Downloaded 252 times
































![Scaling out (Z/Y/Z axis)
[X-Axis]: Horizontal duplication (design to clone things)
[Y-Axis]: Split by Function, Service or Resource (design to split diff things)
[Z-Axis]: Lookups split (design to split similar things)](https://image.slidesharecdn.com/distributedsystemsandscalabilityrules-131021042922-phpapp01/85/Distributed-systems-and-scalability-rules-39-320.jpg)

































![Scaling out (Z/Y/Z axis)
[X-Axis]: Horizontal duplication (design to clone things)
[Y-Axis]: Split by Function, Service or Resource (design to split diff things)
[Z-Axis]: Lookups split (design to split similar things)](https://image.slidesharecdn.com/distributedsystemsandscalabilityrules-131021042922-phpapp01/75/Distributed-systems-and-scalability-rules-39-2048.jpg)


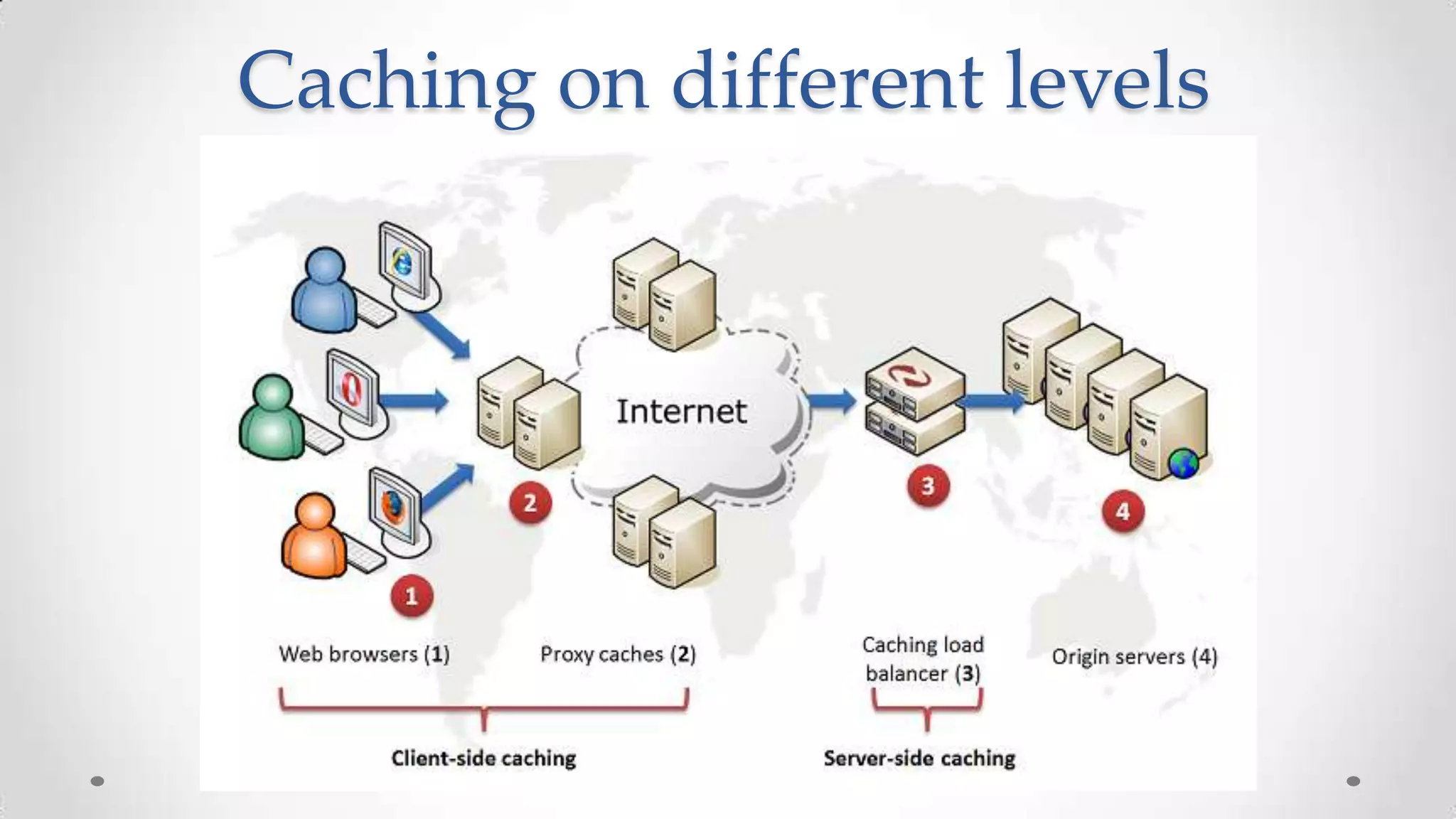
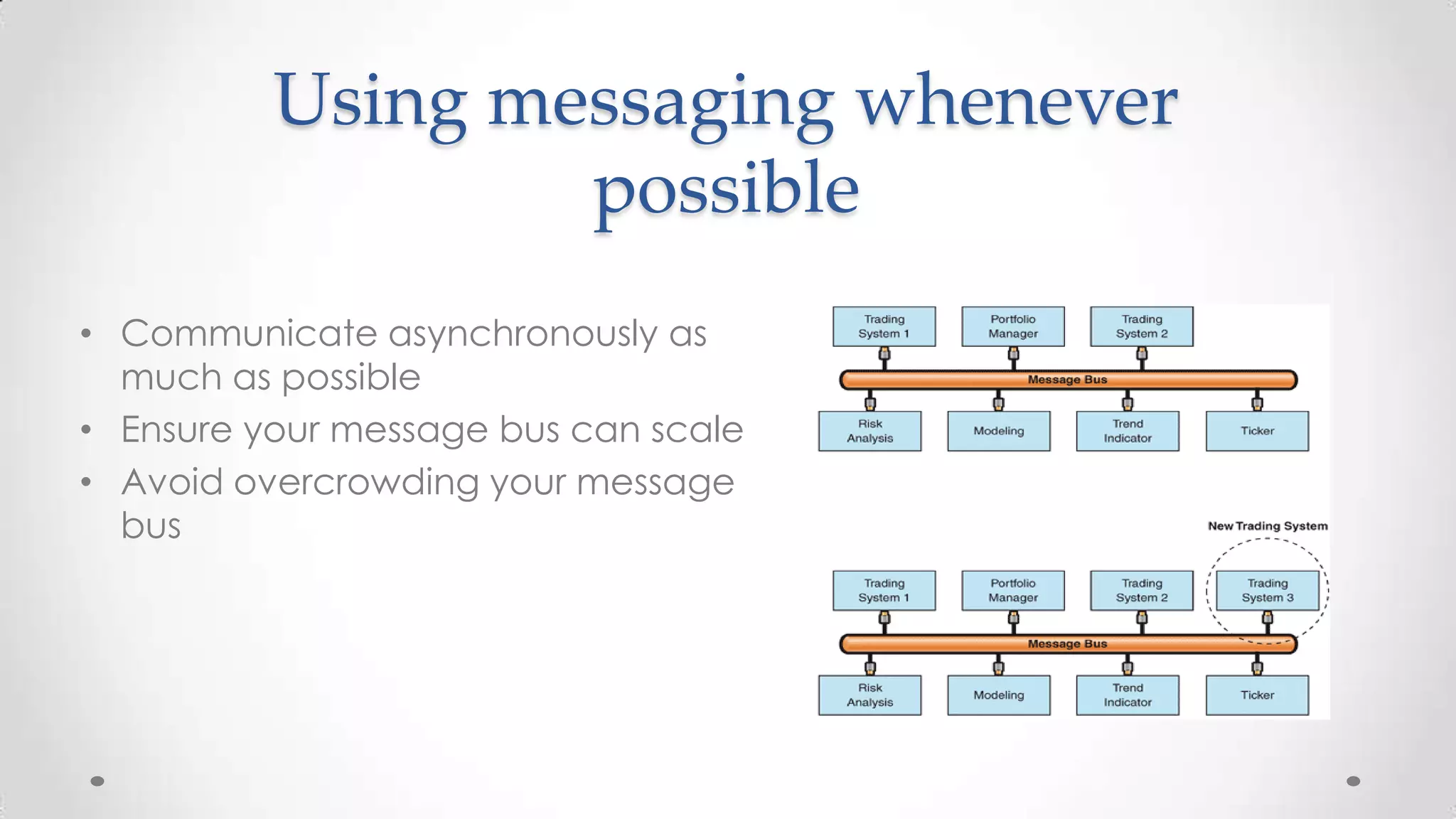



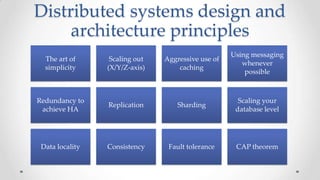
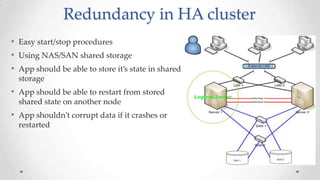
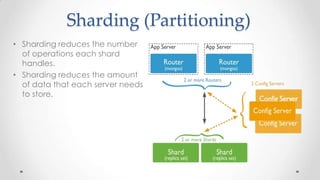
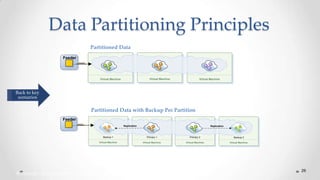
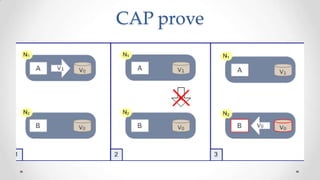
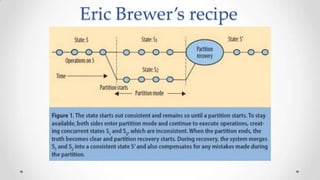
