Downloaded 52 times




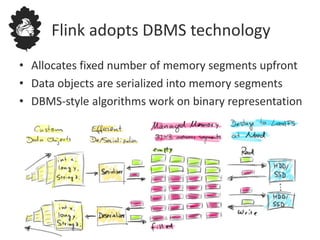




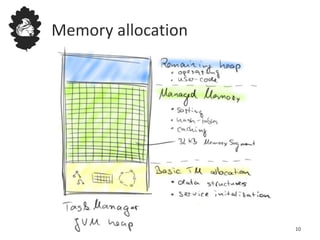




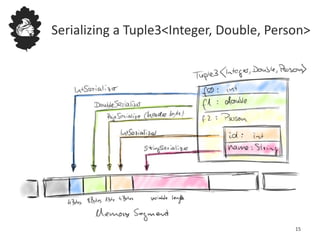


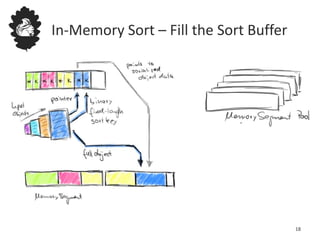
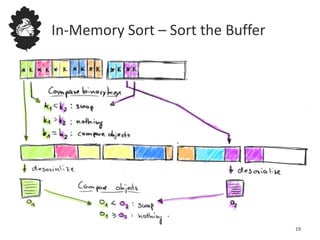
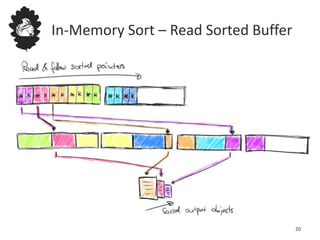



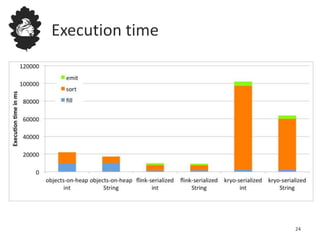
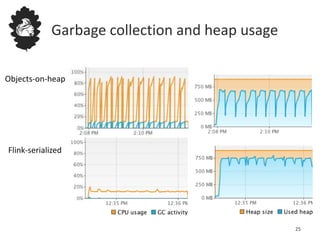
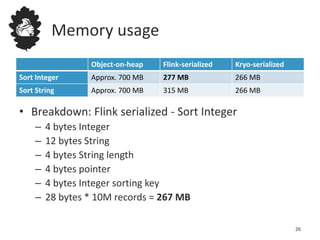








