Downloaded 55 times

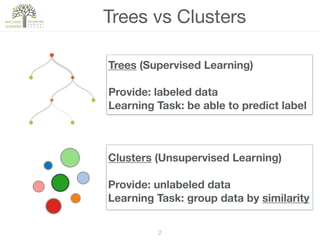
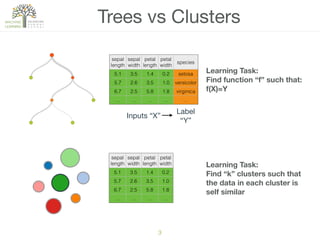

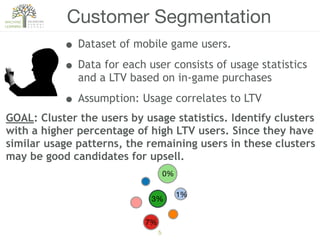







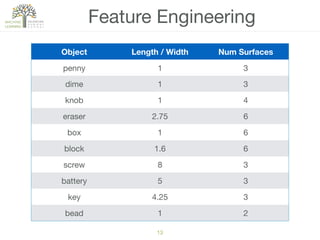


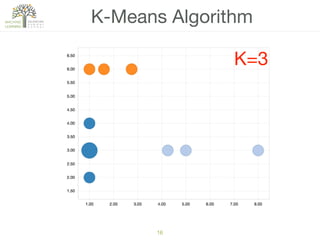
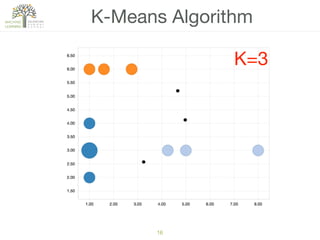
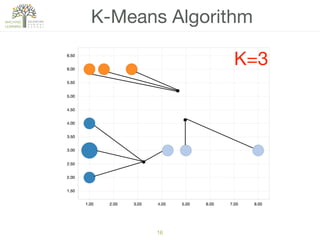
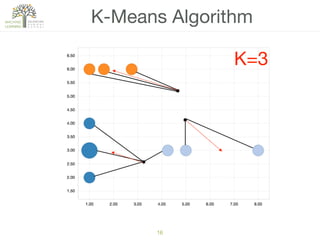
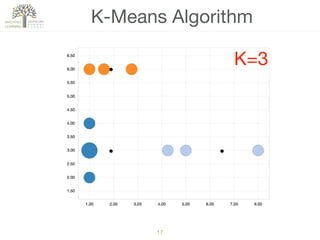
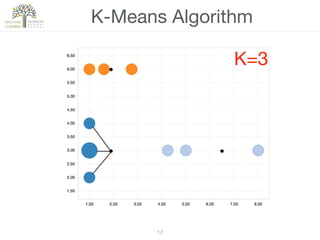

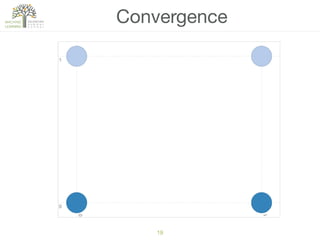
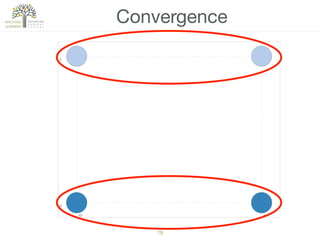
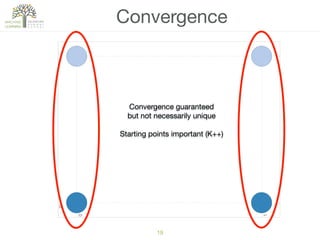

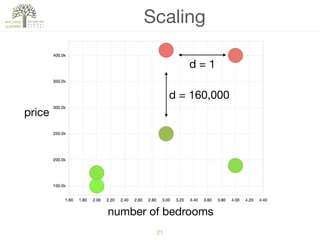





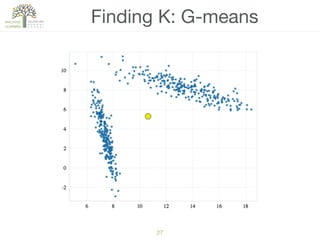
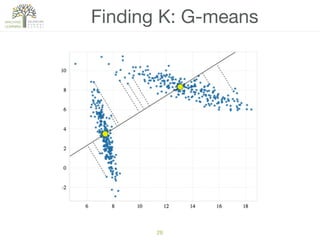
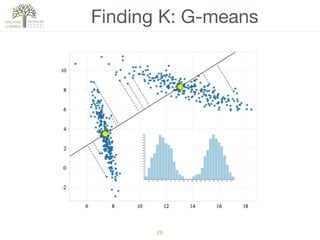
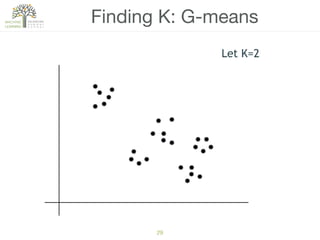
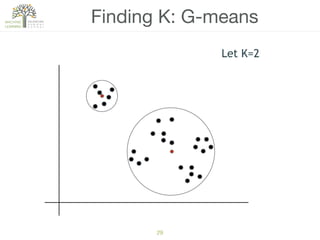
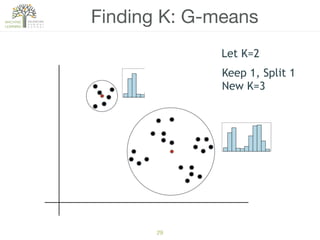

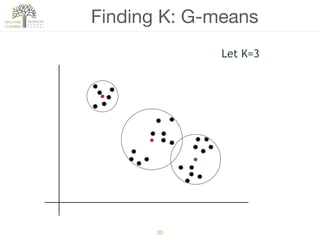
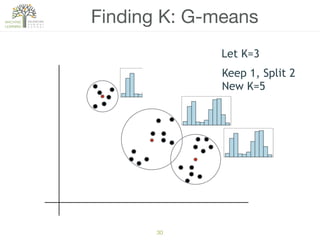
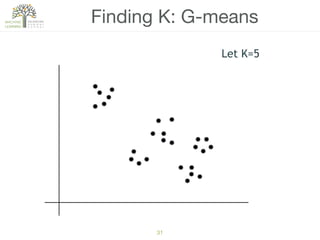
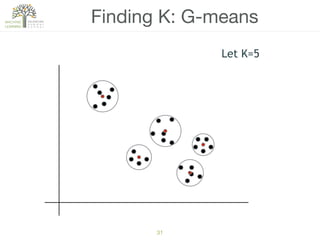

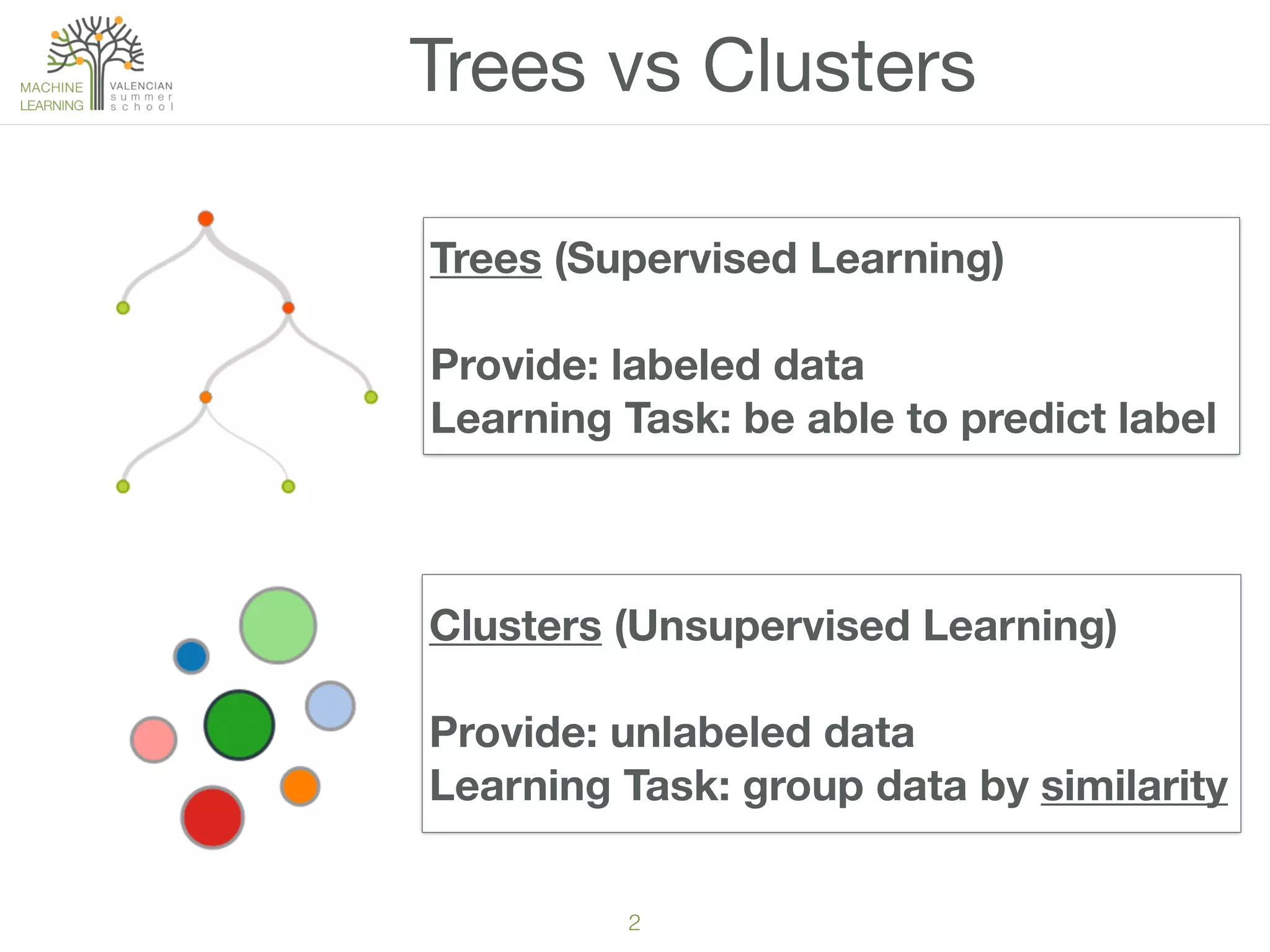
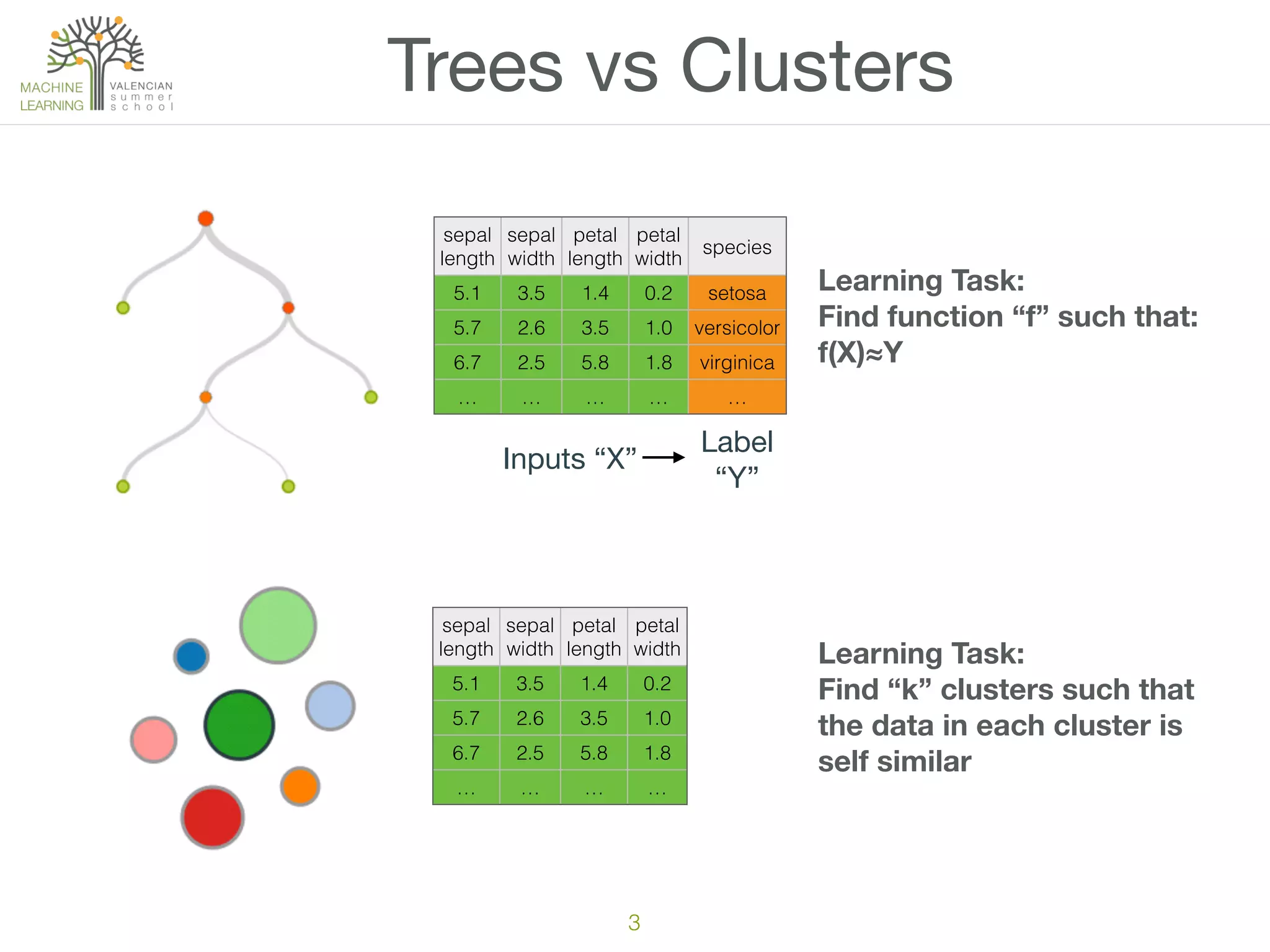

