Download as PDF, PPTX














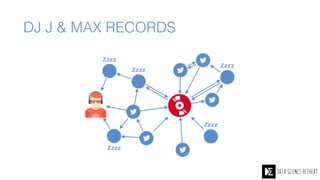
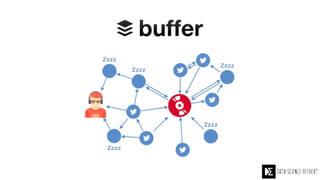
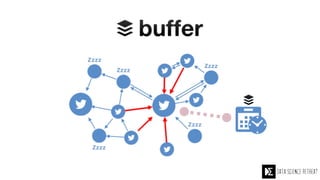
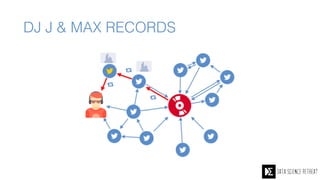
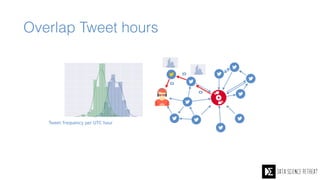





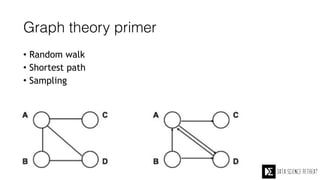

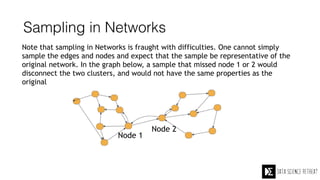
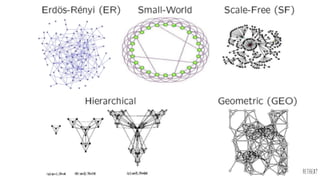


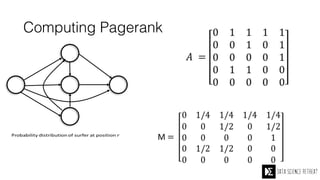
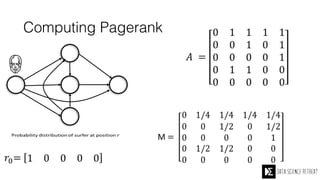
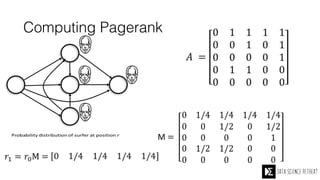
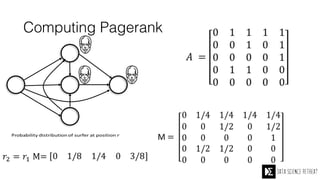
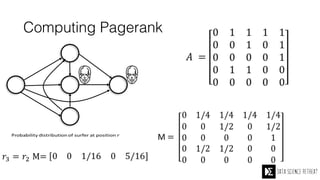
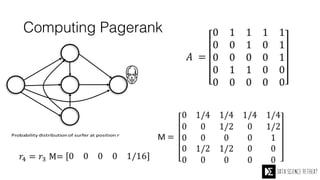
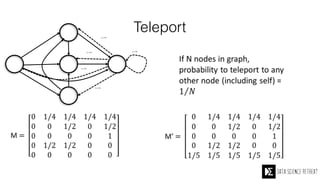
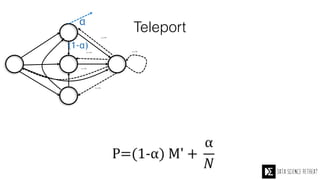
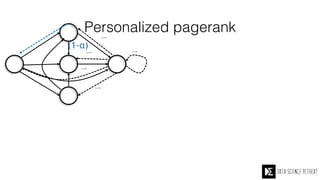
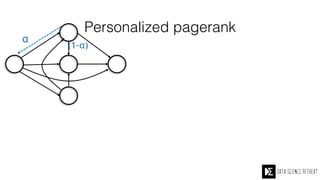

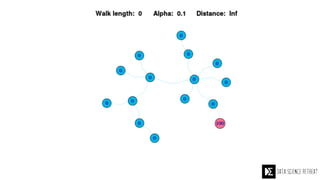
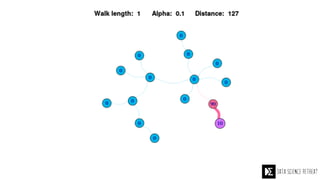

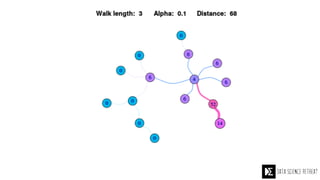
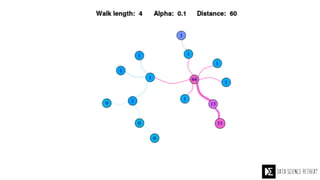
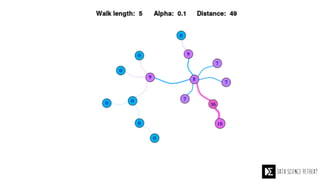
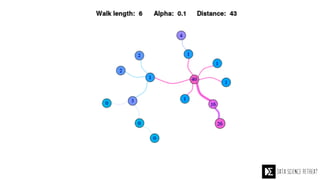
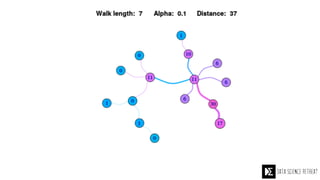
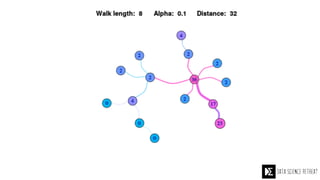
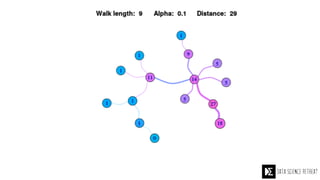
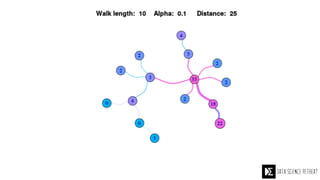
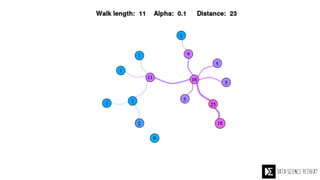
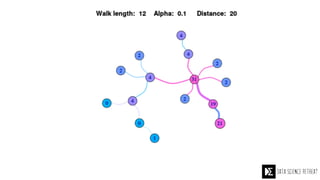
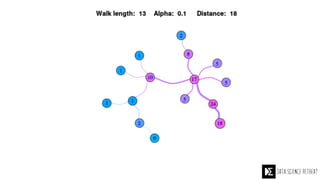
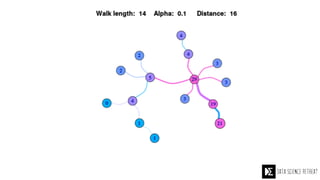
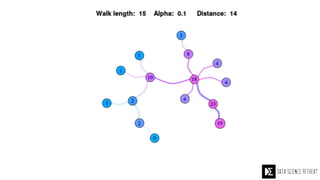
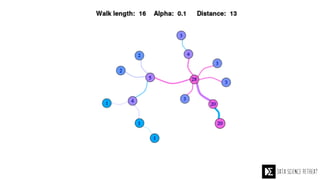
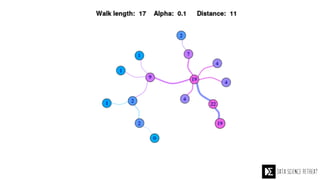
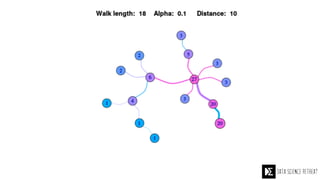
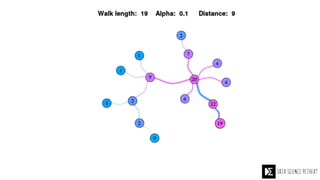
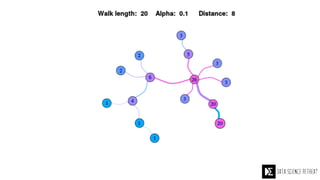
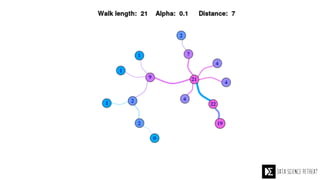
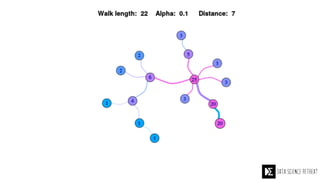
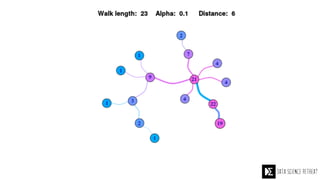
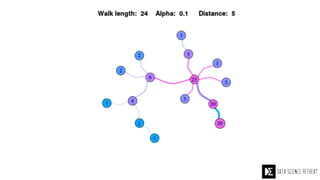
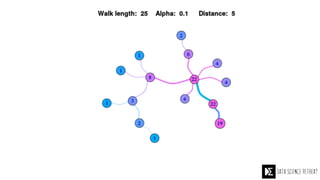
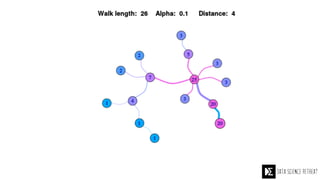
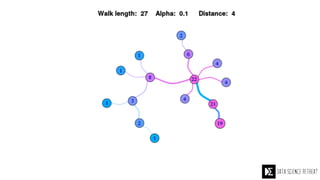
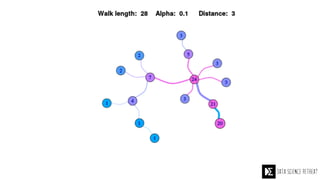
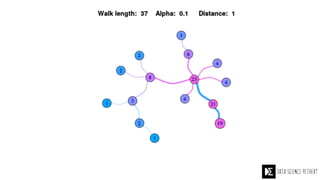
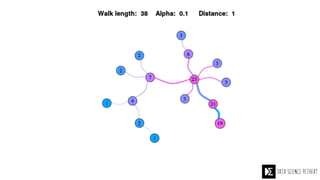
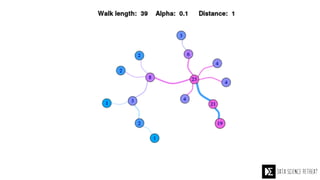
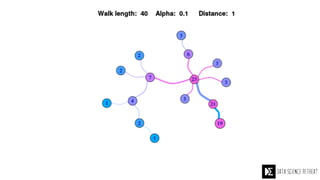
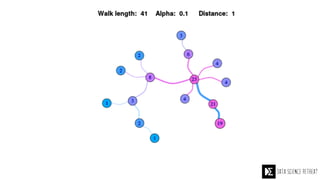
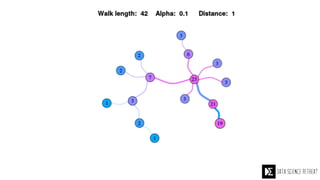
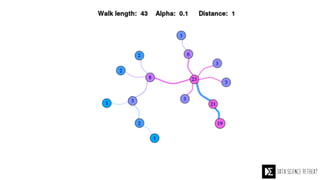
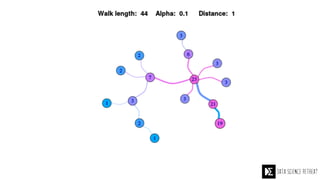
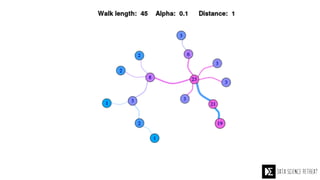
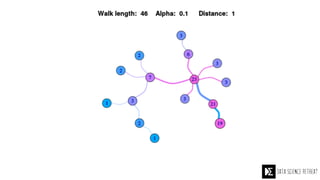
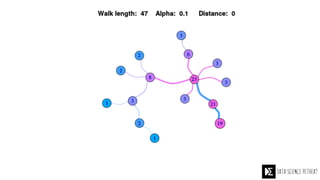






