Downloaded 213 times








































































The document discusses hierarchical clustering techniques in Python, covering theory, practical applications, and relevant methodologies for data analysis. It highlights the importance of various clustering methods, metrics, and considerations for achieving efficient results, particularly in relation to search keyword analysis. Additionally, it emphasizes the role of visualization tools and the necessity of preprocessing data for effective clustering outcomes.
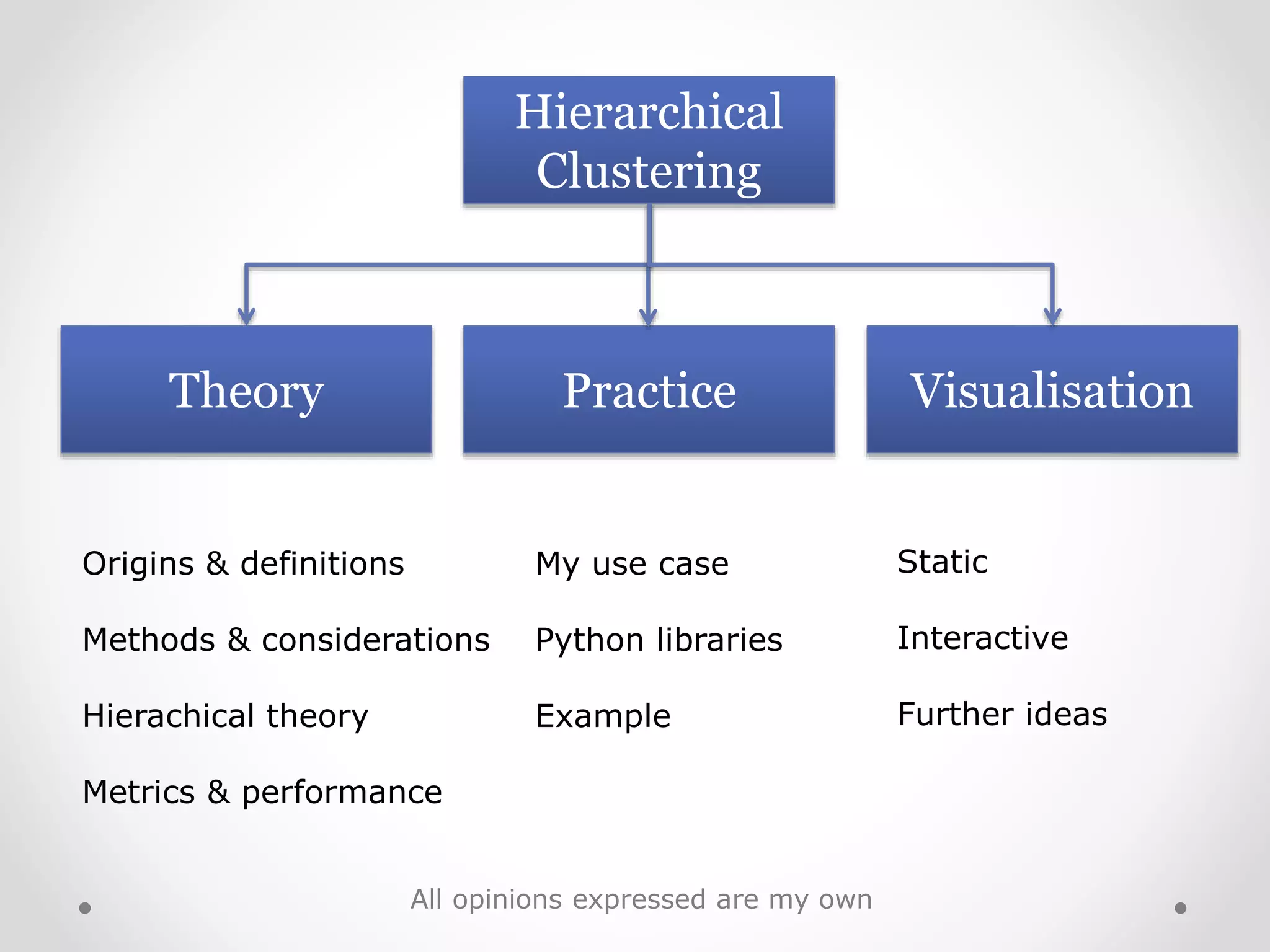
Overview of hierarchical clustering methods, theories, visualizations, and use cases.