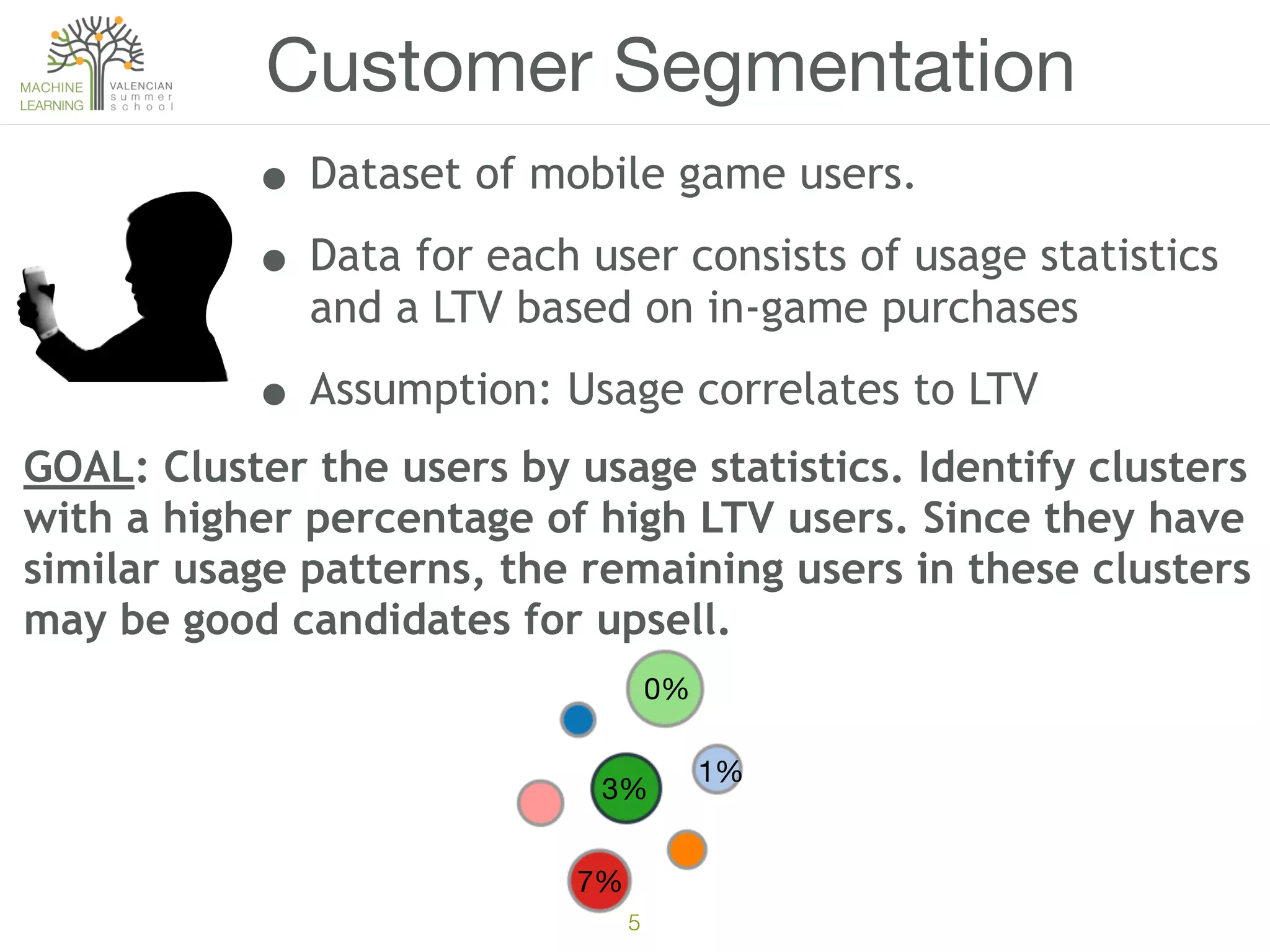







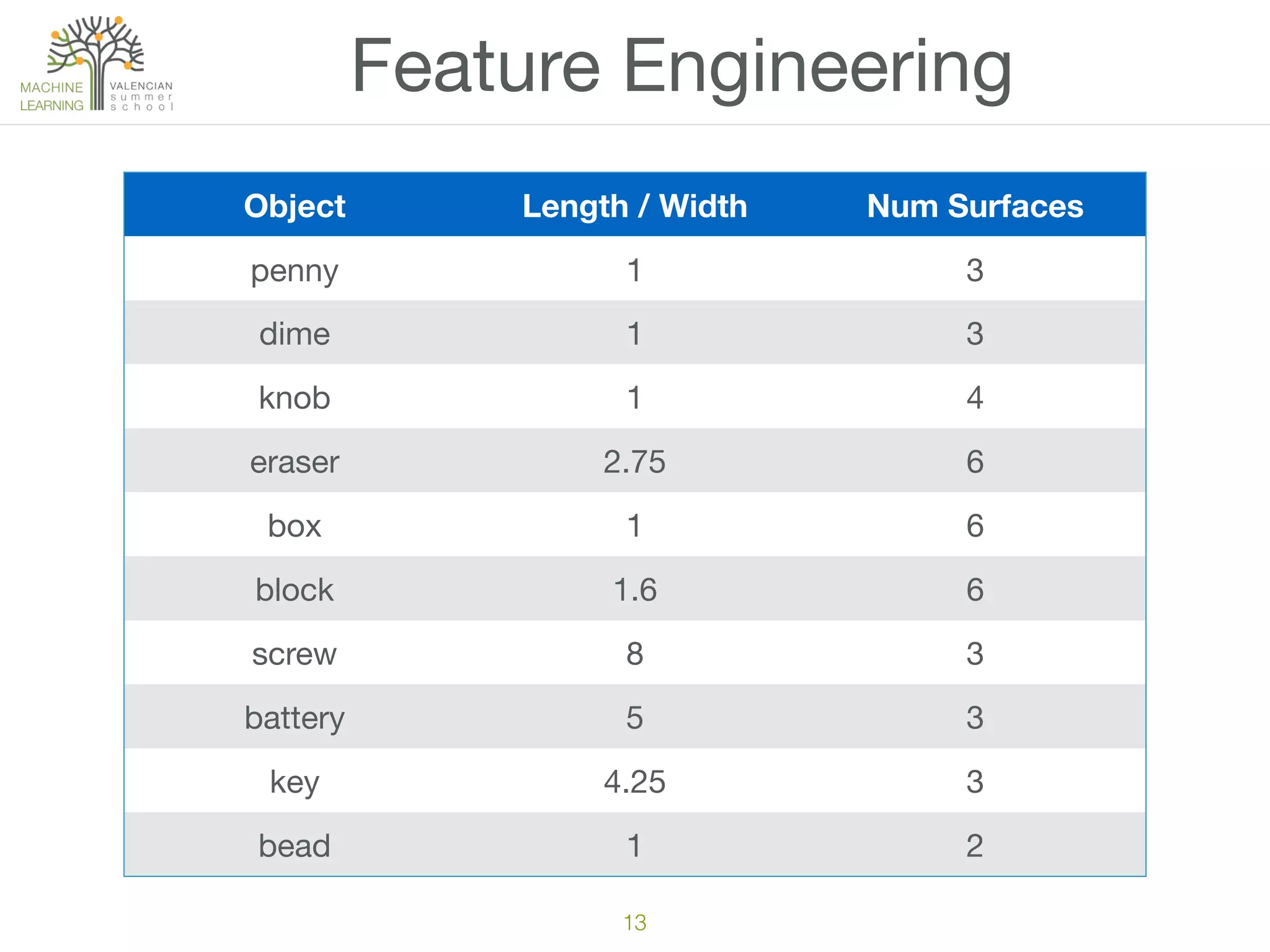
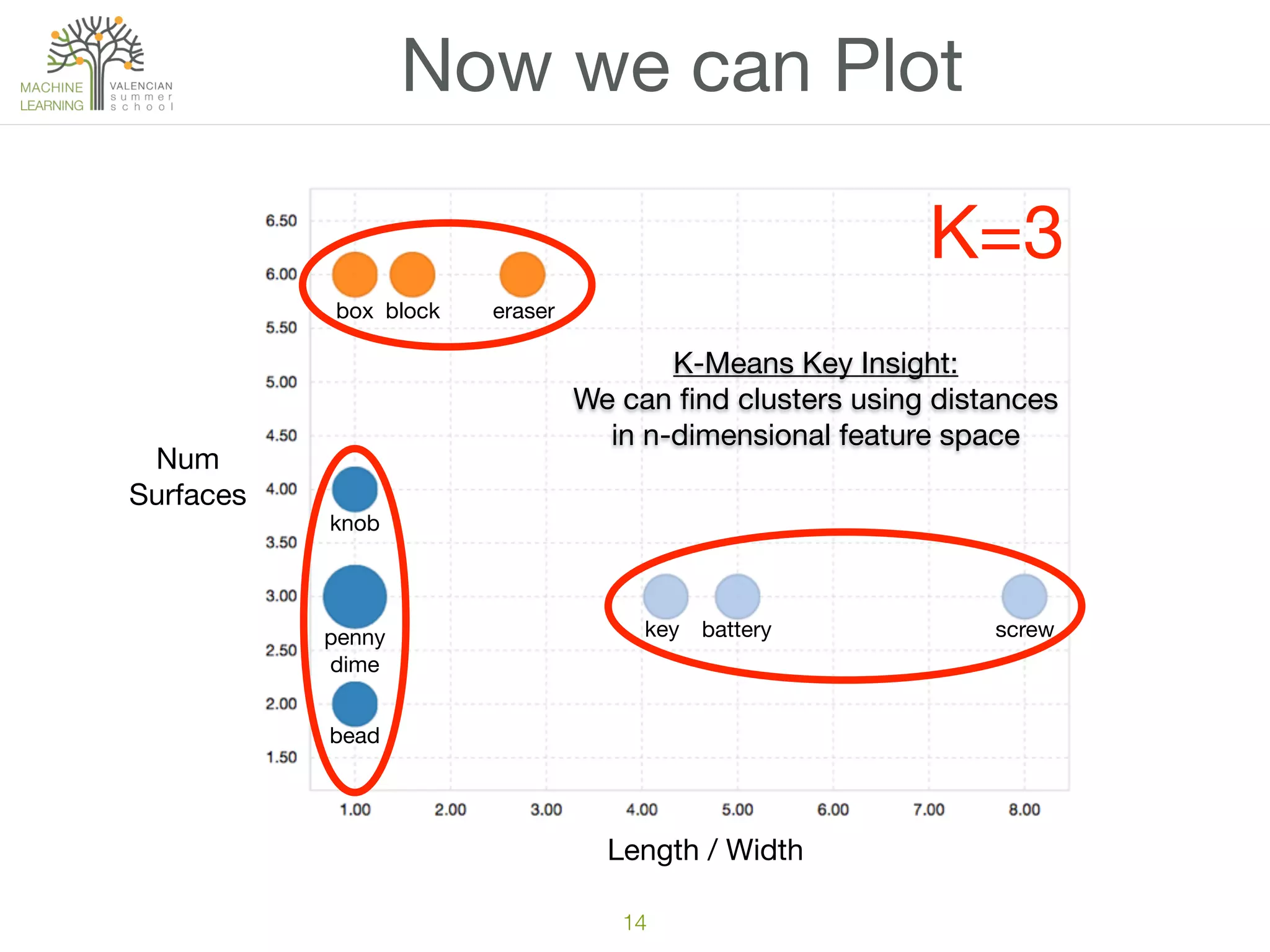

