Downloaded 48 times






![Iterative PageRank in Python
def pageRank(G, s = .85, maxerr = .001):
n = G.shape[0]
# transform G into markov matrix M
M = csc_matrix(G,dtype=np.float)
rsums = np.array(M.sum(1))[:,0]
ri, ci = M.nonzero()
M.data /= rsums[ri]
sink = rsums==0 # bool array of sink states
# Compute pagerank r until we converge
ro, r = np.zeros(n), np.ones(n)
while np.sum(np.abs(r-ro)) > maxerr:
ro = r.copy()
for i in xrange(0,n):
Ii = np.array(M[:,i].todense())[:,0] # inlinks of state i
Si = sink / float(n) # account for sink states
Ti = np.ones(n) / float(n) # account for teleportation
r[i] = ro.dot( Ii*s + Si*s + Ti*(1-s) )
return r/sum(r) # return normalized pagerank](https://image.slidesharecdn.com/graph-basedanalysisofrelationaldata-presentation-150507161658-lva1-app6892/85/Graph-Based-Machine-Learning-on-Relational-Data-8-320.jpg)
![Graph-Based PageRank in Gremlin
pagerank = [:].withDefault{0}
size = uris.size();
uris.each{
count = it.outE.count();
if(count == 0 || rand.nextDouble() > 0.85) {
rank = pagerank[it]
uris.each {
pagerank[it] = pagerank[it] / uris.size()
}
}
rank = pagerank[it] / it.outE.count();
it.out.each{
pagerank[it] = pagerank[it] + rank;
}
}](https://image.slidesharecdn.com/graph-basedanalysisofrelationaldata-presentation-150507161658-lva1-app6892/85/Graph-Based-Machine-Learning-on-Relational-Data-9-320.jpg)
























![Iterative PageRank in Python
def pageRank(G, s = .85, maxerr = .001):
n = G.shape[0]
# transform G into markov matrix M
M = csc_matrix(G,dtype=np.float)
rsums = np.array(M.sum(1))[:,0]
ri, ci = M.nonzero()
M.data /= rsums[ri]
sink = rsums==0 # bool array of sink states
# Compute pagerank r until we converge
ro, r = np.zeros(n), np.ones(n)
while np.sum(np.abs(r-ro)) > maxerr:
ro = r.copy()
for i in xrange(0,n):
Ii = np.array(M[:,i].todense())[:,0] # inlinks of state i