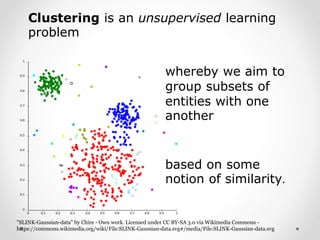
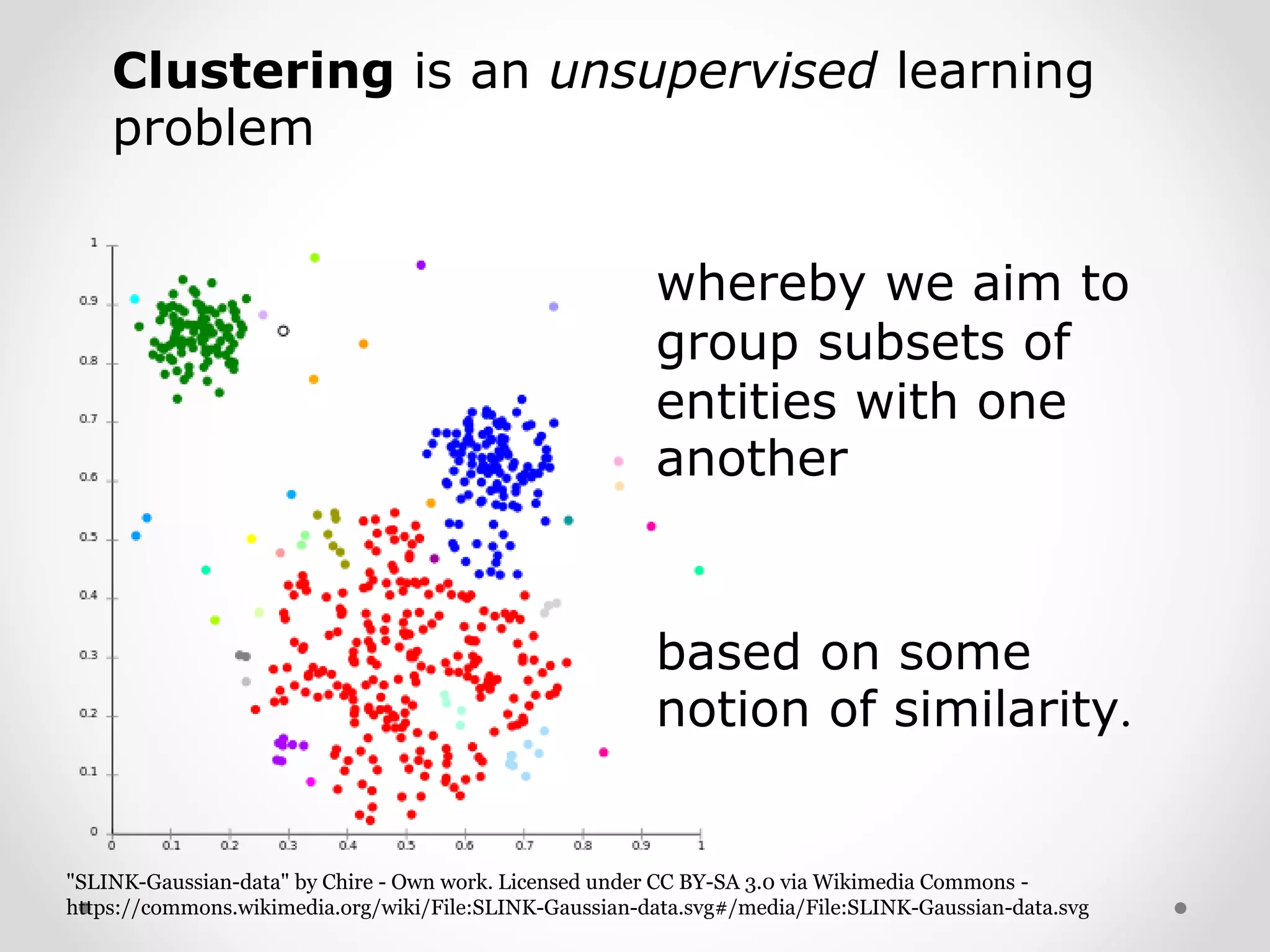
Clustering as an unsupervised learning tool to group similar entities based on data similarity.
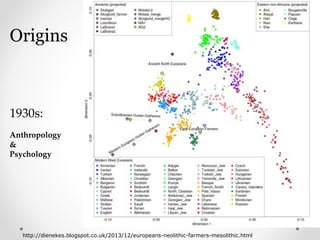
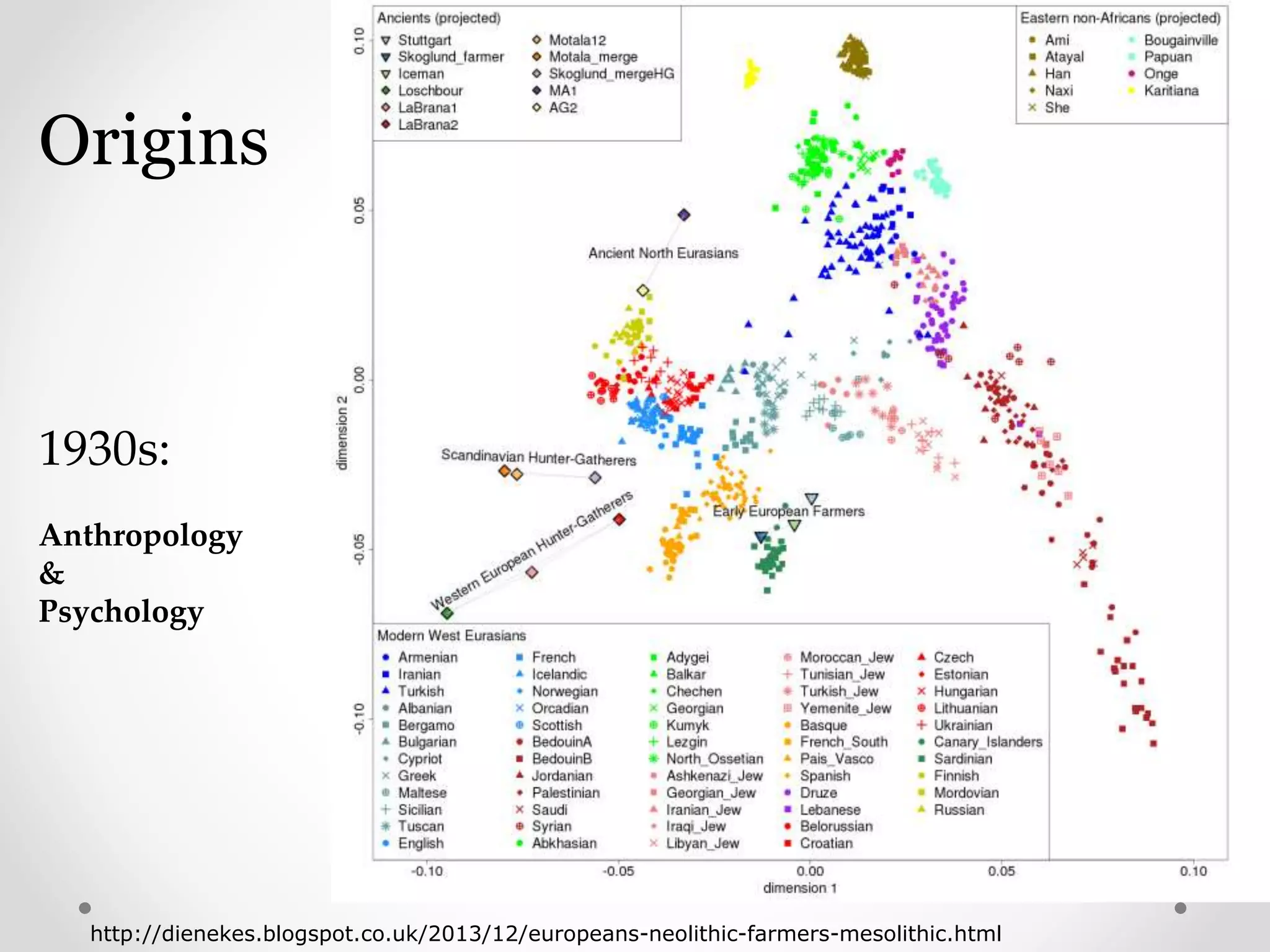
Origins of clustering in anthropology and psychology with diverse applications.