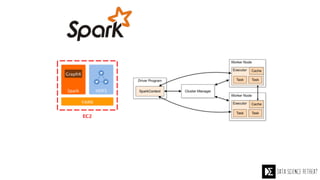




















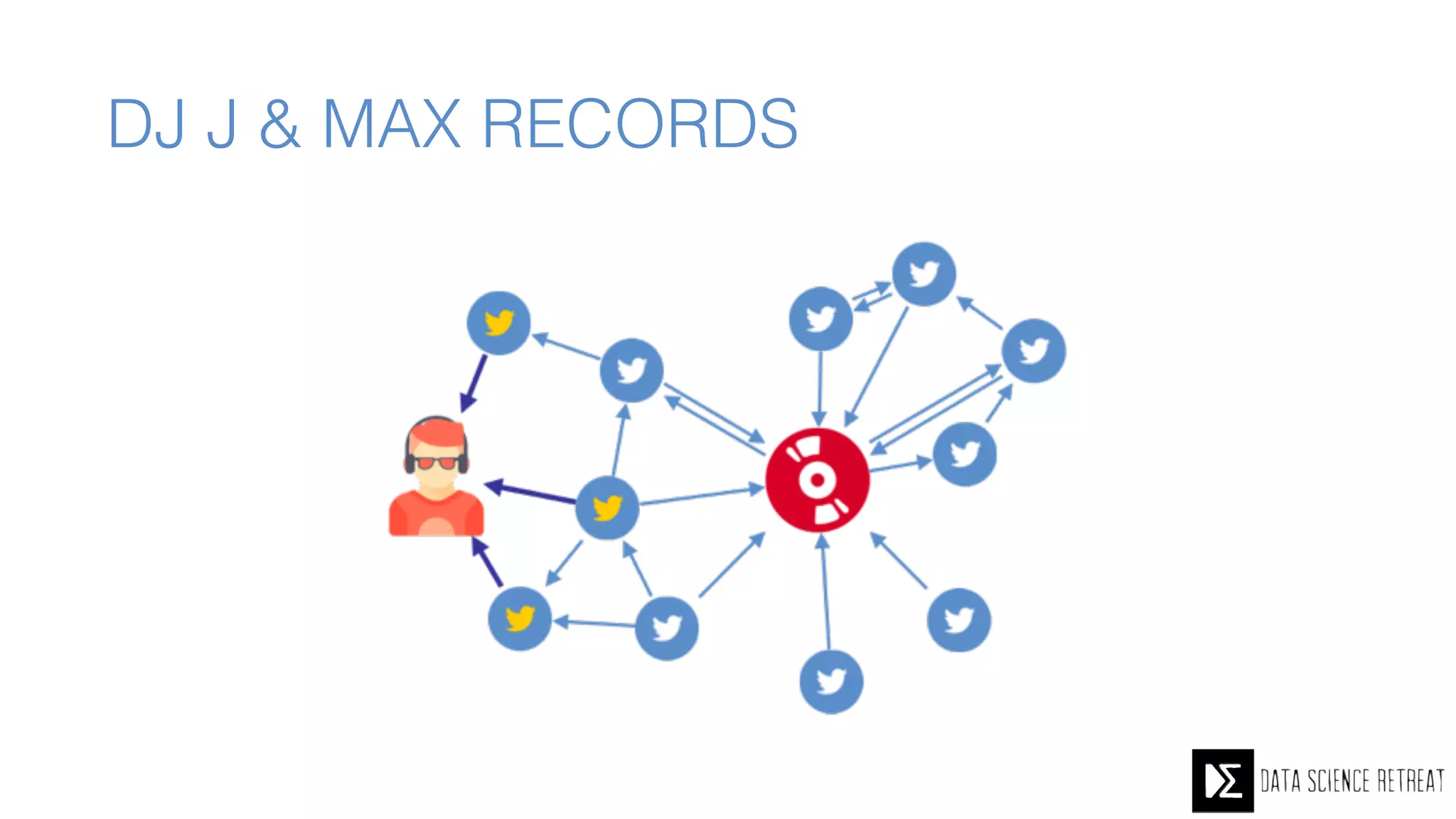
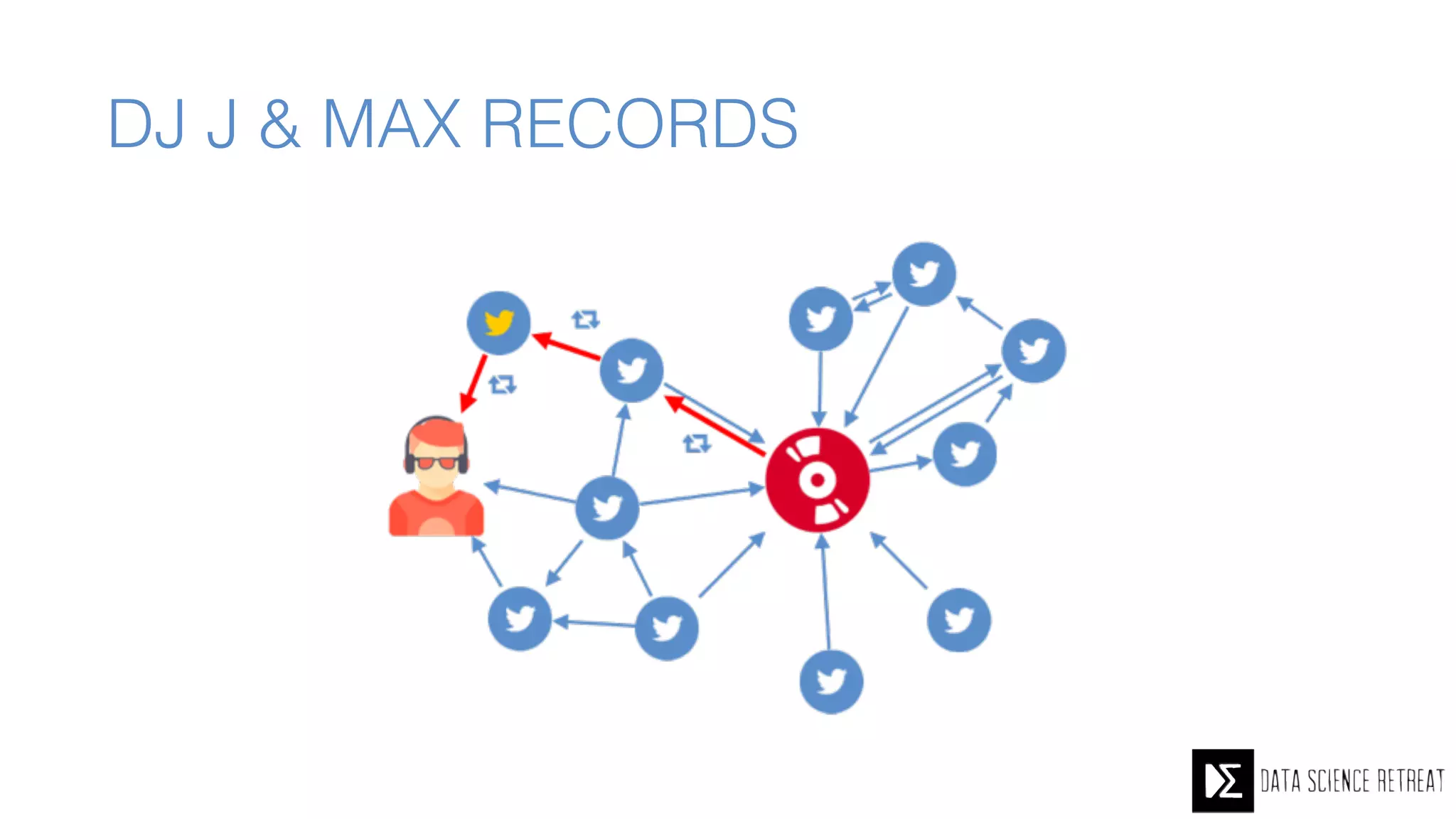
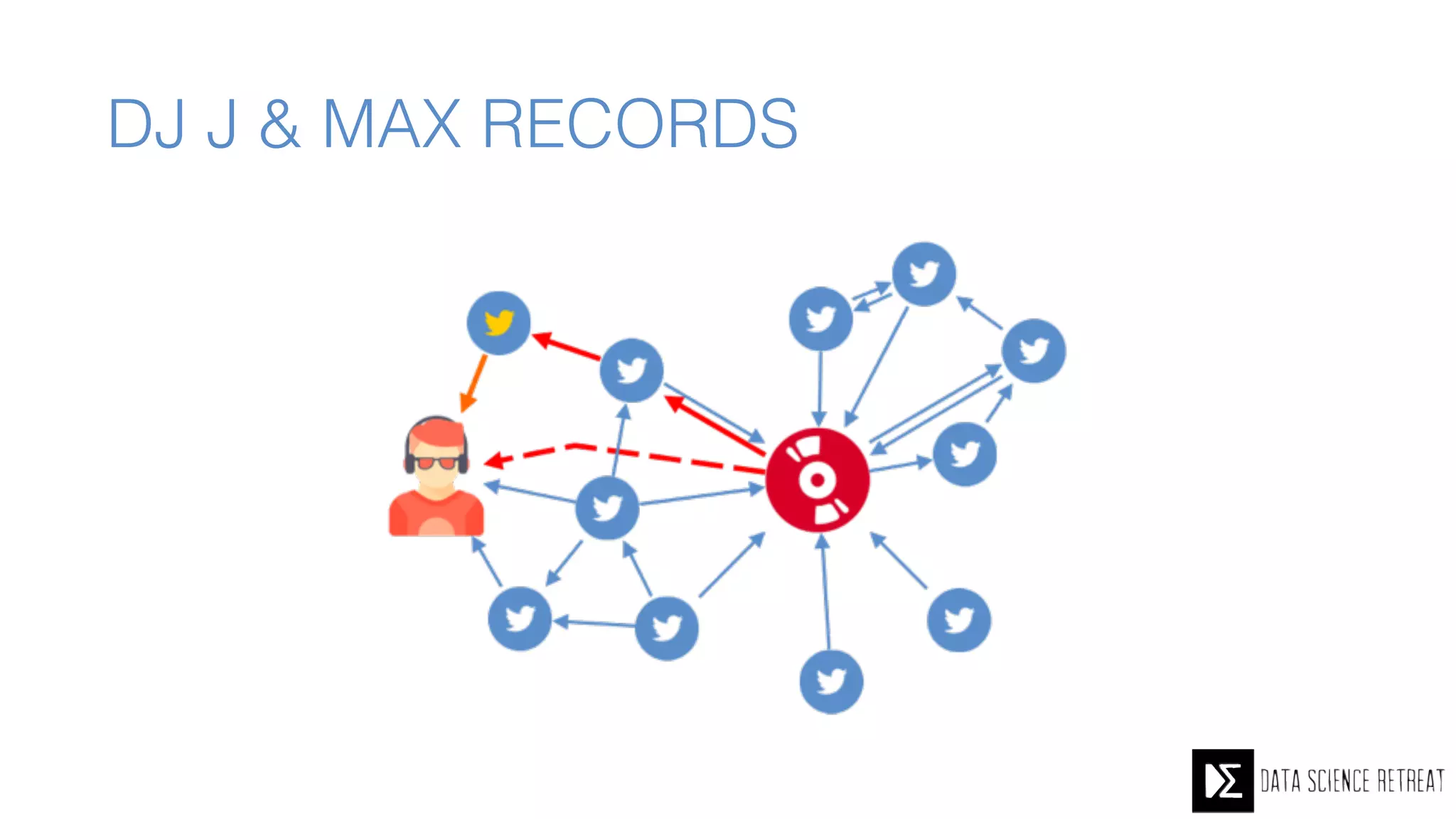
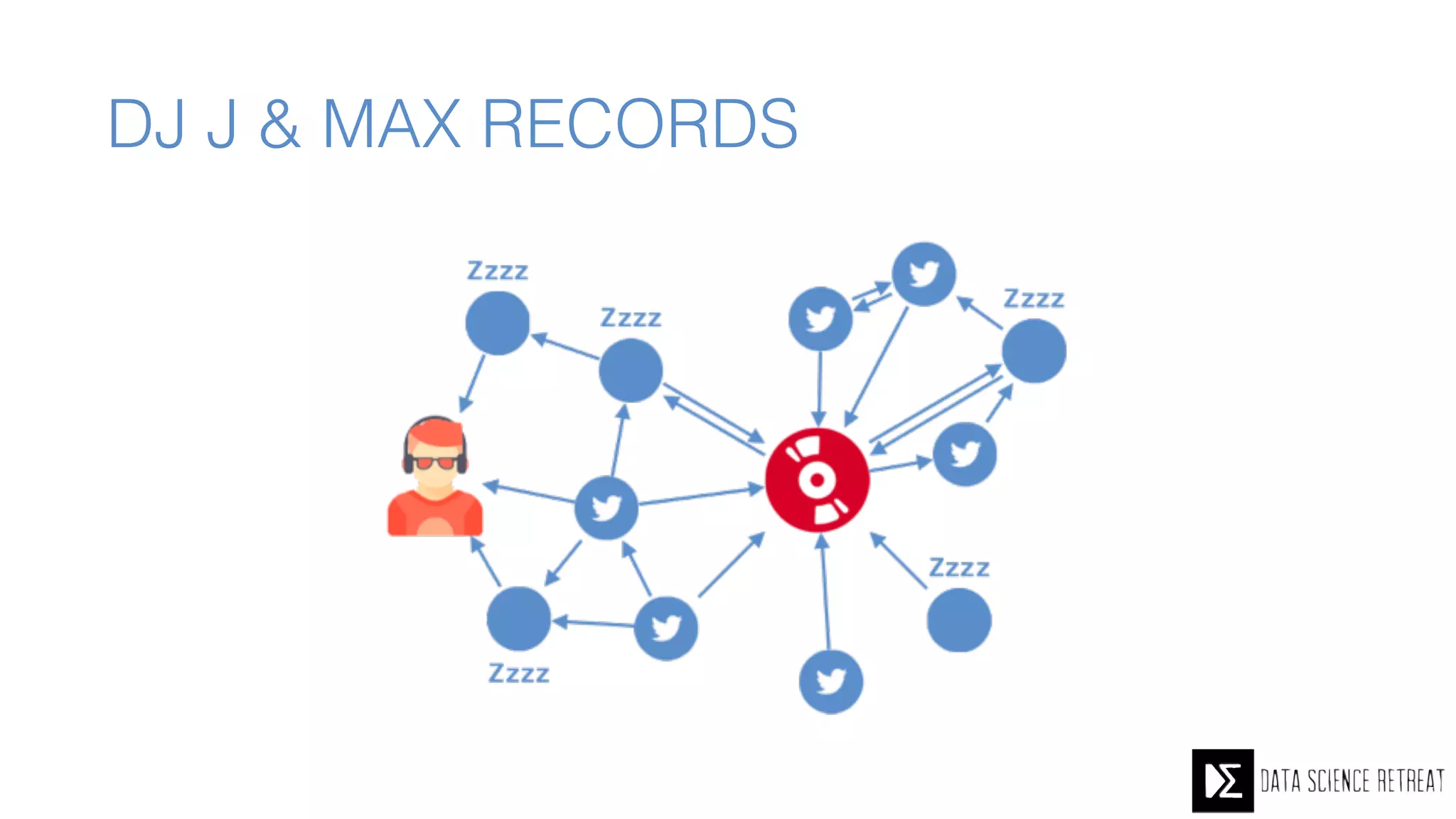
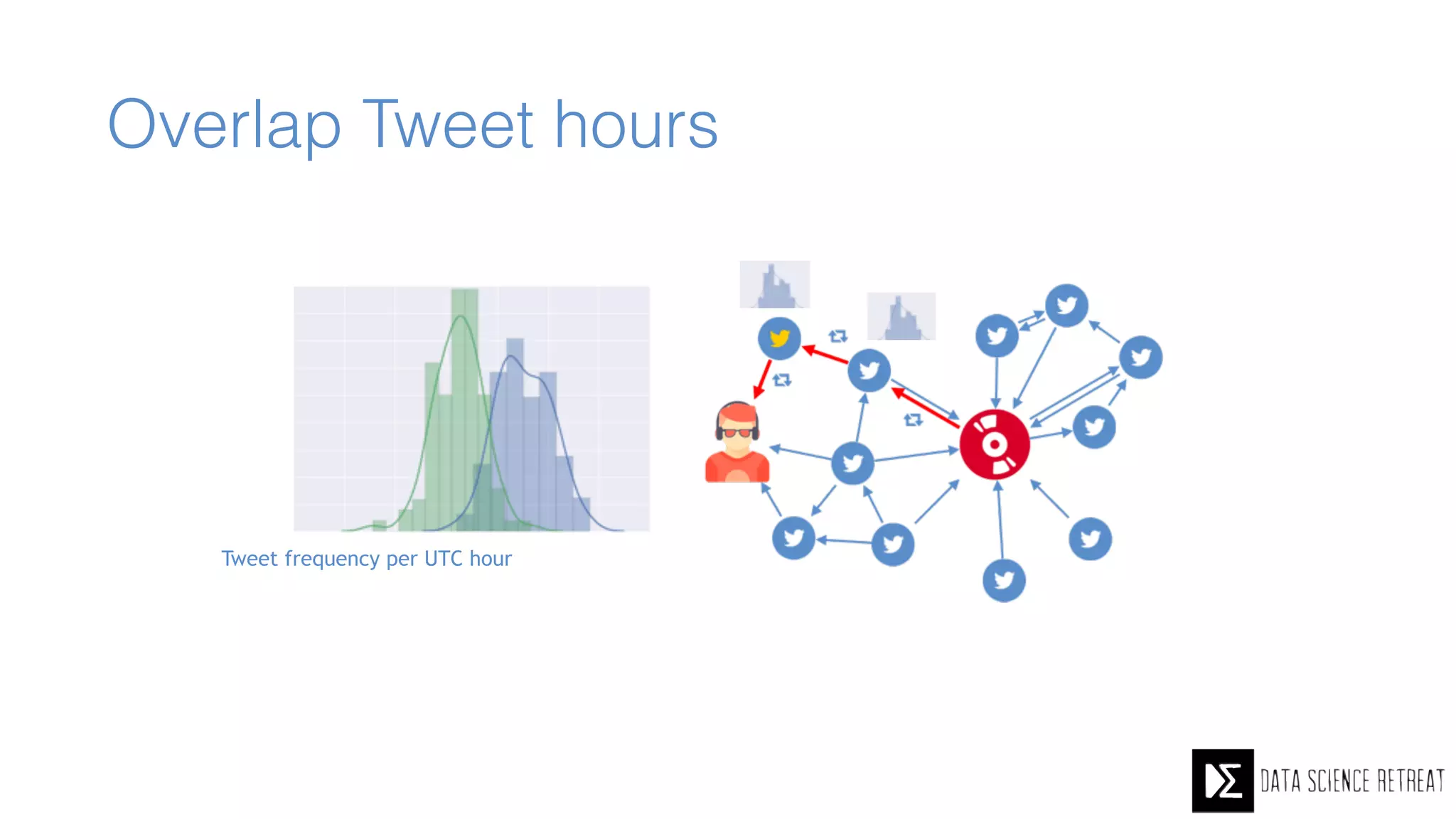





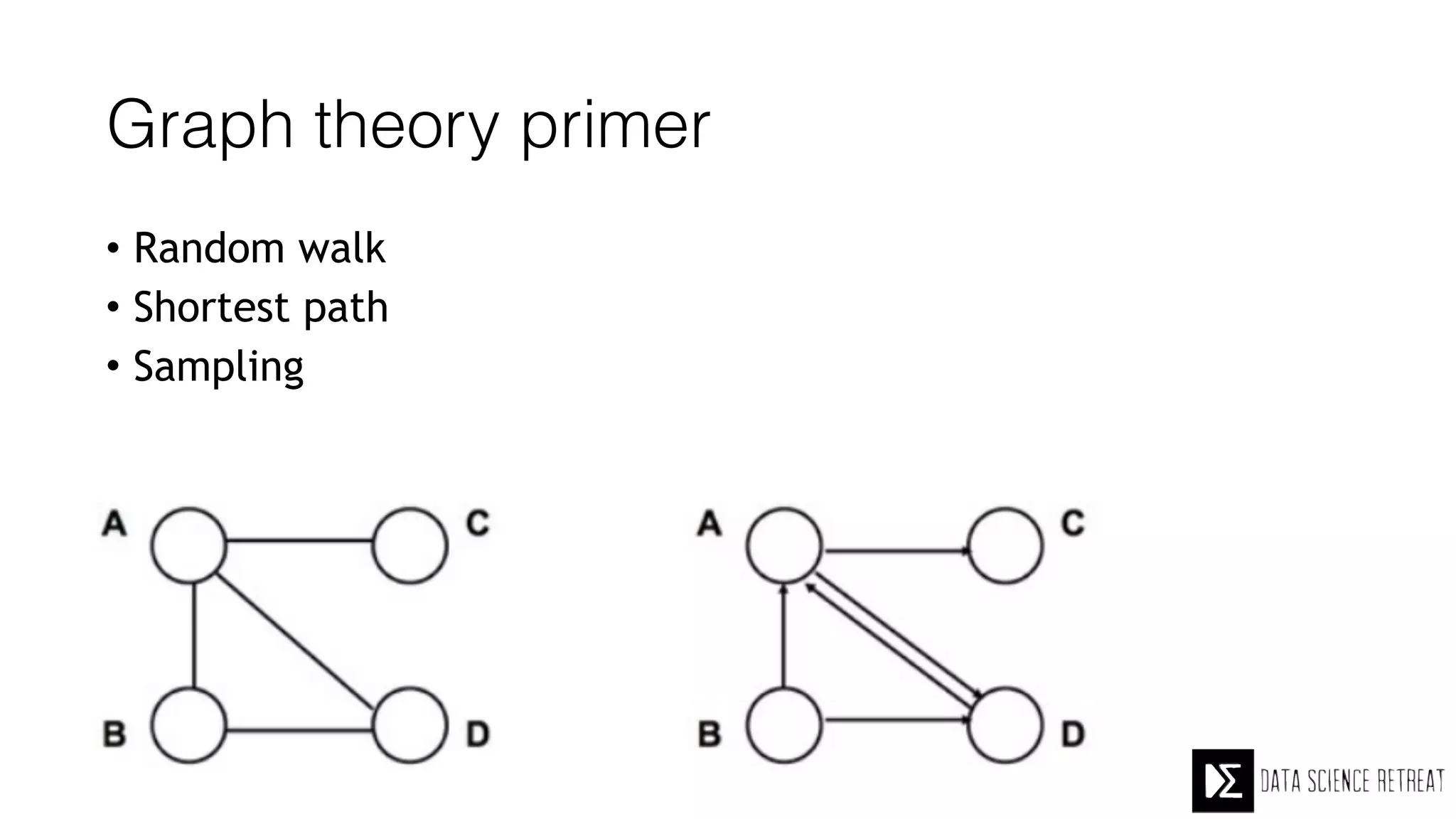

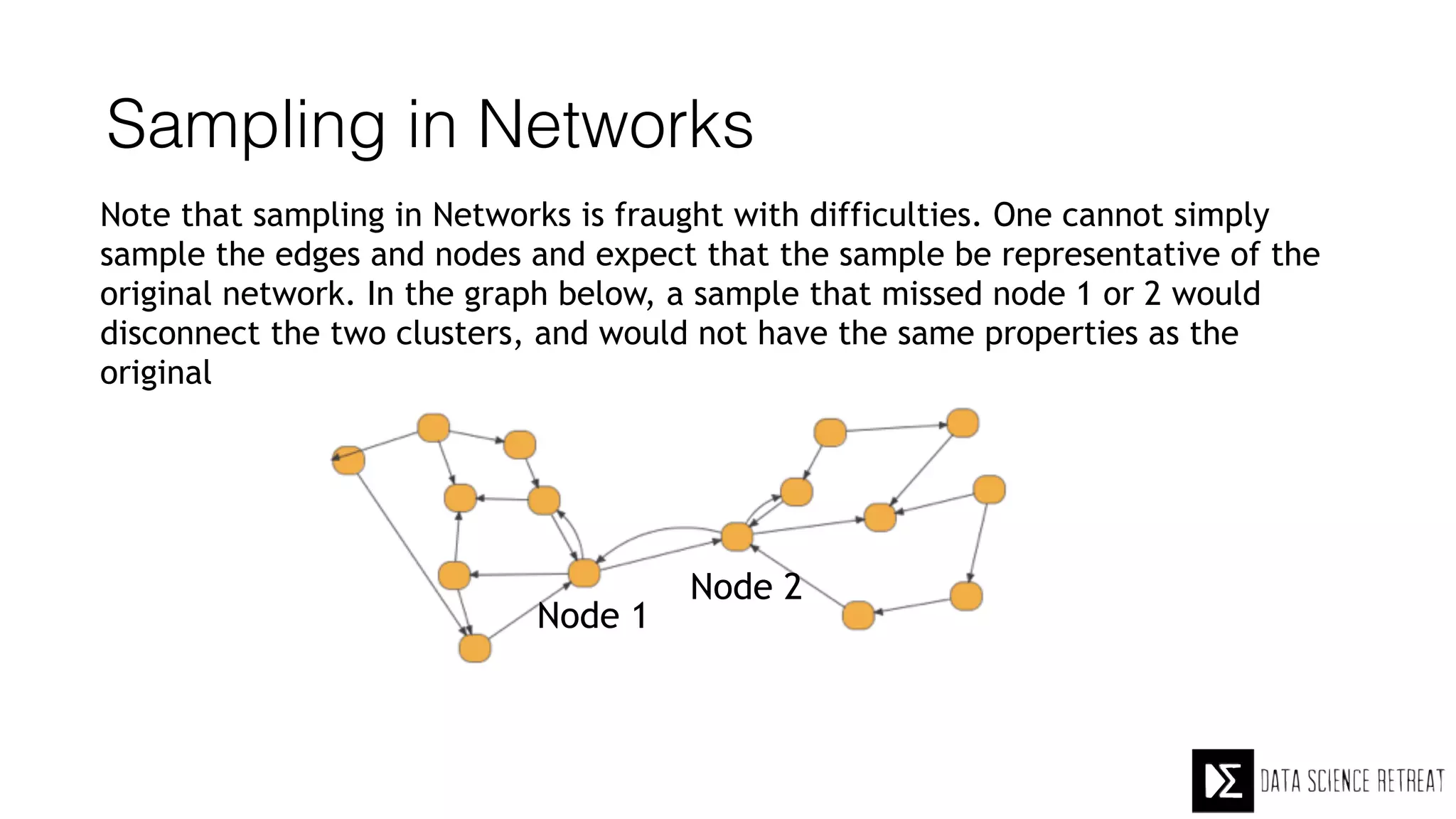
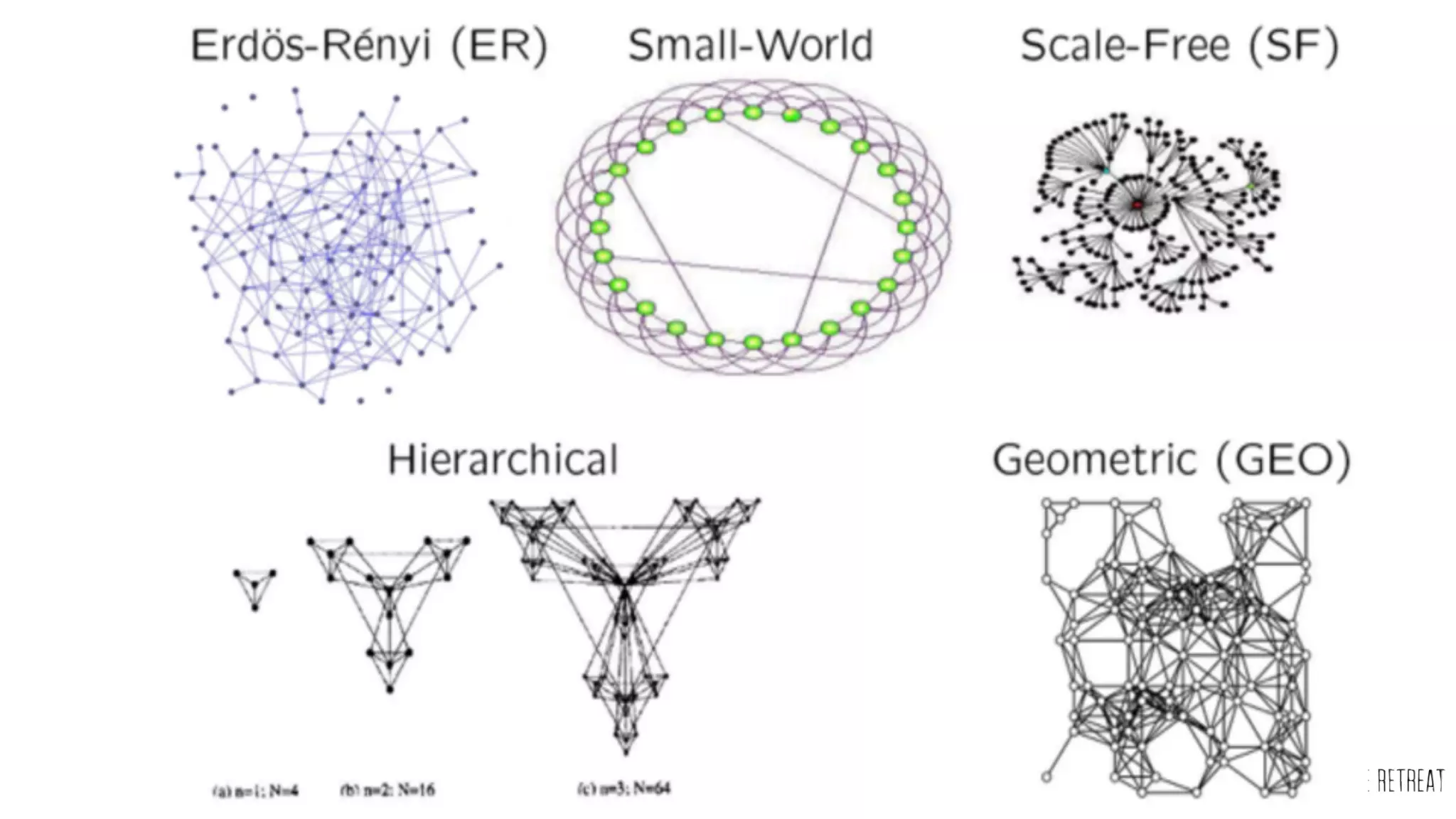