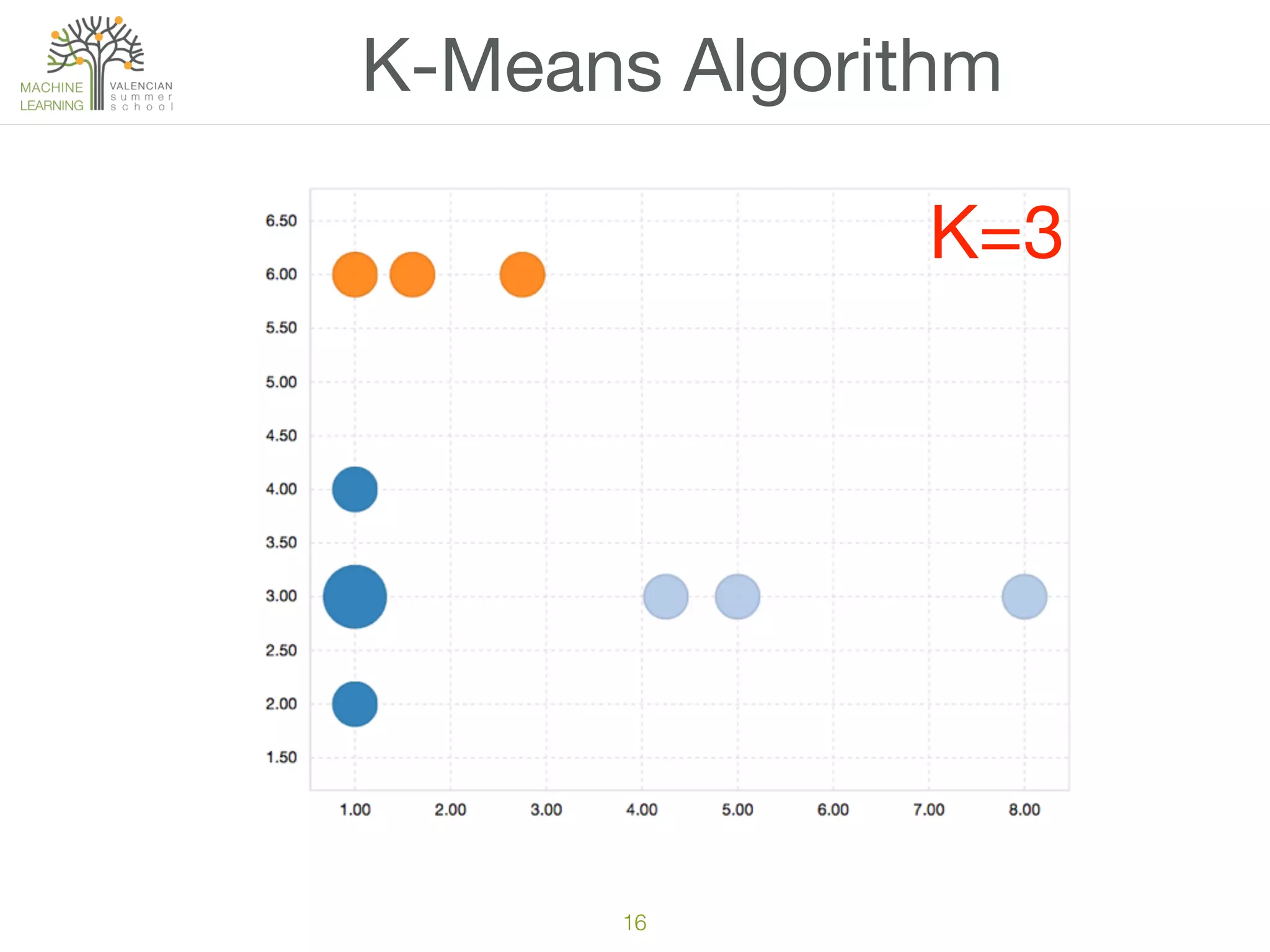
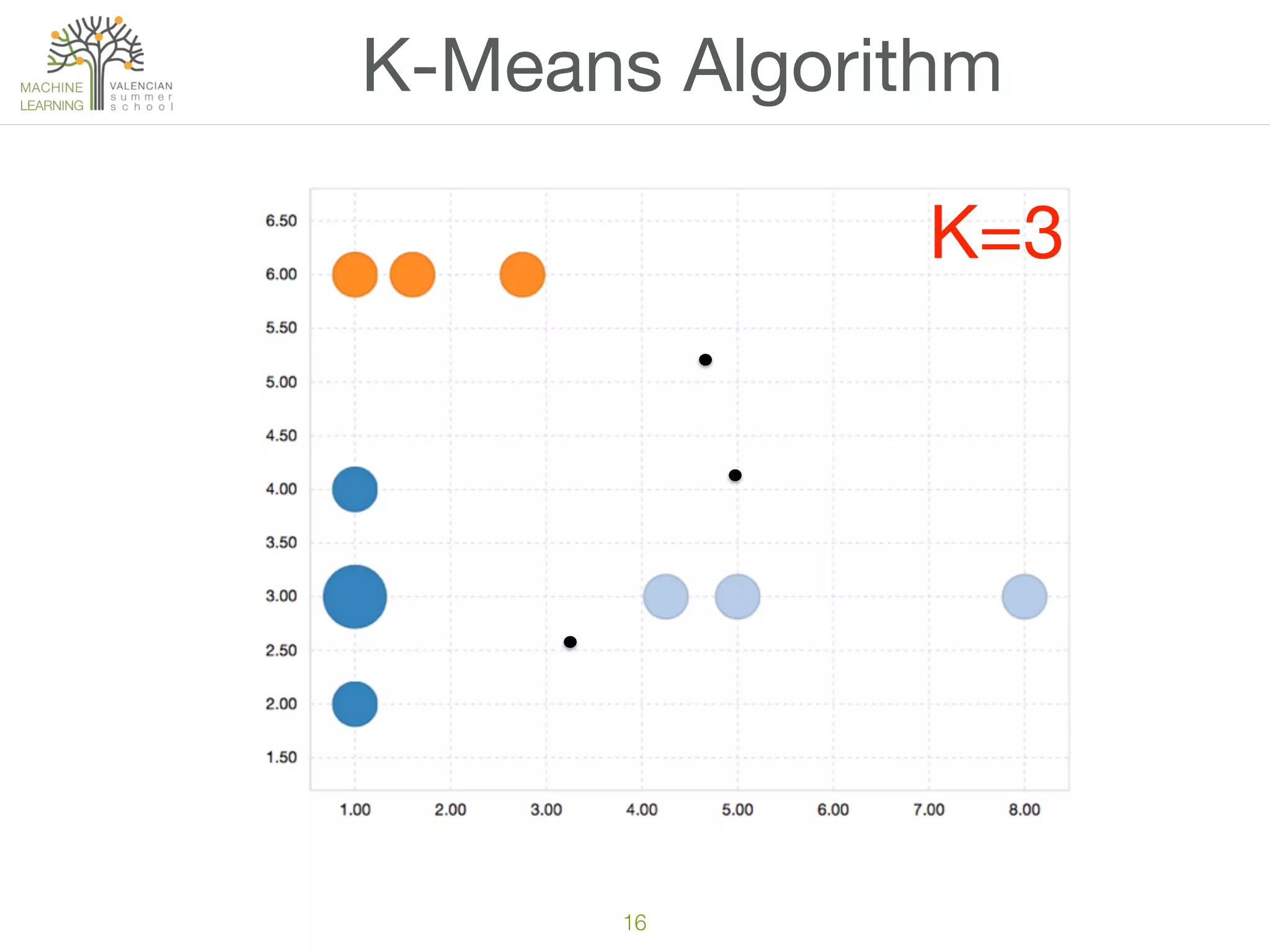
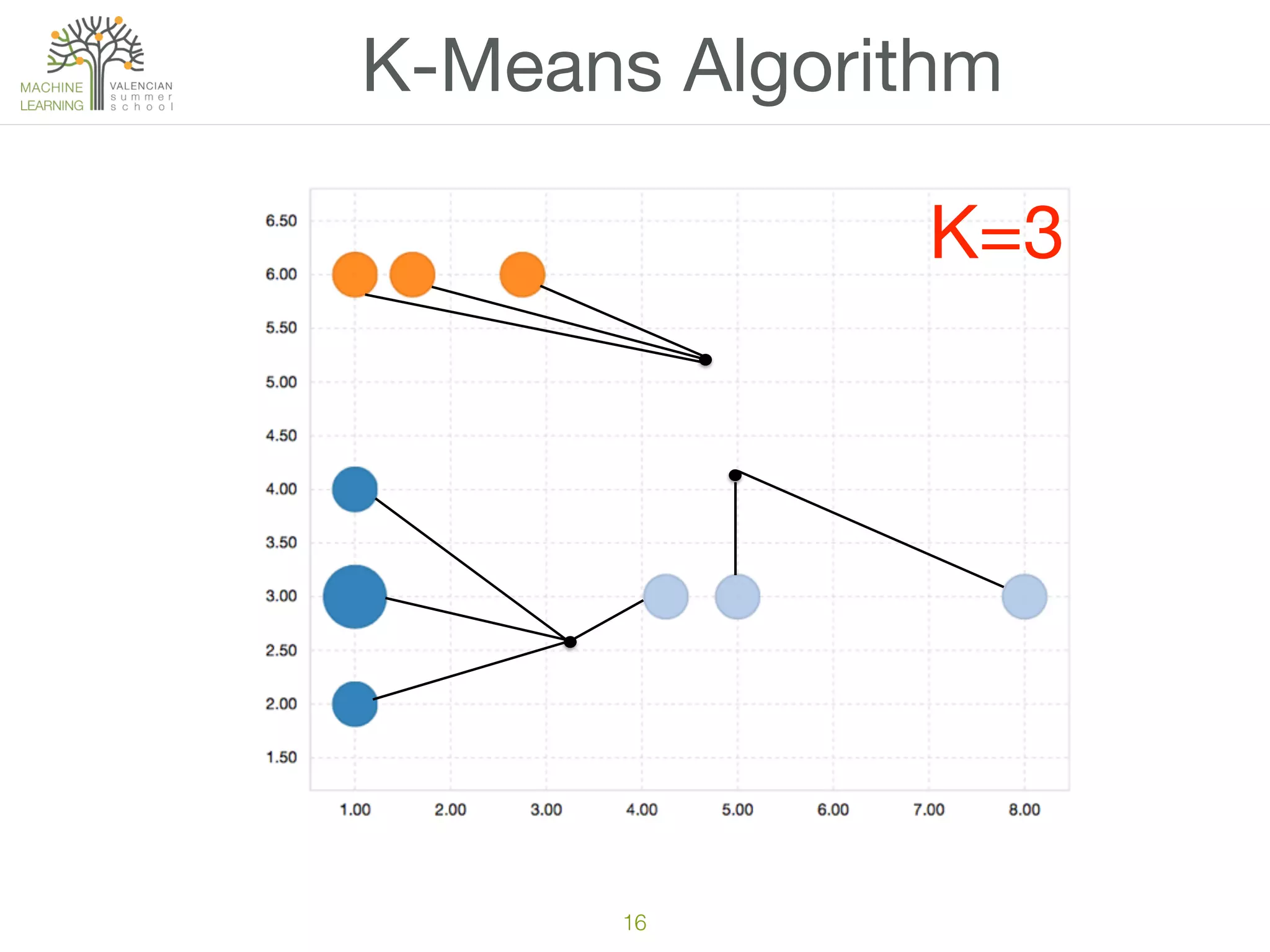
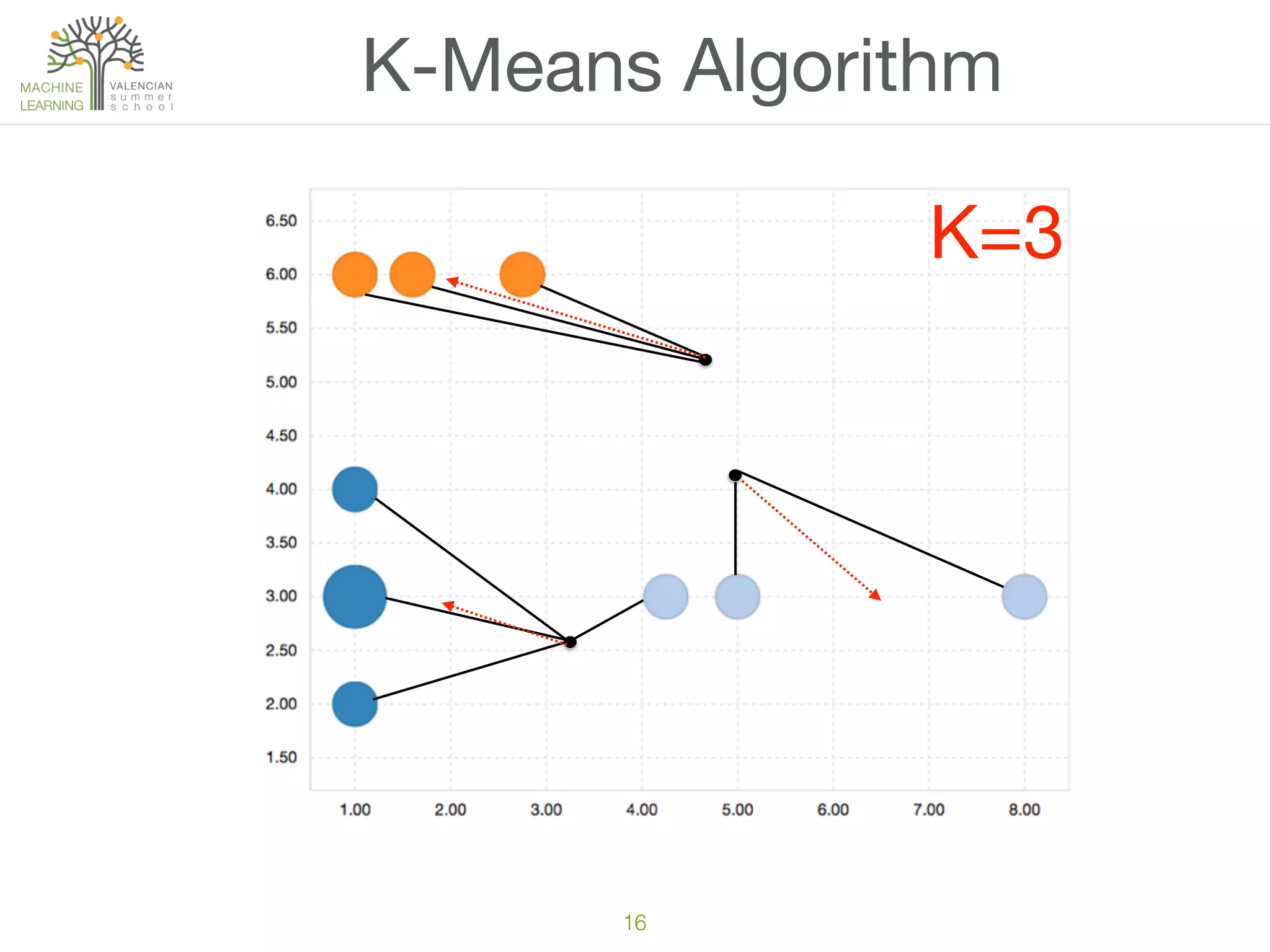
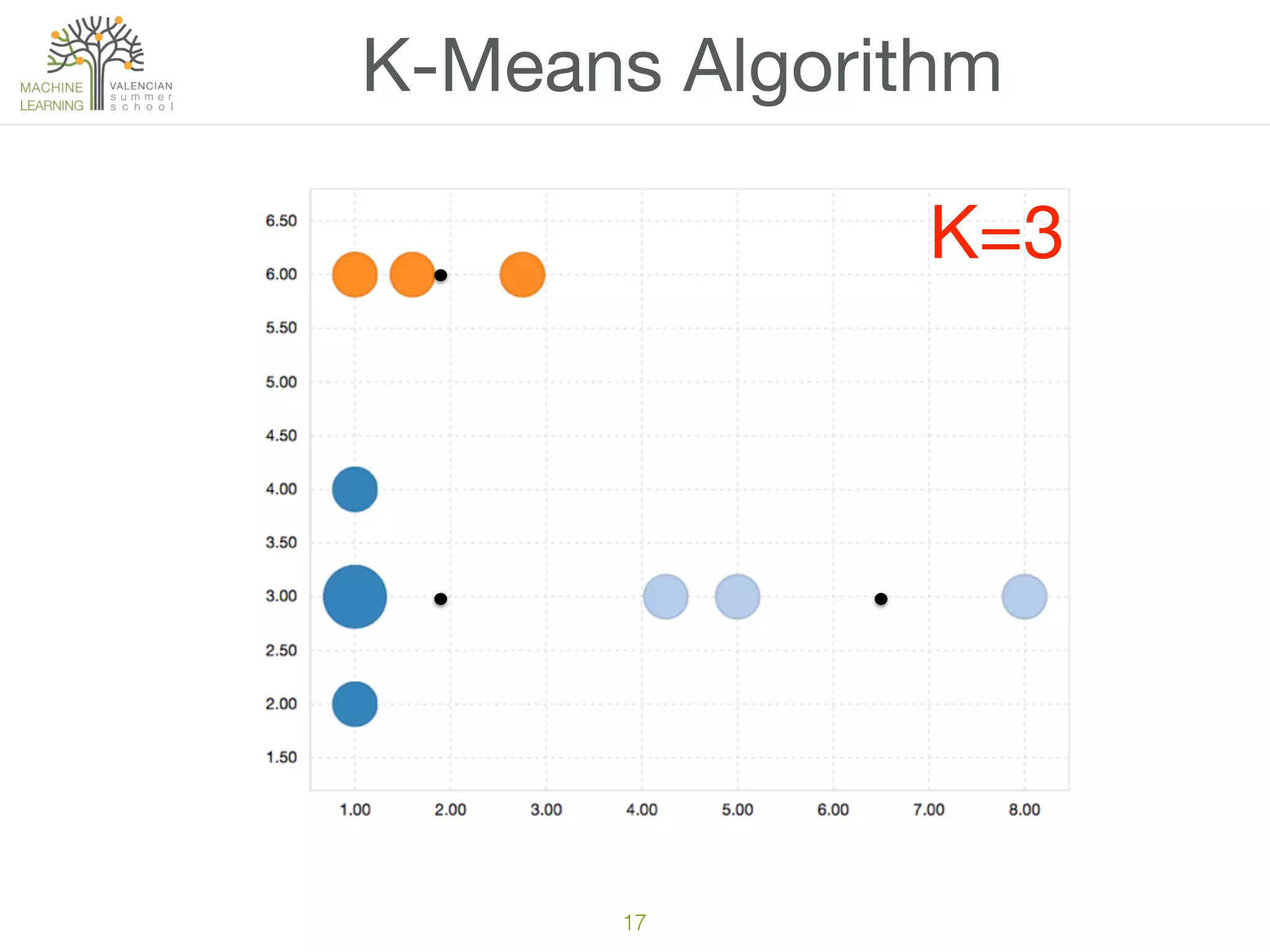
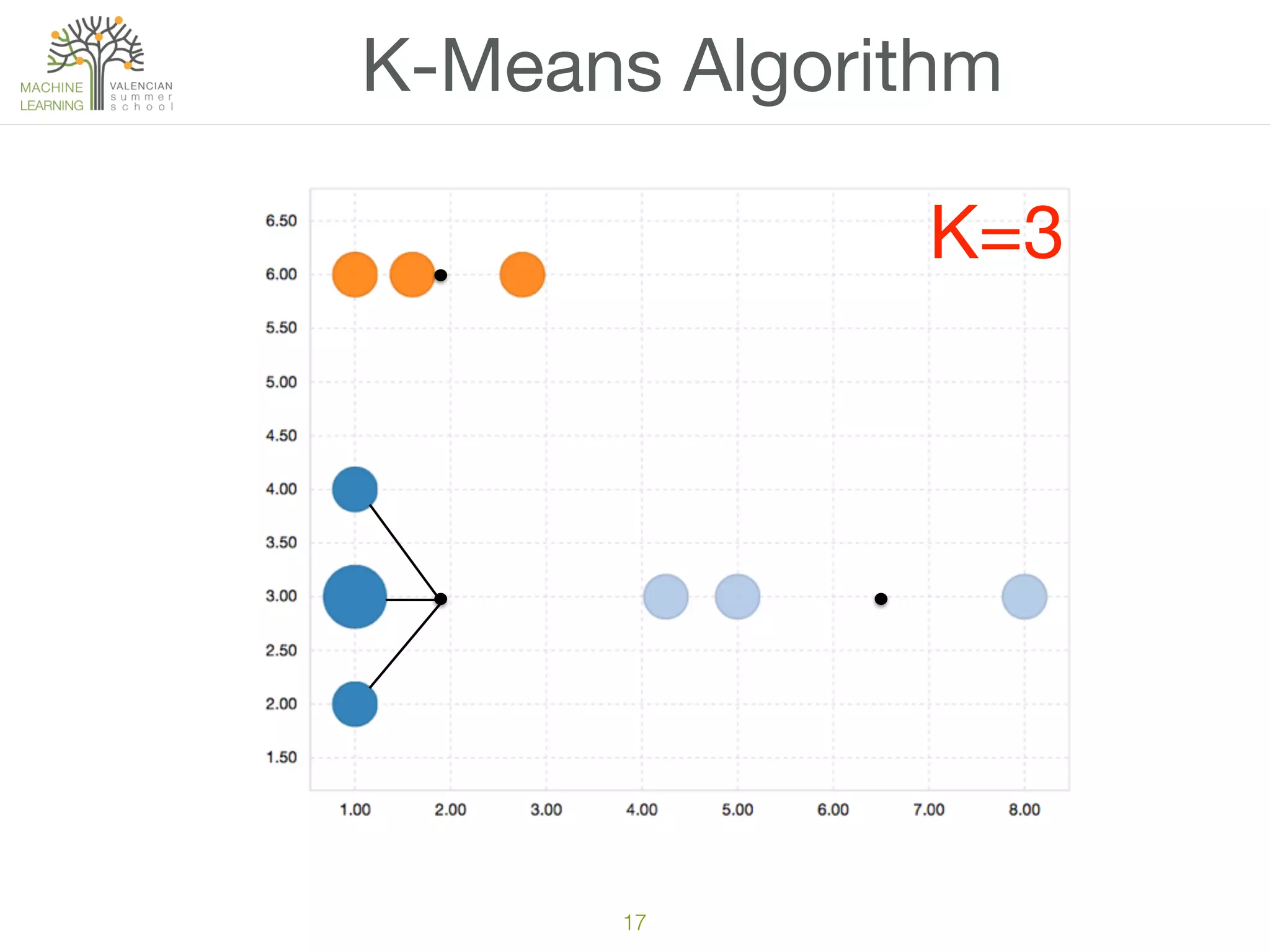

