Download as PDF, PPTX













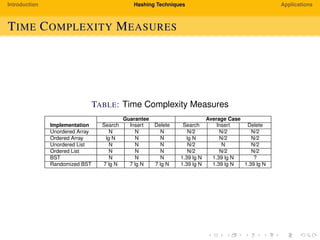





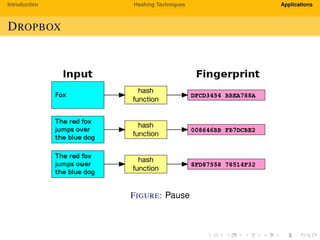

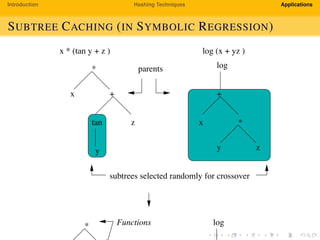












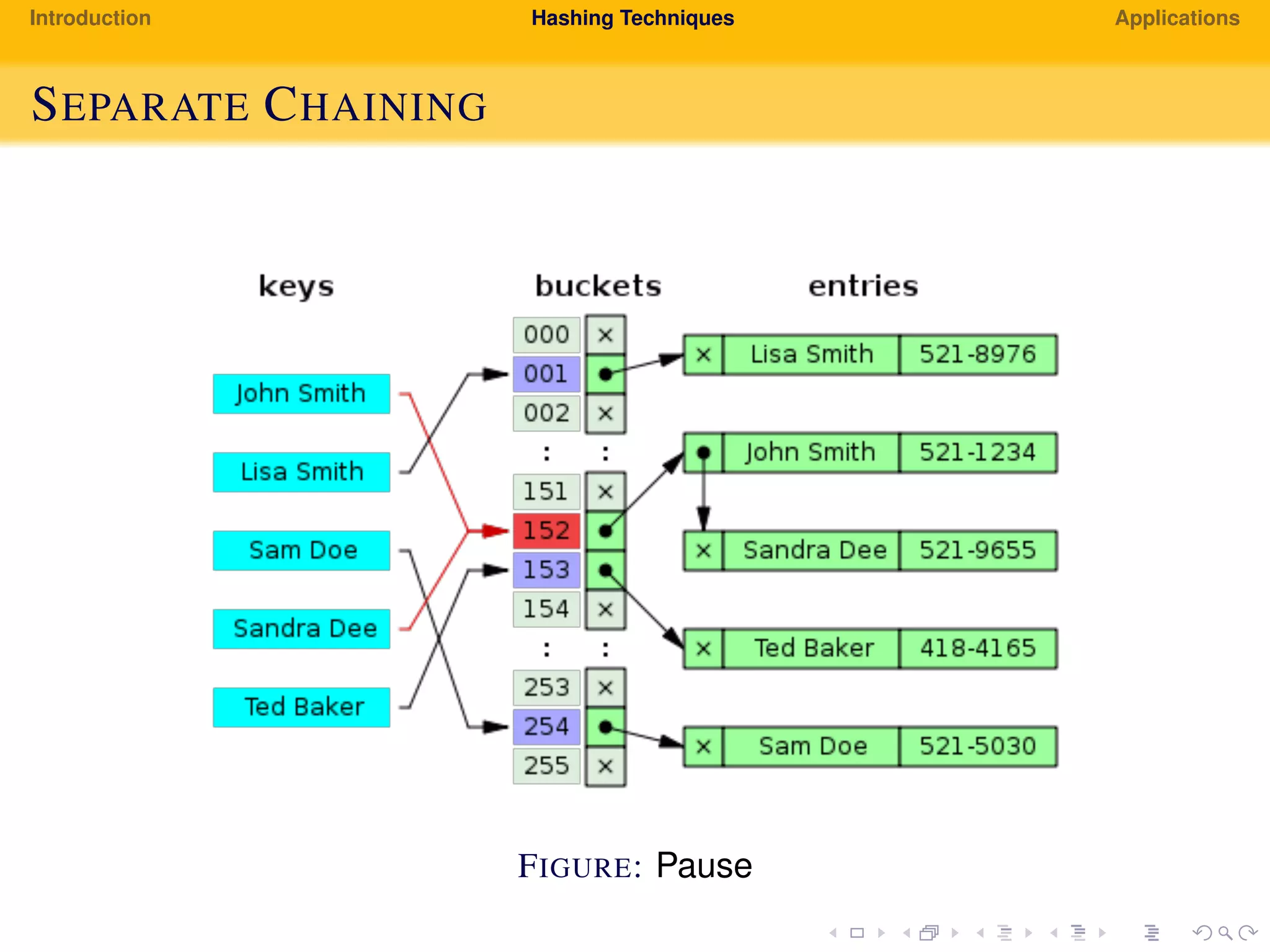


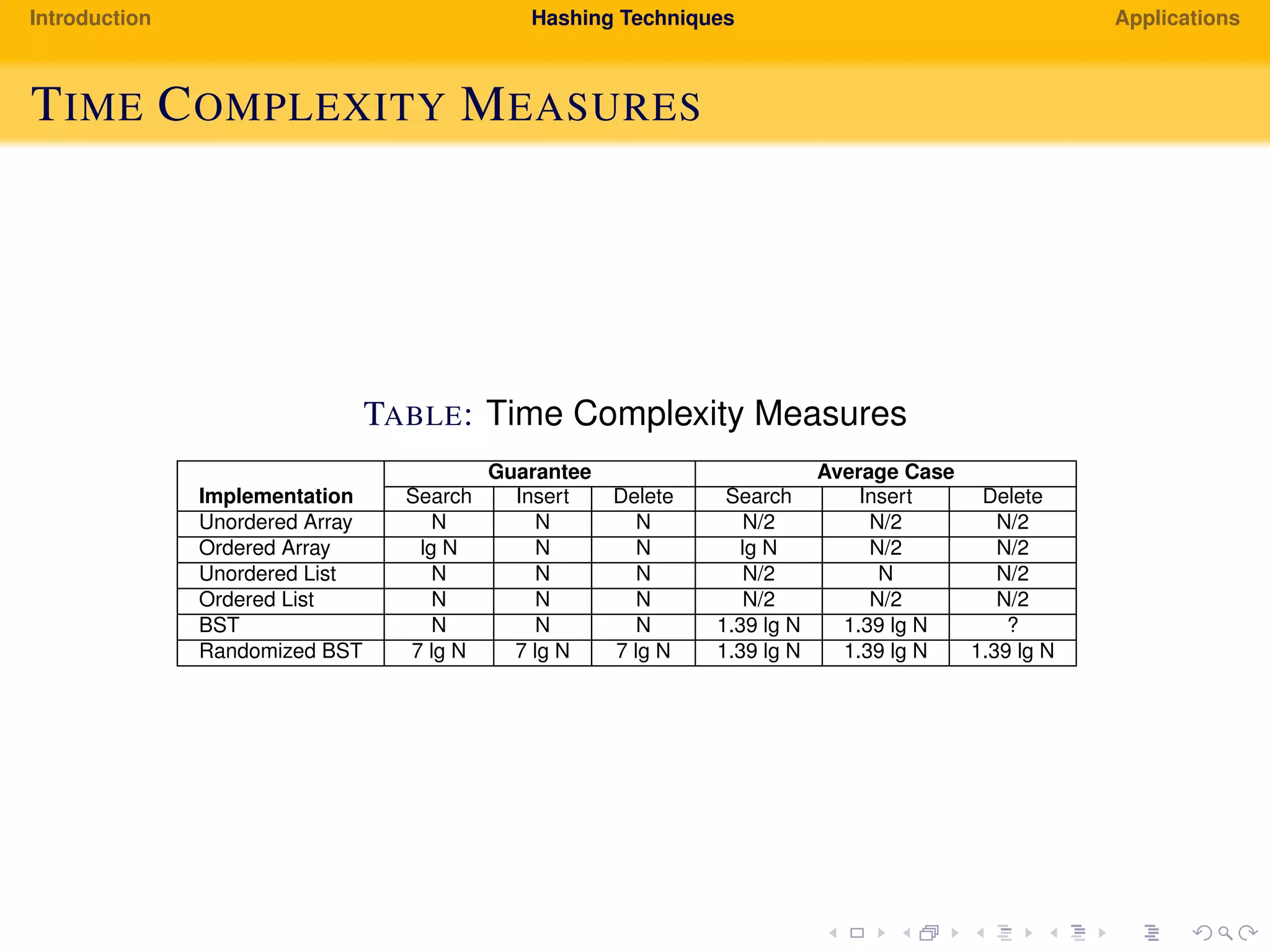