Si = sink / float(n) # account for sink states
Ti = np.ones(n) / float(n) # account for teleportation
r[i] = ro.dot( Ii*s + Si*s + Ti*(1-s) )
return r/sum(r) # return normalized pagerank](https://image.slidesharecdn.com/graph-basedanalysisofrelationaldata-presentation-150507161658-lva1-app6892/75/Graph-Based-Machine-Learning-on-Relational-Data-8-2048.jpg)
![Graph-Based PageRank in Gremlin
pagerank = [:].withDefault{0}
size = uris.size();
uris.each{
count = it.outE.count();
if(count == 0 || rand.nextDouble() > 0.85) {
rank = pagerank[it]
uris.each {
pagerank[it] = pagerank[it] / uris.size()
}
}
rank = pagerank[it] / it.outE.count();
it.out.each{
pagerank[it] = pagerank[it] + rank;
}
}](https://image.slidesharecdn.com/graph-basedanalysisofrelationaldata-presentation-150507161658-lva1-app6892/75/Graph-Based-Machine-Learning-on-Relational-Data-9-2048.jpg)









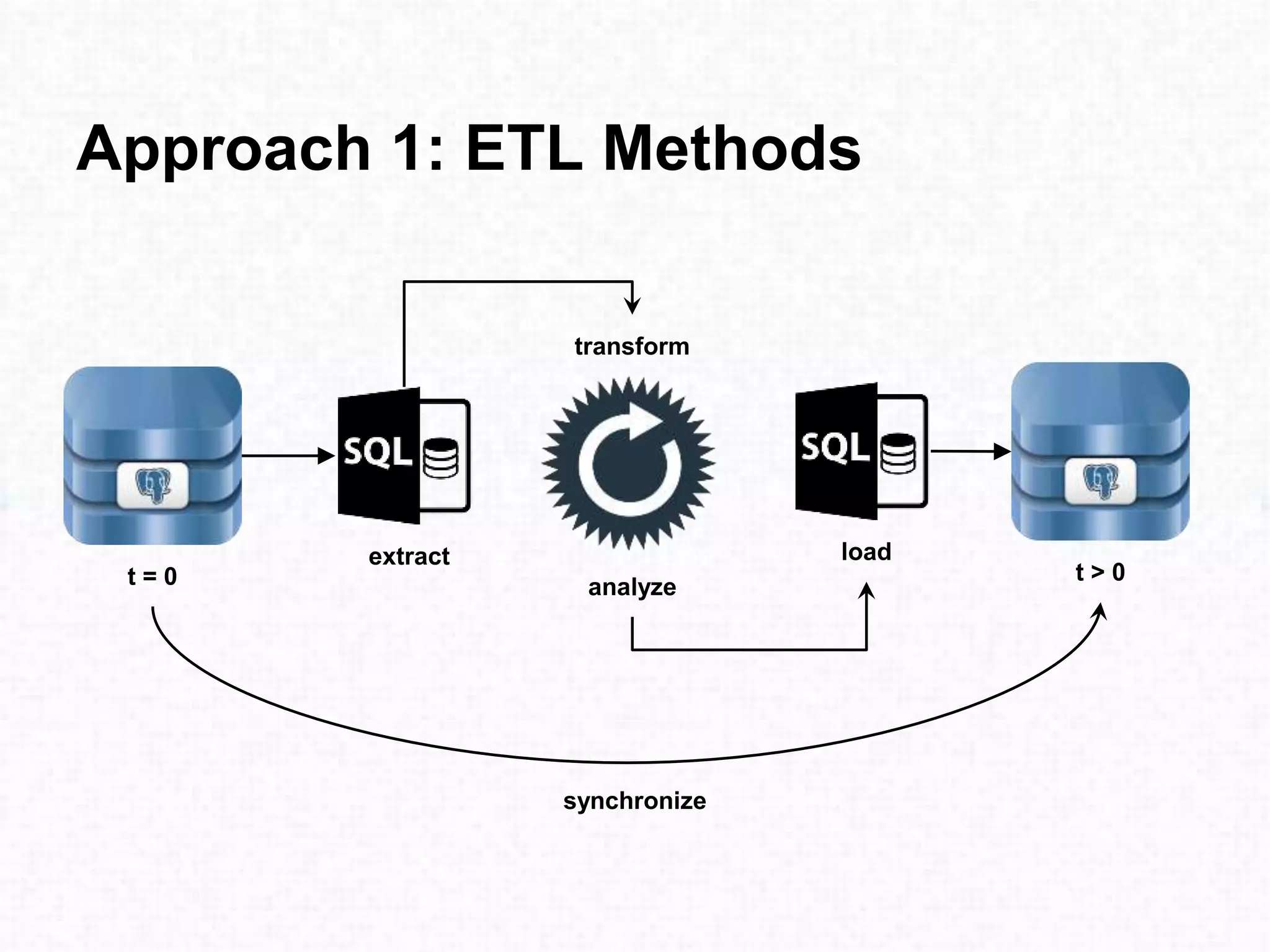





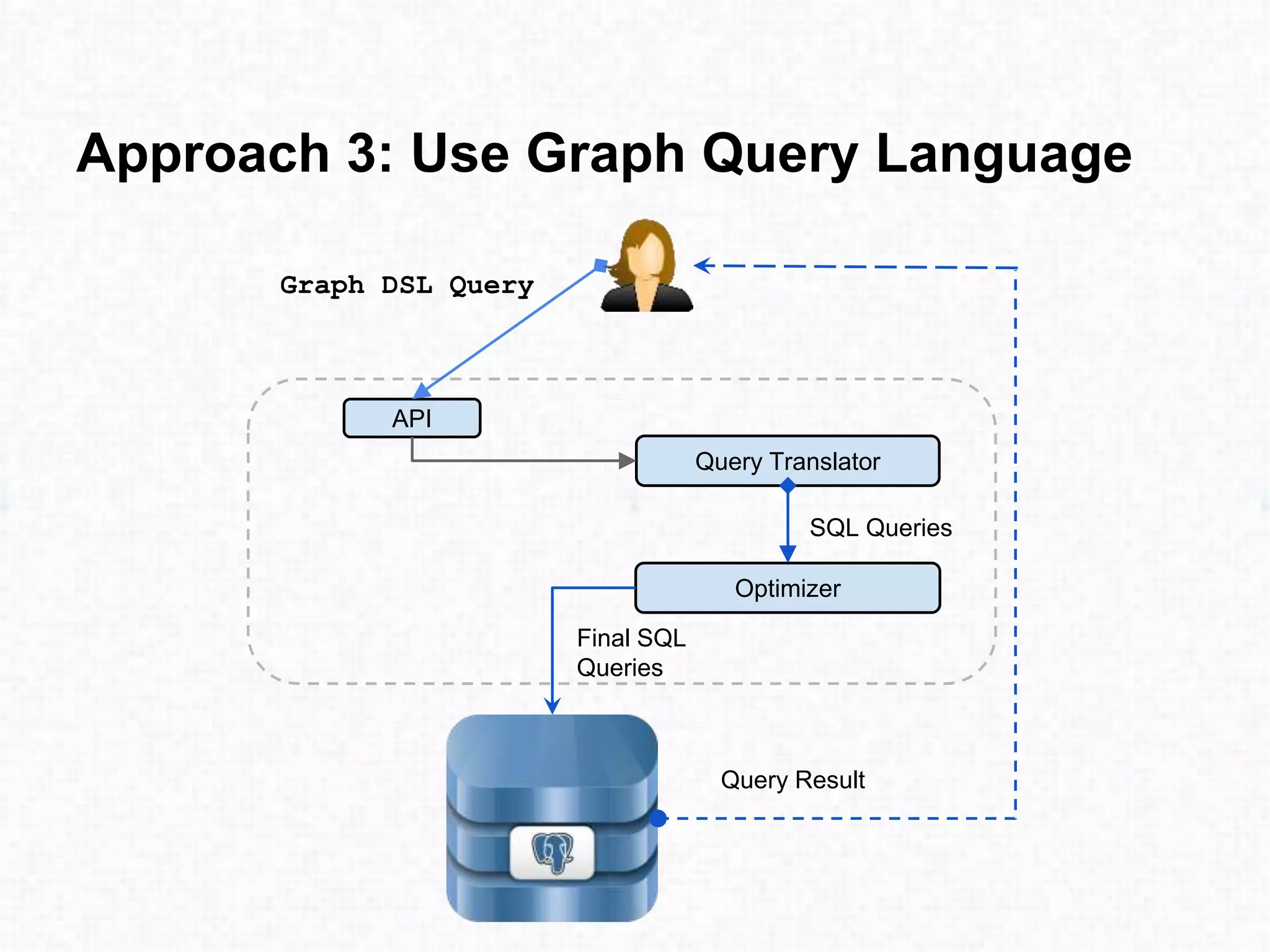





