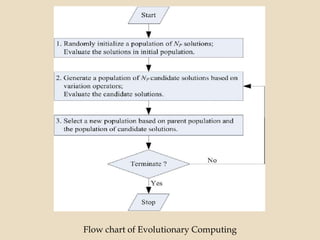
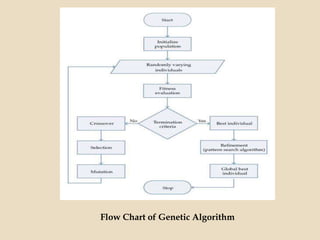
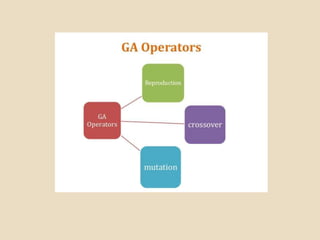
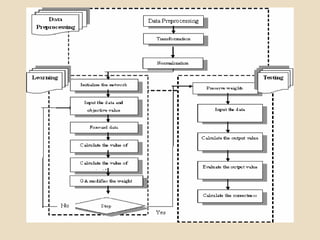
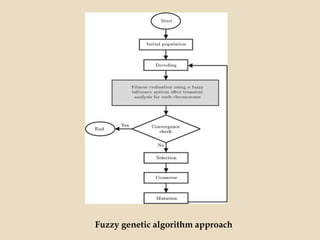