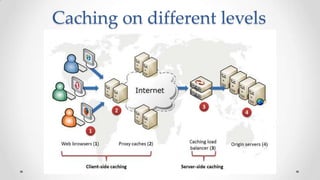
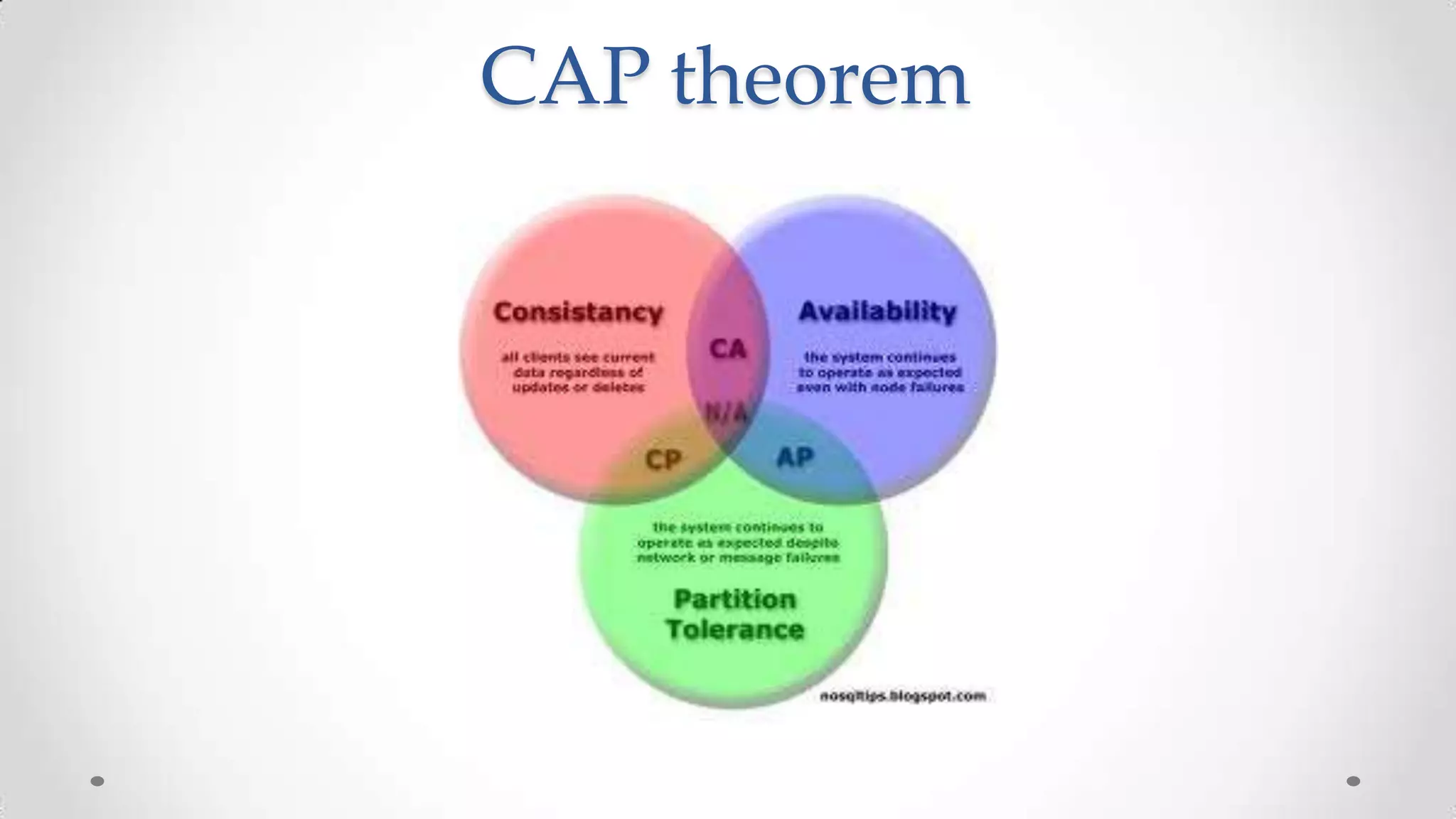
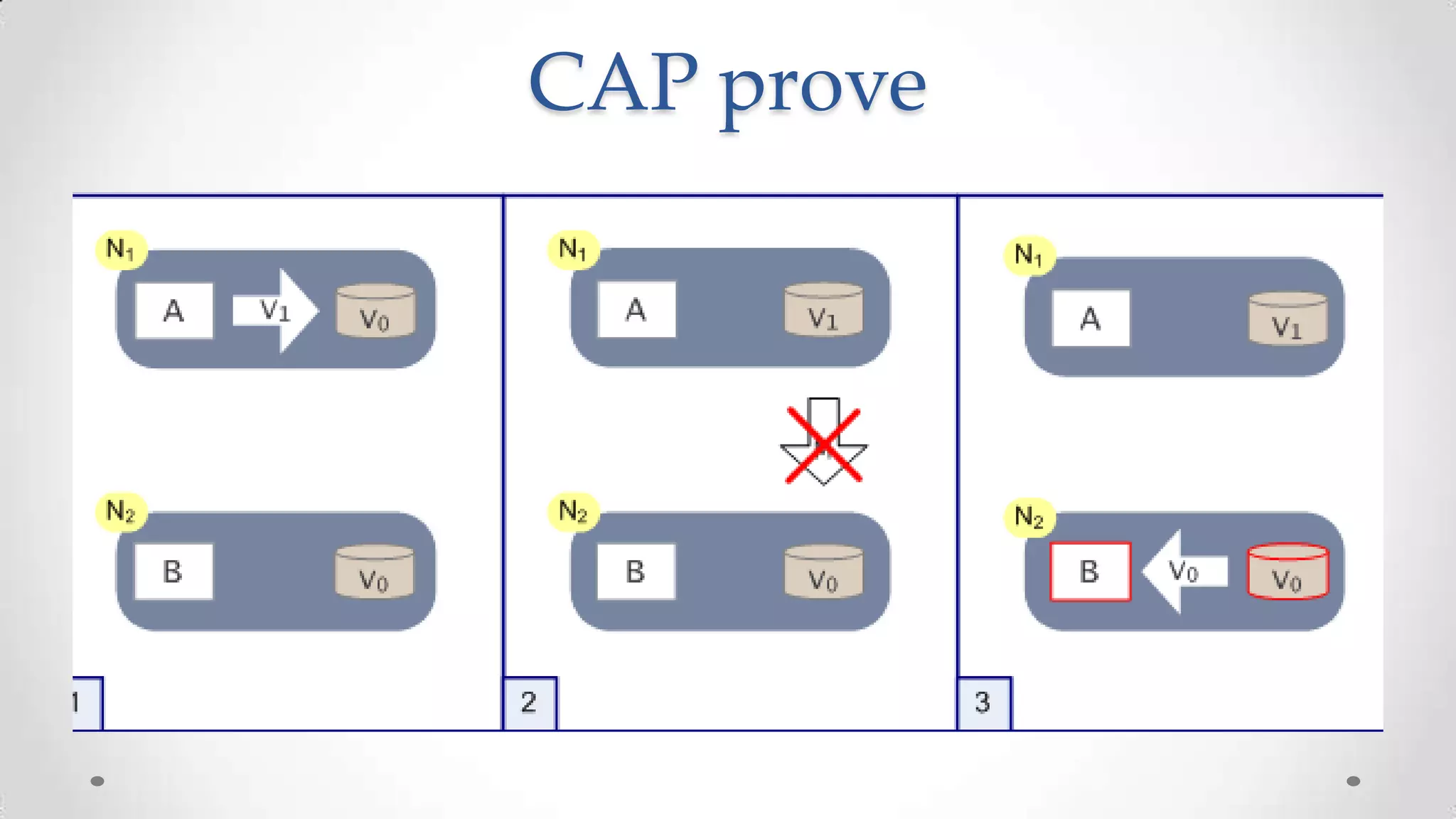
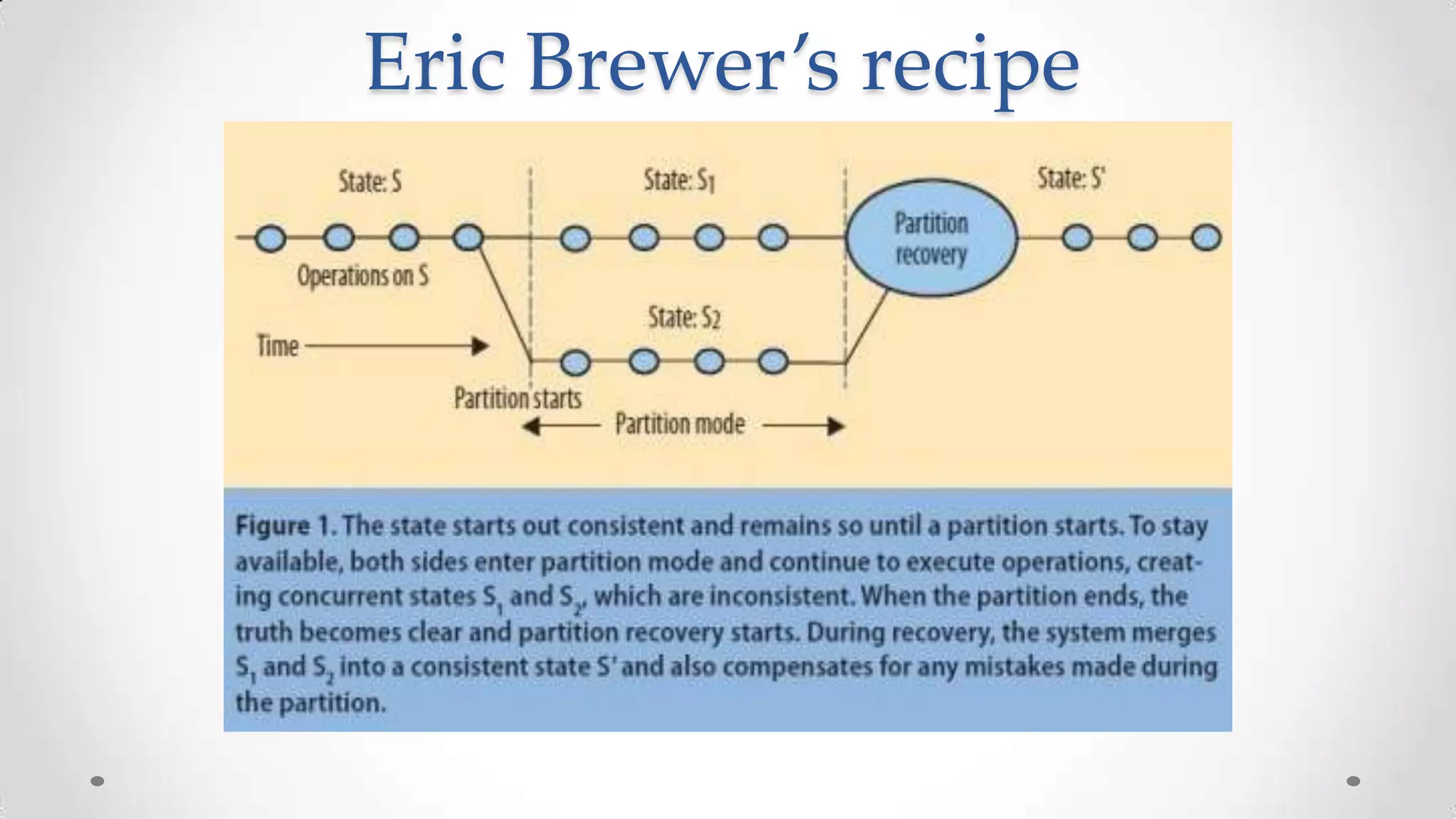
The document outlines the concepts and principles of distributed systems, highlighting their need for scalability, reliability, and cost-efficiency. It discusses various types of distributed systems, such as cluster and grid computing, and addresses key challenges like fault tolerance and consistency issues, including the CAP theorem. Additionally, it covers design principles and strategies for redundancy, replication, and sharding to enhance performance and ensure data integrity.





































































