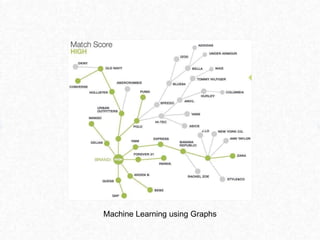
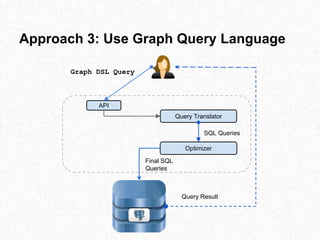
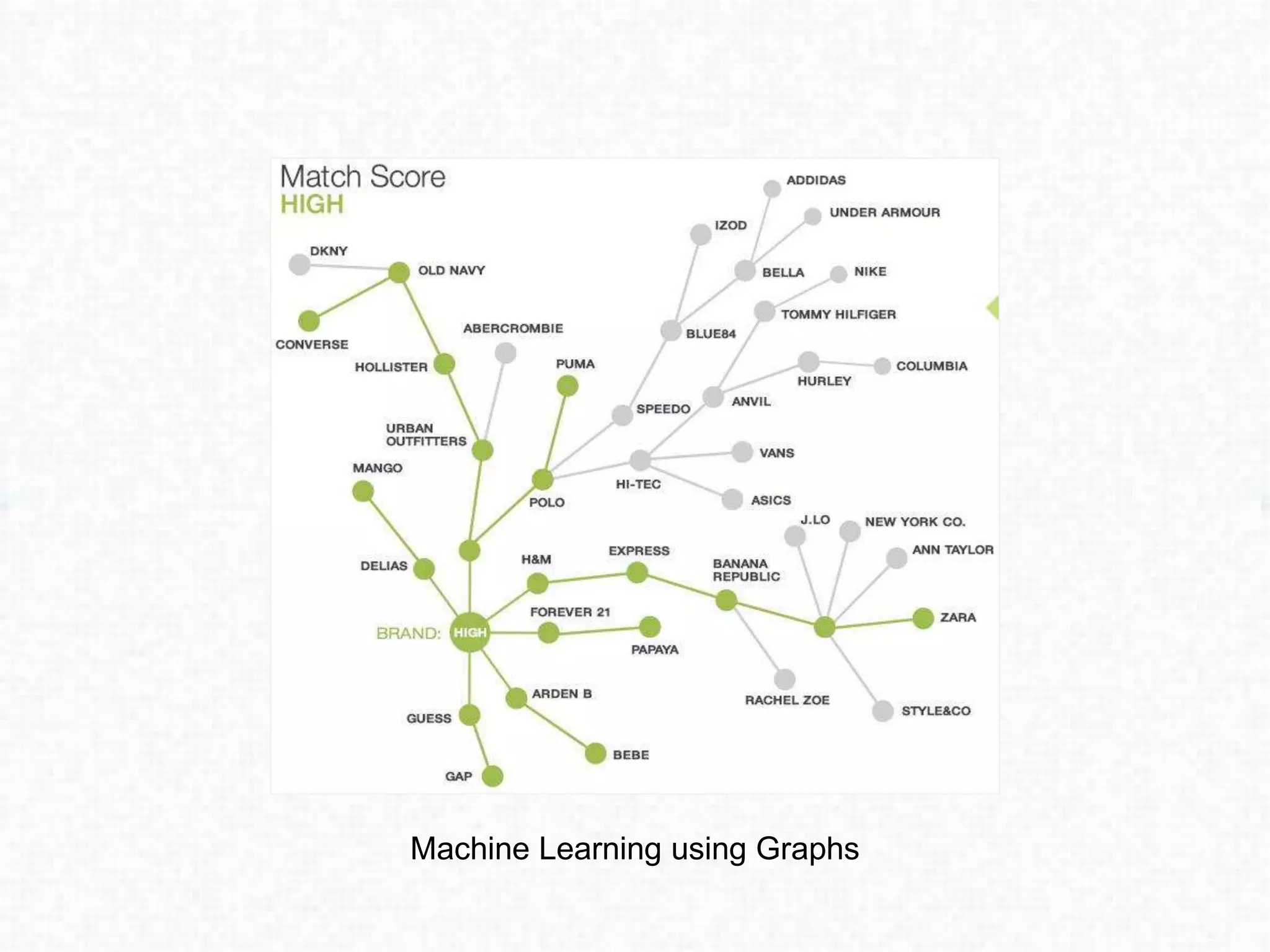
This document discusses approaches for performing machine learning on graph-structured relational data stored in databases. It describes how machine learning is iterative like graph traversal. Common domains like healthcare and finance can be modeled as graphs stored in databases. Three approaches are described: 1) extract-transform-load methods to synchronize an external analytics system with the database, 2) storing the graph natively in the database, and 3) using a graph query language to translate queries to the database. Each approach has advantages and disadvantages regarding performance, ability to leverage the database, and flexibility to explore graph structures in the data.












































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