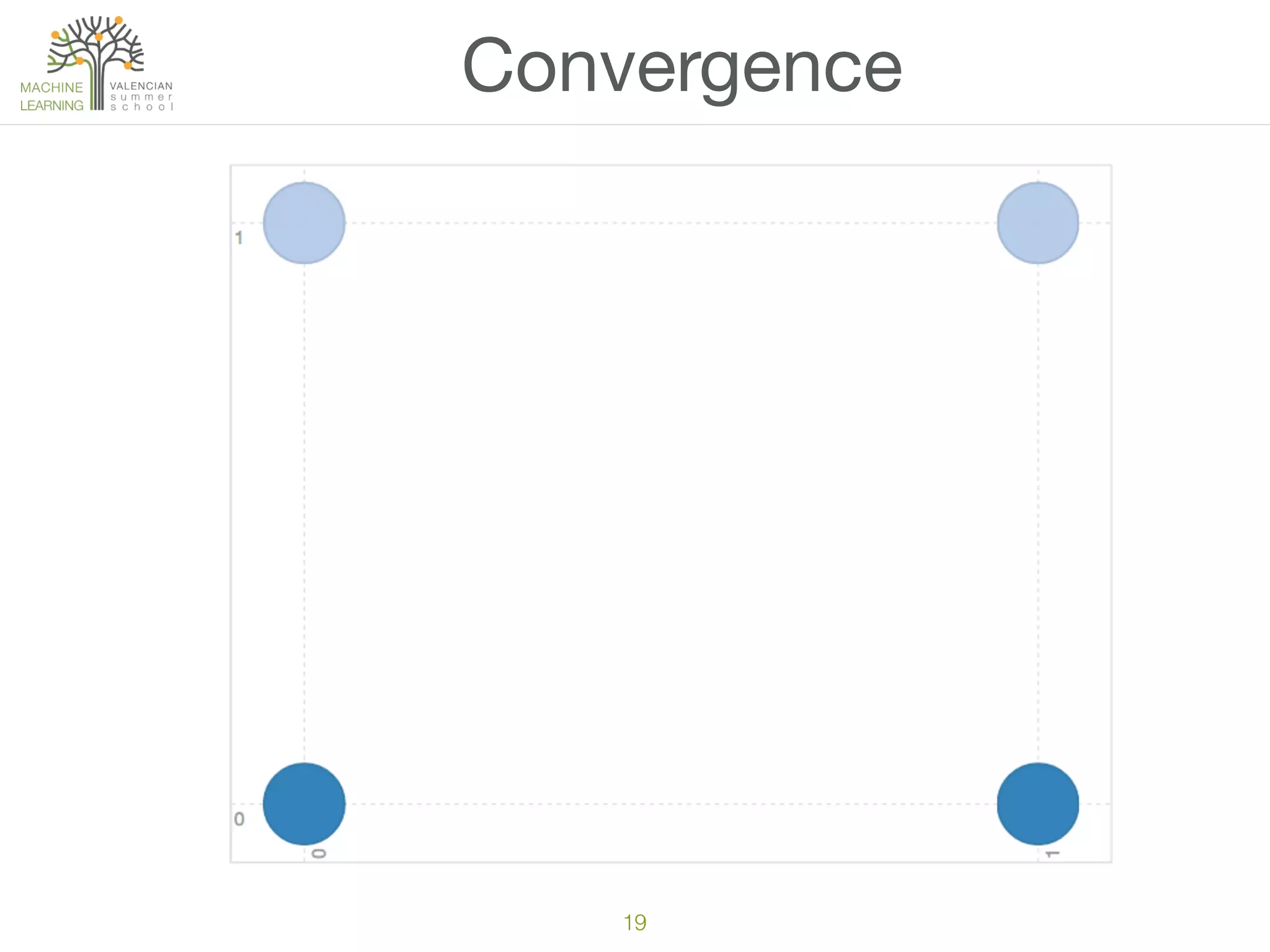
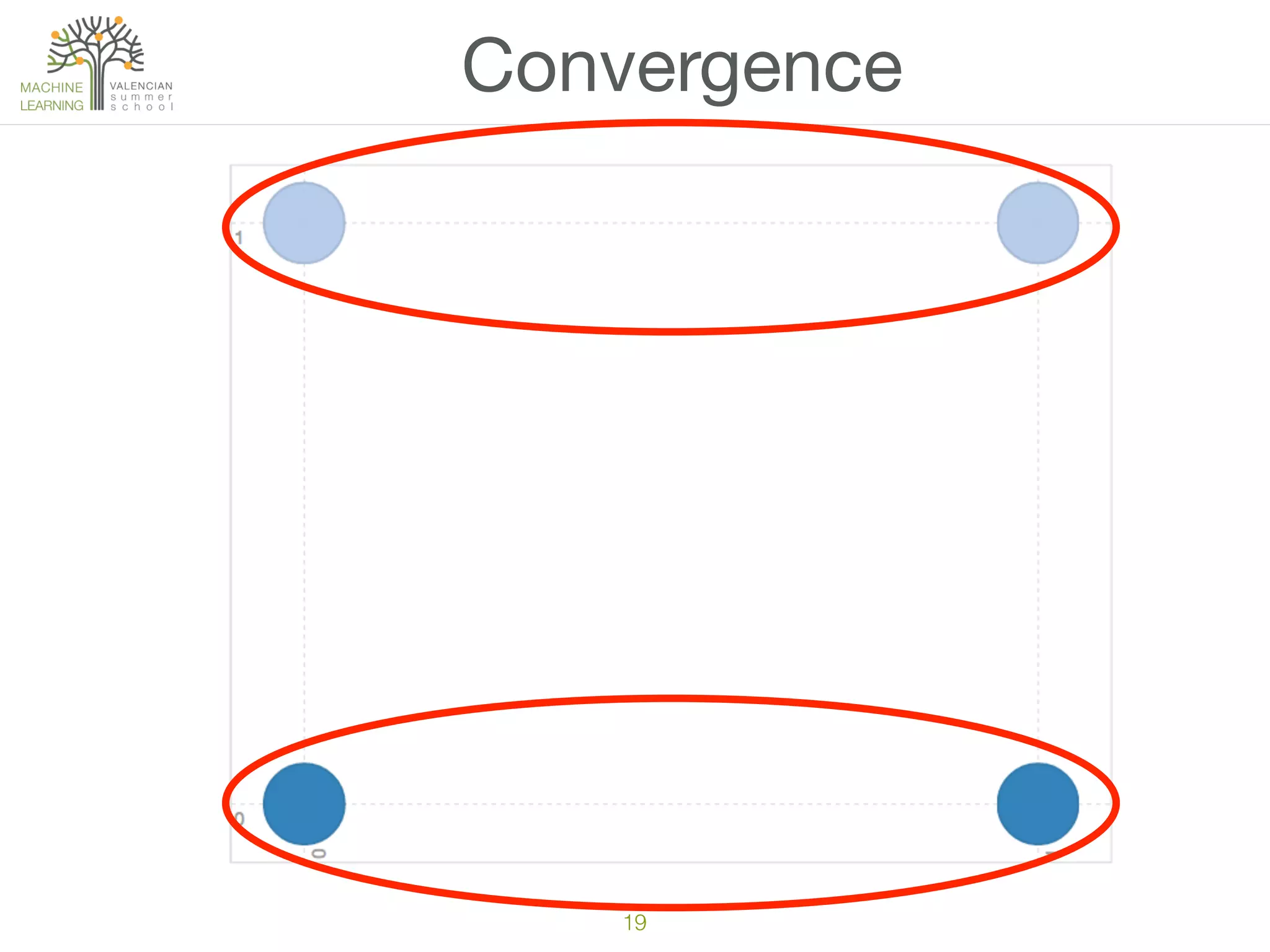