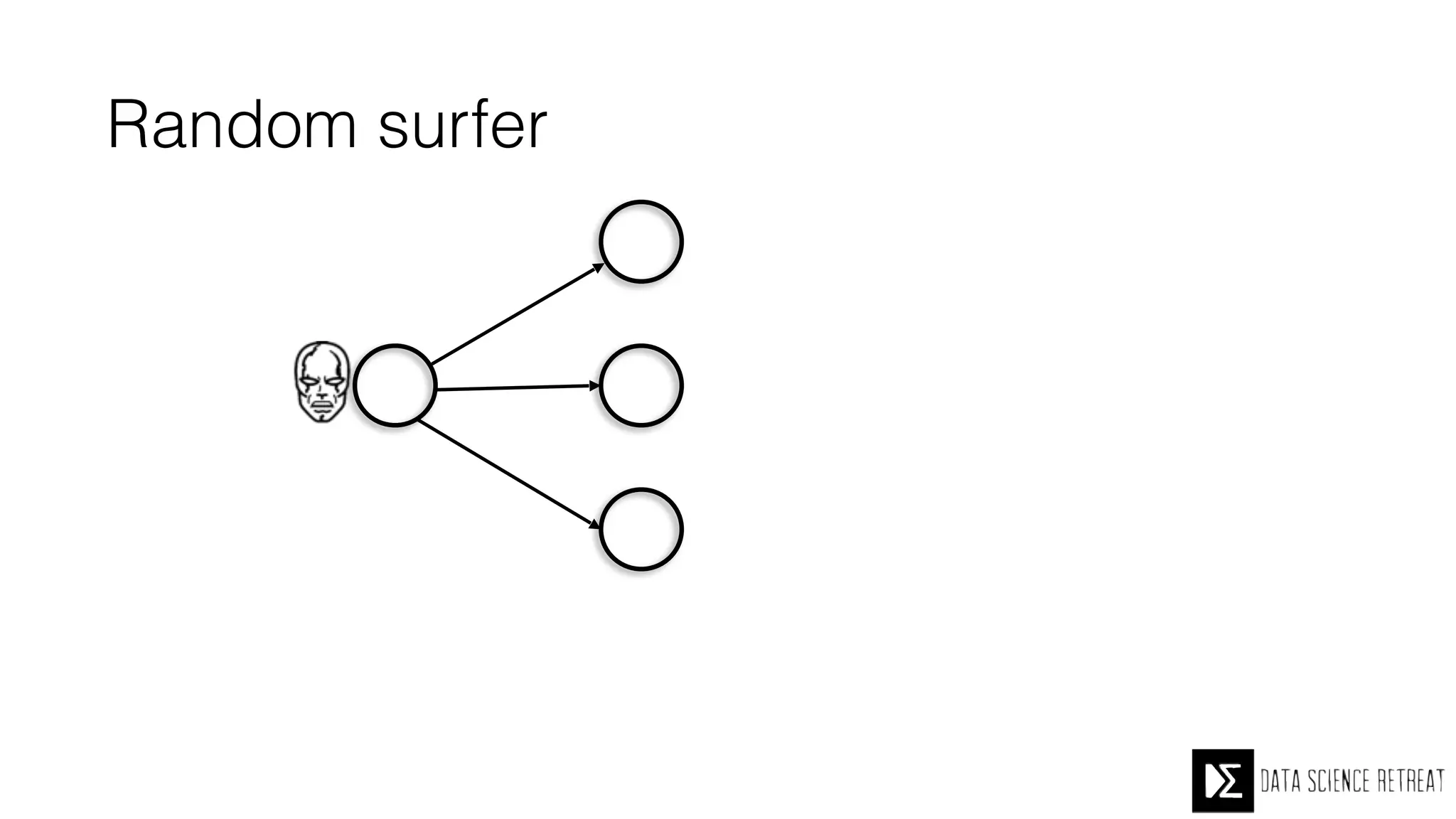
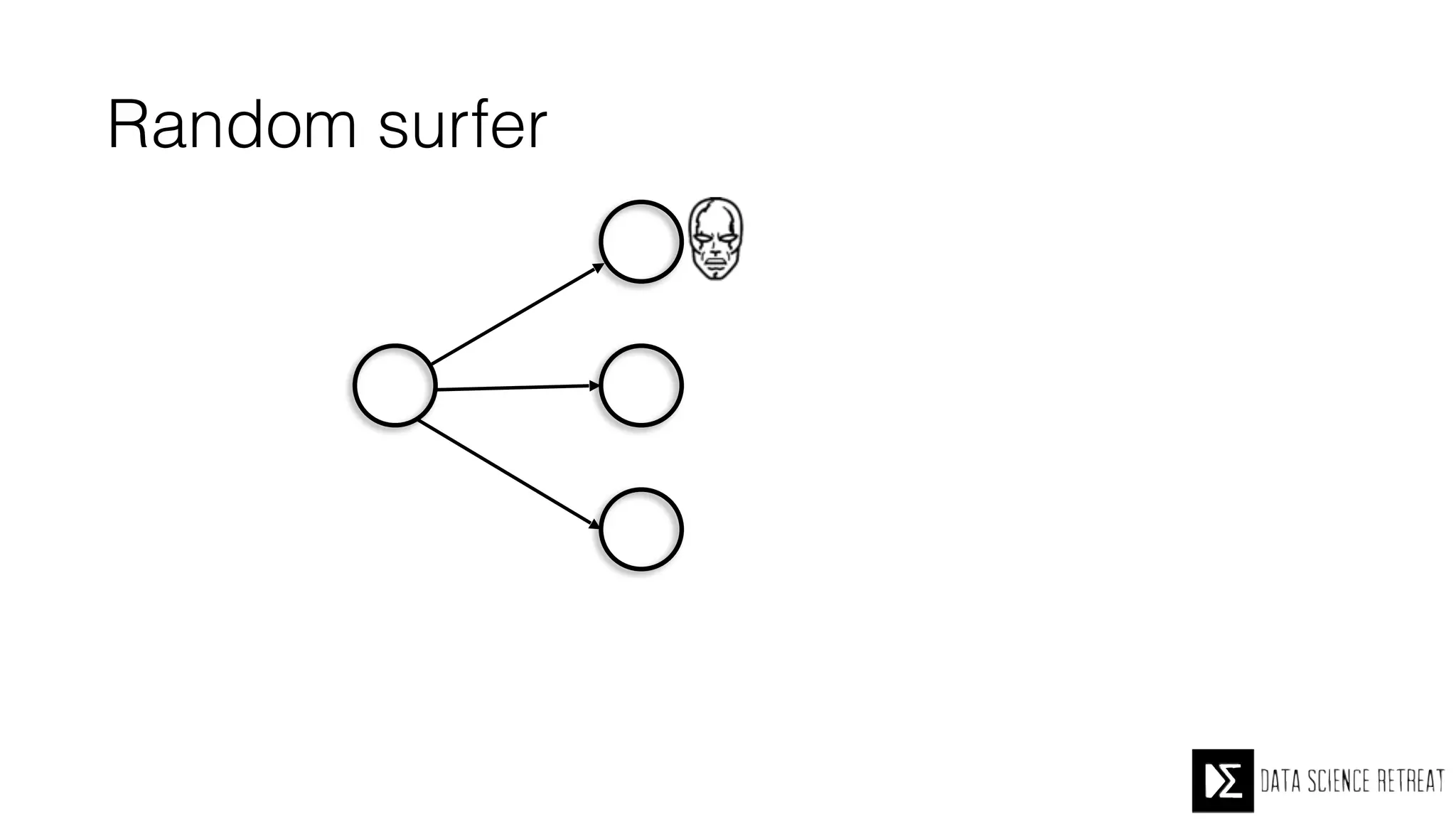
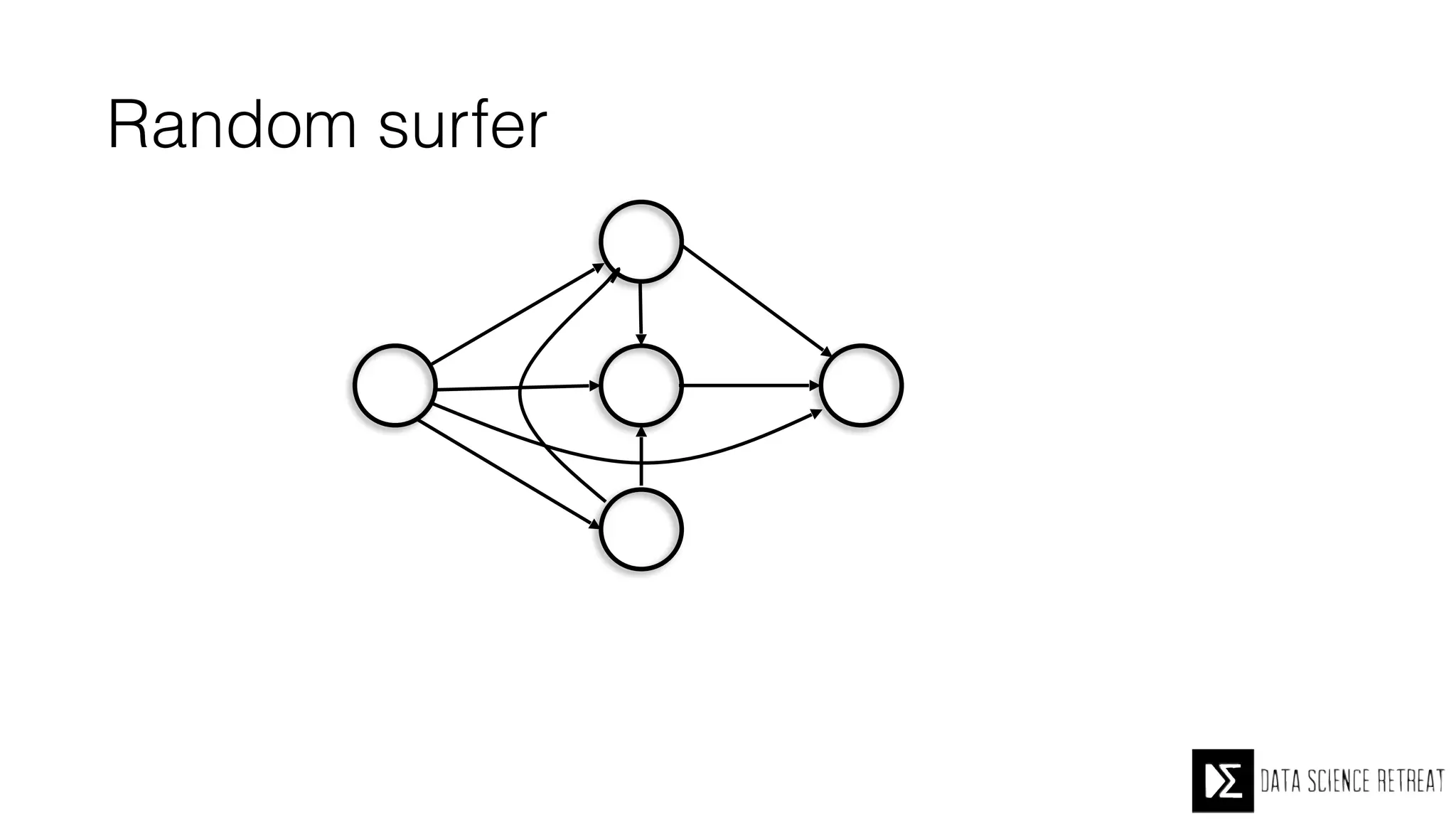
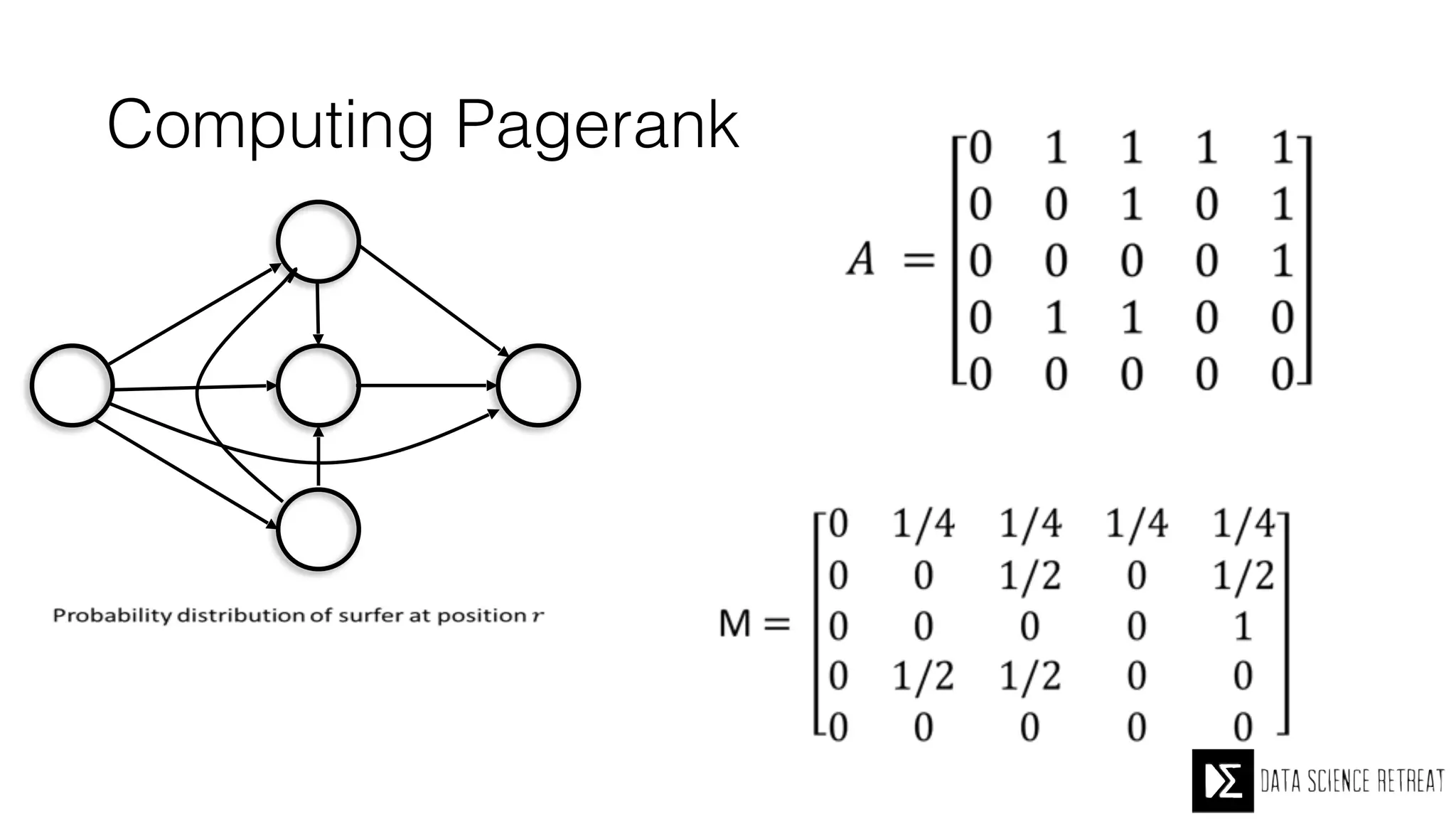
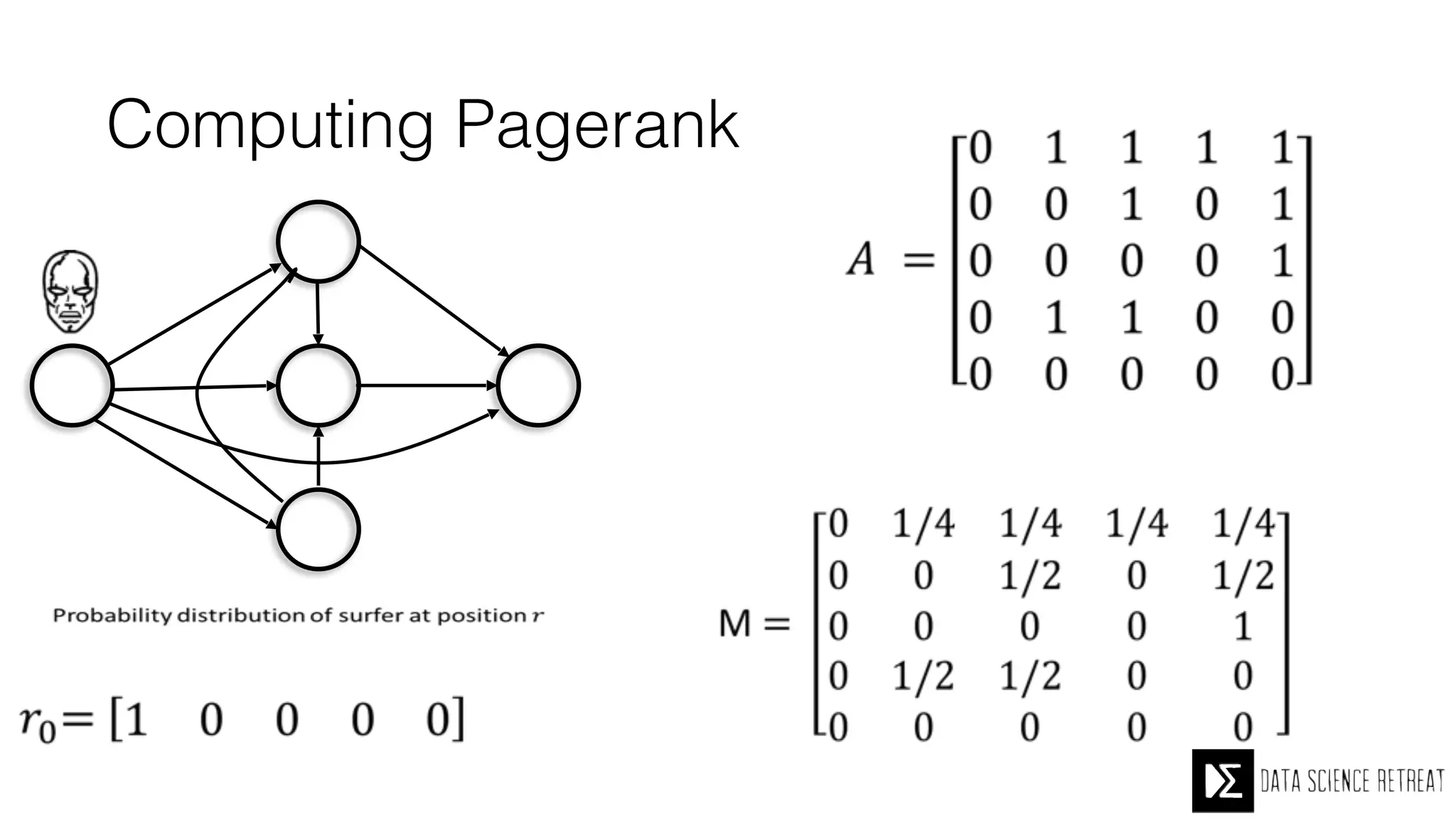
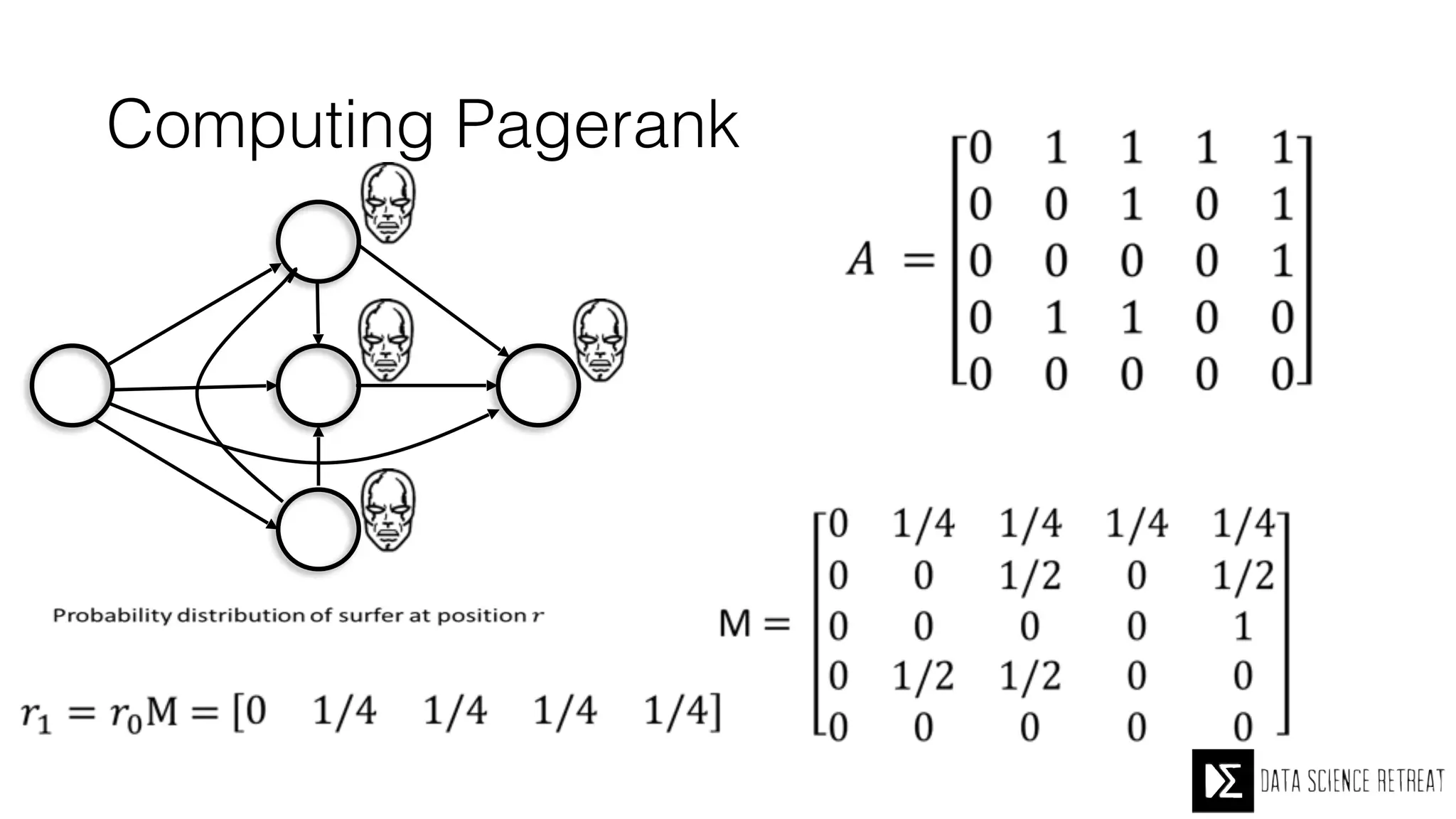
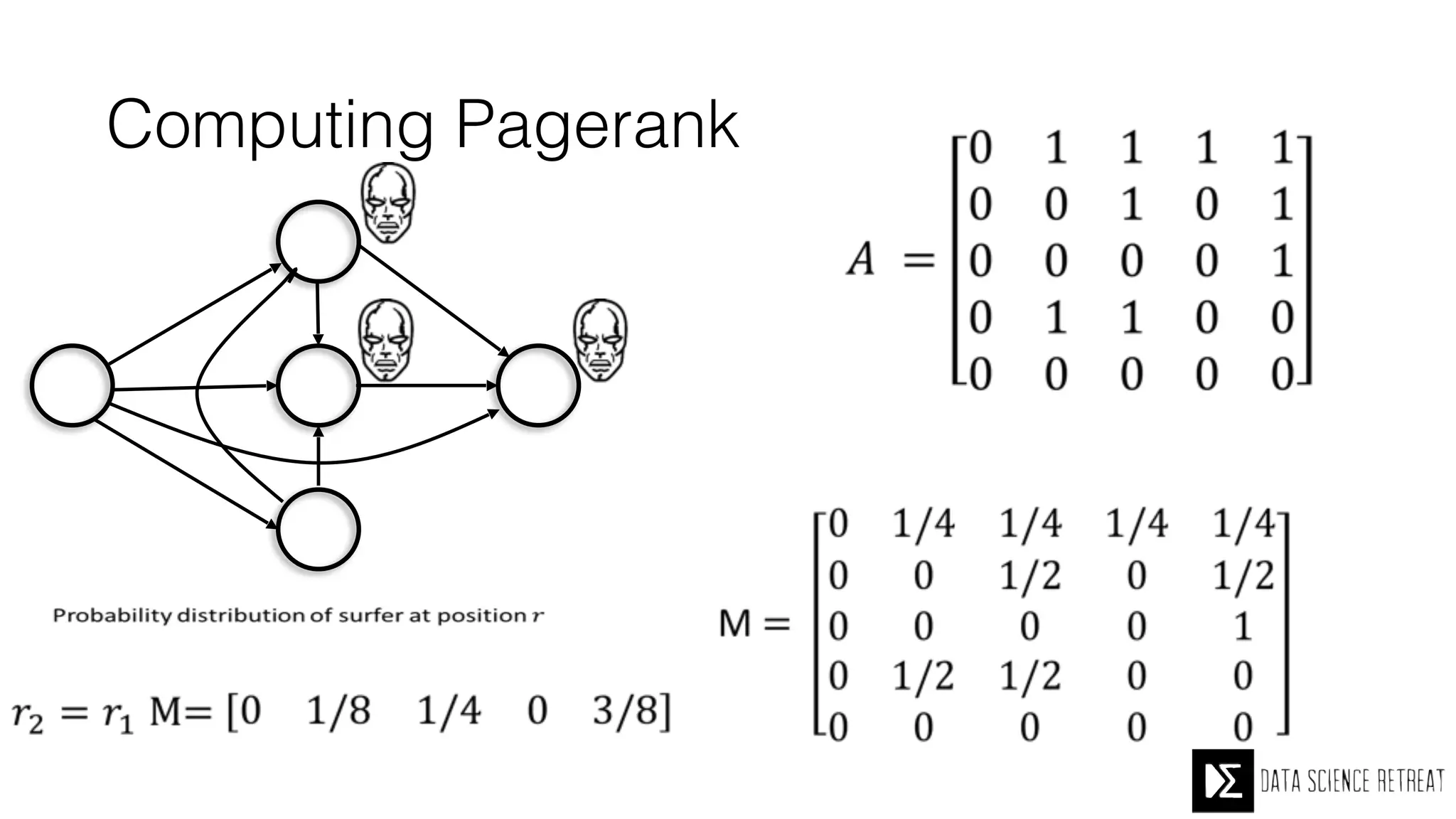