Clustering can be used for exploratory analysis and as part of supervised learning pipelines.
Important factors in clustering including criteria, space, separation types, and similarity measures.
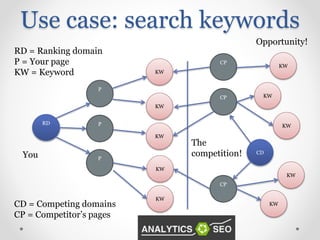
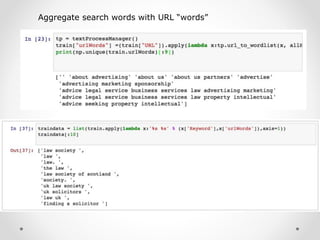
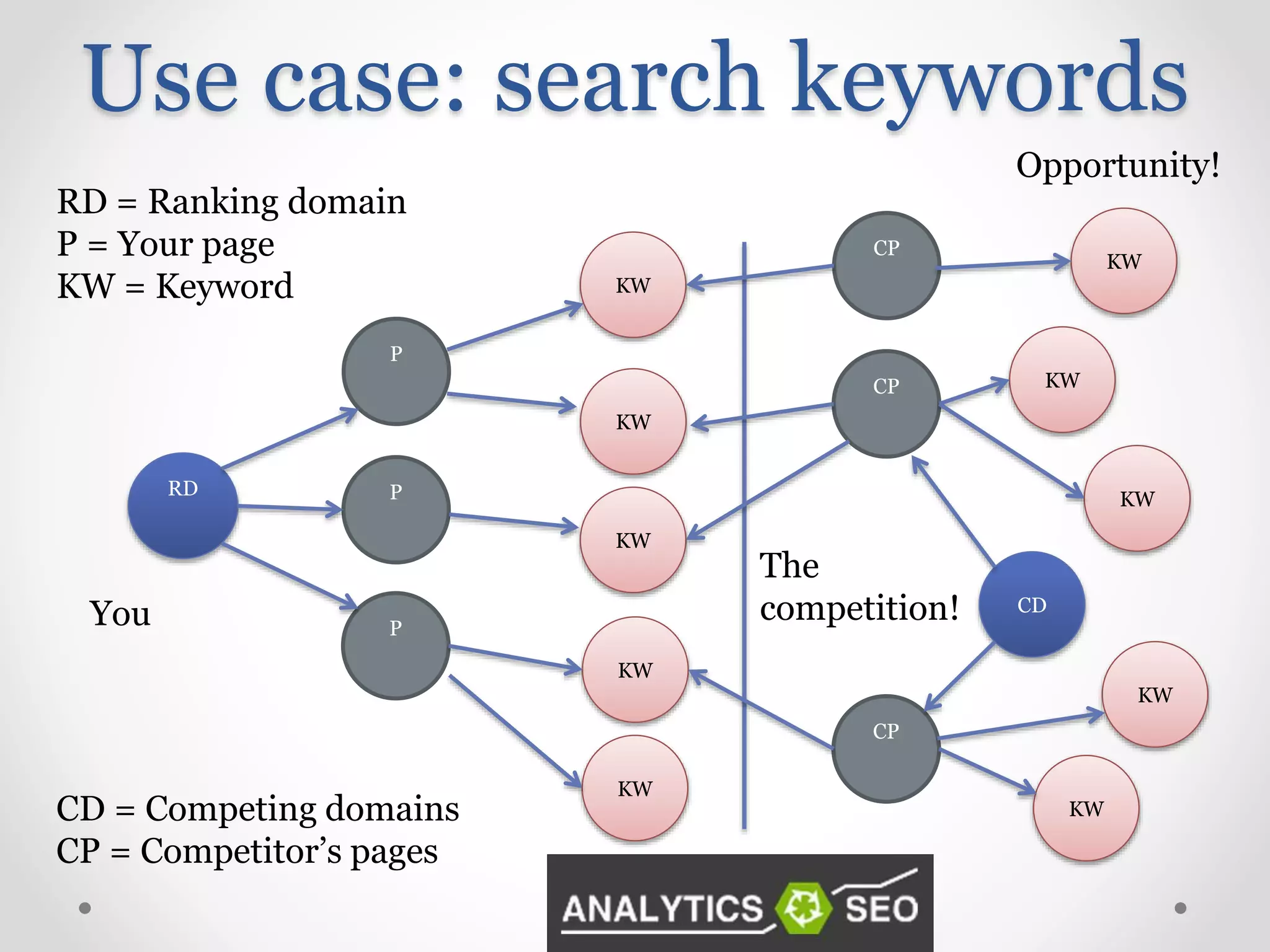
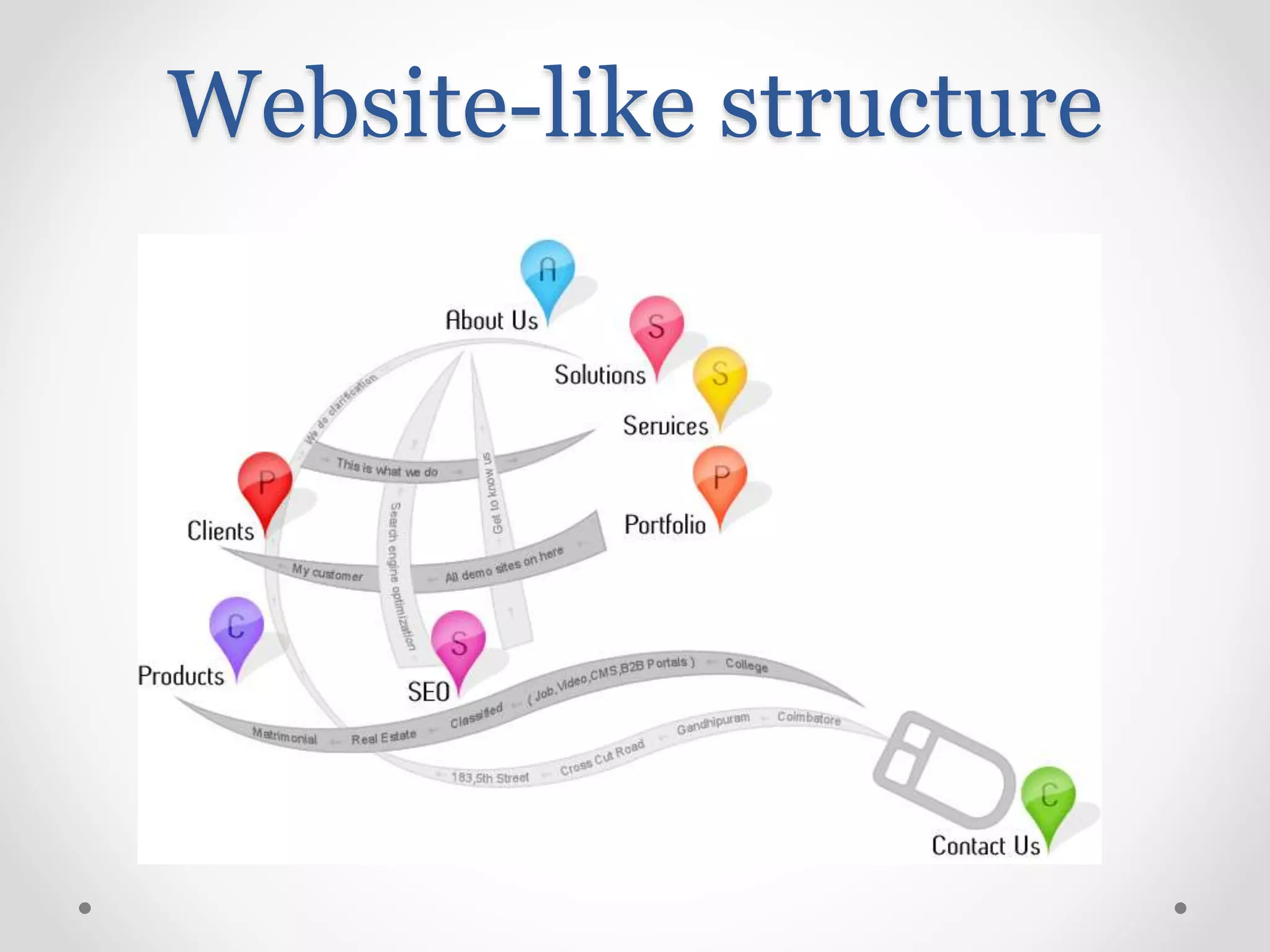
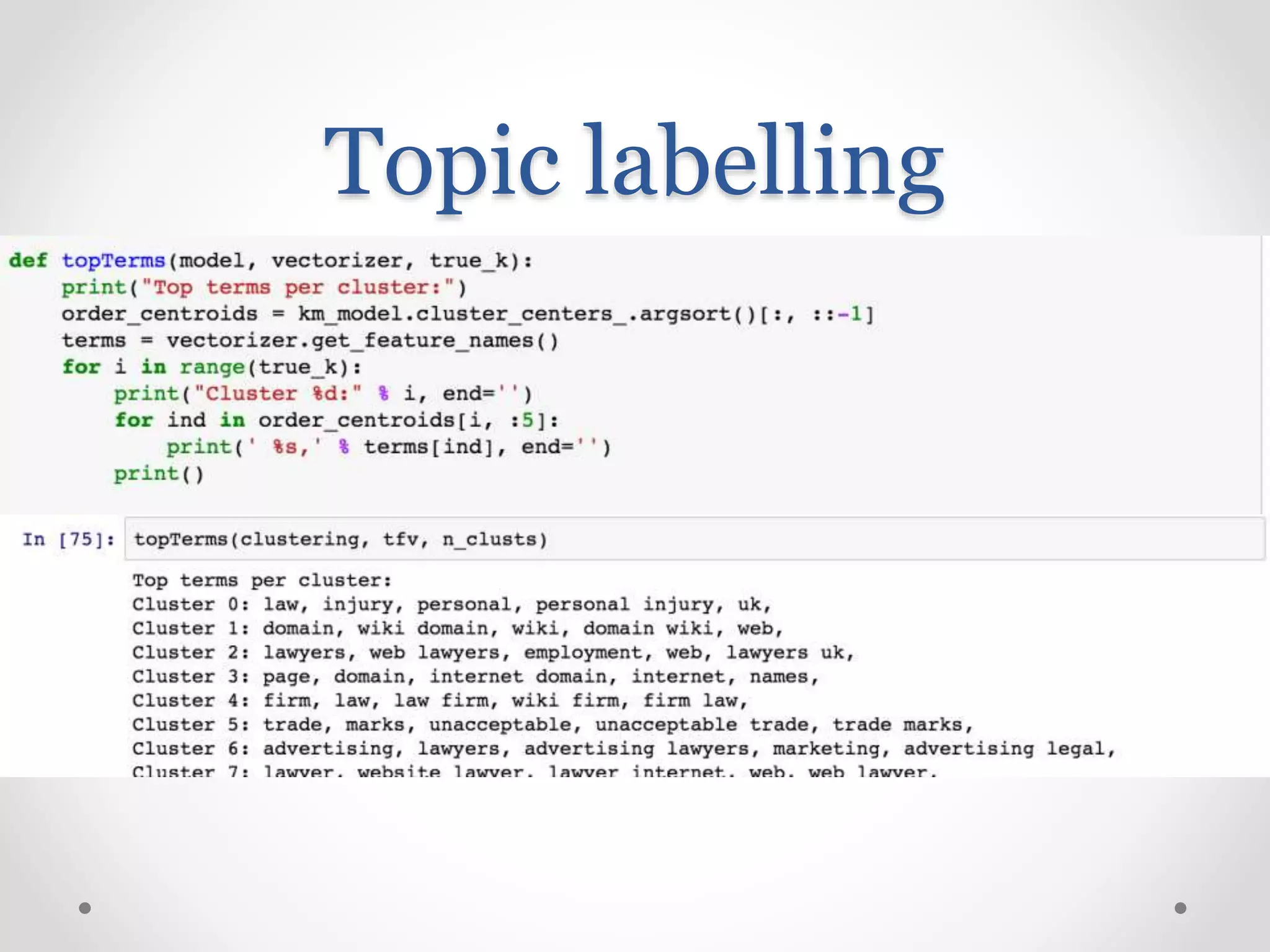
Exploration of clustering search keywords for better website alignment and opportunity identification.
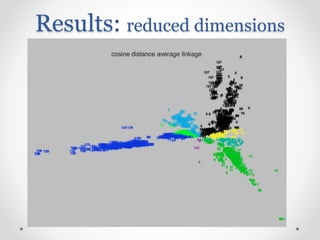
