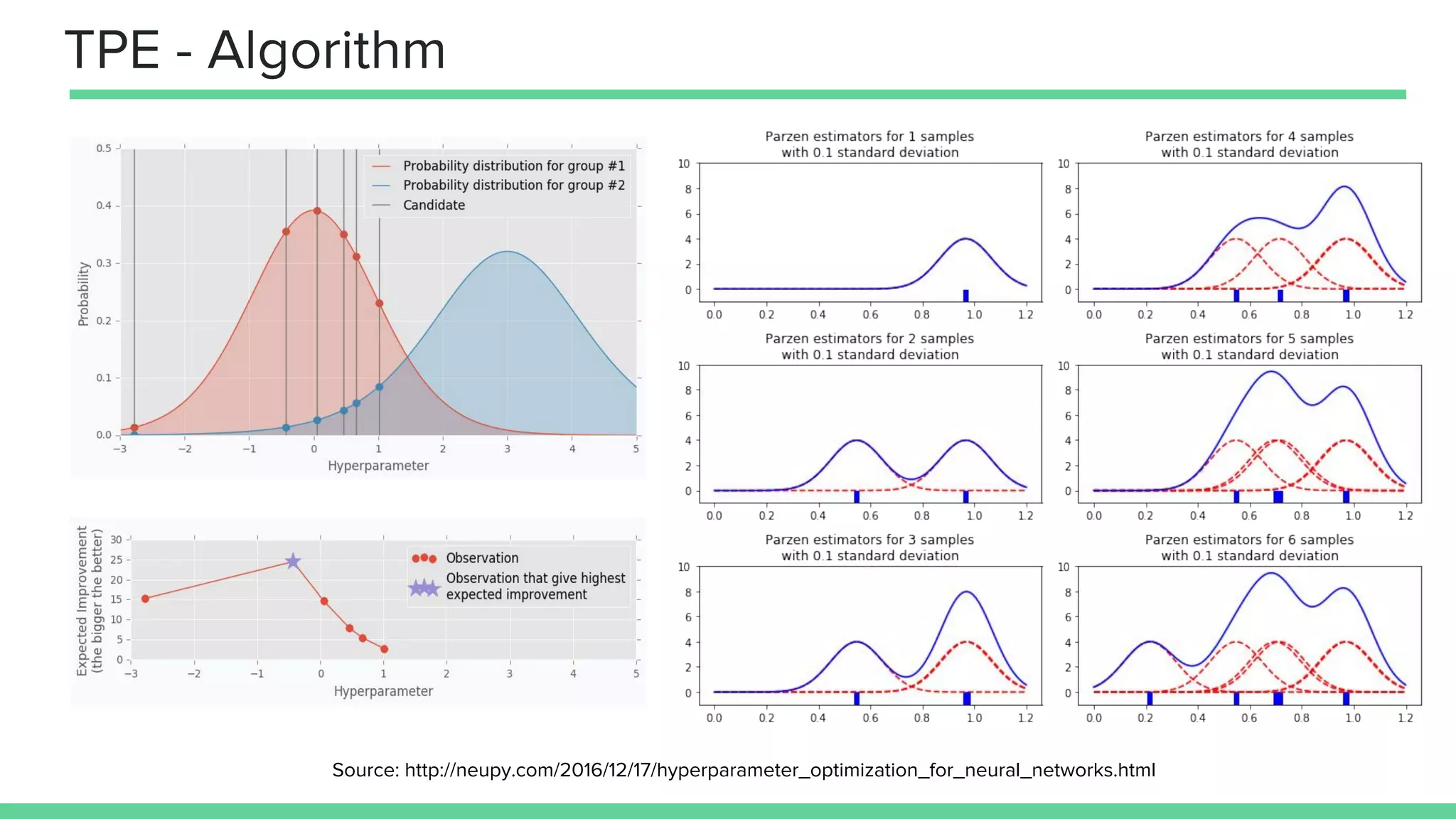
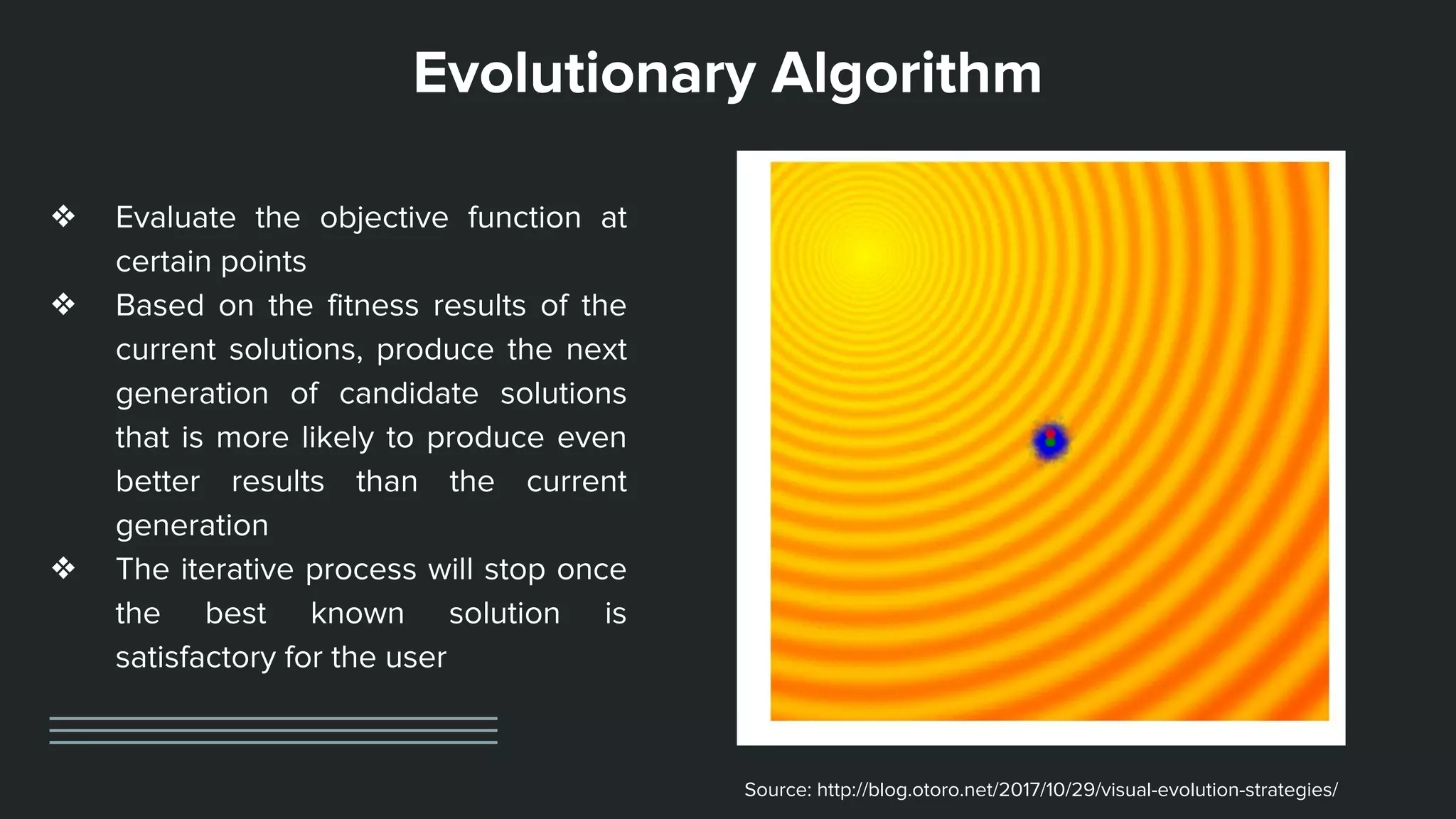

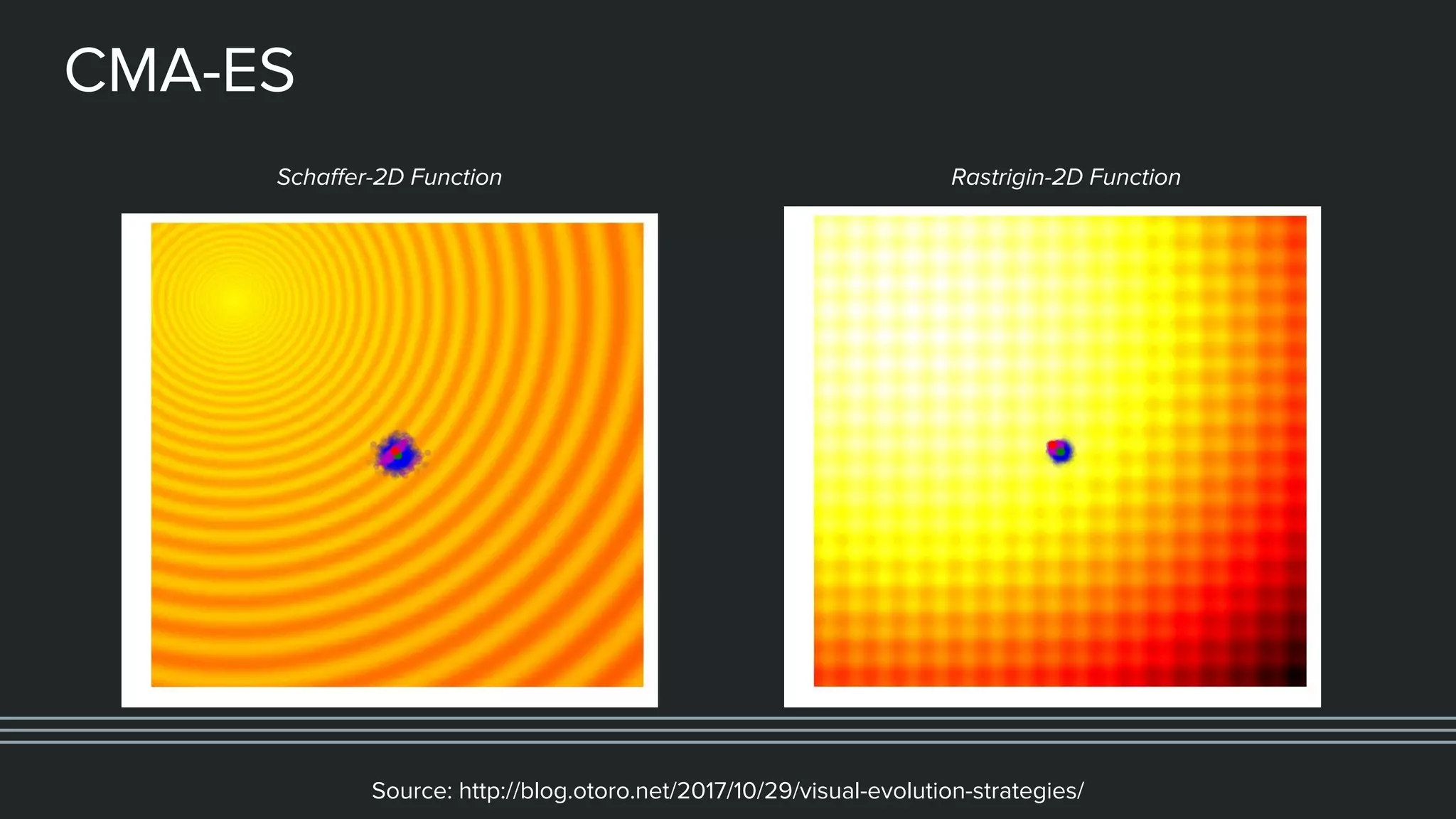


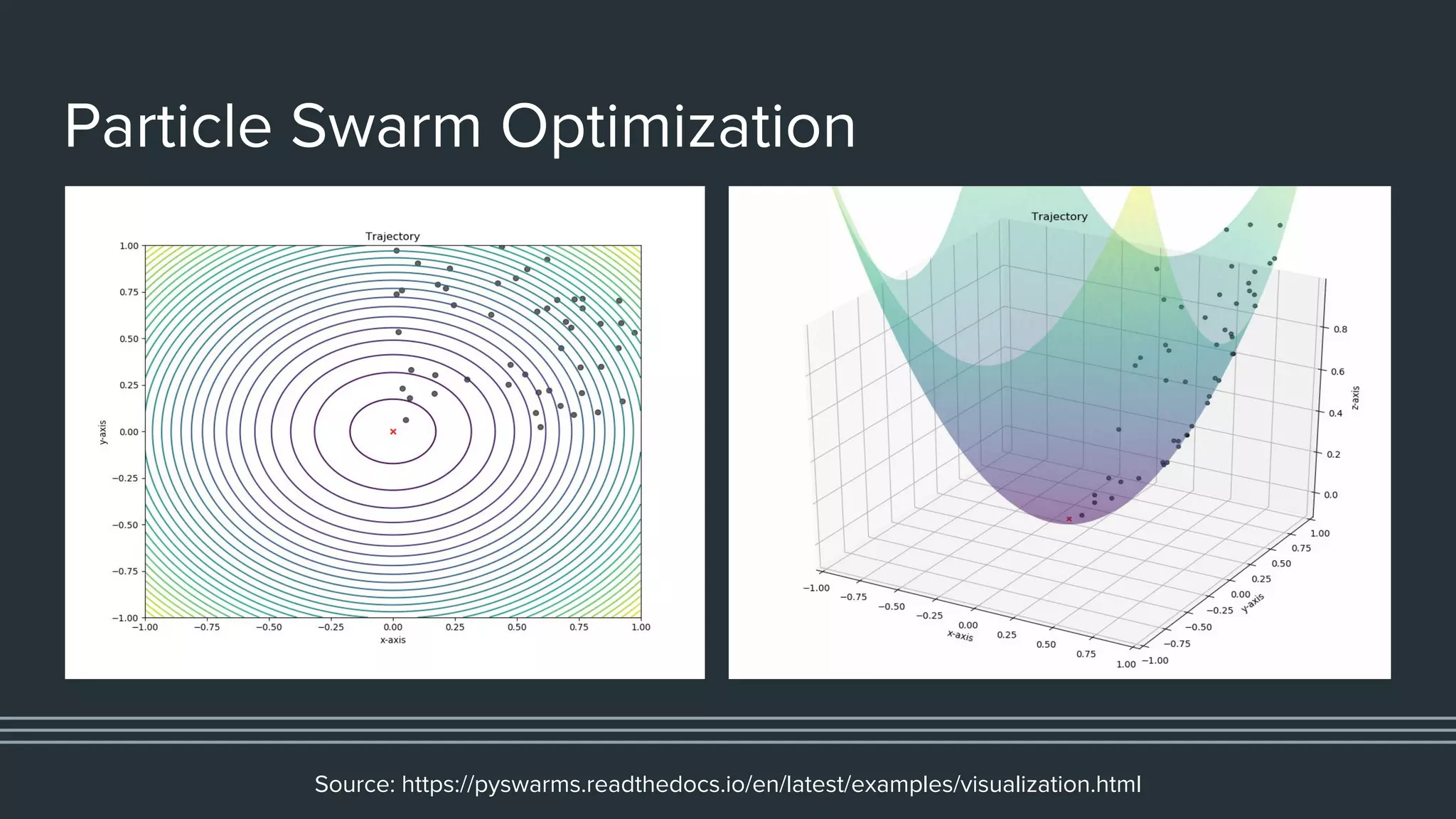