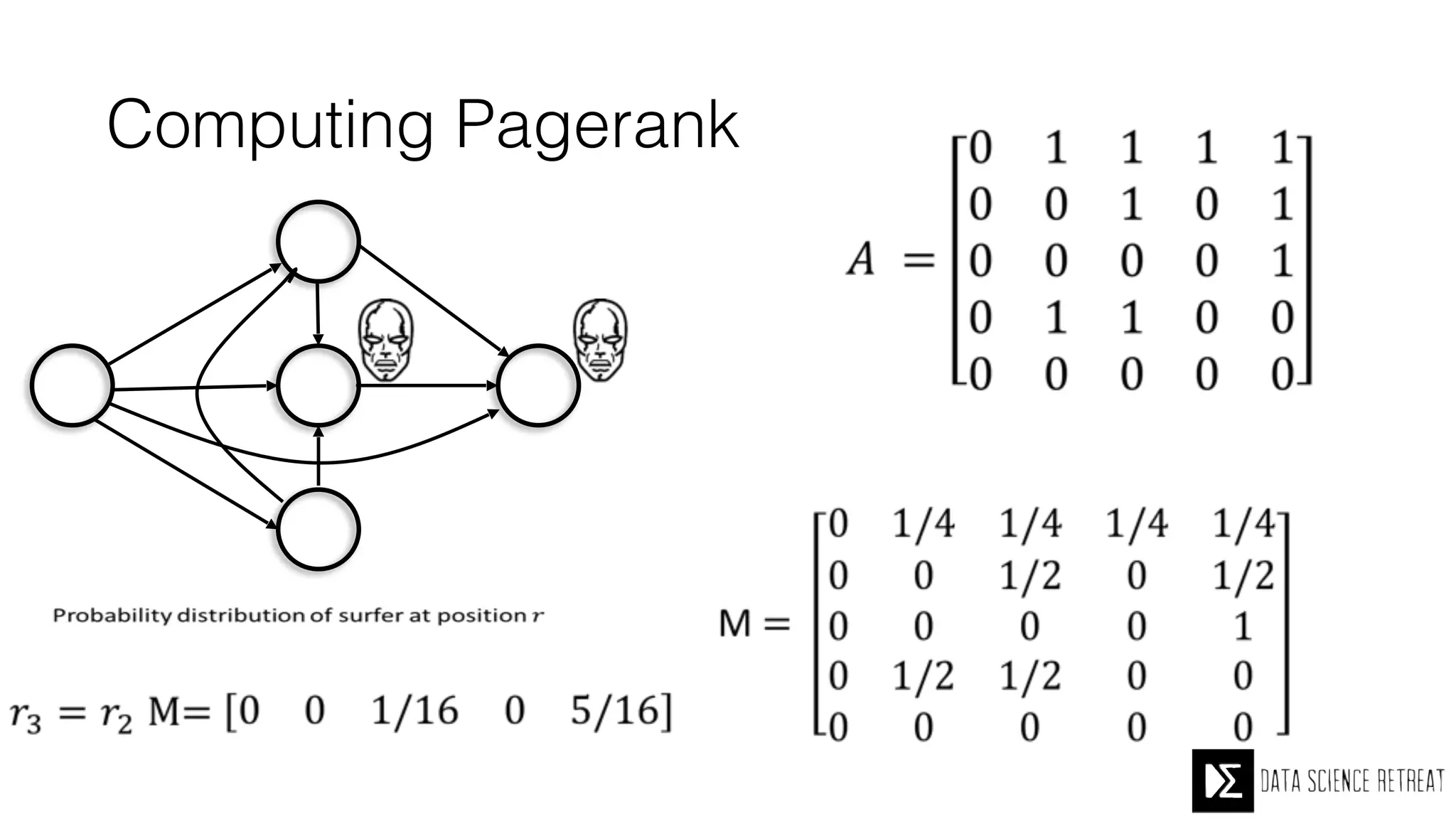
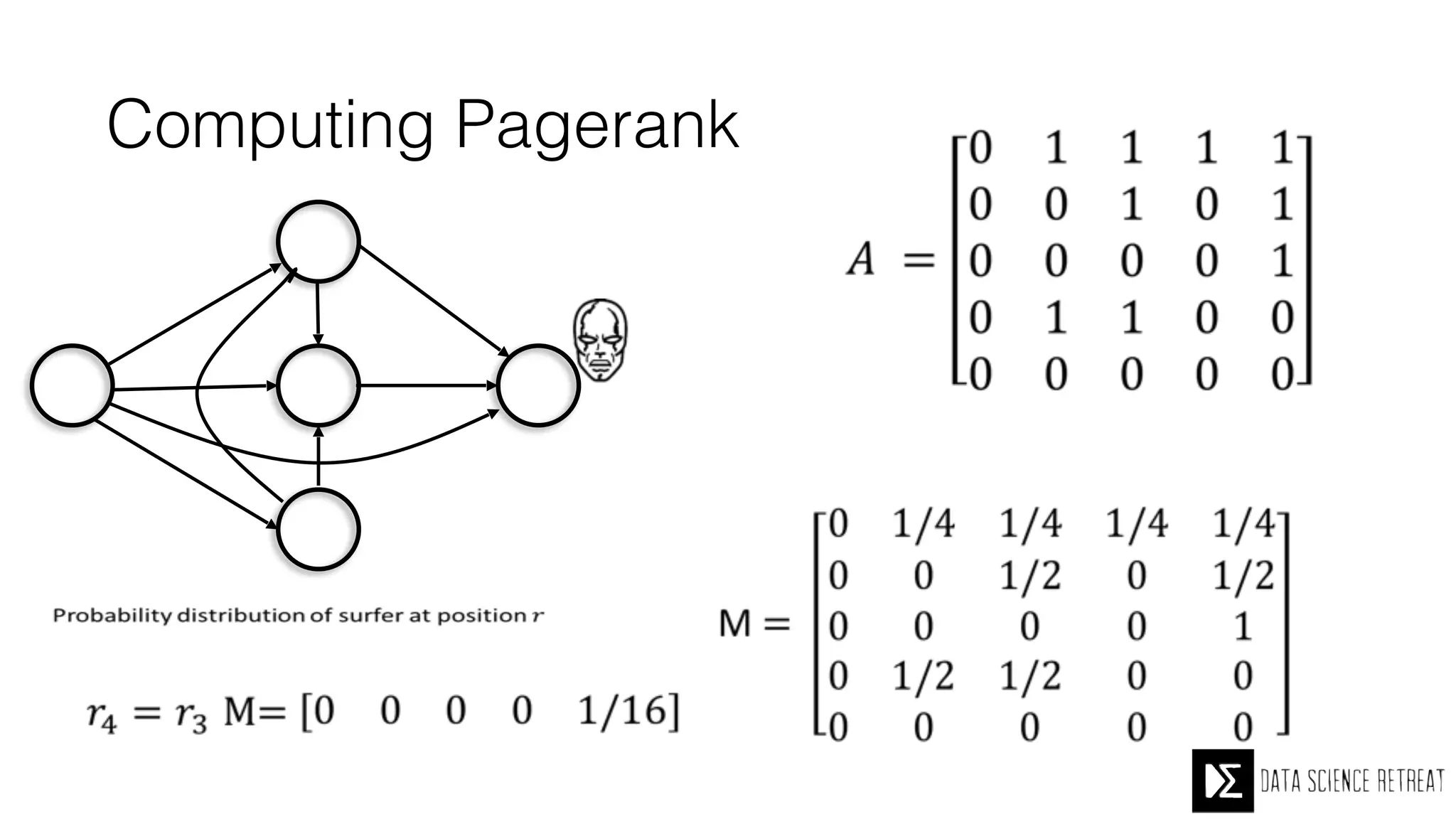
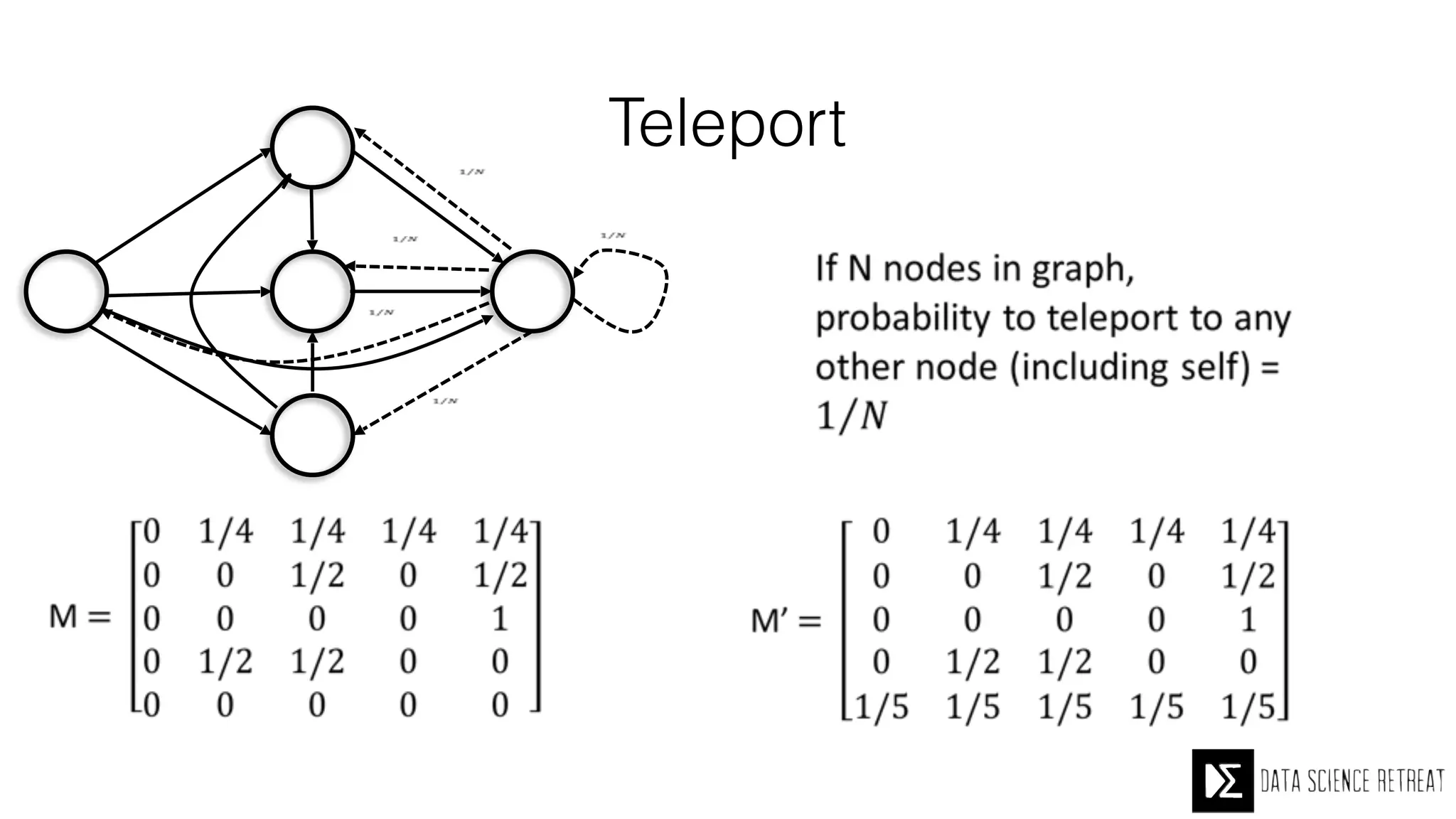
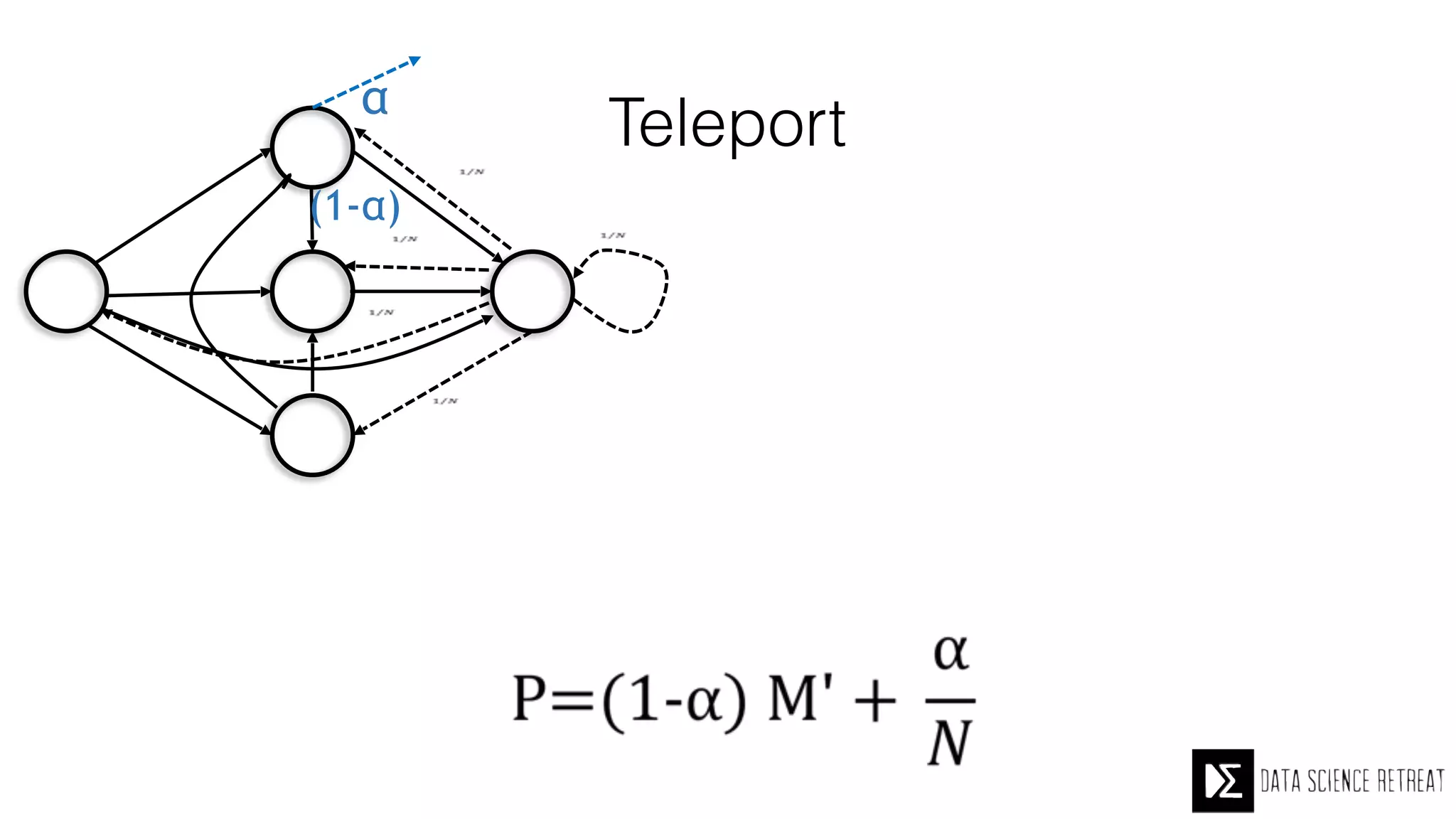
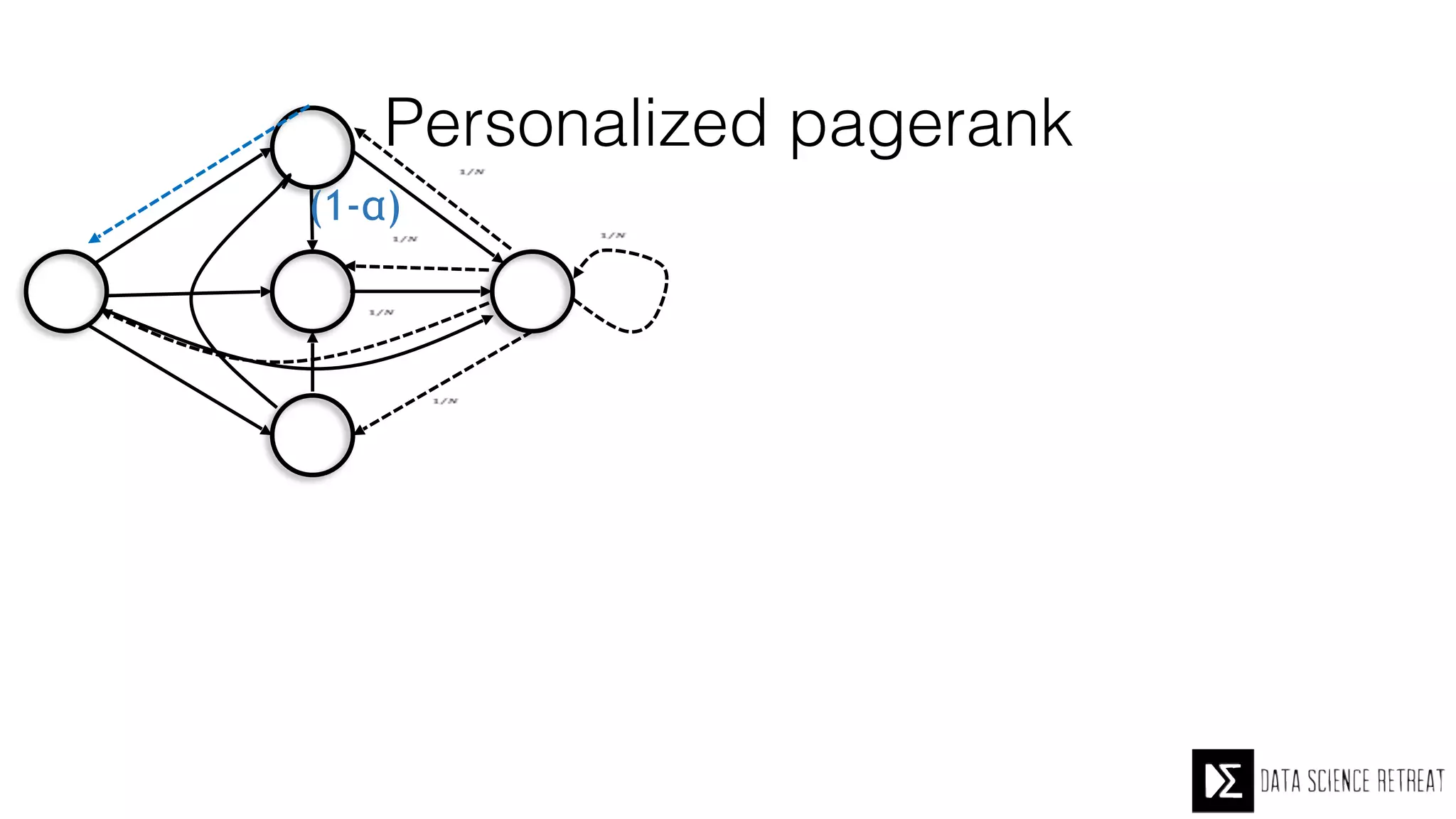
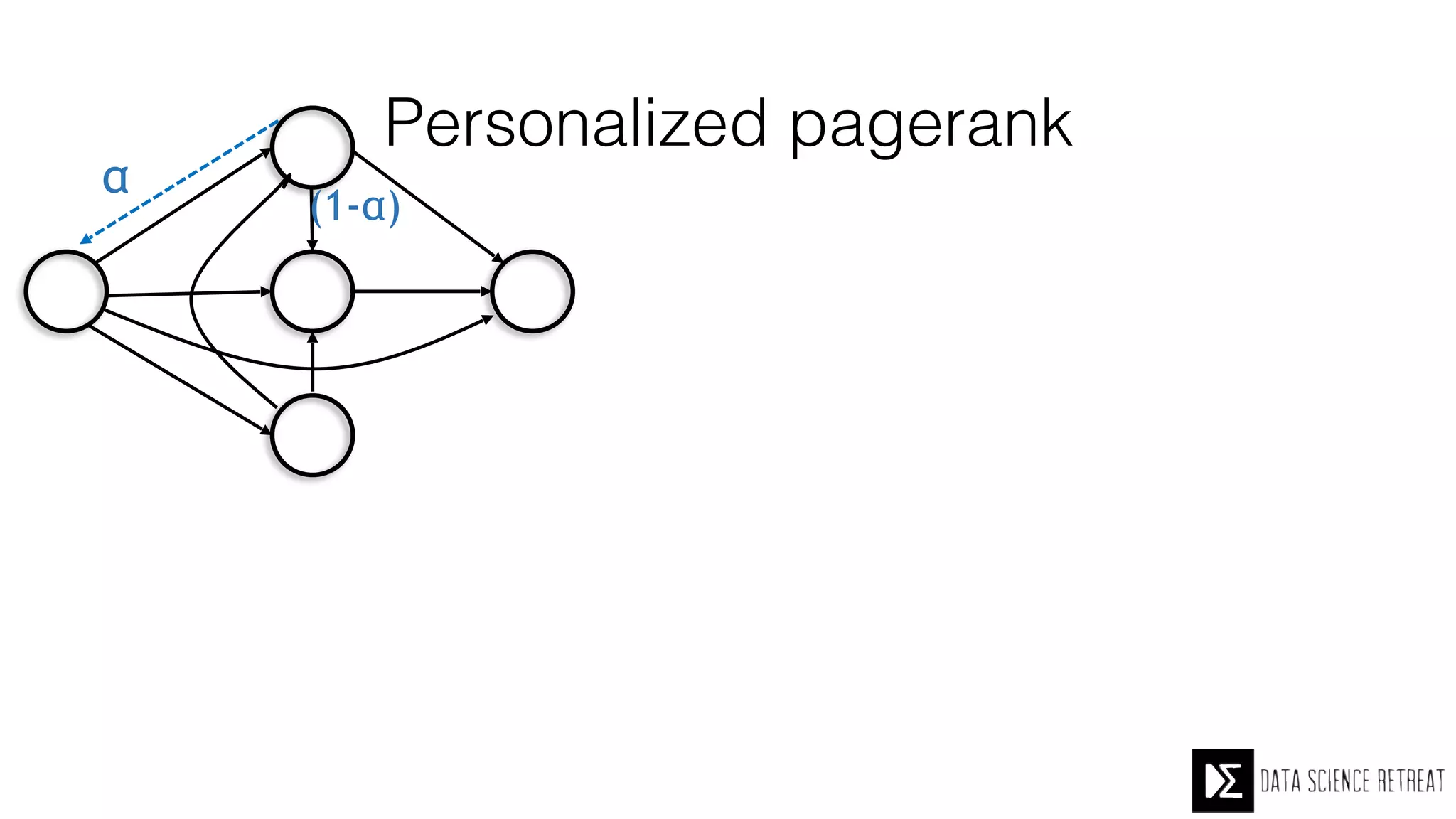

