Downloaded 13 times









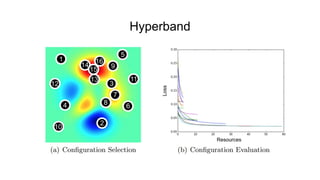



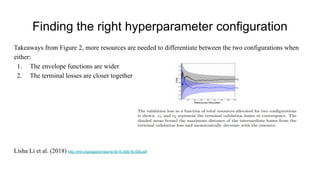
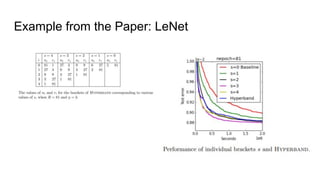

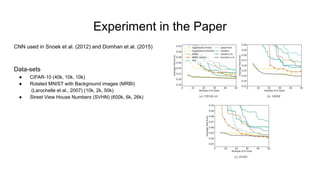
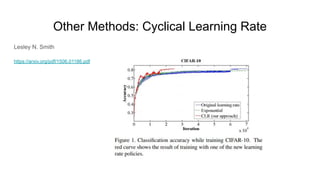
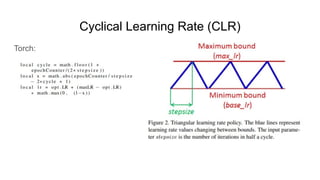











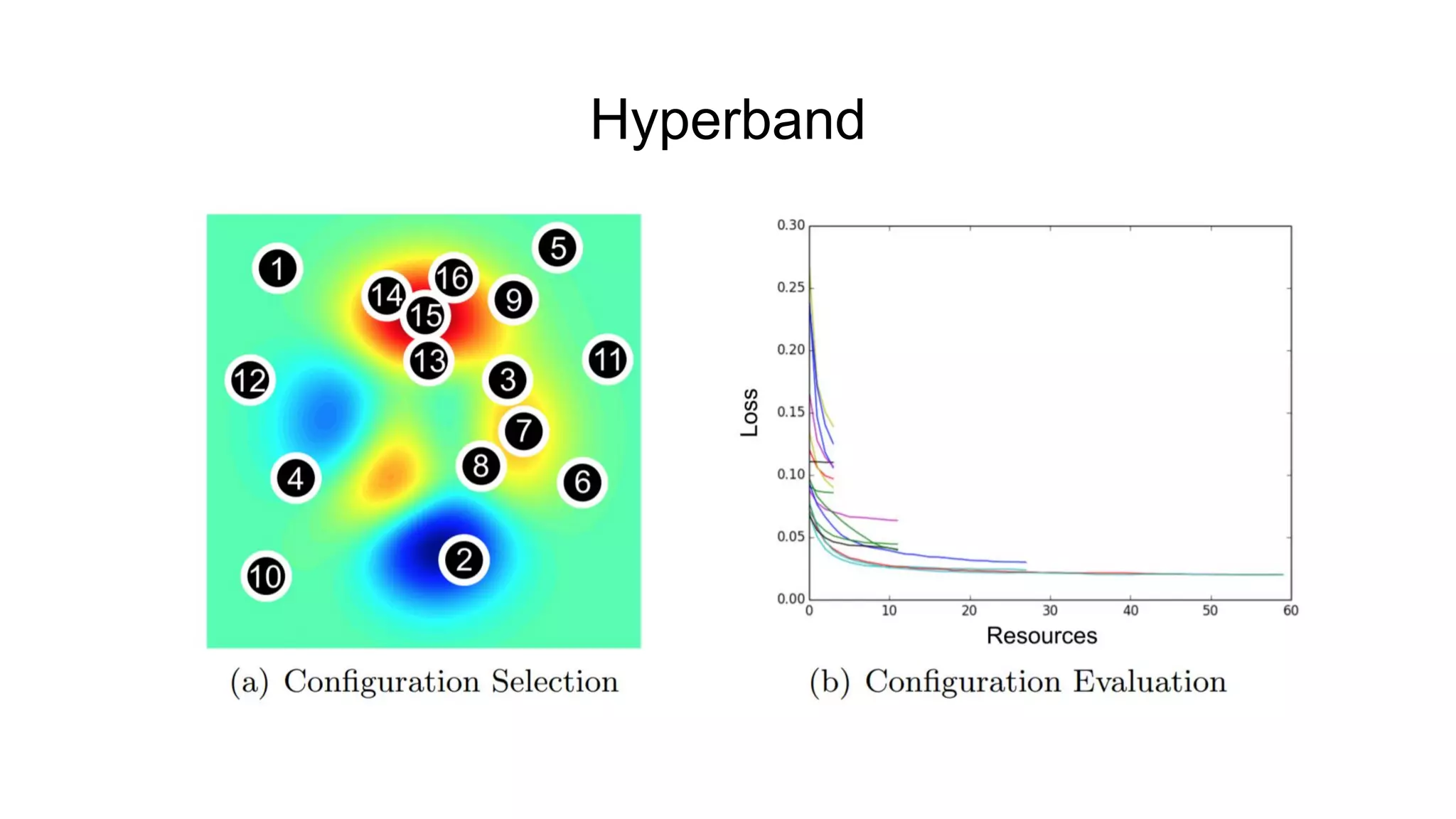




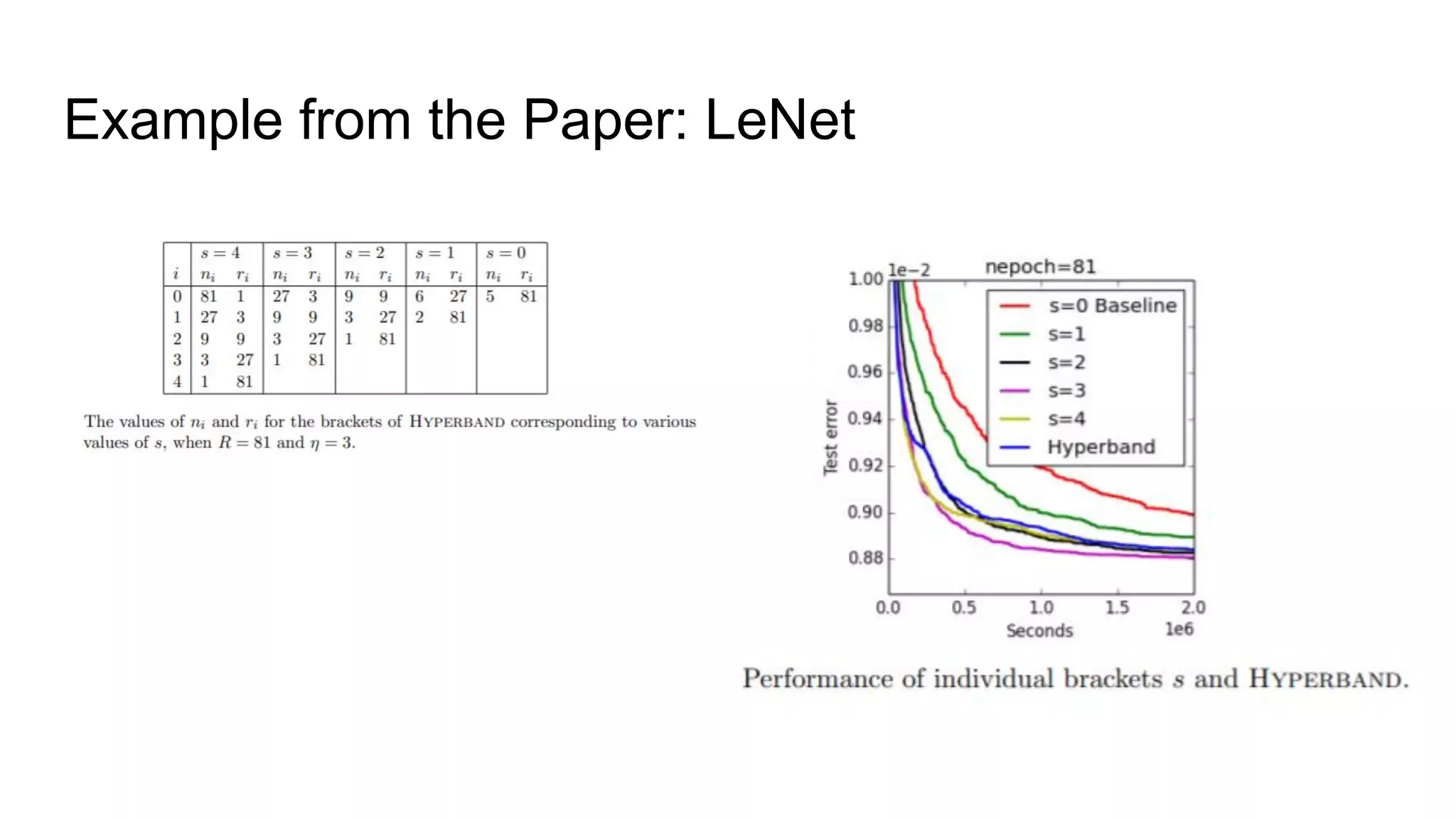

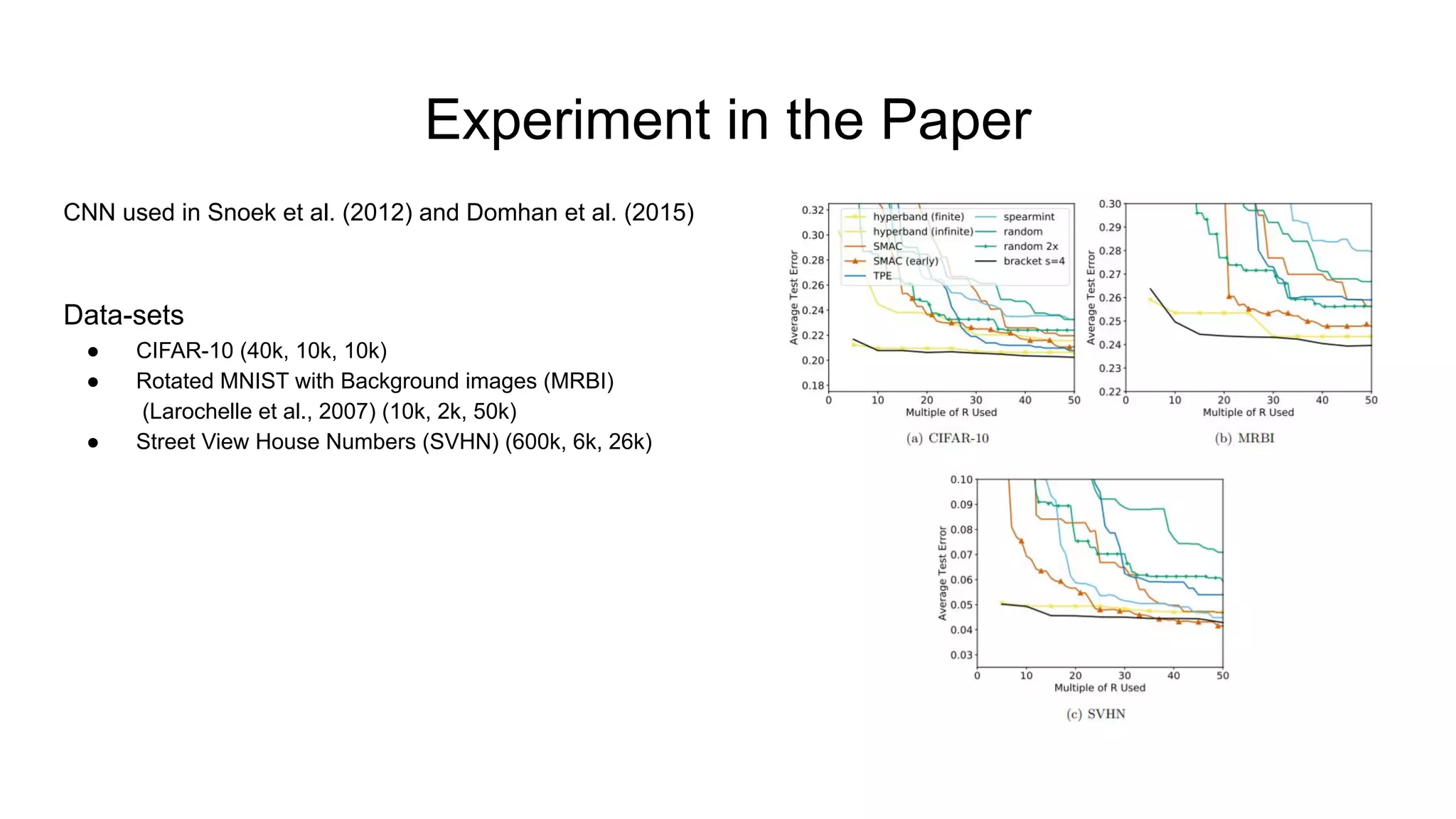
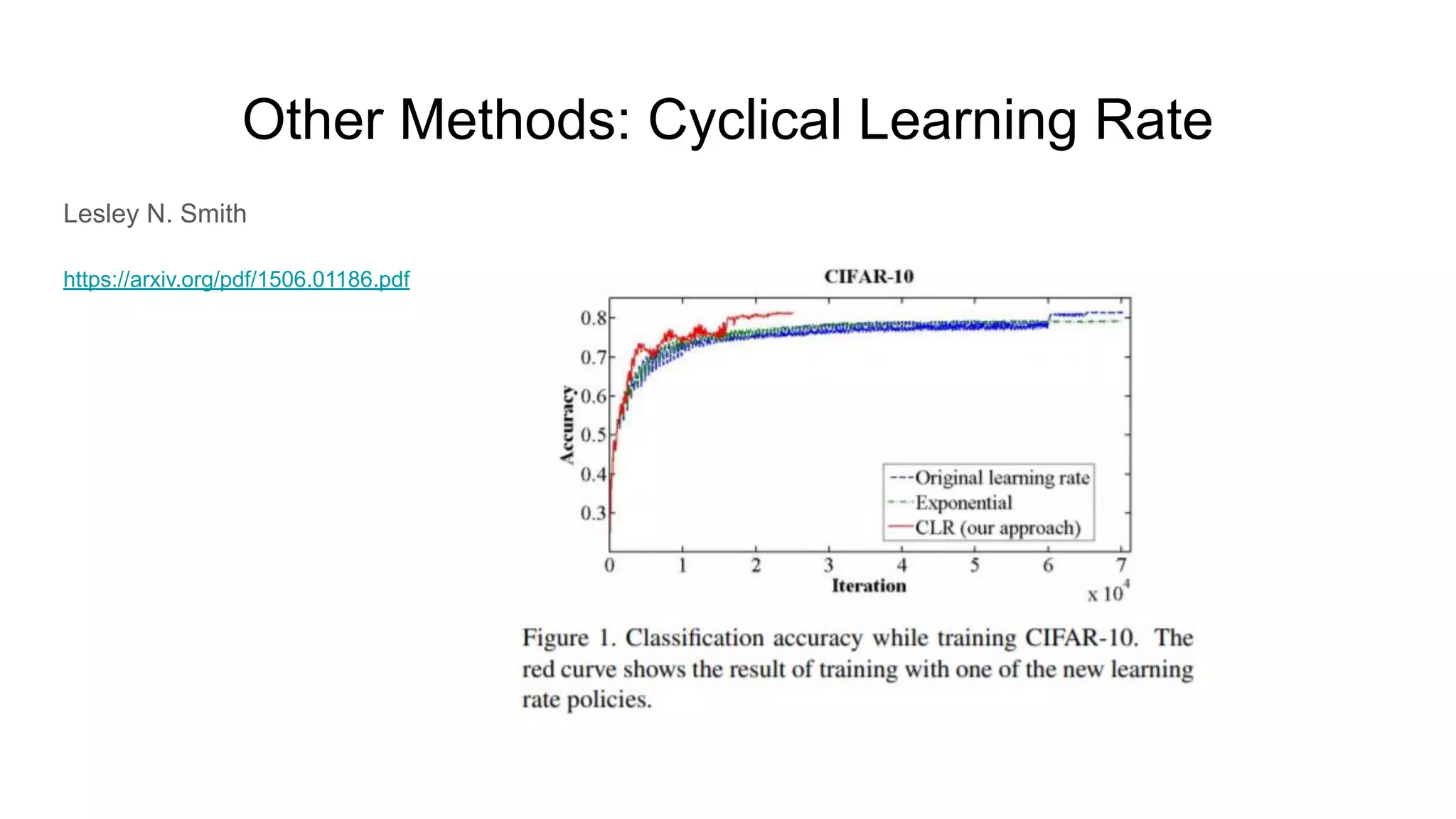