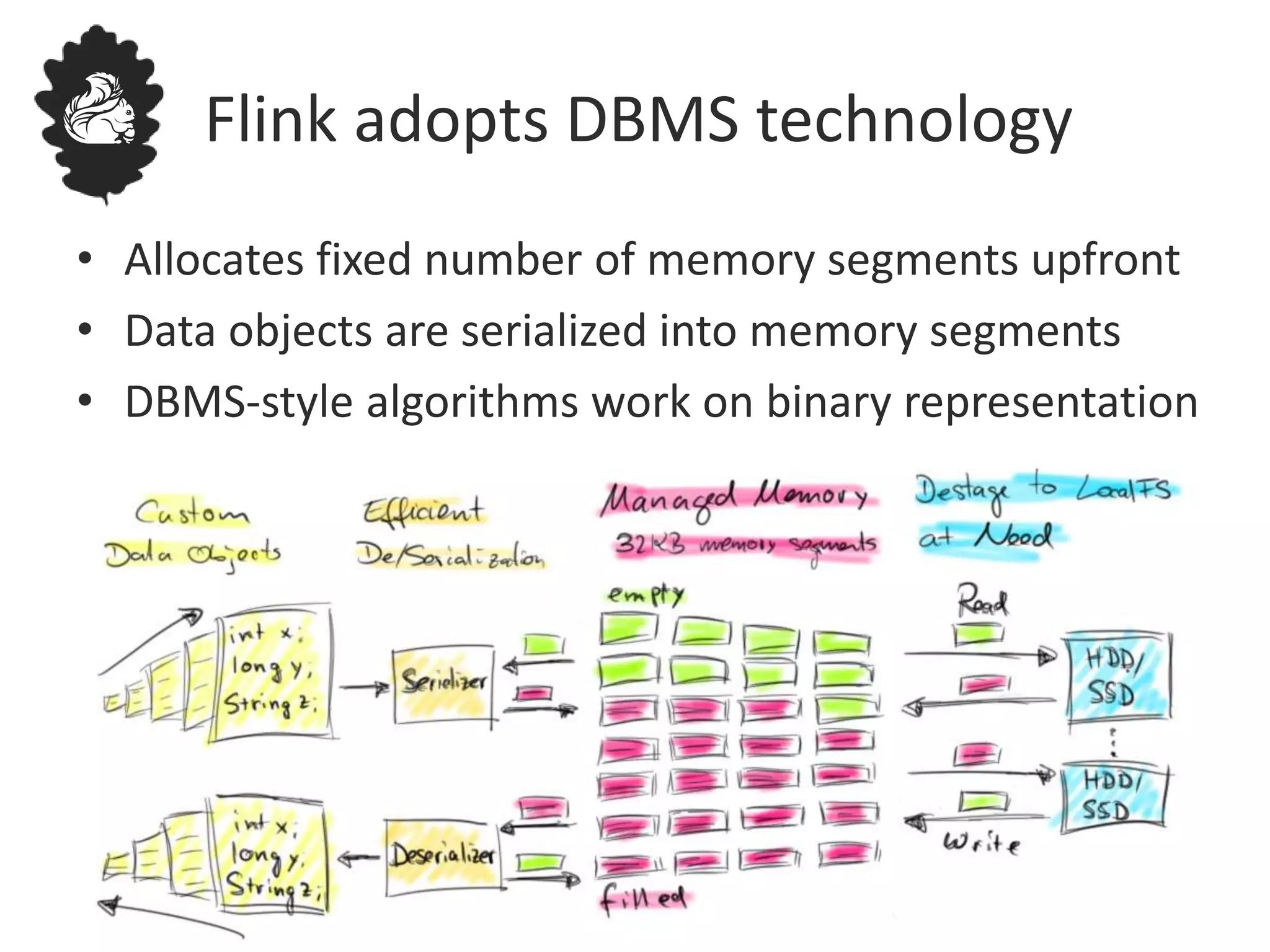




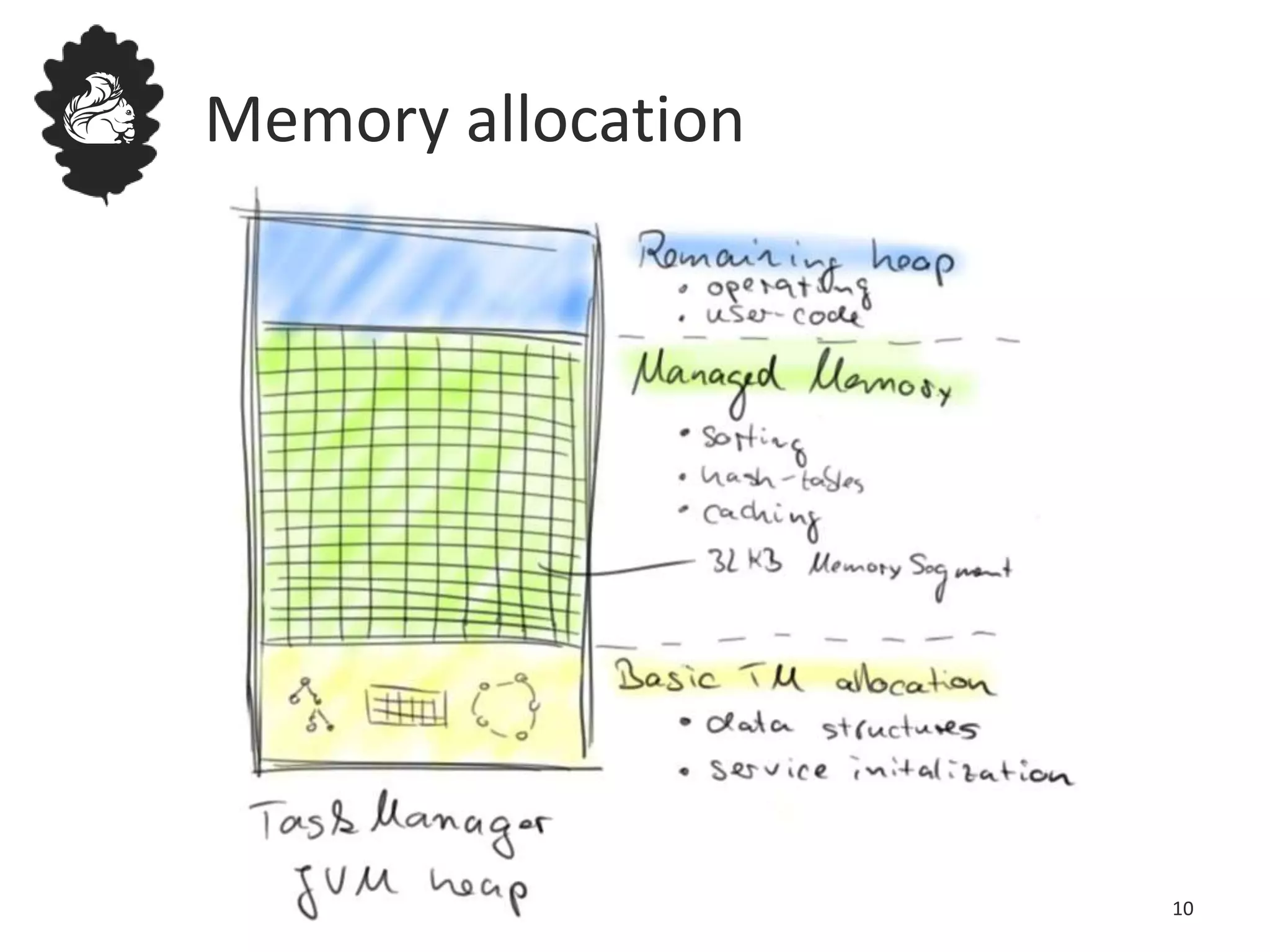




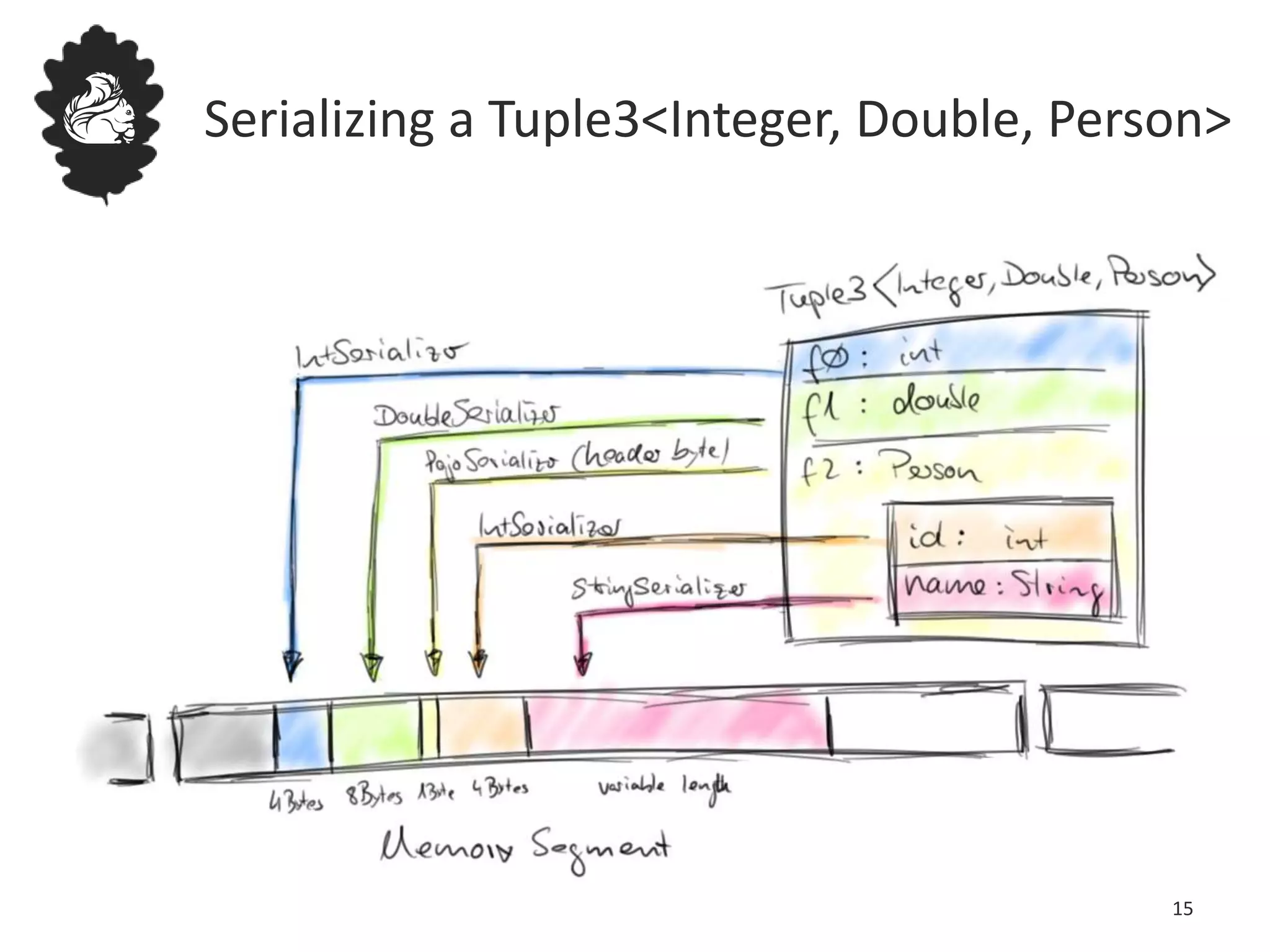


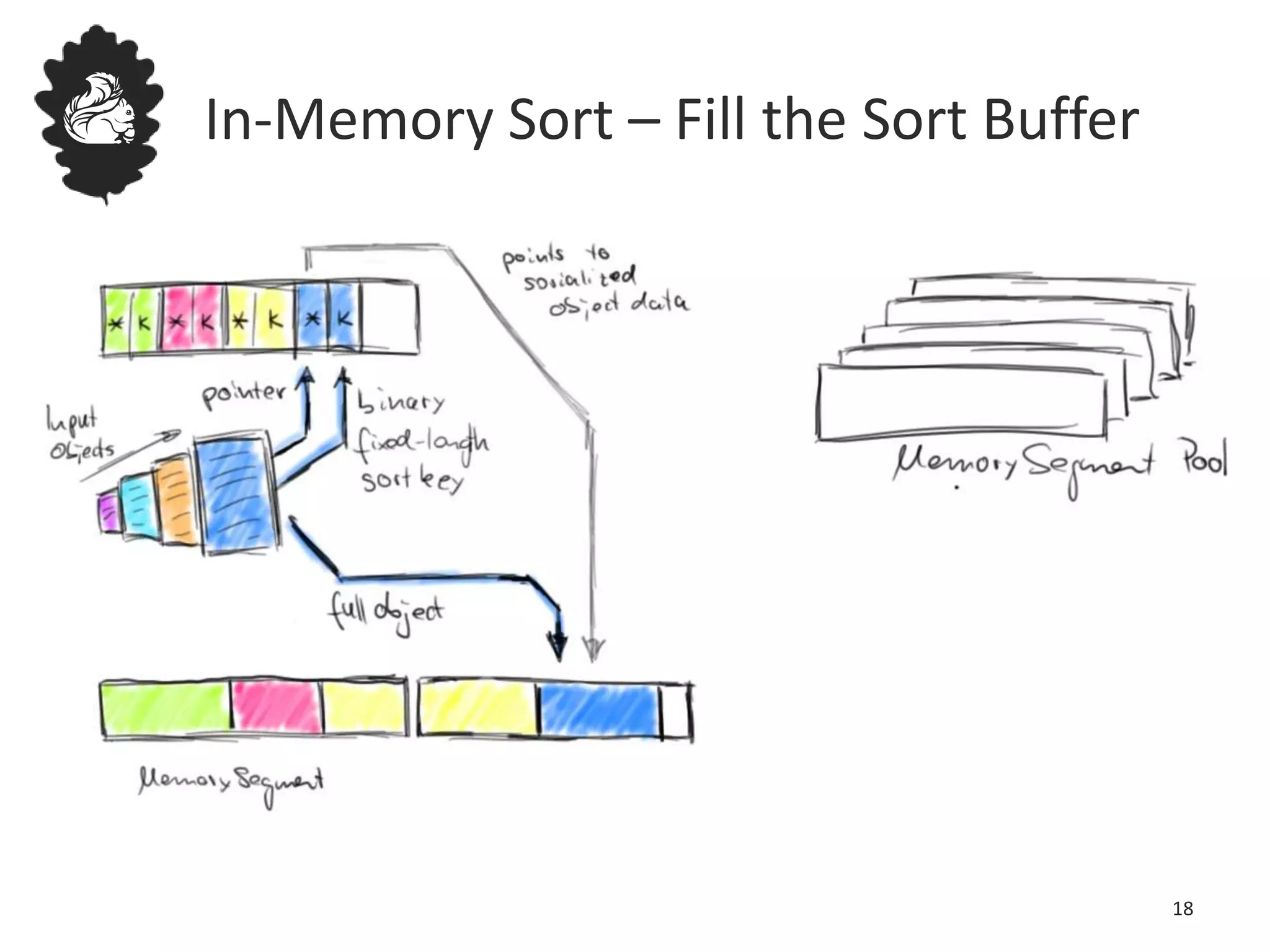