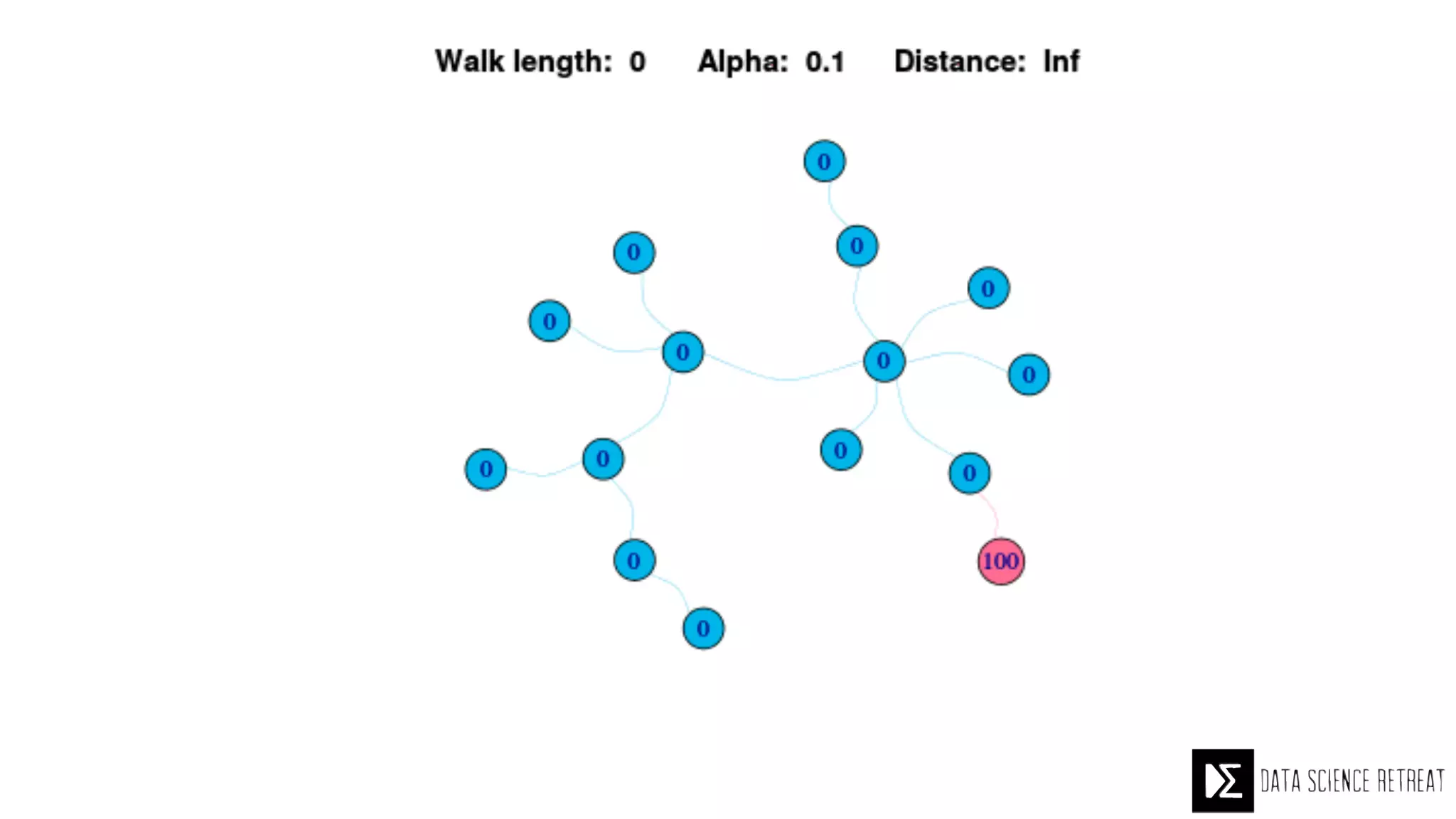
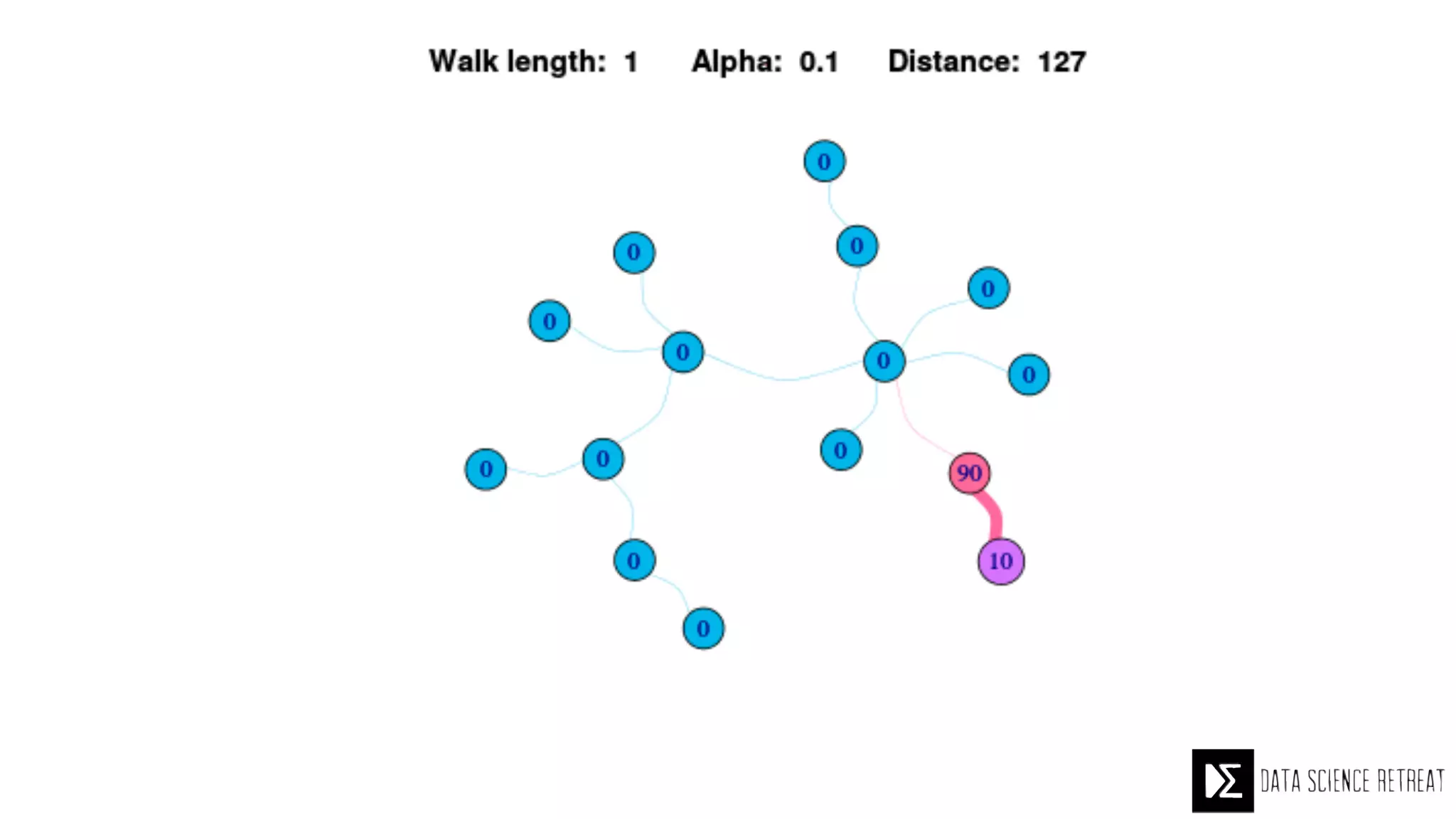
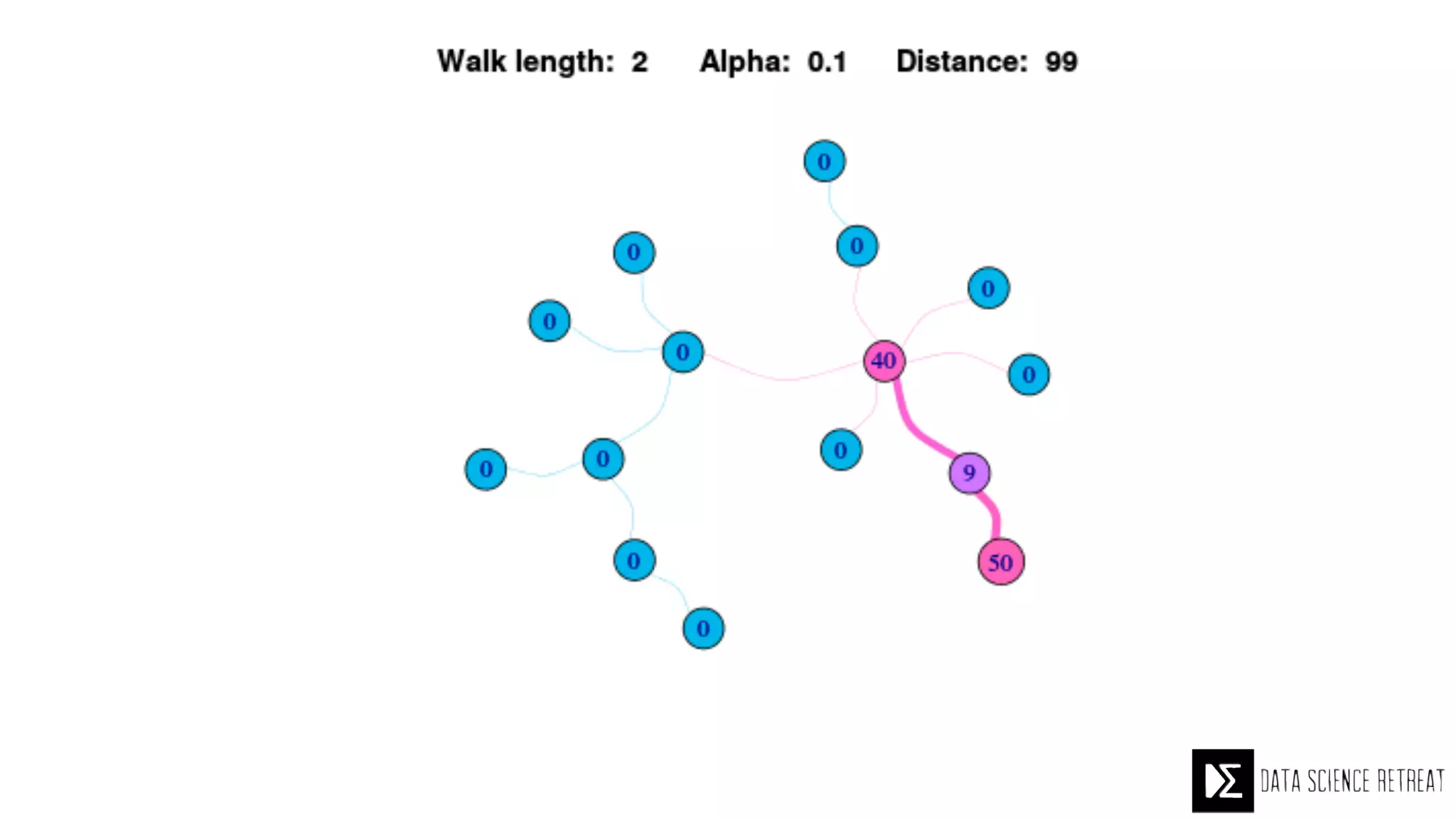
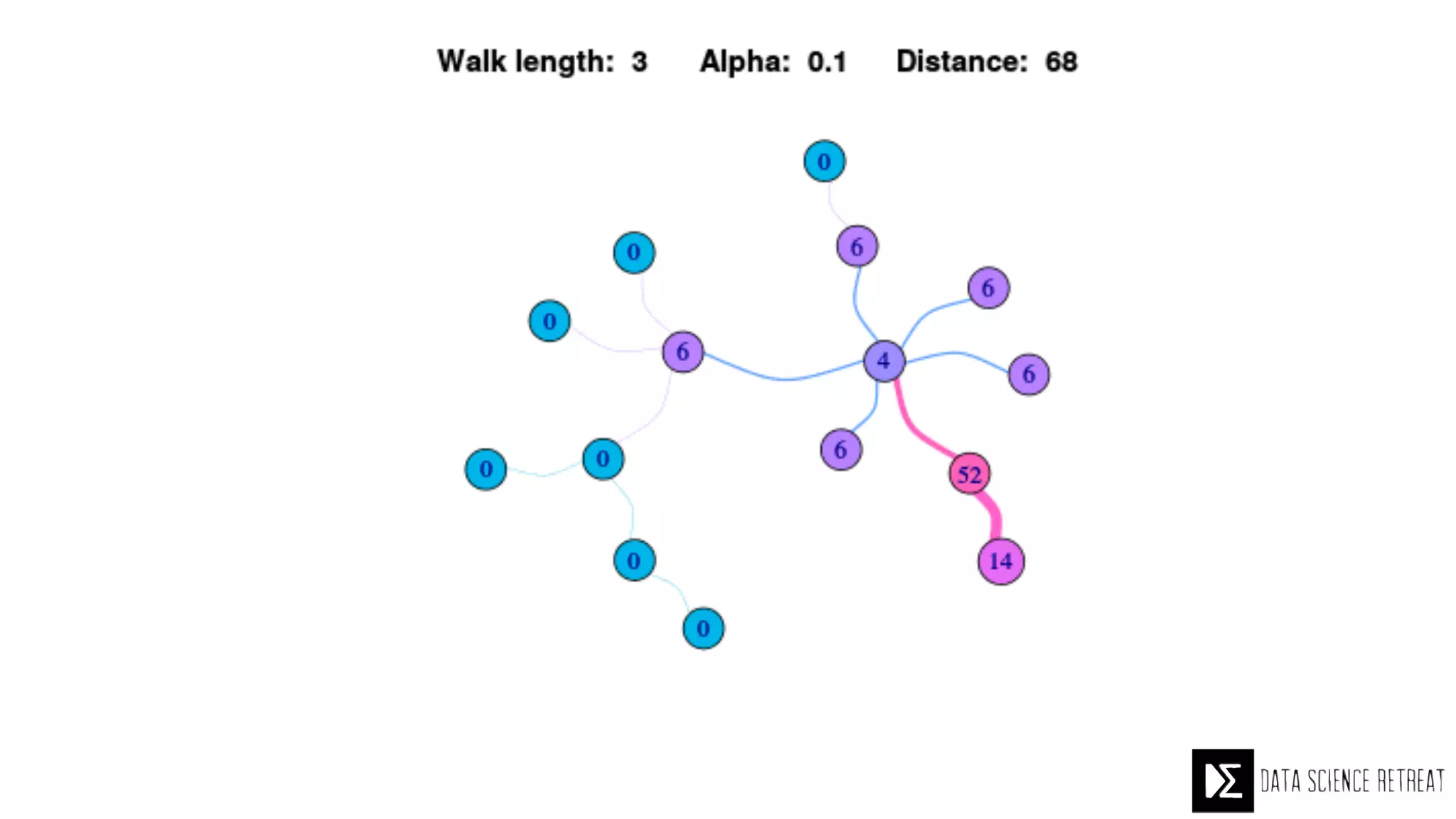
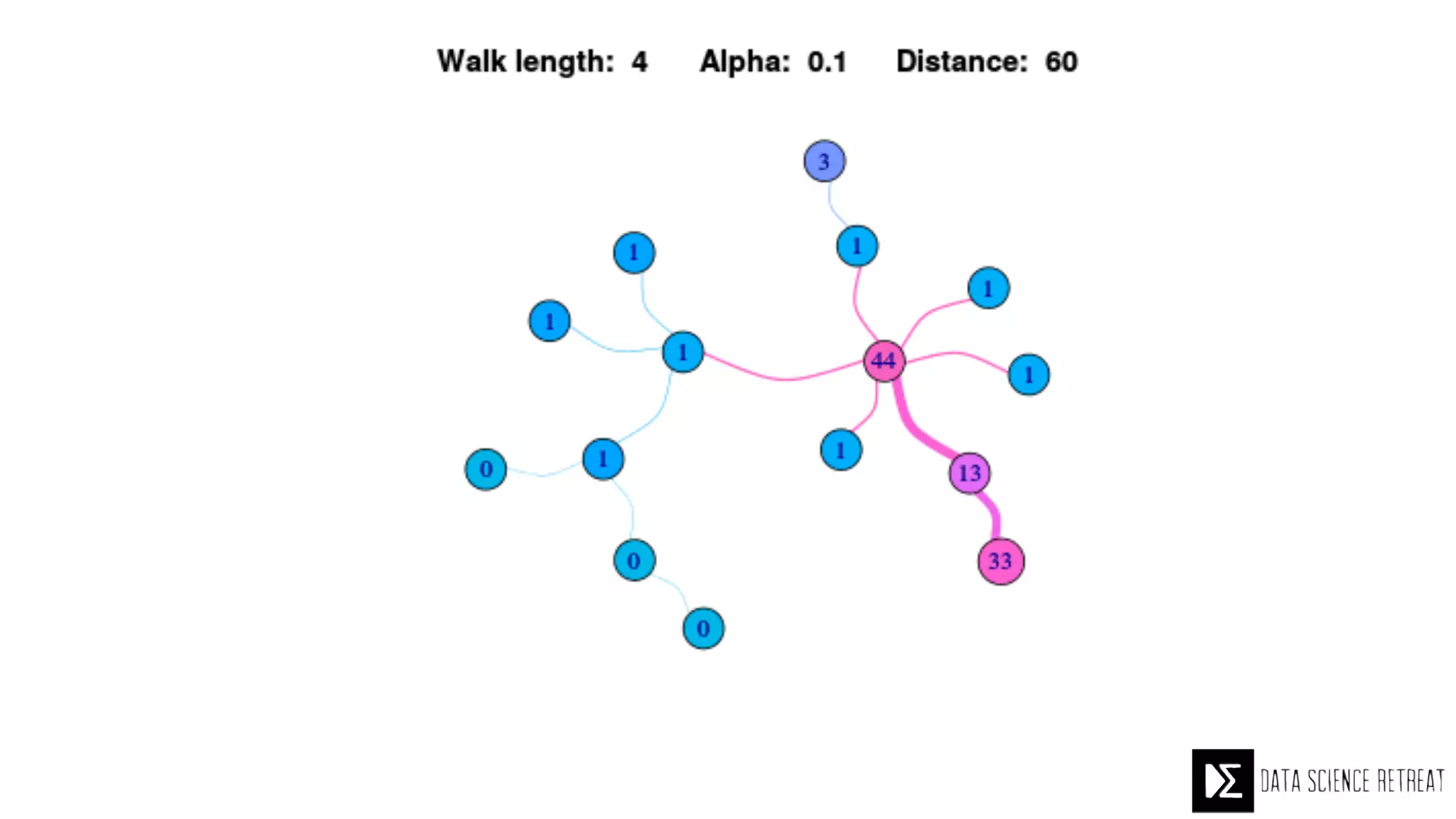
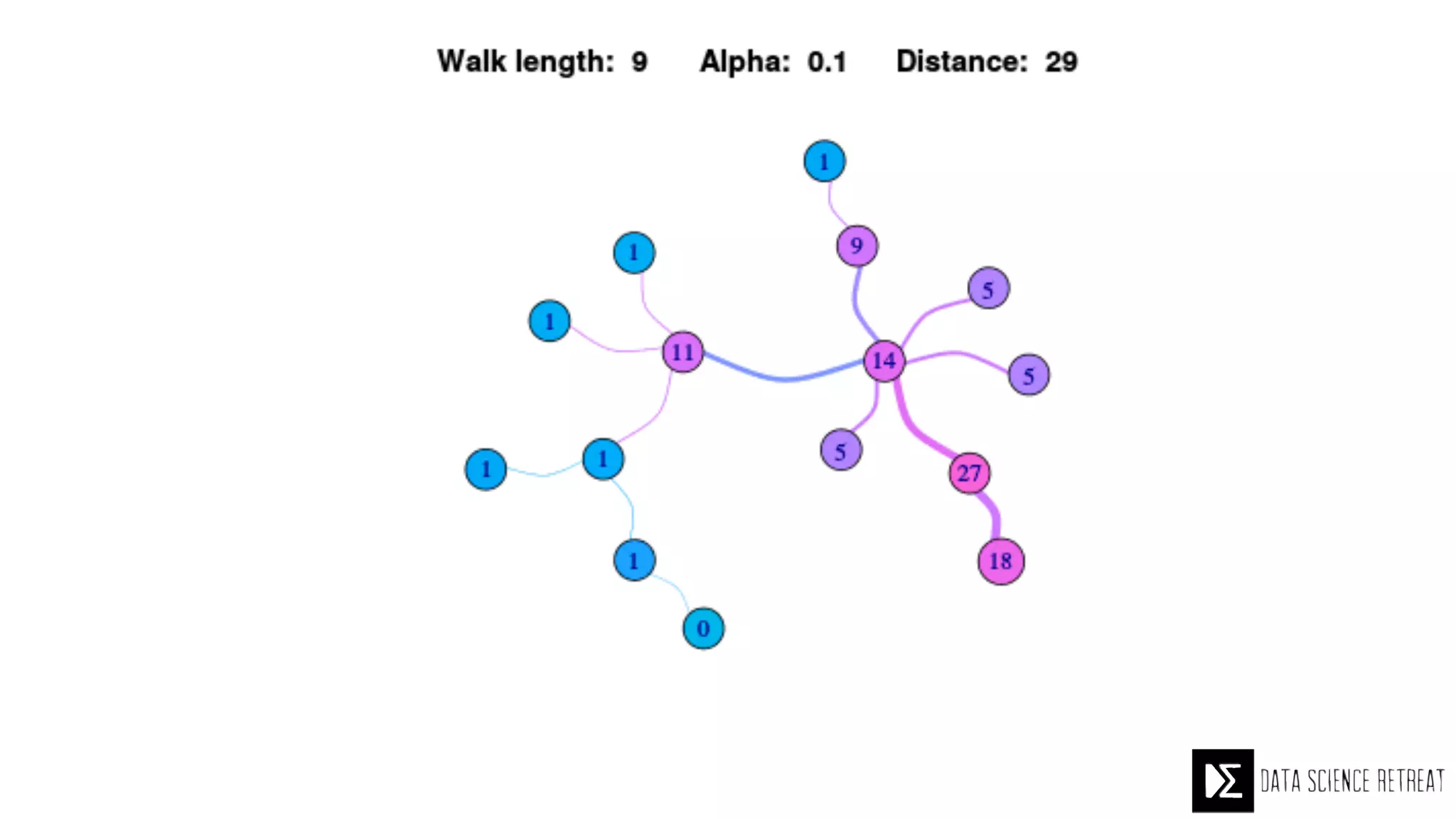
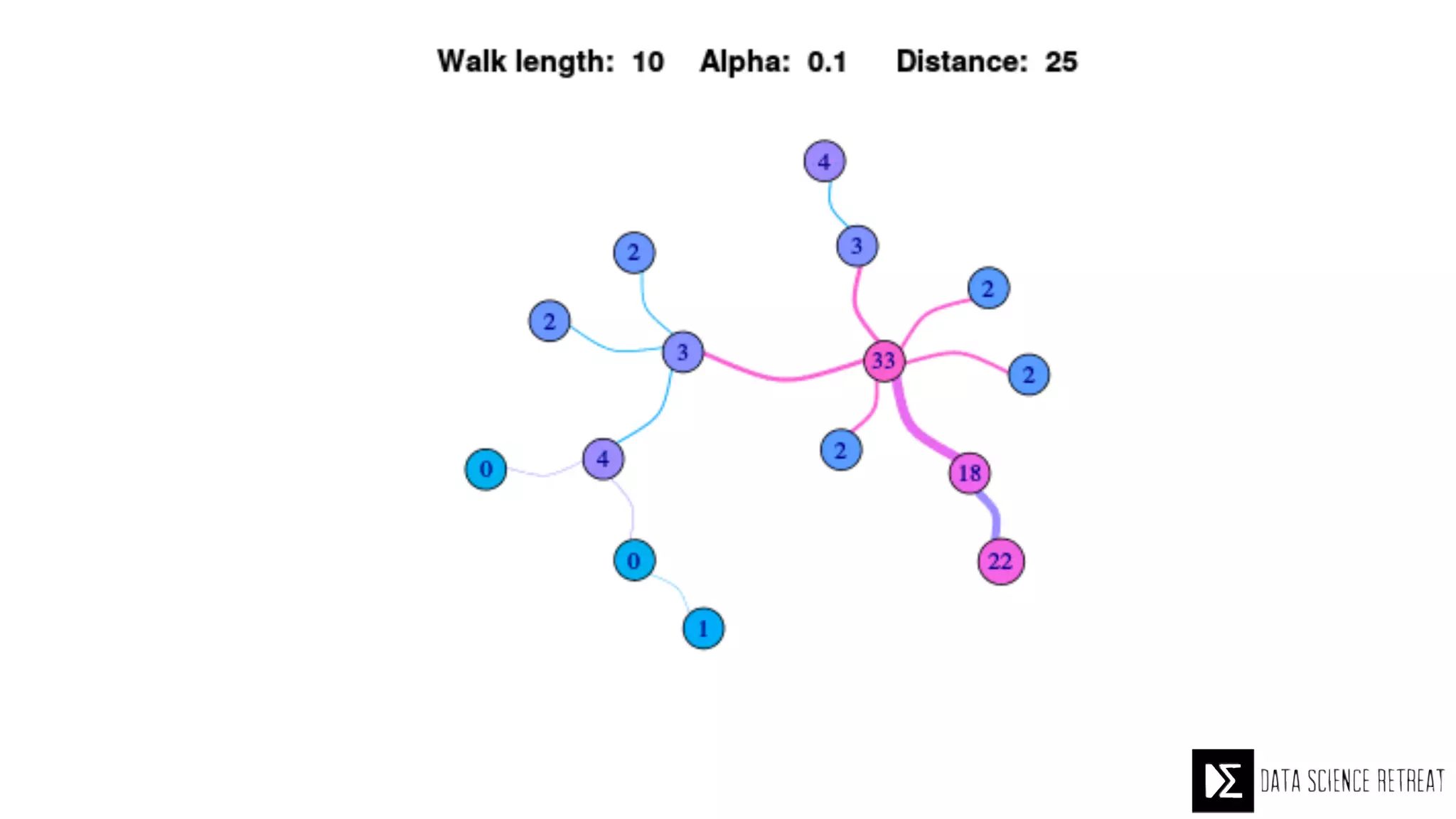
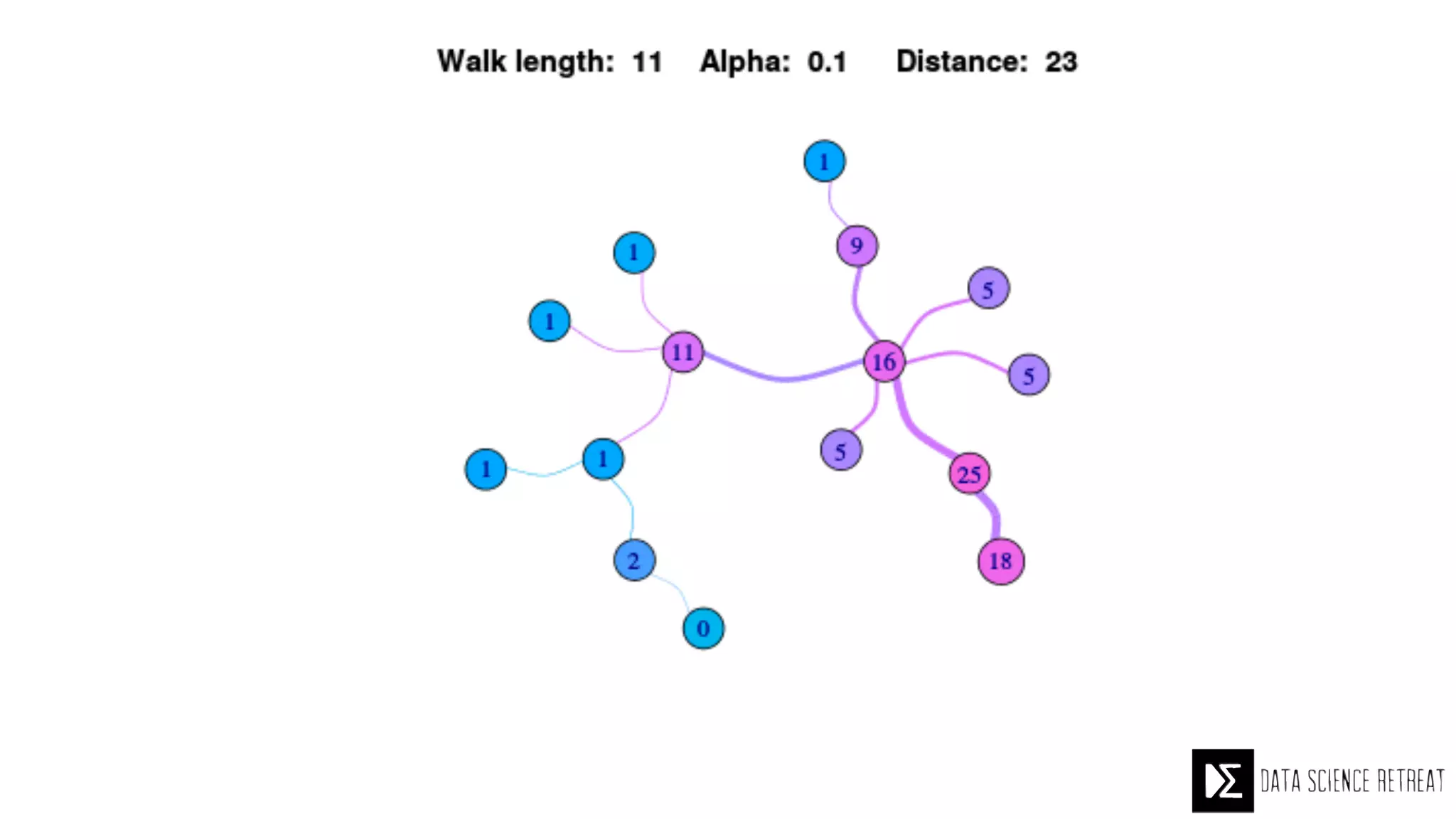
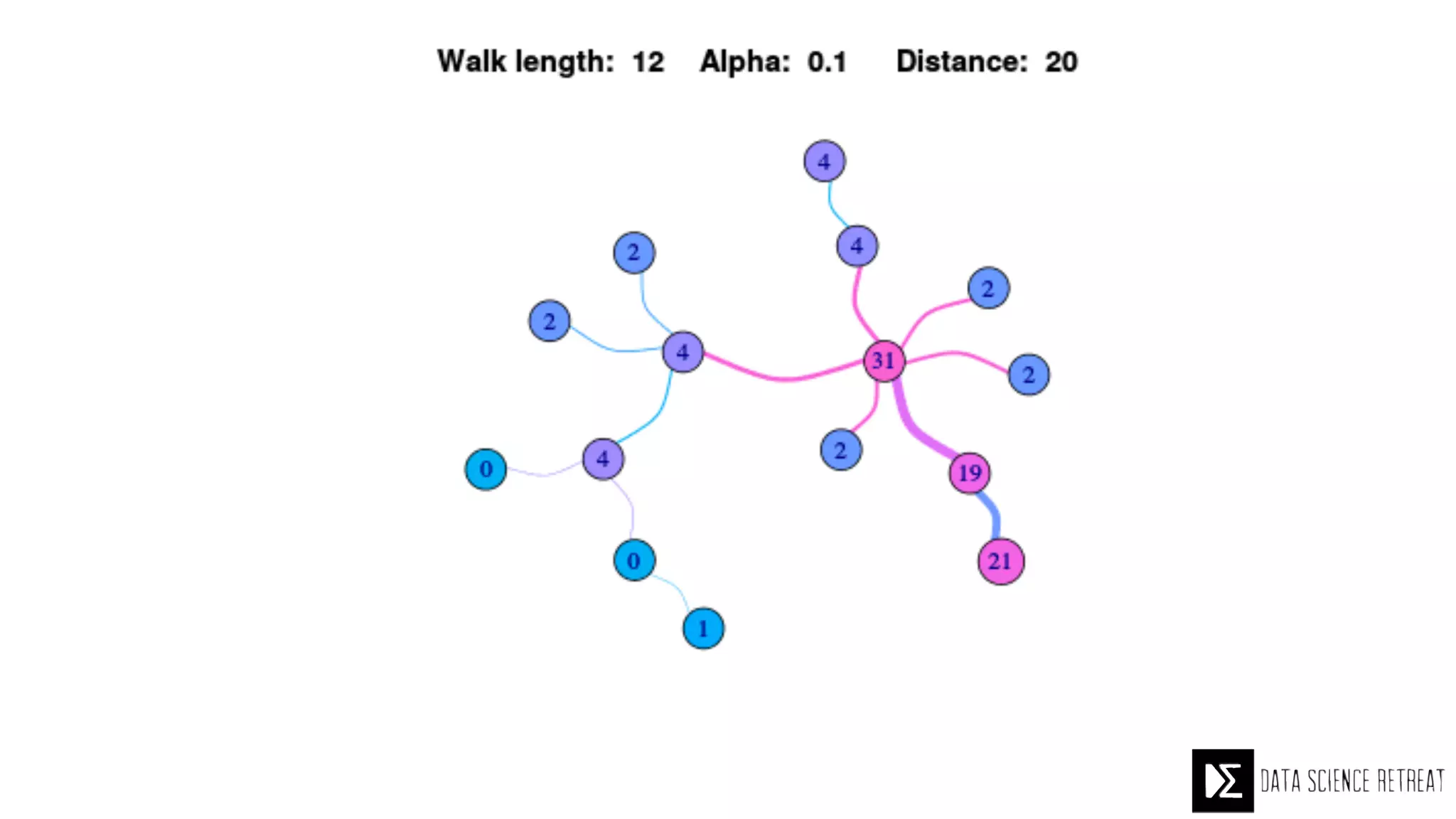
