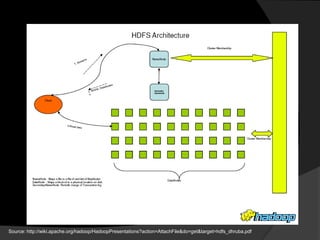
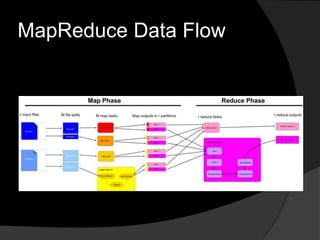
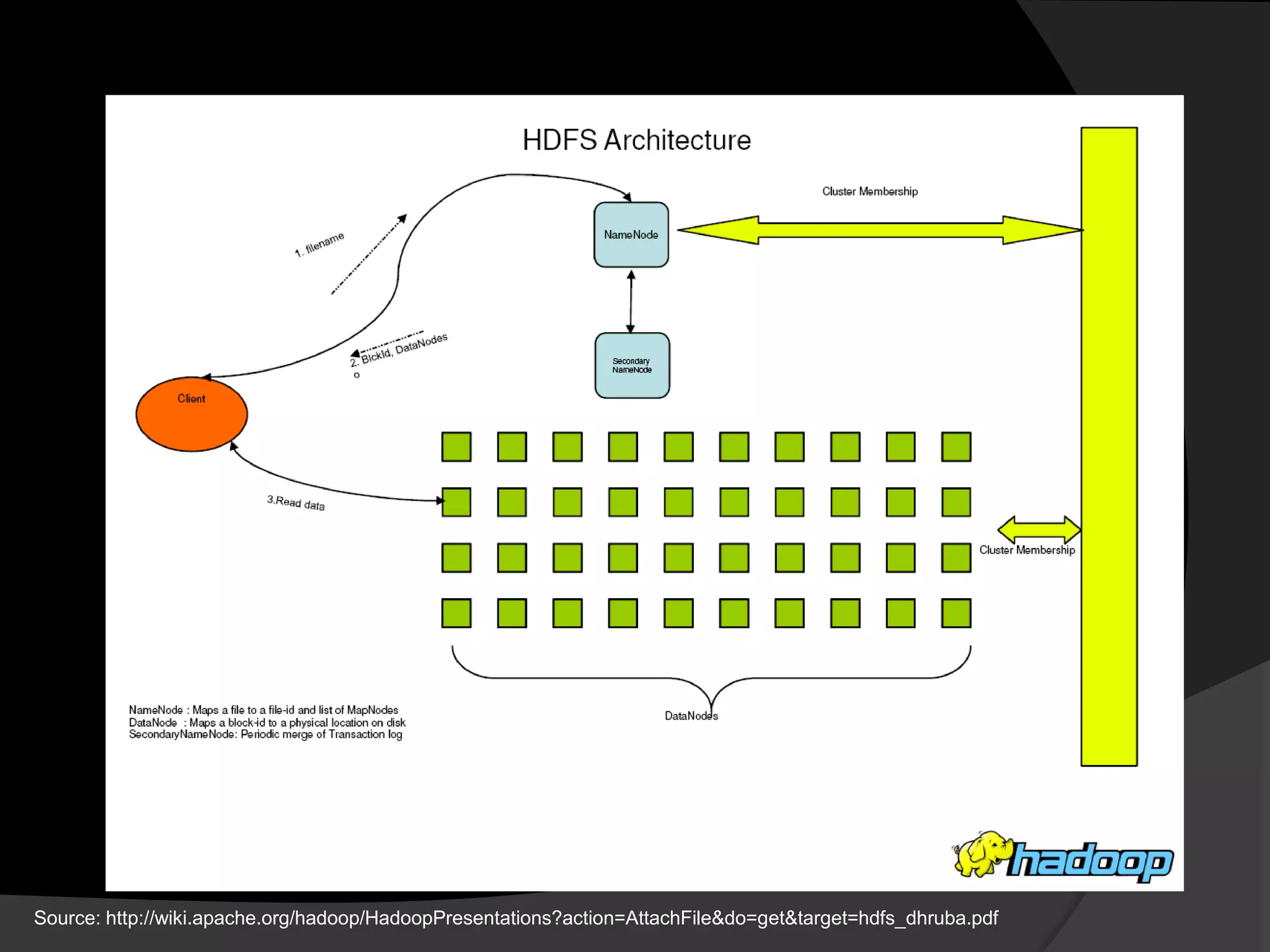
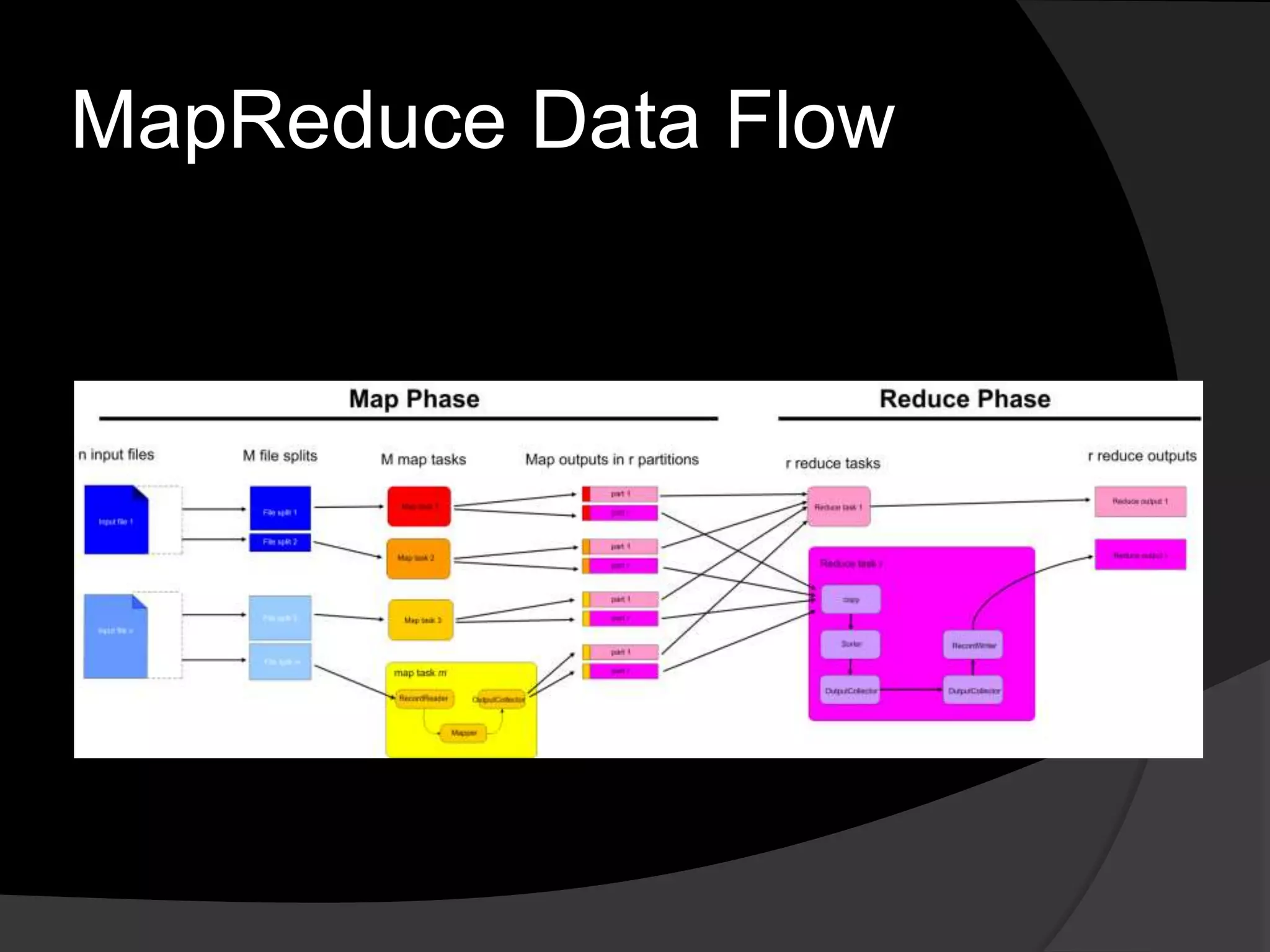
This document summarizes a presentation about using Hadoop for large scale data analysis. It introduces Hadoop's architecture which uses a distributed file system and MapReduce programming model. It discusses how Hadoop can handle large amounts of data reliably across commodity hardware. Examples shown include word count and stock analysis algorithms in MapReduce. The document concludes by mentioning other Hadoop projects like HBase, Pig and Hive that extend its capabilities.




































































































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)