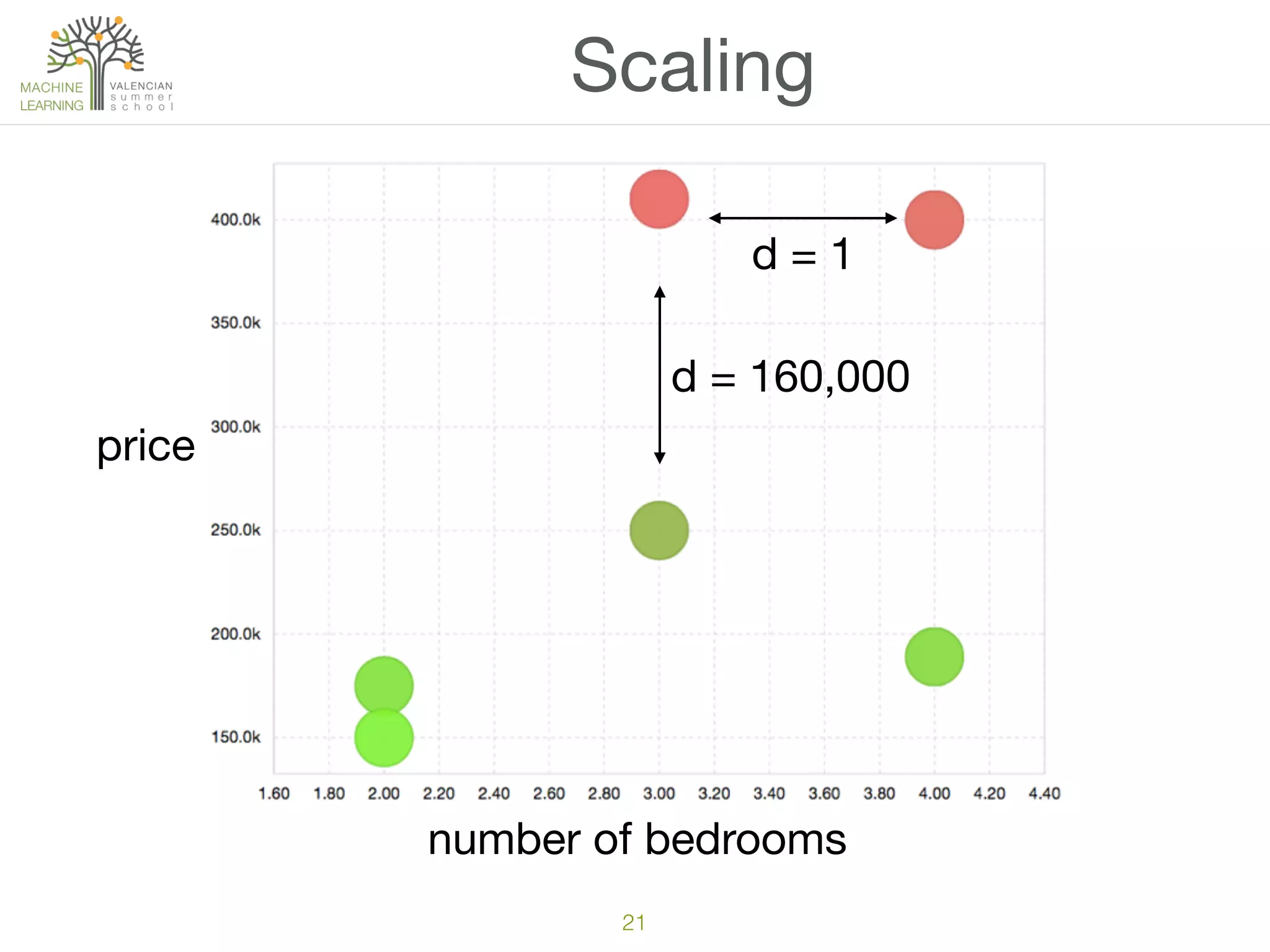





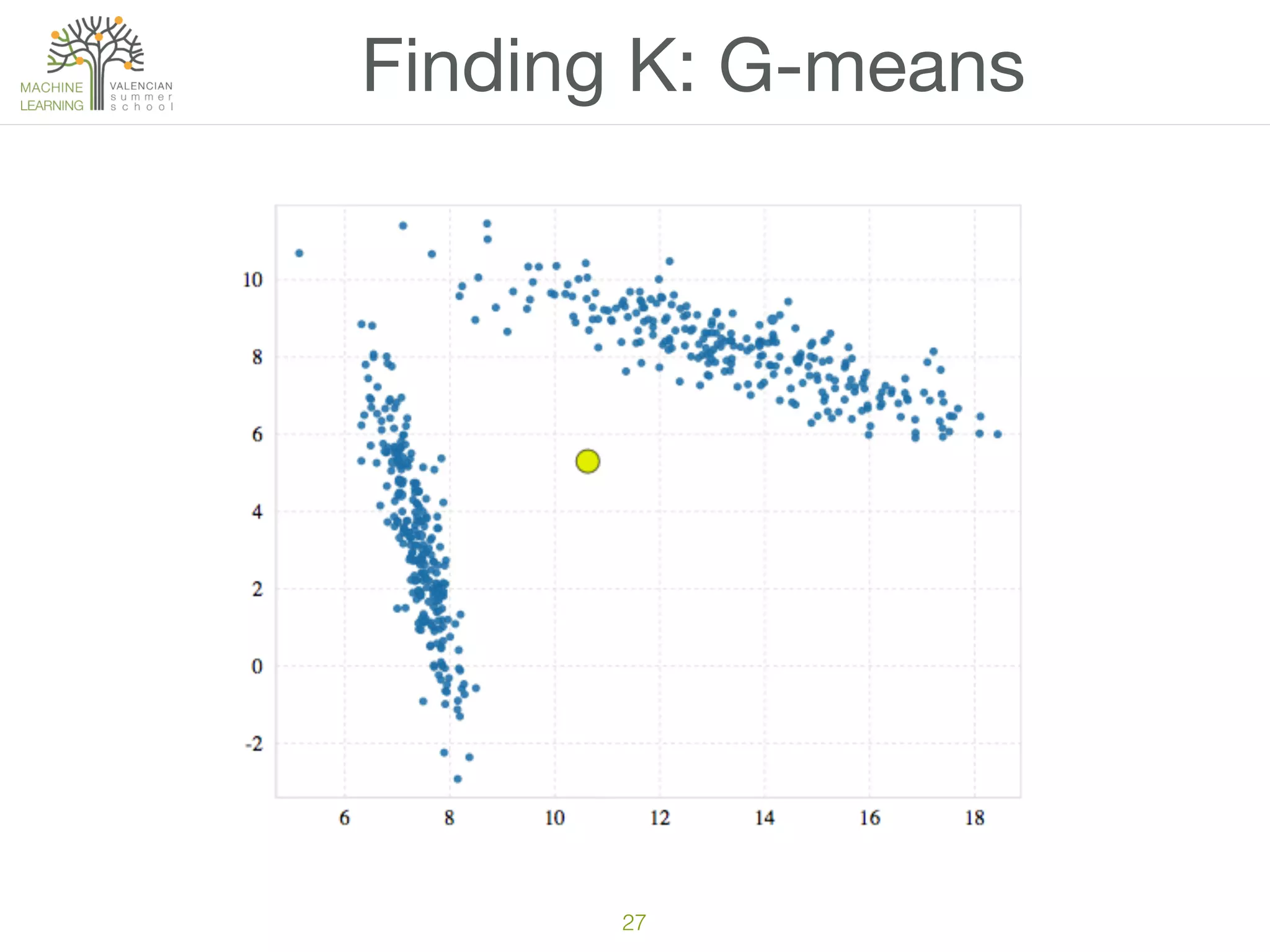
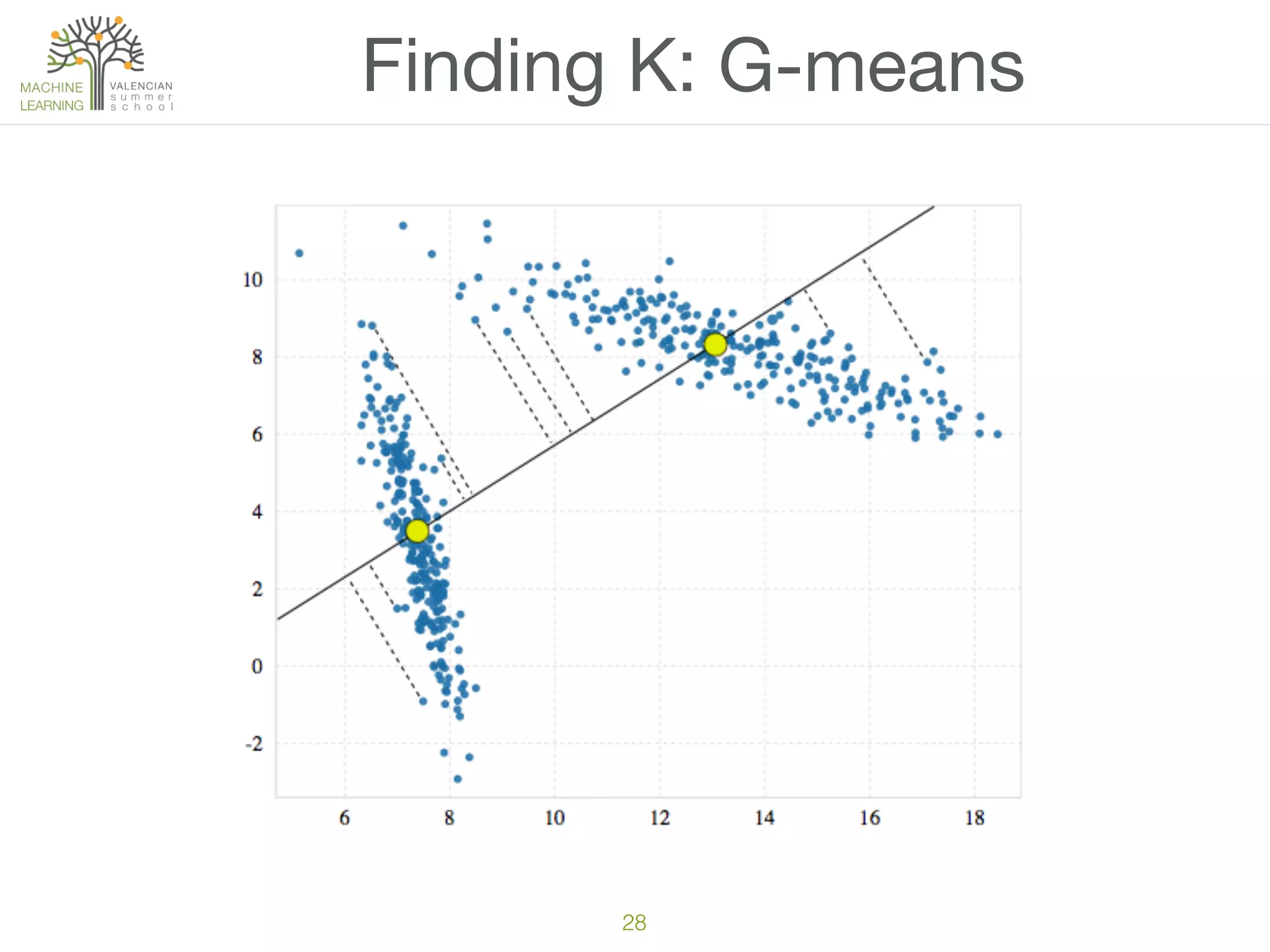
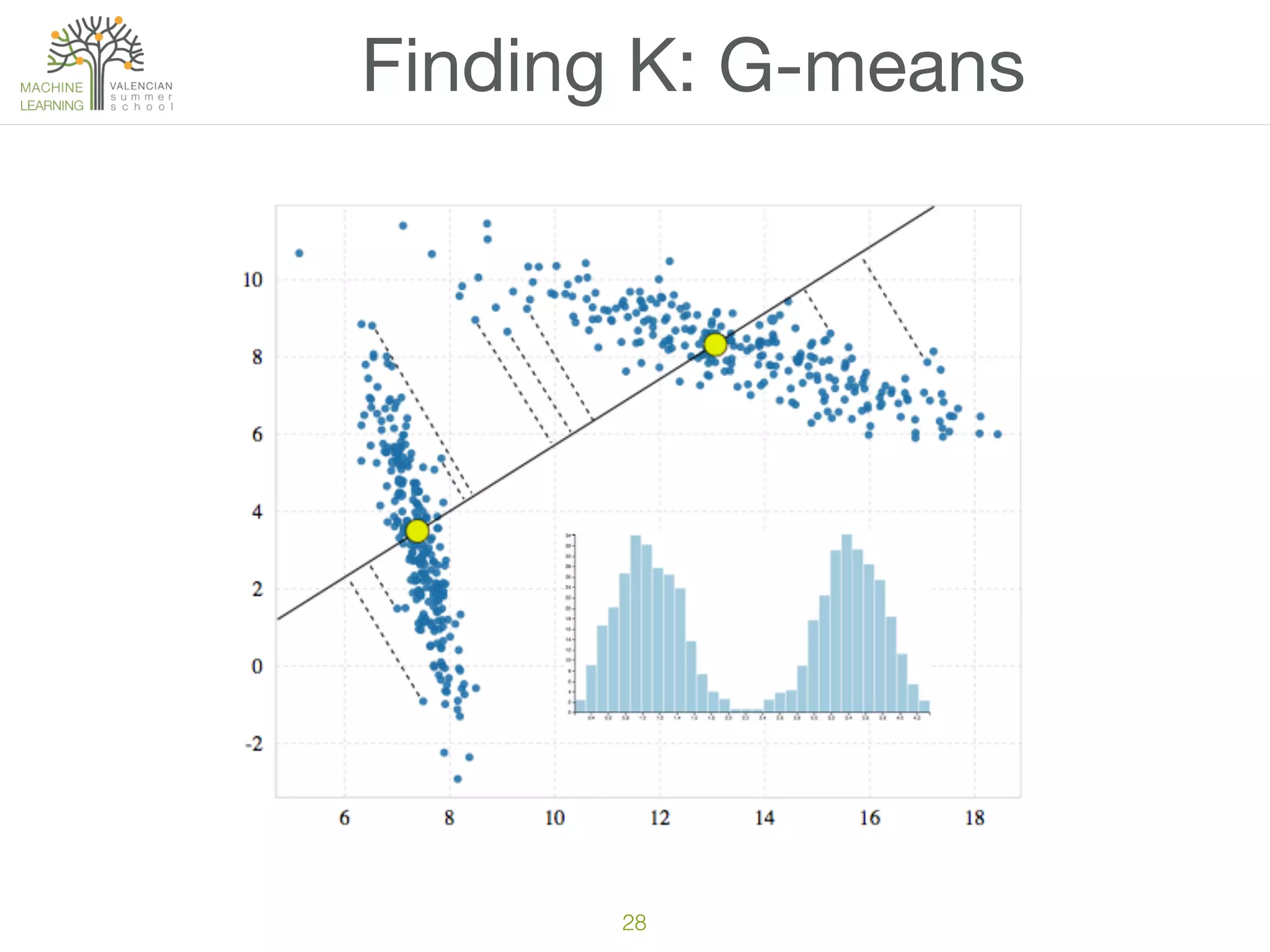
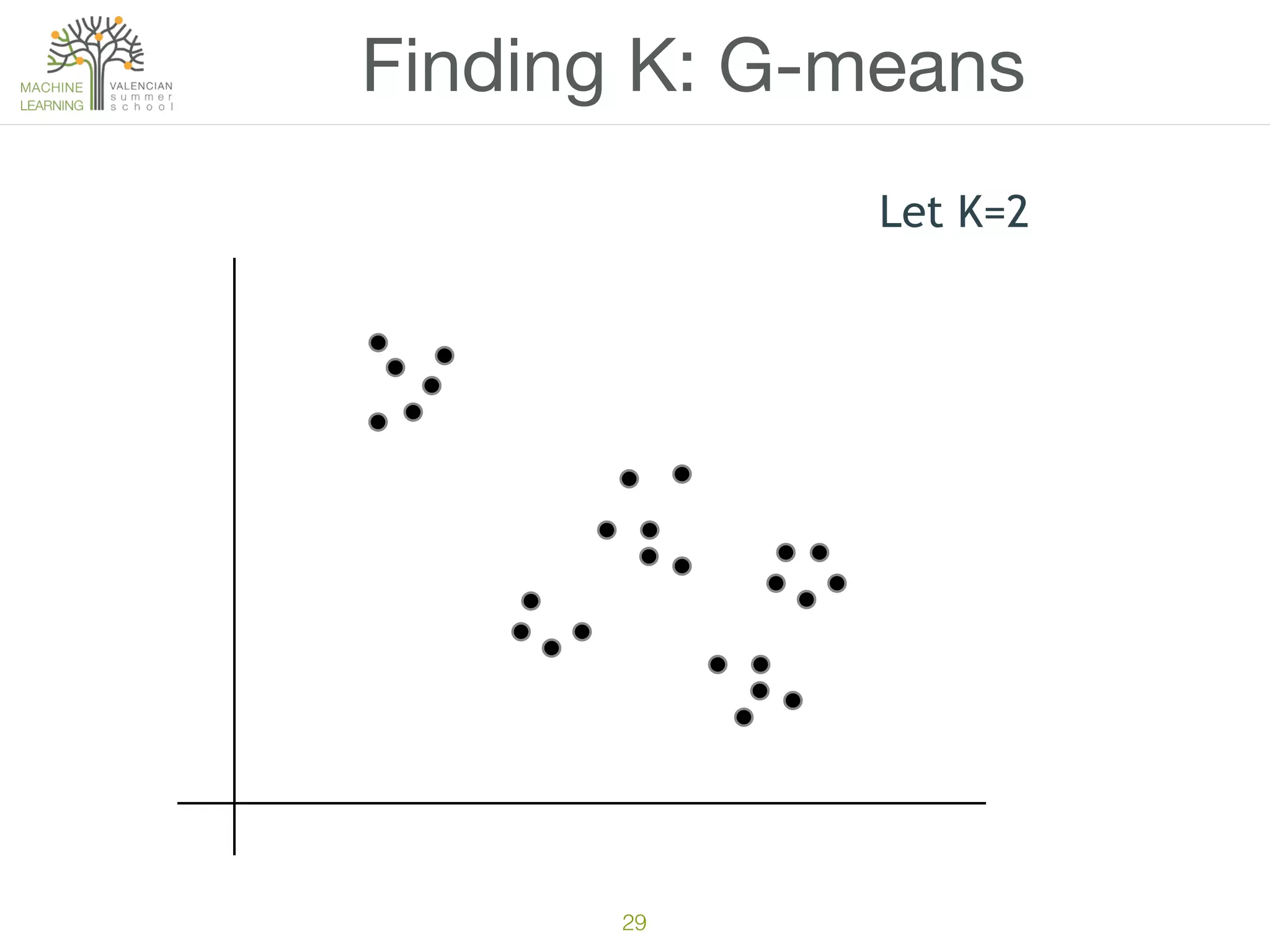
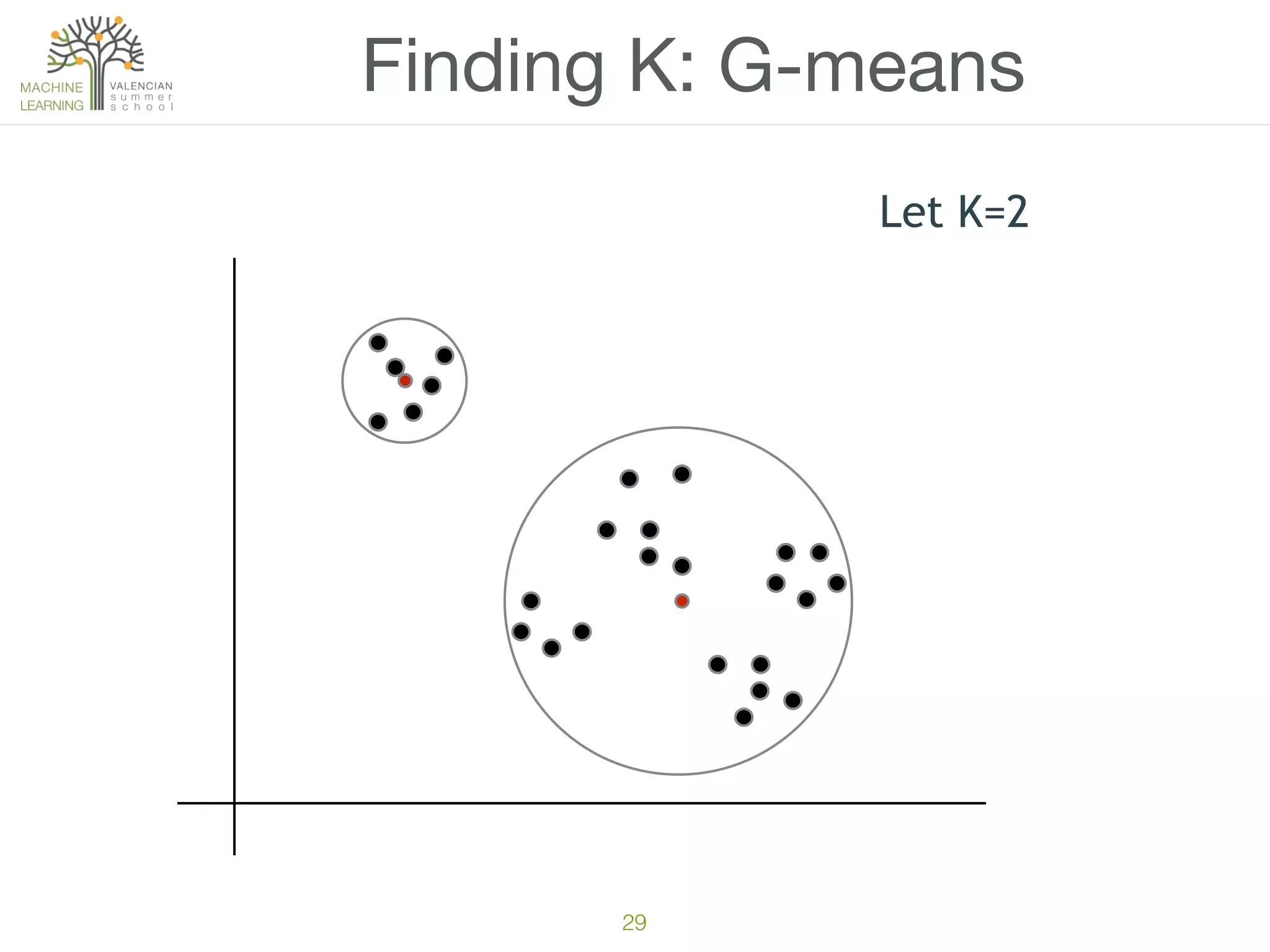
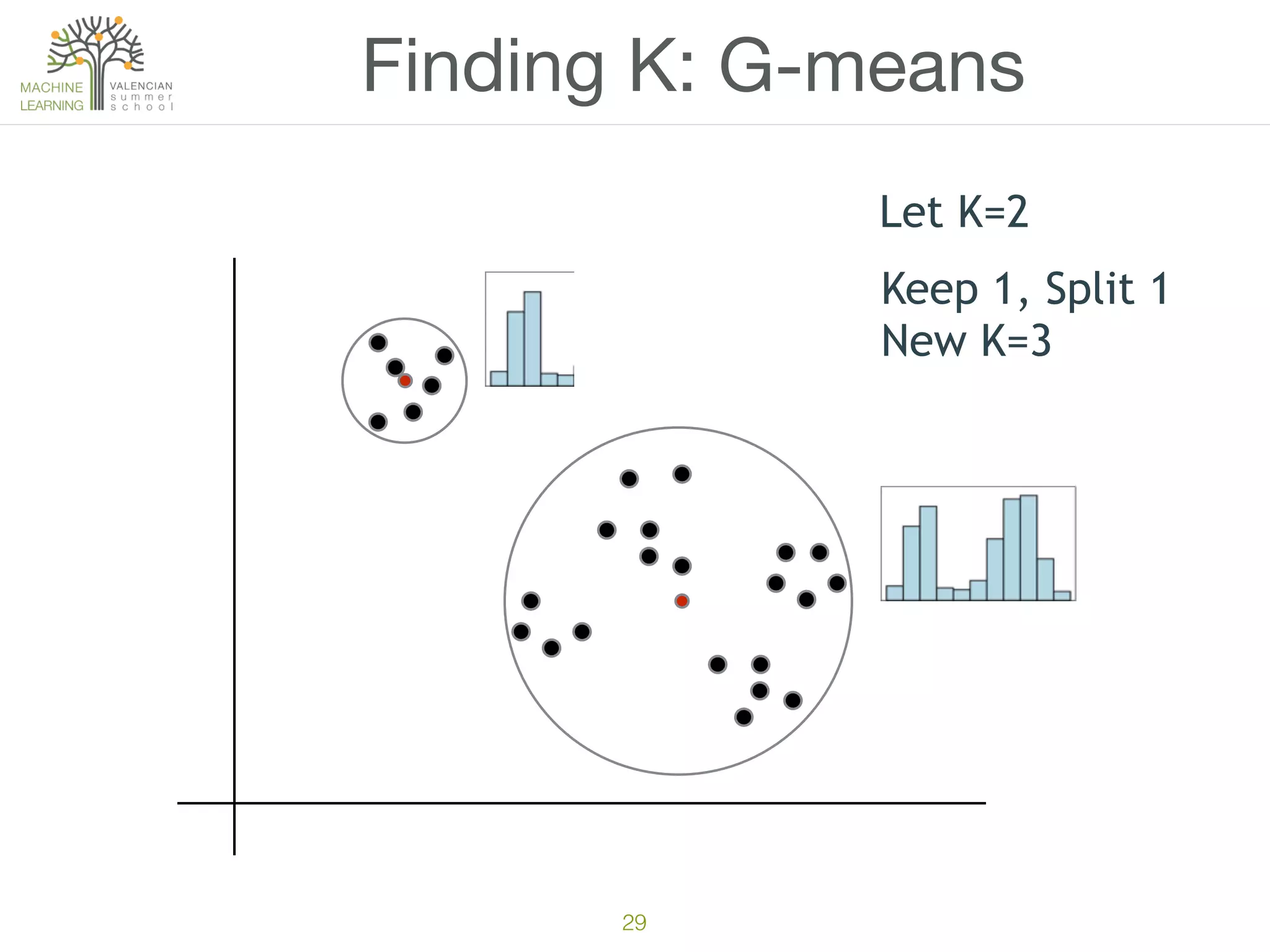