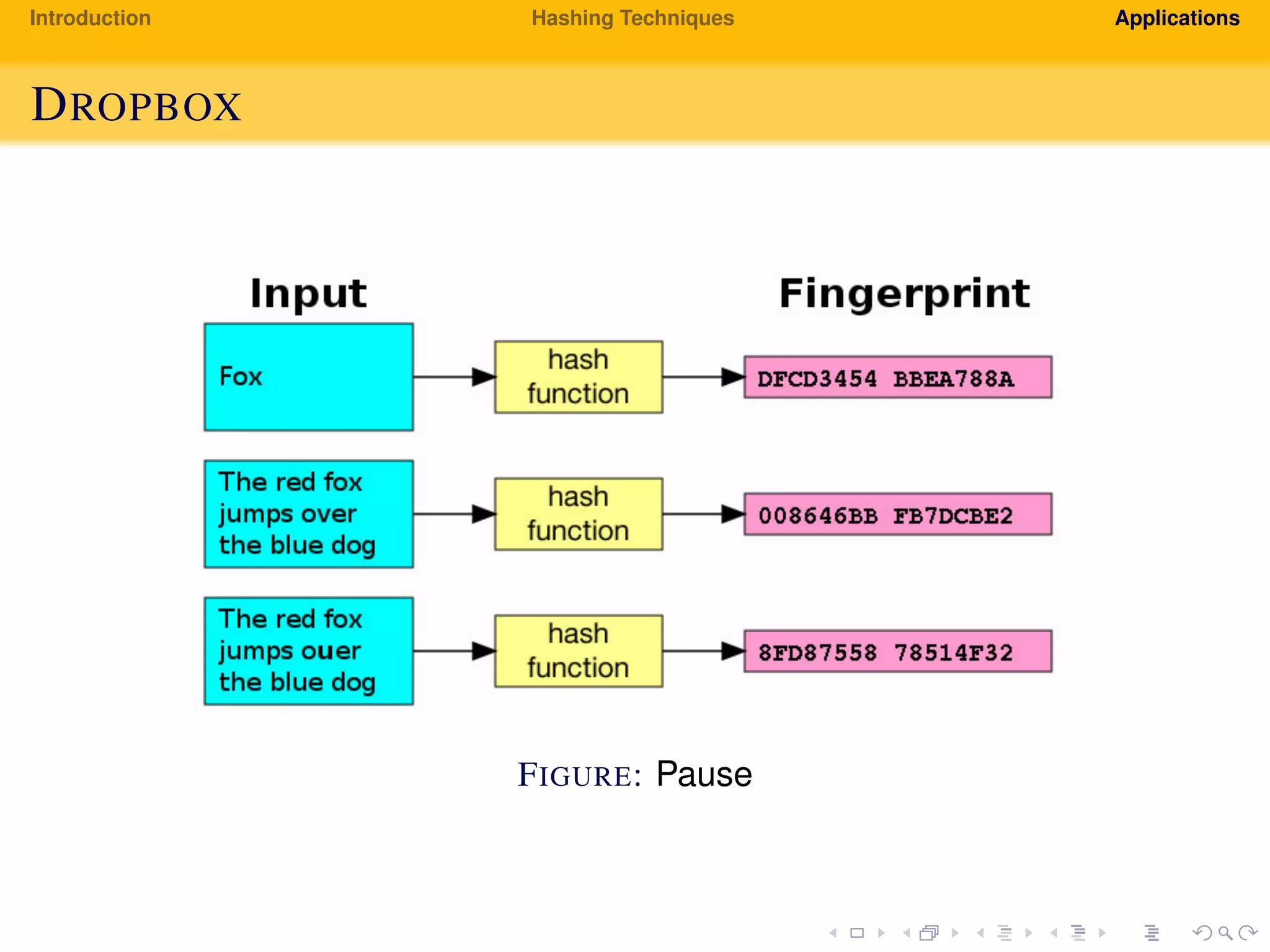

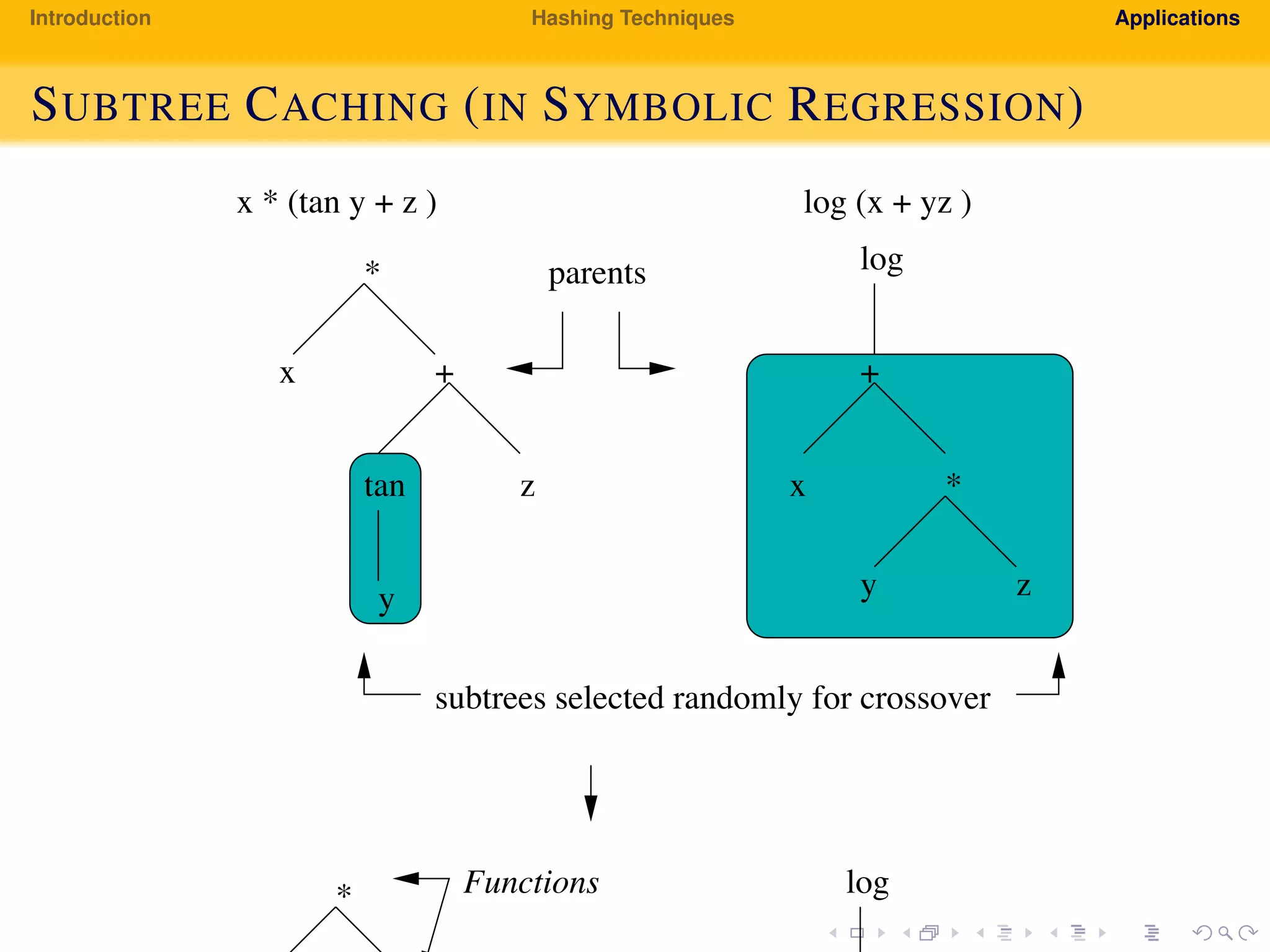



The document provides an introduction to hashing techniques and their applications. It discusses hashing as a technique to distribute dataset entries across an array of buckets using a hash function. It then describes various hashing techniques like separate chaining and open addressing to resolve collisions. Some applications discussed include how Dropbox uses hashing to check for copyrighted content sharing and how subtree caching is used in symbolic regression.






















![Data Structures - Lecture 10 [Graphs]](https://cdn.slidesharecdn.com/ss_thumbnails/datastructures-lecture10graphs-150305004608-conversion-gate01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















































































