


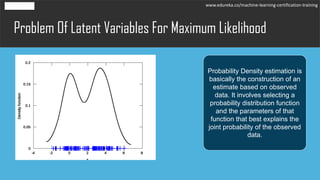





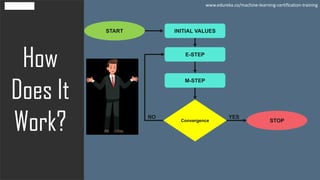

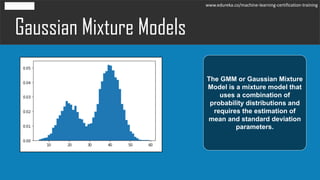













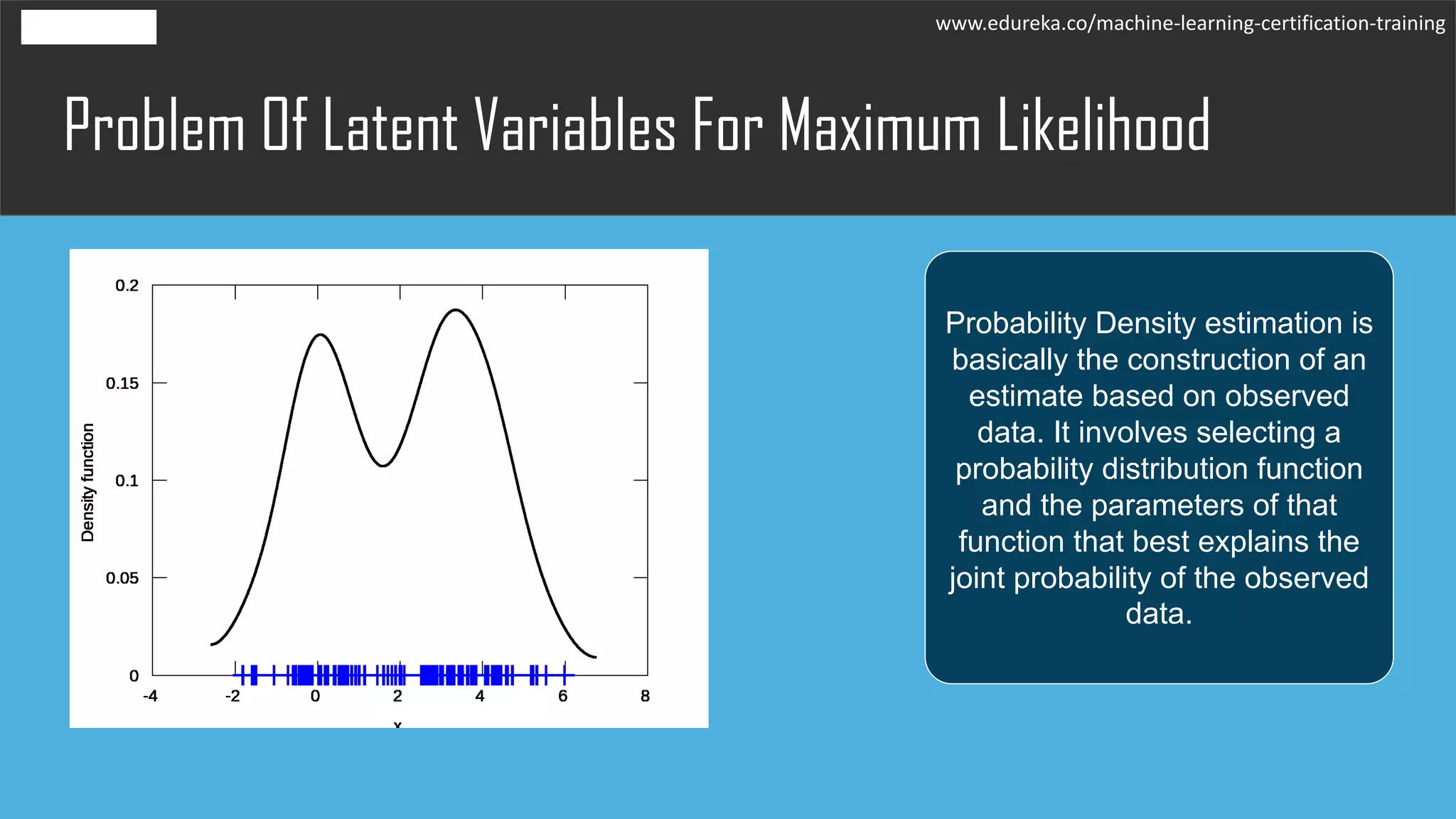





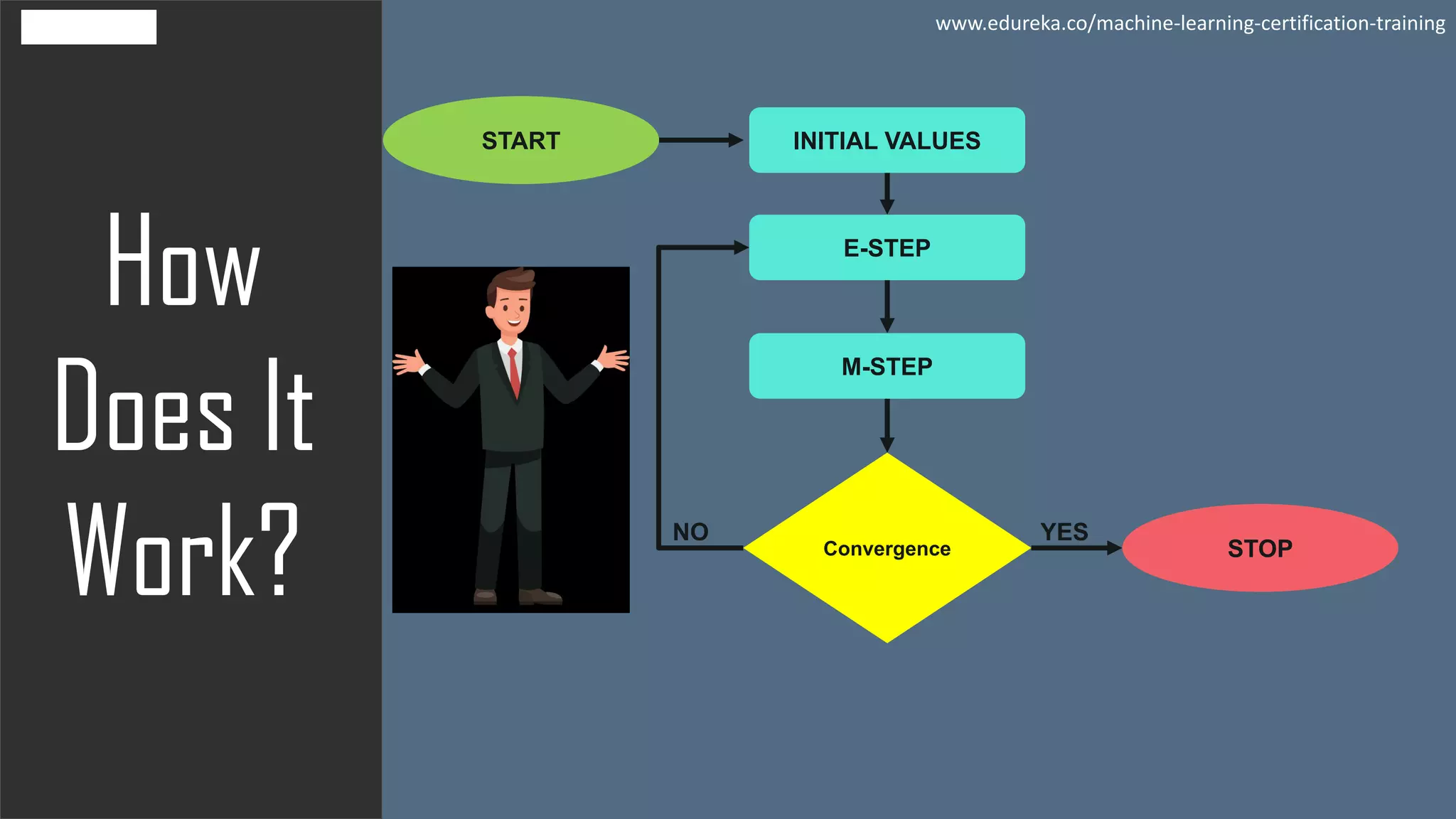

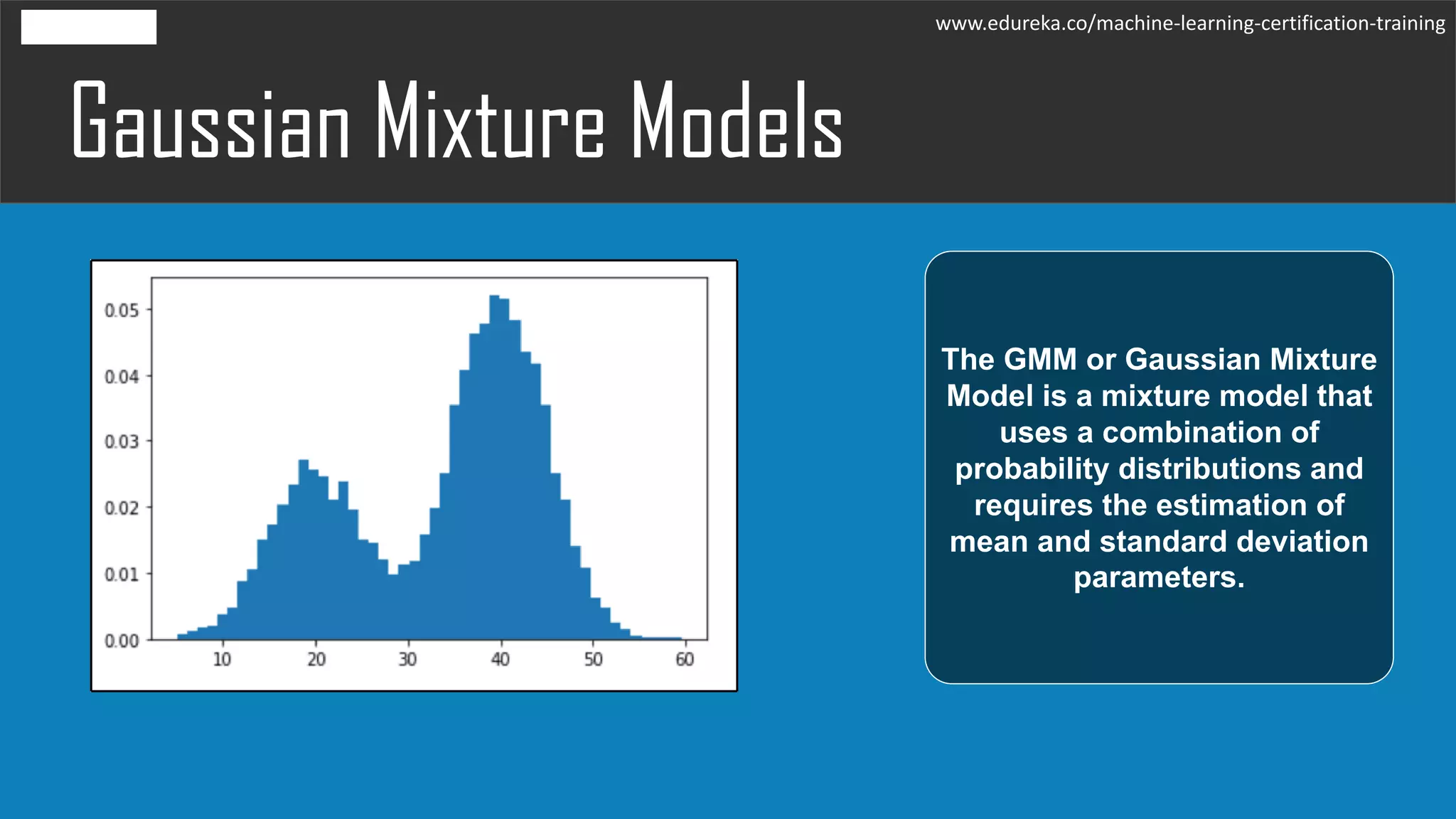










The document discusses the Expectation-Maximization (EM) algorithm in machine learning, particularly in relation to latent variables and the Gaussian Mixture Model (GMM). It outlines how the algorithm works, highlighting its advantages such as guaranteed likelihood increase and ease of M-step solutions, as well as disadvantages like slow convergence and susceptibility to local optima. Additionally, it covers the role of probability density estimation in analyzing observed data.












































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