Need for visual insights in clustering high-dimensional data and recommended methods for text clustering.
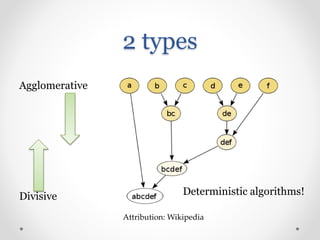
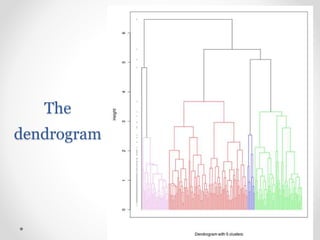
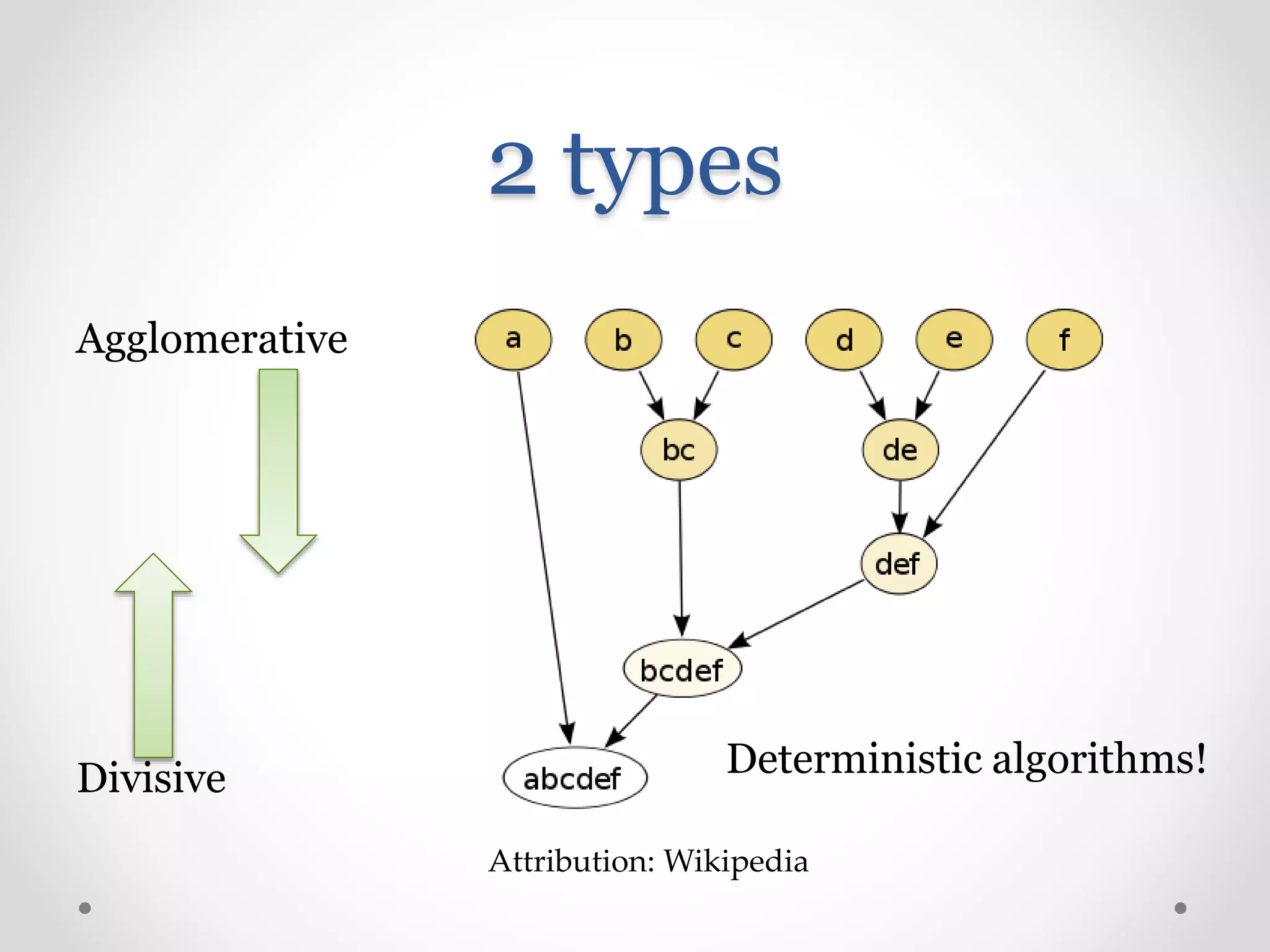
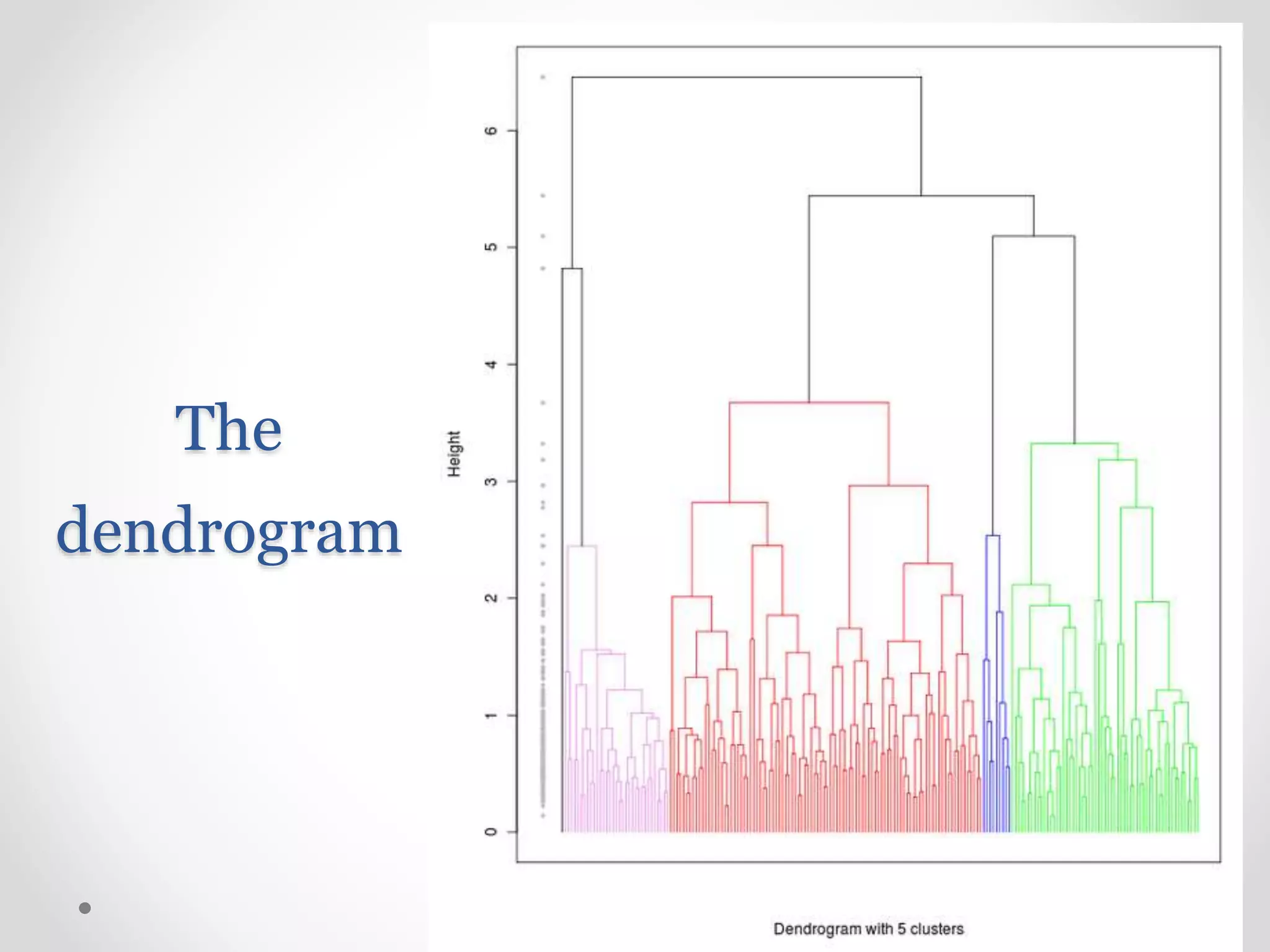
Introduction to agglomerative and divisive hierarchical clustering techniques.
Various linkage types in agglomerative clustering including single, complete, and Ward’s criterion.
Different measures of similarity used in clustering such as Euclidean and Cosine similarity.