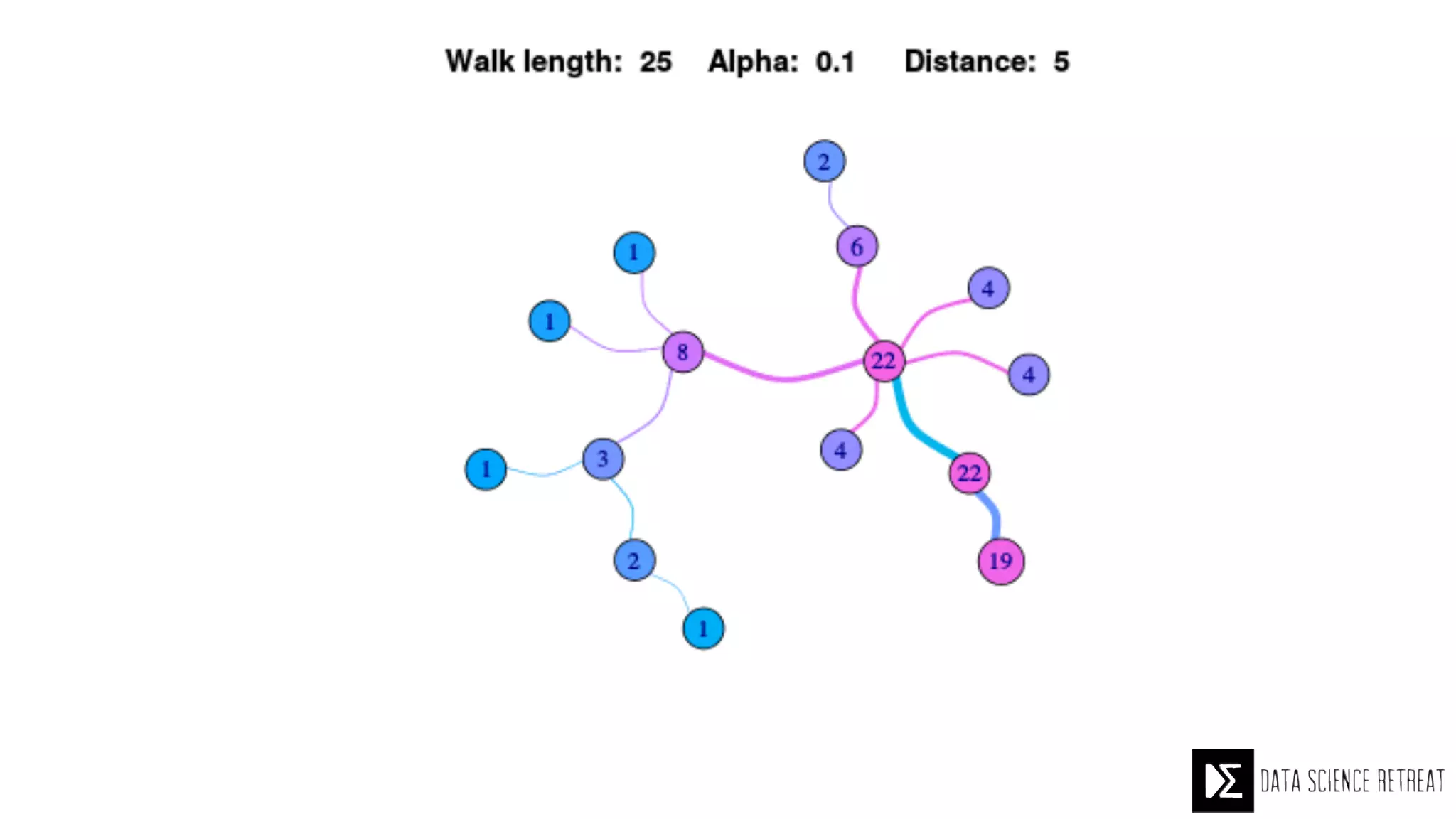
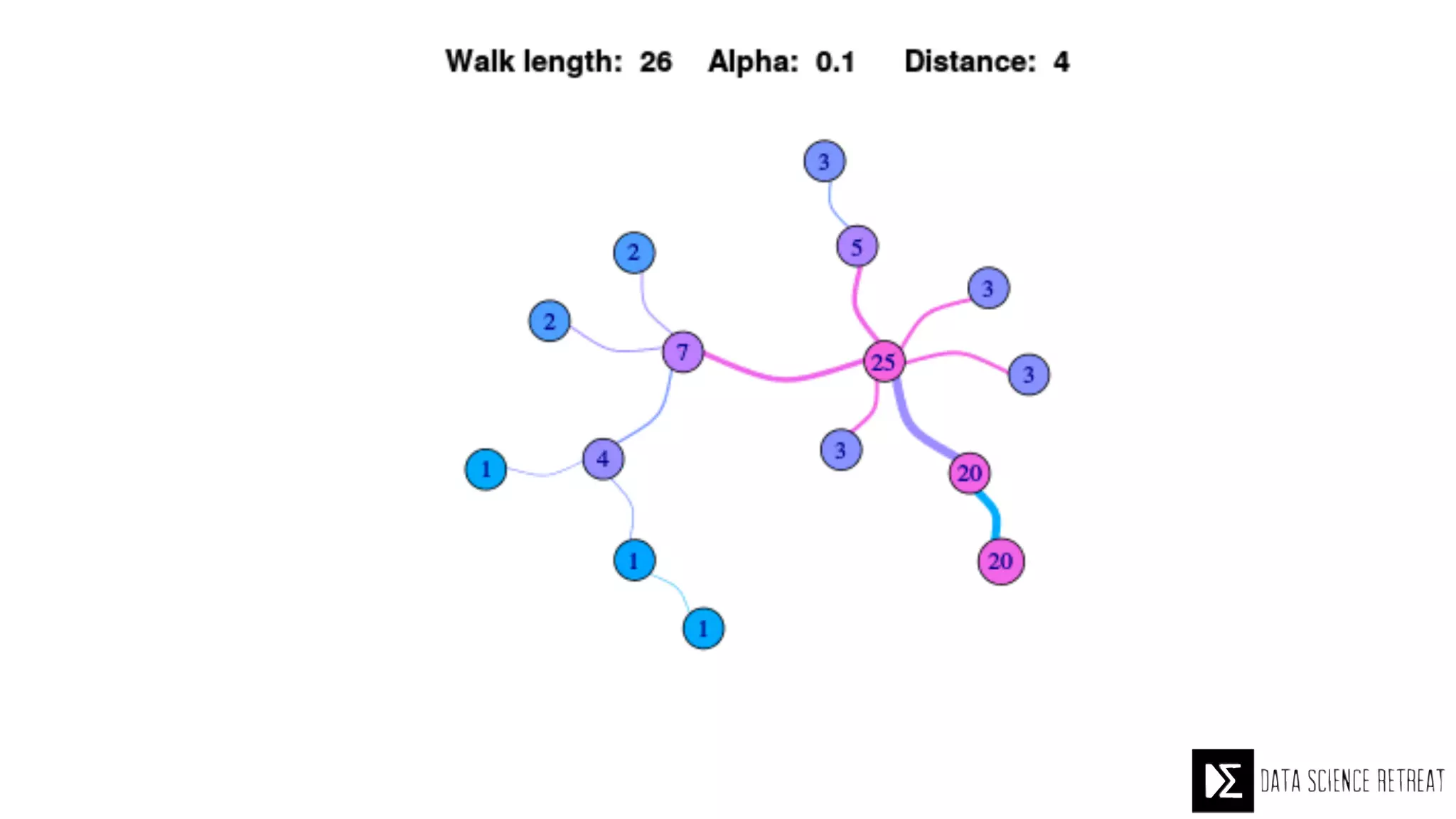
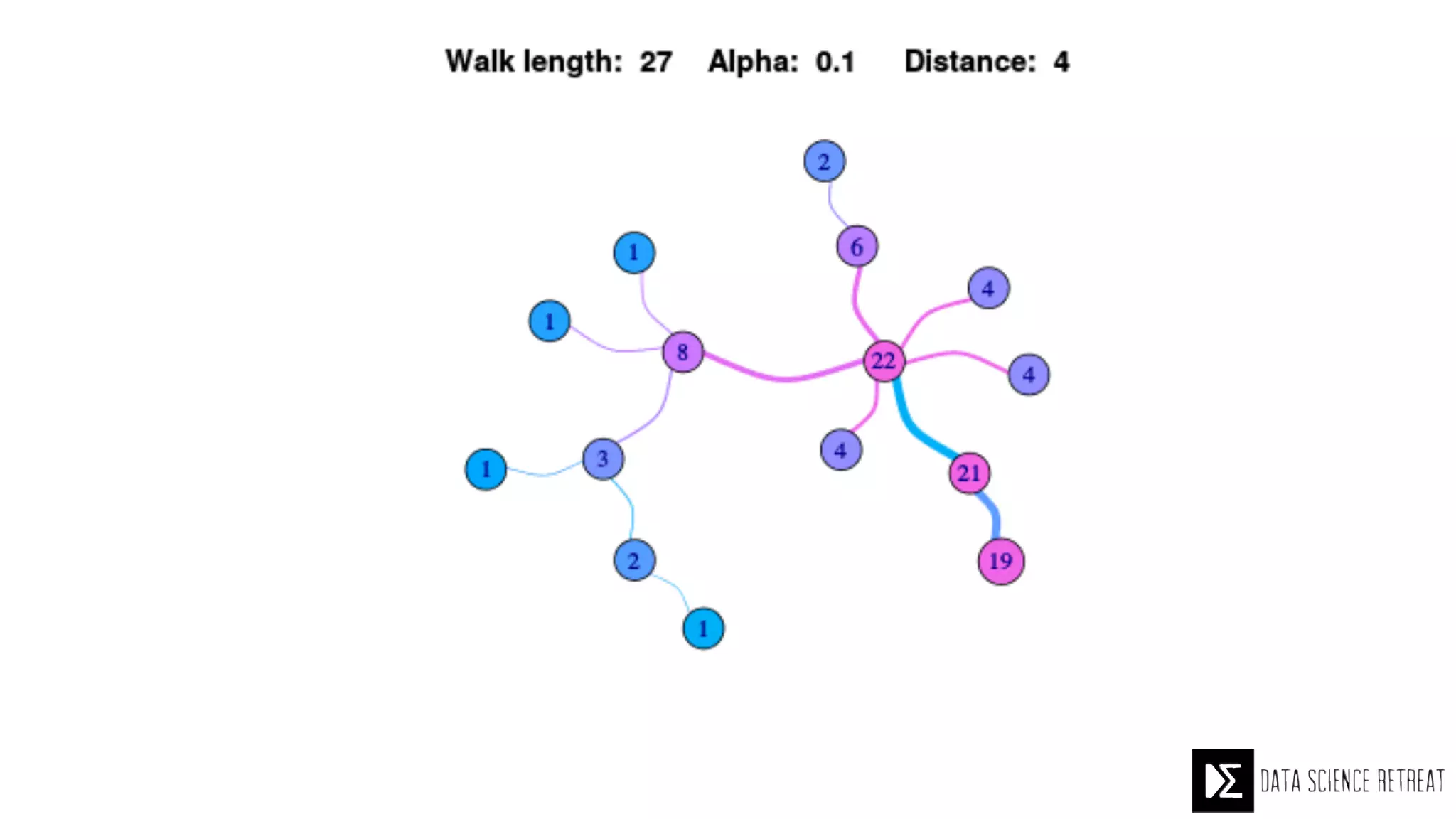
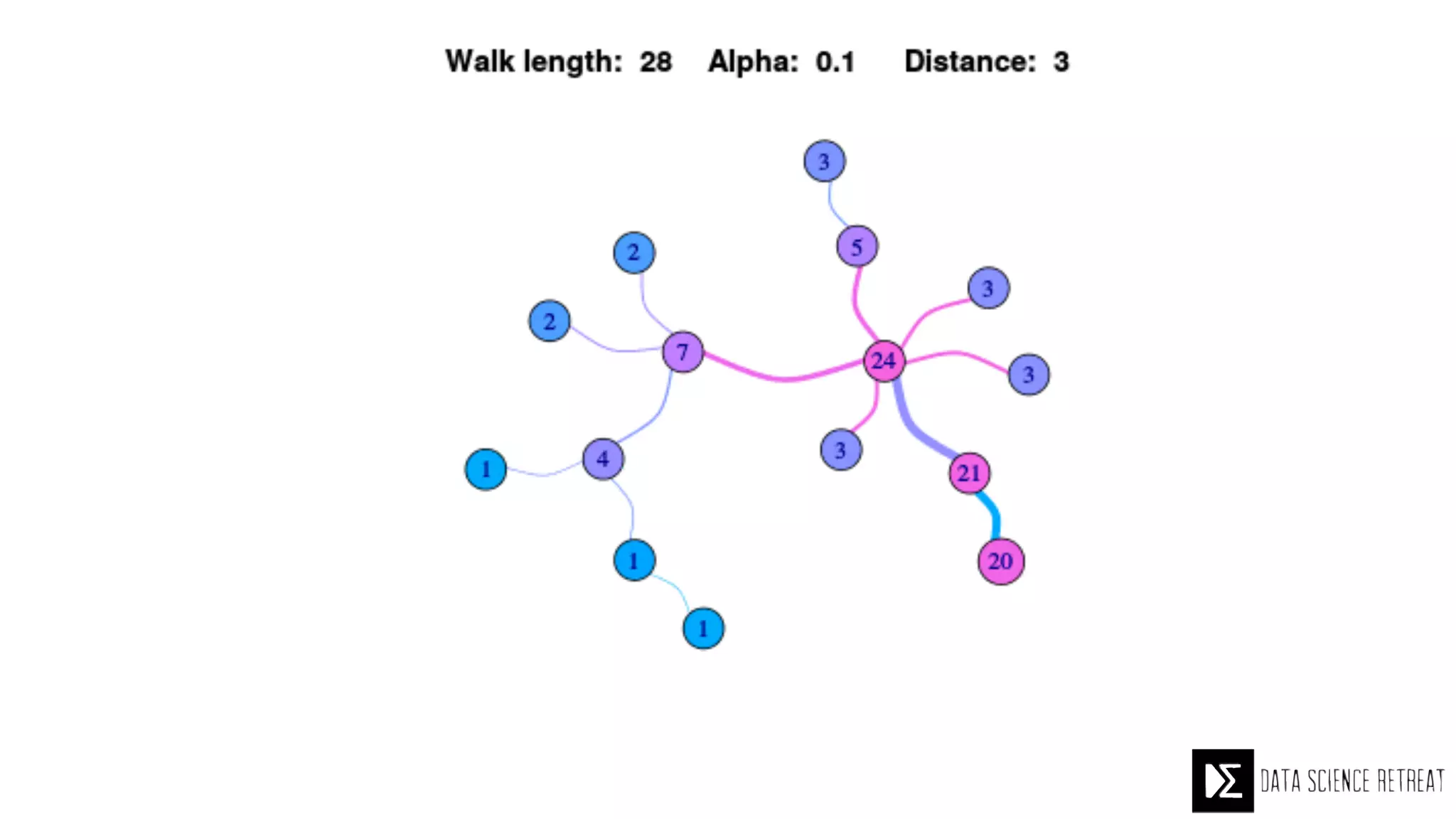
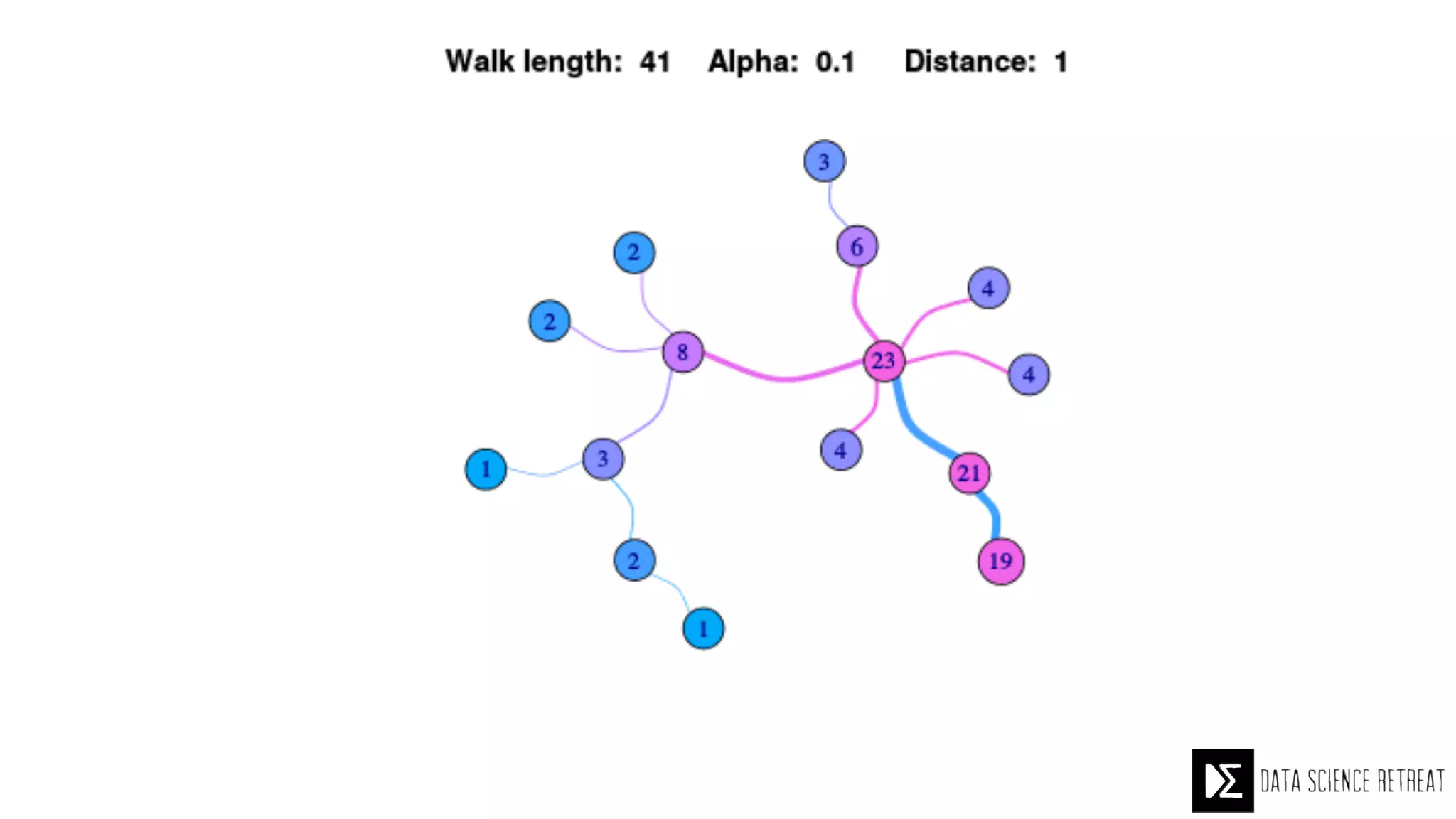
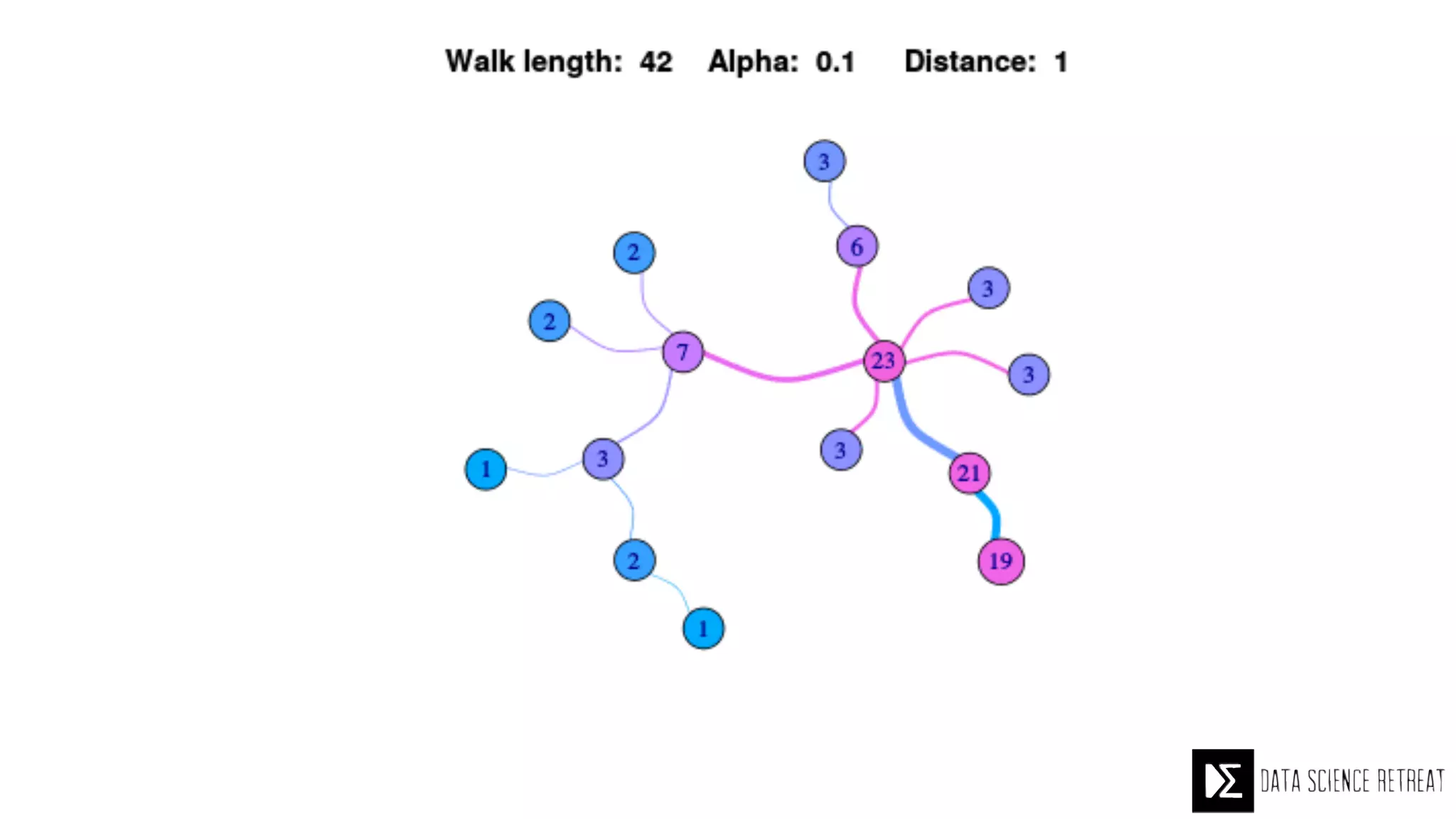
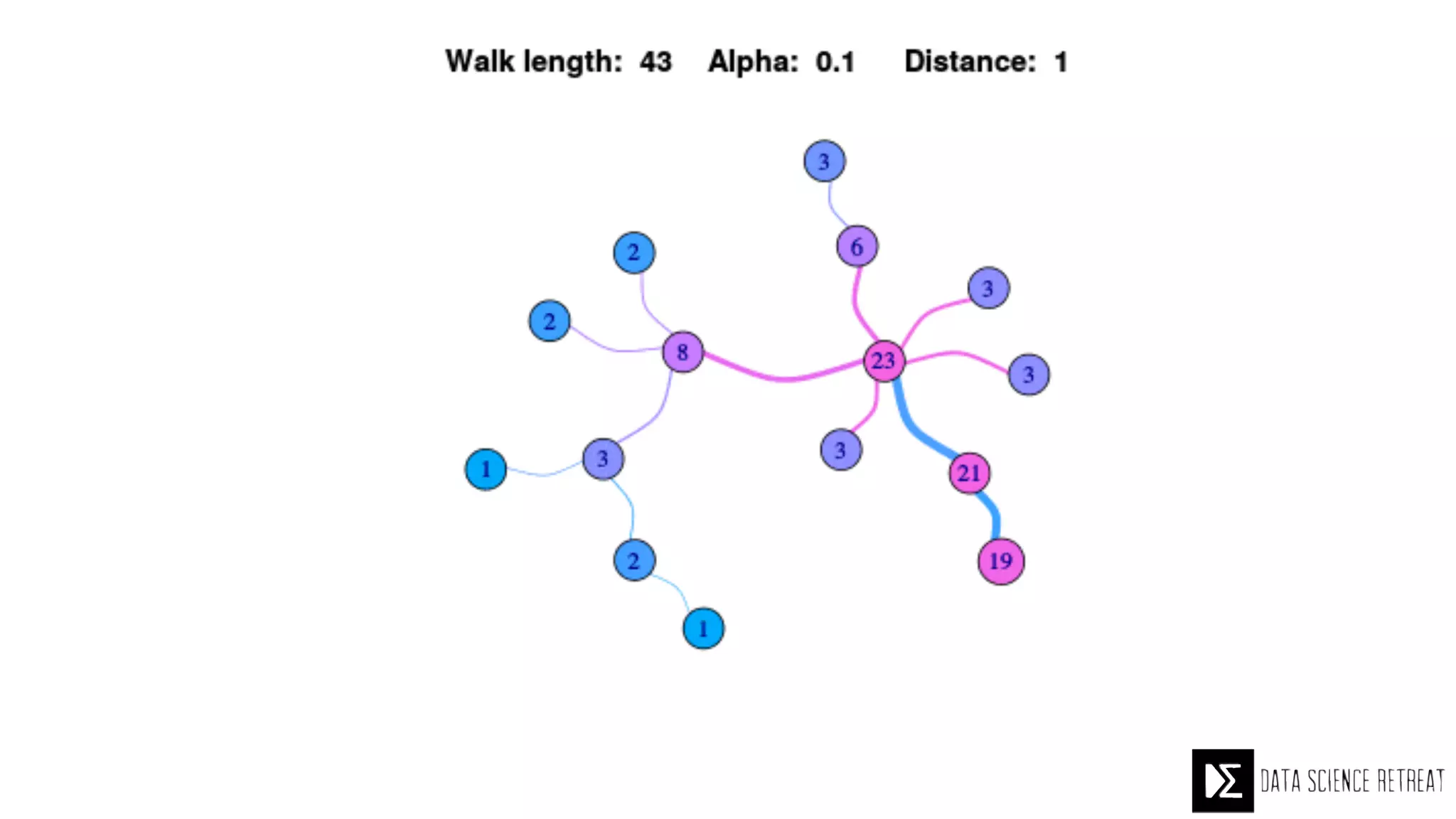
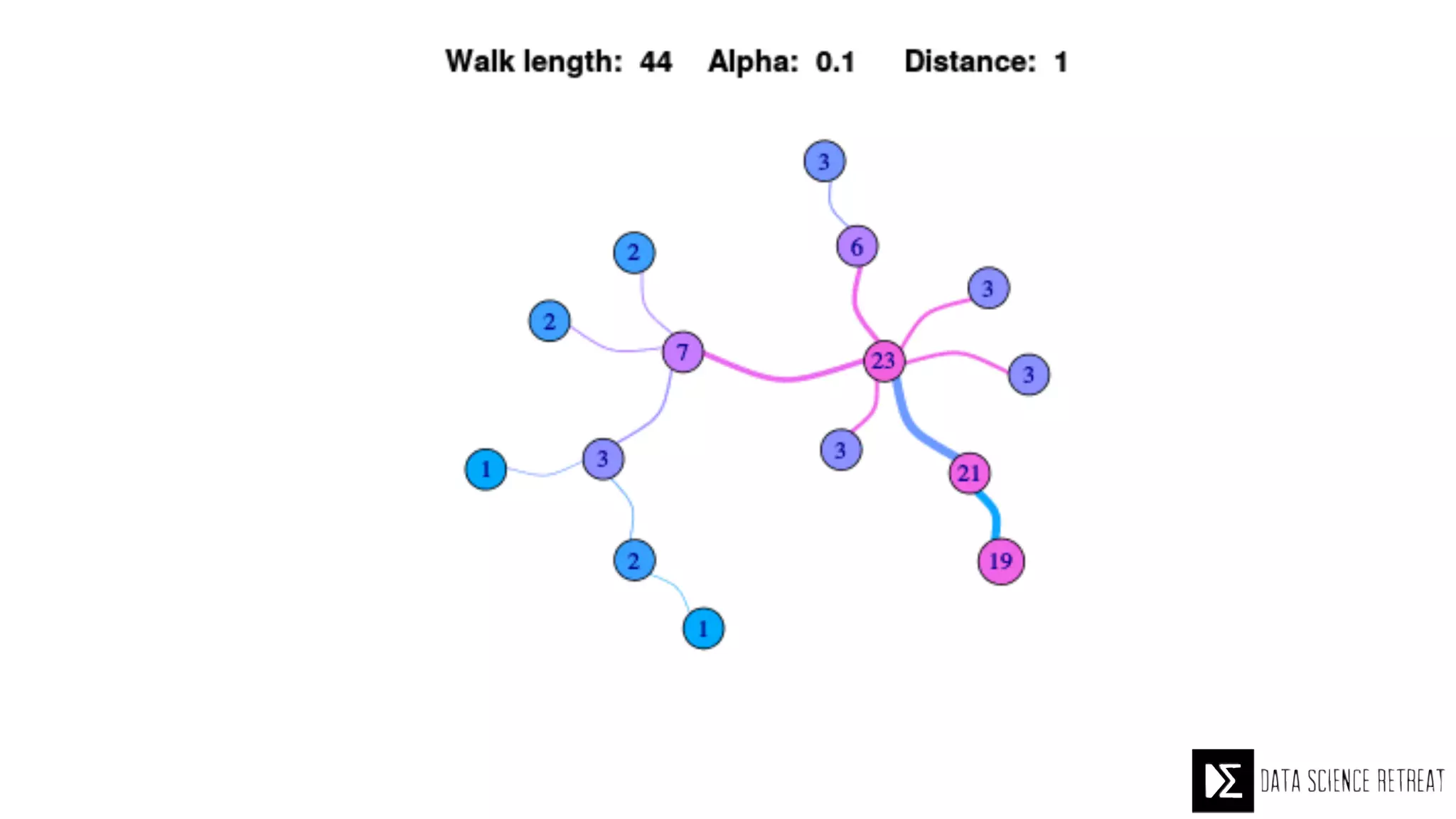