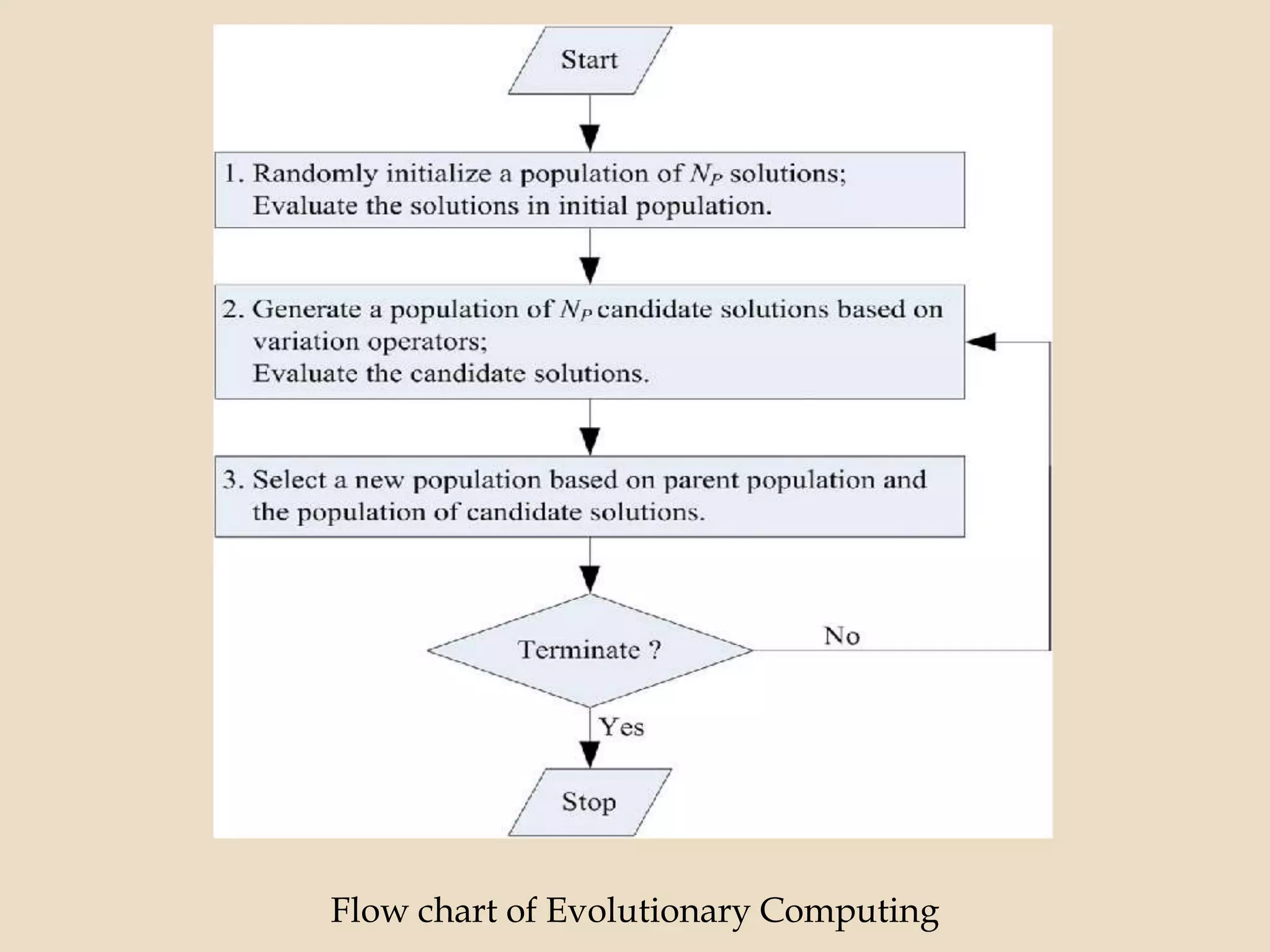
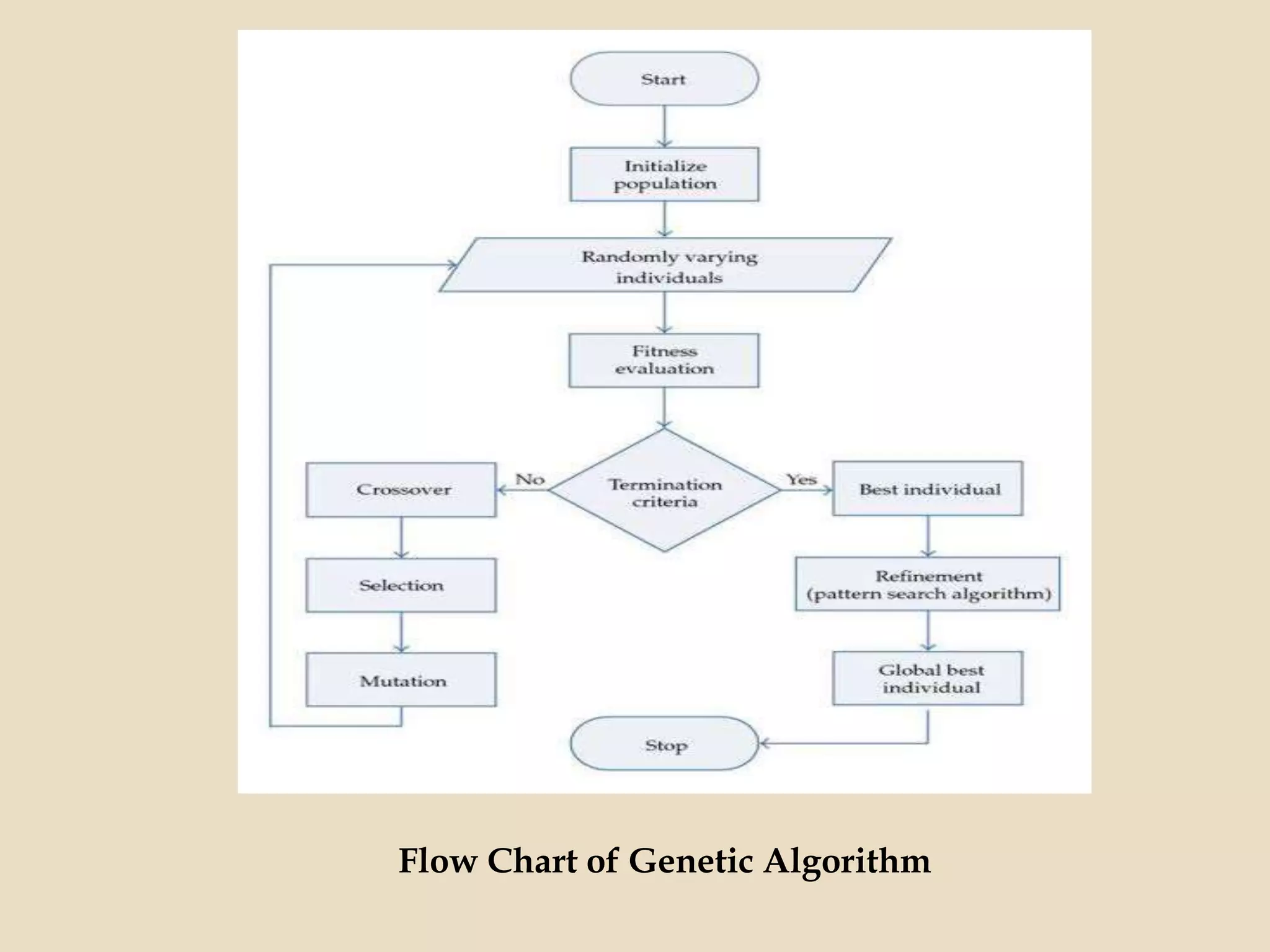
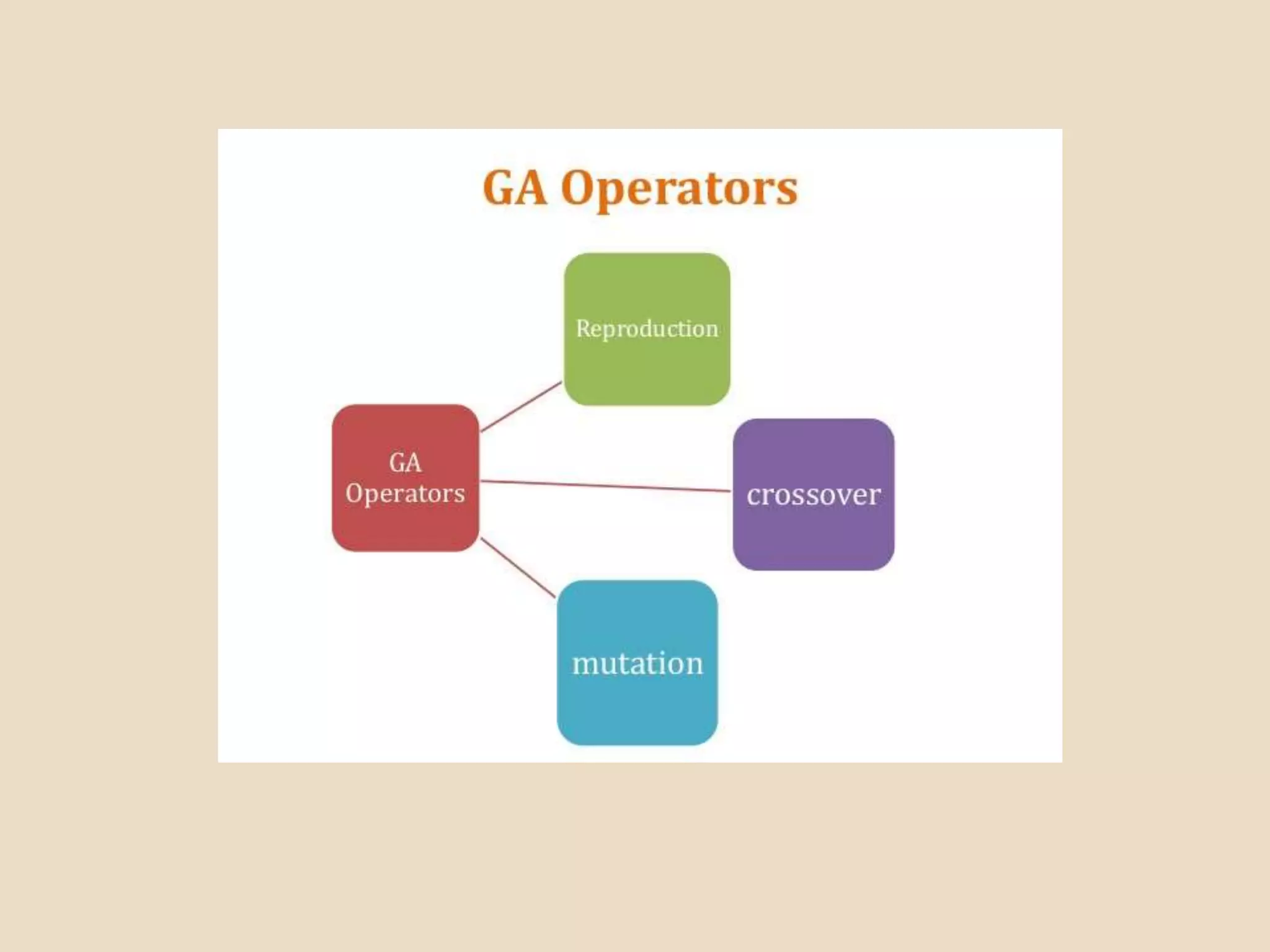
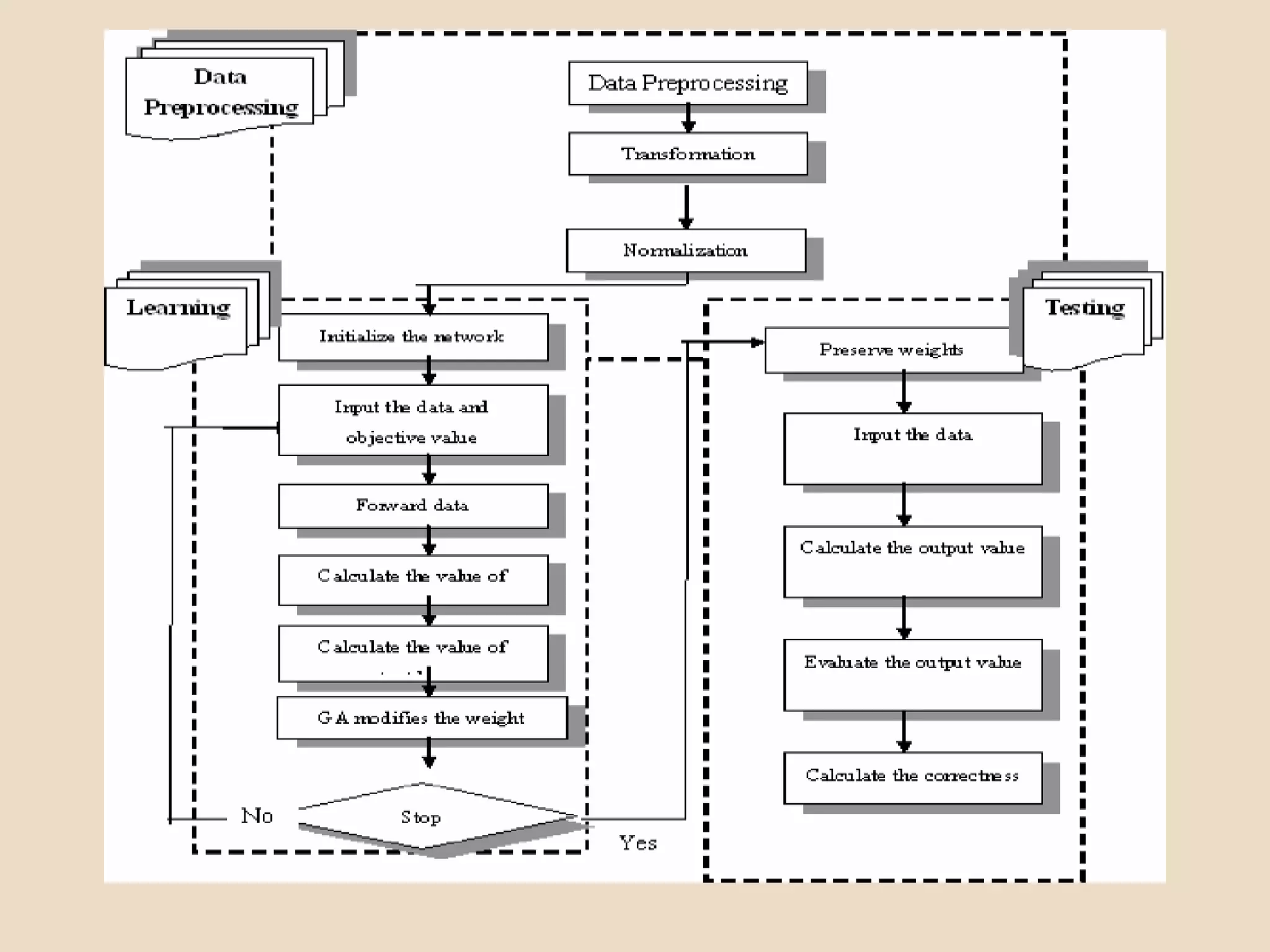
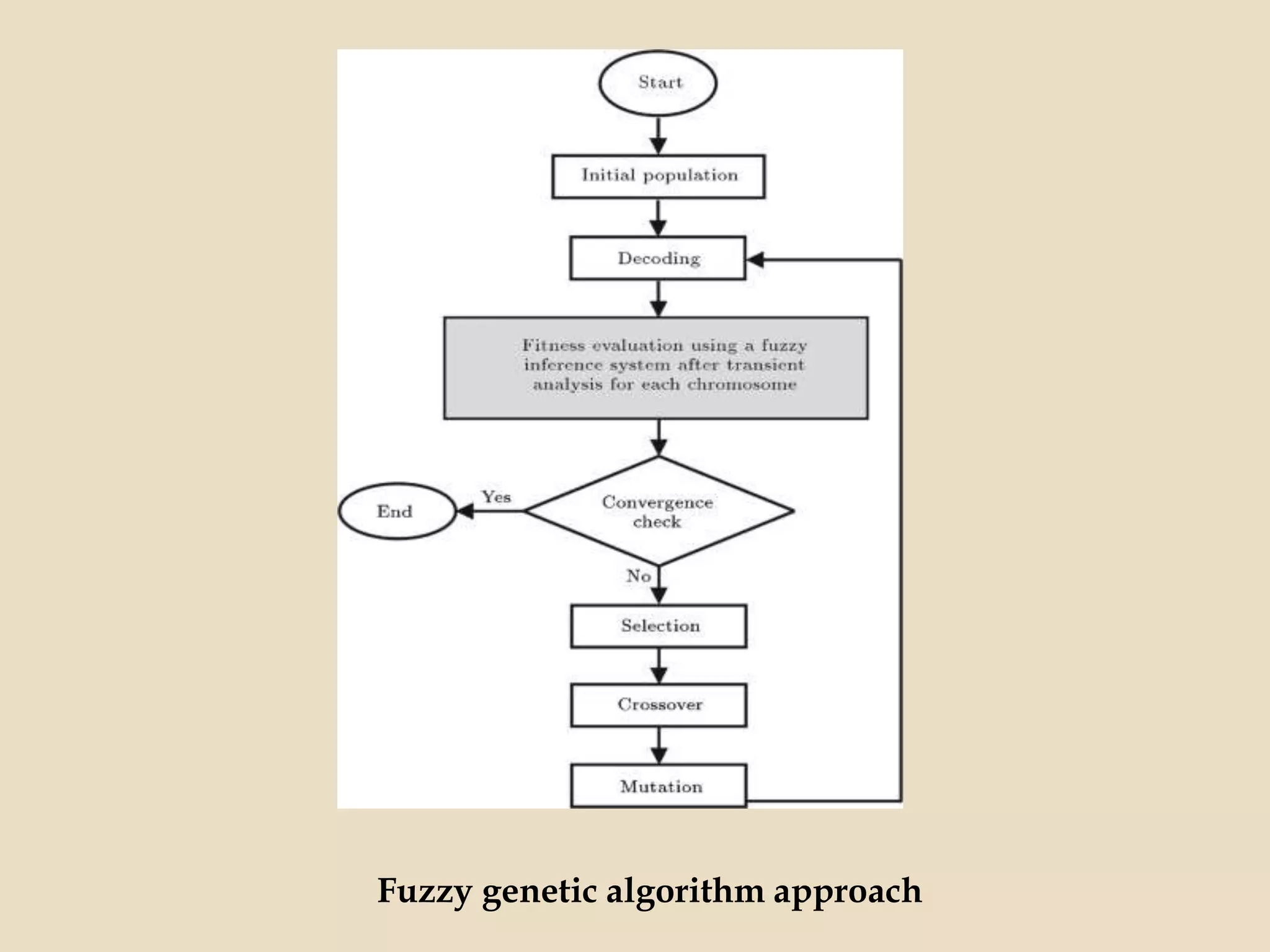
Evolutionary computing is a branch of computer science inspired by natural evolution, utilizing trial-and-error methods for problem-solving and producing optimized solutions across various domains. Genetic algorithms, as a key technique in evolutionary computation, involve creating populations of potential solutions, where operators such as mutation, crossover, and selection drive the evolution towards better solutions. The document also discusses the integration of genetic algorithms with neural networks and fuzzy systems to improve optimization and function approximation tasks.