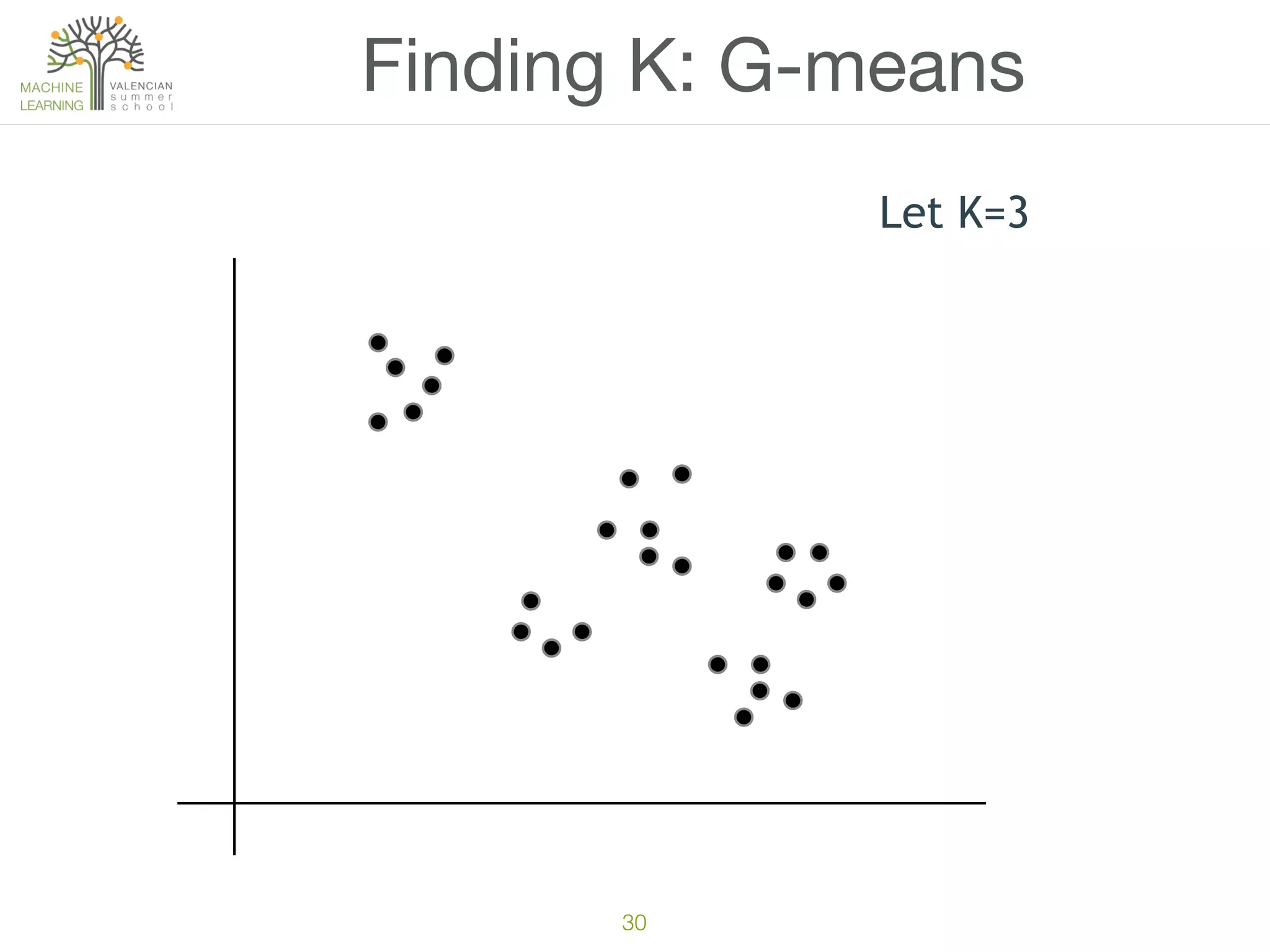
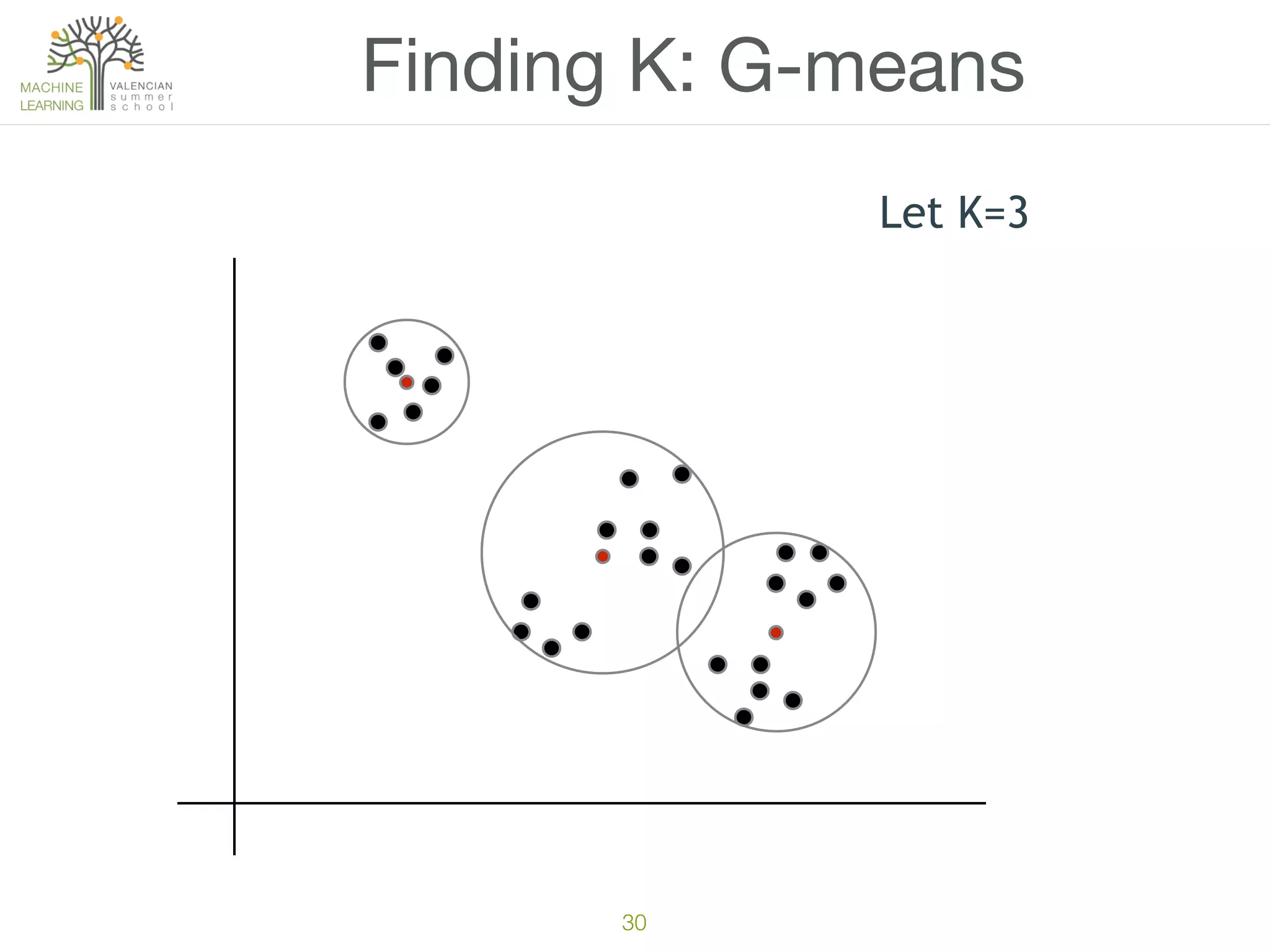
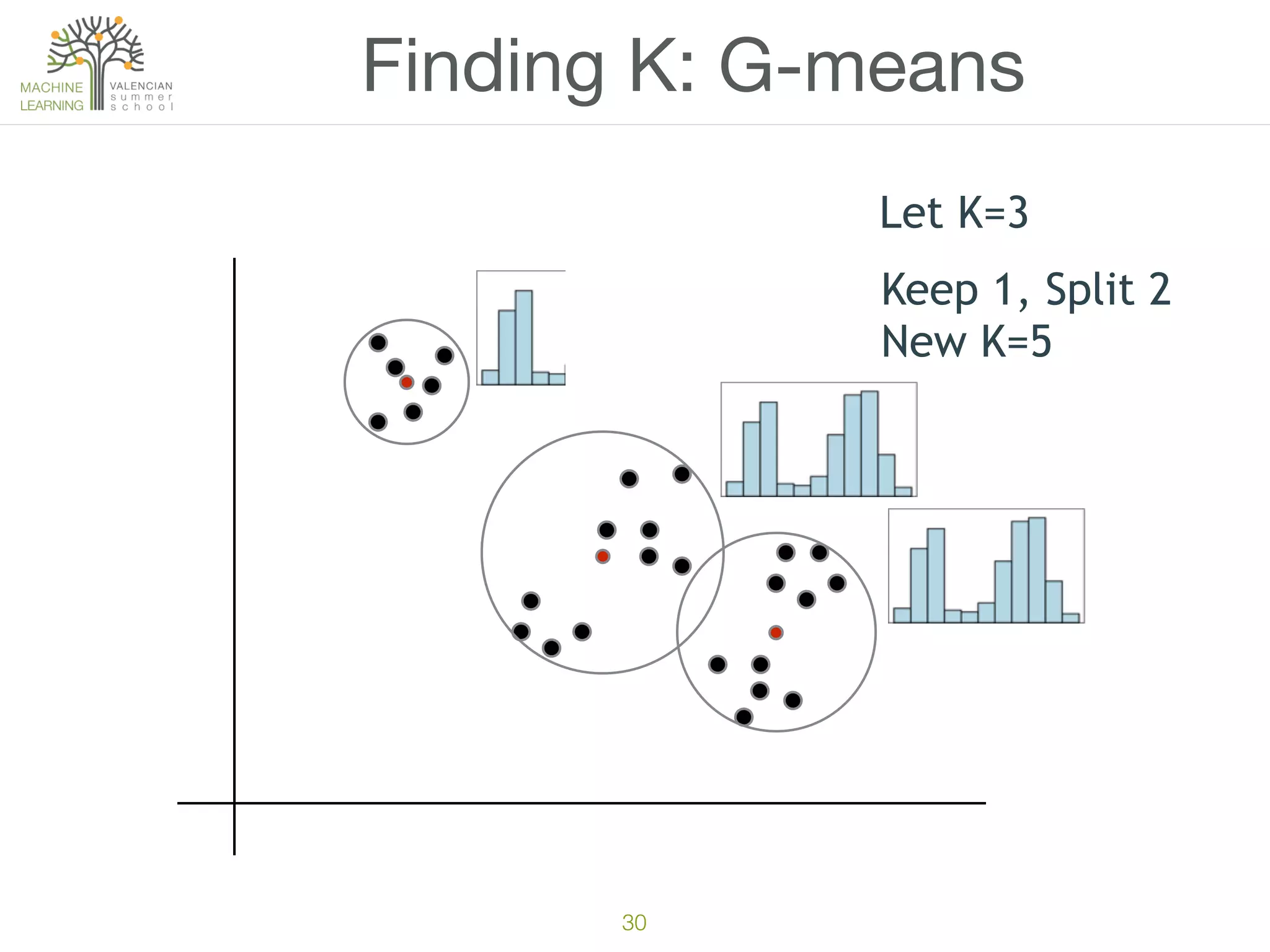
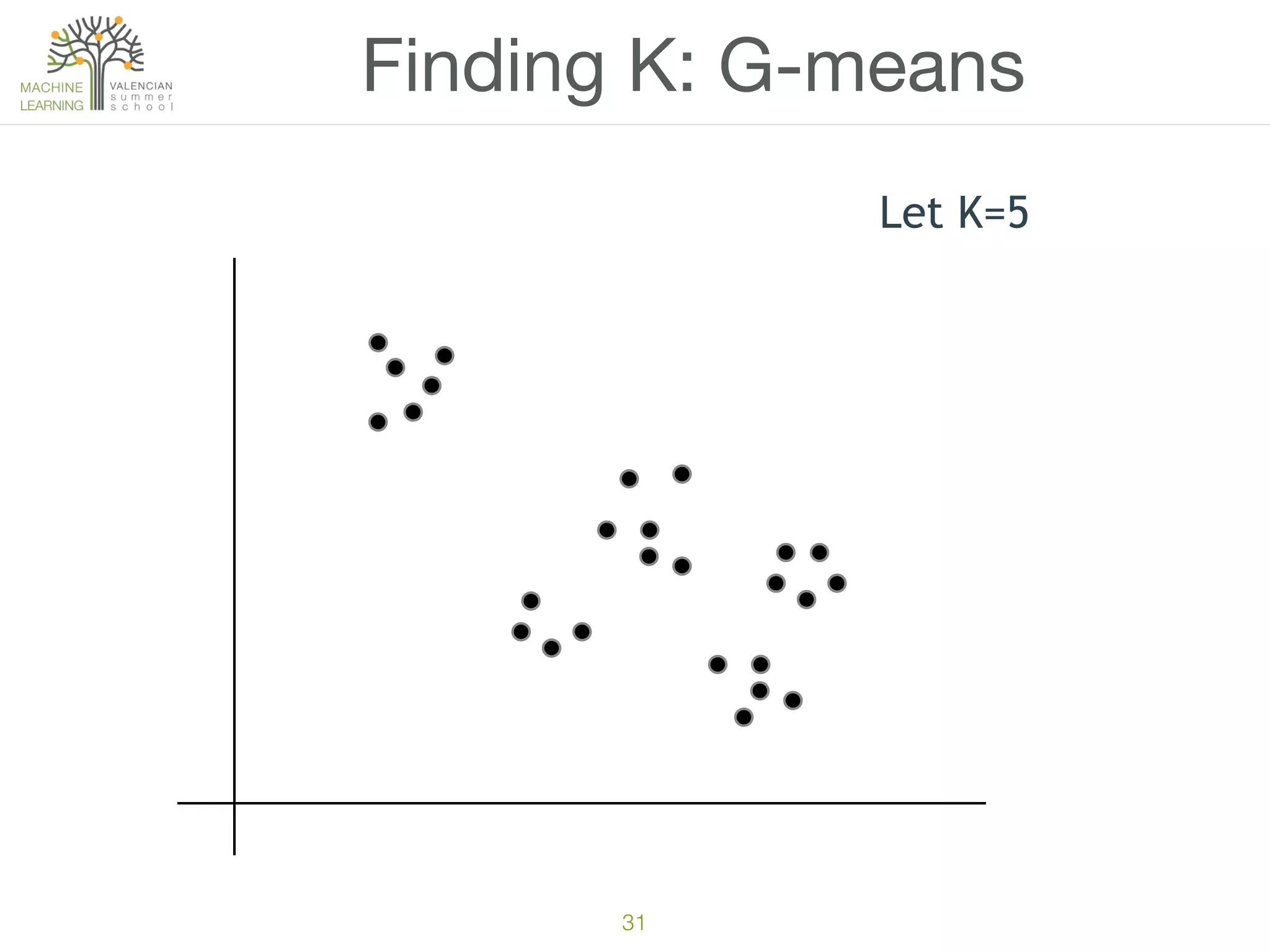
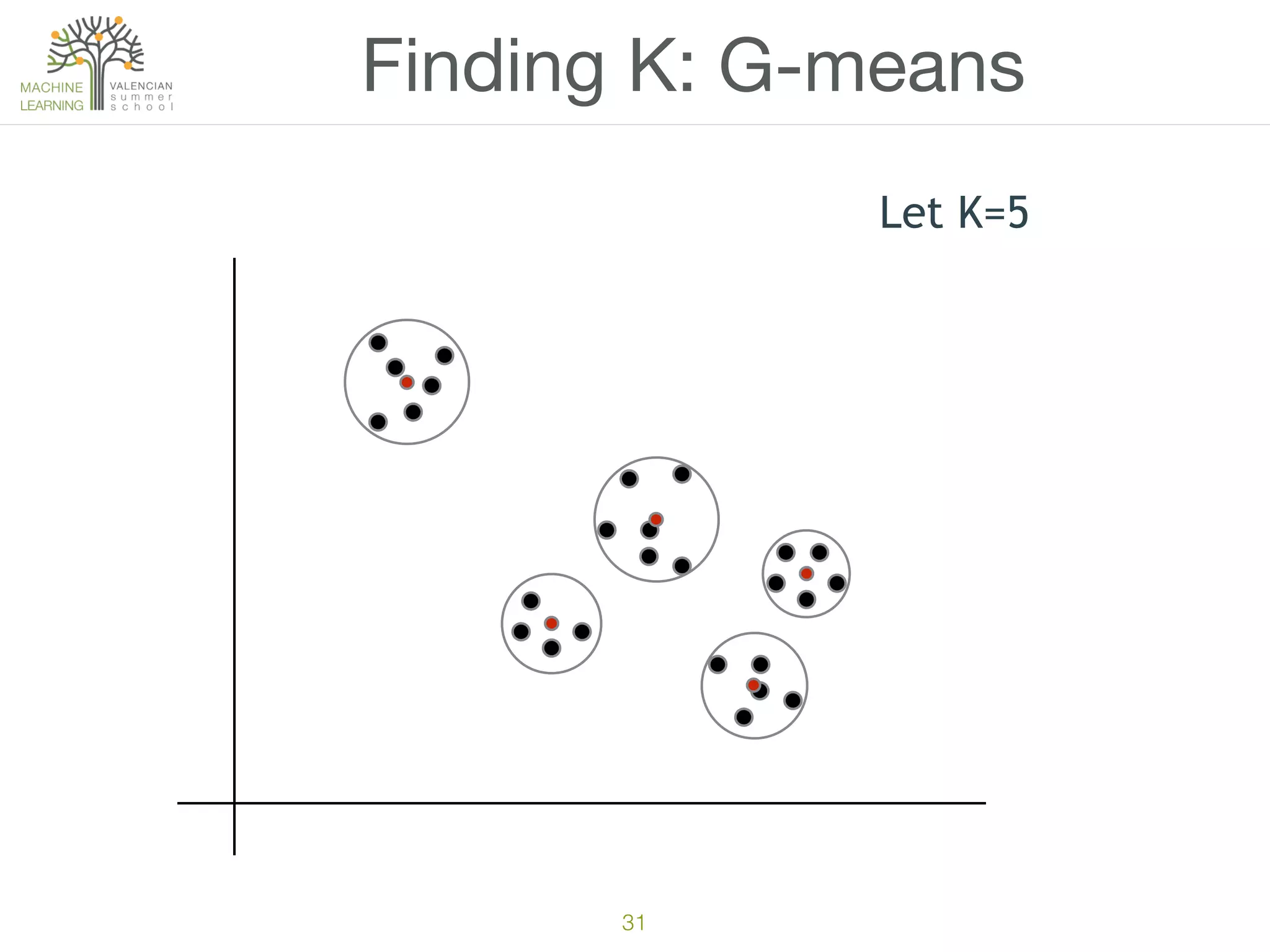
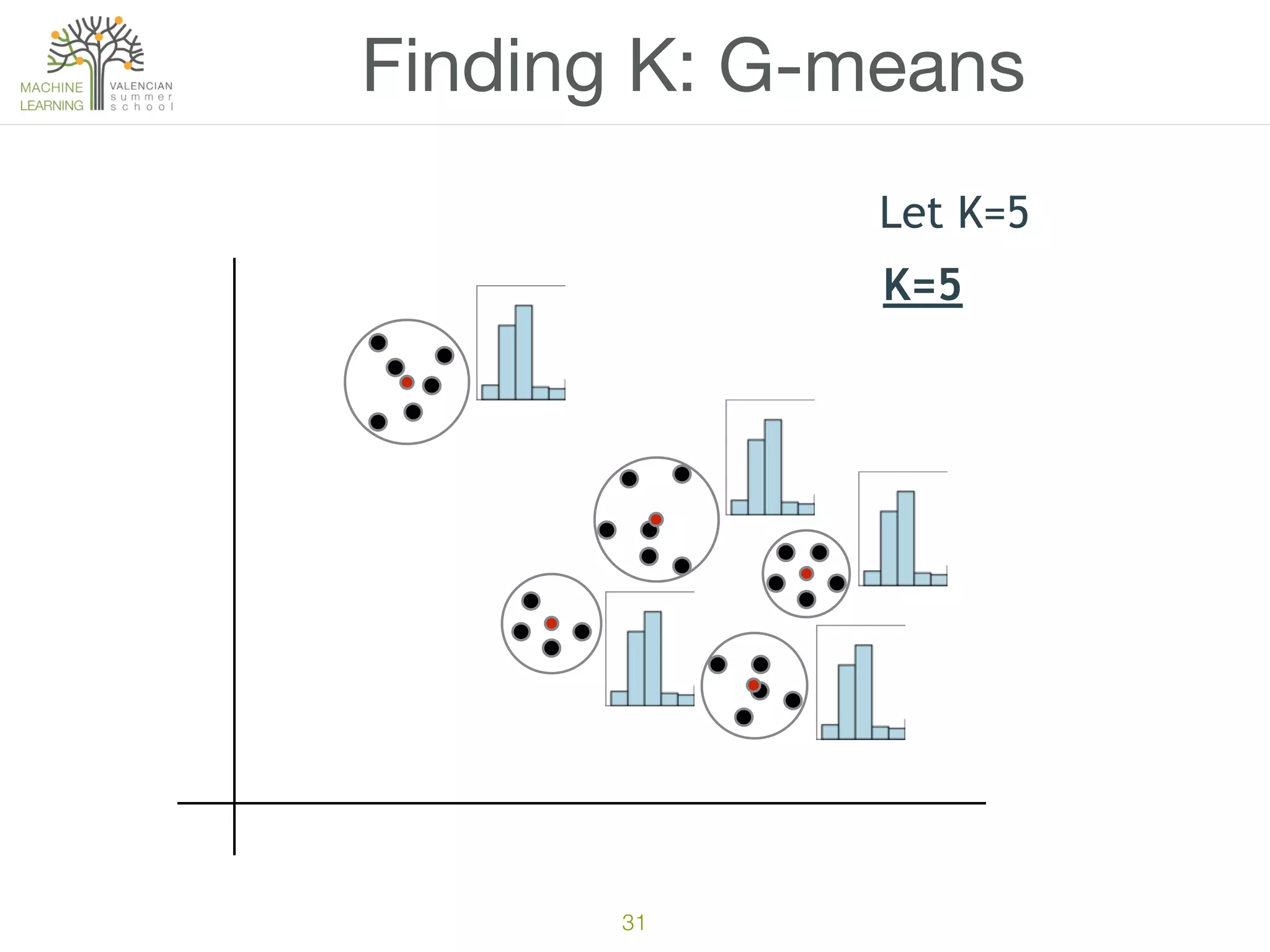

The document discusses concepts of cluster analysis in machine learning, contrasting supervised and unsupervised learning, and showcasing applications such as customer segmentation and item discovery. It introduces the k-means algorithm, feature engineering, and methods for handling missing values and categorical data in clustering contexts. Additionally, it describes techniques for determining the optimal number of clusters (k) using approaches like g-means.
































































![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)