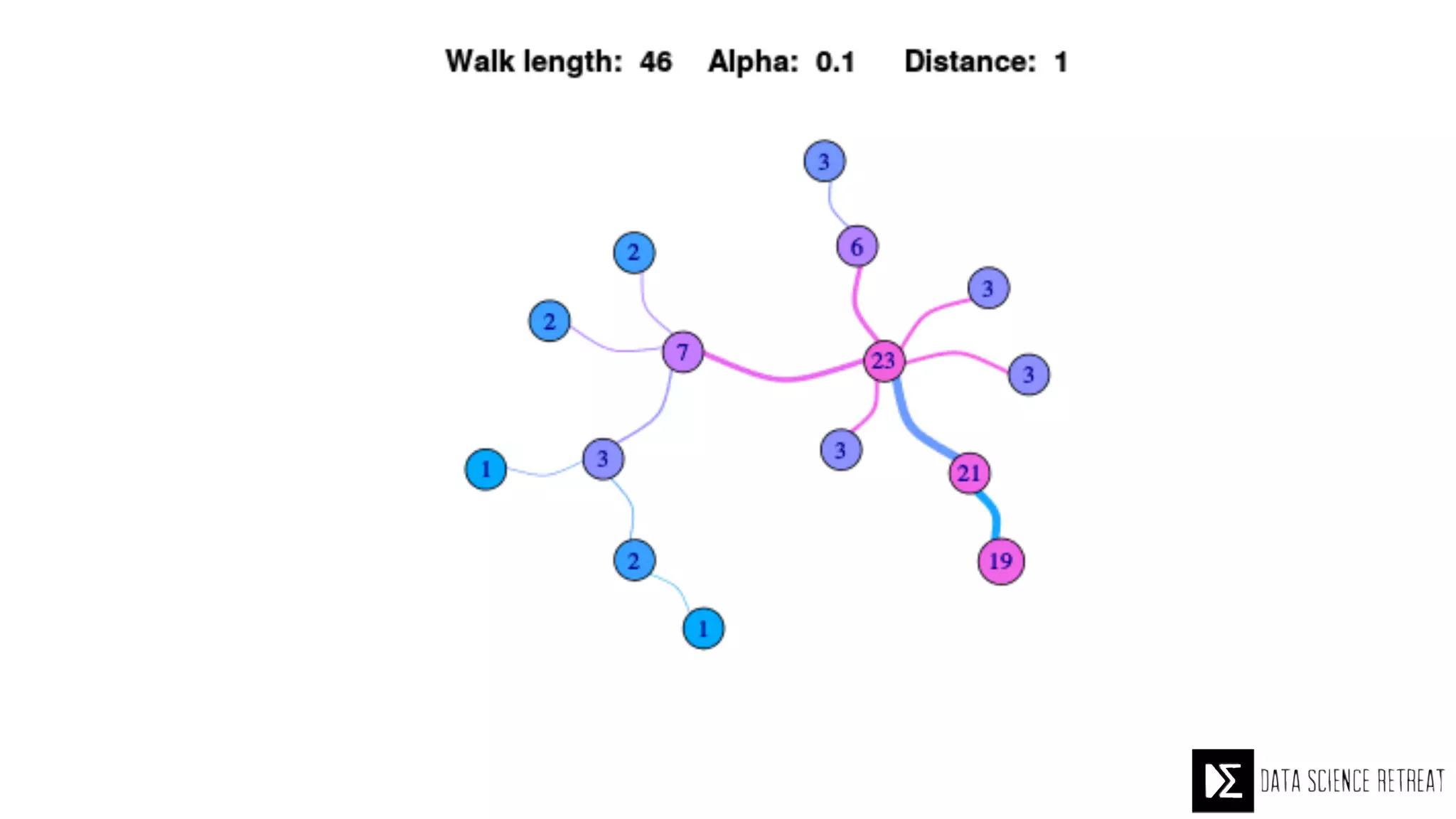
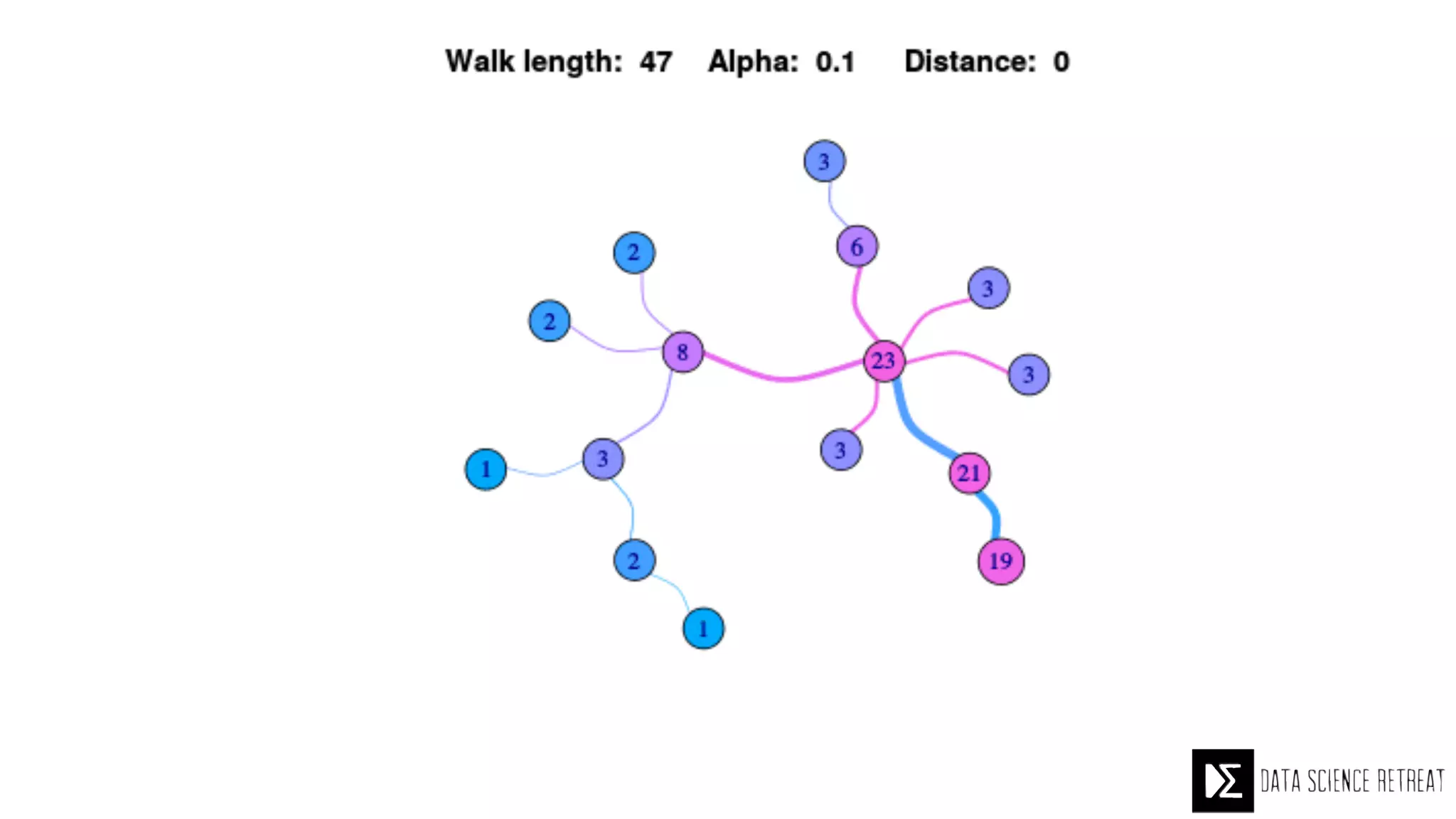