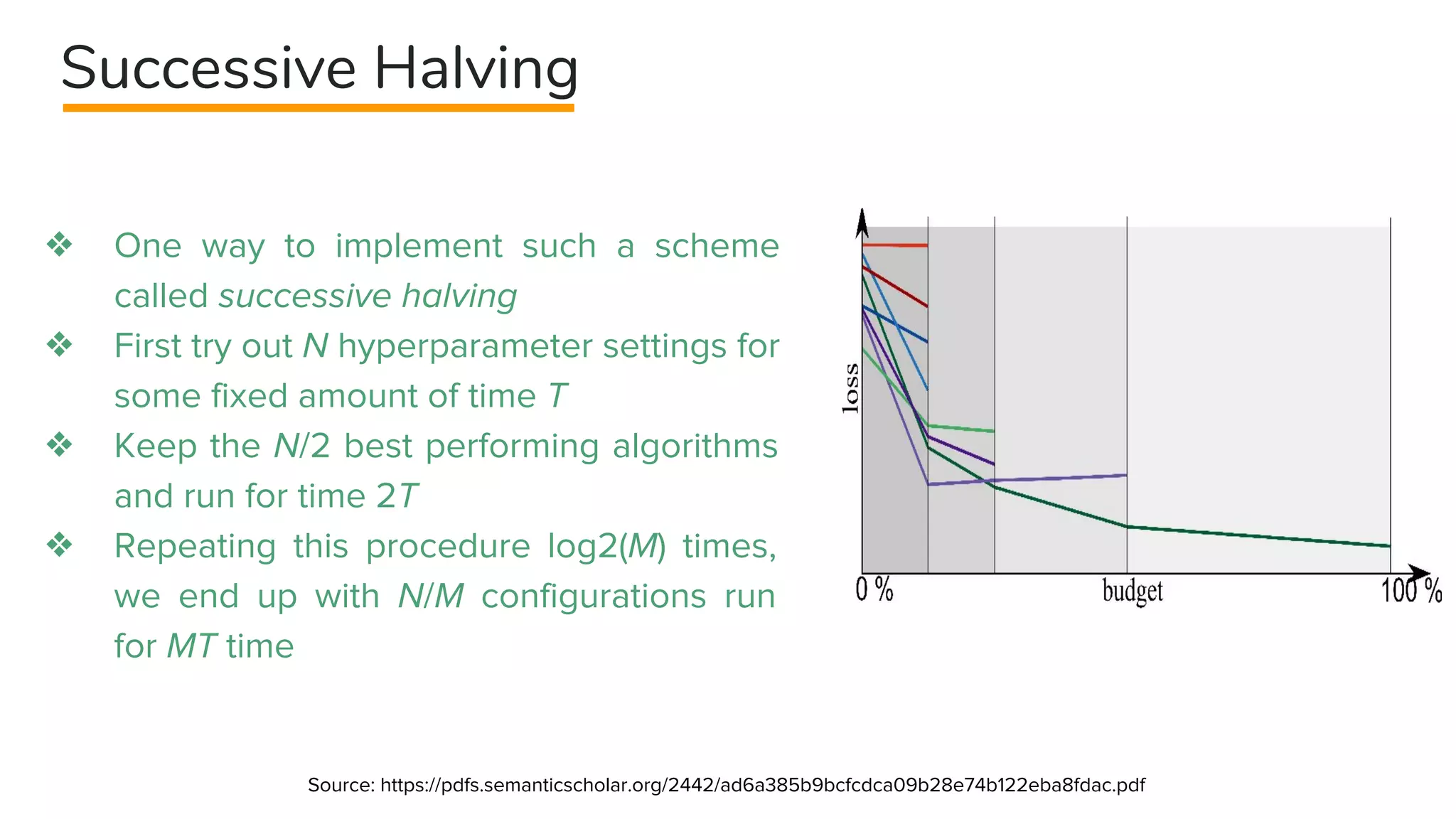
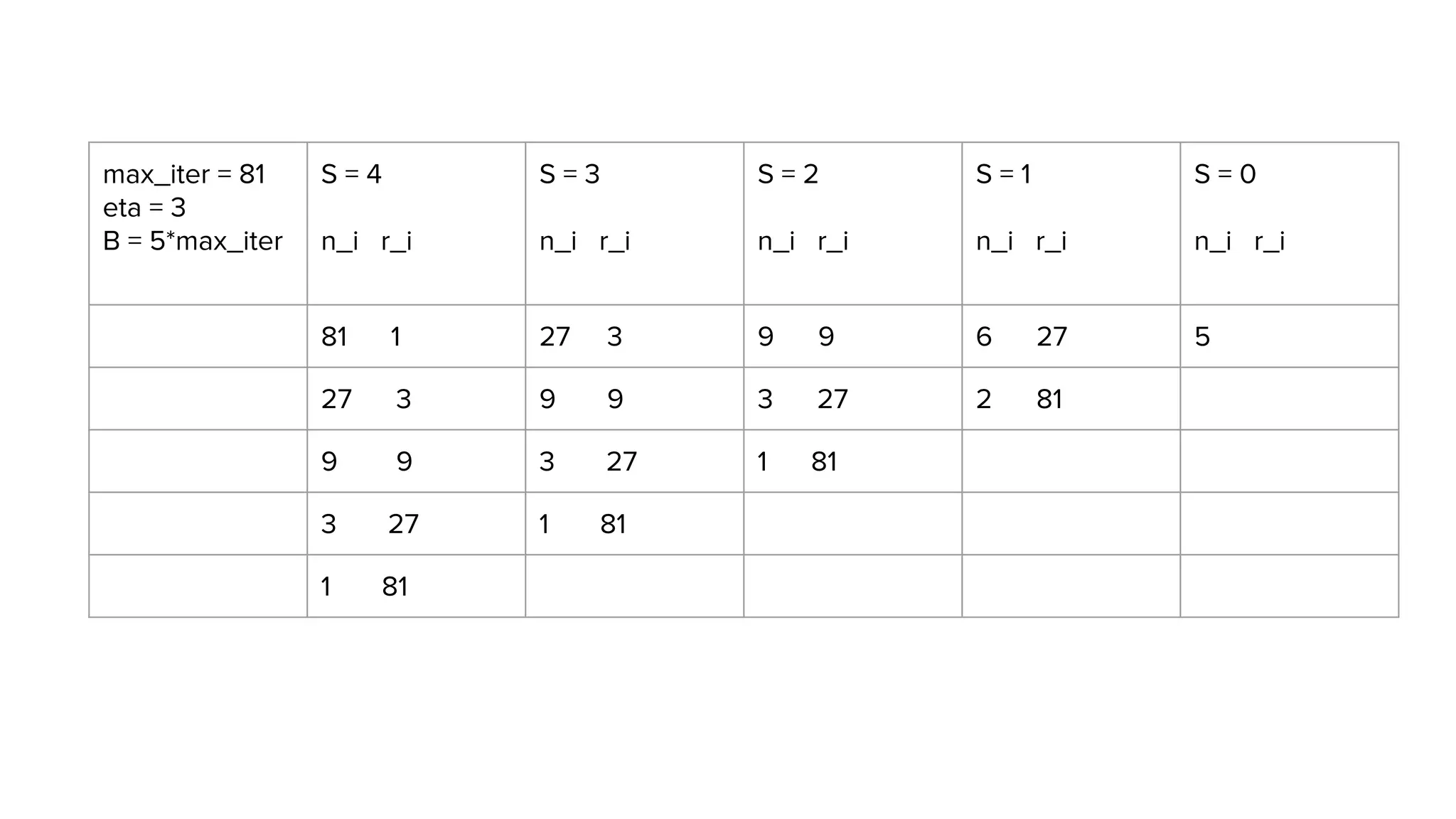

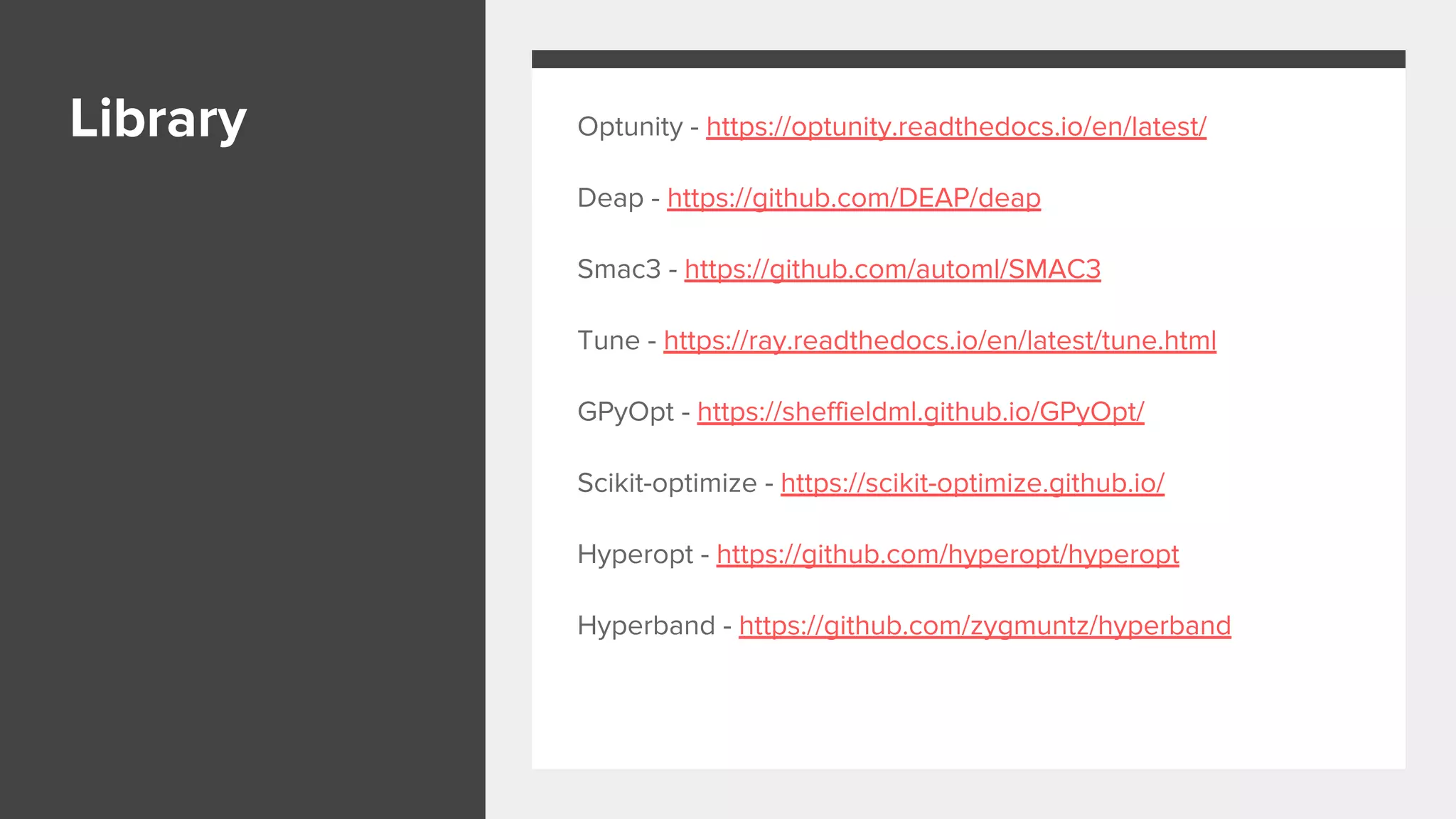


This document provides an overview of different techniques for hyperparameter tuning in machine learning models. It begins with introductions to grid search and random search, then discusses sequential model-based optimization techniques like Bayesian optimization and Tree-of-Parzen Estimators. Evolutionary algorithms like CMA-ES and particle-based methods like particle swarm optimization are also covered. Multi-fidelity methods like successive halving and Hyperband are described, along with recommendations on when to use different techniques. The document concludes by listing several popular libraries for hyperparameter tuning.


















































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