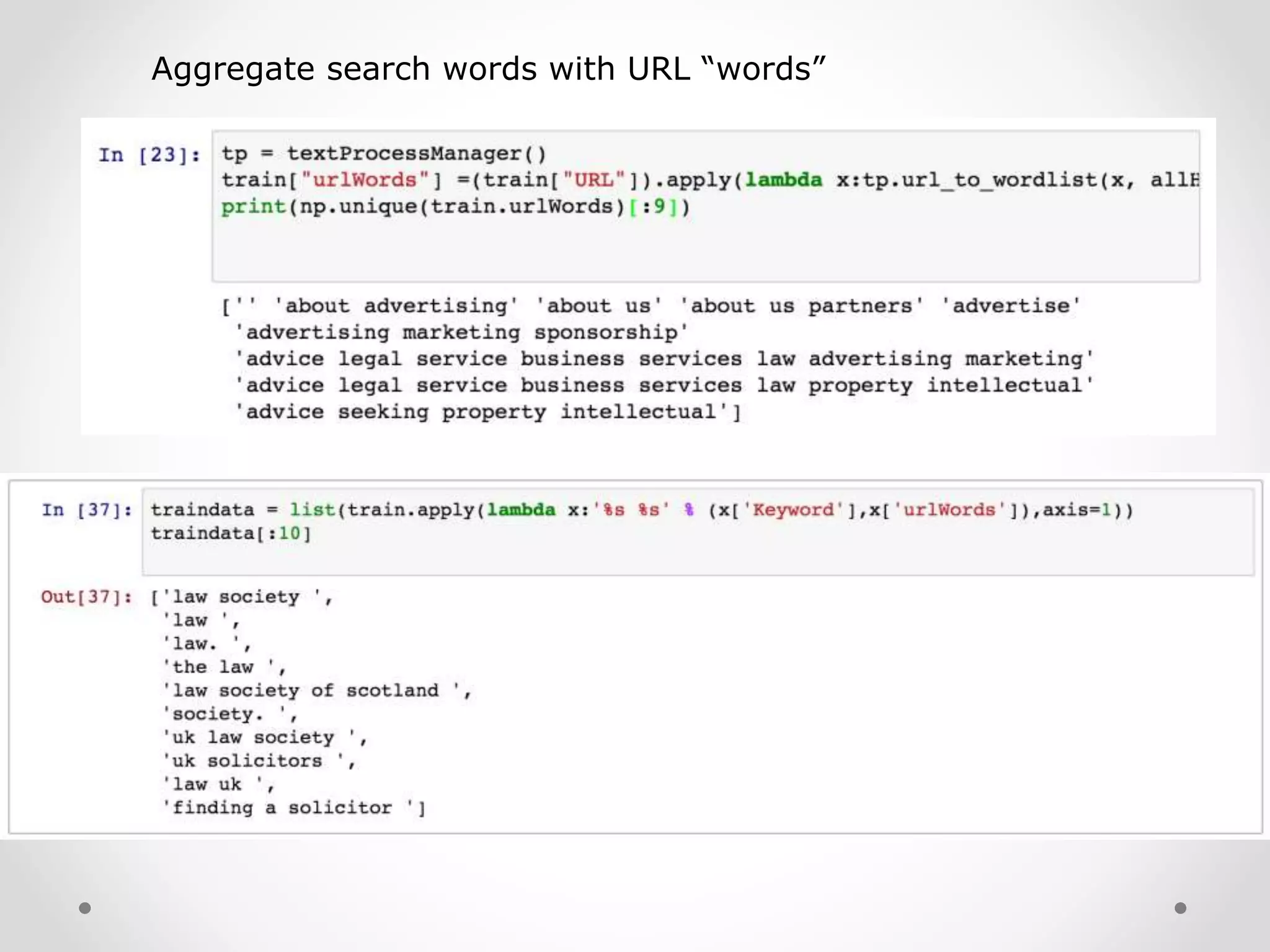
Preparation of text clustering including keyword aggregation and tokenization.
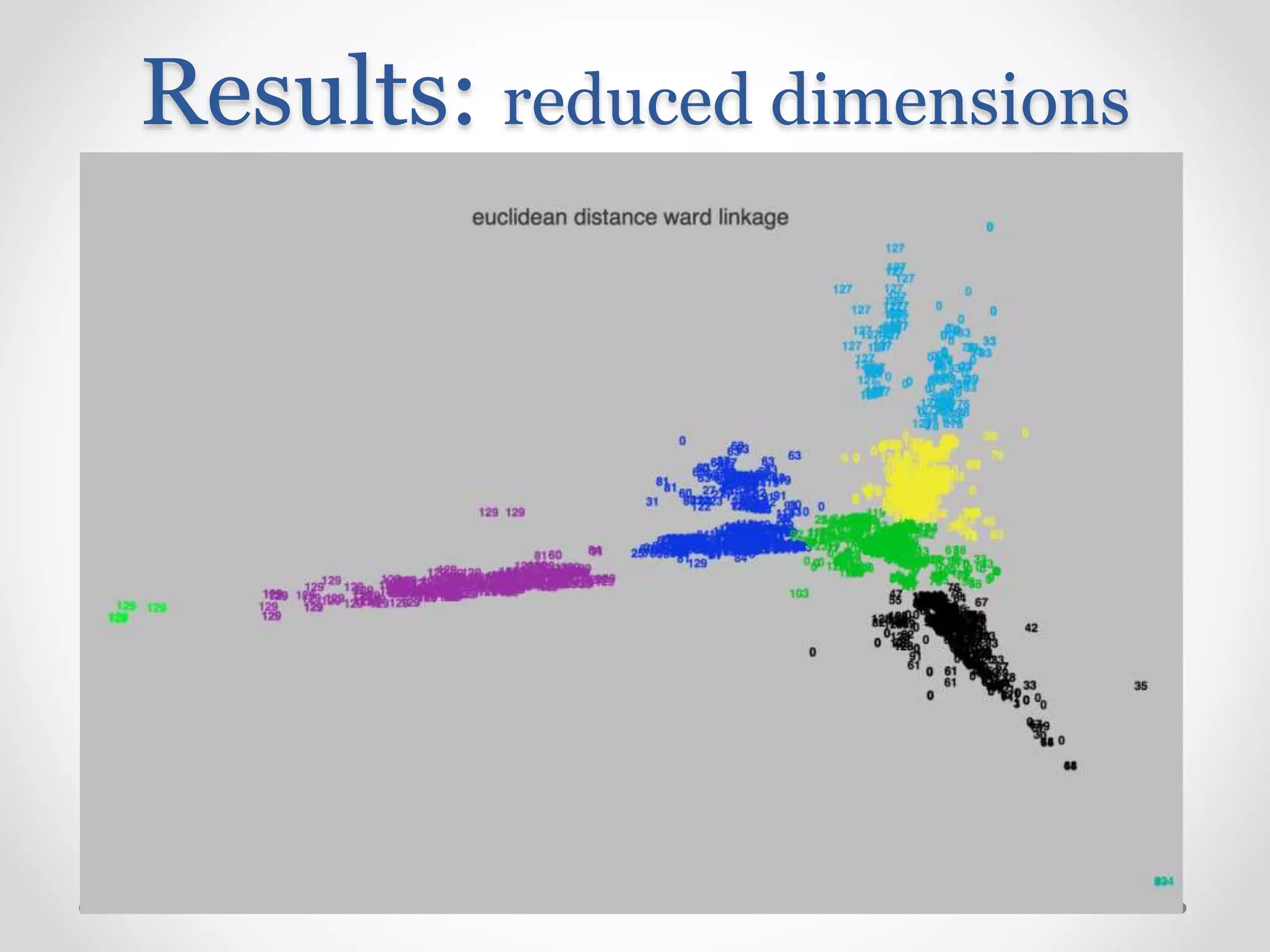
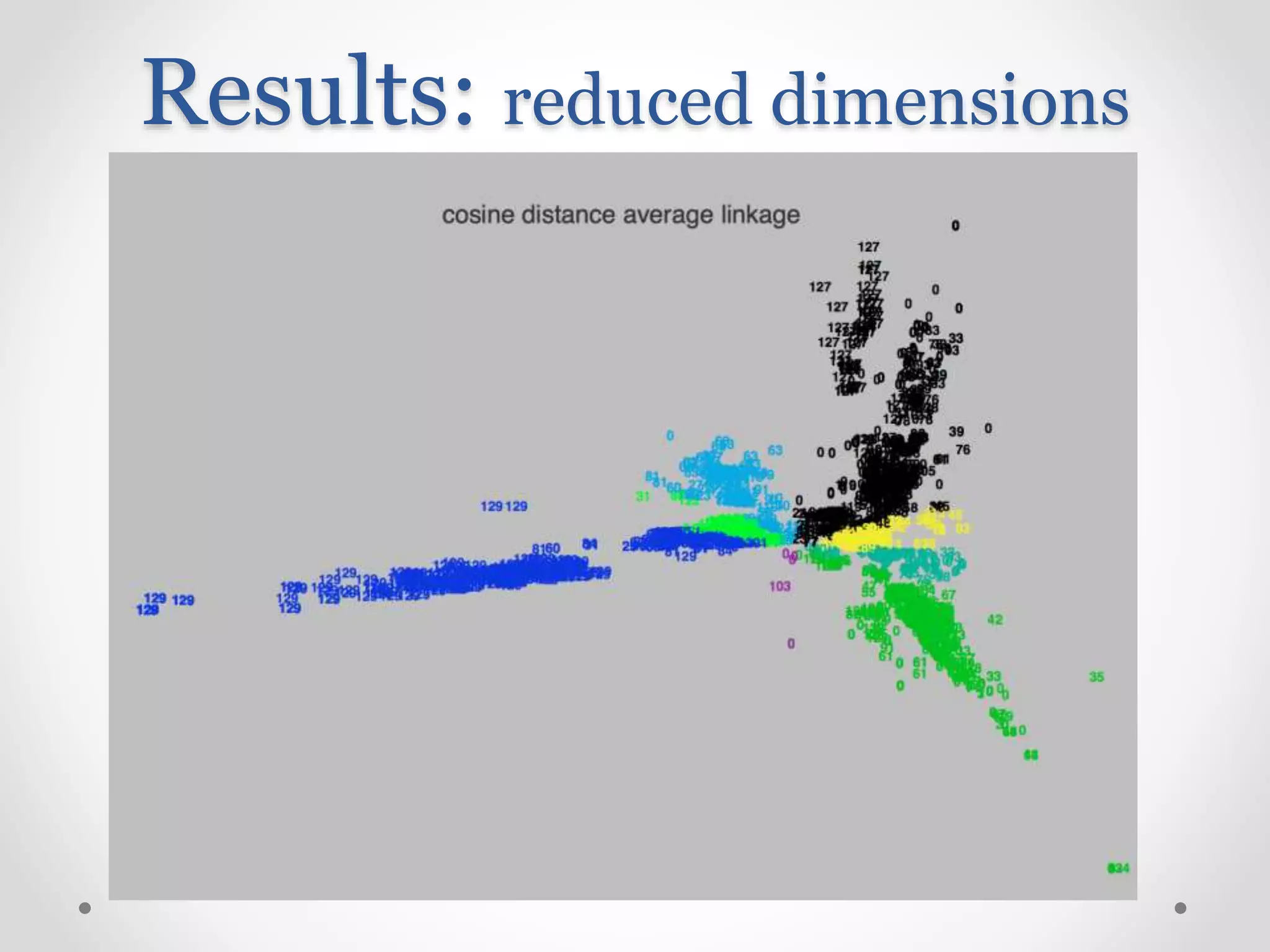
Challenges and techniques for reducing dimensionality in high-dimensional clustering datasets.
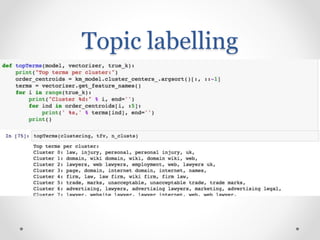
Methods for assessing cluster quality through metrics like purity and adjusted Rand index.
Integration of clustering within Elasticsearch and introduction to Lingo 3G algorithm for clustering.
Drawbacks of hierarchical clustering and challenges including scalability and irreversibility of merges.
Resources for learning more about clustering techniques and why working within databases is beneficial.














































![[Karger+ NIPS11] Iterative Learning for Reliable Crowdsourcing Systems](https://cdn.slidesharecdn.com/ss_thumbnails/karger-croudsourcing-nips11-120408005300-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








