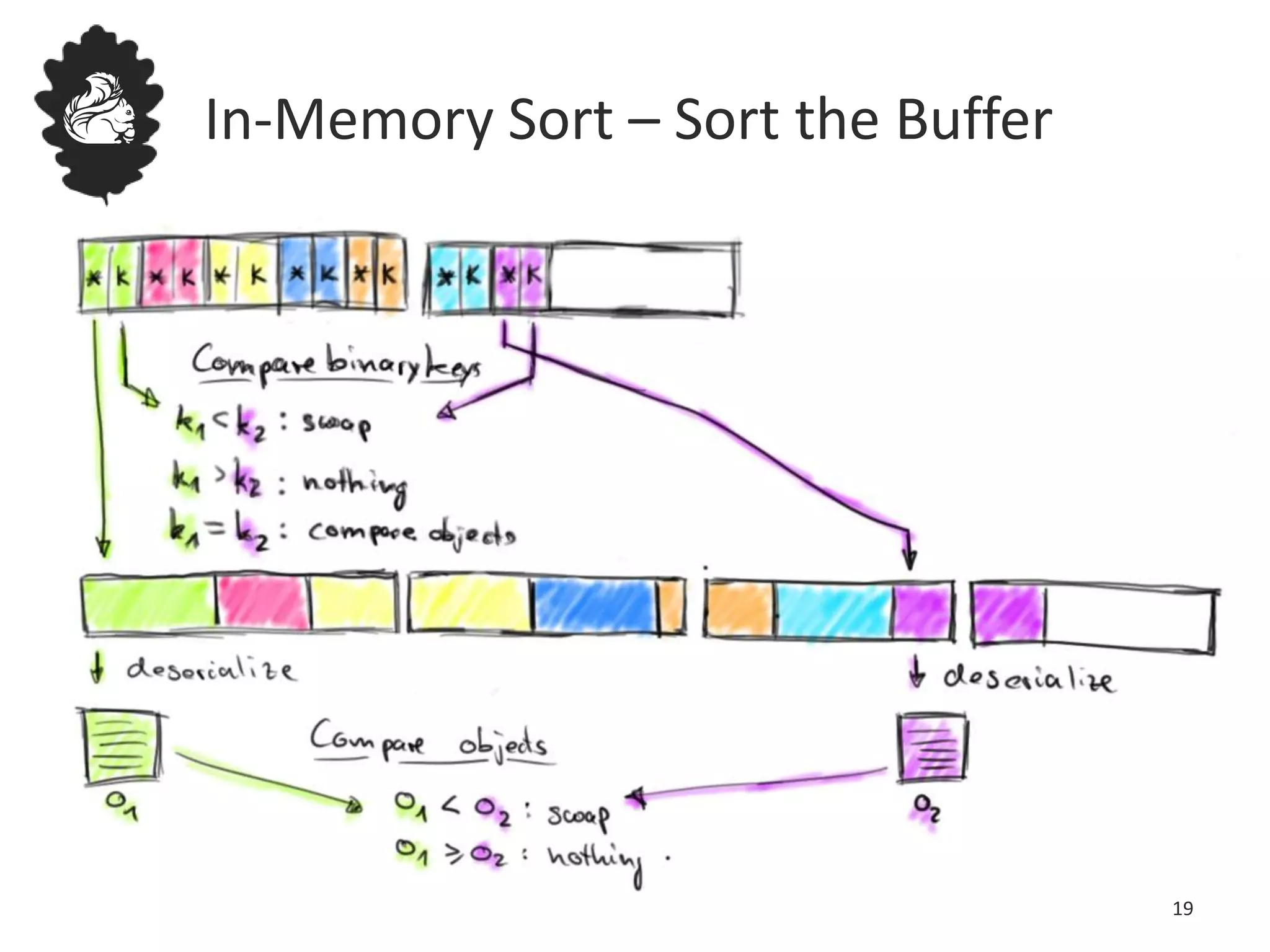
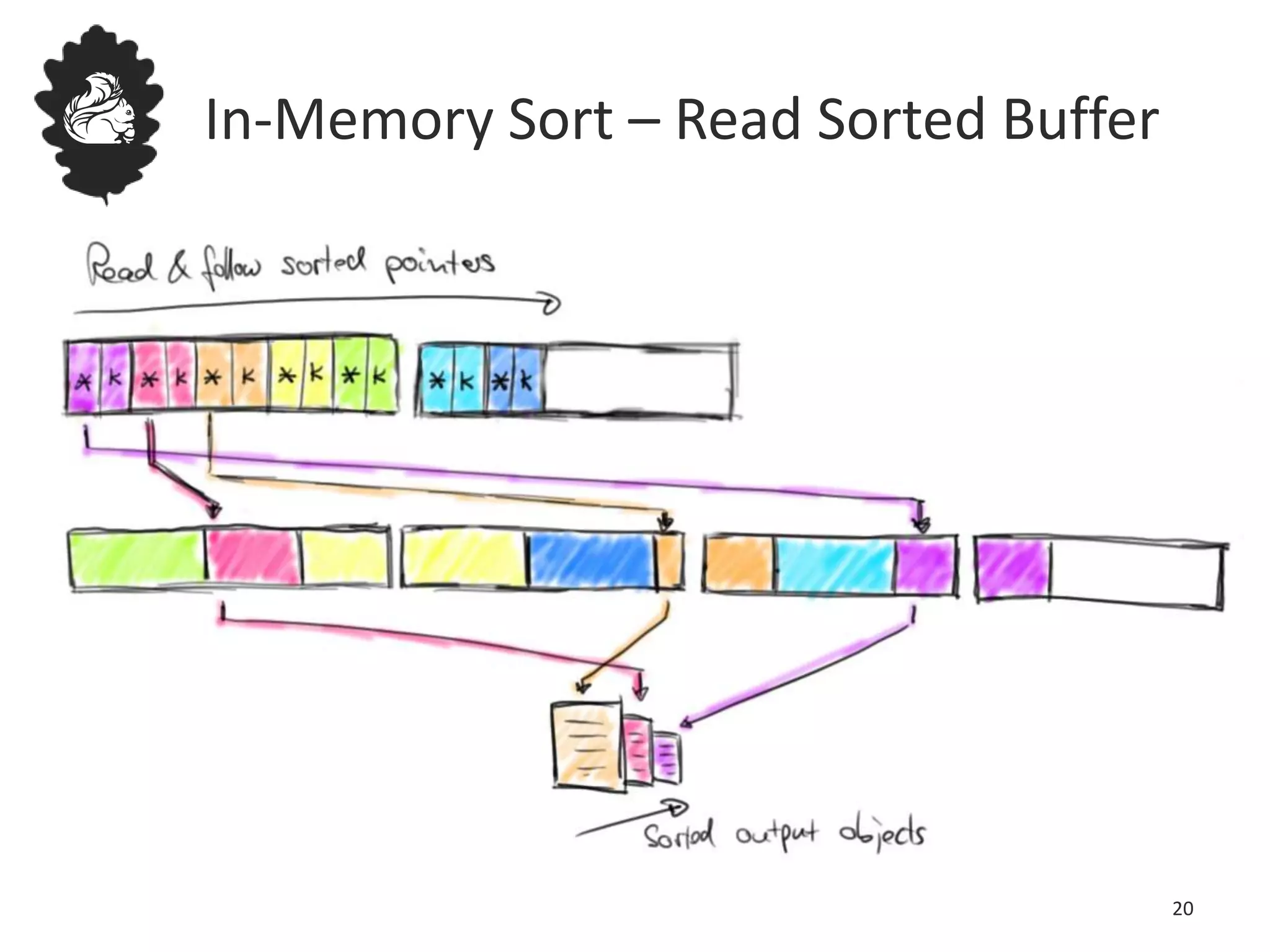



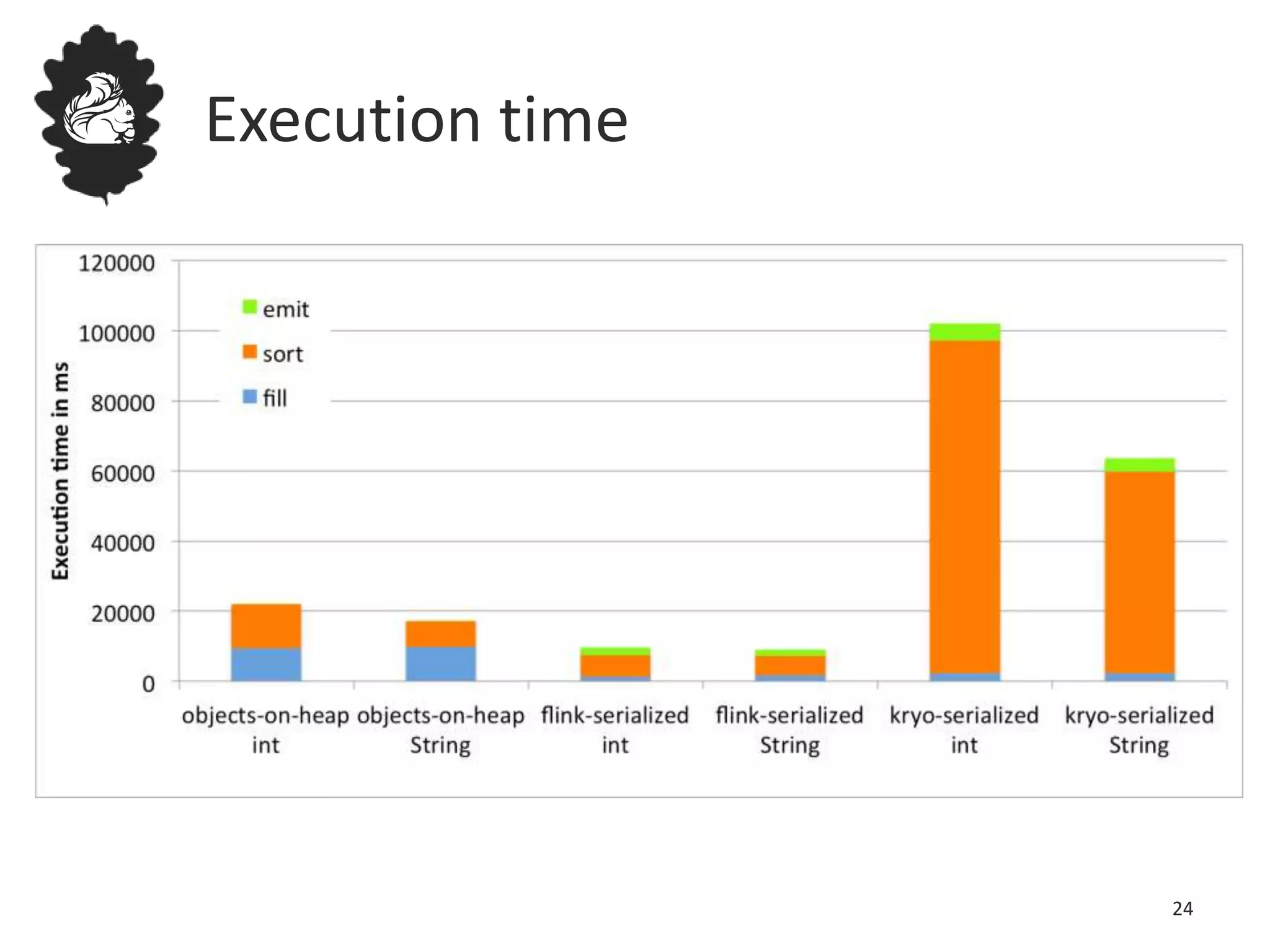
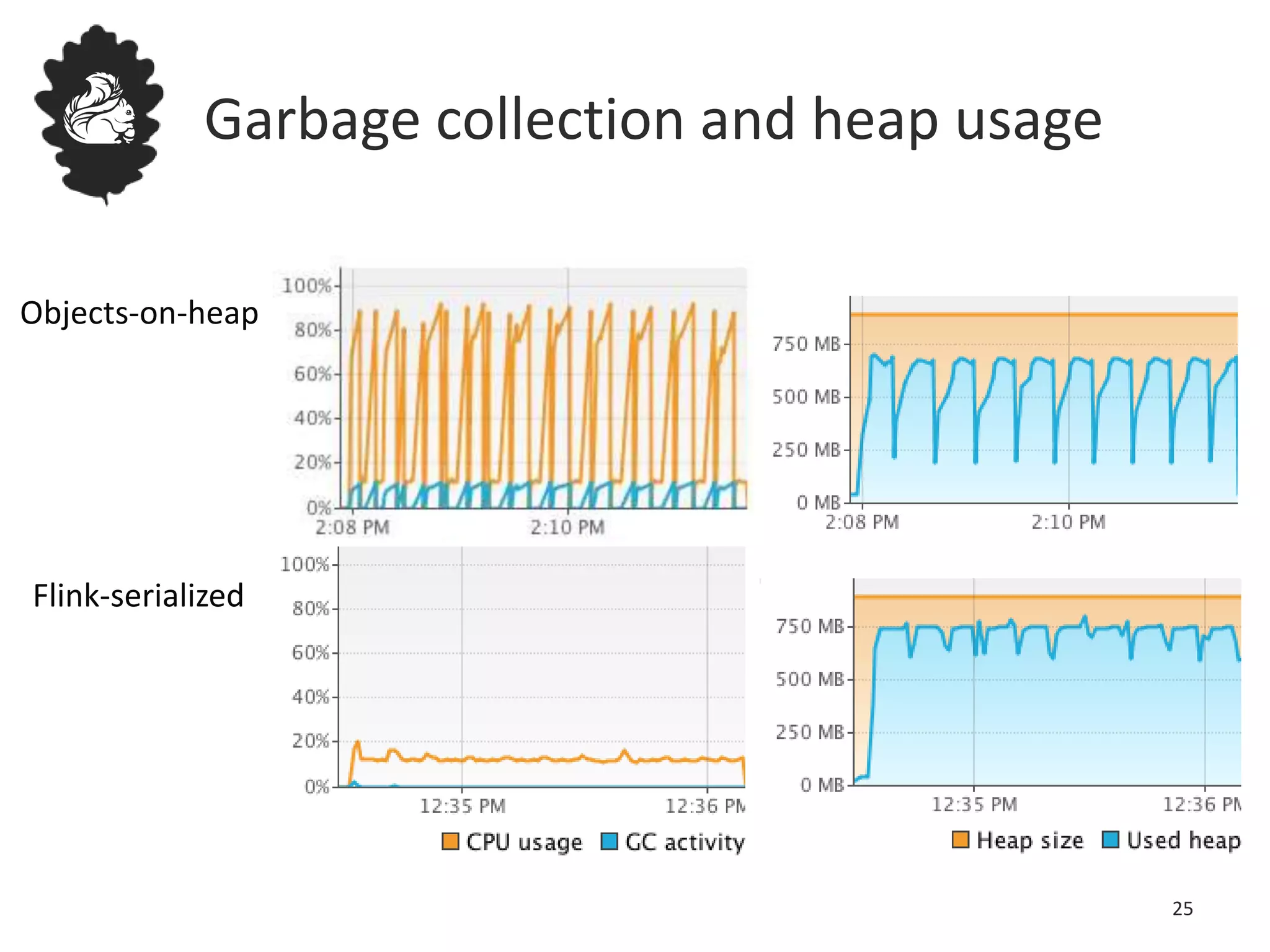






Flink uses a database management system approach to memory management and data serialization that allows it to efficiently operate on binary data representations. It allocates fixed memory segments upfront, serializes data objects into these segments, and implements database algorithms that work directly on the binary data. This approach avoids out of memory errors, reduces garbage collection overhead, and allows data to be efficiently sorted, joined, and aggregated in memory or spilled to disk. It provides reliable and high performance data processing through its custom serialization stack and ability to operate directly on serialized data representations.
















































































![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