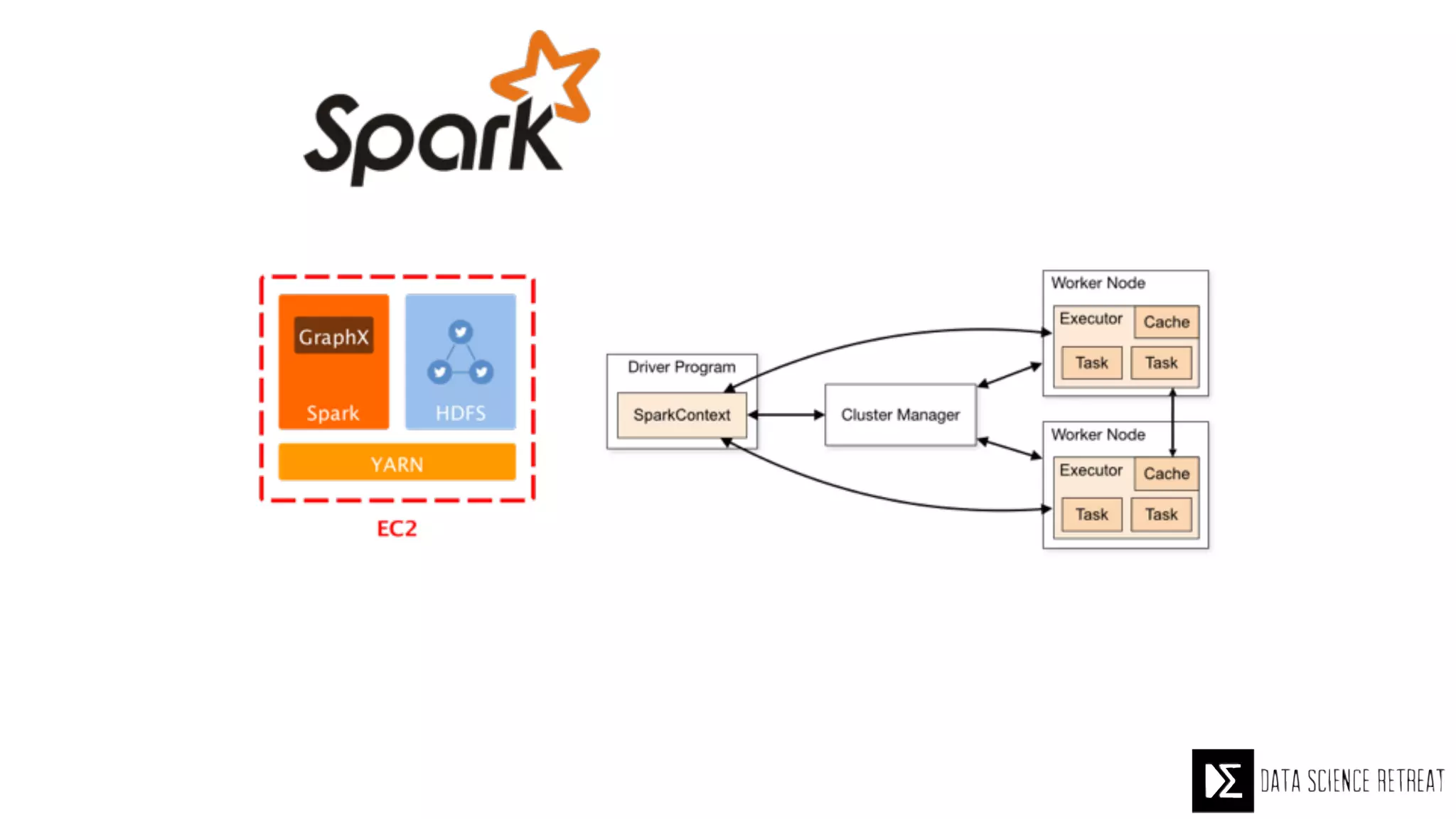
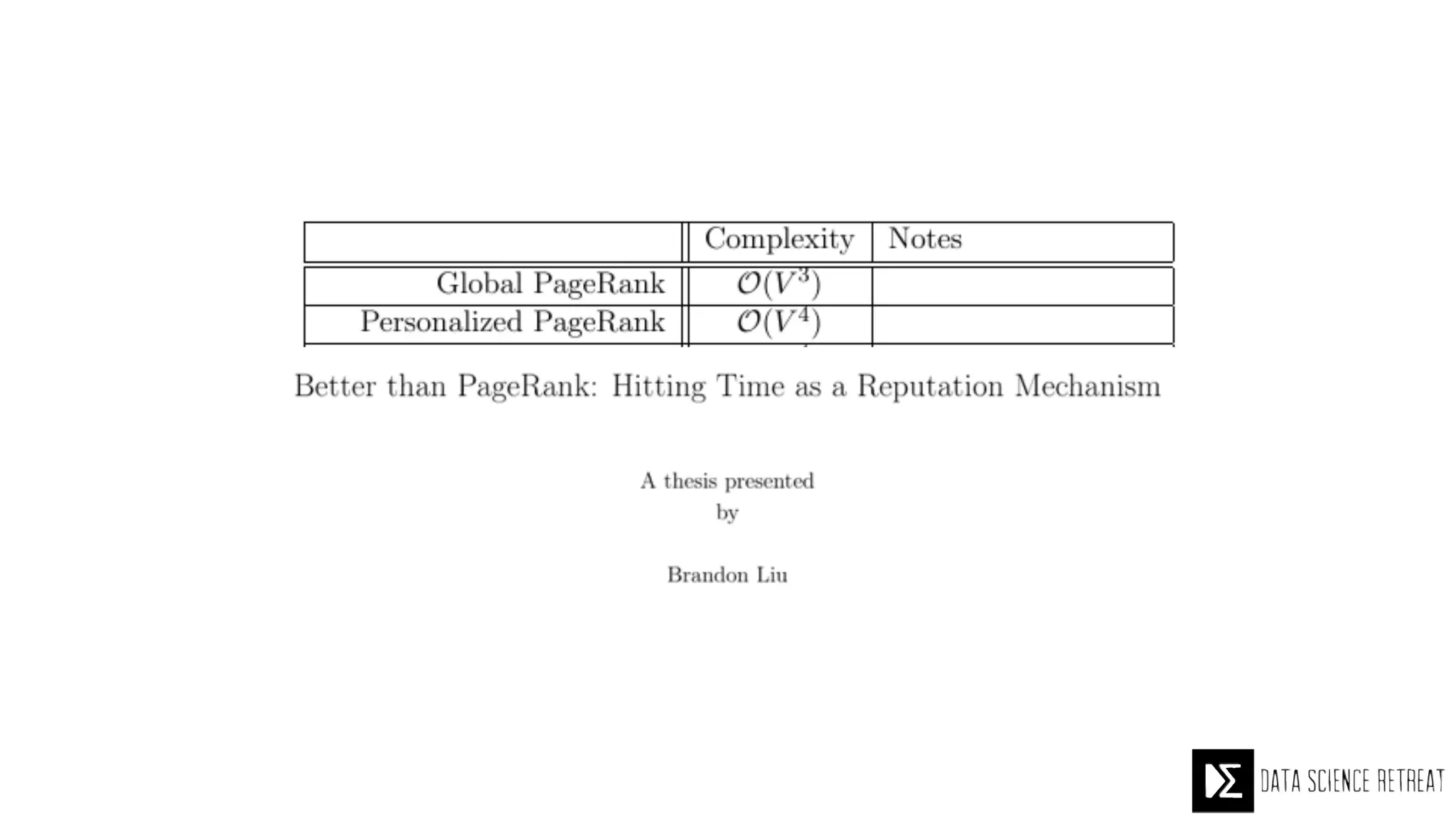








The Data Science Retreat (DSR), directed by Jose Quesada, accepts fewer than 5% of applicants and emphasizes commercial awareness, with participants completing portfolio projects. The document details graph theory concepts and the implementation of distributed graph processing using Apache Spark's GraphX and GraphFrames, highlighting their advantages and challenges. Additionally, it discusses the importance of formulating effective questions in data science and offers resources for further learning.












































