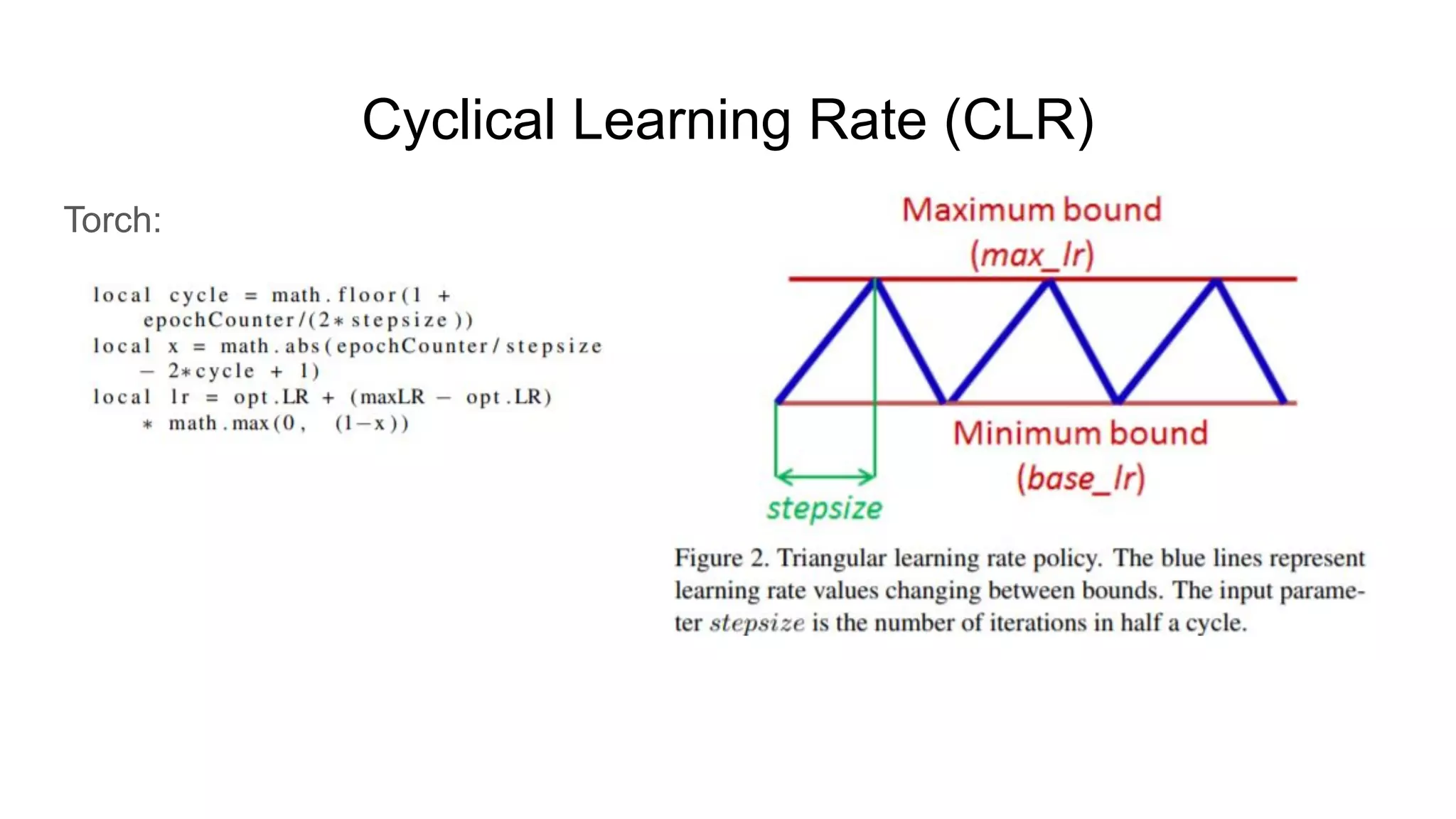


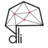
The document discusses various methods for hyperparameter optimization, including random search, Bayesian optimization, Hyperband, and cyclical learning rates. Hyperband extends successive halving to more efficiently allocate resources to promising hyperparameter configurations. It was shown to outperform random search and Bayesian optimization in experiments tuning a CNN on image classification tasks. Keras Tuner and PyTorch implementations provide APIs for hyperparameter search including Hyperband.























































































